Miłowski, R. Alexander. “XML in the Browser: the Next Decade.” Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). https://doi.org/10.4242/BalisageVol3.Milowski01.
Balisage: The Markup Conference 2009 August 11 - 14, 2009
Balisage Paper: XML in the Browser: the Next Decade
Alex Milowski is a technologist, entrepreneur, developer, and
mathematician who has worked on markup technologies and their use
since 1990. Mr. Milowski is also an active and past participant on a
number of different standards efforts at the W3C: he is currently a
co-editor of XProc and has been involved in XSLT and XML Schema in
the past.
Mr. Milowski is also an advocate of open source software and
its use for accessible content. He's an avid Firefox extension
developer--several of which are open source. He is currently working
on contract for Benetech to produce a Firefox extension that is a
DAISY e-book reader for the visually disabled.
At the 1999 XTech conference in San Jose, Netscape demonstrated
their web browser natively rendering an XML document for the first time.
It is now a decade later, browsers have changed, and there has possibly
been forward progress. This paper briefly describes the demonstration
from 1999 and then questions whether current browsers can or cannot
handle what was demonstrated in 1999. It also details how new XML
vocabularies can be integrated into the browser to provide a new way
forward for XML in the browser.
It was Thursday, March 11th and the last day of XTech 1999 in San
Jose, California, just before lunch. We'd just heard a presentation from
Microsoft about their vision for client and server XML and what we should
expect in IE (Internet Explorer) 5. I and few of my colleagues were
standing in the back, arms crossed, ready for the session to be over. The
next presentation [apparao1999-1] was from Netscape
about their new Gecko rendering engine and what came next was going to
make our day.
The first six slides went through more technical information than
most wanted about how it was all going to work together and on the seventh
slide was a demo. The demo consisted of a simple XML document listing six
books, their titles, authors, and ISBN numbers that had been rendered via
CSS natively for the first time in a widely used, open-source, commercial
web browser [apparao1999-2]. For some of us, that
was delivery on the promise of rendering XML on the web and surprise to
many in the room. It deserved and received a standing ovation.
The demo continued in that not only was the document able to be
rendered, but Javascript was used to add semantics to a set of buttons
that toggled the sort order (via title, author, or ISBN) and the style (as
a simple list or boxes). The style changes were simply enabling and
disabling of different CSS stylesheets with a dramatic effect on the
document. This again deserved applause.
They could have stopped there with some success but there was more
to be seen. A few slides later was a final demo that demonstrated
client-side harvesting of information [apparao1999-3]. An IRS document in XML was presented
that contained a small box with a button labeled "Contents" on the right.
When this button was pressed, TOC items were harvested from the document
and a collapsible table of contents was displayed on the left side of the
document. When a TOC item was clicked, the document navigated to the
item's location in the document. Unbeknownst to the users at the
conference, this was accomplished via Simple XLinks [xlink] embedded in the TOC.
Elated and hungry we all went to lunch with "success" on our minds.
We had just stood witness to the start of an avalanche, or so we thought,
of delivery of XML content to users. We were no longer bound to the
perceived limitations of HTML.
The Status Quo
Given the demos from 1999, the simple question is where are we today
after a decade of "progress". Testing with IE 6, IE7, IE 8, Firefox,
Safari, and Andriod's WebKit-based mobile browser, we get these
results:
Table I
Browser
Books Demo
TOC Demo
Firefox 3.x
Yes
Yes
Safari 4.x
Yes
Partial
Andriod (WebKit)
Yes
Partial
IE 6
No - Blank Page
No - Errors
IE 7
No - Blank Page
No - Errors
IE 8
No - Blank Page
No - Errors
The books demo uses CSS for rendering and Javascript via a
"borrowed" HTML script element. The CSS is provided by three
separate stylesheets. In the case of all the "recent" versions of IE, the
browser fails to render the document and provides no indication of what
failed. All the other browsers give a consistent rendering and user
experience--including the loading and execution of the Javascript.
As for the TOC demo, since this demo uses XLink and only Firefox
completely implements simple links, only Firefox can display this demo
correctly. WebKit and all WebKit based browsers have some ability to
detect simple links and provide the hover/click semantics for rendering
display, but the show/replace semantics are not implemented. For this
demo, all versions of IE have the same Javascript error related to
unimplemented parts of the DOM level 2 specification [dom2].
Based on browser usage statistics [usage] and
grouping all WebKit based browser together, we get a penetration of 32.74%
of browsers that can render XML (excluding XLink handling) as of July 9th,
2009. Given that IE fails for both demos and consists of around 65.5% on
that same date, that leaves roughly 1.76% in an unknown state of whether
they can render and manipulate XML documents. That's not a very good
result for a decade of browser development--mainly due to IE's dominance
and failures.
The question remains as to where the decade has gone. One large
factor has been the stagnation of browser development due to the demise of
Netscape and the resulting reluctance of Microsoft to really implement the
W3C's recommendations. Only recently has the public--either general or
developers--understood the need for conformance to these W3C
recommendations and how failing to do so affects both the bottom line and
the user's experience.
Nevertheless, the open source community has emerged strong with two
viable contenders for core browser technology--Firefox [mozilla] and WebKit [webkit]. While
readers are probably more familiar with Mozilla Firefox, the WebKit
project is the core technology inside Safari, Chrome, the iPhone's web
browser, and Andriod's web browser. Also, the WebKit project is both open
source and supported by large companies such as Google and Apple.
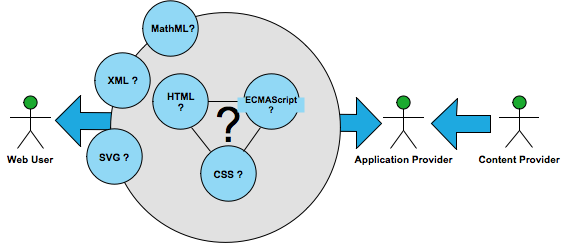
Browser Application Delivery
Figure 1
The Current Model of Application Delivery
Over the last decade the browser's intrinsic ability to handle
deliver of complex applications based on some combination of HTML,
Javascript (ECMAScript), and CSS has dramatically increased such that it
is an economic force. Delivery of goods and services via browser based
applications have become not only common but critical to a company's
continued success. In addition, new kinds of services have been enabled by
the flexibility provided by the browser as a semi-consistent network-based
thin client.
This success has been driven by the fact that HTML, not XML, in
conjunction with CSS and ECMAScript has been spiraling towards a
consistent target platform--dragging Microsoft kicking and screaming along
the way. The Application Provider is then responsible
for bridging the gap between any Content Providers
and the target application that will properly render and present their
content intertwined with an application. Many creative and resourceful
developers have found ways around browser quirks and lack-of-conformance
issues to provide consistent toolkits for use by the application
provider.
The result is the Web User receives the
application and content intertwined as unrecognizable HTML from whatever
source received from the Content Provider. The
unfortunate consequence is that they cannot necessarily re-purpose the
information they receive. For many this is not an issue but, depending on
user's needs, such lack of information repurpose means they may not be
able to even read or use the application due to accessibility or other
human constraints. Further, the user may be unable to use augmentation
tools--such as browser extensions--to extract additional information or
enhance their user experience from the same lack of the original
content.
Even with these restrictions, this model has been wildly successful
and has delivered, on both the business and user sides, a web with some
aspect of ubiquity. All of this is without much XML involved in the
client-side delivery of content to the browser. XML has largely been
hidden on the server-side of the application.
Intrinsic Vocabularies
Any markup that a web browser can natively process with some
well-defined non-trivial semantic without the aid of additional
constructs (e.g. stylesheets) we'll call an Intrinsic
Vocabulary. By that definition, HTML is an intrinsic
vocabulary. Notably, XML is not an intrinsic vocabulary as some
semantics--at least via something like CSS--are needed to give the
browser some instructions as what to do with a specific XML
document.
An application provider can rely upon an intrinsic vocabulary to
have some baseline semantic. They can still enhance the semantics by
using additional augmentations such as a stylesheet or ECMAScript. In
some cases, like SVG or MathML, while a stylesheet may enhance the
rendering, the vocabulary itself is self-contained and the mere act of
delivering the vocabulary invokes the intended result.
Given a sufficient set of intrinsic vocabularies for linking,
diagramming, and specialized communications like Mathematics, an
application developer can deliver content to the browser with some
expected result and semantics for the user. In the case of domains like
Mathematics, by having MathML as an intrinsic vocabulary, augmentation
by tools or accessibility can be achieved by the simple fact that the
markup is there instead of a representation (e.g like an image of the
mathematics).
Unfortunately, the set of currently available intrinsic vocabularies
is across the different browsers is limited to a subset of HTML
4. MathML [mathml], SVG [svg], and
other possible intrinsic vocabularies are limited to specific browsers
and their implementations are incomplete.
The Core Intrinsic Vocabularies
There are many choices for core intrinsic vocabularies but it is
clear that the likely near-term outcomes are the following:
HTML5 - provides needed enhancements to
HTML while providing a standard way of including other vocabularies
like MathML or SVG and, at the same time, provides an option for an
XML syntax.
SVG - provides interactive diagrams that
can be affected by stylesheets and/or ECMAScript much like
HTML.
MathML - provides essential content
models for mathematical, scientific, or education content.
While HTML5 is currently under development, the promise of the
ability to mix MathML and SVG into an HTML document is very powerful.
Add to that the ability to deliver an HTML document in XML syntax
without it being thought of as a separate vocabulary means we can
utilize all the work that has gone into making XML
internationalized.
Also, SVG has shown up recently in several browsers. The support
for this essential vocabulary will certainly grow over time in the
open-source community. Whether commercial browser vendors like Microsoft
will support SVG is unknown.
Finally, MathML support is currently only native to Firefox. While
MathML was the first XML vocabulary produced by the W3C in April 1998,
only the Mozilla developers have chosen to integrate it into their
browser--which is, unfortunately, an incomplete implementation. While
Mathematics is a universal human language with a long history,
intertwined into so many subjects, and involved in so many
communications, MathML support has been largely ignored by browser
vendors.
Nevertheless, what separates an intrinsic vocabulary from a
non-intrinsic vocabulary is the ability to map from one to the other. A
non-intrinsic vocabulary can be composed out of intrinsic vocabulary
components via some kind of mapping. In contrast, an intrinsic
vocabulary is difficult to implement correctly and efficiently. We need
our browser vendors to build-in support for intrinsic vocabularies as
the average developer cannot do so.
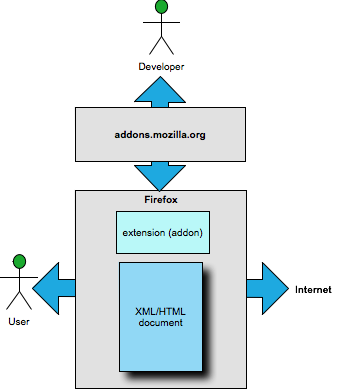
Firefox Extensions for Non-Intrinsic Vocabularies
Unlike many other desktop browsers, Firefox provides the ability
to write "extensions" [extensions] in addition to
"plugins". A plugin typically provides:
the ability to handle a specific media type,
the ability to render that media type via an HTML
object element.
In contrast, Firefox has a very successful extensions model that
provides augmentations to the browser. Extensions can provide what a plugin
provides as well as add UI elements (menus, sidebars, etc.) and other
internal components. These augmentations can be used in concert to
provide a completely new experience for specific tasks or
services.
An extension is installed by the user and always present, unlike
plugins which are invoked as necessary by the browser to handle a
specific media type. Accordingly, the user can add extensions that they
rely upon for their "every day" experience when using the browser.
The user can find new extensions by visiting a registry provided
by Mozilla. Within Firefox, a user can search and access an application
registry (addons.mozilla.org) where developers have uploaded extensions.
These extensions have been put through a basic approval process by which
a user has a minimum level of confidence that the extension isn't
malicious. Afterwards, the same services are used to allow the developer
to upload and distribute updates to their extensions.
Figure 2
Firefox Extensions
Somewhat unique to Firefox is the ability to register new internal
components via an extension that can be used by other extensions or web
pages. These components become part of the browser's ecosystem. As such,
an extension developer can truly "extend" the basic core of the browser
and add the ability to process new XML vocabularies.
Firefox's extension architecture enables a new application model
for developing and deploying markup semantics. Previously, had we wanted
to deliver XML content directly the browser, either it was one of the
browser's intrinsic vocabularies or it was delegated to a plugin and
accessible only as a standalone or via a HTML 'object' element. Within
this new model, we can develop an extension to the browser that
understands the XML media type and delegates to our own components using
the browser's ecosystem and intrinsic capabilities to render the
document.
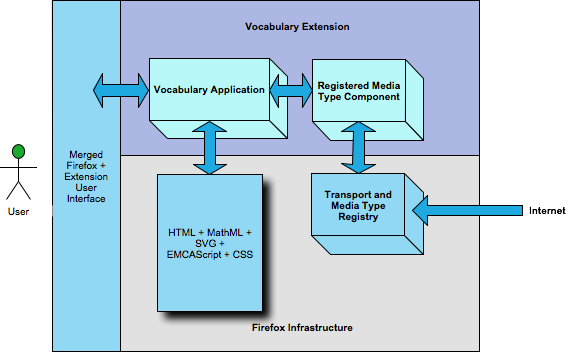
With this architecture we can extend Firefox such that it can
handle any XML vocabulary we choose to send to it as long as it can be
uniquely identified either by namespace or media type (preferably by
media type). The basic process by which the extension does this is by
registering a media type handler component with Firefox's internal
registry. This component is responsible for handling, parsing, and
otherwise processing the XML data stream coming across any transport
Firefox supports (e.g. files, http/https, ftp, etc.).
Since we have a non-intrinsic vocabulary, the extension can
provide whatever internal semantics to translate, transform, other
otherwise orchestrate the use of intrinsic vocabularies like HTML,
MathML, SVG, etc. to render the document and provide user interface
components to the browser user. From the perspective of the browser
user, ultimately, the XML document received is just another tab in their
browser window. From the perspective of the developer, the user
interface provided can be much more rich in UI widgets, semantics, and
privileges than what a typical HTML document provides. The end result is
a merged view of the application and the document's rendering within the
Firefox user interface.
Figure 3
Firefox Extensions
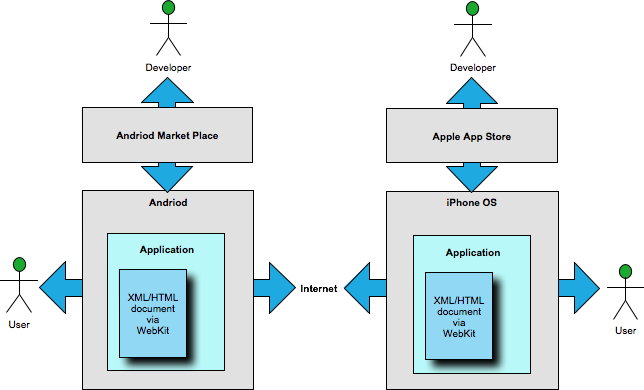
Mobile Applications
Mobile applications as architected by Google for their Andriod OS
and Apple for their iPhone OS are both remarkably similar to each other
as well as similar, in a limited way, to Firefox extensions. A mobile
application is essentially a program that runs on the mobile OS platform
with access to certain system services. On both the Andriod and iPhone
platforms, one of these system services is the ability to construct a
web browser environment based on WebKit.
Much like Firefox's addon registry, the developer uploads the
application to the "marketplace" where users can download it and add it
to their mobile phone's environment. Unlike a Firefox browser extension,
it isn't really merged into the browser and does not augment the general
web browser's capability. Instead, it provides a separate launching icon
where the user must go to initiate the application.
Figure 4
Mobile Application Markets
Even given the limitations in augmenting the general web browser
on these platforms, the mobile application can do remarkably similar
things. Within the environment a developer can instantiate a browser
instance, load content, and manipulate the browser's environment. To
some extent, the mobile developer can mimic some of the Firefox browser
extension environment by building their own application.
What a developer cannot do is change the browser's handling of
media types. If a document is requested that uses some specialized XML
vocabulary, it will get rendered using the same rules as if the user
were using the platforms browser application. As such, the application
developer needs to understand and control what is being given to the
browser much more so than within Firefox.
In addition, once the application has rendered an XML document
into some kind of HTML/Intrinsic vocabulary application being displayed
by the WebKit instance, there are platform-specific limitations as to
what kinds of interactions between the application and document can
occur. This can be broken down further into these useful application
categories:
Affect Global Environment: Can the application provide global
objects accessibly by any document loaded by the browser
instance?
Execute Inside: Can the application execute ECMAScript within
the browser's document?
Execute Outside: Can the document execute scripts or access
objects within the application's environment?
Table II
OS/Browser
Affect Global Environment
Execute Inside
Execute Outside
Andriod/WebKit
Yes
No
Yes
iPhone OS/WebKit
No
Yes
No
Firefox
Yes
Yes
Yes
The result of this analysis is that Andriod applications cannot
affect their documents once loaded but their documents can initiate a
request causing such a change. As such, an Andriod application can work
around this limitation by a few clever bootstrapping tricks where there
is always an internal document which proxies subsequently loaded
documents in an iframe.
Conversely, an iPhone OS application can affect their documents by
executing scripts within their documents but the document cannot
interact with the application and the application cannot affect the
global environment in which the document exists. This severely limits a
browser based application because the document cannot tell the
application about an event unless the application regularly inquires
about its status. Similarly, there is no ability to pass continuous data
streams (e.g. Accelerometer events) to an application without constant
execution of scripts.
Nevertheless, in both these mobile application platforms you can
build an application that loads, intercepts, and understands XML
vocabularies while utilizing the intrinsic abilities of the mobile
browser to handle the rendering and UI semantics. The application has to do
a lot more of the "heavy lifting" than in the case of a Firefox
extension and it also cannot integrate quite seamlessly into the
browser's internals.
The Unified Application Model
Common between Firefox extensions and applications on the iPhone
or Andriod platforms is:
an "application registry" or "store" where users can readily
get new functionality,
the use of the browser as a core application user interface
component,
the reliance on HTML and associated intrinsic capability of
the browser for application functionality.
Unfortunately, in the case of both the mobile platforms, the
browser's integration into the application is limited. While we can
possibly write an application that interacts with our XML content, we
can only do so within the confines of our application. The regular
browser on the mobile platform remains ignorant of what to do with such
XML content.
What we want is for the browser itself to be augmented to handle our
media type so that the user experience inside and outside of any mobile
or desktop application is the same. We don't want to duplicate the
browser's architecture for handling transports, media types, and linking
that it already does well. Instead, we want to augment the existing
known media type handlers and insert a portion (if not all) of our
application.
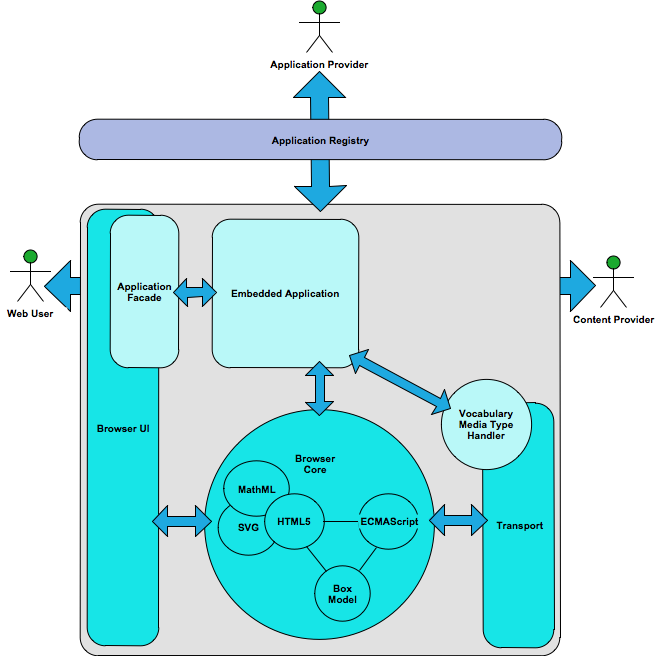
Figure 5
Unified Model
A simplified scenario for how this works internally can be
described as this sequence of events:
A XML media type is recognized at the transport layer.
The media type is associated with our embedded application's
media type handler for that XML vocabulary.
The XML data stream and metadata is transferred to our
application component registered for that media type.
From the XML content received, our embedded application
component constructs user interface elements and/or web content
documents in the browser's intrinsic vocabularies.
The unified experience of our application facade and the web
content documents are presented to the user.
The end result is the user's experience is much like that of any
other HTML application they might use a browser to access. The
difference is that over the transport they received the XML content
rather than some single-purpose rendition of that content. As such, they
can choose the embedded application appropriate to the experience that
they desire.
The DAISY Book Example
The DAISY/NISO standard, ANSI/NISO Z39.86 [daisy3], commonly known as DAISY 3, is an e-book
specification developed with accessibility for the visually disabled in
mind. While the specification itself is not limited to only such special
purpose software environments, the focus of development has been around
the such special needs users. In the end, the e-book specification is a
collection of XML vocabularies that work together to form a single
e-book.
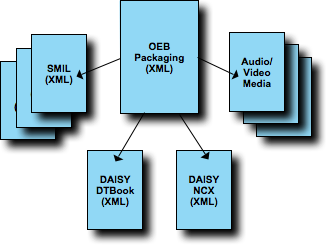
Figure 6
A DAISY Book
The anatomy of a DAISY 3 book starts with a manifest document called
a "OEB Package File". This XML document type was developed by the Open
E-Book Forum/International Digital Publishing Forum [idpf] and provides a manifest of all the parts of the DAISY
e-book. From such a manifest you can access:
The DAISY DTBook XML instance which contains the e-book
content,
The DAISY NCX XML instance which contains navigation information
about the e-book (e.g. table of contents),
SMIL XML documents used to provide playback scripts for the
e-book content,
Any ancillary media objects used by the playback or book.
For a browser to open and display such an e-book, assuming we start
with the OEB Packaging, the browser must first collect all the related
parts and then decide what to render. The starting point of the packaging
file gives the typical XML rendering very little to display. As such, just
associating a CSS stylesheet or an XSLT transformation for rendering is
insufficient.
Solving this requires a browser extension that understands the OEB
Packaging file's media type, application/oebps-package+xml,
and invokes a DAISY browser extension. This component is the responsible
for locating the different documents linked by the manifest in the OEB
Packaging document. The collection of document located is then used to
assemble an appropriate UI within the browser.
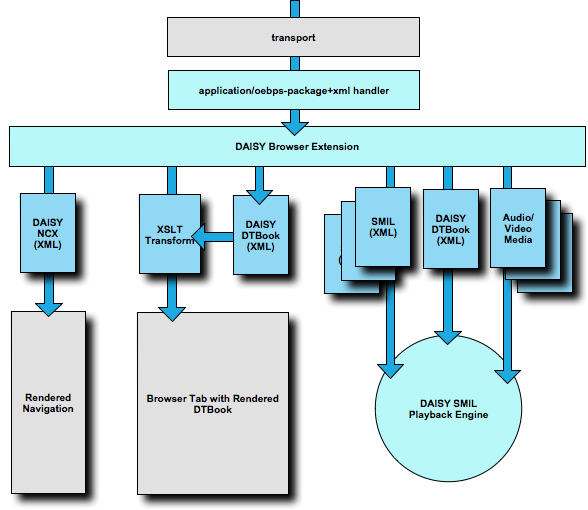
Figure 7
A DAISY Browser Extension
The DAISY NCX document is used to provide a navigation aid, such as
a table of contents, to the user. This document has links into the DAISY
DTBook instance, which is the e-book content. These documents are used to
present the user with a browser tab with e-book content via some XSLT
transformation.
The book itself can be "played" to the user via the linked SMIL
documents. These XML documents describe how the content from the original
DAISY DTBook instance should be sequenced. As such, care must be taken in
the transformations to preserve the identity of content elements so the
SMIL references will work. In the end, the user is presented with playback
options that sequence the book's content.
The end result is the user "opens" a DAISY book just like they do any
other web document. They just follow a link or type in a URL to a DAISY
book's packaging document and read the content. They don't need to know
that there is some more complicated processing going on behind the
interface presented to them.
The crucial point here is that for accessibility, since DAISY was
started as an e-book format for blind and otherwise visually disabled
people and since the DTBook content is translated into an intrinsic
vocabulary (HTML) that the browser already understands, the tools used by
these people to read web documents still work. The vendors of such tools
like screen readers do not need to add specialized support for the DAISY
book reader because, to them, the user is just reading a regular HTML web
document. The combination of standardized intrinsic vocabularies and
widespread software supported by these vendors means that specialized
software like the DAISY browser extension can "hide" in the background and
allow the user the same experience they are used to when they browse the
web.
This DAISY book extension has been implemented as a Firefox
extension and is now open-source. It is available for download from
launchpad.net [daisyextension].
A Peek Into the Future
Making predictions is certainly risky business. Many of us at that
1999 XTech presentation thought we were at the start of the ability to
deliver high quality XML content to users over the web and into their
browsers. What we didn't understand was the complexity of the
interactivity model being developed within HTML, the explosion of
sufficiency from "regular HTML" based web applications, and the relative
high complexity of delivering a true XML application to a client-side
browser.
In 2009, we've found ourselves at another crossroad where high
quality browser technology is now simultaneously scalable to the mobile
platform and open-source as WebKit or Firefox. The promise of WebKit
provides the unique ability to contribute to open-source efforts and
bridge the gap between the ultimate flexibility of the Firefox Mozilla
platform and the streamlined and compliant nature of WebKit. That is, we
can make WebKit what we need simply by actively contributing or otherwise
supporting its development.
In the past, we waited for the browser vendors to do "the right
thing". Now we can make what we want to happen by embracing our
open-source browser technologies and have them do "the right thing"
because we implemented the code to do so. That's our choice: to contribute
or let our ideas fail.
In the spirit of this, I present these challenges for the
reader:
We need intrinsic vocabularies and semantics we can rely upon.
We must have HTML5, SVG, and MathML.
We won't wait for "someone else" to develop our browser
enhancements.
We will embrace the idea of intrinsic vocabularies, like HTML,
because such things take an inordinate amount of time to
develop.
We will replicate the browser extension model championed by
Firefox because it enables direct delivery of XML vocabularies without
obscene acts.
We will support open-source and make it easy to use because it
is our "big stick" we use to get what we want.
Commercial vendors of browser technologies need to catch up or perish.
The drag that has been created by certain browsers not implementing the
most basic of recommendations from the W3C has caused enormous delay as
well as economic consequences. While it is the user who suffers, they also
often have a choice and can choose one that works.
The ability to deliver XML content paired with applications directly
to users has existed for quite awhile--but only in Firefox. That ability
has been buried inside Firefox and delegated to the brave souls who want
to dig through the source code. We need to bring that ability to the
surface and make it easy to use.
Having only one browser that does "cool things" is not enough. We
need to propagate the ability to extend a web browser by extending it at
its core. We need the ability to do serious work along side other
components inside the browser in addition to augmenting the user interface
to add in our "gadgets". It is really our choice to propagate a new model
based on this knowledge and experience for the next decade.