Walsh, Norman. “Investigating the streamability of XProc pipelines.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Walsh01.
Balisage: The Markup Conference 2009 August 11 - 14, 2009
Balisage Paper: Investigating the streamability of XProc pipelines
Norman Walsh
Principal Technologist
Mark Logic Corporation
Norman Walsh is a Principal Technologist in the Information
& Media group at Mark Logic Corporation where he assists in the
design and deployment of advanced content applications. Norm is also
an active participant in a number of standards efforts worldwide: he
is chair of the XML Processing Model Working Group at the W3C where he
is also co-chair of the XML Core Working Group. At OASIS, he is chair
of the DocBook Technical Committee.
Before joining Mark Logic, he participated in XML-related
projects and standards efforts at Sun Microsystems. With more than a
decade of industry experience, Mr. Walsh is well known for his work on
DocBook and a wide range of open source projets. He is the principle
author of DocBook: The Definitive Guide
XProc: An XML Pipeline Language is a
specification being developed by the W3C for describing a sequence of
XML operations performed over a set of input documents. Not all of the
steps in XProc are known to streamable and consequently,
the XProc specification does not require implementations to support
streaming.
It's an open question whether or not a streaming implementation
would be likely to achieve significant performance improvements over a
similar non-streaming implementation. Using data collected from
real-world pipelines, this paper examines that question.
XProc is a language for expressing a pipeline of XML operations. One
simple example of the sort of use cases that XProc is designed to meet is
this pipeline:
When XProc development first began, there were a lot of opinions
about streamability. Some people suggested the constraint that all
XProc steps must be streamable. Others suggested only that they should
be streamable.
In the end, the working group determined that it would impose no
streamability constraints on implementations. Instead it would attempt
to define steps such that it was (at least usually) possible to stream
them and leave the actual streamability as a quality of implementation
issue.
There seems to be an informal consensus that a streaming
implementation would be expected to outperform a similar non-streaming
implementation. In the particular case of XProc, the author believes
that this depends significantly on the extent to which real world
pipelines are composed of streamable steps.
The standard XProc steps can be divided roughly into three
categories: those for which a streaming can always be achieved (e.g.,
p:identity), those for which streaming can often be
achieved (e.g., p:delete), and those for which no
general, streaming implementation is known (e.g.,
p:xslt).
The distinction between the first and second catagories amounts
to the question of XPath streamability. The p:delete step,
for example, is streamable precisely to the extent that the XPath
expression used to select the nodes to be deleted is
streamable.
Taking an optimistic view, this paper assumes that if a step
could be streamable then it is. This won't always be true, of course,
but taking that view will establish an upper bound on the number of
streamable pipelines.
With that in mind, we assume that the following steps can
not be streamed:
p:exec,
p:http-request,
p:validate-with-relaxng,
p:validate-with-schematron,
p:validate-with-xml-schema,
p:xquery, and
p:xslt. We assume that all other steps can be streamed.
XML Calabash
XML Calabash
is the author's implementation of XProc. XML Calabash is written in
Java and is built on top of the Saxon 9 APIs. The author's principle
motivation for writing XML Calabash is to demonstrate a complete and
correct implementation. Demonstrating at least two complete and
correct implementations of every feature is a necessary prerequisite
for getting XProc approved as a W3C Recommendation.
At the present time, XML Calabash (version 0.9.13) evaluates all
pipelines in a linear, non-streaming, single-threaded fashion. Future
versions of XML Calabash may provide streaming and multi-threading,
though high performance is not a stated goal at this time.
Collecting data about real world pipelines
XML Calabash has a feature for collecting information about
actual pipelines that are being used. By default, XML Calabash sends a
simple report about each pipeline that it runs back to a central
server. This report includes some basic information about the pipeline
and a list of each step that was run and the order in which they were
run.
In the interests of privacy, XML Calabash
never collects any information about the
documents that are processed by the pipeline. Users who feel
uncomfortable about this data collection service can disable it
completely.
Data collected
This paper reports on the data collected by XML Calabash between
21 Dec 2008 and 11 Jul 2009. During that period,
data was collected on more than 294,000 pipeline runs.
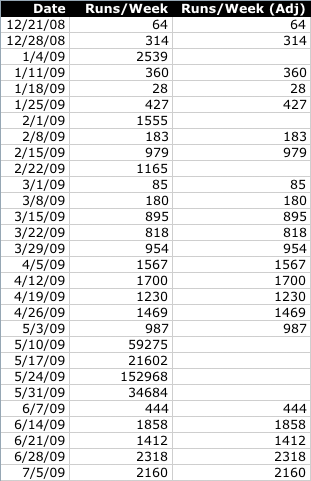
Figure 1: Runs per week
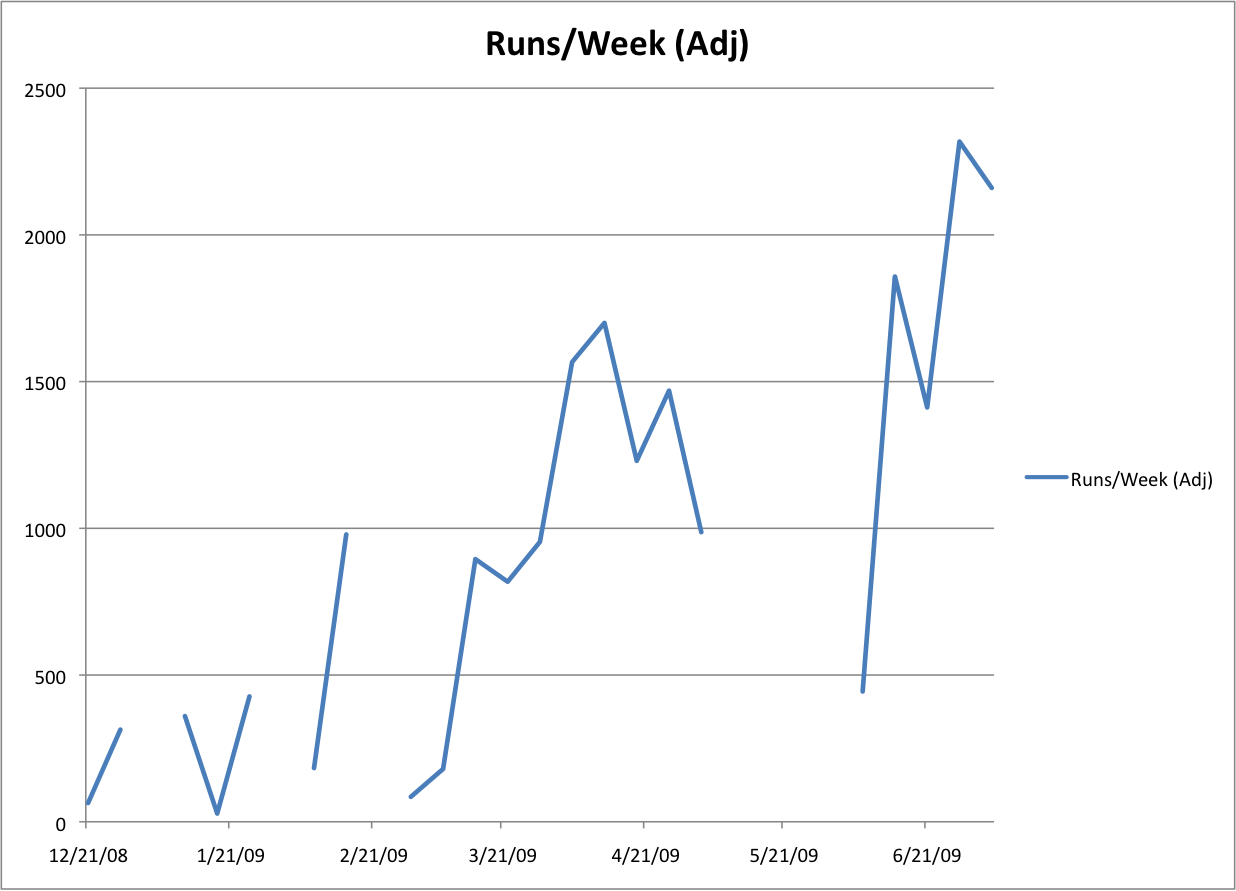
Ignoring the outliners, this data shows reasonably steady growth in
XML Calabash usage.
Figure 2: Runs per week
Data aggregation
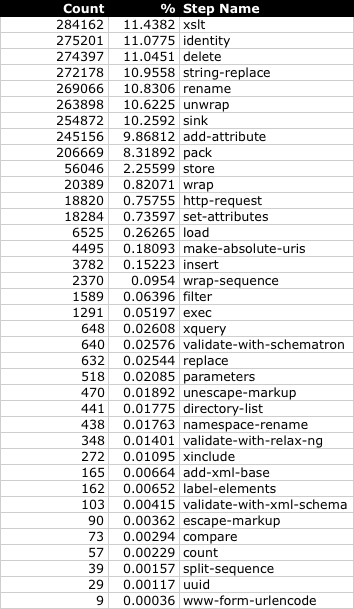
Figure 3 presents a summary of the raw data,
showing for each step how many times it was used in the data
collected.
Figure 3: Summary of the raw data
Not shown in that table are the errors: 396 pipelines failed
with static errors, 7778 failed with dynamic errors.
The whole collection of pipeline reports includes many runs of
the same pipeline. So while there are almost 300,000 runs over six
months, there are no where near that many distinct pipelines. The
reports have a very consistent structure. This consistency allows us
to easily identify duplicate runs.
What is a duplicate run? Two runs are considered to be the same
if they come from the same IP address and perform the same steps in
the same order at runtime. Note that this does not mean that the
source pipelines were necessarily the same,
though it's certainly likely that most duplicate runs are from the
same pipeline. Note also that the same pipeline might produce runs of
different lengths when presented with different data.
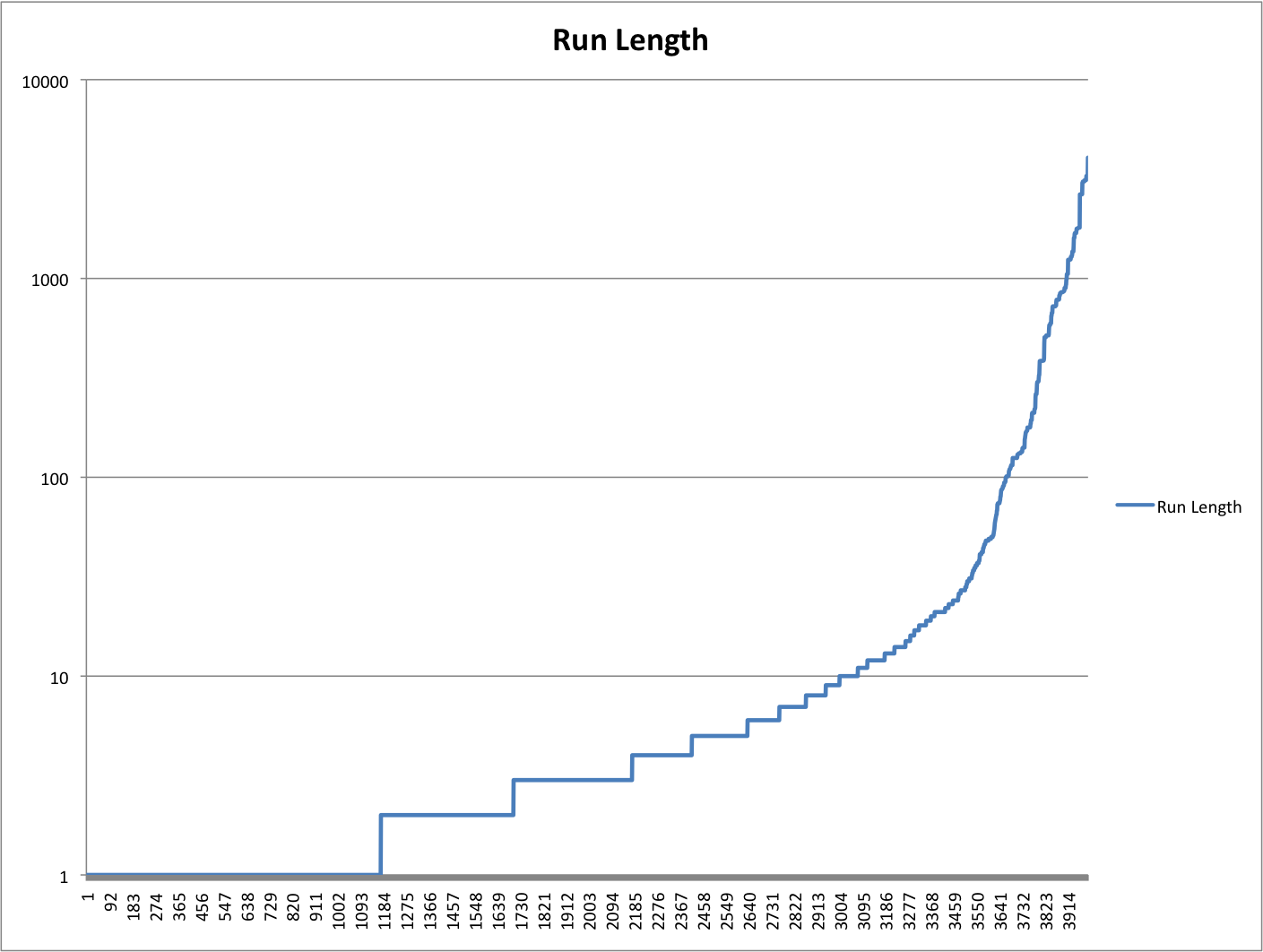
Our analysis reveals that there are 3,994 distinct runs in the
data collected. Many pipelines run only a single step, but one
pipeline ran 4,051 steps. (For an average of 73.8 steps/pipeline.)
Figure 4: Length of pipeline run in steps
Figure Figure 4 plots each unique pipeline
against the length of its run, sorted by length of run. Plots of different
ranges of this graph show a very similar structure.
It's an open question whether analysis of the
unique runs is more or less valuable than
analysis of all the runs. Using only the unique runs biases against
pipelines that were run many times, for which performance could be an
important factor. Using all the data baises against distinct runs that
occurred only once.
Since the focus of this paper is on the characteristics of XProc
in general, and not the efficiencies of individual pipelines, the
balance of this paper consideres only the set of unique pipeline
runs.
Data analysis
Now let us consider the streamability of a pipeline. At one
extreme, if a pipeline consists entirely of steps which cannot be
streamed, then streaming offers no advantage for that pipeline. At the
other extreme, if a pipeline consists entirely of streamable steps,
then streaming would offer the most possible benefit for that
pipeline. In the middle are those pipelines that contain a mixture of
streamable and non-streamable steps.
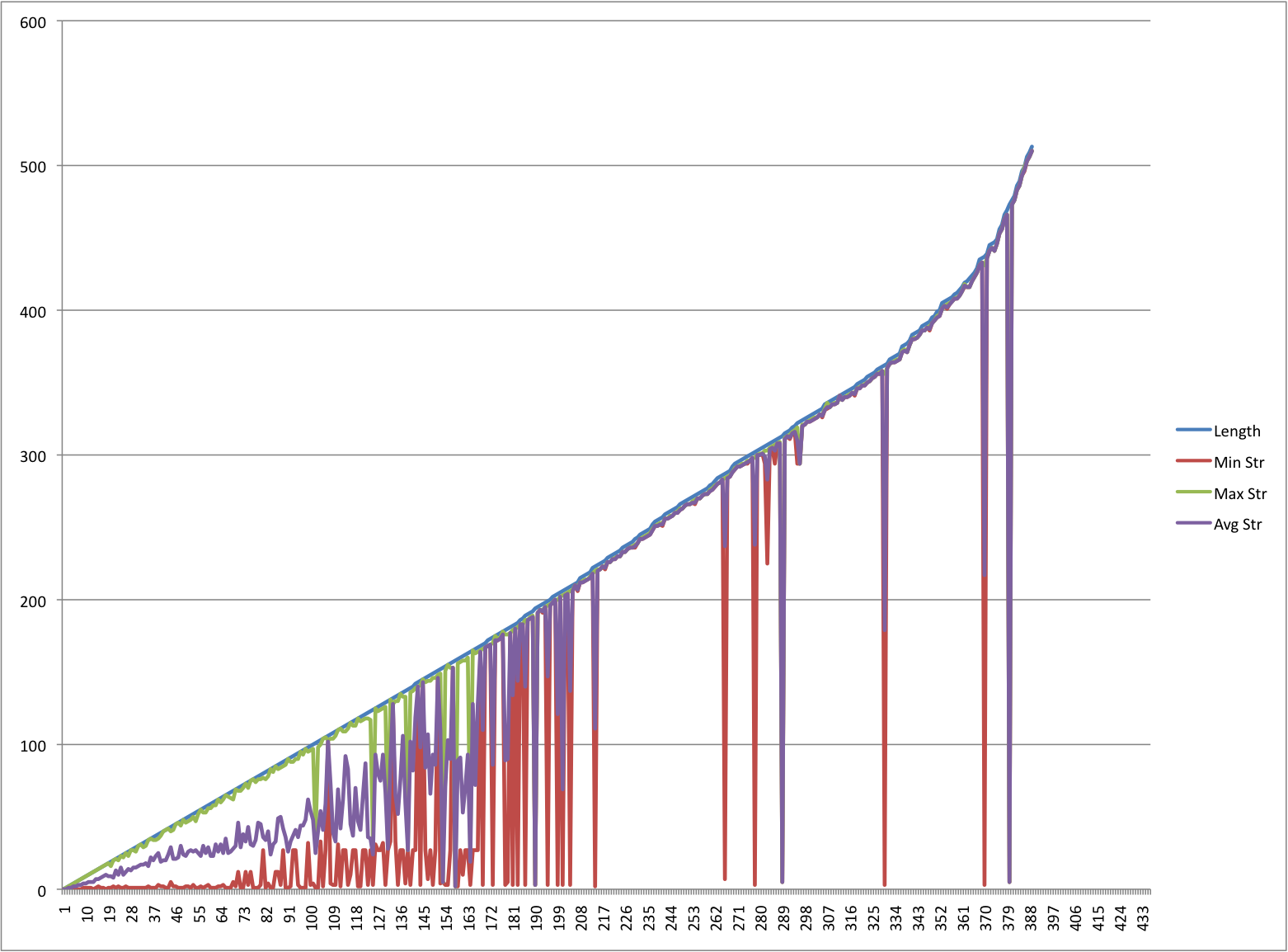
For a collection of pipeline runs that are “n” steps long, we
can compute three values: the length of the longest streamable subpipeline,
the length of the shortest streamable subpipeline, and the corresponding
average length. From this data, we obtain
Figure 5.
Figure 5: Streamable Subpipeline Length
(A small number of runs consisting of thousands of steps significantly
reduced the readability of the graph; they have been elided.)
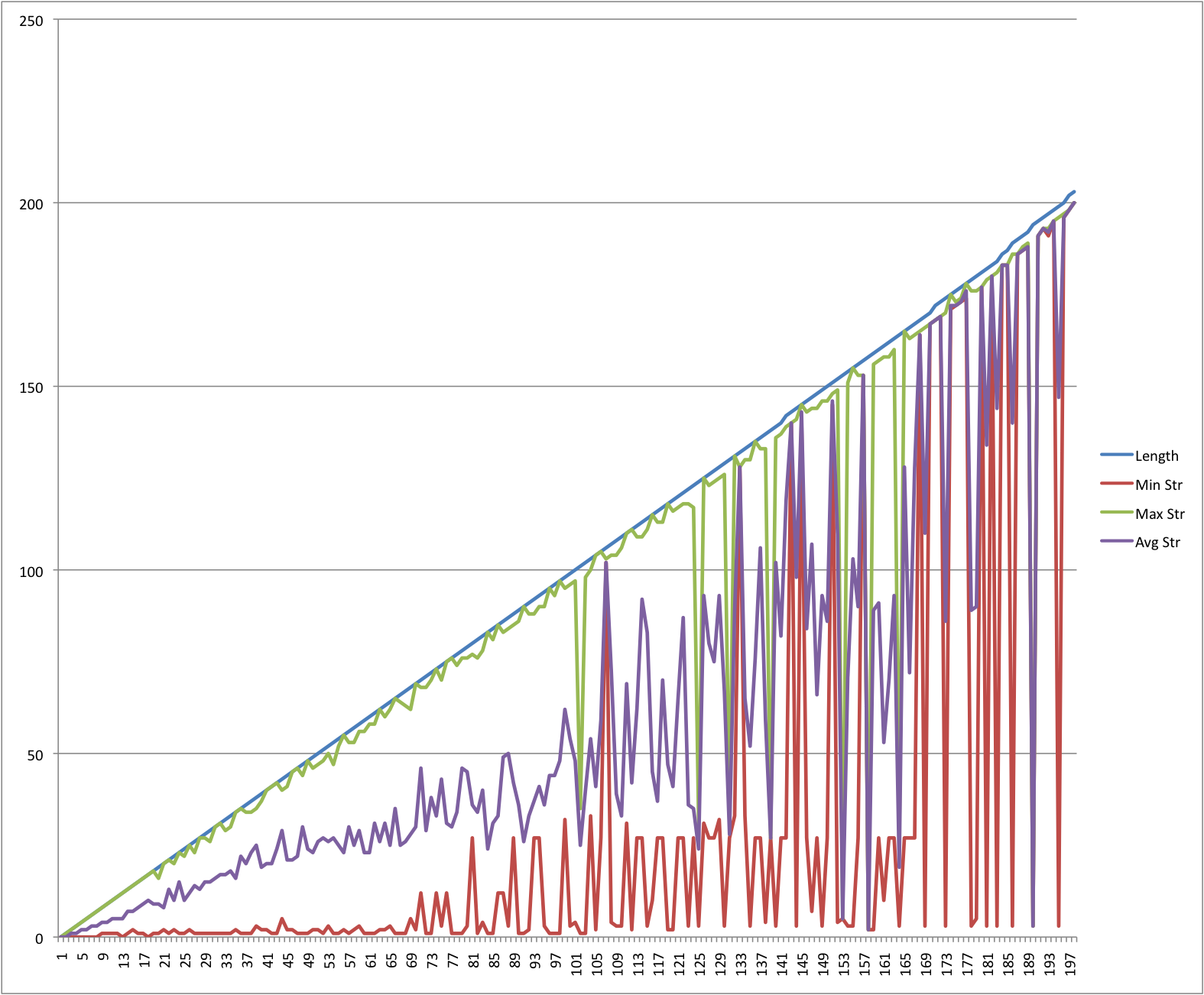
Figure 6 shows a magnified version of
the first portion of this graph.
With respect to our earlier simlifying assumption that all steps
that can be streamed are streamed, a casual inspection of the actual match
patterns used revealed that to be true at least 80% of the time.
Conclusions
The preliminary analysis performed when this paper was proposed
suggested that less than half “real world” pipelines would benefit
from a streaming implementation.
The data above seems to indicate that the benefits may be
considerably larger than that. Although it is clear that there are
piplines for which streaming wouldn't offer significant advantages,
it's equally clear that for essentially any set of pipelines of a
given length, there are pipelines which would be almost entirely
streamble.
Perhaps the most interesting aspect of this analysis is the fact
that as pipeline runs grow longer, they appear to become more and more
amenable to streaming. That is to say, it appears that a pipeline that
runs to 300 steps is, on average, more likely to benefit from
streaming than one that's only 100 steps long.
We have not yet had a chance to investigate why this is the case.
Caveats
In the interests of openness, it should
be noted that there are several weaknesses in the data.
The data is collected on an “opt-out” basis. That makes it very difficult
to publish the raw data. Without explicit consent from users, I'm reluctant.
On the other hand, it's likely that much less data would be available if an
explicit, “opt-in” approach had been taken.
The XProc specification is currently a Candidate Recommendation.
Today's users represent the very leading edge of adoption. It's not
obvious that the usage patterns apparent in this data will accurately
reflect the usage that occurs when XProc is widely adopted.