Schwarzman, Alexander B., and Jennifer Mayfield. “Using BITS for conference paper conversion.” Presented at Balisage: The Markup Conference 2019, Washington, DC, July 30 - August 2, 2019. In Proceedings of Balisage: The Markup Conference 2019. Balisage Series on Markup Technologies, vol. 23 (2019). https://doi.org/10.4242/BalisageVol23.Schwarzman01.
Balisage: The Markup Conference 2019 July 30 - August 2, 2019
Balisage Paper: Using BITS for conference paper conversion
Alexander (Sasha) Schwarzman has twenty years of experience in markup technologies, beginning with
SGML, and later with XML, XPath, Schematron, and native XML databases. As Content
Technology Architect at The Optical Society (OSA), he is involved in quality control
and semantic of published and converted content, as well as effective management of
XML-centric workflows. Prior to joining OSA, Sasha worked as Information Systems Analyst
at the American Geophysical Union (AGU) and served as a co-chair of the NISO/NFAIS
Working Group on Supplemental Materials to Journal Article. He holds an equivalent
of Master of Science degree in Mechanical Engineering from the Saint Petersburg State
Polytechnic University, Russia, and a Master of Library Science degree from the University
of Maryland, College Park, USA.
Jennifer Mayfield
The Optical Society
Jennifer Mayfield is the Deputy Senior Director of Electronic Publishing at The Optical
Society. She has worked in electronic publishing for over twenty years, previously
as the Managing Editor for Optics Express, the first electronic journal in the physical sciences and now the 12th largest journal
in the world. Currently she manages OSA Publishing, the society’s digital library
platform. She holds a Master of Arts degree in English concentrating in Linguistics
from George Mason University.
As is typical for many society publishers, OSA–The Optical Society, has both a journal
and a conference program. Integrating both journal articles and conference papers
within a single data source opens up a pathway to conduct business intelligence analysis
over the entire corpus of the published research material, which can benefit both
programs and advance the society’s mission.
In 2017, having successfully completed a project to convert almost 100 years of its
journal legacy material to JATS XML, OSA decided to convert its conference content
as well, tag it in a JATS-compatible way, and to combine both content segments in
a single MarkLogic database. While it has been well-accepted that JATS and BITS cover
the markup needs for journal and book content, respectively, it is less clear what
Tag Set would be most suitable for tagging conference proceedings.
Even though we thought we had seen it all in converting journal content, in the course of the project we learned that handling
conference metadata and journal metadata presents very different challenges. In this
paper, we share our experience with using BITS for marking up individual conference
papers and how our business decisions shaped how we structure the XML. We demonstrate
that because BITS was explicitly designed to enable the construction of books composed
of units that could be part of many collections, the BITS metadata model is well-suited
for representing conference paper’s nested collections, both event- and publication-related.
To ensure data quality, we have built workflows, designed XML tools (e.g., Tag Subset,
Schematron), and instituted visual QC procedures that allowed us to achieve our objective.
We conclude our paper with lessons learned from this project and new opportunities
its successful completion has opened up.
This presentation was given at Balisage 2019 as an Encore Presentation. The Balisage program consisted of all new material on a wide variety of topics related to markup.
At the time the program was assembled, the Conference Committee believed that every
one of the speakers who accepted a spot on the program would be able to come to Balisage and make a presentation. Unfortunately, sometimes things happen, and from time to
time, scheduled speakers are unable to give their presentations. Balisage attendees who have previously delivered markup-related presentations are invited
then to offer them as fill-ins. This presentation was such an Encore Presentation. Originally presented at JATS-Con 2019, this paper is also included in that conference’s proceedings (https://www.ncbi.nlm.nih.gov/books/NBK541143/).
Introduction
OSA began posting its conference content in OSA Publishing, OSA’s digital library
platform, in 2006. We initiated the first conversion project by scanning the conference
publications[1] for the most recent nine years, creating PDF files for conference papers and XML
files with their metadata. We continued to work backwards to convert and load the
previous 35 years’ worth of content. Currently, OSA Publishing hosts more than 175,000
conference papers from over 700 meetings and over 500 unique conference publications.
OSA developed a proprietary DTD to publish its journal and conference content because
the NLM DTD did not fit our needs at the time for both journal and conference content.
Later, OSA made an attempt to fit the conference paper content into the NLM 3.0 model:
an OSA subset of the NLM 3.0 DTD worked using a combination of <journal>, <conference>, and <custom-meta> tags. The <custom-meta> tags were required for certain metadata like session names and session acronyms that
do not have a logical place in a journal tag set. This turned out not to be an ideal
solution, and we continued to rely on the proprietary OSA DTD for publishing the conference
content.
The proprietary OSA XML gave us the basics of what we needed to display the conference
papers on our publishing platform, but we were missing critical metadata that would
improve the accuracy and overall discoverability of the content. Our ability to use
the content for analysis and business intelligence was also limited because of the
unreliability of the content quality in the XML. In the OSA XML, we captured the author
listing and affiliations based on what the authors entered in the submission system,
rather than what was published in the PDF file, which is considered the version of
record. There are typically citations in the paper, but we were not capturing these
references in the XML. We were extracting full-text from the PDF file, but it was
unstructured and that made machine indexing of the content less accurate and reliable.
By 2017 we completed the full-text conversion of almost 100 years’ worth of OSA journal
content and understood the benefits and flexibility of having accurate and well-structured
content. We wanted to leverage MarkLogic, a native XML database already populated
with our journal content, as a repository for well-structured conference paper XML
that would contain important metadata, tagged references, semantic indexing, and more-structured
body markup.
The difficulties of capturing the complexities of a conference paper in XML proved
to be an ongoing challenge for us. In many ways, publishing journal article content
is more straightforward compared to conference papers. Journal metadata is consistent
for the most part; e.g., journal titles do not change frequently, if at all. In contrast,
conference metadata can change frequently. Slight changes in the scope of the same
conference from year to year can lead to changes in its name, which can make it challenging
to tie all of the related conferences together. Also, an interesting feature of the
OSA Conference program is that OSA often hosts multiple events simultaneously as co-located
conferences[2]. There could be as many as 10 different conferences occurring at the same time with
the papers published together in the same publication and with joint papers that are
associated across all of the conferences.
Because of the complexities of how we needed to tie all of the related conferences
together and to display the co-located conferences on OSA Publishing, we had to rely
on more than just the XML to organize the content. Since the first conversion project
the heart of conference publishing architecture has been a Relational Database that
holds conference metadata on various levels of granularity and drives conference presentation
in OSA Publishing. The important role the Relational Database plays in conference
publishing architecture has influenced how we modeled conference content in XML. More
information on how we present conference papers in OSA Publishing and the role of
the Relational Database can be found in the Appendix A.
Project scope
The advent of BITS 2.0 in 2016 provided OSA an opportunity to re-evaluate the XML
model for our conference papers with the purpose to improve the quality and structure
of that content. A multifaceted solution had to be put into place to take advantage
of the publishing platform, two databases involved, and XML.
Thus, in 2017, OSA embarked on the project to convert legacy conference papers from
1975 to 2017, as well as new papers going forward, to BITS XML in order to improve
metadata quality, machine indexing accuracy, and overall discoverability. The corpus
of back-content for conversion was about 175,000 papers totaling approximately 400,000
pages. The estimated current and future conversion volume is 10,000 papers (30,000
pages) annually.
As inputs to the conversion process, for each conference OSA provided an Excel file
with conference and article metadata (exported from the Relational Database) and PDF
files for all papers presented at the conference. While event and conference publication
details were captured from the Excel file, article title, author names, affiliations,
abstracts, and references were recaptured from the PDF, because the PDF file is considered
the version of record. The body text was captured from the PDF source as well.
Because we did not intend to use the XML to create an HTML or EPUB representation
of the conference paper but rather to aid in semantic enrichment, the conversion requirements
for article body were simplified as compared to typical publishing conversions. Capturing
figure images and extracting funding information was out of scope, as was tagging
of equations, tables, cross-references, and face markup.
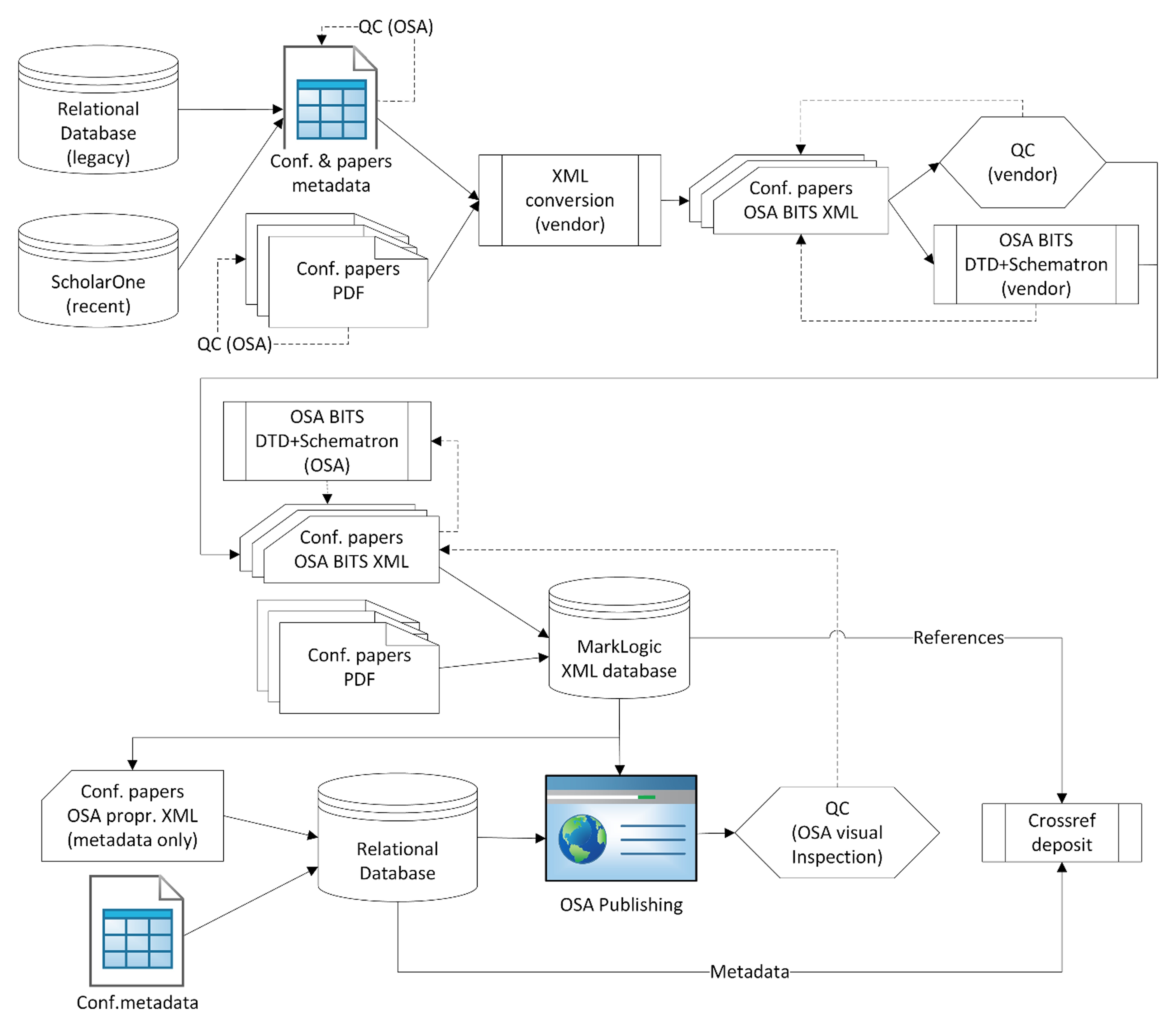
Conversion workflow
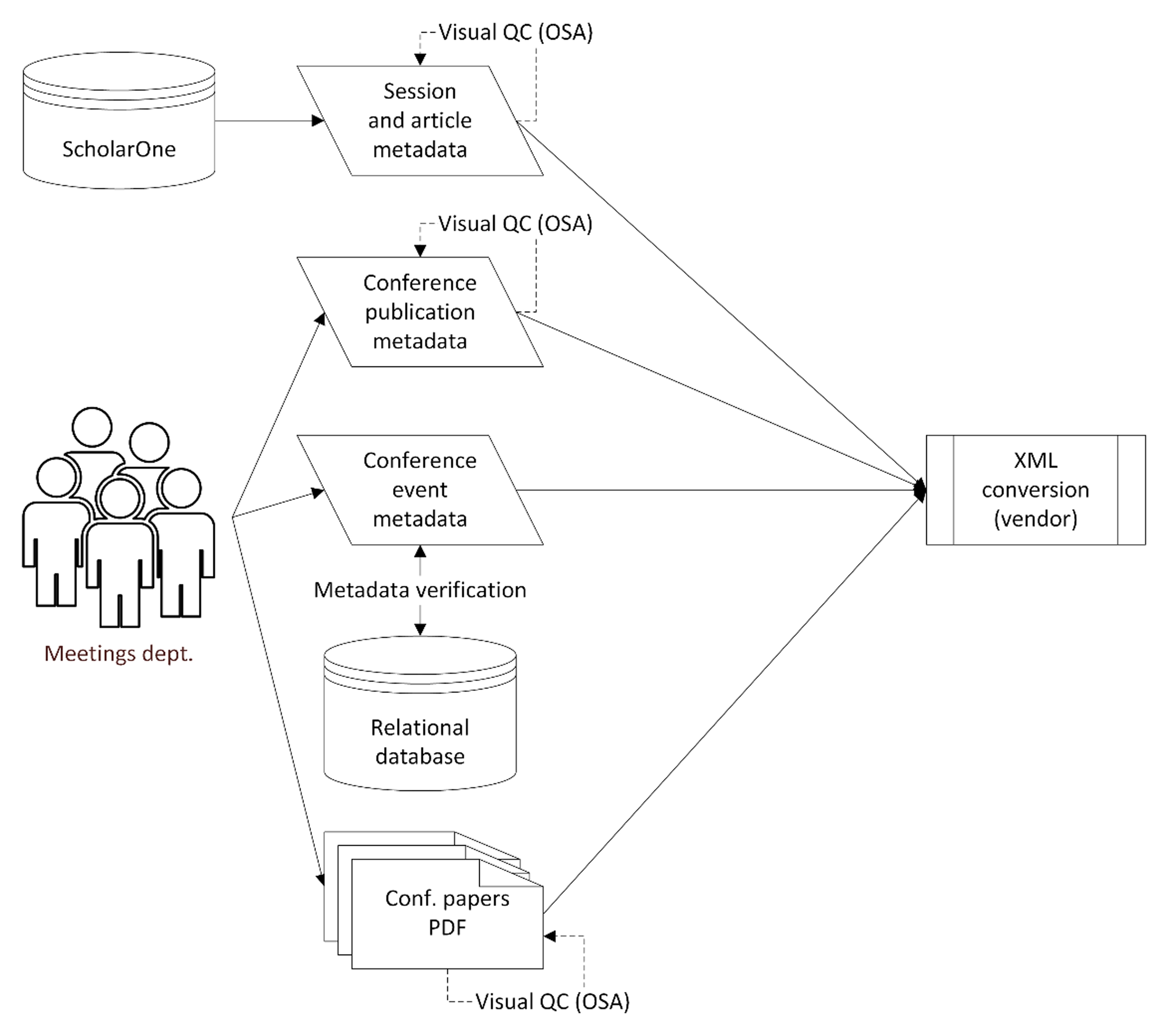
The workflows for the conversion project and that for live production publishing of
conference paper content are similar (Figure 1). OSA delivers an Excel spreadsheet for each year of each conference that contains
the conference and article metadata to the vendor. The vendor uses that metadata,
combined with metadata and references extracted from the PDF file, to create BITS
XML for each article. The vendor then validates the XML against the OSA’s proper subset
of BITS and runs OSA BITS Schematron before delivering the content back to OSA. OSA
validates the files again vis-à-vis the OSA’s proper subset of BITS, runs a stricter
version of OSA BITS Schematron, and addresses any warnings that involve human judgement
to correct. Occasionally, when there is a question about an error or warning, the
vendor needs to contact OSA before delivering the files. This gives OSA the opportunity
to make enhancements to the Schematron along the way as needed.
Figure 1: Conversion workflow
Once the files pass the quality control step, we load the XML and PDF content into
the MarkLogic database. At this point, semantic enrichment takes place on the content.
Finally, the content is pushed into the Relational Database using OSA XML. At this
point, the content is available in OSA Publishing for visual inspection.
The last step after visual inspection is to redeposit the Crossref metadata and complete
remaining content fulfillment tasks to ensure the enhanced content is distributed
to other indexers.
Conference paper modeling
In this section we will go into the details of how we modeled the BITS XML. We have
chosen <book-part book-part-type="conf-paper"> element to model a conference paper. One of the two top-level BITS elements, <book-part-wrapper content-type="conf-paper-wrap">, serves as a <book-part>’s container.
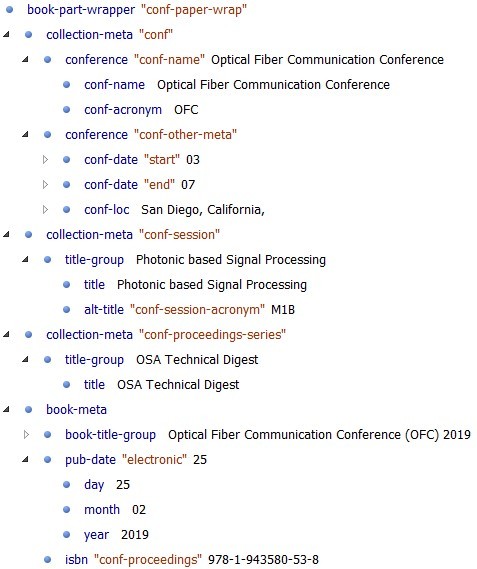
Event-related and publication-related collections
A conference paper can be modeled as part of several nested collections, both event-
and publication-related. A conference paper *presentation* (whether oral or poster)
is an event that is part of a session, which is part of a conference that may be co-located
with other conferences; a conference paper *publication* becomes a part of conference
proceedings or digest, which are often part of a series.
Because BITS design allows an individual <book-part> to belong to multiple collections, a conference paper can be modeled as part of several
collections nested within <book-part-wrapper> (Figure 2). Some of those collections contain *event metadata* for the entire conference and
for the individual conference session, while other collections contain *publication
metadata* for the entire series (if it exists) and for the individual conference publication.
Figure 2: Collections a conference paper is a part of
Collections with event metadata:
<collection-meta collection-type="conf"> – conference name, acronym, date, and location
<collection-meta collection-type="conf-session"> – conference session title and acronym
Collections with publication metadata:
<collection-meta collection-type="conf-proceedings-series"> – series title
<book-meta> – conference publication title, publication date, and ISBN
Because the Relational Database holds information about co-located conferences and
connects all variations of the same conference together by using a base acronym, we
made a decision not to introduce two additional collections to represent this information
in the XML for an individual conference paper.
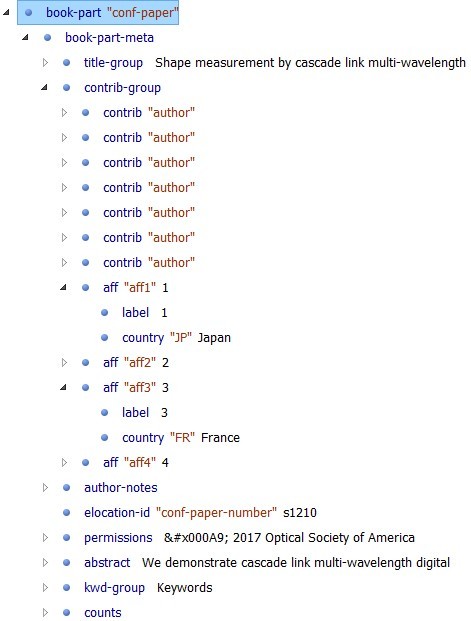
Conference paper model: OSA BITS Conference Tag Subset
We have modeled a conference paper itself as <book-part book-part-type="conf-paper"> element, which contains the paper’s metadata, body, and backmatter (Figure 3).
Figure 3: Conference paper model
Conference paper metadata
As part of the conference paper metadata, we capture the title, contributors (authors),
their affiliations, paper number, permissions, abstract, keywords, and the total number
of pages (Figure 4). As part of affiliations markup, we tag ISO-3166-2 country code in order to be able
to gather geographical distribution statistics.
Figure 4: Conference paper metadata
Conference paper body
Among the project goals was to enhance the conference content discoverability and
to improve business intelligence. That is why we have decided to capture the paper’s
entire body in machine-readable form. However, because it was not a requirement to
create a conference paper’s HTML or EPUB representation, we decided not to go any
more granular than capturing textual paragraphs (Figure 5). That decision was an important factor in delivering expected results in time and
under budget.
Figure 5: Conference paper body
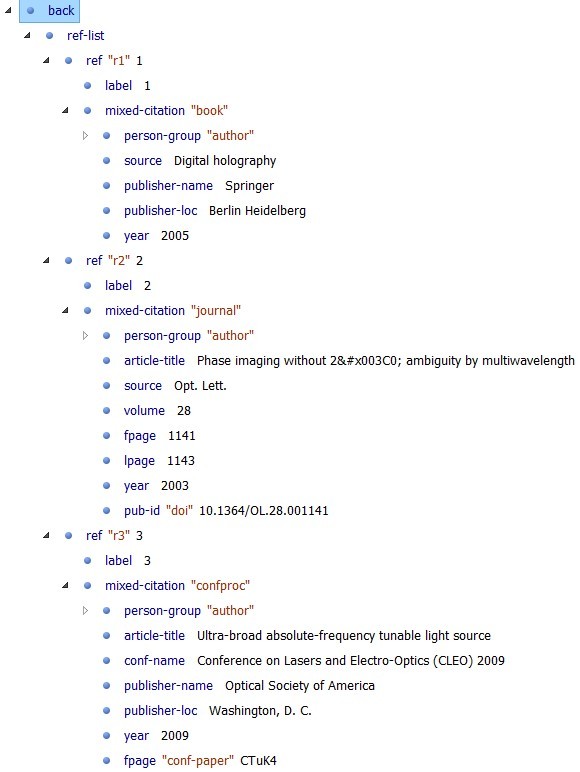
Conference paper backmatter
It was a requirement to provide full reference markup, and that is what we did (Figure 6). Having tagged references allows us to perform citation analysis. Also, because
we deposit conference content to Crossref, this markup can serve as a source of Cited-by
links.
Figure 6: Conference backmatter – full reference markup
Building on existing journal model
OSA uses OSA Journal Publishing Tag Subset (OSA JPTS), a proper subset of Journal
Publishing Tag Set, to tag all 10 primary journals it publishes. OSA JPTS was also
used for converting almost 100 years’ worth of legacy material going back to inaugural
issue of the Journal of the Optical Society of America in 1917.
Because BITS models contain many structures that are not needed to tag conference
content, we tailored the tag set to our needs by constraining content models and building
OSA BITS Conference Tag Subset as a proper BITS subset.
In order to take advantage of the previously developed OSA journal reference model
(and, potentially, the body model—if, in the future, we decide to fully tag the conference
paper body), it made sense to build OSA BITS Conference model on the basis of OSA
JPTS. Using the standard JATS customization mechanism of redefining parameter entities
in the class, mix, and model overrides and then adding new models, we architected
OSA BITS Conference Tag Subset as a five-tier edifice:
OSA BITS Conference Tag Subset
Book Interchange Tag Suite (BITS)
OSA Journal Publishing Tag Subset (OSA JPTS)
Journal Publishing Tag Set
Journal Article Tag Suite (JATS)
Figure 7 illustrates part of this architecture – class overrides in the OSA BITS Conference
Tag Subset.
Figure 7: Class overrides mechanism
Quality control
Vendor QC
As was mentioned above, requirements for the body content are quite straightforward:
there is no need to tag equations, tables, cross-references, and face markup. Accordingly,
the vendor has implemented a highly automated, lower-cost QC process, which met OSA’s
specifications while reducing the need for visual review. To QC body content, the
vendor uses tailored spellcheck software to identify and remove extraneous hyphens,
identify words running together due to stripped hyphens, identify ligatures and other
unusual characters, and provide a spell check report for each file processed. Items
for which correction rules could reasonably be identified are fixed automatically,
and a spell check report displaying misspelled or run-together words in context, is
supplied. This additional reporting provides us a further opportunity for data review.
OSA BITS Conference Schematron
Building a restrictive BITS subset goes a long way to ensure XML quality by having
a validating parser check the XML against the DTD. However, even the most prescriptive
tag set cannot check certain business rules, e.g., co-occurrence constraints, presence
of optional attributes, checking of element contents against the list of approved
values, etc.
In order to enforce such business rules, we have built OSA BITS Conference Schematron.
It consists of a library with modules such as meta.sch (for checking metadata), country.sch (for checking country codes), several authority lists, and a file utility.xsl that contains supporting XSLT operations, such as variables, functions, and keys
required by the Schematron.
OSA BITS Conference Schematron is relatively simple, it contains only one-top-level
Schematron, six modules, 36 requirements, and 36 assert/report tests within 19 rules.
(For comparison, OSA JATS Schematron contains eight top-level Schematrons, 26 modules,
592 requirements, and 648 assert/report tests within 227 rules.)
To move QC as upstream in the workflow as possible, we have provided OSA BITS Conference
Schematron to the vendor, have the vendor run the Schematron, and do not allow delivery
of XML files with Schematron errors.
In keeping with the trust but verify principle, we run Schematron on our end as well, including the osa-in-house.sch module that contains verifications to be performed at OSA only.
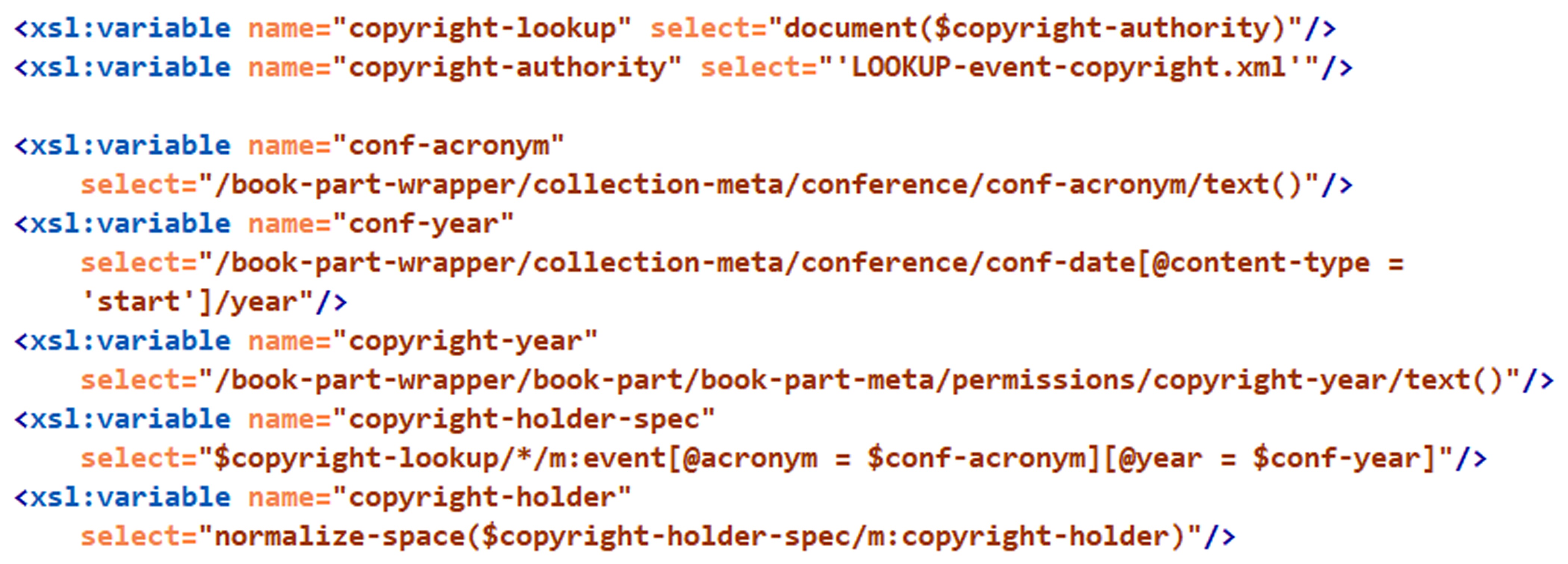
Here is an example of a rule that requires verification against an authority list.
The respective variables are defined in the utility.xsl file:
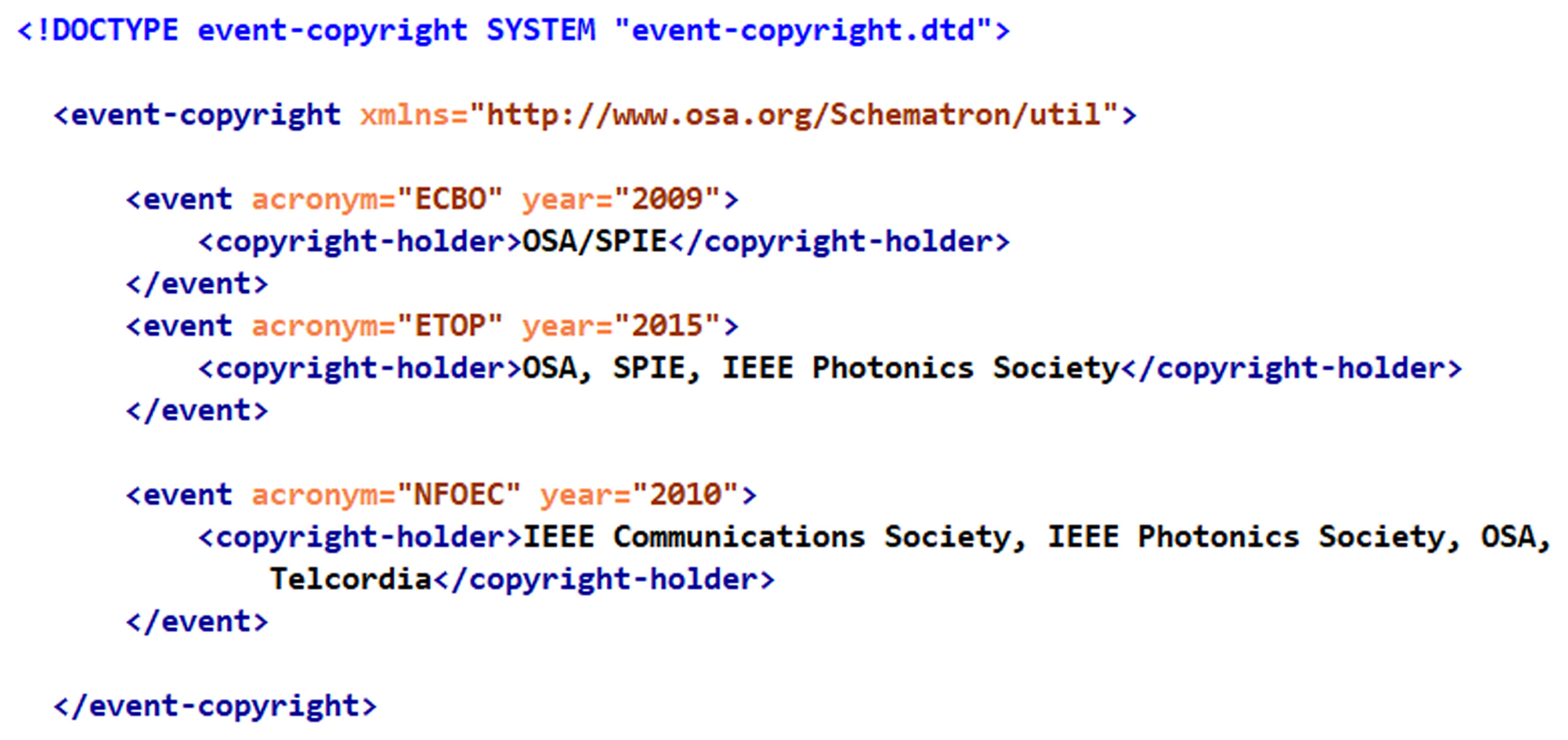
And here is a fragment of the copyright holder authority file LOOKUP-event-copyright.xml:
If a conference paper XML file contains incorrect copyright holder:
then Schematron emits an error:
ERROR [OCP:META160]: expected <copyright-holder>
to be "OSA/SPIE", found "OSA, SPIE"
OSA QC
After conference papers are posted in OSA Publishing, they undergo visual inspection
that entails checking the accuracy of the following metadata for select papers.
Author name and affiliation (checked against the article PDF)
Abstract presence
Reference citations completeness and DOI linking
Presence of Related Topics (assigned by the semantic indexing software in MarkLogic)
Copyright, licensing, and open access
No show papers identified as not presented at the conference
Business intelligence
Having conference paper content in machine-readable format consistent with that of
a journal article and placing both kinds of content in a single repository (MarkLogic
database) opens an opportunity to enhance business intelligence. Both the journal
and the conference content segments undergo machine indexing by OSA’s Optics and Photonics
Topics—a thesaurus of about 2,400 terms with more than 5,000 synonyms and variants.
While using the similarity algorithm results in the ability to display Related Topics
next to a content item, using the classification algorithm improves search results
across all content.
Because all the references have been marked up, it is now possible to do citation
analysis across conference content, gleaning valuable insights.
Having all conference content in MarkLogic allows us, potentially, to identify emerging
trends in the discipline and help journal editors propose feature issues on those
topics, expand the peer reviewer pool, etc. Because conference papers are early indicators
of hot topics, trend analysis of conference papers can guide publishers’ timely data
to consider when making decisions about journals programs.
Challenges
Current material
Initiating the BITS XML conversion for the current conference content exposed additional
challenges compared to the legacy conversion. For live production work, we do not
already have the curated content loaded into the Relational Database to export metadata
for the vendor to use. Instead, we have to rely on receiving the initial metadata
from the conference managers in the OSA Meetings department and the ScholarOne submission
and session scheduling system that they maintain. The initial metadata can present
problems. Oftentimes, the publishing team will receive conference metadata that does
not match up to what was used for previous years, or there could be a slight change
to the conference name that would go unnoticed. The publishing team must verify each
piece of information and compare all metadata to previous years to ensure its consistency
and accuracy. Also, the quality of the actual conference papers might not even meet
our standards for publication; e.g., a paper could be missing a title, an abstract,
a copyright statement, etc. Since introducing the new workflow, the publishing team
has taken on a new role of being the gatekeeper for enforcing quality of the conference
metadata and PDF files. Figure 8 illustrates the workflow for converting current conference material.
Figure 8: Conversion workflow fragment for current conference material
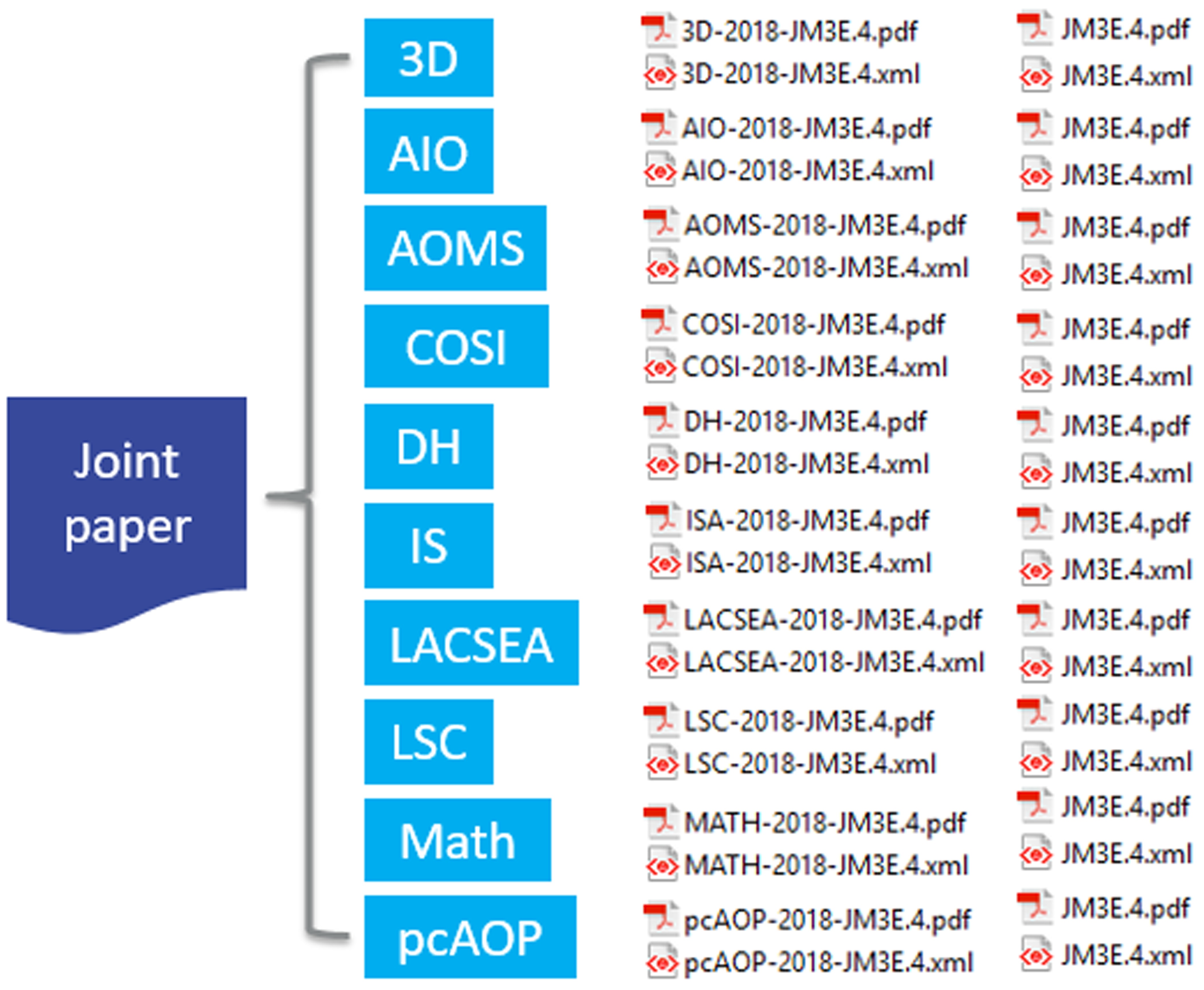
Co-located meetings and joint sessions
As mentioned above, for OSA it is not unusual to have several co-located conferences.
This means that if a paper belongs to a joint session then it must appear in each
of the co-located meetings. Thus if there are 10 co-located conferences, then a paper
in a joint session will be posted 10 times in OSA Publishing. This goes back to OSA’s
business decision to represent the individual conference rather than the publication.
There will be only one DOI assigned to the joint paper, because the article, session,
and publication (e.g., ISBN) metadata is identical for all 10 papers. The only difference
is the conference metadata represented by <collection-meta collection-type="conf">. Curating joint papers does present challenges at times, especially when a correction
needs to be made to the paper. The number of corrections, of course, depends on the
number of co-located conferences. Figure 9 shows the file proliferation for the joint papers and that a correction to one means
a correction to all.
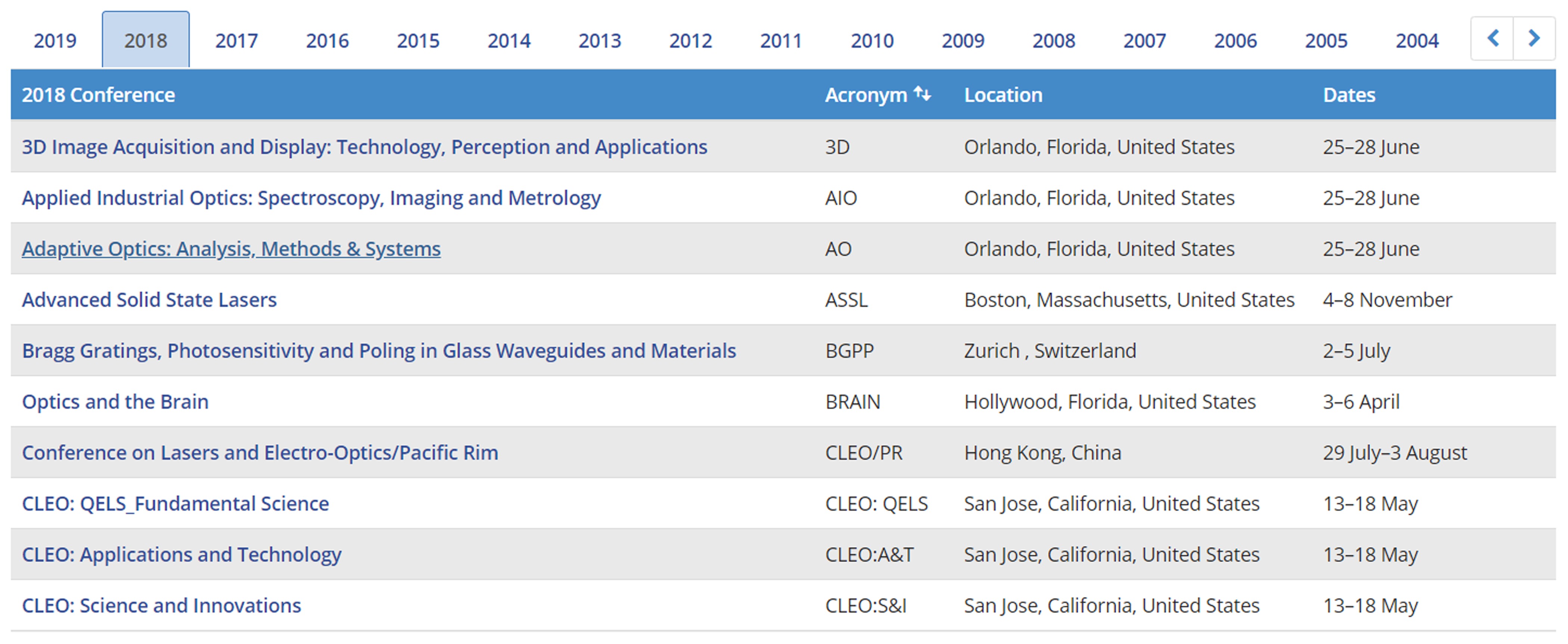
Figure 9: Joint sessions for the Imaging and Applied Optics 2018 co-located conferences (3D,
AO, AIO, COSI, DH, IS, LACSEA, LS&C, MATH, and pcAOP)
Another challenge related to current conferences is removing withdrawn papers prior
to publishing. In order to do that, we generate a Schematron lookup file that lists
withdrawn papers and then run Schematron with the osa-in-house.sch module plugged in on the content of the entire conference. If the paper is withdrawn,
Schematron emits an error message:
ERROR [OCP:OSAH110]: FiO-2018-FTh3D.1 status is WITHDRAWN.
Please remove the XML and PDF from the repository and do not
publish this paper.
Again, if a withdrawn paper is part of the joint session, then this Schematron procedure
needs to be repeated on the content of each of the co-located conferences.
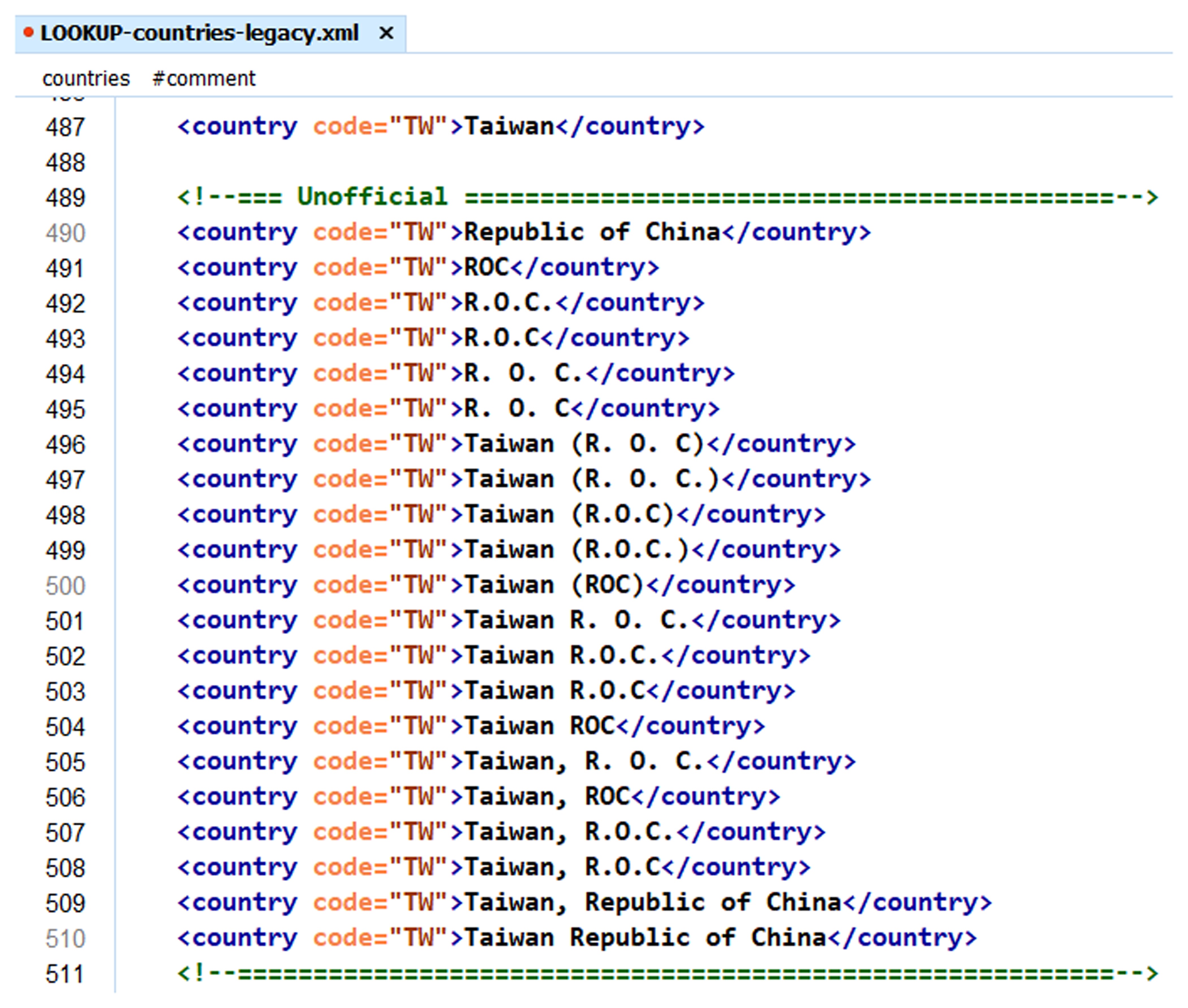
Country verification
To gather valuable statistics, we require the vendor to tag country code in author
affiliations. To provide some degree of quality control, we have implemented a check
of country name against its country code. However, because we cannot change the version
of record, in the country authority file we have to account for the variations in
how authors have specified their country names. Figure 10 and Figure 11 show the variations for China and Taiwan.
Figure 10: Country authority file: China
Figure 11: Country authority file: Taiwan
Conclusions
As we finalize the conversion project and begin to see the benefits of having JATS-compatible
XML, we feel like we made the right decision to use the BITS model for our conference
paper content. The release of BITS 2.0 came at an opportune time shortly before we
decided to initiate a new conversion project. BITS is well-suited for conference publications
and can represent the event metadata along with the article and publication metadata.
We were presented with many challenges to ensure the BITS XML is modeled to fit our
needs based on how we needed to organize, publish, and display the content. We created
workflows and designed XML tools to ensure quality of the content for both the legacy
conversion project and for ongoing work.
Throughout the course of the project, we have learned several lessons along the way:
It is important to determine what the version of record is for different metadata
elements, especially if there is a discrepancy between data sources, for example,
if metadata in the conference paper submission system is different from that in the
paper’s PDF.
Building conversion workflow, tag sets, and QC tools, as challenging as all that may
be, pales in comparison with bridging the gap between the cultures of different departments
within the same organization. To avoid the garbage in, garbage out problem, it is imperative to establish and document how data flows from Meetings
department to Publications department and institute strict QC measures to ensure data
quality.
In terms of BITS modeling, it might have made sense to introduce two additional collections
for the event metadata: one that would tie all related conferences together via a
base acronym, and the other that would identify the co-located conference where the
paper was presented. Even though that would increase the modeling complexity and present
additional QC challenges, doing so would allow us to build an architectural solution
around the native XML MarkLogic database only, without the Relational Database.
Tagging conference content in well-structured and thoroughly QC’d BITS XML and combining
it with JATS-tagged journal content within the single MarkLogic database improved
conference papers discoverability and afforded us an opportunity to conduct business
intelligence analysis across the entire corpus of published research, thereby benefitting
the OSA’s mission to share knowledge in the science of Optics and Photonics.
Acknowledgment
The authors would like to thank M. Scott Dineen for his valuable critique and suggestions.
Appendix A.
At the time when we started the first conversion project, our stakeholders made important
business decisions that would affect how we would build our platform to accommodate
the conference papers and how we would need to model the XML. We decided to not present
conference papers in the same fashion as journals; i.e., there would not be a table
of contents and page numbers as they are represented in the published book. The goal
was to represent the actual conference and not just the publication as a result of
the conference. The Relational Database connects all instances of the same conference
by tying them together and holds information about the co-located conferences and
their joint sessions. For example, if the name of a conference changes, we need a
new acronym to assign to the new conference name. To tie all of the related conferences
together, we use a base acronym: the base acronym is typically the original acronym
associated with the conference that has been in use for years and is already well-known
within the community. This is the type of information we store in the Relational Database
instead of curating that content in the XML.
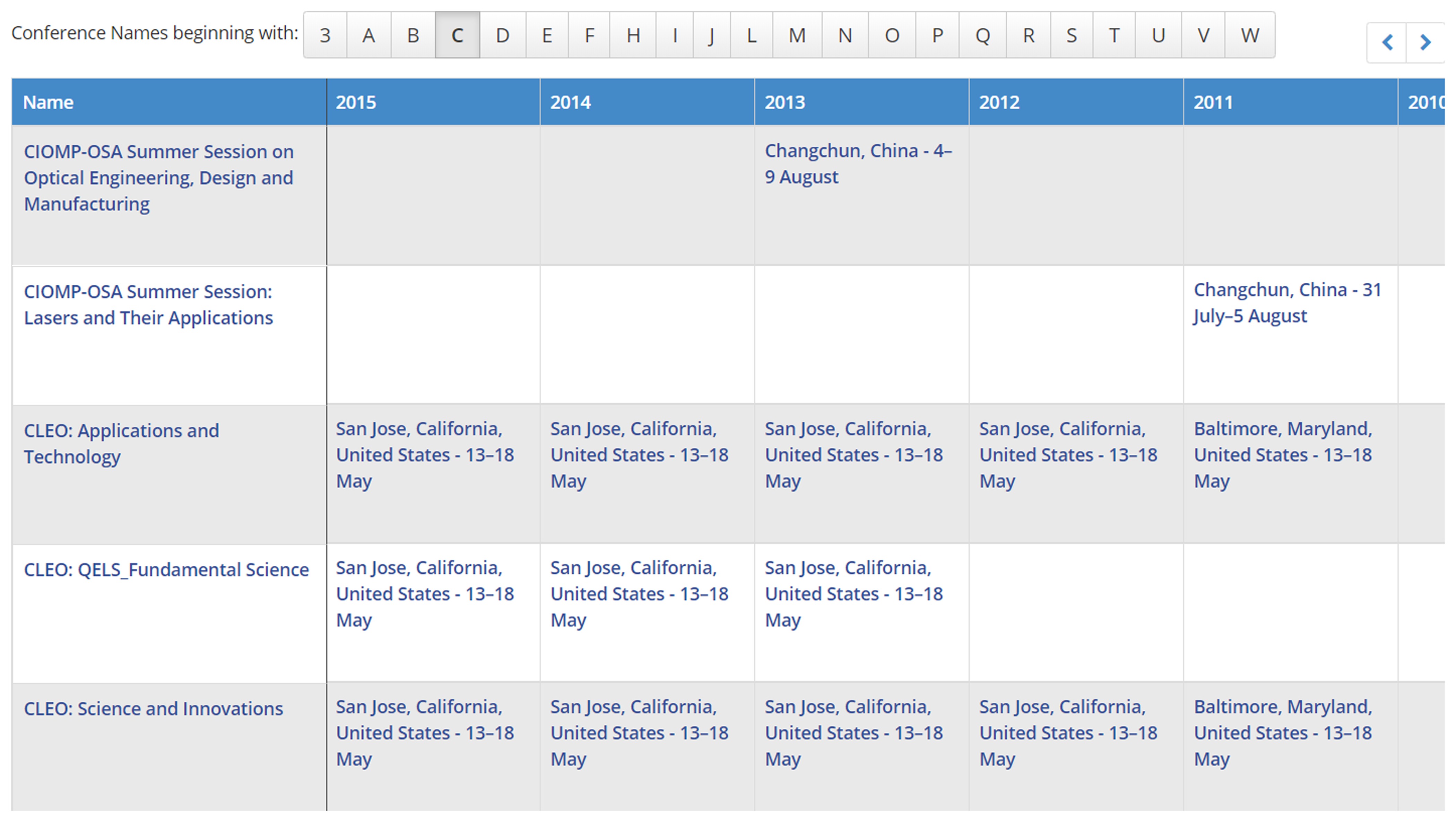
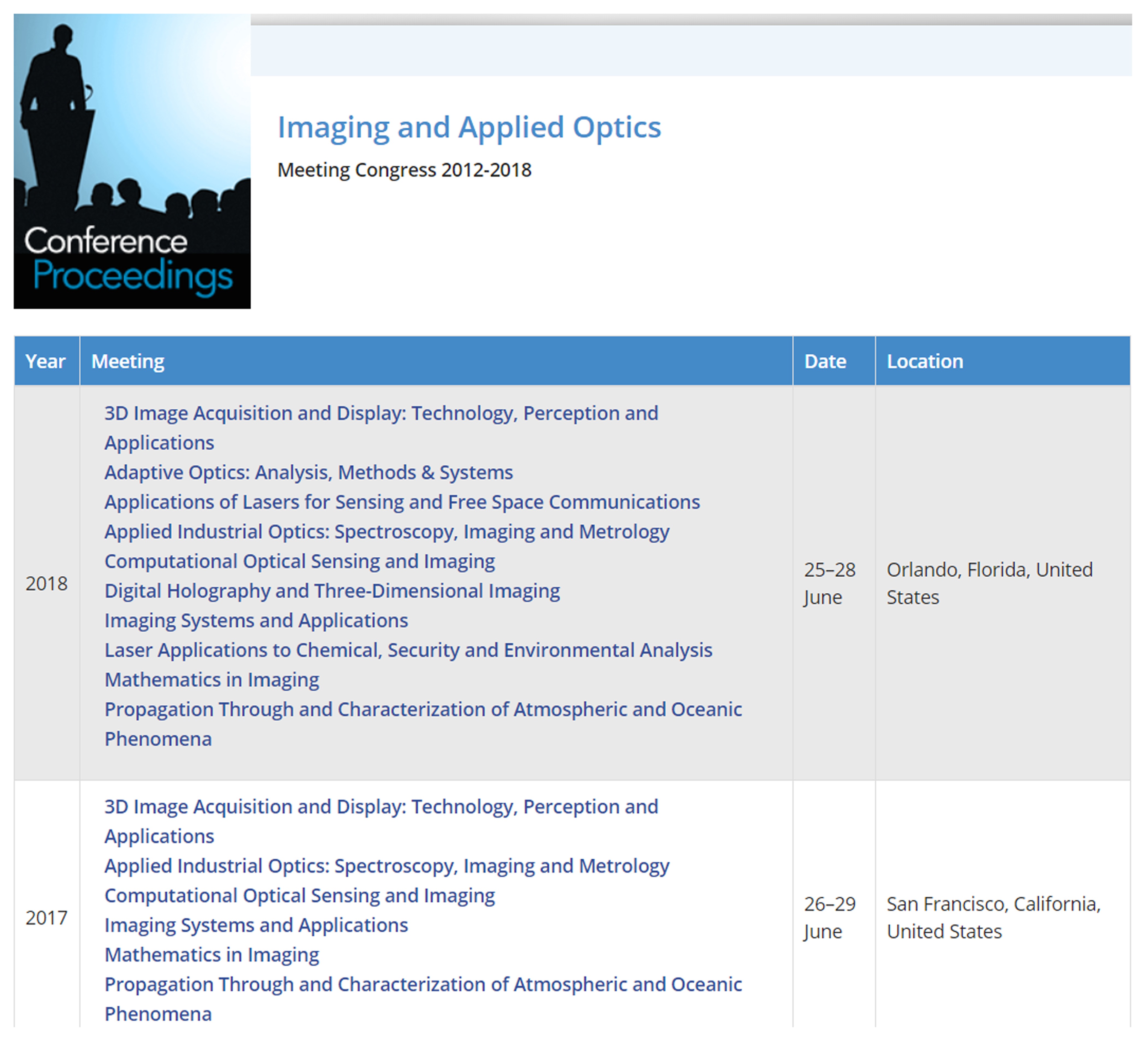
Figure 12 and Figure 13 illustrate how conferences are represented in OSA Publishing. Figure 13 shows that conferences CLEO:QELS, CLEO:AT&T, and CLEO:S&I are co-located. As Figure 14 illustrates, there can be as many as 10 different conferences occurring at the same
time, with the papers published together in the same publication.
Figure 12: Arrangement by conference
Figure 13: Arrangement by year
Figure 14: Co-located conferences
[1]Conference publications hereinafter denote both Technical Digests and Proceedings.
[2] Co-located conferences are referred in OSA as a meeting congress. In this paper, we avoid this term and use co-located conferences for clarity.