Altheim, Murray. “Informal Ontology Design: A Wiki-Based Assertion Framework.” Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 - 15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). https://doi.org/10.4242/BalisageVol1.Altheim01.
Balisage: The Markup Conference 2008 August 12 - 15, 2008
Through 2005 he was a Ph.D. student reading in Knowledge Representation and Artificial
Intelligence
at the Knowledge Media Institute, until he realized the futility of it all and after
some time in
the Mediterranean decided he'd rather be near the sea in a much warmer place. Through
January of 2002
he was employed in the XML Technology Center at Sun Microsystems in Menlo Park, California.
Through
February 1997 he was a Program Manager of Software Engineering at Spyglass, Inc. in
Cambridge, MA.
Through mid-January 1996, he was an Information Systems Analyst with the National
Technology Transfer
Center in Wheeling, West Virginia. Previously he was a Senior Systems Analyst contracted
to NASA
Headquarters' Office of Advanced Concepts and Technology, where he created and administered
the NASA
Commercial Technology Network web site. Prior to NASA he worked as a consultant and
systems analyst
at California State University in Sacramento, where he developed an executive information
system for
university planning and policy development. Prior to that he worked in the university's
computer
center for 357 years. Prior to that he was a mollusk.
He is author of various proposals on modularizing the HTML DTD, such as a draft proposal
of a modular,
XML version of HTML 4.0, as well as earlier documents such as the Structured HTML
(SHML) DTD, available
even today as a working draft, although one might prefer the W3C Recommendation Modularization
of XHTML.
He has functioned as Sun's representative to the W3C HTML Working Group, where he
was co-author of a
number of XHTML-related specifications and principal editor of the modular XHTML DTDs.
During most of
2000-2001 he devoted a lot of time and energy to XML Topic Maps. He's also been enthusiastically
involved in discussions regarding the Open Hyperdocument System (OHS), part of Doug
Englebart's
bootstrapping strategy, and in the past has been actively involved in the Standard
Upper Ontology,
Conceptual Graphs, and Common Logic mailing lists. All of this allows him to use a
lot of big words with
impunity.
Wiki software has historically provided little support for any form of
organizational structure. Even given the assumption that the majority of wiki
users have previous experience with file system-like hierarchies, most wiki
systems keep things simple (as is the wiki way) and employ a flat page structure.
As a wiki grows beyond a few dozen pages, some form of organization becomes
increasingly necessary. This has typically been accomplished by adding
“category links” to each page, essentially
ad hoc terms from an unstructured and
uncontrolled vocabulary. Because these terms are themselves
often undefined it can be difficult to ascertain the reason why a given page
belongs to a category. Even when this is done carefully, as the number of terms
in the categorization grows a classification scheme for the terms themselves
likewise becomes increasingly necessary.
This paper describes problems with existing wiki and “semantic
wiki” categorization schemes and outlines an approach to information
organization that avoids the pitfalls of computer-based ontologies by instead
looking to library science for solutions. It describes the design and
implementation of a wiki system permitting user-authored
assertions, which are dynamically harvested to
create a Topic Map graph mirroring the explicit structure of the wiki and providing
it with an underlying classification system.
As with any document collection, as a wiki grows its need for some form of organization
increases
proportionately. It's not uncommon for wikis to have hundreds or even thousands of
pages, without
even considering the rather atypical Wikipedia (which as of July 2008 claims “approximately
ten million articles in 253 languages”). Yet Wikipedia has no explicit classification
scheme.
Category Links
— Gregory Bateson, Steps to an Ecology of Mind
[…] knowledge is all sort of knitted together, or woven, like cloth, and each
piece of knowledge is only meaningful or useful because of the other pieces.
A common (some might say traditional) approach to categorization[1]
on wikis relies on untyped web links,
usually camel-case prefixing a category name with the word "Category" (e.g.,
“CategoryHomePage”, “CategoryDiscussion”, etc.). Any wiki page containing such a
link is considered categorized under that category. There a number of problems with
such a system. First,
any wiki page containing a given link is categorized accordingly even if that was
not the intention of
the link author, as the mere presence of a link – not its traversal – establishes
the categorization.
Another is that as the categorization of a given wiki page must be expressed on the
page itself, there is no
way to categorize a collection of pages from a different page, via a list or other
external structure. The
categorization naming scheme is also bound to the link names; there are no synonyms,
homographs, equivalent
terms; no way of characterizing the relations between terms, no thesaurus-like hierarchy,
indeed, no explicit
structure at all. One can add or remove categories from a page, but to change the
categorization of a page one
must change its name, which breaks existing links, and there is no facility for synthetic
or combinatory categories
apart from creating longer and more complicated wiki page names. It is a simple system
and works reasonably well
for small document sets.
In library science, free language indexing permits the assignment of any word
as an indexing term. One type often performed via an automated process, the terms
used in
natural language indexing are derived from the natural language of a document
rather than a controlled vocabulary of a classification system. Like free language
indexing, user-created wiki
categorization suffers in the same way due to mismatches between content and search
terms and a lack of
terminology control. One of the main questions faced in the design of our own system
was trying to mitigate
these problems.
Classification Systems
Despite being a Linux user, like most people buying a new laptop I had no choice but
to purchase Microsoft
Vista. One of the first things I did was remove all of the anti-virus software since
it was so horribly
annoying, such that subsequently going online would be akin to putting my head in
an electric oven. Given that
my use of Windows is strictly offline, deciding to write this paper in Word became
a matter of discipline.
Admittedly it does have rather beautiful typography.
Now, while scanning the shiny new Vista menus I came upon OneNote, a software application
I didn't even
know I owned. OneNote is touted as something I might be very interested in:
OneNote is an idea processor, a notebook, an information organizer — some even call
it
an "add-on pack for your brain." … a place for gathering, organizing, searching,
and sharing notes, clippings, thoughts, reference materials, and other information.
All your
notes will be visible here — organized by notebooks, sections, and pages.
So how does it organize information? Typical of most software applications devoted
to the organization
of notes, it uses the staid metaphor of folders, which in the library world might
be called an
enumerated classification scheme: every subject gets a folder. In
OneNote's case the central innovation is that you can put folders inside folders,
and change the
folder of an item at will. Even in their introductory documentation one can see a
foreshadowing of the
unfolding nightmare:
As you use OneNote and create more notes, you may want to organize your notes differently:
If you find yourself creating a lot of pages for a topic, try dragging them into a
new section
If you find yourself creating many sections in one notebook, try putting some of them
into a separate notebook
Make navigation between notes more convenient by creating several notebooks at the
top level, rather than putting everything inside one notebook
As any librarian will tell you, the problem with enumerated schemes is that they are
inflexible,
don't take account of the fact that most resources don't fit neatly into one category
(e.g., a book on 19th century French seascape paintings fits into at least four),
and there is no
ability to map context. OneNote users go through the same process as a librarian classifying
a collection
of books in the early 19th century: as a book arrives it gets put on a shelf next
to books at that moment
deemed similar. If there isn't a suitable shelf a new shelf is created. If a suitable
category
isn't clear, one doesn't have the time or has abandoned all hope, OneNote includes
the obligatory
category “Unfiled Notes”.
It's okay if this section gets big. You can drag the pages to other sections later,
or just use search to find them in this section.
Do you get the feeling a lot of people store most of their notes in Unfiled Notes?
The perennial question
“where did I put that?” is once again answered by search. This is not an innovation.
Knowledge Representation
— John Steinbeck, Sweet Thursday
Suzy said, "You mean I'm fish?"
"You're fish," said Fauna.
“Knowledge representation” is a strange concept, when you think about it. What exactly
is
knowledge? How does one represent knowledge?
A world of difficulty is opened up by the decomposition of even the simplest statements
in
natural language. While one might agree that the above sentences communicate
information, do they also represent knowledge? Does the spoken word? How does the
word “fish” relate
to our conception of the word, its meaning in our minds? How is the concept of the
word altered by its being
composed within the context of the above statements, with their strange (perhaps erroneous)
grammatical
constructions? Does what we know about the author or our realization that the characters
are fictional influence
our understanding of the word? If we've not read the book, might we assume Suzy is
a fish, instead of
understanding that (in the “reality” or context of the book) Fauna is explaining Suzy's
horoscope
to her, that she was born under the sign of Pisces, the sign of the fish? Are
the statements correct, and given any notion of judgment of such correctness,
in what context can they be evaluated? And more obliquely, what does "being a Pisces"
really mean?
Apart from astrology, these questions are properly in the realms of linguistics,
semiotics, and phenomenology, the study of the
relationship between directly-experienced reality and phenomena (i.e., our awareness
of reality, as received via
our perceptions) and how meaning is imparted to phenomena by culture.
Any system dealing with the interplay of knowledge representation and phenomenology
is also complicated by the
presence of ambiguity in natural language. While considered a favorable quality of
poets and writers it isn't
appropriate for description within the sciences, even though the terminology found
in the domains of knowledge
representation and ontological engineering is rife with it. As Allen Newell noted
in his influential address to
the AI community, The Knowledge LevelNewell, the use of the term
“knowledge” within that community is “informal”. Despite people's common anthropomorphization
of machines, “intelligent systems” are not actually intelligent in any real sense;
“knowledge
based systems” do not operate based upon human knowledge but on a fixed program or
set of rules;
likewise “common sense reasoning” relies on mistaken notions of a “common sense” and
“reasoning”. The list goes on. The historical use of seductive marketing language
as a means of obtaining
grant funding made the introduction of “semantic” to the lexicon of the Web almost
inevitable. Now
everything is “semantic”.
Semantics, Shemantics
— Alan Kay
I don't know who invented water, but it wasn't a fish. –
The extant literature on the "Semantic Web" — as promulgated by the World Wide Web
Consortium (W3C)
and the plethora of academics now beavering away under its auspices — suggests a world
populated by engineers
with little grasp of the last half-century's progress in either philosophy or library
science, designing systems
that promise abilities that cannot possibly be delivered, ignoring profound epistemological
issues, linguistic and
cultural chasms that have never been breached, at the same time passing over the enormous
successes within the field
of library science in organizing and classifying information.
In what might be considered part of the ongoing tradition of 1920's visions of bubble
cities on Mars, 1970's visions
of chatty household robotic butlers enlivened by “artificial intelligence” as they
deliver our
martinis[2],
the “Semantic Web” often appears as merely the latest flight of future fantasy (italics
courtesy of the
author):
The Semantic Web is an evolving extension of the World Wide Web in which the semantics
of information
and services on the web is defined, making it possible for the web to
understand and satisfy the requests
of people and machines to use the web content. It derives from W3C director Tim Berners-Lee's
vision
of the Web as a universal medium for data, information, and
knowledge exchange.
WikipediaSW
Even the short excerpt above, taken from Wikipedia's SW page (and typical of the hype),
is riddled with
terminological problems. Decomposing any one of these terms raises issues that are
never addressed
in any except the most hand-waving fashion, not to mention the anthropomorphization
of the Web itself. We are meant
to understand that machines will “comprehend semantic documents and data”
BernersLee2001,
where “comprehend” is defined by the Random House dictionary as to understand
the nature or meaning of; to grasp with the mind. This is surely the realm of science fiction.
Other elements of the SW are expressed in a large number of formal specifications;
in their entirety they
are intended to provide a formal meta-framework for description and use of concepts,
terms, and
relationships within a given knowledge domain.
If the language describing these designs is to be believed, the systems themselves
must have found
solutions to some rather nagging epistemological problems, in particular the connection
between
informal language usage, computational linguistics and formal logic. The reality of
the SW hardly
seems to be the following of a unified vision, but merely the ongoing collection of
normative
specifications for markup syntaxes, several dozen “vocabularies” and roughly fifty
technologies and assorted software projects that purport to be part of this grand
vision.
SWOver
While this profusion of activity might seem to indicate success, there is nothing
in any of this work
to indicate that any of it has broached the real problems of
representing knowledge, if indeed that is something that is actually
possible. Robert Brandom suggests
When we try to understand the thought or discourse of others, the task can be divided
initially into
two parts: understanding what they are thinking or talking about and understanding
what they are
thinking or saying about it. My primary aim here is to present a view of the relation
between what
is said or thought and what it is
said or thought about. The former is the propositional dimension of
thought and talk, and the latter is its representational dimension.
The question I address is why any state or utterance that has propositional content
also should be
understood as having representational content. (For this is so much as to be a question,
it must be
possible to characterize propositional content in nonrepresentational terms.)
The answer I defend is that the representational dimension of propositional contents
should be
understood in terms of their social articulation – how a
propositionally contentful belief or claim can have a different significance from
the perspective of
the individual or claimer, on the one hand, than it does from the perspective of one
who attributes
that belief or claim to the individual, on the other. The context within which concern
with what is
thought and talked about arises is the assessment of how the judgments
of one individual can serve as reasons for another. The representational content of
claims and the
beliefs they express reflect the social dimension of the game of giving and asking
for reasons.
Brandom
A key proposition here is that the entire enterprise of shared representation is a
form of
social agreement, an instance of human communication, not an expression
of a universal truth, and that the value of a proposition is not its truth but its
utility. This viewpoint is not necessarily shared by a unanimity of
philosophers but Brandom's argument does reflect a distinct break from analytic philosophy
within the
ranks of contemporary philosophers following the work of Ludwig Wittgenstein, whose
Philosophical Investigations (Philosophische Untersuchungen)
was published in 1953, denouncing the “dogma” in the earlier analytic philosophy of
his
Tractatus Logico-Philosophicus. More generally, this line of pragmatists and
“neo-pragmatists” influenced by Wittgenstein includes John Dewey, Wilfred Sellars,
Richard Rorty,
Jürgen Habermas, and Hilary Putnam, among others.
Informality
— Chuang Tzu, ~320 B.C.E (Burton Watson, trans.)
Words are not just wind. Words have something to say. But what if what they have to
say is not
fixed, then do they really say something? Or do they say nothing? People suppose that
words are
different from the peeps of baby birds, but is there a difference, or isn't there?
It should be noted that as described above, we could hardly design a system that relied
on formal logic.
The design is therefore distinctly informal, i.e., it is not backed by
a formal model conforming to any foundationalist or otherwise representational logic.
Its organizational
structure is instead considered as a form of human communication — a classification
system with no
a priori terms — where the meaning of a term is identified entirely
with its usage, akin to Inferential Role Semantics IRS.
In this regard the system should not be considered formal in any sense; it is by definition
a system
that supports an informal ontology.
That said, the use of terms that in other contexts might denote an expression of logic
(e.g.,
“type”, “class”, “subclass”, etc.) should not be considered as bridging any
logical chasm — they are just convenient natural language terms; no claims are made
to Platonic,
universal terms or self-justifying beliefs.
This is epistemologically a delicate balancing act. In what is known as
deductive-nomological theory, the causality of declarative sentences is
replaced by what are termed constant regularities, where rather than say that
AcausesB we only state that
A is regularly followed by B. As Manuel DeLanda
notes, it is only theory-obsessed philosophies that can afford to forget about causal connections
and concentrate exclusively on logical relations.DeLanda
We need to be clear that this is not an attempt to subordinate what might otherwise
be considered statements
of causality or truth claims behind linguistic statements, rather to claim that this
is
all they entail – the interpretation (and thus error-checking) of the
system is entirely in human hands.
It could be argued that all computer-based ontological systems such as the SW fall
under this same set of
constraints; a further discussion is out of scope for this paper. Suffice it to say
that I consider the flaws
in putatively formal systems due to epistemological issues as so profound as to demonstrably
render them
useless, or worse, useful (and therefore dangerous). It is much safer to design a
system that is by design
an informal toy and is delivered with a healthy disclaimer of having no truth conditional
claims, again, as
merely to facilitate expressions of human communication.
One of the central tenets of the philosophical investigation of the past century is
an understanding of the
failure of logic to describe the world
[3], and that the role of philosophy is not to provide a framework (logical
or otherwise) for understanding the world but, as someone like John Dewey or Jürgen
Habermas might advocate,
the therapeutic tools to improve it. This has had a profound effect on the
nature of epistemological inquiry, indeed, some to suggest that it, like God, has
died. But whether or not
epistemology has died, it's perhaps time to pay a bit more attention to it even as
it wriggles on the ground.
Semantic Wikis
There exist a growing number of “structured” and “semantic” wiki projects, many basing
their structure on category and/or typed links, others incorporating formal ontology
(e.g., RDF or OWL)
features directly into the wiki. Some, like Wikipedia's Semantic MediaWikiSMW, use “semantic annotations” to characterize content
according to an implicit or explicit vocabulary of terms.
In many cases these “semantic wikis” may provide a logical framework but often no
classification scheme
whatsoever, so we may have IsSubclassOf but nothing to subclass. It's a wiki categorization
scheme on steroids, i.e., this is categorization, not classification. There are a
number of difficulties with
this approach, including the complexity of the augmented wiki syntax; weak or absent
metadata; a lack of
user-friendly schema documentation; the requirement of user expertise; lack of support
for synonymous, homographic
and polysemous (multireferential) terms, and other limitations in the available classification
schemes (where they
exist at all). Categorization terms or annotations are themselves often ungrounded,
undefined, or when they are,
they force users into a predefined schema, often defined in a formal logic not otherwise
followed by, related or
appropriate to the user-created structure, such as using set-theoretic language to
describe the genealogical
relationships.
This is in addition to the more profound problems of: linguistic/grammatical ambiguity
(e.g., homographs,
polysemes, unconnected synonymous terms); lack of context (e.g., temporal, spatial,
cultural, individual
use of language); ill-, undefined, or misspelled terms; ill- or undefined subject
identity; the recursive
requirement for a core of a priori terms based on closed-world, monotonic
reasoning, or other epistemological and ontological errors. Many if not most of these
problems are
insurmountable unless one forces users to understand and follow proscriptive rules,
lives in ignorance or denial,
or throws one's hands up declaring defeat.
The Wrong Solution to the Wrong Problem
— Gregory Bateson, Pathologies of Epistemology, Ibid.
When you have an effective enough technology so that you can really act upon your
epistemological
errors and can create havoc in the world in which you live, then the error is lethal.
These ambitious projects are typically “knowledge modeling” tools and are
not a suitable fit for use by anyone except those whose expertise and expectations
comes
from the world of artificial intelligence, knowledge representation, expert systems
and
the like, people who already understand and/or at least accept terms and technologies
like
RDFS, OWL, XSDT, SPARQL, and GRDDL.
Even for those who putatively do, how many truly understand the ontological commitments
they are making? Given that the entire RDF-based world of the SW is predicated on
a
principle of entailment, defined by Pat Hayes in
RDF Semantics as
the key idea which connects model-theoretic semantics to real-world applications.
[…] Through the
notions of satisfaction, entailment and validity, formal semantics gives a rigorous
definition to a notion
of "meaning" that can be related directly to computable methods of determining whether
or not
meaning is preserved by some transformation on a representation of knowledge. (RDFSemantics, §2)
Should we expect the layperson to understand and accept this? Pat is trying to be
helpful when he writes:
Readers who are familiar with conventional logical semantics may find it useful to
think of RDF as a
version of existential binary relational logic in which relations are first-class
entities in the
universe of quantification. Such a logic can be obtained by encoding the relational
atom R(a,b)
into a conventional logical syntax, using a notional three-place relation Triple(a,R,b);
the basic semantics described here can be reconstructed from this intuition by defining
the extension
of y as the set {<x,z> : Triple(x,y,z)} and noting that this would be
precisely the denotation of R in the conventional Tarskian model theory of the original
form R(a,b) of the relational atom.
(RDFSemantics, §1.1)
If we build systems for use by the public with the knowledge that those systems seldom
define or follow
a formal model theory[4],
and knowing that the average user will hardly pay attention to this, much less
understand it, can we be said to be acting responsibly as designers and engineers?
First, it's not the Web that is monotonic (whatever that would mean) but the reasoning
from
Web resources that must be monotonic. […] Nonmonotonic reasoning is therefore inherently
unsafe on the Web. In fact, nonmonotonic reasoning is inherently unsafe anywhere,
which is
why all classical reasoning is monotonic; this isn't anything particularly new. But
the
open-ended assumption that seems to underlie much thinking about reasoning on the
semantic
web makes the issue a little more acute than it often is in many of the situations
where
logic has been put to use in computer science.
For example, if you are reasoning with a particular database of information, it is
often
assumed that the dbase is complete, in the sense that if some item is missing, then
it is
assumed to be false […]. But open-ended domains are not like this, and it is very
dangerous
to rely on this kind of reasoning when one has no license to assume that the world
is closed
in the appropriate way. If there were ever an open-ended domain it is surely the semantic
web. […]
The global advantages of monotonicity should not be casually tossed aside, but at
the same
time the computational advantages of nonmonotonic reasoning modes is hard to deny,
and they are
widely used in the current state of the art. We need ways for them to co-exist smoothly.
Hayes2001
John McCarthy and Pat Hayes were publishing papers on the situation calculus while
Richard
Nixon was president of the US McCHay69,
and it's not that there hasn't been significant research in knowledge representation
in the decades since. The frame problem and calculus accounts for time, concurrency,
processes,
uncertainty, and decision theory within the situation calculus provide an “embarrassing
richness” of proposed solutions (Reiter2001, 44-46; 149; 283; 335);
there has been halting but steady progress in common sense ontologies, including the
open source
release of the Cyc ontology and associated tools as OpenCyc OpenCyc;
and there is a lively and ongoing bi-yearly conference schedule on context
Context07.
After all, NASA has a couple of semi-autonomous robots very successfully roaming around
Mars.
Still, almost nothing has been done to breach the epistemological divide between knowledge
representation theory and the real world of language and human culture, and contemporary
research
in related and relevant disciplines such as computational linguistics, narratology
and philosophical
inquiry hardly seems to be on SW researchers' radar. Much of the work has been focused
on
syntax and schema development.
One approach might be to use these sophisticated tools without fully understanding
them, as
Tim Berners-Lee writes that Semantic Web researchers […] accept that paradoxes and unanswerable
questions are a price that must be paid to achieve versatilityBernersLee2001.
The problem here is not so much the possibility of paradox, it is the premise that
the Web and
its users can be made to behave according to rules of entailment rigid enough to produce
satisfactory results. If money, health, safety, or security
are involved this hardly seems responsible.
Another approach might be to chill out, not take life (in particular, machine reasoning
and
computer-based ontologies) so seriously, or perhaps to stop using formal logic to
describe the
informal world and go elsewhere for a solution to the problem of organizing information.
Librarians are Sexy
In addition to not paying much if any attention to epistemology, the SW folks at the
W3C
don't seem to have paid much attention to the demonstrable success of metadata and
classification schemes within the field of library science. Now, not all the problems
the
SW is trying to address are related to information organization (e.g., “intelligent”
agents, military surveillance) but it does seem telling that library science has been
so
summarily ignored. It's perhaps not as sexy as AI, but is demonstrably a lot more
important in this age of infoglut: we need information
organization a lot more than we need robotic butlers, even if we did have
complete trust in their ability to make important
decisions for us.
Despite the close ties between the W3C and the Online Computer Library Center (OCLC)
and
its Dublin Core metadata project, a recent search of the over 115,000 pages on the
W3C Web
site for the word “librarian” returns only 59 hits, and only 324 for
“digital library”[5]. So perhaps it's not too surprising that a site search
for an important text on information organization published by the MIT Press – MIT
is the founding organization of the W3C – produces no hits. Not a one.
For those not acquainted with Elaine Svenonius' book
The Intellectual Foundation of Information OrganizationSvenonius2000,
they might be surprised to find lucidly stated solutions to many of the thorny
“semantic” problems of information systems, vocabulary and metadata design, as
well as other issues germane to the SW. This is not simply theory but a description
of
demonstrably functional approaches to information organization that are current practice
within the library world. We'll revisit this later; suffice it to say that Svenonius'
book has been highly informative in the design of this project.
Background
This section describes the goals, history and requirements of the
Ceryle Project, and the requirements that led to its design and
implementation of the Assertion Framework.
The Ceryle Project
The original intent of the Ceryle Project – now in development for over seven years,
admittedly a bit
of a kitchen sink – was to develop a software application to organize notes, planning
documents,
bibliographic references and other research materials, a document management system
that permitted user
creation and management of its own classification system, a bounded (but only partly-controlled)
vocabulary of terms and relations between those terms, where each term must be defined,
and all relations typed,
again by a defined term.
This was simply the next in a long line of attempts at organizing the matériel for
a work of historical
fiction that had overflowed dozens of paper notebooks since the early 1990s. Transcribing
those notes to a
computer hadn't solved the problem, as there were still neither any organizational
principles nor tools; I
found myself spending almost as much time in wading through the morass as I did in
research and writing (and as
a writer I'm an expert procrastinator).
After my involvement with the XML Topic Map 1.0 (XTM) specification, the project was
also a means of exploring
how XTM and other XML markup might be merged with various types of library classification
systems in supporting
such a software application.
The Ceryle Project began as a content management system (CMS) marrying a text editor,
an embedded XML database,
search engine, various categorization and classification features, and a graph visualization
engine. Originally,
Ceryle was a standalone UI application, but after a few years an embedded web server
and wiki were added –
largely to provide a local rich text editing environment as an alternative to the
Java Swing UI. It now resembles
a digital library application with a relatively sophisticated user interface as well
as a web interface and
nascent RESTful web services.
Māori Subject Headings & the Iwi Hapū List
The National Library of New Zealand has been a sponsor in the development of two projects
that use a thesaurus
database to organize Māori-related cultural materials:
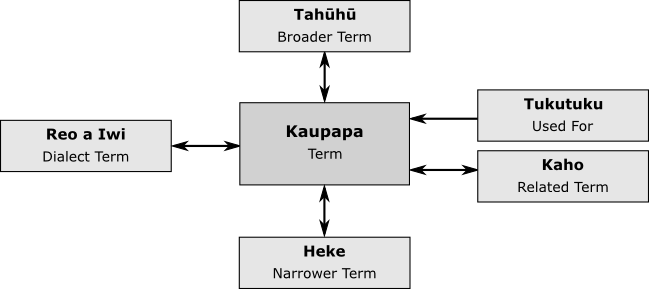
Figure 1: Ngā Ūpoko Tukutuku structure
Ngā Ūpoko Tukutuku / Māori Subject Headings (MSH)
expresses a set of library subject headings in te reo Māori, with mappings to their
English subject
heading equivalents. Documentation (scope notes) and relations between terms are expressed
in both languages.
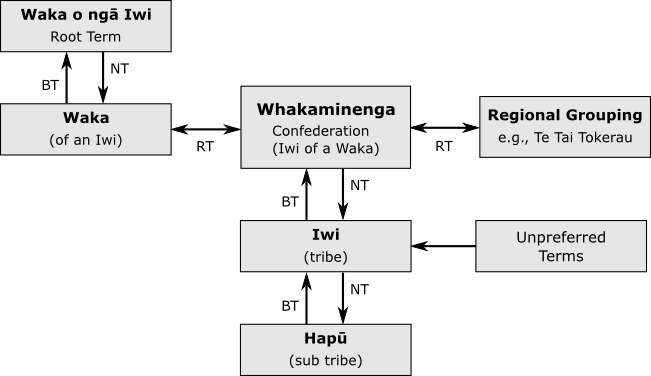
Iwi Hapū Names List (IHL)
expresses the structure of Māori whakapapa (genealogy) from
waka (canoe) to whakaminenga (confederation)
to iwi (tribe) to hapū (sub-tribe
or family group)[6].
These databases use the standardized thesaurus structure Z3919 to represent existing relationships between records (see Domain Ontology below
for details).
Figure 2: Iwi Hapū List structure
The source materials exhibited hierarchical, mereological, collection, and other relation
types, which were shoehorned
into the existing thesaurus relationships. For example, the reflexive HasIwiOf and IsIwiOf
relations are subclasses of the Z39.19 Broader Term and
Narrower Term relations, respectively. The use of thesaurus software as a means of
library classification system development is not uncommon (Turner, 111-117).
One benefit of the project is that it has permitted these two databases to be merged
into one system while still
maintaining their respective scopes. We were lucky in that of the thousands of records
there were only two name clashes.
Had there been a substantial number we may have had to resort to a Wikipedia-like
name disambiguation strategy.
Requirements
In a nutshell, the basic requirements of the Assertion Framework were to provide a
wiki environment that permitted
expression of an underlying structure using a relatively simple wiki-like syntax.
In more detail, the system should:
presume no underlying model; that the design be able to declare its semantics over
clear and
uncluttered ground
avoid the problems of the simplistic wiki category links but neither require users
to learn a
classification scheme, a set of rules for its use, nor any arcane, complicated syntax
— the
system was to be as "wiki-like" as possible. Any augmentation to wiki functionality
should also be “wiki-like” and use a syntax that is easy to learn and understand,
an
informal system usable by untrained, lay people, not just “knowledge engineers”
permit structuring of the wiki based on explicit typed links (relations) between pages
(with page
names as terms), expressing a graph structure implemented as a user-editable, REST-conforming
Web
service REST, where each URL could be used as a subject identifier
permit the user-modifiable structure to be based on an underlying, unmodifiable
endorsed structure, protecting the endorsed structure while
permitting view differentiation of the endorsed- from the user-edited structure. This
is not to
advocate a set of truths but permit an expression and differentiation of a
corporate and public opinion.
substantial parts of the semantics (particularly domain-specific predicates) should
be
community-definable
all terms in the vocabulary must be defined (and those definitions readily accessible)
expose the structure for improved user navigation
the underlying ontology (structure) must be exposed and shareable across multiple
wikis, and use a
standardized notation (in this case, XTM 1.0 was chosen since the wiki structure is
maintained as a
Topic Map)
the overall system must be capable of being archived in such a way as to permit reconstruction
of any
given moment in its history (so as to be able to reconstruct the context of a given
assertion), likewise
users must be able to view snapshots of a set of wiki pages at any given point in
the wiki's history
be based on modifiable, popular (i.e., relatively stable) open source software
Design
This section describes the design of an Assertion Framework, a software library
that provides capabilities for categorizing, classifying and organizing a repository
or corpus of documents; how
classification and ontology are defined and used
in the project; the abstractions used in creating assertions and finally how these
assertions fit together to create an informal ontology.
The following section then describes the implementation of this design.
Classification vs. Ontology
We have a readily available solution for an organizational structure that avoids the
epistemological conundrums of
computer-based ontologies by appealing to the functional (i.e., functionalist) approach
of classification systems
within library science.
Svenonius describes a subject language as an artificial language that is used to
depict what a document is about. It is the language providing the terms used to
compose a classification scheme. The chapter Subject Languages: Referential and Relational
Semantics (Svenonius2000, 147-171) begins:
This chapter looks at the semantic treatment needed to transform a natural language
into a
subject language. […] a subject language is based on a natural language but differs
from
it primarily in the semantic structures it uses to normalize vocabulary by setting
up a
one-to-one relationship between terms and their referents. The referential semantics
of a
subject language deals with the generalized homonym problem. It consists of methods
for
restricting term referents so that any given term has one and only one meaning. The
relational
semantics of a subject language deals with the generalized synonym problem and consists
of
methods for linking terms within similar or related meanings.
If we consider each page on a wiki as the community's “canonical” information about
a
given subject, with its unique page title serving as a descriptor of that subject,
the set of page
titles taken as a whole comprises the subject language of the wiki. The wiki page
name and its associated
URL act as unambiguous subject identifiers; each use of a term is also a link to its
reference documentation.
The terms in a subject language differ referentially from those in ontology or in
natural language in that
they do not refer to entities or concepts in the real world but to subjects.
The extensional meaning of a term in a subject language does not refer to the class
of all entities denoted by
the term but to the class of documents that the term denotes. From an inferential
role semantics point of view,
the evolutionary development of a classification structure based on user design and
behavior would (assuming
active usage) tend towards validating those terms and relations between terms within
the classification system
that are frequently traversed, with infrequently or unused assertional links potentially
deprecated or at least
called into question. This warrants further investigation.
Homographs, Polysemes and Other Multireferential Words
One of the problems in classification schemes is due to the multireferentiality of
words. Briefly,
homographs are words that are spelled the same but have different meanings.
Polysemes are words that are spelled the same, have different meanings, but
their meanings are related. These constitute only two of a variety of what are called
multireferential words. Even words that aren't usually considered
multireferential may be interpreted with subtly different meanings when used in different
contexts, domains of
discourse, in different grammatical constructions, or by different people or groups
of people (e.g., children
vs. adults).
Library classification systems have dealt with the issue of multireferential terms
in various ways. Svenonius
notes that this can be accomplished either semantically, via domain specification,
qualifiers and/or annotations,
or syntactically (Svenonius2000, 148-155).
The latter, called nonsemantic disambiguation, is a natural solution for wikis
where the use of camel-cased combinatory terms as wiki page names is the norm.
Over the years wiki communities have discussed at length and less frequently experimented
with the use of namespaces,
similar to the use of colonized tokens in XML. There are a variety of problems with
this, such as the incompatibility
between various characters as delimiters and URLs, but even with a functional syntax
the biggest deterrent is likely
to be the additional complexity for the user.
Faceted Classification
Classification methodologies used in modern libraries have been profoundly influenced
by S.R. Ranganathan's
Colon Classification system ISKOI,
developed in the 1930's. While Ranganathan's system[7]
did not itself survive, it was subsequently a profound influence on other classification
schemes, including both
Dewey Decimal and US Library of Congress (LoC), and led to the development of
Faceted Classification (FC), where the predominant terms of a given domain of
knowledge are sorted into homogeneous, mutually exclusive conceptual categories or
facets, each derived from the parent domain by a single characteristic. FC differs
from a traditional enumerated scheme in that “it does not assign fixed slots to subjects
in sequence, using
instead clearly defined, mutually exclusive, and collectively exhaustive aspects,
properties or characteristics of a
class or given subject.” Wynar.
As an example, Gregory Bateson's seminal work Steps to an Ecology of Mind contains
the US Library of Congress Cataloging-in-Publication (CIP) data on its copyright page,
used by libraries in cataloging
the book. This includes:
1. Anthropology, Cultural – Collected works. 2. Knowledge, Theory of – Collected works.
3. Psychiatry – Collected works. 4. Evolution – Collected works. I. Title. II. Series.
[DNLM: 1. Anthropology, Cultural – collected works. 2. Ecology – collected works.
3. Evolution – collected works. 4. Schizophrenic Psychology – collected works.
5. Thinking – collected works. GN 6 B329s 1972a].
Anyone interested in this book has a good chance of locating it by subject amongst
the plenitude
found in a library card catalog, even if they cannot remember the title or author.
But it is
rather unfortunate that the categories listed for Steps to an Ecology of Mind
don't include cybernetics, cognitive science, and systems theory, though Bateson's
ideas have been
profoundly influential in the foundation of these sciences. We can perhaps forgive
the librarians who classified
a book that has broken so many boundaries. All classification schemes have their limitations
and failings,
including the very human problem of an inability to see into the future. The flexibility
of allowing classifications
to evolve without breaking is extremely important, especially during the early stages,
where categories are still
relatively unformed. Notably, this problem plagued expert systems implementations,
where later changes to root level
concepts were very difficult to accomplish (e.g., a change of logical foundations,
such as from first order to modal
logic).
Many of the refinements in the system have been in the approach to defining the interrelationships
between terms.
There are two fundamental Faceted Classification relationship types: semantic and
syntactic.
A semantic relationship is independent of context and is by definition a permanent
relationship, arising from the subjects involved. Semantic relationships are further
divided into three types:
equivalence relationships, where terms are synonyms (and would be cross-referenced
under the same category); two types of hierarchical relationships,
superclass-subclass and mereological (whole-part);
and affinitive/associative relationships, which are domain-specific relationships
such as cause and effect, coordination, sequence, genetic, etc.
A syntactic relationship is an ad hoc relationship
denoting otherwise unrelated concepts brought together as a composite subject in a
specific context. This is the
equivalent of how terms would appear together in a common sentence. It operates similarly
to how we use keyword
searches on the Web, such as “biblical archaeology”, “poetry by 12th century Japanese
authors”,
or “medieval weapon manufacture”. This approach is at the heart of the resource organization
approach taken
by most wikis in their use of camel-cased wiki page names. In the Assertion Framework
we didn't set out to avoid
the use of wiki page names as subject identifiers, but were looking to supplant the
klunky use of category names by
use of typed assertions between pages.
A highly recommended text on library classification schemes is Essential ClassificationBroughton, whose author is an active researcher in
Faceted Classification.
User Tagging or “Folksonomies”
A user tag permits the non-hierarchical assignment of a term or keyword to a
resource. The syntax of user tagging in most social software sites (e.g., del.icio.us,
Flickr) is a simple comma-
or whitespace-delimited list of tokens. Whereas on these sites users are generally
permitted to add tags to a
resource at will (absent any validation or even spell-checking), in our case this
would mean that many or most tags
would remain undefined and outside the Assertion Framework.
Tags could be seen as keywords in a Dublin Core list of subjects and would in our
implementation be therefore
searchable, but we wanted tags to play a larger role than that of metadata given their
current popularity.
While Faceted Classification permits synthetic classification, its facets are still
usually derived from a controlled
vocabulary. If each tag were represented by a wiki page, where each definition is
discoverable, tags could then be seen
as facets. The decision was therefore made to require each tag to be represented by
a wiki page, even if this may be
seen by some users as onerous. We don't yet have feedback that would permit us to
evaluate how this may affect
the willingness of people to tag resources.
Assertions
The basic graph design centers around a simple construct called an Assertion, a
form of simple declarative sentence using the Subject-Predicate-Object grammar common
to natural
language[8]
as well as other abstract syntaxes (e.g., RDF, where it is called a triple).
In this model each of the three components of the sentence is a Term:
Subject Predicate Object
E.g., an Assertion stating that Gary Snyder is a poet might look like:
GarySnyder IsA Poet
The Terms available for use in Assertions are not composed from a controlled vocabulary
in the library sense, but
given that the validation of a new Assertion uses the set of Terms dynamically derived
from the extant wiki pages,
the vocabulary may not be controlled but is at least nominally defined. Users may
create new wiki pages as necessary
to make available the Terms necessary to their Assertions.
The interpretation of an Assertion is similar (but not equivalent) to the definition
in
RDF Semantics:
The basic intuition of model-theoretic semantics is that asserting a sentence makes
a claim
about the world: it is another way of saying that the world is, in fact, so arranged
as to be
an interpretation which makes the sentence true. In other words, an assertion amounts
to
stating a constraint on the possible ways the world might be. (RDFSemantics, §1.3)
Throwing out the assumption of a model theory and discarding any notion of a universal
truth, we
may more usefully consider an assertion in a socio-linguistic sense: a statement of
belief made
by a person about the world. Given that these Assertions are being made by many people
in the
collaborative environment of a wiki, this is quite a reasonable
stance. In other words, we may infer – based on the stated beliefs of the community
–
a statement of potentially equal believability.
The set of the wiki's extant Assertion triples forms a bipartite graph, where each
pair of
Subject and Object Terms are graph nodes linked by their respective Predicates. This
bounded
corpus of Assertions taken together is considered a form of informal
ontology[9].
Core Predicates
In simple terms, taxonomy is a restricted form of ontology, a hierarchy where all
relations
share a common ancestor type. Because our design uses hierarchical as well as other
relation types
it cannot be considered a proper taxonomy, but it does include a taxonomic “layer”.
Ontological hierarchies can be composed of a variety of formal relations, based on
sets,
classes, collections, etc. (depending on the underlying logic, derivation, and context
of use).
Because we are distinctly trying to avoid connoting formal (e.g., set theoretic) foundations
as
well as promote simple natural language terminology, the names of the predicates avoid
formal titles
but make reference to a formal, traditional relation type in their documentation.
There are three fundamental Predicates that compose the core of the ontology:
Kind Of
the superclass-subclass relation
Is A
the class-instance relation
Part Of
the mereological part-whole relation
The "Kind Of" and "Part Of" assertions together form a hybrid hierarchy,
with instances or individuals related via "Is A" Assertions[10].
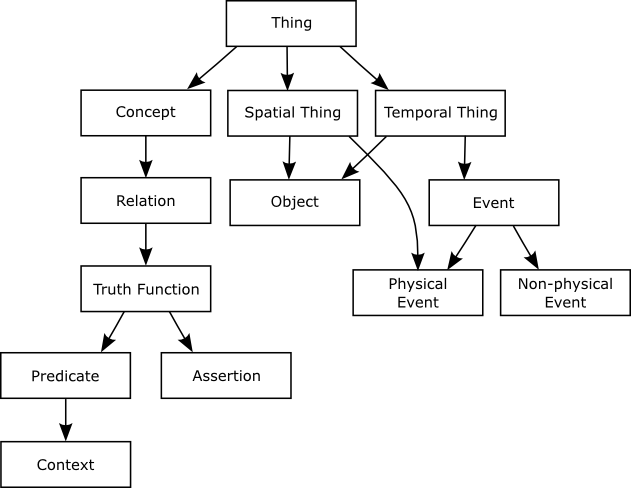
Upper Ontology
Figure 3: Core Ontology
As with many ontological models, all graph nodes are some descendant of a root Term
called Thing (“everything is a kind of thing”),
such that the system is composed of a single connected graph. All Predicates are some
descendant subclass of an ur-Predicate called
Relation. The core or base ontology is a very
simple, as shown in Figure 3.
Most Terms are related via a Kind Of (superclass-subclass) relation. The basic
foundation of the ontology is primarily taxonomic, with some additions of mereological
components.
Support for Faceted Classification is provided by the relation
Has Facet
the facet relation
With the addition of various additional relations the “upper ontology”
contains roughly 50 terms and 50 relations.
Domain Ontology
Domain ontologies using additional affinitive or associative relations are considered
as “layers” on the Upper Ontology's taxonomical/mereological structure.
Being domain-related, these are the most likely to be augmented and/or modified by
users. Syntactic relationships are considered as the coming together of other relationship
types, e.g., in constructing a character, a setting, an event, or a scene in a narrative
ontology.
The project currently includes two domain ontologies:
Z39.19
includes the complete set of terms and relations as described by the Z39.19 standard.
This includes complete role and relation templates for all Z39.19 predicates actually
used by the system. All Z39.19 terms and relations are included as Terms even if
currently unused.
Māori Subject Headings / Iwi Hapū Names List
this includes the set of terms and relations used in the Māori Subject Headings and
Iwi Hapū List, with mappings to equivalent relations in Z39.19.
Other domain ontologies developed for the Ceryle Project may be included as needed
in the project.
Relationship to Z39.19
The ANSI/NISO standard Z39.19 Guidelines for the Construction, Format, and
Management of Monolingual Controlled Vocabularies (Z39.19 2005) provides features for
support of controlled vocabularies, thesaurus terminology and base relation types.
This is used in the context of the wiki using the following definitions (where Z39.19
definitions are in bold):
each wiki page is a precoordinated term reifying a single concept or subject
the wiki page name is considered the subject heading
wiki Assertions are used rather than untyped links between pages to establish semantic relationships
the inherent predicate of each Z39.19 semantic relation is reified as a wiki page
the wiki is considered a controlled vocabulary as dynamically bounded by gamut of wiki pages.
all domain-based predicates are likewise defined as wiki pages
Z39.19 defines three types of semantic (as opposed to syntactic) relationships used
in
controlled vocabularies: Equivalency (§8.2); Hierarchy (§8.3); and Association
(§8.4).
Equivalency relations include synonymy, near synonymy, and lexical variants. This is notably
not
an equivalency relation under any logic, i.e., it does not relate equivalent concepts
or entities but
equivalent terms. Our ontology maps these to Use
and UsedFor. (This does not map to the logical connective
Equivalent relation found in our middle ontology, which is used only for
logical relations.)
Our project mirrors the Hierarchy relations, though sadly the Z39.19 standard
reflects a common error in knowledge representation texts of conflating IsA with a
superclass-subclass relation. This results in Z39.19 using the same IsA name for
the “Generic Relation” (ostensibly, superclass-subclass) and
“Instance” (class-instance) relations. We provide the two Z39.19 generic
relations as IsBroaderThan and IsNarrowerThan, with IsRelatedTo used when hierarchy
is unknown or otherwise not implied.
In our ontology we use IsA for class-instance and KindOf
for superclass-subclass, where the latter may be seen as a synonym for IsNarrowerThan.
The mereological whole-part relation is in our ontology named PartOf.
Note that we do not differentiate set theoretic from collection-based semantics;
this is not a formal system.
Z39.19 defines eleven Associative relations (e.g., Cause / Effect, Process / Agent),
and while they are included in the ontology and instantiated as wiki pages, they are
not used in our source materials hence are not described here further, but again,
these are considered as relations between vocabulary terms, not logical relations.
Endorsement
The concept of an endorsed set means that some Terms and Predicates are
protected from being removed or redefined by users, as they are considered part
of the required semantics of the application. This was a requirement of the system,
in that the set of terms and relations delivered to the public may be seen as a
corporate endorsement of their definition or validity. Given that the public is to
be permitted the ability to modify portions of this information there must be a
way to either protect endorsed content or at least be able to differentiate the
endorsed from unendorsed. This is done via scoping (in the Topic Map sense).
User-created Assertions (i.e., those made via plugins on wiki pages) currently
have no ability to express scope, so their scope in the resulting Topic Map is
hardwired by the plugin itself.
If desired, administrators of the system may wish to develop a workflow-based
endorsement process (policies and practices) whereby user-created terms and
predicates can be migrated into the endorsed ontology.
Implementation
While the expression language and the functional implementation of the
Assertion Framework is largely tied in this instance to its origins in the
Ceryle Project and/or its current wiki implementation, in abstraction most
elements of this design could be reused in non-wiki applications.
A Software “Framework”
One aspect of Ceryle that was clear early on was that in addition to supporting
the stated functional requirements it also needed to serve as its own development
laboratory. Over the years there have been a large number of experiments with
features, software libraries, conversion tools, visualization capabilities, some
of which have survived, though many only in backup archives. As a framework it has
gradually matured and now includes user scripting and various extensibility features.
The Assertion Framework described in this paper is a module added to the embedded
wiki functioning within the Ceryle standalone application, but has also been installed
as part of a generic JSPWiki distribution running on Apache Tomcat; in the latter
case
there are no dependencies on the standalone Ceryle application.
Choice of Wiki Software
There were two primary requirements that led to the addition of a wiki: the ability
to provide simple formatting markup in a non-WYSIWYG text editor; and to provide an
online
and/or collaborative editing environment that could function in either a standalone
(local)
or online environment.
The availability of software libraries, compatibility with the Ceryle application
as a
development environment, and my own previous experience made Java the programming
language
of choice. An evaluation was made among the offerings of web servers and wiki software,
based on features, ease of embedding, extensibility, stability, and the health of
their
respective communities and/or sponsors. Jetty[11]
was chosen as the embedded web server (there
was little competition). No modifications to Jetty were needed apart from some configuration
and embedding code. Following an evaluation of available open source wiki software
applications,
JSPWiki[12]
was chosen as the most versatile and extensible for our purposes. In the past year
JSPWiki has been selected by the Apache Foundation as its wiki solution.
Data Conversion
The initial content for the present implementation was derived from the Māori Subject
Headings
and Iwi Hapū Names List thesaurus (Z39.19-compliant) databases and converted via Groovy
scripts
into interim XHTML documents, which were then converted into Linear Topic Map (LTM)
source files
to provide a backing structure for the wiki as well as generating an individual wiki
page for
each record.
Initially, the database export was only available as a plain text format. The MSH
database software
has been recently upgraded and now supports an XML export, so the Groovy script was
updated to
process the new format. This could have been accomplished via XSLT but the existing
investment
and rapid development of the scripting solution was considered important.
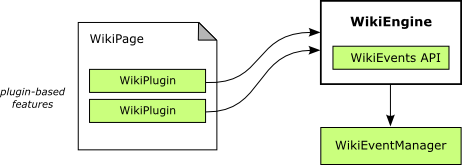
WikiEvents and the WikiEventManager
While JSPWiki was considered a good foundation, earlier versions of JSPWiki did not
include any
event handling code, so a general purpose WikiEvents API, a number of WikiEvent classes
and a
WikiEventManager (see Figure 4. WikiEventManager)
were developed for this project. This permitted application-level events to be fired
as wiki
pages were created, edited, renamed, deleted, and displayed. This general purpose
wiki events
API and implementation are now part of the Apache JSPWiki distribution.
Figure 4: WikiEventManager
Each wiki page editing session fires a number of associated WikiEvents. By filtering
on event
type we can capture specific life cycle events for a wiki page.
Wiki Plugins
Given that the basic idea was to permit users to make Assertions, we needed a means
of
expressing them using a simple wiki-like syntax. JSPWiki has a number of extensibility
features, the WikiPlugin API being the most suitable for developing syntax-level functionality.
JSPWiki augments its formatting and linking syntax with a plugin syntax, where a reference
to the plugin name is followed by a plugin body, which may contain one or more named
parameters.
For example, to transclude the wiki page “CopyrightStatement” using the InsertPage
plugin one would include the following wiki text:
[{InsertPage page='CopyrightStatement'}]
When the WikiEngine encounters this plugin syntax it instantiates a plugin object
based on the plugin's name as mapped
to a Java class name. The plugin object's method is called and the plugin then performs
its programmed tasks.
From the user's perspective, our entire system is implemented via a set of custom
plugins, as described below. We've
therefore augmented the default JSPWiki wiki text syntax with an additional assertion-related
vocabulary, this vocabulary
in keeping with the rest of JSPWiki's plugin syntax. Users already familiar with other
JSPWiki plugins would find nothing
unusual using the syntax of these new assertion features, and in fact, some of the
plugins simplify the JSPWiki plugin
syntax by not requiring use of explicit parameters.
Assertion Plugins
The implementation provides both assertion expression and query plugins, including:
Plugin Name
Alias
Description
AssertionPlugin
Assert
assert a single Subject-Predicate-Object sentence
AssertionFormPlugin
AssertForm
asserts properties based on a form template
AssertedPlugin
Asserted
query for Assertions matching a given pattern
AssertTagPlugin
Tag
assert one or more tags as properties of the Subject
HasAssertedTagOfPlugin
HasTagOf
query for wiki pages matching one or more tags
TopicMapPlugin
TopicMap
query the backing Topic Map (administrative use)
The AssertionPlugin syntax is quite simple, just wrapping the abstract assertion syntax:
[{Assert [GarySnyder] IsA [Poet] }]
Assertion Templates[13]
use the same syntax but include a flag parameter, using the links to assert the roles
played by the subject and object in Assertions of that type:
[{Assert template='true' [Instance] IsA [Class] }]
Likewise, the query syntax is similar but uses parameters:
This would return all Assertions having a Predicate “IsA” and an Object of “Poet”.
Regular expressions
are also supported. The current wiki page can be referenced in the syntax by “[.]”.
In practice almost all of the plugins developed for the project are domain-specific
subclasses of either the
AssertionPlugin or AssertedPlugin, developed to provide a specific feature based on
a shorthand wiki text syntax.
Some plugins are aliased to provide simpler or alternative names or to preset certain
default values. For example,
the Z39.19 predicates (e.g., “IsNarrowerThan”) were all included by presetting the
current wiki page as
the Subject and a fixed predicate name so that rather than
[{Assert [Whare] IsNarrowerThan [WhareT?puna] }]
the user need only type
[{IsNarrowerThan WhareT?puna }]
It is hoped that these types of syntax simplifications will keep users from getting
bogged down in the details of the
syntax. Even the use of the word “assert” might be seen as overly technical by many.
As the terminology
used is easily changed we look forward to improving the system via user feedback.
User Tagging
A WikiTag feature was developed to provide the ability to tag a wiki page,
query pages matching one or more tags, or display a tag cloud. This again uses wiki
plugins:
Plugin Name
Alias
Description
TagPlugin
Tag
assert one or more tags as properties of the Subject
HasTagOfPlugin
HasTagOf
query for wiki pages matching one or more tags
TagCloudPlugin
TagCloud
display a tag cloud based on a query
Users can add tags to a page using a simplified plugin syntax:
[{Tag Person Actor Honcho }]
This uses a TagManager that functions independently of the Assertion Framework, so
that JSPWiki installations
can be provided with a user tagging feature and augment the wiki at a later date with
the Assertion Framework
without any change in syntax. In this case, the only change necessary is the addition
of the Assertion
Framework library (jar file) and the re-aliasing of the plugins, e.g., changing the
“Tag”
alias from the TagPlugin to the AssertTagPlugin, the “HasTagOf” alias from the HasTagOfPlugin
to the HasAssertedTagOfPlugin. JSPWiki provides this configuration feature via an
XML file.
User tags are instantiated within the system as facets, such that the actual relationship
between
a page and one of its tags is a HasFacet relation. While this is a form of typed
property assignment, the system does not currently support property
typing of tags, though this can be done using via an assertion, eg.,
But this kind of thing might be seen as pushing the envelope on a wiki…
Assertion Framework
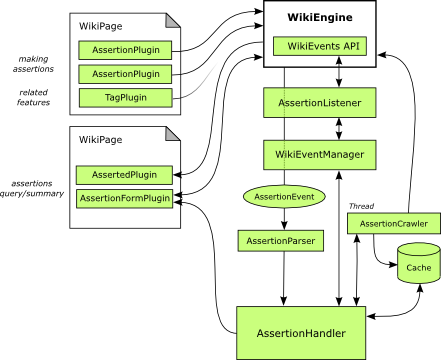
When an instance of an AssertionPlugin is parsed on a wiki page it fires a subclass
of
WikiEvent called an AssertionEvent. An event listener filtering for AssertionEvents
passes this on
to a parser which generates an Assertion object corresponding to the parameters of
the plugin
syntax. In addition to Subject, Predicate, and Object we also capture the name of
its origin wiki
page and a creation timestamp[14].
Figure 5: Assertion Framework
The system supporting the expression, generation, caching and querying of Assertion
objects
is called an Assertion Framework
(see Figure 5),
which can be thought of in both static and dynamic terms: static in the sense that
at any point in
time a snapshot of the system provides the set of extant Assertions; dynamic in the
sense that the
system is mutable, continually changing as people create and modify the wiki pages.
The workhorse of the system is the AssertionHandler, which handles all incoming Assertion
objects,
and managing a cache containing the set of all Assertions on the wiki. The initial
set of Assertions
is generated by an AssertionCrawler scan of all pages.
The AssertionHandler also provides methods to query the set of Assertions.
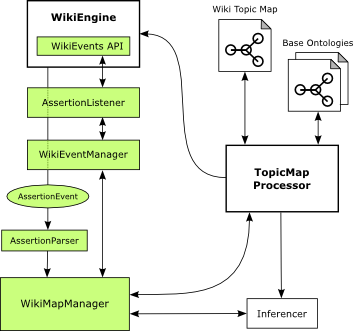
WikiMapManager
In the current implementation, the life of the AssertionHandler is very short. While
the Assertion
Framework using an AssertionHandler is a functional system, our requirements are better
met by
queries from a Topic Map.
Figure 6: WikiMapManager
Following initialization of the WikiEngine on startup, the AssertionCrawler crawls
the wiki pages.
Once this has finished it fires a completion event which triggers creation of a
WikiMapManager
(see Figure 6),
which also implements the AssertionHandler API.
The WikiMapManager obtains the set of Assertion objects from the existing AssertionHandler
and
converts them into Topics and Associations in an in-memory TopicMap object using the
TM4J Topic Map engine.
Given our model of Assertions as simple binary relations, the translation to a Topic
Map is straightforward.
As described previously, the Assertion object contains references to the wiki page
names for Subject,
Predicate, and Object, the origin wiki page and a creation timestamp. Each wiki page
name reference is
converted to a Topic whose base name matches the wiki page name, with the page URL
as a subject identifier.
The Predicate is further typed as some descendant class of Relation within the Topic
Map's subsumption
hierarchy for relations. The Assertion itself is converted to a Topic Map Association,
typed by the
Predicate's Topic and also reified as a Topic. The timestamp is added as a property
to this Association.
If any of the wiki page name references match an existing Topic name the existing
Topic is used. We are not
currently scoping page names but will likely add scope to all names in the future
given the current
development project is multilingual.
Once this conversion is complete the WikiMapManager usurps the functioning of the
existing AssertionHandler
(which is then destroyed), so that incoming AssertionEvents are now processed as modifications
and queries
on the Topic Map.
The author of an Assertion relies upon the ability to read the respective wiki page
documentation related
to the sentence components at the moment of its expression. Since the system is mutable
it must also be
possible to view a snapshot of the system at the moment when the expression was made
in order for others to
interpret the Assertion correctly.
Topic Map Interfaces
The TopicMapPlugin is currently used to perform diagnostic queries on the Topic Map
from a wiki page. The result
of a query via a wiki plugin can return an XHTML fragment or content which could be
processed via a Java Applet,
so this usage is limited to direct display or visualization features.
There have been a few Web service experiments that return Topic Map (XTM) fragments,
e.g., Topic and Association
serializations corresponding to a set of Assertion objects. Though an interesting
feature, there is no specific
application requirement for inter-wiki sharing of structures that can't currently
be accomplished via the
existing XML-RPC features, so this remains as yet undeveloped.
Note that “Inferencer” is shown as a small box in the diagram. This is to indicate
that this is
not some big fancy inference engine, just a single Java class that performs simple
queries on the Topic Map,
such as returning simple transitive inferences upon relations whose predicates have
been marked as transitive,
such as ancestor and descendant tests, plus a few utility methods. Most return a boolean
value so that they can
be chained. As this functionality can easily be accommodated within the current use
of wiki plugins no additional
interfaces have been developed.
Topic Map Modules
One of the features of the system is the ability to provide run-time augmentation
with the addition of drop-in
LTM files as Topic Map modules. For example, if a user creates a wiki page called
“Portugal” and
asserts that Portugal IsA Country, we look up the
page name in the ISO 3166 Country Codes for Topic Maps, as well as making any additional
assertions about that
Topic based on any Associations in the Topic Map.
Modules available, in development, or planned include ontologies for languages and
countries, places, place
names, events, geocode, measurement and datatypes, mappings to other library subject
headings, and various other
subject domains. One idea in the works incorporates a place names to latitude-longitude
database to permit
inclusion of Google Maps. For example, any wiki page asserted as a place would look
up its wiki page name in
the place names database, then use a wiki plugin to insert a Google Map for that location.
This remains an area
ripe for further exploration, and will likely be determined in part by user feedback.
Endorsement
Implementation-wise, all endorsed Topics and Associations within the backing
Topic Map are scoped by an endorsing Topic. All user-created content within the Topic
Map is either left unscoped,
or scoped as "Unendorsed". In the case of the Māori Subject Headings and Iwi Hapū
Names List,
their Topics are scoped accordingly so that we may in the future extract Topic Maps
corresponding to their
respective domains.
Wiki Features
With all of this additional machinery behind the scenes, what effect does this have
on the user experience?
It must be said that, to reiterate one of the requirements, there is little desire
to expose a great deal of
complexity, particularly for readers. We likewise have on occasion decided not to
implement a feature when it
was seen to significantly add to the complexity of either the browsing or editing
experience. Thus, most of
the Assertion Framework features are experienced as links, structure displays or improved
search or navigation.
For example, the generated output from an AssertionPlugin shows the Subject, Predicate
and Object as active
wiki page links. A hideable navigational panel has been added to the page footer that
displays any assertions
or other information queried from the Topic Map for that wiki page.
We still have not investigated fully the use of many of these features and look forward
to doing so following
public release of the service.
Next Steps
Some future features are planned and/or partially implemented:
the project is currently being socialized amongst funding organizations
further develop query and inferencing functionality
provide term equivalence, related term, term aliasing, and term disambiguation features,
both
manual (explicit) and automated (implicit) to deal with both homonyms and polysemes
provide enhanced search features based on assertions, tags, and collative terms
protect endorsed terms and relations using scope
permit scope-based filtering on queries
further develop basic ontologies and improve existing documentation
create forums for discussion of ontology development
with a current reliance on RecentChanges to manually discover errors, develop features
for
structural analysis and validation
develop features to assist users in classifying new wiki pages (terms)
develop drop-in Topic Map-based ontologies
wiki hive functionality (sharing classifications across multiple wikis)
develop administrative features
develop (likely off-line) visualization features for analysis of the wiki structure
develop better internationalization/localization support
develop a RESTful web service providing queries on the Topic Map
performance improvement & scalability testing
Conclusion
The Assertion Framework is still in a prototype state so there are many questions
as to the viability of both
the approach and implementation. An upcoming National Library of New Zealand project
related to the Māori
Subject Headings has been proposed that would use two wikis to perform a cross-dialect
comparison of terms
between the predominant te reo Māori language and a Taranaki dialect. We look forward
to testing the
system in a semi-controlled environment.
This paper has put a substantial focus on epistemological and design issues rather
than on implementation details.
The reason for this is that the central innovation is not seen as the marrying of
a Topic Map engine with a wiki
– any programmer could accomplish that – but in the investigation into what the use
of this
means, i.e., does the expression of declarative statements incur an entailment
or not? And if so, of what order? Surely there is no single answer to this question,
but in the same way as people
commonly anthropomorphize machines (hell, we anthropomorphize rocks), this paper
is, if anything, meant to inject a note of caution into inferring that the systems
we develop do more than they do,
that our claims notwithstanding we are in large part still playing with toys.
[Brandom]
Brandom, Robert. “A Social Route from Reasoning to Representing.” In
Articulating Reasons, by Robert Brandom, 157-183.
Cambridge, Massachusetts: Harvard University Press, 2000.
[DeLanda]
“Virtuality and the Laws of Physics.” In
Intensive Science & Virtual Philosophy,
by Manuel DeLanda, 117+. London: Continuum, 2002.
[REST]
Fielding, Roy T., and Richard N. Taylor. “Principled Design of the Modern Web Architecture.”
ACM Transactions on Internet Technology (TOIT)
(Association for Computing Machinery) 2, no. 2 (2002-2005): 115-150.
doi:https://doi.org/10.1145/514183.514185.
[McCHay69]
McCarthy, John, and Pat Hayes. “Some philosophical problems from the Standpoint of
Artificial Intelligence.”
Edited by B. Meltzer and D. Michie.
Machine Intelligence
(Edinburgh University Press) 4 (1969).
[Reiter2001]
Reiter, Raymond.
Knowledge in Action: Logical Foundations for Specifying and Implementing Dynamical
Systems.
Cambridge, Massachusetts; London, England: The MIT Press, 2001.
[Wynar]
Wynar, Bohdan S.
Introduction to Cataloguing and Classification.
Boulder, Colorado: Libraries Unlimited, Inc., 1992.
[1]
We define category as an ad hoc division within a subject domain
absent an explicit classification scheme. Whereas classification may be said to be
systematic,
categorization need not be. Categorization is a preliminary process in the creation
of a classification
scheme but in informal or colloquial systems may be the only process. In library science
a category is
sometimes considered synonymous with a facet (from Faceted Classification).
[3]
To be fair to the SW folks, these charges are hardly new, and reflect the same issues
present over three
decades ago with the similar academic flourish of “artificial intelligence”, which
assuredly
after all these years still deserves quote marks.
[4]
It seems that few researchers and/or developers understand RDF Semantics much less
follow it in practice, given that the majority of projects I've reviewed bear little
relation to the RDF
model theory, either in definition or stated references. Indeed, many seem to be in
direct conflict with
one or more RDF axioms or have extended it in ways contradictory to the model theory
(e.g., reference to
non-FOL logics, non-monotonicity). I've long thought that the buzz over RDF is simply
a misplaced
enthusiasm for basic graph theory.
[6]
It does not currently include the whānau (family unit), but in
the future a public version of the site may permit individuals to create pages for
their own whānau.
‘wh’ in te reo Māori is pronounced as an ‘f’, e.g., whānau is
pronounced “faah′-na-u”.
[7]
Ranganathan's scheme included five “fundamental” facets: Personality, Matter, Energy,
Space
and Time. Contemporary FC research tends to ignore this archaism but retains the methodology.
[8] This could also be localized for VSO or other grammars as necessary; the specific
syntax is unimportant.
[9]
We will subsequently be using the term “ontology” in this context, i.e., without
reference to any formalized model theory.
[10]
For brevity' sake, not all details are included here, e.g., the Terms defined for
roles
played in each relation type have not been included; other ontological structures
have been
simplified or omitted.
Brandom, Robert. “A Social Route from Reasoning to Representing.” In
Articulating Reasons, by Robert Brandom, 157-183.
Cambridge, Massachusetts: Harvard University Press, 2000.
Fielding, Roy T., and Richard N. Taylor. “Principled Design of the Modern Web Architecture.”
ACM Transactions on Internet Technology (TOIT)
(Association for Computing Machinery) 2, no. 2 (2002-2005): 115-150.
doi:https://doi.org/10.1145/514183.514185.
McCarthy, John, and Pat Hayes. “Some philosophical problems from the Standpoint of
Artificial Intelligence.”
Edited by B. Meltzer and D. Michie.
Machine Intelligence
(Edinburgh University Press) 4 (1969).
Reiter, Raymond.
Knowledge in Action: Logical Foundations for Specifying and Implementing Dynamical
Systems.
Cambridge, Massachusetts; London, England: The MIT Press, 2001.