The foundation of the SAS analytics ecosystem is the SAS programming language. First developed in the 1970s, SAS has since grown organically to become a powerful, robust language with the quirks and edge cases one would expect in a 40-year-old language. Documenting its features, functionality, and syntax for SAS users is a core responsibility of the Documentation Department.
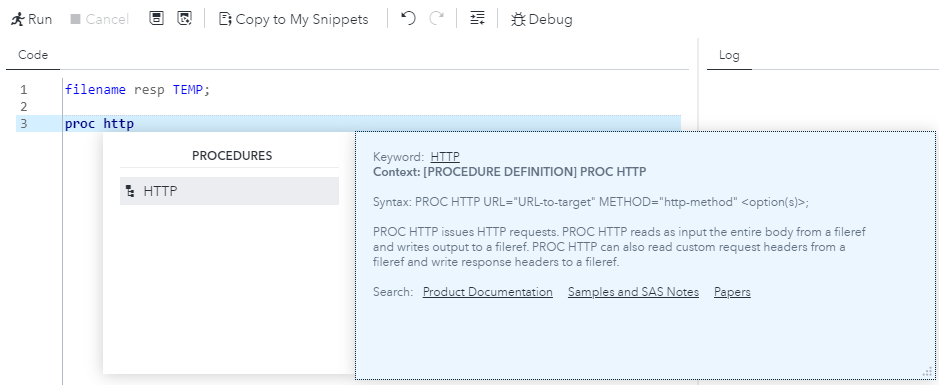
Historically, to support syntax highlighting and code completion in IDEs (see Figure 1), a single employee in another department monitored changes in the SAS documentation and made updates to source code for the IDE. This was a race condition with no way to measure accuracy. Previous attempts to replace this manual process by extracting syntax from the SAS code base were unsuccessful due to the aforementioned nuances of a mature, organically growing programming language. As release cadence accelerates and the organization moves to a continuous integration/continuous delivery construct, this process has become increasingly unmaintainable.
Figure 1: PROC HTTP Procedure Statement code completion
Given the lack of automation and the barrier to self-documentation in our existing code base, we embarked on a collaborative effort to develop a new process for extracting code-completion syntax from the XML for the software documentation and hosting it in a REST service. Since writers update software documentation simultaneously with changes to the software, syntax extracted from it should always be current.
In the following paper, we explore various aspects of interest in this ongoing project: project justification, guiding principles, information architecture, conversion, and reauthoring; the XSL→JSON→service pipeline; lessons learned; and current status. It should serve as a case study for similar endeavors and as an alternative approach to software, API, and language self-documentation from source code where circumstances make such modern documentation practices untenable.
Project Justification—Or, What's So Wrong With the Status Quo?
SAS is a unique programming language. The sum of its parts allows programmatic access to most of the software across the entire SAS ecosystem; thus, it has an extensive vocabulary. It is also a language that has evolved for over 40 years, and its organic maturation is apparent. While syntax rules exists, it is far from entirely consistent, and edge cases make it hard to infer the lexical meaning of a given element in a SAS program based on syntax alone. Further, during the 40 years since its genesis, additional languages emerged. Programs from entirely different languages—Lua, Groovy, SQL, even XSLT—can be wrapped in the SAS Procedures and executed in SAS. Given this complexity, code completion and code highlighting is a challenge, and SAS IDEs often highlight incorrectly and inconsistently. Access to a complete language dictionary would simplify this task greatly.
Such a dictionary currently exists; however, it is want for improvement. The existing syntax XML and maintenance process lacks automation and scalability. It has no DTD or schema, and its tagging dictionary is particularly spartan. It is maintained by a single person in R&D, who watches for documentation changes and updates accordingly. Large swathes of modern corners of the SAS language remain undocumented as a result of the inefficiences of this process. Sample legacy XML can be found in Appendix A. A brief review of the legacy XML reveals many deficiencies, such as:
-
Semantic information of interest to its consumers is captured in comments or within the "help" text, e.g.,
<!--Required Arguments-->, preventing consumers from identifying:-
required vs. optional arguments
-
allowed values for arguments with a controlled list
-
required delimiters
-
-
Most text is captured in <![CDATA[]]> in an effort to produce formatting
-
Headings like "Syntax" are keyed into the <ProcedureHelp/> presenting internationalization inefficiencies
Guiding Principles
With the goal of replacing the existing R&D-maintained syntax extraction in mind, the team began the project with some general guiding principles. The first principle for this project is one that will no doubt be familiar to XML practitioners: single-sourcing. The existing source XML maintained by R&D exists outside both the documentation and the software development cycle. By designing a process to extract and deliver syntax content from the documentation, this decoupling will be addressed by single-sourcing, reducing maintenance overhead and inconsistency. Focus was also placed on producing adequate content with the least tagging requirements. As detailed in the next section, SAS XML has a history of verbosity allowing for myriad ways to achieve the same rendered output. Further, avoiding undue tagging burden on the technical writing staff was a primary concern given ever increasing documentation responsibilities and constrained resources. This principle necessitated striking a balance between requiring explicit, thorough tagging and algorithmic syntax information extraction.
Documenting Syntax
Before designing the service, the team undertook an exercise in information architecture to define the best XML structures to capture syntax information that would both facilitate extraction for the syntax service and production of traditional documentation deliverables. That work is summarized in this section, in which the team explored the structure of the legacy syntax information XML and the design considerations and requirements for the JSON objects and developed the new architecture of the documentation XML from which it would be derived. Included in Appendix A is an abridged sample of the legacy XML, the corresponding documentation XML, the transformed JSON object, and a sample of the results for code completion in SAS Studio.[1]
Legacy XML Review
Foundational to this project was an effort to clearly define the needs of the proposed syntax service. The project began with an analysis of the existing legacy R&D-maintained syntax XML to define a satisfactory JSON model and to map documentation XML to the new model. Without a DTD, literal document-by-document analysis was required to discern structure and content. As discussed in the project justification section above, the shortcomings of both the structure and content of the XML were fairly clear as is the process for developing and maintaining this XML. From this baseline, the team next worked with R&D to define the object model for the new syntax prior to designing XML from which it would be derived.
JSON Design and Documentation
As part of a wider organization-wide initiative to standardize API
development, SAS has adopted OpenAPI for API documentation and mandated that
services should, at the least, support the application/json media type.
With this requirement in mind, the R&D consumers of the syntax service have
designed around and made a requirement that the service be primarily focused on
syntax elements modeled in JSON objects. Thus, the team first established the JSON
model with the intention of working from it to develop adequate XML markup. The
design process began with an analysis of the language element it should model. Each
SAS language element has lexical features unique to its element class relevant to
its model. In the case of procedures, the model is as follows:
-
Each Procedure has:
-
a name
-
one or more statements, including the procedure statement (the procedure that begins with the procedure name)
-
-
Each statement in a procedure has:
-
a name
-
one or more arguments
-
optional aliases
-
-
Each statement argument has:
-
a name
-
a type
-
possible nested arguments
-
Figure 2: Example Means Procedure

In addition to the literal statements and arguments associated with a given procedure, R&D identified additional required metadata that would be of use to syntax consumers at each level of a procedure to be included in the JSON object in the syntax service:
-
Procedures:
-
Product groups – the SAS products in which a given procedure is available
-
SAS Release – the SAS software release with which a given procedure is associated
-
Locale – the language of the object
-
Interactivity – a boolean value indicating whether or not a procedure is interactive
-
-
Statements:
-
Description
-
Example syntax
-
-
Arguments
-
Description
-
Example syntax
-
Optional – is the argument required?
-
Placeholder – Is the text displayed for the argument name text to be replaced by the user?
-
Follows delimiter – does the argument appear after a delimiting character?
-
Type – each argument can be one of the following types:
-
dataset
-
standalone
-
value
-
standalone or value
-
choice
-
-
The final procedure JSON structure appears below.
{
"id": "string",
"name": "string",
"updated": "string",
"locale": "string",
"sasRelease": "string",
"productGroups": [
{
"name": "string"
}
],
"interactive": true,
"statements": [
{
"name": "string",
"description": "string",
"help": "string",
"aliases": [
"string"
],
"arguments": [
{
"name": "string",
"optional": true,
"placeholder": true,
"followsDelimiter": "string",
"aliases": [
"string"
],
"description": "string",
"help": "string",
"type": "string",
"arguments": [
null
],
"supportSiteTargetFragment": "string"
}
],
"supportSiteTargetFile": "string"
}
],
"supportSiteInformation": {
"docsetId": "string",
"docsetVersion": "string",
"docsetTargetFile": "string"
},
"version": 0
}
Documentation XML Design
SAS documentation has used a proprietary DTD since migrating from SGML. The
traditional DTD, informally known as the authoring.dtd, had various
means of documenting the SAS language, depending on the type of language element and
the intent of the writer. Developed organically through feature requests and
requirements changes, the DTD grew to contain over 500 elements. Several years ago,
an effort to create a new, streamlined DTD began. The new DTD, named the
document.dtd, was designed without extraneous tags and features
until equivalency with the authoring.dtd was explicitly
requested.
Analysis of the R&D syntax documentation requirements revealed both gaps
in the authoring.dtd tagging structure and too lenient a tagging
structure to produce consistent syntax extraction results. Rather than introduce
breaking changes to the authoring.dtd, requiring conversion and
manipulation of legacy content, the Document Architecture group decided to develop
a
new syntax documentation model in the document.dtd and to create XSLT
to convert old authoring.dtd content to the new DTD to migrate all
syntax documentation when necessary. Where possible redundant elements were
consolidated and eliminated. The resulting final version of the
document.dtd with full feature parity for
authoring.dtd is currently 348 elements—a substantially smaller tag
set. Some examples of element refactoring and consolidation are illustrated in Figure 3.
Figure 3: Refactored Elements Related to Syntax Extraction
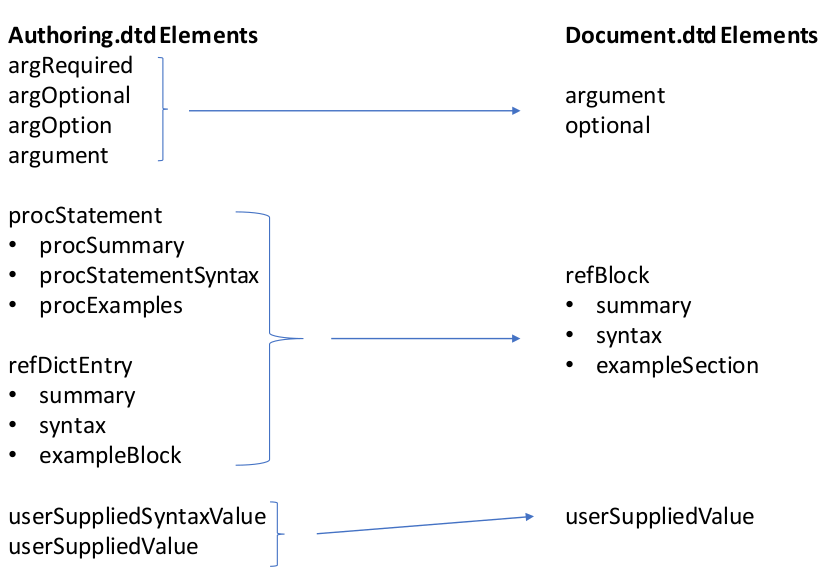
Most important to syntax extraction is the <refBlock> element. It replaced
two elements in the authoring.dtd and is designed to be flexible enough
to capture syntax documentation for numerous SAS language elements, including
statements, functions, formats, and informats. By designing this element to document
most SAS language elements, the XSL for syntax extraction can share code for
extracting these different elements and vary only slightly at the edges, reducing
transformation complexity. <refBlock> are the child of either <refProc> or
<refDictEntryCollection>. <refDictEntryCollection> is a tag retaining its
authoring.dtd name intended to group numerous related refBlock
describing language elements. <refProc> is a tag designed to document SAS
procedures, and it contains both syntax and also information supplemental to the
syntax documentation. It produces a special organizational structure in the output,
for an example see the httpproccite in
the Base SAS Procedures Guide.
From a <refBlock>, its <name> maps to the name of a language element, and its <shortDescription> maps to the description. The syntactic structure of the syntax is captured in <syntaxSimple> within the <syntax> element, while the arguments are documented in <argDescriptionPair> within the <syntaxDescription> element. To facilitate documenting nested arguments, <argumentDescription>s can contain nested <argDescriptionPair>, producing the nested argument objects as shown in Appendix A. Figure 4 demonstrates how some of the XML maps to content in the code completion window.
Figure 4: Procedure arguments and syntax help
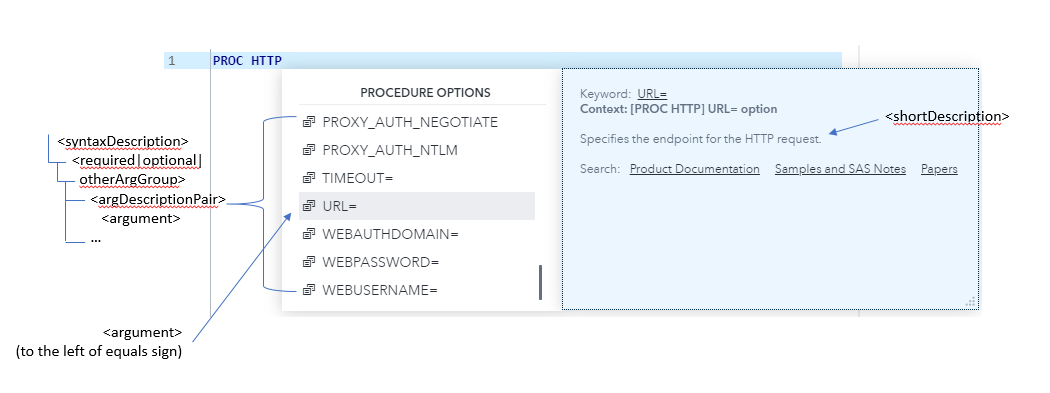
The improvements over the legacy R&D maintained syntax XML are numerous. Whereas previously, the syntax for a language element was keyed in CDATA, the new XML contains numerous semantic tags. This produces better formatting in the code completion window and facilitates algorithmic identification of argument type in the extraction, such that writers do not have to tag arguments with their type. Procedure statements are now grouped in several semantically significant parent tags (<requiredArgGroup>, <optionalArgGroup>, <otherArgGroup>). By grouping in this manner, the service will be able to indicate which statements are required and which are optional—information previously only present in the CDATA of the <statementHelp> and not accessible to syntax documentation consumers. This should allow for future enhancements to the code completion to sort code completion suggestions and warn of missing required arguments. Additionally, now that the syntax information is extracted from the documentation, direct links from the code completion to relevant documentation are possible by including the UUID of source in the syntax objects. Prior to this new service, the IDE simply linked by way of a link to search results for the topic in our documentation.
Conversion and Reauthoring
Despite best efforts, the changes necessary to the document.dtd
necessitated significant conversion and reauthoring work. There were breaking
changes to the document.dtd, namely the elimination of redundant tags
and some restructuring. Additionally, all existing syntax documentation was authored
in the authoring.dtd, so the team developed both an
authoring-to-document and a document-to-document XSL transformation.
To facilitate tech writer use, the team created a parameterized jenkins job through which authors could batch convert their documentation projects to the new DTD. Where possible, the conversion was hands off, but where incompatibilities and questions arose, the conversion inserted processing instructions with comments configured to surface when the author transformed the content to an HTML preview, if possible, or included DTD validation failures in the Jenkins job log to debug and triage.
The Syntax Extraction and Service
The deployed syntax-from-doc service is comprised of three components developed by documentation engineering: 1) the syntax extraction XSL, 2) the syntax REST API service, and 3) the syntax viewer. The following section explores these three components structure and functionality. Figure 5 represents the flow of syntax documentation to the syntax service.
Figure 5: Syntax extraction flow from XML to REST Service
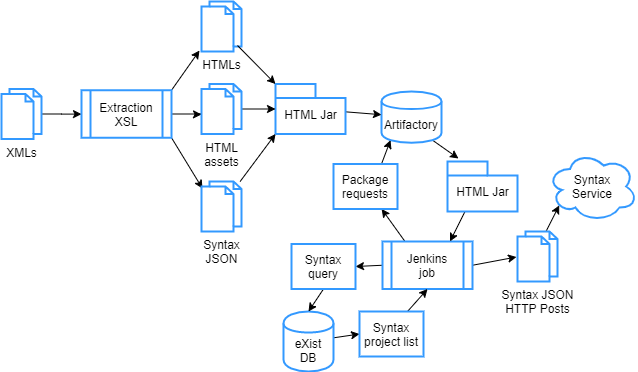
Extracting Syntax From Doc
The majority of the SAS language documentation is authored in XML maintained in projects versioned in CVS. When writers commit changes to CVS, jenkins builds produce build artifacts (e.g., HTML, PDF, ePub) stored in artifactory. To deliver extracted syntax to the syntax REST service, the team added a new step in the HTML build, so that extracted syntax would end up in the HTML artifact after each build.
The XSL stylesheets consist of a controller stylesheet called from the
Java-based build pipeline, executed using Saxon EE. The controller is an XSL 3.0
stylesheet that passes a flattened XML file using fn:transform() to
external stylesheets that return a map of result XML documents. The controller then
iterates through the returned map serializing each to JSON files using
fn:xml-to-json(). Each SAS language element type has its own
external stylesheet to handle the minor extraction differences between elements and
to gather like elements based on structure and attributes. These stylesheets include
a common stylesheet for shared templates that do not vary based on context. An
example of the technique for controlling procedure extraction via external
stylesheet is presented below.
<!-- The root template in ExtractSyntaxController.xsl contains a series of the following variable
and call-template, each pointing to a different XSL stylesheet to extract different syntax doc
The source node is a flattened XML file of an entire "docset"-->
<xsl:variable name="stylesheetParams"
select="
map {
QName('', 'output_dir'): $output_dir,
QName('', 'docsetVersion'): $docsetVersion,
QName('', 'docsetId'): $docsetId
}"
/>
<xsl:variable name="procResults"
select="
transform(
map {
'source-node': .,
'stylesheet-location': 'extractProcSyntaxJSON.xsl',
'stylesheet-params': $stylesheetParams
}
)"
/>
<!-- This template iterates over the returned map of result documents
and writes each to the file system, either as XML if debugging is enabled
or as JSON using fn:xml-to-json() -->
<xsl:call-template name="outputResults">
<xsl:with-param name="results" select="$procResults"/>
</xsl:call-template>
This stylesheet structure yields several benefits. By using a controller
stylesheet and fn:transform(), Saxon is only invoked once, though the
XML is processed several times, offering some performance benefit and moves process
flow from its traditional place in the Java build to more easily maintained XSL.
Furthermore, the syntax-from-doc project is an iterative one. The service is being
introduced a syntax element at a time—first procedures, second functions, and so
forth. Each stylesheet can be developed and tested on its own. Once finalized,
adding an additional pass in the controller is trivial.
The Syntax Service
Consumers of extracted syntax information consume it via the syntax microservice REST API. The service itself is a springboot app utilizing httpd for routing and postgres as a database. It is deployed via docker container. Endpoints, HTTP requests supported, and JSON object models are documented in swagger OpenUI and accessible via an internal SAS Swagger Hub. The service is populated by a Jenkins job that runs nightly after the documentation builds. It first queries an internal existdb database containing all SAS XML documentation to compile a list of every project containing syntax. With a list of syntax projects, the service then retrieves the HTML artifacts from Artifactory for each project, extracts the JAR files, and collects the JSON objects for each syntax language element. Finally, the Jenkins job POSTs each object to the appropriate syntax service endpoint, replacing the existing object in the service with the most recently extracted content. The result of this pipeline process is a service easily maintained by the authors, wherein updates to syntax appear in the service in a fully-automated fashion.
The Syntax Viewer
For now, SAS customers will interact with the result of the syntax-from-doc project only in the SAS IDEs. On the other hand, internal users, especially SAS technical writers and editors, need visibility into the extracted syntax as they both confirm accuracy of extraction and revise and adapt their tagging to meet the more stringent requirements of this new service. For this purpose, the documentation engineering team developed a syntax viewing service. This viewer allows writers to see a user-friendly representation of the syntax information rather than expecting them to review raw JSON objects.
The syntax viewer is a relatively simple Vue.js front-end app built on technology already in use for several other internal documentation web application front-ends. Essentially, it provides a UI for the syntax service, so authors can explore and view the collections of syntax objects, with search, filtering, and sorting by element type and SAS release. Once viewing an individual syntax element, the UI is utilitarian, offering a formatted view of the key/value pairs of the JSON objects. Where appropriate, it translates escaped HTML and character entities to render text as it would appear in the IDE. It is a viewer only. If content changes are required, writers must go back to the source XML, make them there. When the writers finish updates, their committed changes will trigger a Jenkins build, and their updated syntax will appear in the syntax viewer.
Challenges and Lessons Learned
Author Communication and Tagging Quality
At the heart of the syntax-from-doc project lies the new tagging introduced to facilitate extraction. The document architecture team invested considerable effort into the resulting tagging architecture. Despite this effort, its roll out was not seamless, and the new tagging still presents recurring questions and requires regular modification as requirements continue to be refined. While management held information sessions to explore the new tagging, conversion, and expectations, confusion still surrounds tagging best practices. Prior to this new service, writers needed only to tag to produce visually appealing HTML/PDF deliverables. Now, semantic information is far more important. Thus, writers must adopt more rigorous tagging conventions. With each language element added to the extraction, large swathes of tagging inconsistencies and workarounds are surfaced that produce passable deliverables but inaccurate syntax service objects. The cleanup effort is ongoing and monumental.
Confusion also still surrounds how the tagging effects the resulting extracted documentation, and work is underway to develop tagging best practices. Provided with the syntax viewer, writers can easily see an approximation of the extracted JSON from their documentation. However, the connection between what's displayed in the viewer and what will be displayed in the applications consuming the syntax is still befuddling writers. There is still room for improvement in conveying what particular key/value pairs in the syntax objects will control in the IDE and what those values are meant to indicate. Compounding the confusion is a side effect of a guiding principle to seek to reduce tagging burden on writers. Some information provided in the syntax is inferred from the contents of the syntax documentation, rather than keying off specific tags. For instance, data type of statement arguments is determined in the XSL transformation by a combination of identifying certain tagging structures and regex pattern matching. Lessons learned and practices adopted to address these issues:
-
Communicate tagging guidelines early and often.
-
Involve writing staff as early as possible to socialize change.
-
Develop tagging best practices and sample content.
-
Leverage XQuery and XML databases to surface common problems and make content authors aware.
-
Address tagging complacency and develop Schematron rules to check for tagging guidelines unenforceable with DTD or schema.
Evolving Requirements
Several DTD changes have arisen after the initial DTD was released. On the XML
authoring side, there are instances where tagging for one deliverable produces
suboptimal artifacts for another. For example, some language elements are documented
in multiple projects with differing content. The syntax service needs a single
object for each element, so soon after developing a beta version of the service, a
new @excludeFromSyntaxExtraction attribute was introduced to control
which content is extracted. Conversely, there is concern that there are times when
the tagging required to produce accurately extracted content may not be appropriate
for documentation, such that an @excludeFromDoc will be warranted, if,
for instance, it would make the documentation particularly verbose or redundant. As
of yet, we have refrained from introducing this attribute, since it would then be
another example of a failure in single-sourcing, requiring the content owners to
maintain two sets of documentation of the same syntax. Finally, the team has also
added several elements to provide more contextual information to the syntax
consumers. @followsDelimiter indicates whether an argument group
follows a specified delimiter, and @functionContext specifies in which
software packages the descendant function documentation is applicable.
Formatting Syntax and Help Content
The challenge of formatting syntax help is one with which we are still grappling.
The legacy XML made copious use of <![CDATA]]> wrapped text to
allow for manual formatting of syntax and help content. In the new service, we have
resorted to escaped HTML, new-line characters, and spaces to produce syntax examples
and readable descriptions. With escaped HTML, the possibility is there for producing
fairly well-structured syntax help, but it is far from the ideal solution. Already
the service must produce italic text for syntax examples. Further, there are
instances where the XSL is now extracting and producing escaped unordered lists in
the help field. There are almost assuredly other edge cases yet uncovered by the
proofing and revision process that may necessitate other formatting acrobatics. Here
lies an underlying shortcoming with JSON as the de facto API standard for
information exchange.
LaTeX Doc
Not all documentation at SAS is XML. A significant portion of the content documenting statistical procedures and tooling is authored, not by technical writers and editors, but by the developers themselves in LaTeX. This content follows its own production pipeline to be delivered along side XML-authored content in the customer-facing documentation. This LaTeX doc contains syntax information necessary to code completion, but, unfortunately, is not conducive to extraction and delivery in the syntax service. Its markup simply does not have the granularity or semantic information to produce content for the syntax service.
With no good options, the syntax team decided to use the legacy R&D-authored code completion syntax XML, convert it to the document.dtd, and store it in a project that will serve as the source for syntax extraction. By doing so, the documentation group takes ownership of the the content in the syntax service representing LaTeX-authored documentation, and its writers and editors can use SAS XML tooling to do maintain it. This solution is far from ideal and does not meet all the goals set out for the project. This XML is presently only used as the source for syntax extraction; thus, it represents duplicated content, as the LaTeX documentation continues to be the source for all other customer-facing documentation. Thus, this documentation requires dual maintenance, and breaks the direct connection between documentation revision and software or language behavior development. As of today, there is no regular revision schedule, nor any designated owner for the content. It may only be updated when defects are identified.
Further, since the XML that generates the syntax help for LaTeX documented language elements is not the source of the end-user documentation, establishing a connection between the syntax help and the user documentation was a project unto itself. The team eventually resorted to parsing other XML documentation that contains maintained links to the LaTeX doc and extracting those links to deliver in the service.
Current State and Next Steps
The syntax-from-doc project is still in active development. Thus far, only SAS procedures, functions, and non-procedure statements are in the service. The plan is to introduce more language element models in an iterative fashion until the entire language is represented. SAS Studio, the primary internal customer for the syntax service, has a beta version of the IDE that leverages the service; however, no tools do so in production yet. A production release is slated for sometime in 2020. As mentioned previously, there is also discussion regarding possibly productionizing and making public the syntax service for developers outside of SAS. In addition, more extensive internal use could be on the horizon. Finally, improvements to the extraction and service itself are possible. One possibility is to move extraction from at project build time to incorporating the XSL as part of an extension to the eXist database, such that the syntax service or a new service could call the eXist database for language objects and POST them to the service, rather than retrieving physical files from Artifactory. As the process and service matures and use cases materialize, assuredly more improvements will arise. And from these trials and tribulations and lessons learned, one might be left to ponder—if given a fresh start and a new code base, could there be a better way to document a language? A topic for another time...
Appendix A. PROC HTTP Sample Syntax
What follows is abridged sample legacy syntax XML, the analogous documentation XML, and finally the corresponding JSON object for the SAS language PROC HTTP procedure statement. See the httpproccite in the SAS Documentation for the HTML deliverable produced by the XML documented below.
Legacy XML
<Procedure>
<Name>HTTP</Name>
<ProductGroup>BASE</ProductGroup>
<ProcedureHelp><![CDATA[Syntax: PROC HTTP URL="URL-to-target" METHOD="http-method" <option(s)>;
PROC HTTP issues HTTP requests. PROC HTTP reads as input the entire body from a fileref
and writes output to a fileref. PROC HTTP can also read custom request headers from a
fileref and write response headers to a fileref.]]>
</ProcedureHelp>
<ProcedureOptions>
<!--Required Arguments-->
<ProcedureOption>
<ProcedureOptionName>URL=</ProcedureOptionName>
<ProcedureOptionHelp><![CDATA[Specifies the endpoint for the HTTP request.]]></ProcedureOptionHelp>
<ProcedureOptionType>RV</ProcedureOptionType>
</ProcedureOption>
<!--Optional Arguments-->
. . .
<ProcedureOption>
<ProcedureOptionName>IN=</ProcedureOptionName>
<ProcedureOptionHelp><![CDATA[Syntax: IN="string" | fileref
Specifies the input data.
Beginning in the third maintenance release of SAS 9.4, you can specify input data in a quoted string
or in a fileref. Previous SAS releases require that you specify a fileref.
Requirement: This option is required when the POST and PUT methods are used.]]></ProcedureOptionHelp>
<ProcedureOptionType>V</ProcedureOptionType>
</ProcedureOption>
. . .
</ProcedureOptions>
<ProcedureStatement>
<StatementName>HEADERS</StatementName>
<StatementHelp><![CDATA[Syntax: HEADERS "HeaderName"="HeaderValue" <"HeaderName-n"="HeaderValue-n">
Specifies request headers for the HTTP request.
Required Argument
"HeaderName"="HeaderValue"
is a name and value pair that represents a header name and its value. The HeaderName can be a standard
header name or a custom header name. For information about header field definitions, see the HTTP/1.1
specification at www.w3.org.
Note: Do not specify a colon (:) in the header name. The name=value pairs are automatically translated
into the following form:
HeaderName : HeaderValue]]></StatementHelp>
<StatementOptions />
</ProcedureStatement>
</Procedure>
Documentation XML
<refProc excludeFromSyntaxExtraction="no">
<name>HTTP</name>
<product productName="base"/>
<product productName="viya"/>
<refBlock type="statementProcedure" excludeFromSyntaxExtraction="no">
<name>PROC HTTP</name>
<shortDescription>Invokes a web service that issues requests.</shortDescription>
<syntax formLabels="no">
<syntaxSimple>
<syntaxLevel><keyword>PROC HTTP</keyword><argument>URL="<userSuppliedValue>URL-to-target</userSuppliedValue><optional>/redirect/<userSuppliedValue>n</userSuppliedValue></optional>"</argument>
<syntaxLevel><optional><argument>METHOD=<optional>"</optional><userSuppliedValue>http-method</userSuppliedValue><optional>"</optional></argument></optional></syntaxLevel>
. . .
</syntaxSimple>
<syntaxDescription>
<requiredArgGroup excludeFromDoc="no" excludeFromSyntaxExtraction="no">
<argDescriptionPair>
<argument>URL="<userSuppliedValue>URL-to-target</userSuppliedValue>"</argument>
<argumentDescription includeShortDescription="no">
<shortDescription>specifies the endpoint for the HTTP request.</shortDescription>
. . .
</argumentDescription>
</argDescriptionPair>
</requiredArgGroup>
<optionalArgGroup>
<argDescriptionPair>
<argument>IN=<choice><userSuppliedValue>fileref</userSuppliedValue></choice>
<choice>FORM (<userSuppliedValue>arguments</userSuppliedValue>)</choice>
<choice>MULTI <optional><userSuppliedValue>options</userSuppliedValue></optional></choice>
<choice>"<userSuppliedValue>string</userSuppliedValue>"</choice>
</argument>
<argumentDescription includeShortDescription="no">
<shortDescription>specifies the input data.</shortDescription>
<argDescriptionPair>
<argument>fileref</argument>
<argumentDescription>
<paragraph eid="p1cnv96d5jyw4an18vgwgl2az0u9">specifies a fileref. The
fileref is a pointer to data that exists in another
location. A fileref is assigned with the FILENAME
statement.</paragraph>
</argumentDescription>
</argDescriptionPair>
. . .
</argumentDescription>
</argDescriptionPair>
</optionalArgGroup>
</syntaxDescription>
</syntax>
</refBlock>
</refProc>
JSON Object
{
"name": "HTTP",
"version": 1,
"supportSiteInformation": {
"docsetId": "proc",
"docsetVersion": "v_001",
"docsetTargetFile": "n0bdg5vmrpyi7jn1pbgbje2atoov.htm"
},
"productGroups": [
{"name": "base"},
{"name": "viya"}
]
"statements": [
{
"name": "PROC HTTP",
"description": "Invokes a web service that issues requests.",
"help": "PROC HTTP URL=\"<i>URL-to-target<\/i>\" <<i>options<\/i>>;\n\tDEBUG <i>options<\/i>;\n\tHEADERS \"<i>HeaderName<\/i>\"=\"<i>HeaderValue<\/i>\" \n\t\t<\"<i>HeaderName-n<\/i>\"=\"<i>HeaderValue-n<\/i>\">;\n\tSSLPARMS <i>host-specific-SSL-options<\/i>;",
"arguments": [
{
"name": "URL=",
"help": "URL=\"<i>URL-to-target<\/i>\"",
"description": "specifies the endpoint for the HTTP request.",
"type": "value",
"supportSiteTargetFragment": "n1vkwm3g1bln7vn1mbt2da6jtul5"
},
{
"name": "IN=",
"help": "IN=<i>fileref<\/i> | FORM (<i>arguments<\/i>) | MULTI <<i>options<\/i>> | \"<i>string<\/i>\"",
"description": "specifies the input data.",
"arguments": [
{
"name": "fileref",
"description": "specifies a fileref. The fileref is a pointer to data that exists in another location. A fileref is assigned with the FILENAME statement.",
"type": "standalone",
"supportSiteTargetFragment": "p0z462ggw4a5z2n17taq7gufkg6x"
},
. . .
],
"optional": true,
"type": "choice",
"supportSiteTargetFragment": "p12fhuxpr8l8aen0z6foe88r2dfl"
},
}
]
}References
[httpd] Apache. (2020). httpd. https://httpd.apache.org/docs/2.4/programs/httpd.html
[docker] Docker. (2020). https://www.docker.com/
[existdb] Exist Solutions. (2020). exist-db. http://exist-db.org/exist/apps/homepage/index.html
[jenkins] Jenkins. (2020). https://jenkins.io/
[artifactory] JFrog. (2020). Artifactory. https://jfrog.com/artifactory/
[postgres] PostGRES. (2020). https://www.postgresql.org/
[prism] Prism.JS. (2020). http://www.prismjs.com
[httpproccite] SAS (2020). HTTP Procedure. Base SAS Procedures Guide. https://go.documentation.sas.com/?cdcId=pgmsascdc&cdcVersion=9.4_3.5&docsetId=proc&docsetTarget=n0bdg5vmrpyi7jn1pbgbje2atoov.htm&locale=en
[springboot] Spring. (2020). Spring Boot. https://spring.io/projects/spring-boot
[swagger] SmartBear. (2020). Swagger. https://swagger.io/
[1] The SAS language is comprised of several elements, e.g., procedures, functions, global statements, and formats. The long-term goal of the syntax service project is to provide information about all elements, but for the purposes of this case study and the initial phase of the project, we focus on procedures.