Introduction
Ontario Scholars Portal (SP) is an XML-based digital repository containing over 32
Million
articles from more than 13,000 full text journals of 24 publishers which covers every
academic
discipline. The E-journal service is available to faculty and students of 21 universities
spread across the province of Ontario. The data provided by the publishers are in
XML or SGML
format typically with different DTD or schema. The publishers’ native data is transformed
to
the NLM Journal Interchange and Archiving Tag Set in SP in order to normalize data
elements to
a single standard for archiving, display and searching. To fulfill OCUL’s mission
of
provide and preserve academic resources essential for teaching, learning and research
(OCUL 2012)
, SP has established high standards to ensure the high
quality of their resource and service. A series of procedures and tools have been
implemented
throughout the workflow. In addition, SP is undergoing the TDR (Trustworthy Digital
Repository) audit process since January 2012 to further make the content reliable
and
long-term preservation.
Background
The SP development team began planning for a migration of the Scholars Portal e-journals repository from ScienceServer to a new XML-based database using MarkLogic in 2006. During this process SP team decided to adopt Archiving and Interchange DTD (NLM 2012) as the standard for the new e-journal system. The publishers’ native data is transformed to the NLM Journal Interchange and Archiving Tag Set v.3.0. The transformed NLM XML files are then stored in MarkLogic database for display and searching while the publisher’s source data resides on the file system for long-term preservation. SP ingests the data from 25 vendors, 10 of these vendors provides descriptive metadata in XML file using NLM DTD suite. The remaining vendors use their home-developed DTDs in XML, SGML header or text file as the descriptive metadata. The quality of the incoming data varies with publishers causing data problems as previously addressed by Portico, the data is not always processed with standard tools that enforced well-formedness or validity (Morrissey 2010). Some of the issues with incoming data to SP includes: omitting the DTD or encoding declarations, employ the elements which is not included in the DTD, adopts a new DTD without notification and includes invalid entities.
Here are some examples of the publisher's data with errors.
Example 1 shows the invalid value in <mm>:
<jrn_info>
<jrn_title>First Language</jrn_title>
<ISSN>0142-7237</ISSN>
<vol>32</vol>
<iss>1-2</iss>
<date>
<yy>2012</yy>
<mm>Data incorrect-05</mm>
</date>
<jrn_info>
Example 2 shows valid xml elements <volume> and <issue> but holds invalid data:
<pub-date pubtype="epub">
<day>5</day>
<month>1</month>
<year>2011</year>
</pub-date>
<volume>00</volume>
<issue>00</issue>
<fpage>483</fpage>
<lpage>490</lpage>
...
Example 3 shows the entity not being processed properly:
<surname>Orr[ugrave]</surname>
<article-title> From ℋℐ and RDF to OWL</article-title>
A local loading agreement is signed when the vendor agrees to load their content on Scholars Portal. In this agreement, the licensor agrees to provide Licensed Materials in SGML or XML structure information (metadata) for each article conforming to the publishers DTD or XML Schema (OCUL). In practice, some publishers do not check the well-formedness or validate the data before sending the data and in some cases do not have the technical resource to do so. Some small publishers contact the third party to supply the data and causing communication problems.
Quality Control Practice
Scholars Portal is committed to ensuring the integrity of digital objects within the repository. Scholars Portal quality control standards include checking fixity each time the digital object is moved during the ingest process. This ensures that the file has been transferred correctly without becoming corrupted during the process. Errors are recorded automatically in an error log and an email notification is send immediately to the metadata librarian. Then the cause of errors were analyzed and corrected as soon as possible (Scholars Portal 2012).
The Ingest Process Overview (Figure 1) shows the different aspects of the digital object's journey from the time it is ingested into the repository to the time it is made accessible to the designated community.
Figure 1: Scholarsportal Ingest Process Overview
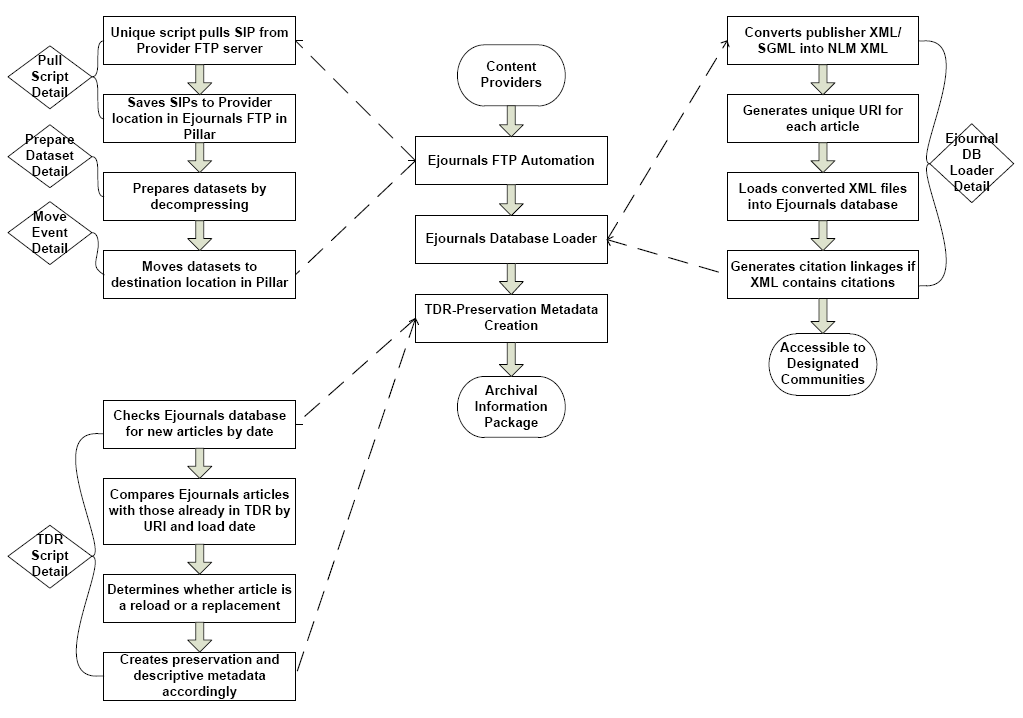
1. Quality Control procedures during FTP automation
Depending on the publisher, incoming data is either pulled or pushed from the
publisher's FTP into SP Ejournals FTP location. After a new dataset is saved into
the
Ejournals FTP, it is retrieved and the file size is compared to that of the original
copy
held in the publisher FTP server. If the file size does not match, the script sets
the error
flag and increments the try count. Once the try count hits three with an error flag,
the
file is deemed to be corrupted and an email is sent to the responsible members within
SP.
Datasets with successful results from the file size comparison proceeds to the next
step of
decompression. If there is an error during decompression, the script writes the file
name to
the error log and saves the error file to a temporary directory for further investigation.
The log file information is then emailed to JIRA (Scholars Portal 2012). Here is an
example of the log with decompressing error.
Figure 2: Decompression Error Log
2. Quality Control procedures during E-journals loading
The data transformation from the publishers’ native data to Scholars Portal NLM XML data is processed in two steps - mapping and coding. Creating XML transformations in these two separate steps not only maximizes the skills of various team members, but also reduces development time and cost, and increases accuracy of the finished code (Usdin). First, the mapping is created by metadata librarian who posses strong analytical skills, ability to articulate complex relationships and familiarity with both publisher’s data structure and NLM data structure. The crosswalk includes the mapping of the path from source to target data and the explanation of decisions and compromises. Second, the programmer with coding experiences then develops the loader according to the crosswalk using Java. A test environment is set up so the transformations are tested before the data is loaded into production. The metadata librarian inspects the output with the crosswalk mapping and go through several iterations to make sure the data are transformed completely and explicitly. After loading into production system, the transformation of each dataset has been logged for any errors (Zhao 2010).
2.1 Parsing the source file
SP receives the publisher's data either in SGML or XML. In case of SGML format, OSX is used to parse and validate the SGML document and to write an equivalent XML document to a temporary directory for further transformation.
The java library(javax.xml.parsers) parses the content of the given input source as an XML document and return a new DOM Document object. SAXException is thrown in case of any error during parsing.
Some of the common issues in source file are:
Problem a: Different encoding in the source file (example: iso-8859-1 , UTF-8)
Action: The source file is converted to UTF-8 encoding in java before parsing. datastring.getBytes("UTF-8")
Problem b: Errors are thrown due to the presence of Character Entity in the source file and not declared.
Action: External Entity file is added to the source file <DOCTYPE before parsing.
Problem c: If the tag is not terminated by the matching end-tag or due to the presence of any invalid tags that are not specified in the DTD.
Action: Inform the publisher about the error and request them to correct and resend the data.
Figure 3 shows the log file indicating the invalid tags used in the source data
Figure 3
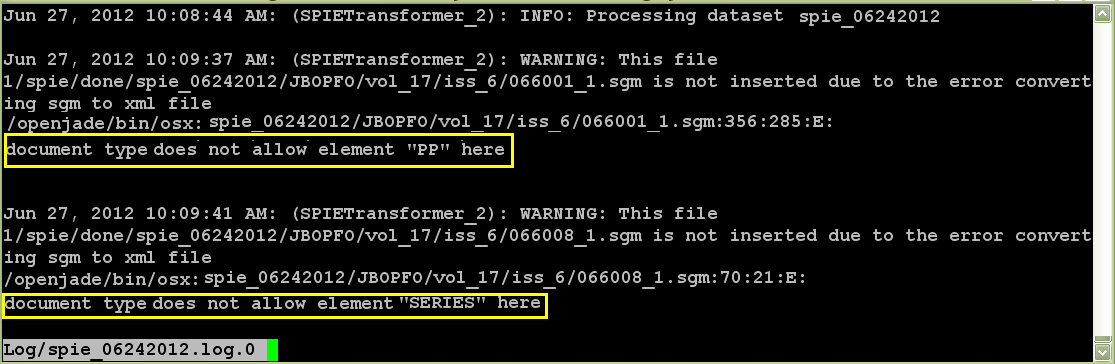
Problem d: The implementation of new DTD is done in publisher data without advance notice from publisher.
Action: The error is logged and the email is sent to the publisher requesting for the new DTD.
2.2 Transforming to NLM xml
After parsing the source file, a well-formatted xml file is ready to be processed by the transforming program. The transforming process is based on the crosswalk to convert the parsed xml file to NLM xml data structure. After the conversion, the document is validated by several criteria which are listed below before adding to MarkLogic database:
2.2.1. Mandatory fields
ISSN and Publication Date which are used for indexing are mandatory fields for loading articles into the database. Missing mandatory fields will cause the article to not load into the database and an error message is generated in the log file.
2.2.2. Missing content
When there is missing content, the team makes their best effort to maximize the usage of the data provided by the publisher for the benefits of the end users.
Some of the common issues are:
Problem a: Missing pdf - In the loader program, a check is made if the pdf file is available in the physical location and the link to the pdf file is created in the xml file. If the pdf file is missing, an error message is generated in the log file. The article is loaded with metadata only. The error is reported in the log file and the QA staff contacts the publisher to request the pdf file. The publishers usually send the pdf with metadata again, and the article will be replaced with full content.
Problem b: Missing figures - If any of the figures of a article is missing, the full text article is still loaded to the database if the pdf file is available. The <body> element’s attribute is set to display=no for this article so the content of the body can be used for searching and indexing, but not for displaying.
Problem c: Not properly tagged in <body> - Another scenario when setting display=no for the <body> element is that when the content is not properly tagged, then there would be no full-text display in the interface. However, the article is loaded into the database for searching and indexing purposes.
Sample Log files:
Figure 4
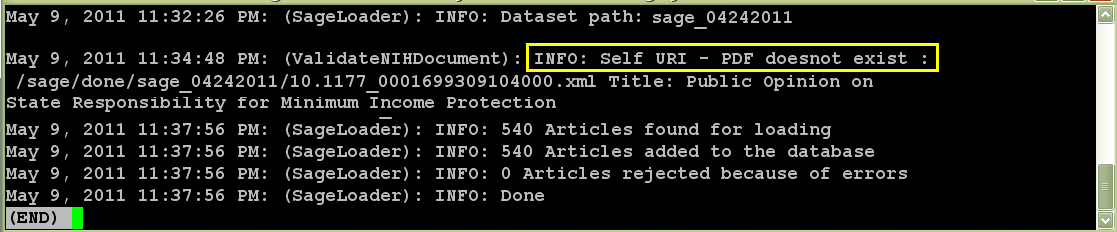
Figure 5
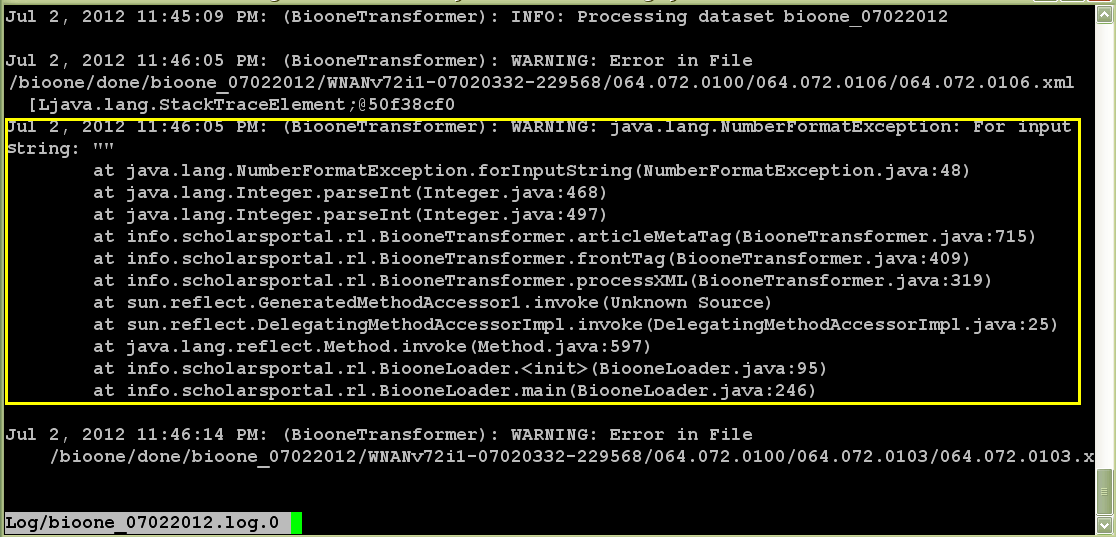
3. Log file checking procedures
The data loading log files are examined daily by an automated script and report any error to JIRA and email to the team.
JIRA is used as a tool to track all the problems during data ingest process. QA staff reviews the JIRA issues and analyze the problem which then is reported to the publisher or assigned to the programmer for loader modification.
Figure 6: Flowchart for Log File Check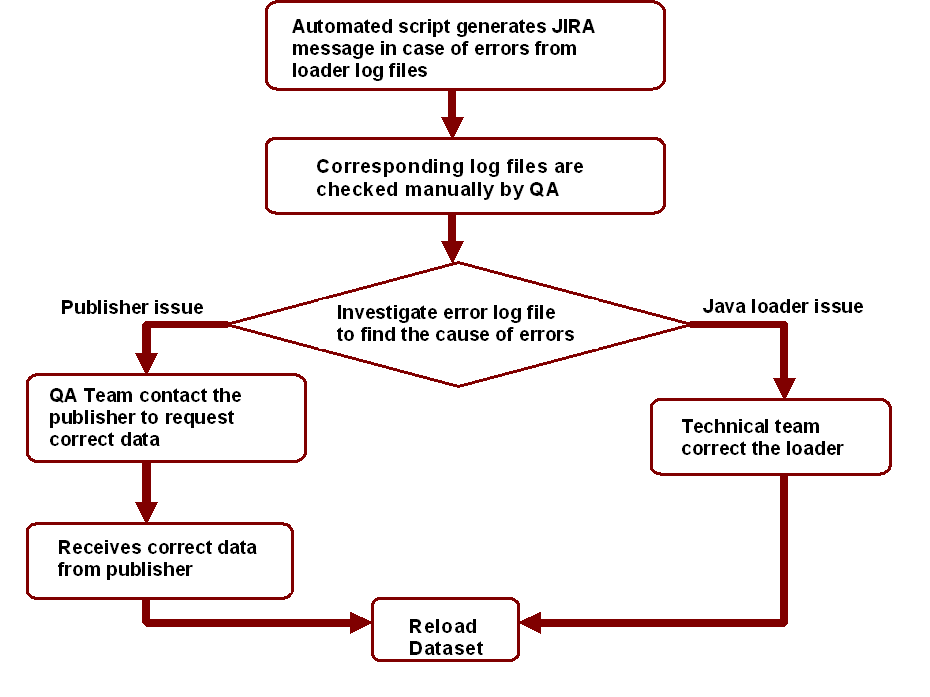
An example of the process for a JIRA issue solved shown as 6 steps below:
-
Step 1: JIRA issue created daily by the automated java script in case of errors.
Figure 7: JIRA Error Log
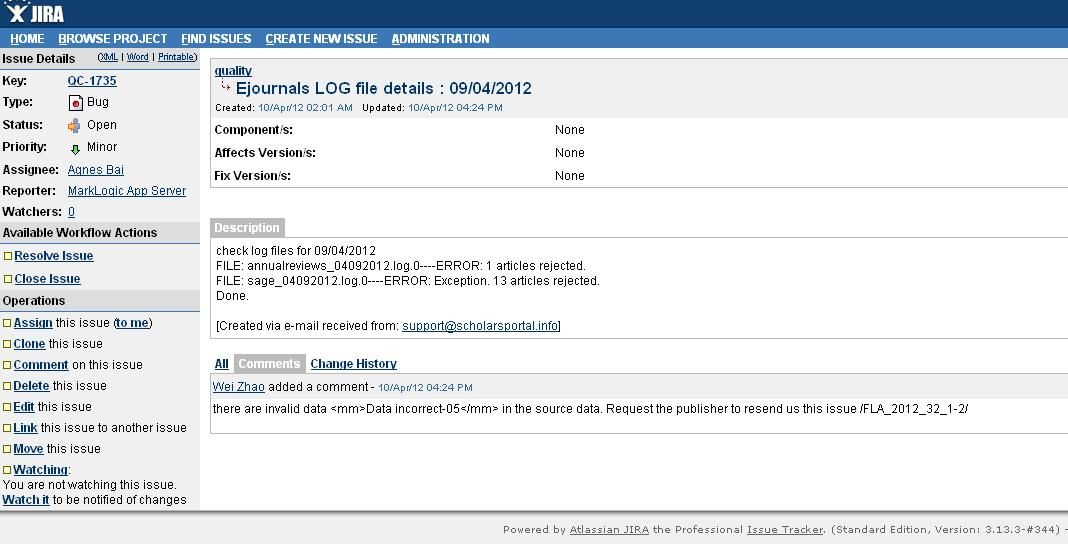
-
Step 2: The log file reviewed by the QA staff
Figure 8: Log File

-
Step 3: The source data problem identified
Figure 9: Sage Source File

-
Step 4: Problem addressed and request sent to the publisher
Figure 10: Email to the Publisher

-
Step 5: The corrected data received under new dataset
Figure 11: New dataset

-
Step 6: The data loading log file showing no error
Figure 12: Log file

To ensure the publishers continue sending the current updated content, a script is scheduled to run monthly to check the latest dataset loaded from each publisher. If any unusual gap is found, the QA team investigates the cause of any missing updates.
Besides those generated automatically by the system, error reports also are sent to SP QA staff by the librarians, faculty and students who rely on the e-journals repository for research, teaching and learning. A form has been posted on SP website for the end user to send the report and track the problem solving process.
Conclusion
Scholars Portal E-journals repository is ever growing with approximately 75,000 records added daily in 2012. The technology offers the ability to monitor and report the errors automatically; however, the problem solving highly rely on the human interface—the Scholars Portal QA and technical staff and the publishers’ content supply support team. Scholars Portal’s policy is not to correct the publisher’s source data but to report the problem back to the publisher when it cannot be handled by SP loader program. Some publishers provide prompt response which helps SP team to have the data available to the user community without any delays. To divide the staff time wisely to handle the fast-growing daily new content and to fix the problem is the challenge to SP team.
Acknowledgements
The workflow charts are created by Aurianne Steinman.
References
[OCUL 2012] OCUL. Strategic Plan. [online] [cited 19 April 2012] http://www.ocul.on.ca/sites/default/files/OCUL_Strategic_Plan.pdf
[NLM 2012] NLM. Archiving and Interchange Tag Set Version 3.0. [online]. [cited 19 April 2012] http://dtd.nlm.nih.gov/archiving/tag-library/3.0/index.html
[Morrissey 2010] Morrissey, Sheila, John Meyer, Sushil
Bhattarai, Sachin Kurdikar, Jie Ling, Matthew Stoeffler and Umadevi Thanneeru. Portico:
A Case Study in the Use of XML for the Long-Term Preservation of Digital Artifacts.
Presented at International Symposium on XML for the Long Haul: Issues in the Long-term
Preservation of XML, Montréal, Canada, August 2, 2010. In Proceedings of
the International Symposium on XML for the Long Haul: Issues in the Long-term Preservation
of XML. Balisage Series on Markup Technologies, vol. 6 (2010).
doi:https://doi.org/10.4242/BalisageVol6.Morrissey01.
[Scholars Portal 2012] Scholars Portal. Quality Control Specifications. [online]. [cited 19 April 2012]. http://spotdocs.scholarsportal.info/display/OAIS/Quality+Control+Specifications
[OCUL] OCUL. Local Loading License. [online]. [cited 19 April 2012] . http://www.ocul.on.ca/node/114
[Usdin] Usdin, Tommie, Piez Wendell . Separating Mapping from Coding in Transformation Tasks. Presented at: XML 2007; 2007 Dec 3-5; Boston, MA.
[Zhao 2010] Zhao, W, Arvind, V. Aggregating E-Journals: Adopting the Journal Archiving and Interchange Tag Set to Build a Shared E-Journal Archive for Ontario. In: Proceedings of the Journal Article Tag Suite Conference 2011 [Internet]. Bethesda (MD): National Center for Biotechnology Information (US); 2011