Introduction
During the last decade, design patterns have become increasingly popular as general and reusable solutions to commonly occurring software design problems in the object-oriented community. Nowadays, almost every developed application, component, or API written in an object-oriented language is built using design patterns (e.g. [Cooper2000, Cooper2002]). Such patterns improve software development in the following perspectives [Gamma1994]:
-
Reusable Software and Design: Design Patterns are often key drivers to provide better encapsulation and reduce coupling between software components. As a consequence, software exhibiting design patterns is more reusable, flexible, and extensible.
-
Documentation: Using the name of a pattern in software documentation allows developers to recognize/remember the structure and design of an API instantly.
-
Communication and Teaching: Design patterns constitute a common language to improve the communication between software designers and analysts. Additionally, an established vocabulary eases discussions between developers with a different programming language background.
Although, being widely accepted and applied within the object-oriented community, design patterns have rarely been evaluated outside of this community. For example, in the functional world they have never been evaluated on a complex application programming level. In "Functional Logic Design Patterns" [AntoyHanus02FLOPS] design patterns have been evaluated within a functional language to solve specific problems on a very low level; whereas [Narbel2007] discusses on a meta level. From this perspective, the fear of Tom DeMarco from 1996 has been proven reasonable:
"Because Design Patterns bills itself as being concerned with object oriented software alone, I fear that software developers outside the object community may ignore it. This would be a shame. [...] All software designers use patterns; understanding better the reusable abstractions of our work can only make us better at it." [DeMarco96]
XQuery [XQ11] -- a functional and declarative language -- has been designed by the World Wide Web Consortium as a general purpose XML processing language, useful in a variety of architectures and environments. Although, in the beginning, XQuery was mainly used to query XML data within database systems (e.g. [XQueryInAction]), it has more and more become a complete application programming language. One such scenario in which XQuery is used as a full-fledged programming language is called the end-to-end XML architecture. In such an architecture, XML is the primary form in which information is stored and processed. This information is persistent across successive invocations of programs, and XQuery is the primary language for accessing this information for search, filter, transform, update, and for writing more complex application workflows. Moreover, in such programs, XQuery has also become fluent with web entities such as web services, Atom, JSON, HTTP messages, and common authentication techniques such as OpenID or OAuth. Together with its extension specifications XQuery Update [XQUF], XQuery Scripting [XQSE], and XQuery Full Text [XQFT], XQuery nowadays plays in the same league as general purpose programming languages such as Java, Python, or Ruby while keeping its edge in terms of expressiveness and first-class support for dealing with web resources.
Overall, these recent changes are directly related to the growth of complex XQuery applications [Kaufmann2009]. One example of such an application is developed by a customer of the company the authors work for. This application is an Enterprise Resource Planning (ERP) application entirely written in XQuery on top of the Sausalito Web Application Server [Sausalito2010]. This application consists of 28.000 lines of XQuery code implemented in 135 XQuery modules. By auditing this application, we found common symptoms in both the codebase and the development processes:
-
Modules have strong coupling between each other. They are based on complex collaborations that are reducing their reusability in other frameworks or applications. In most cases, extending or composing a module would require intrusive code refactoring.
-
Some recurring structural designs are referred to using a different vocabulary. Even though they can be looked at as identical from an abstract point of view. This increases the entry barrier into the codebase significantly.
As described at the beginning of this section, such problems have been solved in the object-oriented community by developing and applying design patterns. Encouraged by this observation, we decided to start using design patterns to overcome the misfits described above. Besides motivating the use of design patterns for XQuery, the contributions of this paper are (1) to identify misfits in a real-world application and (2) to show how these misfits can be remedied by using design patterns. Specifically, we present four design patterns and describe how each of them solves one specific design problem in our (running) example application.
The remainder of this paper is structured as follows. In Section 2, we describe the use cases for our running example. This example will be used to point out design problems that exist in real world applications. In each of the following four sections (i.e. Sections 3, 4, 5, and 6), we present one design pattern to solve one of the identified design problems. Section 7 concludes the paper and gives an outlook on future work.
Running Example: An AtomPub Application
The Atom Publishing Protocol (AtomPub; see RFC5023) is an HTTP-based protocol for creating and updating resources on the web. Lately, it became widely used to implement APIs for cloud services. The most prominent example is probably the Google Data Protocol[1]. AtomPub is built up on the Atom Syndication Format which is an XML representation of arbitrary collection of resources (e.g. web feeds). Hence, XQuery is a natural fit for implementing AtomPub-based (cloud) services.
We use an AtomPub application in order to present design patterns for XQuery. This application is particularly well-suited for many (common) patterns because most of it's components need to be reusable by other components of the application. Moreover, leveraging existing libraries (e.g. for HTTP communication and authentication) requires some careful design decisions to be made. Essentially, the AtomPub application consists of two major components: a client and a server. The client is an XQuery application which should implement the following two basic use cases:
-
Use Case 1: Send an HTTP request to create an Atom entry.
-
Use Case 2: Send an HTTP request to retrieve a particular Atom entry. The resulting entry should be transformed into HTML.
-
Use Case 3: Receive an AtomPub entry and store it. It should be possible to store entries in arbitrary locations such as the file system or XQuery collections.
-
Use Case 4: Post a message on Twitter for each entry created in Use Case 3.
In the next sections of the paper, we show how the design challenges of implementing the described use cases can be solved leveraging design patterns. We start with Use Cases 1 and 2 of the client in Sections 3 and 4, respectively. After this, Sections 5 and 6 describe the design and implementation of Use Cases 3 and 4. The following table depicts the mapping of use cases, sections, required XQuery features, and the names of the pattern that is used to implement the feature in question.
Table I
Mapping between use cases, sections, patterns, and required XQuery features.
| Section | Pattern Name | Language | Description | |
|---|---|---|---|---|
| Use Case 1 | 3 | Chain of Responsibility | XQuery 1.0 | Send an HTTP request to create an Atom entry. |
| Use Case 2 | 4 | Translator | XQuery 1.1 | Transforms an Atom entry to XHTML. |
| Use Case 3 | 5 | Strategy | XQuery 1.1 | Store an Atom entry on the server. |
| Use Case 4 | 6 | Observer | XQuery 1.1 + Scripting | Advertise new Atom entries on Twitter. |
The XQuery application can be downloaded from http://patterns.28msec.com. Each use case is ready to be executed, i.e. the package contains one XQuery main module for each use case. [2]
Chain of Responsibility
In this section, we discuss the implementation of Use Case 1. That is, we want to develop an XQuery program that publishes an Atom entry to an AtomPub enabled server. Since not everybody is allowed to publish an entry, the AtomPub server requires authentication using the basic HTTP authentication mechanism. The AtomPub protocol specifies that an entry is published by sending an HTTP POST request to the server. The payload of this request contains the entry to be published. The basic HTTP authentication requires the username and password to be part of the HTTP-Header.
For making HTTP calls in an XQuery program, we decided to rely on the (de-facto standard)
EXPath HTTP Client (see HTTPClient).
This HTTP Client works by passing an XDM element describing the request to a function
called send-request.
For example, a program that is sending a HTTP GET request to http://www.example.com could look as follows:
http-client:send-request(
<http:request href="http://www.example.com/" method="GET" />
)
In order to implement our first use case, the AtomPub client could be implemented with a hard wired dependency between the module that is responsible for configuring and sending the HTTP request and the module responsible for the authentication. However, this would clearly make the AtomPub client less flexible and reusable in other scenarios. For example, changing the authentication mechanism to something like OAuth or OpenID would require intrusive changes to the AtomPub module or would result in another highly redundant codebase.
To improve the flexibility and reusability of our application, we specify the following two design requirements. The AtomPub client should be decoupled from
-
any authentication mechanism it may collaborate with at runtime.
-
a particular implementation of the transport layer, i.e. the HTTP client.
In order to meet these requirements, we have designed the AtomPub client using the Chain of Responsibility pattern [Gamma1994]. The intent of this pattern is as follows:
Reduce coupling between different modules by moving nested dependencies outside of a module and integrate dependent functions consecutively into a chain. Pass an item along the chain and give each of these functions the chance to manipulate or process the item.
Description
Applying the Chain of Responsibility to our use case results in making a separation between the code that is responsible for sending the request and each of the functions configuring the request (i.e. setup the request for AtomPub and putting authentication information in the request). In order to do so, we identify the following participants (also see Fig. 1):
-
Request: The XDM instance representation of an HTTP request.
-
Handler: Function in the chain which is configuring or processing the request instance.
-
Client: Initiates the request, passes it to each function in the chain, and returns the result.
Spreading the functionality among the three participants allows us to easily rewrite the client, for example to use a different authentication strategy. In particular, we avoid that different library modules "know about" each other, i.e. they are not imported into each other.
1

Structure of the Chain of Responsibility.
Implementation
In this section, we describe one possible implementation of our use case by applying the Chain of Responsibility pattern. [3]
First, we start with a description of the implementation of the client which is implemented
in a function called local:post-entry.
After this, we describe the two functions atompub-client:post and http-auth:basic.
Each of these functions takes as first parameter the request item which is prepared
in the body of each function.
(:
: This function initializes the HTTP request, passes it to three
: chained functions (atompub-client:post, http-auth:basic, and
: httpclient:send-request), and returns the result of the last
: invoked function.
:)
declare sequential function local:post-entry() as item()*
{
(: Initialize the request :)
declare $request := validate {
<http:request href="http://atompubtest.my28msec.com/blog/feed"
method="GET" />
};
(: Update the request according to the AtomPub protocol
: $local:entry is the Atom entry to be sent
:)
atompub-client:post($request, $local:entry);
(: Basic HTTP Authentication. :)
http-auth:basic($request, "Username", "Password");
(: Finally, send the request to the AtomPub server :)
http-client:send-request($request);
};
In the code snippet above, the HTTP request element ($request) is declared and initialized containing the URL of the AtomPub server.
This element is passed along the chain of functions atompub-client:post and http-auth:basic ending up in a call to the http-client:send-request() function.
The latter function takes over the responsibility of executing the request.
(:
: AtomPub POST handler.
: Update the HTTP request according to the
: AtomPub protocol specification.
:)
declare updating function atompub-client:post(
$request as schema-element(http:request),
$entry as schema-element(atom:entry))
{
replace value of node $request/@method with "POST",
insert node <http:body media-type="application/xml"
method="xml">{$entry}</http:body>
as last into $request
};
The function atompub-client:post() "massages" the request item (using XQuery update) according to the AtomPub specification.
Specifically, this function makes sure that the HTTP request method is set to POST.
Moreover, it configures the body of the HTTP request to contain the entry to be published.
After that, the http-auth:basic() function adds username and password attributes to the request and sets the authentication
method to basic.
(:
: Basic HTTP Auth handler.
: Update the HTTP request according to the
: basic HTTP authentication specification.
:)
declare updating function http-auth:basic(
$request as schema-element(http:request),
$username as xs:string,
$password as xs:string)
{
insert node (attribute username { $username },
attribute password { $password },
attribute auth-method { "basic" })
into $request
};
Implementation Considerations
In the implementation presented in the last section, we made some decisions in order to make the essence of the paper easier to understand and improve the readability of the code. Neither are these decisions mandatory for implementing Chain of Responsibility nor might they be optimal. Therefore this pattern can be implemented in XQuery 1.0. In this section, we discuss some alternative implementation aspects.
-
Consideration 1: The implementation of the client, chains the participating functions using XQuery Scripting. However, there are many ways to implement the chaining. For example, the chain could be implemented using Continuation Passing Style or by using a sequence of function items which are executed consecutively.
-
Consideration 2: Another decision that we took in order to make the code more crisp is to implement the participating functions (i.e.
atompub-client:postandhttp-auth:basic) using the XQuery Update Facility. Alternative implementations could copy and transform the request element and return it as a result of the function. In this case, the client needs to make sure that the returned element is passed as an argument to the next function.
Conclusion
The Chain of Responsibility helped us to improve the flexibility and reusability of the modules involved to implement Use Case 1. As a result, we gained the following:
-
Reduced coupling: The AtomPub client has been decoupled from the HTTP Client and other optional modules such as HTTP authentication, OAuth Client, or OpenID.
-
Added flexibility: Any function in the chain can configure the request or even take over the responsibility to process the request. More than that, the code can effortlessly be reused in a different setting. For example, a different authentication method could be used by replacing the
http-auth:basic()function with an appropriate function from a different authentication module.
Use Chain of Responsibility if
-
an execution process can be abstracted in a configurable XDM item, e.g. a request.
-
an execution process can be divided into different responsibilities.
-
different configuration settings can be freely combined.
-
you want to issue a request to one of several functions without specifying the receiver explicitly.
Translator
In this section, we present the accomplishment of Use Case 2 (see Sec. 2): retrieving an Atom feed and rendering it as an HTML page. Thanks to XQuery's expressiveness to deal with XML data, transforming an Atom feed into an HTML page is a straightforward operation. For example, one could easily come up with a function as follows:
declare function to-xhtml:get-feed(
$feed as schema-element(atom:feed))
as element(xhtml:html)
{
let $title := $feed/atom:title
return
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>{$title}</title>
</head>
<body>
<h1>{$title}</h1>
{for $entry in $feed/atom:entry
return to-xhtml:get-entry($entry)}
</body>
</html>
};
However, on the web, most feeds contain heterogeneous data (i.e. they contain elements
from multiple different namespaces).
The most prominent examples are Google's or Twitter's extensions (see http://tinyurl.com/gdata-format and http://tinyurl.com/twitter-format).
Another example is shown in the following feed that contains instances of the GeoRSS
Application Schema.
<?xml version="1.0" encoding="utf-8"?>
<feed xmlns="http://www.w3.org/2005/Atom"
xmlns:georss="http://www.georss.org/georss">
<title>Where is Waldo?</title>
<link href="http://example.org/"/>
<entry>
<title>Caecilienstrasse 5, 8032 Zurich, Switzerland</title>
<link href="http://example.org/2009/09/09/atom01"/>
<updated>2009-08-17T07:02:32Z</updated>
<georss:point>45.256 -71.92</georss:point>
</entry>
</feed>
Usually, the information contained in such feeds should be converted into HTML as
well.
Obviously, one could extend the get-feed function above by incorporating nested loops over elements in different namespaces.
However, this is not desirable for several reasons:
-
Having to transform a large number of heterogeneous elements will usually lead to ''spaghetti code''.
-
Interweaved code lowers the reusability.
-
The structure of a feed (i.e. which namespaces are actually contained in a feed), might not be known in advance.
Separate interpretations of heterogeneous elements Translator. Translator brings XSLT programming paradigm into XQuery.
Description
Since the goal of Translator is to bring the XSLT programming paradigm into XQuery, the participants involved in this pattern have the same names and also have a similar semantics as their complements in XSLT. The participants involved are the following:
-
applyfunction: Theapplyfunction contains the code that does the transformation of an XDM instance if thematchfunction returned true. The parameters of theapplyfunction are: (1) The XDM instance to transform, (2) thetransformfunction itself, and (3) the templates involved in the process. -
matchfunction: This function decides whether an accordingapplyfunction should be executed given a selected XDM instance. -
transformfunction: Thetransformfunction is driving the transformation process (i.e. callingmatchandapply. It is invoked by the client. -
Template: A template is a sequence of two function items. The first item is representing the
matchand the secondapplyfunction, respectively. -
Client: The client invokes the
transformfunction by providing the XDM instance to be transformed and a sequence of templates.
Figure 2 shows the dependencies between the participants for Translator applied to the GeoRSS
example describe in the previous section.
The figure illustrates that
(1) only the Atom templates (apply and match for Atom feeds and entries) need to know the Atom schema,
(2) the template responsible for transforming GeoRSS only knows the GeoRSS schema,
and
(3) the transform function orchestrates the transformation process by invoking the function items of
the templates.
2
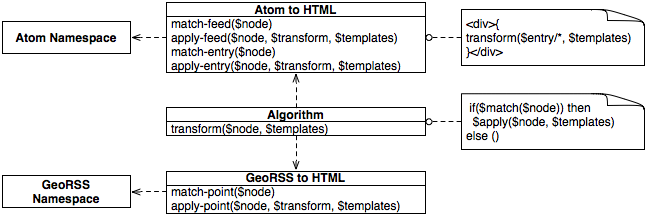
Structure of Translator.
Figure 3 depicts this orchestration of the translation process.
The client invokes the transform function passing the XDM instance and the templates as parameters.
For each template, the transform function first executes the match function passing the current XDM instance as parameter.
If the result of the invocation of match is true, then the apply function is invoked on this instance.
Please note that the apply function itself may repeatably invoke the transform function to further transform nested structures.
3
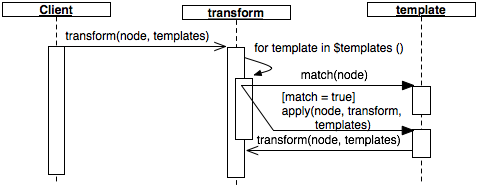
Collaborations in Translator.
Implementation
In this section, we describe the implementation of Translator for the GeoRSS-to-HTML
transformation (see above).[4].
We start with a presentation of the transform function which receives the XDM instance to transform (i.e. the Atom feed) and the
transformation templates as parameters.
declare function converter:transform(
$i as item()*,
$templates as function(*)+) as item()*
{
for $tpl in $templates
let $template := $tpl()
let $match := $template[1]
let $apply := $template[2]
return
if($match($i)) then
$apply($i, converter:transform#2, $templates)
else()
};
This function invokes the apply and match functions for all templates.
The example application contains templates for Atom feeds, Atom entries, and GeoRSS
points.
For instance, it contains an xhtml-template module which contains templates to transform Atom feeds and entries into XHTML.
Moreover, it contains a module to match and apply GeoRSS points.[5]
For example, the Atom module contains two templates each consisting of a match and an apply function:
-
Atom feed template:
match-feedandapply-feedfunctions. -
Atom entry template:
match-entryandapply-entryfunctions.
The functions match-feed and match-entry are respectively checking if the XDM instance is an Atom feed or entry.
declare function html-templates:match-feed($item) as xs:boolean
{
$item instance of schema-element(atom:feed)
};
declare function html-templates:match-entry($item) as xs:boolean
{
$item instance of schema-element(atom:entry)
};
Both of the match functions are associated to apply functions, namely apply-feed and apply-entry.
Each of the apply functions shown below is invoking the transform function.
More specifically, in apply-feed, the transform function is invoked for each Atom entry in the feed.
In apply-entry, the transform function is invoked for all children of an entry.
If one of the children is contained in the GeoRSS namespace, it will be transformed
by a matching template.
declare function html-templates:apply-feed(
$feed as schema-element(atom:feed),
$transform as (function(item()*, function(*)+) as item()*),
$templates as function(*)+)
{
<html xmlns="http://www.w3.org/1999/xhtml">
<h1>{$feed/atom:title/text()}</h1>
<div id="entries">{
for $entry in $feed/atom:entry
return $transform($entry, $templates)
}</div>
</html>
};
declare function html-templates:apply-entry(
$entry as schema-element(atom:entry),
$transform as (function(item()*, function(*)+) as item()*),
$templates as function(*)+)
{
<div class="atom:content"
xmlns="http://www.w3.org/1999/xhtml">
<h2>{$entry/atom:title/text()}</h2>
<div class="atom:content">
{$entry/atom:content/text()}
</div>
{for $child in $entry/*
return $transform($child, $templates)}
</div>
};
Finally, the client invokes the transform function for the first time, passing as first argument an instance of an Atom feed
to be converted and as second argument the templates as parameters.
(: Display the Atom feed :)
let $feed := local:get-feed()
return algo:transform($feed, tohtml:get-templates());
Implementation Considerations
In the previous section, we have introduce one possible implementation of Translator. In this section, we consider some alternative implementation aspects.
-
Consideration 1: This pattern is based on functional parametrization therefore XQuery 1.1 is required to implement Translator.
-
Consideration 2: The
transformfunction can vary. In our implementation, if the given input hasn't been matched by any template, it stops the process. However, alternative implementation of thetransformfunction may look at the children of the XDM input. -
Consideration 3: If an
applyfunction invokes thetransformfunction, it may invoke it with a different implementation of thetransformfunction than the one received as parameter. The same variation can apply for the templates passed as parameter to thetransformfunction.
Conclusion
By implementing Use Case 2 (Sec. 2) using Translator, we have improved the application on the following perspectives:
-
Independent modules can collaborate easily on the same XDM instance.
-
Extending transformations is easy. With Translator, templates are loosely coupled. New templates can be introduced without affecting the others.
-
Bring the XSLT programing paradigm to XQuery.
-
Transform and/or interpret an heterogeneous XML document with a modular partitioning of the function involved.
Strategy
In this section, we present the design and implementation of parts of the AtomPub server (see Section 2). Specifically, we discuss the module that is responsible for retrieving and storing and Atom entry posted to the server.
If an Atom entry is posted to the server, the server must store it and add it to the Atom feed. For example, Feeds can be stored in the file system or in a transaction-enabled XML database (i.e. in XQuery collections backed by the database). Coupling the AtomPub server module to a specific storage module is not desirable for the following reasons:
-
If the AtomPub server is depending on many storage modules, the code base becomes larger and harder to maintain.
-
Storage modules often depend on the environment. For example, different databases are available on different platforms.
This problem can be solved by encapsulating each available storage algorithm in a function item. Such a particular implementation of a functionality is called a Strategy. The intent of the Strategy Pattern is as follows:
Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm implementations vary independently from clients that use it. [Gamma1994].
Description
In order to implement our use case with the Strategy Pattern, we have to decouple the AtomPub operations from the storage operations. Therefore, we call the AtomPub operations passing a function item encapsulating the storage Strategy as parameter. Strategy defines the following participants (cf. Gamma1994):
-
Strategy: Interface and functionality implicitly defined by the ContextFunction. This interface applies to all ConcreteStrategy implementations.
-
ConcreteStrategy: A specific implementation of a commonly defined Strategy.
-
ContextFunction: Is called with a ConcreteStrategy and all required data as parameters. For example, the ContextFunction
atompub:postis called with the concrete filesystem storage strategy as parameter. -
Context: Imports a ConcreteStrategy to use and passes it to the ContextFunction as parameter.
ContextFunction and ConcreteStrategy interact to implement the Strategy chosen by the server. A ContextFunction may pass all data required to the ConcreteStrategy at runtime. The client creates and passes a ConcreteStrategy to a ContextFunction.
4

Structure of the Strategy Pattern.
In Figure 4, the atompub:post function is responsible for creating a new Atom entry.
The create-strategy argument is a function item that encapsulates the functionality to store an entry.
Therefore, it represents a concrete Strategy that stores the entry, for example in
a collection.
Different concrete storage strategies are implemented within different modules that
have no dependencies with the AtomPub server module.
For instance, atompub:post could use one of these strategies:
-
File System Store: implements the storage of entries on the file system. I/O operations on the file system are based on Zorba file API [XQDDF].
-
Collection Store: implements the storage of entries within collections. This implementation is based on the XQuery Data Definition Facility [XQUF].
-
REST Store: implements a remote storage of entries through a REST API. This store is based on EXPath HTTP Client [HTTPClient].
Whenever the AtomPub server has to retrieve or create data, it forwards the responsibility to the concrete Strategy which is passed as a function argument.
Implementation
Within this section, we describe one possible implementation of the AtomPub server use case using the Strategy pattern [6].
First, we show how a ConcreteStrategy is chosen and used within the Context, i.e.
the main module; in our example application we use the concrete file system storage
Strategy.
After that, we present the usage of the ConcreteStrategy within the atompub:post ContextFunction.
Finally, we will present the concrete implementation of the create algorithm, i.e. a chosen ConcreteStrategy implemented in the store:create function.
The code listing below shows the main server module which handles an Atom entry posting
from a client.
By importing the file system store (not shown in the code snippet below) the main
module chooses the concrete store strategy.
It then calls atompub:post passing store:create as the chosen storage strategy.
(: : Post the entry, the result is the URI of the entry : using store:create#2 as the storage strategy :) let $feed-uri := "http://www.example.org/blog" let $entry-uri := atompub:post($feed-uri, $local:entry, store:create#2) (: Get the newly created entry :) return store:retrieve-entry($entry-uri)
The ContextFunction atompub:post shown below is processing an Atom entry posted by a client.
It takes three parameters: the feed uri, the entry to be aggregated, and the storage
strategy.
First, the entry is processed.
Then it is passed as parameter to the invoked strategy function item.
(: Post an entry :)
declare sequential function atompub:post(
$feed-uri as xs:string,
$entry as schema-element(atom:entry),
$create-strategy
as (function(xs:string, schema-element(atom:entry)) as item()*)
) as xs:string
{
(: Prepare the entry :)
declare $id := util:uuid();
declare $entry-uri := concat($feed-uri, "/", $id);
insert nodes (<atom:id>{$id}</atom:id>,
<atom:link href="{$entry-uri}" rel="self" />)
into $entry;
(: Use strategy to store the entry :)
$create-strategy($feed-uri, $entry);
(: Return the entry URI :)
$entry-uri;
};
The common interface of the create-strategy algorithm to create an entry is implicitly defined as function(xs:string, schema-element(atom:entry)).
Within XQuery there is no explicit mechanism to define an interface in the manner
of an object oriented language like Java.
Therefore, one implicit way to define the common interface for the actual Strategy
is by definition of the function item parameter within the signature of the ContextFunction.
declare sequential function store:create(
$feed-uri as xs:string,
$entry as schema-element(atom:entry))
{
declare $filename := store:get-filename($feed-uri);
declare $meta-feed := validate {
fs:read-xml($filename)/atom:feed
};
declare $entry-uri :=
$entry/atom:link[string(@rel) eq "self"]/@href;
(: Create the entry in the file system :)
fs:write(store:get-filename($entry-uri), $entry, ());
(: Update the feed metadata :)
insert node <atom:link href="{$entry-uri}" rel="entry" />
as first into $meta-feed;
fs:write($filename, $meta-feed, ());
};
As an example of a concrete implementation of the entry creation strategy we present
our sample implementation within the file system store above.
The implementation stores the feed metadata in one file and each entry in a separate
file.
To preserve the order of all contained entries the store:create function has to insert an atom:link element into the feed metadata for each new entry which points to the according entry
file.
Implementation Considerations
When implementing the Strategy pattern, the Strategy may be optional [Gamma1994]. If no Strategy is provided, we execute the default behavior of the function.
The Strategy implemented in our use case has side effects: it stores data in the file system. Therefore the use of XQuery Scripting Extension depends on the algorithm implementation that needs to be achieved, not on the Strategy pattern itself.
Conclusion
By adapting the Strategy pattern in our example application we gained the following benefits (cf. Gamma1994):
-
Reduced coupling: Using Strategy enabled the AtomPub server module to be loosely coupled with any storage module.
-
Reusability: All storage modules are defining a family of algorithms for contexts to use and reuse.
-
Flexibility: Switching code to a different desired behavior can be done by changing only one import statement.
We encourage usage of the Strategy pattern when
-
you need different implementations of a specific component having a uniform interface. Using Strategies you can simply configure different behaviors.
-
you want to hide specific implementation details from a module.
-
you are using several nested
if..then..elsestatements to emulate configurability for different behaviors within functions. Such functions can be refactored using the Strategy pattern.
Observer
In this section, we discuss the implementation of Use Case 4: sending a message on Twitter for each new Atom entry that is created on the server. In this use case, the AtomPub module automatically becomes dependent on the module that provides the functionality to send messages on Twitter. A requirement for the AtomPub server module is to enable cooperation with an arbitrary number of modules that exist outside the Atom library. Moreover, the AtomPub server should not depend on any of these extension modules. For example, one could easily think of modules that do logging, spam detection, or email notification. However, all such modules should not be tightly coupled because this prevents from using them in other scenarios.
The Observer pattern describes how to establish such loosely-coupled collaborations between functions:
Define a one-to-many dependency between functions so that when one is called, all its dependents are notified automatically [Gamma1994].
Description
When applying the Observer pattern to our use case, we have decoupled collaborative modules by introducing a subscription mechanism for functions to be invoked on particular events in the application.
The Observer pattern defines the following participants (cf. Gamma1994):
-
Subject: keep track of its observers. Subject notifies its observers when an event occurred.
-
Observer: function invoked to be notified about an event. Observer receives as parameter information about the event that triggered its invocation.
-
Client: attach Observers to the Subject.
Observers are attached to the Subject. If a particular event occurs, the subject invokes all its observers and provides each of them with data about the event that triggered the invocation. A Subject can have many Observers, each Observer implementing a different functionality.
Subjects and Observers are loosely coupled: they can vary independently [Gamma1994]. Consider our use case, adding/removing Observers doesn't affect neither the AtomPub server module nor the Twitter Observer function. Both modules (AtomPub and Twitter) can operate without the other. The Observer pattern is enables collaborations between these two decoupled modules.
Implementation
In this section, we discuss the implementation of the Observer pattern in our application
[7].
Figure 4 describes the structure of our Observer implementation.
The implementation of the Observer pattern in our application involves the AtomPub
server module (the Subject) and the tweet-entry function (the Observer).
4
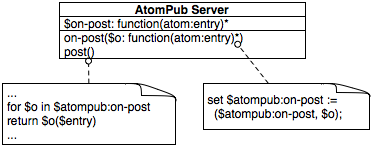
Structure of Observer.
The on-post function is responsible for attaching new observers to the AtomPub server module
(the Subject).
The AtomPub server is keeping track of all its observers with the on-post module variable.
(: Hold the observer references :)
declare variable $atompub:on-post
as (function(schema-element(atom:entry)) as item()*)* := ();
(: Add an observer to the post request :)
declare sequential function atompub:on-post(
$o as (function(schema-element(atom:entry)) as item()*))
{
set $atompub:on-post := ($atompub:on-post, $o)
};
In order for the subject to be able to invoke an Observer, all observers must have
the same function signature. For instance, in the AtomPub server module, each observer
must be a subtype of function(schema-element(atom:entry)) as item()*.
The single parameter of the observer, (schema-element(atom:entry)) is an instance of the Atom entry that has been created on the server.
The tweet-entry function is the Observer we will use in our use case: it will be executed for each
new entry created on the server.
It takes an Atom entry as parameter and sends a message on Twitter with the following
format: entry title, tiny url of the entry.
The function signature is compatible with the observer signature defined in the AtomPub
server module (function(schema-element(atom:entry)) as item()*).
(: The tweet will be formatted as following: Title + tiny url :)
declare function twitter:tweet-entry(
$entry as schema-element(atom:entry))
{
(: Get the title :)
let $title := $entry/atom:title/text()
(: Create a tiny link :)
let $uri := twitter:get-tiny-url(
string($entry/atom:link[@rel = "self"]/@href)
)
(: Send the status on twitter :)
return twitter:tweet(concat($title, ": ", $uri))
};
The Client registers the tweet-entry function as an Observer of the AtomPub server module.
(: Register the Twitter observer :)
atompub:on-post(twitter:tweet-entry#1);
When a new Atom entry is added to the server, each Observer is notified and receives the entry as parameter.
(: Notify observers :)
for $o in $atompub:on-post
return $o($entry);
Implementation Considerations
In the previous section, we introduced an implementation of the observer pattern. In this section, we discuss how this implementation can vary:
-
Consideration 1: In our implementation, the AtomPub server module is using the XQuery Scripting Extension to keep track of its observers. However, variants of the Observer pattern can be implemented using only the XQuery 1.1 core specification. For instance, an alternative implementation could access Observers as function parameter:
let $observers := twitter:tweet-entry#1 return atompub:post($feed-uri, $entry, $observers) -
Consideration 2: Notifying observers has a performance cost in the application. Therefore, when implementing Observer, the event granularity must be carefully designed in order to avoid a large number of useless event notification.
-
Consideration 3: Observers producing side-effects may trigger an infinite amount of event notifications. This can happen if the observer code is triggering the same event that triggered its own invocation. If an Observer implementor is writing side-effects, she must avoid this scenarios.
-
Consideration 4: Observers should be independent of each other. For instance, consider a spam checker observer that removes a newly created Atom entry because the author's e-mail address is blacklisted. In such situation, all observers become dependent on the outcome of the spam checker observer. For example, they might process an entry that has already been removed by the spam checker or they could have already sent a notification for a spam post.
Conclusion
By using Observer to implement Use Case 4, the application has improved in the following perspectives:
-
The behavior the AtomPub server has been extended, by sending messages to Twitter without any changes to the code of the AtomPub server.
-
The AtomPub server module can collaborate with an arbitrary number of functions in the application but stays loosely coupled.
In conclusion, use the Observer pattern if you want to:
-
Use the Publish/Subscribe messaging paradigm within XQuery.
-
To keep state consistency between independent entities in the application.
Conclusion & Outlook
In this paper, we motivated the need for XQuery design patterns. The reason therefore is that there exist more and more large XQuery applications most of them showing symptoms which are well-known in the object-oriented world and have there been solved using design patterns. In more detail, we have presented four design problems along the lines of a running example. Moreover, we have shown how each of these problems can be solved by applying a particular design pattern.
We have chosen to use an AtomPub client and server implementation as a running example. For the AtomPub client, we used the Chain of Responsibility (see Sec. 3) which is using several loosely coupled modules to construct and send an HTTP request. Translator (see Sec. 4) helped us to provide a flexible and extensible HTML rendering engine of Atom entries. For the AtomPub server, the Strategy Pattern (Sec. 5) allows for configurable storage algorithms by exhibiting higher-order functions. Last, the Observer Pattern (Sec. 6) provided a way to register services (e.g. Twitter notification) which are automatically notified if a state of an observed object changes.
Generally, the most important aspect of each of the patterns presented in this paper is to decouple XQuery functions and modules. For instance, in the Chain of Responsibility, we achieved this by removing dependencies between functions by agreeing on a common XML Schema element (i.e. the request item). The Strategy and Observer patterns both leverage higher-order functions as a decoupling mechanism.
However, the four patterns presented in this paper are only a starting point. In the future, we want to develop an extensive catalog of reusable design solutions for the most recurring XQuery design problems. Also, we want to classify these design patterns according to (1) language features (i.e. pure functional XQuery, XQuery Update, and XQuery Scripting) and (2) categories (i.e. creational, structural, and behavioral).
Finally, we hope that XQuery design patterns help the XQuery community to capture recurring design problems and develop extensible XQuery applications. Therefore, we started to publish a pattern catalog online at http://patterns.28msec.com/. We are open and very interested in comments, suggestions, and other contributions to our effort and this catalog.
References
[Cooper2000] J. W. Cooper. Java design patterns: a tutorial. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 2000.
[Cooper2002] J. W. Cooper. C# design patterns: a tutorial. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 2002.
[Gamma1994] E. Gamma, R. Helm, R. Johnson, and J. M. Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley Professional, illustrated edition edition, November 1994.
[DeMarco96] T. DeMarco. Book review: Design patterns: Elements of reusable object-oriented software. IEEE Software Magazine, 1996. http://www.systemsguild.com/GuildSite/TDM/Gamma.html.
[AntoyHanus02FLOPS] S. Antoy and M. Hanus. Functional logic design patterns. In 6th Int'l Symp, on Functional and Logic Programming (FLOPS'02), pages 67-87, Aizu, Japan, 9 2002. Springer LNCS 2441. doi:https://doi.org/10.1007/3-540-45788-7_4.
[Narbel2007] P. Narbel. A Multiparadigmatic Study of the Object-Oriented Design Patterns. 2007.
[XQ11] W3C. XQuery 1.1: An XML Query Language. Website, 2009. http://www.w3.org/TR/xquery-11/.
[Liu2005] Liu, Z. H., Krishnaprasad, M., and Arora, V. Native xquery processing in oracle xmldb. In SIGMOD '05: Proceedings of the 2005 ACM SIGMOD international conference on Management of data (New York, NY, USA, 2005), ACM, pp. 828-833. doi:https://doi.org/10.1145/1066157.1066259.
[Nicola2005] Nicola, M., and van der Linden, B. Native XML Support in db2 Universal Database. In VLDB '05: Proceedings of the 31st international conference on Very large data bases (2005), VLDB Endowment, pp. 1164-1174.
[Brian2006] Brian, D. The Definitive Guide to Berkeley DB XML. Apress, Berkely, CA, USA, 2006.
[XQUF] W3C. XQuery Update Facility 1.0. Website, 2009. http://www.w3.org/TR/xquery-update-10/.
[XQSE] W3C. XQuery Scripting Extension 1.0. Website, 2008. http://www.w3.org/TR/xquery-sx-10/.
[XQFT] W3C. XQuery and XPath Full Text 1.0. Website, 2010. http://www.w3.org/TR/xpath-full-text-10/.
[Kaufmann2009] Kaufmann, M., and Kossmann, D. Developing an Enterprise Web Application in XQuery. In ICWE (2009), vol. 5648 of Lecture Notes in Computer Science, Springer, pp. 465-468. doi:https://doi.org/10.1007/978-3-642-02818-2_39.
[Sausalito2010] 28msec Inc. Sausalito Developer Guide. Website, 2010. http://sausalito.28msec.com.
[RFC5023] Gregorio, J., and de hOra, B. The Atom Publishing Protocol. RFC 5023 (Proposed Standard), Oct. 2007. http://www.ietf.org/rfc/rfc5023.txt.
[HTTPClient] Georges, F. HTTP Client Module. Candidate, EXPath, January 2010. http://www.expath.org/modules/http-client.html.
[XQDDF] FLWOR Foundation XQuery Data Definition Facility. http://www.zorba-xquery.com/doc/zorba-latest/zorba/html/XQDDF.html.
[Translator] Kühne, T. The Translator Pattern - External Functionality with Homomorphic Mappings. TOOLS '97: Proceedings of the Tools-23: Technology of Object-Oriented Languages and Systems, 1997.
[XQueryInAction] W3C. Examples of XML Query In Action. Website, 2010. http://www.w3.org/XML/Query/#examples
[1] Google Data Protocol: http://code.google.com/apis/gdata/docs/developers-guide.html.
[2] Please note that the implementation requires features that might not be present in every XQuery processor (i.e.\ XQuery Scripting, Function Items, and File module). For example, the latest SVN revision (> 8071) of the Zorba XQuery Processor (http://www.zorba-xquery.com) is capable of running all examples.
[3] The code presented in this section can be found within AtomPub/chain_of_responsibility.xq.
[4] You can find the code presented in this section in AtomPub/translator.xq
[5] However, the code is not shown in this paper but contained in the example application
[6] You can find the code presented in this section in AtomPub/strategy.xq
[7] You can find the code presented in this section in AtomPub/observer.xq