Stührenberg, Maik, and Daniela Goecke. “SGF - An integrated model for multiple annotations and its application in a linguistic
domain.” Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 - 15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). https://doi.org/10.4242/BalisageVol1.Stuehrenberg01.
Balisage: The Markup Conference 2008 August 12 - 15, 2008
Balisage Paper: SGF - An integrated model for multiple annotations and its application in a linguistic
domain
Maik Stührenberg
Maik Stührenberg studied Computational Linguistics at Bielefeld University. He worked
four years as research assistant at Giessen University in different text-technological
projects (both funded by the German government and the German Research Foundation).
He now
works as a research assistant at Bielefeld University together with Andreas Witt,
Dieter
Metzing and Daniela Goecke in the Sekimo project of the
Research Group Text-technological modelling of
information funded by the German Research Foundation. His main research
interests include specifications for structuring multiple annotated data and query
languages and query processing.
Daniela Goecke
Daniela Goecke studied Computational Linguistics at Bielefeld University. She finished
her master thesis in cooperation with IBM Scientific Center Heidelberg and worked
four
years at Philips Speech Processing Aachen. She now works as a research assistant at
Bielefeld University together with Andreas Witt, Dieter Metzing and Maik Stührenberg
in
the Sekimo project of the Research Group 437 Text-technological modelling of information funded by the German
Research Foundation. Her main research topics are the unification of text-technological
resources and anaphora resolution.
Seamless integration of various, often heterogeneous linguistic resources (in terms
of
their output formats) and merging of the respective annotation layers are crucial
tasks for
linguistic research. After a decade of concentration on the development of formats
in order
to structure single annotations for specific linguistic issues, a variety of specifications
to store multiple annotations over the same primary data has been developed in the
last
years. Among these approaches three main architectures can be identified: Prolog-based
architectures, XML-related approaches and graph-based models that follow the XML syntax.
However, these architectures are not free of disadvantages when used in real world
applications. In the Sekimo project the XML-based Sekimo Generic Format (SGF) was developed for the purpose of
storing multiple annotations on the same primary data and examine relationships between
elements of different annotation layers without prepended conversion. SGF is based
on the
design principles of graph-based approaches but makes use of the XML-inherent tree
structures whenever possible to reduce processing costs. Analysing data stored in
SGF can be
done via standard XML-related specifications such as XPath, XSLT or XQuery and is
done in
our project in the linguistic application domain of anaphora resolution.
The work presented in this paper is part of the project A2 (Sekimo) of the Research Group 437 Text-technological
modelling of information funded by the German Research Foundation.[1]
Introduction
There is a large amount of machine-readable structured linguistic documents (often
XML
annotated) available to the public as well as several NLP tools which allow for the
analysis
of linguistic data. Besides corpora annotated for several linguistic phenomena, external
knowledge bases like lexical nets (WordNet, cf. Fellbaum, 1998GermaNet, cf. Hamp and Feldweg, 1997) are an important
source for linguistic studies. However, these resources are often heterogeneous in
respect to
both, the underlying schema of the output format and the functionality provided. Furthermore,
their use for (semi-) automatic annotation can lead to the problem as to how to represent
multi-dimensional, possibly overlapping markup - which often occurs when different
linguistic
annotation levels are unified (e.g. syllables vs. morphemes). Different methods for
the
annotation of multiple information levels have been developed: separation of multiple
annotation levels in separate files, fragmentation or milestones (cf. Sperberg-McQueen and Burnard, 2002). In the Sekimo project
different approaches for the integration of heterogeneous linguistic resources were
developed
and applied in the domain of anaphora resolution. For the task of anaphora resolution
different types of information are necessary: POS, syntactic knowledge, world knowledge
(e.g.
in terms of an ontology) and the like. Therefore various linguistic resources such
as parsers,
dictionaries, wordnets or ontologies have to be combined. However, in most cases the
output
format of a linguistic resource A is not suitable as input format for a linguistic
resource B,
which means that a cascaded application of several resources is not possible. After
experiences with a Prolog fact base approach (cf. section “Prolog-based architectures”) we have
developed an XML-based abstract representation format similar to the standoff annotation
model
described by Thompson and McKelvie, 1997 which encodes the same textual data in separate
files according to different document grammars addressing different relevant phenomena.
Information structuring can always be split up into a conceptual process and a technical
realization. We follow the discussion in Goecke et al., 2008 and use the term
level to refer to the information modelling concept (e.g.,
morphological structure, phrase structure) and the term layer
for the technical realization, i.e. the XML markup. Levels and layers can be in different
relations (1:1 relation, 1:n, m:1 or n:m) which can lead to overlapping markup in
the layer
structure. The annotation format described in Witt et al., 2005 solves this issue and
ensures a 1:1 relation. For clarification issues we prefer the term multi-rooted trees in favor of multiple
annotations when talking about the architecture used in our project because the
different levels of annotation are stored in a single representation.
The remainder of this paper is structured as follows: At first we will give an overview
of
different approaches for integrating multiple annotated data, followed by a description
of the
Sekimo Generic Format (SGF) sketched out in section “The Sekimo Generic Format”. In section “Application of SGF” we will demonstrate how the SGF is used in the application
domain of anaphora resolution. Finally, the paper closes with section “Conclusion and outlook” in which possible extensions and future work are
discussed.
Different approaches to multiple annotated markup
There is a variety of approaches for dealing with multiple annotated data (or multiple
hierarchies) already available. DeRose, 2004 summarizes some solutions
(including both XML-based and non-XML-based approaches) with their respective strengths
and
weaknesses. We propose to group a selection of the available solutions into three
categories:
Prolog-based architectures.
XML-related architectures.
Graph-based architectures that follow the XML syntax.
The reason for this grouping is partially due to a chronological ordering (e.g. the
roots
of the Prolog-based architectures go back more than ten years) and partially because
of the
underlying technical foundation (e.g. the separation of XML-based and non-XML-based
architectures). The last point is crucial with respect to the support in terms of
tools (e.g.
parsers, transformation processors, query tools) when it comes to the application of a specific architecture (cf. section “Application of SGF”).
Prolog-based architectures
In Sperberg-McQueen et al., 2000 and Sperberg-McQueen et al., 2002 an
abstract representation format to represent meaning and interpretation of markup based
on a
Prolog fact base was introduced. Witt, 2002 extended this architecture for
dealing with multiple annotated data. In this extension textual data and annotation
are
split up in order to avoid overlapping markup (cf. Bayerl et al., 2003 for a
further discussion). The elements, attributes and text nodes of the annotation layers
are
stored as Prolog predicates which contain the following information (for details refer
to
Witt et al., 2005):
The type of node (element, attribute or text) as the name of the predicate.
The name of the annotation layer.
The absolute start and end positions of the annotated text sequence.
The position of the node in the document tree.
The name of the element or attribute.
The value of an attribute.
Each character in the text base (the primary data) can
be addressed by its offset (its position) as shown in Figure 1. A single
character has a start and end position and a step size of 1.
Figure 1: Addressing character positions
T h i s i s a s e n t e n c e .
00|01|02|03|04|05|06|07|08|09|10|11|12|13|14|15|16|17|18|19
On the basis of the Prolog fact base format, possible relationships between element
instances of different annotation levels can be examined via Prolog predicates (cf.
Durusau and O'Donnell, 2002 and Witt et al., 2005). As further option, a unified
version can be created and exported back to XML where overlaps are handled by using
milestones or fragments.
Although the conversion itself can be done very quickly (two implementations are
available, one programmed in Python, another one in Perl), the fact remains that a
conversion from XML to Prolog is necessary both for markup unification and for analysing
relations between different annotation levels. The need for information about the
position
of each single character of the primary data - which is demanded for reconstructing
the
primary data - and the distributed storing of element and attribute information results
in
rather large Prolog fact bases: for the largest single text stored in our corpus a
single
annotation layer of 1.7 MB in size is converted to a 6.4 MB-size Prolog fact base,
the
combined three annotation layers that are used in our project (logical document structure,
POS, anaphoric relations) result in a 14.3 MB-size Prolog fact base.
Although some of these approaches (e.g. LMNL, TexMECS, XCONCUR) support inline
annotation of multiple annotation layers, these documents can get very complex when
dealing
with a large number of annotation layers. As a drawback, both, design and implementation
of
most of these architectures, rely on the work of only a few people. Therefore,
specifications such as XCONCUR roughly remain in the state of experimental markup
languages
lacking the support of the large number of tools that is available for XML-based
solutions.
Graph-based architectures
A variety of graph-based architectures that use the XML syntax has been developed
in
recent years. Starting with the Annotation Graph (AG) model presented by Bird and Liberman, 1999 and Bird and Liberman, 2001, architectures such as the NITE Object Model (cf. Carletta et al., 2003) in
conjunction with NITE-XML, ATLAS (cf. Bird et al., 2000; Laprun et al., 2002) and the
ATLAS Interchange Format (AIF), the Linguistic Annotation Framework pivot format (cf.
Ide and Romary, 2004) and the similar Potsdam Austauschformat für
Linguistische Annotationen (PAULA, cf. Dipper, 2005), the
Graph-based Format for Linguistic Annotation (GraF, cf. Ide and Suderman, 2007) or the
Graph Exchange Language (GXL, cf. Holt et al., 2006, firstly used in the
graph-based linguistic database HyGraphDB[2] to represent linguistic data structures) were published.
In principle, these graph-based formats allow the annotation of nearly every possible
linguistic annotation. However, as these formats tend to split even single annotation
layers
into separate files (such as a markable/token file which delimits text spans used
in
annotation, a structure file for storing relations between annotation elements and
a feature
file which stores the former annotation), they are often used only as interchange
formats.
In addition, the higher complexity of computing graph structures in contrast to tree
structures in combination with the fact that at least most single annotation layers
can be
structured in trees, leads to a certain inefficiency (cf. Dipper et al., 2007 who
transform a standoff annotation into a an inline representation for efficient querying).
Because our main focus was the development of a tool allowing for the comparison of
different annotations we decided to implement an additional standoff format: The Sekimo Generic Format, SGF.
The Sekimo Generic Format
After the experiences made with the Prolog fact base format the decision was made
to
develop a similar representation based on XML. The initial goal was to use a native
XML
database as storage backend, however, during the development of the Sekimo Generic
Format
(SGF) several implementations were tested, including the use on a per-file basis,
different
native XML databases (e.g. eXist[3], Berkeley DB XML[4], Qizx/db[5], IBM DB2 Express-C 9.5[6]), and a relational database (MySQL[7], cf. section “SGF as import and export format”). In the following sections we will present
SGF in detail. The annotation layers shown in Figure 2 and Figure 3 will serve for demonstration purposes. In section “Application of SGF” we will show a real world example from the domain of anaphora
resolution.
SGF was developed for storing multiple annotated linguistic corpus data and examining
relationships between elements derived from different annotation layers. The format
consists
of a base layer, providing the structure of an SGF instance and global attributes
that are
imported by the different annotation layers (cf. section “The base layer”). The use of
metadata in SGF is described in section “Metadata” while section “Adding layers”, section “Disjoints and continuous segments” and section “Validation” deal with different aspects of the format. Finally, we will
discuss processing and querying of SGF annotated data in section “Querying” and
conclude with possible caveats of the format in section “Caveats and problems”.
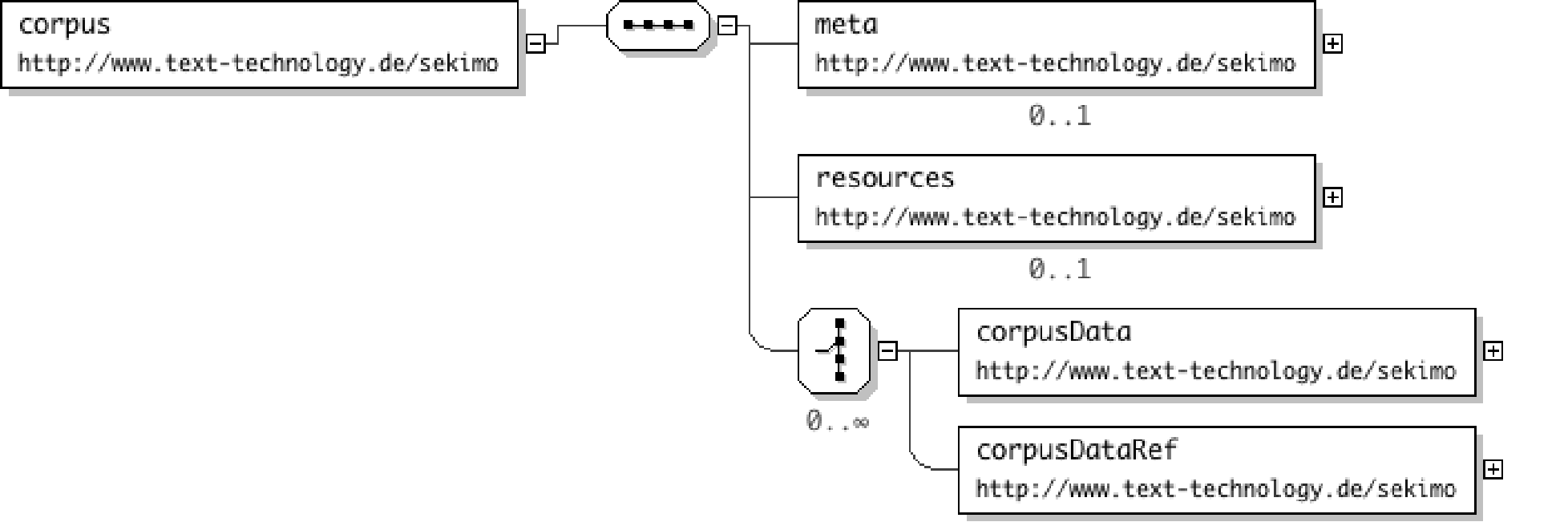
Figure 4: Diagram of the corpus root element
SGF can be used in two different ways as shown in Figure 4:
As a container format that contains optional meta data (cf. section “Metadata”) and the corpus data, i.e. the whole corpus is saved as a
single SGF instance. This is the appropriate way when using SGF for storing small
and
medium sized corpora in conjunction with a native XML database (cf. Figure 5).
On a per-file basis or when dealing with larger corpora a meta SGF file is used
containing (again optional) metadata for and references to the actual corpus files
(cf. Figure 6).
Figure 5: Storing a whole corpus in a single SGF instance
In both cases the root element is the corpus element; underneath this a
corpusDataRef element or a corpusData element can be inserted.
The empty corpusDataRef element allows for referring to an external file
containing a corpus entry via its uri attribute and for specifying the external
data in terms of encoding and mime-types (respective attributes of the same name).
In this
case the root element of the corpus entry instances that are referenced by the SGF
meta file
should be the corpusData element (cf. section “The base layer”).
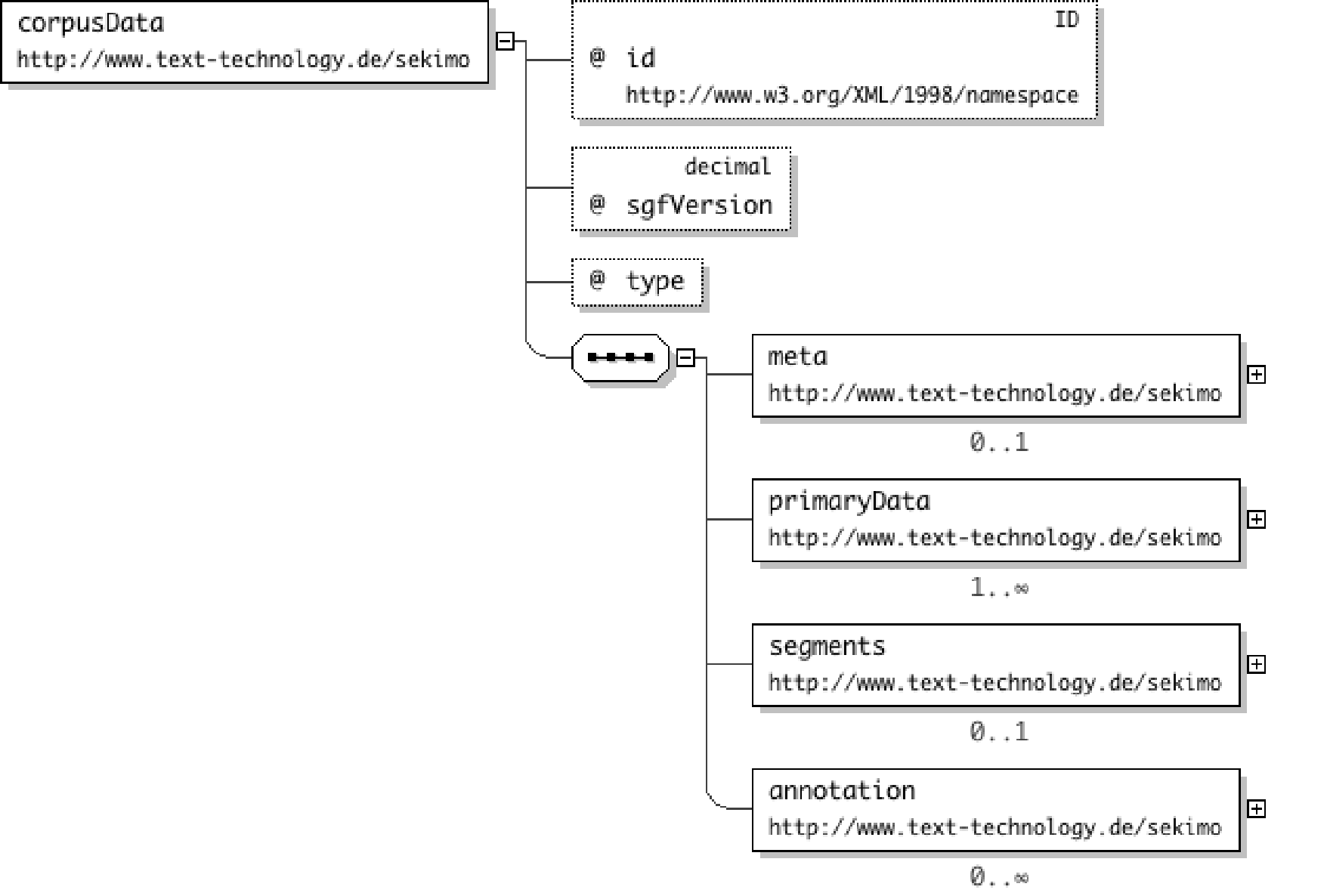
The base layer
The corpusData element is used for storing a single corpus entry containing
optional metadata (cf. section “Metadata”), the primary data, the segmentation of
the primary data, and zero or more respective annotation layer(s) (cf. section “Adding layers”). An example base layer is shown in Figure 8. The xml:id attribute is obligatory while the sgfVersion
attribute is optional (with a default value of 1.0)
The corpusData element holds the type attribute which can be
either set to the value text or multimodal while the primaryData child element contains either
the textual primary data (i.e. the text that is used as basis for annotation) as text
node
of the textualContent element or a reference to a file containing the primary
data (in case of larger texts or non-textual primary data) via a location child
element (not shown in the example listing). In the latter case an optional checksum
of the
input file can be provided in the corresponding element to preserve integrity of primary
data when dealing with multiple annotation resources. Note, that we do not handle
any byte
offset problems derived by different encodings (e.g. Latin 1 vs. UTF-16), therefore,
the use
of the encoding attribute is highly recommended.[8]
When using SGF for storing multimodal annotations, multiple primaryData
elements are allowed. In this case, the attribute role has to be provided which
marks exactly one primary data file as "master" while the other primary
data files are marked as "slaves". The master primary data file sets the
timeline, the slave files can be aligned to the master file via an optional
offset attribute.
Metadata
Metadata can be used in several locations in an SGF instance: as child element of
the
corpus element (for information regarding the whole corpus), underneath a
corpusData entry (denoting metadata related to a single corpus entry and its
annotation layer(s)), or as child of an annotation level. In the underlying XML schema
description of the base layer the meta element is declared wrapper element for
elements derived from a different namespace while the processContents attribute
is set to lax, i.e. if an optional XML schema description
for the referenced namespace is available it should be used for validation. In our
case we
use OLAC metadata (cf. Simons and Bird, 2003) which has turned out to be an adequate
solution for a variety of linguistic data. Figure 10 shows an SGF
instance containing OLAC metadata.
Adding layers
Several annotations of the primary data can be stored inside a corpusData
element. Whenever an annotation layer is added, two steps have to be undertaken:
The segments which delimit the annotated parts of the primary data are
defined.
A converted representation of the original annotation is stored.
The segments element consists of at least one segment. Each
segment is defined by its start and end position in the character stream - similar
to the
Prolog fact base format discussed in section “Prolog-based architectures” (for an alternative
definition of segments cf. section “Disjoints and continuous segments”). We use simple numeric attributes
(defined as nonNegativInteger data type in the underlying XML Schema, cf. section “Validation” and XML Schema Part 2, 2004) for defining the start
and end position - in contrast to the PAULA format (Dipper, 2005), which
uses XLink (DeRose et al., 2001) and the XPointer framework (Grosso et al., 2003) to identify text spans. Because single characters have a step size
of 1 (cf. Figure 1), empty elements use the same value for start and end
position. An optional segment type attribute can be used to provide more
information about the segment (available values are empty,
char for character data, ws for whitespace characters, pun for
punctuation characters, dur for duration in case of
multimodal primary data and seg for referring to already
defined segments, cf. section “Disjoints and continuous segments”).
Figure 10 shows the SGF representation of the two annotation layers
given in Figure 2 and Figure 3. Note that a segment
has to be defined only once, even if it is used in different annotation layers - in
contrast
to some other graph-based approaches (cf. section “Graph-based architectures”) which define the same
character span separately for each annotation layer. This results in a smaller amount
of
segments that has to be defined even for a large number of annotation layers.
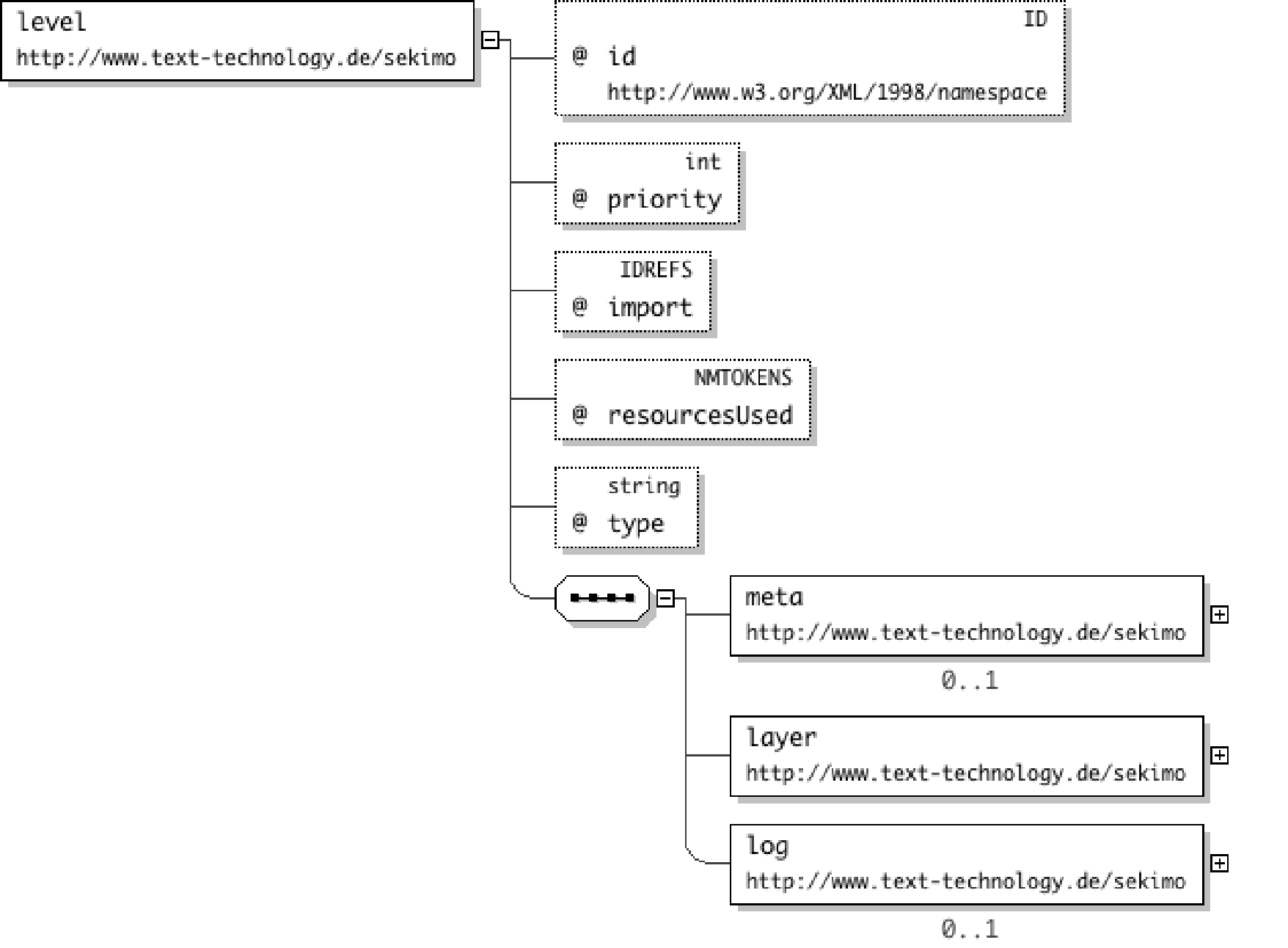
The annotation of the primary data is stored in the corresponding element. Following
the
terminological distinction between levels and layers (cf. section “Introduction”), each level element contains - in addition to optional metadata - exactly
one layer element consisting of the markup representation of the corresponding
annotation level. An annotation element may contain more than one
level element, this mechanism can be used for subsuming annotation levels (e.g.
when the corresponding elements are declared in the same document grammar). The
layer element is a wrapper element containing elements derived from a different
namespace, similar to the meta element (cf. section “Metadata”). However, while the
value of the processContents attribute of the latter is set to lax, the value of the respective attribute of the
layer element is set to strict, resulting in
the fact that an XML schema has to be provided for each annotation layer (cf. section “Validation”).
Figure 9: Diagram of the level element
Figure 10: SGF instance containing two annotation layers
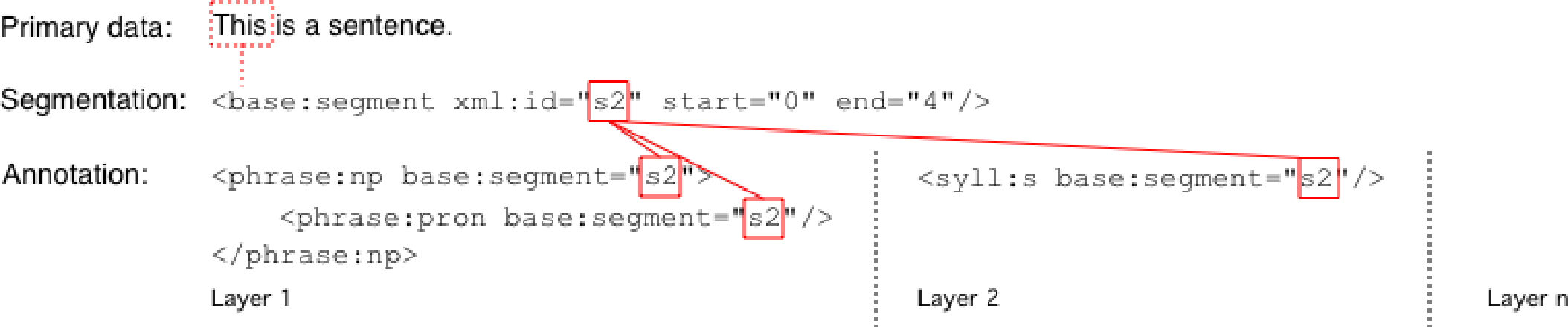
As one can observe in Figure 11, SGF heavily makes use of XML's
inherent ID/IDREF(S) mechanism to connect segments of the primary data with single
or
multiple annotation layers (displayed as solid red lines).
Figure 11: Use of XML's ID/IREF(S) mechanism in SGF
When comparing the two annotation layers with the namespace prefixes phrase
and syll with their respective original representation given in Figure 2 and Figure 3, a second design goal of SGF is made
visible: to conserve as much of the former annotation format as possible. Still, a
conversion has to be made consisting of the following steps:
Elements with a mixed content model are converted into container elements.
Elements containing text nodes are converted into empty elements.
The base:segment attribute is added to former non-empty elements as
an obligatory attribute (and as an optional attribute for empty elements).
The same conversion rules are applied to the underlying XSD (cf. section “Validation”). As shown in Figure 10 the hierarchy of
elements and all attributes remain intact, i.e. there is no need for additional files
such
as structure files which are needed for the graph-based annotation formats discussed
in
section “Graph-based architectures”. However, this statement is only true as long as the
XML-inherent tree structures are adequate.[9] An XSLT implementation is available for converting arbitrary inline annotation
layers into their respective SGF representation while a second XSLT script merges
different
annotation layers according to the same primary data into a single SGF instance. Therefore,
it is possible to add additional annotation elements to an already existing SGF
instance at any time (as long as the primary data is not changed). Work has begun
on a
second implementation (written in Java).
Disjoints and continuous segments
Often segments consist of other segments making it possible to create new segments
not
only by defining their start and end positions but by referring to already defined
segments
using the segments attribute, too (cf. Figure 12). In
order to distinguish if these newly established segments include all segments starting
from
the first referred segment up to the last referred one, or define a disjoint span,
the
attribute mode has to be set to the value continuous or disjoint, respectively. The
example in Figure 12 shows a disjoint span.
Figure 12: Definition of a disjoint segment by referring to already established
ones
Note that this feature of SGF could be used for conversion between SGF instances and
architectures mentioned in section “XML-related architectures”, however, up to now it has been of
theoretical use only.
Validation
An important aspect when dealing with multiple annotated data is the question of
validating this data. In case of overlaps it is strictly impossible to provide a document
grammar that is feasible for validating the unification of different annotation layers
-
even without the amount of work that has to be done for producing such a document
grammar.
Therefore, we propose that each annotation level is validated separately - in addition
to
the SGF instance as a whole - with a transformed version of its original document
grammar.
This conversion follows the conversion of the annotation layer described in section “Adding layers”.
We decided to use W3C XML Schema Description Language (XSD) (cf. XML Schema Part 1, 2004) as the underlying schema language for SGF for different
reasons. As already stated, SGF relies heavily on two aspects:
ID/IDREF(S) mechanism, and
Namespace support.
While ID/IDREF(S) is already present in XML Document Type Definitions, DTDs
lack real support for XML namespaces. Furthermore, SGF makes use of XML Schema data
types
(XML Schema Part 2, 2004) and when external document grammars (for annotation
layers and metadata) are imported, the control of the processing of the imported document
grammars is crucial (cf. section “SGF as import and export format” for the discussion of the Serengeti
log functionality and the role of XML Schema's processContents attribute).
Because of this we had to choose one of the XML schema languages available. XSD was
favoured over RELAX NG (ISO/IEC 19757-2:2003) because of the better software support,
e.g. with Saxon-SA[10] a schema-aware XSLT and XQuery engine is available which allows for the use of
the id() and idref() functions for the task of comparing different annotation layers
(cf.
section “Analysing annotations”). Of course it would be possible to use simple string
comparisons, however, XML IDs are usually indexed by the XSLT processor (for Saxon
cf.
http://saxon.wiki.sourceforge.net/indexing)
and are for this reason - in most cases - much more efficient than the equivalent
XPath
expression using a string comparison predicate (cf. Kay 2008, p. 802-804.).
This helps reducing processing costs when dealing with larger SGF instances, however,
the
downside is that the validation of each XSD associated takes some time (approximately
one to
two seconds in our case).
Apart from XSD validation, embedded Schematron (ISO/IEC 19757-3:2006) asserts
are used as additional constraints, for example for refusing end positions of segments
that
are less than start positions (cf. Robertson, 2002). In the upcoming version
1.1 of XML Schema, the assert element will be used for fulfilling this task
(XML Schema 1.1 Part 1, 2008).
Querying
One of the goals during the development of SGF has been the possibility of analyzing
the
relationships between elements of different layers. In contrast to the work described
by
Alink et al., 2006 and Alink et al., 2006a, which involves new standoff
XPath axis steps, or the linguistic query language LPath, which extends the XPath
1.0 syntax
and which was introduced by Bird et al., 2006, SGF uses unchanged XML-related
specifications for querying data. Up to now we have employed XSLT 2.0, XPath 2.0 and
XQuery
1.0 queries for typical tasks carried out in our project (cf. section “Application of SGF”). Bird et al., 2006 and Dipper et al., 2007
suggest different example queries to evaluate their architectures. By now, Q1
("Find all sentences that include the word 'kam'"), Q2 ("Find all
sentences that do not include the word 'kam'"), Q3 ("Find all NPs. Return
the reference to that NP") and Q7 ("Find all pairs of anaphors and direct
antecedents in which the anaphor is a personal pronoun") described in Dipper et al., 2007 were implemented.
[11]Figure 13 shows Q7 for our
corpus.
Figure 13: XQuery Q7 adapted for the corpus under investigation
declare boundary-space strip;
declare namespace base="http://www.text-technology.de/sekimo";
declare namespace doc="http://www.text-technology.de/sekimo/doc";
declare namespace cnx="http://www.text-technology.de/cnx";
declare namespace chs="http://www.text-technology.de/sekimo/chs";
declare variable $doc := "ling-deu-003-sgf-noWS.xml";
<resultset file="{$doc}">
{
let $d := doc($doc)
for $s in $d//chs:semRel/chs:cospecLink[id(@phorIDRef)/
id(@base:segment)/idref(@xml:id)/..[name()='cnx:token'
and @pos='PRON' and contains(@morpho,'Pers')]]
return
<relation>
{$s/@*}
{<anapher>
{$s/id(@phorIDRef)/id(@headRef)/data(@text)}
</anapher>,
<antecedent>
{$s/id(@antecedentIDRefs)/id(@headRef)/data(@text)}
</antecedent>}
</relation>
}
</resultset>
In addition, we have implemented Q8 ("Find all pairs of anaphors and
antecedents and their respective parent(s) on the logical document layer"), for
which it is necessary for the XQuery processor to traverse back to the segments, compare
several segment elements and then to find the corresponding annotations. Most
of the queries perform comparable to the respective inline queries referred to in
Dipper et al., 2007, but in general they are difficult to compare since our corpus (six
German scientific articles and eight German newspaper articles, containing 3,084 sentences,
56,203 tokens, 11,740 markables, 4,323 anaphoric relations, three annotation levels:
logical
document structure, POS, anaphoric relations) is different both in terms of size and
annotation levels. Apart from Q7, most parts of the queries can be performed inline
(which
is a benefit of SGF over other architectures discussed in section “Graph-based architectures”),
which allows us to abstain from converting SGF instances to inline representation
prior to
analyzing the relations (which was one of the motivations in developing SGF) as proposed
by
Dipper et al., 2007.
For a first evaluation we have chosen both the aforementioned complete corpus and
our
largest single text, a German scientific article comprising 157 paragraphs, 696 sentences,
12,345 token, 2,550 markables and 1,358 anaphoric relations (14,985 segments in total),
annotated on the three annotation levels described above. All values are average results
after five executions on two different machines:
PC1: a Sun Fire V20z equipped with dual single core AMD Opteron 248 clocked at 2,2
GHz and 6 GB RAM running on Sun Solaris 10 (64bit) with Saxon-SA 9.0.0.1J on Java
1.5.0_15 (2 GB RAM allocated for Java VM) and SWI-Prolog 5.6.21 (128 MB allocated
as
local stack limit).
PC2: a standard PC equipped with a Intel dual core Core2Duo E6600 clocked at 2,99
GHz with 3.12 GB RAM running on Microsoft Windows XP SP3 (32bit) with Saxon-SA
9.0.0.1J on Java 1.6.0_06 (1 GB RAM allocated for Java VM) and SWI-Prolog 5.6.57 (128
MB allocated as local stack limit).
Included in the XQuery results is the validation of five XSD files (-val parameter) and the output of an XML file (-o parameter) with a resultset root element and the
corresponding query results underneath. For comparison, we evaluated the same queries
for
the Prolog fact base architecture used in the first project phase (cf. section “Prolog-based architectures”) on the same two machines. For the latter the amount of time for
consulting the Prolog fact base containing the annotated data (14.3 MB in size, 3.37
sec on
PC1; 2.94 sec on PC2) and the Prolog query file (4.3 KB in size, 0.0 sec on both machines)
is not included in the results. The query results are output to a separate text file.
Table I
Evaluation results (in seconds). Average of five executions.
Query
Prolog query results for single text (PC1 / PC2)
XQuery results for single text (PC1 / PC2)
XQuery results for whole corpus (PC1 / PC2)
Q1
0.22 / 0.054
4.612 / 1.244
9.609 / 4.162
Q2
13.502 / 4.554
5.161 / 1.234
9.390 / 4.357
Q3
0.084 / 0.03
4.035 / 1.219
9.556 / 4.084
Q7
30.66 / 7.798
5.764 / 1.481
11.669 / 5.35
Q8
84.16 / 24.738
15.379 / 11.134
152.683 / 114.525
Note that in contrast to the graph-based architectures described in section “Graph-based architectures”, the XQueries and their evaluation results depend on the annotation
layers that are imported into the SGF base layer. This means that especially Q1, Q2
and Q3
are very fast because they can be performed inline in our corpus (i.e. both sentence
and
token information are descendants of the same annotation element - and the
token element contains its textual content in its text attribute).
For Q7, information derived from different annotation layers has to be taken into
account,
however, since only the id() function is used, the results are satisfactory as well.
Q8 is
the single XQuery that requires the identification of the respective segment
element and the use of the idref() function afterwards in order to get the corresponding
annotations. For these reasons, the advantage when using SGF over comparable architectures
rises or drops depending on the imported annotation layers. To further reduce processing
costs it is possible to use merged inline annotation layers (e.g. a logical document
layer
and a POS layer) as a combined, single SGF layer and use separate SGF layers only
when
overlaps occur. In this case the XML-inherent hierarchies can be used for (inline)
analyzing
of wide parts of the annotated data while a reversion to SGF's use of the ID/IDREF
mechanism
should only be made if not avoidable.
The performance figures for the Prolog fact base format show higher performance for
simple queries but lower performance for more complex ones. These figures result from
the
fact that our corpus annotation makes heavy use of attributes, which leads to distributed
information. We believe that a re-implemented Prolog fact base format could both reduce
file
size and speed up the querying.
Caveats and problems
Up to now, several former inline annotation layers have been converted into SGF and
the
format as such is quite stable (although minor changes may occur). Apart from the
huge
amount of markup that is necessary to do this kind of analysis, problems may arise
when the
annotation layers that are stored in SGF are exported back into their original inline
representation. This is especially true when the annotation layers contain empty elements,
for which it is impossible to provide the exact position in the original document
tree (of
course the base:segment attribute can be used for these elements as well; when
a large number of empty elements appears in a row, the values of all their respective
base:segment attributes would be identical). Although our largest SGF
instance is at 6 MB including optional whitespace segments (4.8 MB without optional
whitespace segments), it is still smaller than the respective Prolog fact base
representation at 14.3 MB, cf. section “Prolog-based architectures”.
When it comes to queries, SGF relies on the imported annotation layers. For this reason,
there is no standard set of queries available and the execution time cannot be easily
predicted.
Application of SGF
Various application domains require the analysis of different information resources
in
order to answer a specific question. Alink et al., 2006, Alink et al., 2006a, for example, describe the analysis of multiple markup in the domain of digital forensics.
In our project, we focus on linguistic phenomena, especially on anaphora resolution.
Anaphora
occurs when the interpretation of a linguistic unit (the anaphor) is dependent on
the
interpretation of another element in the previous context (the antecedent). The anaphor
is
often an abbreviated or reformulated reference to its antecedent and thus provides
for the
progression of discourse topics and discourse coherence. Anaphoric relations can be
categorized according different axes (cf. Mitkov, 2002 for an overview): Type
of anaphora (pronoun, NP, adverb, etc.), type of antecedent (e.g. nominal vs. abstract
entity)
and type of relation. In this paper, we will focus on nominal anaphora with nominal
antecedents only. According the relation type, anaphoric relations may either express
reference identity between the anaphor and its antecedent (Example 1) or the
respective expressions are related via associative links (Example 2).
I met a man yesterday. He told me a story.
(example taken from Clark, 1977, p. 414)
I looked into the room. The ceiling was very high.
(example taken from Clark, 1977, p. 415)
In order to resolve anaphoric relations, different kinds of information have to be
taken
into account that are provided by different resources: POS tagger, Chunker, Parser,
word net
and ontologies. These resources provide information on gender or number agreement,
noun
phrases, grammatical function, lexico-semantic relations and domain or world knowledge.
The
resolution of the anaphoric relation given in Example 1 is dependent on agreement
information of the pronoun he whereas the resolution of Example 2 requires the knowledge that a room typically has a ceiling which is
provided in terminological nets such as WordNet (Fellbaum, 1998) or other ontological resources.[12]
We apply SGF for the integration of different resources and access to these data.
In terms
of levels and layers, each resource provides information for a specific level and
this
information is stored in a respective layer: A POS tagger provides information on
part of
speech tags and respective markup is generated in the tool's output file whereas access
to a
word net provides information on semantic relatedness of words in terms of distance
between
word's synsets. This information has to be stored and accessed for the anaphora resolution
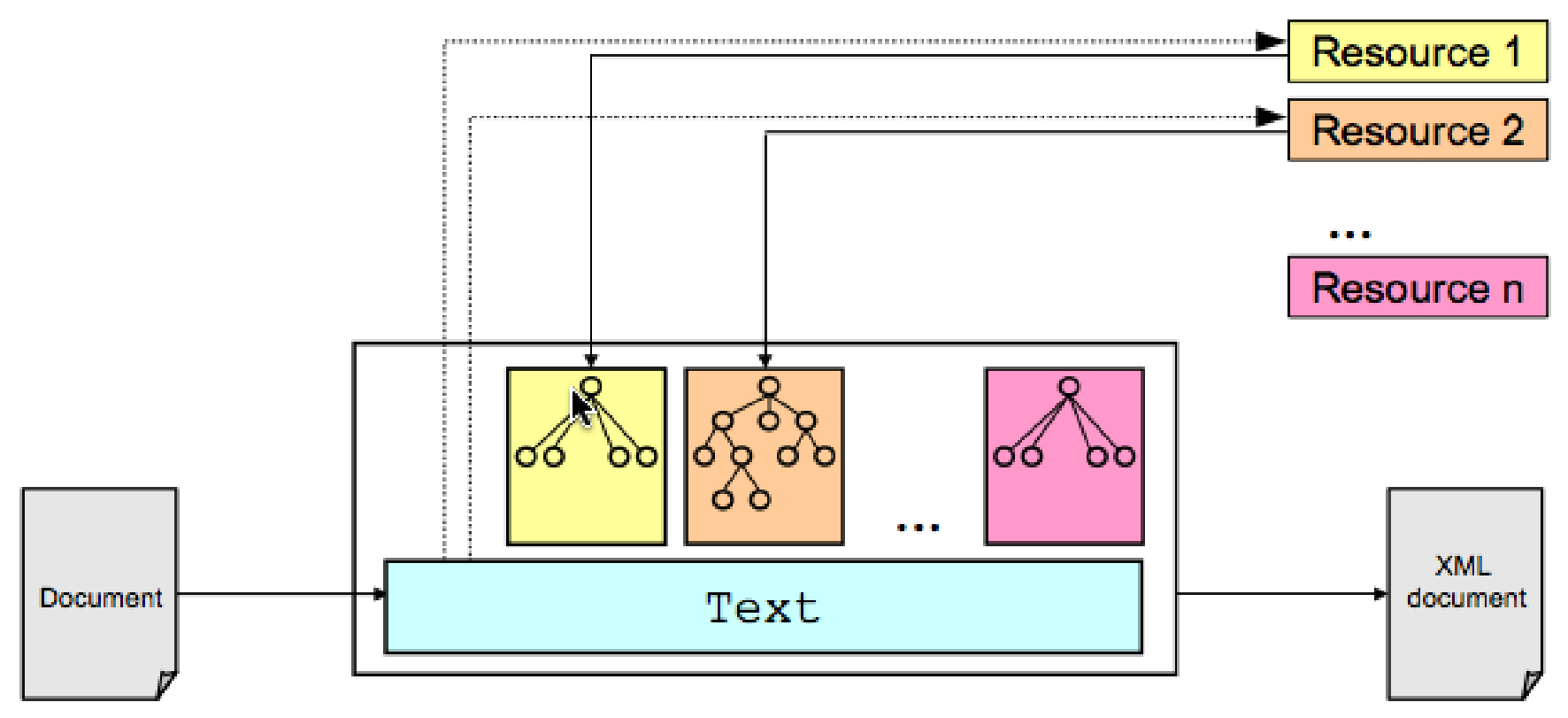
process. Figure 14 exemplifies the integration: Each resource is applied
and the resulting markup is stored independently from the primary data. On the basis
of the
information stored in SGF it is possible to query the data, to create new markup
layers, or to create inline versions of the markup and the primary data.
Figure 14: Application of multiple resources
Analysing annotations
In the application domain of anaphora resolution, a raw text document is taken as
input
and annotation layers are created for different levels. All layers are converted to
SGF and
can be analyzed afterwards. For the task of anaphora resolution, a set of antecedent
candidates is created for each anaphoric element via an XSLT script (cf. Figure 16, an example candidate list is shown in Figure 17). The candidate list consists of several semRel elements each containing one
anaphor element and several antecedentCandidate elements.
Information on the relation type between anaphor and correct antecedent is stored
as
attribute information in the semRel element. The anaphor element
describes properties of the anaphoric element whereas the antecedentCandidate elements describe
information on the antecedent candidates. In both cases this information is stored
in terms
of attributes. Number or gender agreement can be computed from the morpho
attribute. Additional information is given for
part of speech (pos), grammatical function (syntax), dependency
structure (dependHead), position of element in the whole document (position), the parent element on the logical document layer (docParent) as
well as for the head noun both in surface form (text) and lemma
(lemma). Together with other pieces of information a score for the most
probable antecedent candidate can be computed (cf. Goecke et al. (to appear) for a similar approach). For the
anaphora resolution system each anaphor-candidate-pair is interpreted as a feature
vector
which is used for training a classifier. Information on the correct antecedent candidate
is
necessary in order to classify positive and negative training examples (cf. Soon et al., 2001, Strube and Müller, 2003, Yang et al., 2004).
The annotated example sentence in Figure 15 is an extract of a
German newspaper article that is part of our corpus. The content of the text excerpt
is as
follows:
Lurup ist ein sozialer Brennpunkt der Hansestadt, ein Vorort mit Einzelhäusern, aber
auch vielen Wohnblocks im Westen der Stadt.
which is translated into:
Lurup is a social ghetto of the hanseatic city (Hansestadt), an outskirt with single
unit houses but also many apartment blocks in the west of the city (Stadt).
In Figure 15 all levels that are used in the Sekimo project can be observed: the logical document structure (namespace
prefix doc), the output of the commercial Parser/Tagger Machinese Syntax by Connexor Oy (namespace prefix cnx), the
discourse entity level and the semantic relations level (namespace prefix chs).
The segment seg1 delimits the whole text, while seg2 delimits a
paragraph (containing a single sentence, cf. the doc:text and
doc:para elements in the logical document layer and the
cnx:sentece element in the cnx layer). The segments identified by
seg1589 and seg1620 mark the two token (and respective discourse
entities) "Hansestadt" and "Stadt". There is a
cospecification relation (to be more specific: a hypernym relation) between these
two
discourse entities which is stored in the chs:cospecLink element located in the
chs layer.
Figure 15: SGF instance of a German newspaper text (excerpt)
Apart from resources that have already been mentioned, further information is needed
in
order to create a suitable set of antecedent candidates for training and resolution.
In
general, a fixed search window in terms of markables (i.e. elements between which
anaphoric
relations can hold), sentences or paragraphs is chosen. This approach works well for
pronoun
anaphora due to the fact that pronouns tend to find their antecedents within a short
distance (cf. Mitkov, 2002). However, for the resolution of non-pronominal
definite noun phrases (definite descriptions) and the processing of long texts the
application of a fixed search window is not feasible because definite descriptions
tend to
find their antecedents at a greater distance than pronouns. For the corpus under
investigation that has been manually annotated for anaphoric relations (cf. Diewald et al. (submitted) for further information regarding the corpus and the annotation
scheme), 26.8% of all non-pronominal anaphors (i.e. 20.9% of all anaphors in the corpus)
find their antecedent at a distance of two or more paragraphs. We apply structural
information to create candidate sets that include not only candidates at a short distance
but also those at a larger distance. A small excerpt of the XSLT stylesheet that is
used for
the extraction is shown in Figure 16.
Figure 16: Excerpt of the XSLT stylesheet used for extracting candidates
Because the segment element is the central and critical mechanism in SGF
(cf. Figure 11) we have to use the id() and idref() XPath functions to
analyze elements derived from different annotation layers. Figure 17
shows a result candidate list, extracted with a maximum distance of 10 discourse entities.
Figure 17: Candidate list extracted from the SGF instance
For all antecedentCandidate elements (i.e. former chs:de
elements) position and deDistance attributes have been added.
Apart from the discourse structure that is used to model accessibility of antecedent
candidates (cf. Polanyi, 1988), the logical document structure provides
information on the hierarchical structure of texts by describing
the organisation of the text document in terms of chapters, sections, paragraphs,
and the
like and is stored in the doc layer of the SGF instance.[13] Based on this information which can be accessed from DocBook, OpenDocument, or
LaTeX, a layout-oriented presentation can be generated which is application independent.
Especially for texts from e-publishing sources a set of logical document structure
elements
is easily available which can be used to identify different text segments. The influence
of
the logical document structure on the choice of an antecedent might be either (a)
a direct
influence on the markables (or antecedent life span) or (b) an influence on the search
window (cf. Goecke and Witt, 2006). In our candidate list shown in Figure 17 the docParent attribute supplies information about
the (virtual) parent element of the logical document layer, i.e. the element of the
logical
document layer that refers to a segment whose start position is lower or equal and
whose end
position is greater or equal to that of the segment referred to by the element analyzed.
Regarding the document structure, corpus evidence shows that some discourse entities
are
more prominent throughout the whole document than others, e.g. markables occurring
in the
abstract of a text might be accessible during the whole text whereas markables that
occur in
a footnote-structure are less likely as an antecedent for anaphoric elements in the
main
text. Corpus evidence shows that in a corpus consisting of 4323 anaphoric relations
65.3% of
all anaphor-antecedent-pairs are located in the same segment. Regarding the remaining
anaphor-antecedent-pairs, we expect markables described in hierarchically higher elements
(e.g. subsection) to be much more prone to finding their antecedents in structuring
elements of a
higher level (section) than in a preceding but hierarchically lower segment
(subsubsection). Thus, the influence on the search window may either enlarge the search
window, i.e. the antecedent may be located outside the standard window (e.g. located
in the
whole paragraph or in a preceding one), or may narrow the search window, e.g. due
to the
start of a new chapter or section. Furthermore, the position of an antecedent candidate
within a paragraph gives hints as to how likely that candidate is chosen as the correct
one.
An analysis of our corpus data shows that 50.2% of the antecedents are located
paragraph-initial and 29.1% are located paragraph-final whereas only 20.2% are located
in
the middle of the paragraph. Thus in addition to the information regarding the search
window, information on logical document structure might give cues for selecting the
correct
antecedent from a set of candidates.
SGF as import and export format
While the main reason for the development of SGF was analyzing relations between
elements derived from different annotations (cf. section “Application of SGF”), the
format is used in a another application in our project. The Serengeti web-based annotation tool described in Stührenberg et al., 2007 is currently enhanced to support different annotation schemes. This upcoming version
of
Serengeti will be used not only at Bielefeld University but also as an expert annotation
tool in the AnaWiki project (cf. Poesio and Kruschwitz 2008) and will use SGF as its import and export format. For this reason, an SGF API (written
in Perl) was implemented that allows the mapping of SGF to the relational MySQL database
that is used as a backend for Serengeti.
During this development a log functionality was added to SGF ensuring that the
information of added, deleted or modified data is not only stored in the Serengeti
application but can be included in the exported SGF instance. A log can be
stored as child element of an annotation level and contains at least one log
entry, consisting of optional metadata and one or more action
elements. The user responsible for the log entry is identified via a respective attribute,
together with the time the entry was made (timestamp attribute). Each action is
specified by its type attribute (add,
delete, modify) and
refers to the affected elements via an optional IDREF affectedItem attribute
(not when the type attribute's value is set to add). The content of an action element is a sequence of elements
from any namespace (otherwise modification of segments would not be possible), however,
XML
Schema's processContents attribute is set to skip, therefore, it is possible to use the same IDs several times (e.g. when
modifying a segment element).
In addition, an SGF application for storing lexical chains was developed. SGF-LC, a lightweight XSD that is imported into the SGF base layer
and that makes use of the attributes provided by the base layer is described in Waltinger et al., 2008 and is used as export format for the Scientific Workplace tool[14] developed by the project A4 (Indogram) of our
Research Group.
Conclusion and outlook
In this paper we presented the Sekimo Generic Format (SGF) as an alternative approach
for
storing multiple annotated data amongst a variety of already established architectures
and
formats. SGF is used as an XML-based solution for storing and especially analyzing
a corpus of
multiple annotated documents (multi-rooted trees) in the linguistic application domain
of
anaphora resolution. Future work regarding our linguistic task of anaphora resolution
focuses
on the analysis of relations between logical document structure and the distribution
of
antecedent detection. On the technical side, we will adapt SGF to the upcoming version
1.1 of
XML Schema, which includes assertions similar to the Schematron asserts used in the
current
version of SGF. Other possible developments include the implementation of converter
scripts
between SGF and some of the graph-based architectures mentioned and the further testing
of the
efficiency of SGF in large scale corpora using a wider set of sample queries.
References
[Alink et al., 2006] Alink, W., Bhoedjang, R., de
Vries, A. P., and Boncz, P. A. Efficient XQuery Support for Stand-Off
Annotation. In: Proceedings of the 3rd International Workshop on XQuery
Implementation, Experience and Perspectives, in cooperation with ACM SIGMOD, Chicago,
USA,
2006.
[Alink et al., 2006a] Alink, W., Jijkoun, V., Ahn,
D., and de Rijke, M. Representing and Querying Multi-dimensional Markup
for Question Answering. In: Proceedings of the 5th EACL Workshop on NLP and XML
(NLPXML-2006): Multi-Dimensional Markup in Natural Language Processing}, Trento, 2006.
[Bayerl et al., 2003] Bayerl, P. S., Lüngen, H.,
Goecke, D., Witt, A. and Naber, D. Methods for the semantic analysis of
document markup. In: Roisin, C.; Muson, E. and Vanoirbeek, C. (ed.), Proceedings
of the 3rd ACM Symposium on Document Engineering (DocEng), Grenoble, pages 161-170,
2003.
[Bird and Liberman, 1999] Bird, S. and Liberman,
M.Annotation graphs as a framework for multidimensional linguistic
data analysis. In: Proceedings of the Workshop "Towards Standards and Tools for
Discourse Tagging", pages 1–10. Association for Computational Linguistics, 1999.
[Bird et al., 2000] Bird, S., Day, D., Garofolo, J.,
Henderson,J., Laprun, C. and Liberman,M. ATLAS: A flexible and
extensible architecture for linguistic annotation. In: Proceedings of the Second
International Conference on Language Resources and Evaluation, pages 1699–1706, Paris,
2000.
European Language Resources Association.
[Bird et al., 2006] Bird, S., Chen, Y., Davidson, S.,
Lee, H. and Zheng,Y. Designing and Evaluating an XPath Dialect for
Linguistic Queries. In: Proceedings of the 22nd International Conference on Data
Engineering (ICDE), Atlanta, USA., 2006
[Carletta et al., 2003] Carletta, J., Kilgour, J.,
O’Donnel, T. J., Evert, S. and Voormann, H. The NITE Object Model
Library for Handling Structured Linguistic Annotation on Multimodal Data Sets.
In: Proceedings of the EACL Workshop on Language Technology and the Semantic Web (3rd
Workshop
on NLP and XML (NLPXML-2003)), Budapest, Ungarn, 2003.
[Clark, 1977] Clark, H. (1977). Bridging. In: Johnson-Laird, P.N. and Wason, P.C. (eds.): Thinking: Readings in
Cognitive Science. Cambridge : Cambridge University Press, 1977, S. 411 - 420.
[Cowan et al., 2006] J. Cowan, J. Tennison, and Piez,
W. LMNL update. In: Proceedings of Extreme Markup Languages,
Montréal, Québec, 2006.
[DeRose, 2004] DeRose, S. J. Markup Overlap: A Review and a Horse. In: Proceedings of Extreme Markup
Languages, 2004.
[Diewald et al. (submitted)] Diewald, N.,
Stührenberg, M., Garbar, A. and Goecke, D. Serengeti -- Webbasierte
Annotation semantischer Relationen. To appear in LDV Forum - Zeitschrift für
Computerlinguistik und Sprachtechnologie.
[Dipper, 2005] Dipper, S. XML-based stand-off representation and exploitation of multi-level linguistic
annotation. In: Proceedings of Berliner XML Tage 2005 (BXML 2005), pages 39–50,
Berlin, Deutschland, 2005.
[Dipper et al., 2007] Dipper, S., Götze, M.,
Küssner, U. and Stede, M. Representing and Querying Standoff
XML. In: Rehm, G., Witt, A. and Lemnitzer, L. editors, Datenstrukturen für
linguistische Ressourcen und ihre Anwendungen. Data Structures for Linguistic Resources
and
Applications. Proceedings of the Biennial GLDV Conference 2007, pages 337–346, Tübingen,
2007.
Gunter Narr Verlag.
[Durusau and O'Donnell, 2002] Durusau, P. and
O'Donnell, M.B.. Concurrent Markup for XML Documents. In:
Proceedings of the XML Europe conference 2002.
[Fellbaum, 1998] Fellbaum, C. WordNet: An electronic lexical database. Cambridge, Mass.: MIT Press, 1998.
[Gleim et al., 2007] Gleim, R., Mehler, A. and
Eikmeyer, H.-J. Representing and Maintaining Large Corpora.
In: Proceedings of the Corpus Linguistics 2007 Conference, Birmingham (UK), 2007.
[Goecke and Witt, 2006] Goecke, D. and Witt, A.
Exploiting Logical Document Structure for Anaphora
Resolution. In: Proceedings of the 5th International Conference on Language
Resources and Evaluation (LREC 2006). Genoa, Italy, 2006.
[Goecke et al. (to appear)] Goecke, D., Stührenberg,
M. and Wandmacher, T. Extraction and representation of semantic
relations for resolving definite descriptions. To appear in LDV Forum -
Zeitschrift für Computerlinguistik und Sprachtechnologie.
[Goecke et al., 2008] Goecke, D., Lüngen, H.,
Metzing, D., Stührenberg, M. and Witt, A. Different Views on Markup.
Distinguishing levels and layers. In: Linguistic modeling of information and
Markup Languages. Contributions to language technology. Springer, 2008.
[Hamp and Feldweg, 1997] Hamp, B. and Feldweg, H.
GermaNet - a Lexical-Semantic Net for German. In:
Proceedings of ACL workshop "Automatic Information Extraction and Building of Lexical
Semantic Resources for NLP Applications", pages 9–15, New Brunswick, New Jersey,
1997. Association for Computational Linguistics.
[Hilbert, 2005] Hilbert, M. MuLaX – ein Modell zur Verarbeitung mehrfach XML-strukturierter Daten. Diploma
thesis, Bielefeld University, 2005.
[Hilbert et al., 2005] M. Hilbert, O. Schonefeld,
and A. Witt. Making CONCUR work. In: Proceedings of Extreme
Markup Languages, 2005.
[Huitfeldt and Sperberg-McQueen, 2001] Huitfeldt,
C. and Sperberg-McQueen, C.M. Texmecs: An experimental markup
meta-language for complex documents. Markup Languages and Complex Documents
(MLCD) Project, Februar 2001.
[Ide and Romary, 2007] Ide, N. and Romary, L.
Towards International Standards for Language Resources. In:
Dybkjaer, L., Hemsen, H., and Minker, W., editors, Evaluation of Text and Speech Systems,
pages 263--284. Springer.
[Ide and Suderman, 2007] Ide, N. and Suderman, K.
GrAF: A Graph-based Format for Linguistic Annotations. In:
Proceedings of the Linguistic Annotation Workshop, pages 1-8, Prague, Czech Republic.
Association for Computational Linguistics, 2007.
[Laprun et al., 2002] Laprun, C., Fiscus, J. G.,
Garofolo, J. and Pajot, S. Recent improvements to the ATLAS
architecture. In: Proceedings of HLT 2002, Second International Conference on Human
Language Technology Research, 2002.
[ISO/IEC 19757-2:2003] ISO/IEC 19757-2:2003.
Information technology – Document Schema Definition Language (DSDL) –
Part 2: Regular-grammar-based validation – RELAX NG (ISO/IEC 19757-2).
International Standard, International Organization for Standardization, Geneva, 2003.
[ISO/IEC 19757-3:2006] ISO/IEC 19757-3:2006.
Information technology – Document Schema Definition Language (DSDL) –
Part 3: Rule-based validation – Schematron. International standard, International
Organization for Standardization, Geneva, 2006.
[Jagadish et al., 2004] Jagadish, H. V.,
Lakshmanany, L. V. S., Scannapieco, M., Srivastava, D. and Wiwatwattana, N. Colorful XML: One hierarchy isn’t enough. In: Proceedings of ACM
SIGMOD International Conference on Management of Data (SIGMOD 2004), pages 251–262,
Paris,
June 13-18 2004. ACM Press New York, NY, USA.
[Kay 2008] M. Kay. XSLT 2.0 and
XPath 2.0 Programmer’s Reference. Wiley Publishing, Indianapolis, 4th edition,
2008.
[Le Maitre, 2006] Le Maitre, J. Describing multistructured XML documents by means of delay nodes. In:
DocEng ’06: Proceedings of the 2006 ACM symposium on Document engineering, pages 155–164,
New
York, NY, USA, 2006. ACM Press.
[Mitkov, 2002] Mitkov, R. Anaphora resolution. London: Longman, 2002
[Poesio and Kruschwitz 2008] Poesio, M. and
Kruschwitz, U. Anawiki: Creating anaphorically annotated resources
through web cooperation. In: Proceedings of LREC 2008.
[Schonefeld, 2007] O. Schonefeld. XCONCUR and XCONCUR-CL: A constraint-based approach for the validation of
concurrent markup. In: Rehm, G., Witt, A., Lemnitzer, L. (eds.), Datenstrukturen
für linguistische Ressourcen und ihre Anwendungen. Data Structures for Linguistic
Resources
and Applications. Proceedings of the Biennial GLDV Conference 2007, Tübingen, Germany,
2007.
Gunter Narr Verlag.
[Soon et al., 2001] Soon, W.M., Lim, D.C.Y. and Ng,
H.T. (2001). A Machine Learning Approach to Coreference Resolution of
Noun Phrases. In: Computational Linguistics 27 (2001), No. 4, pages 521-544.
[Sperberg-McQueen et al., 2002] Sperberg-McQueen, C. M., Dubin, D., Huitfeldt, C. and Renear, A. Drawing inferences on the basis of markup. In: Proceedings of Extreme Markup
Languages, 2002.
[Sperberg-McQueen and Burnard, 2002]
C. Sperberg-McQueen, C. M. and Burnard, L. (eds.). TEI P4: Guidelines
for Electronic Text Encoding and Interchange. published for the TEI Consortium by
Humanities Computing Unit, University of Oxford, Oxford, Providence, Charlottesville,
Bergen,
2002.
[Sperberg-McQueen and Huitfeldt, 2004]
Sperberg-McQueen, C. M. and Huitfeldt, C. GODDAG: A Data Structure for
Overlapping Hierarchies. In: King, P. and Munson, E. V. (eds.), Proceedings of
the 5th International Workshop on the Principles of Digital Document Processing (PODDP
2000),
volume 2023 of Lecture Notes in Computer Science, pages 139–160. Springer, 2004.
[Strube and Müller, 2003] Strube, M. and Müller, C.
(2003). A machine learning approach to pronoun resolution in spoken
dialogue. In: ACL '03: Proceedings of the 41st Annual Meeting on Association for
Computational Linguistics. Morristown, NJ, USA : Association for Computational Linguistics,
2003, pages 168-175.
[Stührenberg et al., 2007] Stührenberg, M.,
Goecke, D, Diewald, N., Cramer, I. and Mehler, A. Web-based annotation
of anaphoric relations and lexical chains. In: Proceedings of the Linguistic
Annotation Workshop (LAW), pages 140–147, Prague. Association for Computational Linguistics,
2007
[Tennison, 2002] Tennison, J. Layered Markup and Annotation Language (LMNL). In: Proceedings of
Extreme Markup Languages, Montréal, Québec, 2002.
[Thompson and McKelvie, 1997] Thompson, H. S. and
D. McKelvie. Hyperlink semantics for standoff markup of read-only
documents. In: Proceedings of SGML Europe ’97: The next decade – Pushing the
Envelope, pages 227–229, Barcelona, 1997.
[Waltinger et al., 2008] Waltinger, U., Mehler,
A. Mehler, and Stührenberg, M. An Integrated Model of Lexical Chaining:
Application, Resources and its Format. Accepted for Proceedings of Konvens 2008.
[Witt, 2002] Witt, A. Meaning
and interpretation of concurrent markup. In: Proceedings of ALLC-ACH2002, Joint
Conference of the ALLC and ACH, 2002.
[Witt, 2004] Witt, A. Multiple
hierarchies: New Aspects of an Old Solution. In: Proceedings of Extreme Markup
Languages, 2004.
[Witt et al., 2005] Witt, A., Goecke, D., Sasaki, F.,
and Lüngen, H. Unification of XML Documents with Concurrent
Markup. Literary and Lingustic Computing, 20(1): pages 103-116, 2005.
doi:https://doi.org/10.1093/llc/fqh046.
[Witt et al., 2007] Witt, A., Schonefeld, O., Rehm,
G., Khoo, J. and Evang, K. On the lossless transformation of
single-file, multi-layer annotations into multi-rooted trees. In: Proceedings of
Extreme Markup Languages, Montréal, Québec, 2007.
[Yang et al., 2004] Yang, X., Su, J., Zhou, G. and Tan,
C. L. (2004). Improving pronoun resolution by incorporating
coreferential information of candidates. In: Proceedings of the 42nd Annual
Meeting of the Association for Computational Linguistics (ACL04). Barcelona, Spain,
2004.
[2] The HyGraphDB (cf. Gleim et al., 2007) has been developed as part of the X1
project of the collaborative research centre (CRC) 673 Alignment
in Communication and of the Indogram
project of the Research Group 437 Text-technological modelling of
information.
[8] Relying on character offsets can be a source of trouble. For that reason one has to
assure that whitespace differences between the textual primary data and annotation
layers are normalized. Different whitespace normalizer tools were developed as part
of
our project.
[9] Of course it is possible to use graph-based annotation layers as well, however, the
advantages of SGF over the formats discussed in section “Graph-based architectures” would be
minimized in such cases (cf. section “Querying”).
Alink, W., Bhoedjang, R., de
Vries, A. P., and Boncz, P. A. Efficient XQuery Support for Stand-Off
Annotation. In: Proceedings of the 3rd International Workshop on XQuery
Implementation, Experience and Perspectives, in cooperation with ACM SIGMOD, Chicago,
USA,
2006.
Alink, W., Jijkoun, V., Ahn,
D., and de Rijke, M. Representing and Querying Multi-dimensional Markup
for Question Answering. In: Proceedings of the 5th EACL Workshop on NLP and XML
(NLPXML-2006): Multi-Dimensional Markup in Natural Language Processing}, Trento, 2006.
Bayerl, P. S., Lüngen, H.,
Goecke, D., Witt, A. and Naber, D. Methods for the semantic analysis of
document markup. In: Roisin, C.; Muson, E. and Vanoirbeek, C. (ed.), Proceedings
of the 3rd ACM Symposium on Document Engineering (DocEng), Grenoble, pages 161-170,
2003.
Bird, S. and Liberman,
M.Annotation graphs as a framework for multidimensional linguistic
data analysis. In: Proceedings of the Workshop "Towards Standards and Tools for
Discourse Tagging", pages 1–10. Association for Computational Linguistics, 1999.
Bird, S., Day, D., Garofolo, J.,
Henderson,J., Laprun, C. and Liberman,M. ATLAS: A flexible and
extensible architecture for linguistic annotation. In: Proceedings of the Second
International Conference on Language Resources and Evaluation, pages 1699–1706, Paris,
2000.
European Language Resources Association.
Bird, S., Chen, Y., Davidson, S.,
Lee, H. and Zheng,Y. Designing and Evaluating an XPath Dialect for
Linguistic Queries. In: Proceedings of the 22nd International Conference on Data
Engineering (ICDE), Atlanta, USA., 2006
Carletta, J., Kilgour, J.,
O’Donnel, T. J., Evert, S. and Voormann, H. The NITE Object Model
Library for Handling Structured Linguistic Annotation on Multimodal Data Sets.
In: Proceedings of the EACL Workshop on Language Technology and the Semantic Web (3rd
Workshop
on NLP and XML (NLPXML-2003)), Budapest, Ungarn, 2003.
DeRose, S., Maler, E. and
Orchard, D. XML Linking Language (XLink) Version 1.0. W3C
Recommendation, World Wide Web Consortium, June 2001. Online: http://www.w3.org/TR/2001/REC-xlink-20010627/.
Diewald, N.,
Stührenberg, M., Garbar, A. and Goecke, D. Serengeti -- Webbasierte
Annotation semantischer Relationen. To appear in LDV Forum - Zeitschrift für
Computerlinguistik und Sprachtechnologie.
Dipper, S. XML-based stand-off representation and exploitation of multi-level linguistic
annotation. In: Proceedings of Berliner XML Tage 2005 (BXML 2005), pages 39–50,
Berlin, Deutschland, 2005.
Dipper, S., Götze, M.,
Küssner, U. and Stede, M. Representing and Querying Standoff
XML. In: Rehm, G., Witt, A. and Lemnitzer, L. editors, Datenstrukturen für
linguistische Ressourcen und ihre Anwendungen. Data Structures for Linguistic Resources
and
Applications. Proceedings of the Biennial GLDV Conference 2007, pages 337–346, Tübingen,
2007.
Gunter Narr Verlag.
Gleim, R., Mehler, A. and
Eikmeyer, H.-J. Representing and Maintaining Large Corpora.
In: Proceedings of the Corpus Linguistics 2007 Conference, Birmingham (UK), 2007.
Goecke, D. and Witt, A.
Exploiting Logical Document Structure for Anaphora
Resolution. In: Proceedings of the 5th International Conference on Language
Resources and Evaluation (LREC 2006). Genoa, Italy, 2006.
Goecke, D., Stührenberg,
M. and Wandmacher, T. Extraction and representation of semantic
relations for resolving definite descriptions. To appear in LDV Forum -
Zeitschrift für Computerlinguistik und Sprachtechnologie.
Goecke, D., Lüngen, H.,
Metzing, D., Stührenberg, M. and Witt, A. Different Views on Markup.
Distinguishing levels and layers. In: Linguistic modeling of information and
Markup Languages. Contributions to language technology. Springer, 2008.
Hamp, B. and Feldweg, H.
GermaNet - a Lexical-Semantic Net for German. In:
Proceedings of ACL workshop "Automatic Information Extraction and Building of Lexical
Semantic Resources for NLP Applications", pages 9–15, New Brunswick, New Jersey,
1997. Association for Computational Linguistics.
Holt, R., Schürr, A., Elliott Sim,
S and Winter, A. GXL: A graph-based standard exchange format for
reengineering. In: Science of Computer Programming, 60(2): 149-170, 2006.
doi:https://doi.org/10.1016/j.scico.2005.10.003.
Huitfeldt,
C. and Sperberg-McQueen, C.M. Texmecs: An experimental markup
meta-language for complex documents. Markup Languages and Complex Documents
(MLCD) Project, Februar 2001.
Ide, N. and Romary, L. International Standard for a Linguistic Annotation Framework. Journal
of Natural Language Engineering, 10(3-4): pages 211-225, 2004.
doi:https://doi.org/10.1017/S135132490400350X.
Ide, N. and Romary, L.
Towards International Standards for Language Resources. In:
Dybkjaer, L., Hemsen, H., and Minker, W., editors, Evaluation of Text and Speech Systems,
pages 263--284. Springer.
Ide, N. and Suderman, K.
GrAF: A Graph-based Format for Linguistic Annotations. In:
Proceedings of the Linguistic Annotation Workshop, pages 1-8, Prague, Czech Republic.
Association for Computational Linguistics, 2007.
Laprun, C., Fiscus, J. G.,
Garofolo, J. and Pajot, S. Recent improvements to the ATLAS
architecture. In: Proceedings of HLT 2002, Second International Conference on Human
Language Technology Research, 2002.
ISO/IEC 19757-2:2003.
Information technology – Document Schema Definition Language (DSDL) –
Part 2: Regular-grammar-based validation – RELAX NG (ISO/IEC 19757-2).
International Standard, International Organization for Standardization, Geneva, 2003.
ISO/IEC 19757-3:2006.
Information technology – Document Schema Definition Language (DSDL) –
Part 3: Rule-based validation – Schematron. International standard, International
Organization for Standardization, Geneva, 2006.
Jagadish, H. V.,
Lakshmanany, L. V. S., Scannapieco, M., Srivastava, D. and Wiwatwattana, N. Colorful XML: One hierarchy isn’t enough. In: Proceedings of ACM
SIGMOD International Conference on Management of Data (SIGMOD 2004), pages 251–262,
Paris,
June 13-18 2004. ACM Press New York, NY, USA.
Le Maitre, J. Describing multistructured XML documents by means of delay nodes. In:
DocEng ’06: Proceedings of the 2006 ACM symposium on Document engineering, pages 155–164,
New
York, NY, USA, 2006. ACM Press.
O. Schonefeld. XCONCUR and XCONCUR-CL: A constraint-based approach for the validation of
concurrent markup. In: Rehm, G., Witt, A., Lemnitzer, L. (eds.), Datenstrukturen
für linguistische Ressourcen und ihre Anwendungen. Data Structures for Linguistic
Resources
and Applications. Proceedings of the Biennial GLDV Conference 2007, Tübingen, Germany,
2007.
Gunter Narr Verlag.
Sperberg-McQueen, C. M., Huitfeldt, C. and Renear, A.. Meaning and
Interpretation of markup. Markup Languages - Theory & Practice, 2, pages
215-234, 2000. doi:https://doi.org/10.1162/109966200750363599.
Sperberg-McQueen, C. M., Dubin, D., Huitfeldt, C. and Renear, A. Drawing inferences on the basis of markup. In: Proceedings of Extreme Markup
Languages, 2002.
C. Sperberg-McQueen, C. M. and Burnard, L. (eds.). TEI P4: Guidelines
for Electronic Text Encoding and Interchange. published for the TEI Consortium by
Humanities Computing Unit, University of Oxford, Oxford, Providence, Charlottesville,
Bergen,
2002.
Sperberg-McQueen, C. M. and Huitfeldt, C. GODDAG: A Data Structure for
Overlapping Hierarchies. In: King, P. and Munson, E. V. (eds.), Proceedings of
the 5th International Workshop on the Principles of Digital Document Processing (PODDP
2000),
volume 2023 of Lecture Notes in Computer Science, pages 139–160. Springer, 2004.
Strube, M. and Müller, C.
(2003). A machine learning approach to pronoun resolution in spoken
dialogue. In: ACL '03: Proceedings of the 41st Annual Meeting on Association for
Computational Linguistics. Morristown, NJ, USA : Association for Computational Linguistics,
2003, pages 168-175.
Stührenberg, M.,
Goecke, D, Diewald, N., Cramer, I. and Mehler, A. Web-based annotation
of anaphoric relations and lexical chains. In: Proceedings of the Linguistic
Annotation Workshop (LAW), pages 140–147, Prague. Association for Computational Linguistics,
2007
Thompson, H. S. and
D. McKelvie. Hyperlink semantics for standoff markup of read-only
documents. In: Proceedings of SGML Europe ’97: The next decade – Pushing the
Envelope, pages 227–229, Barcelona, 1997.
Waltinger, U., Mehler,
A. Mehler, and Stührenberg, M. An Integrated Model of Lexical Chaining:
Application, Resources and its Format. Accepted for Proceedings of Konvens 2008.
Witt, A., Goecke, D., Sasaki, F.,
and Lüngen, H. Unification of XML Documents with Concurrent
Markup. Literary and Lingustic Computing, 20(1): pages 103-116, 2005.
doi:https://doi.org/10.1093/llc/fqh046.
Witt, A., Schonefeld, O., Rehm,
G., Khoo, J. and Evang, K. On the lossless transformation of
single-file, multi-layer annotations into multi-rooted trees. In: Proceedings of
Extreme Markup Languages, Montréal, Québec, 2007.
Yang, X., Su, J., Zhou, G. and Tan,
C. L. (2004). Improving pronoun resolution by incorporating
coreferential information of candidates. In: Proceedings of the 42nd Annual
Meeting of the Association for Computational Linguistics (ACL04). Barcelona, Spain,
2004.