Introduction
We outline a (nearly) language-neutral approach to embedding in ordinary source code semantic information that we use to generate documentation for multiple audiences, unit tests, and code translation templates. Our approach is within the literate programming tradition for enhancing the usability of software documentation, specifically the variants that focus on inline documentation. Accordingly, we embed the structured documentation within the ordinary comment syntax available in all common programming languages.[1]
Knuth (1984, 1992) introduced literate programming to negotiate the fundamental tension between the needs of two readerships for computer programs: humans and compilers. Knuth’s original recommendation and most implementations work from a hybrid literate document containing the information needed to generate both machine-readable code and human-readable documentation.[2]For example, Knuth’s (1984) first implementation, called WEB, provided two toolchains to export information from the literate source file: (a) TANGLE extracted executable source code for delivery to a Pascal compiler; and (b) WEAVE extracted documentation for delivery to a TeX interpreter.
Despite its impeccable pedigree and a devoted community of supporters, literate
programming as originally envisioned has not gained widespread acceptance. Wilson
(2011)
even calls it a beautiful idea that failed.
The psychological
order
requirement that literate source documents be arranged to best serve
the human reader implicitly places a heavy burden on the programmer, whose human-facing
literate document must simultaneously satisfy an error-intolerant compiler. The
programmer must have fluency in both the literate syntax and the compiler syntax.
Even
for coders with both skills, there is a cognitive cost to switching repeatedly between
the two commingled dialects-- one unwoven and the other untangled. As a result, the
original literate programming paradigm is perhaps best suited to applications where
the
emphasis is inverted: pretty printing is indispensable and the code itself is in a
sense
secondary, as in Leisch’s (2002) Sweave, which allows statistical code to be embedded
in
scientific source documents to enable reproducible research.
On the other hand, less orthodox
technologies in the literate tradition (i.e.,
combining executable source code with structured documentation) have been quite
successful. Javadoc and its generalized peer Doxygen, which rely on structured comments
embedded in source code to generate documentation, are among the most prominent
examples. Similarly, tools like Python’s pydoc generate documentation from docstrings,
string literals that are retained and accessible at runtime as special properties
of
objects. Under both approaches, the comparison to orthodox literate programming is
instructive: structured documentation is still embedded with executable source code,
but
the requirement of psychological ordering is dropped. The compiler, by being stubbornly
inflexible, has won the battle over how to order the statements in the source
file.
Orthogonal to the literate programming paradigm, but still important for our project, is the realization by Peters (1999) that the usefulness of docstrings for documentation purposes could be harnessed to provide users with a simple, inline method for generating unit tests. This realization led to his creation of doctest.
Our approach, outlined in the following sections, follows in the tradition of Javadoc-style inline documentation, but we use XML intermediates with XSLT not only to allow for the generation of documentation for multiple audiences, but additionally to define and generate unit tests, as in doctest, and to generate templates for code translation. Section 2 provides further context for our project, section 3 describes the targeted use cases, and section 4 concludes.
Context and objectives
Function libraries play a prominent role in scientific computing.[3]A function library is a collection of well documented, callable routines of the form y = f(x), where each function takes some argument list, x, executes one or more statements depending only on x, and returns a list of values, y. Scientific functions tend to involve specialized, technical logic that can be obscure to non-experts. As a result, there is a greater-than-usual need for good documentation and extensive testing. At the same time, scientific routines typically adhere to the functional-programming convention of exhibiting no side effects. Routines without side effects are especially amenable to unit testing, and we restrict attention to this class of functions to contain the scope of this exercise. Lastly, scientific libraries are more likely than most to address technical issues that are abstract to the implementation context. For example, an invocation of a quadratic programming routine will have essentially the same meaning (execution logic) regardless of the language in which it is written; the same is not true for a resize_frame routine in a GUI windowing toolkit. Because of this, scientific routines are more amenable to porting from one programming language to another.
Our technique is at once more and less ambitious than orthodox literate programming.
We
similarly target multiple simultaneous readerships, both human (e.g., coders, testers,
analysts, etc.) and compilers/interpreters (e.g., C++, Python, Fortran, etc.). However,
like Javadoc, and in keeping with Dijkstra’s (1972) admonition that, brainpower
is by far our scarcest resource,
we concede the impracticality of
psychological ordering. In particular, there is no tangling
to extract
executable statements; instead we work with valid source files that can be delivered
to
the compiler as is. We also hesitate to propose our method as broadly applicable to
any
programming paradigm. For example, our source-code portability proposal would likely
be
more complicated in an object-oriented environment, due to the possible presence of
state-altering side effects and the (typically) fragmented sequence of control.
Since we use a form of inline documentation that, like Javadoc and others, exploits the existing commenting syntax available in some form in all common programming dialects, ours is highly versatile with respect to the choice of source language, to the point of being nearly language-neutral. This provides significant benefits when developing parallel implementations of scientific function libraries in a number of languages.
On the ambitious side of the ledger, we are interested in more than simply
weaving
handsome end-user documentation from embedded, structured
documentation, although pretty printing is very much in scope. We also extend the
basic
methodology to encompass basic unit testing of functional logic. In the absence of
side
effects, it becomes straightforward to state the most common unit-test assertions
declaratively and embed these declarations within comments in the source code. Due
to
the desire to be language-neutral, ours is not as straightforward or elegant as doctest,
but it does provide many of the same benefits. Lastly, we use the template processor
required by our documentation generation toolchain to offer a method for creating
function prototypes-- including pseudocode-- for ports of an existing program to
essentially an arbitrary target programming language.
While none of the individual components of this approach is by itself novel, we find that at least within the restricted scope of scientific function libraries without side effects, significant benefits are provided by the flexibility of our approach and the synergistic effects of using all of the individual elements of inline documentation, unit test generation, and code translation in concert.
Specifically, we note that the problem of code translation consists of three sub-problems: ensuring that the logic of a particular function is consistent across languages, performing the syntactic translation between languages, and optimizing the implementation within each language. Of these, the implementation is where a good programmer is needed most, both to write code that makes use of the appropriate idioms provided by a language, and to optimize the implementation of a particular set of logic. Thus, by providing a programmer with a template for a function that both defines the function signature and provides ready-made documentation from another language, we reduce unnecessary burdens on programmers porting the original source code. Additionally, by providing unit test routines, we enable easier verification of ported code. Finally, by examining discrepancies between implementations, we reduce the model risk inherent in any single implementation.
We consider our approach to be a simplified variation of the literate programming paradigm, targeting multiple simultaneous readerships, both human (e.g., coders, testers, analysts, etc.) and compilers/interpreters (e.g., C++, Python, Fortran, etc.). We offer a prototype implementation in XSLT and DocBook.
Usage scenarios
In this section, we describe the process in somewhat greater detail. As indicated above, the techniques cover three important usage scenarios for managing source code in function libraries.
End-user documentation
Knuth’s (1984, 1992) original vision for literate programming emphasized the need for source code to communicate with human programmers as well as with compilers or interpreters. A well documented program should speak clearly to the coder about what the code is doing, and the programmer should speak back by enhancing and refining the documentation. Knuth quotes a well known passage from Hoare (1973, 3),
documentation must be regarded as an integral part of the process of design
and coding. A good programming language will encourage and assist the programmer
to write clear self-documenting code, and even perhaps to develop and display a
pleasant style of writing. The readability of programs is immeasurably more
important than their writeablility.
Knuth’s (1984) initial implementation, called WEB, mixed discussion and logic in a single source file, which is then pulled apart to create both executable code and typographic source for onward processing by Pascal and TeX, respectively. Figure 1 depicts the basic structure of the workflow in WEB (adapted from Figure 1 in Pieterse, Kourie and Boake, 2004, 113):
Figure 1: Figure 1
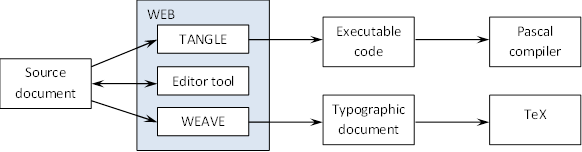
Literate programming workflow in WEB
A key design decision here is to mix documentation and logic as co-equals in the
source. Because the source document adheres to psychological ordering rather than
executable ordering, a burden falls on the programmer to think
bilingually
(see Wilson, 2011) to understand how the source document
will be simultaneously tangled and woven to the executable and typographic
dialects.
We adopt a variation on this basic workflow, similarly mixing documentation and logic in a single source file, depicted in Figure 2 (a familiar example of this same workflow is Javadoc):
Figure 2: Figure 2
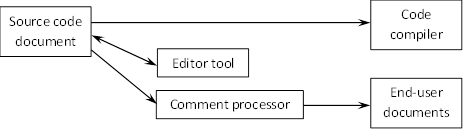
Documentation and logic in Javadoc
An important difference in this architecture relative to orthodox literate programming is the use of a compiler-valid source document. Because compilers impose rigid validation rules on executable code, this relationship can be and is typically managed by programming IDEs with facilities such as real-time validation, syntax highlighting, debuggers, profilers, etc., sharply reducing the bilingual burden.
As described above, we embed documentation steganographically in the ordinary
comment lines within the source code. A sample appears in Figure 3, using standard
XML angle brackets as documentation markup within a Matlab or Octave source file.
Comments containing content intended for delivery to the final end-user documents
get a special syntax, %#
instead of simply %
. Given a
source document in this form, the comment processor performs four straightforward
pre-processing steps, resulting in valid XML that encapsulates all of the content
required for end-user documentation:
-
Wrap any executable statements in <code> tags
-
Delete ordinary comment lines
-
Convert documentation comments by removing the leading
%#
markers -
Wrap the entire document in <codefile> tags
Figure 3: Figure 3
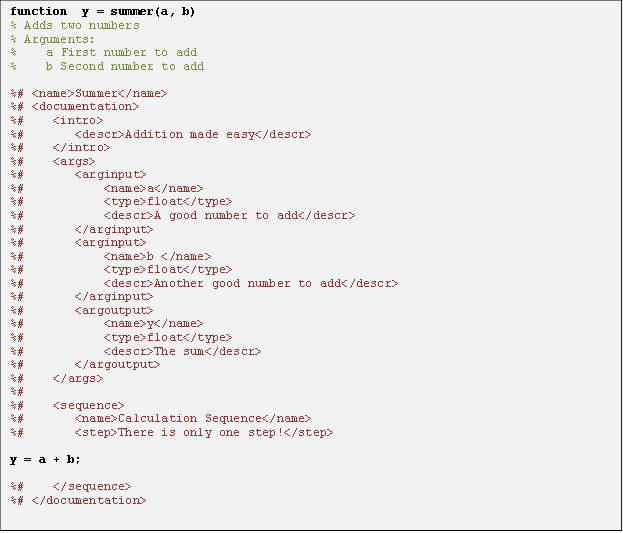
A working example of steganographic documentation
An obvious (and planned) enhancement to this is to replace the angle brackets with a more felicitous markup scheme, such as Markdown, Textile or YAML.[4] Note that we have prototyped this process on Matlab/Octave source files, but it should work with any programming language that supports inline comments containing arbitrary text. The pre-processing routine is therefore customized to each source language, but the subsequent processing steps would be the same for any source language. Given a valid XML representation output by the preprocessing step, the next processing phase is an XSLT transformation to a standard publication format such as DocBook or DITA. Transformation from this intermediate form to final print or web format is then straightforward via standard tools.[5]
Unit testing
Section 3.1 outlines the basic process, which we also propose to extend to black-box unit testing. In this use-case, we embed structured unit-testing rules (rather than documentation content) within comments in the source code. There are precedents for this sort of inline testing (e.g., the aforementioned doctest package in Python), but to our knowledge these are limited to single-language contexts. There are also language-neutral domain-specific rule languages for unit testing (e.g., the TestML package; see Net, 2012), but these have not been used for inline tests. We propose to use a language-neutral rule syntax to specify unit tests declaratively, and then embed them in source-code comments.
Programmatic unit testing is particularly important for scientific function libraries, partly because a well defined functional API will try to isolate logic so that relatively few dependencies exist between routines at the API level, but also because scientific routines frequently involve subtle and highly technical execution logic, so that errors in output may not be immediately obvious to human observers. (For example, do you know offhand whether this square-root calculation is correct: sqrt(88) => 9.276442 ?) Note that the steganographic method could also be extended to white-box testing, if the code generates a structured log file containing intermediate results.
Source code portability
Scientific function libraries are frequently written in one programming language, and then ported to another language to support source-level compatibility. As noted above, this is more likely to occur for scientific code, because the concepts represented are typically unrelated to the programming dialect. Linear algebra is the same, whether implemented in C, Fortran or Java. Indeed, Feldman (1990) exploits the grammatical equivalence between Fortran 77 and C to implement a direct language-level converter. [6] This converter was then used to port the Numerical Recipes function library in that direction (see Press, et al., 2007).
In general, grammatical equivalence will not hold, and programmatic language-level
conversion cannot reasonably be achieved. Even where it is possible, there are
typically optimizations and refactorings that an expert in the target language would
want to apply. The upshot is that post-translation manual intervention to debug or
refine the target code should naturally be part of the process. Nonetheless, for any
function library written in a particular language, there will be some family of
alternative languages to which it could (in principle) be ported.[7] This family of languages then defines an equivalence class of mutual
pseudocode
for the routine or library. That is, if one starts with a working
program written language A, and wishes-- with the services of an expert in language
B-- to port the code, then the original program (in A) can serve as pseudocode for
the target program (in B). Most developers have personal experience with applying
this general process, so we are not inventing anything new here. The only real
innovation is the recognition that much of the programming effort required for such
a port-- namely the documentation and testing-- can be specified declaratively and
in a structured way, as described in sections 3.1 and 3.2. An accurate programmatic
conversion of the documentation and test plan is possible, using the sort of XSLT
transformations described above. What remains is for a target-language expert to
re-implement the pseudocode (i.e., the verbatim copies of source-language executable
statements) as optimized target-language code. Note finally that the
post-translation availability of dual implementations of the identical scientific
logic opens up the possibility of automated comparative unit testing: if both
implementations are supposed to do the same thing, then they should (typically,
within machine precision) return identical outputs for identical inputs.
Conclusions
We have outlined a general approach to automated documentation, unit-testing and code portability for scientific function libraries, using the ordinary comment syntax as a vehicle to embed declarative logic steganographically in the source code. This addresses immediate and practical needs in our workplace, and may be useful to others similarly situated. We have a working prototype of significant portions of this tool chain, and are working to build it out further.
References
[Allen (2012)] Allen, Dean, 2012, Textile:
A Humane Web Text Generator,
Internet resource, Textism, downloaded 15 April
2012. http://www.textism.com/tools/textile/
[Anderson, et al. (1999)] Anderson, E., Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. McKenney, D. Sorensen, 1999, LAPACK Users' Guide, Third Edition, Society for Industrial and Applied Mathematics (SIAM). http://www.netlib.org/lapack/lug/
[Beebe (2012)] Beebe, Nelson, 2012, A
Bibliography of Literate Programming,
technical report, University of Utah.
ftp://ftp.math.utah.edu/pub/tex/bib/litprog.ps.gz
[Ben-Kiki, Evans and Net (2009)] Ben-Kiki, Oren, Clark Evans and Ingy döt Net, 2009, YAML Ain’t Markup Language
(YAMLTM), Version 1.2, 3rd Edition, Patched at 2009-10-01,
technical report,
YAML.org, downloaded 18 April 2012. http://yaml.org/spec/1.2/spec.pdf
[CERN (2004)] CERN - European Organization for
Nuclear Research, 2004, Colt: Open Source Libraries for High Performance
Scientific and Technical Computing in Java,
Internet resource, downloaded 17
April 2012. http://acs.lbl.gov/software/colt/api/index.html
[Dijkstra (1972)] Dijkstra, E. W., 1972,
The Humble Programmer [ACM Turing Lecture 1972],
Communications of the ACM, 15(10), pp. 859-66.
http://www.cs.utexas.edu/~EWD/transcriptions/EWD03xx/EWD340.html. doi:https://doi.org/10.1145/355604.361591.
[Feldman (1990)] Feldman, S. I., 1990, A
Fortran to C Converter,
ACM SIGPLAN Fortran Forum, 9(2), 21-22.
http://dl.acm.org/citation.cfm?id=101366%C3%DC
[Gruber (2012)] Gruber, John, 2012,
Markdown,
Internet resource, Daring Fireball, downloaded 15 April
2012. http://daringfireball.net/projects/markdown/
[Hellmann (2011)] Hellmann, Doug, 2011, The Python Standard Library by Example, Addison-Wesley.
[Hoare (1973)] Hoare, C. A. R., 1973, Hints
on Programming Language Design,
technical report STAN-CS-73-403, Stanford
Artificial Intelligence Laboratory, December.
ftp://reports.stanford.edu/pub/cstr/reports/cs/tr/73/403/CS-TR-73-403.pdf
[Knuth (1984)] Knuth, Donald E., 1984,
Literate Programming,
The Computer Journal, 27(2), 97-111. doi:https://doi.org/10.1093/comjnl/27.2.97.
[Knuth (1992)] Knuth, Donald E., 1992, Literate Programming, Center for the Study of Language and Information - Lecture Notes.
[Leisch (2002)] Leisch, Freidrich, 2002,
Sweave: Dynamic generation of statistical reports using literate data
analysis,
Compstat 2002 - Proceedings in Computational Statistics,
575-580.
[McGrath (2005)] McGrath, Sean,
2005, Semantic Steganography,
Internet resource, accessed July 17,
2012. http://seanmcgrath.blogspot.com/2005/04/semantic-steganography.html
[Net (2012)] Net, Ingy dot, 2012, TestML User
Manual,
Internet resource, downloaded 18 April 2012.
http://testml.org/documentation/user-manual/
[NAG (2009)] Numerical Algorithms Group Limited
(NAG), 2009, NAG Library Manual, Mark 22,
Internet resource, downloaded
17 April 2012.
http://www.nag.co.uk/numeric/fl/nagdoc_fl22/xhtml/FRONTMATTER/manconts.xml
[OASIS (2010)] OASIS, 2010, Darwin Information Typing Architecture (DITA), Version 1.2, OASIS Standard, 1 December 2010, downloaded 18 April 2012. http://docs.oasis-open.org/dita/v1.2/os/spec/DITA1.2-spec.pdf
[Peters (1999)] Peters, Time, 1999,
docstring-driven-testing,
comp.lang.python, accessed June 12,
2012. https://groups.google.com/forum/?fromgroups#!msg/comp.lang.python/DfzH5Nrt05E/Yyd3s7fPVxwJ
[Pieterse, et al., (2004)] Pieterse, Vreda,
Derrick G. Kourie, and Andrew Boake, 2004, A Case for Contemporary Literate
Programming,
Proceedings of SAICSIT ’04, 2-9.
http://espresso.cs.up.ac.za/publications/vpieterse_etal_saicsit.pdf
[Press, et al. (2007)] Press, William H., Saul A. Teukolsky, William T. Vetterling, and Brian P. Flannery, 2007, Numerical Recipes: The Art of Scientific Computing, 3rd Ed., Cambridge University Press. http://www.nr.com/
[Schulte, et al., (2012)] Schulte, Eric, Dan
Davison, Thomas Dye, and Carsten Dominik, 2012, A Multi-Language Computing
Environment for Literate Programming and Reproducible Research,
Journal of Statistical Software, 46(3), January.
http://www.jstatsoft.org/v46/i03/paper
[SciPy (2012)] SciPy Community, 2012, SciPy
Reference Guide: Release 0.11.0.dev-bdfdc65,
technical report, downloaded 16
April 2012. http://docs.scipy.org/doc/scipy/scipy-ref.pdf
[Stayton (2007)] Stayton, Bob, 2007, DocBook XSL: The Complete Guide (4th Edition), Sagehill Enterprises. http://www.sagehill.net/book-description.html
[Walsh (2010)] Walsh, Norman, 2010, DocBook 5: The Definitive Guide, O’Reilly Media. http://shop.oreilly.com/product/9780596805012.do
[Wilson (2011)] Wilson, Greg, 2011,
Literate Programming,
Internet resource, Software Carpentry,
downloaded 14 April 2012.
http://software-carpentry.org/2011/03/4069/
[Zaytsev and Lämmel (2011)] Zaytsev, Vadim
and Lämmel, Ralf, 2011, A Unified Format for Language Documents,
in: B.
Malloy, S. Staab, and M. van den Brand (eds.), Software Language Engineering,
Lecture Notes in Computer Science, 6563, Springer Verlag, 206-225.
http://www.springerlink.com/content/126476612j05082n/
[1] Our approach to the embedding of semantic information in source also has parallels to McGrath’s (2005) concept of “Semantic Steganography.”
[2] Beebe (2012) provides a very useful bibliography of literate programming. Pieterse, Kourie, and Boake (2004) survey a number of literate implementations, identifying six essential qualities of literate programming, all emphasizing the needs of the human user:
-
Literate quality (crisp and artistic descriptions and definitions)
-
Psychological order (arranged to maximize human understanding)
-
Integrated documentation (commingling of documentation and executable statements)
-
Table of contents, index and cross references
-
Pretty printing
-
Verisimilitude (single source document for both documentation and executable statements)
[3] Examples are too numerous to survey here. Prominent contributions include Anderson, et al. (1999), CERN (2004), NAG (2009), and Press, et al. (2007).
[4] We are at a very preliminary prototyping stage currently, and are evaluating various markup options. On Textile, see Allen (2012); on YAML, see Ben-Kiki, Evans and Net (2009); on Markdown, see Gruber (2012). Use of a non-XML syntax would an extra up-conversion step to achieve valid XML output from the pre-processor.
[5] Our prototype relies on DocBook, but we are evaluating DITA as an alternative path. Supporting XSLT stylesheets for both (and/or additional) publication standards should be possible. For further details on DocBook, see Walsh (2010) and Stayton (2007); for further details on DITA see OASIS (2010).
[6] To a first approximation, Fortran 77 is a linguistic subset of C. Any statement that can be represented in Fortran 77 can be represented in C.
[7] For example, at the extreme, it is theoretically possible to represent any program written in a Turing-complete language in any other Turing-complete language. In practice, we do not advise arbitrary translation.