Vion-Dury, Jean-Yves. “Secured Management of Online XML Document Services through Structure Preserving Asymmetric
Encryption.” Presented at Balisage: The Markup Conference 2011, Montréal, Canada, August 2 - 5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). https://doi.org/10.4242/BalisageVol7.Vion-Dury01.
Balisage: The Markup Conference 2011 August 2 - 5, 2011
Balisage Paper: Secured Management of Online XML Document Services through Structure Preserving Asymmetric
Encryption
Jean-Yves Vion-Dury holds an CS engineering degree from the "Conservatoire
National des Arts et Métiers, Paris" (1993) and graduated with a PhD in CS from
Université Joseph Fourier, Grenoble in 1999. He has been working at Xerox
Research Centre Europe (in Grenoble, France) since 1995, as a research
scientist; he has also been on a two year sabbatical with Vincent Quint's team
at INRIA in 2002-2004. His research interests relate to various aspect of XML
including models, the impact of standards, validation/transformation languages
and architectures, with theoretical background in programming languages,
compilation, type systems and formal logics.
Jean-Yves was Program Chair of DocEng (ACM Document Engineering Symposium ) in
2004, is member of its Program Committee since 2003, and member of its Steering
Committee since 2005.
Externalizing document management is a problem when individual or corporate
privacy is to be ensured. Provided that the decryption key is not known from service
side, pure storage/archiving of encrypted documents is highly secure, but of poor
interest as no operation can be performed on hosted data. Thus, current document
management systems offer restricted privacy mechanisms, roughly based on secured
communication channels and sometimes encrypted storage. However, many value-added
processing operations require decrypting the document, and no formal guaranty is
granted regarding the safety of system behaviors. As an example of known issue,
there is the problem of data remanence (persisting information on disk after file
system deletion), bugs or viruses acting on various level of the software
architecture. This paper describes a method to allow restricted (but yet
meaningful) ways of processing encrypted XML documents without needing decryption
phase. The encryption process we propose allows isomorphic encryption of data (XML
document owned by customers) and operator transformations (verification and
transformation operated by the Service Provider) in such a way that full secrecy is
ensured simply because the decoding key is not known by the Service Provider. Once
transformed, operators can handle encrypted documents with equivalent results up to
the decryption operation.
This paper describes a method to allow restricted (but yet meaningful) ways of
processing encrypted XML documents without needing decryption phase. The encryption
process we propose allows isomorphic encryption of data (XML document owned by
customers) and operator transformations (verification and transformation operated
by the
Service Provider) in such a way that full secrecy is ensured simply because the decoding
key is not known by the Service Provider. Once transformed, operators can handle
encrypted documents with equivalent results up to the decryption operation.
Nowadays, when a customer wants an external service provider to host and manage
confidential documents, he has to fully trust them, their information system and
internal policies. The confidential documents may be transmitted to the hosting system
over a secured channel using encryption to protect the sensitive information from
any
spying software potentially able to intercept and interpret the data.
However, an XML document, once encrypted using standard approaches , is like an opaque
and flat bit packet on which only two basic operations can be undertaken: integrity
checking and decryption [1].
Therefore, once hosted, the document must be decrypted in order to be able to offer
some
more complex processing such as those involved in basic services, e.g. indexation,
validation and transformation. And in order to decrypt, the service provider must
share
the decryption key with the customer, which is a risk against which nobody can guaranty
full protection (see 1 and 2 for examples
of document services in this area today ; note that both use a symmetric ciphering
method 4 which requires for the service provider owning the
customer's private key, and naturally, performing decryption when needed by the
system).
Do not decrypt documents: make operators compatible!
Our contribution applies on structured documents (typically XML, but any similar
approaches could be addressed by this method) where an attributed tree-like structure
captures the syntax and semantic of the data. In XML, it is commonly understood that
textual content is mainly stored in the leaves (the so called text nodes) whereas
meta-information such as presentation style are conveyed by namespaces, tag names
and
additional attributes-values pairs.
According to this, we propose first to encrypt the content of the document (textual
leaves) using a private key, only known by the document owner, and to encrypt the
structural part (tag names, namespaces and attribute-value pairs) through an asymmetric
encryption mechanism (see 3 for a general presentation) in such a
way that the resulting document still complies with XML lexical constraints (in other
words, XML wellformedness property remains ensured). Beyond preserving better isolation
between the two cryptographic subsystems, private key encryption comes with fast,
possibly stream based, ciphering algorithms, with obvious application in large document
processing.
In asymmetric encryption schemes, a public key allows encryption, whereas decryption
can only be performed thanks to a secret (private) key.
The Service provider may use the public key in order to transform its operators in
such a way that they can be adapted to operate directly on the encrypted documents.
The
central idea of our proposal is here: applying an encryption
aware transformation on the operators, so that they become compatible
with the encrypted instances. In other word, rather that decrypting the customer's
documents in order to process them, we propose to adapt the operators in order to
make
it possible for them to operate on encrypted document. More precisely, operators are
transformed using a public encryption key as parameter. Obviously, not all operators
can
be used this way, but only those that do not use textual content but only structural
information (which still covers a large class of practical applications for structured
document processing).
This way, the customer performs the structure-preserving encryption with a public
key,
and the textual content encryption with a private key they will never communicate.
The
composite-encryption algorithm is implemented and furnished by the Service Provider,
and
is run by the customers in their protected space. The resulting document can be sent
to
the Service Provider together with the public key, without particular precaution.
The
provider can archive the ciphered document, together with the public key, and moreover,
will use the latter to transform the relevant operators in order to operate on the
customer's documents. The customer data privacy/confidentiality is not put at risk
by
the provider software, communication channels and systems.
When required, the documents resulting from remote operations (validation reports,
transformation products…) can be sent back to the customer, who will be able to fully
decrypt them locally through his two private keys.
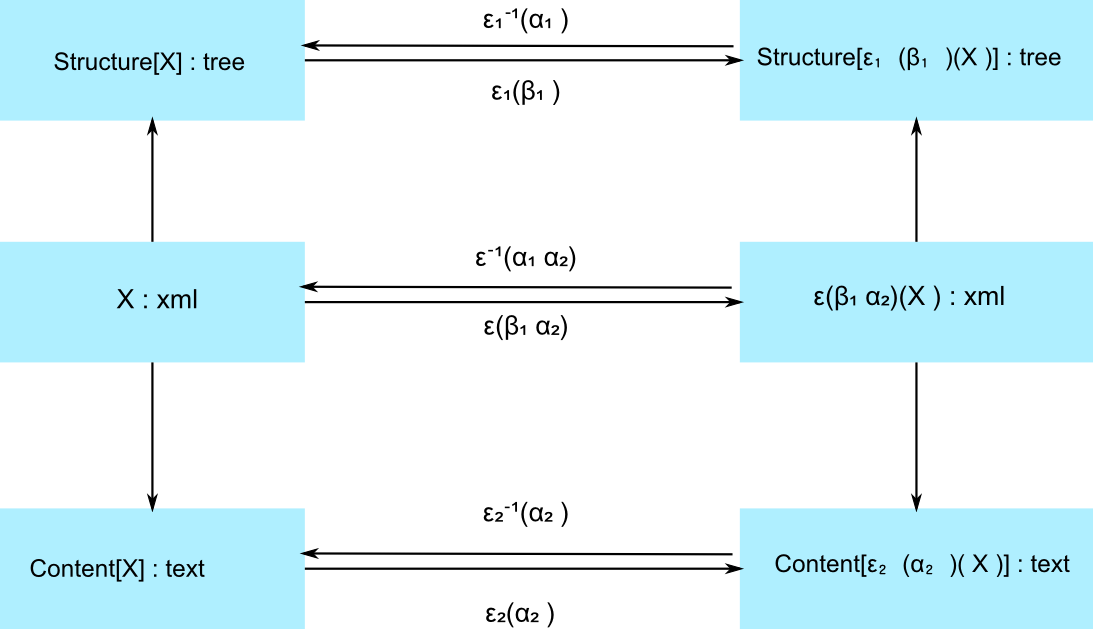
The figure below illustrates the composite encryption process:
Figure 1
ε1(β1) represents an asymmetric
encryption process (applied to the structural part of the document) using a
public key β1.
ε 2(α2) represents the symmetric
encryption process (applied to textual content and attribute values) using a
private key α2.
ε (β1, α2) represents the
combined encryption process over an XML document.
Essentially, this figure expresses the isomorphic properties of our encoding: typing
properties of the object are preserved by ε
(β1, α2) , so that some standard
XML analysis tools can operate before and after encryption as well.
Note
We recall that symmetric encryption ε and decryption
ε-1 obey to the following laws (here α is the secret
private key and x the message):
Table I
symmetric keys
ε-1(α , ε(α , x)) = x
α ≠ α'
⇒
ε-1(α' , ε(α , x)) ≠ x
Similarly, for asymmetric encryption functions where (α is the private key, and β
is the public key):
Table II
ε-1(α ,
ε(β , x)) = x
α ≠ α'
⇒
ε-1(α' , ε(β , x)) ≠ x
Keys α,β, are integers whose valuation space is so huge, that it is practically extremely
hard for an attacker to guess their value. These laws just capture in an
abstract way the reversibility of encryption and the sensitivity of underlying algorithms
to key
information.
Encryption aware transformation of XML operators
The composite encryption we proposed preserves lexical and logical structure. It is
an
algorithm that encrypts tag names (and attribute names) in such a way that all XML
lexical constraints remain satisfied, but do not change the tree structure.
We used in our experiments the combination of an RSA based asymmetric encryption
applied separately to namespace prefix and local tag/attribute names (general purpose
XML attributes such as xmlns, xml:base,
xml:space,
xml:id are not encrypted, in order to
allow standard behavior of XML processors) . Then our encryption algorithm translates
the result into a base16 encoded sequences of ASCII characters and substitutes the
new
names to the old ones. The algorithm process all tags and attributes recursively over
the tree structure.
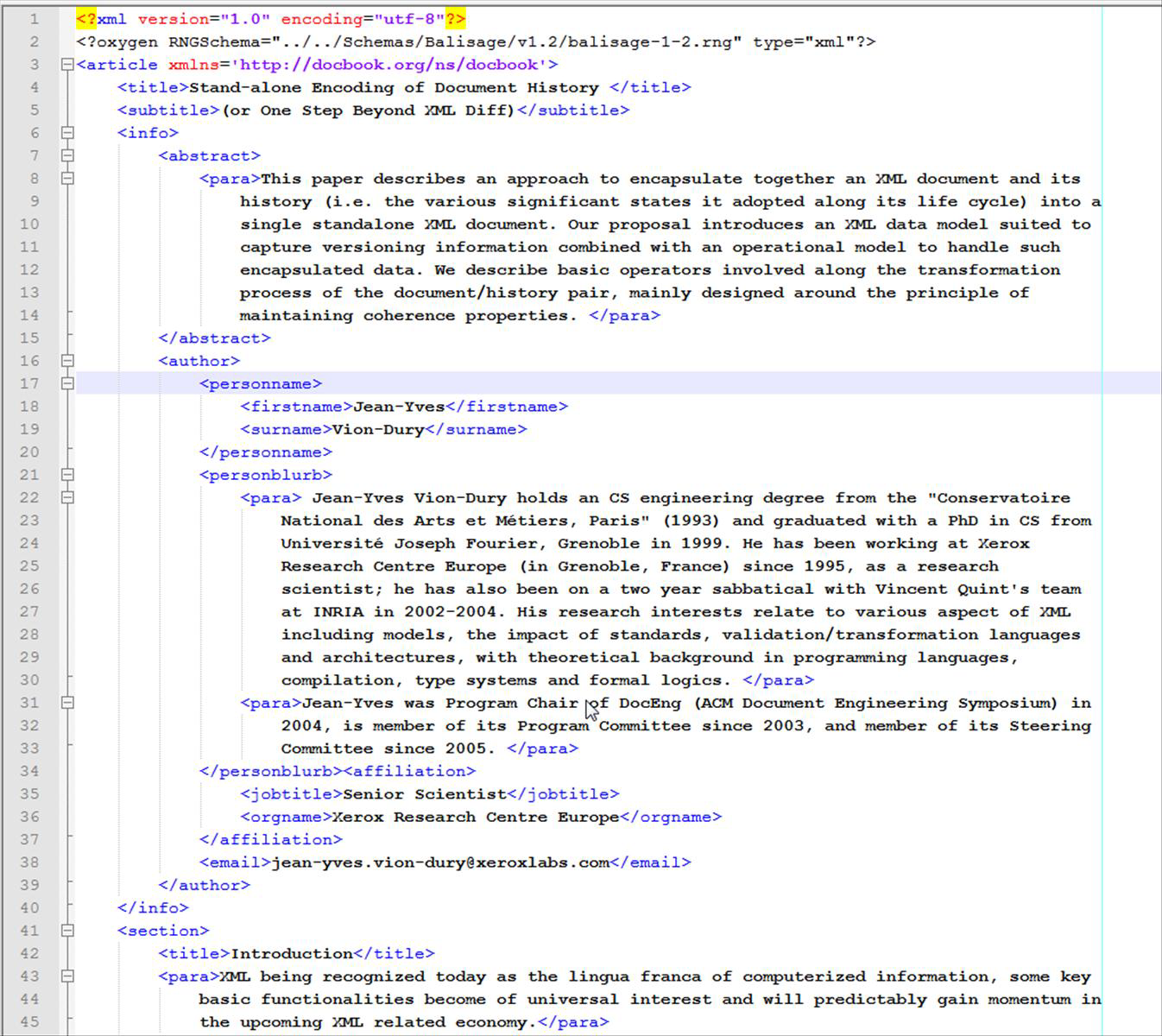
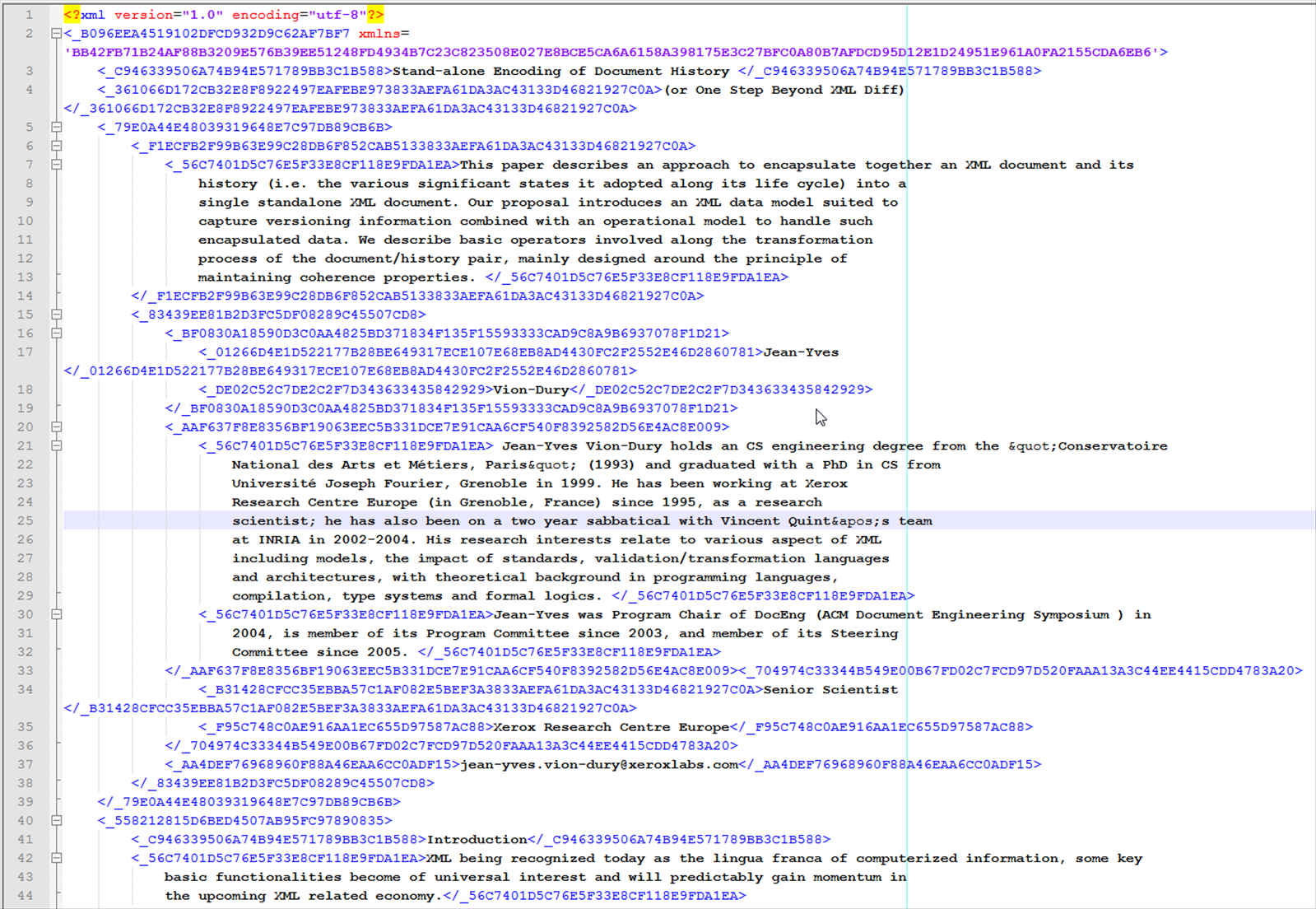
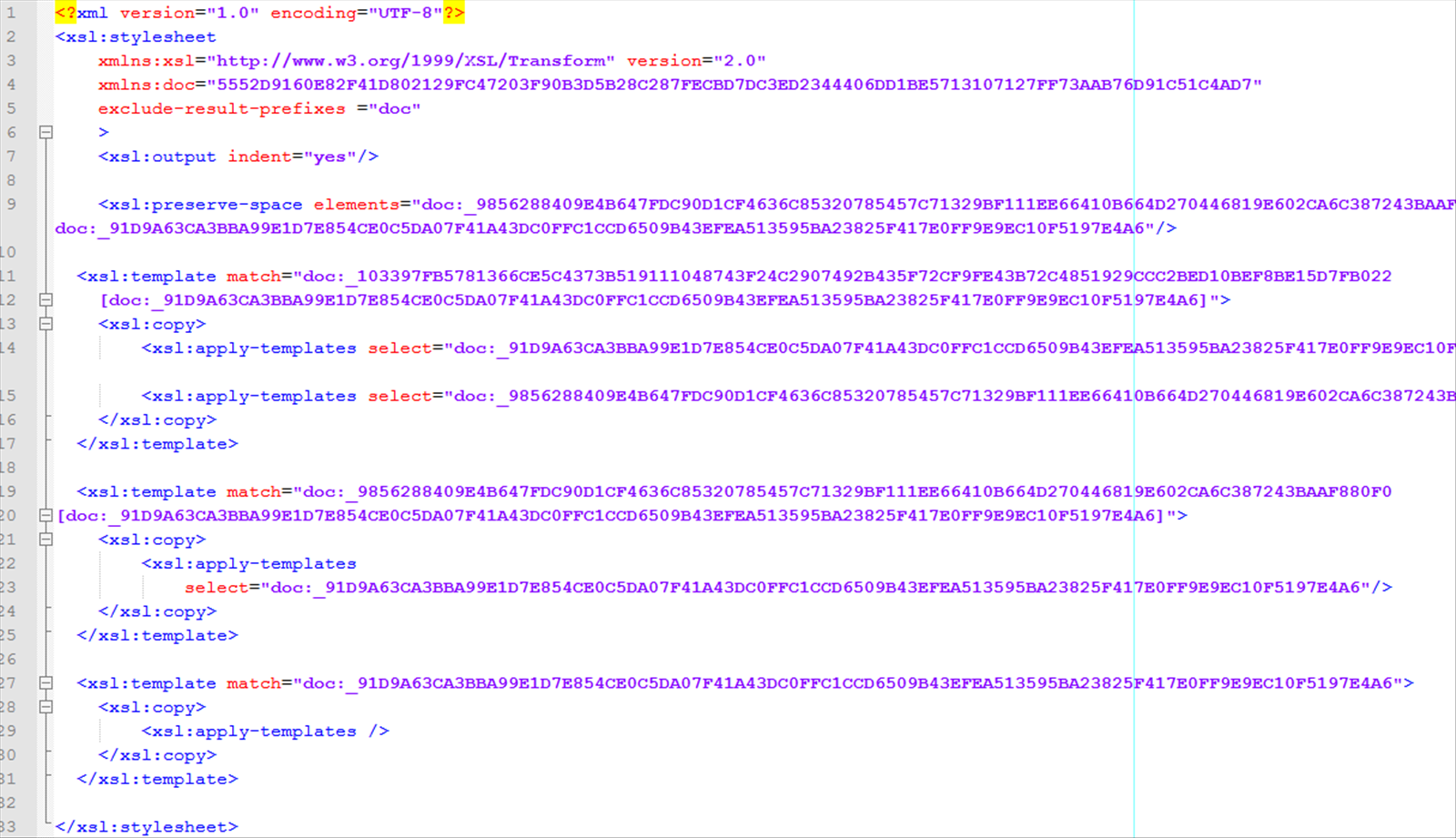
Figure Figure 2 is an example of such a transformation (note that content encryption has not
been applied here for illustration purpose). The image shows the original document
(the
specialized DocBook XML schema used for the Balisage conference proceedings...), and
the
second one below shows the same document after the structure preserving encryption
(for
clarity, textual content was not encrypted using symmetric ciphering algorithm).
We propose now to examine 4 fundamental classes of document operators that
can be tailored to process structure preserving encrypted documents.
Validation Engine
Typically, a tree grammar schema can be automatically modified by changing
element names, according to the public encryption key.
provided that, for a given encryption key β ,
ε1(β "html") = _012A321B839B167C ,
ε1(β "header") = _2842FA3D2B8317A8 and
ε1(β "body") = _3A78B91537E65F45
If the new labels comply with the inherent lexical constraints of the
formalism (in this case XML), then the corresponding recognition automaton can
be derived in the standard way in order to check the validity of the encrypted
document. RelaxNG, for instance, is a validation standard focused on structural
validation, although some extensions allow dealing with attribute or textual
content. In latter cases, the transcription cannot be achieved stricto sensu (no access to encrypted textual
content), but we argue that it is always feasible to derive from such grammars a
more general schema that only captures the structural information (this can even
be automated for the general case).
Document Rewriting and Querying
Many such transformations do not have to deal with textual content. As an
example, a table of content construction, outline extraction, link extraction,
tags reorganization …
For instance, the following sample rule from an illustrative tree rewriting system
provided that, for a given encryption key β ,
ε1(β "title") = _123E456A8421F745 ,
ε1(β "p") = _164C3812A7945B14
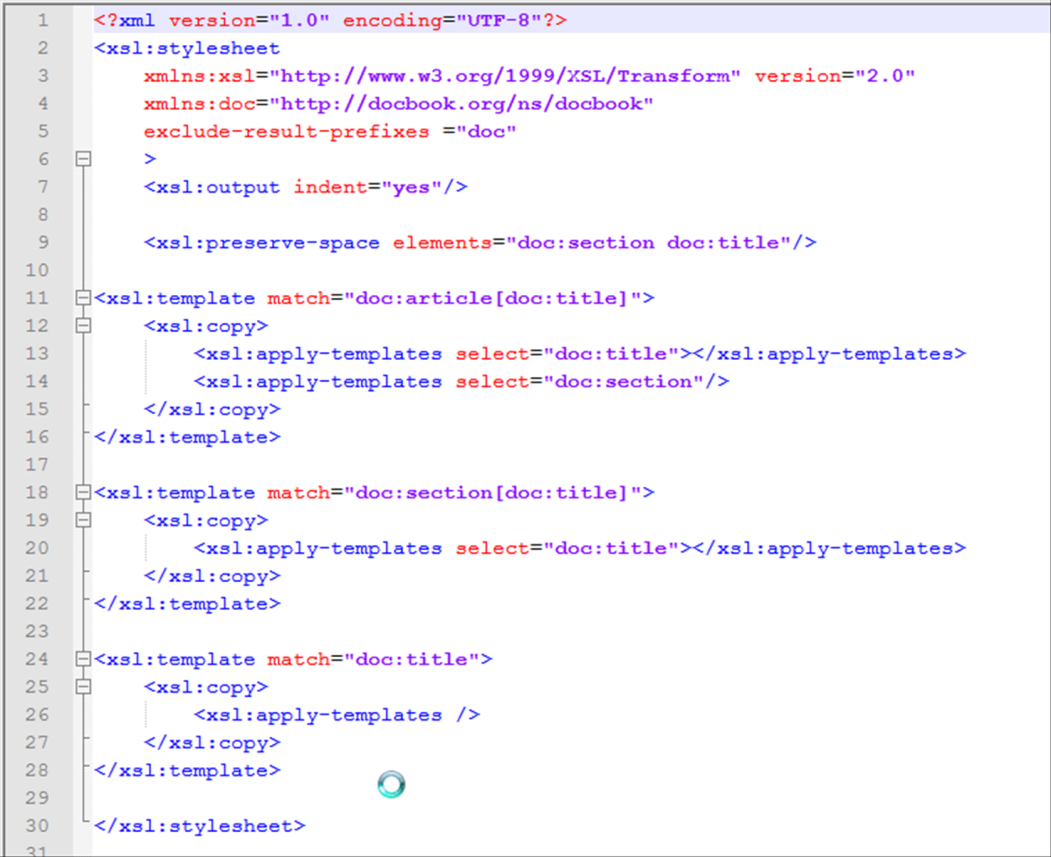
Regarding standard technologies such as XSLT or XQuery, they are based on
XPath to capture structural information. In our prototype, we rewrite structural
XPath expressions in order to encrypt tag names and attribute names. Structural
XPath expressions do not use tests on attribute and textual values. Figures Figure 4
and Figure 5 show an XSLT stylesheet designed for computing DocBook outlines, before
and after transformation. Note that XPath expressions have been rewritten
according to tag name ciphering.
Document versioning
These services are based of Tree diff algorithms, based on structural analysis
of tree node hierarchy and on node comparison. They are therefore compatible
with our encoding proposal, since they do not address diff analysis of original textual
content.
Document Indexation
These algorithms relies on various techniques, most importantly using
structural information (see eXist structural indexes 15, or Apache‟s Xindice
16) that can be handled using the technique we propose.
Novelty
The problem of authorizing general arithmetic computation on ciphered data has been
coined
as fully homomorphic encryption6, and has been the
holy grail of cryptologists for decades. The area is quite active recently, but is
certainly not mature enough to find practical applications before a long time especially
because the operators are of algebraic nature (very low level and generic: addition,
multiplication, subtraction and division) rather than algorithmic.
The related work section below discusses existing approaches in the field of XML
databases. In the best case, the authors propose very specific index construction
algorithms that only allows simplified query over encrypted documents (see 14, 17). Our approach, much broader
and simple, enable four major operations: transformation, validation, versioning and
indexing, by using restricted but standardized technologies (XPath, XSLT, XQuery,
RelaxNG…). More significantly, all proposals we examined so far in the literature
made
use of symmetric encryption. It just means that the provider must share the private
key
with the customer (therefore, representing a potential security hole) or that
encryption/decryption operation can be done exclusively from the client side.
Discussion
Encrypting tag names may raise a safety issue due to the low entropy level of XML
vocabulary, especially when the target namespace is known or guessed by an attacker.
For
instance, if the code breaker knows that the document is using the HTML namespace,
he
could try breaking the code using “html” as the plaintext input of the encrypted top
level tag. Indeed, this approach is particularly vulnerable to (so-called) chosen
plaintext attacks.
A solution is using optimal asymmetric encryption padding
78 and its more recent
amelioration 9. We have indeed implemented this latter approach, consisting of using two
ancillary secure Hash functions (SHA and MD5 in our prototype) and a random pattern
in
order to increase the entropy of input message.
Our prototype also revealed that, if working with long keys for reaching very high
level of safety, the tag/attribute names are transformed in very long labels, as
compared to original ones. However, our prototype did not exhibit any problem with
respect to this side effect, and runtime and memory performances are almost not
impacted
[2].
During the exchange of documents between the client and the provider, one could
imagine applying a supplemental global encryption using a symmetric scheme with a
private key that would be shared between the two parties, thanks to a standard secured
key exchange protocol. Of course this key would be different than the private key
used
by the client to encode the document content, and would provide a supplemental security
barrier to communication based attacks (this can be done e.g. through the standard
HTTPS
protocol and SSL libraries).
Related Work
In 1819, Mittal and Srivastava propose a somehow similar
approach. However, the authors clearly encode the hierarchical structure into a
distinct, specific data structure [3]. As a consequence, standard XML tools cannot be used, since the links
between structure and content are managed externally. The document is no longer an
XML
document after the encryption and compression operations proposed in this approach.
Using standard language is an important plus, as the provider may propose to run
customer made style sheets on customer data. In addition, using standard methodology
is a major
advantage to develop transformations and validation schemas, among others.
Various approaches have been explored in literature to secure documents hosted by
an
outsourcing service, especially in the field of XML databases. Existing proposals
are
organized around minimizing decryption operations (for obvious response time and CPU
cost saving; and also for security reasons too, when minimization is based on document
partitioning 10) or preparation of specific indexes to allows
restricted queries on encrypted documents 1214. Other studies focused on protecting information during
encrypted exchanges between the service provider and the client, preventing statistical
analysis based on expected frequencies of query terms 13. However, our approach does not need to focus on
communication, since transformation work is done locally on secured documents.
Figure 2
Input document (excerpt)
Figure 3
Structural encryption: Input document with encrypted tags
Figure 4
Operator: The XSL stylesheet to be applied to input document
Figure 5
Encryption aware Operator: The XSL stylesheet customized thanks to the public
encryption key. This transformed style sheet is intended to be run on provider's
site.
Figure 6
The result of style sheet application on the fully encrypted input document (sent
back by the service provider)
Figure 7
The final result is obtained by decrypting both the structural part and the
content part thanks to the two secret keys. This operation is done locally by the
customer in a secured environment.
[8] Optimal Asymmetric Encryption -- How to encrypt with
RSA, M. Bellare, P. Rogaway. Extended abstract in Advances in Cryptology -
Eurocrypt '94 Proceedings, Lecture Notes in Computer Science Vol. 950, A. De Santis
ed,
Springer-Verlag, 1995.
http://www-cse.ucsd.edu/users/mihir/papers/oae.pdf
[9] OAEP Reconsidered, Victor Shoup. IBM Zurich Research
Lab, Saumerstr. 4, 8803 Ruschlikon, Switzerland. September 18, 2001.
(Full length version of the extended abstract in Proc. Crypto 2001)
http://www.shoup.net/papers/oaep.pdf
[10] Querying Encrypted XML Documents, Ravi Chandra Jammalamadaka and Sharad Mehrotra.
Proceedings of the 10th International Database Engineering and Applications Symposium,
p.129-136, December 11-14, 2006
doi:https://doi.org/10.1109/IDEAS.2006.39
[12] Securing XML data in third-party distribution systems,
Barbara Carminati, Elena Ferrari, and Elisa Bertino. Proceedings of the 14th ACM
international conference on Information and knowledge management (CIKM '05), New York,
NY, USA. doi:https://doi.org/10.1145/1099554.1099575
[13] Efficient Secure Query Evaluation over Encrypted XML Database,
Hui Wang and Laks V.S. Lakshmanan.
VLDB „06, September 12-15, 2006, Seoul, Korea.
[14] A Survey on Querying Encrypted XML Documents for Databases as a Service,
Ozan Ünay and Taflan Gündem.
SIGMOD Record, March 2008 (Vol. 37, No. 1)
[17] SemCrypt-Ensuring Privacy of Electronic Documents Through Semantic-Based Encrypted
Query Processing,
M. Schrefl, K. Grun, and J. Dorn.
Proceedings of the 21st International conference on Data Engineering Workshop, 2005,
IEEE computer society.
[19] Exploring Queriability of Encrypted and Compressed XML Data ,
I. Elgedawy, B. Srivastava, and S. Mittal.
24th International Symposium on Computer and Information Sciences, 14-16 Sept. 2009
(ISCIS 2009).
doi:https://doi.org/10.1109/ISCIS.2009.5291834
[1] The W3C recommendation describes encryption processing
20 in a way that preserve compatibility with XML
requirement, but doesn't change the fundamental issue we address.
[2] We indeed used a hash table to memorize the encrypted code for recurrent
tag/attribute names.
[3] an RSA encryption (asymmetric scheme 5) is
applied on both the content and the structure with a common key, leading to a
less secure protection since cracking the code through attacks on structure will
give direct access to the content.
Optimal Asymmetric Encryption -- How to encrypt with
RSA, M. Bellare, P. Rogaway. Extended abstract in Advances in Cryptology -
Eurocrypt '94 Proceedings, Lecture Notes in Computer Science Vol. 950, A. De Santis
ed,
Springer-Verlag, 1995.
http://www-cse.ucsd.edu/users/mihir/papers/oae.pdf
OAEP Reconsidered, Victor Shoup. IBM Zurich Research
Lab, Saumerstr. 4, 8803 Ruschlikon, Switzerland. September 18, 2001.
(Full length version of the extended abstract in Proc. Crypto 2001)
http://www.shoup.net/papers/oaep.pdf
Querying Encrypted XML Documents, Ravi Chandra Jammalamadaka and Sharad Mehrotra.
Proceedings of the 10th International Database Engineering and Applications Symposium,
p.129-136, December 11-14, 2006
doi:https://doi.org/10.1109/IDEAS.2006.39
Securing XML data in third-party distribution systems,
Barbara Carminati, Elena Ferrari, and Elisa Bertino. Proceedings of the 14th ACM
international conference on Information and knowledge management (CIKM '05), New York,
NY, USA. doi:https://doi.org/10.1145/1099554.1099575
SemCrypt-Ensuring Privacy of Electronic Documents Through Semantic-Based Encrypted
Query Processing,
M. Schrefl, K. Grun, and J. Dorn.
Proceedings of the 21st International conference on Data Engineering Workshop, 2005,
IEEE computer society.
Exploring Queriability of Encrypted and Compressed XML Data ,
I. Elgedawy, B. Srivastava, and S. Mittal.
24th International Symposium on Computer and Information Sciences, 14-16 Sept. 2009
(ISCIS 2009).
doi:https://doi.org/10.1109/ISCIS.2009.5291834