Tovey, Bethan Siân. “You’re not the POS of me: part-of-speech tagging as a markup problem.” Presented at Balisage: The Markup Conference 2019, Washington, DC, July 30 - August 2, 2019. In Proceedings of Balisage: The Markup Conference 2019. Balisage Series on Markup Technologies, vol. 23 (2019). https://doi.org/10.4242/BalisageVol23.Tovey01.
Balisage: The Markup Conference 2019 July 30 - August 2, 2019
Balisage Paper: You’re not the POS of me: part-of-speech tagging as a markup problem
Bethan Tovey is a PhD student in linguistics, studying the language-mixing
behaviour of Welsh-English bilinguals, and is working on a part-of-speech tagger
for mixed Welsh-English texts. She is particularly interested in the problem of
automatic language recognition for individual words. She was formerly a content
architect at Oxford University Press. Even more formerly, she worked for the
Oxford English Dictionary, specialising in medieval English.
Part of speech tagging, labeling every token in a text with its
grammatical category, is a complicated business. Natural language is
messy, especially when that language consists of social-media
conversations between bilinguals. The process can be done with or
without human intervention, in a supervised or unsupervised manner, on
a statistical basis or by the application of rules. Often, it involves
a combination of these methods. It is, on the one hand, an obvious
markup problem: mark up the tokens with appropriate grammatical
categories. But it is also much richer than that. Theoretical problems
that have been identified in the domain of markup can throw light on
the problem of grammatical category disambiguation. Topics considered
include subjectivity and objectivity, the semantics of tag sets,
licensing of inference, proleptic and metaleptic markup, and the
interesting characteristics of the Welsh “verbnoun”.
Part-of-speech tagging (hereafter PoS tagging; also called
grammatical tagging or word-class
disambiguation) is the process of annotating each linguistic unit in a text
with the grammatical category to which it belongs. Most PoS tagging done today
identifies both a broad PoS category (verb, noun, adverb) and more granular information
about the word’s morphosyntactic category or lexicosemantic features (distinguishing
past from present tense verbs, common from proper nouns, singular from plural pronouns,
and so on) [Voutilainen 2003]. Although
PoS tagging can be performed by humans, either from scratch or on pre-processed texts
whose machine-generated tags require human validation, the term is most commonly
associated with computational methods in corpus linguistics and natural language
processing (NLP). This paper specifically discusses the computational process. The
units
to be tagged are usually what we think of as words, but this is not
always the case. In syntactic terms, a form such as won’t might be
treated as two separate units (a form of the verb will plus the
adverb not), while light bulb might be treated
as a single unit (a compound noun, in conformity with the alternate spellings
lightbulb and light-bulb). Instead of
word, therefore, the broader term token is
used for anything that the PoS tagger treats as a taggable unit. The input to a PoS
tagger generally includes all the non-whitespace characters of a text, split into
tokens. A token may therefore be a punctuation character, a
numeral, or an emoji, as well as an alphabetic string [Manning et al. 2009].
Taggers tend to follow a similar series of steps: tokenization; lexicon lookup of
tokens; guessing processes for unknown tokens; and disambiguation of tokens for which
more than one tag has been found [Voutilainen
2003], [Leech et al. 1994]. The
greatest challenge for PoS tagging is disambiguating lexical tokens which share the
same
written form but belong to different categories [DeRose
1988]. These may be words from the same root, such as
number as a noun and as a verb meaning “enumerate”, or words whose
identical spelling is coincidental, such as either of the foregoing examples alongside
number as a comparative adjective meaning “more numb”. Ideally, a
PoS tagger will be able to identify the form number in each of the
following examples correctly:
The number was chosen randomly (noun)
Number the examples sequentially (verb)
Her face felt number after the second injection
(adjective)
A related disambiguation problem comes from words which have the same
basic grammatical category, but differ in some feature such as tense (for verbs) or
number (for nouns). The token wound can be a verb in the present
tense, or the past tense or past participle form of wind. The token
bowls can be a singular noun, denoting a lawn game, or the plural
form of the noun bowl. On the other hand, tokens that have the same
written form and grammatical category but differ in meaning, such as
row (noun: “line”) and row (noun: “argument”),
are not generally a problem for PoS tagging, which does not attempt to establish the
semantics of a token.
Broadly speaking, PoS tagging can be either supervised or unsupervised, and either
statistical or rule-based (although models which use a combination of approaches exist).
Supervised tagging uses pre-tagged linguistic data as a training set to train the
tagger; unsupervised tagging uses an untagged training set [Clark and Lappin, 2009]. The earliest PoS taggers
were rule-based, using disambiguation rules written by hand. These rules may take
the
form of finite-state automata based on regular expressions, which accept or reject
potential sentence readings, or they may encode context-patterns and select or reject
PoS analyses based on a token’s context frame [Voutilainen 2003, DeRose 1988].
Later development of rule-based tagging notably resulted in the constraint-grammar
formalism, which allows detailed construction of fine-grained rules, taking into account
short- and long-range context of a token as well as its structural relations with
other
tokens [Bick and Didriksen, 2015]. Both
supervised and unsupervised rule-based tagging is possible, the latter having been
most
famously used by Eric Brill, using transformation-based error-driven learning to derive
appropriate rules [Brill 1995]. Statistical PoS
tagging (also sometimes called probabilistic or
stochastic) disambiguates by using the likelihood of occurrence of
a particular token with a proposed PoS tag in the immediate context of its surrounding
tokens, often using (Hidden) Markov Models. This likelihood may be statistically
computed from either pre-tagged or untagged training sets, using a variety of different
approaches [Abney 2007, Merialdo 1991].
It is evident that PoS tagging is a markup problem in a very trivial sense. The
process of annotating units in a text is precisely what markup is, after all. However,
what I mean by calling PoS tagging “a markup problem” is not simply that PoS tagging
is markup. What I want to investigate here is how the theoretical
problems that have been identified in the domain of markup can throw light on the
problem of grammatical category disambiguation.
Unless specified otherwise, the linguistic examples in this paper will be adapted
from
the corpus collected for the DERWen PoS tagger, which is an offshoot of my PhD research
into Welsh-English bilingualism. My dissertation focuses specifically on the presence
of
English-origin items in Welsh discourse, and considers whether it is necessary or
possible to distinguish borrowings (defined as words which have been adapted and adopted
into the Welsh lexicon) from code-switches (words which belong exclusively to the
English lexicon, and indicate that the speaker is, in some sense, switching between
the
two languages). DERWen is an attempt to produce a tagger capable of tagging
mixed-language Welsh-English Twitter discourse. It is worth explaining briefly the
particular problems posed by this kind of language, in order to provide context for
the
discussion that follows.
“Hwn yn textbook styff”: The nature of mixed Welsh-English social-media data
The data to be analysed by DERWen is around a million words taken from Twitter. The
tweets were selected using Welsh keyword searching, and cleaned to remove corporate
accounts, obvious quotations (lines from certain famous Welsh songs are extremely
popular on Twitter whenever the Welsh men’s rugby team plays an international), and
false positives. Since the search criteria only used very common Welsh words as search
terms, there was no attempt to control how many English-origin items would appear
in the
corpus.
Before social media provided the potential to access naturalistic, colloquial written
data, large corpora of contemporary (or near-contemporary) language tended to be
composed of published written texts and/or prepared transcripts of spoken discourse.
In
these cases, the standard conventions of written language (such as use of whitespace
and
punctuation) are usually maintained. Data from social media, in contrast, tend to
be
unconventional and unpredictable [Derczynski et
al 2013]. This provides opportunities to gather large samples of colloquial
language which, in many ways, mirrors linguistic characteristics of speech (such as
code-switching). However, it also means that NLP tasks become much more difficult
[Owoputi et al. 2013]. NLP tasks often rely,
at least partially, on pre-built dictionaries of known words with standardized spelling
and on algorithms pre-trained with standard forms of language [Neunerdt et al. 2013]. Non-standard spelling,
omitted punctutation, typos, abbreviations, neologisms, and playful distortions of
language are all common in social media discourse.
Welsh Twitter is no exception to the linguistic messiness of social media, with the
additional complication that it is often messy in two languages, as well as in a third,
hybrid set of lexical items which belong to both languages. Welsh speakers are always
at
least bilingual, with fluency in English almost universal (apart from some members
of
the small Welsh community in Patagonia, who are instead fluent in Spanish). Intensive
lexical borrowing by a sociopolitically subordinate language in close geographic and/or
cultural contact with a dominant language is common (although by no means universal
[Wohlgemuth 2009]), and this is certainly
the case for Welsh and English. Code-switching by bilinguals is also a common
phenomenon, particularly when communicating with others who speak the same language
pair. Although mixing languages in single sentences or clauses is often stigmatised,
there is now substantial agreement that it is a sign of balanced skill in the two
languages [Myers-Scotton 1993]; speakers
who have mastered the linguistic systems of both languages to an equal extent tend
to be
those who code-switch most intensively [Poplack
1980]. Given this, it is no surprise that a Welsh-language Twitter corpus
should feature numerous English-origin items (as illustrated in Figure 1).
Figure 1: English-origin items in Welsh-language tweets
Hmm neb arall famous ar timeline fi.
Hmm nobody else famous on my timeline.
Bois bach ma hwn yn Hell of a ceffyl.
Goodness gracious this is a Hell of a horse.
Such words present one kind of challenge to PoS tagging. However, these words which
retain their original English form are not the only kind of English-origin items to
be
found in the corpus, as seen in Figure 2 and Figure 3. The first of these figures shows English-origin words which
have been adapted to Welsh orthography. Welsh has a fairly shallow orthography,
especially in comparison with English, which means that there is little ambiguity
about
the sound represented by a sequence of written letters. However, the letters used
by
Welsh for a variety of sounds differ from those commonly used in English. For example,
the vowel sound in English “but” can only be spelled with the letter
y in Welsh, while the vowel sound in “boot” is always written
w. The vowel sound in “beat” is the most variable in terms of
possible Welsh spellings: it can be represented by i,
u, or y. As a result of the significant
differences between Welsh and English orthographic conventions, it is very common
for
loanwords into Welsh to change their spelling. Figure 2 shows an established loanword
with a long history in Welsh (busnes / “business”) and three which
appear to be off-the-cuff adaptations of English words (garantîd /
“guaranteed”, findalŵ / “vindaloo”, styff / “stuff”)[1]. All are respelled using Welsh orthography.
Figure 2: English-origin items using Welsh orthography
Sole trader oedd dad pan wnaeth e ddechrau busnes bach.
Dad was a sole trader when he started a small
business.
Garantîd o fod yn boeth — ond dim rhaid i chi gael y findalŵ.
Guaranteed to be hot — but you don’t have to have the
vindaloo.
Hwn yn textbook styff.
This is textbook stuff.
In Figure 3, we see how English-origin words may be adapted
morphologically when used in Welsh discourse, with Welsh plural endings
(grwpiau / “groups”), verbal inflection
(bownsiais / “I bounced”), and initial consonant mutation
(chapsiwn / “caption”).
Figure 3: English-origin items with Welsh morphology
Roedd gobaith y byddai’r grwpiau yn parhau.
There was hope that the groups would continue.
Bownsiais i ar hyd y ar rhedfa.
I bounced along the runway.
Dim ond llun a chapsiwn hir.
Only a picture with a long caption.
This kind of language mixing makes PoS tagging harder, both in terms of the
identification of word forms themselves, and in terms of the data modelling that
underpins the tagging process.
Putting somethings into computers: an overview of three key
discussions in markup theory
Texts cannot be put into computers. — Michael Sperberg-McQueen
A full survey of markup theory would be impossible in the space available here. I
will
therefore only attempt a brief overview of a few foundational theoretical discussions
that seem to me particularly relevant to PoS tagging.
Subjectivity and objectivity in markup vocabularies
Markup is, of course, always a layer (or layers) of information added to
something. The nature of that something has been a matter of
discussion for a number of theorists. For DeRose et al. (1990) and others, content
elements constitute a document; if the content elements change, the document is no
longer the same. Changing the markup, in contrast, may change how the document is
interpreted, how it can be stored or shared, and what use can be made of its
content; but regardless of such changes, the content — and therefore the document
itself — remains the same [DeRose et al.
1990]. It is important to consider here Sperberg-McQueen’s (1991)
assertion that the document is not the text: the text is an abstraction, which is
realized in one or more physical (analogue or digital) forms. A representation of
a
text is, in Sperberg-McQueen’s view, never impartial; it results from and is shaped
by the creator’s inevitable biases and judgements [Sperberg-McQueen 1991]. Combining these two
perspectives leads to the conclusion that a marked-up document is a palimpsest
formed of three layers: the text itself; the text representation; and the markup.
Each of these layers introduces uncertainty because each is the result of human
cognitive processes, and human cognition is nothing if not unreliable.
A central task of a well-organized markup project is the preparation of a data
model, represented by some kind of schema. Klein and Hirscheim (1987) describe a
schema as the representation of a “Universe of Discourse”: some subset of existing
objects and structures. The authors seek to unpack the sense in which these objects
and structures “exist”, by considering how data modelling approach both the ontology
and epistemology of the universe of discourse. They argue that the ontology may be
approached from one of two philosophical standpoints: realism or nominalism.
Realists see the universe of discourse as a representation of some immutable,
objective set of objects and structures, which have empirical existence prior to the
creation of the schema. Nominalists, in contrast, see reality as a subjective
construct, whose representation in a schema is guided by the creator’s sociocultural
assumptions and linguistic background [Klein
and Hirschheim 1987]. Sperberg-McQueen's assertion of the partiality of
text representations aligns with this nominalist approach to markup, leading to the
insight that both the text representation and the markup schema are (in different
ways) partial or biased renderings of the text abstraction.
The epistemology of the universe of discourse, that is our understanding of what
we know about it and how we know it, may also be approached in one of two ways. A
positivist approach explains observable phenomena by identifying causal
relationships, and selecting the causal model that best fits those phenomena.
Meanwhile, an interpretivist approach asserts that a causal model is inappropriate
for understanding phenomena mediated through human action. The data modeller cannot
avoid using socially conditioned pre-understanding of the subject, and so can only
understand from a subjective point of view, not from some objective, outsider’s
standpoint. The tendency is for ontological and epistemological approaches to align
in only one configuration, creating an objective (realist-positivist) paradigm on
the one hand, and a subjective (nominalist-interpretivist) paradigm on the other
[Klein and Hirschheim 1987]. We
will see later how these paradigms can help us to think about the construction and
application of PoS tagsets.
Markup as a theory of the text
Sperberg-McQueen imagines the markup scheme as a theory of the text for which it
is intended. Markup schemes provide a particular view of a text, and shape what we
are likely to do with that text by making certain tasks easier to conceive and
perform than others [Sperberg-McQueen
1991]. Maximizing reusability of texts in a variety of ways is (or should
be) a key aim of PoS tagging for corpus annotation, in particular, since corpus
creations tends to be expensive in time, effort, and money [Kahrel et al. 1997]. This aim is perhaps best
served by a declarative markup scheme, in which we represent what the text is, not
how it should be processed [Sperberg-McQueen
1994]. When the markup project takes as its object not the text
abstraction but a specific text representation, however, it may be necessary for the
markup scheme to make a distinction between the essence of the text and how it
should be represented. This distinction may be conceptualized as that between the
markup-object’s deep structure and its surface
structure [Ide and Véronis
1995]. If the aim of the markup scheme is to allow creation of a
facsimile of a particular text representation, then it will necessarily be to some
extent procedural. It will also encode what Coombs et al. (1987) call
presentational markup: the kind of markup which includes line
breaks and page numbers, and which is conventionally used for physically printed
text [Coombs et al. 1987]. These are not
elements that markup would generally aim to capture since, to repeat
Sperberg-McQueen’s maxim, “the text is not the same as the page” [Sperberg-McQueen 1994]. Of course, one way
of reconciling facsimile markup schemas with this maxim is to conceive of the
text-representation in question as a new text abstraction, different from the
abstraction that generated the representation originally. The markup scheme is
therefore a theory of the text-representation-as-text-abstraction, and not of the
original text abstraction.
The problem of facsimile-markup schemes is illuminated by Birnbaum and Mundie
(1999) who, like Ide and Véronis [Ide and Véronis
1995], consider markup schemata created for dictionaries [Birnbaum and Mundie 1999]. While the
abstract text of a dictionary — its deep structure — is evidently of significant
interest to many users, there are equally those for whom the historical record of
the dictionary’s physical form — its surface structure — are important information.
That is to say, we may want to consult a dictionary’s text representation in order
to access the abstract information contained in it (the definition or spelling of
a
word, or its date of first attestation, for example); but we may also want to know
exactly how the Oxford English Dictionary (OED)’s entry for a
word looked on the page when it first appeared in print. Alongside Ide and Véronis'
deep/surface distinction, we might here consider Piez’ (2001) distinction between
proleptic and metaleptic markup. The
former looks to the document’s future, and the uses to which it may be put; the
latter looks backwards, towards the pre-existing features of the data’s structure
[Piez 2001]. Proleptic markup facilitates
future production and interchange, because it is focused primarily on what we might
want to do with the data. Metaleptic markup facilitates accurate representation of
structures that are derived from the data; it is not interested in how the data may
be used, but in what it seeks to describe [Piez
2001]. Whereas preparing a facsimile representation of the OED is clearly
metaleptic, representing the OED’s content so that it can be queried, transformed,
and distributed is proleptic. Piez’ distinction clarifies the important fact that
both types of markup scheme have value and purpose; choosing which one to privilege
may therefore pose difficulties.
Birnbaum and Mundie note that the structure of entries in the OED’s first and
second editions is not always entirely regular. There are rules governing which
elements are obligatory in an entry, and in what order they should appear. However,
it is not entirely uncommon to find that errors have crept in, leading to
incorrectly structured entries. A markup scheme author for such a text must find a
way to resolve this problem: either the scheme must become extremely flexible, to
allow for (in principle) any kind of violation; or the scheme must include what the
authors term an “escape-hatch” structure for deviant data; or the text must be
modified, to conform to the scheme [Birnbaum
and Mundie 1999][2]. These options all allow the marked-up document to be processed
automatically as valid. However, all three also require compromise on the theory of
the text represented by the schema[3]. In the first case (editorial correction), the theory privileges the
idealised text abstraction, and sidelines the text representation where it fails to
conform. The second case (the flexible DTD) theorises the text abstraction as a
collection of loosely-structured information lacking structural specificity, and
thereby fails to recognise that the text abstraction in fact has a strict
intended structure, even if the text representation does not
always convey that structure validly. Acknowledging the intended structure is an
important aspect of representing the meaning of the abstract text: dictionary
entries are presented in such a way as to maximize space and to guide the reader to
an understanding of the entry’s information structure in an efficient and
unambiguous manner. Finally, the third solution (the escape hatch) allows the
representation of divergent data by offering alternative elements whose structure
parallels, but is far looser than, the canonically-structured elements. The theory
of the text implied here is that it is validly composed of strictly-structured data,
interspersed with the occasional passage of deliberately unstructured data. Even if
the escape-hatch elements are named in such a way as to make clear that the
structures they contain are irregular or erroneous, this identification of error is
purely semantic [Birnbaum and Mundie
1999]. It elides the fact that such entries are not
syntactically valid, according to the original text
abstraction, even if they are validly a part of the text representation's
abstraction.
The solution offered by Birnbaum and Mundie is to theorize the document as having
(at least) two structural layers: the idealised one and the concrete one. These
layers, they argue, are analogous to the distinction in descriptive linguistics
between competence (the idealized abilities of a language user,
including knowledge of linguistic rules) and performance (how
the user actually uses the language, including errors, slips of the tongue, etc.).
They propose that the relationship between these two layers may be represented as
transformation rules. The valid, corrected version of the text is maintained for
convenience, alongside a set of transformation rules which can be used to derive the
invalid “facsimile” form of the text-representation [Birnbaum and Mundie 1999]. This ingenious
solution theorises the text as an abstraction, and the text-representation as a
transformation of that abstraction into a concrete instance, which makes some
attempt to represent the structure of the abstraction consistently, but may
ultimately fail to do so. Nevertheless, even an imperfect text representation
becomes its own text abstraction when it is the object of an attempt to mark it up.
The text behind a text-representation is therefore theorised, not as a single
abstraction, but as two: the text abstraction that generated the representation; and
the text abstraction that the representation generates. This theoretical approach
to
anomalous data will become important later, as we consider the abilities of PoS
tagsets to theorise non-standard and mixed language varieties.
The semantics of a markup vocabulary
Renear et al. (2002, 2003) wrestle with the problem of markup vocabulary
semantics. Whereas the syntax of a markup vocabulary can be specified in a schema
document, there is no comparable way of specifying the semantics of a vocabulary.
As
a result, users have to conjecture what the vocabulary designer may have intended,
or — at best — rely on prose documentation, which is not formally verifiable and is
prone to human error [Renear et al.
2002, Renear et al. 2002].
The disconnection between designers and users, between vocabulary and instance,
leads to the use of tags to “mean” things that were unintended by the modellers
[Piez 2001]. Taken to an extreme, it might
mean that two instances using the “same” vocabulary are not, in fact, representing
data in comparable or compatible ways. Renear et al. propose that some means of
specifying the semantics intended by a markup vocabulary would reduce ambiguity and
tag abuse, as well as making processing easier to automate. A formal specification
of a vocabulary’s semantics is, after all, the only way for a non-human interpreter
to “understand”, for example, that a <title> element child of a <head>
is the title of the <document>, but that a <title> child of a
<chapter> is the title of its parent element, and that both of these are
different from the <title> in a bibliographic reference [Renear et al. 2002]. Other types of information
that, according to the authors, can only be understood semantically include class
relationships between elements and attributes, the propagation of attributes and
their values from parent to child elements, and ontological variation in the
reference of an element. Ontological variation is the problem that a single element
may in fact be a conflation of a number of different referents. A <sentence>
element, for example, may refer to the sentence as an abstraction, to the
proposition expressed by the sentence, and to the concrete character data used to
render the sentence. Each of these referent of the element might be addressed by
different attributes, which (in a syntactic analysis) would be interpreted simply
as
attributes of the same element [Renear et al.
2002].
Tennison (2002) discusses the importance of combining both syntactic and semantic
understanding of markup in attempting to automate transformations between different
markup vocabularies. An effective transformation application needs to be able to
measure the distance between languages, and to determine from that information that
the best way to transform vocabulary A into vocabulary B is to perform an
intermediate transformation into vocabulary C or D or E [Tennison 2002]. Tennison proposes that a
potentially useful measure of the distance between vocabularies is how much
information is lost and/or gained in the transformation from one to the other.
Vocabularies show assymetry in terms of which information they choose to represent,
to what level of specificity, and with what kinds of labels or structures. In a
similar vein, Sperberg-McQueen (2011) is concerned with how to measure the success
of data format conversion, in the context of digital preservation. He explores the
case of conversion between markup vocabularies to outline a model of “noise-free
lossless conversion”. According to this model (drawing on prior work by e.g.
[Renear et al. 2002], [Renear et al. 2003], [Marcoux 2006]) the meaning of a document’s markup
is the sum of the inferences licensed by that markup (that is, the things that are
accepted as being true as a result of the markup). Noise-free lossless conversion
between vocabularies can be said to have occurred if the output format licenses the
same (and only the same) inferences as the input does. Lossless conversion requires
that all the input inferences be present in the output; noise-free conversion
requires that no inferences be present in the output that were not present in the
input [Sperberg-McQueen 2011].
The problems of semantic and syntactic differences in tagsets and of
(in)compatibility between descriptive models for different languages will be the
subject of much of what follows in this paper.
The language of lions: whose universe of discourse is represented in PoS
tagging?
Wenn ein Löwe sprechen könnte, wir könnten ihn nicht verstehen. — Ludwig
Wittgenstein
Whether relying on pre-tagged natural-language data, dictionaries, or even on untagged
data, PoS-tagging approaches generally have in common that they presuppose a tagset.
The
process of assigning a PoS tag, or of disambiguating assigned tags, is successful
when
it selects a PoS tag that is (at worst, only plausibly) correct according to a human
linguistic analysis, and belongs to a PoS category that occurs in the language of
the
text being tagged[4]. Even unsupervised models need to have some knowledge of the categories to
be assigned to the tokens in output: this may not immediately seem to be a particularly
thorny issue. However, although ten word classes[5] are traditionally accepted, their ability to account for the nuances of
grammatical description, or for the grammar of all human languages, is not clear
[Haspelmath 2009]. Furthermore, once we go
beyond these basic categories and consider the possibilities for representing
subcategories in the tagset, we begin to see significant differences in the conception
of the lexico-semantic inventory of a language. As an illustration of this issue,
let us
consider the case of the Welsh grammatical category traditionally known as the
berfenw (“verbnoun” or “verbal noun”).
The Welsh berfenw: a case study in linguistic tag
abuse?
According to many, if not most, grammars of Welsh, the berfenw is a non-finite
verb. It is used in combination with finite verbs to express past, future, and
present time. It also has other functions, which are generally translated into
English using a present participle. Figure 4 gives examples of
some of the major uses of the berfenw (an italicised term in the second line of each
example indicates a berfenw in the original text).
Figure 4: The Welsh berfenw
(4a) Wnes i joio!
(did I enjoy)
I really enjoyed!.
(4b) Ma hwn yn mynd i swnio’n hurt.
(is this in go to sound-in
ridiculous.)
This is going to sound ridiculous
(4c) Efallai bydd hwn yn perswadio fi.
(maybe will-be this in persuade me)
Maybe this will persuade me.
(4d) Dwi heb neud braidd dim ers misoedd.
(I-am without do almost nothing since months)
I’ve not done anything for months.
(4e) Dim y ffigyrau gwylio yw’r broblem.
(not the figures view are-the problem)
The viewing figures aren’t the problem.
(4f) rwan dim ond normaleiddio sydd angen
(now nothing but normalize is need)
Now it’s only normalizing [or “normalization”] that’s
needed.
The partcipation of the berfenw in constructions which, in English, are
accomplished with verbs (4a–4d) as well as the ability to translate other uses with
English forms derived from verbs, such as participial adjectives (4e) and gerunds
(4f), contributes to the understanding of the form as a kind of verb. However, the
“enw” component of berfenw means “noun”, and reflects the fact
that the berfenw is very commonly used as in example 4e. Furthermore, decomposing
these constructions with the berfenw shows that, in every case, it is structurally
better understood as a noun than as a verb. Figure 5
repeats the previous set of examples, but this time with an unidiomatic English
translation that reflects the actual grammatical structure of the original with
respect to the function of the berfenw.
Figure 5: The Welsh berfenw
(5a) Wnes i joio!
I did enjoyment!
(5b) Ma hwn yn mynd i swnio’n hurt.
This is at going towards sounding in
ridiculous.
(5c) Efallai bydd hwn yn perswadio fi.
Maybe this will be at my persuading.
(5d) Dwi heb neud braidd dim ers misoedd.
I’m without the doing of almost anything for
months.
(5e) Dim y ffigyrau gwylio yw’r broblem.
The figures of viewing aren’t the problem.
(5f) Rwan dim ond normaleiddio sydd angen
Now only normalizing is needed.
The constructions in a–d are what is known as “light-verb” constructions, in which
the main verb of the sentence (usually a verb meaning something like
be or do) carries little semantic content.
The semantics of the event or action are instead carried by another element. This
is
not a usual way of expressing such semantics in most varieties of English. However,
such constructions are common in the Celtic languages; echoes of them may be heard
in a quintessentially Irish-English way of talking about something that has been
done (a construction sometimes known as the after perfect:
“it’s after upsetting him” (meaning “it has upset him”); “I’m after being in at the
mart” (meaning “I’ve just been in at the mart”) [Carey
2016]. It is be alone which performs the grammatical
function of the verb in these sentences; the semantic function of expressing the
action that has occurred is performed by the gerund (i.e. a noun which is derived
from a verb). Nonetheless, the berfenw-type forms are predominantly labelled as
verbs in work on all the Celtic languages [Jeffers
1978], [Li 2004]. Despite
persuasive analysis by [Willis 1988], who
argues for classifying the berfenw exclusively as a noun, it is still almost always
called a verb in modern Welsh linguistics.
The early linguistics of vernacular Indo-European languages was heavily influenced
by the linguistics of Latin and Greek, with categories from these languages either
carried over wholesale, or adapted to the needs of the vernaculars. While undeniably
an artificial constriction of language description, this nonetheless also provided
a
coherent framework in which knowledge of the vernaculars could be codified and
exchanged [Raby and Andrieu 2018]. A
potential problem with describing a language with grammatical categories derived
from different languages is that, if one knows that there are “nouns” and “verbs”,
one approaches linguistic data by trying to find the nouns and the verbs. It is
difficult, if not impossible, to conceptualise the structure of a new language
without reference to alreadyknown linguistic terms and concepts. This, I would
argue, is why the Welsh berfenw is called a “verb”: linguistics, like history, is
written by the victors; and English established itself as victor over Welsh early
on. Welsh linguistics has, until very recently, essentially been the province of
people who received their formal education in some other language. From the early
history of public education in the British Isles through the latter half of the
twentieth century, formally educated Welsh people received their education through
the medium of English. English was considered the best route to educational and
social achievement, and the point of entry into modernity, even for children who
spoke nothing but Welsh at home, and whose communities were primarily or entirely
Welsh-speaking [A. Davies 2003]. It is
only in the last half century that significant numbers of children have been able
to
receive an education through the medium of Welsh. Curricula and learning materials,
however, have generally been centrally mandated by the English government and
adapted or translated for the Welsh-language context. As a result, there is no
Welsh-first tradition of education or of scholarship in linguistics or the sciences
that might challenge the use of English-derived linguistic description for
Welsh.
Traditional English grammatical categories have no place for a noun that carries
the semantic content of a verb, other than calling it a non-finite verb form
performing the functions of a noun. Klein and Hirscheim’s distinction between
entity-based and rule-based modelling [Klein
and Hirschheim 1987] helps us to focus on this issue as a problem of data
modelling. Are the members of a PoS tagset conceived as entities or as the sum of
a
set of rules? That is, does the presence of a tag <non-finite-verb> in the
tagset indicate a belief that the noun has an objective existence as a linguistic
entity, and that the purpose of tagging is to find the tokens that “are” non-finite
verbs? Or does it express belief in the existence of a set of conventionalized
linguistic rules, which justify tagging a token as a non-finite verb if it satisfies
those rules? The former approach adheres to an objectivist conception of the
universe of discourse represented by the tagset, and the latter to a subjectivist
conception. The tagging of the Welsh berfenw as a non-finite verb requires a
conception of “verb” and “noun” that ignores the grammatical rules used to identify
these categories in English and other languages, and instead insists that the Welsh
non-finite verb exists, despite all the evidence that the berfenw behaves like a noun[6]. The berfenw-as-verb is an entity. The berfenw-as-noun, in contrast, is
the product of a rule-based construction of the universe of discourse, in which the
approach when tagging tokens is not “where are the non-finite verbs?”, but “the tag
<non-finite-verb> will be used for any token which satisifes the conventional
criteria by which we identify tokens as non-finite verbs”. The tagset, although
pre-created in the sense that the rules for named categories are known, is not
pre-assumed. It is possible for words that are traditionally called “verbs”, or
which perform the semantic functions fulfilled in other languages by verbs, to be
tagged as nouns because they follow the rules for nouns.
Encoding information and licensing inferences about English pronouns
A significant problem in all kinds of linguistic annotation of data is that
different projects develop or adapt markup vocabularies which differ more or less
substantially from those used by other projects or for other languages. The problem
described above, where there is disagreement about the appropriate category to
assign to a token, is paralleled by the problem of disagreement on how to model
categories upon which there is agreement. Even on the level of
supposedly unifying ontologies for linguistic annotation, at least three major
projects exist, each of which takes a different approach and draws on different
pools of expertise [Chiarcos and Sukhareva
2015]. For English, a well-resourced language with a wealth of scholarly
discussion informing NLP, major tagsets vary in size from the Penn
Treebank tagset, with 36 PoS tags [Taylor et al. 2003], through the Oxford English
Corpus tagset (101 PoS tags) [www.sketchengine.eu], to the
CLAWS tagset (at least 150 tags; the exact
number dependent on the tagset version) [CLAWS]. While these tagsets do, at least, broadly agree with each other
on what the parts of speech are (there are no “verbnoun”-type problems here), they
nonetheless disagree on how to categorize them, to what level of detail, and with
what labels — in short, they disagree in the inferences that the markup licenses
[Sperberg-McQueen 2011].
The Penn Treebank tagset (hereafter
Penn), for example, conflates prepositions and subordinating
conjunctions: the token “for” would therefore be given the same tag, <IN>, in
the sentences “It was for my mother” and “She went, for she had no reason not to”.
Subject and object pronouns are also tagged with a single tag in
Penn (<PRP>), and distinguished from possessive pronouns
(<PRP$>) whereas the Oxford English Corpus tagset
(hereafter OEC) distinguishes objective personal or possessive
pronouns (tagged <OPP>) from subjective personal or possessive pronouns
(<SPP>). Meanwhile, the latest CLAWS
tagset, version C7, distinguishes the possessive pronouns (<PPGE>) from the
(non-reflexive) personal pronouns, which are then subdivided into ten categories.
These distinguish the neuter it as either subject or object
(<PPH1>) and the second-person singular/plural subject/object pronoun
you (<PPY>) from the third-person and first-person
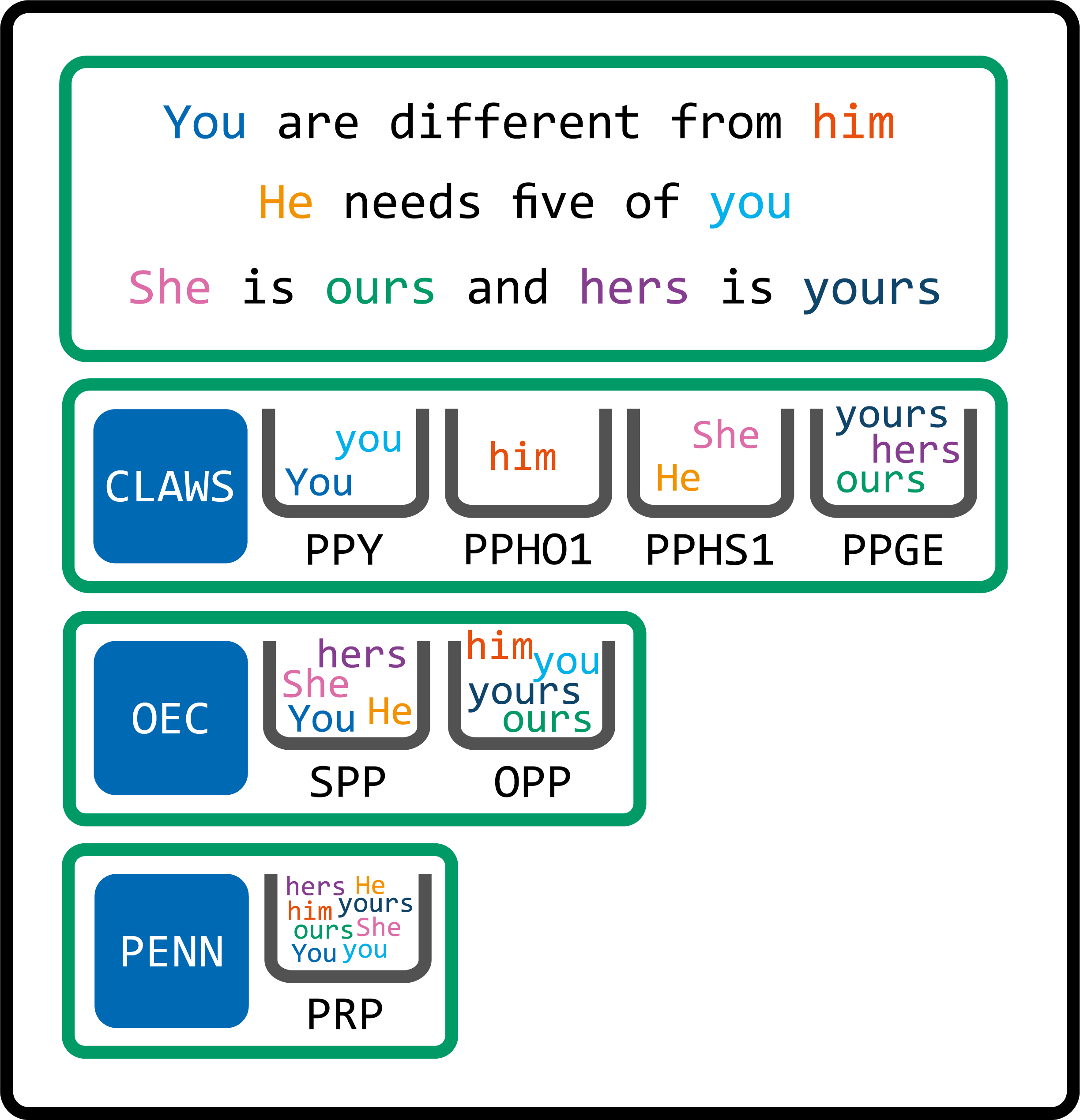
singular and plural subject and object pronouns. Figure 6 shows
how the three tagsets categorize eight pronouns as used in three example
sentences.
Figure 6: Tagset categorization
As we can see, the three tagsets categorise the tokens differently.
CLAWS provides the most fine-grained analysis. However, it is
not capable of distinguishing the two instances of you.
OEC, which is generally much less informative, does encode the
information about the token’s syntactic role as subject or object that provides one
way to distinguish the you tokens. The main types of
information that could be encoded about these pronouns are
shown in Figure 7.
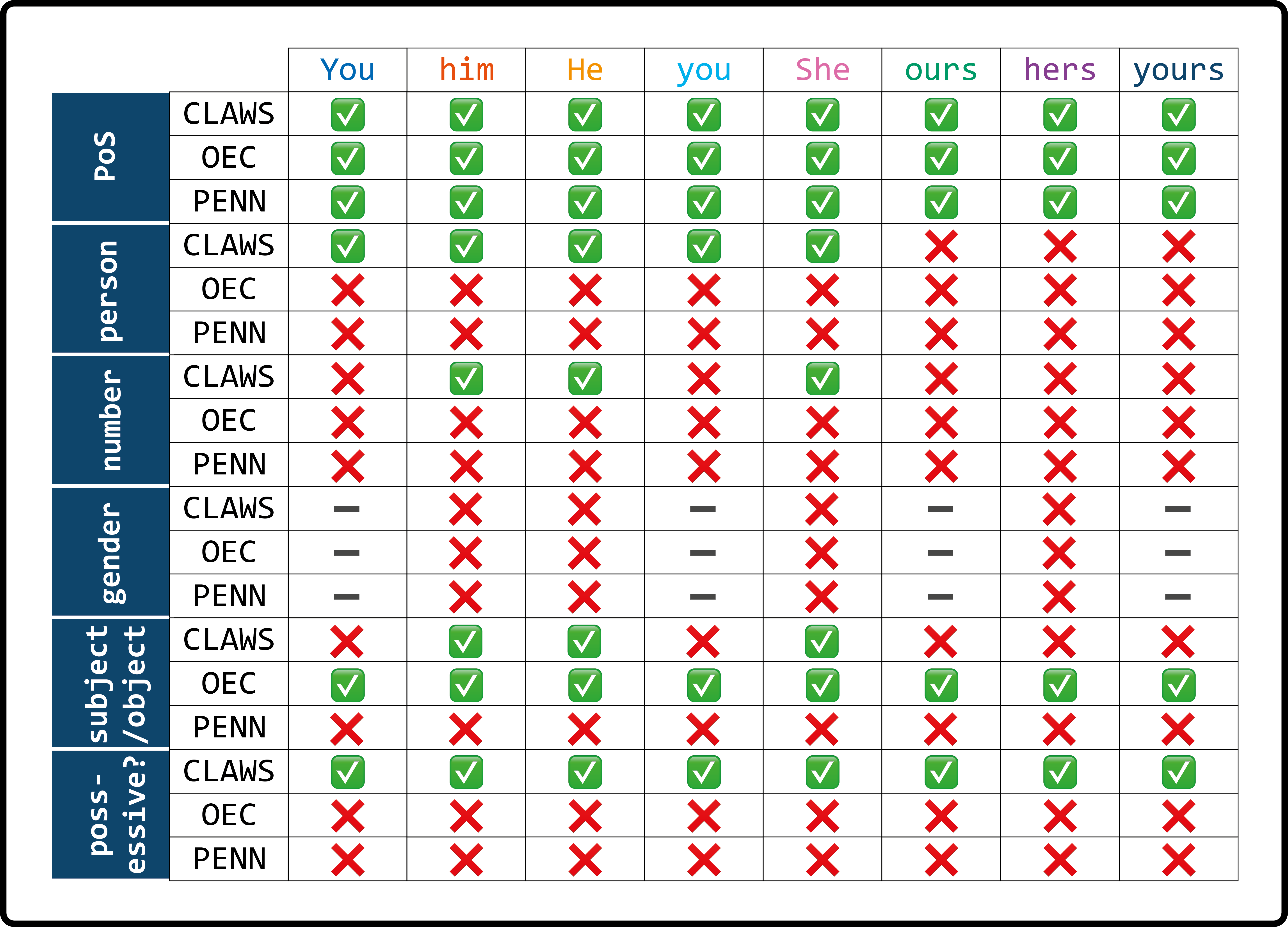
Figure 7: Information about encoded pronouns
The encoding scheme is a theory of the text it encodes; electronic representations
embody ideas of what is important in a text [Sperberg-McQueen 1991]. As we would expect, all of the tagsets encode
the various pronouns’ basic PoS; whether they conceive of the eight tokens as
belonging to a single category (Penn) or split them into two
categories (OEC) or four, (CLAWS), the
labels for those categories all indicate that the token is unambiguously a pronoun.
In contrast, none of the tagsets encodes information about the grammatical gender
of
gendered pronouns. (Ungendered pronouns are indicated by a dash in the relevant
table cells). CLAWS is the only tagset that encodes grammatical
number, but only does so for those tokens which have a different form in singular
and plural; the same is true for its encoding of the subject/object distinction.
This means that it is not capable of capturing number or subject/object information
about “you” tokens. It does, however, distinguish between the personal pronouns
“you” and the possessive pronoun “yours”, unlike either of the others.
Penn is the only tagset that fails to distinguish entirely
between pronouns used as subject or object. The only distinction asserted by the
tagset, in fact, is that these pronouns are distinct from "adjectival possessive"
pronouns (tagged <PRP$>) [Santorini 1990], such as
his and my. These forms, I would argue,
are not pronouns at all, but determiners. Penn therefore gives
no extra categorial information about personal pronouns, except that they
are personal pronouns and not possessive determiners.
The set of potentially interesting features in a text is infinite [Sperberg-McQueen 1991], and which are
deemed worthy of representation in a markup scheme will vary according to many
factors, including whose interest provides the defining context
of “interesting”. There will often be a tension between general applicability and
precision in tagset creation [Ide and Véronis
1995]. A focus on what is lost when translating between markup
vocabularies, as recommended by both Sperberg-McQueen and Tennison (and discussed
above), highlights the problems of the three tagets in focus here, as regards the
precision with which they are able to encode linguistic data. If we were to mark up
the three sentences shown in Figure 1 according to either Penn
or OEC, conversion to CLAWS would be
impossible, since neither of the smaller tagsets encodes enough information to
select CLAWS tags correctly. Conversion from
Penn to OEC, is also impossible, since
Penn does not encode the subject/object distinction encoded by
OEC. Meanwhile, conversion from CLAWS to
OEC would not only sacrifice the more granular information
encoded by CLAWS, it would also be made impossible by the fact
that OEC needs to know whether the very first token is a
subject or an object pronoun, and CLAWS does not encode this
information. The only lossless conversion possible between these tagsets (assuming
that the conversion is being done automatically, without reanalysis of the text
content in order to access information missing in the original encoding) is from
either CLAWS or OEC to
Penn, and these are only possible because
Penn would throw away all of the extra information about these
pronouns encoded by the other two tagsets. The rationale behind the decision not to
encode this information was an attempt to reduce redundancy, modifying the tagset
used previously for the Brown Corpus, and conflating tags if the differences they
encoded were recoverable either from the character data they contained or from the
parse tree in the alternative, parsed version of the Penn Treebank corpus [Taylor et al. 2003]. The distinction between the
two “you” tokens in Figure 1 would require the latter approach, while distinctions
between “she”, “him”, “them”, and “theirs” on the basis of number, person, gender,
subject/object role, and possessive/personal distinction can all be retrieved from
the actual word forms in question (e.g. “him” can only be a singular, third person,
masculine, object personal pronoun).
It is perhaps not terribly surprising that a tagset developed for a specific
project has idiosyncrasies that tie it to the needs of that project. For a language
with a fairly limited inventory of personal pronouns, there is some sense in not
multiplying categories too far. Penn would be entirely
inadequate for representing Welsh, which has a significantly more complex inventory
of personal pronouns. Penn’s theory of the text (the text, in
this case, being the linguistic data to which the tagset is applied) is oddly
antipathetic to the usual purposes of descriptive markup or of PoS tagging. Markup
is intended to license inferences [Sperberg-McQueen 2011], to codify information that is not made explicit
by the text content. Linguistic information is, of course, recoverable from the text
content; that, after all, is what PoS tagging does. But the tagging process should
remove the need for prospective users of the text to repeat the analysis themselves.
Penn is a particularly proleptic tagset, in Piez’ terms. It
assumes that the marked-up text will only be used by those who additionally have
access to the Penn Treebank parsed corpus, and who are able to do the work of
enriching the sparse PoS tag for the pronouns analysed above using both information
from that corpus and from the text data itself. As much as a theory of the text,
Penn is a theory of the text representation’s end-uses and
end-users.
Weirding language: PoS tagging of mixed-language data
“Verbing weirds language.” — Calvin and Hobbes
Standardized language models and linguistic hegemony
The argument that Penn’s personal/possessive pronoun category
avoids the proliferation of individual tags which are only ever used for a single
wordform seems at first to have some legitimacy on its own terms, at least. After
all, as a glance at the CLAWS tagset confirms, a more granular
tagset which distinguishes categories such as person, number, etc. might end up with
individual tags for the first person singular subjective pronoun (“I”) and its
objective counterpart (“me”), and for their plural counterparts
(“we”, “us”), and so on. The intended text to be marked up by the tagset, according
to this argument, must be theorized as containing entirely regular language in a
standardized dialect of English, such as British Standard English or General
American. Other dialects often use the pronouns differently, or use different
pronouns altogether. I is used as an objective pronoun in some
forms of Caribbean English, and I and I is used by some
Rastafarian speakers as a singular or plural, subjective or objective first-person
form. Us is used in some dialects as a singular first-person
pronoun, and in others as the plural subjective form rather than the objective.
Forms such as we-all and we-uns are used
as first person plurals in some U.S. dialects, while myself (in
standard usage, a reflexive first-person pronoun) is used as a subjective and
objective first-person singular pronoun especially in Irish English. (All examples
are taken from [OED Online].) Not only does
Penn strain our understanding of how markup should license
inferences about the text, it also conceives of the abstract text to which the
markup might be applied as an instance of English as the authorities say it
should be used, not as it actually is used.
The DERWen PoS tagger began with open-source code created for the CorCenCC modern
Welsh corpus project [Neale et al.
2018], which was written with monolingual Welsh texts in mind. DERWen’s
first step was to add an English lexicon alongside CorCenCC’s Welsh one, for initial
lookup and naive assignment of PoS categories to be fed into the constraint grammar
for disambiguation. The next step was to adapt the tokenizer with rules for English
tokenization. A problem which became obvious early on was that both the tokenizer
and the naive PoS tagger were making assumptions based on a standardized model of
language which was inadequate for unnormalized Twitter data. In English, the tokens
its and it’s, for example, pose a
significant problem. The tokenizer splits it’s into the pronoun
it and the clitic ’s, whereas it does not
split its, which is assumed to be the neuter form of the
possessive pronoun. Yet, predictably, these two forms are often used in ways that
are inconsistent with the standardized English model. In Welsh, colloquial written
language often features forms which compound a series of tokens, often a verb,
pronoun, and (optionally) a negative modifier (e.g. allaim,
which would canonically be written as “alla’ i ddim” (literally “can I not”, meaning
“I can’t”). These forms are entirely unstandardized and, although to some extent
predictable, are not easy to identify reliably during tokenization. Errors at the
tokenization stage, of course, leave a text representation which is impossible to
PoS tag correctly. I have not yet settled on a solution for these forms. If we think
of the abstract text as a series of tokens, represented by the written data, we
might theorize the use of compounds and other structures (deliberate or erroneous)
which obscure the token boundaries in unexpected ways as a kind of anomalous
representation of the text abstraction, following Birnbaum and Mundie (1999). It
would then be possible to develop something like the “escape hatch” structure they
describe from the TEI’s tagset for dictionaries, perhaps by adding a special tag for
otherwise unknown tokens which match the common morphological features of the
compound forms, which could be used to “warn” the constraint grammar that a token
may represent a series of PoS categories rather than a single one. However,
theorizing these written forms as anomalous risks implying that there is a
non-anomalous way of representing the text abstraction, and
that it is represented by the standardized written form(s) of the language, which
is
predictable and can therefore usually be formalized in a way that is automatically
tokenizable. The prescriptivist implications of such a theorization are somewhat at
odds with the aims and principles of descriptive linguistics [7].
One lesson that can be learned from any attempt to perform PoS tagging on
colloquial language is that it is never safe to assume that any token is limited as
to its PoS classification. Certainly, there are some words that are exceedingly
likely to belong to the category assigned them in a standard dictionary of the
language in question. But humans are endlessly inventive and creative with language
(even if prescriptivists might like to pretend that non-standard language use is in
some meaningful, abstract sense “incorrect”, rather than simply following rules that
are not those of the dominant linguistic authorities). One recent example is the
word because, which was quite clearly a subordinating
conjunction (with the odd, rare use as a noun or an adverb) until fairly recently,
and yet is now regularly used as a preposition, as reflected in the title of
McCulloch’s (2019) groundbreaking study of internet linguistics, Because
Internet. As discussed above, data from sources such as Twitter can be
particularly noisy and messy, both intentionally and unintentionally. A markup
scheme for even monolingual Twitter data must start with a theory of the text
abstraction that conceives of it as a far looser, more playful, more error-prone,
and far more pluricentric system than any standardized model of a language can
encompass. The safest approach to tagging any such data must be to assume that
at least the linguistic categories and distinctions which are
known to exist in standardized forms of the language will be present in the data,
that they will all probably be of some linguistic interest, and that they may be
instantiated in unexpected ways using unpredictable tokens.
Proleptic conclusions: looking towards the future
As the discussion of the berfenw above suggests, it is necessary to be careful
when mixing tagsets originally intended for different languages, because it may be
that similarities in semantics between two tagsets (e.g. a “verb” category) obscures
differences in the underlying conception of what that category should contain.
Nonetheless, it is also important to generate a tagset that can be used for both
languages, in order to avoid implying a neat kind of linguistic separation that does
not exist in bilingual (or multilingual) reality. The universe of discourse of the
bilingual language user is not simply the union of the universes of discourse of
monolinguals in each of the relevant languages. Rather, it is a complex system which
draws on both languages but has features which belong to neither. The English-origin
tokens with Welsh orthography and/or morphology discussed above are one example of
such a feature, although there is slippage between the innovative forms here and the
conventionalized forms of borrowings from English. (Since there is no such thing as
a monolingual Welsh speaker, it is impossible to say for certain that a feature used
in mixed Welsh-English data is entirely missing from Welsh.) Approaches to PoS
tagging for mixed data have included a number which tagged the text in two passes,
using monolingual taggers for the two languages involved, with a fairly high degree
of accuracy [Jamatia et al. 2015].
This is a theoretically very unsatisfactory approach, and on a practical level seems
likely to fail on forms that belong to the bilingual language system rather than to
either of the monolingual systems.
There have been attempts to create “universal”, or at least multilingual, PoS
tagsets. One of the most promising currently is that of the [Universal Dependencies] (UD) project. The
outline of the project given in [Nivre et al.
2016] is extremely encouraging from the perspective of markup theory. The
authors note that the UD project is a merger of a number of separate initiatives,
which suggests an approach that prioritizes interoperability and actively seeks to
integrate previous tagsets rather than simply adding yet another notional
“standard”. They also emphasize the extensibility of their tagset, satisfying
Sperberg-McQueen’s requirement that markup schemes must be extensible, because the
set of features worth marking up in a text and the set of texts to be studied are
both infinite [Sperberg-McQueen
1991] (something which cannot be truer than when the text-as-abstraction
in question is the sum of all possible utterances in any human language, which must
be the notional object of a universal PoS tagset). Moreover, both the paper authors
and the UD website are clear about the theoretical underpinning of UD’s approach to
tokenization (and, therefore, to the creation of the text representation that will
ultimately be marked up by the tagger). This implies their awareness of the
subjective nature of their markup scheme, which — although aiming for universality
in its application to all human language — does not lay claim to objectivity. UD
imagines the text abstraction as consisting of syntactically-defined tokens, more
than one of which may be represented by a single orthographic object (like the Welsh
compounds discussed above).
Conversion of the DERWen PoS tagger to use the UD tagset is at a very early stage.
It currently uses an extended version of the CorCenCC tagger used by the code on
which DERWen is based, with the addition of tags needed for English categories as
well as some Twitter-specific categories (such as emoticons and hashtags).
Nonetheless, the apparent theoretical engagement of UD with the issues of markup
theory that have been explored here (whether grounded in markup theory itself or
not) is encouraging. I hope to be able to report soon on some successful experiments
in using the UD tagset for mixed-language Welsh-English PoS tagging.
References
[Abney2007] Abney, Steven. Semisupervised learning for
computational linguistics. Chapman and Hall/CRC. 2007.
[BickDidriksen2015] Bick, Eckhard, Tino Didriksen. “CG-3—beyond
classical constraint grammar”. pp 31—39. In Proceedings of the 20th Nordic
Conference of Computational Linguistics, NODALIDA 2015. 2015.
[Brill1995] Brill, Eric. “Transformation-based error-driven learning and
natural language processing: A case study in part-of-speech tagging”. pp 543—565.
In
Computational Linguistics. v21. 1995.
[ClarkLappin2010] Clark, Alexander, Shalom Lappin.
Unsupervised learning and grammar induction. Clark, Alexander, C
Fox, Shalom Lappin. The handbook of computational linguistics and natural
language processing. Wiley-Blackwell. 2010.
[Coombsetal1987] Coombs, James H, Allen H Renear, Steven J DeRose. “Markup
systems and the future of scholarly text processing”. pp 933—947. In
Communications of the ACM. v30. 1987. doi:https://doi.org/10.1145/32206.32209.
[ADavies2003] Davies, Alan. The native speaker: Myth and
reality. Multilingual Matters. 2003.
[DeRoseetal1990] DeRose, Steven J, David G Durand, Elli Mylonas, Allen H
Renear. “What is text, really?”. pp 3—26. In Journal of Computing in Higher
Education. v1. 1990. doi:https://doi.org/10.1007/BF02941632.
[DeRose1988] DeRose, Steven J. “Grammatical category disambiguation by
statistical optimization”. pp 31—39. In Computational Linguistics.
v14. 1988.
[Derczynskietal2013] Derczynski, Leon, Alan Ritter, Sam Clark, Kalina
Bontcheva. “Twitter part-of-speech tagging for all: Overcoming sparse and noisy data”.
pp 198—206. In Proceedings of the International Conference: Recent Advances in
Natural Language Processing. 2013.
[Haspelmath2009] Haspelmath, Martin. Lexical borrowing:
concepts and issues. Haspelmath, Martin, Uri Tadmor. Loanwords in
the world’s languages: a comparative handbook. Walter de Gruyter. 2009.
[IdeVeronis1995] Ide, Nancy, Jean Véronis. Encoding
dictionaries. Ide, Nancy, Jean Véronis. Text Encoding
Initiative. Springer. 1995.
[Jeffers1978] Jeffers, Robert J. “Old Irish verbal-nouns”. pp 1—12. In
Ériu. v29. 1978.
[Jamatiaetal2015] Jamatia, Anupam, Björn Gambäck, Amitava Das.
“Part-of-speech tagging for code-mixed English-Hindi Twitter and Facebook chat
messages”. pp 239—248. In Proceedings of the International Conference: Recent
Advances in Natural Language Processing. 2015. doi:https://doi.org/10.13140/RG.2.1.1222.0640.
[Kahreletal1997] Kahrel, Peter, Ruthanna Barnett, Geoffrey Leech.
Towards cross-linguistic standards or guidelines for the annotation of
corpora. Garside, Roger, Geoffrey N Leech, Tony McEnery. Corpus
annotation: linguistic information from computer text corpora. Taylor &
Francis. 1997.
[Leechetal1994] Leech, Geoffrey, Roger Garside, Michael Bryant. “CLAWS4:
the tagging of the British National Corpus”. pp 622—628. In COLING 1994 Volume
1: The 15th International Conference on Computational Linguistics. 1994. doi:https://doi.org/10.3115/991886.991996.
[Li2004] Li, Chao. “On verbal nouns in Celtic languages”. pp 163—194. In
Proceedings of the Harvard Celtic Colloquium. 2004.
[Lynnetal2015] Lynn, Teresa, Kevin Scannell, Eimear Maguire. “Minority
language Twitter: Part-of-speech tagging and analysis of Irish tweets”. pp 1—8. In
Proceedings of the Workshop on Noisy User-generated Text. 2015. doi:https://doi.org/10.18653/v1/W15-4301.
[Marcoux2006] Marcoux, Yves. “A natural-language approach to modeling:
Why is some XML so difficult to write”. In Proceedings of the Extreme Markup
Languages 2006 Conference. 2006.
[Mitkov2003] Mitkov, Ruslan, editor. The Oxford handbook of
computational linguistics. Oxford University Press. 2004.
[Manningetal2009] Manning, Christopher D., Prabhakar Raghavan, Hinrich
Schütze. An introduction to information retrieval. Cambridge
University Press. 2009.
[MyersScotton1993] Myers-Scotton, Carol. Duelling languages:
Grammatical structure in codeswitching. Oxford University Press. 1993.
[Nivreetal2016] Nivre, Joakim, Marie-Catherine De Marneffe, Filip
Ginter, Yoav Goldberg, Jan Hajic, Christopher D Manning, Ryan McDonald, Slav Petrov,
Sampo Pyysalo, Natalia Silveira, Reut Tsarfaty, Daniel Zeman. “Universal dependencies
v1: A multilingual treebank collection”. pp 1659—1666. In Proceedings of the
Tenth International Conference on Language Resources and Evaluation (LREC
2016). 2016.
[Nealeetal2018] Neale, Steven, Kevin Donnelly, Gareth Watkins, Dawn
Knight. “Leveraging lexical resources and constraint grammar for rule-based
part-of-speech tagging in Welsh”. In Proceedings of the Eleventh International
Conference on Language Resources and Evaluation (LREC-2018). 2018.
[Owoputi2013] Owoputi, Olutobi, Brendan O’Connor, Chris Dyer, Kevin
Gimpel, Nathan Schneider, Noah A Smith. “Improved part-of-speech tagging for online
conversational text with word clusters”. pp 380—390. In Proceedings of the
2013 Conference of the North American Chapter of the Association for Computational
Linguistics: Human Language Technologies. 2013.
[Pilliereetal2018] Pillière, Linda, Wilfrid Andrieu, Valérie Kerfelec,
Diana Lewis. Standardising English: norms and margins in the history of the
English language. Cambridge University Press. 2018.
[Poplack1980] Poplack, Shana. “Sometimes I’ll start a sentence in
Spanish y termino en Español: toward a typology of code-switching”. pp 581—618. In
Linguistics. v18. 1980. doi:https://doi.org/10.1515/ling-2013-0039.
[RabyAndrieu2018] Raby, Valérie, Wilfrid Andrieu. Norms and
rules in the history of grammar: French and English handbooks in the seventeenth
century. Pillière, Linda, Wilfrid Andrieu, Valérie Kerfelec, Diana Lewis.
Standardising English: norms and margins in the history of the English
language. Cambridge University Press. 2018.
[Renearetal2002] Renear, Allen, David Dubin, C Michael Sperberg-McQueen,
Claus Huitfeldt. “Towards a semantics for XML markup”. pp 119—126. In
Proceedings of the 2002 ACM Symposium on Document Engineering.
2002. doi:https://doi.org/10.1145/585058.585081.
[Renearetal2003] Renear, Allen, David Dubin, C Michael Sperberg-McQueen,
Claus Huitfeldt. “XML semantics and digital libraries”. pp 303—305. In 2003
Joint Conference on Digital Libraries, 2003. 2003. doi:https://doi.org/10.1109/JCDL.2003.1204879.
[Santorini1990] Santorini, Beatrice. Part-of-speech Tagging Guidelines for the Penn
Treebank Project. Technical report MS-CIS-90-47, Department of Computer
and Information Science, University of Pennsylvania. 1990.
[SperbergMcQueen1991] Sperberg-McQueen, C Michael. “Text in the
electronic age: Texual study and textual study and text encoding, with examples from
medieval texts”. pp 34—46. In Literary and linguistic computing.
v6. 1991. doi:https://doi.org/10.1093/llc/6.1.34.
[SperbergMcQueen1994] Sperberg-McQueen, C Michael. “The Text Encoding
Initiative: Electronic text markup for research”. pp 35—55. In Literary texts
in an electronic age: Scholarly implications and library services. (Papers presented
at
the 1994 Clinic on Library Applications of Data Processing). 1994.
[SperbergMcQueen2011] Sperberg-McQueen, CM. “What constitutes successful
format conversion? towards a formalization of ‘intellectual content’”. pp 153—164.
In
The International Journal of Digital Curation. v6. 2011. doi:https://doi.org/10.2218/ijdc.v6i1.179.
[Tennison2002] Tennison, Jenni. “Comparing markup languages”. In
Proceedings of the Extreme Markup Languages 2002 Conference. 2002.
[Tayloretal2003] Taylor, Ann, Mitchell Marcus, Beatrice Santorini.
The Penn Treebank: An overview. Abeillé, Anne, editor.
Treebanks: Building and Using Parsed Corpora. Springer. 2003.
[Wohlgemuth2009] Wohlgemuth, Jan. A typology of verbal
borrowings. Walter de Gruyter. 2009.
[1] Welsh has an established borrowed form of “stuff”, which is spelled
stwff and pronounced to rhyme with English “woof”;
styff is not a standard form, but is an accurate rendering of
the English pronunciation into Welsh orthography.
[2] Birnbaum and Mundie’s fourth option is to keep the text precisely as it is,
and produce an invalid document. Although this is evidently an option, it seems
to me rather less interesting for understanding the possibilities and
constraints of markup as applied to text representations. For better or for
worse, therefore, I will not discuss it further here.
[3] The following discussion draws on Birnbaum and Mundie’s appraisal of the
relative drawbacks of these three solutions, and frames them in terms of the
markup schema as a theory of the text. Although my discussion is therefore
indebted to [Birnbaum and Mundie
1999], errors or misjudgements in reinterpreting their arguments in
light of Sperberg-McQueen's understanding of the text are my own.
[4] Although words that technically belong to categories not occurring in the language
of the text might appear, these can only be words belonging to a different language;
words with foreign morphology are either adapted to the grammatical system of the
language in question, or remain as they are (in which case, they are considered as
insertions from that language). Tagsets generally have some variant of a
<foreign> tag to mark words that cannot be categorised as belonging to the
language of the text.
[6] Undoubtedly, the berfenw must be thought of as a special type of noun. Two of
its most obvious linguistic features are that it cannot be pluralized, and that
it is associated with a specific morphological ending (-io
or -o). This ending is used very frequently to convert an
English borrowed verb into a Welsh berfenw: “dim socket i chargeo ffôn” —
no socket for charging a phone. The ending is generally
added only to root forms, which are usually shared by an inflected verb with the
same meaning (a notable exception is the berfenw mynd
("go"), whose corresponding verb has the root a-). A tagset
for Welsh should ideally model the berfenw as a kind of noun, but ensure that it
has its own tag to distinguish it from other nouns. (See [Lynn et al. 2015] for a similar decision made
in Irish PoS tagging).
[7] Attention to the semantics of the tag might mitigate this somewhat, of course,
but (as discussed above) the semantics of markup are not formalizable and, as
such, may be considered less implicationally significant to the theory of the
text abstraction than the syntax. The fact of having an “escape hatch” implies a
model of the token as anomalous, regardless of the tag’s label.
Birnbaum, David J, David A Mundie. “The problem of
anomalous data: A transformational approach”. pp 1—19. In Markup Languages:
Theory and Practice. v1. 1999. doi:https://doi.org/10.1162/109966299760283157.
Brill, Eric. “Transformation-based error-driven learning and
natural language processing: A case study in part-of-speech tagging”. pp 543—565.
In
Computational Linguistics. v21. 1995.
Clark, Alexander, Shalom Lappin.
Unsupervised learning and grammar induction. Clark, Alexander, C
Fox, Shalom Lappin. The handbook of computational linguistics and natural
language processing. Wiley-Blackwell. 2010.
Coombs, James H, Allen H Renear, Steven J DeRose. “Markup
systems and the future of scholarly text processing”. pp 933—947. In
Communications of the ACM. v30. 1987. doi:https://doi.org/10.1145/32206.32209.
Chiarcos, Christian, Maria Sukhareva.
“OLiA—Ontologies of Linguistic Annotation”. pp 379—386. In Semantic
Web. v6. 2015. doi:https://doi.org/10.3233/SW-140167.
DeRose, Steven J, David G Durand, Elli Mylonas, Allen H
Renear. “What is text, really?”. pp 3—26. In Journal of Computing in Higher
Education. v1. 1990. doi:https://doi.org/10.1007/BF02941632.
Derczynski, Leon, Alan Ritter, Sam Clark, Kalina
Bontcheva. “Twitter part-of-speech tagging for all: Overcoming sparse and noisy data”.
pp 198—206. In Proceedings of the International Conference: Recent Advances in
Natural Language Processing. 2013.
Haspelmath, Martin. Lexical borrowing:
concepts and issues. Haspelmath, Martin, Uri Tadmor. Loanwords in
the world’s languages: a comparative handbook. Walter de Gruyter. 2009.
Jamatia, Anupam, Björn Gambäck, Amitava Das.
“Part-of-speech tagging for code-mixed English-Hindi Twitter and Facebook chat
messages”. pp 239—248. In Proceedings of the International Conference: Recent
Advances in Natural Language Processing. 2015. doi:https://doi.org/10.13140/RG.2.1.1222.0640.
Kahrel, Peter, Ruthanna Barnett, Geoffrey Leech.
Towards cross-linguistic standards or guidelines for the annotation of
corpora. Garside, Roger, Geoffrey N Leech, Tony McEnery. Corpus
annotation: linguistic information from computer text corpora. Taylor &
Francis. 1997.
Klein, Heinz K., RA Hirschheim. “A comparative
framework of data modelling paradigms and approaches”. pp 8—15. In The
computer journal. v30. 1987. doi:https://doi.org/10.1093/comjnl/30.1.8.
Leech, Geoffrey, Roger Garside, Michael Bryant. “CLAWS4:
the tagging of the British National Corpus”. pp 622—628. In COLING 1994 Volume
1: The 15th International Conference on Computational Linguistics. 1994. doi:https://doi.org/10.3115/991886.991996.
Lynn, Teresa, Kevin Scannell, Eimear Maguire. “Minority
language Twitter: Part-of-speech tagging and analysis of Irish tweets”. pp 1—8. In
Proceedings of the Workshop on Noisy User-generated Text. 2015. doi:https://doi.org/10.18653/v1/W15-4301.
Marcoux, Yves. “A natural-language approach to modeling:
Why is some XML so difficult to write”. In Proceedings of the Extreme Markup
Languages 2006 Conference. 2006.
Merialdo, Bernard. “Tagging text with a probabilistic
model”. pp 809—812. In ICASSP 91: International Conference on Acoustics,
Speech, and Signal Processing. 1991. doi:https://doi.org/10.1109/ICASSP.1991.150460.
Nivre, Joakim, Marie-Catherine De Marneffe, Filip
Ginter, Yoav Goldberg, Jan Hajic, Christopher D Manning, Ryan McDonald, Slav Petrov,
Sampo Pyysalo, Natalia Silveira, Reut Tsarfaty, Daniel Zeman. “Universal dependencies
v1: A multilingual treebank collection”. pp 1659—1666. In Proceedings of the
Tenth International Conference on Language Resources and Evaluation (LREC
2016). 2016.
Neale, Steven, Kevin Donnelly, Gareth Watkins, Dawn
Knight. “Leveraging lexical resources and constraint grammar for rule-based
part-of-speech tagging in Welsh”. In Proceedings of the Eleventh International
Conference on Language Resources and Evaluation (LREC-2018). 2018.
Neunerdt, Melanie, Bianka Trevisan, Michael Reyer,
Rudolf Mathar. “Part-of-speech tagging for social media texts”. pp 139—150. In
Language Processing and Knowledge in the Web. 2013. doi:https://doi.org/10.1007/978-3-642-40722-2_15.
Owoputi, Olutobi, Brendan O’Connor, Chris Dyer, Kevin
Gimpel, Nathan Schneider, Noah A Smith. “Improved part-of-speech tagging for online
conversational text with word clusters”. pp 380—390. In Proceedings of the
2013 Conference of the North American Chapter of the Association for Computational
Linguistics: Human Language Technologies. 2013.
Pillière, Linda, Wilfrid Andrieu, Valérie Kerfelec,
Diana Lewis. Standardising English: norms and margins in the history of the
English language. Cambridge University Press. 2018.
Piez, Wendell. “Beyond the ‘descriptive vs. procedural’
distinction”. pp 141—172. In Markup Languages: Theory and Practice.
v3. iss 2. 2001. doi:https://doi.org/10.1162/109966201317356380.
Poplack, Shana. “Sometimes I’ll start a sentence in
Spanish y termino en Español: toward a typology of code-switching”. pp 581—618. In
Linguistics. v18. 1980. doi:https://doi.org/10.1515/ling-2013-0039.
Raby, Valérie, Wilfrid Andrieu. Norms and
rules in the history of grammar: French and English handbooks in the seventeenth
century. Pillière, Linda, Wilfrid Andrieu, Valérie Kerfelec, Diana Lewis.
Standardising English: norms and margins in the history of the English
language. Cambridge University Press. 2018.
Renear, Allen, David Dubin, C Michael Sperberg-McQueen,
Claus Huitfeldt. “Towards a semantics for XML markup”. pp 119—126. In
Proceedings of the 2002 ACM Symposium on Document Engineering.
2002. doi:https://doi.org/10.1145/585058.585081.
Renear, Allen, David Dubin, C Michael Sperberg-McQueen,
Claus Huitfeldt. “XML semantics and digital libraries”. pp 303—305. In 2003
Joint Conference on Digital Libraries, 2003. 2003. doi:https://doi.org/10.1109/JCDL.2003.1204879.
Santorini, Beatrice. Part-of-speech Tagging Guidelines for the Penn
Treebank Project. Technical report MS-CIS-90-47, Department of Computer
and Information Science, University of Pennsylvania. 1990.
Sperberg-McQueen, C Michael. “Text in the
electronic age: Texual study and textual study and text encoding, with examples from
medieval texts”. pp 34—46. In Literary and linguistic computing.
v6. 1991. doi:https://doi.org/10.1093/llc/6.1.34.
Sperberg-McQueen, C Michael. “The Text Encoding
Initiative: Electronic text markup for research”. pp 35—55. In Literary texts
in an electronic age: Scholarly implications and library services. (Papers presented
at
the 1994 Clinic on Library Applications of Data Processing). 1994.
Sperberg-McQueen, CM. “What constitutes successful
format conversion? towards a formalization of ‘intellectual content’”. pp 153—164.
In
The International Journal of Digital Curation. v6. 2011. doi:https://doi.org/10.2218/ijdc.v6i1.179.
Taylor, Ann, Mitchell Marcus, Beatrice Santorini.
The Penn Treebank: An overview. Abeillé, Anne, editor.
Treebanks: Building and Using Parsed Corpora. Springer. 2003.