Nordström, Ari, and Jean Kaplansky. “Migrating DocBook to Uncharted Waters.” Presented at Balisage: The Markup Conference 2022, Washington, DC, August 1 - 5, 2022. In Proceedings of Balisage: The Markup Conference 2022. Balisage Series on Markup Technologies, vol. 27 (2022). https://doi.org/10.4242/BalisageVol27.Nordstrom01.
Balisage: The Markup Conference 2022 August 1 - 5, 2022
Balisage Paper: Migrating DocBook to Uncharted Waters
Ari Nordström
Ari is an independent markup geek based in Göteborg, Sweden. He has provided
angled brackets to many organisations and companies across a number of borders
over the years, some of which deliver the rule of law, help dairy farmers make a
living, and assist in servicing commercial aircraft. And others are just for
fun.
Ari is the proud owner and head projectionist of Western Sweden's last
functioning 35/70mm cinema, situated in his garage, which should explain why he
once wrote a paper on automating commercial cinemas using XML.
Jean Kaplansky
Jean Kaplansky is a proven and experienced Publishing Content Platform
Solutions Architect with a background in working in the small, medium, and
enterprise business environments across multiple industries, including Software,
Hardware, Aerospace, Insurance, Scholarly Publishing, and the instructional
design and publishing of education content. Jean has accomplished extensive
DocBook stylesheet design and content analysis throughout her career.
Jean enjoys a challenge in addition to solving problems and explaining
technical things to non-technical people. Jean has contributed to publishing
taxonomies, schemas, authoring tools, Content Management, and Automated
Publishing systems development. Jean also contributes to designing new business
workflows and processes based on information architecture, knowledge management
science, and best practices.
Kaplan North America (KNA) is migrating all XML source content across business
lines to a new technology stack. The stack uses Alfresco
Community Edition and Componize for Component Content
Managent System (CCMS) capabilities, and Oxygen XML Web
Author for editing and authoring new content. Approximately 50 GB of
content scheduled for migration exists in DocBook 4.0 and MathML 3.1. All
XML content is stored in Arbortext Content Manager (ACM), a content management system built by
PTC, and based on the Windchill Product Lifecycle Management (PLM) software.
This article aims to document the XSLT and XProc pipeline solution built to
migrate KNA's content and, further, to create HTML with metadata for ingestion into
KNA's Learning Management System (LMS) as a product. No project is perfect, however.
As a result, we experienced a few hard-learned lessons as consultants while we
worked our way through the project. We were excited to work on a DocBook project
with XML tools — work we greatly enjoy — which led to a over-confidence that
rendered us slightly stuck in the project's human variables. We learned (and
continue to learn) valuable lessons about consulting and acting as trusted advisors
throughout the project.
Successfully migrating 50 GB of Kaplan North America's (KNA) DocBook content included specific requirements:
to implement an extensive content analysis of forty-year-old content,
to understand a partially documented Learning Management System (LMS) metadata,
and
to identify the best approach to modify DOCTYPE statements reflecting
an association with Oxygen XML Web
Editor.
Mission Statement
Finding the right people to work on a project to migrate 50 GB of mature DocBook content to modern content management and authoring solutions is a
challenge in 2022! Finding service vendors in the United States to work with old DocBook
content was unsuccessful. Some vendors required reminding that their product did support
DocBook once. Other service vendors were willing to write XSLT but did not want to
create the necessary pipeline to move the content through syntax cleanup and
transformation to the required LMS HTML output. One after another, service vendors
declined to work with Kaplan's DocBook content in 2021. Moreover, an LMS publishing
deadline was fast approaching.
The quest: Kaplan North America's (KNA) engineering
licensing test preparation content originated in the mid-1970s. The engineering,
architecture, and design content is product content used across various Kaplan-based
programs, including test preparation, education services, and professional license
programs. The content is part of services provided to corporations, government agencies,
student groups, universities, and professionals. Kaplan's programs set the standard
for
license review and advanced educational services.
Kaplan's highly technical engineering content originated in 1975. It evolved through
a
variety of markup languages, eventually migrating into DocBook 4.0 authored, managed,
and published with an Arbortext Editor (AE), Arbortext Publishing Engine (APE), and
Arbortext Content Manager (ACM) implementation in 2015. Previous content migration
efforts did not explicitly include a project step to thoroughly scrub the content
for
dated SGML/XML syntax components, including character entity syntaxes, extensive Math
markup, and table formatting partially specified by Arbortext Processing Instructions
(PIs). By 2021 the entire body of engineering content existed wholly in the Arbortext
ecosystem and included many Arbortext-specific markup inserts to help control editor
state content management.
The Quest: Migrate 50 GB of legacy content from the
Arbortext ecosystem to Alfresco and Componize as a Component Content Management System
(CCMS) using Oxygen XML Web Author for future editing and new content creation in
2022.
Rendered product output includes HTML with precise specific metadata for LMS ingestion
in addition to printed books and digital EPUB content.
It became evident early on in planning the DocBook content migration that one or more
transforms in a pipeline were required to clean up the content syntax, remove remnants
of older content management and authoring solutions, and, most importantly, produce
output ready for ingestion into Alfresco Componize and check-out with Oxygen XML Web
Author.
Quest and challenges accepted!
Jean Kaplansky, Kaplan's Solutions Architect for the new content platform, finally
found someone willing to write XSLT and XProc to take Kaplan's DocBook content through
a
series of transformations to clean the codebase, enable future content editing, and
authoring with Oxygen XML Web Author, and produce LMS-ingestible HTML in late September
2021. With an initial publishing deadline set for late November 2021. Ari Nordström
came
forward willing to take on the unknown with a strong background in content
transformation and pipelines — including an XProc framework of his invention, XProc
Batch [XProc Batch Wrapper Scripts].
Given Jean's extensive analysis of one of the more significant DocBook titles, the
tasks seemed pretty straight-forward[1]:
Clean up and convert DocBook 4.0 to 4.3 while maintaining the association with
MathML 3.1 and content referenced by ACM-style XIncludes
Migrate the newly cleaned and converted DocBook to a logical content
management organization in Alfresco Content Services Community Edition with the
XML managed by Componize's Alfresco plug-in to make Alfresco "XML-aware."
Convert the newly housed DocBook 4.3 to (X)HTML including specific LMS
metadata
Easy, right? Ari's first thought was pipelines, followed by ooh,
I can do XProc again. We moved forward — and immediately ran into multiple
and previously unconsidered challenges — because DocBook! XProc! We get to work on
a
cool project!
XSLT Pipelines Overview
Those recollecting previous Balisage papers may remember Ari's fascination with
XSLT pipelines [Pipelined XSLT Transformations]. While the paper at hand is not about how
XSLT pipelines work, the idea is simple enough:
A sequence of XSLT stylesheets listed in an XML manifest line runs in the order
presented, with the previous XSLT's output providing the input to the next. Each
XSLT transform handles one thing and one thing only.[2], and that is really about it. Every XSLT is essentially an ID transform
with a few tweaks, and since the full transformation is a sequence of these XSLTs,
it is easy to modify the transform by adding, removing, and moving the individual
XSLTs. For example, this manifest is the XSLT pipeline part of the DocBook cleanup
described in the following section:
<manifest xmlns="http://www.corbas.co.uk/ns/transforms/data" xml:base=".">
<group description="Initial stuff" xml:base="../xslt/common/">
<item href="idtransform.xsl" description="UTF-8 serialisation to get rid of the character entities"/>
<item href="remove-wc-protocol.xsl" description="Remove Windchill protocol from hrefs"/>
<item href="clean-hrefs.xsl" description="Remove unwanted chars in hrefs"/>
<item href="uri-encode-hrefs.xsl" description="URI-encode refs"/>
</group>
<group description="Main processing" xml:base="../xslt/db-cleanup/">
<item href="fix-xi-namespaces.xsl" description="Move any non-standard XIncludes to the right namespace"/>
<item href="normalize-docbook.xsl" description="Normalise XIncludes, remove namespaces, serialise to UTF-8" enabled="false"/>
<item href="orphaned-table.xsl" description="Reinsert title and tgroup in table orphaned by Tagsoup"/>
<item href="convert-table-pi.xsl" description="Table PI handling"/>
<item href="cleanup.xsl" description="Various cleanup"/>
</group>
</manifest>
Did we mention that it's practically self-documenting?
DocBook Cleanup
The DocBook 4.0 sources had some complicating factors, all of which we need to
address:
The character encoding, sort of ISO 8859-ish, with some company-specific
entities sprinkled throughout
The old Arbortext Editor/Arbortext Content Manager (ACM) authoring and Content
Management System (CMS) environment:
XIncludes, some with fake namespace declarations[3]
DOCTYPE declarations only in the root XML,
not the XIncluded content
An ACM-specific file protocol (see fake namespace declarations,
above)
Arbortext processing instructions to manually override automatic
formatting
(Lots of) MathML equations, some with fake namespace declarations
Inconsistent file naming including characters that should never appear in a
file name[4]
And more, some of which only came to light later, when we examined additional
books.
Above all, we needed to encode everything in Unicode and UTF-8. The Arbortext PIs
and
other Arbortext-specific constructs needed to go, and the XInclude targets should
have
normalised DOCTYPE statements.
A hard requirement remained for us to continue working with a DocBook 4.3 doctype
statement including an internal subset to include MathML.
Encoding and DOCTYPE
Character entities, of course, are only possible to convert if declarations are
present. In the case of DocBook 4.0 or any other DTD-validated XML documents, the
place to look for character entity definitions in the DTD. A parser normally
accesses the DTD by reading the document's DOCTYPE declaration.
However, what if the DOCTYPE definition is missing?
In a nutshell, the DocBook 4.0 source consisted of multiple files, with the
top-level (root) file containing XInclude links pointing out
chapters, which in turn would point out sections or Q and A entries. However, only
the top-level XML had a DOCTYPE statement. The lower-level XML filed
did not require a DOCTYPE statement to work in Arbortext's ecosystem,
creating an interesting chicken-or-egg problem.
See, if a parser finds a character entity it can't resolve, it usually reports an
error and exits. The XIncluded files contained character entities but no
DOCTYPEs statements resulting in attemptes to open XML files that
immediately resulted in errors because the initial cleanup scripts threw errors and
exited because entities did not resolve properly.
So, before fixing the encoding, the files needed DOCTYPE declarations
where missing, thus ruling out anything XSLT[5] and most things XProc[6], so what, then? How about something in an Ant build script that would
then run the actual cleanup? Ant, an XML-based pipelining language, offers many
tools to process XML, but very few would uncritically open and read an XML file that
is not well-formed.
Regular expressions are always an option, of course, but just look at these two
variations:
The previous example has no DOCTYPE to begin with, so it may be
possible to match the root element. But what about this one?:
<!-- Fragment document type declaration subset:
Arbortext, Inc., 1988-2017, v.4002
<!DOCTYPE set PUBLIC "-//Arbortext//DTD DocBook XML V4.0 + MathML//EN"
"axdocbook_math.dtd" [
<!ENTITY minus "&#8722;">
]>
-->
<?Pub EntList alpha bull copy rArr sect trade lbrace rbrace thinsp delta
Delta?>
<?Pub Inc?>
<qandaentry id="qandaentryFEBB06-014" role="1of4" vendor="0000080121">
This one is sneaky because the DOCTYPE is out-commented over multiple
lines (and has the wrong document element). You must match the comment markup and
then the DOCTYPE inside it to know.
And so on. There are a couple of things to do here:
Find out if there is a DOCTYPE already (we don't want to
include two).
Get the root element (because it's part of the
DOCTYPE).
Compose and add the DOCTYPE.
A few of the XIncluded files had out-commented DOCTYPE declarations,
complicating Step 1. Also, getting the root element was not obvious because of the
comments, processing instructions, etc, so the regex idea was a no-go.
OK, so maybe an Ant exec task to run external software that adds the
DOCTYPE? Most parsers are out of the question because of the basic
well-formedness issues, but there is something called Tagsoup
[TagSoup - Just Keep On Truckin'], a rather
brilliant piece of software intended to fix bad HTML. Among other things, it can add
any DOCTYPE declaration to a file, not just HTML, but more importantly,
it doesn't care if the file contains unresolved character entities—that is one of
the problems it's designed to ignore while fixing other things!
It doesn't do reporting very well, however, so it couldn't reliably check for an
existing DOCTYPE and only then, if there wasn't one, add it. For
checking for the existence of one, we ended up using xmllint
[Installing Libxml/xmllint for Windows][7]
Note
An added complication was the fact that all this needed to run on Windows
machines. As a Linux user since the mid-90s, Ari was accustomed to SGML and XML
toolkits, from OpenSP to libxml, being
readily available and only an apt-get install away; he was shocked
to realise how much effort it took to add xmllint.
XIncludes
With the character encoding handled, the next task was processing the XIncludes.
We promptly learned that ACM used a non-standard file protocol:
Handling this was straight-forward in an XSLT step and a regular
expression.
While the normalisation of XIncludes (that is, recursively pulling in the XInclude
contents into a single file) is not a complex problem, the fact that there was no
way to know which of the hundreds of XML files in an input folder was the root
complicated matters. Once you have pulled in an XInclude target in the parent file,
you no longer have to process the child; you can leave it behind and only process
the normalised parent. How do I leave them all behind?
The XSLT pipeline acts on an input directory: it lists the files in that directory
and then iterates through the list, applying the pipeline to each one. Here is the
clever bit, though: you can apply to include and exclude filters on the operation
by
using regular expressions.
A pre-processing pipeline step first walks through all of the input files, opening
each of them in turn, and compiles a list of the XInclude targets, each separated
with a | (pipe) character (whitespace added for readability):
We could extend the exclude filter, but the principle was easy enough except for
the filenames.
Filenames
The first few tests had filenames without particular issues, but the first
complete book we examined highlighted the weakness of the exclude filter approach
described above.
The Arbortext system happily processes filenames with any number of weird
characters while some of the pipeline tools choked. For example, some file names
contained multiple spaces, parentheses, square brackets, commas, and other
characters not typically found in file names.
If you know your regular expressions, you will know that several of these would
have to be escaped if used in a pattern. So, when listing the XInclude targets and
using the list as an exclude filter (see above), the list would be unusable as a
pattern unless every offending filename character was escaped correctly in the
regex. This was not an attractive proposition, especially after examining more book
sources.
Easier was writing a pre-processing step to rename the files by removing (or
replacing) the offending characters and then opening each file and applying the same
renaming rules to any referenced files—all this had to be run before the actual
cleanup and normalisation to make sure that the XInclude target list used as an
exclude filter would not break[8].
The rename step eventually became a separate XProc library where XSLT stylesheets
handled most of the heavy lifting.
4.0 to 4.3 and Cleanup
The actual DocBook 4.0 to 4.3 conversion held very little excitement when compared
to the above: a handful of XSLTs to get rid of Arbortext PIs for formatting and
other functionality and to unify namespaces—for some reason, authors had sometimes
added, um, alternative namespace URLs for MathML and XInclude. The DocBook versions
as such are very similar.
The 4.3 DOCTYPE
A final cleanup complication was that the full DOCTYPE for the target
files required an internal subset:
[
<!-- Will use "m" as a prefix.-->
<!ENTITY % equation.content "(alt?, (graphic|mediaobject|m:math)+)">
<!ENTITY % inlineequation.content "(alt?, (graphic|inlinemediaobject|m:math)+)">
<!ENTITY % NS.prefixed "INCLUDE">
<!ENTITY % MATHML.prefix "m">
<!ENTITY % NamespaceDecl.attrib "
xmlns:m
CDATA #FIXED 'http://www.w3.org/1998/Math/MathML'
">
<!-- Include the MathML DTD -->
<!ENTITY % mathml PUBLIC "-//W3C//DTD MathML 3.0//EN"
"http://www.w3.org/TR/MathML3/dtd/mathml3.dtd">
%mathml;
<!ENTITY % xinclude SYSTEM "http://www.docbook.org/xml/4.4/xinclude.mod" >
%xinclude;
]
The XML world has been moving away from DTDs and DOCTYPE declarations
ever since XML first came out, 24 years ago. You can't actually output an internal
subset or serialise an ENTITY declaration using XSLT[9]. You can still serialise a basic DOCTYPE, though, with
PUBLIC and SYSTEM identifiers.
This was good enough. Remember the Ant build wrapped around everything? Well, we
had an external text file with the internal subset, and then, last in the build,
after provisioning the processed files with vanilla DocBook 4. DOCTYPE
declarations, this added that external text file to the
DOCTYPEs:
The second part of the mission statement was to transform DocBook 4.3 to (X)HTML;
this
would mostly be a vanilla HTML transform, but with some bits, mainly publishing-specific
metadata on Q and A entries, sections, and chapters added.
The initial idea was to use the standard DocBook XSLT package as included in oXygen.
As Ari wasn't keen on using them—XSLT 1.0 is just so last century—and really wanted
to
try xslTNG [DocBook xslTNG],
Norm Walsh's XSLT 3.0 package presented at Balisage 2020 [XSLT 3.0 on ordinary prose], the
plan morphed into doing some initial pipelining to preprocess the DocBook 4.3 to add
the
required metadata and other content[11], and then simply hand over everything to xslTNG with a few tweaks in the
calling XSLT.
While the theory was that since the HTML output would be in fragments we should be
able to simply convert the input DocBook XInclude fragments (see section “XIncludes”) directly, the
required output fragments did not actually match the input. This little tidbit was
not
part of the original statement of work; it only came to light later.
For example, while the Q and A entries were separate source XML files, some published
books (Reference Manuals, known as RM books) would include them inside
their parent chapters with everything normalised, while other book types required
them
to be in separate files. Similarly, there were other conditions governing the output
fragmentation. This would also mean that the metadata to be inserted would vary—if
output as separate files, the Q and A entries required metadata headers; if included
inside the chapters, no metadata was needed.
In other words, context would decide where the books would need
to be split apart, not the input fragmentation.
Normalisation and Split Markup
All this meant that we'd have to start by normalising the sources after all,
insert markup to identify where they would be pulled apart again, later in the
pipeline, and then add metadata and other structures.
This is where the XInclude normalisation step [section “XIncludes”] to preprocess
the XInludes to use the XInclude targets in an exclude filter to the directory
listing became a lifesaver. The main book file would grow significantly larger in
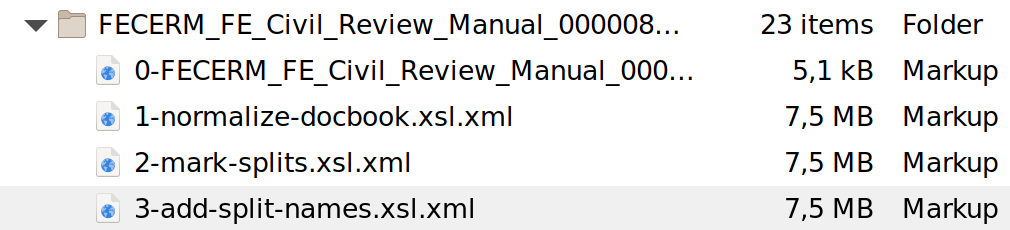
the first step since everything was pulled in, as seen in this debug listing:
Figure 1: Normalisation
Here, the normalisation is followed by steps to prepare the newly assembled book
to be split again. Some conditions had to be done as part of the normalisation
because those required examining filenames and containing folders to produce
context markup[12]:
<!-- Find out stuff about the filename to use for later naming and split -->
<xsl:template match="*[not(parent::*)]">
<xsl:variable name="name" select="name(.)"/>
<xsl:variable name="filename" select="tokenize(base-uri(.),'/')[last()]"/>
<xsl:variable name="label">
<xsl:choose>
<!-- Properly marked-up chapter -->
<xsl:when test="@label and @label!='' and $name='chapter'">
<xsl:value-of select="@label"/>
</xsl:when>
<!-- Diagnostic -->
<xsl:when test="matches(@id,'diag')">
<xsl:analyze-string select="@id" regex="^(.*)diag([0-9]+)$">
<xsl:matching-substring>
<xsl:value-of select="format-number(number(regex-group(2)),'1')"/>
</xsl:matching-substring>
<xsl:non-matching-substring/>
</xsl:analyze-string>
</xsl:when>
<!-- Is it a front matter chapter? -->
<xsl:when test="matches(@id,'^(.*)00$')">
<xsl:value-of select="'0'"/>
</xsl:when>
<!-- Gleaned from @id -->
<xsl:when test="matches(@id,'^chapter[A-Z]+[0-9]+$')">
<xsl:analyze-string select="@id" regex="^chapter[A-Z]+([0-9]+)$">
<xsl:matching-substring>
<xsl:value-of select="format-number(number(regex-group(1)),'1')"/>
</xsl:matching-substring>
</xsl:analyze-string>
</xsl:when>
<xsl:otherwise>
<xsl:value-of select="''"/>
</xsl:otherwise>
</xsl:choose>
</xsl:variable>
<xsl:variable name="title" select="string-join(title//text())" as="xs:string?"/>
<!-- ID with 'diag' means diagnostic -->
<xsl:variable name="dg" select="if (matches(@id,'diag')) then ('diag') else ()"/>
<!-- RM books are identified thusly -->
<xsl:variable name="rm" select="if (matches($path,'RM/data/$')) then ('rm') else ()"/>
<xsl:variable name="prefix">
<xsl:choose>
<xsl:when test="$name=('chapter','bookinfo')">
<xsl:value-of select="'Chapter'"/>
</xsl:when>
<xsl:when test="$name='qandaentry'"/>
<xsl:otherwise>
<xsl:value-of select="$name"/>
</xsl:otherwise>
</xsl:choose>
</xsl:variable>
<xsl:variable name="identifier" as="xs:string">
<xsl:choose>
<!-- Intro front matter chapter -->
<xsl:when test="$title='Introduction' or $label = '0.50'"><!-- FIXME -->
<xsl:value-of select="'0.50'"/>
</xsl:when>
<!-- Diagnostic test inside the book, chapter label xx.50 -->
<xsl:when test="$name='chapter' and matches($filename,'_DG_')">
...
</xsl:when>
<!-- Labelled (non-diagnostic) chapter -->
<xsl:when test="$name='chapter' and $label!='0' and $label!=''">
<xsl:value-of select="$label"/>
</xsl:when>
...
</xsl:choose>
</xsl:variable>
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:attribute name="prefix" select="$prefix"/>
<xsl:attribute name="identifier" select="$identifier"/>
<xsl:attribute name="dg" select="$dg"/>
<xsl:if test="$rm='rm'">
<xsl:attribute name="rm" select="$rm"/>
</xsl:if>
<xsl:apply-templates select="node()"/>
</xsl:copy>
</xsl:template>
Based on this, the next step would then identify splits, like in this
example:
<xsl:if test="name(.)=$split-elements and not(ancestor::chapter[@rm='rm'])">
<xsl:attribute name="split" select="true()"/>
</xsl:if>
A step that named the soon-to-be fragments in a temporary @name
attribute then followed. For example:
Note that none of this was part of the initial pipeline—the original statement of
work left out everything having to do with splitting based on context, type of
book.
Note
This sort of thing is where a pipelined apporach will excel. It's much easier
to add processing in the middle of a multi-step pipeline than a monolithic XSLT
transform.
Metadata
The metadata depended on context and the type of book, essentially the same
criteria used to determine where to split the normalised files. For example, the
@rm attribute, added during normalisation to identify the Reference
Manual book type context, determined if the Q and A entries needed metadata or
not:
<xsl:template match="orderedlist[(ancestor::chapter[@rm='' or not(@rm)]) and
ancestor::question and listitem[@role='correct']]">
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:attribute name="class" select="'ktp-answer-set'"/>
<xsl:apply-templates select="node()">
<xsl:with-param name="property" select="'ktp:answer'" tunnel="yes"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
Another example, also pre-converting selected structures to
HTML:
What metadata was added to what elements and in what contexts also changed during
the project, and again, the pipeline approach proved its worth.
Structural Tweaks
We ended up using seven pipeline steps to add metadata to the required DocBook
structures, with another four to tweak them further, and it proved easier to convert
these to HTML as part of the metadata additions rather than having xslTNG do it
later.
The Q and A entries, for example, use lists for both to list possible answers and
for, well, listing things. While it was certainly possible to convert them to HTML
using xslTNG, it was easier in a pipeline step:
<xsl:template match="orderedlist[ancestor::question]">
<xhtml:ol keep="true">
<xsl:copy-of select="@*"/>
<xsl:if test="not(@class) and (ancestor::chapter[@rm='' or not(@rm)]) and not(@numeration='upperroman')">
<xsl:attribute name="class" select="'ktp-answer-set'"/>
</xsl:if>
<xsl:choose>
<xsl:when test="@numeration='upperroman'">
<xsl:attribute name="style" select="'list-style: upper-roman'"/>
</xsl:when>
</xsl:choose>
<xsl:apply-templates select="node()"/>
</xhtml:ol>
</xsl:template>
<xsl:template match="listitem[ancestor::question]">
<xhtml:li keep="true">
<xsl:copy-of select="@* except @role"/>
<xsl:if test="not(@property) and (ancestor::chapter[@rm='' or not(@rm)]) and not(ancestor::orderedlist[@numeration='upperroman'])">
<xsl:attribute name="property" select="'ktp:answer'"/>
<xsl:attribute name="typeof" select="'ktp:Answer'"/>
<xsl:processing-instruction name="no-correct-answer-given"/>
</xsl:if>
<xsl:apply-templates select="node()"/>
</xhtml:li>
</xsl:template>
Note keep="true". These were inserted whenever converting to HTML and
told xslTNG to not touch that particular node.
Note
@keep has two possible values: true means
don't touch the current element and its attributes, and
copy means don't touch the current node or any
descendants.
Other tweaks included generating cross-reference labels[13], tweaking footnotes, adding table and equation caption labels and
numbering, and adding @class attributes for the publishing CSS. One
late-breaking step also replaced .eps image file suffixes with
.png when the client changed the image format.
Cleanup and Split
XSLT pipelines tend to end with cleanup steps, from removing processing attributes
to getting rid of unwanted namespace prefixes and so on. This one was no exception.
However, once the XSLT pipeline, a matter of running XSLTs listed in a manifest file
in sequence, was finished, it was still necessary to split the files, which added
a
separate XSLT file to the XProc itself.
Why not in the XSLT pipeline? The XProc step running the XSLT pipeline manifest
is, for practical purposes, a black box that accepts an input folder of files and
hands over a converted result folder, all as part of a single XProc step. If we
wanted to do secondary output from that final XSLT, we would have to do much
tweaking inside that black box. It was far easier to add an XSLT splitting the
output of the XSLT pipeline to a result-document and iterating through
that in XProc.
Notes on xslTNG
In hindsight, the final pipeline ended up converting more DocBook to HTML than
planned; we had simply assumed that xslTNG would do most of the heavy lifting. Ari
really wanted to test it in a live setting, having watched Norm's presentation at
Balisage in 2020 [XSLT 3.0 on ordinary prose], but doing the entire conversion in the
pipeline would have resulted in an easier-to-maintain transform.
There's also the not-at-all-insignificant fact that what we have here is DocBook
4.3, whereas xslTNG much prefers DB 5.0 and later. 4.3 still has
INCLUDE/IGNORE sections for SGML, and the DocBook elements do not
live in a namespace[14].
As it stands, the calling XSLT does a few tweaks, from tweaking IDs to changing
section numbering. It sets a few variables, and, above all, it makes sure that the
@keep attributes are respected.
Final Tweaking
In the end, one additional XSLT, run after xslTNG, removed some final bits and
pieces (DocBook attributes that xslTNG didn't seem to recognise, for one thing) and
restored HTML wrappers that went missing in xslTNG, either
because Ari missed some vital information in the excellent documentation [DocBook xslTNG Reference] or
(more likely) the code leading to xslTNG.
XProc, As Ever
Ari's been an XProc convert since before 1.0 came out. The basic idea is fabulous;
you black-box everything, connect the boxes, and out comes the result(s). The spec
is somewhat less than the sum of it parts; it always gave the impression of knowing
about the latest and the greatest while not quite being able to deliver it. You
could do amazing things but only within strict confines and never without some
pain.
It follows that for all that other processing — the pain — you were resigned to
Ant processing or similar, and so it was with the subject at hand. Because of XProc
1.0's strict confines, Ant was a necessity.
This year — this month, actually — XProc 3.0 was finally released. The libraries
that do the heavy lifting have all been converted to XProc 3.0 now (again, this
month!), and had this project happened a few months later, it would all have been
XProc 3.0. Maybe next year's talk.
Project Learning Outcomes: If only we had...
Even experienced XML publishing consultants can empathize too much with clients who
say they have a hard deadline. Despite our best efforts to put together a Statement
of
Work that defined the complete scope of work, we learned some hard lessons:
Lesson learned: Ensure all identification of all
stakeholders at the beginning of the project — We went into the
project thinking in goodwill and faith in our client to provide adequate
guidance and collateral to finish the project within the constraints we thought
we put in the SOW. Unfortunately, we did not realize the presence of a second
project stakeholder: The team responsible for ingesting the HTML content into
the company's current LMS platform.
Our original stakeholder representative provided access to a repository of
historical project information; however, much of the current process
documentation focused on meeting requirements for ingesting content to a
different LMS. Further, access to specific information about ingesting content
into the older LMS was less than transparent, and the LMS-specific metadata was
applied "on-the-fly" during content ingestion.
Lesson learned: Each stakeholder must have a direct
representative participating in the project — We specifically
asked for the information we needed to complete the project from the onset,
relying on the client's point person, the current CMS and DocBook solutions
administrator, to gather required documentation based from our collective
experience working with XML content migrations. Our first point person is the
current DocBook CMS and workflow system administrator, who is deeply involved in
the DocBook content architecture required to produce content for delivery to the
previous LMS, EPUB, and print products. We expected our DocBook point person to
specify the detailed documentation required to clean up existing markup and
migrate the content from one authoring and content management system to
another.
However, we missed a critical outcome expectation: Ingesting HTML with
required metadata values into the current LMS platform.
Our DocBook project point person initially shared some HTML metadata ingestion
requirements but obtained requirements from a pilot project that pulled content
into the LMS from the previous LMS instead of the DocBook 4.3 files coming out
of the pipeline. Much confusion about the precise HTML metadata required in the
content ensued. We had many meetings where the entire project team (sometimes
ourselves) required continual reminders that the current effort was to create a
DocBook to HTML transform destined for the current LMS
platform. As a result, our DocBook point person was not entirely aware of the
HTML metadata required to ingest and process the DocBook HTML originating from
the XProc pipeline.
The rabbit hole: the LMS platform team,
filled with a sense of "we are on a deadline," tested HTML ingestion from
content pulled from a previous LMS to the current LMS platform. We collectively
realized that the required LMS platform HTML metadata documentation was still a
work in progress in the context of the HTML produced from DocBook through the
XProc pipeline. We required significant input and documentation from the LMS
team for Ari to write an HTML transform to produce a critical part of the
project's expected outcomes. Multiple meetings happened before all of the
stakeholders, and Ari and Jean fully understood the difference between the
initial testing by the LMS team and the HTML produced by the XProc
pipeline.
The requirement for the HTML transforms pipeline to generate HTML metadata
required by the current LMS platform initially looked like scope creep from our
original SOW. Our "aha" moment regarding the LMS platform HTML metadata
requirements documentation and project scope required to refactor the HTML
transform was a collective headache for ourselves and the multiple stakeholders
across the project team.
Lesson learned: Project teams may determine their own
single-sourcing XML best practices different from other industries
— ...and a client may insist on continuing to follow their own
best practices regardless of what is considered an industry best practice. We
had extensive conversations about best practices with our DocBook point person.
The project team built a quirky (but it worked for them) single-sourcing
architecture that caused hiccups in how we needed the transforms to handle XML
content. Our stakeholders vehemently defended their chosen approach to content
architecture contrary to what we, consultants, know as single-sourcing XML best
practices. We reluctantly learned to adapt to match the client's
adamance.
Lesson learned: Make sure the stakeholder has adequate
resources to handle required work; Training may take longer than anticipated
— We provided extensive "how to run the pipeline" training to a
single person. Our understanding was that we were "training the trainer." The
reality of the effort required to transform pipelines on large bodies of content
destined for migration and ingestion into an LMS was overwhelming for the
stakeholder's available resources. We added two more people to help run the
project content through the transform pipelines. Even so, we did not adequately
anticipate the amount of training and step-by-step walkthroughs required to
enable people to run the pipeline independently.
Lesson learned: Stakeholders may change priorities in
the "messy" middle — When we realized the extent of LMS platform
HTML metadata ingestion requirements, our DocBook stakeholders had already lost
sight of the project's original purpose:
Create DocBook XML stored in the Alfresco Componize CCMS
for future editing with Oxygen XML Web Author.
Create an XProc-based pipeline to create HTML output for ingestion
into the client's LMS.
Over time, our DocBook stakeholders became more and more focused on the LMS
ingestion and publishing deadline, leaving the Alfresco/Componize-ready DocBook
content to sit uningested to the target repository. The change in priority means
the project will not be complete until the client reprioritizes ingesting the
cleaned and Oxygen XML Web Author-aware DocBook content into the Alfresco
Componize CCMS for future authoring publishing efforts.
Lesson learned: Always provide a preferred format for
client feedback at the project's outset — For example, while we
are both familiar with working in GitHub with GitHub issues, our client was more
familiar with collecting feedback from multiple sources in Google Docs. We spent
significant time analyzing stakeholder feedback and identifying and confirming
real issues from duplicates and what we considered fundamental misunderstandings
about the nature of markup with the LMS team. To our credit, we eventually
concluded that moving all feedback and related communications to GitHub issues
where we could track the discussion and gather previously missing information on
an issue-by-issue basis.
Moving to GitHub Issues was no panacea for our communication issues, however.
To communicate more effectively, we had to provide in-depth Git and GitHub
education to our DocBook stakeholders.
Lesson learned: Set expectations about the role of the
consultant firmly at the beginning of the project — At one point,
our stakeholders started to blur the lines between the role of consultants and
the role of content processing services resulting in scope creep. We had to
remind the individuals filing GitHub issues that they could not file issues
stating a brand new issue as "a problem to fix" as part of the original scope of
work.
We noticed that individuals did not know a specific issue existed until they
filed a GitHub issue. We continually vetted each issue to determine whether or
not the problem was in scope or a new problem to solve. Further, unexpected
variance in markup patterns often required us to make the call whether or not
the issue was in scope.
We had to reset stakeholder expectations: individuals filing GitHub issues
were not allowed to "drip" new and out-of-scope requirements into issues to
resolve one by one. It is easy to lose track of how far the scope creeps from
the SOW without properly defining expectations upfront about what is genuinely a
"problem to solve" issue and what is an entirely new requirement. It is too easy
to have stakeholders take advantage of a consultant's goodwill as a trusted
advisor. Keep a parking lot for newly discovered requirements during the
project. Write another SOW to implement the new requirements as required.
Lesson learned: Do not put aside legal and financial
aspects of setting up the SOW contract BEFORE starting work —
…even for a friend who represents the stakeholder. It is too easy for
stakeholders to take advantage of a consultant's goodwill while blaming hang-ups
with settling contractual issues on finance or legal departments. Our
stakeholders panicked and became distracted about meeting what turned out to be
an unrealistic deadline. We allowed ourselves to become too empathetic with the
stakeholder's panic and the distraction affected our better judgment.
Aside from our lessons learned from our admitted over-eagerness to have great fun
getting our hands deep into DocBook once again, the project eventually turned a corner
into a workflow that succeeds in meeting the original content migration goals AND
producing correct HTML content for LMS ingestion. The internal project team eventually
learned how vital the XProc pipeline was to their migration effort and completed content
migration of the most extensive product series. The client resolved internal accounting
issues eventually, and Ari received payment. The project team continues to work with
the
XProc pipeline today as the primary tool enabling content migration of the remaining
series products from ACM to Alfresco and from Arbortext Editor to Oxygen XML Web
Author.
Project Learning Outcomes: The XML Community is Alive and Kicking!
There was no way this project could come together without input from additional
colleagues in the greater XML community. We are grateful to both Tommie Usdin and
Liam
Quin for their assistance behind the scenes in creating a workable scenario that made
it
possible for one developer in Sweden to work with another developer in New York for
a
project based in San Francisco.
We faced continual stakeholder challenges throughout the project, but we had fun
working together on DocBook content in a clever solution that addressed the original
problem specified as the SOW scope. In addition, DocBook projects are great late-night
projects for developing lasting friendships and potential project colleagues in future
consulting efforts.
[1] Straightforward was an erroneous assumption. In hindsight, Jean should have
analyzed at least five titles from each of three product series.
[2] The trick is to define what that one thing is.
[3] This is confusing to a developer until one precisely realizes
why content is not coming through the XSLT.
[4] Know the POSIX standard? Well, this wasn't even close. Multiple
whitespace, forbidden characters, unsuitable characters...
[5] Because the input must be well-formed, it is probably possible to do
something with regular expressions, but here we much preferred not to; there
were too many variations to consider.
[6] For this project, we had XProc 1.0, which really will only deal with (at
least) well-formed XML. XProc 3.0 can do a lot better in this regard.
[7] Moreover, no, xmllint cannot add a
DOCTYPE, unfortunately. It can, however, give the same
error message every time there is not one.
[8] Ari: After I had written the pre-processing steps to normalise the
XIncludes, Jean told me there was no need; the client now decided they
wanted to keep the pieces as-is.
[9] Unless you're outputting your DOCTYPE with
xsl:text, which is not a unique approach.
[10] For those of you who do not read Ant, it's essentially a regular
expression matching the newly inserted DOCTYPE in
all XML files in the output directory and inserting
the internal subset last in that DOCTYPE.
[11] Cross-reference labels, various @class attribute values,
captions, etc.
[12] As seen in the XSLT example, we pulled some information from attribute
values.
[13] Again, certainly possible in xslTNG, but easier in the pipeline.
[14] Also, I could not understand why my ID tweaks did not work for quite some
time. That is, until remembering that later DocBook versions use
@xml:id, not @id…