Müldner, Tomasz, Christopher Fry, Jan Krzysztof Miziołek and Scott Durno. “XSAQCT: XML Queryable Compressor.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Muldner01.
Balisage: The Markup Conference 2009 August 11 - 14, 2009
Balisage Paper: XSAQCT: XML Queryable Compressor
Tomasz Müldner
Professor
Jodrey School of Computer Science, Acadia University
Tomasz Müldner is a professor of computer science at Acadia University in Nova Scotia,
one of Canada's top undergraduate universities. He has received numerous teaching
awards, including the prestigious Acadia University Alumni Excellence in Teaching
Award in 1996. He is the author of several books and numerous research papers. Dr.
Müldner received his Ph.D. in mathematics from the Polish Academy of Science in Warsaw,
Poland in 1975. His current research includes XML compression and encryption, and
website internationalization.
Christopher Fry
Graduate Student
Jodrey School of Computer Science, Acadia University
Christopher Fry graduated in May 2009 from Acadia University with a Bachelor of Computer
Science with Honours. He will be returning to Acadia University to pursue his masters
degree in computer science
Jan Krzysztof Miziołek
Director
Computing Services Centre for Studies on the Classical Tradition in Poland and East-Central
Europe, University of Warsaw, Warsaw, Poland
Jan Krzysztof Miziołek works for the University of Warsaw, Poland. Dr. Miziołek received
his Ph.D. in mathematics from Technical University of Lodz, Poland in 1981. He worked
on design and implementation of a high-level programming language, LOGLAN-82. His
current research includes XML compression and encryption.
Scott Durno
Graduate Student
Jodrey School of Computer Science, Acadia University
Scott Durno graduated in October of 2004 with a Bachelor of Computer Science with
Honours degree from Acadia University. He is currently studying at Acadia University
pursuing his masters degree in computer science
Recently, there has been a growing interest in queryable XML compressors, which can
be used to query compressed data with minimal decompression. At the same time, there
are very few applications that have been made available for testing and comparisons.
In this paper we report our current work on a novel queryable XML compressor, XSAQCT.
While our work is in its early stage, our experiments show that our approach successfully
competes with other known queryable compressors.
XML (Extensible Markup Language) [xml06] is a meta-language (developed by the W3C, World Wide Web Consortium in 1996), which
represents semi-structured data using markups. While the use of XML facilitates the
interchange and access of data, its verbose nature tends to considerably increase
the size of a data file. This increase in size limits applications of XML, in particular,
because of time efficiency of storage on large data files, and because of space considerations
of storage on mobile devices. Besides storing (possibly compressed) XML data, one
is also interested in being able to query them in order to obtain specific information; such as the information pertaining
to all patients who visited the emergency room of a specific hospital in the last
year.
The reasons for querying a compressed XML file are:
Querying a compressed XML file is generally faster than completely decompressing the
compressed file and then querying it.
Portable devices may not have disk space available for a complete decompression of
the XML file.
There are many known XML-aware compressors, i.e. compressors, which can take advantage
of XML syntax. Some of these XML compressors are grammar-free, in other words, information
available to the compressor is limited to the XML document. Other XML compressors
are grammar-based, i.e. the compressor is aware of the grammar for which the input
document is valid. Grammar-based compressors may produce better results - in terms
of both compression rate and time - than grammar-free compressors because they can
take advantage of information available in the grammar, but in many applications the
grammar is not known and so this approach is not always practical. In the case of
the widely used Wratislava corpus [Skibinski et al, 2007], out of seven XML documents, only two provide an XML Schema (enwikibooks and enwikinews),
two reference a DTD (shakespeare and dblp), while the others use no schema. Finally,
even if an XML Schema is provided, it may define elements that never actually appear
in the XML document to be compressed.
In this paper, we describe a queryable, grammar-free XML compressor, called XSAQCT
(pronounced exact). Our technique borrows from other XML compressors in that it separates
the document structure from the text values and attribute values (collectively called
data values), which makes up the content of the document. What is new in our technique
is that we first encode the document to succinctly store information about the input
document. Next, we apply the appropriate back-end data compressors to the container
that stores the document structure and to the containers storing the data values (the
type of the data, derived from the containers, may be used to guide the choice of
back-end compressors used for various containers). It is well known that, on average,
the structure of the XML document represents between 10 and 20 percent of the size
of the entire document, and the remaining 80 percent represents text and attribute
values. Since the main focus of our work is on queryable compression, our encoding of the document structure supports lazy decompression, i.e. during the querying process of the compressed document; we decompress “as little
as possible”. Well-known XML compressors differ in their use of container granularity;
some compressors use a single container, while others tend to create many separate
containers for related values. The former approach is based on the promise that standard
data compressors achieve better results when they get large data sets, but require
complete decompression in order to perform a query. On the other hand, the latter
approach may suffer from poor compression ratios, but it requires the decompression
of only a few (possibly just one) containers. In our approach, we attempt to strike
a balance between these two extremes; using containers that will be large enough so
that they can be effectively compressed, but at the same time the container structure
does not require a full decompression to answer a query. In addition, while our design
supports lazy decompression, it is designed to support future extensions and performs
operations directly on compressed data, without any decompression. In what follows,
we provide a more detailed description of XSAQCT.
Contributions. There are two main contributions of this paper: (1) an algorithm, which
given an XML document D, produces a concise representation of D in a form of an annotated
document tree, and stores data values in containers; and (2) the compressor, which
compresses the annotated tree and containers, the decompressor, which restores the
original document, and the query processor, which operates on a compressed document,
and decompresses “as little as possible”. Since the compressor uses a single SAX pass
of the input document, our technique is applicable to processing very large XML files
and to streaming. In addition, we provide results of our experiments on a representative
XML corpus, showing that on average XSAQCT compresses documents in this corpus to
12% of the original file size, and outperforms TREECHOP, the only other XML compressor
available for testing.
Currently, XSAQCT only supports simple queries of the form: "/a/b" or "/a/b/text()".
Future work will focus on supporting core XQuery queries.
This paper is organized as follows: Section 2 provides related work, and Section 3 describes XSAQCT. Section 4 provides a description the implementation of XSAQCT. Section 5 gives results of testing of our compressor, while conclusions and future work are
described in Section 6.
2. Related Work
Existing queryable XML compressors can be classified based on their approach to compression
with respect to the structure of the uncompressed XML document and their method of
querying the compressed document. Regarding the former, a compressor either retains
the original document's structure or separates the structure and the data values;
the latter indicates whether or not the queryable compressor features random or sequential
queries over the document in the compressed domain.
XGrind [tolani2002] is the earliest XML compressor to support querying of the compressed document and
it is DTD schema aware. XGrind features a homomorphic compression scheme where data
are encoded using a non-adaptive Huffman algorithm. XPRESS [min03] uses a method called reverse arithmetic encoding to represent unique label paths
and a semi-adaptive encoding that provides improved homomorphic compression over XGrind
plus the ability to handle some range queries in the compressed domain.
TREECHOP [tre05] is another queryable XML compressor that employs a homomorphic compression scheme
and implements a sequential query algorithm and lazy decompression. TREECHOP, like
XPRESS, is not schema aware and implements top-down exact-match and range queries
of the compressed document. TREECHOP's compression algorithm is highly efficient and
the single pass scheme makes it ideal for data exchange across networks.
XQueC [arion07] is a recent queryable XML compressor that separates the structure from the data
of the original XML document into the tree structure, separate data containers and
a structure summary. XQueC attempts to group data containers to facilitate efficient
querying while reducing the costs of storing compressed data and the time required
to decompress the document.
XSAQCT is a queryable XML schema-free compressor. The early description of our work
appeared in (non-refereed) Dagstuhl Seminar Proceedings [dag08], and here it is extended by the updated versions of all algorithms and results of
our experiments.
When dealing with any kind of data compression, one compares their compressor with
other compressors, using a specific set of input documents. In this paper, we follow
[Skibinski et al] and for our experiments, we use the Wratislavia XML corpus [wra] from this paper.
Binary XML is similar to XML compressors; in that, it allows a more compact form of
XML representation, while still retaining the advantage of interoperability of XML.
Presently, there are various competing formats of Binary XML including Efficient
XML Interchange [exi08] defined by the W3C. While parsing of Binary XML may be faster than parsing regular
XML, Binary XML is not particularly designed for query efficiency. Furthermore, Binary
XML may be limited in the types of compression used; for example, EXI only allows
DEFLATE based compression.
3. Introduction to XSAQCT
In this section we provide the basic terminology, and a general introduction to our
compression technique.
3.1. Basic Terminology
XSAQCT can be characterized as (1) a database application, that concentrates on queryable compression with random access, and decompression
speed; (2) an interactive compressor that can expect any kind of queries (rather than a batch compressor that know a priori the so-called workloads (containing queries that can be used); (3) a compressor that supports both lossless compression (the only differences between the recreated document and the input document
are those permitted by the XML canonicalization process, such as the order of occurrence of attributes; see [can]), and compression, which also allows removal of spurious whitespace; and (4) uses
indexing and caching. To our knowledge, currently there is no compressor available
with all four attributes.
Two absolute paths are called similar if they are identical, possibly with the exception
of the last component, which is the data value. For example, the paths /a/b/t1 and
/a/b/t2 are similar while the paths /a/b/t1 and /a/c/t1 are not.
3.2. Architecture of XSAQCT
The top-level description of the architecture of the XSAQCT compressor is as follows.
First, the input file is compressed. Then the user can start a session, during which
the compressed file is queried and/or decompressed to recreate the original file.
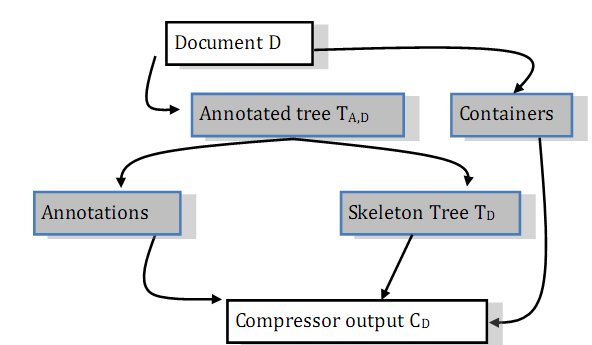
More details of the architecture are provided in Figure 1, in which shaded boxes represent intermediate stages of the compression.
fig_process
The architecture of XSAQCT.
Given a document D, we perform a single SAX traversal of D to encode it; creating
an annotated tree (TA,D). At the same time, data values are written to the appropriate data containers. Note
that TA,D provides a faithful but succinct representation of the structure of the input document D. Next, TA,D is compressed by first writing its annotations to one container and the skeleton tree (TD) without annotations to another container. Finally, all remaining containers are
compressed, using user specified back-end compressors, and written to create the compressor’s
output CD.
This approach resembles a permutation-based approach, in which a document is re-arranged to localize repetitions. However, in
our work, TA,D preserves all information about the ordering of elements, and a single container
stores only related data values (specifically, we use a single container to store text values for all similar paths). Each container may be compressed using different back-end compressor, depending
on the type of value in the container (the encoded information about the selected
back-end compressor is added to the container). In other words, our approach is in
a sense a homomorphic approach, but the annotated tree never has two or more similar paths (they have been
“merged” into a single path). The main back-end compressors used include GZIP [gzip], BZIP2 [bzip2] and PAQ8 [paq], but the user can add more compressors.
The decompressor has the following logical passes (more details of the actual implementation
are provided in Section 4.2):
use the back-end decompressors to restore the contents of all containers
re-annotation: use (retrieved from containers) annotations and the skeleton tree TD to recreate TA,D
restoring: use TA,D to restore the decompressed file
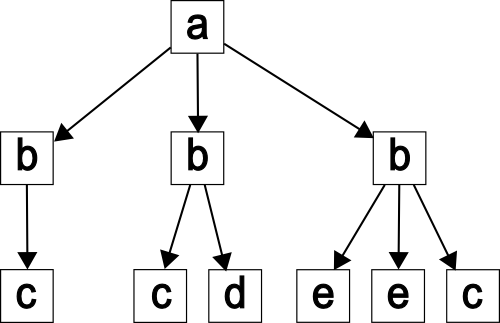
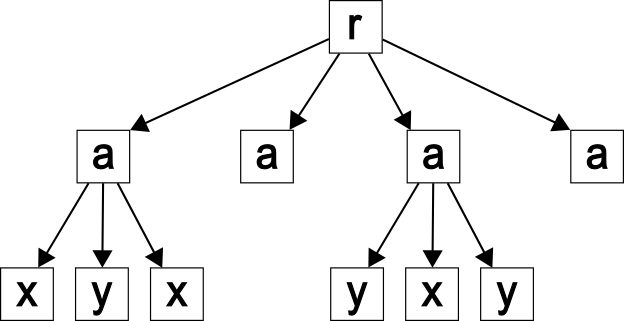
Example 1. Consider the document D, shown as the document tree without any data values, in
Figure 2. Here, there are three similar paths /a/b/c and two similar paths /a/b/e. Note that
in this example, we concentrate on handling elements and describe handing attributes
and text values in Section 3.3.
fig2
The document D.
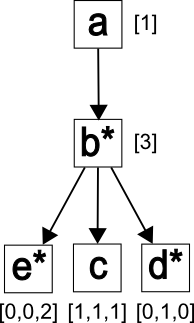
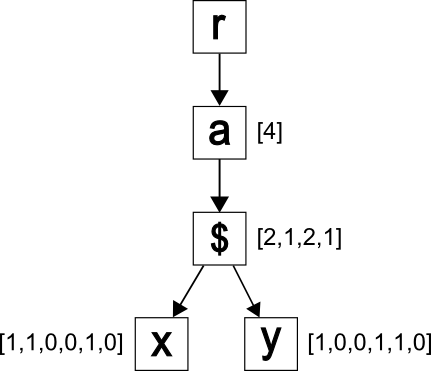
The annotated tree TA,D, which represents D, is shown in Figure 3. Similar paths have been merged, for this example there is only one path /a/b/c and
one path /a/b/e. To support decompression, annotations have been added to the nodes
of the tree TA,D.
fig_annotated_tree
The annotated tree TA,D.
Let’s use this example to explain the idea behind annotations. In this example, as
well in most examples we investigated, the document tree is wide, while the corresponding
annotated tree is much narrower (both trees always have the same height). The annotation
associated with node n, which is a child of the node m, provides the information as
to the number of children of m, labeled by n. Specifically, in this example, the node
“b” in TA,D is annotated with [3], because there are three children labeled by “b” of the node
“a” in the document D. Now, consider the node “e” in TA,D. This node is annotated with [0,0,2], because in the document D, there are no children
labeled “e” for the first two occurrences of the node “b”, and there are two children
labeled “e” for the third occurrence of the node “b”.
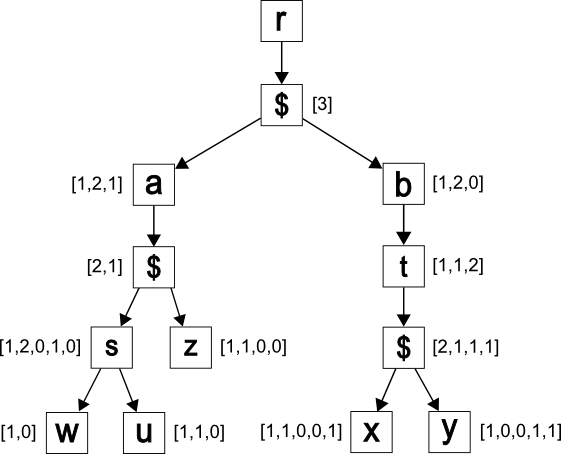
Now, we summarize some properties of the annotated tree TA,D for the document D. First of all, the height of D is equal to the height of TA,D. For a node A of TA,D, consider its annotation ann(A) = [a1,…,ak] and let |ann(A)| be the number of integers
in the ann(A), {A} be the sum of a1,…,ak. Then, the following properties hold:
3.1 In D, there are a1,…,ak occurrences of A
3.2 If A has children B1,…,Bm in TA,D, then
ann(Bj) = [bj,1,…,bj,{A}], i.e. the number of integers in the annotation of each child is equal to the sum
of integers in the annotation of the parent
in D, the node Aj has:
bj,1 children labeled by B1
…
bj,{A} children labeled by B{A}
For Example 1, and the node “b” in TA,D, we have ann(b) = [3] and from 3.1, there are three occurrences of the node “b” in
D. From 3.2 a), annotations of children of this node have three integers. To show
an example of 3.2b), consider Figure 11 and the node ”$”, which is a child of the
node “a”, and has two children; “s”, annotated by [1,2,0,1,0] and “z”, annotated by
[0,1,1,0,0]. As the Figure 12 shows, there are five corresponding occurrences of the
node “$” in D; with the following children:
the first occurrence of “$” has one child labeled by “s” and no children labeled by
“z”
the second occurrence of “$” has two children labeled by “s” and one child labeled
by “z”
the third occurrence of “$” has no children labeled by “s” and one child labeled by
“z”
the fourth occurrence of “$” has one child labeled by “s” and no children labeled
by “z”
the fifth occurrence of “$” has no children.
For any element s, which may appear a various number of times as a child of the same
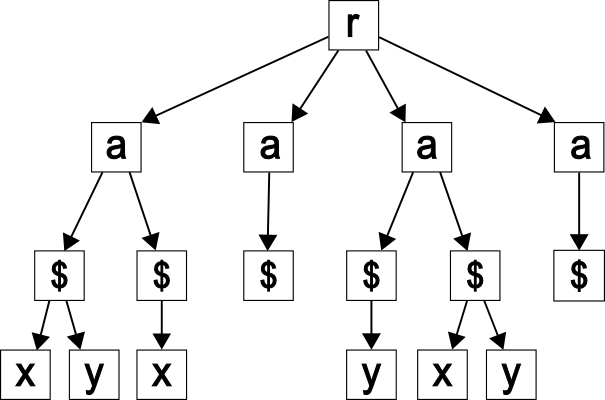
node, in our figures, the element s will have an appended *. Element s is called dirty if it has an appended *; otherwise it is called clean. The only clean element in Figure 2 is the one labeled with “c”. Since clean nodes always appear exactly once, they
are not actually being annotated. However, for the sake of clarity in Figure 3, we showed all annotations.
The next section describes handing of attributes and mixed content.
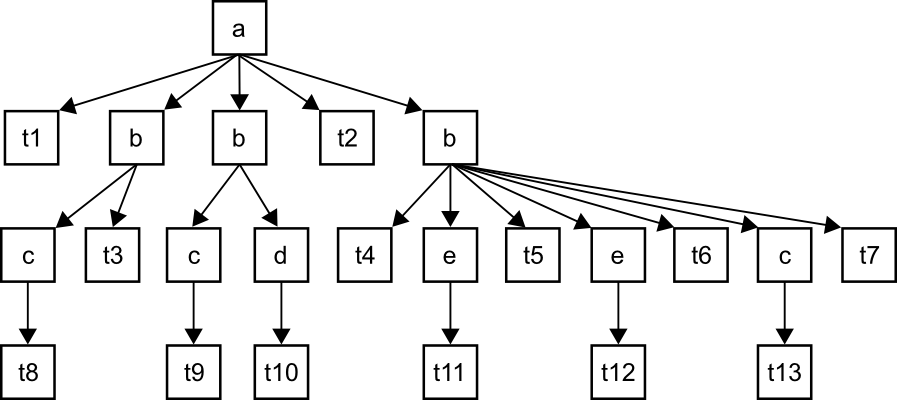
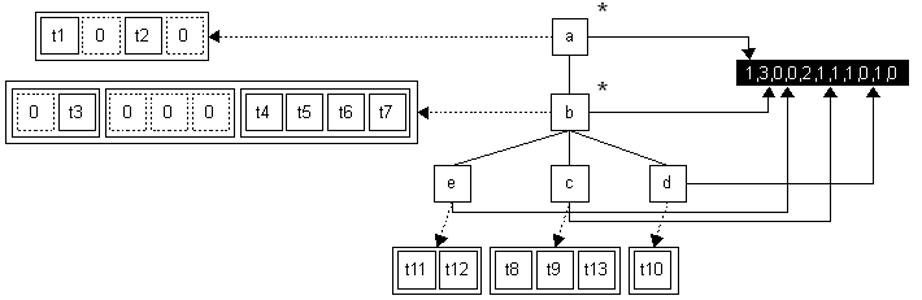
3.3. Attributes and Mixed Content
Attributes are treated as if they were elements, i.e. their names (preceded by “@”),
and annotations are recorded in TA,D. Figure 4 shows a simple document with various text nodes, including mixed content. The tree
TA,D is shown in Figure 5, and text containers (the bottom of the figure). Nodes of the tree are marked with
a asterisk in Figure 5, if the corresponding element has mixed content, and in such a case empty text (shown
as a box containing “0”) is inserted in the text container when needed. All annotations
appear in a separate container, with the pointer from each node pointing to the beginning
of its annotations (the length of the annotation can be computed using the property
3.2 from Section 3.2). Note that the Figure 5 shows the logical format for the annotated tree TA,D, more details of the actual implementation are provided in Section 4.
fig_4
Handling mixed content.
fig_5
Tree TA,D and text containers.
3.4. Querying
At the time of writing this paper, our query processor was under development, and
only simple queries have been implemented (specifically, we have implemented absolute
paths; similarly to TREECHOP [tre05], but additionally including some predicates such as “position()=2”). A query, which
ends in an element, can be immediately answered using the annotated tree, and therefore
it only requires a decompression of this tree. Now, consider a query, which calls
for text values for a given path. As mentioned earlier, the compressor creates a separate
container storing all values for similar paths (comp. Figure 4 and Figure 5). Therefore, to answer this type of a query it is enough to decompress a single data
container, and then return the text values stored in this container. Since text values
are stored within a container in a dfs-order, a query that calls for a specific text
value (such as the i-th value) can be answered by traversing a single decompressed
container to locate the i-th value.
Example 2. Consider the document D shown in Figure 4 and Figure 5. Now, consider the following queries:
/a/b
Based on the annotated tree, the answer is {b, b, b}
/a/b/c/text()
Based on the annotated tree, the first container is decompressed and its content {t8,
t9, t13} is returned.
/a/b[2]/c/text()
Based on the annotated tree and the second container, the answer is {t9}.
4. Implementation of XSAQCT
In this section, we first describe building the annotated tree, and next the re-annotator
and restorer used in decompression.
4.1. Building an Annotated Tree
We will say that a document D has a cycle if there exists a node n in D such that there are two children x and y of n, which
satisfy this condition: x < y and y < x (here, “<” denotes the document order). If
there are cycles, then add a “dummy tag name” to the annotated tree TA,D, here denoted by $, which will be used to avoid cycles. The annotated tree TA,D may have dummy nodes, and if so they will be removed by the decompressor to recreate
the original document.
Cycles may occur in the following two cases:
Node NA appears before node NB and then NA appears after NB, where NA and NB have the same parent node. For example:
<parent>
<a></a>
<b></b>
<a></b>
</parent>
NA appears before NB and both are the children of the same Nparent1. Later NB appears before NA and both are children of a different node Nparent2 where Nparent1 and Nparent2 have the same path (i.e. they both have the same ancestor in the Skeleton Tree).
For example:
During parsing, it is unclear whether the Skeleton Tree should place the corresponding
element of node a before or after node b. Either choice would cause the compressed
file to be incorrect, because either all a's would appear before all b's or all b's
would appear before all a's. Therefore, our algorithm creates multiple graphs, which
are later topologically sorted. A topological sort can also be used to detect cycles
in a graph. Here, the vertices of the graph are the child elements of some parent
element in TA and the edges between these child elements are created during parsing. If the topological
sort reveals a cycle in this graph then this situation can be handled by adding a
dummy node to the parent element.
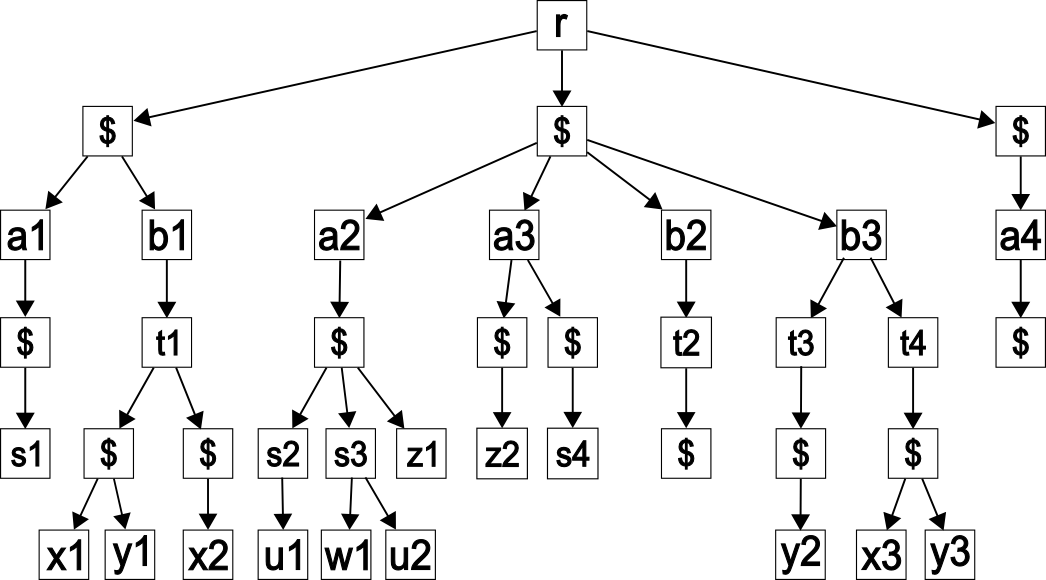
Example 3. Document D (which has cycles on x and y) is shown in Figure 6.
fig_6
Sample document D.
The annotated document tree (with dummy nodes) is shown in Figure 7.
fig_7
The annotated document tree.
The restored document tree (with dummy nodes) is shown in Figure 8.
fig_8
Restored document tree of D (with dummy nodes).
Algorithm 4.1
Input: An XML document D.
Output: An annotated document tree TA,D.
To describe details of the process of building the annotated document tree, we use
the following notations:
ann($)+=1 means: if the annotation of $ ends with “,” then append “1,”; otherwise
append “,”
ann(x)+= 1 (for another annotation) means: if this annotation ends with “,” then append
“0,”; otherwise append “,”
There is a table T, each row has 3 entries: a full path, a graph associated with this
path, as in the previous description, (possibly one node of this graph is “current”
– see below), and an annotation for $ (this entry may be empty)
“close(absolute path p)” means: for each node x in the graph associated with p perform
ann(x)+=1, and also if path p has a non-empty annotation for “$” then perform ann($)+=1
“cycle(x)” means that we are considering the node x and adding x to the graph would
create a cycle (e.g. if we have a graph: a ← b and we want to add a node a; this would
create a cycle a ← b ← a)
Method: Elements are added to the annotated tree when they are encountered for the
first time. We use a single SAX [SAX] traversal of the document D and perform the following actions:
Going up from the node x to y: if x was the last (rightmost) child of y and so the
next action would be going up to the parent of y, then close(x) and unset the current
node in the graph
Going down to node x:
- try to add x to the appropriate graph (see example below)
-if a cycle would be created then close(x) (see 4), then add 1 to ann(x), and increment by 1 the annotation of $ (if such annotation
does not exist or it ends with “,”, then create it and initialize to 2)
- if no cycle would be created, then add x to the graph (a new node, or just increment
the annotation of existing x), and make it current node in the graph
After completion, check annotations and add leading 0’s for regular nodes and 1’s
for dummies (i.e. $’s).
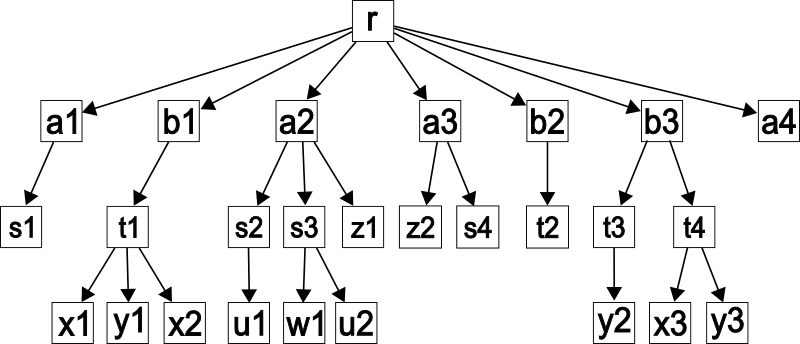
Example 4. Consider a document D shown in Figure 9. Here, we use indices for explanations, e.g. a1 is just a.
fig_9
Sample document D.
Table 1 shows all major steps in creating the annotated document tree for the document D
from Figure 8; for each step there is a description (if required) specifying which node of the
document is encountered during the SAX traversal, wherever there is a change then
a path and its graph (the graph is not shown if it is empty), and the annotation of
$ if it exists. The current node is shown in bold. Entries for leaves (where graphs
are empty) are omitted. When appropriate, we show below the path and the graph; e.g.
(/r a[1]) indicates the graph consisting of a single node a, annotated by 1, for
the path “/r”). Only the paths/graphs that have changed from the previous step are
shown. Sometimes “empty graphs” are omitted.
Table I
Trace of the execution of Algorithm 4.1.
Step #
Action
Annotations
$
1
Root r
Graph /r
2
a1
(/r, a[1])
(/r/a, empty)
3
s1
(/r/a, s[1])
4
Go up to a1; close(/r/a), unset current
(/r/a, s[1,]
5
Go to b1, add a new node b to the graph for /r and an edge between b and a
(/r, a[1]<- b[1])
6
Go to t1
(r/b/, t[1])
7
Go to x1
(/r/b/t, x[1])
8
Go to y1; try to add an edge between y and x (because x is current)
(/r/b/t, x[1]<-y[1])
9
Go to x2: this would have created a cycle. Use a rule for a cycle (above)
(/r/b/t, x[1,1]<-y[1,])
$[2]
10
Go up to t1, no occurrence of y
Close /r/b/t: not current anymore.
(/r/b/t, x[1,1,]<-y[1,0,])
$[2,]
11
Go to b1, close /r/b/
(/r/b, t[1,])
12
a2: cycle
(/r, a[1,1]<-b[1,])
$[2]
13
s2
(/r/a, s[1,1])
14
u1
(/r/a/s, u[1])
15
Go up to s2: close
(/r/a/s, u[1,])
16
s3:
(/r/a, s[1,2])
17
w1: the graph consists of 2 isolated
nodes (because it had no current before)
(/r/a/s, u[1,] w[1])
18
u2, no cycle
(/r/a/s, w[1]<-u[1,1])
19
s3: close
(/r/a/s, w[1,]<-u[1,1,])
20
z1
(/r/a, s[1,2]<-z[1])
21
a2: close
(/r/a, s[1,2,]<-z[1,])
22
a3
(/r, a[1,2]<-b[1,])
$[2]
23
z2
(/r/a, s[1,2,]<-z[1,1])
24
s4: cycle
(/r/a, s[1,2,0,1]<-z[1,1,])
$[2]
25
Close /r/a/s
(/r/a/s, w[1,0,]<-u[1,1,0,])
26
Up to a3; close
(/r/a, s[1,2,0,1,]<-z[1,1,0,])
$[2,]
27
b2:
(/r, a[1,2]<-b[1,1])
$[2]
28
t2:
(/r/b, t[1,1])
29
Up to b2: close
(/r/b/t, x[1,1,0,]<-y[1,0,0,])
$[2,1,]
30
Up: close
(/r/b, t[1,1,])
31
b3
(/r, a[1,2]<-b[1,2])
$[2]
32
t3
(/r/b/, t[1,1,1])
33
y2
(/r/b/t, x[1,1,0,]<-y[1,0,0,1])
$[2,1,1]
34
Up: close
(/r/b/t, x[1,1,0,0,]<-y[1,0,0,1,])
$[2,1,1,]
35
t4
(/r/b, t[1,1,2])
36
x3
(/r/b/t, x[1,1,0,0,1]<-y[1,0,0,1,])
$[2,1,1,]
37
y3
(/r/b/t, x[1,1,0,0,1]<-y[1,0,0,1,1])
$[2,1,1,]
38
Up to t4: close
(/r/b/t,x[1,1,0,0,1,]<-y[1,0,0,1,1,])
$[2,1,1,1,]
39
Up to b3: close
(/r/b, t[1,1,2,])
40
a4: cycle
(/r, a[1,2,1]<-b[1,2,])
$[3]
41
Finish: close /r/a and then /r
(/r/a, s[1,2,0,1,0,]<-z[1,1,0,0,])
(/r, a[1,2,1,]<-b[1,2,0,])
$[2,1,]
$[3,]
Note: we will add leading 0’s and 1’s when creating the annotated document tree in
order to make sure that the number of positions in the annotations is correct. The
annotated document tree created from the above table is shown in Figure 10.
fig_10
The incomplete annotated document tree.
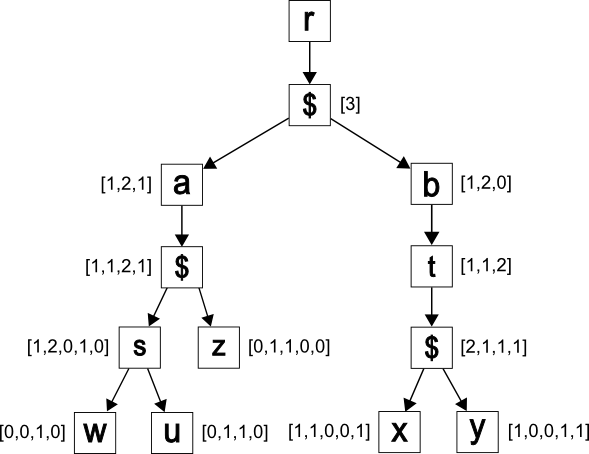
The annotated document tree in which leading 0’s are added to node annotations and
leading 1’s are added to $’s annotations is shown in Figure 11.
fig_11
The complete annotated document tree.
The restored document tree obtained from the complete annotated tree, in which dummy
nodes are not removed, is shown in Figure 12.
fig_12
The restored document tree (dummy nodes are not removed).
It is easy to see that removing dummy nodes from the tree shown in Figure 12 will produce the original document tree shown in Figure 9.
4.2 Decompression
The skeleton tree TD is first re-annotated to create the annotated tree TA,D, and then TA,D is used to output the restored document. Reannotator performs a dfs-traversal of
TD and fetches annotations from their respective container (see Figure 4), using the property 3.2 from Section 3.2. Details of the reannotator follow.
4.2.1 Reannotator
Here, we use a global variable, called number, initialized to 1.
re-ann(SkeletonTreeNode current)
{
for every child c of current
{
if(clean(c))
annotate c with “number” of 1’s
else
{ // dirty c
fetch “number” digits from Seq and store into the sequence “els”
annotate c with “els”
number = sum of all digits in “els”
}
re-ann(c)
}
number = sum of all digits in the annotation of n
}
4.2.2 Restorer
Finally, the restorer performs a dfs-traversal of TA,D to output the document D:
re-ann(root of SkeletonTreeNode)
output <tag of the root>
d-dfs(root of SkeletonTreeNode)
output <\end of tag for the root>
where d-dfs() is described below using the following notations (1) ann(n) is the first
digit in the annotation of the node n; (2) chop(n) results in removing the first digit
in the annotation of n (always 0); (3) dec(n) decrements by one the first digit in
the annotation of n (never 0); and (4) LC(n) and RS(n) denote respectively the leftmost
child and right sibling of n.
The initial implementation of our compressor was completed using Java and Xerces.
The time taken to compress the XML files on the Wratislavia corpus are reported in
Table 2.
Table II
Compression time of XSAQCT
Compression time in seconds
XML File
XSAQCT using GZIP
TREECHOP Compression
dblp
39.9
25.16
enwikibooks
23.3
25.06
enwikinews
7.7
7.67
lineitem
4.4
5.66
shakespeare
3.7
2.59
SwissProt
29.8
20.43
uwm
1.3
1.2
The compression rate results of our experiments are reported in Table 3. The results of our experiments on the Wratislavia corpus are reported in the following
table. XSAQCT allows use of different data compressors such as two well-known fast
compressors GZIP and BZIP2, and PAQ8o8 (the best compression rate and the expenses
of compression time). Our results show that for this corpus (when using BZIP2 for
compression) XSAQCT considerably shrinks their sizes to 12% (on average) of the original
sizes.
Table III
Size of compressed XML documents
Compressed Size in Bytes
XML File
XSAQCT using GZIP
XSAQCT using BZIP2
XSAQCT using PAQ8o8
TREECHOP
Uncompressed Size
dblp
19,436,979
14,386,289
10,331,426
22,757,793
133,862,735
enwikibooks
44,501,499
36,587,294
25,534,846
44,838,217
156,300,597
enwikinews
12,595,156
9,599,207
6,634,071
12,681,978
46,418,850
lineitem
1,436,510
993,735
848,494
2,327,681
32,295,475
shakespeare
1,896,034
1,441,177
1,168,917
2,016,475
7,894,983
SwissProt
7,515,915
5,852,123
4,118,792
12,384,686
114,820,211
uwm
102,986
87,895
66,887
126,744
2,337,522
Table 4 shows the time taken to query various simple paths using both XSAQCT and TREECHOP.
Each of the seven XML files in the corpus were queried using two different query paths
and the time taken to process each query is shown in seconds. XSAQCT queried each
path faster than TREECHOP and the difference in query time tended to be larger when
larger XML files were queried (e.g. dblp and SwissProt). The biggest difference in
times taken to query by XSAQCT and TREECHOP is seen when querying with the path '/mediawiki/siteinfo/sitename'.
The element sitename only appears once in the entire document; this means that XSAQCT
can easily extract the contents of sitename's container, whereas TREECHOP must find
the text data of sitename by searching the entire compressed file.
Table IV
Query Time of XSAQCT
Query Time in seconds
File Name
Query
XSAQCT
TREECHOP
dblp.xml
/dblp/article/cdrom
10.92
15.49
dblp.xml
/dblp/mastersthesis/@key
10.76
15.15
enwikibooks-20061201-pages-articles.xml
/mediawiki/page/revision/text/@xml:space
2.44
14.6
enwikibooks-20061201-pages-articles.xml
/mediawiki/siteinfo/sitename
0.65
12.75
enwikinews-20061201-pages-articles.xml
/mediawiki/page/revision/contributor/username
1.57
5.49
enwikinews-20061201-pages-articles.xml
/mediawiki/page/title
3.83
5.54
lineitem.xml
/table/T/L_COMMENT
5.49
6.22
lineitem.xml
/table/T/L_ORDERKEY
1.96
5.06
shakespeare.xml
/PLAYS/PLAY/TITLE
0.65
1.56
shakespeare.xml
PLAYS/PLAY/ACT/SCENE/STAGEDIR
1.06
1.44
SwissProt.xml
/root/Entry/@id
7.93
17
SwissProt.xml
/root/Entry/Ref/Comment
9.08
16.63
uwm.xml
/root/course_listing/course
0.45
1.11
uwm.xml
/root/course_listing/restrictions/A/@HREF
0.31
0.8
The time taken to decompress the compressed XML corpus files is shown in Table 5. In most cases XSAQCT decompresses faster than TREECHOP (five out of seven files)
and in the remaining cases has a decompression time that is not much longer than TREECHOP's.
Table V
Decompression Time of XSAQCT
Decompression Time in seconds
File Name
XSAQCT
TREECHOP
dblp.xml
24.52
26.39
enwikibooks-20061201-pages-articles.xml
13.49
20.55
enwikinews-20061201-pages-articles.xml
4.51
7.23
lineitem.xml
3.84
6.17
shakespeare.xml
4.01
2.49
SwissProt.xml
24.04
27.44
uwm.xml
1.78
1.51
Other results on the Wratislavia corpus are shown in Table 6. This includes the number of total nodes in the skeleton tree, the number of dummy
nodes, the size of the skeleton tree uncompressed and the size compressed.
Table VI
Compressed XML document Skeleton Tree information.
uwm
shakespeare
lineitem
swissprot
enwikinews
enwikibooks
dblp
Nodes in ST
43
155
37
394
50
50
313
Number of dummy nodes
0
9
0
2
0
0
10
ST size uncompressed
384
1051
383
3495
467
467
2248
ST size compressed
211
309
200
779
251
251
570
6. Conclusion and Future Work
In this paper, we described our current work on a queryable XML compressor, which
uses lazy decompression. While this work is in its early stage, the design of this
compressor and the results of our experiments indicate that it successfully competes
with other known queryable XML compressors. Our future work includes (1) improving
the compression time by rewriting the code using C++ rather than Java; (2) building
a complete query processor.
7. Acknowledgments
Chris Fry implemented and tested all algorithms described in this paper. The work
of the first author was partially supported by the NSERC RGPIN grant (2004-2009).
References
[ski07] P. Skibiński, Sz. Grabowski, and J. Swacha - "Effective asymmetric XML compression",
Software - Practice & Experience, 2007/2008. doi:https://doi.org/10.1002/spe.v38:10.
[dag08] Tomasz Müldner, Christopher Fry, Jan Krzysztof Miziołek, Scott Durno, SXSAQCT and
XSAQCT: XML Queryable Compressors, Dagstuhl Seminar Proceedings 08261, 2008.
[tre05] Gregory Leighton, Tomasz Müldner, James Diamond, TREECHOP: A Tree-based Query-able
Compressor For XML. In Proceedings of the Ninth Canadian Workshop on Information Theory
(CWIT 2005), pages 115-118, 2005.
P. Skibiński, Sz. Grabowski, and J. Swacha - "Effective asymmetric XML compression",
Software - Practice & Experience, 2007/2008. doi:https://doi.org/10.1002/spe.v38:10.
Tomasz Müldner, Christopher Fry, Jan Krzysztof Miziołek, Scott Durno, SXSAQCT and
XSAQCT: XML Queryable Compressors, Dagstuhl Seminar Proceedings 08261, 2008.
Gregory Leighton, Tomasz Müldner, James Diamond, TREECHOP: A Tree-based Query-able
Compressor For XML. In Proceedings of the Ninth Canadian Workshop on Information Theory
(CWIT 2005), pages 115-118, 2005.
A. Arion, A. Bonifati, I. Manolescu and A. Pugliese: XQueC: A Query-Conscious
Compressed XML Database. ACM TOIT 7(2), 2007. doi:https://doi.org/10.1145/1239971.1239974.