Probst, Martin. “Processing Arbitrarily Large XML using a Persistent DOM.” Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). https://doi.org/10.4242/BalisageVol5.Probst01.
Balisage: The Markup Conference 2010 August 3 - 6, 2010
Balisage Paper: Processing Arbitrarily Large XML using a Persistent DOM
Martin Probst
Martin Probst is a senior software engineer at EMC, working on EMC Documentum xDB.
He
has been working on XML databases and XQuery in particular since 2004. Martin holds
a MSc.
in Software Engineering from Hasso Plattner Institute in Potsdam, Germany.
As the adoption of XML reaches more and more application domains, data sizes increase,
and efficient XML handling gets more and more important. Many applications face scalability
problems due to the overhead of XML parsing, the difficulty of effectively finding
particular XML nodes, or the sheer size of XML documents, which nowadays can easily
exceed
gigabytes of data.
In particular the latter issue can make certain tasks seemingly impossible to handle,
as
many applications depend on parsing XML documents completely into a Document Object
Model
(DOM) memory structure. Parsing XML into a DOM typically requires close to or even
more
memory as the serialized XML would consume, thus making it prohibitively expensive
to handle
XML documents in the gigabyte range. Recent research and development suggests that
it is
possible to modify these applications to run a wide range of tasks in a streaming
fashion,
thus limiting the memory consumption of individual applications. However this requires
not
only changes in the underlying tools, but often also in user code, such as XSLT style
sheets. These required changes can often be unintuitive and complicate user code.
A different approach is to run applications against an efficient, persistent, hard-disk
backed DOM implementation that does not require entire documents to be in memory at
a time.
This talk will discuss such a DOM implementation, EMC's xDB, showing how to use binary
XML
and efficient backend structures to provide a standards compliant, non-memory-backed,
transactional DOM implementation, with little overhead compared to regular memory-based
DOMs. It will also give performance comparisons and show how to run existing applications
transparently against xDB's DOM implementation, using XSLT stylesheets as an example.
As the adoption of XML reaches more and more application domains, data sizes increase,
and
efficient XML handling gets more and more important. Many applications face scalability
problems due to the overhead of XML parsing, the difficulty of effectively finding
particular
XML nodes, or the sheer size of XML documents, which nowadays can exceed gigabytes
of
data.
Parsing a sample 20 MB XML document[1] containing Wikipedia document abstracts into a DOM tree using the Xerces library
roughly consumes about 100 MB of RAM. Other document model implementations[2] such as Saxon's TinyTree are more memory efficient; parsing the same document in
Saxon consumes about 50 MB of memory. These numbers will vary with document contents,
but
generally the required memory scales linearly with document size, and is typically
a
single-digit multiple of the file size on disk. Extrapolating from these (unscientific)
numbers, we can easily see that handling documents that range in the hundreds of megabytes
will easily outgrow available memory on today's workstations, that typically have
several
gigabytes of memory available. Even when documents do not outgrow available memory,
memory use
is a concern in many applications, particularly in servers processing multiple requests
in
parallel.
Parsing the 20 MB XML file into xDB requires 16 MB of disk space. The amount of memory
required is not related to document size and can be very small (in the kilobyte range).
Related Work
One approach to overcome memory issues is to perform streaming operations in very
specific situations. Peng and Chawathe (Peng05) present a
streaming implementation for a limited subset of XPath operations, Florescu, Hillery
et al.
(Florescu03) achieve the same for XQuery; the Streaming
Transformations for XML (STX) language defines a language similar to XSLT geared at
streamed
execution (STX); and the unreleased XSLT 2.1 specification will
contain special syntax to allow a limited streaming execution mode (Kay10).
However, streaming is a very limiting programming model. Many real world XML
applications require access to preceding or following nodes, like the title of the
section a
node is contained in. To achieve streaming execution, the above approaches have to
exclude
or severly limit commonly used operations like backwards navigating axes.
Another approach is to use databases to store XML documents, moving them out of memory
to secondary storage. There is a wide range of literature on the topic, with early
efforts
focusing on shredding XML documents to store them in relational databases, either
in tables
tailored to a specific XML schemata, or in a generic structure (Tatarinov02). As requiring schemata upfront contradicted user expectations and a generic database
layout results in too many join operations for common hierarchy navigation, later
approaches
propose a variety of numbering schemes to encode the document structure (Meier02). While different solutions with different features exist, these
numbering schemes generally support resolving at least some structural queries based
on the
numbering. Early schemes required re-numbering on document modifications, later ones
overcome this limitation (ONeil04).
Using databases with numbering schemes, we can overcome main memory limitations for
storage and search. However the question of how to efficiently process potentially
large XML
documents in application code remains.
Contributions
This paper presents a different approach: a persistent, hard-disk based DOM that can
store arbitrarily large XML documents and provides read/write access to them through
the
regular Java DOM API without using a node numbering scheme. Regular XML applications
can use
the familiar DOM programming model and the wealth of available XML tools relying on
the DOM
interface. This paper is based on EMC Documentum xDB's implementation of the presented
concepts.
xDB differs from other persistent XML stores and other persistent DOM implementations
in
that it is optimized for direct DOM access. Navigation operations corresponding to
the
common DOM operations are executed in constant time comparable to main-memory based
DOM
implementations. xDB, unlike other XML databases, does not use a node numbering scheme
but
relies on indexes for fast value lookups.
We extensively describe xDB's data organization and storage layout, with a particular
focus on efficient encoding of node data. We provide performance comparisons with
two
different main memory DOM implementations.
Document Model Storage Structure
Traditional Document Model Implementation
DOM implementations (or any document model) usually create classes for the various
XML
node types, and have fields to store the node's properties, like the node name, the
list of
children, the parent node, and so on.
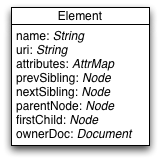
Figure 1 shows a typical DOM element implementation, ignoring
any inheritance chain and inlining all fields for the sake of simplicity. We can see
that
the Element node keeps references to other nodes in the tree, some basic references
like the
first child and the next sibling to implicitly form the tree itself, and some to enhance
navigation speed, like the parent reference or the previous sibling reference, that
could be
emulated using the basic references.
Figure 1: A typical DOM Element Implementation (simplified)
There are many different ways of representing an XML document, differing in memory
consumption, navigation speed for particular axes, whether the document can be modified
after parsing, and so on. Some implementations avoid storing immediate object references
to
limit the number of objects held in memory, but still store the complete document
in memory.
However they all rely on the assumption that the complete document is parsed at once,
and
kept in memory while operating on it.
This leads to the observed limitations in supported document size caused by memory
exhaustion.
Disk based DOM architecture
Our DOM implementation avoids this limitation by storing a binary representation of
an
XML document on the hard disk. While this representation avoids keeping the whole
document
in memory at all times, it is still directly navigable from the programming interface,
without requiring re-parsing or buffering parts of the document during program execution.
Documents are also mutable — nodes can modified after initial parsing, again without
requiring the whole document to be in memory.
Nodes are identified using a 64 bit number and stored in data pages that allocate
individual nodes in slots. The first 54 bit of a node identifier point to the page,
the
latter 10 bits identify a slot within a particular page. As the pages are stored in
files in
the file system, within the first 54 bits, 20 bits are used to identify a particular
file
used for storage. Node identifiers directly point to the physical location of a node;
there
is no indirection between node identifiers and physical node location (see section “Modifications” for a detailed discussion of the impact on updates).
xDB node identifiers can be considered "physical identifiers".
This approach is quite different from other XML databases, that typically use a node
numbering scheme to identify nodes, separating the logical node identifier from its
physical
identifier/location. A node numbering scheme can be helpful to answer unbounded structural
queries, such as the XPath /bib//book//author. On the other hand, such
numbering schemes only help evaluating queries over a large node set; navigating within
individual nodes in a DOM-like fashion will probably be slower due to the additional
indirection required (i.e., typically an index lookup by node ID). We assert that
unbounded
structural queries are rare in actual applications. Applications typically either
search for
specific pieces of information, or process a complete document or document fragment.
Searching within XML can be mapped to value based indexes, while
processing XML commonly means visiting more or less every node of the
document, thus requiring efficient navigation. xDB provides configurable index structures
that can answer combined structure and value queries (e.g. /bib//book[author/lastname
= 'Doe']) to support efficient searching for nodes. To process nodes once they have
been found, xDB resorts to efficient navigation using physical node identifiers.
Pages are of configurable size but should be identical in size to the underlying file
system's page size, for reasons of data consistency in write operations[3]. This means pages are usually 4 kilobytes (Windows, Linux, Mac OS X) or 8
kilobytes (certain UNIXes).
Individual XML documents can spread across any number of physical files, pages, and
slots, but always use at least one complete page; pages are not shared between multiple
documents. The minimum storage size consumed by a document is thus one page (typically
4
kilobytes). The theoretical maximum size for an individual document is the number
of
possible files times the number of pages in a file, times the individual page size.
A
database configured with just a single file can thus (assuming 4096 bytes page size,
using
non-SI prefixes) hold documents up to 234 *
212 bytes = 246 ≈ 64
terabytes in size; an ideally configured database with 220 files
could theoretically hold 266 bytes ≈ 64 exabytes. The
attentive reader will have precluded that we have not been able to test the implementation
with exabytes of storage. This is left as an exercise to the first customer reaching
that
database size. Databases with dozens of terabytes of data are common in customer
deployments.
These theoretical storage limits refer to the size of documents in xDB's internal,
proprietary binary XML format. We will show that this does not necessarily correspond
to
regular serialized XML size, but is typically comparable or slightly less.
Storage Layout
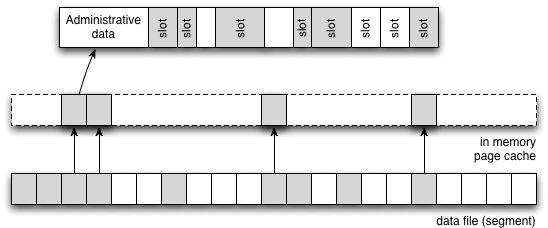
xDB's storage layout is depicted in Figure 2. Pages are
stored in one of potentially many data files grouped together in segments. Data files
are
cached in main memory within a data structure called page cache. Each page contains
multiple slots, which in turn store individual nodes. Slot size is not fixed - different
nodes, even of the same type, can have different lengths. Slot allocation information
is
stored in an administrative section within the data page, giving start and end locations
for each slot.
Figure 2: Storage Layout in xDB
The layout of an individual slot depends on the node's type. Storage layout is defined
through an XML dialect, which is then used to generate Java source code through an
XSL
transformation as part of the build process.
Node Structure
xDB stores node trees much like other DOM implementations, spanning a tree through
first-child and next-sibling pointers. The major difference is that xDB takes great
care
to reduce the size of objects, and that xDB directly operates on byte arrays to store
nodes.
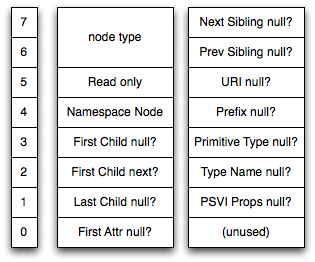
Figure 3 shows the bit layout of the two bytes comprising an
XML Element header. All nodes start with a sequence of bits determining the node type.
The
most common nodes (elements and text nodes) only need two bits of storage for the
type, as
their type codes are 01 and 00. Other node types are stored
using longer bit sequences starting with a bit 1. The following bits all
represent booleans, indicating the presence or absence of fields in the elements storage
and other properties of the node and its storage layout. This reduces on-disk storage
consumption for elements that do not have children or siblings and documents that
do not
use various features like namespaces, post schema validation infoset (PSVI) information,
and so on. The bit fields read only and namespace node handle two special cases. Inlined
entity reference nodes are marked as read only to protect against incorrect modifications,
thus the bit field. Additionally, xDB supports DOM Level 1 documents that do not have
namespace support. For those documents, compliant DOM implementations must return
null for calls to the namespace-aware methods like
getLocalName(). If the bit is set to 0, xDB will return
null on those calls.
Figure 3: DOM Element Header
For an element, this header is followed by the following, partially optional fields:
Parent reference
Next sibling reference (optional)
Previous sibling reference (optional)
First child reference (optional)
Last child reference (optional)
Local name code (integer)
Namespace URI code (integer, optional)
Prefix name code (integer, optional)
First attribute reference (optional)
Primitive type name code (integer, optional)
Complete type name code (integer, optional)
PSVI properties (integer, optional)
These fields following this header can have different types: 32 bit numbers, 64 bit
numbers, node references as relative 64 bit node IDs, strings, and string lists. The
presence of optional fields if governed by their respective bit field in the element
header. If a field is absent, it takes no storage space at all and retrieving it will
return a specified default value, for example null for node references or
-1 for undefined namebase codes.
Another storage size optimization is the First Child next? bit field. If
true, the following node on the data page is the first child of this node, allowing
us not
to store the node ID. This reflects the observation that most XML documents are parsed
once and rarely modified. In that case, the parsing process will cause an element's
children to be stored directly following the element within the data page.
xDB stores all different DOM node types using this scheme, exploiting the various
optimizations possible for different node types - for example, attribute nodes do
not need
a type field as their type is implicitly known at the place where they are
referenced.
Encoding of Primitives
All numeric fields, i.e. integers, longs, and node references, are stored using
run-length encoded numbers. This means that, for example, a 64 bit number that would
normally consume 8 bytes of storage space will be compressed depending on its actual
magnitude. Values below 0x80 (128 decimal) take only one byte of storage
space, values below 0x4000 (16384 decimal) take only two bytes, and so on.
This significantly reduces storage size as node references are not stored as the complete
node ID, but as the relative offset to the current node ID, giving small numbers even
in
large databases. Node references are additionally left shifted and then complemented
if
negative so that small negative offsets are stored as small positive numbers, giving
a
more compressed number. Because nodes are typically added in batch (either during
parsing,
or during larger modifications), nodes usually reference other nodes that are very
close
to them on the data pages. This means we can typically store node references in a
byte or
two. The same applies to the 32 bit numbers used for namebase codes (see below).
Text data from XML text nodes, CDATA sections, and attribute values is stored using
an
encoding scheme similar to UTF-8. In UTF-8 encoded text, it is always possible to
identify
whether a byte is starting a new Unicode codepoint, or if it is part of a multi-byte
encoded codepoint that started earlier. To support this, UTF-8 'wastes' some bits
that
could otherwise be used to encode the codepoints themselves more compact. xDB does
not
need this functionality as our storage layout explicitly marks start and end of strings,
allowing us to encode text data a bit compacter. Text data longer than a single database
page is stored using special text-only database pages to avoid the overhead of page
administration.
String lists, such as the value of attributes of type NMTOKENS, are stored as a list
of zero-byte separated strings.
Namebase Codes
xDB stores node names using a so-called namebase, a table mapping integer codes to
individual NCNames. This both reduces storage size and replaces string comparisons
with
simple integer comparisons for name comparisons. URI, prefix, and local name are stored
separately to speed up queries using wildcard XPath name tests like prefix:*.
While namespace prefixes are not significant according to the XML infoset standard
and
standards like XPath, they are significant in other standards, like the DOM. Because
of
this, and because of the user expectation to have complete document fidelity, we store
the
namespace prefix.
Modifications
Modifying a node simply means modifying the underlying data page, to reflect the
changes that are made to the node. All DOM operations, such as replaceNode,
are directly reflected in the underlying byte arrays.
A problem with the very condensed layout of nodes is that a node might require more
storage space than available in its slot after an update. For example, if we add a
child
element to an XML element node that was previously empty, the element will need more
storage space. In the simple case, the space in the data page that is immediately
following the element is unused, and we can simply grow the element.
In the complex case however, the space following the element node is already used
by
another node, and we cannot grow the node. At the same time, we cannot simply store
the
element at a different place and free the originally used storage space, as other
nodes
will be directly pointing to the current location of the node. If we were to move
a node,
we would have to update all existing pointers to this node, which is a potentially
very
expensive operation, requiring the complete database to be scanned.
To avoid this, xDB replaces the current node store with a forwarding pointer that
will
always be small enough to fit in the available space. The pointer references the actual
location of the node in the database, and all operations on nodes are safeguarded
by a
check for a forwarding reference.
This scheme has the drawback that documents receiving many update operations can
fragment over time. It is possible to create degenerate cases where many nodes will
be
replaced by forwarding pointers. Again, the observation is that most XML documents
are
parsed exactly once and hardly ever modified.
Implementation
Nodes are represented at runtime by regular Java objects. The node storage layout
is
defined by an XML file that also specifies class name, super class, and the class
this
node is owned by (e.g. document for most DOM nodes). In the build process, an XSLT
stylesheet transforms these XML definitions into a Java source file, by convention
ending
in 'Store' (e.g. DomElementStore). The Java file defines an abstract class
that provides getters and setters for the node's fields operating directly on the
page
byte array. This is then extended by a concrete class that provides the public API
for a
given DOM node, e.g. DomElement. This class then implements the respective
org.w3c.dom interface, typically along several other xDB specific ones.
That allows us to keep generated and handwritten code separate.
From a Java perspective, every DOM node object instance references only the page (as
a
Java object) and the slot (as an int), thus instantiated DOM node objects consume,
depending on JVM implementation and CPU architecture, between 16 and 32 bytes of main
memory. The page object references the byte array storing page data only through a
level
of indirection, so even if a DOM node is instantiated in a Java program, the underlying
data page can be swapped out by the cache manager.
Method calls on a DOM interface cause the data page to be obtained (and loaded into
memory, if necessary), after which we decode the requested information through a sequence
of bit operations. The traditional "fields" of an XML element like children, node
name,
etc. are never cached. This allows us to keep the memory footprint of a Java application
minimal - only DOM nodes directly referenced by a user program are actually kept in
memory.
shows the Java code retrieving the first child
of a DOM element node, pretty printed and simplified from the original, generated
version.
The actual code is guarded by a method that checks permissions and whether the current
transaction is open or interrupted.
The code then retrieves the byte array holding the data of the page where the node
is
stored. This might trigger the page to be swapped in if needed. The code then determines
the start and end offsets of this node within the data page. If the node is marked
as a
forwarding object, the code will retrieve the actual data page and update start and
end
offsets (not shown).
In the series of if statements afterwards, we check the bit fields in the
first byte of the element header, referenced by a[start]. The first
comparison checks the third bit ("First Child null?") and returns null if true, the
second
comparison checks if "First Child Next?". In that case, the diff (offset of
the first child node relative to this node) is one — it is the next node on this
page. Otherwise, we have to actually read the node reference, by first finding it
in the
storage and putting the position in the variable fs. First we add two to skip
the element header (two bytes). Because we don't know the length of the first reference
(the parent), we then read the long, and skip as many bytes as it consumes in storage
(packedLongLen()). The next two references are optional, so we check
whether they are present using bit comparisons again, and skip ahead if they are present.
Afterwards we read the actual difference, convert the transformed relative difference
back, and add it to our current node identifier (getPageAndSlot() in the
code), retrieve a page object and compute the slot from the number. The call to
DomNode.newDomNode() will inspect the type field of the referenced object
and return a new instance of the appropriate subclass, pointing to the new node ID.
Figure 4: Retrieving the first child of an element (Java)
DomNode getFirstChildRef() {
Page slotpage = getPage();
byte[] a = slotpage.getDataReadOnly();
int slot = getSlot();
int offset = getOffset(a, slot);
int start = Page.unpack2(a, offset);
int end = Page.unpack2(a, offset - 2);
if (a[start] <= FORWARD_OBJECT) {
// handle forwarded objects by updating a, start, and end
}
long diff;
if ((a[start] & 1 << 3) != 0) {
return null;
} else if ((a[start] & 1 << 2) != 0) {
diff = 1L;
} else {
int fs = start;
fs += 2;
fs += packedLongLen(a, fs);
if ((a[start + 1] & 1 << 7) == 0)
fs += packedLongLen(a, fs);
if ((a[start + 1] & 1 << 6) == 0)
fs += packedLongLen(a, fs);
assert fs < end;
diff = getRelDiff(unpackLong(a, fs));
}
long id = getPageAndSlot() + diff;
Page idpage = getPageFromPS(id);
int idslot = getSlotFromPS(id);
return DomNode.newDomNode(idpage, idslot);
}
Because we don't reference or cache constructed child objects, in xDB's DOM
implementation one logical node might be represented by many different Java object
instances. This is in line with the W3C DOM specification that requires users to compare
nodes for identity using the function isSameNode(), but sometimes surprising
to programmers that expect a simple equality comparison (node1 == node2) to
be sufficient. Modifications to logical nodes are immediately reflected by all Java
DOM
node instances, because they are reflected in the underlying byte arrays.
The amount of work needed for something as simple as retrieving the first child of
an
element might seem staggering, but the time these bit shift operations take is quite
small
in practice, as we will show in section “Performance Comparisons”.
On Disk Layout Example
Figure 5 shows a simple example document, and the
binary representation of the first two elements on disk in the canonical hex formatting.
The bytes surrounding the two elements are blanked out as they are of no
interest.
The document root element, <address_list/>, is stored in the five
bytes on the first line. The first two bytes, representing the element header, indicate
that this is a regular element node with no sibling or attributes, but a first and
a
last child, the first child being the immediately following node on the page. These
bytes are then followed by the parent offset (encoded as 01, meaning an
offset of -1, i.e. the previous node), the offset of the last child (70),
and the namebase code of the local name (00).
The document was parsed with the element-content-whitespace option
disabled, so the white space characters preceding the first <address/>
element were stripped and did not result in a DOM text node.
The first <address/> element is stored in 8 bytes. The header
indicates that all node reference fields are present, except for the previous sibling.
This is then followed by the encoded offset of the parent (again, -1), the next sibling
(1a), the offsets of first and last child (04 and
16), the namespace code (01), and the offset of the first
attribute (02, meaning +1).
The root element <address_list/> consumes 29 bytes of disk storage
when stored as regular XML on disk in UTF-8 (opening and closing tag). In xDB's binary
format, it shrinks to 5 bytes, plus 4 bytes for the slot information (not shown above),
plus a certain amount of storage for the namebase entry which is shared among all
elements with the same name. The more complex <address/> element
consumes 19 vs 8 bytes. This reduction in size depends on the document and the use
of
XML features, such as validation and namespaces. However we can see that in particular
elements containing predominantly elements will shrink in size.
The original addresslist XML document consumed 1138 bytes of disk space, 975 bytes
with ignorable whitespace removed. The binary document representation consumes 768
bytes
(within a 4kb page), giving a bloat factor of ~0.78. These numbers can greatly vary
from
document to document, depending on factors such as namespace use, number of nodes,
and
so on. The general experience with XML documents is that the bloat factor will typically
be around 0.9, giving a 10% compression.
Memory Consumption
As mentioned above, in xDB DOM nodes are only shallow pointers into the data storage.
The
data itself is stored in files, and partially paged into memory in a page cache. These
pages
are kept in Java byte arrays at runtime and DOM operations directly operate on the
byte
arrays. As DOM nodes only indirectly reference these byte arrays, the database engine
is free
to evict data pages from the cache and/or load other cache pages in.
A JVM running an xDB database server will allocate a fixed amount of memory to the
xDB
page cache, similar to other databases. The amount of memory taken is configurable,
and the
database can run correctly with only one data page of cache memory. However, again
like other
databases, less cache memory means more page faults, which in turn means slower operation.
The
ideal amount of memory to allocate for cache pages is difficult to determine, as more
cache
memory will mean that less memory is available to the regular Java application code.
A very
large cache will thus cause more garbage collection runs, which will again slow down
the
application. Depending on the application, the available Java heaps space might even
get
exhausted if it is mostly consumed by xDB cache pages. As a rule of thumb, users are
advised
to allocate half of the Java heap to the database cache, which works well in most
cases.
xDB's page cache uses a combination of Least Recently Used (LRU) and an aging cache
scheme. This means that if the cache has to evict a page, it will attempt to first
evict pages
that have not been used for a long time, but prefer evicting pages that have been
used few
times over pages that have been used frequently. If a user program uses a piece of
data
frequently and also scans a large set of data, only referencing every page once, this
means
that the cache will not be completely overwritten by the large scan.
Beyond the amount of memory allocated for the page cache, xDB itself uses some memory
for
internal data structures like the cache itself, administrative data for background
threads,
and so on. The amount of memory used for these data structures is however fixed, and
not
proportional to the size of documents or other structures contained in the library.
A full xDB
database server can run in a JVM with 16 megabytes of RAM allocated to it.
Because xDB does not force DOM structures to stay in memory, applications can perform
DOM
operations on documents of effectively arbitrary size. However it is still possible
to write
the user application in a way that causes memory exhaustion. For example, a program
traversing
a large document and adding all DOM nodes it encounters to a data structure will exhaust
memory, because it keeps the individual DOM node objects from being garbage collected.
Our
experience however shows that such programs are a not common.
Programming Model
xDB is a compliant implementation of the W3C DOM level 3 standard. xDB's DOM nodes
implement the relevant Java interfaces of the org.w3c.dom package, including the
extensions for loading and saving documents (DOM LS).
This means that program code written against the familiar classes, such as e.g.
org.w3.dom.Element, will work without modification when using xDB. The only
differences in program code will be in the way the initial Document instance is
obtained.
Figure 6 shows a sample code snippet operating on an
xDB-backed DOM. The code first obtains an XhiveDriverIf, which is the main Java
entry point to all xDB operations. After initializing the driver, which will start
background
threads and allocate the page cache, the code creates a new XhiveSessionIf, which
represents the context of transactional operations. The code then begins a new transaction,
retrieves a document that is stored in the database's root library[4]. The object representing the document implements the
org.w3c.dom.Document interface. Any program code written for any Java DOM
implementation can now operate on the document. In particular, XSLT engines that support
DOM
documents (i.e. all Java XSLT engines) can transparently perform transformations on
these
documents. All changes to the document will be persisted in the session.commit()
call, or rolled back on session.rollback(), if the user code throws an unexpected
exception. Multiple transactions can operate on database and library contents concurrently
in
complete isolation. xDB transactions are of serializable isolation level and conform
to the
ACID properties.
xDB locks database contents to avoid concurrent modifications. Locking happens on
a
per-document basis; parallel transactions can modify separate documents concurrently,
but if a
document is already locked by another transaction, the transaction will block. Deadlocks
are
resolved by selecting a victim, whose transaction will be cancelled and rolled back.
Performance Comparisons
While the indirection of storage and the bit operations cause a certain overhead,
performance is comparable to other DOM implementations. Some synthetic benchmarks[5] show that common XML operations take on the order of twice as long in execution as
in other implementations, while requiring significantly less memory. XSL transformations
on
gigabyte-sized XML documents are possible and run in reasonable time.
All the following benchmarks have been run on a MacBook Pro 2.8 GHz Core 2 Duo machine
with 4 GB of DDR3 RAM and a solid state disk drive. The Java implementation was Apple's
modified distribution of the Sun HotSpot JVM in server mode (-server), giving 512
MB of RAM if not otherwise indicated (-Xmx512M). All times were measured after
running the benchmark code several times in a warmup phase to account for Just-In-Time
compilation (JIT). All implementation tests were run in a clean JVM to avoid skewing
results
through the effects of class loading and the different compilation results it can
produce.
After warmup, individual benchmarks were run 100 times (except for the long running
large XSLT
transformation tests, which were run 10 times each); results are given as the average
runtime
with standard deviation.
The three implementations used were Saxon 9.2.0.6 Home Edition, xDB 10.0.0, Xerces
2.10.0,
and Xalan 2.7.1.
Parsing
An important performance benchmark in XML processing is parsing XML documents. In
this
benchmark, we parsed a 20 MB XML document of Wikipedia article titles, URLs, abstracts,
and
links. The document has a relatively simple, flat structure, with an element for every
document that has several children for the document's details.
Table I
Parsing a 20 MB XML document
Implementation
Average Runtime (ms)
Standard Deviation (ms)
Saxon
696
45
xDB
1388
8
xDB (-Xmx64M)
1565
7
Xerces
624
98
xDB's parser and DOM implementation take about twice as long to parse a document,
probably due to the conversions necessary for xDB's internal storage. The lower standard
deviation compared to the other two implementations is most likely because xDB creates
less
objects in memory, and thus is affected less by Java garbage collection.
Reducing the available memory to 64 megabytes, the other two implementations failed
parsing the document due to memory exhaustion. xDB's parsing time increases, as the
parsed
document will no longer easily fit the available cache memory and parts have to be
paged
out. If we increase document size further or decrease available memory more, the parsing
process will be effectively limited by the throughput of the hard disk.
More thorough scalability tests of xDB XML parsing can be found in a whitepaper by
Jeroen van Rotterdam (vanRotterdam09)
DOM navigation
In this test, we walk the document from the parsing test using DOM navigation, or
in
the case of Saxon using it's XDM data model. The tests performs an in-order visit
of all
nodes in the document, retrieving text values for attributes and text nodes, and node
names
for nodes that have a name (elements, attributes, processing instructions). The numbers
for
Saxon are not entirely comparable, as the code uses a different document object model
to
achieve the same task. Document parsing time is not included in the numbers.
Table II
Walking a 20 MB XML DOM
Implementation
Average Runtime (ms)
Standard Deviation (ms)
Saxon
78.6
1.1
xDB
204.2
0.8
xDB (-Xmx64M)
348.9
0.8
Xerces
95.8
0.4
Again, processing takes about twice as long on xDB's DOM implementation. Runtime
increases slightly with constrained memory.
XSL transformation
In this test, we transform the aforementioned document using a simple XSLT 1.0
stylesheet. We use the Saxon and Xalan XSLT implementations, both on their native
DOM
implementations (Xerces for Xalan), and both on xDB's DOM implementation.
We can again see that xDB's DOM is slower than the XSLT processor's native
implementations, but again the overhead is tolerable. Saxon performs slightly worse
than
Xalan on xDB's DOM; initial investigation suggest this might be due to Saxon's DOM
driver
that operates on DOM node lists, which are computationally expensive as they have
to be live
lists, directly reflecting any changes in the parent node. This is problematic in
an
implementation such as xDB, where single logical DOM nodes can be represented by many
different objects. In addition, xDB does not maintain a list with all children of
a node, so
that indexed access to a child within a DOM list is not O(1) in all cases.
Table III
XSLT transformation of a 20 MB XML document
Implementation
Average Runtime (ms)
Standard Deviation (ms)
Saxon
90
6
xDB (Xalan)
160
4
xDB (Saxon)
251
10
Xalan (Xerces)
155
17
We performed the same test on an identically structured document of 900 MB. Neither
Saxon nor Xalan were able to parse the document, even with 3.5 GB of memory available.
Running Xalan on xDB exhausted memory as well, as the implementation appears to copy
some of
the DOM structure into it's own data structures, exhausting memory in the process.
Running Saxon on top of xDB's DOM implementation managed to transform the document
in
reasonable time. Both with a large (512 MB) and a small heap (64 MB), the document
was
transformed in less than a minute. Available memory has no noticeable impact on performance;
runtime is effectively limited by IO throughput as xDB loads cache pages from the
disk. This
also explains the supra-linear runtime growth from 250 ms for a 20 MB document to
45 seconds
for a 900 MB document; the first test exclusively uses heap memory, while the second
test is
limited at least in part by disk performance.
Table IV
XSLT transformation of a 900 MB document using Saxon on an xDB DOM with different
Java heap sizes
Available JVM Heap Memory
Average Runtime (seconds)
Standard Deviation (seconds)
64 MB
47
1
512 MB
45
2
Interestingly, runtime profiling of these simple XSLT transformations shows that
significant time (15-20%) is spent looking up element names by their namebase code.
This
could be entirely avoided if the DOM API provided an interface to create an implementation
specific node name matcher. That would not only allow us to avoid the namebase lookup
but
also reduce relatively expensive string comparisons on node names to integer comparisons
on
namebase codes in xDB's case.
Discussion
The benchmark results show that xDB's hard-disk backed DOM implementation is slower
than
alternative main memory based implementations for small document sizes. On the other
hand,
our scheme makes it possible to handle documents of sizes that simply cannot be processed
using main memory implementations. Beyond that, xDB ofcourse offers many other database
features that might be useful to users.
The fact that xDB performs well compared to a DOM implementation such as Xerces might
be
surprising, given that, when navigating to the first child of an element, a Xerces
DOM node
can simply return the value of a field (or the first value of an array) where xDB
has to
perform a whole series of bit manipulations. We believe that this is an effect of
a modern
processor's memory hierarchy. As CPU internal caches and clock rates are significantly
faster than main memory access, modern CPUs spend most of their clock cycles waiting
for
memory to be loaded into the CPU's cache (Manegold00, Chilimbi99). xDB's compact storage layout sacrifices several CPU
operations for reduced memory use, but those CPU operations can execute in the time
a CPU
would normally spend waiting for memory to be loaded. Because related nodes are allocated
in
contiguous byte arrays, it is also more likely that the CPU already holds the memory
location for the next node in a cache line.
Note that these benchmarks assume a document that is parsed once to be processed,
and
then discarded. In real world applications, documents will often be processed many
times.
Because of its persistent storage, xDB can avoid re-parsing documents over and over
again,
giving substantial benefits for such applications.
[Florescu03] Daniela Florescu, Chris
Hillery, Donald Kossmann, Paul Lucas, Fabio Riccardi, Till Westmann, Michael J. Carey,
Arvind
Sundararajan, Geetika Agrawal: The BEA Streaming XQuery Processor. The VLDB Journal
(2003)
[Tatarinov02] I. Tatarinov, S. D. Viglas, K. Beyer,
J. Shanmugasundaram, E. Shekita, C. Zhang: Storing and Querying Ordered XML Using
a Relational
Database System. SIGMOD (2002). doi:https://doi.org/10.1145/564691.564715
[1] Encoded as UTF-8 text. In UTF-16, the same document (as expected) takes about 40
MB.
[2] While technically, DOM is the name of a particular standardized XML document model
programming interface, for the sake of this paper, any document model implementation
is
equivalent. We are concerned with how to store XML documents as navigable structures,
not
any particular programming interface against them. As the DOM is the most prevalent
document model interface, we use the term interchangeably.
[3] When flushing data to disk, it is only guaranteed that an individual page is written
atomically. Thus, if your data pages are larger than the file system data page, you
might risk partially-written pages in the case of system failures.
[4] xDB databases are structured like UNIX file systems; all documents are contained in
libraries, which in turn belong to other libraries, and the complete database is
descendant of a root library.
[5] These benchmarks, as all benchmarks, should be taken with a grain of salt. We do not
claim that these benchmarks hold much scientific significance or represent performance
in
your particular XML application. Readers should also be aware that there is always
bias if
an implementer tests his own implementation. However the results should give a rough
impression of the overhead associated with this DOM implementation model.
Daniela Florescu, Chris
Hillery, Donald Kossmann, Paul Lucas, Fabio Riccardi, Till Westmann, Michael J. Carey,
Arvind
Sundararajan, Geetika Agrawal: The BEA Streaming XQuery Processor. The VLDB Journal
(2003)
P. O’Neil, E. O’Neil, S. Pal, I. Cseri, G.
Schaller, and N. Westbury. ORDPATH: Insert-Friendly XML Node Labels. SIGMOD,
2004. doi:https://doi.org/10.1145/1007568.1007686
I. Tatarinov, S. D. Viglas, K. Beyer,
J. Shanmugasundaram, E. Shekita, C. Zhang: Storing and Querying Ordered XML Using
a Relational
Database System. SIGMOD (2002). doi:https://doi.org/10.1145/564691.564715