Morrissey, Sheila, John Meyer, Sushil Bhattarai, Sachin Kurdikar, Jie Ling, Matthew Stoeffler and Umadevi Thanneeru. “Portico: A Case Study in the Use of XML for the Long-Term Preservation of Digital
Artifacts.” Presented at International Symposium on XML for the Long Haul: Issues in the Long-term Preservation
of XML, Montréal, Canada, August 2, 2010. In Proceedings of the International Symposium on XML for the Long Haul: Issues in the
Long-term Preservation of XML. Balisage Series on Markup Technologies, vol. 6 (2010). https://doi.org/10.4242/BalisageVol6.Morrissey01.
International Symposium on XML for the Long Haul: Issues in the Long-term Preservation
of XML August 2, 2010
Balisage Paper: Portico: A Case Study in the Use of XML for the Long-Term Preservation of Digital
Artifacts
In the problem space of long-term preservation of digital objects, the disciplined
use of XML affords a reasonable solution to many of the issues associated with ensuring
the interpretability and renderability of at least some digital artifacts. This paper
describes the experience of Portico, a digital preservation service that preserves
scholarly literature in electronic form. It describes some of the challenges and practices
entailed in processing and producing XML for the archive, including issues of syntax,
semantics, linking, versioning, and prospective issues of scale, variety of formats,
and the larger infrastructure of tools and practices required for the use of XML for
the long haul.
On September 5 1977, NASA launched the Voyager 1 satellite. Voyager 1 followed its
previously-launched twin, Voyager 2, on a fly-by photo shoot of Jupiter, Saturn, Uranus,
and Neptune, before heading past the heliosphere, into interstellar space.
Nestled inside each satellite is a copy of the “Golden Record”. NASA NASA_a describes the Golden Record as
a kind of time capsule, intended to communicate a story of our world to extraterrestrials.
The Voyager message is carried by a phonograph record-a 12-inch gold-plated copper
disk containing sounds and images selected to portray the diversity of life and culture
on Earth. The contents of the record were selected for NASA by a committee chaired
by Carl Sagan of Cornell University, et. al. Dr. Sagan and his associates assembled
115 images and a variety of natural sounds, such as those made by surf, wind and thunder,
birds, whales, and other animals. To this they added musical selections from different
cultures and eras, and spoken greetings from Earth-people in fifty-five languages,
and printed messages from President Carter and U.N. Secretary General Waldheim. Each
record is encased in a protective aluminum jacket, together with a cartridge and a
needle. Instructions, in symbolic language, explain the origin of the spacecraft and
indicate how the record is to be played. The 115 images are encoded in analog form.
The remainder of the record is in audio, designed to be played at 16-2/3 revolutions
per minute. It contains the spoken greetings, beginning with Akkadian, which was spoken
in Sumer about six thousand years ago, and ending with Wu, a modern Chinese dialect.
Following the section on the sounds of Earth, there is an eclectic 90-minute selection
of music, including both Eastern and Western classics and a variety of ethnic music.
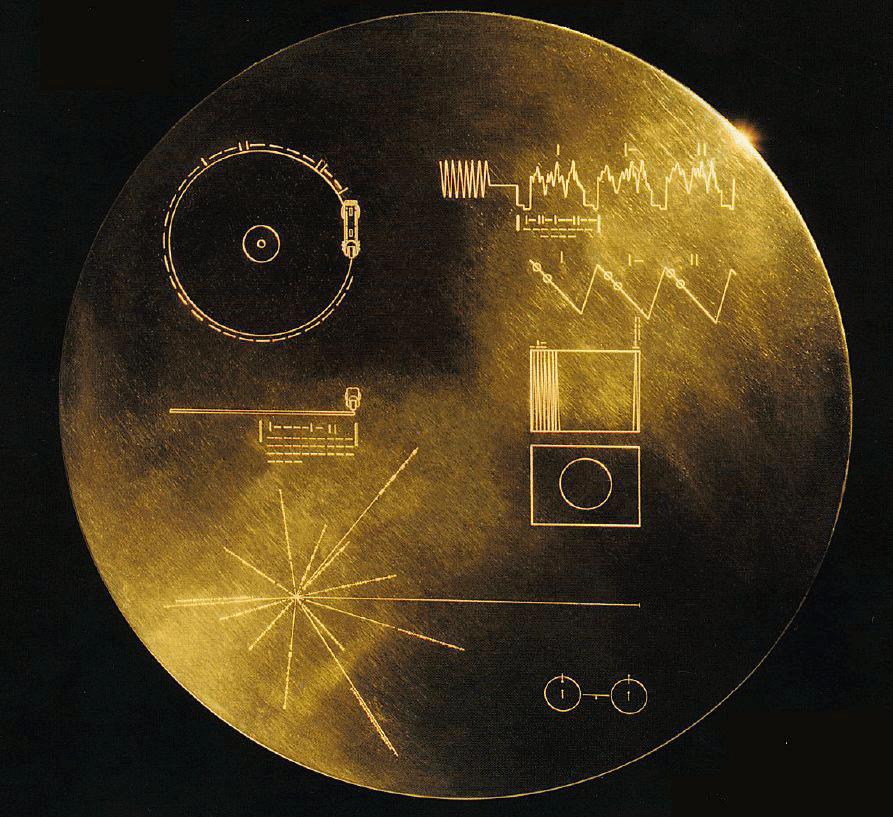
Here is what the recording cover looks like:
goldenRec: The Golden Record (Courtesy
NASA/JPL-Caltech)NASA_a
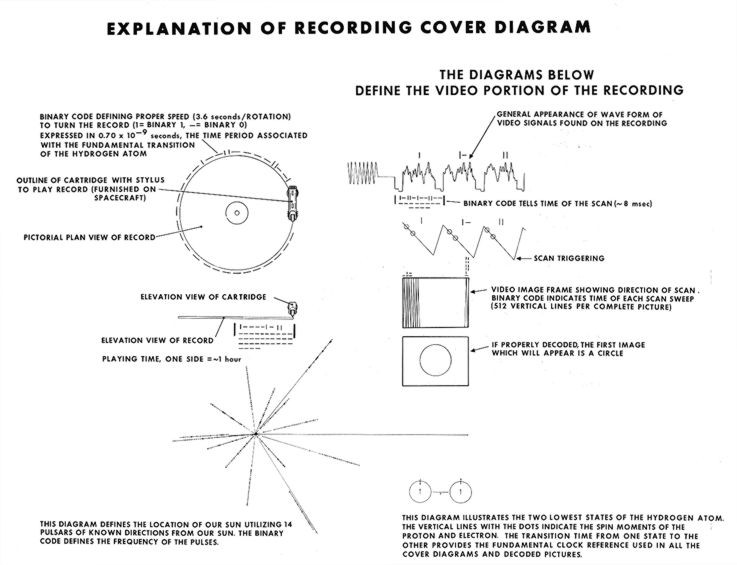
Conveniently for us (but, sadly, not for any interstellar anthropologist who might
encounter the Golden Record in its flight), NASA provides a key for interpreting the
images on the record cover:
goldenRecExpl: Explanation of the Golden Record (Courtesy
NASA/JPL-Caltech)NASA_b
In addition to the technical metadata that is provided to explain how to decode the
Golden Record, an interesting indicator of provenance NASA_b is also embedded in the package:
Electroplated onto the record's cover is an ultra-pure source of uranium-238 with
a radioactivity of about 0.00026 microcuries. The steady decay of the uranium source
into its daughter isotopes makes it a kind of radioactive clock. Half of the uranium-238
will decay in 4.51 billion years. Thus, by examining this two-centimeter diameter
area on the record plate and measuring the amount of daughter elements to the remaining
uranium-238, an extraterrestrial recipient of the Voyager spacecraft could calculate
the time elapsed since a spot of uranium was placed aboard the spacecraft. This should
be a check on the epoch of launch, which is also described by the pulsar map on the
record cover.
At a distance of nearly 33 years and over 10 billion miles Peat, how do we assess this attempt at interoperability with the future (not to say with
future curious alien intelligences) of this space-age would-be Rosetta Stone?
Well, on the plus side: What we have here is an artifact that includes self-describing
technical metadata; whose physical medium was constructed with an eye toward viability
and fixity in the punishing environment of interstellar space; that contains physical
and logical indicators of authenticity; that comes provided with instruments to render
its contents; and that provides what are intended as (literally) universally comprehensible
directions for interpretation of the information embedded in this artifact.
Viability (I can retrieve the bits from the medium), fixity (The bits you sent are the bits I am retrieving), authenticity (I am what I purport to be), interpretability (How are these bits organized), renderability (How do these organized bits become comprehensible to me): this sounds exactly like the enumeration of those characteristics that make a digital
object usable over time (Abrams 2004,Abrams et al 2005b). And encapsulated in the package is what might be called self-describing technical,
descriptive, events, and agent metadata. So you could argue that, at the very least,
the designers understood the issues entailed in the transmission of information over
the long haul -- whether that long haul is defined as one of spatial or of temporal
or of cultural distance.
As to the solution: given the difficulties even scientists contemporaneous with the
creation of the Golden Record had in decoding its semiotics, perhaps it is tempting
to smile at the host of unarticulated assumptions incorporated in the design of this
artifact. Nothing however is more transparent, or more invisible to us, than our own
operating assumptions. Perhaps we would do well to remember the caution given in another
context by Oliver Wendell Holmes Holmes:
But certainty generally is illusion, and repose is not the destiny of man.
What is Portico?
Portico is a digital preservation service for electronic journals, books, and other content.
Portico is a service of ITHAKA, a not-for-profit organization dedicated to helping the academic community use digital
technologies to preserve the scholarly record and to advance research and teaching
in sustainable ways. Portico understands digital preservation as the series of management
policies and activities necessary to ensure the enduring usability, authenticity,
discoverability, and accessibility of content over the very long-term. By this Portico
means Kirchoff:
usability: the intellectual content of the item must remain usable
via the delivery mechanism of current technology
authenticity: the provenance of the content must be proven and the
content an authentic replica of the original
discoverability: the content must have logical bibliographic
metadata so that the content can be found by end-users through
time
accessibility: the content must be available for use to the
appropriate community
Portico serves as a permanent archive for the content of over 110 publishers (on behalf
of over 2000 learned societies and associations), with, as of this writing, 11,330
committed electronic journal titles, 43,253 committed e-book titles, and 10 digitized
historical and current newspaper collections. The archive contains nearly 15 million
archival units (journal articles, e-books, etc.), comprising approximately 176 million
preserved files.
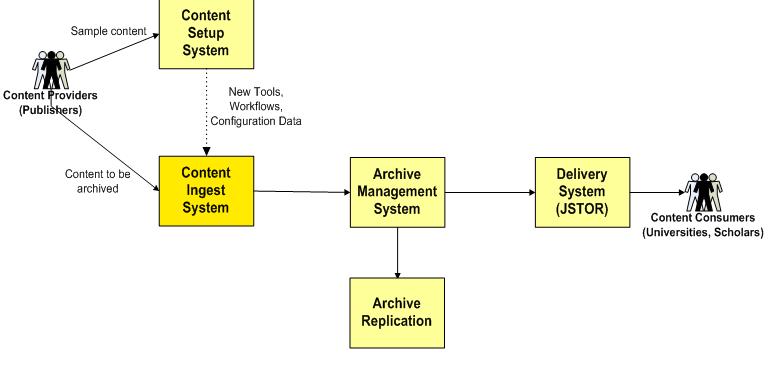
How does Portico use XML to Preserve Digital Content?
The technological design goals of the Portico archive were, to the extent possible,
to preserve content in an application-neutral manner, and to produce a bootstrapable archive of XML metadata plus the digital objects themselves (Owens 2006). Bootstrapable in this context means that each archived object can be packaged in a ZIP file, with
all original publisher-provided digital artifacts, along with any Portico-created
digital artifacts and XML metadata associated with it, and the entire archive can
be reconstituted as a file system object, using non-platform-specific readers, completely
independent of the Portico archive system. The archive is designed to be OAIS-compliant
OAIS, and is subject to a process of continual review to ensure that it continues to conform
to commonly accepted standards and best practices as they are understood in the digital
preservation community (METS, PREMIS, LOC). This review process includes a recently-completed external third-party audit by
the Center for Research Libraries (CRL), who have accredited Portico as a trustworthy repository, in conformance with its TRAC (Trustworthy Repositories Audit and Certification) protocol.
Portico preserves all original publisher-provided digital artifacts, along with any
Portico-created digital artifacts associated with the item. These latter include structural,
technical, descriptive, and events metadata (preserved in a Portico-defined XML file),
PDF page images created from TIFF files as needed, and a normalization of the publisher-provided
full-text or bibliographic (header-only) metadata files to Portico’s journal or e-book archiving DTD (based on, and fully
convertible to, the National Library of Medicine’s archiving DTDs NLM). Portico does not attempt to preserve the look and feel of journal articles on the publisher website, as we have found that, given continual
variation over time both in browser look and feel effects and publisher presentation styles, this is something of a chimera.
For each item it archives, Portico receives either a full-text or header-only XML
or SGML file, in one of over 170 different XML or SGML vocabularies. This file will
be accompanied by one or more page image files (typically PDF, though sometimes TIFF),
and often additional supplemental files (images, formulae, figures, tables, data,
executables, moving images, spreadsheets, etc.) in roughly 136 different formats,
to which there are sometimes references in the XML or SGML files. Publishers do not
use a standard delivery package format -- each follows its own file and directory
naming conventions in the ZIP and TAR files they send, or in the FTP folders from
which they provide their content. Typically there are undocumented business rules
implicit in the XML and SGML files, including boilerplate text, punctuation, or white
space that appears in the publisher's printed edition of a document but is only implicit
in the mark-up. As part of its preservation strategy, Portico migrates these XML and
SGML files to the NLM DTD as they are received, to ensure that the distinctive publisher
vocabularies and their varying usages can be well understood while those knowledgable
in their use are still available as resources. Additionally, the uniform format enables
Portico more efficiently to manage the archive at scale now and for the long haul.
Portico also uses XML as part of its processing system. XML registry files (format
information, workflow tool lists, cross-walks from various format registry namespaces,
metadata curation rule sets, workflow messages) drive the content preparation workflow
system. An XML profile for each publisher stream defines the rules for associating
the digital artifacts, distributed across the non-standard delivery packages described
above, that comprise an archival unit such as a journal article.
Challenges and Practices: Processing and Producing XML for the Archive
There are well-known and generally accepted reasons why both publishers and Portico
would select XML as the format of choice for journal and e-book content and metadata,
including the ability to provide rich structural and semantic metadata (DAITSS). Key to its selection as a long-term repository format is the fact that XML is not
platform-specific, that there is a durable open public specification (at least for
XML itself, and for the NLM archival format), and that there is a rich ecosystem of
related open specifications (XSL, XPATH, XSCHEMA, etc.) and application tools (Java
and other language libraries, Schematron, etc.). But there have been challenges as
well.
Syntax
Many business applications of XML entail the exchange of messages (i.e. content)
between different entities – often outside a single organizational or corporate
entity. This has the advantage of enforcing early detection of validity errors in
that content: if the receiving party cannot parse the message you send, the feedback
is often swift and noticeable. Prior to submission of their XML (and SGML) content
to third-party archives for long term preservation, however, this was not
necessarily the case for either the document type definitions (DTDs and schemas) nor
the documents themselves produced by scholarly publishers. Content was processed by
their internal systems only; and it was not always processed with standard tools
that enforced well-formedness or validity. While this may have made for internal
development or processing efficiencies, such practices open up the possibility that
some content can “break” when users downstream in space or time, external to the
producing entity, and operating under assumptions of either well-formedness or
validity, attempt to read it using standard tools.
Some of the DTDs Portico has received failed validity tests. Some documents were
not well-formed; some would not validate against the DTD or schema which defines
them. Some document type declarations contained unresolvable public or system
identifers. Some contained white space or comments before the XML declaration.
Encoding declarations were sometimes omitted where the default (UTF-8) encoding was
not the one employed by the document. Some documents incorrectly declared one
encoding and employed another. Some documents declared they are instances of one
version of a publisher DTD, but employed elements from a later version of that DTD.
Some documents incorrectly declare that they are standalone. Such
errors are relatively rare -- comprising less than 1% of the content Portico has
processed. They are also easily avoided –- by mandating and enforcing a check of
well-formedness and validity at the point of origin
of XML documents (as Portico itself does when it produces both normalized XML
article content and XML metadata).
By policy, Portico does not ingest into the archive any XML full-text or
bibliographic metadata document that does not pass well-formedness and validity
tests. Portico maintains and preserves a local copy of every DTD or schema that
defines XML content in the archive, along with (where permitted by contract) a copy
of any supporting documentation the publisher provides. Portico uses these local
copies to perform checks of well-formedness and validity. Access to a copy of the
document type definition has proved essential for validation, in particular in the
case of those definitions which include the use of defaults for attribute values.
Portico has developed a set of Java filters to enable resolution of system
identifiers to these locally-maintained document type definitions, to handle
incorrect encoding or standalone declarations, and to stream past content before the
XML declaration.
For many publishers, a single XML document is comprised of more than a single XML
file. Sometimes the document fragments are referenced from within one of the files,
as external parsed general entities. Often, however, there is no such intrinsic,
express linking amongst the components of the document. The publisher's creating
application assumes that a downstream process (presumably one of the
publisher's own) will know how and where to inject these fragments.
Any downstream process outside of the publisher's own workflow, of course, must
reverse-engineer this association of components. The XML profiles described above
provide the Portico workflow with sufficient information, typically based on file
path and file name signatures, to associate the component files, and to pass them
to
a concatenating XSL transform prior to normalization. (The Portico-generated XML
metadata that is associated with the archival artifact details the links among the
components of a multi-file XML document, as well as the links from that document to
the other supplemental files described above). A somewhat more challenging operation
is required in the case where the constitutent files contain something other than
XML fragments. The workflow has been instrumented to handle the case where one or
more of the components of a document are fragments of HTML. These fragments are
filtered using the JTIDY
tool to create well-formed fragments, and then are concatenated, along with other
XML fragments, within a Portico-defined wrapper element, and are passed to a
normalizing transform. The transforms similarly invoke JTIDY, wrapped in
Portico-developed XSL extension functions, when a document comprised of just a
single file contains HTML markup interspersed in the text.
Semantics
A yet more subtle challenge to be faced in the use of XML as an instrument of
long-term preservation is the issue of semantics. As Jerome McDonough has pointed
out (McDonough), information interchange even in the present between
users of what nominally are the same XML vocabularies, but whose semantics are fact
construed in different ways, is far from seamless. As Wendell Piez has discussed
Piez 2001, there is a gap between formalism (which lends itself
easily to automated tools) and the meanings people attach to those formalisms. As
Piez says, we cannot automate signification itself.
To perform the normalization of the many publisher XML vocabularies in which
content is received, Portico undertakes an intensive analysis of each publisher’s
use (or, more commonly, given the frequent subcontracting of content creation to
external vendors, uses) of its vocabularies, whether the DTD or schema is
supplemented by publisher documentation or not. When a new publisher stream is
initiated, Portico undertakes a non-automated (though aided with automated tools)
investigation of the distinct contexts of all elements and attributes, the actual
versus the possible use of element contexts or attribute values, and the
manifestation of the content of those elements and attributes in print and online
versions of the digital resource. XSL transformations to normalize that content to
NLM are coded defensively: if the transformation encounters an element or attribute
in a context not detected in the analysis, for example, an error is raised and
processing of that document halts for investigation and, as required, modification
of the transformation.
Portico's analysis of publisher content adumbrates the publisher DTD’s use of
character entity files. These are analyzed for conformance to standard entity files
and to identify publisher-specific non-Unicode private characters. Any discrepancies
with the standard entity files are resolved with the publisher. Portico transforms
any publisher character entities to Unicode where appropriate. Similarly, comments
and processing instructions are scrutinized. Any part of the transform which results
in making explicit the “generated text,” or implied data in a publisher document
(described below), clearly labels the resulting elements as having been generated
by
the archive, and not by the publisher.
The transformations are tested in a setup environment which runs the same tools as
the production content preparation system. The outputs on this setup system are
subject to visual inspection by a quality assurance team. Only after this period of
analysis and test are the publisher-specific tools directed to the production
(archive ingest) system, where processed content is again sampled and subject to
visual inspection after automated quality assurance checks have been performed, and
before content is ingested into the archive.
setup: Portico Content Setup and Ingest Environments
Generated Text
Two key components of Portico's data normalization strategy are neither to
lose data from, nor tacitly to add data to, publisher content. The use of what
Portico refers to as generated text -- actual textual content,
such as citation punctuation or boiler plate text, that does not appear in the
marked up document, but does appear in print and online manifiestations -- is an
example of the challenges of what Wendell Piez has called
procedural markup (Piez 2001). It is also the
near occasion of loss of meaning in transformation, if not
scrupulously handled. As an example, consider the following two instances of
markup. The first is a reference to a book:
Here is the rendition for the first reference on the publisher website:
book
Here is the rendition for the second reference on the publisher website:
thesis
In the first case, the <source> element is
rendered in italic, and no quotation marks are added; in the second case, the
element is not rendered in italic, and quotation marks are added. This proved to
be a consistent, not anomolous, application of behavior based on an identical
content model, triggered by a different attribute value. The business rule
however was implicit in the document, and was undocumented in the DTD.
This challenge of detecting procedural semantics, whether from
syntactic cues in the XML document, or from a comparison of the source XML
document to its various renditions (in PDF, or on the publisher website)
manifests itself even when converting from what is nominally the same, or nearly
the same, document type definition. Nearly a third of the different publisher
vocabularies currently processed by Portico are some version or variant of the
NLM journal archiving or journal publishing DTDs. In theory, normalizing this
content should amount to not much more than an identity transform. In practise,
while these transforms are in fact considerably simpler than those from document types
outside of the NLM family, care must be taken to make explicit the implicit
semantics sometimes buried in the publisher's implementation of the document
type definition. By design, the NLM DTDs allow for a great deal of leeway in,
for example, declaring whether an element or attribute is required or optional, or
providing suggested rather than controlled lists for attribute values for such
things as a publication type, or suggesting but not enforcing the use of values as
defined in RFC 1766 for language codes in the
xml:lang attribute. For this and for other reasons,
normalization is not always straightforward. For example, we have found:
a publisher who places text (for example, punctuation, such
as a period after an author's middle initial) in a processing
instruction, rather than in the the text of the
element
a publisher who extracts the content of the id
attribute of a <p> (paragrah) element and
inserts it at the beginning of the text of that paragragh (but only
for two of the journal titles in that publisher content
stream)
a publisher who employs default style information for table
cell (<td>) elements when the
style attribute is omitted
a publisher who generates the text (Russian).
or (French). in citation
elements whenever the xml:lang attribute of the
article-title element has a value of
ru or fr,
respectively, and does not otherwise employ the xml:lang attribute for that element
As mentioned above, while careful to ensure such implicit text is not lost in
translation, Portico does not tacitly alter publisher content. Any
generated text is demarcated within an
<x>element, whose x-type attribute
is set to the value archive, to distinguish the source of that
text as Portico. So, for example, in the case of generated language name
mentioned above, the transform for that element looks like:
<xsl:choose>
<xsl:when test="article-title[@xml:lang='ru']">
<x x-type="archive">(Russian). </x>
</xsl:when>
<xsl:when test="article-title[@xml:lang='fr']">
<x x-type="archive">(French). </x>
</xsl:when>
<xsl:when test="article-title/@xml:lang">
<-- defensive error handling code for unexpected attribute
use in this context here -->
</xsl:when>
</xsl:choose>
Metadata Curation
As part of its strategy for managing a large and growing archive of scholarly
content, Portico extracts and curates descriptive (bibliographic) metadata from
the publisher-provided XML documents. This curated metadata is packaged in the
Portico-generated metadata file associated with each archival unit. Portico does
not correct or edit publisher content, but does curate (transform or correct)
that data as needed in the associated metadata file. Examples of such curated
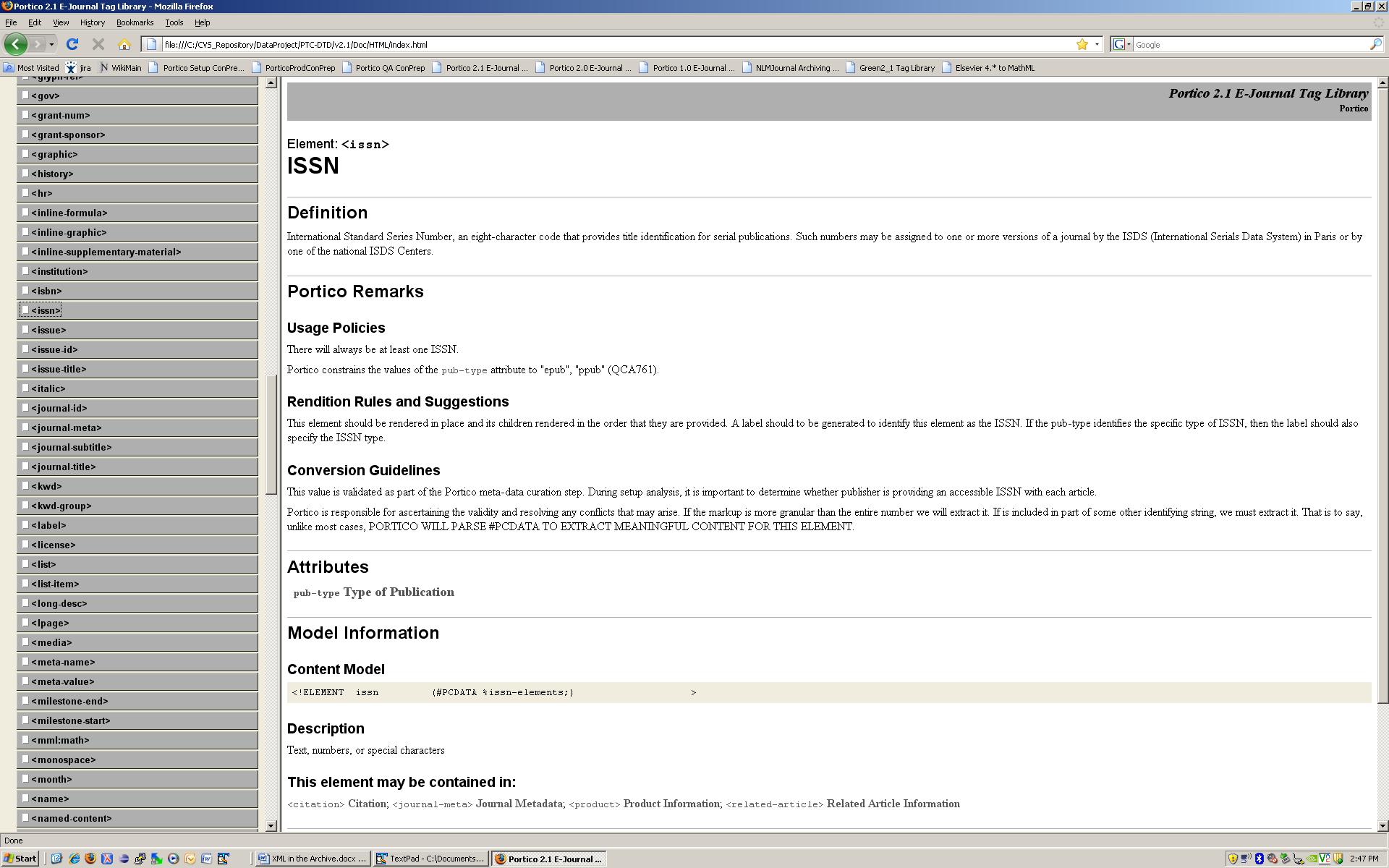
metadata are
ISSN or ISBN
publisher name
journal title
bibliographic citation (volume, page
number)
publication date
article or book title
author names
copyright information
Perhaps surprisingly, there is no industry-wide controlled list
for such things as publisher name or journal title; nor a single agreed-upon
format for publisher dates. Portico curates content with month values like
32. This is not a case of bad data. In this
publisher's processing system, month 32 is translated into a
generally-understood value. Again, however, that translation is an implicit
business rule, neither documented nor packaged with the document. Another
publisher provides no publication dates in the XML document; Portico constructed
an XML file to map from journal name/volume/issue to publication date, and
incorporates that information during transformation and curation. Another
publisher does not provide ISSN information in its XML source files; again,
Portico constructed an XML controlled list mapping from journal titles to ISSN
for curation of that publisher's content.
Documenting and Enforcing Usage Policies
In producing a normalized version of an article, Portico itself is a content
creator. Portico endeavors to document in detail its interpretation of the
semantics of the NLM DTD to which the content is normalized, as well as Portico
usage policies. Portico maintains a customized version of the public NLM
documentation created by Mulberry Technologies. This customized documentation
contains a section accompanying each element and attribute, detailing Portico’s
interpretation of the semantics and usage of these objects, especially where
such interpretation or usage is in any way a refinement or restriction of that
expressed in the standard NLM documentation. In addition, Portico enforces its
usage conventions where possible with immediate Schematron validation (in
addition to DTD validation) immediately upon creation of the transformed file.
Figure 6: Portico NLM DTD Documentation
Linking
Many of the XML article files received by Portico contain links to supplemental
files provided along with the XML file, as well as other sorts of linking
information. These external links can be addresses (email, ftp, web
URL) or well-known persistent identifiers of one sort or another, such as CrossRef’s
DOI, or keys that map to content in the gene or protein databanks
The presence of these links has obvious implications for the long-term.
preservation of this content. No one can guarantee the future stability of the
targets of any of these links over the very long term. Portico preserves all link
information, and, if enough information is provided in the source document, attempts
to characterize the link type. But as a matter of policy, Portico can only warrant
the stability of links to those supplemental artifacts actually packaged with the
source document, and preserved in the archive.
Versioning
Both publisher and archive document type definitions are subject to revision, some
backwardly-compatible, some not.
With respect to publisher document type definitions, even absent prior
notification of a change, Portico’s practice of validating all provided input and
defensively coding transformations to detect new elements and attributes, new
contexts for elements and attributes, or new values for attributes, enables
automated detection of any such changes.
Since Portico’s inception, there have been six minor (i.e. backwardly-compatible)
and one major (non-backwardly-compatible) revision of the Portico XML archival unit
metadata schema, in concert with a single non-backwardly-compatible extension of the
content model of the objects comprising the archive. The major version change was
made with a view toward enabling a richer set of content types, and more complex
relationships among the components (text, images, supplemental files, versions of
the same object, different manifestations of the same conceptual object) of those
content types. Portico’s experience as it moved through the six minor versions was
instructive when it came time to develop a schema that can be more flexibly extended
with, for example, new event types from a controlled list. This flexibility comes
at
the reasonable price of a richer consistency enforcement mechanism than validation
against a schema alone. Consistency in the case of the new metadata model is
enforced via Schematron, which was also applied, along with schema validation, to
metadata migrated from the version 1.x to version 2.0. The content model underlying
the new schema, the data dictionary for the schema, the mapping from the 1.x to 2.0
versions, as well as the mapping to analogous elements in METS and PREMIS, are all
documented in detail.
Looking Ahead: Some Unknown Unknowns
Digital preservation, in Chris Rusbridge’s memorable phrase, is a series of
holding positions, or perhaps a relayRusbridge. In the problem space of long-term preservation of digital
objects, the disciplined use of XML affords a reasonable solution to many of the issues
associated with ensuring the interpretability and renderability of at least some digital
artifacts – certainly for the first leg of the relay, and certainly for such artifacts
as electronic journals and books. What might concern us about its use further in the
future?
Scale
Fifteen million of anything is a lot, and can take a long time to process, and a
lot of space to store. The fifteen million archival units presently preserved in the
Portico archive comprise over 176 million files, and fifteen terabytes, with nearly
100 gigabytes of metadata for every terabyte of content. It required careful
planning to scale up the Portico content preparation system from an initial capacity
of roughly 75,000 archival units per month, to a capacity of 2,000,000 archival
units per month – scaling that involved not just hardware and software, but
organizational practices and procedures as well (Owens et al 2008. Any attempt
to get our arms around long-haul preservation of digital content, XML or otherwise,
necessitates getting our arms around issues of scale. As Clay Shirkey Shirky noted, commenting on the Archive and Ingest Handling Test,
Scale is a mysterious phenomenon -- processes that work fine at one scale
can fail at 10 times that size, and processes that successfully handle a
10-times scale can fail at 100 times. […] Institutions offering tools and
systems for digital preservation should be careful to explain the scale(s)
at which their systems have been tested, and institutions implementing such
systems should ideally test them at scales far above their intended daily
operation, probably using dummy data, in order to have a sense of when
scaling issues are likely to appear.
Preserving content at scale means automation, including automation of the
generation of metadata: technical metadata about file format instances,
bibliographic metadata, including search term generation and indexing, event
metadata recording provenance information about the handling and processing of
digital artifacts. Not just the quantity, but even the individual size of these
artifacts, generated by machine, and by and large intended for machine processing,
can be problematic. As an example, Portico uses the JHOVE object validation tool
to extract technical feature information and to perform object validation for
digital objects in XML, SGML, PDF, TIFF, GIF, ZIP, GZIP, TAR, WAV, JPEG, and
JPEG2000 formats. The XML output containing the technical metadata generated by
JHOVE is stored in the Portico medatafile associated with each archival unit. This
XML output can be quite large, and quite deeply nested. Portico has encountered
output describing a technically valid PDF instance, which validates successfully
against the JHOVE schema, but which could not be processed by Saxon 8.7.b without causing a stack
overflow, because of the deeply-nested nature (over 2000 levels deep ) of the
metadata. These automated artifacts must also be subject to scrutiny, to ensure that
they too can successfully be handled by downstream processes, whether
downtream means in the very near, or the the very long,
term.
Scale will likely be a determinant in whether and how XML can be used to solve the
problem of preservation of very large digital data sets.
Non-XML artifacts
Both electronic journals and e-books in their current state are at base electronic
realizations of an underlying print paradigm. As a consequence, they and their
associated bibliographic, technical, provenance and other event metadata map very
well to XML. Some of the supplementary files accompanying journal articles, for
example, such as HTML fragments, are amenable to conversion and preservation as XML.
By and large, however, it is not at all clear that, apart from their metadata,
supplemental non-text files -– not to mention other born-digital content such as
very large data sets, or electronic games, or such ephemeral digital objects that
might be described as behaviors (the effect of an interaction with server-side
software) -- are as well served by preservation in XML. However, even if such
artifacts are not best preserved as XML, we may well find that such XML-based
preservation tools as the PLANETS project's eXtensible Characterization Language (XCL) Becker et al and its associated file characterization tools will give us
information essential to evaluate different automated methods of migration or
emulation at scale of non-XML artifacts, and to assess the lossiness
of any such preservation actions.
Culture
Despite the litany of challenges rehearsed above, the critical issues, the
difficult problems in the preservation of digital objects are not technical - -they
are institutional, organizational, and financial. Will perduring organizations with
adequate funding, will, and technical know-how self-organize to meet the needs of
ongoing stewardship of digital assets?
There is a cultural aspect as well to the viability of XML as a tool in the kit of
digital preservationists. While it is true that an XML document can be read by
nearly any plain text reader application, it is nevertheless the case that the power
of XML comes from a rich ecosystem of public standards, a rich application toolset
(including many free and open source tools and libraries in a variety of languages),
and a large community of practice. Many of the tools and libraries in particular
have had substantial corporate financial support, from which the XML community at
large has benefited
What happens if this support disappears? What happens when a new generation of
developers, for whom XML is no longer the new, new thing, looks to new
technologies, or new paradigms for modeling information – information that no longer
finds its natural form as page image or text? What if a (possibly cyclic) graph rather
than an
XML tree becomes the mental idiom for structuring digital content –- even
essentially textual content? What if the tree depth of automated XML metadata
becomes, practicably, too deep? Will structured key-value stores be seen as the
solution to this difficulty in semi-structured or even in structured data,
as it has begun to be for large-scale distributed data
stores? There is a life-cycle not just to platforms and languages, but also to the
larger idioms of coding, modeling, and design Morrissey. Will we be able
to detect the sell-by date for XML applications?
Concluding Heuristics
We live forward, we understand backward, as the philosopher said James. There are no guarantees in the world of digital preservation. In
the best of all possible preservation worlds, cultural and memory institutions will
have
the resources to secure physical copies of digital assets; they will have practices
in
place to ensure the physical accessibility (currently usable media) and the physical
integrity (fixity check and repair) of those assets, and sufficient metadata or search
mechanisms to make those assets discoverable. Even given this, even acknowledging
the
platform and tool independence of XML artifacts, present experience with the long-term
fragility of links, and the varying usage in which the semantic richness of XML
vocabularies often results, suggest that we employ the admittedly conservative practices
that, in Portico’s view, assist in assuring the semantic stability of these digital
assets.
Design document definitions flexibly; test resulting
documents against expectations rigorously. Use controlled lists
where appropriate, and enforce their usage.
Be explicit. Avoid the evil
default. Avoid implicit content – even boilerplate
content.
Validate early and often. Validate what you
receive. Validate what you send before you send
it – even if you are only sending it to your own file system.
Document everything. Document controlled lists;
document the values in those lists.
Let the sunshine in. Test the viability of
your content outside your own systems and your own customary processes.
Transform defensively.
Don’t assume.
Don’t assume you didn’t assume.
Always ask: What’s next?
Acknowledgements
This paper is a reflection of the experiences, principles, and practices developed
by
the Data Team at Portico since its inception. The authors, who are members of that
team,
would like to acknowledge two former teammates: our late colleague, Charles
Chuck Wine, and especially Evan P. Owens, formerly Chief Technology
Officer of Portico, and Vice President of Content Management, ITHAKA, whose experience
and vision were the source of much that appears in this paper.
References
[Abrams 2004] Abrams and McGath, “Format Dependencies in
Repository Operation,” DLF Fall Forum, Baltimore,
November 25-27, 2004
[Abrams et al 2005b] Abrams, Stephen, “Digital Formats
and Preservation”, International Conference on Preservation of Digital Objects
Göttingen, Germany, November 15-16, 2005
Abrams, Stephen, “Digital Formats
and Preservation”, International Conference on Preservation of Digital Objects
Göttingen, Germany, November 15-16, 2005
Library of Congress, Sustainability of Digital Formats: Planning for Library of Congress
Collections, available at
http://www.digitalpreservation.gov/formats (accessed 20 June
2010)
McDonough, Jerome. “Structural Metadata and
the Social Limitation of Interoperability: A Sociotechnical View of XML and Digital
Library Standards Development.” Presented at Balisage: The Markup Conference 2008,
Montréal, Canada, August 12 - 15, 2008. In Proceedings of
Balisage: The Markup Conference 2008. Balisage Series on Markup
Technologies, vol. 1 (2008) [doi:https://doi.org/10.4242/BalisageVol1.McDonough01] available at
http://www.balisage.net/Proceedings/vol1/html/McDonough01/BalisageVol1-McDonough01.html
(accessed 20 June 2010)
Owens, Evan, Cheruku , Vinay, Meyer,
John, and Morrissey, Sheila, “Digital Content Management at Scale:A Case Study from
Portico” DLF Spring Forum, Minneapolis, April 28-30,
2008, available at
http://www.diglib.org/forums/spring2008/presentations/Owens.pdf
(accessed 20 June 2010)