Smith, Norman Earl. “Parser Possibilities: Why Write A Markup Parser.” Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 - 15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). https://doi.org/10.4242/BalisageVol1.Smith01.
Balisage: The Markup Conference 2008 August 12 - 15, 2008
Balisage Paper: Parser Possibilities: Why Write A Markup Parser
Norman Earl Smith
SAIC Technical Fellow and Assistant VP of Technology
Mr. Smith has been a software developer for 30+ years and involved with
markup applications starting with SGML in 1990. He has worked for SAIC for 26
years on a variety of projects ranging from automated document creation to
robotics to web applications. He has authored 12 books including two on
SGML/XML. Mr. Smith was selected as an SAIC Technical Fellow in 2004.
Copyright, Science Applications International Corporation. All rights reserved. Unpublished
rights reserved under copyright laws of the United States.
Abstract
In the early days of XML, there seemed to be a new XML parser just about
every week. This was in stark contrast to SGML where there might be half a
dozen working parsers ever written. As XML matured and SAX became the first defacto
XML
parser API, the new parser stream pretty much slowed to a trickle.
Once robust XML parsers, such as Expat,
became widely available, there seemed little reason left to write you own parser.
Expat is robust, fast, and still provides the XML under pinnings for many programming
languages.
I believe there remain many valid reasons for writing your own markup
language parser. This paper identifies reasons you might want to write a custom
parser and examines the choices I made writing mlParser.
XML and SGML parsers are available that are mature, robust,
and widely used. It's not like the early days of XML when it seemed that every new
week brought a new parser. Soon, the first SAX-based XML parsers appeared,
followed by DOM (Document Object Model) parsers with standard APIs. Once
high-quality validating parsers, such as Expat and AElfred, became widely available,
the community seemed to lose interest in writing new parsers. Many of
the early XML parsers were non-validating because they were considerably easier
to write
than validating parsers.
SAX was originally patterned after the ESIS (Element Structure Information Set)
output from the SGMLS and NSGMLS
SGML parsers. (SeeClarkJ)
DOM implementations usually use an underlying SAX parser to feed the
content to the DOM objects. SAX-based applications are generally faster and
require less memory than a DOM-based application. My experience is that an
event-based parsing model, like SAX, can easily handle 80% to 90% of XML applications.
Either are appropriate for the next 5% to 10% of applications, and the last 5%
of applications really need DOM or something similar.
Even with numerous XML parser options, I have never been completely
satisfied with the available XML parsers because I still deal with SGML and other
markup languages. The remainder of this paper looks at reasons for
writing a parser. Questions that you should ask yourself before starting to write
a custom parser and the road to writing my own mlParser are also examined.
What's A Markup Parser
A markup language, such as XML, is a language for writing application-level
markup languages. HTML and DocBook are examples of application-level
markup languages. The dual use of the term "markup language" is especially
confusing to non-technical people. Wikipedia's definition of SGML
(SeeWikipediaSGML) describes it
as "a metalanguage in which one can define markup languages" and I believe the
term metalanguage is appropriate. Wikipedia further defines markup language as "a
set of annotations to text that describe how it is to be structured, laid out,
or formatted."
Both SGML and XML use "<" and ">" to delimit markup. Common usage
has evolved to the point that just about any markup that uses "<" and ">"
is called XML. Notice that I have been using the term "markup language parser" instead
of "XML parser" for the most part so far. This is done on purpose.
There are four types of markup language
in use that I know of:
SGML
XML
WordML
*SP
HTML and DocBook are not included in the list because they are
XML/SGML application-level markup languages, not markup meta languages.
WordML and *SP are not meta-markup lanugages. However, their syntax
sufficiently differs from XML and SGML such that normal parsers don't handle
them either. They are included to show markup that might require a
custom parser to process, and because mlParser can handle both.
SGML, or Standard Generalized Markup Language, is an ISO standard. Its
heritage is in the publishing industry and it has an IBM General Markup Language
(GML) lineage. Computers in the early days had limited processing power for the
individual, which translated to no SGML editor that performed real-time validation
and formatting. Therefore, SGML contained many features to minimize the
keystrokes required to enter content. For example, end tags could be declared optional.
The structure of an SGML document is defined by a Document Type Definition (DTD).
SGML is a markup metalanguage. My general belief is that SGML is still best for
defining publishing markup languages.
XML, or eXtensible Markup Language, has its roots in the database
world. It is a direct result of Tim Bray's work at OpenText for handing
structured data that may or may not be SGML compliant. XML is also a markup
metalanguage. Element structure may be defined thru a variety of "languages"
including DTDs, Schemas, and RelaxNG. It is an SGML subset with just enough
syntax differences to prevent processing markup files with each other's tools.
I know because I tried for years to treat markup as SGML for some tools and the
same markup as XML with other tools with limited success.
XML also introduced the concept of valid versus well-formed XML documents. A
valid document is one that has been validated successfully against its DTD or Schema
with a
validating parser. A well-formed document is one that has matching start and
end tags and follows the other rules of XML markup syntax. A well-formed
document may or may not be valid. For that matter, it may or may not have a DTD
or Schema.
There is no concept of well-formed documents in SGML, only
valid or not valid. Most SGML tools validate the document every time it is
used. A common real-world view is that a document only needs to be validated in
specific cases:
The document is edited by a human.
During program development, until you are sure that valid markup is
generated.
When data is supplied from an external source, markup may or may not
need to be validated on every data exchange depending on
circumstances.
WordML is my name for the output from saving a Microsoft Word document
as Filtered HTML. The markup appears to follow some XML syntax rules, some SGML
syntax rules, and some of its own, unique syntax rules.
Much
Word-specific data is stored in comments. I have even run across a few WordML
documents that were not well formed! Few XML parsers can handle WordML.
*SP represents the various Serve Page markup languages such as ASP and
JSP. It is not often that a Java developer attempts to run Java Server Pages
thru an external parser. The JSP compiler normally takes care of the parsing.
There are times when it can be very revealing. The output of the JSP compiler
is a Java program that generates an HTML page. Normally, the embedded Java code
generates dynamic values on the page. XML parsers do not normally handle
*SP files.
Finally, the answer to the question "What's a markup parser?" A markup parser
basically reads data that contains application-level markup, extracts tags and
attributes from the markup, and generates some output. Validating parsers also
read the structure definition in the form of a DTD, Schema, or other format.
The output may range from structural error messages to ESIS output or anything
in between. Some parsers, like OmniMark have built-in programming languages.
Others provide SAX or DOM programming language interfaces. The possibilities
are limited only by the requirements of the application and imagination of the
developer. A markup parser may handle multiple types of
markup, not just XML or SGML, from the point of view presented here.
ESIS is the primary output for
the SGMLS and NSGMLS parsers. It is a record-oriented format where the first
character on each line represents the markup event and the rest of the line is
data. For example, a start tag event is represented by an '(' event type and
the rest of the line is data. The tag name is the data in this case.
'(mytag' is the ESIS output generated for <MYTAG> in the input document.
ESIS is very significant from a historical prospective. Back in prime
SGML days of the early 1990s, SGMLS was just about the only widely available
free SGML parser. Commercial SGML tools were all expensive because of the cost
of either writing or licensing an SGML parser to include in the tools. Taking
advantage of the SGMLS ESIS output was the only way to test-drive SGML without
spending a lot of money. ESIS format is easy to process and a good programmer
could do amazing things with ESIS output and a Perl script or two.
ESIS also contains the idea behind SAX. The call-back events in programs
logically work on an ESIS stream.
Why Write A Parser?
With the parser background out of the way, let's take a look at reasons both to
write your own parser and reasons not to write your own parser. First, there are
good reasons for not writing a custom parser:
Writing a basic parser is a lot of work
Writing a validating parser is a lot more work
Implementing XSL/XSLT/X-Path/XQuery, etc., support is not practical for most
individual developers
Writing a parser, even a non-validating parser that implements SAX
and/or DOM, is a huge effort
There are multiple, structure definition languages, such as DTD,
Schema, RelaxNG, etc., needed for validation that are complex
Writing any markup parser is hard work. The additional complexity and
effort required to write a validating parser instead of a
non-validating/well-formed parser is significant. For many cases,
it exceeds the point of diminishing returns . Writing a validating parser
requires writing the
validating part, plus the code to parse a DTD or schema, and implement the code
to actually validate the element structure at each change-in-tag state.
Are the benefits worth the effort?
The "X" add-ons are also complex. They require a very sharp staff to
implement the standards. The resources to properly implement
XSL/XSLT/X-Path/XQuery is substantial. These are usually beyond the
average individual developer for short-term projects.
Complexity and the associated learning curve are the main
impediments.
Both the SAX and DOM API's are large and fairly complex, which means the
average developer won't implement them
completely, if at all. I know from experience; I didn't
bother implementing either.
A validating parser also requires the code to load allowable element
structure in order to be able to validate a document, with another increase in
code complexity and size.
All of these items represent increased implementation effort that just
might not be worth the trouble if an existing parser meets most of your
requirements. You have to carefully gauge the value proposition for
each increase in effort that the next step brings. It may or may not be worth
the effort.
On the other hand, there are still many reasons for writing your own
markup parser. The rest of this section takes a look as some of those reasons.
They include:
The learning experience.
No existing parser meets your specific requirements.
You have complete control.
You can mix and match markup languages, i.e., SGML, XML,
etc.
Not tied to existing APIs.
You need to create documents with "live" content.
The following paragraphs expand these points.
The learning experience. Writing a markup parser, even a
"simple" non-validating parser, is always a learning experience. There are a
number of learning experience possibilities, such as:
Learning about markup languages. Writing a parser will teach you
about markup language rules. Having to account for every possible condition
in the markup will quickly enlighten you!
Learning about software state machines. I have used the state
machine technique for writing a parser more than once. It is a straight-forward
way to work thru the program. An in depth knowledge of the rules of the markup
language is required. There is a basic state machine for parsing SGML published
in the Practical Guide To SGML And XML Filters.
(SeeSmith1998)
If you don't know
what a State Transition Diagram is, you will learn a lot of new things
writing a markup parser.
Providing a vehicle to learn a new language. I wrote the first implementation
of mlParser because I needed to write a non-trivial program to learn
Java and I already understood the ins and outs of SGML.
This allowed me to concentrate
on learning the programming language and not the application.
As you can see, there are many things that can be learned from the
experience of writing a parser.
No existing parser meets your specific requirements. This is
not an unusual occurrence, especially if your application is a little
non-standard. Reasons include:
Need a light-weight parser
Need to parse multiple markup meta languages
The programming language for an application is incompatible with
existing parsers
Robert Bajzat (SeeBajzat)
needed a light-weight XML parser for his Thinlet package,
which is a small (39k) Java windowing framework aimed at cell phones. The
on-screen widgets for a Thinlet-based application are in simple XML. The Thinlet
XML parser handles its slightly restricted XML syntax. Comments
not spanning a line is an example restrictions.
The Thinlet parser also is closely tied to the application
and knows how to handle just the widget markup. The Thinlet parser is an
integral part of the framework, and the short cuts in syntax make it tiny!
Incompatibility with existing parsers usually means the markup data
buries information within comments, does not follow the syntax rules, or mixes
and matches syntax rules from different markup meta languages. WordML is a good
example of this. WordML is what I call the result of saving a Word document as
"Filtered HTML." It appears to follow some SGML rules, some XML rules, invents
a few rules, and puts a great deal of information into comments. Few parsers
can handle this markup.
You have complete control.
This is the real reason most people write their
own version of an application. Tailoring a program to meet your system
requirements has a strong draw for many people. I would rather write a
hand-tuned set of Java classes to represent markup data, for example,
than use one of the
canned frameworks that seems to create hundreds of classes/methods when three
or four well-designed classes are easier to understand and more efficient.
Control extends to which markup features are supported. The parser may not
need to handle attributes at all if the data does not
contain attributes and is record-oriented. The
parser may do simple transforms as the input stream goes by that will
significantly simplify downstream code. The parser
doesn't always have to stop on
errors.
You can mix and match markup languages. I started out using
SGML around 1990. I have been thru the start of XML and the rise of Server Page
languages such as JSP and ASP. There have been plenty of times when I wanted
to mix and match SGML and XML files, in particular. Writing your own parser
makes this practical.
Not tied to existing APIs. The existing SAX and DOM APIs are
large and complex. If you go back and examine ESIS closely, basic markup
processing can be done with a much simpler subset API. But once you make the
leap that you don't have to implement existing APIs, you are free to build what
meets your application requirements. That said, I firmly believe that this is
the least acceptable reason in my list for writing a parser.
You need to create documents with "live" content. A favorite
application technique of mine is creating a live document. By live, I mean that
some portion of the content is dynamically generated. Executing an external
script, nesting the output of another parse, running an SQL query, or retrieving
a URN are some of the many things that can be incorporated transparently with a
custom parser. The data just shows up in the data to the downstream processing
programs. A great deal of extra functionality can be transparently dropped into
a markup-based application by including the ability to execute arbitrary
programs/code on a parsing event.
The Road To mlParser
I initially wrote my markup language parser, mlParser, in 2002. The
journey from being thrown into the SGML ocean in 1990 to the birth of mlParser
and its subsequent evolution into a multi, meta-markup language parser was a
long road. In the early SGML days, SGML tools were expensive. My customer wanted
to
use SGML as the exchange format for bibliographic data and could not justify
the expense of purchasing SGML tools without being sure of success. We
developed small-scale applications around SGMLS using
Perl scripts to process ESIS output. It worked well, and I
learned a lot about processing an ESIS stream.
The following markup file is used as input for sample code for the examples
that follow:
The ESIS output from mlParser for the above markup is:
# mlParser (c) Science Applications International Corporation, 2002, 2006, 2007.
All rights reserved.
(records
-\n
(record
-\n
(name
-John Doe
)name
-\n
(phone
-555-123-4567
)phone
-\n
(email
-JDoe@anymail.com
)email
-\n
(state
-Confusion
)state
-\n
)record
-\n
(record
-\n
(name
-Jane Smith
)name
-\n
(phone
-555-345-9876
)phone
-\n
(email
-smithj@anymail.com
)email
-\n
(state
-Nirvana
)state
-\n
)record
)records
C
Done
The code described in the following paragraphs produces this output:
Name: John Doe Email: JDoe@anymail.com
Name: Jane Smith Email: smithj@anymail.com
Over the years, I wrote two other parsers. The first was part of a Forth
(SeeSmith1997)
interpreter. The only restriction on Forth function names is that the name
cannot contain white space. Therefore, a function name can be a tag name. So,
<RECORD> is both a tag and a function. A function
definition begins with ':' and ends
with ';'. Forth is a stack-oriented language that has a Reverse Polish syntax,
which means that parameters come before the function name and no parens are
necessary. A function is called by simply referencing its name.
The application implementation approach was:
Define a function for each tag
Each function must consume characters up to the
next tag/end tag
A document processed itself when fed to the
Forth interpreter
The document effectively executed itself. It was an interesting idea
that never got past the toy stage. The following is a snippet of
Forth code used to
process the markup file described above:
The cload function loads and interprets the filename
test.xml.
the collect function consumes
the charcters up to the next '<' and store it in
content.
The document executes itself generating the
output. The parser was implemented as a state machine.
My next parser was a Perl library, which was based completely on regular
expressions. The primary functions were:
get_XML_field() returns the contents
of <TAG> from the string of markup. It is useful when processing
record oriented markup one record at a time.
get_next_XML_field() extracts a
repeating tag from the markup string, returning a status, the tag
contents, and the remainder of the markup string. Typically, the whole
file is read into a string and get_next_XML_field()
extracts the next record to operate on. Then calls to
get_XML_field() pull out the fields
individually for processing.
The approach for using this parser was:
Read data into a string
Extract a "wrapper" element into another string
Extract individual fields from the wrapper string
Do whatever processing is needed
The following Perl code snippet generates the example output:
require "xml.pl";
my $file;
my $record;
my $name;
my $email;
my $template ="Name: \$name Email: \$email\n";
$/ = "</RECORD>";
while(<STDIN>){ # Read a record
$record = $_;
$name = &get_XML_field($record,"NAME");
$email = &get_XML_field($record,"EMAIL");
eval("print \"$template\"");
}
exit;
This Perl parsing library has been used successfully in several production
applications. The constraints are that the markup does not contain attributes
and that huge records have to fit in memory.
Both of these solutions worked for a small subset of applications with
simplified markup. They handle start tags, content, and end tags and that's
about it. Neither ever grew into a robust, general purpose parser.
The Perl library has found its way into several production
applications though.
The following code snippet is part of the mlParser program to
process the sample input file. It has the call-backs for the parser
output events. The simple nature of the input markup, makes for an
extremely simple Java example.
...
HashMap element = new HashMap();
String content = "";
...
public void writeStartTag(String sTag)
{
String tag = sTag.toLowerCase();
if(tag.equals("record"){
element.clear(); // Wipe the hash for each record.
}
}
...
public void writeEndTag(String eTag)
{
String tag = eTag.toLowerCase();
if(tag.equals("record")){
system.out.print("Name: " + element.get("name") +
" Email: " + element.get("email") + "\n";
}else{
element.put(tag, content); // Collect all element content in a Hash
}
}
Assume that the content callback happens and leaves the
content in the content global variable.
The only processing needed in the writeStartTag()
method clears the element hash. All of
the other processing occurs in writeEndTag(). When
the end tag is </RECORD>, we know that all of the fields in the
record have been collected. Simply putting the content in a hash with
the tag as the key is a convenient way to collect the data without
testing for each tag as it passes by.
Mixing SGML And XML
I am an old-time SGMLer who was as skeptical as the next person about XML
when it first came out of the closet at the 1996 SGML Conference. The false
promise that got a lot of the SGML community on the XML train was that "XML is
just SGML without DTDs" and XML is a subset of SGML. I had often wished to
process SGML files without a DTD. The implication I misread into the original
XML discussions was being able to process SGML markup with XML tools.
Not being able to do much without a DTD was always an SGML issue for two
reasons. First, I never saw the need to validate an SGML file every time it
was touched. An SGML file only needs to be validated when modified. Second, I
received SGML files from external sources without a DTD with enough regularity
that having to reverse engineer a DTD in order to be able to use SGML tools
became a real annoyance. Most of the time, only a handful of tags were
processed. Writing what was essentially a throw-away DTD always rubbed me the
wrong way.
An XML well-formed document versus a valid document was the leap that was
supposed to enable the "SGML without DTDs" concept. Well, that didn't quite
happen. By the time XML hit the streets, minor syntax changes and the fact that
non-validating parsers threw errors when processing virtually every SGML file made
feeding an SGML file to a non-validating XML parser a waste of CPU cycles.
Error examples include:
The first line of the file had to be the XML declaration
(<?xml version="1.0" encoding="UTF-8"?>),
which is a processing instruction in SGML.
The SGML empty tag representation causes
the document not to be well-formed and
therefore causes parsing problems.
Any entity reference not in the default XML set (<, >, and
&) threw errors.
I eventually found xmln, which seemed to be the answer
for a while. The C source was available and it generated an ESIS-like output
stream, which meant it could be utilized by programs
such as the Perl scripts I had already written
to use the
ESIS output from SGMLS. I thought I could modify xmln to handle SGML files as
well but could never track down one of the C header files, which forced an end
to my customization attempts.
I attempted to use markup interchangeably as SGML and XML for a couple
of years. I finally threw in the towel when a couple of developers started using
Java XML tools on a project. Since then, I consider SGML and XML
cousins at best. XML is not
a subset of SGML as originally advertised!
I work with some systems that started life as SGML applications. Eventually,
the data and code will be migrated to XML data and tools. In the meantime,
wouldn't it be convenient to mix SGML data and XML data transparently rather
than have to do a conversion? I believe this is still a valid requirement for
mixing XML and SGML interchangeably and a good reason to write a custom
parser.
This section discusses my frustration mixing SGML and XML and
the road to writing my own parser. mlParser
did not happen directly as a result, rather the knowledge gained along the way
was applied to its initial implementation and eventual evolution.
mlParser
In 2002, my next project required that I be fluent in Java. I had done
light Java maintenance up to that point. The project seemed pretty important, so
I needed to be productive on day one! I knew several programming
languages at that point - getting up to speed did not seem impossible. The
obvious approach was writing a non-trivial Java program.
I decided to implement the parser described by the software finite state
machine from
Practical Guide To SGML/XML Filters.
(SeeSmith1998) Having experimented
with both state machines and simple parsers in the past, I knew the technique
and subject area. This allowed me to concentrate on the learning Java aspect in
writing the parser.
The initial implementation started as a simple, pretty-much exact
implementation from the book. The parser generated an ESIS output stream. I
verified the output by comparing the mlParser ESIS output
with the NSGMLS output. The
first implementation was much easier than I had expected.
The second version implemented a few of the XML syntax differences, such
as the <TAG/> empty tag. By the time I
got the parser digesting basic SGML
and XML, I began to see the potential for my own parser!
The third iteration was a restructuring of the code with interfaces for
input processing, the parsing engine, and the output call-back class. My
thinking was:
Input Interface. The assumption was
a developer could supply
a markup stream from any source, not just a file. The default input interface
class handles the file as a stream, which was a good choice because of the
large number of input types that can be mapped into a stream. There has been no
need to implement another input class, but I still see the
potential for custom
input classes.
Parsing Engine. The interface makes it possible to replace
the default state machine with some other parsing engine. The state machine is
the
heart of mlParser and its ability to parse multiple meta-markup languages is
an important capability for me, so I don't see replacing current the state machine.
However, it is possible.
Output Call-Backs. Each markup event triggers a call-back
to an interface-defined method. The interface is organized around ESIS events
plus a couple, such as document start and end. The interface is reminiscent of
SAX, only a great deal simpler. This interface is the hook to embed mlParser into
applications.
Two additional implementation cycles added a couple of significant
capabilities, parsing WordML and *SP files. Not long after SGML and XML parsing
were stable, I saved a Microsoft Word document
as Filtered HTML and
fed it to mlParser. mlParser did not get very far. I was disappointed, but not
surprised. There was no immediate requirement to parse Word output. I wanted
mlParser to handle all common markup types transparently by this time.
Examination of a WordML file reveals that it follows some SGML rules,
some XML rules, and invents a few of its own. Additionally, a great deal of
formatting data is stored in comments. I wrote a program to convert WordML to a
very generic HTML as an excuse to keep tweaking the parser. Successfully
parsing WordML became an obsession and mlParser was a time-consuming hobby
at this point.
I volunteered to convert Word documents to HTML many times over the next
couple of years. Each document seemed to present some unaccounted-for nuance
that required a code tweak to the state machine class. The mlParser and WordML
converter program now handles most Word documents, although the generated HTML
is often ugly. The HTML is usually good enough to pass a validating parser with
no significant validation errors.
I put some thought into what additional features would be necessary to
make mlParser useful in a production application. The obvious items
included:
Identifying empty tags without a DTD or Schema
Simple entity resolution
Setting most options via the command line
The option to stop on errors or continue processing a file
Implementing additional input data sources such as strings and
URNs
Allowing nested parsing
SGML and XML have different markup syntax for empty elements.
XML uses the form <Tag/> and SGML just uses a start tag
and no end tag. The XML form enables recognizing an empty element
without a DTD or Schema. The SGML requires that empty tags be
explicitly identified. The mlParser approach is simply a file
that identifies empty elements that get loaded into a hash at
startup. It's simple and effective. When a missing end tag is
detected, a check of the hash determines whether or not it is an
empty element, and the processing handles the
condition correctly. This approach allows
SGML files that contain empty elements to work properly.
Simple entity substitution is a similar problem to empty
elements; how do you represent entity values without a DTD
or Schema? The mlParser solution is a simple Java properties
file with the entity string as the name and the substitution
value as the value. The default entity translation file looks
like this:
&=&
<=<
>=>
If no entity property file is specified, a default set is used. Entities not
found in the property file are passed thru unchanged
instead of generating an error.
Some applications, such as a browser or building a document,
may require that a markup parser continue even when errors occur.
Other applications may need to stop on each error so they can be
corrected. mlParser can do either and allows the user to specify
the behavior as a command-line option. Applications that embed
mlParser can set the option via a setter method.
A definite requirement for using mlParser in several of my
applications is the ability to launch nested parses. Instantiating
another parser object is straightforward and adds almost no complication
to application code.
The Java JSP compiler is pretty forgiving, and as long as it can parse the
Java code out of "<%" and "%>" delimiters, it is happy. What happens when
the JSP compiler is successful and there is a missing angle bracket or two
in the HTML markup? The result is usually
unexplained "stuff" on the generated HTML page. What do you do? You
use mlParser, which can handle the server page
syntax, and parse the problem JSP file. Even if the parser only checks that the
file is well formed, you may find problems. This actually happened on one project.
mlParser showed the JSP file to not be well formed. When the markup was fixed in
the JSP file, the unexplained "stuff" went away.
At this point, mlParser is mature with the capabilities identified above
and is used in multiple production applications on multiple projects.
The remainder of this section gives a brief overview of the Software
Finite State Machine that is the mlParser parsing engine. I first ran across
state machines about 20 years ago in a presentation about navigation in an
Adventure game where the current state represented room or location on the adventure
map. The direction selection by the user caused the state to transition to a
new location. State machines have fascinated me ever since and I have managed to
use
them a few times over the years. Markup parsers are close to an ideal
state machine application.
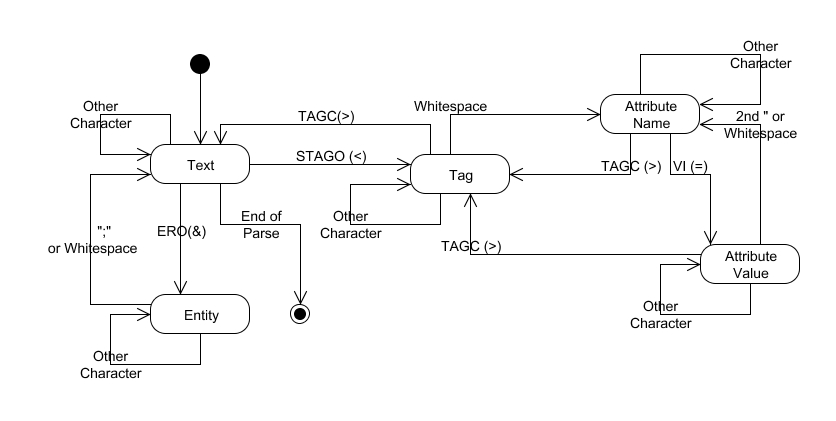
The following State Transition Diagram shows the states for a simple
SGML parser:
SGML State Transistion Diagram
Simple SGML State Transition Diagram
The state machine has to handle every character in the input stream. The
initial state is TEXT. State changes often correspond to parsing events, although
the State Transition Diagram does not show the call-back points. All parsing
states eventually return to the TEXT state.
Two characters are significant in the TEXT state - the Start Tag Open
(STAGO), which is '<' and Entity Reference Open (ERO), which is '&'.
STAGO fires a call-back to the Content method and changes the state to TAG.
ERO changes to the ENTITY state to handle collection and substitution of
the entity. A ';' or white-space character triggers transition back into the TEXT
state. All other characters do not cause the state machine to exit the ENTITY
state and are accumulated to form the entity name.
The TAG state is entered from the TEXT state via the '<' character. A
white-space
character triggers transition into ATTRIBUTE Name state. The Tag Close (TAGC)
character '>' exits TAG state back to TEXT state and fires a call-back to
the start tag method. Call-backs to the attribute method fire at the end of
each attribute. This is one difference between mlParser and SAX. mlParser fires
a call-back for each attribute and SAX returns the attributes in an
Attributes object. Attributes are available when the start tag method
call-back executes in both.
There are two sub-states for collecting attributes: Attribute Name and
Attribute Value. The top level state is ATTRIBUTE. The need for sub-states may
not be obvious, but works well. The attribute name ends with either an '='
character or a '>' character. In either case, a state change is triggered.
The Attribute Value sub-state is a little complicated because the value may be
enclosed in quotes or simply terminated by white space. The end of Attribute
Value sub-state also signals the end of ATTRIBUTE. The current state changes
back to TAG because the TAGC character will eventually be found.
In practice, there are sub-states for several states. A global
variable keeps track of the current state.
The ability to look ahead one
character simplifies the state machine code significantly. Reading the next
character needs to be a method and not just a read loop around the state cases.
The sub-states certainly contribute to needing to be able to read characters at
any point, and I believe a read character method is the right approach for this
type of state machine application.
The state transition diagram certainly helps to think thru a state
machine implementation at its start. I usually draw
these diagrams during design. I then prepare
a State Transition Table by the time I start coding. It speeds up the coding
process significantly. The following State Transition Table corresponds to the
State Transition diagram above:
Table I
State Transition Table
Current State
Character
STAGO (<)
Whitespace
TAGC (>)
=
ERO(&)
ERC(;)
Other
Text
Tag
Text
Text
Text
Entity
Text
Tag
Attribute
Text
Tag
Attribute
Tag
Switch sub-states
Attribute
Entity
Text
Text
Entity
The table contains more details than the diagram. The table also points
out potential error conditions. Any cell without an entry
usually represents an error
condition that should be examined closely before
deciding if it is truly an error condition
or if it can be ignored. For example, the cell at TEXT state and TAGC was blank
in the initial version. The cell should have had TEXT because a lone '>' is
just another text character. The
empty cell at TAG state and STAGO
is definitely an error and must be handled.
A software finite state machine is the ideal implementation technique
for a markup parser. There are a relatively small number of states, a limited
number of state change conditions, and the implementation is not overly
complex. The current State Machine class in mlParser is about 1800 lines of
heavily commented Java. The whole parser is about 3000
lines and the compiled mlParser JAR file is only 22K.
mlParser Today
This section covers mlParser in its present form. Design choices I made
and implemented features are discussed. mlParser has grown and
evolved a great deal since that first Java implementation. It is a
robust markup parsing tool that is at the heart of several internal
applications and is being used on multiple projects. The most significant
mlParser use is as the core for an integrated software documentation tool where
it has displaced OmniMark applications.
Early sections of this paper identified reasons for writing a parser and
design choices to make before you get too far into the effort. My initial
reason for writing mlParser was learning Java. My reasons for continuing
development evolved almost as much as the code itself. My current list
is:
Mixing different markup meta-languages
An application development framework
An easily customizable parsing package when XML-type markup just
won't work
Fullfilling the "SGML without DTDs" vision
Replacing all my OmniMark code
The integrated software documentation tool has been in use for several
years; there are thousands of SGML files across many projects. The software
will eventually migrate completely to XML;
however, the legacy SGML files will never be converted
to XML. There will be a period where
documents will be built from some SGML files and
some XML files. The system must handle the legacy SGML on demand for the
foreseeable future. mlParser enables this mixed markup environment.
An application development framework has grown up with mlparser. The
output call-back interface forms the basis for mlParser application
development. A new application can often be implemented with just two classes.
One class is the main program that collects command line arguments, registers
the output call-back class, and launches the parsing engine. Starting the
parsing process is done by simply invoking the state machine class. Simple
applications usually do not require additional classes. Applications that
handle multiple document types will need to invoke multiple parser objects with
associated, output call-back classes. Each document type should have its own
parsing object.
My intimate knowledge of the internals, especially the state machine,
allows me to customize the parser for specific applications. For example, there
is an application that uses an HTML subset plus a handful of extra tags. I want
to use generic, out-of-the-box OpenOffice as the editor so the user never
sees a tag. We tried processing instructions in
place of the extra tags without success. For OpenOffice to work as the editor
for this application, editing must be done in normal WYSIWYG mode. Our solution
was to include the extra three or four tags in the document with '{' and '}' as
tag
delimiters instead the normal '<' and '>'. It turned out to be a simple
solution from both the developer's and user's points of view. The developer was
happy because no extra code was required to be able to use OpenOffice, and the
user was happy because he didn't have to deal with tags
for the most part. OpenOffice happily
passes around the special
tags unmodified, and the application code sees
them as normal tags. Tweaking mlParser was straightforward and the result was
a major editing improvement from the user's perspective without
affecting application code.
The "XML is just SGML without DTDs" sales pitch from the XML faction at
the 1996 SGML Conference convinced me and the SGML community at large that
XML was worth pursuing. I envisioned XML as a true SGML subset where I could
transparently use the expensive SGML tools that I fought so hard to purchase
over the years. New XML
tools would certainly be less expensive and compatible. By the time that the
XML 1.0 standard hit the streets, that fantasy was crushed. I never gave up the
dream of transparent markup though. I wanted to be able to treat markup as SGML
to use SGML tools and XML to use XML tools transparently. mlParser essentially
allows me to treat both XML and SGML as just markup. The mlParser
parsing engine recognizes the syntax differences between the two, and therefore
fulfills the "XML is just SGML without DTDs" as "XML and SGML are just markup,"
which is even better!
mlParser is built around the following design/features:
Runs either from the command line or embedded in an
application
Generates an ESIS output stream by default
Handles simple entity character substitution
Non-validating parser
Handles both SGML and XML empty elements
Allows nested parsing
Sets most parsing options from the command line
Handles multiple types of markup transparently (XML, SGML,
WordML)
Can include or exclude comments from the output stream
Handles CDATA
Does not implement marked sections
Includes the option to stop on parsing errors or continue when
possible
Built around ESIS events
Based on a relatively simple software state machine
Includes a sample output call-back class that implements a jump
table for "document" applications
Supports multiple input sources
The same Java JAR file is used for both the stand-alone program and when
embedded in an application. Simple entity substitution is driven via a
Java properties file. If no entity property file
is specified, a default set is used. Entities not
found in the property file are passed thru unchanged. A full-blown entity
implementation seemed to be almost as much effort as the rest of the parser; and
for me, simple entity substitution is sufficient.
Several of my applications require nested parsing with different DTDs.
An application simply invokes another parser object, handles the output from
the nested parser object, and picks up where it left off in the original input
stream.
The need to stop on a parsing error or continue transparently is
application specific. Stopping on an error is the default behavior for
stand-alone parser operation. An application
processing a document may want to simply
unwind the element stack, fire end tag call-backs and keep going. This works
reasonably well for missing end tags, but can create a mess with a missing
start tag. mlParser provides the option to stop or continue when errors
are detected.
Multiple input sources is a useful feature. Markup traditionally comes
from files and must be complete. mlParser accepts files, strings, or URNs.
Parsing a string implies well-formed markup, but no <!DOCTYPE and no XML
declaration. Transparently handling URNs allows an application to
parse markup directly from the web or some external source such as a
Subversion repository. Building a multi-file document directly from a
Subversion repository ensures that the output document contains the latest
checked-in files without a process to manually extract and process them.
The default output call-back interface for handling documents is
constructed around two jump tables and Java Reflection. There is one jump table
for start tags and one for end tags. The jump tables are constructed as
HashMaps with the tag as the key, and the value is the Java method via
Reflection. This approach creates a level of indirection between the tags and
the code that processes them:
One method can handle multiple tags. For example, the same method
can be used for dropping a tag and its contents or for passing the tag
unchanged.
Only tags of interest have to be accounted for; all others can be
automatically ignored. An unexpected tag will not cause an exception to be
thrown or the program to bomb.
The source code does not contain page-after-page of nested
if statements to determine which method to call to process a specific
tag.
The following start tag call-back method uses the jump table approach:
Handling a new tag requires no code change here. Instead, a new entry
is simply added to the Start Tag Action hash. I find the jump table approach
clean, flexible, and elegant. The jump
table approach can be used with any SAX-based parser, not just mlParser.
mlParser has evolved over the years from a learning exercise with
potential to a major part of my markup applications. The thought of
implementing the current
mlParser from scratch is a daunting one. Starting small and adding capabilities
as needed is a doable job.
Summary
This paper discusses reasons to write your own markup parser and
documents my journey to writing my own parser. mlParser
started with very modest beginnings and has evolved into a
primary tool in my markup application toolkit. I use it to generate ESIS
streams that are processed by Perl scripts, for the core of
an integrated software documentation tool, and for
markup conversion applications.
I don't believe that I would have tackled writing a parser with
all of the features and capabilities that are currently in
mlParser. Starting with a small, simple, and flexible base
allowed me to evolve a useful and capable parsing tool!
I found out along the way that while XML is king for record-oriented
markup, I still prefer SGML for documents. SGML's inclusions,
exclusions, and default attribute values make a developer's life
much less stressful for document-centric applications.
The experience has shown that there are still many valid reasons
to write a markup parser. This paper has identified and explored
many of these reasons. Not finding a parser that meets your needs
is what most of the reasons boil down to. Don't be afraid to
follow the path to your own parser!
References
[Bajzat] Bajzat, Robert,
Thinlet Home Page,
http://www.thinlet.com/index.html.
[ClarkJ] Clark, James,
Nsgmls Output Format,
http://www.jclark.com/sp/.