Communities, Data, and Markup Languages
Two markup languages failed to excite me when I first encountered them: JSON, and backslash notations like USFM that are used in the Bible translation world. Markdown was more compelling to me, perhaps because it better addressed needs I had at the time, but I expected it to have a very limited audience. Enthusiastic users were excited about each of these languages -- they cared deeply about their data, embraced a markup language that they interacted with directly in their own work, and felt a sense of ownership and community with others working with the same kind of data. Over time, I came to realize that each of these communities understood their needs quite well, developing solutions that work for them, choosing another markup language over XML for good reasons. In each case, the overhead introduced by XML was not acceptable to users of these other markup languages. For people who want only to record the content of objects, JSON has become the markup language of choice. For people who want to write Wikipedia articles or other simple documents without worrying about document structure, Markdown had become the markup language of choice. And for editing Scripture, even for complex publications, a backslash notation called USFM (Universal Standard Format Markers) has become the language of choice. In each case, I was initially resistant. In each case, I came to recognize the wisdom of the community that created or embraced a non-XML markup language.
As we structure our systems and data, we serve communities that often have a great deal to teach us. I now use all three of these markup languages in adddition to XML. Markup languages and datasets are built by communities that each have their own culture and their own ways of understanding their world of data. In the XML community, we initially had the vision of one universal markup language that would be used for all purposes, and some of us still have that vision, but the world around us has not embraced that vision. As XML professionals, we often convert these markup languages to XML and integrate them with XML data. XML has remained the hub language I use for data integration and in most applications.
SGML and XML were my first markup languages. After learning to love JSON for object data, I started a new career in software used in the Bible translation community, where I have come to appreciate USFM. In this paper, we will look at the reasons that USFM has become so popular for Bible translation and publishing. But USFM is designed for specific kinds of documents, and Bible translation tools need to support a wide variety of documents. We will also look at the reasons that Paratext has chosen to add support for XML viewing and editing in addition to USFM. For aligning reference systems, JSON has advantages over both USFM and XML. We will discuss that as well.
USFM in the Bible Translation Community
This paper focuses on USFM (Universal Standard Format Markers), a language that has become dominant for Bible translation and Bible publishing. USFM was derived from a variety of languages called SFMs in the Bible translation world. These languages used backslash-delimited markers, were used for field linguistics, dictionary development, Bible translation, and a variety of other purposes, and generally corresponded to a specific tool. The SFMs used for a given purpose might depend on the region or the translation organization. Users liked SFMs because they could make up their own tags and ask their programmers to support them. But this caused obvious difficulties for their software support teams, and it made it difficult for users from different areas to use each other's data. An early article that promoted a standard, “universal” USFM described the problem:
The use of Standard Format Markers (SFMs) for markup of scripture in process has been well established for many years. There have been some differences among the standard sets used by the various field entities, publishing centers, and partner organizations; but each group has been isolated enough and independent enough that the slight variations among the SFMs have not been a major hindrance. But our world is getting smaller and more tightly interconnected. Now our technologies and partnerships are becoming more complex and integrated, and our technical support resources are being stretched thinner.
Each set of SFMs usually requires a corresponding matching set of utilities, tables, and other tools to provide a smooth flow for the various processes in the lifecycle of the text. Separate maintenance of these duplicated tools is becoming increasingly costly and inefficient.
— “USFM -- the emerging standard for scripture markup.” Karelin Seitz.
USFM is a standard, widely used throughout the Bible translation and publishing world. It contains the tags used to represent Bibles[2]. A corresponding XML syntax for USFM, USX, is widely used for electronic publishing on the Web - it is essentially the same language with an XML-based syntax and the same tags. Both focus on the structure of a document rather than formatting and presentation, but USX is easier to parse than USFM[3]. USFM and USX designed specifically for publishing Scripture, so they have sophisticated support for the kinds of markup needed for this task, including:
-
Introductions
-
Titles, Headings, and Labels
-
Chapters and Verses
-
Paragraphs
-
Poetry - with direct support for the kinds of poetry found in biblical text
-
Lists
-
Tables
-
Footnotes
-
Cross References
-
Specific Kinds of Text such as text added by the translator, quoted book titles, liturgical notes, proper names, etc.
-
Milestones
-
Extended Study Content
The following examples show the start of Psalm 8 in a print preview, USFM 3.0, and USX 3.0.
Figure 1: Formatted Representation
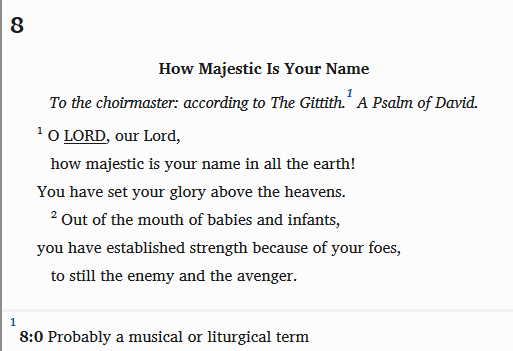
Figure 2: USFM 3.0
\c 8 \s How Majestic Is Your Name \d To the choirmaster: according to The Gittith. \f + \fr 8:0 \ft Probably a musical or liturgical term\f* A Psalm of David. \q1 \v 1 O \nd LORD\nd*, our Lord, \q2 how majestic is your name in all the earth! \q1 You have set your glory above the heavens. \q2 \v 2 Out of the mouth of babies and infants, \q1 you have established strength because of your foes, \q2 to still the enemy and the avenger.
Figure 3: USX 3.0
<chapter number="8" style="c" />
<para style="s">How Majestic Is Your Name</para>
<para style="d">To the choirmaster: according to The Gittith.
<note caller="+" style="f"><char style="fr" closed="false">8:0 </char><char style="ft" closed="false">Probably a musical or liturgical term</char></note>
A Psalm of David.</para>
<para style="q1">
<verse number="1" style="v" />O <char style="nd">LORD</char>, our Lord,</para>
<para style="q2">how majestic is your name in all the earth!</para>
<para style="q1">You have set your glory above the heavens.</para>
<para style="q2">
<verse number="2" style="v" />Out of the mouth of babies and infants,</para>
<para style="q1">you have established strength because of your foes,</para>
<para style="q2">to still the enemy and the avenger.</para>
One reason that Bible translators and publishers like USFM is that it is unubtrusive, and it is easy to show formatted text together with markers. Here is one of the most popular editing modes in Paratext. Even though the markers are visible, it is easy to visualize the formatted result while editing. By the time OSIS was being developed, Paratext users were comfortable with USFM and thought about the structure of their documents primarily in terms of the language they were familiar with.
Figure 4: Editing USFM in Paratext
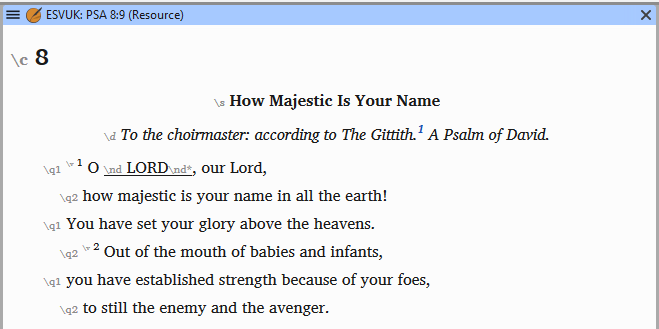
Another reason that Bible translators and publishers like USFM is that it is tailored for Bibles. For instance, the example shown above contains these tags, which would not normally be found in other kinds of content. OSIS did a good job of meeting these same needs, but by the time OSIS was created, both users and developers in the Bible translation community tended to think very concretely in terms of the language they had grown used to, USFM[4].
|
|
Descriptive title (or “Hebrew subtitle”). Sometimes used in Psalms under the section heading (e.g. “For the director of Music”). |
|
|
Poetic line. The variable # represents the level of indent (i.e. q1, q2, q3 etc.). |
|
|
Name of God (name of Deity). |
Support for specialized semantics of biblical content is important to Bible translators. Consider this markup:
\v 1 O \nd LORD\nd*, our Lord
In the phrase “O LORD our Lord” (יְהוָ֤ה אֲדֹנֵ֗ינוּ), “LORD” translates the
Tetragrammaton, the name of God, which was not pronounced in Hebrew. Some translations
render this name as LORD, others transliterate it as Yahweh or Jehovah or YHWH. The
\nd marker indicates use of this name.
Another reason that Bible translators and publishers like USFM is that it provides a simple, unubtrusive solution to the overlapping hierarchies found in Scripture. In prose, verse markers can overlap with paragraphs, quotes can span verses or paragraphs. USFM makes the paragraph hierarchy primary, treating chapters and verses as milestones. Quotes can be either milestones or defined ranges. Because UFSFM tags are small and unubtrusive, these milestones do not interfere with editing[5].
A major reason for the popularity of USFM is that was invented within the translation community. It is the markup language used in Paratext, a content management system for Bible translation that was designed in close collaboration with Bible translators in the field. The community has a sense of ownership for both Paratext and USFM. Because Paratext is used for most translations, they will be created in whatever format Paratext uses. And Paratext never adopted OSIS.
Paratext combines an editing environment, version control, workflow, project management, many specialized kinds of validation, and features to support communication among team members. It also provides a rich set of reference materials to translators, including translation handbooks, lexicons, articles, consultant notes, and tools for working with Hebrew and Greek. These references are designed to scroll together and to link among each other, and translators refer to these references frequently as they work. In addition, Paratext provides specialized quality checking tools that can be used for a wide variety of tasks, including quotation checking and spell-checking for even languages with few speakers and no existing literature, evaluating translation consistency for important terms, and ensuring that every verse exists and is found in the right order.
Paratext addresses many challenges that most content management systems do not. It is used in 175 countries, serving over 10,000 translation team members from over 300 organizations who are translating into more than 2,900 languages, including a range of organizations from commercial Bible publishers to small church-based translations. Translation team members may have multiple PhDs, but they may also have only modest formal education, and a given team may a wide range of educational levels and comfort levels with computers. In many areas, team members may not have daily access to the Internet. For some languages, team members need to invent an alphabet before translation work can begin.
Paratext has created a dedicated USFM community that uses USFM for the same reasons that many of us use XML. USFM files can be validated at a variety of levels. The location and order in which markers can occur within a USFM file is defined in two stylesheets[6]. A parser can be created from these stylesheet[7]. A parser based on a Parsing Expression Grammar is available at https://github.com/Bridgeconn/usfm-grammar, supporting both strict and relaxed parsing. USFM also supports custom stylesheets that specify formatting. Even though Paratext is designed for USFM, it uses the XML stack heavily in its implementation, and people creating resources for Paratext may use XSLT, XQuery, and other XML technologies that do not exist for USFM. For this reason, implementers who work with USFM are often familiar with XML.
XML Viewing and Authoring in Paratext
Bible translators and Bible publishers are only two communities that work with biblical text, and USFM is not widely used outside of their circles. For biblical scholars in academic institutions, TEI plays an important role, and GitHub is full of useful biblical resources in XML, JSON, and CSV/TSV. Until recently, adding these resources to Paratext required transformations or custom programming or both. By adding support for XML viewing, Paratext gives its users access to important resources created outside the USFM community, including Greek and Hebrew lexicons, and grammars; it also provides a way to support documents the USFM community creates for itself that are not structured like scripture, such as reference guides for USFM. In addition, XML resources created within Paratext can easily be used in other environments that do not work with USFM.
Starting with Paratext 9.2, Paratext is adding support for XML viewing. It will add support for XML editing in Paratext 9.3. Here is Abbott-Smith, an out-of-copyright Greek lexicon that is available in GitHub, shown in Paratext using the XML viewer:

To make an XML resource viewable in Paratext, a configuration file is written to identify the type of the resource (dictionary, book-chapter-verse, or outline) and to specify the path expressions needed to find structures within the file. For instance, this example shows a dictionary, there is a path expression that identifies dictionary entries, and there is another path expression that identifies the headwords of a dictionary entry. That information is sufficient to allow Paratext to use this dictionary in its standard dictionary viewer.
Adding support for XML viewing solves only part of the problem for the Bible translation community. Scholars in the translation community are creating resources that include translation handbooks, theological dictionaries, and exegetical guides. These resources often do not fit the structure of USFM. Because Paratext provides a useful environment for working with biblical languages and useful tools for teams collaborating to create content (including project plans, workflow, project annotations, and version history), some of the teams creating these resources in USFM in Paratext even though the USFM tagset does not support the semantics of the resources they are creating. When the mismatch is particularly painful, they have asked for changes to Paratext and to USFFM. Extending USFM to support these use cases is likely to complicate and pollute USFM without providing good support for these new document types. XML already provides rich support for defining new structured document types. Adding support for XML authoring in Paratext was a better solution to this problem.
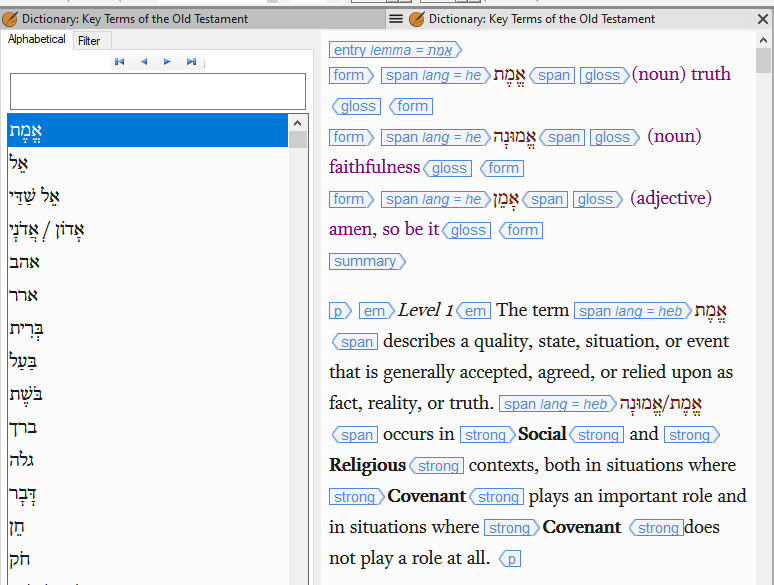
A lexicon created in this environment can be made available to Paratext users via the XML viewer:
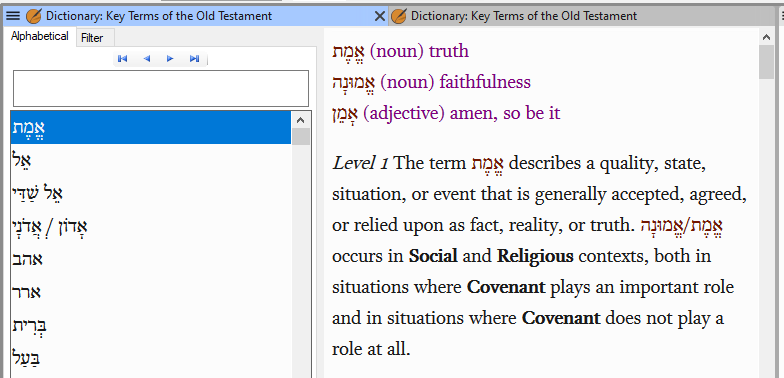
The XML authoring environment can be used together with other Paratext resources to see how Greek or Hebrew words are used in specific passages, how the Greek Septuagint translates Hebrew words, how other lexicons define a word, how various translations have rendered a word, etc. For instance, a scholar working on a Hebrew lexicon in India might find this view convenient.
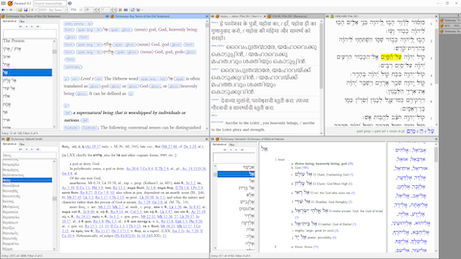
Mediating between USFM and XML using Reference Systems
We need common reference systems if we want to make XML resources work in Paratext or to make USFM and USX resources work outside Paratext. For dictionaries, we need a way to identify the words that are being described, senses of these words, and lists of references that contain them. For texts indexed by book, chapter, and verse, we need ways to identify the units of reference and to relate them to other versification schemes used in other translations or source texts. This section explores two issues involving such reference systems, a full exploration is beyond the scope of this paper.
Reference Systems: Verses and Dictionary Headwords (Lemmas)
Reference systems are essential in order to use resources together. Even something as simple as looking at a set of translations for the same verse or looking up a word in multiple dictionaries requires commnon reference systems - and this involves some complexities that are not obvious to people who have not worked with this kind of data.
Why Chapter and Verse Gets Complicated
Bible software often needs to make chapter/verse references in one translation correspond to another. For instance, a user might want to see a verse in the original language and in a set of translations:
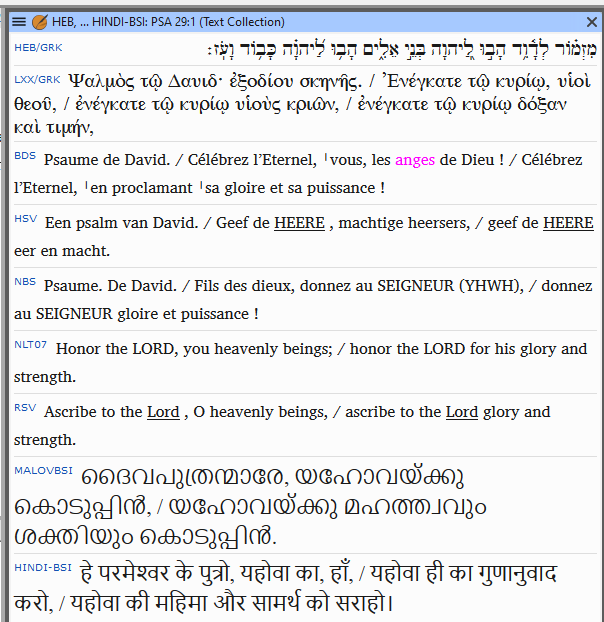
For a Bible reader who only uses Bibles in one particular culture and religious tradition, chapter and verse numbers make it easy to find any Bible passage. In some churches, it is common for a preacher to mention a chapter and verse, expecting members of the congregation to look up a given passage so they can read along, even if they are using different translations. This is also common in Bible studies.
Anyone who has been in a Bible study that includes Protestants, Catholics, and Orthodox knows that some passages are not numbered the same way in Bibles used by these different traditions. Many of the most significant differences are in the Old Testament, involving differences between the Hebrew Masoretic Text and ancient Greek translations, both based on earlier Hebrew textual traditions[8]. For instance, these traditions number the Psalms differently, so Psalm 29 in one resource may correspond to Psalm 28 in another:
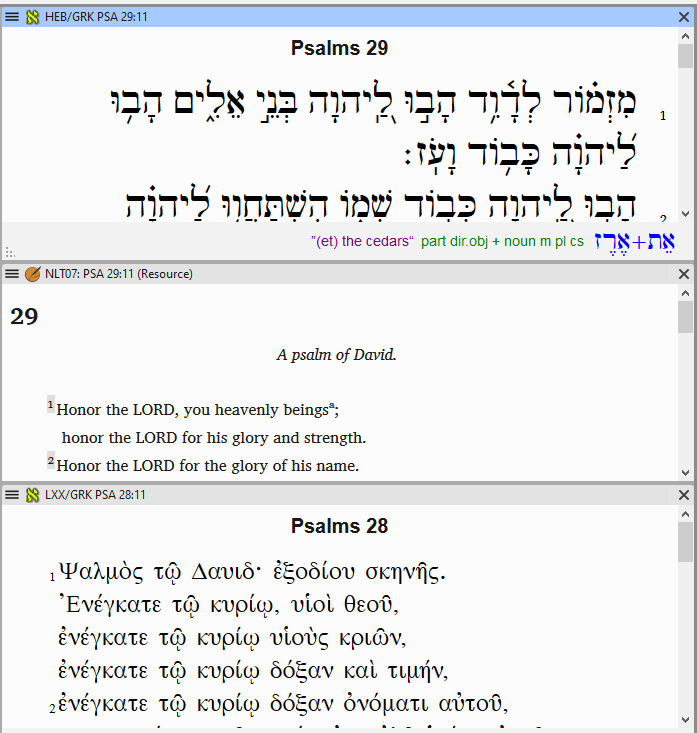
The numbering of the Psalms is only one difference in versification. For instance, the Septuagint Greek contains three pericopes in Daniel that are not found in the Masoretic Hebrew text (The Prayer of Azariah and Song of the Three Holy Children, Susanna and the Elders, Bel and the Dragon). Some translations omit these entirely, others separate them out into an Apocrypha that is translated but not considered Scripture, others include them where the Septuagint did. This causes obvious issues for versification.
Because Paratext is used by translators of all faiths all over the world, often together with ancient texts, it has developed verse alignment data to allow it to identify equivalent verses across all these traditions. For many years, this data was hidden away in internal CSV files, but it is now becoming a Copenhagen Alliance standard, using a JSON format. The basic strategy is simple: a hypothetical hub versification includes chapter and verse numbers for every verse that can occur in any translation. A given translation can produce a mapping to identify differences between its versification and the hub versification. Mapping between two translations involves two map lookups - a lookup from the first translation to the hub, and a lookup from the hub to the second translation. JSON was chosen because it is straightforward to use in JavaScript, Python, and most modern programming languages. Using JSON also made it easy to provide documentation in a Jupyter Notebook format, which allows programmers to experiment with mappings as they develop code[9].
Fortunately, there are rules that can be used to identify the versification used for most translations. These rules involve the number of verses in a chapter, the length of a verse, etc., and Tyndale House has created a spreadsheet containing these rules[10]. Python scripts have been developed to extract these rules, convert them to JSON, and use them to compute the versification scheme for a given translation or manuscript[11].
Dictionary Headwords (Lemmas)
Suppose you had two dictionaries and they used different forms as the headwords of entries for verbs. For instance, one dictionary might use the form “swim” as the headword, another might use the form “swimming”. Unfortunately, Greek lexicons have this problem, they use different forms of words as dictionary headwords. Fortunately, James Tauber has created Greek lemma mappings for most of the major lexicons used for Ancient and Hellenistic Greek[12]. By using these mappings, we can ensure that looking up words works the same way for each of these lexicons. These mappings are found in a YAML file.
Dictionary Senses and Semantic Domains
Identifying the headword for a dictionary entry is not enough for an application that needs to identify the specific meaning in use for a given word. For instance, the Hebrew word פְּרִי (pǝrî) can refer to the fruit of plants, but it can also refer to offspring, viewed as the “fruit of the womb”. A Bible application may help the reader by identifying the sense(s) of a word that are in play in a given context.
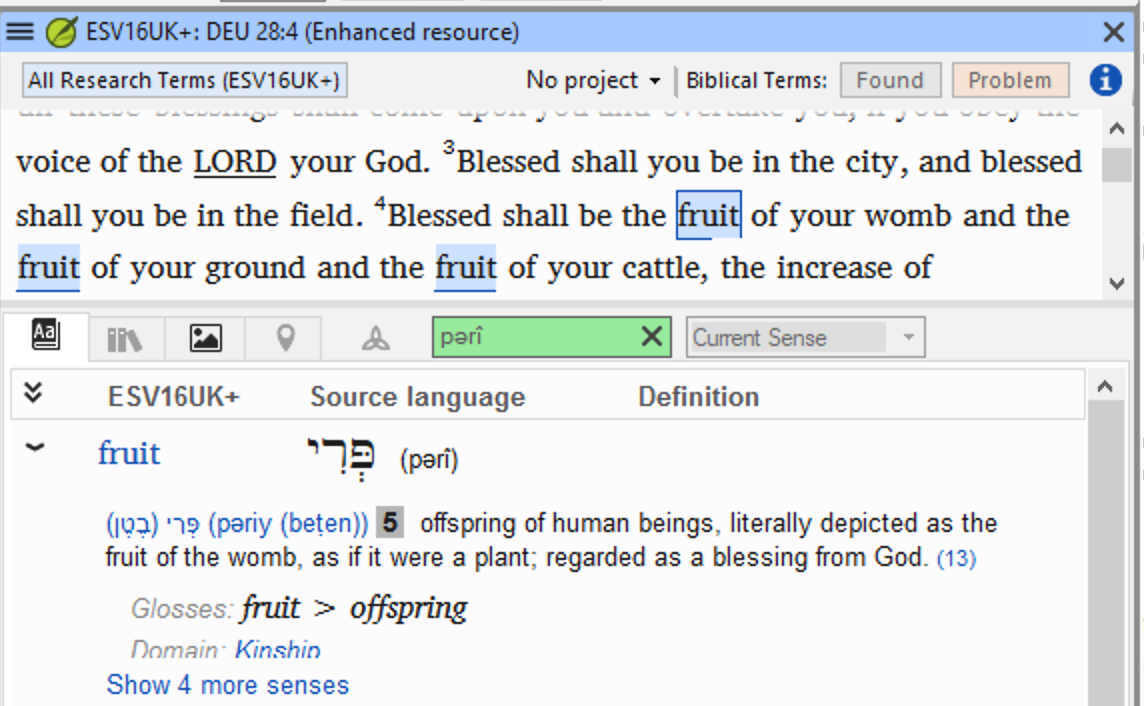
Unfortunately, each dictionary has its own senses, there is no universal set of dictionary senses used across languages. The example shown in the paper comes from the Semantic Dictionary of Biblical Hebrew, which has different senses from other lexicons. As a Semantic Domain lexicon, it is based on a sophisticated ontology, but the ontology is different from the ontology used in the Semantic Dictionary of Biblical Greek, largely because it was created by different authors and in different decades, but partly because languages differ in the way they divide up the world.
SIL International has created a set of semantic domains that work reasonably well across languages (see SIL Semantic Domains), it is designed to be used when semantic domains need to be aligned with each other across resources and across languages. Currently, the most practical way to disambiguate word senses is to refer to a specific lexicon for a given language. In the long run, there may be ways to leverage the SIL Semantic Domains to provide a standard set of “hub senses” across lexicons and languages, which would be practically useful, but would require substantial effort and a degree of compromise[13].
What does Paratext teach us about communities, data, and markup languages?
In many environments, users interact directly with the markup language that represents their data. When working with communities and their data, we need to carefully understand why they create and structure data the way they do, whether they want to consider other formats, and what they value about the formats they are using. We also need to understand the frustrations and limitations they face when using their own data.
Paratext uses USFM for many of the same purposes most XML professionals would use XML for. Paratext users love USFM, it represents their specialized data well and works very well in views that show the markup in a semi-formatted view because the markup is unubtrusive. USFM is well-suited for Scripture editing. For web-based applications and publishing, though, an XML representation is much more useful. USX meets that need. Paratext users would like to be able to create new resources that have a structure quite different from Scripture, so the lack of extensibility in USFM is a bottleneck for these resources. By adding XML viewing and authoring to Paratext, we allow users to create and use important resources that previously could not be added without custom programming. These XML resources are also easily used in XML-based environments outside of Paratext, particularly when they are based on common reference systems.
In practice, creating systems that use data presented in different markup languages is annoying, but not difficult. The real bottlenecks are the same ones faced by systems that use only one markup language: creating logical and maintainable structures to represent the data and creating appropriate reference systems to support relationships in the data. By working with the data - and not fighting it - creative data management systems can be created to provide users with sophisticated functionality for the data they care about most. But this is not easy, it requires time and effort, and it requires communities that care enough about their data to curate it and rethink it over time. Creating and shepherding communities that really understand and care about their data is more important than ensuring that all data uses the same format.
References
[ebibleEncoding] “Bible File Encoding for Bible Translators, Publishers, and Software Developers.” Accessed March 29, 2021. https://ebible.org/usfx/Bible-encoding.htm.
[usfm-grammar] GitHub. “Bridgeconn/Usfm-Grammar.” Accessed March 29, 2021. https://github.com/Bridgeconn/usfm-grammar.
[USFMtoOSIS] “Converting SFM Bibles to OSIS - CrossWire Bible Society.” Accessed April 2, 2021. https://wiki.crosswire.org/Converting_SFM_Bibles_to_OSIS.
[DBL] “Digital Bible Library.” Accessed March 25, 2021. https://app.thedigitalbiblelibrary.org/.
[DeRose] DeRose, Steven. “Markup Overlap: A Review and a Horse,” n.d., 17.
[EpiDoc] “EpiDoc: Epigraphic Documents in TEI XML / Home / Home.” Accessed March 27, 2021. https://sourceforge.net/p/epidoc/wiki/Home/.
[FieldLinguistsToolkbox] “Field Linguist’s Toolbox.” Accessed April 2, 2021. https://software.sil.org/toolbox/.
[Paratext] “Paratext.” https://paratext.org.
[Fieldworks] “FieldWorks.” Accessed April 2, 2021. https://software.sil.org/fieldworks/.
[Glanz] Glanz, Oliver. “Bible Software on the Workbench of the Biblical Scholar: Assessment and Perspective.” Andrews University Seminary Studies (AUSS) 56, no. 1 (July 19, 2018): 5–45.
[Howe] “Graham-Howe-Epub.pdf.” Accessed April 1, 2021. https://archive.xmlprague.cz/2011/presentations/graham-howe-epub.pdf.
[Grassick] Grassick, Clayton, and Hart Wiens. “Paratext: User-Driven Development:” The Bible Translator, April 1, 2011. doi:https://doi.org/10.1177/026009351106200205.
[Haiola] “Haiola Scripture Publishing Software.” Accessed April 2, 2021. http://haiola.org/.
[Haiola] Little, Chris. Chrislit/Usfm2osis. Python, 2021. https://github.com/chrislit/usfm2osis.
[OSIS2.1.1] “OSIS 2.1.1 User Manual 06March2006.pdf.” Accessed April 1, 2021. https://crosswire.org/osis/OSIS%202.1.1%20User%20Manual%2006March2006.pdf.
[PTXprint] “PTXprint – Bible Layout For Everyone - SIL Language Technology.” Accessed March 27, 2021. https://software.sil.org/ptxprint/.
[PublishingAssistant] “Publishing Assistant.” Accessed March 27, 2021. https://pubassist.paratext.org/.
[Rapidwords] “Rapidwords.Net |.” Accessed April 2, 2021. https://rapidwords.net/.
[Kees2011] Regt, Lénart J. de, and Kees de Blois. Of Translations, Revisions, Scripts and Software: Contributions Presented to Kees de Blois. Reading: United Bible Societies, 2011.
[u2o] Ryan. Adyeths/U2o. Python, 2021. https://github.com/adyeths/u2o.
[SBLStandards] “Biblical Scholars, Standards and the SBL,” SBL Publications. Accessed March 27, 2021. https://www.sbl-site.org/publications/article.aspx?ArticleId=45.
[Bosak97] “SGML, Java, and the Future of the Web (1996.11.17).” Accessed April 2, 2021. https://www.ibiblio.org/pub/sun-info/standards/xml/why/xmlapps.961117.htm.
[ptx2pdf] GitHub. “Sillsdev/Ptx2pdf.” Accessed April 2, 2021. https://github.com/sillsdev/ptx2pdf.
[Proskomma] “The Challenges — Proskomma 0.1 Documentation.” Accessed April 1, 2021. https://doc.proskomma.bible/en/latest/big_idea/challenges.html#why-is-usfm-so-popular.
[OSIS] “The CrossWire Bible Society - OSIS - A Common Format for Multiple Visions.” Accessed April 1, 2021. https://crosswire.org/osis/.
[USFM 3.0] “USFM Documentation — Unified Standard Format Markers 3.0.0 Documentation.” Accessed March 25, 2021. https://ubsicap.github.io/usfm/.
“Usfm/Usfm.Sty at Master · Ubsicap/Usfm · GitHub.” Accessed March 29, 2021. https://github.com/ubsicap/usfm/blob/master/sty/
[USX 3.0] “USX Documentation — Unified Scripture XML 3.0.0 Documentation.” Accessed March 25, 2021. https://ubsicap.github.io/usx/.
Vries, Lourens de. “Paratext and Skopos of Bible Translations.” Paratext and Megatext as Channels of Jewish and Christian Traditions, December 20, 2003, 176–93. doi:https://doi.org/10.1163/9789004421431_009.
[Copenhagen Workshop 2019] Winther-Nielsen, Nicolai. “Papers for the Copenhagen Workshop on Open Biblical Resources.” HIPHIL Novum 5, no. 2 (November 20, 2019): 1–5.
[XQuery 3.0] “XQuery 3.0: An XML Query Language.” Accessed April 2, 2021. https://www.w3.org/TR/xquery-30/.
[Semantic Dictionary of Biblical Hebrew] Semantic Dictionary of Biblical Hebrew, edited by Reinier de Blois, with the assistance of Enio R. Mueller, ©2000-2021 United Bible Societies. Available online at https://semanticdictionary.org/.
[Semantic Dictionary of Biblical Greek] Semantic Dictionary of Biblical Greek, Semantic Dictionary of the Greek New Testament, based on Louw & Nida's Greek-English Lexicon of the New Testament, ©1988-2021 United Bible Societies. Available online at https://semanticdictionary.org/.
[SIL Semantic Domains] SIL Semantic Domains. Available online at https://semdom.org/.
[1] I have discussed this with former members of the Paratext team who told me that three previous attempts to replace USFM with XML vocabularies had also failed to dislodge USFM.
[2] Many tagsets used for other purposes are not found in USFM - this problem is one of the reasons that adding better support for XML in tooling used for Bible translation was important.
[3] When a USFM document is converted to USX, the conversion does not add formatting. The two languages are semantically equivalent.
[4] USX, the format used for publishing, uses the same abstractions and tag names as USFM, so it does not require people to think differently.
[5] For a more complete treatment of milestones in USFM and USX, see https://ubsicap.github.io/usfm/milestones/index.html?highlight=overlap and https://ubsicap.github.io/usx/elements.html?highlight=overlap
[7] For a parser that does this, see __init__.py and
usfm.pyin
https://github.com/sillsdev/ptx2pdf/tree/master/python/lib/ptxprint/sfm
[8] “When God Spoke Greek” is an interesting, readable narrative of how the Septuagint and later Hebrew traditions developed over time.
[9] This Jupyter Notebook can be found at vhttps://github.com/Copenhagen-Alliance/versification-specification/blob/master/versification-mappings/VersificationMappings.ipynb.
[10] https://docs.google.com/spreadsheets/d/1mxUu7HJ5DScA7wOQLd-qFUMuG_MHnWjM6KxJ79qQs9Q/edit#gid=1869211794
[11] https://github.com/Copenhagen-Alliance/versification-specification/tree/master/versification-sniffing
[13] As Elaine Svenonius pointed out at one Balisage conference, this is an instance of the merged ontology problem, a known-hard problem. That does not rule out useful solutions, but it does rule out simple solutions and perfect solutions.