Wrightson, Ann. “Platform Independence 2010 - Helping Documents Fly Well in Emerging Architectures.” Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Wrightson01.
Balisage: The Markup Conference 2010 August 3 - 6, 2010
Balisage Paper: Platform Independence 2010 - Helping Documents Fly Well in Emerging Architectures
Ann Wrightson
IT Consultant - Technical Architecture
Informing Healthcare (NHS Wales)
Ann Wrightson has been working with markup since 1978, from typesetting
languages & fielded records through generic coding to SGML & XML. She
has experience of using markup for interoperability and platform-independence
across a wide range of content including published reference works, technical
publications, e-learning, legal codes & materials, and semantic
interoperability standards for information systems in healthcare.
Parallel processing and memory bottlenecks dominate current platform architecture
conversations. After many years on the sidelines, parallel architectures are rapidly
becoming mainstream, with more parallelism the obvious way to gain yet more
performance. Feeding data to and from all these parallel cycles is also becoming
more challenging.
What does this have to do with XML? Surely all this is under the hood, something
for compiler designers, software architects and other non-content people to worry
about? The answer is that these issues can't be totally hidden under the hood.
Balisageurs as content-folks and interoperability-folks need to pay attention now
to
the high level information design heuristics that will prevent our data structures
being the ones that happen to run like treacle (or molasses) on the coming
generations of faster, larger and neater systems.
Ever faster sequential computations in single ever-larger memory spaces has been
"just how it is" in mainstream computing for about a generation - long enough
for design considerations that are actually dependent on this environment to become
invisible, unthought assumptions. After many years on the sidelines, parallel
architectures are becoming mainstream, with more parallelism now the obvious way to
gain
more performance. Memory performance has been growing more slowly, so feeding data
to
and from all these parallel cycles is also a major challenge, with platform architecture
solutions generally focussing on efficient ways to move data through deep hierarchies
spanning the range from distant network resources to on-chip caches. Large and
distributed data in particular needs to move efficiently through many layers of memory
hierarchy, with each layer behaving as a cache with respect to the previous layer,
that
is, being significantly smaller and faster, and with a different block or page size.
What does this have to do with XML? Surely all this is under the hood or behind the
scenes, something for compiler designers, software architects and other non-content
people to worry about? After all, a platform is a just a platform, and XML and many
XML
tools are platform-independent.
To an extent this is true. Compiler designers, software architects and especially
database vendors are busy worrying right now, and much thought from the Balisage
community and others will also undoubtedly go into making basic XML tools work well
on
the new platforms. However, notwithstanding these efforts, data designed with due
attention to the fundamental characteristics of emerging platform architectures are
likely to fare better, especially in speed of processing, than data designed for the
"old world".
Against this background, the premise underlying this paper is that since parallel
processing and managing data flows within memory hierarchies are increasingly prominent
in mainstream platform architecture, any large data structure, or collection of data
that is usually processed together, now needs to be more or less parallel-friendly,
cache-oblivious, and distribution-tolerant, to be really platform-independent - and
this
includes XML instances. This paper is about the attention we need to pay now as
designers of XML content to the structural design patterns that will promote or prevent
our data structures being the ones that happen to start running unexpectedly slowly
next
year or the year after.
Note on language
In this paper, the common parlance "XML vocabularies" is deprecated in
favour of discussing XML data structures and design features of instances of XML
content. This is partly from personal preference, but also from a suspicion that
thinking about XML in terms of vocabularies may inhibit the kind of thinking that
this paper is intended to encourage. Markup that contains terms reflecting natural
language does function like language vocabulary in some ways (see Wrightson 05) however XML instances are also structured data, and
the latter is the aspect that predominates in the issues discussed in this paper.
What are these emerging architectures?
This section provides a concise account of emerging processor architectures and the
state of the art in data access. Implications for platform-independent XML content
design are discussed in the following section.
Single processor architecture becoming multi-, then many-core
About 2003-4, performance improvement in sequential processors slowed down very
significantly. Power density was a major factor, but so was the growing difficulty
of getting even cleverer about executing single sequences of instructions really
fast. With a way still to go in raw chip capacity, a consensus rapidly emerged
amongst the majority of processing-chip designers that the only way forward was to
put multiple processing "cores" on a chip, first two or four, then twelve,
sixty-four, eighty... The latest edition of Patterson & Hennesey's classic
textbook on processor architecture provides a fuller account of this phenomenon (Patterson & Hennessey 09, Chapter 7).
Graphics processors and some other niche processing applications had already made
some progress into gaining performance through large-scale parallel processing, but
for the rest of the industry there was a fairly sudden realization a few years ago
that all that weird parallel stuff from the 1980s onward that no-one except the
high-performance crowd had been taking seriously was on its way back in with a
vengeance. Following this realization, and taking into account the head start
achieved by graphics applications, graphics processors and general purpose
processors are on an interesting journey of combination and convergence, for example
in Intel's "Larrabee" architecture (Seiler et al 08).
While various parallel computation models have been proposed and investigated, two
of the most durable have been BSP (bulk-synchronous-parallelism) and nested
parallelism. BSP (Valliant 90, Skillicorn et al 96) formalizes the notion of performing a bunch of parallel
computations then collating the results before setting up and performing another
bunch of parallel computations, in a regular cycle of
compute-communicate/collate-compute. Nested parallelism (Blelloch et al 94,Peyton Jones et al 08) is more of a language model, enabling a programmer to
describe a large computation as a recursively nested structure of parallel
parts.
The main point for our purposes is that in order to work well in a parallel world,
computation (and its requisite data) needs to come apart into independent pieces,
at
least for long enough to be useful in getting some work done. Two interesting
special cases are where many computations run in parallel on the same data, and
where a single computation runs the same instruction stream to process many
different, similar items of data. The latter is the basis of graphics processing
units. Both put a disproportionate cost on variation, in data content and processing
respectively, compared to sequential processing, so that replication of common parts
and separating rather than combining similar cases becomes more efficient.
This is very counterintuitive to those engineers and information designers,
including many who have come into markup since XML emerged as a mainstream force in
1998-2000, whose intuitions have been formed in situations that take for granted
single (increasingly fast) computation and single (increasingly fast and capacious)
memory. Based on personal conversations and anecdotal evidence, there is a mixed
reaction from the older hands who did not play in the parallel pond, and remember
what it took to keep computations and working memory compact on smaller machines or
in the small job partitions in early multitasking architectures. To caricature
somewhat, some feel that after a period of deep illusion, computing has finally
woken up once more to some essential design disciplines - and some feel this is
separating the engineer even further from the real machine, which is becoming ever
more deeply incomprehensible.
Memory and storage hierarchy
Memory performance has been growing continually alongside processor performance,
over decades. In recent years it has become a commonplace to say that the rate of
growth in memory performance is markedly slower than for processing, leading to a
large and increasing performance gap. This is broadly true, but stated simply
obscures a more interesting detailed picture of evolving patterns of memory and
storage access over a range of hardware, media and networks (Patterson & Hennessey 09, 5.13).
Multiple cache levels within processors, deep memory hierarchies using different
types of hardware, delegating disk access management to on-board processors within
disk drives, and introducing specialized storage network managers, have between them
taken the strain to a large extent. However, the very intensity and diversity of
this effort means that different platforms are more likely than before to have
different memory hierarchies and storage characteristics.A practical consequence is
that fine tuning of memory hierarchy assumptions and data design to make data fast
on one platform can very easily slow it down on another.
This is an area where a good theory has turned out to be very practical as a tool
for thinking. Cache-obliviousness (better named hierarchy-obliviousness, but as
usual the initial name has stuck) is the core concept of an area of research on data
structures that are not only fast to process in principle, but remain fast however
the memory hierarchy (and storage network, at larger scale) is structured.
Cache-oblivious data structures have high locality with respect to whatever the
usual operations are on the data.That is, if an instance of a cache-oblivious data
structure is broken arbitrarily into pieces of any size (for example, loaded a page at a time into
a cache, hence the name) the common operations on the data structure are, on
average, highly likely to need data that is within the same piece. The value of this
area of work for our purposes is not so much in the detail as in the overall
concept. Data structures that follow this design pattern are likely to "fly
well" in a wide range of memory hierarchies, since at any scale, the usual
kinds of processing are less likely to walk or reference out of the piece that is
already in fast(er) memory.
For readers interested in following up the detail of the theory, there is a
thorough introduction to cache-obliviousness by Erik Demaine (Demaine 02) in the papers from a European summer school on large data
structures in 2002 (Massive Data Sets 02).
Platform Independence 2010++?
So what is it to be platform independent in 2010 and beyond? What do we need to be
independent of, specifically? In simple terms, the key platform features are:
A processing model that uses many processing units, breaking large computations
into many independent, different tasks that run simultaneously. This happens
within a many-core chip, and also happens when computations are deployed across
several processors with different data processing characteristics (one example
that is already mainstream is a desktop computer with a separate graphics
processor that is highly data-parallel);
A memory hierarchy of arbitrary depth and width, with considerable variation
in the detail of how data is moved up and down the hierarchy; and
Greater variation in platform architectures as architecture concepts developed
in niche areas (especially high performance scientific computing and graphics
processing) are brought to bear in mainstream computing platforms.
Any one platform can be assumed to have clever low-level software that is designed
to
hide its complexity and weirdness, so that everything still works correctly. Preserving
correct processing is a high priority in designing new processor architectures with
forward compatibility from older ones - however it turns out that data designed for
the
"old world" , although not broken, can be unexpectedly slow in emerging
architectures. This can also lead indirectly to faults, for example when timing
assumptions are broken.
The main evidence I have for this is anecdotal - side-remarks in talks and
water-cooler chat with infrastructure-specialist colleagues who are managing a range
of
data-intensive applications in a growing data centre. Suffice it to say that there
are
people who earn a living advising how to get this right, and that my colleagues tell
me
that more than one well-established product has needed updates to resolve performance
problems in a more distributed, parallel environment.
Abstracting away from platform features into data processing, the key features are
as
follows.
Significant performance speed-up by separating large computations into smaller
pieces of computation that can run independently long enough to get some useful
work done (task parallelism).
Significant performance speed-up by executing exactly the same process
simultaneously and independently across numbers (8, 16, 32...) of data items
(data parallelism);
Separating large data structures into smaller pieces that are usable in
isolation long enough to get some useful work done (required in both task
parallelism and data parallelism).
Moving data up (read) and down (write) a deep memory hierarchy. At each level
some size of data will need to be broken into parts (in a very simple manner, eg
pages), and there is significant performance benefit if, on average, such parts
of data (at any level) are usable in isolation long enough to get some useful
work done.
Moving data between the pieces of a parallel computation so that each piece
has the data it needs, respecting dependencies regarding data integrity (eg read
vs write) and the intended overall flow of computation.
The balance of emphasis between these features varies across the different
architectures involved, for example scheduling dependencies and data exchange (rather
than just data partitioning) become more prominent the more communication is needed
between pieces of computation. Data exchange operates at different scales such as
a
multicore chip passing data between independently processing cores that have separate
caches, and a multi-processor architecture passing data between processors (such as
the
common example of a desktop computer with a separate graphics processor).
A fundamental research result regarding data exchange is that, in the general case
where the structures at each end are different, and a computation is needed to map
data
from one to the other, the computational complexity of a data exchange is exponentially
related to the complexity of the data schemas at each end. The complexity of a data
schema is a combination of complexity measures on the actual data structure and how
it
is described (Kolaitis et al 06).
This result is no great surprise, since data exchange feels like a hard problem in
practice. However, when data exchange becomes a larger proportionate part of general
computation, its exponential general complexity properties suggest that there are
significant benefits to be gained from keeping data structures and the ways they are
described as simple as possible.
Partitioning data and computation is a more familiar problem, though one effect of
a
generation of ever-more-capable sequential processing environments with ever-larger
memory spaces has been a tendency to regard such concerns as rather old-fashioned.
High
performance computing for scientific data analysis has kept this area of work alive,
especially in relation to arrays of data and matrix computations (for example Lee & Zedem 2002) and automatic data partitioning on this kind of data in XML
has also been investigated (Head et al 09).
Design Principles for Platform-Independence
This section suggests a few rules of thumb that are likely to make larger documents,
and smaller documents (such as messages) that turn up in large numbers, more truly
platform independent over these changes in processing architecture. Some of the rules
come naturally when writing or designing documents by hand, but are pretty easy to
break
or ignore when marked-up data is generated by a program. Others may look like obvious
bad practice from the point of view of writing and maintaining documents by hand,
but
look more like candidates for sensible design trade-offs when marked-up data is being
generated by a program. (Note that "generated by a program" includes using one
of the many authoring tools that provide an illusion of manual editing. If you are
not
seeing all the grim details of the pointy brackets as you type, then your data is
being
generated by a program.)
Note that it is specifically NOT assumed here that the current usual-suspect XML
processing tools will be used to process or pre-process the document instances
concerned. These tools may or may not be able to overcome fundamental problems in
data
characterstics " under the hood ", even if rewritten, and new tools will come.
The only assumptions made below are the structural properties of XML instances.
Minimize action at a distance
Ensure that the intended scope of influence of any data value that
represents a parameter for processing data in the document propagates in a
direction from root to leaf along the tree structure of the document.
Minimize cross-references in the data (in particular when purely implicit
in the data and not made evident in the raw XML structure) that mean that a
computation on the data finds out in flight that it needs to look at a
distant part of the tree.
Help processing to "shop local"
Put things that are relevant to each other for processing, close to each
other in the document, that is, few steps apart in the document tree. Expect
the document tree to be cut into branches, twig-bunches or even small twigs
for processing, and think about what computations can be completed in-twig
with larger and smaller twig-sizes.
Keep document structure aligned with probable processing structures. Think
about the flow of information through expected computations on the document,
and see if it follows a natural decompositon of the document structure. A
simple positive example is hyphenation a paragraph at a time over many
paragraphs making up a chapter of a novel.
Replication may be your friend
Repeating pieces of data in different places seems wasteful, yet it may be
a really good idea. If a document is generated by a program, so that the
conceptual burden of repetition and likelihood of error are small, then
there is no reason not to replicate data items it if it helps to reduce
action at a distance.
Detailed differences across lots of sort-of-similar things may be costly
If a processor with data-parallel capabilities thinks that some bunch of
things are all the same, then it may decide to process them in a
data-parallel way, that is, assume that their processing is identical. A
consequence of this is that, from the point of view of any arbitrary one of
the parallel processing threads, it has to wait idly through the work needed
to cope with all the detailed optional differences that apply to any of the
others. If this really is efficient for your data, fine, however it may be
better have more different kinds of things, and less optionality within the
same kind of thing, so that the under-the-hood gnomes can make more
efficient choices more easily for parallel processing.
Examples
The performance penalties discussed above would be expected to be felt mainly at
large scale, that is, on large documents or high volume processing of smaller
documents. However, the structural patterns in the rules of thumb can be illustrated
using small examples, and that is the purpose of this section.
Action at a distance, "shopping local", and replication
These patterns are illustrated in this section using two contrasting examples.
Each example is based on the structural characteristics of a (different) real
data format designed for exchanging information extracted from patient records.
The first example has instances divided into in two main parts. First, a list
of entities (people, roles and locations), and second, a list of recorded events
involving these entitites. Entities are included in events by reference to a
unique identifier for each entity.
As the number of events grows, then because a patient will tend to interact
with the same people and be treated in the same places, the proportion of
entities compared to events will decrease.
There are two motivating ideas underlying these design features. One is to
minimize repetition of data, and the other is to facilitate data transfer
between instances of software applications having similar (relational) database
structures that are closely aligned with the structure of the data. These aims
lead to a structure that explicitly avoids replication and has a strong tendency
not to "shop local". In addition, the references to
identifiers are well hidden in the data from the point of view of XML parsing,
and the majority of references are between two subtrees that diverge near the
root of the document (" action at a distance").
In the second example, data about the people and places involved in a care
event are given directly in each event subtree of the record extract. This data
format was designed to convey information from a number of different software
applications into a common store, from which it is then retrieved on a per-event
basis. An explicit design criterion was to make no assumptions about the
internal structure of the data store, and in the real situation this is based
on, there are several such stores with different internal database structures.
This example also illustrates the role of replicating subtrees of data. A
location address may appear many times, however the benefits of replication were
judged to outweigh the costs, and the sending system is unlikely to make errors
putting the same data into a number of events in a transferred record.
Variation in content between apparently similar things
The next example illustrates in principle how parallel processing of instances
of the same element is slowed down by optionality in the data, in a processor
that runs the same instruction stream in parallel on many data instances (SIMD).
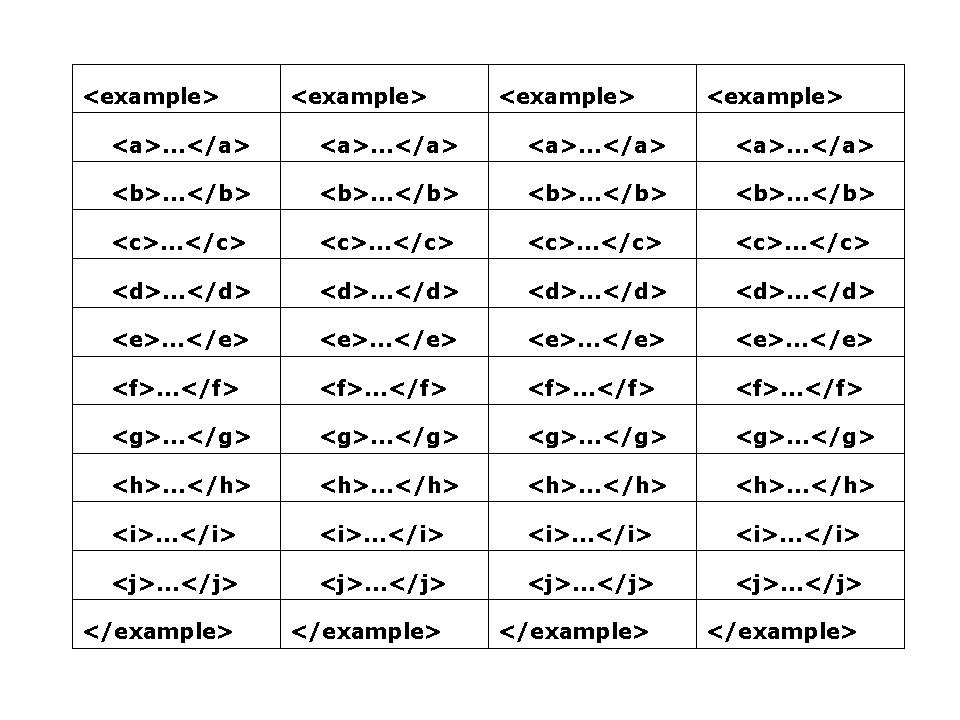
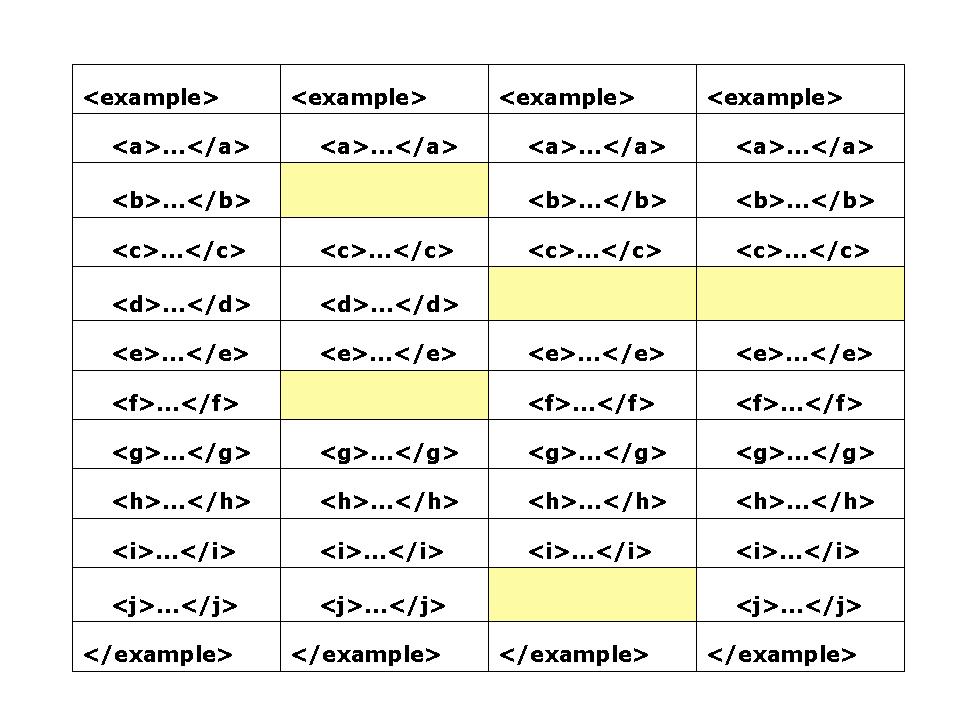
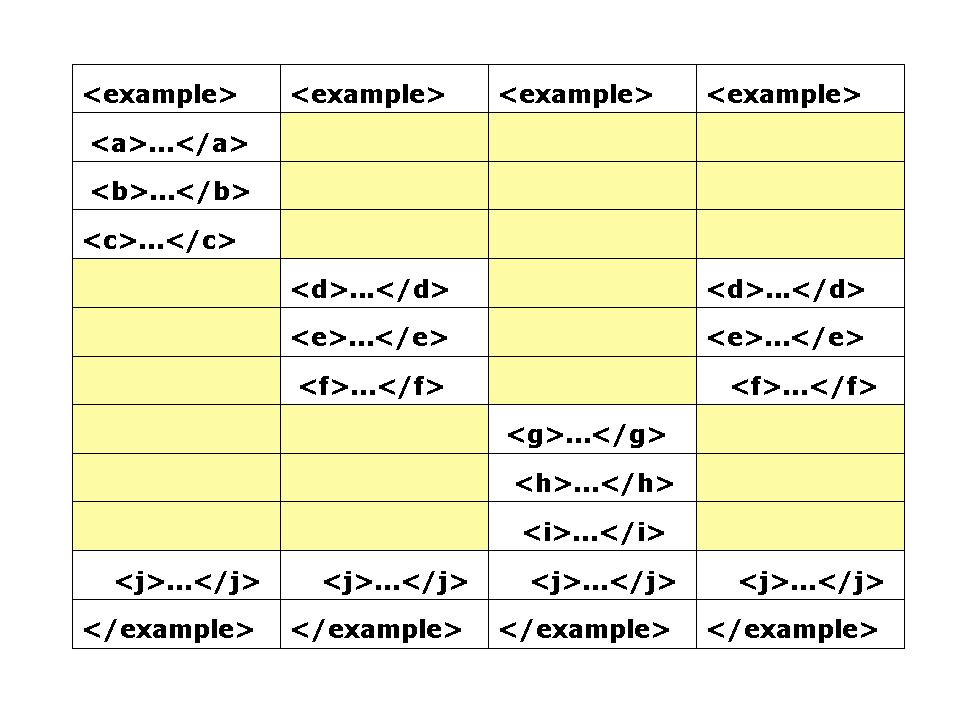
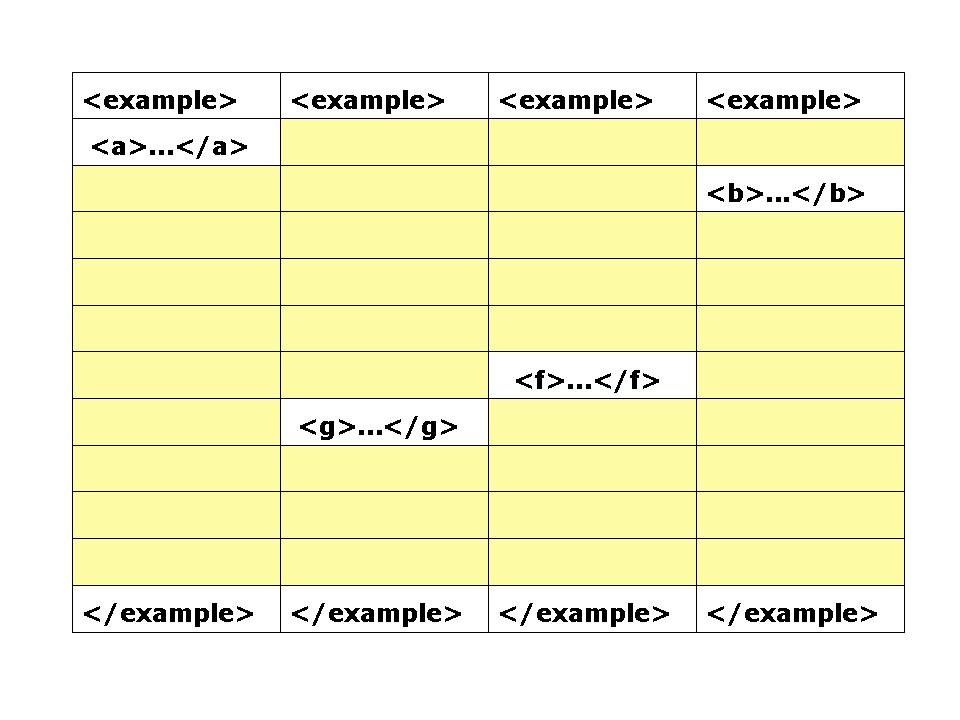
Each picture in the series shows the effect of progressively more variation
between instances. Coloured cells indicate steps where no progress is made in
processing that element.
The first picture below shows element instances with no variation at all, and
there is no loss of performance. In the next, some items are optional. Any
instance that lacks an optional item will be waiting while the other instances
use that part of the instruction stream. The next one after shows what happens
when a content model has a choice of sequences of elements. Finally, the fourth
picture shows the result of having many possible options (for example, a rich XML
vocabulary) with only a few used in
any one data instance.
Figure 3: No optionality
Figure 4: Sparse optionality
Figure 5: Alternative substructures
Figure 6: Selective use of a large vocabulary
A simple count provides a rough indication of the magnitude of the effect.
Taking the content of the example element only, in the first case,
all steps are active. In the second, there are 5 idle steps out of 40, giving a
crude efficiency measure of 87.5%. In the third case, 24 steps out of 40 are
idle, i.e. 45% are active. In the final case, the majority of the steps relate
to options not represented in the data, and only 4 steps out of 40 are active,
i.e. 10%.
It must be emphasized that this is only a rough indication in principle; real
effects will depend on a combination of data structures, application-level
algorithms, programming language implementations, and operating system and
processor strategies. However, even this crude analysis indicates the potential
value of, for example, reconfiguring messages that have repetitive internal
structure to use different element names in preference to naming elements by
role and varying their internal structure, in order to provide easy
opportunities for efficient data-parallel processing.
Conclusion
Only experience will show conclusively what effect emerging architectures may have
on
processing XML and other markup language instances. It just might turn out that the
under-the-hood gnomes in the new architectures are so clever that most document and
data
designers can safely ignore these issues. However, the factors discussed above suggest
that developers and owners of XML vocabularies, document types and data architectures
should give some thought to the effect of emerging architectures on the realities
of
platform-independence.
This paper has focussed strongly on XML instances, independent from schemas, data
models and processing models. Thorough consideration of these from the perspective
of
platform independence on emerging archtitectures may well either show some of the
concerns in the paper to be groundless, or (more likely) yield more refined guidance
on
design principles. In particular, it is worth noting that the functional style of
XSLT,
and the explicitly context-limited formal semantics of XQuery, are both favourable
characteristics (XPath/XQuery formal semantics, XPath/XQuery data model, XSLT 2.0) .
Another possible area of further work would be to analyse data exchange complexity
specifically for XML to XML data exchanges. Theoretical work on data exchange complexity
mostly uses relational database schemas as a reference model of data structure, and
the
work on XML-to-XML data exchange that came to light in researching this paper (though
well short of a thorough literature review on the topic) indicated a tendency to work
from oversimplified models of XML without apparent knowledge of foundational XML-related
work such as the XPath/XQuery data model and formal semantics.
References
[Lee & Zedem 2002] P Lee, Z Kedem Automatic Data and Computation
Decomposition on Distributed Memory Parallel Computers ACM Transactions
on Programming Languages and Systems, Vol. 24, No. 1, January 2002, Pages 1–50. doi:https://doi.org/10.1145/509705.509706
[Par Lab 09] Asanovic, Bodik et al A view of the parallel computing
landscape. Commun. ACM 52, 10 (Oct. 2009), 56-67.
doi:https://doi.org/10.1145/1562764.1562783
[Skillicorn et al 96] D Skillicorn, J Hill and W McColl Questions
and Answers about BSP Oxford University Computing Laboratory
PRG-TR-15-96 November 1996
[Peyton Jones et al 08] S Peyton Jones et al Harnessing the Multicores: Nested Data
Parallelism in Haskell Foundations of Software Technology and
Theoretical Computer Science (Bangalore) 2008.
[Patterson & Hennessey 09] D Patterson, J Hennessey Computer
Organization and Design: The Hardware/Software Interface 4th edition,
Morgan Kaufmann 2009.
[Demaine 02] E Demaine Cache-Oblivious Algorithms and Data Structures
EEF Summer School on Massive Data Sets June 27-July 1, 2002, BRICS,
University of Aarhus, Denmark http://www.brics.dk/MassiveData02/
[Head et al 09] M Head & M Govindaraju Performance enhancement with
speculative execution based parallelism for processing large-scale xml-based
application data 18th ACM international symposium on High performance
distributed computing 2009. doi:https://doi.org/10.1145/1551609.1551615
[Wrightson 05] A Wrightson Semantics of Well Formed XML as a Human
and Machine Readable LanguageExtreme Markup Languages 2005
P Lee, Z Kedem Automatic Data and Computation
Decomposition on Distributed Memory Parallel Computers ACM Transactions
on Programming Languages and Systems, Vol. 24, No. 1, January 2002, Pages 1–50. doi:https://doi.org/10.1145/509705.509706
L Seiler et al Larrabee: A Many-Core x86
Architecture for Visual Computing ACM Transactions on Graphics, Vol. 27,
No. 3, Article 18 August 2008. doi:https://doi.org/10.1145/1360612.1360617
S Peyton Jones et al Harnessing the Multicores: Nested Data
Parallelism in Haskell Foundations of Software Technology and
Theoretical Computer Science (Bangalore) 2008.
P Kolaitis, J Panttaja, W Tan The Complexity of Data Exchange
ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems (PODS)
2006. doi:https://doi.org/10.1145/1142351.1142357
G Blelloch et al Implementation of a Portable
Nested Data-Parallel Language Journal of Parallel and Distributed
Computing, 21(1), April 1994. doi:https://doi.org/10.1006/jpdc.1994.1038
E Demaine Cache-Oblivious Algorithms and Data Structures
EEF Summer School on Massive Data Sets June 27-July 1, 2002, BRICS,
University of Aarhus, Denmark http://www.brics.dk/MassiveData02/
M Head & M Govindaraju Performance enhancement with
speculative execution based parallelism for processing large-scale xml-based
application data 18th ACM international symposium on High performance
distributed computing 2009. doi:https://doi.org/10.1145/1551609.1551615