Piez, Wendell. “Abstract generic microformats for coverage, comprehensiveness, and adaptability.” Presented at Balisage: The Markup Conference 2011, Montréal, Canada, August 2 - 5, 2011. In Proceedings of Balisage: The Markup Conference 2011. Balisage Series on Markup Technologies, vol. 7 (2011). https://doi.org/10.4242/BalisageVol7.Piez01.
Balisage: The Markup Conference 2011 August 2 - 5, 2011
Balisage Paper: Abstract generic microformats for coverage, comprehensiveness, and adaptability
Lead developer of the Proceedings of Balisage: The Markup Conference, Wendell Piez
has
worked at Mulberry Technologies, Inc., since 1998, where he provides advice, assistance
and training in XML, XSLT, and related technologies.
Markup languages that attempt not only to support particular applications, but to
provide encoding standards for decentralized communities, face a particular problem:
how do
they adapt to new requirements for data description? The most usual approach is a
schema
extensibility mechanism, but many projects avoid them, since they fork the local application
from the core tag set, complicating implementation, maintenance, and document interchange
and thus undermining many of the advantages of using a standard. Yet the easy alternative,
creatively reusing and abusing available elements and attributes, is even worse: it
introduces signal disguised as noise, degrades the semantics of repurposed elements
and
hides the interchange problem without solving it.
This dilemma follows from the way we have conceived of our models for text. If designing
an encoding format for one work must compromise its fitness for any other – because
the clean and powerful descriptive markup for one kind of text is inevitably unsuitable
for
another – we will always be our own worst enemies. Yet texts in the
wild are purposefully divergent in the structures, features and affordances of
their design at both micro and macro levels. This suggests that at least in tag sets
intended for wide use across decentralized communities, we must support design innovation
not only in the schema, but in the instance – in particular documents and sets of
documents. By defining, in the schema, a set of abstract generic elements for microformats,
we can appropriate tag abuse (at one time making it unnecessary and capturing the
initiative
it represents), expose significant and useful semantic variation, and support bottom-up
development of new semantic types.
The power and utility of descriptive markup has been well understood and widely
demonstrated for years and now decades; so it doesn't need to be defended here. However,
for
all the demonstrable usefulness of descriptive formats, and of standards that propose
particular descriptions for documents (in the form of XML element and attribute sets)
such as
Docbook, TEI, NISO/NLM and DITA, a number of problems continue to inhibit their adoption
for
the widest applications of text encoding, including (significantly) that large and
open-ended
set of documents we loosely designate as books. One of the most vexing of these
is in how we define and manage the boundaries of application of a particular markup
language
– what does it seek to do, for what sorts of documents. We can identify this problem
with the terms coverage, comprehensiveness and adaptability:
Coverage
What are the limits of description? What sorts of documents can be described using
the tag set? Is the set bounded in advance (as for example when converting a defined
set of extant historical documents), or unbounded?
For example, the coverage of NISO/NLM JATS (the Journal Article Tag Set) is
defined as journal articles, especially (though not exclusively) for STM
(scientific/technical/medical) journals. It does not seek to encode musical
scores.
Document types and tag sets (families of related document types such as NLM/NISO
or TEI) vary in how much coverage they attempt and in how open-ended that coverage
is.
Comprehensiveness
This is the complement to coverage: not how broadly a tag set seeks to describe
texts, but how deeply. Given a set of documents to be encoded, what are the purposes
of their description? Are there processing requirements to be addressed, either
directly or indirectly? To what extent must variations among the texts be registered;
how detailed, exact and complete must the description be? What is the scope of
description? For example, can two blocks of text separated by vertical whitespace
in
rendition both be called paragraph, or are there cases and conditions
in which this is not sufficient, and further distinctions to be made?
The comprehensiveness problem might come up for NISO/NLM JATS if a journal article
were to turn up that contained a segment of musical notation. Without a requirement
to
treat the notation in any particular way, owners or publishers of this information
might choose to encode it as something they do recognize, such as an ordinary
graphic.
It is natural to consider coverage and comprehensiveness together as a problem of
scoping. If a document type, formalized by a schema, does not explicitly define its
scope of application (what the documents are, and how and for what purposes elements
within them are to be distinguished), it will do so implicitly, in its
application.
Adaptability
If an encoding format is adequate to the description of a well-defined (bounded)
document set for the purposes of a known and well-understood set of applications,
it
does not have to be adaptable: we will never have to introduce new elements,
attributes or tag semantics, as these can all be distinguished and defined up front.
But most schemas in actual use need to be able to stretch, either to describe new
documents, or to identify new structures and features of documents already considered
in scope. That is, they need to adapt, in both their coverage and their
comprehensiveness.
Adaptability will be a problem to the extent that it is needed (that is, coverage
and comprehensiveness are problems) and available mechanisms are not adequate to meet
the need.
We now have enough experience with XML encoding to have a good sense of how well our
mechanisms work in the face of these issues. Whether they work well enough for you
depends on
who you are; more generally, it depends on the scope of control exerted by schema
designers
(either directly or by proxy) over documents.[1]
When descriptive schemas work
The short answer is that how well a descriptive schema works in operation depends
not
only on its fitness for the data and task (i.e., whether its coverage is appropriate
and it
is adequately comprehensive), but also to the extent that document encoders have editorial
control over the information, both in its content and organization. This should not
come as
a surprise, since indeed the roots of XML technologies are in publishing systems in
which it
is more or less imperative to exercise such control, and the promise of externalizing,
rationalizing and simplifying these control mechanisms is much of the point of descriptive
markup. The classic application of this principle, of course, is in the publishing
of a
manual, technical series or periodical, in which authors or contributors (on the one
hand)
and production staff and designers (on the other) assent to creative decisions of
editors,
and document markup can serve transparently to represent editorial intent.
When control is centralized in this way, the circle is complete: once an encoding
format is
defined, content can be selected, composed and modified to conform to its capabilities.
Requirements for change and adaptability are managed in balance against other needs
for
consistency and stability. System operators resort, when necessary, to editorial
policy-making to forestall, prioritize, and schedule any innovations likely to have
a
destabilizing effect.
The limits of description: the case of the book
The inverse is also true. Descriptive schemas work well to the extent that control
over
the data is centralized and consistency in the application of markup can be enforced.
But
when it is not so centralized, they do not work so well. This can happen anywhere,
but it
happens most notably and inescapably in a community of use which shares a common schema
or
tag set (using that term to identify a family of related schemas) without sharing
local
goals and objectives. Maybe they have an interest in a common encoding standard for
purposes
ostensibly of document interchange; similarly, they may wish to take advantage of
common
knowledge and a shared tool base. Of course, this is exactly the case with the
big general-purpose document encoding standards and community initiatives,
such as TEI, Docbook, and NLM/NISO.
The limits of a descriptive encoding can be readily illustrated by considering
information artifacts in the wild – that is, as actually found, and apart from any
considerations of how they may be encoded electronically (or not) by the authors,
editors,
designers and publishers who have composed and produced them. Texts in the wild –
even
if we limit consideration to those texts we are content to designate as books
– are not perfectly regular, but only mostly so. Indeed this semi-regularity is an
important (perhaps the most important) general feature of books, inasmuch as significant variation within pattern might serve as a definition of
information itself: the structures of books cannot be entirely regularized
without sometimes destroying the book. Sometimes this works at a very granular level.
Figure 1: Specialized structures across a series of books
Michael Kay's XSLT 2.0 and XPath 2.0 Programmer's
Reference is a convenient example of a book whose internal structures are
more elaborate than may be typical of a generic book. Yet unless we wish
to say this book is not a book, but something else, a viable book model has to support
such structures either natively or by means of extensions to be introduced by the
author
or publisher. It is possible that the markup needed here could be useful across all
the
books of the series to which this book belongs; in any case, it might be useful to
the
publisher and to application designers who wished to design interfaces to this content
if it were.
Figure 2: Specialized structures across a single book
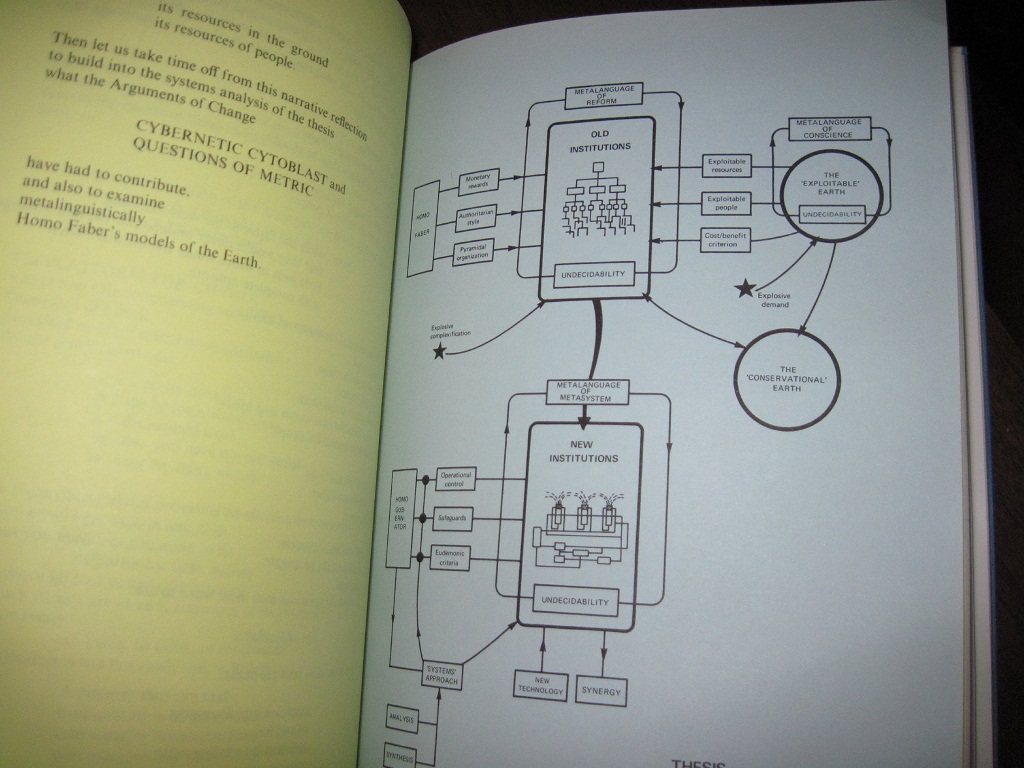
Stafford Beer's Platform for Change (1975), like
many other literary or quasi-literary productions, is a fascinating example of a book
whose structure is peculiar to itself. Beer's volume is not unusual in having figures
and diagrams, although one appears on the inside of the dust jacket; but it does have
structured prose (it is not verse, or so the author asserts), and its chapters are
differentiated by type, as indicated by page colors.
Does a generic book model need to be able to accommodate works of this kind? We can
agree to say no, this book is out of scope: the coverage problem again. Or say that
although it is a book, we will force-fit it within available semantics (risking tag
abuse to deal with inadequate comprehensiveness). Or we have to find a way of dealing
with its special requirements: the adaptability problem.
For what it's worth, even unextended TEI does not provide elements directly capable
of marking up this text, as it has no elements for lineated (structured) prose, only
verse.
Figure 3: Specialized structures within a single book
Thomas Carlyle's Sartor Resartus (1833) should be
required reading for all students of semiology. It is mostly conventional in structure;
or at least, much of its point is in how it observes some of the more elaborate
conventions of nineteenth-century scholarship. But an epitaph pops up in the middle.
Students of literature know that such things are less uncommon than you might think,
even leaving aside Tristram Shandy. (Illustration from
Google Books.)
Again, we have either to extend our coverage of what's a book (or what's in a book),
or provide a way for a markup language to be adapted to purposes like this.
Three examples appear in Figures 1-3, showing this phenomenon at the level of the
series
(the Wrox Programmer to Programmer series, shown here by
Michael Kay's XSLT 2.0 and XPath 2.0: Programmer's
Reference[2]); the level of the book (Stafford Beer's Platform for
Change); and within the book (the epitaph appearing in Sartor Resartus). Of course, many more examples could be shown to demonstrate
how every book – and every structure within a book – is potentially a one-off, a
thing unique unto itself. In part, this reflects the fact that books as functioning
information objects can and must be designed to serve sometimes very distinct and
peculiar
purposes, which may even be intended specifically to differentiate them from other
books.
One of the core requirements addressed by book design, that is, is that a particular
design
may be distinctive, at least in part, not only in its features but even in the requirements
it addresses, which will be different from the requirements addressed by any generalized
design. This reflects a different balance of power in book publishing from journal
publishing: the center of gravity for design decisions shifts from publisher to author
– which is why, as a class, books are less tractable for descriptive
markup than journals that maintain a consistent structure (expressed in their design,
layout
and page formatting) across articles.
Of course, the irony here is that this will be true of books as a
class even while individual books or certain genres, types or formal series of
books might well be suitable and profitable objects for description. (And so we generally
deal with this problem by limiting our coverage to particular books, leaving
books in the abstract out of scope.) Because coverage – what,
exactly, constitutes a book, and what sorts of documents are not books
– is not well defined, the comprehensiveness of any markup applied to nominal books
will also be at issue. In practice this means that descriptive encoding hits a wall,
since
to whatever extent we try and provide appropriate handling of every structure we see,
our
markup language grows into a Tower of Babel: a single megalo-description supporting
this
differentiation ultimately fragments under its own weight, since any instance may
have
structures peculiar to it, while no instance includes all (or even many of) the structures
necessary for the others. While this may be a fascinating state of affairs to a media
critic
or markup language designer, it is no basis for a common information standard that
needs to
normalize description at some level, if only to enable and regulate processing.
This paradox results from the foundational insight of descriptive encoding. The
operative dogma is that we can and should clearly distinguish presentation from content,
where the organization of content is regular and in some way normative, even while
the
presentation and indeed application of that content may vary. (In effect, this is
a
model/view/controller paradigm applied to documents, in which the document itself
is a model
that can be subjected to multiple views in one or more applications as controllers.)
As
noted earlier, this tends to be the case within collections of documents that can
have such
regularity imposed on them – consistently designed works such as journal articles
or
technical manuals, that is, where control of both content and composition is top-down
and centralized.[3] So the design of markup languages is focused on defining that regularity and
normativity, in a sense leveling the differentiation into those classes of things
(we try to
identify these with element types) that can be adequately, if not always
comprehensively, distinguished with an encoding system.
Yet in order to do this, we have to pretend that some distinctions between things
which
we choose to identify as the same type are not, and cannot be, significant. And we
never
know which one or another of the distinctions to which a particular markup system
has a
blind spot will turn out to be important as soon as we turn the page of a book or
of any
work outside our controlled set. In other words, depending on the type of work, anomalous
structures may be more or less unusual, and regarded as more or less anomalous; but
when
they occur, they can be very anomalous. The structures of actual books, that is, have
a
fractal quality, inasmuch as what constitutes an anomaly (as opposed to merely another
regular if unusual feature) depends on the level of scale – and yet there is no level
at which anomalies disappear.[4]
Different markup languages deal with this problem differently, depending on the extent
to which their design targets a distinct genre or application domain. But in
every markup language, we can see this stress between coverage and comprehensiveness
on the
one hand, and adaptability on the other. To whatever extent coverage is well defined
and
comprehensiveness is achieved within it – by virtue of the meaningful distinctions
being made and the incidental ones elided – adaptability also becomes important
– because a distinction never made in one context, or made only incidentally, becomes
meaningful in another. (In contrast, precisely because it is relatively uncomprehensive
across a very wide coverage, a markup language such as HTML needs to adapt less; the
price
for this, of course, is that its semantics are weak.) But adaptability by its nature
threatens the integrity of the boundaries (the coverage) that make the semantic labeling
function of a markup language useful.
The root of the problem here is in a question not often asked about descriptive markup
(except, possibly, at Balisage), namely what is it that markup should be intended
to
describe. Sometimes, naïve proponets of descriptive markup have been content to argue
that
what is being described is the thing itself, but this of course begs the
question. A successful markup application works precisely because it does not seek
to
capture every distinguishable feature or detail of anything it describes, but instead
represents and abstracts from it. The model it offers is an optimization: more accessible,
tractable and useful, at least for certain purposes (including automation), than the
thing
itself. This reduction of differences to (supposed) essentials reflects the way, in
information processing systems, everything we do is on the basis of the differences and differentiations (and similarities) we can register
and retain within and between different data objects, as is well established in information
theory from Saussure [Saussure 1916] to Shannon [Shannon 1948].[5] And this means that we necessarily make assertions (by our names and labels)
that erase some distinctions between things, precisely so that we can assert others.
It is
in recognition of this that in SGML terminology, an element name is called a generic
identifier.[6]
This erasure of distinctions by calling different things by the same names, as long
as
they are alike in certain crucial aspects – crucial being defined in
the relation between an information type and its application domains – is the
balancing factor that prevents descriptive markup from going out of control and failing
in
its mission sine qua non, namely the automatability that
follows on our ability to know in advance the limits we will work within. For a markup
application to be viable, in other words, it must have a fairly limited set of elements,
whose semantics are known and respected and whose structural arrangements are predictable
(indeed this is the entire point of a schema).[7] To the extent this set grows and changes (either because new elements and
attributes are added or because the semantics of old ones are elaborated), viability
is
endangered, to the point where (if the rate of change outstrips the capability of
the rest
of the system to change with it) applications of the language become unsustainable
and the
language itself becomes, at best, a literary artifact.
Of course, this limitation inhibits adaptability, insofar as an element set defined
in
advance will (ipso facto) fail to account for any semantic
features of the information type that are newly defined or recognized, whether accounting
for new phenomena to be described, addressing new applications, or for any other reason.
And
this is the crux of the paradox, the precise dilemma on whose horns the problem of
descriptive markup is stuck.
The problem with schema extensibility
The usual way of providing an encoding format with adaptability is to allow that a
schema
may be extended and customized for local use. If you need new element types, this is
how to add them etc., sometimes with elaborations in the form of class systems,
metalanguages (TEI ODD), architectural forms, and so forth. Such mechanisms can be
ingenious;
they can also be useful – especially for publishers who can exert top-down control.
Yet
this solution often works less well in the real world than it should, as it has problems
of
its own. Extensions to a tag set, even as they successfully address new requirements,
raise
interoperability issues with systems that do not know about them. When we address
this problem
in turn by allowing extensions to make it back into the development trunk of the markup
language, we end up making the entire system more complex, more unwieldy, and more
expensive
to develop with, use and maintain. In effect, we have a devil's choice: fork, or bloat.
In the
one case, having extended the schema I find my documents will no longer be interchangeable,
even nominally, with yours. In the other, we will reconcile and merge my extensions
back into
the main schema, where you and everyone else who works with it will have to live with
them
(even if you will never need them), and all our common tools must be larger and more
complex
to accommodate them.
Schema extensibility also gets it wrong in another way: it assumes that adapting a
tag set
to meet new requirements for data description is properly the task of a schema designer,
and
not of the content creator, editor or owner who is actually responsible for the document.
Again, this differentiation in roles is less of a problem for organizations with strong
top-down control, where coordination between the different parties can be expected,
and a
schema designer is available either to give or to take orders. But many tag sets aim
to
support wide deployment across a user community with a greater variation in needs,
goals and
available resources, where project principals may have neither expertise, nor resources,
nor
the inclination to take on the task of schema modification, especially as it distracts
from
the immediate and more important task of producing the document itself.[8] In other words, to customize a community standard for local uses works best, as a
solution, for those organizations who need it least – who are best able to exert
top-down centralized control, who have schema developers on call, and who are probably
able
(if they do not see other benefits to using a standard) to manage completely on their
own.
And finally, there is a simple cost issue whenever we consider cases that are,
effectively, one-offs. Even in an organization with the resources to do so, it may
be too much
of an effort to introduce customizations to accommodate a single book, or a single
interesting
textual artifact appearing on a single page in a single book.
We commonly assume that this means the game is over, since how can a content creator
introduce new descriptions to the data without schema extension, at least not without
resorting to tag abuse, forcibly attempting to carry new semantics on elements provided
for
other purposes? In effect, what is needed is an extension mechanism that happens in
the
instance, not in the schema – and yet in a way that enables authors, editors and
production (not markup) designers without compromising the integrity of the markup
language as
a whole (which is what happens when tag abuse becomes rampant). This implies not that
we have
more elements or more easy ways to add new elements, but rather a smaller set of elements
that
are nevertheless, paradoxically, capable of more expressiveness and wider application.
Extension in the instance with abstract generic microformats
The mechanism we need to do this is already in front of us. We routinely permit content
creators to introduce exactly such ad hoc semantic extensions
to the language, whenever we invite them to qualify their element types with attributes.
TEI
@type, HTML @class, Docbook @role, the various
NLM/NISO subtyping attributes: these are there specifically so that we can identify
particular
instances of elements such as div, p, figure,
table, seg, sec, span and so forth with
particular semantics over and above the generic semantics of the parent element. The
practice
has come to be an essential feature in HTML, inasmuch as @class attributes as
much as element types provide the semantic hooks for display and behavior in the browser,
in
the preferred fashion (as supported by CSS). It is the recommended solution also in
TEI for
handing chapters, parts, books, sections, cantos or what have you as arbitrary text-segmenting
elements, which are all unified as div (or lg or what have you) with
a @type attribute available for the subtyping.
Indeed, successful documentary markup languages commonly have elements whose native
semantics are especially loose, as if specifically to allow escape-hatch markup
for ad-hoc inclusion of structures not naturally described otherwise.[9] TEI: div, floatingText, ab,
seg. NLM/NISO JATS: sec, app,
named-content, custom-meta. Docbook: blockquote,
informalTable, note, phrase. HTML: div
and span. While using such elements in this way is not always officially
encouraged, in any widely used markup system it soon enough becomes a widespread practice,
if
only informally. Sometimes an element that supposedly has a strong semantic comes
to serve
this way simply by having been widely abused: no one actually assumes that an HTML
blockquote must always be a quotation, or that dl, dt
and dd must always be terms and definitions. Such a two-tier description is a way
of evading the problem of constraining the markup too stringently in the schema, by
allowing
the balance between generic and specific to be struck in the instance, where the
same things (p or div elements, for example) can be
differentiated by different class assignments. Descriptive semantics are provided
to tabular
data by this mechanism probably more often than by providing content-oriented elements
in a
schema, if only because tables are so often peculiar or one-of-a-kind that it is the
only
practical way to do it.[10]
Nor does this have to mean any loss of control or normalization, since we have learned
to
validate constraints on attribute assignments, using means such as Schematron. On
the
contrary, it means that we can assert levels of validity: a basic level of schema
validation
can be supplemented by a profile validation that is defined locally and peculiarly
for only a
subset of all documents valid to the schema. This exact strategy is in fact happening
more and
more commonly, as a way of balancing a requirement for standards conformance (to TEI
or
NLM/NISO JATS, for example) with more particular local requirements being addressed
by local
schema subsetting and profiling.
Another way of putting it is that we should look not to schema extensibility but to
microformats defined locally as the primary means of providing specialized semantics
for local
processing. (There is a more or less coherent movement to codify HTML microformats
at
http://www.microformats.org; but as the TEI among others demonstrates, the
basic idea of carrying primary semantics in attributes predates the web and is more
general
than HTML.[11]) The only thing remaining to complete this picture is to provide scaffolding for
such a mechanism, in the form of a set of elements defined neutrally enough (that
is, with
generic enough semantics of their own) that they can readily be devoted to such a
use, without
compromising the stronger semantics of more properly descriptive elements. Such a
built-in
adaptability mechanism would implicitly address issues of both coverage and comprehensiveness.[12]
It is also feasible, since even across hypermedia, the basic display and functional
elements of text media are fairly well known and stable: they are inline objects (the
very
fact that I don't have to explain to the Balisage audience what I mean by this term
makes my
point here); blocks; conceptual containers (wrappers) for blocks allowing them
to be grouped and for common features to be inherited together; tabular layout objects;
perhaps lists (which might be considered a special kind of table); and links and images
(allowing that an image element can be thought of as a transcluding link). Along these
lines,
a comprehensive taxonomy can be derived by identifying basic common formatting properties
of
elements in relation to other elements.
This fact suggests that a set of abstract structural elements be defined that map
directly
straightforwardly to the semantics of known result formats of transformation, including
CSS
and XSL-FO. Elements as generic as div, block, and
inline allowing @class or @type attributes to specify
semantics for applications further downstream, would provide strong enough semantics
at a base
line, supporting presentation, to be useful, while nevertheless alerting developers,
by their
use, that more particular kinds of handling might also be called for. In effect, the
implicit
contract offered by element typing mechanisms (that all elements will be handled downstream
in
ways appropriate to them) would be suspended for these abstract generics in
favor of another, allowing and encouraging local developers to take advantage of them
for
local purposes. Even without specialized functionalities (including very strong validation)
for these elements by default, they could nonetheless be differentiated enough from
one
another and from the main set of elements to do something reasonable in display and
in other
applications – up to and including useful generic functionalities, such as simply
exposing the values of their @type or @class assignments in the HTML
results of a transformation, where they would be available for mapping to display
semantics in
CSS.
A proposal
So here is a straw-man proposal for a set of such elements and attributes:
div (division)
Named after div in HTML and TEI. Permitted to appear anywhere a
block may appear (like HTML div, more like TEI
floatingText than TEI div). Unlike NLM/NISO
sec, Docbook section or TEI div, a title is
not required, although generic metadata may be permitted. div is
permitted to contain any block-level object, such as paragraphs, figures or tables,
display quotes, div or ab elements.
In general, div may be expected to map to HTML div or
XSL-FO fo:block for display. For conversion, given sufficient
constraints imposed on div or on attribute-qualifed families of
div, they may become TEI div or
floatingText, NLM/NISO sec, display-quote,
or boxed-text, Docbook section, blockquote or
informalTable, or the like.
ab (abstract block)
Named after TEI ab, an abstract block. This element
is an analogue for a paragraph or a list item. It is permitted to contain any mixed
content or any block-level item (and not only the other abstract generics, but any
inline content permitted in the host language), but it will not have its own
metadata.
For display, ab will become HTML div or
p, or XSL-FO fo:block. For conversion, ab
will often become a paragraph or paragraph-like object.
ap, pair (abstract pairing, pair)
ap or abstract pairing, along with
pair, can serve to represent all kinds of labeled lists, paired lists
such as glossaries, definition lists and indexes. Such a generic element does not
carry the semantic baggage of any particular kind of list or associated array, all
of which are especially liable to tag abuse in the wild.
pair could be validated as ((ab | line | span), (ab | line |
span)) in order to enforce the pairings. (Additionally, RelaxNG or
Schematron could validate ap to see that every enclosed
pair has the same content model.) Of course, any of these constituent
elements could be qualified with @class or @type of their
own (which might similarly be validated across pairs within an
ap).
Both ap and pair will also become div or
p in HTML and fo:block in FO, when they do not map
directly to especially formatted lists (ul, ol,
dl with li, fo:list-block with
fo:list-item), or even to tables.
And pair might additionally be allowed to appear anywhere
ab, line, or any block-level element appears – or
even (at any rate when it contains only span elements) in line, as a
proxy for structures such as TEI choice.
line
A line element is a block that may contain inline elements, but not
other block elements. This is much like TEI l, except that
l is restricted in TEI usage to lines of verse or poetry, and this
element should be available for any use, any time a new line is required. (It should
not preclude an element for a line break in tag sets that need it.)
Like ab, line will usually become div or
p in HTML, although not necessarily with vertical white space; and
its indenting may vary. Occasionally, sequences of line elements within
a div (and without other siblings) may map to dl/dt or
ul/li, as a simple (unmarked) list item. In XSL-FO, line
will become fo:block.
For modeling purposes, we could use ab everywhere we might want
this element; but line may feel more appropriate than ab
for isolable units of text such as headings or titles; and because it cannot contain
block structures (such as ab), it also comes with a useful constraint
for conversion and formatting.
span
Of course, this is the inline object, analogous to HTML span, TEI
seg, Docbook phrase and NLM/NISO
named-content. For display, span would generally become
fo:inline or HTML span, when not a more specific inline
element. Similarly, in conversion, given suitable qualification, a span
might map to any inline element in the target language. Given sufficient control,
a
sequence of span elements within a line or ab
enclosed in a div may sometimes become table cells in a table.
link
Analogous to general-purpose inline linking elements. We might simply allow the
full panoply of XLink attributes on this element to make it a general-purpose
element suitable for arbitrary linking.
As noted above, images and other media objects are really special-purpose links
(which may imply transclusion of their targets on rendering), so they can be
accommodated by link.
@type
Let @type assert (implicitly and when possible explicitly, by means
of documentation) a class or type assignment whose value is controlled across a
document collection.
Multiple values of @type can be provided as space-delimited values of this
attribute. Explicit mappings to known tag sets, such as docbook:para,
tei:p, html:p and so forth might be provided by using
the namespace-qualified type names of appropriate elements.
@class
Let @class identify subtypes of elements within a single document
instance, in a more ad hoc way than does @type. The expectation would
be that when @type is also present, @class offers a
subtype. Like @type, and like @class in HTML (where it
provides bindings for CSS selectors), multiple values can be provided with space
delimiters.
Of course, the distinction offered here between @type and
@class is not absolute nor even enforceable in the general case. It
is up to particular systems and implementations of abstract generic elements to
enforce the constraints over these attributes they need. Offering both allows a
local system to constrain @type, for example, while leaving
@class free for use.
@which
@which is intended to serve as a general-purpose pointer, either to
another element or to an implicit or explicit taxonomy, local or general. Its
lexical form is unconstrained, and it may have as many values as a local application
may need.
For example, in an abstract rendition of information intended to be represented in
tabular form, a single value given to two or more places (to be rendered as spanning
cells) might show its multiple placement using @which.
@xml:id
For generalized purposes of cross-reference, we will potentially need a unique
identifier for any element.
@style
Finally, I suggest we allow any of the abstract generic elements to include
explicit styling information, in the form of a widely recognized syntax such as CSS3.
Of course, this clearly breaches the content/format divide, but it does so in a
strategic way. By allowing this attribute on the abstract generics, we relieve the
design stress on other elements in the markup language to provide their own styling
overrides – the fact that a name, say, needs specialized styling by itself
suggests it is a special kind of name and might be described with an abstract
generic.
It should be noted that a number of industry-standard schemas for documents
allow this kind of thing already, either as an escape hatch on a few elements, or
on
a wider basis. Indeed, TEI P5 has two attributes
with the sole purpose of specifying rendition, namely @rend and
@rendition. (@rendition is supposed to carry CSS while
@rend is more free-form.) And at least one of the NLM/NISO tag sets
similarly permits an inline element called styled-content.
Some purist systems might choose to ignore this attribute, to deprecate its use
and validate against it, and/or to recognize patterns of usage and promote the
elements that show them into other representations of the information they
carry.
It is important to stress that this element set would be intended to supplement, not
replace, the basic core elements of a capable document-oriented tag set – although
it
is also conceivable that a valid (and useful) document might contain nothing but these
element types.
One limitation of abstract generic elements is if they cannot be provided with arbitrary
attributes. How severe an encumbrance this would on the general use of abstract generics
for
ordinary purposes can only be known by trying it.
But at least two possible workarounds can be imagined: (1) where attributes are needed
to provide subclassing, either or both the @class or @type
assignment of the abstract generic can be overloaded. (2) In general, child elements
or
element structures can be recruited for use to carry values that might otherwise be
given in
attributes.
An example: an approach to drama
An example in TEI markup:
<stage>Enter EGEUS, HERMIA, LYSANDER, and DEMETRIUS</stage>
<sp>
<speaker>EGEUS</speaker>
<l>Happy be Theseus, our renowned duke!</l>
</sp>
<sp>
<speaker>THESEUS</speaker>
<l>Thanks, good Egeus: what's the news with thee?</l>
</sp>
<sp>
<speaker>EGEUS</speaker>
<l>Full of vexation come I, with complaint</l>
<l>Against my child, my daughter Hermia....</l>
</sp>
The same example could be tagged as follows in a schema that supported abstract generic
elements:
<div type="drama">
<line type="stage">Enter EGEUS, HERMIA, LYSANDER, and DEMETRIUS</line>
<pair type="sp">
<line type="speaker">EGEUS</line>
<ab type="speech">
<line>Happy be Theseus, our renowned duke!</line>
</ab>
</pair>
<pair type="sp">
<line type="speaker">THESEUS</line>
<ab type="speech">
<line>Thanks, good Egeus: what's the news with thee?</line>
</ab>
</pair>
<pair type="sp">
<line type="speaker">EGEUS</line>
<ab type="speech">
<line>Full of vexation come I, with complaint</line>
<line>Against my child, my daughter Hermia....</line>
</ab>
</pair>
</div>
It is important to note here that stylesheets or display engines that don't know what
to
do with these attributes could nevertheless do something reasonable with the elements.
For
processes that need the more specific semantics, they are available – as they are
available to be validated using Schematron or by way of a transformation into a more
tightly
defined schema.
Note
A more fully worked example, with stylesheets for display, is provided as a
demonstration with the Slides and Materials attached to this paper.
Issues and ideas
Let's say we proceed to implement a small tag set of this sort and integrate it into
a
known schema (or perhaps better, a relatively lightweight subset of one). What issues
and
objections might be raised against this design idea? What questions remain as to how
to
engineer and deploy such a system, and what do we have to know before we can answer
them? What
problems can we expect if it should be widely used, and what opportunities might it
present?
Merging with a host language: tight or loose?
At least two different ways of integrating a set of abstract generics with a host
language can be considered:
Tight
Since most host languages already have families of elements in their architecture
corresponding to the different abstract generics – section-level, block-level,
and inline – it should in most cases be relatively straightforward to integrate
the abstract generics into them.
In this design, an abstract generic div element, say, could contain
the host language's own block-level elements along with the generic div,
ab, ap and line. The advantage here is that
the stronger semantics of elements from the host language will be available to the
contents of the abstract generics.
Of course, a system that does this would need abstract generic elements and
attributes consistent with the semantics of other element and attribute types in the
host language.
Loose
It is also tempting to consider deploying abstract generics as a relatively
discrete set of tags, whose use would provide a clean escape hatch from
a host language, in a way more or less entirely divorced from it.
The way to do this would be to restrict the content of the abstract generics to
other abstract generics. The abstract span, for example, would contain
only text and/or the abstract span, without permitting any inline
elements from the host language.
The advantages of doing this would be that it would simplify deployment, and that
subtrees of abstract generics would be readily portable without modification.
A family of abstract generics designed to work like this could be given its own
namespace, allowing it to be integrated into more than one host language.
It seems reasonable to suppose that both these approaches could be useful for different
reasons and in different contexts.
Validation and validibility
Introducing custom semantics in a secondary layer using attribute values raises the
problem of how to validate them. Obvious alternatives for validation of microformats
include
RelaxNG and Schematron. Additionally, transformation pipelines can be used to formalize
the
relation between a microformat defined using abstract generic elements, and more tightly
defined elements in target markup languages.
RelaxNG
As demonstrated in Clark, Cowan and Murata 2003 (section 15: Non-restrictions),
RelaxNG can be used to specify microformats by asserting attribute bindings along
with
element types.
Schematron
As it is based on XPath, which can freely interrogate and test attribute values,
Schematron is well-suited for testing the kinds of complex co-occurrences to be
expected between attribute values in the semantic layer, as a supplement to or
replacement for RelaxNG.
Pipelines
Another strategy for validation will be to map microformats into more highly
controlled target formats for validation. XProc pipelines provide a capable framework
for this: an XSLT transformation can convert an instance containing microformats into
one in which they are expressed more formally, and validated by traditional means.
While this approach will not, ordinarily, provide much in the way of useful feedback
when data in a microformat is invalid (since it will not found to be invalid until
after conversion into something different), this could nonetheless be a useful way
of
validating the design of a microformat intended as a mirror of a target
format whose semantics are expressed in element types.
Of possibly greater importance, however, than the means of validation, might be the
shift in emphasis on stages of validation necessitated by the presence of abstract
generics
in the model – since the very idea is to relax both the demand and the expectation
for
uniformity and consistency of element usage across system boundaries. Validation will
no
longer, in other words, be as simple as thumbs-up vs thumbs-down against a common
schema,
but will also entail more nuanced specifications and tests.
Interchange and interoperability
Isn't this an invitation to chaos, as users are encouraged to introduce their own
idiosyncratic usages of the abstract generic elements?
Whether allowing microformats based on abstract generic elements would in fact make
it
harder than it presently is to achieve interoperability or even interchange across
organizational boundaries depends on what we take that baseline to be. To the extent
that
stronger typing of schema-validated element types now supports interchange, obviously
to
rely on labeling abstract generics to assert the same semantics in the instance would
be a
step backwards. However, it should be considered whether experience has not shown
that
beyond a very basic level (hardly beyond the level of XML well-formedness), interchange
cannot be guaranteed by schema validation alone in any case, at least for properly
descriptive markup languages, not markup applications that are
essentially serializations of object models bound to applications (such as XSL-FO
or SVG).[13]
There is, in other words, a difference between the mythic ideal of interchange, and
the
actual fact of it; and in fact, when it is achieved at all, data interchange at scale
happens as a deliberate outcome of a negotiated process, in which a shared tag set
may be a
useful starting point, but will not by itself be a guarantor of success. It might
be better
if we considered transparent or blind interchange to be a functional
requirement to be considered among others – and considered in its particulars as they
apply to specific parties to interchange rather than simply asserted as an abstract
principle that remains unrealized. Doing so would mean that we would be free not only
to
consider the actual costs and benefits of achieving interchange, but also to balance
this
requirement against others, such as the need for expressiveness and adaptability simply
so a
tag set can address local goals that are, after all, sometimes more pressing.
In view of this, allowing document creators and editors the means to extend the
semantics of their markup openly would be better than the status quo, in which they
do this
anyway, but hide their practices behind the premises of interchange offered by standard
semantic tagging. When standard semantic tagging is used in non-standard ways, in
other
words, it is not standard any more. This is why we call it tag abuse, because
such practice not only mislabels the contents with elements designed for other purposes;
it
also degrades the semantics of the misused element type even where it is used
properly.
Since abstract generic elements are designed to accommodate the very behaviors that
constitute abuse when used on properly descriptive elements, they would (at least
to the
extent they are used) should relieve the pressure to do so. And to the extent problems
with
interchange and interoperability will exist across systems that use the abstract generics
differently, it is reasonable to wonder whether it does not actually reflect the
requirements for description itself, which would otherwise have been hidden behind
creative tag use and misuse. That is, to the extent a system uses abstract
elements instead of abusing other elements, its tag usage will be more open and transparent
– while the abstract generics provide a base level of interoperability even without
any implementation of their local semantics.
Thus, when parties to interchange find that they don't know how to handle the semantics
of one another's abstract generics, they will have a basis for identifying, isolating
and
analyzing the issues. Already, markup systems engineers who are not deploying their
own
schemas or schema customizations are doing this all the time, and successfully, with
HTML.
(The success does not come without effort; the point is that it is possible at all.)
To
introduce abstract generic elements and encourage the development of microformats
on that
basis would not be to license bad behavior so much as it is to adopt and appropriate
the
good motivations that might, under too strict a regiment, lead to it.
Addressing production workflow concerns
One of the virtues of abstract generic elements with microformatting is that it fits
well within a production model in which XML encoding happens later, after authors
and
designers have made commitments to structures in their content that serve expressive
and
rhetorical purposes rather than the goals of any technology as such. In other words,
if a
tag set is to be a suitable target format for upconversion of arbitrary content (such
as is
produced in word processors or derived by OCR from page images), it needs to be arbitrarily
flexible, if only to capture structures at the edges of normal. Then too (and
for the same reason), most authors who have worked in XML have also had to confront
limits
in the expressiveness of the tag set in use, and would welcome an opportunity to use
more
abstract tagging, with attributes to signal semantics for possible application downstream,
when the situation warrants it.
Yet both these scenarios raise the question of what should happen in a production
system
when these elements are encountered: clearly, these capabilities are somewhat at odds
with
processing requirements, since to hide semantics in attributes is in no way
the same as extending an application framework to support them. Yet (as noted above)
there
is a great advantage in having a set of elements designated especially for this purpose,
as
opposed to the present state of affairs, in which this already happens, but in a way
much
less amenable to improvement, because the elements being appropriated are already
designated
for other purposes.
Again, layered validation, where only the basic structures are validated in the core
schema, and supplementary validation logic is provided elsewhere (in schemas, Schematron,
XSLT or custom logic), provides a way to negotiate the challenges here. The abstract
generic
elements are already provided with a baseline of functionality by virtue of their
mappings
to common display types. Provide for alerts in the system when unknown labels or
combinations are used, and developers can then address them more specifically, whether
by
extending processing, retagging, or pushing the questions they raise back for editorial
consideration.
Microformats as a driver for evolutionary change
A set of abstract generic elements can offer a way for users to mark up structures
of
arbitrary description and complexity as they are encountered. But if this concept
works in
the field, it will be due to the willingness of users and application developers to
work to
support it. Is half a loaf really better than none?
Experience with HTML shows that local users are able, and eager, to take good advantage
of such capabilities, given the right level of support by generic tools. Furthermore,
this
reservation has its counter-argument built into it: anything that rewards users for
taking
such responsibility – confronting practical issues of schema design and document
modeling and getting hands-on experience with transformations – will be a good
thing.
While good design is accomplished by design, markup technologies do not develop in
a
technological or cultural vacuum, and no design can foresee exactly the ways in which
it can
be put to use. In this kind of world, we can rely also on evolutionary mechanisms
–
selecting and promulgating the most successful from among those attempted – to help
us
distinguish the best available solutions to any set of problems. But this requires
alternatives from which we can select.
In a widely deployed tag set, variations in tagging practices are certain to occur;
and
in an environment in which many different approaches can be tried, some will persist
and
spread. While including a set of abstract generic elements will make any tag set better
fitted for use across a disparate community, the argument for fitness does not end
with
this. Abstract generic elements may also serve as useful laboratories for tagging
practice;
and on this basis, common microformats for common kinds of data and common markup
problems
may emerge, and even micro-standards, perhaps, maintained much like the core standards
although across more localized application domains within and across organizations.
It should be stressed that the aim here is to serve bottom-up as well as top-down
design
for XML applications in use – not because XML schemas don't work, but because they
do.
Precisely because, and insofar as, communities are able to
take advantage of shared practices and tools, the needs of authors, editors and publishers
to design their own models will continue to be felt. Giving them the means to do this
will
enable and empower them, while maintaining the integrity of the community standards
they
share.
References
Beer, Stafford. Platform for change: A message from Stafford
Beer. New York: John Wiley and Sons, 1975.
Hillesund, Terje.Many Outputs — Many Inputs: XML for Publishers and E-book
Designers. Journal of Digital Information, Vol 3, No 1 (2002).
http://journals.tdl.org/jodi/article/view/76.
Journal Article Tag Suite (JATS). National Center for Biotechnology Information,
National Library of Medicine (NCBI/NLM).
http://jats.nlm.nih.gov/index.html
Kay, Michael. XSLT 2.0 and XPath 2.0 Programmer's
Reference. New York: John Wiley and Sons, 2008.
[Piez 2009] Piez, Wendell. How to Play XML:
Markup Technologies as Nomic Game. Presented at Balisage: The Markup Conference
2009, Montréal, Canada, August 11-14, 2009. In Proceedings of Balisage:
The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3
(2009). doi:https://doi.org/10.4242/BalisageVol3.Piez01.
[Saussure 1916] Saussure, Ferdinand de. Course in General Linguistics. 1916. Trans. Wade Baskin. The
Philosophical Library, 1955. Reprint New York: McGraw-Hill, 1966.
[1] In passing, it is worth noting that none of these problems arise in XML document types
or formats that are designed to face applications (such as, say, XSL formatting objects
or
SVG), rather than describe information directly without regard to how it may be processed.
This is because an application format, as opposed to a descriptive format, defines
its
coverage and comprehensiveness in the design of the application. From this, we can
reason
backwards and see that the problems discussed here are inherent in the very idea of
descriptive markup, since to posit a description of a text that is not bound to a
particular application is to raise the question of how we define that description's
coverage and comprehensiveness.
[2] I offer this example without being able to confirm that the design of Kay's book
actually shares its structures exactly with other books in the series. But even if
it
does not, we all know of cases like this.
[3] I know a publisher that forbids formatted lists, either numbered or bulleted. Markup
designers like this sort of thing: no lists to worry about. The onus is on the authors
to do without them.
[4] Take epitaphs in prose fiction as an example. Among Menippean satires, the genre to
which Sartor Resartus belongs, they are perhaps not
uncommon. But shift the scope to nineteenth-century fictional monographs, in a corpus
of
one or a dozen or a hundred instances including Sartor
Resartus, we may find just the one epitaph, an anomaly. Yet in a thousand,
maybe there are three or four epitaphs, in ten thousand, thirty or forty – still
unusual, but no longer quite anomalies. But now we discover a dinner menu. If we had
randomly picked the single work with the dinner menu earlier, we would have seen this
anomaly earlier – but in smaller samples, it is more likely not to find dinner
menus at all.
[5] Shannon puts this mathematically as our ability to select which of a possible set
of
messages we have in front of us. To select correctly from among possibilities is to
differentiate. See also Spencer-Brown 1969.
[6] This is not to argue that we do not rely frequently or even always on information
whose transmission is not perfectly reliable, such as the expectation that the term
para will be taken to assert something particular to a recipient. It is
only to point out that from the machine's point of view, all we have said by labeling
something a para is that it is like other things with the markup
para, and unlike things marked div or span or
anything else not para. Whether this likeness or unlikeness will have any
consequences in processing is again a different matter.
[7] See my 2001 paper on this topic, Beyond the ‘Descriptive vs
Procedural’ Distinction
[Piez 2001].
[8] To provide for an optimized method for schema extension as Docbook and NLM/NISO do
through modular design, and TEI and DITA through their more specialized mechanisms,
does
not actually alleviate this problem, inasmuch as it demands familiarity with a whole
new
set of technical arcana in order to make things easier. This is not to say
that such measures are without advantage or value, just that their value is not in
making
schema modification more accessible to non-experts.
[9] I described this sort of mechanism in my 2009 Balisage paper, How to Play XML:
Markup technologies as nomic game
[Piez 2009].
[10] That is, the issue is not that more properly descriptive markup is not possible or
useful for tables (see Birnbaum 2007), but that to design, deploy and
support correct, descriptive markup ad hoc
for every table (or even most sets of tables) is simply impractical. The related workflow
problem – that insofar as it separates description from presentation, markup tends
to take the design of a table's presentation out of the hands of people who are properly
responsible for it (that is, authors or editors who understand the information's
intellectual structure, which that presentation must reflect not just generically
but in
the particular instance) – is related to this.
It should be added, however, that information that is presented in tabular form might
well be marked up using more abstract structures, leaving presentational issues to
a
processing step, without having particular elements devoted to the particular semantics
of
every particular table.
[11] To be sure, the application of microformats I suggest here, and its rationale, is
somewhat different from microformats (at least as usually promoted) in HTML, where
they
are all about implicit application binding by way of semantic labels, as opposed to
description in the stricter sense. Yet there is a wide spectrum between these two
extremes, which can and should be filled as much by users addressing their local problems
as by engineers building a system out: in both cases, the promise is that applications
can
be built on top of the standard without having to modify and extend the standard
itself.
[12] In paraphrasing this talk at Balisage 2011, Michael Sperberg-McQueen helpfully
described this mechanism as control points for extensibility in the
instance. This is a nice way of indicating that far from being an allowance for
less control over content, the essence of the proposal is to make it possible for
both
schema designers and document creators to assert more
control, by asserting it gently when it cannot be asserted strongly.
[13] See in particular Bauman 2011 and Kimber 2011 on
this topic. Also see Piez 2001 for more on the distinction between
descriptive tagging and applications of markup to application-centric data
modeling.
Hillesund, Terje.Many Outputs — Many Inputs: XML for Publishers and E-book
Designers. Journal of Digital Information, Vol 3, No 1 (2002).
http://journals.tdl.org/jodi/article/view/76.
Journal Article Tag Suite (JATS). National Center for Biotechnology Information,
National Library of Medicine (NCBI/NLM).
http://jats.nlm.nih.gov/index.html
Piez, Wendell. How to Play XML:
Markup Technologies as Nomic Game. Presented at Balisage: The Markup Conference
2009, Montréal, Canada, August 11-14, 2009. In Proceedings of Balisage:
The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3
(2009). doi:https://doi.org/10.4242/BalisageVol3.Piez01.