Dubin, David, Megan Senseney and Jacob Jett. “What it is vs. how we shall: complementary agendas for data models and architectures.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Dubin01.
Balisage: The Markup Conference 2013 August 6 - 9, 2013
Balisage Paper: What it is vs. how we shall: complementary agendas for data models and architectures
David Dubin is a Research Associate Professor at the
University of Illinois Graduate School of Library and Information
Science in Champaign, IL. David conducts research on foundational
issues of information representation and description.
Megan Senseney is Project Coordinator for Research
Services at the Graduate School of Library and Information Science,
University of Illinois at Urbana-Champaign.
Data models play two kinds of role in
information interchange. Descriptively, they offer domain models. Prescriptively,
they propose plans of action. While stipulative definitions fill in a model's representational
gaps, elegance and descriptive power reduce the need for arbitrary choices in standards
and specifications. Proposals for modeling digital annotation serve to illustrate
competing representational and cohortative agendas.
There are usually two ways to look at the consensus
represented by a data model or architecture: as the interpretation of
a domain and as a plan of action. XML schemas, UML diagrams, SQL
relational definitions, RDF vocabularies, and many other familiar tools
can be read both as accounts of the entities and relational properties
in a domain, and as guidelines for uniformity of naming and encoding.
These two understandings are not necessarily at odds with each other:
a specification may lay out both how its authors understand what
they're modeling and how they have agreed to maintain consistency in
expressing their data. But for purposes of promoting adoption,
one often finds more relative emphasis on either the social power of
uniform practice or on the generality of an elegant declarative
account. We may rely on one of these more than the other because it's
simply difficult to agree either on how we understand our domains or
how we'll standardize our practices (let alone both).
For an example of where we might emphasize one modeling
agenda over another, consider the application of encoding
machine-readable annotations of digital resources. In an address to a
humanities computing symposium at King's College, John Unsworth listed
annotation among seven scholarly primitives, i.e., "basic functions
common to scholarly activity across disciplines, over time, and
independent of theoretical orientation" (Unsworth, 2000).
Supporting digital annotation has long been a core use case in the
humanities, but the growing role of response and feedback in both
online social media and digital commerce has encouraged the
understanding of annotations as a resource genre in their own
right. A variety of architectures have consequently been
adopted or proposed as bases for digital annotation, including HyTime
(Calabretto and Pinon, 1997), the Multivalent Framework (Phelps and Wilensky, 1997),
the Linguistic Annotation Framework
(ISO, 2012) and the Open Annotation Data
Model (Sanderson et al., 2013).
Open Annotation (OA) is an RDF vocabulary for relationships
among resources, and for metadata about those relationships. OA is
developed and published by a confluence of earlier projects now called
the Open Annotation Community. The following OA serialization is taken from
their cookbook of examples:[1]
In this example, the body of the
annotation is a web page describing the content of an image, the
target of the annotation. In OA, an annotation
body can be any resource that is somehow "about" another resource,
i.e., that stands in some kind of annotating relation to the target.
On the one hand, this is a descriptively general account of
annotations as a class. But on reflection, OA's generality seems to
beg the question of what specific gap it fills in the RDF model of
resource associations. If, according to OA, annotations are sets of
related resources, what is it that distinguishes an annotation from
any other RDF description? OA's answer would seem to be that
annotations are exactly those descriptions serialized by the OA
community employing the OA vocabulary. But instead of a common
vocabulary, why not connect resources in a common architecture
across diverse RDF applications? Suppose an annotation vocabulary were
linked to specific annotating properties in local
languages—something like an ISO 10744 enabling architecture.
Properties such as comment_on or
reviews could be declared as subproperties of
annotation, and resources linked by these annotating relations
inferred to be targets and bodies via domain and range declarations
as in Figure 2:
Figure 2
Equation (a)
annotatingRelation ⊑ annotates
Equation (b)
⊤ ⊑ ∀annotates.Target
Equation (c)
∃annotates.⊤ ⊑ Body
Annotation as a superproperty
This enabling architecture approach offers some advantages.
Adopters of such a model would not have to convert their data to a
different serialization, for example, and the question of what exactly can
be annotated or serve as an annotation body could be governed by range
and domain constraints on local subproperties (product reviews annotating
products, footnotes annotating essays, etc.). Currently, OACG recommends
the Dublin Core Types vocabulary for typing annotation targets and
bodies, but the range of the hasTarget and
hasBody relations are purposefully undefined. As
a result, nothing in the current OA specifications forbids
interpretively challenging examples such as a person serving as the
annotation body for a target integer or a geographic location as the
body for a target person.
On the other hand, the descriptive approach has
disadvantages as well. The OA community views annotations
as distinct from annotation bodies, but still as individuals with
properties of their own. Modeling annotations as relational instances
would therefore seem to require reification of either RDF statements or named graphs
(or the full existential quantification of first order
logic) if annotations are to stand in relations as individuals. So the
flexibility of using one's own vocabulary comes at the cost of
complexity or a requirement for greater expressive power.
Where do we annotate?
Prescriptive and descriptive emphases can also be
contrasted in how particular regions of a resource are targeted for
annotation. The OA Specifiers Module recommends particular addressing
systems (including XPointer, W3C Media Fragments, etc.) and organizes
them by type: fragment selectors, range selectors, and area selectors.
But the OA specification does not make clear whether these three
categories are exhaustive, or even whether the particular methods
listed exhaust the categories (for example, whether there are area
selectors in addition to the one listed for SVG files).
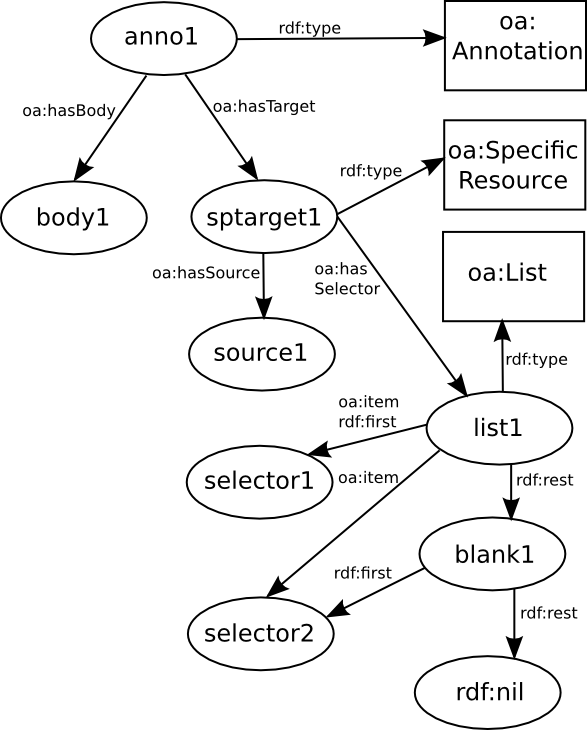
Figure 3 shows OA's provisional recommendation for
combining selectors: they are arranged in an ordered list from most
general to most specific. Caveats warn the reader that this chaining
method may eventually be deprecated if the RDF community recommends a
better approach to expressing order in graph structures[2]
.
Figure 3
OA List Composite for chained selectors
Compare the current iterative recommendation in
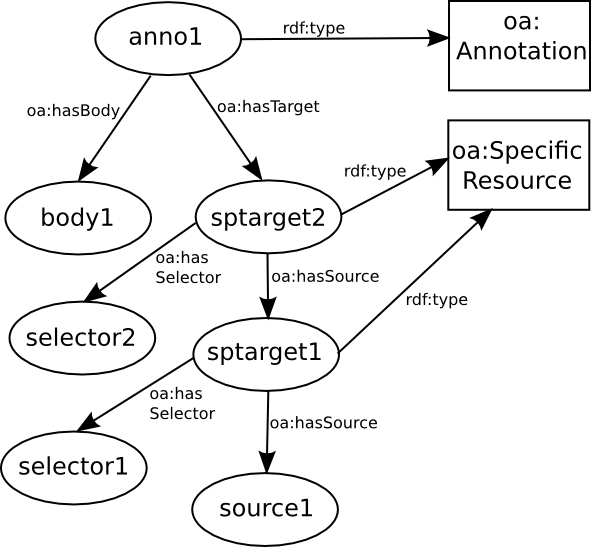
Figure 3 with the (hypothetical) recursive approach
shown in Figure 4. This alternative is inspired by
HyTime's location ladders, and dispenses with the need for list
composites. The targets are organized from specific to general,
allowing a more consistent range for the
oa:hasSelector property: Figure 3
shows lists in the range, even though lists are not selectors. The
point of the example is not that recursion is better than iteration,
but that the second solution relies more on a proposed semantics for
selectors, while the first appeals to broader community decisions on
how best to express ordered relations in RDF.
Figure 4
If OA used HyTime's location ladders
Summary and Generalization: Data Model Roles
Data models and architectures play two kinds of role in
information interchange. On the one hand they present a theory of how
one should understand the domain of a specification or application,
and on the other hand they offer a plan of action. One might call the
former role a representational agenda: the
interest in doing justice to whatever it is that is being modeled. The
second role we'll call a cohortative agenda:
promoting uniformity of practice through stipulative definitions.
Successful data models need to address both the
representational and cohortative agendas to some extent. Models by their
nature are simplifications of reality, and never represent the
richness of their domains with full fidelity. Developers adopting a
specification must therefore accept its architecture with whatever
limitations they find. On the other hand, data models must offer some
semantic and expressive adequacy—they won't be adopted if
they're not inclusive enough for stakeholders' use cases or if they
simply make no sense.
Just as stipulative definitions fill in a model's
representational gaps, elegance and descriptive power reduce the need
for arbitrary choices. As a result of this trade-off one sees two
complementary costs in standards adoption: that of relinquishing
full control over stipulations to a broader community vs. the complexity
necessary for generality of scope and flexibility of application. But
the language of information standards doesn't lay out this
complementarity to their audience: RDF schemas and UML
diagrams don't announce the degree to which we should read them as
micro-theories as opposed to operational definitions.
David Birnbaum presents a vivid illustration of these
competing model agendas in his 1996 recommendations for Unicode
encoding of early Cyrillic materials (Birnbaum, 1996).
Unicode organizes writing systems at the level of the script, rather
than the language-specific alphabet or orthography, but specifies that
characters convey distinctions in sound or meaning. As Birnbaum points
out, orthographic systems that share the same script may assign
different sounds or meanings to the same grapheme. The range of
languages, regions, and time periods covered in Cyrillic materials
scholarship therefore challenges Unicode's representational weakness
in ways that typical business uses do not. But, as Birnbaum explains,
although distinctions important to Slavic scholars may not always be
straightforward to express in Unicode, the "academic and computational
chaos and parochialism" that preceded Unicode's introduction lead to
even more difficult text rendering and processing problems. Therefore
Birnbaum's proposed encoding guidelines for Cyrillic texts address a
range of problems for Slavic scholarship, while keeping Unicode's
standardization and uniformity. This article is a rare example of
making clear both the descriptive limitations of an architecture and
the attraction of workarounds for leveraging the power of simply
getting on board despite the problems.
Although the Open Annotation specifications don't lay out
descriptive/prescriptive tensions as directly, details that may seem
at first like semantic infelicities make more sense from a cohortative
perspective. OA is primarily a set of encoding guidelines, not a
theory of annotation. One adopts the Open Annotation Data Model for
the value of participating in a collective enterprise, and reads the
specification as a record of the working group's decisions. The
promise of OA lies more in prospects for social success than in the
model's descriptive power.
Standards development and adoption are social
activities—even formal aspects like data modeling. Decisions on
which standards to adopt require that we weigh different kinds of
costs against each other (e.g., complexity vs. stipulation costs).
These decisions take place against a backdrop of social factors that
usually aren't documented in standards or discussed in their
supporting literature. But each conceptual framework, layered
architecture or RDF schema we're offered has something to assert about
how things are, and some plan to propose on how to proceed.
Acknowledgments
This research was supported by Libraries:
Transformation of Humanities (LG-06-11-0326), an
IMLS-funded project focused on building a network of resource
collections for the humanities and creating research tools for a
wide range of users. The authors thank Karen M. Wickett, Sayeed
Choudhury, Gregory Crane, Bridget Almas, Timothy DiLauro, Jim
Martino and the anonymous Balisage reviewers for discussions and
feedback on earlier versions of this paper.
[Calabretto and Pinon, 1997] Sylvie
Calabretto and Jean-Marie Pinon.
Modeling a medieval manuscript database with HyTime.
In John Smith, editor, Proceedings of ICCC/IFIP Conference on
Electronic Publishing: EP'97 New Models and Opportunities, pages
336–345, Canterbury (Great Britain), April 1997. ICCC Press.
[ISO, 1997] ISO.
ISO/IEC 10744:1997 Information technology — Hypermedia/Time-based
Structuring Language (HyTime).
International Organization for Standardization, Geneva, 1997.
[ISO, 2012] ISO.
ISO 24612:2012 Language resource management — Linguistic annotation
framework (LAF).
International Organization for Standardization, Geneva, 2012.
[Sanderson et al., 2013] Robert Sanderson, Paolo
Ciccarese, and Herbert Van de Sompel, editors.
Open Annotation Data Model.
World Wide Web Consortium, 2013.
[Unsworth, 2000] John Unsworth.
Scholarly primitives: what methods do humanities researchers have in common,
and how might our tools reflect this?
Presented at Humanities Computing: formal methods, experimental practice,
King's College, London, May 2000.
David Birnbaum.
Standardizing characters, glyphs, and sgml entities for encoding early
Cyrillic writing.
Computer Standards and Interfaces, 18:201–252, 1996. doi:https://doi.org/10.1016/0920-5489(95)00096-8.
Sylvie
Calabretto and Jean-Marie Pinon.
Modeling a medieval manuscript database with HyTime.
In John Smith, editor, Proceedings of ICCC/IFIP Conference on
Electronic Publishing: EP'97 New Models and Opportunities, pages
336–345, Canterbury (Great Britain), April 1997. ICCC Press.
ISO.
ISO/IEC 10744:1997 Information technology — Hypermedia/Time-based
Structuring Language (HyTime).
International Organization for Standardization, Geneva, 1997.
ISO.
ISO 24612:2012 Language resource management — Linguistic annotation
framework (LAF).
International Organization for Standardization, Geneva, 2012.
Thomas A. Phelps and
Robert Wilensky.
Multivalent annotations.
In Research and Advanced Technology for Digital Libraries, pages
287–303. Springer, Berlin Heidelberg, 1997. doi:https://doi.org/10.1007/BFb0026734.
John Unsworth.
Scholarly primitives: what methods do humanities researchers have in common,
and how might our tools reflect this?
Presented at Humanities Computing: formal methods, experimental practice,
King's College, London, May 2000.