Note
The work presented in this paper is part of the project A2 (Sekimo) of the Research Group 437 Text-technological modelling of information funded by the German Research Foundation[1].
Introduction
Multi-dimensionally annotated linguistic corpora have been established as a means for thorough linguistic analysis during the last years. An overview of architectures for complex or concurrent markup including non-XML based approaches such as the Layered Markup and Annotation Language (LMNL, cf. Tennison, 2002, Cowan et al., 2006) in conjunction with Trojan milestones following the HORSE (Hierarchy-Obfuscating Really Spiffy Encoding) or CLIX model can be found in DeRose, 2004. Sperberg-McQueen, 2007 and Marinelli et al., 2008, too, discuss and compare state of the art approaches in overlapping markup such as colored XML (cf. Jagadish et al., 2004) and the tabling approach described by Durusau and O'Donnel, 2004, further approaches can be found in Stührenberg and Goecke, 2008. However, since standardization efforts with respect to a sustainable (i.e. preferable XML-based) annotation format and mechanism (e.g. the Graph-based Format for Linguistic Annotations, GrAF, cf. Ide and Suderman, 2007) have not yet been finished, other XML-based solutions are available, such as using multiple or twin documents (as Marinelli et al., 2008 call them if they share some annotation, the so-called sacred markup). The Text Encoding Initiative (TEI, Burnard and Bauman, 2008) proposes additional solutions for dealing with multi-dimensional markup: apart from standoff markup, (cf. Thompson and McKelvie, 1997 and TEI's chapters 16.9 and 20.4), milestone elements (chapter 20.2) or fragmentations and joints (chapter 20.3) can be used. Witt et al., 2009 describe a system that adopts TEI's feature structures (chapter 18) as a meta-format for representing heterogenous complex markup.
While most of the before mentioned approaches target at the representation of multi-dimensional annotation, their usage in validating and analyzing multiple annotation layers is restricted: non-XML-based formats usually lack mechanisms for validating overlapping markup, since most proposed document grammar formalisms remain in a proposal state only, such as Rabbit/Duck grammars for GODDAG (general ordered-descendant directed acyclic graph) structures/TexMECS (cf. Sperberg-McQueen, 2006), XCONCUR-CL (cf. Schonefeld, 2007) or Creole (Composable Regular Expressions for Overlapping Languages etc., cf. Tennison, 2007) a powerful extension to RELAX NG (ISO/IEC 19757-2:2003) developed in the LMNL community. The same holds for the support for XML's companion specifications such as XPath, XSLT or XQuery (although at least alternative query languages have been proposed by Jagadish et al., 2004, Iacob and Dekhtyar, 2005, Iacob and Dekhtyar, 2005a, Alink et al., 2006, Alink et al., 2006a and especially Bird et al., 2006 for linguistic analysis). So if validating complex markup is an issue, it is easier to stick with XML-based approaches, such as NITE (cf. Carletta et al., 2003, Carletta et al., 2005), PAULA (Potsdam Austauschformat für Linguistische Annotationen, Potsdam Interchange Format for Linguistic Annotation, cf. Dipper, 2005, Dipper et al., 2007) or the Sekimo Generic Format (SGF, cf. Stührenberg and Goecke, 2008 and the following section).
SGF – the story so far
The development of the Sekimo Generic Format (SGF) has begun in 2006 and has been grounded on the Prolog fact base format that was introduced by Witt, 2002 and Witt, 2004 after first proposals by Sperberg-McQueen et al., 2000 and Sperberg-McQueen et al., 2002. SGF was developed for storing multiple annotated linguistic corpus data and examining relationships between elements derived from different annotation layers in an XML conformant way. Speaking in technical terms, SGF follows the Annotation Graph's formal model (cf. Bird and Liberman, 1999, Bird and Liberman, 2001) and modifies the classic standoff approach in the way that multiple annotation layers are stored together in a single instance while XML namespaces are used to differentiate between SGF's base layer, metadata and annotation layers. This allows for the application of SGF for a large variety of linguistic annotations, including diachronic corpora and multimodal annotation, amongst others.
The basic principle of the Sekimo Generic Format (and its successor, XStandoff, cf. section “The development of SGF to XStandoff”) is the use of positions in the character stream (or in time) for referring to annotations[2].
Figure 1: Addressing character positions
T h e s u n s h i n e s b r i g h t e r . 00|01|02|03|04|05|06|07|08|09|10|11|12|13|14|15|16|17|18|19|20|21|22|23|24
This character stream is used to link between annotations and the primary data. A classic example of concurring annotations where overlaps may occur is the combination of morpheme and syllable annotation. We start with the morpheme annotation shown in Figure 2.
Figure 2: Morpheme annotation for a simple sentence
<morphemes xmlns="http://www.xstandoff.net/morphemes" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.text-technology.de/sekimo/morphemes ../xsd/morphemes.xsd"> <m>The</m> <m>sun</m> <m>shine</m> <m>s</m> <m>bright</m> <m>er</m>. </morphemes>
The graphic representation of this annotation layer can be seen in Figure 3.
Figure 3: Graphic representation of the morpheme annotation layer
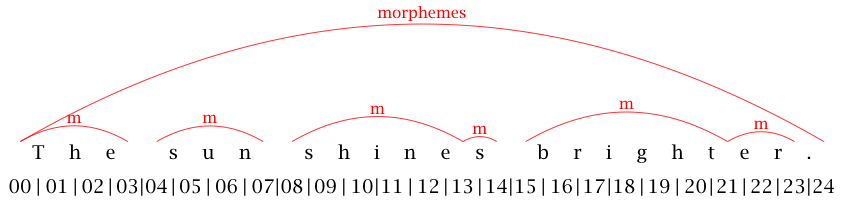
We then add a second layer containing syllable annotation, similar to the one shown in Figure 4.
Figure 4: Syllable annotation layer for a simple sentence
<syllables xmlns="http://www.xstandoff.net/syllables" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.text-technology.de/sekimo/syllables ../xsd/syllables.xsd"> <s>The</s> <s>sun</s> <s>shines</s> <s>brigh</s> <s>ter</s>. </syllables>
The graphic representation of this annotation can be seen in Figure 5.
Figure 5: Graphic representation of the syllable annotation layer
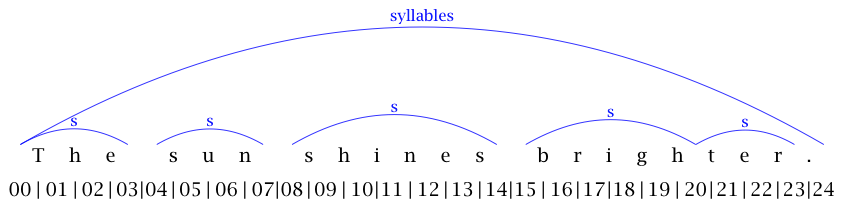
When one tries to combine both annotation levels an overlap occurs at the position of the 't' in the word 'brighter', which can easily be observed in Figure 6.
Figure 6: Combined graphic representation of both annotation layers (labels removed for readability reasons)
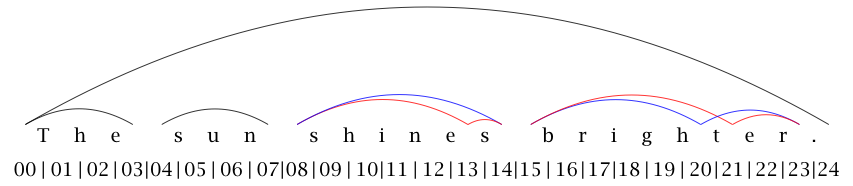
Classic XML-based inline annotation formats fail to model these overlapping structures due to their formal model of a single-rooted tree while classic standoff annotation (i.e. using markup separated from the primary data and storing different annotation layers in separate files) lacks mechanisms for analyzing relations between several annotation layers. The Sekimo Generic Format was developed for storing multiple annotated linguistic corpus data and examining relationships between elements derived from different annotation layers in a single file and therefore tries to use the benefits of standoff markup without taking the before-mentioned problems into account.
A second design goal during the development of SGF was the possibility to reuse the
structure and features of existing annotation formats. SGF consists only of a base
layer which
serves as meta-markup language or as a container for standoff representations of the
original
inline annotations. In addition, the base layer supports storing of the primary data
(i.e.,
the data that is annotated), its segmentation, metadata regarding both the primary
data and
its annotation (either internally inside the SGF instance or via a reference to external
metadata resources), and provides SGF's log functionality (i.e. the possibility to
store an
instance's edit history). Segmentation of the primary data is application driven,
i.e. for
textual primary data usually a character based segmentation is established by importing
a
single inline annotation and computing the start and end positions of each annotation
element
(cf. section “Building XStandoff instances: inline2XF.xsl”). XML's inherent ID/IDREF mechnism is used for
linking between annotation elements and the corresponding segments of the primary
data which
are defined by SGF's segment element. Overlapping segments may occur and a single
character range (a segment) may be part of multiple annotation levels, reducing the
overall
amount of segments by eliminating duplicates. SGF is defined by a number of XML schema
files
containing embedded Schematron (ISO/IEC 19757-3:2006) assertions for additional
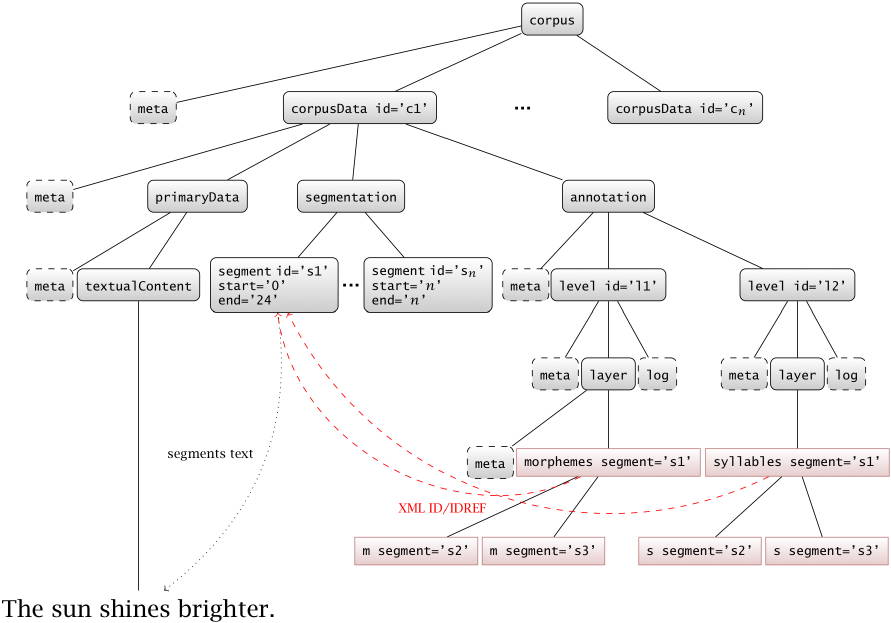
validation constraints and is available under the LGPL 3 license[3].Figure 7 shows a graphical overview of a prototypic SGF
instance's structure. Note that both corpus and corpusData are valid
root elements of an SGF instance allowing for storing single corpus entries or whole
corpora
in a single instance. Following Goecke et al., 2009 we differentiate between the
concept that serves as the background for the annotation (the level) and its XML serialization
(the layer). Elements drawn with dashed borders are optional (not every possible occurence
shown due to space restrictions), elements colored red do not belong to the SGF namespace
and
are shown for demonstration purposes only.
Figure 7: The structure of an SGF instance
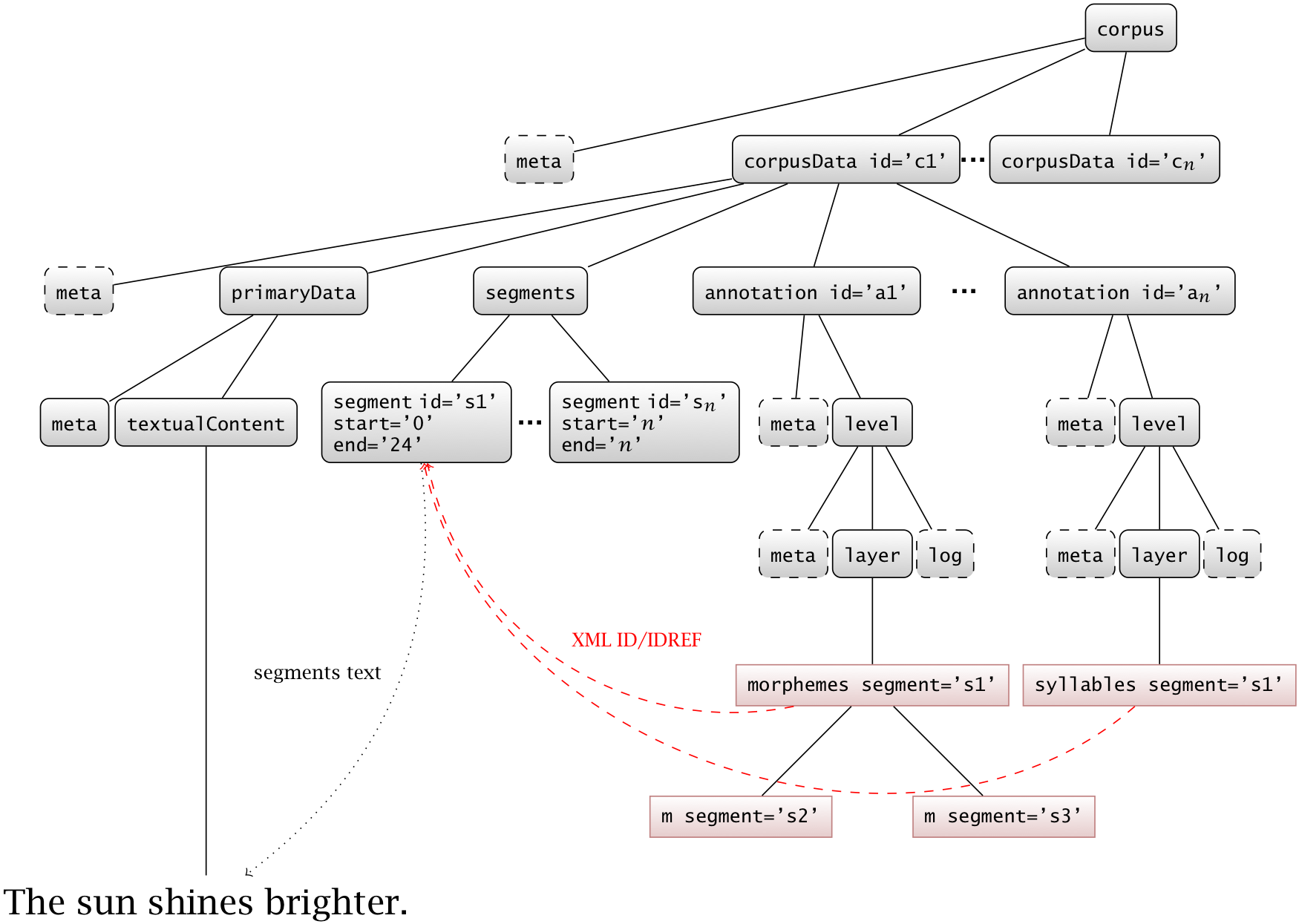
Figure 8 shows the respective SGF instance containing both annotation layers.
Figure 8: The SGF instance containing both syllable and morpheme annotation
<sgf:corpusData xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.text-technology.de/sekimo ../xsd/sgf.xsd"
xmlns="http://www.text-technology.de/sekimo"
xmlns:sgf="http://www.text-technology.de/sekimo"
xml:id="c1" sgfVersion="1.0">
<sgf:primaryData start="0" end="24" xml:lang="en">
<textualContent>The sun shines brighter.</textualContent>
</sgf:primaryData>
<sgf:segments>
<sgf:segment xml:id="seg1" type="char" start="0" end="24"/>
<sgf:segment xml:id="seg2" type="char" start="0" end="3"/>
<sgf:segment xml:id="seg3" type="char" start="4" end="7"/>
<sgf:segment xml:id="seg4" type="char" start="8" end="14"/>
<sgf:segment xml:id="seg5" type="char" start="8" end="13"/>
<sgf:segment xml:id="seg6" type="char" start="13" end="14"/>
<sgf:segment xml:id="seg7" type="char" start="15" end="21"/>
<sgf:segment xml:id="seg8" type="char" start="15" end="20"/>
<sgf:segment xml:id="seg9" type="char" start="20" end="23"/>
<sgf:segment xml:id="seg10" type="char" start="21" end="23"/>
</sgf:segments>
<sgf:annotation xml:id="a_morph">
<sgf:level xml:id="l_morph" priority="1">
<sgf:layer xmlns:morph="http://www.text-technology.de/sekimo/morphemes"
xsi:schemaLocation="http://www.text-technology.de/sekimo/morphemes ../xsd/morphemes.xsd">
<morph:morphemes sgf:segment="seg1">
<morph:m sgf:segment="seg2"/>
<morph:m sgf:segment="seg3"/>
<morph:m sgf:segment="seg5"/>
<morph:m sgf:segment="seg6"/>
<morph:m sgf:segment="seg7"/>
<morph:m sgf:segment="seg10"/>
</morph:morphemes>
</sgf:layer>
</sgf:level>
</sgf:annotation>
<sgf:annotation xml:id="a_syll">
<sgf:level xml:id="l_syll" priority="0">
<sgf:layer xmlns:syll="http://www.text-technology.de/sekimo/syllables"
xsi:schemaLocation="http://www.text-technology.de/sekimo/syllables ../xsd/syllables.xsd">
<syll:syllables sgf:segment="seg1">
<syll:s sgf:segment="seg2"/>
<syll:s sgf:segment="seg3"/>
<syll:s sgf:segment="seg4"/>
<syll:s sgf:segment="seg8"/>
<syll:s sgf:segment="seg9"/>
</syll:syllables>
</sgf:layer>
</sgf:level>
</sgf:annotation>
</sgf:corpusData>SGF's main benefit with respect to other non-XML-based developments such as TexMECS (cf. Huitfeldt and Sperberg-McQueen, 2001) or the above-mentioned approaches is the usage of standard, non-extended XML together with its accompanying technologies, such as XPath, XSLT and XQuery. We believe that this may be an argument when it comes to the sustainability aspect of larger corpora. In our project, we have developed a corpus consisting of 14 texts (both german scientific and newspaper articles, 3,084 sentences, 56,203 tokens, 11,740 discourse entities, 4,323 anaphoric relations in total), densely annotated on four different levels (logical document structure, syntactic annotation, discourse entities and anaphoric relations). A partner project adopted SGF as export format for lexical chaining (SGF-LC, cf. Waltinger et al., 2008). In addition, it is used as import and export format of the web based annotation tool Serengeti (cf. Stührenberg et al., 2007) and was chosen as one of the possible pivot formats for the Anaphoric Bank (cf. http://www.anaphoricbank.org and Poesio et al., 2009). Cf. Stührenberg and Goecke, 2008 and Witt et al., 2009a for a detailed discussion of SGF and its use in analyzing the before-mentioned linguistic corpus.
The development of SGF to XStandoff
The version of SGF discussed in Stührenberg and Goecke, 2008 is considered as stable version 1.0. However, work has begun on a forthcoming version addressing some minor issues – this developer version is called XStandoff (XStandoff version 1.1 internally, although the final version number may change during the ongoing development process). These newer developments which are described in this section are accompanied by the creation of different tools which allow the broader use of XStandoff for the analysis of multi-dimensional markup (discussed in section “The XStandoff toolkit”).
The changes made to the SGF's base layer can be divided into structural changes that
affect the compatibility between SGF 1.0 and XStandoff 1.1 instances (some of which
break the
compatibility – for this reason a new name and namespace was chosen) and changes
made in the underlying XML schemas that define the XStandoff meta format. XStandoff
1.1
supports external metadata via the newly introduced metaRef element which can be
used as child element of the corpus, corpusData,
resource, annotation, level, layer and
log elements as an alternative to the already established meta
element. Analogical, SGF's location element that has been used for providing a
reference to a file containing the primary data was dropped in favor of the new
primaryDataRef element. Both, metaRef and
primaryDataRef share the same globally defined RefType type
(together with the corpusDataRef and resourceRef elements) which
stores the attributes uri, encoding and mime-type,
improving the readability of the underlying XStandoff schema. The type attribute
which was located at the corpusData element in SGF and was used to differentiate
between textual and multimodal corpus entries was removed, since corpusData
elements containing multiple primaryDataRef children depicting primary data files
of different mime-types (e.g. video, audio and text files) should not have a singular
type.
The priority attribute was moved from the level element to the
layer element. The attribute has been used to prioritize annotation layers
(i.e. the XML serialization) in case of overlapping markup, therefore the re-arrangement
should clarify its application.
Other elements have been renamed: segments is now called
segmentation and the annotation element may only appear once at
most underneath a corpusData entry. SGF allowed several annotation
elements but since XStandoff supports multiple levels and layers, the annotation
element serves only as a wrapper similar to the segmentation element.
The XML schema for XStandoff's log functionality is now incorporated into XStandoff's base schema and can be considered as an integrated component of XStandoff's core functionality (although it is still application-driven). Figure 9 shows the resulting new structure. Again, keep in mind that the elements colored red do not belong to the XStandoff meta language.
Figure 9: The structure of an XStandoff instance
In general, valid SGF instances can be updated with little or no effort at all (depending on the use of former optional attributes and elements) to fully comply to XStandoff.
Disjoints and continuous segments and containment and dominance
Annotating discontinuous or disjoint such as non-contiguous multi word expressions or separable verbs structures (e.g. in German) is a challenging task in XML (cf. Pianta and Bentivogli, 2004). Although it would be possible to use separate layers in XStandoff to describe these structures as a workaround, disjoints and continuous segments are supported natively. As a concrete example, take the well-known beginning of 'Alice in Wonderland' (cf. Sperberg-McQueen and Huitfeldt, 2008 for a general discussion of the problems raised by discontinuity).
Alice was beginning to get very tired of sitting by her sister on the bank and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, "and what is the use of a book," thought Alice, "without pictures or conversations?"
The XStandoff instance of this example is shown in Figure 10.
Since both, p and q element belong to the logical document
structure level, only one level element is included. The quotation is annotated
as a q element constructed by the disjoint segment with the
identifier seg4 which itself uses the segments seg2 and seg3.
Figure 10: Disjoint segments in XStandoff
<xsf:corpusData xmlns="http://www.xstandoff.net/2009/xstandoff/1.1"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsf="http://www.xstandoff.net/2009/xstandoff/1.1"
xsi:schemaLocation="http://www.xstandoff.net/2009/xstandoff/1.1 ../xsd/xsf.xsd"
xsfVersion="1.1" xml:id="alice">
<xsf:primaryData start="0" end="302">
<textualContent>Alice was beginning to get very tired of sitting by her
sister on the bank and of having nothing to do: once or twice she had
peeped into the book her sister was reading, but it had no pictures or
conversations in it, "and what is the use of a book," thought Alice,
"without pictures or conversations?"</textualContent>
</xsf:primaryData>
<xsf:segmentation>
<xsf:segment xml:id="seg1" type="char" start="0" end="302"/>
<xsf:segment xml:id="seg2" type="char" start="218" end="250"/>
<xsf:segment xml:id="seg3" type="char" start="266" end="302"/>
<xsf:segment xml:id="seg4" type="seg" segments="seg2 seg3" mode="disjoint"/>
</xsf:segmentation>
<xsf:annotation>
<xsf:level xml:id="alice-log">
<xsf:layer xmlns:log="http://www.xstandoff.net/alice/log"
xsi:schemaLocation="http://www.xstandoff.net/alice/log ../xsd/alice-log.xsd"
priority="0">
<log:text xsf:segment="seg1">
<log:p xsf:segment="seg1">
<log:q xsf:segment="seg4"/>
</log:p>
</log:text>
</xsf:layer>
</xsf:level>
</xsf:annotation>
</xsf:corpusData>Due to the differentiation between the annotation concept (the level) and its XML
representation (the layer), it is possible to sum up different XML serializations
underneath
the very same level element. XStandoff's layer element serves as a wrapper for
the slightly converted representation of the former inline annotation – the only
changes that are made concern the deletion of text nodes and the addition of the
segment attribute that links to the corresponding segment
element. The conversion applies to both the annotation instance and its underlying
XML
schema description (into which XStandoff's base layer is imported to add the
segment attribute to all element nodes as optional attribute) – the
latter can be used both for validating the original inline annotation and the converted
representation as part of the XStandoff instance. In contrast to other approaches
the
hierarchical structure of and the attributes included in the imported annotation layers
remain unchanged.
In Sperberg-McQueen and Huitfeldt, 2008 the authors make an argument for
distinguishing more broadly between dominance and containment. The former should be
regarded
as Sperberg-McQueen and Huitfeldt, 2008 while the latter is regarded as Sperberg-McQueen and Huitfeldt, 2008. To clarify this distinction between both
concepts different XStandoff representations are possible as well (cf. Figure 11 and Figure 12). In these
alternative representations, dominance is encoded as hierarchical relationship between
the
two nodes p and q while containment is encoded via the
corresponding segments' start and end positions.
Figure 11: Disjoint segments in XStandoff – Excerpt of an alternative representation
in which p dominates the q fragments
<!-- ... -->
<xsf:layer xmlns:log="http://www.xstandoff.net/alice/log"
xsi:schemaLocation="http://www.xstandoff.net/alice/log ../xsd/alice-log.xsd"
priority="0">
<log:text xsf:segment="seg1">
<log:p xsf:segment="seg1">
<log:q xsf:segment="seg2"/>
<log:q xsf:segment="seg3"/>
</log:p>
<log:q xsf:segment="seg4"/>
</log:text>
</xsf:layer>
<!-- ... -->Figure 12: Disjoint segments in XStandoff – Excerpt of an alternative representation
in which p does not dominate q
<!-- ... -->
<xsf:layer xmlns:log="http://www.xstandoff.net/alice/log"
xsi:schemaLocation="http://www.xstandoff.net/alice/log ../xsd/alice-log.xsd"
priority="0">
<log:text xsf:segment="seg1">
<log:p xsf:segment="seg1"/>
<log:q xsf:segment="seg4"/>
</log:text>
</xsf:layer>
<!-- ... -->Other possible XStandoff instances include the separation of the q element
from the p layer at all (i.e. using separate layer elements which
is permitted by XStandoff), however, as already stated above, when dealing with disjoints
units, the inherent methods should be preferred.
Inline XStandoff
In contrast to SGF, XStandoff supports a newly introduced inline representation (cf.
Section section “Building inline XStandoff annotations: XSF2inline.xsl”), containing the virtual root element
inline and the generic milestone element (modelled according to
the respective TEI element, cf. Burnard and Bauman, 2008). During the Sekimo project
Schiller's 'Die Bürgschaft' was annotated on the following annotation levels: words,
morphemes, syllables, verse, prose and phrase[4]. We've converted these six levels into a single XStandoff instance[5]. The inline representation shown in Figure 13 was
generated afterwards (cf. section “Demonstration: Creating an inline XStandoff annotation”).
Figure 13: Part of the inline XStandoff instance of Schiller's 'Die Bürgschaft' annotated on six levels.
<xsf:inline xmlns:xsf="http://www.xstandoff.net/2009/xstandoff/1.1"
xmlns="http://www.xstandoff.net/2009/xstandoff/1.1"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:silbe="http://www.xstandoff.net/buergschaft/silbe"
xmlns:wort="http://www.xstandoff.net/buergschaft/wort"
xmlns:vers="http://www.xstandoff.net/buergschaft/vers"
xmlns:morpheme="http://www.xstandoff.net/buergschaft/morpheme"
xmlns:prosa="http://www.xstandoff.net/buergschaft/prosa"
xmlns:phrase="http://www.xstandoff.net/buergschaft/phrase">
<silbe:text xsf:segment="seg1">
<silbe:body xsf:segment="seg1">
<wort:text xsf:segment="seg1">
<wort:body xsf:segment="seg1">
<vers:text a="b" xsf:segment="seg1">
<vers:body xsf:segment="seg1">
<morpheme:text xsf:segment="seg1">
<morpheme:body xsf:segment="seg1">
<prosa:text xsf:segment="seg1">
<prosa:body xsf:segment="seg1">
<phrase:text xsf:segment="seg1">
<phrase:body xsf:segment="seg1">
<silbe:head xsf:segment="seg2">
<wort:head xsf:segment="seg2">
<vers:head xsf:segment="seg2">
<morpheme:head xsf:segment="seg2">
<prosa:head xsf:segment="seg2">
<phrase:head xsf:segment="seg2">Die Bürgschaft</phrase:head>
</prosa:head>
</morpheme:head>
</vers:head>
<!-- ... -->
</xsf:inline>Since each single annotation layer contains a text root element, a
body and a head element, these elements occur six times in the
resulting XStandoff instance. It should be noted, that in this case the inline XStandoff
instance is more than two-thirds bigger in size than the 'classic' (i.e. standoff)
XStandoff
instance (763.9 KB vs. 452.5 KB) and is far from being easily readable.
Introducing the 'all' namespace
For both 'classic' XStandoff and especially for inline XStandoff instances, a new
namespace – http://www.xstandoff.net/2009/all – was
introduced. Elements belonging to this namespace do not only share the same range
of
characters but the generic identifier and are present in all annotation layers (e.g.
the
above mentioned text root element). Figure 14 shows
the same part of the inline XStandoff instance using the newly introduced namespace.
Note
that the a attribute of the text element of the verse layer
remains intact. Cf. Figure 19 in section “Demonstration: Creating an inline XStandoff annotation” for an
extended excerpt.
Figure 14: Excerpt of the inline XStandoff instance of Schiller's 'Die Bürgschaft' using the all namespace.
<xsf:inline xmlns:sgf="http://www.text-technology.de/sekimo"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.xstandoff.net/2009/xstandoff/1.1"
xmlns:all="http://www.xstandoff.net/2009/all"
xmlns:silbe="http://www.xstandoff.net/buergschaft/silbe"
xmlns:wort="http://www.xstandoff.net/buergschaft/wort"
xmlns:vers="http://www.xstandoff.net/buergschaft/vers"
xmlns:morpheme="http://www.xstandoff.net/buergschaft/morphem"
xmlns:prosa="http://www.xstandoff.net/buergschaft/prosa"
xmlns:phrase="http://www.xstandoff.net/buergschaft/phrase">
<all:text xsf:segment="seg1" vers:a="b">
<all:body xsf:segment="seg1">
<all:head xsf:segment="seg2">Die Bürgschaft</all:head>
<!-- ... -->
</xsf:inline>This mechanism allows for a better readability of a multi-dimensional annotated inline XStandoff instance. However, one should be aware that the all namespace should only be used when the respective elements not only bear the same generic identifier and character range but also the same semantic value.
Note that the inline XStandoff instance lacks the support for validation of multi-dimensional annotations that is present in 'classic' XStandoff instances and should be therefore considered for demonstration purposes only.
The XStandoff toolkit
In the context of XStandoff's development several XSLT 2.0 stylesheets (cf. Kay, 2007, Kay 2008) have been created which allow for the convenient generation and editing of XStandoff files[6]. Since there are no product specific extensions, transformations should be able to be executed by every XSLT processor supporting XSLT 2.0. The transformations during the test phase of the stylesheets have been performed by the Saxon XSLT processor which is available both as Open Source version Saxon-B and as optimized, schema-aware, commercial version Saxon-SA[7].
Currently the XStandoff toolkit consists of four stylesheets which perform basic processing of XStandoff instances. They are responsible for the conversion of a single inline annotation to XStandoff, the merging of XStandoff annotation layers corresponding to the same primary data, the removing of single layers from an XStandoff file and, the conversion of an XStandoff instance to an XStandoff inline annotation (cf. section “The development of SGF to XStandoff”). These tasks might seem simple, but as you will see it would hardly be possible to perform them manually.
Building XStandoff instances: inline2XF.xsl
At the moment the easiest way of building XStandoff files is to transform an inline annotation into XStandoff by the stylesheet inline2XSF.xsl. This excludes the coverage of overlapping markup at first sight because of the inline annotation not including such structures. But we will show how to include more than one inline annotation into a single XStandoff file by merging several XStandoff annotations (cf. section “Merging XStandoff instances: mergeXSF.xsl”). By this means overlapping structures can be covered.
The transformation into XStandoff requires an input XML file ideally containing elements bound by XML namespaces. Every single namespace evokes the output of a layer in XStandoff which contains the elements of the namespace. Thereby the default (or empty) namespace is treated like the named ones. Thus inline annotations without explicit namespace declarations can also be processed (in this case a namespace will be generated).
The process of converting an inline annotation to XStandoff is divided into two steps: Firstly, segments are built on the basis of the occurring elements. There are two possible ways of mapping the element boundaries to the textual content in the form of character positions. The preferred way of reaching such a mapping is the use of a primary data file which contains the bare text without annotations. The name of this file can be provided during the transformation call by specifying the stylesheet parameter primary-data. Providing the location of a primary data file leads to a comparison of the content of the primary data file and the textual content of the input file of the transformation. This guarantees primary data identity. If no primary data location is provided, the textual content of the input file is used to build up the primary data. This has certain disadvantages such as the lack of line breaks since these cannot easily be inferred by the textual content of an XML file. Furthermore, the automatic conversion of the textual content of the input file to be used as primary data relies on heuristics which have to detect white space characters. Because of the complexity of this task it is possible to get undesirable results.
After the building of segments, the second step of the transformation is to return layers on the basis of namespaces. Thus for every namespace the corresponding elements are released from the initial inline annotation and copied into the layer maintaining the embedding relations. Meanwhile the elements in the XStandoff layer get connected to the according segments by ID/IDREF binding. In this manner one segment can serve as a reference for elements from different layers.
There are several additional optional parameters which can control certain aspects of the transformation from inline to XStandoff. The most important of them will be briefly outlined below.
-
virtual-root (data type: xs:string; default value: '')
Specifies a unique element (if no error occurs) which serves as the starting point of the conversion of the input file. By default the whole file will be converted starting at the document root.
-
meta-root (data type: xs:string; default value: 'header')
This parameter determines the location of metadata in the input XML document (if any). By this means it can be copied into the XStandoff instance. Analogous to the parameter virtual-root an element name is expected as a value of meta-root.
-
local-xsd (data type: xs:boolean; default value: 0)
Determines whether the corresponding XStandoff XML Schema files are stored locally or shall be taken from the WWW (i.e. from
http://www.xstandoff.net/2009/xstandoff/1.1). By default the global XSDs are used. -
include-ws-segments (data type: xs:boolean; default value: 0)
XStandoff uses segments for referencing units of the primary data annotated in one or more annotation layers. Additional segments for non-character data (i.e. white space characters, such as blanks, line breaks, etc.) can be computed and returned by the stylesheet as well if the parameter include-ws-segments is set to '1'.
-
all-layer (data type: xs:boolean; default value: 0)
The output of an 'all-layer' (cf. section “Inline XStandoff”) containing elements present in all annotation layers depends on the specification of this parameter. By default its value is set to '0' which avoids the transfer of the respective elements into the 'all-layer' (cf. section “Introducing the 'all' namespace”).
Merging XStandoff instances: mergeXSF.xsl
Due to the frequent use of the ID/IDREF mechanism in XStandoff for establishing
connections between segment elements (i.e. the limits of the respective text
span in the primary data's character stream) and the corresponding annotation, manually
merging XStandoff files seems quite unpromising. The XSLT stylesheet
mergeXSF.xsl transforms two XStandoff instances into a single one containing
the annotation levels (or layers) from both input files. The first XStandoff file
is
provided as the input file of the transformation, the second file's name has to be
included
via the stylesheet parameter merge-with.
The main problem is to adapt the segments from the involved XStandoff files to each other. On the one hand there are segments in the different files spanning over the same string of the primary data, but having distinct IDs. In this case the two segments have to be replaced by one. On the other hand there will be segments with the same ID, but spanning over different character positions. These have to get new unique IDs. The merging of the XStandoff files in general leads to a complete reorganization of the segment list making it necessary to update the segment references of the elements in the XStandoff layers. After fulfilling this duty, the XStandoff layers are included in the new XStandoff file.
The reorganization of the segment list can be disabled by configuring the stylesheet parameter keep-segments. Specifying the value '1' causes the perpetuation of the segments of the input XStandoff file. However, the segments of the file provided by the merge-with parameter are always subject to a reorganization.
In addition, the stylesheet handles the optional output of the 'all-layer'. Setting the value of the all-layer parameter to '1' evokes the inclusion of this special layer containing the elements that are present in every single annotation layer. It is irrelevant if there was an 'all-layer' present in the input files or not. Though it might happen that no such layer is returned, namely if there are no elements in the several layers which share the required features.
Currently the stylesheet only supports the merging of two single XStandoff files. Naturally this allows for a successive merging of more than two files. However it would be more straightforward to have the possibility of merging more than two XStandoff files during a single transformation. A future version of the stylesheet supporting multi-file-merge is in preparation.
Deleting parts of XStandoff instances: removeXSFcontent.xsl
For deletion of parts of an XStandoff instance the stylesheet removeXSFcontent.xsl can be applied. During the transformation call one has to
supply the ID of the element to be deleted (either level or layer)
via the value of the remove-ID parameter. The matching
element is removed from the XStandoff file and the list of segments is updated, i.e.
the
segments which solely were referenced by descendant elements of the mentioned element
are
excluded. This, admittedly, again leads to a reorganzation of the segments since these
by
default get a continuous numbering.
Similar to the usage of the mergeXSF.xsl stylesheet the reorganization of the segments can be disabled by the stylesheet parameter keep-segments. The value '1' lets the stylesheet keep the old segments, but without those only referenced by descendant elements of the deleted element.
Furthermore, the removed XStandoff content can be returned in a separate file. Specifying the value '1' for the stylesheet parameter return-removed will encourage the stylesheet to return the removed content into a new XStandoff instance. Accordingly, the new file will contain the segments referenced by elements of the removed content and the removed content itself.
Building inline XStandoff annotations: XSF2inline.xsl
In addition to the inline2XSF.xsl stylesheet there is a counterpart. XSF2inline.xsl creates an inline annotation on the basis of an XStandoff instance. The approach covers the handling of overlapping markup insofar as these structures are represented by milestone elements in the resulting inline annotation (cf. Figure 13 in section “The development of SGF to XStandoff”). Concerning this matter, the first task of the stylesheet is to detect segments whose start and end position information constitute an overlap. These segments are split up into segments representing milestones so that they can be used as an adequate basis to build an inline annotation. The linear list of segments is processed recursively by taking the currently outermost segments (those who are not included in other segments' spans which respectively are determined by their start and end positions in the character range of the primary data). The elements of the XStandoff layers which are referenced by the outermost segments are copied into the inline annotation. The segments which are embedded in the outermost segments are processed recursively.
However, copying the elements from the XStandoff layers has to be controlled by a mechanism regarding the possibility of elements from different layers referencing the same segment. These elements share the same positions for start and end tags and therefore a decision has to be made in which order they should be nested into one another. The optional stylesheet parameter sort-by refers to this circumstance. Its default value is 'measure' which means that a statistical analysis is performed by the stylesheet that diagnoses the embedding relations of all occuring element types by frequency. An expected result would be that elements representing sentence boundaries are embedded into those for paragraphs because this embedding relation is more frequent than vice versa. The only case this approach could be inadequate for are elements of different layers for which no definite statistical result for embedding can be achieved. For instance, there could be elements whose boundaries always share the same character positions, but which can clearly semantically be assigned to a certain embedding. This case cannot be covered by the statistical method.
In addition, the embedding can be based on the priority attribute of the
level (in SGF version 1.0) or the layer (in XStandoff version
1.1, cf. section “The development of SGF to XStandoff”) element. This strategy can be accessed by
specifying the value 'priority' for the parameter sort-by.
Low values of the priority attribute in the XStandoff annotation are nested
deeper in the inline annotation than higher ones. By this means the user can specify
the
embedding manually, but one has to be sure to set the values of the attribute correctly
to
get the desired result. This method underlies the assumption that there can be a
semantically grounded, definite decision for the embedding. The most promising concept
was a
mixture of the both approaches which has to be realized in future work.
There is an additional optional stylesheet parameter return-segID which can be very helpful to retain a connection between the
XStandoff file and the resulting inline annotation. By default the value of this parameter
is set to '1' which means that the segment attribute is retained throughout the
conversion process. The parameter has been added mainly for control issues.
Demonstration: Creating an inline XStandoff annotation
In this section the conversion of six original annotations into one inline XStandoff annotation will be outlined. This will demonstrate the function and execution of the several XSLT stylesheets which are involved in this process. An extract of the final result of the conversion process can be seen in section “Inline XStandoff” where the inline XStandoff annotation was introduced.
There are three major steps in order to create one inline XStandoff annotation out of the six input annotations:
-
Applying the stylesheet inline2XSF.xsl to each input annotation
-
Successively merging the resulting standoff XStandoff files into one with mergeXSF.xsl
-
Creating an inline XStandoff instance via the stylesheet XSF2inline.xsl
Applying inline2XSF.xsl
The six original annotation files are given by different annotations of Schiller's 'Die Bürgschaft' which cover several linguistic fields: words, morphemes, syllables, verse, prose and phrase.[8]
Figure 15 shows an extract of one of the original annotations. In case of missing namespaces these are created automatically by the stylesheet. For the sake of readability the namespace prefix 'wort' was added to the elements derived from this namespace.
Figure 15: The original word level annotation of 'Die Bürgschaft'
(buergschaft-wort.xml)
<wort:text xmlns:wort="http://www.xstandoff.net/buergschaft/wort">
<wort:body>
<wort:head>Die Bürgschaft</wort:head>
<wort:ws> </wort:ws>
<wort:bibl><wort:author>Friedrich Schiller</wort:author></wort:bibl>
<wort:ws> </wort:ws>
<wort:p>
<wort:s>
<wort:w>Zu</wort:w>
<wort:w>Dionys</wort:w>
<wort:w>dem</wort:w>
<wort:w>Tirannen</wort:w>
<wort:w>schlich</wort:w>
<wort:w>Damon</wort:w>,
<!--...-->
</wort:text>The corresponding primary data file buergschaft-pd.txt has the following plain text
content:
Figure 16: Primary data of 'Die Bürgschaft' (buergschaft-pd.txt)
Die Bürgschaft Friedrich Schiller Zu Dionys dem Tirannen schlich Damon, den Dolch im Gewande, Ihn schlugen (...)
The result of the invoked transformation (saxon buergschaft-wort.xml
inline2XSF.xsl primary-data=buergschaft-pd.txt) is an XStandoff instance
containing the converted annotation including references to the respective spans in
the
primary data's character stream defined by the segments elements (cf. Figure 17).
Figure 17: The converted word level annotation of 'Die Bürgschaft'
(buergschaft-wort-xsf.xml)
<xsf:corpusData xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsf="http://www.xstandoff.net/2009/xstandoff/1.1"
xsi:schemaLocation="http://www.xstandoff.net/2009/xstandoff/1.1 ../xsd/xsf.xsd"
xsfVersion="1.1"
xml:id="wort-ns">
<xsf:primaryData start="0" end="5188">
<primaryDataRef xmlns="http://www.xstandoff.net/2009/xstandoff/1.1" uri="buergschaft-pd.txt"/>
</xsf:primaryData>
<xsf:segmentation>
<xsf:segment xml:id="seg1" type="char" start="0" end="5186"/>
<xsf:segment xml:id="seg2" type="char" start="0" end="14"/>
<xsf:segment xml:id="seg3" type="char" start="14" end="15"/>
<xsf:segment xml:id="seg4" type="char" start="15" end="33"/>
<xsf:segment xml:id="seg5" type="char" start="33" end="34"/>
<!--...-->
</xsf:segmentation>
<xsf:annotation>
<xsf:level xml:id="wort-ns-level1">
<xsf:layer xmlns:wort="http://www.xstandoff.net/buergschaft/wort" priority="0"
xsi:schemaLocation="http://www.xstandoff.net/buergschaft/wort ../xsd/buergschaft_wort.xsd">
<wort:text xsf:segment="seg1">
<wort:body xsf:segment="seg1">
<wort:head xsf:segment="seg2"/>
<wort:ws xsf:segment="seg3"/>
<wort:bibl xsf:segment="seg4">
<wort:author xsf:segment="seg4"/>
</wort:bibl>
<wort:ws xsf:segment="seg5"/>
<wort:p xsf:segment="seg6">
<wort:s xsf:segment="seg7">
<wort:w xsf:segment="seg8"/>
<wort:w xsf:segment="seg9"/>
<wort:w xsf:segment="seg10"/>
<!--...-->
</xsf:corpusData>The other five input annotations are transformed analogously, serving as the basis for the next processing step: the application of the mergeXSF stylesheet.
Merging XStandoff instances
As mentioned above, several different XStandoff instances relying on the same primary
data can be combined into a single XStandoff file. However, it is not yet possible
to
integrate the respective annotation levels and layers within a single transformation
call.
In order to get a single result instance, one has to use five calls in total. The
first
call merges two of the instances (e.g. saxon -o <RESULT>.xml
buergschaft-wort-xsf.xml mergeXSF.xsl merge-with=buergschaft-silbe-xsf.xml
all-layer=1).
The next four transformation calls merge the result
(<RESULT>.xml from the previous call) with the single
remaining XStandoff instances. Due to the stylesheet parameter all-layer which is set to 1 in the call, the result will
contain a layer which stores those elements present in all layers (cf. section “Merging XStandoff instances: mergeXSF.xsl”). Figure 18 shows an extract of the
result of the five mergeXSF transformations.
Figure 18: The merged XStandoff annotation of 'Die Bürgschaft'
(buergschaft-wort-prosa-silbe-vers-phrase-morphem-xsf.xml)
<xsf:corpusData xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsf="http://www.xstandoff.net/2009/xstandoff/1.1"
xsfVersion="1.1"
xml:id="wort-ns-prosa-ns-silbe-ns-vers-ns-phrase-ns-morphem-ns"
xsi:schemaLocation="http://www.xstandoff.net/2009/xstandoff/1.1 ../xsd/xsf.xsd">
<!-- ... -->
<xsf:annotation>
<xsf:level xml:id="all-level">
<xsf:layer xmlns:all="http://www.xstandoff.net/2009/all" priority="0"
xsi:schemaLocation="http://www.xstandoff.net/2009/all ../xsd/xsf.xsd">
<all:text xmlns:vers="http://www.xstandoff.net/buergschaft/vers"
xsf:segment="seg1"
vers:a="b">
<all:body xsf:segment="seg1">
<all:head xsf:segment="seg2"/>
<!--...-->
</all:body>
</all:text>
</xsf:layer>
</xsf:level>
<xsf:level xml:id="wort-ns-level1">
<xsf:layer xmlns:wort="http://www.xstandoff.net/buergschaft/wort" priority="0"
xsi:schemaLocation="http://www.xstandoff.net/buergschaft/wort ../xsd/buergschaft_wort.xsd">
<wort:p xsf:segment="seg6">
<!--...-->
</wort:p>
</xsf:layer>
</xsf:level>
<xsf:level xml:id="prosa-ns-level1">
<xsf:layer xmlns:prosa="http://www.xstandoff.net/buergschaft/prosa" priority="0"
xsi:schemaLocation="http://www.xstandoff.net/buergschaft/prosa ../xsd/buergschaft_prosa.xsd">
<prosa:p xsf:segment="seg6">
<!--...-->
</xsf:corpusData>Converting standoff to inline
The last step which has to be applied in order to get an inline XStandoff annotation
created from the six original input annotations is the transformation done by the
stylesheet XSF2inline.xsl (saxon -o <RESULT>.xml
buergschaft-wort-prosa-silbe-vers-phrase-morphem-xsf.xml XSF2inline.xsl).
Overlaps which may occur, are covered by insertion of the newly introduced
milestone element.
Figure 19: The inline XStandoff annotation of 'Die Bürgschaft'
(buergschaft-wort-prosa-silbe-vers-phrase-morphem-inline.xml)
<xsf:inline xmlns:xsf="http://www.xstandoff.net/2009/xstandoff/1.1"
xmlns:silbe="http://www.xstandoff.net/buergschaft/silbe"
xmlns:wort="http://www.xstandoff.net/buergschaft/wort"
xmlns:vers="http://www.xstandoff.net/buergschaft/vers"
xmlns:morphem="http://www.xstandoff.net/buergschaft/morphem"
xmlns:prosa="http://www.xstandoff.net/buergschaft/prosa"
xmlns:phrase="http://www.xstandoff.net/buergschaft/phrase"
xmlns:all="http://www.xstandoff.net/2009/all">
<all:text xsf:segment="seg1" vers:a="b">
<all:body xsf:segment="seg1">
<all:head xsf:segment="seg2">Die Bürgschaft</all:head>
<all:bibl xsf:segment="seg3">
<all:author xsf:segment="seg3">Friedrich Schiller</all:author>
</all:bibl>
<silbe:p xsf:segment="seg4">
<wort:p xsf:segment="seg4">
<vers:lg xsf:segment="seg4">
<morphem:p xsf:segment="seg4">
<prosa:p xsf:segment="seg4">
<phrase:p xsf:segment="seg4">
<!--...-->
<xsf:milestone xsf:segment="seg16~1" xsf:unit="morphem:m" xsf:n="1" xsf:charpos="49"
xsf:type="start"/>
<wort:w xsf:segment="seg15">
<silbe:syll xsf:segment="seg17">Ti</silbe:syll>
<silbe:syll xsf:segment="seg18">ran</silbe:syll>
<silbe:syll xsf:segment="seg19">n<xsf:milestone xsf:segment="seg16~2"
xsf:unit="morphem:m" xsf:n="2" xsf:charpos="55" xsf:type="end"/>
<morphem:m xsf:segment="seg20">en</morphem:m>
</silbe:syll>
</wort:w>
<!--...-->
</xsf:inline Note that the above listing contains the representation of an overlap. Since morpheme
and syllable level contain concurring annotations
(<morphem:m>Tiran<silbe:syll>n</morphem:m>en</silbe:syll>)
milestone elements have been added to mark the original boundaries of the morphem:m
element.
Analyzing cross-level relations with XStandoff and XQuery
Since XStandoff is a meta language based on standard XML, a variety of XML processing tools may be used. In addition to the XStandoff toolkit an XQuery script is available as a first starting point for analyzing relations between elements derived from different annotation levels (and layers respectively). The query takes a valid XStandoff instance as input and demands to provide a target element on an included layer which is used as starting point for the finding of relations to other elements derived on different annotation layers. For this example we have chosen the English translation of Brothers Grimm's 'The three lazy ones' which was annotated with two different linguistic parsers: the freely available TreeTagger[9] and the POS tagger that is part of the eHumanities Desktop[10] which can be used at no charge as an online resource (cf. Gleim et al., 2009). The resulting XStandoff instance can be downloaded at http://www.xstandoff.net/examples/grimm.html. The output of the query contains the target element and the corresponding elements on other layers, starting with elements that share the same segment (and share therefore the identical text span in the primary data). The relations identified by the XQuery are based on the work done by Durusau and O'Donnell, 2002. An excerpt of the output can be seen in Figure 20.
Figure 20: Excerpt of the output of the XQuery applied to the 'The three lazy ones'
<results>
<relations docID="grimm_the_three_lazy_ones">
<targetElement xmlns:xsf="http://www.xstandoff.net/2009/xstandoff/1.1" start="0" end="1"
name="eHD:w" xml:id="w1_wo1" type="XY" lemma="A" xsf:segment="seg3" part="N">
<identical start="0" end="1" name="tree:token" word="a" pos="DT" xsf:segment="seg3"/>
<startPointIdentical start="0" end="1091" name="eHD:text" xml:id="t0" xsf:segment="seg1"/>
<startPointIdentical start="0" end="1091" name="eHD:body" xml:id="b0" xsf:segment="seg1"/>
<startPointIdentical start="0" end="1091" name="eHD:div" xml:id="w1_di1" xsf:segment="seg1"
part="N" org="uniform" sample="complete"/>
<startPointIdentical start="0" end="1091" name="eHD:p" xml:id="w1_pa1" xsf:segment="seg1"/>
<startPointIdentical start="0" end="127" name="eHD:s" xml:id="w1_se1" xsf:segment="seg2"
part="N"/>
<startPointIdentical start="0" end="1091" name="tree:corpus" xsf:segment="seg1"/>
</targetElement>
<targetElement xmlns:xsf="http://www.xstandoff.net/2009/xstandoff/1.1" start="2" end="6"
name="eHD:w" xml:id="w1_wo2" type="NN" lemma="king" xsf:segment="seg4" part="N">
<identical start="2" end="6" name="tree:token" word="king" pos="NN" xsf:segment="seg4"/>
<inclusion start="0" end="1091" name="eHD:text" xml:id="t0" xsf:segment="seg1"/>
<inclusion start="0" end="1091" name="eHD:body" xml:id="b0" xsf:segment="seg1"/>
<inclusion start="0" end="1091" name="eHD:div" xml:id="w1_di1" xsf:segment="seg1" part="N"
org="uniform" sample="complete"/>
<inclusion start="0" end="1091" name="eHD:p" xml:id="w1_pa1" xsf:segment="seg1"/>
<inclusion start="0" end="127" name="eHD:s" xml:id="w1_se1" xsf:segment="seg2" part="N"/>
<inclusion start="0" end="1091" name="tree:corpus" xsf:segment="seg1"/>
</targetElement>
<!-- ... -->
</relations>
</results>In this example the eHD:w element (derived from eHumanities Desktop's
tagger) is used as target element. An element that shares the same segment of the
primary data
is the tree:token element (marked as identical element) derived from
the TreeTagger parse. Since the target element is the first element other elements
share the
same starting point, such as eHD:text, eHD:body,
eHD:div, eHD:p and eHD:s (on the same layer) and
tree:corpus (derived from the TreeTagger output). The second target element
(the second eHD:w element) is again identical to the tree:token element, and is
included (in the sense of containment, cf. section “Disjoints and continuous segments and containment and dominance”) by a variety of
other elements.
In this scenario XStandoff can be used for different purposes: for comparing different linguistic resources' output in terms of both quality and quantity of the annotation, for refining and boosting overall annotation performance by combining several resources, and of course for analyzing virtual parenthoods between elements derived from different annotation layers (cf. Stührenberg and Goecke, 2008 for a real-world example).
Conclusion and Future Work
We have demonstrated both the further developments that have been made to the Sekimo Generic Format, resulting in XStandoff, and the respective XSLT stylesheets that can be used to generate and modify XStandoff instances. It is planned that XStandoff's current development version will be finished as a stable version in time with XML Schema 1.1 which is in the Working Draft status at the time of writing (XML Schema 1.1 Part 1, 2009) and which would allow us to dismiss the embedded Schematron assertions. Regarding the XSLT part of the XStandoff toolkit, future enhancements are supposable in the support of the containment/dominance feature and since the creation of XStandoff instances is a multi-step process (cf. section “Demonstration: Creating an inline XStandoff annotation”), providing an XProc pipeline (cf. XProc 2009) is another future option. Further perspectives include the building of a corpus of multi-dimensional annotated (and possibly overlapping) markup for further developments regarding both XStandoff's specification and the respective XSLT stylesheets (a starting point has been made at http://www.xstandoff.net/examples/index.html). This corpus should be gathered together with other interested parties, e.g. the Markup Languages for Complex Documents (MLCD) project, the XCONCUR developers and the LMNL community. Alternative XQuery realizations of the discussed XSLT stylesheets should give clues about further optimizations regarding the processing times (cf. Stührenberg and Goecke, 2008 for a small test example). In addition, it would be promising to share our developments with the framework for format translations described by Marinelli et al., 2008.
Although XStandoff's formal model is considered as multi-rooted tree – at least if one restricts oneself to not using discontinous segments – additional future work has to be made regarding its expressiveness compared to other approaches, including GODDAG structures (cf. Sperberg-McQueen and Huitfeldt, 2004, Sperberg-McQueen and Huitfeldt, 2008a, Marcoux 2008 and Marcoux 2008a) and LMNL. This holds especially for an examination of the containment and dominance relations described in Sperberg-McQueen and Huitfeldt, 2008 but also to other formal aspects of concurrent markup.
References
[Alink et al., 2006] Alink, W., Bhoedjang, R., de Vries, A. P., and Boncz, P. A. Efficient XQuery Support for Stand-Off Annotation. In: Proceedings of the 3rd International Workshop on XQuery Implementation, Experience and Perspectives, in cooperation with ACM SIGMOD, Chicago, USA, 2006
[Alink et al., 2006a] Alink, W., Jijkoun, V., Ahn, D., and de Rijke, M. Representing and Querying Multi-dimensional Markup for Question Answering. In: Proceedings of the 5th EACL Workshop on NLP and XML (NLPXML-2006): Multi-Dimensional Markup in Natural Language Processing, Trento, 2006
[Bird and Liberman, 1999] Bird, S. and Liberman, M. Annotation graphs as a framework for multidimensional linguistic data analysis. In: Proceedings of the Workshop "Towards Standards and Tools for Discourse Tagging", pages 1–10. Association for Computational Linguistics, 1999
[Bird and Liberman, 2001] Bird, S. and Liberman, M. A formal framework for linguistic annotation. Speech Communication, 33(1–2): pages 23–60, 2001. doi:https://doi.org/10.1016/S0167-6393(00)00068-6
[Bird et al., 2006] Bird, S., Chen, Y., Davidson, S., Lee, H. and Zheng,Y. Designing and Evaluating an XPath Dialect for Linguistic Queries. In: Proceedings of the 22nd International Conference on Data Engineering (ICDE), Atlanta, USA, 2006. doi:https://doi.org/10.1109/ICDE.2006.48
[Burnard and Bauman, 2008] Burnard, L., and Bauman, S. (eds.). TEI P5: Guidelines for Electronic Text Encoding and Interchange. published for the TEI Consortium by Humanities Computing Unit, University of Oxford, Oxford, Providence, Charlottesville, Nancy, 2008
[Carletta et al., 2003] Carletta, J., Kilgour, J., O’Donnel, T. J., Evert, S. and Voormann, H. The NITE Object Model Library for Handling Structured Linguistic Annotation on Multimodal Data Sets. In: Proceedings of the EACL Workshop on Language Technology and the Semantic Web (3rd Workshop on NLP and XML (NLPXML-2003)), Budapest, Ungarn, 2003
[Carletta et al., 2005] Carletta, J.; Evert, S.; Heid, U. and Kilgour, J. The NITE XML Toolkit: data model and query language. In: Language Resources and Evaluation, Springer, Dordrecht, 2005, 39, pages 313-334. doi:https://doi.org/10.1007/s10579-006-9001-9
[Cowan et al., 2006] Cowan, J., Tennison J., and Piez, W. LMNL update. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2006
[DeRose, 2004] DeRose, S. J. Markup Overlap: A Review and a Horse. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2004
[Dipper, 2005] Dipper, S. XML-based stand-off representation and exploitation of multi-level linguistic annotation. In: Proceedings of Berliner XML Tage 2005 (BXML 2005), pages 39–50, Berlin, Germany, 2005
[Dipper et al., 2007] Dipper, S., Götze, M., Küssner, U. and Stede, M. Representing and Querying Standoff XML. In: Rehm, G., Witt, A. and Lemnitzer, L. (eds.), Datenstrukturen für linguistische Ressourcen und ihre Anwendungen. Data Structures for Linguistic Resources and Applications. Proceedings of the Biennial GLDV Conference 2007, pages 337–346, Tübingen, 2007. Gunter Narr Verlag
[Durusau and O'Donnell, 2002] Durusau, P. and O'Donnell, M.B.. Concurrent Markup for XML Documents. In: Proceedings of the XML Europe conference 2002.
[Durusau and O'Donnel, 2004] Durusau, P. & O'Donnel, M. B. Tabling the Overlap Discussion. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2004
[Goecke et al., 2009] Goecke, D., Lüngen, H., Metzing, D., Stührenberg, M. and Witt, A. Different Views on Markup. Distinguishing levels and layers. In: Linguistic modeling of information and Markup Languages. Contributions to language technology. Springer, 2009. To appear
[Gleim et al., 2009] Gleim, R., Waltinger, U., Ernst, A., Mehler, A., Esch, D., and Feith, T. The eHumanities Desktop – An Online System for Corpus Management and Analysis in Support of Computing in the Humanities. In: Proceedings of the Demonstrations Session of the 12th Conference of the European Chapter of the Association for Computational Linguistics EACL 2009, 30 March – 3 April, Athens, 2009
[Huitfeldt and Sperberg-McQueen, 2001] Huitfeldt, C. and Sperberg-McQueen, C. M. TexMECS: An experimental markup meta-language for complex documents. Markup Languages and Complex Documents (MLCD) Project, February 2001
[Iacob and Dekhtyar, 2005] Iacob, I. E. and Dekhtyar, A. Processing XML documents with overlapping hierarchies In: JCDL '05: Proceedings of the 5th ACM/IEEE-CS joint conference on Digital libraries, ACM Press, 2005, pages 409-409. doi:https://doi.org/10.1145/1065385.1065513
[Iacob and Dekhtyar, 2005a] Iacob, I. E. and Dekhtyar, A. Towards a Query Language for Multihierarchical XML: Revisiting XPath. In: Proceedings of the 8th International Workshop on the Web & Databases (WebDB 2005), 2005, pages 49-54
[Ide and Romary, 2007] Ide, N. and Romary, L. Towards International Standards for Language Resources. In: Dybkjaer, L., Hemsen, H., and Minker, W., (eds.), Evaluation of Text and Speech Systems, pages 263-284. Springer
[Ide and Suderman, 2007] Ide, N. and Suderman, K. GrAF: A Graph-based Format for Linguistic Annotations. In: Proceedings of the Linguistic Annotation Workshop, pages 1-8, Prague, Czech Republic. Association for Computational Linguistics, 2007
[ISO/IEC 19757-2:2003] ISO/IEC 19757-2:2003. Information technology – Document Schema Definition Language (DSDL) – Part 2: Regular-grammar-based validation – RELAX NG (ISO/IEC 19757-2). International Standard, International Organization for Standardization, Geneva, 2003
[ISO/IEC 19757-3:2006] ISO/IEC 19757-3:2006. Information technology – Document Schema Definition Language (DSDL) – Part 3: Rule-based validation – Schematron. International standard, International Organization for Standardization, Geneva, 2006
[Jagadish et al., 2004] Jagadish, H. V., Lakshmanany, L. V. S., Scannapieco, M., Srivastava, D. and Wiwatwattana, N. Colorful XML: One hierarchy isn’t enough. In: Proceedings of ACM SIGMOD International Conference on Management of Data (SIGMOD 2004), pages 251–262, Paris, June 13-18 2004. ACM Press New York, NY, USA. doi:https://doi.org/10.1145/1007568.1007598
[Kay, 2007] Kay, M. XSL Transformations (XSLT) Version 2.0. World Wide Web Consortium. 2007. – W3C Recommendation
[Kay 2008] Kay, M. XSLT 2.0 and XPath 2.0 Programmer’s Reference. Wiley Publishing, Indianapolis, 4th edition, 2008
[Marinelli et al., 2008] Marinelli, P., Vitali, F., and Zacchiroli, S. Towards the unification of formats for overlapping markup. In: New Review of Hypermedia and Multimedia, 14(1): pages 57-94, 2008. doi:https://doi.org/10.1080/13614560802316145
[Marcoux 2008] Marcoux, Y. Graph characterization of overlap-only texmecs and other overlapping markup formalisms. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2008
[Marcoux 2008a] Marcoux, Y. Variants of GODDAGs and suitable first-layer semantics. Presentation given at the GODDAG workshop, Amsterdam, 1-5 December 2008
[Pianta and Bentivogli, 2004] Pianta, E. and Bentivogli., L. Annotating Discontinuous Structures in XML: the Multiword Case. In: Proceedings of LREC 2004 Workshop on ”XML-based richly annotated corpora”, pages 30–37, Lisbon, Portugal.
[Poesio et al., 2009] Poesio, M., Diewald, N., Stührenberg, M., Chamberlain, J., Jettka, D., Goecke, D. and Kruschwitz, U. Markup Infrastructure for the Anaphoric Bank, Part I: Supporting Web Collaboration. In: Mehler, A., Kühnberger, K.-U., Lobin, H., Lüngen, H., Storrer, A. and Witt, A. (eds.), Modelling, Learning and Processing of Text Technological Data Structures, Dordrecht: Springer, Berlin, New York. To appear
[Schonefeld, 2007] Schonefeld, O. XCONCUR and XCONCUR-CL: A constraint-based approach for the validation of concurrent markup. In: Rehm, G., Witt, A., Lemnitzer, L. (eds.), Datenstrukturen für linguistische Ressourcen und ihre Anwendungen. Data Structures for Linguistic Resources and Applications. Proceedings of the Biennial GLDV Conference 2007, Tübingen, Germany, 2007. Gunter Narr Verlag
[Sperberg-McQueen et al., 2000] Sperberg-McQueen, C. M., Huitfeldt, C. and Renear, A.. Meaning and Interpretation of markup. Markup Languages – Theory & Practice, 2, pages 215-234, 2000. doi:https://doi.org/10.1162/109966200750363599
[Sperberg-McQueen et al., 2002] Sperberg-McQueen, C. M., Dubin, D., Huitfeldt, C. and Renear, A. Drawing inferences on the basis of markup. In: Proceedings of Extreme Markup Languages, 2002
[Sperberg-McQueen and Huitfeldt, 2004] Sperberg-McQueen, C. M. and Huitfeldt, C. GODDAG: A Data Structure for Overlapping Hierarchies. In: King, P. and Munson, E. V. (eds.), Proceedings of the 5th International Workshop on the Principles of Digital Document Processing (PODDP 2000), volume 2023 of Lecture Notes in Computer Science, pages 139–160. Springer, 2004
[Sperberg-McQueen, 2006] Sperberg-McQueen, C. M. Rabbit/Duck grammars: a validation method for overlapping structures. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2006
[Sperberg-McQueen, 2007] Sperberg-McQueen, C. M. Representation of overlapping structures. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2007
[Sperberg-McQueen and Huitfeldt, 2008] Sperberg-McQueen, C. M. and Huitfeldt, C. Markup Discontinued Discontinuity in TexMecs, Goddag structures, and rabbit/duck grammars. Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 - 15, 2008. In: Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). doi:https://doi.org/10.4242/BalisageVol1.Sperberg-McQueen01
[Sperberg-McQueen and Huitfeldt, 2008a] Sperberg-McQueen, C. M. and Huitfeldt, C. GODDAG. Presented at the Goddag workshop, Amsterdam, 1-5 December 2008
[Stührenberg et al., 2007] Stührenberg, M., Goecke, D, Diewald, N., Cramer, I. and Mehler, A. Web-based annotation of anaphoric relations and lexical chains. In: Proceedings of the Linguistic Annotation Workshop (LAW), pages 140–147, Prague. Association for Computational Linguistics, 2007
[Stührenberg and Goecke, 2008] Stührenberg, M. and Goecke, D.SGF – An integrated model for multiple annotations and its application in a linguistic domain. Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 - 15, 2008. In: Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). doi:https://doi.org/10.4242/BalisageVol1.Stuehrenberg01
[Tennison, 2002] Tennison, J. Layered Markup and Annotation Language (LMNL). In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2002
[Tennison, 2007] Tennison, J. Creole: Validating Overlapping Markup.In: Proceedings of XTech 2007: The Ubiquitous Web Conference, 2007
[Thompson and McKelvie, 1997] Thompson, H. S. and D. McKelvie. Hyperlink semantics for standoff markup of read-only documents. In: Proceedings of SGML Europe ’97: The next decade – Pushing the Envelope, pages 227–229, Barcelona, 1997
[Waltinger et al., 2008] Waltinger, U., Mehler, A. Mehler, and Stührenberg, M. An Integrated Model of Lexical Chaining: Application, Resources and its Format. Proceedings of the 9th Conference on Natural Language Processing (KONVENS 2008)
[XProc 2009] Walsh, N., Milowski, A., and Thompson, H. S. (2009). XProc: An XML Pipeline Language. W3C Candidate Recommendation 28 May 2009, World Wide Web Consortium.
[Witt, 2002] Witt, A. Meaning and interpretation of concurrent markup. In: Proceedings of ALLC-ACH2002, Joint Conference of the ALLC and ACH, 2002
[Witt, 2004] Witt, A. Multiple hierarchies: New Aspects of an Old Solution. In: Proceedings of Extreme Markup Languages, 2004
[Witt et al., 2009] Witt, A., Rehm, G., Hinrichs, E., Lehmberg, T. and Stegmann, J. SusTEInability of Linguistic Resources through Feature Structures. In: Literary and Linguistic Computing, 24(3): pages 363-372, 2009. doi:https://doi.org/10.1093/llc/fqp024
[Witt et al., 2009a] Witt, A., Stührenberg, M., Goecke, D. and Metzing, D. Integrated Linguistic Annotation Models and their Application in the Domain of Antecedent Detection. In: Mehler, A., Kühnberger, K.-U., Lobin, H., Lüngen, H., Storrer, A. and Witt, A. (eds.), Modelling, Learning and Processing of Text Technological Data Structures, Dordrecht: Springer, Berlin, New York. To appear
[XML Schema 1.1 Part 1, 2009] W3C XML Schema Definition Language (XSD) 1.1 Part 1: Structures. W3C Working Draft, World Wide Web Consortium, W3C Candidate Recommendation 30 April 2009. Online: http://www.w3.org/TR/2009/CR-xmlschema11-1-20090430/
[1] More information about the project can be obtained at http://www.text-technology.de/Sekimo.
[2] Other segmentation units such as bytes or frames are possible as well but not supported by the XStandoff toolkit.
[3] All SGF XML Schema files can be found at http://www.xstandoff.net.
[4] All single annotation instances are available at http://coli.lili.uni-bielefeld.de/Texttechnologie/Forschergruppe/Phase1/sekimo/internet-praesentation/buergschaft.html.
[5] The converted XStandoff instance is available at http://www.xstandoff.net/examples/buergschaft.html.
[6] The stylesheets are available at http://www.xstandoff.net/files/xsf_stylesheets.zip. An additional Java implemention with a restricted functionality can be obtained as well.
[7] Download the Open Source version at http://saxon.sourceforge.net, for the commercial Saxon-SA visit http://www.saxonica.com.
[8] As already stated in section “Inline XStandoff” the single-layered annotation instances are available at http://coli.lili.uni-bielefeld.de/Texttechnologie/Forschergruppe/Phase1/sekimo/internet-praesentation/buergschaft.html.
[9] Download available at http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/.
[10] The eHumanities Desktop can be found at http://hudesktop.hucompute.org/.