Takeda, Joey, and Martin Holmes. “Serverless Searching with XSLT and JavaScript: Introducing staticSearch.” Presented at Balisage: The Markup Conference 2022, Washington, DC, August 1 - 5, 2022. In Proceedings of Balisage: The Markup Conference 2022. Balisage Series on Markup Technologies, vol. 27 (2022). https://doi.org/10.4242/BalisageVol27.Takeda01.
Balisage: The Markup Conference 2022 August 1 - 5, 2022
Balisage Paper: Serverless Searching with XSLT and JavaScript
Introducing staticSearch
Joey Takeda
Digital Humanities Innovation Lab, Simon Fraser
University
Joey Takeda is a Digital Humanities Developer at Simon
Fraser University’s Digital Humanities Innovation Lab. He holds an MA in
English Literature from the University of British Columbia. He currently
serves as Technical Editor for the Winnifred Eaton Archive and is a
member of TEI By Example’s International Advisory Committee.
Martin Holmes
Humanities Computing and Media Centre, University of
Victoria
Martin Holmes is a programmer in the University of
Victoria Humanities Computing and Media Centre. He served on the TEI
Technical Council from 2010 to 2015 and was managing editor of the
Journal of the Text Encoding Initiative from 2013 to 2015. He is lead
programmer on several large DH projects, including The Map of Early
Modern London and Digital Victorian Periodical Poetry.
Copyright rests with the authors.
Abstract
Increasing awareness of the burdens of technical debt and the
risks and costs associated with complex server infrastructures
have prompted digital humanists to consider moving to purely
static HTML/CSS/JS websites for projects such as online digital
editions. Building static sites is not difficult, but digital
editions also require sophisticated search capabilities,
incorporating text search with stemming and wildcards as well as a
rich array of filters tuned to the contents of the edition itself.
Responding to this need, we created staticSearch, a system which
builds search indexes offline with XSLT and queries them
statically using JavaScript, providing a straightforward approach
to search for purely static websites. This presentation will
describe how staticSearch works, and discuss some of the
interesting and challenging problems that such a system has to
overcome.
The Endings project is a SSHRC-funded collaboration between
scholars, programmers, and librarians to devise and implement
guidelines and practices that ensure the long-term survival and
archivability of digital edition projects, not just as data but as
functioning web applications. In the first phase of the project,
we converted numerous projects, ranging from small collections of
texts to densely interlinked documents and datasets, from eXist-db
backends into entirely static sites consisting only of HTML, CSS,
and JavaScript [Holmes and Takeda 2019a; Holmes and Takeda 2019b;
Holmes and Takeda Forthcoming].
Having demonstrated the feasibility of building large sites which
are both static and interactive, we were left with one remaining
issue: how to provide a search engine for our collections without
adding an unwanted technical debt in the form of a server-side
backend. Searching is often an essential component of digital
edition projects and most, if not all, of our projects are built
with the assumption that there will be some sort of searching
ability available in the future; much of our encoding work is
predicated on the notion that good, clean encoding produces not
only better texts, but ones more amenable to complex and specific
querying in the future. These projects thus require robust search
mechanisms that can allow for a range of queries—from simple word
searches to complex faceted searches, to aid in both the usability
and discoverability of documents.
This paper introduces staticSearch: a serverless text-search
engine with full stemming, wildcard, keyword-in-context, and
filter support.[1] It is made up of two distinct, albeit interdependent,
components: an XSLT-based indexer that generates an inverted index
of JSON files from a collection of XHTML files and an associated
JavaScript module for querying and displaying search
results.[2] While our initial expectation was that staticSearch
would be practical for smaller sites and perhaps not realistic for
our larger ones which have tens of thousands of documents, our
pessimism has proved unwarranted. Now nearing its second major
release, staticSearch has become a core part of over a dozen
projects, many of which contain thousands of documents, and its
performance has surprised us.
Prior Work and Existing Solutions
As we note in Holmes and Takeda Forthcoming, static websites have
become popular due, in part, to their long-term durability. Static
sites, once deployed, require minimal maintenance; unlike
server-side applications, there is no risk of incompatible
upgrades that either break your application, forcing the site to
be remade, remediated, or retired, or, if ignored, make your site
vulnerable to attacks or pre-emptive shutdown by system
administrators. While the Endings project initially focused on
generating static versions of existing web applications for
long-term preservation, we quickly realized that creating static
sites from the outset is relatively straightforward, and offers
significant improvements in terms of workflow, project
consistency, maintenance costs, and project management. The
majority of the projects developed at the HCMC are now entirely
static from the start.
While full-text search engines like eXist and Solr offer powerful
and well-documented mechanisms for indexing and querying large
document collections, there is a lack of good options when it
comes to adding search to static websites. As we detailed in
Holmes and Takeda 2018, we tested a number of approaches, including
invoking Google Custom Search Engine (CSE)—which the authors of
O’Reilly’s introduction to static website development nominate as
the best solution and the undisputed king of search
[Camden and Rinaldi 2018]—and hooking into a centralized Library-run
Solr indexer, but all of these systems had significant drawbacks.
External services such as Google CSE and the Library’s Solr are
not only fragile, but also difficult to customize for our needs
and challenging to update. The Lunr.js JavaScript library, which
bills itself as [a] bit like Solr, but much smaller and not
as bright [Nightingale 2011], is another popular mechanism
for adding search to static sites [Wikle, Williamson, and Becker 2020].
Lunr.js only requires a pre-built JSON index file, which it can
then parse in-memory to display search results. One of serious
drawback of Lunr, however, is that it requires a single JSON file
in memory, which can quickly become overwhelmed by large volumes
of data. The assumption is that the index will be comprised of
simple text or Markdown files, but our HTML is often highly nested
and enriched with data attributes and classes that retain
important information from the source documents; while not all of
the information contained in the HTML is critical, much of it is
important when it comes to fine-tuning and configuring specific
site searches.
There are, of course, many other ways to index a document
collection beyond those services list above, but our ultimate goal
was creating a search engine that could easily fit within our
established infrastructure of XML languages and software. As
Kraetke and Imsieske 2016 note, XSLT offers a modern, powerful
static website generator, one that, we realized, could quite
capably handle all of the tasks required by an indexing system.
What is staticSearch?
Broadly, staticSearch works by first taking in a user supplied XML
configuration file that tells the staticSearch build process where
to find the documents and the search page and sets various options
such as the number and length of keyword-in-context fragments to
harvest for each stem.[3] It then runs the build process as follows:
Checks and validates the input document collection.
Checks the user’s configuration file, and if it is valid, uses
it to build an XSLT configuration file for the remaining
processes.
Processes all documents in the collection to create versions
in which stemmed tokens are tagged, and each tagged token has
additional information about its context (more on this later).
Each document is given an identifier consisting of its path
relative to the search page.
Uses the tokenized texts to build a collection of JSON files
which are used to power the search.
Creates the search page itself.
Creates a report on the process.
Figure 1
There is one stipulation: the input document collection must
consist of well-formed HTML5 in the XHTML namespace.
Well-formedness is essential because we use Saxon to process the
collection; the XHTML namespace arises purely out of our own
prejudice.[4] That staticSearch uses and produces HTML, however, is
an infrastructural feature. While extending staticSearch to other
namespaces and to other XML dialects in general is certainly
feasible and, in fact, our HTML documents are frequently derived
from TEI XML encoded documents, it is difficult, in our minds, to
imagine cases where indexing and tokenizing non-HTML files would
be more effective. Since the search is meant to power a web
application, users of the search are looking for information that
they can find in the mass of HTML files, not the source documents
from which they are produced. Our index, in other words, reflects
the documents that are available in the collection and thus search
results can be easily linked to the places in the source document
where a term appears.
We will now discuss the technical implementation in further
detail.
Configuration
The structure and syntax of the configuration file is defined by
staticSearch’s custom schema (expressed as a TEI ODD file) and
provides specific options for the staticSearch build process. A
basic configuration file looks something like this:
There are many interesting configuration options that are beyond
the scope of this paper (full documentation of each option is
available on the project’s website and the GitHub repository),
but the crucial parameter here is the
<searchFile>.
<searchFile> contains the path
(relative to the configuration file) for the page in the
collection that will be populated with the search form and
controls for filters. This page may or may not already exist. If
that page exists, then it must contain an HTML block element
(<div>,
<section>, etc) with the id
"staticSearch"; if that page does not exist, then the
page is created during the build process. The
<searchFile> parameter also gives the
location of the collection to index; in the above case,
staticSearch will index all of the HTML files in the
test/ directory.
This configuration file is transformed into an XSLT stylesheet
that is included in all subsequent steps of the build process.
It is necessary to convert the configuration file into its own
XSLT as some configuration options, like weighting rules and
context specifications, rely on XPath match statements. For
example, elements can be assigned weights[5] via the <rule> element in
the configuration file:
The @weight attribute above signals the
multiplier that should be applied to each instance of that
element within a document when computing a term’s score. We make
some assumptions about specific weighting of elements (all
heading-like elements <h1> etc are
given a weight of 2). A weight of 0 means that the indexer
should ignore the element entirely).
The rule element (and other elements that bear a
@match) are converted into
<xsl:template>s that are run during the
multi-phase tokenization process.
Tokenizing
Cleaning and Pre-Processing
What we refer to as the "tokenization" process is a
bit of a misnomer: it refers to a single monolithic
stylesheet—tokenize.xsl—that processes each
source document in multiple passes in order to create the
minimal HTML structure necessary for generating the
index.[6] The first stage in the process is to remove
irrelevant content, retaining only the information that is
necessary for the indexing process and removing ignored
elements, unnecessary wrappers, and most attributes. In most
cases, input documents will contain a significant amount of
boilerplate HTML that appears on every page and should be
completely ignored by the indexer, like the site menu,
sidebar, or footer. As the example above shows, these elements
are given a weight of 0, which means they are removed from the
tokenized document. The tokenization process also removes
elements that will have no bearing on the indexing process;
this includes most inline elements, like links, spans, etc,
unless these elements must be retained for a specific reason
(i.e. they are assigned a higher weight or they contain a
fragment identifier, which can be linked from the search
results).
Often, a well-configured instance of staticSearch will produce
tokenized documents that are significantly smaller than the
original. For example, consider this line from a poem in the
Digital Victorian Periodical Poetry
Project:
<div class="l" data-el="l" id="l_1"><span class="lineContent"><span data-el="hi" class="hi" style="font-variant: small-caps; letter-spacing: 0.06em;">A blush</span>, a smile, a dusk sweet vio<span class="rhyme label_a" data-el="rhyme" title="Masculine rhyme (Final syllable rhymes exactly; for example, Keats/beets.); label: a">let</span>—</span><span class="lineNum">1</span></div>
After being run through the tokenizer, all classes, data
attributes, superfluous wrapping elements, and other
information irrelevant to the indexer are removed:
The second process is, of course, tokenization. The
tokenization stage wraps each token in a span element and
decorates the element with the token’s stem, position, weight,
et cetera. Each meaningful text node is matched and analyzed
using <xsl:analyze-string> to
identify each word where a word is
understood as:
A number [\d]+([\.,]?\d+)
An alphanumeric word [\p{L}\p{M}]+
A hyphenated word:
$alphanumeric(-$alphanumeric)*)
We also consider apostrophes and quotation marks (both
straight and curly) as part of a word,
so the constructed Regular Expression is slightly more
complicated when expressed in the XSLT:
If a word is indeed a word and is neither too short nor a
stopword, it is then run through the user-configured XSLT
stemmer. At the moment, staticSearch has four different
stemmers: the Porter stemming algorithms for English and
French (Porter 1980; Porter 2002; Porter French) ; an
identity stemmer; and a diacritic stemmer, which
simply strips diacritics and is otherwise
idempotent.[7] Users can specify their own stemmers, but, at the
moment, the stemmers need to be implemented identically in
both XSLT and JavaScript. We are currently exploring options
for integrating existing implementations of Porter’s stemming
algorithms in Java and JavaScript (for Saxon and the browser,
respectively).
Indexing
staticSearch works by generating an inverted index
from the tokenized documents (Zobel and Moffat 2006). This index is
simply a directory full of JSON files on the file system: each
unique stemmed term has a JSON file to itself, named for itself
('book.json', 'walk.json', etc.) that contains information about
the documents in which that term appears. This means that when
the search page queries the index, it need only retrieve the
individual JSON files for the terms which are in the search; the
bulk of the index is never retrieved.
The many JSON files range in size depending, of course, on their
frequency within the document collection; in most cases, the
individual JSON files are trivially small, but for very common
words not included in the stopwords file, they can reach into
MBs. However, given that these are texts files and most servers
can serve GZIP compression, the files can be highly compressed
and thus retrieved almost instantly. As shown in Appendix A,
regardless of compression, the JSON index is significantly
smaller than the input document collection.
Stem Files
Here’s an example of the stem file for the term
glow:
{
"stem": "glow",
"instances": [
{
"docUri": "poems/twilight.html",
"score": 1,
"contexts": [
{
"form": "glow",
"weight": "1",
"pos": 49,
"context": "Twilight for dreams, the dun and dying <mark>glow</mark>",
"fid": "l_9"
}
]
}
]
}
This contains an entry for each document which contains the
stem, an overall score for that stem in that document, and
precise information about each individual instance, including
a keyword-in-context extract in which it is marked.
Each stem is created by grouping the entire set of stems by
their @ss-stem value.
The makeMap template takes each group of
stems and creates an XML map in the JSON
namespace[8] for the file:
<xsl:template name="makeMap" as="element(j:map)">
<!--The term we're creating a JSON file for, inherited from the createMap template -->
<xsl:variable name="stem" select="current-grouping-key()" as="xs:string"/>
<!--The group of all the terms (so all of the spans that have this particular term
in its @ss-stem -->
<xsl:variable name="stemGroup" select="current-group()" as="element(span)*"/>
<!--Create the outermost part of the structure-->
<map xmlns="http://www.w3.org/2005/xpath-functions">
<!--The stem is the top level string key for this map; it should be
the same as the JSON file name.-->
<string key="stem">
<xsl:value-of select="$stem"/>
</string>
<!--Start instances array: this contains all of the instances of the stem
per document -->
<array key="instances">
<!--If every HTML document processed has an @id at the root,
then use that as the grouping-key; otherwise,
use the document uri -->
<xsl:for-each-group select="$stemGroup"
group-by="document-uri(/)">
<!--Sort the documents so that the document with the
most number of this hit comes first-->
<xsl:sort select="count(current-group())" order="descending"/>
<!--The current document uri, which functions
as the key for grouping the spans-->
<xsl:variable name="currDocUri" select="current-grouping-key()"
as="xs:string"/>
<!--The spans that are contained within this document-->
<xsl:variable name="thisDocSpans"
select="current-group()" as="element(span)*"/>
<!--Get the total number of documents
(i.e. the number of iterations that this
for-each-group will perform) for this span-->
<xsl:variable name="stemDocsCount" select="last()" as="xs:integer"/>
<!--The document that we want to process
will always be the ancestor html of
any item of the current-group() -->
<xsl:variable name="thisDoc"
select="current-group()[1]/ancestor::html"
as="element(html)"/>
<!--Get the raw score of all the spans by getting the weight for
each span and then adding them all together -->
<xsl:variable name="rawScore"
select="sum(for $span in $thisDocSpans
return hcmc:returnWeight($span))"
as="xs:integer"/>
<!--Map for each document that has this token-->
<map xmlns="http://www.w3.org/2005/xpath-functions">
<string key="docId">
<xsl:value-of select="$thisDoc/@id"/>
</string>
<!--And the relative URI from the document, which is to be used
for linking from the KWIC to the document. We've created this
already in the tokenization stage and stored it in a custom
data-attribute-->
<string key="docUri">
<xsl:value-of select="$thisDoc/@data-staticSearch-relativeUri"/>
</string>
<!--The document's score, forked depending on configured
algorithm -->
<number key="score">
<xsl:choose>
<xsl:when test="$scoringAlgorithm = 'tf-idf'">
<xsl:sequence select="hcmc:returnTfIdf($rawScore, $stemDocsCount, $currDocUri)"/>
</xsl:when>
<xsl:otherwise>
<xsl:sequence select="$rawScore"/>
</xsl:otherwise>
</xsl:choose>
</number>
<!--Now add the contexts array, if specified to do so -->
<xsl:if test="$phrasalSearch or $createContexts">
<xsl:call-template name="returnContextsArray"/>
</xsl:if>
</map>
</xsl:for-each-group>
</array>
</map>
</xsl:template>
Each stem files contains precise information about each
individual instance in which that stem appears. This is the
most onerous part of the process as each context contains the
a keyword-in-context string, which shows this word
in situ.
This has been difficult to optimize. Our approach so far has
been to move up the tree and use node comparison operators
(<< and >>)
to compile all of the nodes that precede the span and the
nodes that follow and then trim each string to the configured
length.
This can still lead to very long strings being stored in
memory, however, and so we have tried to optimize by iterating
through each node using <xsl:iterate>
and breaking once a string of the desired length has been
found.
<xsl:function name="hcmc:returnSnippet" as="xs:string?">
<xsl:param name="nodes" as="node()*"/>
<xsl:param name="isStartSnippet" as="xs:boolean"/>
<!--Iterate through the nodes:
if we're in the start snippet we want to go from the end to the beginning-->
<xsl:iterate select="if ($isStartSnippet) then reverse($nodes) else $nodes">
<xsl:param name="stringSoFar" as="xs:string?"/>
<xsl:param name="tokenCount" select="0" as="xs:integer"/>
<!--If the iteration completes, then just return the full string-->
<xsl:on-completion>
<xsl:sequence select="$stringSoFar"/>
</xsl:on-completion>
<xsl:variable name="thisNode" select="."/>
<!--Normalize and determine the word count of the text-->
<xsl:variable name="thisText" select="replace(string($thisNode),'\s+', ' ')" as="xs:string"/>
<xsl:variable name="tokens" select="tokenize($thisText)" as="xs:string*"/>
<xsl:variable name="currTokenCount" select="count($tokens)" as="xs:integer"/>
<xsl:variable name="fullTokenCount" select="$tokenCount + $currTokenCount" as="xs:integer"/>
<xsl:choose>
<!--If the number of preceding tokens plus the number of current tokens is
less than half of the kwicLimit, then continue on, passing
the new token count and the new string-->
<xsl:when test="$fullTokenCount lt $kwicLengthHalf + 1">
<xsl:next-iteration>
<xsl:with-param name="tokenCount" select="$fullTokenCount"/>
<!--If we're processing the startSnippet, prepend the current text;
otherwise, append the current text-->
<xsl:with-param name="stringSoFar"
select="if ($isStartSnippet)
then ($thisText || $stringSoFar)
else ($stringSoFar || $thisText)"/>
</xsl:next-iteration>
</xsl:when>
<xsl:otherwise>
<!--Otherwise, break out of the loop and output the current context string-->
<xsl:break>
<!--Figure out how many tokens we need to snag from the current text-->
<xsl:variable name="tokenDiff" select="1 + $kwicLengthHalf - $tokenCount"/>
<xsl:choose>
<xsl:when test="$isStartSnippet">
<!--We need to see if there's a space before the token we care about:
(there often is, but that is removed when we tokenized above) -->
<xsl:variable name="endSpace"
select="if (matches($thisText,'\s$')) then ' ' else ()"
as="xs:string?"/>
<!--Get all of the tokens that we want from the string by:
* Reversing the current token sequence
* Getting the subset of tokens we need to hit the limit
* And then reversing that sequence of tokens again.
-->
<xsl:variable name="newTokens"
select="reverse(subsequence(reverse($tokens), 1, $tokenDiff))"
as="xs:string*"/>
<!--Return the string: we know we have to add the truncation string here too-->
<xsl:sequence
select="$kwicTruncateString || string-join($newTokens,' ') || $endSpace || $stringSoFar "/>
</xsl:when>
<xsl:otherwise>
<!--Otherwise, we're going left to right, which is simpler
to handle: the same as above, but with no reversing -->
<xsl:variable name="startSpace"
select="if (matches($thisText,'^\s')) then ' ' else ()"
as="xs:string?"/>
<xsl:variable name="newTokens"
select="subsequence($tokens, 1, $tokenDiff)"
as="xs:string*"/>
<xsl:sequence
select="$stringSoFar || $startSpace || string-join($newTokens,' ') || $kwicTruncateString"/>
</xsl:otherwise>
</xsl:choose>
</xsl:break>
</xsl:otherwise>
</xsl:choose>
</xsl:iterate>
</xsl:function>
Additional Files
In addition to the stem files, the build process also creates
the following individual JSON files:
ssTitles.json
This maps each document’s unique identifier (its path
relative to the search page) to its title. It may also
include an icon with which to identify the document in
search results, and an optional sort key to be used instead
of its title when search results with the same score are
being listed.
ssWordString.json
This is a plain-text list of all the individual (unstemmed)
words appearing in the collection, separated by pipes:
This file is used when processing wildcard searches. When
the user enters a wildcard term, it is expanded into a
regular expression which is used to extract all of the
individual matching words from the word string JSON list.
Each of those words is a potential match, so it is stemmed,
and its stem file is retrieved. Then a search is made
through all the contexts in those files to find matches for
the wildcard/regex term in their contexts, so that all
actual hits can be found.
For exact phrase (i.e. quoted string) searches, the quoted
string is tokenized and the first non-stopword is extracted
from it; that word is stemmed, and its stem file retrieved.
Then all the contexts in that stem file are searched for an
exact match for the phrase.
Filter Files
In addition to the text search, the user can trigger the
creation of a range of different search filter controls on the
search page, by including some HTML meta tags with specific
formats in the document. For example, if a document has these
three meta tags:
then the containing document will be classified as belonging
to two document categories, Poems and
Translations, in the Document type
selection filter (which we refer to as a description
filter). A second date range filter will also be
created. If an end-user searches for documents in either of
those categories, using a date-range that includes 1895-01-05,
then this document will be selected. Other filter types
include boolean, number range, and feature
filters, which provide a typeahead searchable list of
keywords. The build process creates a separate JSON file for
each of these filters.
The JSON for a description filter looks like this (heavily
truncated example):
When an end-user’s search makes use of a filter control, then
required filter JSON will also be downloaded along with any
stem files needed, but the filter files are also downloaded in
the background on page load so that most are already available
by the time a user has initiated a search.
When filters are combined with text search, the list of
documents containing hits for the text search are first
computed, then those hits are filtered based on the filter
settings. The small size and innate compressibility of the
JSON files enables staticSearch to produce results quite
rapidly, even from relatively large document collections.
Search Page
Once the documents have been indexed, staticSearch then creates
the search page using data assembled by the indexing
process.[9] This search page is pre-populated with all necessary
values for the search, including the query input, checkboxes for
filters, inputs for dates and numeric filters, et cetera; the
form itself also bears custom HTML data-attributes specifying
some of the configuration options—the name of the folder that
contains the index, the number of results to show, and so on—to
be used by the JavaScript.
Building the page beforehand means that the client-side script
does not need to retrieve and parse any of the filters in order
for the page to display the necessary controls; while some
files—the list of stopwords, the word string, and the titles
file—are crucial for any search to be performed and are thus
fetched immediately on page load, staticSearch retrieves these
asynchronously in the background such that the page is
immediately responsive and usable.
Conclusion
While in many cases, staticSearch has been implemented in projects
as a replacement for pre-existing search engines, we find
ourselves using staticSearch from the start with many our
projects. Since staticSearch runs on HTML files, it could be
integrated into any publishing workflow that produces well-formed
HTML5. We are also continuing to research ways that the static
index produced by staticSearch could be packaged with a web
archive file (WARC) such that web archives displayed on the
Wayback Machine and other web archive viewers would retain their
essential search functionality.
Overall, this paper has outlined our approach behind staticSearch
and demonstrates how XSLT can be used to generate a robust search
index without the use of server-side technologies.
Appendix A. Statistics
The following table details statistics about staticSearch’s
indexing process for three different projects: the very small
staticSearch test set of documents; the Winnifred
Eaton Archive’s (Chapman 2022) documents, including
transcriptions; and the Landscapes of
Injustice’s (Stanger-Ross 2021) large archive of
primary and secondary source materials. Statistics below were
taken on an Apple MacBook Pro running 16GB of RAM and silicon
architecture (M1 Pro); timing and sizes are as reported by
gtime, a port of GNU time
for macOS.
[Holmes and Takeda 2019b] Holmes, M.D. and Takeda, J. 2019. Beyond Validation: Using Programmed Diagnostics to Learn About, Monitor, and Successfully
Complete Your DH Project.Digital Scholarship in the Humanities, 34 (suppl_1) (December 2019): i100–i109. Oxford University Press/EADH. doi:https://doi.org/10.1093/llc/fqz011.
[Holmes and Takeda Forthcoming] Holmes, M.D. and Takeda, J. Forthcoming. From Tamagotchis to Pet Rocks: Static Websites for Long-term Sustainability. In peer review with Digital Humanities Quarterly, 2022.
[Kraetke and Imsieske 2016] Kraetke, Martin, and Gerrit Imsieke. 2016. XSLT as a Modern, Powerful Static Website Generator: Publishing Hogrefe’s Clinical
Handbook of Psychotropic Drugs as a Web App. Presented at XML In, Web Out: International Symposium on sub rosa XML, Washington,
DC, August 1, 2016. In Proceedings of XML In, Web Out: International Symposium on sub rosa XML. Balisage Series on Markup Technologies, vol. 18. doi:https://doi.org/10.4242/BalisageVol18.Kraetke02.
[Quin 2008] Quin, Liam R.E. 2008. Text Retrieval for XML-Encoded Corpora: A Lexical Approach. Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 -
15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1. doi:https://doi.org/10.4242/BalisageVol1.Quin01.
[2]
While this paper focuses primarily on the XSLT-based indexer,
we would like to address the concerns helpfully raised by a
reviewer about the sustainability of using JavaScript for the
client-side retrieval. While much of the history of JavaScript
has been defined by the use of libraries like JQuery (which
often cause critical problems within applications due to
incompatibility of upgrades, changed pointers, etc.), the
language itself has been remarkably stable and
backwards-compatible since the 1990s. What makes client-side
scripts fragile, in our view, is not the language itself, but
changes in browser security policies (e.g. the recent rollout
of CSP rules), which are ultimately managed at the server
level anyway, as well the multiple points of failure
introduced by external dependencies (and, crucially, the
dependency’s dependencies). staticSearch is written entirely
in ES6 JavaScript and does not have any dependencies (either
bundled with it or as external scripts).
[4]
Our insistence on well-formed HTML5 in the XHTML namespace is
part ideological—given our fealty to XML, our hope is that
this constraint will encourage projects to create well-formed
our HTML—and part practical: it is beyond the scope of our
project to try and handle the range of ill-formed tag-soup
HTML that is common in the wild. That said, since staticSearch
does not modify the input files, implementers could use any
number of existing conversion tools to pre-process their files
into well-formed HTML (such as Tidy or the TagSoup parser in
Python); as well, since the codebase is open-source,
implementers could fork the repository and use a custom parser
in Saxon.
[5]Weight here is a slightly misleading term; most
discussions of search engines refer to what we call
weight as boost where what we call
score is usually framed as weight.
[6]Quin 2008 discusses possible solutions for full-text
querying of XML with lq-text and notes that, while
tedious, a pragmatic approach is to re-write
documents before indexing them, perhaps with XSLT.
While we were not aware of Quin’s extensions to lq-text
hitherto working on staticSearch, the approach described
in many ways pre-figures and anticipates our own.
[7]
While the identity stemmer is not necessarily
ideal, it does vastly simplify the creation of a search
engine for multi-lingual documents and document
collections. It also provides a convenient starting point
for users who might want to implement their own stemmers.
[8]
The advantage of using this structure rather than XPath
maps and arrays is the ease with which we can construct an
array at least until such time that the proposed XSLT 4.0
<xsl:array> instruction becomes
available.
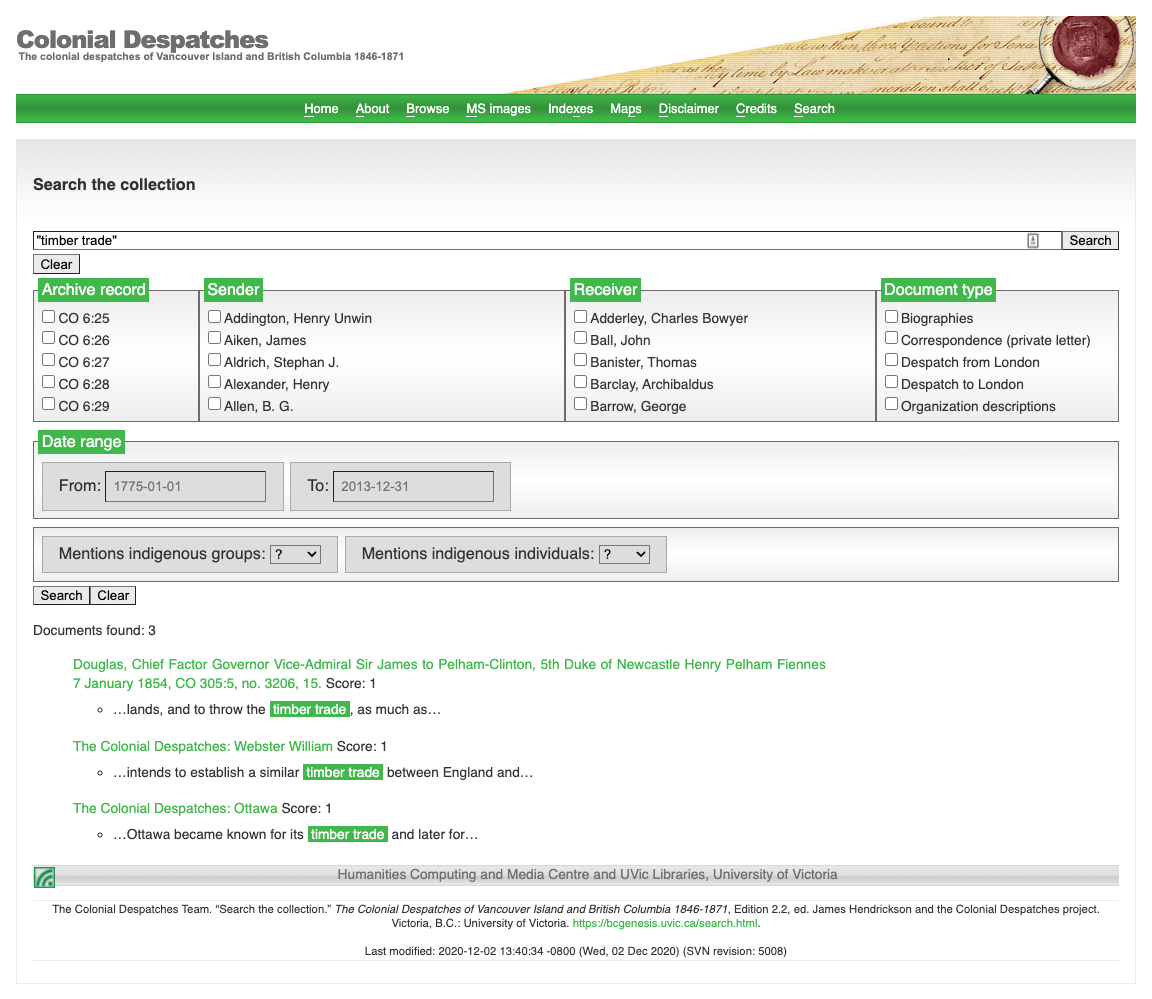
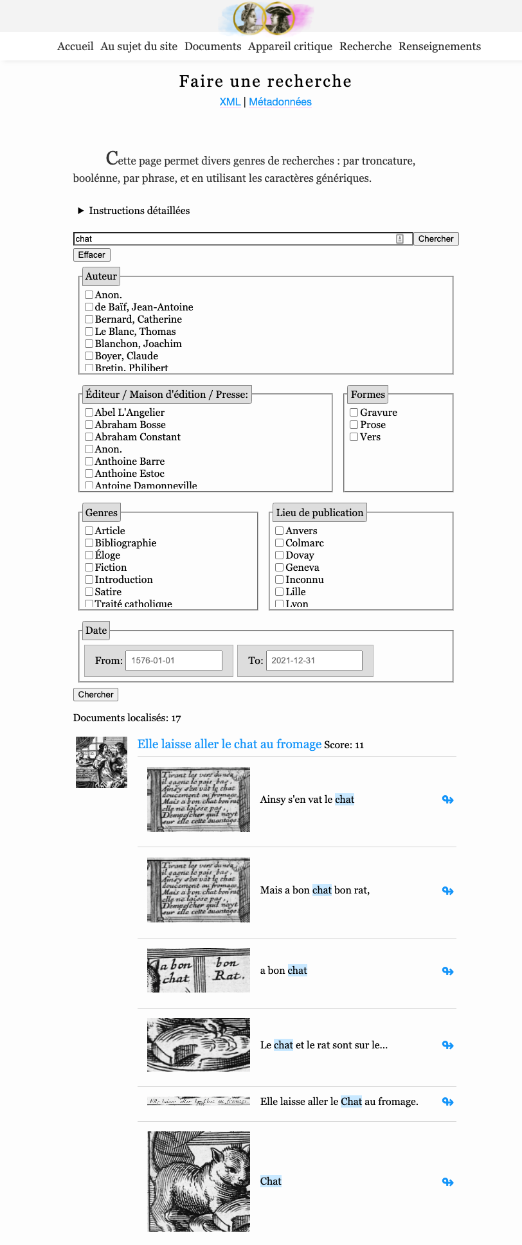
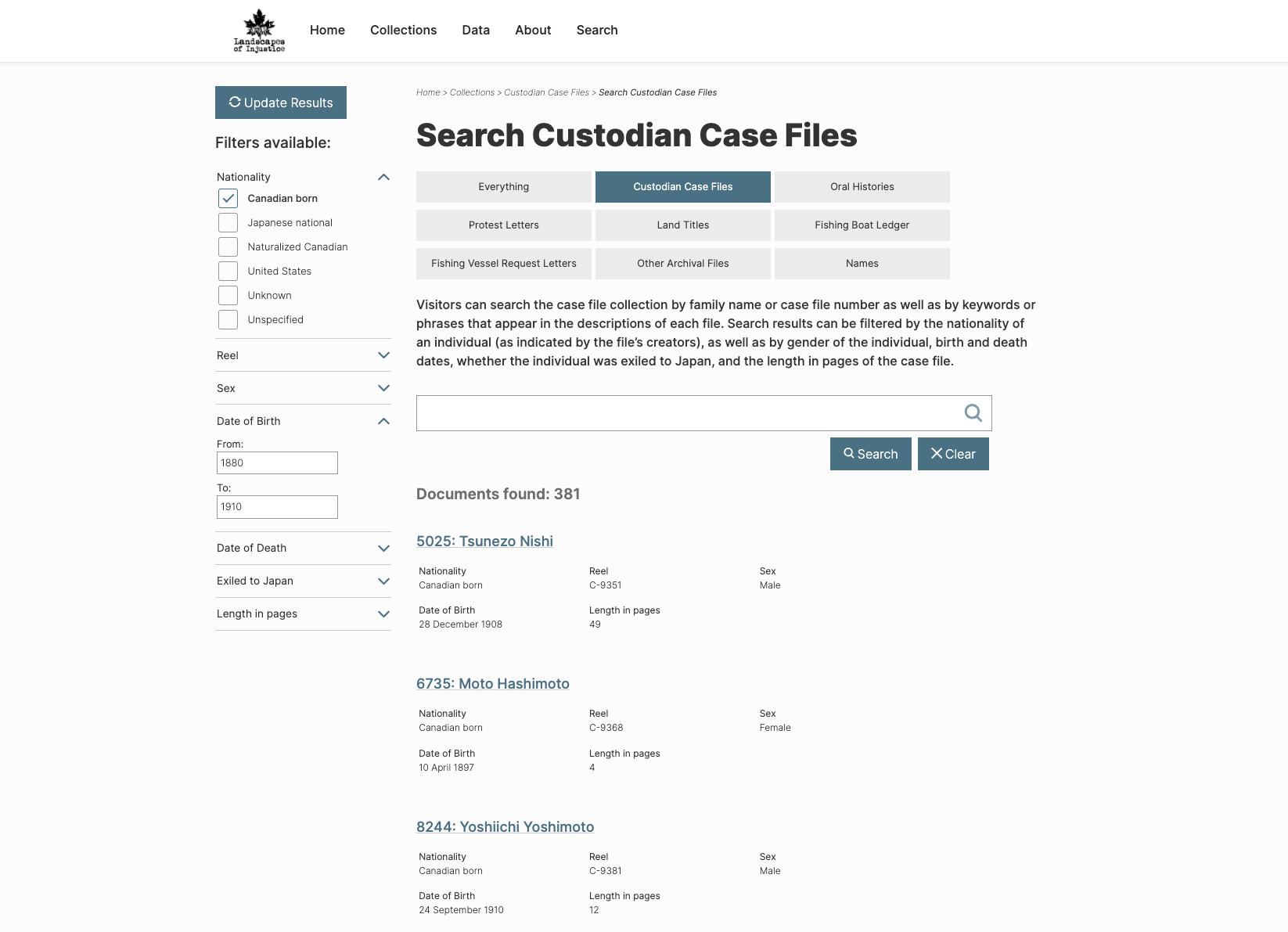
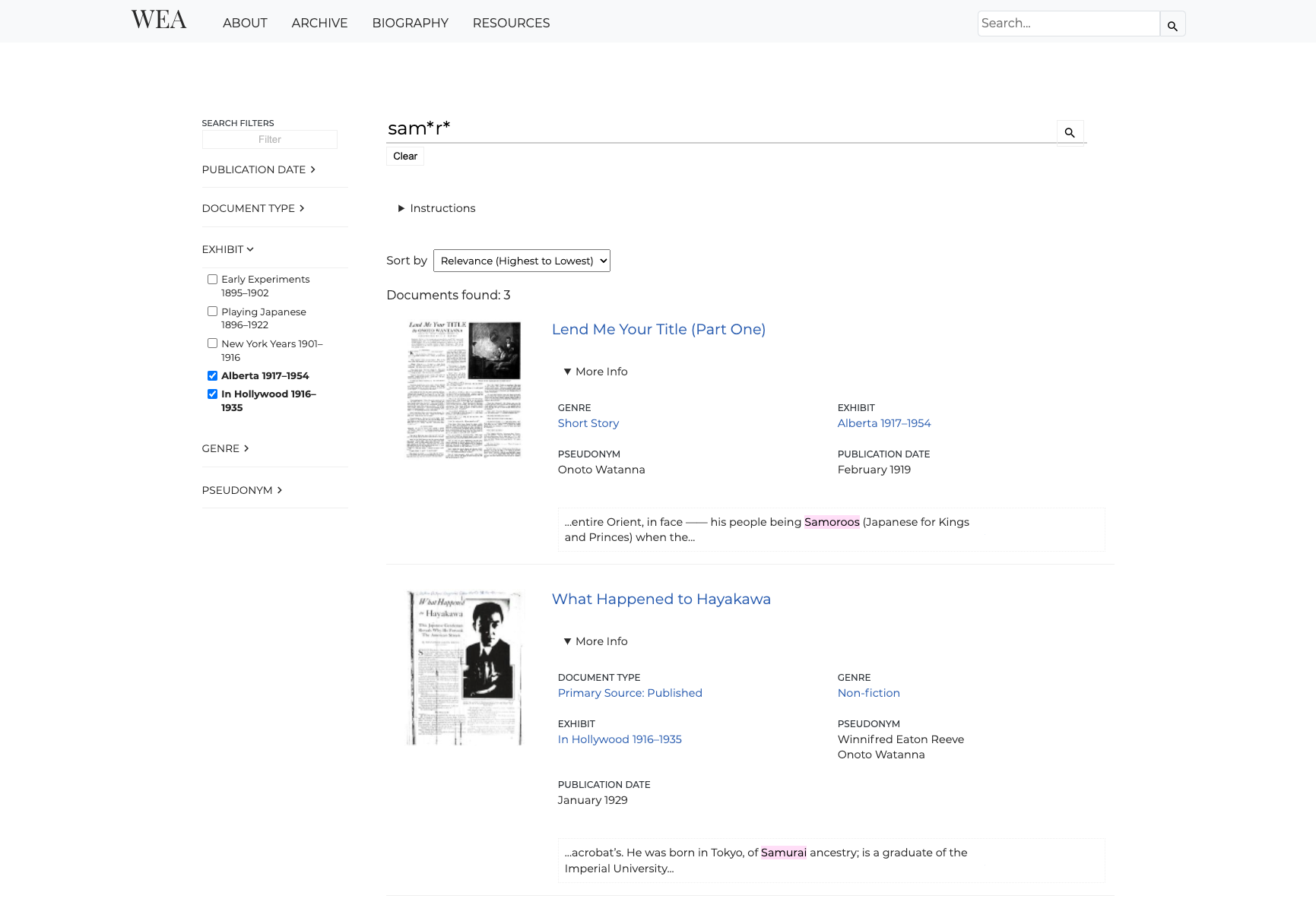
[9]
See Appendix B for examples of
the search pages produced by staticSearch.
Holmes, M.D. and Takeda, J. 2019. Beyond Validation: Using Programmed Diagnostics to Learn About, Monitor, and Successfully
Complete Your DH Project.Digital Scholarship in the Humanities, 34 (suppl_1) (December 2019): i100–i109. Oxford University Press/EADH. doi:https://doi.org/10.1093/llc/fqz011.
Holmes, M.D. and Takeda, J. Forthcoming. From Tamagotchis to Pet Rocks: Static Websites for Long-term Sustainability. In peer review with Digital Humanities Quarterly, 2022.
Kraetke, Martin, and Gerrit Imsieke. 2016. XSLT as a Modern, Powerful Static Website Generator: Publishing Hogrefe’s Clinical
Handbook of Psychotropic Drugs as a Web App. Presented at XML In, Web Out: International Symposium on sub rosa XML, Washington,
DC, August 1, 2016. In Proceedings of XML In, Web Out: International Symposium on sub rosa XML. Balisage Series on Markup Technologies, vol. 18. doi:https://doi.org/10.4242/BalisageVol18.Kraetke02.
Quin, Liam R.E. 2008. Text Retrieval for XML-Encoded Corpora: A Lexical Approach. Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 -
15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1. doi:https://doi.org/10.4242/BalisageVol1.Quin01.