Current practices for vocabulary relations
The common practice of customizing standard XML vocabularies results in variant vocabularies. Subset vocabularies are particularly useful because they can be converted to the standard vocabulary for interoperability. Restrictive substitution guarantees subset vocabularies but has practical limitations on flexibility and process. A method for recognizing the common superset of independent derivations has significant potential benefits.
Community and its discontents
In accepted XML practice, a community typically meets its requirements for representing the data or discourse for a domain by creating a standard vocabulary. At the present time, the Organization for the Advancement of Structured Information Standards (OASIS) has approved over 30 distinct standard vocabularies for different domains (including electronic business, elections, emergency alerting, security assertions, and so on). Of course, many domain vocabularies are maintained at other consortia or independently. Such standard efforts take on the difficult challenge of arriving at a consensual definition of the knowledge of a community.
As an equally common practice, the committee writing the schema that defines the standard provides mechanisms for customizing the vocabulary. For instance, HTML DTDs have long supported adding or deleting elements or attributes in any content model. A former member of the W3C Technical Architecture Group has gone so far as to mandate extensibility as a prime rule for any vocabulary (see ORCHARD). This emphasis on customization argues that a standard vocabulary is often only an approximation of the real requirements of adopters.
The divergent imperatives for conformance and customization reflect a fundamental tension between the value of community and individuality:
-
Conformance minimizes adoption effort, encourages vendor independence, and guarantees interoperability with other conformant adopters.
-
Customization meets real requirements, allows innovation, and represents the adopter's knowledge without compromise.
Customizations can pose to a lesser degree the same interchange challenges as unrelated vocabularies. For instance, interchange between a DocBook customization and standard DocBook can require a custom transform. Depending on the extent of customization, such transforms can be brittle at the edge, posing interpretation problems where an element has no equivalent in the target vocabulary and leading to tag abuse. In short, the DocBook committee has good reason to warn that any customization is no longer DocBook (see DOCBOOK).
More formally, customizations can result in a vocabulary that has a subset, superset, intersect, or disjunct relationship with the standard vocabulary. The TEI committee recognizes customizations that create a pure subset of TEI as clean customizations (see TEI). Subset customizations merit particular attention because they can convert a customized instance to a valid base instance, providing interoperability with other adopters and thus reducing concerns about customization. Superset customizations, by contrast, convert to a base instance only if the the additions in the customized instance are possible to ignore without producing a garbled document.
Vocabulary relations through formal types in XSD
XML Schema (XSD) provides mechanisms for establishing formal relationships between vocabularies. In particular, XSD supports definition of formal types with inheritance relations (see XSD). In XSD, a derived type can have either of two relations to an existing base type:
|
Extension |
A superset relation. The extended type must allow all of the content of the base type as well as the additions. Instances of the base type have a guaranteed conversion to the extended type. |
|
Restriction |
A subset relation. The new type can restrict the range of occurrences of the content of the base type. For instance, a particle with zero or one occurrences can be reduced to one and only one occurrence. The new type can also replace a contained type in the content with a restricted type for the contained type (or with a substitution group including any combination of the contained type and its restrictions). Instances of the restricted type have a guaranteed conversion to the base type. |
Because the new type has exactly one base type in XSD, the type relations construct a dependency hierarchy with a single root. The superset-subset relations established through these dependencies do not constitute a hierarchy. In particular, through extension, new types can add many different supersets of an existing type. As with well-established Object-Oriented programming languages like Java, the type relations are an immutable design feature of the type.
XSD manages type relations for design and validation but does not expose type relations for application processing. Instead, Schema Component Designators (see SCD), a companion standard, makes type relations available for inspection and processing.
Subset vocabularies in DITA
The Darwin Information Typing Architecture (see DITA) provides a method called specialization for defining vocabularies by deriving new types from base types. At present, DITA doesn't implement specialization with XSD type restrictions. The designer implements vocabularies in either DTD or XSD modules, following the rule that each new type restricts its base type and using tools to check conformance. Specialization emphasizes semantic as well as structural derivation. That is, the derived type must have a meaning narrower than and subsumed in the base type. As in XSD, the type relations construct a single hierarchy, but the type hierarchy reflects restriction instead of dependency.
DITA implements most of the vocabulary approved as part of the standard through specialized types. Adopters have also used specialization to derive vocabularies for automotive, financial, learning, legal, medical, and other domains. The base vocabulary provides a number of benefits for the design work on these vocabularies:
-
Seeding designs with the vocabulary so the design effort becomes one of selection and refinement rather than starting from scratch.
-
Minimizing the implementation effort through reuse of portions of the base implementation.
-
Grounding interpretation of each derived type in a familiar base type.
-
Guaranteeing interoperability at a general level.
Applications recognize vocabularies by inspecting the defaulted values of architectural attributes. Each element instance declares its type ancestry, but types that are not instanced in the document are not visible. Instead, instanced types are associated with modules, and all modules are declared with an architectural attribute. That is, applications can inspect and compare vocabularies at module rather than type granularity.
General semantics and loose models in the restriction base
For clarity, this paper will use the term
restrictive substitution for the type relationship
(known as restriction
in XSD and as specialization
in DITA) that produces subset vocabularies.
Restrictive substitution provides flexibility for vocabulary design only
when the base vocabulary includes at least a few semantically general types
with loose content models.
In particular, a recursive general type with any occurrence of mixed content can supply a base for deriving any element structure. For example, consider a recursive name structure as declared by the following grammar fragment:
<NameStructure> Content: (text | NameStructure)* </NameStructure>
By substituting a derived type with text content for NameStructure, a designer can represent a name as simple text content:
<SimpleName> Content: (text)* </SimpleName>
Another designer can derive types to represent a name with carefully structured name parts (by substituting derived types as both container and contained types):
<PersonName>
Content: (FirstName?, OtherName*, Surname, Lineage?)
</PersonName>The two derivations embody very different notions of the content that represents a name, but a valid instance of either derivation can convert to a valid instance of NameStructure. In the conversion, the semantics of the derivation are lost, but that accurately reflects the more abstract representation of the content at the base level.
Rationale for restrictive substitution
Even in cases without a strong semantic relationship between the broader and narrower types, restrictive substitution has value:
-
For many specialized domains, a portion of the authored content consists of structured text without more specific semantics — sections, tables, lists, paragraphs, phrases, terms, and the like (as in the legislative domain; see MCGRATH). That is, many domain vocabularies require general-purpose types.
-
Where the markup annotates readable data or discourse, conversion to a base markup with enough structure to format the text still has value through support of human readability.
For example, rows of geolocated data still have utility as a readable table even after dropping the special column semantics for typing the cell values.
-
Where the markup captures values that are not meaningful text but, instead, parameterize an object or interaction, preserving the values as ignored text in a base representation still has utility.
Developers can inspect the values in context and more easily implement the necessary interpretation. (Of course, such cases are often best handled with a textual fallback that's recognized at the base level but ignored by processing that recognizes the special semantics, as with multimedia objects.)
Limitations of restrictive substitution
Some factors limit the problems solvable through restrictive substitution alone.
First, when an adopter has an understanding of a content type that is broader than or intersects with the standard type, the only alternatives are requesting expansion of the standard type or implementing a competing non-standard type with no relation to the standard type. For instance, while the DITA 1.0 design for the task type met the requirements of its initial adopters, subsequent adopters had requirements for a broader content model with the same semantic. The requesters have had to wait for DITA 1.2 for this change.
Orchard (see ORCHARD) has recommended providing wildcards in content models to solve this problem. A derived type tolerated through a wildcard, however, has no interpretation or processing at the base level. That is, the instances of the derived type can only be ignored at the base level, which is not optimal for data or discourse that has special semantics but can be formatted as structured text.
In short, with restrictive substitution alone, the designer has the burden of trying to anticipate the diversity of reasonable variant perspectives on the information in the domain. As a consequence, the knowledge representation for the domain cannot grow through decentralized, independent activity.
Second, a derived vocabulary that provides a precise representation for a domain is no longer a good base for subsequent restrictive substitution. In particular, for many data structures, the content models have particles with precise an occurrence of at most one. As a result, substitution cannot increase the number of types in the content model. For instance, in the PersonName example, the FirstName, Surname, and Lineage types have at most one occurrence. In such cases, restrictive substitution cannot insert more particles a content model.
Type relations in OWL
OWL (see OWLOVER) has a core goal of enabling concurrent creation of distributed and related vocabularies. The solutions employed by RDF raise useful considerations for XML vocabularies:
-
As part of the principle that anyone can make statements about any resource (see RDFCONCEPT), the OWL definitions of classes can be independent of the definitions of relationships between those classes.
Applied to markup types, this principle suggests an ability to maintain type relationships independent of the markup types definitions.
-
An OWL subclass can have many base classes, and the OWL subclass relation is transitive (see RDFSCHEMA).
Consider two grocers. One asserts that Orange is a subclass of Fruit. Another asserts that Lemon is a subclass of Citrus. These independent class relations can be integrated for interoperability without invalidating or modifying existing class relations merely by adding new assertions that Orange is a subclass of Citrus and that Citrus is a subclass of Fruit.
Type insertion: Inserting a base type
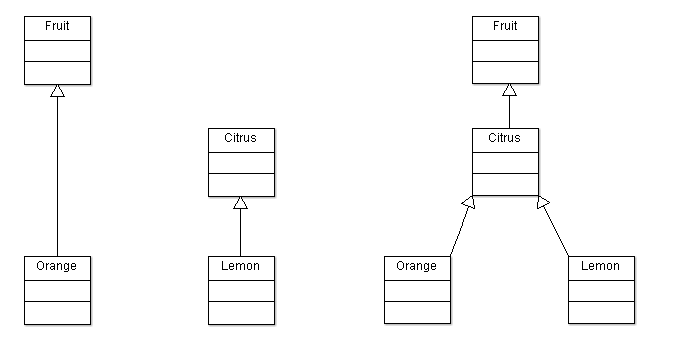
Distinct types integrated by inserting the Citrus base type between the Orange derived type and the existing Fruit base type.
Applied to markup type relations, this principle suggests the ability to add new, less restrictive base types as needed to recogize commonality between types in different vocabularies.
-
Under the Open World Assumption, the distributed OWL / RDF graph tolerates multiple perspectives with the expectation that each processor will use common objects and properties without commitment to all persectives (see OWLGUIDE).
Graph subset intersect: Intersecting subsets of a graph
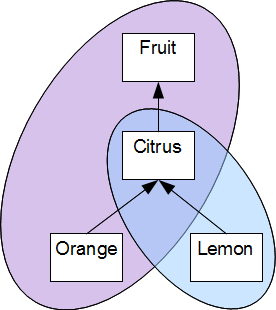
Different, intersecting subsets of the graph representing the type relations of interest to different adopters.
Applied to markup type relations, this principle suggests that processors can use the base types related to current interchange or other processing and ignore uninteresting base types.
-
An OWL class has a set of unique properties with cardinality but not sequence or nested grouping.
Applied to markup type relations, this principle suggests that formal types could have similar simplified content models. As Dattolo et al (see DATTOLO) have pointed out, simplified content models can still support XML processing:
-
If the association between contained type and position is unambiguous for a container type, processes can impose sequence when desired.
-
Nested groups (such as a choice of sequences) can be supported as the content of explicit grouping container types.
Type definitions with simple content models instead of complex grammars have several benefits for tools and vocabulary designers:
-
Dynamic inspection of content model designs becomes easier to implement.
-
Correct restriction of content models becomes an easier design task.
-
Diagnostics for design issues become easier to understand.
Of course, content models without sequence in the type definition do not remove the ability to preserve sequence in instances (any more than a choice with multiple occurrences in a schema removes the need to preserve sequence of instances of the choice in an document).
-
Scenarios for upward expansion
Applying the OWL approaches to the XML technique of restrictive substitution suggests an approach of upward expansion for definition of less restrictive base types without modifying existing type definitions. The following scenarios illustrate the potential benefits of this approach for markup types:
-
In the PersonName example, a new adopter needs to identify persons by name, but some people have epithets (as in
Funes, the Memorious
). The adopter needs a new type that is a pure superset of the existing PersonName type.The adopter can create a new GeneralPersonName type with the same content model as PersonName augmented by an Epithet type and declare it as derived from NameStructure and as a base for PersonName.
<GeneralPersonName> Content: (FirstName?, OtherName*, Surname, Lineage?, Epithet?) </GeneralPersonName>The adopter can now create instances conforming to the existing PersonName vocabulary or instances with epithets. In addition, instances of the PersonName vocabulary can be converted to instances of the new GeneralPersonName vocabulary by a tool that reads the type relationships. A custom transform is not needed.
-
In a variation on the first scenario, a new adopter describes persons who always have epithets and never have lineage. The adopter needs a new type that intersects with the existing PersonName type without a pure subset or superset relation.
The adopter can create the GeneralPersonName type as before but derive a new RenownedPersonName type from GeneralPersonName:
<RenownedPersonName> Content: (FirstName?, OtherName*, Surname, Epithet) </RenownedPersonName>The adopter can now create instances of persons with epithets. Because both this new type and the existing PersonName type convert without loss to the GeneralPersonName type, the adopter retains interoperability with PersonName content at the GeneralPersonName level.
-
In a variant of the second scenario, a practitioner who is unaware of the PersonName type has independently created a renowned-person-name type:
<renowned-person-name> Content: (first-name?, last-name, epithet) </renowned-person-name>The practitioner later discovers a need for interoperability with the PersonName type. The practitioner can derive a new GeneralPersonName type as before and declare it as the base for the PersonName and renowned-person-name types along with similar derivation declarations for the types in the content of renowned-person-name. The new GeneralPersonName type represents the superset of the two, independently created types.
As these quick scenarios illustrate, upward expansion could greatly expand the set of problems solvable through restrictive substitution and, more generally, recognize existing document types as subsets of a more general domain vocabulary.
Theoretical alignments
Managing vocabulary relationships aligns with some work on categories in the Philosophy of Language and Prototype Theory. Given that markup annotates data or discourse with categorical types, these alignments are valuable to consider.
Wittegenstein's discussion of family resemblance and the language game makes two fundamental points (see WITTGENSTEIN). First, that a category such as bird is defined not by a single set of core properties but, instead, by variant and overlapping properties among members as distinct as albatross, flamingo, grouse, parrot, penguin, ostrich, and woodpecker. Second, formal rules establishing more consistent but restricted versions of a category are justified by their utility.
Building on Wittegenstein's work to develop Prototype Theory, Rosch identifies levels of abstraction among categories (see ROSCH). Minimally concrete categories (as with cardinal, eagle, and sparrow) provide as much abstraction as possible without losing easy recognition of members. By contrast, more abstract categories (superordinates such as bird) lack sufficient concrete information for the same degree of confidence in recognition. (For instance, bat is more prone to misidentification as a member of bird than as a member of sparrow.) Special concrete categories (subordinates such as bald eagle and golden eagle) support somewhat better recognition than minimally concrete categories but at the cognitive cost of a proliferation of categories. Finally, Rosch notes that minimally concrete categories typically precede both abstract categories and special concrete categories, which are often constructed by contrast with minimally concrete categories on need.
These theories suggest the following perspective on relationships between markup vocabularies:
-
Intersecting subset vocabularies can fill the role of minimally concrete categories in Prototype Theory, overlapping to express family resemblance.
For example, a ship-tracking vocabulary might share location coordinates but not the depth dimension with a geophysical-event vocabulary. From the perspective of the language game, each basic vocabulary applies its own useful rules for formalizing consistent locations.
-
Superset vocabularies can fill the role of abstract categories in Prototype Theory, integrating minimally concrete categories.
For example, to integrate tremor data with tsunami observations, a general location vocabulary could define a union of the ship-tracking and geophysical-event vocabularies.
-
Subset vocabularies can fill the role of special concrete categories in Prototype Theory, refining a minimally concrete category with narrower semantics and more specific properties.
For instance, a vocabulary for tracking maritime research vessels might capture water temperature and salinity as part of the location.
From this perspective, the base vocabulary supplies general-purpose types for the derivation of minimally concrete vocabularies. The base vocabulary also provides an upper bound for the abstract vocabularies.
Dialects: Defining and managing vocabulary subsets
From the preceding discussion, a solution for vocabulary relationships with upward expansion would have the following features:
-
Definition of subset vocabularies (the dialects) from a base vocabulary through restrictive substitution.
-
Addition of any number of more general dialect types at any time above an existing dialect type for the same base vocabulary.
-
Management of type inheritance and containment relations in a graph inspectable by applications.
-
Separation of the type relation graph from the schema used to validate document instances.
The separation of conceptual and physical models has a long tenure in the database community with parallels in the UML distinction between the conceptual and implementation classes diagrams. Modeling formal types in a graph and XML vocabulary in a schema establishes a similar distinction and is recommended by Bauman (see BAUMAN).
-
Simplified content models facilitating comparison, conversion, and other operations on types.
Note
The Dialects mechanism will be useful only for base vocabularies that include types with the semantic generality and loose content models necessary for restrictive substitution.
Note
Because a processing instruction can represent a name-value pair in the content for any element, a processing instruction might provide a base for adding new attributes to any dialect type. Effectively, such attributes are ignored at the base level. Thus, derivation of attributes from processing instructions is particularly useful for parameters of objects and interactions that should be ignored at the base level instead of formatted as readable text.
Identifying the semantic concepts for markup types
Markup types can reflect different perspectives on the content associated with a concept. For instance, the name of a person might be seen as a simple string or as a structure identifying each part of the name. In particular, markup types representing the same concept can derive from different base markup types (where the markup types represent different perspectives on the information for the concept). To indicate semantic commonality across markup types, the graph must be able to associate a markup type with the concept indicated by the markup type.
RDF offers two methods of definition that could be used to manage information concepts:
|
OWL |
Defines classes of things and their properties (see OWLOVER). |
|
SKOS |
Identifies individual concepts appearing in descriptions (see SKOS). |
Because XML markup represents a wider range of description than the properties of things and because SKOS is lighter-weight than OWL, SKOS offers a better candidate for managing the semantics of markup types. Ogbuji has noted the suitability of SKOS for identifying markup semantics (see OGBUJI).
SKOS provides the convenient terms broader and narrower for relationships between concepts. The same terms can be applied usefully to relations between markup types, reserving the terms base and dialect for the special case of a grounding relationship to the base vocabulary.
Note
DuCharme (see DUCHARME) has noted that RDFa (see RDFA) can provide a method for marking up document instances with markup concepts. RDFa has a primary focus of tunneling through documents to express structured data. RDFa does not offer any assistance for managing type relations independent of document instances.
Metamodel for the type relation graph
A graph with inheritance relations and containment relations for simple content models would require the following classes:
|
Type |
A base or dialect type supporting restrictive substitution of the contained types at its positions. |
|
DocumentType |
A base or dialect document vocabulary containing a single root position and supporting restrictive substitution of the contained type at the root position. |
|
TypeSet |
A set of alternative types. |
|
Position |
A position in the content of a container type with cardinality for a single contained type. |
|
ContainerType |
An abstract class for a type or document type. |
|
ContainedType |
An abstract class for a type or type set. |
|
Concept |
The meaning of a container type as a SKOS concept. |
Metamodel: Metamodel for type relation graph
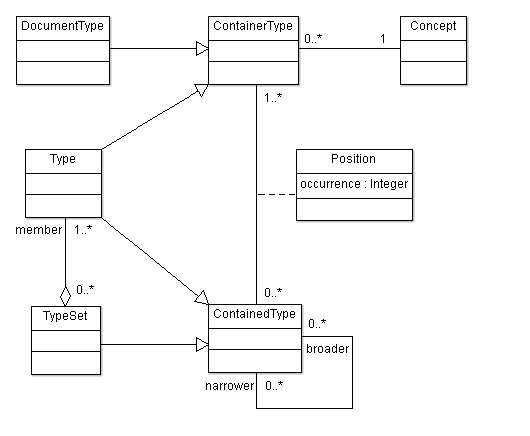
The principal classes and relationships in the type relation graph (for clarity, omitting some details such as the base-dialect subproperty of the broader-narrower property).
Binding the graph to schemas
Associating types in the graph with elements and attributes in schemas enables interpretation of documents and operations such as conversion to a related document type. The binding might take the form of annotations on a manually maintained schema or of mappings that make it possible to generate schemas in different schema languages. In either approach, the binding has the following responsibilities:
-
Assigning names to markup types. Different schemas might use the same name for different types. This practice can improve usability by maximizing the familiarity of elements when an adopter requires multiple variations on the same markup type.
-
Selecting either the attribute or subelement form to represent a markup type with a single value as its content (when positions are not interleaved).
-
Selecting a sequence of positions for the content model.
These mappings might take defaults from the graph or a preferred schema for the base vocabulary.
Document instances might reflect the graph binding either indirectly by means of a catalog entry associating the schema with the document type or directly by annotating the document instance with a namespaced attribute (such as dx:doc) on the root element that has a defaulted value of the document type. Applications can then use the document type from the graph and the element name or combination of element and attribute name to look up the markup type and broader or narrower markup types in the graph.
Variant serializations of document instances
The type relation graph provides applications with detailed insight that would be difficult to represent directly in the document instance. Alternate serializations of the document instance that annotate elements with markup types can, however, make the instance easier to interpret. Some potential serializations:
-
Identify the base dialect type of each element through a namespaced attribute annotation (such as dx:base) on the element with a CURIE (see CURIE) value.
This serialization makes the base types visible in a dialect document. The serialization does not, however, remove the need to look up the markup types for attributes.
-
Convert the dialect document instance to a base document instance (without conversion of added dialect attributes to processing instructions) and annotate each element with its dialect type through an attribute annotation (such as dx:type).
This serialization makes the document instance recognizable as a base instance while retaining visibility of the dialect types on elements and availability of dialect attributes. The serialization may be especially useful for processors that can operate on well-formed instances of known elements, ignoring unknown attributes.
-
Convert to a base document instance (with conversion of added dialect attributes to processing instructions). Where the base markup provides an attribute for lightweight semantic annotation (such as a class or role attribute), the attribute can identify the dialect type (possibly using some alternative to CURIE syntax).
This serialization makes the document instance valid as a base instance while surfacing the dialect types as much as possible.
Finally, multiple document instances can be serialized together with the type relation graph as an RDF XML document in which document types have a property with each instance as an XML literal value.
Processing the type relations graph
General-purpose tools can use the graph to operate on dialects without hard-coding specific knowledge of the base or dialect vocabularies. The following operations can be implemented:
-
Integrity checks on the compatibility of content models.
Content compatibility is necessary to allow inclusion of one position at another position. Content compatibility is also a factor in inheritance relations.
The checker must determine whether each position in the narrower content model has a corresponding position in the broader content model. The checker must also confirm that the aggregated cardinality of the narrower positions are within the cardinality range of the corresponding broader position.
The checker can ignore any type in the content model where its is a member of a type set that also has one of its broader types as a member. By definition, if the broader type is compatible, the narrower type is also compatible.
-
Integrity checks on inheritance relations between markup types.
A broader type must have broader content, a broader concept, and the same base type.
-
Automated discovery of broader dialects as potential conversion targets.
-
Browsing for markup types.
The graph can act as a repository for existing types to incorporate into new vocabularies. A container type can use a markup type if every broader type of the container has a position with a broader type of the contained type.
-
Conversion of document instances from narrower to broader dialects.
A document instance is convertible when the root markup type of the target document type is broader than the root markup type of the source document type (which guarantees that the entire content tree is broader).
-
Role-oriented processing of a narrower document instances against broader dialects.
-
Generation of schemas for validation of XML instance documents from mappings.
For instance, if the graph asserts that the GeneralPerson type is broader than the PersonName type, checking that the content of PersonName can be converted to GeneralPerson confirms the integrity of the graph.
XHTML Dialects
The Dialects mechanism would make it possible to leverage XHTML as a base for representing knowledge in specific domains. XHTML Dialects would have particular value for accessing content in HTML environments (such as web browsers, ePUB, and SCORM) with minimal transforms.
XHTML offers good candidates for restrictive substitution primarily within the body element. Because the div and span elements connote useful general structure (block and inline) and take recursive mixed content, these elements provide a good base for markup of any readable data or discourse. More specific base XHTML elements are preferrable where possible (an approach that microformats guidelines also suggest in MFGUIDE).
HTML profiles (see HTMLPROF) offer a mechanism for incorporating well-known existing vocabularies (such as SVG, XForms, or MathML) into XHTML as part of the base vocabulary for dialects. By definition, dialects of an XHTML profile are effectively dialects of any superset XHTML profile.
Because of the importance of the class attribute in HTML, XHTML Dialects might provide special operations beyond general-purpose dialects to map markup type identifiers to microformat tokens in the class attribute when serializing to base XHTML.
Note
Extensible XHTML Dialects as discussed in this paper are distinct from the antecedant to HTML profiles discussed in http://www.w3.org/TR/WD-doctypes.
Deriving a document type for a microformat
A microformat (see MFOVER) is a structure expressed in HTML with inline annotations on attributes identifying narrower semantics. Thus, by definition, the same structure can be implemented as an XHTML Dialect. An instance of the equivalent XHTML Dialect can be edited and validated with standard XML tools but converted to a microformat instance when appropriate.
For example, consider the draft geo microformat (see MFGEO), a simple data structure for geographic coordinates. Here is an example of the microformat:
<div class="geo"> <abbr class="latitude" title="37.408183">N 37° 24.491</abbr> <abbr class="longitude" title="-122.13855">W 122° 08.313</abbr> </div>
The following actions can implement a XHTML dialect for the microformat:
-
Derive a geo dialect type from the div base.
-
Derive a latitude dialect type from the abbr base.
-
Derive a longitude dialect type from the abbr base.
-
Define a document type incorporating the geo dialect type in a type set with the div base type so geo is available in all div contexts.
-
Map the document type to an schema.
The schema could then validate a document instance similar to following example:
<geo> <latitude title="37.408183">N 37° 24.491</latitude> <longitude title="-122.13855">W 122° 08.313</latitude> </geo>
The dialect representation is not only possible to validate using standard XML tools but also, by hiding the base names and class attribute noise, easier to interpret.
If an organization would like to adopt the geo type but needs to associate a name with each location, the designer can define a NamedGeo type that is broader than the geo type and that contains a LocationName type as well as the latitude and longitude types. Instances of the geo type can be converted to the NamedGeo type or extracted from the NamedGeo type.
This simple geo structure merely scratches the surface of the structures specified by the microformat project. The hAtom microformat (see MFHATOM) offers a more interesting structure that represents the Atom syndication format in XHTML. As with other microformats, hAtom by definition can be represented as an XHTML dialect.
In addition, however, hAtom suggests the potential value of bridging an existing XML vocabulary to an XHTML representation. The bridge preserves the semantics of the the source vocabulary and, in effect, gives the content an alternate serialization as an XHTML document. That option can be especially valuable for RESTful scenarios given the emphasis on HTML as the preferred hypermedia representation of state.
Benefits of XHTML Dialects
Using XHTML Dialects to create vocabularies has the following potential benefits:
-
Leverage XML tools and capabilities for validating vocabularies and manifesting semantics directly as elements (instead of annotating XHTML elements as in microformats).
-
Represent wikitext and wiki templates directly in XML for interchange and easy conversion to HTML.
-
Simplify design for custom vocabularies by starting from familar XHTML instead of from scratch.
-
Render custom vocabularies in browsers or in printable documents via ePUB without having to write and maintain vocabulary-specific transforms, instead using generic conversion to base XHTML.
-
Represent state with explicit semantics and validated content as part of RESTful approaches while retaining the ability to revert to base XHTML through content negotiation for consumers that understand only the XHTML representation.
In short, XHTML Dialects offer a good solution for either data and discourse when the content includes readable text or the deployment includes HTML environments.
Future work
The Dialects proposal can benefit from additional prototyping, experimentation, and discussion. In particular, the following areas require more attention:
-
The graph might be capable of deriving a typed structure from a string through a pattern that maps subfields of the string.
-
It may be possible to convert a document instance when the base type of a source element has narrower content than the base type of the target element. For instance, a span within a div could convert to a div within a div.
-
The graph might be capable of supporting conversions to other base vocabularies that are supersets of the declared base vocabulary.
-
The binding between a type relation graph and an XML vocabulary might not require a one-to-one mapping. For instance, some vocabulary container elements might be cosmetic, and some container type might be inferrable.
-
The graph might benefit from conveniences for defining a dialect type as subsetting or supersetting changes on another type (with generation of the fully defined type).
-
An XHTML Dialect for serializing the graph would be a good demonstration of the capabilities of Dialects and would be useful for consuming portions of the graph through a RESTful service.
In passing, defining an XHTML 4 dialect with the new markup of HTML 5 (especially the new discourse elements) would be another good test and demonstrate a method for agile and experimental evolution of XHTML.
-
A XHTML Dialect mechanism for defining a narrower document type by example in an instance of a broader document type would reduce the barriers for vocabulary designers. Examplotron provides a precedent for this approach, but the narrower types would require only names and model differences.
Summary
The Dialects proposal supplies a mechanism for deriving new dialects from a base document type to support variant representations of the knowledge for a domain without compromising the ability to exchange information within a community. Through upward expansion, Dialects can add new broader dialects as needed to recognize commonality across dialects. By making type relations available to applications, compatibility checks, conversions, role-based processing, and schema generation become feasible and interpretation becomes possible to formalize (leveraging RDF technologies). In particular, XHTML Dialects can enrich the XHTML ecosystem with extensions that validate existing microformats, bridge other XML vocabularies, and represent special information with minimal or no transforms.
References
[BAUMAN] Bauman, Bruce Todd. "Prying Apart Semantics and Implementation: Generating XML Schemata directly from ontologically sound conceptual models." Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Bauman01. http://www.balisage.net/Proceedings/vol3/html/Bauman01/BalisageVol3-Bauman01.html
[CURIE] Birbeck, Mark and McCarron, Shane, Ed. "CURIE Syntax 1.0". W3C, 16 Jan 2009. http://www.w3.org/TR/curie/
[DATTOLO] Dattolo, Antonina et al. "Converting into pattern-based schemas: a formal approach". The Extreme Markup Conference, Montreal, Canada, 2007. http://conferences.idealliance.org/extreme/html/2007/Dattolo01/EML2007Dattolo01.xml
[DITA] Priestley, Michael and Hackos, JoAnn, Ed. "DITA Version 1.1 Architectural Specification". OASIS, 31 May 2007. http://docs.oasis-open.org/dita/v1.1/CS01/archspec/ditaspecialization.html
[DOCBOOK] Walsh, Norman. "DocBook 5: The Definitive Guide". XML Press, 20 May 2010. http://www.docbook.org/tdg5/en/html/ch05.html
[DUCHARME] DuCharme, Bob. "Using RDFa with DITA and DocBook". devx.com, 20 Aug 2009. http://www.devx.com/semantic/Article/42543/1954?pf=true
[MCGRATH] McGrath, Sean. "XML in legislature/parliament environments". 14 June 2010. http://seanmcgrath.blogspot.com/2010/06/xml-in-legislatureparliament_14.html
[MFGEO] Çelik, Tantek, Ed. "Geo" microformats.org, 27 Nov 2009. http://microformats.org/wiki/geo
[MFHATOM] Janes, David, Ed. "hAtom 0.1" microformats.org, 17 Apr 2010. http://microformats.org/wiki/hatom
[MFGUIDE] Çelik, Tantek, Ed. "hCalendar 1.0" microformats.org, 6 May 2010. http://microformats.org/wiki/hcalendar#Semantic_XHTML_Design_Principles
[MFOVER] Messina, Chris et al, Ed. "What are microformats?". microformats.org, 10 Mar 2009. http://microformats.org/wiki/what-are-microformats
[OGBUJI] Ogbuji, Uche. "Thinking XML: Enrich Schema definitions with SKOS". DeveloperWorks, 11 Nov 2008. http://www.ibm.com/developerworks/xml/library/x-think42/
[ORCHARD] Orchard, David. "Extensibility, XML Vocabularies, and XML Schema". xml.com, 27 Oct 2004. http://www.xml.com/lpt/a/1492
[OWLGUIDE] Smith, Michael K. et al, Ed. "OWL Web Ontology Language Guide". W3C, 10 Feb 2004. http://www.w3.org/TR/owl-guide/#term_openworld
[OWLOVER] W3C OWL Working Group, Ed. "OWL 2 Web Ontology Language Document Overview". 27 October 2009. http://www.w3.org/TR/owl2-overview/
[RDFA] Adida, Ben et al, Ed. "RDFa in XHTML: Syntax and Processing". W3C, 14 Oct 2008. http://www.w3.org/TR/rdfa-syntax/
[RDFCONCEPT] Klyne, Graham and Carroll, Jeremy J., Ed. "Resource Description Framework (RDF): Concepts and Abstract Syntax". W3C, 10 Feb 2004. http://www.w3.org/TR/rdf-concepts/#section-anyone
[RDFSCHEMA] Brickley, Dan and Guha, R.V., Ed. "RDF Vocabulary Description Language 1.0: RDF Schema". W3C, 10 Feb 2004. http://www.w3.org/TR/rdf-schema/#ch_subclassof
[ROSCH] Rosch, E. "Classification of Real-World Objects: Origins and Representations in Cognition" in Johnson-Laird, P. and Wason, P, Ed. "Thinking: Readings in Cognitive Science", Cambridge University Press, 1977.
[SCD] Holstege, Mary, and Vedamuthu, Asir S., Ed. "W3C XML Schema Definition Language (XSD): Component Designators". W3C, 19 Jan 2010. http://www.w3.org/TR/xmlschema-ref/
[SKOS] Miles, Alistair and Bechhofer, Sean, Ed. "SKOS Simple Knowledge Organization System Reference". W3C, 18 Aug 2009. http://www.w3.org/TR/skos-reference/
[TEI] Burnard, Lou and Bauman, Syd, Ed. "P5: Guidelines for Electronic Text Encoding and Interchange". TEI Consortium, Feb 12 2010. http://www.tei-c.org/release/doc/tei-p5-doc/en/html/USE.html
[HTMLPROF] W3C HTML Working Group. "XHTML 1.0 The Extensible HyperText Markup Language (Second Edition)" W3C, 1 Aug 2002. http://www.w3.org/TR/html/
[XSD] Thompson, Henry S. et al, Ed. "XML Schema Part 1: Structures Second Edition". W3C, 28 Oct 2004. http://www.w3.org/TR/xmlschema-1/#Type_Derivation
[WITTGENSTEIN] Wittgenstein, Ludwig. "Philosophical Investigations (3rd Edition)". Prentice Hall, 1973. (especially sections 67 and 69)