How to cite this paper
Kalvesmaki, Joel. “Schematron as XSLT Interface, and Advanced Validation Models.” Presented at Balisage: The Markup Conference 2025, Washington, DC, August 4 - 8, 2025. In Proceedings of Balisage: The Markup Conference 2025. Balisage Series on Markup Technologies, vol. 30 (2025). https://doi.org/10.4242/BalisageVol30.Kalvesmaki01.
Balisage: The Markup Conference 2025
August 4 - 8, 2025
Balisage Paper: Schematron as XSLT Interface, and Advanced Validation Models
Joel Kalvesmaki
Joel Kalvesmaki is a software developer for the United States Government
Publishing Office, the creator of the Text Alignment Network, and a scholar
specializing in early Christianity.
© Joel Kalvesmaki, released under a Creative Commons Attribution 4.0 International
License
Abstract
Schematron (ISO/IEC 19757-3:2008, 2016, 2020) is widely enjoyed as perhaps the
most expressive and powerful of all XML schema languages. In this article, I argue
that Schematron is profitably seen as a kind of API (application programming
interface) for a constrained flavor of XSLT. This outlook has immense benefits,
because when we act on that insight, Schematron’s horizons expand to those of XSLT.
Anything an XSLT can create can be reported in Schematron, and together they can
conquer the world. I present four models of validation that closely partner XSLT and
Schematron, and offer suggestions on how that partnership can be strengthened in the
future.
Table of Contents
- Introduction
- Schematron and XSLT
- Schematron Implementations
- Models of XSLT-Driven Schematron
-
- Model A: Only XSLT Variables and Functions
- Model B: Validandum Transformed
- Model C: Context-Agnostic Schematron
- Model D: Push-Me Pull-You
- The Schematron-XSLT Partnership
Introduction
Schematron (ISO/IEC 19757-3:2008, 2016, 2020) is widely enjoyed as perhaps the most
expressive and powerful of XML schema languages. Although the claim would be difficult
to prove formally, I am confident in asserting that any structural rules expressed
in an
existing schema (DTDs, RELAX-NG, XSD) can be expressed in a Schematron file. But the reverse is not the case, because Schematron’s query binding language
allows for an enormously expressive repetoire of validation checks, e.g., those that
engage resources outside the context of the file being validated. (The file to be
validated is what the Schematron specifications call an instance to be validated,
but
for convenience in this article I will call it the validandum.) For
example, a Schematron routine can look for other files and use that material to
determine whether the content of an attribute or element in the
validandum is accurate.
The breathtaking expressiveness of Schematron is seen in the rather self-effacing
graphic on the home page of schematron.com:
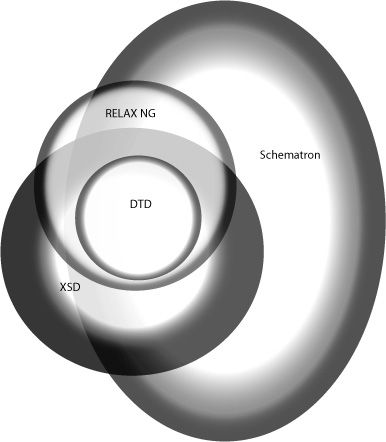
In reality, the Schematron ellipse should subsume all others, except DTDs, which is
capable of doing things impossible for other schema languages.
In this paper, I argue that when Schematron has XSLT as its query language binding,
the Schematron file becomes, in effect, a kind of API (application programming
interface) for a constrained flavor of XSLT. By adopting and embracing this paradigm,
Schematron programmers can go well beyond the merely apparent limits of Schematron
and
develop sophisticated validation routines. Let XSLT perform the complex analysis,
and
let Schematron report the results.
After surveying the formal relationship between Schematron and XSLT, I explore the
field of Schematron implementations/processors. I then present four different advanced
models that pair XSLT with Schematron to do validation that would be inconvenient,
difficult, or impossible, were we compelled to stay within the constraints of a
Schematron file.
This article is written with the assumption that readers have used Schematron before,
and understand the basics, particularly Schematron’s pattern,
rule, assert, and report elements. If that is
not the case, I invite you to visit https://schematron.com/,
learn about the technology, and begin
to use and enjoy it.
Schematron and XSLT
Schematron is a standard of the International Organization for Standardization (ISO)
and the International Electrotechnical Commission (IEC). Versions published in 2008
and
2016 were open source and freely accessible, but the 2020 version, which only slightly
modified the 2016 version, was withdrawn from free public access, to sharp public
criticism (Jeliffe_2020). At the time of this writing, even the
2016 version is no longer accessible at ISO’s Publicly
Available Standards page. A new version of the Schematron standard is
expected in September 2025. My comments below take into account the 2016 version of
Schematron.
Within the specifications, XSLT is but one of many possible query language bindings
(QLB). A QLB is required, to declare the language that should be used to provide general
queries, to set the context scope for rules, and to express true/false tests for reports
and assertions (Schematron_2016 6.4, Siegel 2022a). Among QLBs,
XSLT is given a privileged place insofar as XSLT version 1 is the default QLB, if
one is
not specified.
If XSLT is the QLB, certain XSLT elements are permitted within the Schematron file.
For XSLT version 1, <xsl:key> may be used before
<sch:pattern> elements.
<xsl:copy-of> is also supported, but only without child nodes
and only
within <sch:property>.
If XSLT version 2 or 3 is chosen, version 1 constructs are allowed, as well as
<xsl:function>, again, before any
<sch:pattern>.
To an XSLT programmer, the choices made by the authors of the specifications might
seem unusual. <xsl:copy-of> is already defined by the XSLT
specifications as an empty element, so it is unclear why the Schematron specifications
tell us not to give it children nodes. And if the authors of the specifications thought
it important to restrict what is or is not allowed in that particular XSLT element,
one
wonders if there are similar tacit restrictions to <xsl:function> and
<xsl:key>. Some decisions seem arbitrary, such as the required
position of <xsl:function> and <xsl:key> or why these
particular elements and no others were chosen. In particular, as will be argued below,
the lack of support for <xsl:import> or <xsl:include>
represent a lost opportunity (but the 2025 version will finally seize on that
opportunity). Even without such explicit support, there is a workaround, albeit somewhat
inconvenient, namely the use of fn:transform(), which is accessible in a
Schematron without any XSLT constructs. That is, by invoking fn:transform()
(obviously, with an xslt3 or xpath3 QLB) you can access a
complete XSLT library without restriction, as this example of a global Schematron
variable demonstrates:
<sch:let name="validandum-transformed" value="
transform(
map {
'stylesheet-location': 'validator.xsl',
'source-node': root()
}
)?output"/>
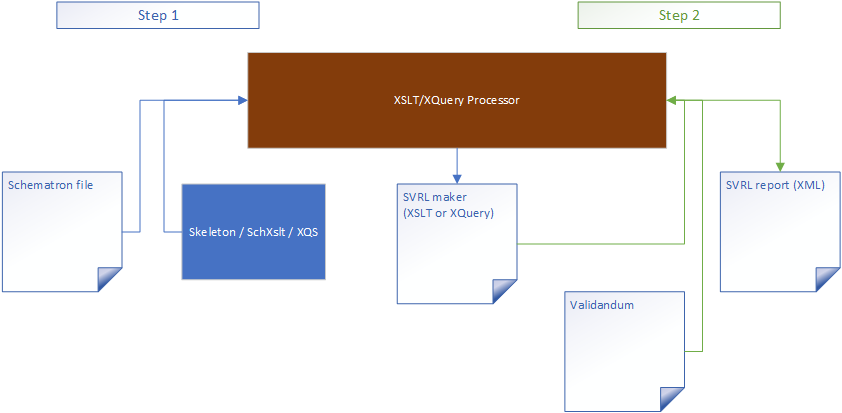
Schematron Implementations
A Schematron implementation is not well defined in the specifications, but the
implications are that it has a wide swathe of responsibility. An implementation is required to take a Schematron file, a
validandum, and a binding language, and produce a validation
report in the form of a Schematron Validation Report Language (SVRL) XML file.
An active list of implementations of Schematron is maintained at https://github.com/Schematron/awesome-schematron. I summarize them here:
-
Skeleton, developed by Rick Jelliffe, an
implementation based on XSLT. An XSLT processor (such as Saxon) takes a
Schematron file as primary input and transforms it using the Skeleton XSLT
library, resulting in a new XSLT file as output. This new XSLT file is
designed to create SVRL reports. The XSLT processor then takes the
validandum as primary input and transforms it using
the new SVRL-creating XSLT file, resulting in an SVRL report as primary
output. How this SVRL report is to be used is determined downstream from the
implementation. Skeleton appears to be the basis for Schematron
implementations in both XMetaL and Oxygen. When an XML file is validated in
Oxygen, messages are prefaced [ISO Schematron],
an alias for Skeleton. The
Skeleton project was archived and rendered read-only in October 2020: https://github.com/Schematron/schematron.
Skeleton enjoys numerous wrappers or handlers. Version 1.5 (from 2002)
formed the core of the Topologi Schematron Validator, a Windows application.
Norm Tovey-Walsh has developed support for Skeleton directly in MarkLogic at
ML-Schematron: https://github.com/ndw/ML-Schematron. A Java wrapper for
Skeleton called ph-schematron has been written by Philip Helger, https://github.com/phax/ph-schematron. At https://github.com/Schematron there are XQuery modules to
use Skeleton in BaseX (https://basex.org/) and eXist databases (http://exist-db.org).
-
SchXslt, developed by David Maus, an
implementation based on XSLT. The process is similar to Skeleton, in that
the XSLT processor passes the Schematron file as primary input through the
SchXslt XSLT library, resulting in a new SVRL-creating XSLT file as output.
The XSLT processor then passes the validandum as
primary input through the new SVRL-creating XSLT file, and the result is an
SVRL report as primary output, to be processed or used downstream from the
implementation. Source code is available at Codeberg: https://codeberg.org/SchXslt/schxslt2. Helger’s ph-schematron
(see above) makes SchXslt available in Java.
-
XQuery for Schematron (XQS), developed by
Andrew Sales, restricts itself to Schematron files that use XQuery as the
QLB. An XQuery processor applies an XQS XQuery to a Schematron file,
resulting in a compiled XQuery script. The XQuery processor then applies
this XQuery script to the validandum to generate the
SVRL report. Because this is an XQuery-centered implementation, it does not
support <xsl:function> or <xsl:key>
constructs. Source code is available at Github: https://github.com/AndrewSales/XQS.
-
PySchematron, developed by Robbert Harms,
represents a pure implementation of Schematron within Python. Because of
this approach, only XPath expressions are supported, and not XSLT functions.
The source code is available at Github: https://github.com/robbert-harms/pyschematron.
-
Node-schematron, developed by Wybe
Minnebo, is a limited Javascript implementation of Schematron. XSLT
functions are not supported. Because it relies on fontoxpath (https://www.npmjs.com/package/fontoxpath), XPath 3.1 is supported.
Source code is available on Github: https://github.com/wvbe/node-schematron.
The last two implementations, PySchematron and node-schematron, exemplify the classic
implementation model. A Schematron file and the validandum go
straight into the processor, and out comes an SVRL report, to be handled downstream
as
the user or implementation wants.
Note, however, the challenges in these two implementations, in that they do not offer
full XSLT support.
The first three implementations—Skeleton, SchXslt, and XQS—follow a different model,
and have much in common. All of them rely upon an XSLT or XQuery processor to do the
actual processing. In none of the implementations is the Schematron file applied
directly to a validandum. Rather, the XSLT or XQuery processor uses
the implementation to convert the Schematron to an intermediary script (XSLT or XQuery),
and then that same processor uses that intermediary script to convert the
validandum to an SVRL report. All three implementations use a
two-step process, where XSLT or XQuery code works hand-in-hand with an XSLT or XQuery
processor. The source implementation code is at the heart of the first step, and its
resultant SVRL-creating code is at the heart of the second step. When we think of
an
XQuery, XSLT, or XProc processor, we think of a single, encapsulated piece of software.
But in these three implementations, a Schematron processor is not a single thing.
Rather, it is a collaboration between three tools: the implementation code base, an
XQuery or XSLT processor, and the compiled code.
We are fortunate to have implementations such as Skeleton and SchXslt, where the
underlying XSLT process is open to investigation. A look inside is inspiring, and
suggestive of a special, closely mapped relationship between Schematron and XSLT.
Consider the first pass. The XSLT processor takes the Schematron file as primary input
and passes it through the implementation code’s template modes, for example in this
snippet from SchXslt’s compiler:
<xsl:template match="sch:rule" mode="schxslt:compile">
<xsl:param name="mode" as="xs:string" required="yes"/>
<xsl:param name="typed-variables" as="xs:boolean" required="yes"/>
<xsl:call-template name="schxslt:check-multiply-defined">
<xsl:with-param name="bindings" select="sch:let" as="element(sch:let)*"/>
</xsl:call-template>
<template match="{@context}" priority="{count(following::sch:rule)}" mode="{$mode}">
<xsl:sequence select="(@xml:base, ../@xml:base)[1]"/> In this code
(at the time of writing, lines 233-242 of
compile-2.0.xsl, seven folders
deep in the source code), a
<sch:rule> is intercepted by the
schxslt:compile mode (line 233). Schematron variables are checked for
duplication (lines 237-239). Then the process converts the
<sch:rule>
into an
<xsl:template>, by binding the Schematron rule’s
@context to the XSLT
@match, and assigning a priority that
reflects the Schematron constraint that the first
<sch:rule> in a
<sch:pattern> wins (the opposite of XSLT’s rule that among competing
template modes of the same priority level, the last one wins). The value of the XSLT
@mode is provided by a generated id for the Schematron
<sch:pattern> (line 241). By copying any local
@xml:base in the Schematron file (line 242), the compiled/intermediate
XSLT can also take the appropriate base.
The close relationship between the input Schematron code and output SVRL-creating
XSLT
code is best seen in an example. Suppose we have this simple Schematron
rule:
<sch:rule context="foo" xml:base="..">
<sch:report test="true()">Hello world</sch:report>
</sch:rule>
The SchXslt compiler produces the following snippet of SVRL-creating XSLT (abbreviated
for
clarity):
<xsl:template match="foo" priority="0" mode="d7e3" xml:base="..">
. . . . . . .
<xsl:if test="true()">
<svrl:successful-report xmlns:svrl="http://purl.oclc.org/dsdl/svrl"
location="{path(.)}"
xml:lang="en">
<xsl:attribute name="test">true()</xsl:attribute>
<svrl:text>Hello world</svrl:text>
</svrl:successful-report>
</xsl:if>
. . . . . . .
<xsl:next-match>
<xsl:with-param name="schxslt:patterns-matched"
as="xs:string*"
select="($schxslt:patterns-matched, 'd7e3')"/>
</xsl:next-match>
. . . . . . .
</xsl:template>
Skeleton’s output for this same example is
similar:
<xsl:template match="foo" priority="1000" mode="M0">
<svrl:fired-rule xmlns:svrl="http://purl.oclc.org/dsdl/svrl" context="foo"/>
<xsl:if test="true()">
<svrl:successful-report xmlns:svrl="http://purl.oclc.org/dsdl/svrl" test="true()">
<xsl:attribute name="location">
<xsl:apply-templates select="." mode="schematron-select-full-path"/>
</xsl:attribute>
<svrl:text>Hello world</svrl:text>
</svrl:successful-report>
</xsl:if>
<xsl:apply-templates select="*|comment()|processing-instruction()" mode="M0"/>
</xsl:template>
We see in these examples very close relationships between the Schematron nodes and
the
output XSLT that will eventually create the SVRL report. <sch:rule>
corresponds to <xsl:template>, @context to
@match, @xml:base to @xml:base,
<sch:report> to <xsl:if>, @test to
@test, and Hello world to
<svrl:text>.
When studying the SVRL-making XSLT that Skeleton and SchXslt create, the nearly
one-to-one correlation between Schematron construct and XSLT construct tempts me to
think, If I wanted, I could dispense with Skeleton or SchXslt, and I can even dispense
with the Schematron file itself, and simply write and modify an XSLT file that makes
an
SVRL report.
I would not act on that impluse, but its motivation is clear: the original
Schematron file is losslessly represented by the SVRL-making XSLT. Just as the former
was converted into the latter, you could probably develop an XSLT stylesheet that
transforms the latter into the former. That is to say, the Schematron and the
SVRL-creating XSLT are interchangeable. When you are writing one, you are writing
the
other.
This leads to my observation: when we write Schematron, it is possible to think of
ourselves writing a kind of constrained XSLT. This is true regardless of whether the
implementation we are using is reliant on XSLT or not. All Schematron implementations
must produce the same results. Regardless of what is happening in the black box of
a
given implementation, we can picture ourselves writing an SVRL-creating XSLT at the
same
time we are writing Schematron.
Models of XSLT-Driven Schematron
As I mentioned earlier, the XSLT constructs <xsl:import> and
<xsl:include> are not allowed by the current specifications. But in
reality, the two implementations that fully support all Schematron features (SchXslt
and
Skeleton) are lenient on this point, and support the constructs. Which means that
it is
possible to use Oxygen or any other application that uses those implementations to
let
our Schematron files tap into the full power of XSLT. There are a number of benefits
to
doing so:
-
Unlike <sch:let>, <xsl:variable> allows
typing (@as), to better control the type of value that is being processed. That means that any Schematron global variable can be pushed to
the XSLT tier.
-
One can use <xsl:template>,
<xsl:accumulator>, <xsl:mode>, and a
host of other top-level declaration constructions that would not be
appropriate, or allowed, to put in a Schematron file.
-
With one simple <xsl:import> declaration, one can dispense
completely with any other top-level XSLT elements in the Schematron file
(such as <xsl:key> or <xsl:function>). Doing
so provides a clean division of responsibilities. The XSLT becomes
responsible for functionality and processing, and the Schematron reports the
results.
-
Once functional code is moved out of Schematron into the XSLT library, it
can be repurposed, perhaps to drive other Schematron files, or to be used in
other XSLT projects.
There are other benefits we will encounter, as we proceed through several
XSLT-Schematron models I have used in the past. What they all have in common, however,
is an initial setup.
-
Make XSLT the QLB.
-
Remove any top-level XSLT elements from a Schematron file (except maybe
<xsl:param>), and instead provide a single
<xsl:import> or <xsl:include> that
points to an XSLT library. Avoid putting more than one of these in your
Schematron file. Instead, coordinate any other include or import statements
within the main XSLT file. This allows better control and diagnostics over
the import process.
-
Find any namespaces invoked in the XSLT code for functions and global
variables, and set them up in the Schematron file, as
<sch:ns> elements.
The setup described above is conformant with Schematron rules, with the sole exception
of the <xsl:import>/<xsl:include> statement. Because
that exception to the specifications is supported by Skeleton and SchXslt, we are
on
solid ground.
Examples for the four models rely upon evaluation of a simple XML file with data about
widgets, which will be checked for consistency and other business
concerns:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-model href="widgets.sch" type="application/xml"
schematypens="http://purl.oclc.org/dsdl/schematron"?>
<widgets>
<widget id="a">
<name>Sparklore</name>
<name>Sparklore</name>
<released>2025-01-01</released>
<unit-cost currency="USD">5.00</unit-cost>
<count>2</count>
</widget>
<widget id="a">
<name>Flumberbund</name>
<released>2024-11-15</released>
<unit-cost currency="USD">15.00</unit-cost>
<count>-3</count>
</widget>
</widgets>
Sample validandum
widgets.xml
Model A: Only XSLT Variables and Functions
Sometimes we just need some basic XSLT functionality. A project is just starting
out, and the needs are minimal. But we want to take advantage of the benefits that
come with doing our primary processing in XSLT. In this model, we rely upon the XSLT
file for our global variables and functions.
Here is a simple example of a paired Schematron file with supporting XSLT
file:
Model A Schematron file widgets.sch
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" queryBinding="xslt3">
<xsl:import href="widgets.xsl"/>
<sch:ns prefix="f" uri="my-functions"/>
<sch:pattern>
<sch:rule context="widget">
<sch:report test="@id = $duplicate-widget-ids">Duplicate id.</sch:report>
</sch:rule>
<sch:rule context="widget/name">
<sch:report test=". = f:duplicate-strings(../name)">Names should not be
duplicated.</sch:report>
</sch:rule>
</sch:pattern>
</sch:schema>Model A XSLT file widgets.xsl
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:f="my-functions"
exclude-result-prefixes="#all" version="3.0">
<xsl:variable name="duplicate-widget-ids" as="xs:string*"
select="f:duplicate-strings(//widget/@id)"/>
<xsl:function name="f:duplicate-strings" as="xs:string*">
<xsl:param name="strings" as="xs:string*"/>
<xsl:for-each-group select="$strings" group-by=".">
<xsl:if test="count(current-group()) gt 1">
<xsl:sequence select="current-grouping-key()"/>
</xsl:if>
</xsl:for-each-group>
</xsl:function>
</xsl:stylesheet>In the example above, the XSLT file defines the function
f:duplicate-strings, which also drives the binding of the global
variable $duplicate-widget-ids. Both the function and the variable are
invoked by the Schematron file, which checks every <widget> for
duplicate ids, and uses f:duplicate-strings to make sure that no
<widget> has a duplicate <name> .
Obviously, both the global variable and the function could have been expressed in
the Schematron file. But one can easily imagine functions and variables that need
much more complex operations. When such expansion is required, we simply expand our
XSLT suite, without complicating our Schematron file.
Model A depends upon a strong asymmetric contract between the XSLT and Schematron
files. In writing the Schematron file, one needs to know what the XSLT is creating,
and but those who write the XSLT file might not need to know about the Schematron
file. This allows the XSLT component to develop into a full-fledged library that may
have purposes much larger than the catalyzing Schematron file. In fact, that XSLT
library may be driving multiple Schematron processes.
Model A is already in use. It is the approach taken by Matthieu Ricaud-Dussarget
in his XSLT Quality project, https://github.com/mricaud/xslt-quality.
Model B: Validandum Transformed
There are more complex situations, where it is wholly more efficient to do some
full transformations of the validandum, then evaluate as
needed. Here is an example of how that might be handled in a Schematron file and its
companion XSLT file. Here we treat the widget XML file as a running series of
orders, where each <widget> represents change in inventory, and we
wish to flag places where the total inventory level dips below a certain point. We
set up the desired reports in the Schematron file:
Model B Schematron file widgets.sch
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" queryBinding="xslt3">
<xsl:import href="widgets.xsl"/>
<sch:ns prefix="f" uri="my-functions"/>
<sch:pattern>
<sch:rule context="widget">
<sch:let name="self-evaluated" value="key('get-by-path', path(.), $input-evaluated)"/>
<sch:let name="count" value="xs:integer($self-evaluated/running-widget-count)"/>
<sch:report test="$count lt 10 and $count gt 0" role="warn">We are low on widgets!
<sch:value-of select="$self-evaluated/running-widget-count"/></sch:report>
<sch:report test="$count le 0">We are out of widgets! <sch:value-of
select="$self-evaluated/running-widget-count"/></sch:report>
</sch:rule>
</sch:pattern>
</sch:schema>Now, in the companion XSLT file, we use an accumulator to keep track of the running
inventory.
Model B XSLT file widgets.xsl
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:f="my-functions"
expand-text="yes"
exclude-result-prefixes="#all" version="3.0">
<xsl:key name="get-by-path" match="*" use="@_path"/>
<xsl:variable name="input-prepped" as="document-node()">
<xsl:apply-templates select="/" mode="prep"/>
</xsl:variable>
<xsl:variable name="input-evaluated" as="document-node()">
<xsl:apply-templates select="$input-prepped" mode="eval"/>
</xsl:variable>
<xsl:mode name="prep" on-no-match="shallow-copy"/>
<xsl:template match="*" priority="1" mode="prep">
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:attribute name="_path" select="path(.)"/>
<xsl:apply-templates mode="#current"/>
</xsl:copy>
</xsl:template>
<xsl:accumulator name="running-widget-count" as="xs:integer" initial-value="0">
<xsl:accumulator-rule match="widget/count" select="$value + xs:integer(.)"/>
</xsl:accumulator>
<xsl:mode name="eval" on-no-match="shallow-copy" use-accumulators="#all"/>
<xsl:template match="widget" mode="eval">
<xsl:copy>
<xsl:copy-of select="@*"/>
<running-widget-count>{accumulator-after('running-widget-count')}</running-widget-count>
<xsl:apply-templates mode="#current"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>Despite the trim Schematron file, the underlying process is busy. The bulk of the
evaluation takes place in the XSLT file, through a two-pass transformation. A copy
of the validandum is made, with a temporary @_path
attribute added to each element, to create a dereferencable unique id, and the
results are bound to $input-prepped. In the second pass, bound to
global variable $input-evaluated, an accumulator is consulted, and a
running inventory is added to each <widget>.
Back in the Schematron file, every <widget> fires a rule. The
local variable $self-evaluated is bound to its counterpart from the
global variable $input-evaluated, i.e., the context node transformed by
the main XSLT file, which has been looking for changes in inventory. The rule then
evaluates the local variable, in this case checking for a running count of widgets,
warning the user when it drops below 10 and raising an error when negative.
Model B requires a strong contract between the XSLT and Schematron files. In
writing the Schematron file, one needs to know what the XSLT is creating, and in
writing the XSLT file, one needs to know what patterns and analysis are of interest.
A benefit to this model is that it is quite flexible and extensible: you can
create as many global variables as you like, with the
validandum transformed in different ways. Such processing
is straightforward in XSLT, and the results are immediately accessible to any
<sch:report> or <sch:assert>.
I am uncertain if any public projects use Model B, but I have used it for a number
of projects for the Federal Government. One such project is the validation of XML
files for the Federal Register. The Federal Register has complex requirements about
where footnote references and the footnotes themselves must be placed. Determining
whether footnote references and footnotes have been placed accurately, and making
sure that the footnote numerals are sequential and pairwise correct requires complex
analysis of the entire document. It is definitely not a job for Schematron. But XSLT
can do this analysis efficiently, and provide the results to the Schematron file to
report anything of concern or interest.
Model C: Context-Agnostic Schematron
It does not take long for a Model B XSLT-Schematron project to grow to the point
where we want the XSLT file to simply do all the evaluation, and use Schematron
simply to report the results. A common motivation for taking this extra step is the
discovery that the logic being put into a traditional Schematron file needs to be
leveraged and repurposed outside the Schematron file. For example, the Schematron
reports and asserts may be giving error codes, but we get to the point where we need
to maintain an inventory of error codes separately, to integrate with documentation
or a regression test suite. Another reason might be the need to take advantage of
XSLT’s template-based approach to shadowing, which is more sophisticated than
Schematron’s. And yet another reason might be that our Schematron Quick Fix library
is getting overly large, and needs to be simplified and refactored into fix
typologies.
With these high-level needs, we abandon the thought of making a
<sch:rule> for every context. We start by making a very simple
and small Schematron file with one rule, and one context, firing for every element.
The XSLT’s job is to reduce the validandum to an arbitrarily
constructed error and warning report, integrated with possible fixes. The Schematron
file simply checks an XSLT-created global variable to see if that particular element
has any warnings, errors, or quick fixes.
Here is an example of Model C, beginning with the Schematron file:
Model C Schematron file widgets.sch
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron"
xmlns:sqf="http://www.schematron-quickfix.com/validator/process"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" queryBinding="xslt3">
<xsl:import href="widgets.xsl"/>
<sch:ns prefix="f" uri="my-functions"/>
<sch:pattern>
<sch:rule context="*">
<sch:let name="errors" value="key('get-by-path', path(.), $all-errors)"/>
<sch:report test="exists($errors[1])" sqf:fix="replace-element">
<sch:value-of select="$errors/message"/></sch:report>
<sqf:fix id="replace-element" use-for-each="$errors/fix[@type = 'replace-element']">
<sqf:description>
<sqf:title><sch:value-of select="$sqf:current/@message"/></sqf:title>
</sqf:description>
<sqf:replace select="$sqf:current/*"/>
</sqf:fix>
</sch:rule>
</sch:pattern>
</sch:schema>Before presenting the XSLT file, which is longer than previous examples, it is
worth noting that the Schematron file is now context-agnostic. The Schematron file
is not looking or specifically named elements. It simply fires at every element, and
checks the XSLT for a list of relevant errors, and reports them. If the error
includes any fixes, they are passed to the appropriate SQF construct. For the sake
of simplicity, I have used only one SQF fix type here, but the types of SQFs can and
do grow. The example also anticipates only the first error for a given element. If
there are multiple errors, there are creative ways these can be administered in the
Schematron file, depending upon what is desired.
The XSLT that drives the whole process is as follows:
Model C XSLT file widgets.xsl
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:f="my-functions"
expand-text="yes"
exclude-result-prefixes="#all" version="3.0">
<xsl:key name="get-by-path" match="*" use="@_path"/>
<xsl:variable name="input-prepped" as="document-node()">
<xsl:apply-templates select="/" mode="prep"/>
</xsl:variable>
<xsl:variable name="all-errors" as="document-node()">
<xsl:document>
<errors>
<xsl:apply-templates select="$input-prepped" mode="errors"/>
</errors>
</xsl:document>
</xsl:variable>
<xsl:mode name="prep" on-no-match="shallow-copy"/>
<xsl:template match="*" priority="1" mode="prep">
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:attribute name="_path" select="path(.)"/>
<xsl:apply-templates mode="#current"/>
</xsl:copy>
</xsl:template>
<xsl:accumulator name="running-widget-count" as="xs:integer" initial-value="0">
<xsl:accumulator-rule match="widget/count" select="$value + xs:integer(.)"/>
</xsl:accumulator>
<xsl:mode name="errors" on-no-match="shallow-skip" use-accumulators="#all"/>
<xsl:template match="widget[accumulator-after('running-widget-count') lt 0]/count" mode="errors">
<error n="1">
<xsl:copy-of select="@_path"/>
<message>We are out of widgets! {accumulator-after('running-widget-count')}</message>
<fix type="replace-element" message="Increase count so running count is zero.">
<xsl:copy>
<xsl:copy-of select="@* except @_path"/>
<xsl:value-of select="xs:integer(.) - accumulator-after('running-widget-count')"/>
</xsl:copy>
</fix>
<fix type="replace-element" message="Add 1,000 to count.">
<xsl:copy>
<xsl:copy-of select="@* except @_path"/>
<xsl:value-of select="xs:integer(.) + 1000"/>
</xsl:copy>
</fix>
</error>
<xsl:next-match/>
</xsl:template>
</xsl:stylesheet>As with Model B, we take the preliminary step of adding the temporary attribute
@_path to each element. The next pass, however, does its best to
reduce the original input to a simple set of elements. The errors
template mode is set to shallow-skip (not shallow-copy, as
in Model B), to reduce the validandum to a (hopefully small)
list of errors. For a long validandum with few errors, the
query time in each <sch:rule> is minimal. The bulk of work (and
therefore performance concerns) are restricted to the XSLT tier.
In Model C, we customize our own error report, along with potential quick fixes,
using whatever structure makes sense to us. In the example above, there is an
<error> element that takes an error code, a message, and zero or
more <fix>es. It has been my experience that some knotty SQFs
benefit from sophisticated XSLT adjustments. Because the SQF process has been moved
into the XSLT tier, we can provide some creative fixes.
Model C depends upon a symmetric but loose contract between the XSLT and
Schematron files. In writing the Schematron file, one does not need to much about
what the XSLT is creating, aside from the structure of the errors and fixes. Those
who write the XSLT file might need to know how those errors will be reported and
those fixes will be applied, but that is all, because the Schematron file is
generic. The XSLT tier essentially subsumes the traditional responsibility of
Schematron.
The error or warning report created by the XSLT is of an arbitrary structure. How
that report is designed is a private affair, exclusively between the XSLT file and
the Schematron handler.
This particular approach is eminently expansible. A project can set up error codes
and messages in a stand-off file, and create a suite of private functions to more
concisely build errors, warnings, and fixes.
I have adopted Model C widely, the best public example being the validation system
behind the Text Alignment Network, https://textalign.net/. In a project I am developing for
the Government Publishing Office, pertaining to marking up legislation that comes
from the U.S. Congress, I have used Model C to do some very nuanced validation, such
as checking to see whether conjunctions (and
/ or
) have been properly placed in
the complex hierarchy. Each error or warning is assigned a code. If a user wishes
to
ignore a particular error, they can squelch specific warnings or errors through the
Oxygen interface, which writes the preferences to a stand-off configuration file for
the user. The Schematron file does not need to worry about these matters. The XSLT
tier checks external resources and makes the decisions about whether a warning or
error should be fired.
Model D: Push-Me Pull-You
Models A, B, and C cover common situations. Model D handles a rarer, but
significant, use case. It should appeal to those who appreciate XSLT recursion.
Let us suppose we have adopted model A or B, and it is dependent upon an
underlying XSLT library. The two become tightly coupled. The XSLT library matures
and begins to serve a variety of needs, not just the Schematron process. The library
grows to the point where it needs to validate a file and incorporate the report into
other processes. That is, the XSLT library needs to get validation information on
an
XML file and do something with it.
We have this feature already, in the case of other schemas. For example, one can
use Charles Foster’s Saxon Jing project (https://www.cfoster.net/saxon-jing/) within XSLT code to validate any
XML file against a given RELAX-NG schema. Or in the case of XML Schema one can use
saxon:evaluate() (https://www.saxonica.com/documentation12/index.html#!functions/saxon/evaluate) or <xsl:evaluate>
to validate any XML file. Once bound to an XSLT variable, such error reports can be
used very creatively. And of course Skeleton or SchXslt could be leveraged to
convert a Schematron into SVRL-making XSLT.
But what if the XSLT library that needs the SVRL report is the very same library
upon which the Schematron file depends? We run up against the constraint of mutual
dependence. Two XSLT files may not include each other (although that may change in
XSLT 4.0). We want to be able to use the Schematron in its own right. But we also
want to compile it to an SVRL-making XSLT file that can be grafted within the main
XSLT project.
This model, although the most sophisticated of the four we have so far examined,
has the most in common with Model A. That is, the Schematron file expresses all our
rules, and draws from the XSLT tier only for variables and functions. The Schematron
file might be quite lengthy, with many patterns and rules.
There are solutions to the problem of mutual inclusion, and the one I have opted
for here requires introducing to the Schematron file a static XSLT parameter.
<xsl:param> is supported by the Skeleton implementation, but not
by SchXslt (at this writing). But SchXslt’s MIT license allows us to make the
necessary modifications.
We also make sure that we use <xsl:import> (not include), because
we are going to declare the same static parameter in the XSLT library, which will
import the XSLT that is built by Skeleton or SchXslt.
The abstract idea is made clear with some example code, with key sections set in
boldface.
Model D Schematron file widgets.sch
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:f="my-functions" queryBinding="xslt3">
<xsl:param name="schematron-is-main-point-of-entry" as="xs:boolean" select="true()" static="yes"/>
<xsl:import href="widgets.xsl" use-when="$schematron-is-main-point-of-entry"/>
<sch:ns prefix="f" uri="my-functions"/>
<sch:pattern>
<sch:rule context="widget">
<sch:report test="@id = $duplicate-widget-ids">Duplicate id.</sch:report>
</sch:rule>
<sch:rule context="widget/name">
<sch:report test=". = f:duplicate-strings(../name)">Names should not be
duplicated.</sch:report>
</sch:rule>
</sch:pattern>
</sch:schema>In the above code sample, note the use of the static parameter and the import
statement, which allows our parameter to shadow the one in the XSLT file. Note also
@use-when, which will determine whether this XSLT element will even
be used.
Now the XSLT library:
Model D XSLT file widgets.xsl
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:f="my-functions"
exclude-result-prefixes="#all" version="3.0" default-mode="widgets">
<xsl:param name="schematron-is-main-point-of-entry" as="xs:boolean" select="false()" static="yes"/>
<xsl:import href="widgets-svrl-maker_thank-you-skeleton.xsl"
use-when="not($schematron-is-main-point-of-entry)"/>
<xsl:import href="widgets-svrl-maker_thank-you-schxslt.xsl"
use-when="not($schematron-is-main-point-of-entry)"/>
<xsl:variable name="duplicate-widget-ids" as="xs:string*"
select="f:duplicate-strings(//widget/@id)"/>
<xsl:function name="f:duplicate-strings" as="xs:string*">
<xsl:param name="strings" as="xs:string*"/>
<xsl:for-each-group select="$strings" group-by=".">
<xsl:if test="count(current-group()) gt 1">
<xsl:sequence select="current-grouping-key()"/>
</xsl:if>
</xsl:for-each-group>
</xsl:function>
<xsl:variable name="skeleton-svrl-report" as="item()*">
<xsl:apply-templates select="/" mode="#unnamed"/>
</xsl:variable>
<xsl:variable name="schxslt-svrl-report" as="item()*">
<xsl:apply-templates select="/" mode="d8e9"/>
</xsl:variable>
<xsl:template match="/" mode="widgets">
<report>
<skeleton>
<xsl:copy-of select="$skeleton-svrl-report"/>
</skeleton>
<schxslt>
<xsl:copy-of select="$schxslt-svrl-report"/>
</schxslt>
</report>
</xsl:template>
</xsl:stylesheet>The <xsl:import> statements presume access to the SVRL-creating
XSLT, courtesy Skeleton or SchXslt. The names of the files referenced by
@href attempt to make clear this subtle point. That is, we need
some system (manual or automated) that can convert the Schematron, on a whim’s
notice, to the appropriate XSLT package.
Just like the Schematron file, the XSLT library invokes the same static parameter
(albeit with the opposite value), and it points with <xsl:import>
declarations to two possible XSLT files that create SVRL reports, one generated by
Skeleton and the other generated by SchXslt.
The @use-when attribute is key. The <xsl:import>
declarations are retained if the file is the main point of entry, and dropped
otherwise. The static parameters ensure that each set of XSLT files can invoke the
other – the push-me pull-you aspect of the model – without triggering a fatal XSLT
error.
The widgets.xsl file presented above does not do very much of
interest. It simply returns the two different SVRL reports, but the global variables
$skeleton-svrl-report and $schxslt-svrl-report could
be used in creative ways in a more developed form of the project.
Model D depends upon a strong symmetric contract between the XSLT and Schematron
files. In writing the Schematron file, one needs to know what the XSLT is creating,
and those who write the XSLT need to know about the Schematron file, or, rather,
they need to know about its SVRL-making XSLT representation. Skeleton takes over the
unnamed template mode as its primary mode, but SchXslt uses a hexadecimal name for
its primary mode. The XSLT tier needs to accommodate the decisions made by either
implementation about how to build the template modes.
I am unaware of any public project that uses Model D. In private development for
the Federal Government, I have used the push-me pull-you method in the GPO XML
Toolkit, where validation of the Federal Register needs to be performed and
presented in different contexts. It needs to be fired directly in an XML editor on
the command line, but it is also necessary to synthesize the validation report into
the validandum to create a visually appealing HTML file. I do
not expect Model D to be used commonly, because it is tailored for projects that
have tightly coupled their Schematron files with an advanced XSLT function library,
and this does not happen often.
The Schematron-XSLT Partnership
I hope it is clear by now that Schematron shares a special relationship with XSLT.
When that relationship is leveraged, Schematron gets an upgrade, from the most
expressive XML schema language
to the most expressive and
powerful XML schema language.
I am not suggesting that the models I
propose here should supplant any others. Quite the contrary. Schematron can be used
and
repurposed in many ways, with different results. I hope that I have shown that when
Schematron is imagined as an interface for a constrained form of XSLT, and when we
embrace that vision, some rather sophisticated models of Schematron emerge.
It is worth concluding with thoughts about how new versions of Schematron might
leverage and enhance that relationship. Here are some ideas:
-
Explicitly allow <xsl:param> and
<xsl:import> as top-level elements (before
<sch:pattern> is fine). Perhaps deprecate (but not
forbid) the use of <xsl:key> and
<xsl:function>, to encourage a stronger separation of
concerns.
-
Create stronger bridges between Schematron phases and XSLT parameters.
This needs a bit of explanation. When a user chooses a phase name, they are
effectively doing the same thing they do when they change the value of a
global parameter in XSLT. Would it not be beneficial to bind phase selection
to a parameter, so that a Schematron phase can affect how the companion XSLT
library behaves? We could postulate that all phase names are tacitly passed
to an assumed XSLT static parameter <xsl:param name="sch:phases"
static="true" as="xs:string*"/>, shadowing any XSLT static
parameters of the same name in any imported XSLT. This mechanism would allow
XSLT developers to adjust their code according to the phases requested by
the user.
Regardless of how Schematron develops, the benefits are already clear. I hope that
these four models of advanced Schematron validation stir your imagination.
References
[Jelliffe_2020] Jelliffe, Rick. ISO Schematron 2020 Released.
Schematron.com, n.d., https://schematron.com/standards/iso_schematron_2020_released.html.
[Kalvesmaki_2022] Kalvesmaki, Joel. String Comparison in XSLT with
tan:diff().
Presented at Balisage: The Markup Conference 2021, Washington, DC, August 2
- 6, 2021. In Proceedings of Balisage: The Markup Conference
2021. Balisage Series on Markup Technologies, vol. 26 (2021). doi:https://doi.org/10.4242/BalisageVol26.Kalvesmaki01.
[Siegel_2022a] Siegel, Erik. Schematron Query Language Binding and
XSLT.
XML.com, Oct. 17, 2022, https://www.xml.com/articles/2022/10/17/schematron-qlb-xslt/.
[Siegel_2022b] Siegel, Erik. Schematron: A
Language for Validating XML. Denver: XML Press, 2022.
[Schematron_2016] ISO/IEC 19757-3:2016 Information
technology — Document Schema Definition Languages (DSDL) — Part 3: Rule-based
validation using Schematron.
×Kalvesmaki, Joel. String Comparison in XSLT with
tan:diff().
Presented at Balisage: The Markup Conference 2021, Washington, DC, August 2
- 6, 2021. In Proceedings of Balisage: The Markup Conference
2021. Balisage Series on Markup Technologies, vol. 26 (2021). doi:https://doi.org/10.4242/BalisageVol26.Kalvesmaki01.
×Siegel, Erik. Schematron: A
Language for Validating XML. Denver: XML Press, 2022.
×ISO/IEC 19757-3:2016 Information
technology — Document Schema Definition Languages (DSDL) — Part 3: Rule-based
validation using Schematron.