Birnbaum, David J., Hugh Cayless, Emmanuelle Morlock, Leif-Jöran Olsson and Joseph Wicentowski. “The integration of XML databases and content management systems in digital
editions: Understanding eXist-db through Reese’s Peanut Butter Cups.” Presented at Balisage: The Markup Conference 2019, Washington, DC, July 30 - August 2, 2019. In Proceedings of Balisage: The Markup Conference 2019. Balisage Series on Markup Technologies, vol. 23 (2019). https://doi.org/10.4242/BalisageVol23.Birnbaum01.
Balisage: The Markup Conference 2019 July 30 - August 2, 2019
Balisage Paper: The integration of XML databases and content management systems in digital editions
Understanding eXist-db through Reese’s Peanut Butter Cups
David J. Birnbaum
Professor and Chair
Department of Slavic Languages and Literatures, University of Pittsburgh (US)
David J. Birnbaum is Professor and Chair of the Department of Slavic Languages and
Literatures at
the University of Pittsburgh. He has been involved in the study of electronic text
technology since
the mid-1980s, has delivered presentations at a variety of electronic text technology
conferences,
and has served on the board of the Association for Computers and the Humanities, the
editorial board
of Markup languages: theory and practice, and the Text Encoding
Initiative Technical Council. Much of his electronic text work intersects with his
research in
medieval Slavic manuscript studies, but he also often writes about issues in the philosophy
of
markup.
Hugh Cayless is Senior Digital Humanities Developer at Duke University, where he provides
architecture, design, and programming support for the Duke Collaboratory for Classics
Computing
(DC3). He has served as an elected member of the TEI Technical Council since 2012
(as its Chair from
2015–2017), and he is a founding member of the EpiDoc Collaborative. Hugh earned a
PhD in Classics
and an MSIS, both from UNC Chapel Hill. His research interests focus on digital critical
editions
and Linked Open Data.
Emmanuelle Morlock
Digital Humanities Research Officer
French National Center for Scientific Research (CNRS) - HiSoMA Reserch Center (UMR
5189)
Emmanuelle Morlock works as an engineer in Digital Humanities at the French National
Center for
Scientific Research (CNRS). Educated in French literature and Library and Information
Science, she
has specialized in the application of the encoding standard TEI EpiDoc. She is also
involved in the
French-speaking digital humanities association Humanistica as a member of the steering
commitee and
co-director of the digital open access journal Humanités
numériques.
Partial support for her contribution to this work was provided by the Consortium CAHIER
(https://cahier.hypotheses.org/).
Leif-Jöran Olsson
Systems Developer
Språkbanken, Department of Swedish, University of Gothenburg (Sweden)
Leif-Jöran Olsson has been employed since 2005 as a systems developer at Språkbanken,
the Swedish
Language bank, University of Gothenburg, where he develops research infrastructure
for language
technology, both nationally and within CLARIN ERIC. His project management experience
involves both
long-term partner projects (e.g., the Swedish Literary Bank, the Selma Lagerlöf Archive,
the Swedish
Drama web) and short-term domain-specific toolboxes (including training and use case
analysis). He
has extensive experience with teaching in language technology and programming. Leif-Jöran
obtained
his MA in Language Technology from Uppsala University in 2004, and he is one of the
core developers
of the open-source eXist-db native XML database.
Joseph Wicentowski is a historian who specializes in the use of open standards to
improve the
accessibility and utility of scholarly editions. Since completing his Ph.D. in History
at Harvard
University in 2007, he has spearheaded a project to convert a major diplomatic documentary
edition
to TEI, leveraging the XML family of technologies to enable editors, researchers,
and the public to
access texts online in multiple open formats. Wicentowski has led workshops on the
XQuery language
and the eXist-db open source native XML database at TEI@Oxford Summer School in 2010–11
and Digital
Humanities 2017, serves as a community liaison for the eXist-db community, and is
co-author of a
forthcoming book on XQuery for digital humanists in the Coding for Humanists series
from Texas
A&M University Press.
Wicentowski’s contributions to this paper represent his views only, and not the view
or policies
of the U.S. Department of State or the U.S. Government.
Creative Commons Attribution 4.0 International License (CC BY 4.0)
Abstract
We have identified four models for integrating digital edition content into eXist-db
[eXist-db], which are, in increasing order of dependence on eXist-db itself: 1) using Apache
[Apache] and PHP [PHP] to mediate between the user and eXist-db, so
that eXist-db provides only XML database services, 2) a pure XQuery framework for
building an eXist-db
web application [Web applications], 3) the eXist-db HTML templating framework [HTML templating], and 4) TEI Publisher [TEI Publisher]. Our examination and
comparison of these ways of conceptualizing and implementing the infrastructure for
a digital edition
reveals that each of them has advantages and disadvantages, primarily from the perspective
of
sustainability. These considerations apply to edition frameworks generally, and are
therefore not
specific to eXist-db, which has been used here as an example because of the number
of editions that
employ it and the variety of models it currently supports.
In the 1980s Reese’s Peanut Butter Cups, long owned by the Hershey Corporation and
one of the best selling
and most popular candy products in the US (Upton 2013), deployed an advertising campaign that
portrayed the idea of eating chocolate and peanut butter together as a serendipitous
pleasure. In one
television advertisement (Reese’s), two persons accidentally walk into each other on the
street, he eating a chocolate bar and she eating peanut butter out of a jar with—perhaps
surprisingly—her
finger. They collide, the chocolate bar winds up embedded in the peanut butter, and
they protest, in unison:
You got your chocolate in my peanut butter and You got peanut butter on my
chocolate! They both then, simultaneously, realize that they like the taste of the combination,
and
proclaim, still in unison, Delicious!, as an older man (apparently a grocer; he wears an
apron) suddenly materializes between them, standing uncomfortably close and silently
ogling the packaged
Reese’s Peanut Butter Cups that he holds up (for the camera; it is behind the field
of view of the two
principals).
Meanwhile, in a galaxy far, far away, the eXist-db native XML database was born in
2000. [Meier 2003] Created by Wolfgang Meier, who at the time was a researcher in the field of
sociology, to support projects that required the efficient processing of XML documents,
eXist-db was
released as a free, open source project that has enjoyed a broad following in the
world of XML and NoSQL
databases. In particular, eXist-db has often been used in publishing and digital edition
projects in the
humanities, including some designed and implemented by authors of the present report.
Since its inception,
eXist-db has provided the services one expects from any database management system
(DBMS): it stores records
(XML documents), builds persistent indexes, supports retrieval with a query language
(XQuery), and provides
the housekeeping functionality (e.g., user authentication) those processes require.
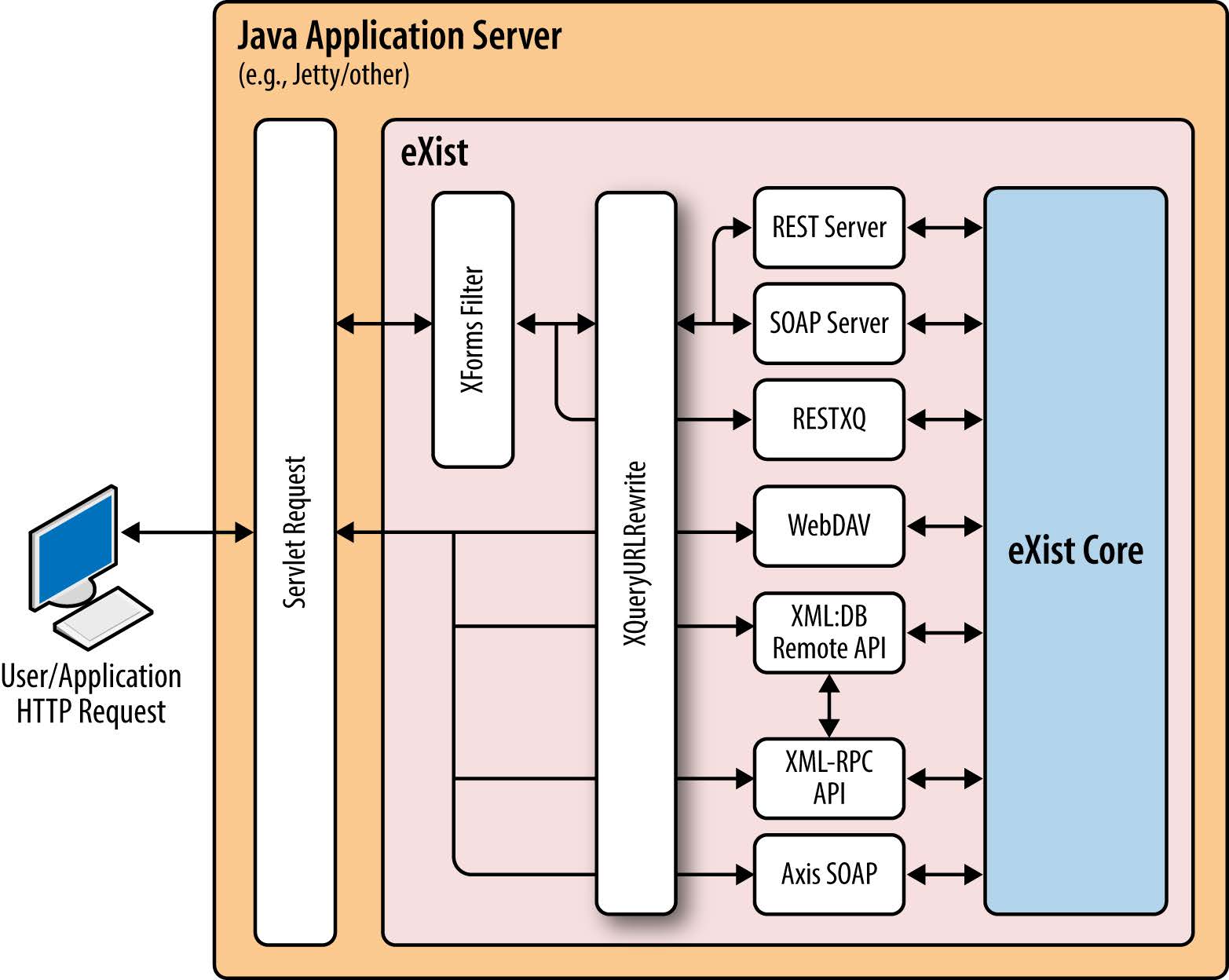
eXist-db is commonly
hosted inside an HTTP server and servlet container (it ships with Jetty, but other hosts
are also supported), which mediates between the user and the eXist-db functionality,
as is illustrated in
this image from Siegel and Retter 2014:
eXist-db web application platform architecture (Siegel and Retter 2014: 72)
Since its early years users have been able to interact with eXist-db by communicating
directly with the
Jetty server, and over time eXist-db has increasingly come to support features that
are more commonly
associated with a Content Management System (CMS) than with a database, such as themes,
templates, and page
management (not just data resource management). We might consider the eXist-db core
functionality, the DBMS
services at the innermost layer of an eXist-db installation, as analogous to the thick
peanut butter center
of a Reese’s Peanut Butter Cup, and the Jetty servlet container, which provides eXist-db’s
REST interface,
as the thin outer layer of chocolate. But the analogy does not depend only on the
fact that the eXist-db
DBMS services are wrapped, as it were, inside Jetty’s CMS ones. Peanut butter and
chocolate have a long
history as independently popular foodstuffs, and neither depends in any necessary,
obvious, or even
intuitive way on the other, yet their combination in a single product has proven impressively
popular with
consumers. Similarly, there is nothing about a DBMS that requires or expects CMS services,
and vice versa,
yet the growing integration of the two types of functionality within eXist-db confirms
that they can be
combined to create a resource for developing and deploying digital editions.
While digital editions based on eXist-db have been produced using a variety of architectures,
the release
of TEI Publisher 4.0 in December 2018 [TEI Publisher 4.0] provides an opportunity for
creators of digital editions, such as the authors of this paper, to review and assess
the existing
architectures in the context of this new one.[1] An implementation of the TEI Processing Model [TEI Processing Model, Turska 2015] that leverages Web Components for its default user
interface [Web Components], TEI Publisher can be said to turn eXist-db into a hosting
platform for digital editions that both goes very far beyond traditional DBMS services
and provides
functionality that would normally be expected from a CMS. The TEI Publisher documentation
says as much
explicitly (see especially the paragraph below the numbered list):
Despite its elegant
simplicity, various projects we realized in the past prove that the TEI Processing
Model is:
1. powerful enough to cover complex transformation needs
2. a truly universal tool for
any kind of digital edition
3. efficient and as fast (or faster) as handwritten
transformations
4. suitable for any XML, not just TEI (this documentation is written in
docbook!)
However, online editions require more than just a text transformation: the
text needs to be embedded into an application context, adding navigation, pagination,
search, facsimile
display and so on. The larger part of TEI Publisher deals with those aspects, providing
all the necessary
building blocks for an online edition. [TEI Publisher Quickstart]
After a digression about web application architecture, which serves as a reference
point for comparison
and discussion, in the following sections we describe four models for integrating
digital edition content
into eXist-db. These are, in increasing order of eXist-db dependence:
using
Apache [Apache] and PHP [PHP] to mediate between the user and eXist-db,
so that eXist-db provides only DBMS services;
using pure XQuery, as
implemented in eXist-db, as the server language for building web applications [Web applications];
using the eXist-db HTML templating framework [HTML templating]; and
Each of these ways of conceptualizing and
implementing the infrastructure for a digital edition has advantages and disadvantages,
primarily from the
perspective of sustainability. Those concerns are applicable to digital edition frameworks
generally, and
are therefore not specific to eXist-db.
Web application architecture
A typical web application architecture has a front end, or user-facing
interface; a middle tier, which handles interactions between the user and
the application data; and a back end, which is a data store of some kind.
In most web applications the front end is HTML, CSS, and JavaScript, and the middle
tier is dealt with by
some piece of software, often developed using a framework that takes care of common
tasks (see the examples
below). In many digital editions, the text exposed by the edition on the front end
may be be relatively
isomorphic with the source TEI XML on the back end. This is typically the case to
a large extent because the
TEI XML markup is an operationalization of a theory of the text, and the model expressed
by the markup is a
large part of the scholarly content that is to be made accessible to the user. Applications
like TEI
Boilerplate [TEI Boilerplate] and the Versioning Machine [Versioning Machine] are
designed for this type of situation; in different ways they select, style, and present
a view of underlying
TEI XML that is organized primarily by the XML hierarchy. CETEIcean offers an in-browser
JavaScript strategy
for rendering the XML TEI directly through the use of web components, and specifically
of HTML custom
elements. [Cayless and Viglianti 2018, CETEIcean] CETEIcean is capable of reorganizing the
DOM to support transformation, and can even create new content, but its developers
describe it as
appropriate especially in situations where the TEI’s model of the text can be usefully leveraged to
allow interesting dynamic functionality in the browser. [Cayless and Viglianti 2018]. Other types of
editions, though, may rely very substantially on structural transformation of the
underlying TEI XML, and on
the creation of new data objects. For example, an SVG graph of character interactions
in a novel (where the
individual nodes and edges do not correspond to specific XML elements or attributes
in the TEI XML source)
or a table of part-of-speech counts (where the counts are generated atomic values
not present in any overt
way in the TEI XML source) is also an expression of the data, but one that is not
at all isomorphic to the
TEI XML model. These views, too, may play a role in a digital edition that is designed
to express
interpretive aspects of textual scholarship that go beyond discrete source-level textual
data.
A digital edition based on the Text Encoding Initiative guidelines has some decisions
to make about its
back-end and front-end architecture. The methods we discuss here all assume that on
the back end the data is
stored in one or more TEI XML documents.[2] How will the content on the front end be created and presented?
Transformed to HTML or SVG or something else using XSLT, XQuery, or some other mechanism?
When will that
conversion occur—ahead of time or upon request? Will the conversion be cached or always
live? Will it happen
on the server or in the browser? Bound up with these questions is the decision of
how to structure the
software that mediates between the back-end content and the front-end presentation.
We use eXist-db as the
data store in all of the examples below, but each example makes different choices
about the proportion of
application logic and source-conversion entrusted to eXist-db.
The decision of where to place the application logic of a digital edition and how
to structure it may be
influenced by many factors, including performance, available developer expertise,
and software
functionality. The latter issue can be acute because of the stagnation of XML technology
development in some
areas. Common application frameworks such as Ruby on Rails [Ruby on Rails], Flask (Python) [Flask], or Django (Python) [Django] rely on libxml2 and libxslt for XML
processing, and therefore are restricted to XSLT 1.0. Java or ASP.Net-based systems
can make use of the more
modern XSLT support available in Saxon [Saxon], and the same is true of Saxon-JS [Saxon-JS]. eXist-db supports XQuery 3.1, but a decision to use it as a complete solution may
mean
relying upon it for things like user management and other functionality that could
be easier to implement on
top of a web framework. In addition, it may be easier to find developers qualified
to work with a common web
application framework than with eXist-db. With all of that said, there are obvious
advantages to working
with XML-related processing solutions when dealing with XML data resources.
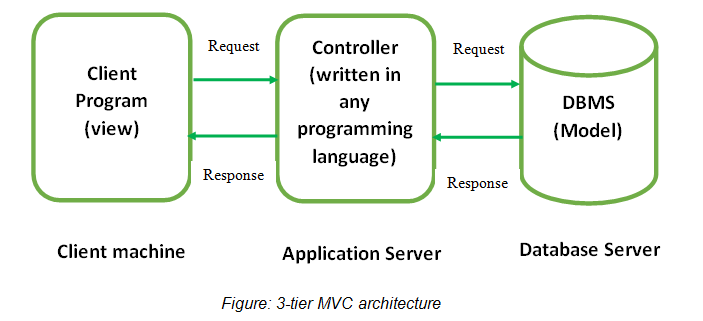
MVC is an architecture that separates an application into three components: Model,
View, and
Controller.[3] The
following explanation is based on MVC architecture:
Model: the data and core DBMS functionality. This corresponds to what we describe
above as the back end.
View: the user
interface (UI), such as web forms that accept user input and the HTML returned to
the user in response to
queries. This corresopnds to what we describe as the front end.
Controller: The interface between the model and the view. The
controller may translate user-supplied values from a web form (part of the view) into
a database query
(interacting with the model) and return the results (drawn from the model) as an HTML
page (part of the
view). This corresponds to what we describe above as middleware.
These
components and the relationships among them may be represented as follows:
The Model in all of the examples below is the XML data stored inside eXist-db and
the core eXist-db
database functionality that interacts with the data (e.g., the ability to interpret
XQuery and navigate
collections and resources). The View in all of the examples is the UI, that is, web
pages as presented to
the user, both those that elicit user input (such as query forms) and those that are
returned in response to
user input (such as formatted results returned from a query). The most variable aspect
of the examples below
is the Controller, that is, the part of the architecture that 1) responds to user
interaction with the View
by interacting with the Model and 2) updates the View in response to user activity,
often recruiting and
manipulating user-specified information retrieved from the Model.[4]
Four ways of building an edition with eXist-db
Web application middleware
A common architecture for web interfaces that incorporate a DBMS (relational, XML,
or other) is that
user requests are mediated by a standard HTTP server, such as Apache running on ports
80 and 443, which
delegates the job of processing requests to some middleware, such as PHP scripts,
web frameworks like
Ruby on Rails or Django, or many other alternatives. Under this approach, the front
end is generated by
the middleware, which queries the database (commonly via a REST interface) for information
to be
presented in the view. Views might be created by transforming XML to HTML with XSLT,
or by including
HTML fragments generated directly from eXist-db using XQuery. This architecture is
similar to that of
the fundamental open-source LAMP stack: Linux (OS), Apache (HTTP server), MySQL (DBMS),
and PHP
(middleware language), with the DBMS role replaced by eXist-db. Obviously, PHP is
only one option for
the middle tier language, and here it should be understood to be replaceable by any
language filling a
similar niche.[5]
The strictest implementation of this type of system in an eXist-db context relies
on eXist-db only as
an XML database, that is, as an alternative to the MySQL component of LAMP. For example,
a PHP script
running inside an Apache server on port 80, which is the only direct point of access
for the end-user,
might incorporate user-supplied form values into a constructed XQuery script that
is then passed into
eXist-db using the eXist-db REST interface. The results of the query are returned
to the PHP script,
which then shapes them into HTML, associates CSS and JavaScript, and returns a response
page to the
user. Under this stricter model, any CSS and JavaScript reside on the Apache server
because they are
part of the front-end functionality, and not of the DBMS services. And the only part
of the content of
the returned page (the modified View) that is connected to eXist-db is information
that depends on XML
stored inside eXist-db. The rest of the HTML returned page is a literal part of the
PHP script.
Looser implementations of this approach might offload additional Controller functionality
onto
eXist-db. For example, XML retrieved from inside the database might be transformed
to HTML markup inside
eXist-db, using the XQuery typeswitch() expression or XSLT by way of the eXist-db
transform:transform() function[6] instead of by the PHP script
after the eXist-db query returns. Looser implementations might also store the XQuery
script inside
eXist-db and pass it user-supplied parameters, instead of integrating the parameters
into the query
within PHP before passing the entire constructed query into eXist-db. And looser implementations
might
store some front-end components inside eXist-db, such as CSS and JavaScript, although
these might most
properly be regarded as aspects of the View, rather than of the Model. What these
variations all have in
common, though, is that PHP provides all or most or, at least, some of the Controller
functionality of
the MVC architecture.
One advantage of using eXist-db only as a DBMS, and limiting its role as Controller,
is reducing
dependency on custom features of eXist-db. To the extent that this separation of concerns
allows the use
of standard XQuery, with no non-standard, implementation-specific features, users
may replace eXist-db
with an alternative XML DBMS, such as BaseX [BaseX] or MarkLogic [Marklogic], with minimal adjustment to the Controller. However, insofar as all XML DBMSs
rely to some extent on custom functions in custom namespaces[7], it is unlikely
that a useful application of any complexity will be able to avoid proprietary features
entirely. It is
nonetheless the case that an application that does not rely on application-specific
features at the
Controller level reduces—even if it does not entirely eliminate—the extent of the
lock-in to a specific
XML DBMS product.[8] The use of Free Software products, such as
eXist-db and BaseX, reduces it further. For certain types of application, a second
advantage may come
from limiting the use for dynamic (and therefore slower) querying of the database
in the construction of
most views. Relatively static outputs can be cached in the middle layer and regenerated
only when the
sources are changed, with dynamic querying therefore restricted to operations like
searching. This kind
of strategy can pay great dividends in application performance, although at the cost
of having to manage
a cache.
The principal disadvantage of using eXist-db only as a DBMS and locating all of the
Controller logic
in the middleware is an increase in the complexity of the overall architecture. Specifically,
in this
arrangement the Controller interjects a PHP layer between the View and the core XML
DBMS services
provided by XQuery within the Model, and the need to communicate between PHP and XQuery
introduces an
additional potential zone of failure. The separation of concerns (Controller in PHP,
which interacts
with a Model that understands XQuery) is generally (and not unreasonably) considered
a virtue because of
its modularity, since the connectivity between the two is mediated through an API.
For example, PHP that
knows how to communicate between a web form and a relational DBMS can be reused to
communicate between
the same form and an XML DBMS by adapting only the API-specific parts (for example,
by replacing SQL
queries with XQuery ones). But this modularity comes at the price of lengthening and
complicating the
distance between the View and the Model. For example, when a query fails during development
under this
approach, the failure may reside in the PHP code, in the XQuery code, or in a miscommunication
(REST
connectivity, API, or other). The PHP layer also complicates deployment because it
requires
configuration of both eXist-db and PHP resources on the host. With that said, this
is an old and very
widespread architecture in the relational DBMS world, as in the familiar LAMP architecture.
We have applied several varieties of this middleware strategy in production. The most
manageable
(easiest to develop, debug, maintain) arrangement has involved the following workflow:
The user enters information into an HTML form and submits the form, which fires a
PHP
script.
The script collects the input, sanitizes and validates it,
and executes a REST call to an XQuery script that has been installed inside eXist-db.
This avoids the
legibility challenges that arise when trying to construct an XQuery script while observing
PHP syntax. A
sample query as formulated within a PHP script might look like the following, where
REST_PATH has been declared with a value like
http://example.com:8080/exist/rest in an imported file, and the $country and
$text variables are user-supplied values retrieved from the web form, after validation
and
sanitation:
eXist-db receives the REST call, dereferences the parameters with
request:get-parameter(), runs the query (previously stored inside eXist-db), transforms the
results to a well-balanced XHTML fragment using typeswitch or XSLT with
transform:transform(), and returns it to the PHP script.
The PHP script inserts the returned result in the correct place, the location of the
echo
file_get_contents($xql); instruction in the example above.
The result is a valid XHTML page, which the PHP script then returns to the user.
XQuery, the server language
Overview
The previous section relegated eXist-db to the MySQL portion of the prototypical LAMP
stack.
However, it is also possible to build applications purely with XQuery. In this architecture,
eXist-db functions as the entire AMP portion of the stack—handling the model, view,
and
controller.[9] The primary advantage of this model is that the edition’s developer need master only
one
core technology—XQuery—rather than many disparate ones. Kurt Cagle articulated this
potential in an
article published just months after XQuery achieved 1.0 status as a W3C Recommendation
in 2007:
Over the years, I’ve had the chance to program in a lot of different server-side
scripting languages—C, Perl, ASP, JSP, PHP, ASP.NET, Python, Ruby, among others …
As an XML
developer, one of the problems that I come across almost invariably within these languages
is the
fact that they are shaped by people who view XML as something of an afterthought,
a small subset of
the overall language that’s intended to satisfy those strange people who think in
angle brackets … A
few recent XML databases have taken XQuery to heart, and use it as the primary mechanism
for
accessing the XML database content. One in particular, the open source eXist-db project,
has gone
somewhat further, by inverting the normal sequence of working with XML where the XML
object or data
store is passed in as an object to the XQuery filter within the context of a server
session. In the
case of eXist-db, the various session objects—request, response, server, and so forth—are
instead
brought into the XQuery engine as externally defined XQuery methods. In other words,
in this
situation, the server-side scripting language is not PHP or ASP.NET or JSP, it’s XQuery.
[Cagle 2007]
Cagle argues that XQuery need not be limited to querying and analyzing XML documents;
it is fully
capable as a server language for web applications. eXist-db’s Request, Response, and
Session
extension modules give developers the ability to access HTTP request parameters (as
well as host
names, server ports, etc.), control session parameters, and return HTTP responses
with customized
status, headers, and body. An eXist-db application can even serve customized URL endpoints
via its
native URL Rewriting Facility or through its support for RESTXQ.
To illustrate the appeal of such an architecture, we explore here the syllabus of
a half-day long
seminar taught by one of this paper’s authors at digital humanities institutes to
participants who
had already completed a Text Encoding Initiative track, but who were not experienced
in application
development. In this short span of time, the instructor leveraged the participants’
newly acquired
knowledge of TEI XML to teach them enough XQuery to create a simple, dynamic, database-driven
web-based application. The goal of the application was to let users browse through
twenty
TEI-encoded issues of Punch, a satirical, Victorian-era periodical
used throughout the institute as a sample dataset. [Punch] Each issue has a title
and a number of sections, many of which are accompanied by illustrations. The application
presents
the reader with a list of issues, and the reader then clicks an issue to view its
contents (at
varying levels of granularity) by transforming the source TEI into HTML on the fly.
For pedagogical reasons the approach to developing this application was divided into
four major
stages, each designed to introduce a new set of techniques in application development
or
capabilities of eXist-db. Those techniques included:
querying a
collection of XML documents with XPath
sorting the results with
XQuery
creating HTML and serializing it in response to requests
from web browsers
transforming TEI into HTML
passing data between requests using dynamically-generated URL parameters
encapsulating commonly used code into functions
importing functions from library modules
implementing full text search
The learning outcome goal was
that by acquiring these skills the institute participants would be empowered to create
editions of
their own as customized applications.
Stage 1: Creating a basic edition
In preparation for building the application, institute participants download and install
eXist-db
on their workstations and upload the sample collection of Punch
issues to the database, using eXide, eXist-db’s built-in integrated development environment
for
XQuery. Participants then build up from simple XPath expressions to a bare-bones application
that
shows a list of issues and lets readers choose an issue to view. They begin this process
by opening
a new XQuery window in eXide and creating an XPath expression that points to the titles
of all
issues in the
collection:
Submitting this query in eXide returns a sequence of TEI <title> elements.
Participants then extend this core XPath expression by constructing an XQuery FLWOR
expression that
iterates over the sequence of <title> elements and returns a new sequence of HTML
<li> elements. The return clause in their XQuery uses an enclosed
expression to obtain the string value of the title, preceded by an order by clause to
sort the sequence
alphabetically:
for $issue in collection("/db/apps/punch/data")/tei:TEI
let $title :=
$issue/tei:teiHeader/tei:fileDesc/tei:titleStmt/tei:title
order by $title
return
<li>{$title/string()}</li>
Because HTML <li> elements are valid only as children of
<ul> or <ol> wrappers, the participants then wrap this FLWOR
expression inside an HTML <ol> element to produce an ordered list. The participants
save this query, which creates valid HTML output, to the database, inside the v1
subcollection for modules for the first version of the application, as v1/list-issues.xq.[10]
Institute participants then leave eXide and navigate in their browsers to the URL
that eXist-db
exposes for their stored query: http://localhost:8080/exist/apps/punch/v1/list-issues.xq. This URL is serviced by
eXist-db’s Jetty server, which is configured to execute queries stored within the
/db/apps database collection via the /exist/apps URL space. By
default the query returns raw XML, which is not the desired result, so the participants
next learn
how to add an XQuery serialization declaration to their query, which instructs eXist-db
to return
the HTML result of the query as a web page instead of as raw XML. Finally, the participants
wrap an
HTML link around each title, pointing to a second stored query and including a URL
parameter, called
issue, containing the issue’s unique identifier (the issue’s file name). This will be
used to return a specified issue when a site visitor eventually clicks on an issue
title in the list
of issues.
To provide that issue view, participants next create a second module, v1/view-whole-issue.xq, which calls on eXist-db’s request:get-parameter()
function to retrieve the issue URL parameter. The query uses this issue identifier to
select the full textual content of the issue, its <text> element, in the
database:
let $issue := request:get-parameter("issue", "")
(: We take $issue, e.g. 1914-07-01.xml, and can reconstruct the path
: to this document in the database by concatenating the base path
: to all Punch data with the $issue parameter. :)
let $doc := doc(concat("/db/apps/punch/data/", $issue))
let $text := $doc//tei:text
(: snip :)
Because the eventual reader will require HTML, and not the TEI XML of the original
source, this
XQuery then passes the TEI XML through a function that transforms the entire TEI
<text> node into HTML, and it then inserts the results as a well-balanced HTML
block inside a <div>
element:
(: continued :)
let $title :=
$doc/tei:TEI/tei:teiHeader/tei:fileDesc/tei:titleStmt/tei:title/text()
return
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>{$title}</title>
</head>
<body>
<div>
<h1>{$title}</h1>
{
(: The tei-to-html:render() function takes 2 arguments:
: 1. The TEI we want to display
: 2. An optional set of parameters. In this case, we provide
: the "relative-image-path" for all TEI graphic elements;
: and we use "show-page-breaks" to specify that
: TEI pb elements should be shown.
:)
tei-to-html:render($text,
<parameters xmlns="">
<param name="relative-image-path"
value="/exist/apps/punch/data/"/>
<param name="show-page-breaks" value="true"/>
</parameters>)
}
</div>
</body>
</html>
This function for transforming TEI into HTML is located in an XQuery library module
supplied to
the participants, modules/tei-to-html.xqm, which we import in the
prolog of the view-whole-issue.xq
query:
import module namespace tei-to-html =
"http://history.state.gov/ns/tei-to-html" at
"../modules/tei-to-html.xqm";
The TEI-to-HTML module’s primary function, tei-to-html:render(), does a bit of
housekeeping and then calls tei-to-html:dispatch(), which recursively walks through the
entire TEI document, using the XQuery typeswitch expression to look at each node of the
TEI document and pass it to the appropriate function:
(: Typeswitch routine: Takes any node in a TEI content and
: either dispatches it to a dedicated function that handles that
: content (e.g. div), ignores it by passing it to the recurse()
: function (e.g. text), or handles it directly (e.g. lb). :)
declare function tei-to-html:dispatch($node as node()*,
$options) as item()* {
typeswitch($node)
case text()
return $node
case element(tei:TEI)
return tei-to-html:recurse($node, $options)
case element(tei:text)
return tei-to-html:recurse($node, $options)
case element(tei:front)
return tei-to-html:recurse($node, $options)
case element(tei:body)
return tei-to-html:recurse($node, $options)
case element(tei:back)
return tei-to-html:recurse($node, $options)
case element(tei:div)
return tei-to-html:div($node, $options)
case element(tei:head)
return tei-to-html:head($node, $options)
case element(tei:p)
return tei-to-html:p($node, $options)
case element(tei:hi)
return tei-to-html:hi($node, $options)
case element(tei:list)
return tei-to-html:list($node, $options)
case element(tei:item)
return tei-to-html:item($node, $options)
case element(tei:label)
return tei-to-html:label($node, $options)
case element(tei:ref)
return tei-to-html:ref($node, $options)
case element(tei:said)
return tei-to-html:said($node, $options)
case element(tei:lb)
return <br/>
case element(tei:figure)
return tei-to-html:figure($node, $options)
case element(tei:graphic)
return tei-to-html:graphic($node, $options)
case element(tei:table)
return tei-to-html:table($node, $options)
case element(tei:row)
return tei-to-html:row($node, $options)
case element(tei:cell)
return tei-to-html:cell($node, $options)
case element(tei:pb)
return tei-to-html:pb($node, $options)
case element(tei:lg)
return tei-to-html:lg($node, $options)
case element(tei:l)
return tei-to-html:l($node, $options)
case element(tei:name)
return tei-to-html:name($node, $options)
case element(tei:milestone)
return tei-to-html:milestone($node, $options)
case element(tei:quote)
return tei-to-html:quote($node, $options)
case element(tei:said)
return tei-to-html:said($node, $options)
default
return tei-to-html:recurse($node, $options)
};
For example, when the typeswitch expression encounters a TEI <hi>
element, it calls the tei-to-html:hi()
function:
declare function tei-to-html:hi($node as element(tei:hi),
$options) as element()* {
let $rend := $node/@rend
return
if ($rend eq "it") then
<em>{
tei-to-html:recurse($node, $options)
}</em>
else if ($rend eq "sc") then
<span style="font-variant: small-caps;">{
tei-to-html:recurse($node, $options)
}</span>
else
<span class="hi">{
tei-to-html:recurse($node, $options)
}</span>
};
While this transformation module is provided as is to the participants (a concession
to time
limitations), they do have the opportunity to experiment by adding CSS specifications
to the output.
This exercise demonstrates that new users can easily learn to customize and extend
the HTML
transformation according to the needs of their particular edition.
The recursive typeswitch method above replicates the functionality of templates in
XSLT push processing, and readers familiar with XSLT may object to this method of
transforming XML
(use XQuery to query, use XSLT to transform!). But the XQuery approach is perfectly
valid with respect to the output it creates, and it has the pedagogical advantage
in the institute
context of allowing learners to focus their limited time on mastering XQuery. It is
certainly a
better alternative to forcing them to learn another language before being able to
transform their
data. which plainly would not be possible in the length of such a seminar. For users
who have
mastered XSLT or are interested in learning it, though, eXist-db has a
transform:transform() function for performing XSLT transformations, which passes the
node and stylesheet to a Saxon servlet that executes the transformation and returns
the result.
Meanwhile, though, this recursive typeswitch method empowers developers to perform
transformations in the same, unified server language—XQuery—as the rest of their application.
Stage 2: Creating a table of contents
The first version of the application works, but participants quickly realize that
it doesn’t make
much sense to display an entire issue on one web page. Thus, in the second version
of the
application, the participants replace the view-whole-issue.xq query
with a table of contents, view-issue-toc.xq. This query uses a
simple XPath //tei:div expression to retrieve all TEI <div> elements
and build a link using their child <head> element as the title of the section and
its associated @xml:id attribute as the section’s unique identifier, which it
incorporates, along with the issue identifier, into a link to a third query, view-section.xq. This query retrieves the two URL parameters, the issue and section
identifiers, and uses them to select the XML fragment corresponding to the
section:
let $issue := request:get-parameter("issue", "")
let $section := request:get-parameter("section", "")
let $doc := doc(concat("/db/apps/punch/data/", $issue))
let $text := $doc/id($section)
Having selected the section, the script passes it to the tei-to-html:render()
function.
This completes the second version of the application. The table of contents view is
a major
enhancement, but it is lacking: it displays the sections as a flat list, rather than
a nested list.
Also, it doesn’t give any sense of the length of a section, which might range from
a paragraph to
many pages. And, in the case of sections without titles, it simply displays (No
title).
Stage 3: Enhancing the table-of-contents view
To address these limitations, in the third version of the application we focus on
enhancing the
table of contents view. We copy the contents of the v2
subcollection into a new v3 subcollection and extend view-issue-toc.xq with a trio of related functions:
generate-toc-from-divs(), which creates a new HTML ordered list and passes child
<div> elements to toc-div(), which handles the text of the section,
calls the get-pages-from-div() function to dynamically generate a page range (which
could be useful for citations or inferring the length of a section), and then recursively
passes any
child sections back through the generate-toc-from-divs() function. This exercise
demonstrates that developers can easily customize their table of contents around the
needs of their
edition.
Stage 4: Creating a library module and packing the application
In the final version of the application, we refactor the code base by moving repeated
code into a
library module, creating a style:assemble-page() function, to which we send each page’s
title and content and which applies a common layout to our HTML page, and adding an
application-wide
search box, served by a search.xq query that presents the results
and is accessed through an eXist-db full text index.[11]
The final step is to add a few files needed to distribute our application as an EXPath
Package
[Package Repository]. The final project is available in a GitHub repository. [Punch]
Discussion
The result is a fairly polished application that is highly customized around the needs
of our
edition. Editions vary in their functionality according to the types of research they
are designed
to support, but the application demonstrates core techniques that will be needed to
build almost any
edition, which here include a collection view listing all issues, a table of contents
view of each
issue, and an item-level view of each section; the use of URL parameters to pass identifiers
needed
to locate items in the database; the use of XQuery to transform whole TEI documents
or portions
thereof into HTML; the use of functions and library modules to encapsulate code and
facilitate its
reuse; the use of the EXPath Package specification to facilitate distribution and
sharing of code;
and the use of eXist-db’s full text index to facilitate searching within the collection.
Institute participants were not expected to master all of these techniques in the
course of the
seminar. Rather, the purpose was to expose them to the iterative approach to hand-crafting
one’s own
edition using pure XQuery, as implemented by eXist-db, limiting dependencies on external
libraries,
which means using XQuery for querying data, transforming it, and publishing it via
web
technologies.
This approach has obvious merits both in general and as a way of introducing new developers
to
building editions that use TEI XML content, and its primary weaknesses are its mixing
of concerns
and its dependence on XQuery expertise. For example, some projects have modest-sized
teams that
enjoy a division of labor between members: a visual designer, a programmer, and a
text encoding
specialist. In the Punch application, in which all HTML output is
generated directly by XQuery script, a visual designer would need to learn XQuery
to alter the HTML
structures generated by the XQuery, and the editor whose focus is the TEI encoding
itself would need
to learn XQuery to understand and adjust how the TEI is transformed into HTML.
Recognizing these challenges, the eXist-db and TEI user communities have developed
new techniques
to accomplish a finer-grained separation of concerns required by many teams in practice.
These
include support for HTML templating and TEI Publisher, described below.
Apps with HTML templating
Like most CMS products, eXist-db has a templating functionality, one that is powerful
and completely
transparent in view components, and that supports annotations. The eXist-db templating
functionality
uses standard HTML5 @data-* attributes, e.g. @data-template for the template
and @data-template-* for optional parameters, and that functionality can be extended with
user-specified namespaced templating functions, e.g.:
Within templating, the current element is available via the %templates:wrap annotation,
and nested template calls have access to application data through the $model variable.
Manual processing control is achieved by calling templates:process.
The templating module can be referenced in the XQuery code:
to insert
the content into the template specified by the with template (here pages.html) at the element with the @id of produce.
Thanks to the power of nested template calls, major benefits of the HTML templating
approach in
eXist-db are 1) a clean separation between HTML and the XQuery code that populates
the HTML and 2) the
ability produce both mock-ups and production view components with more advanced search
forms and result
pages without turning to other solutions. The separation of concerns means that, for
example,
people should be able to look at the HTML view of an application and modify its look
and feel
without knowing XQuery [HTML templating], addressing one of the limitations
identified with the previous architecture.
HTML templating uses parameter injection to identify query parameters
automatically, without requiring explicit calls to the request:get-parameter() function,
and it also performs automatic type conversion. The logic underlying parameter injection
means that the
template processing makes best guesses about what the developer intends, which requires
the developer to
observe certain conventions. This has the virtue of reducing the behaviours that must
be described
through project-specific code, including annoyingly long and repetitive sequences
of assignments from
request:get-parameter() calls, but because some aspects of processing are no longer coded
explicitly by the developer, it requires that the developer remember how eXist-db
prioritizes the steps
it takes to resolve a parameter reference. Developers who have tried to fix a misbehaved
XSLT template
or Schematron rule or CSS specification only to discover that a different rule that
applies to the same
context is at fault may appreciate that at least when you get a parameter value only
by asking for it
specifically with request:get-parameter(), you are less likely to become confused about
where it comes from.
Beyond the inherent cost (and benefit) of ceding control to implicit behaviours, the
principal cost of
HTML templating is the possible need to translate idiosyncrasies of the templates
as implemented inside
eXist-db to a different template language. However, even in that case the initial
domain knowledge and
modeling remain intact and reusable.
TEI Publisher
TEI Publisher is packaged and distributed as an eXist-db web application that can
be installed into
any running eXist-db instance. It consists of two main parts. The first is a core
library, which
implements the TEI Processing Model (PM), introduced above and described in greater
detail below. The
second is a development environment to create customized standalone web applications
with built-in
facilities for navigation, pagination, search, facsimile display, faceted browsing,
etc. Such
applications, like TEI Publisher itself, can be distributed as xar
archives and installed into any running eXist-db instance.[12]
PM is a TEI-native vocabulary for expressing how XML documents should be transformed
and rendered into
various output formats (HTML, EPUB, PDF, etc.). It builds on the TEI ODD (one document does it
all, ODD), a specification originally designed to integrate formalized
documentation into customizations and modifications of the TEI. Because no document
is likely to make
use of the almost six hundred elements provided by the TEI, developers can use the
ODD to constrain
their project-specific schemas by including, excluding, modifying, or extending TEI
components. The ODD
can then export schemas in Relax NG, W3Schema, and DTD format, and because the ODD
incorporates
formalized, machine-actionable documentation, the developer can also generate reference
documentation to
be consulted during tagging. Although this is not always the way developers operate,
the TEI intends
that all TEI projects should be customized and documented with ODD.[13] In its early days the TEI regarded the E part of its name as definitive: the TEI was about text encoding, and not about text processing. PM moves beyond that earlier perspective by
incorporating processing information, in a formalized declarative and output-agnostic
format, into the
ODD alongside the information needed to create schemas and human-readable documentation.
PM lets users map TEI structures onto some two dozen fundamental abstract processing
or rendering
primitives called behaviours, which can be used to declare abstract
rendering information like render <p> elements as blocks, render <hi> elements as inline, render <list> and <item> elements as
components of list structures, etc.[14] The PM thus provides
formal, machine-actionable declarative processing instructions, expressed in TEI,
that are independent
of any specific output format or implementation language. The instructions were conceived
with the
twofold aim of being simple enough to be used by a human editor who is not an XML-technologies
engineer,
while also being sufficiently formalized to serve as operable instructions by a machine.
Editors record
their editorial intentions and expectations about the rendering (in a generic sense)
of their elements
by adding <model> child elements to the specification of an element in the ODD file,
and the <model> elements use attributes to bind these processing expectations for an
element (either globally or in a narrower XPath context) to a behaviour. For example,
a user could
specify how a <hi> element should be rendered along the lines of:
The <model> declaration above matches <hi> elements with a
@rend attribute value of it and expresses the intended rendition (italics)
with a child element <outputRendition>. The content of this element is expressed with
CSS syntax, but it is not restricted to CSS environments; the value represents a generic
assertion of
italics that may be transformed into a processing instruction in another syntax, as
required by the
desired output format. The content parameter in this case specifies that the entire matched
<hi> element should be rendered, but it is also possible to specify not the entire
content, but perhaps an attribute value, or the result of applying an XPath function
to the
content.
Three kinds of high level decisions are incorporated into the <model>. The first is
the content, expressed through a content parameter, which uses XPath expressions to specify
the content to be rendered. The other two pertain to how the content is
rendered, one aspect of which is structural (expressed through
@behaviour values like block or inline) and the other of which
involves appearance values for the <outputRendition>
child element, which might specify italics or small caps. As a more complex example,
to render related
regularization (TEI <reg>) and original (TEI <orig>) values inside
a TEI <choice> wrapper, the developer can specify the @behaviour value
as alternate. With HTML output, this might put the content of the regularization in the
base text and the original source text in a tooltip displayed on mouseover, or vice
versa, but because
the PM specification is high-level, abstract, and declarative, it can also be used
during print output
to write one value into the running text and the other after it inside parentheses.
The PM specification
for these two combines types of behaviour might look like:
If no output rendition is specified, the built-in XQuery function for the designated
combination of
behaviour and output format will be used. In the preceding example, alternate is a
predefined behaviour that creates the tooltip rendering for web output.
The value of @behaviour can be set to omit if the matched element is not to
be included in the output. For example, TEI page beginning (<pb>) elements can be
omitted during rendering with:
PM was developed initially in connection with the definition of the TEI Simple schema,
a schema
offering explicit and standardized options for displaying and querying texts that
a developer could make
use of to build transformations for a given output format (e.g., web, print, epub,
etc.).[15] TEI Publisher implements PM with a library of built-in behaviours defined as
XQuery functions for each output format. This implementation strategy offers sane
default mapping from
PM’s CSS-based style language to the various output formats. It also supports overriding
these defaults
with custom, output format-specific affordances, such as LaTeX boilerplate or XSL-FO
font definitions,
and it exposes extension hooks for XQuery functions for cases where the default PM
defined in the TEI
Simple schema alone cannot accomplish the desired results. For example, if we look
through the lens of
TEI Publisher at the tei-to-html:hi() XQuery function in the Punch tutorial described above, we see that it requires mapping a <hi>
element with a @rend attribute set to it (<hi[@rend='it']>)
in a way that is not served in the list of common behaviours defined by the TEI Guidelines
and used
mainly in the TEI Simple schema that serves as a default PM specification for TEI
Publisher. Earlier
versions of TEI Publisher provided a way to extend the behaviours defined in the TEI
Guidelines by
writing additional XQuery functions. For example, if this new behaviour was to be
called emphasis, it could be written
as:
declare function pmf:emphasis($config as map(*), $node as node(),
$class as xs:string+, $content) {
<em>{pmf:apply-children($config, $node, $content)}</em>
};
The
corresponding ODD model specification could then be mapped to this new behaviour as
follows:
The library part of TEI Publisher (tei-publisher-lib) release 2.5.0
introduced support for templates and user-defined behaviours within the ODD that lets
the user write the
same new behaviour directly in the ODD. For example, this emphasis behaviour could
(= should) now be
written as:
The
added value here is that some discursive documentation can be added in the <desc>
element.
TEI Publisher even leverages PM’s potential to support documents encoded in non-TEI
vocabularies,
which it illustrates by shipping with support for DocBook-encoded documents. The most
recent major
release, 4.0, was redesigned to use Web Components in its views, allowing users to
freely add, remove,
and combine panels containing different views, such as facsimile, translations, and
maps.[16]
Web Components are an upcoming W3C standard (or meta-specification) that provides
web developers with
a means to create reusable UI building blocks that encapsulates all the HTML-, CSS-,
and
JavaScript-based logic required for rendering. The large number of Web Components
already available
makes most adaptations possible with just some foundational knowledge of HTML, but
users with advanced
requirements can implement additional components on the basis of modeling experience
and knowledge of
the HTML5 specification, and specifically of defining new Web Components. As TEI Publisher
4.0 includes
a collection of Web Components targeted at creating digital editions, users are likely
to find that
without customization it already provides ways to embed texts into an application
context, supporting
the integration of navigation, pagination, search, facsimile display, and more.
The principal advantage of TEI Publisher, emphasized in the documentation, is that
by relying on
reusable high-level, generic behaviours, it can substantially reduce the amount of
code needed to create
transformation, a benefit that inheres both in code creation and in code maintenance.
For example,
Turska and Cummings write that:
For the Office of Historian project figures suggest
code reduction by at least two-thirds in size. Numbers are even more impressive realizing
that the
resulting ODD file is not only smaller, but much less dense, consisting mostly of
formulaic
<model> expressions that make it easier to read, understand and maintain, even by less
skilled developers. [Turska and Cummings 2016]
Wicentowski and Turska describe
the advantage of TEI Publisher for this same set of projects as follows:
[T]he new
TEI Processing Model (TEI PM) played a key role in the site’s plan for scalability
and sustainability.
By replacing custom-written code with TEI PM, the project shed years of legacy, custom-written
code–laden with duplication and conditional branches for different publications and
output formats–and
replaced it with a light and lean ODD file containing a single set of TEI Processing
Model instructions
that form the basis of all transformations for the site’s TEI-based publications:
HTML, EPUB, and PDF.
[Wicentowski and Turska 2016]
The principal costs of TEI Publisher, as with other web publishing frameworks, are
twofold. The first
cost lies in the start-up, that is, in the time and resource requirements to perform
a technology
switch. While TEI Publisher builds on ODD and XQuery, which users may have encountered
in other
contexts, they are unlikely to have learned and worked with PM previously. The second
cost, also shared
with any web publishing framework, involves the potential for lock-in, since building
a site within a
particular framework implicitly discourages migration to a different framework at
a later date. TEI
Publisher cannot eliminate these costs, but it mitigates both by using Free Software
and open formats,
and by following both actual (such as HTML5) and de facto (such as TEI) standards,
it reduces both the
start-up cost and the cost of potential future migration.
With regard to the question of potential future migration, it is illuminating to reverse
the
perspective and see it throught the implementation of the TEI Processing Model as
documentation driven.
If one accepts the possibility that in the long term HTML and Web Components might
become outdated and
replaced by other technologies, the technology-agnostic aspect of the formal documentation
within PM
will nonetheless continue to provide consistent and sufficient information about the
logic of the
intended processing and rendering of the elements. Eventual transformation to new
output code may be
inevitable, but the output-independent aspects of PM can at least shorten the portion
of the pipeline
that will need to be rewritten. It is also likely that instead of migration from a
translation of Web
Components into a new technology it will prove more efficient to start anew at the
source of the
intention, that is, the formal TEI expression of user output expectations or instructions.
From that
perspective, within PM the publication framework is documentation driven. By this
we mean that because
PM forces the user to define these instructions in a declarative manner, it can be
said that it enforces
format- and software-agnostic documentation, which may provide the best guarantee
we can have for a long
term transmission if not of the result, at least of the scholarly editorial intention.
The TEI Publisher implementation of PM acts, then, in a controller context, establishing
an efficient
binding from model to view that is also largely independent of the latter. Using the
technology of Web
Components, the views may be seen as modeling streams of documents as autonomous APIs,
which can be
fitted together like assemblable modular blocks, and which will constitute a collection
of standardized
base units that are highly reusable. To illustrate this design orientation towards
web standards and the
reusability principle, the blog post written by TEI Publisher's principal developer,
Wolfgang Maier,
employs the metaphor of Lego blocks:
Moving towards the emerging web component
standard, TEI Publisher 4.0 implements all this functionality as small lego blocks to be
freely arranged, recombined and extended.[17]
The TEI Publisher documentation states that: You do not need to know much about Web Components
to use them in TEI Publisher. In fact, users need to understand only how the web components they
want to use can be connected to the corresponding PM specification in an associated
ODD, a connection
that is implemented by setting the Components properties via attributes. As the Web
Components shipped
in the TEI Publisher are presented in the form of API documentation, users will be
able to understand
which attributes they will need to use. When setting themselves the task of designing
a new template
page for an edition, they will then have to specify the interface Components they
wish to use either
from among the TEI Publisher built-in Web Components or from external libraries, such
as Polyfills. But
insofar as the user will have mastered the data model of the corpus of XML encoded
files—the model—they
will be able to establish that connection successfully and in a way that is appropriate
for their
editorial purposes. Doing that within the framework of TEI Publisher, they will then
produce new
template designs—or views—that could potentially be shared by pushing them to the
Open Source code
repository of TEI Publisher.
To be sure, what is at stake here is not only, or even primarily, the technical reusability
of the UI
web blocks; it is also the underlying theoretical approach supporting the design of
the interface
template. For that reason, the theoretical potential of TEI Publisher will be for
fully attained when
collections of built-in Web Components will be grounded in a robust editorial theory
or a series of
editorial theories, each potentially populated by a subcollection of Web Components,
all supported by
communities of users commited to sharing them through an Open Source digital ecosystem.
Insofar as the
design of the view is a legitimate part of the scholarship, it, too, requires an open
infrastructure for
peer review and reuse. In this way it could be possible that the Lego blocks interface
design approach
implemented by TEI Publisher could play a major role in simplifying the design tasks
of the digital
scholarly editor, thus realizing not only a toolbox to build interfaces, but also
a toolbox to elaborate
proposals of scholarly editorial models that are theoretically and editorially based,
offering a stable infrastructure for digital editions and allowing a community of
academic users to reflect on the features that the scholarly community will consider essential to
a particular type of text or scholarly problem and to agree on some essential models
which take into
account the new affordances offered by the digital.. [Pierazzo 2019] In other word,
the architecture underlying TEI Publisher may be regarded not only a new flavor accidentally
brought to
the market, but as a laboratory of taste, helping users to collectively invent, experiment,
compare, and
refine the new flavors and meals adapted to their lifestyles and aspirations.
Conclusion
The interface and the scholarship
Two presentations at the 2016 University of Graz DiXiT conference Digital scholarly editions as
interfaces offered compelling arguments for regarding the vehicle for presenting edition data,
that is, the interface, as a scholarly product. This means that researchers who develop
digital editions
not only have a legitimate interest in the interface, but may also regard themselves
as under a
scholarly obligation to consider its meaning, because with or without their active
intellectual
engagement, the way a digital edition communicates with its readers is part of how
it expresses and
argues for a theory of the text. And this, in turn, means, among other things, that
the way TEI XML is
rendered in an edition is not a neutral presentation of a scholarly argument that
inheres entirely in
the TEI XML markup, but an inalienable part of that argument. Tara Andrews and Joris
van Zundert write
that:
The user interface of digital scholarly editions is often treated as a
content-free and ideally interchangeable appendage to that which is actually considered
the scholarly
effort or work–the examination and preparation of the text and the scholarly justification
for how this
preparation was carried out. (4) [… but …] Just as there is no clean separation between
data and
interpretation, there is no clean separation between the scholarly content of an argument
and its
rhetorical form (Galey 94).[18] We contend, moreover, that visual display and interactive
functionality are an integral part of rhetorical form. The interface is thus an integral
part of the
argument that an edition makes about a text. (8) […] User interfaces are a means of
communication of a
scholarly argument, and the decisions that go into their design are informed by the
message or messages
that the editor wishes to convey about the text. (30) [Andrews and van Zundert 2018]
Wout Dillen advocates for a similar perspective:
[D]ata visualisations or interfaces
are not the endpoints of our research, they are just the beginning. We use them to
try to make a point
about our data (36) …[T]he interface can be regarded as a second layer of editorial
interpretation:
after offering an interpretation of the edition’s documents by transcribing them,
the editor offers the
user an interpretation of her transcriptions when she decides on how to present them.
Stronger still, it
can be argued that the visualisation itself is at least as important for conveying
the editor’s
interpretation as the transcription on which it is based: as the main text the average
(non-TEI
proficient) user will come into contact with, the interface displays the edited text
in a way that
determines how the user will read and interpret the edition’s documents. The same
goes for the edition’s
navigation, lay-out, and its selection of tools. In a way, the interface is the digital
scholarly
edition’s new paratext: not exactly part of the edited text itself, it still has an
undeniable impact on
the way the user reads and understands the edition. This makes the interface an important
place for the
editor to convey her views on the material. 42) [Dillen 2018 36]
To the extent that the presentation of the edition data, then, is a
scholarly product, it is the proper business of scholars.[19] The TEI
XML alone is not the full or only scholarly product, and neither is its transformation
with a generic
presentation script, such as those provided by uncustomized use of TEI Boilerplate
or the TEI
Stylesheets. [TEI Boilerplate, TEI Stylesheets] If it is to fulfill its
scholarly potential, then, a digital edition publishing framework, such as the four
explored in this
study, should be 1) maximally configurable and 2) usable by digitally capable and
digitally willing
textual scholars. Each of the four frameworks is fully configurable, although they
differ in their ease
of use, perhaps in general, and certainly according to an individual researcher’s
technical expertise.
Those differences are explored below.
In his 2019 consideration of, among other things, the extent to which the data and
the presentation
contribute to constituting the digital edition, James Cummings acknowledges the fundamental
role of the
data; the analytical, interpretive, and communicative scholarly importance of the
interface; and the
unique value of API-mediated access in supporting reuse, that is, scholarship that
the original editor
may not have envisioned. About the centrality of the data Cummings writes that The encoded data
is a good representation of the scholarly edition and one I care about deeply. That is, the data
are essential. This echoes Dillen’s Without […] data, there are no editions–be they digital or in
print. The same cannot be said about interfaces. [Dillen 2018 36] Turning to
interface, Cummings then adds that [i]f part of the point of editing a work is to make it more
accessible, in all senses of that word, then usually some presentation view of the
edition is
required. That is, the presentation is a way of facilitating scholarship by communicating
scholarly interpretation. In part this echoes Andrews and van Zundert, cited above:
The interface
is thus an integral part of the argument that an edition makes about a text. Dillen writes,
similarly: […] it is exactly by reconfiguring our materials in new ways, by constructing an
interface around those materials, by interacting with other people, and by seeing
how the interface
shapes their interpretation of the data, that we keep developing our
own interpretations of those materials. [Dillen 2018 36]
Cummings, however, concentrates on the communicative potential of the interface in
a way that seems to
downplay what Andrews, van Zundert, and Dillen see as its added value as scholarly
analysis and
interpretation, and not merely the communication of scholarly analysis and interpretation
that happens
elsewhere. We thus disagree with the implicitly invidious rhetorical use of merely in
Cummings’s the presentation layer is merely one or more additional views on the data. But
insofar as a view on the data is analytical and interpretive, and therefore informational,
Cummings’s
position may be understood as valorizing the scholarly value of the presentation while
emphasizing that
no interpretation should be regarded as exhaustive or definitive, and that edition
data can and should
be made reusable for alternative analyses and interpretations.
Cummings advocates for the importance of this reuse when he writes that a truly conceptual
editorial object is malleable and recombinable, and an encoded edition, by itself,
is not […] the true
form of a scholarly digital edition would be better expressed as a well-documented
API for the
manipulation and description of editorial objects following an open international
standard for the
representation of digital text. We disagree with the rhetorical use of the true
form, where the definite article invidiously implies that there is only one, and
true invidiously implies that others are false. But insofar as presentations may be
limited by what the editor has anticipated, envisioned, recognized, understood, and
facilitated, we
agree completely that TEI XML plus specific presentational decisions do not exhaust
the potential
information value of an edition.
Cummings focuses on the primacy—at least in some cases—of reuse of the editorial objects
underlying an
edition by others when he writes the following:
[…] the underlying data may in fact
have been created not for a scholarly digital edition as a publication, but as a resource
to be
interrogated, analysed, or queried, rather than published. The publication of a scholarly
digital
edition can, and perhaps more often should, be a mere byproduct of the real research
undertaken. That
such information resources, in this case datasets of editorial objects, become corpora
for research
analysis. [Cummings 2019]
This view is compatible with regarding
the original editor, that is, the person who encodes the digital objects, as the first
such researcher.
In that capacity, fixed digital objects (in, for example, TEI XML) are one scholarly
product, the
interpretive and rhetorical views created by the editor are a different scholarly
product (thus Andrews and van Zundert 2018 and Dillen 2018), and the API is yet another scholarly product (thus
Cummings 2019). All, then, are digital scholarly components of a digital scholarly
edition.
General
Each of the four architectures outlined above is capable of generating a digital edition
from TEI XML
source using eXist-db, and the differences among them may be understood as including,
among other
things, the extent to which they rely on eXist-db-specific functionality. Increasing
reliance on
eXist-db for executing the transformation from model to view typically conveys an
increasing advantage
of lessening the extent to which the developer is required to write and maintain bespoke
code for the
edition, since the developer instead takes advantage, to varying extents, of what
eXist-db (or eXist-db
enhanced with PM support) already knows how to do. But with this reliance comes a
greater dependence on
functionality implemented in a specific way in (or perhaps available only within)
eXist-db. That
eXist-db HTML templating and TEI Publisher are implemented entirely with standardized
technologies like
XQuery and Web Components mitigates the lock-in effect because it means that the implementations
could be ported to a different DBMS/CMS environment. But that
transparency may be of limited immediate value to a user who is comfortable at the
application level
with XQuery, but not at the higher level required for migrating from the eXist-db
infrastructure to that
of BaseX or MarkLogic. On the other hand, the extent to which a commitment to one
of the four methods
described above entails a commitment to a specific platform, such as eXist-db, may
be less important
when we consider the lock-in aspects of the eXist-db URL rewriting facility, its Lucene-based
full text
index and query functions, and its newest feature in the forthcoming eXist-db 5, faceted
browsing (which
also uses Lucene). A project concerned about lock-in might be advised to worry more
about those layers
than about HTML templating or TEI Publisher per se.
TEI Publisher, by any fair measure, exemplifies an integrated and well-developed,
whole-cloth
conception of a starter system for publishing editions. The philosophy underlying
TEI Publisher
prioritizes exposing more control over the output specification while requiring less
programming
expertise. With that said, each project needs to evaluate which model serves it best,
assessing the
importance of each of the following considerations in the context of the project:
minimizing the dependence on any specific DBMS, so that the M layer of the LAMP stack
is limited to the storage and retrieval of data, using, as much as possible, open
and broadly supported
standards, such as pure XQuery and XPath
minimizing the number of
layers and languages (XQuery does it all)
separating concerns and
required skills by segregating HTML templates from the XQuery code that dynamically
populates the
templates (XQuery does it all except HTML scaffolding and superstructure)
minimizing custom transformation code and leveraging common behaviours (One Document
Does it All,
except HTML scaffolding, with XQuery limited to extension behaviours)
Different projects might reasonably make different choices from this menu.
Sustainability
All methods described above except the middleware one can use eXist-db’s xar packaging for one-step replication, distribution, and deployment. In contrast, porting
a
middleware implementation means configuring PHP and eXist-db to communicate, which
is much more
complicated to set up, to troubleshoot, and to maintain. A researcher end-user can
more easily install
eXist-db on a laptop and deploy an edition as a drop-in xar file than
install eXist-db, load data and XQuery into it, and also install and configure Apache,
install and
configure PHP scripts, and ensure that the pieces all communicate effectively.
Ease of use
Cummings argues that as much as possible editors of scholarly digital editions should not be
distracted from editorial tasks by technological concerns if these technological
concerns do not affect their edition. [Cummings 2019, emphasis
added] This idea, and the way it is worded, strikes a wise middle ground between two
extremes. One
extreme is the largely unrealistic requirement, implicit in the complexity of some
infrastructure and
application architectures, that the scholar will have highly developed programming
skills. This is true
of some digital scholarly editors, but not of all. The other extreme is the naive
assumption, implicit
in tools that wholly isolate the researcher from the methods implemented in the software,
that if the
researcher focuses on the content, the technology can be left in the hands of programmers.
Among other
things, software may embed scholarly assumptions that researchers need to understand
if they are to
accept responsibility for adopting the decisions the software makes on their behalf.[20] Ease of use may thus be understood
as not requiring unnecessary technological expertise from the researcher, while also
recognizing that
some technological concerns affect the edition, and thus must be made accessible to
the
researcher.
Ease of use may be measured in different ways. On the one hand, the four methods described
above, in
order from first to last, increasingly simplify configuration and customization within
anticipated,
supported parameters, requiring less—and often much less—custom code than a traditional
LAMP
architecture. On the other hand, in distributing responsibilities these more CMS-like
methods may
require increasingly greater coordination across parts of the CMS. For example, all
of the code for the
middleware approach, as the developer sees it, it located in just two places: the
scripting language
(such as PHP), which processes user input and creates output views, and the XQuery
inside eXist-db,
which retrieves information from the model. At the other extreme, TEI Publisher information
may be
distributed over multiple files in multiple libraries, and while in many cases the
user may not have to
interact explicitly with most of them, customization (such as the incorporation of
a new behaviour
written in XQuery) requires the ability to navigate a more complex resource structure.
It may be helpful
in this context to think of different roles in the development process. From this
perspective, the
greater complexity of the TEI Publisher model may fall only to a professional developer,
who can
reasonably be expected to have or to acquire the necessary skill. Meanwhile, the scholar-editor
may need
only to choose among supported behaviours and CSS-like rendering instructions, which
is a low
requirement for technical expertise. In comparison, the middleware organization, while
architecturally
simpler overall than TEI Publisher, requires much more advanced programming skills
from the user because
it does not aim to distinguish clearly a scholar-editor role and a developer role.
So what about those peanut butter cups?
If we return to our analogy of eXist-db’s XML DBMS services as the peanut butter core
of a Reese’s
Peanut Butter Cup and other eXist-db services (not only Jetty HTTPS services, but
now also app
processing, HTML templating, and PM) as the chocolate around that core, we might say
that the researcher
has a choice. With any of the frameworks described above the developer has control
over the selection,
arrangement, and presentation of the information. But to what extent do you want to
combine your own
peanut butter with your own chocolate and to what extent do you feel that the combination
offered by
Reese’s is superior to what you might produce yourself?
[Cummings 2012] Cummings, James. The compromises and
flexibility of TEI customisation. In Mills, Clare, Michael Pidd, and Esther Ward, eds, Proceedings of the Digital Humanities Congress 2012. Studies in the Digital
Humanities. Sheffield: The Digital Humanities Institute, 2014. Available online at:
https://www.dhi.ac.uk/openbook/chapter/dhc2012-cummings.
[Dillen 2018] Dillen, Wout. The editor in the interface: guiding
the user through texts and images. In Roman Bleier, Martina Bürgermeister, Helmut W. Klug, Frederike
Neuber, Gerlinde Schneider, ed., Digital scholarly editions as interfaces,
Schriften des Instituts für Dokumentologie und Editorik 12. Books on Demand, 2018,
35–59.
https://kups.ub.uni-koeln.de/9085/1/SIDE_12_digital_scholarly_editions_as_interfaces.pdf
[Pierazzo 2019] Pierazzo, Elena. What future for digital
scholarly editions? From Haute Couture to Prêt-à-Porter. July 2019, Volume 1, Issue 2, pp 209–20.
International journal of Digital Humanities (2019) 1: 179.
doi:https://doi.org/10.1007/s42803-019-00019-3
[Punch] Wicentowski, Joe. Punch. A simple application written in
XQuery for eXist-db demonstrating how to create a dynamic, searchable website for
TEI text.https://github.com/joewiz/punch
[1] The release of TEI Publisher 5.0 was announced
on August 2, 2019, too late for it to be included in this report. For details see
TEI Publisher 5.0.
[2] By or more we mean not only that
different witnesses in a critical edition might be stored in separate files, but also
that an edition might
draw on information stored in ancillary documents. For example, an edition that includes
epistolary
correspondence, such as Digital Mitford [Mitford], encodes each letter as a separate TEI
XML document, but metadata about persons, places, etc. for all letters is stored not
in the individual
letters (which would create massive repetition), but in a shared resource called the
site index. An edition of a letter as exposed to readers must incorporate information drawn
from
the site index.
[4] Two areas of variation in
the description of MVC are:
In some descriptions, although the Controller
translates user interaction (in the View) into instructions to the Model, the Model
returns directly to the
View, without passing through the Controller.
The dividing line between
the Controller and the Model is not always clear. Basic XQuery support (that is, support
for XQuery syntax
and the function library) is part of the Model, but whether a particular XQuery script
is part of the Model
(perhaps stored inside the database) or the Controller (perhaps constructed with PHP
and then passed into
the database) is less certain. The boundaries may be even harder to discern when all
three parts of the MVC
architecture are implemented inside eXist-db.
[5] Some other such languages have already been mentioned above, and include
Python, Ruby, and JavaScript.
[6] As of Version 4.6.1 (March 2019) eXist-db
supports a custom transform:transform() function in a custom namespace, but not yet the
standard XPath 3.1 fn:transform() function.
[8] The risk of lock-in with a controller outside eXist-db should also not
be minimized. Migration among PHP, Flask, Ruby on Rails, and Django is not always
seamless, and dominant
middleware products eventually go out of fashion (e.g., Perl CGI). Migration across
major versions of
robust, mature, and widely used CMS products may also be painful, as was the case
for many users with
the migration from Drupal 6 to Drupal 7.
[9] The eXist-db documentation provides advice about deploying the database
in production with a reverse proxy for security [Proxying eXist-db].
[10] Each of the four versions of the application project
are saved to different subfolders, labeled v1, v2, v3, and v4.
[11] eXist-db supports several types
of persistent indexes, one of which is a full-text index implemented via Apache Lucene.
See Configuring database indexes for details.
[13]Each and
every project using the TEI Guidelines is already dependent upon some form of customisation
even if it
is the tei_all example customisation with absolutely everything in the
TEI Guidelines. For many projects this is enough, but it does projects a disservice
if they do not
constrain and control the data entry for their project and document it with a TEI
customisation.
[Cummings 2012]
[15] TEI Simple was later renamed TEI simplePrint, and is described at Burnard et al. 2017. Like
TEI Lite [TEI Lite], TEI simplePrint offers a subset of TEI elements and attributes
regarded as adequate for a wide variety of encoding projects. But TEI simplePrint
goes beyond merely
customizing the TEI schema by also specifying rendering preferences in a formal way
through the use of
PM.
[16] This functionality could be achieved with other View components, such as by building
reusable
components with React.js [React], which brings it closer to web apps, as described
above.
[17] See also the new menu entry "vision" that
outlines the positioning of TEI Publisher as a community effort firmly grounded in
the principles of
Open Source, standards, and reusability.
[18] Galey, Alan. The human presence in digital
artifacts. Willard McCarty, ed., Text and genre in reconstruction: effects
of digitalization on ideas, behaviours, products and institutions, 93–118. Open Book
Publishers, 2010.
[19] The acknowledgement that
interface is scholarship should not be misconstrued as advocating against providing
full and open access
to all research data, which may include TEI XML document instances and the ODD that
defines and
documents how TEI has been used in the edition. There is no incompatibility between
regarding the
interface as scholarship and providing reusable access to all work products.
[20] For
a thoughtful perspective on how the use of software may or may not entail the acceptance
of scholarly
judgments by others see van Zundert and Haentjens Dekker 2017.
Andrews, Tara L. and Joris J. van
Zundert. What are you trying to say? The interface as an integral element of argument. In
Roman Bleier, Martina Bürgermeister, Helmut W. Klug, Frederike Neuber, Gerlinde Schneider,
ed., Digital scholarly editions as interfaces, Schriften des Instituts für Dokumentologie
und Editorik 12. Books on Demand, 2018, 3–33. https://kups.ub.uni-koeln.de/9085/1/SIDE_12_digital_scholarly_editions_as_interfaces.pdf
Cummings, James. The compromises and
flexibility of TEI customisation. In Mills, Clare, Michael Pidd, and Esther Ward, eds, Proceedings of the Digital Humanities Congress 2012. Studies in the Digital
Humanities. Sheffield: The Digital Humanities Institute, 2014. Available online at:
https://www.dhi.ac.uk/openbook/chapter/dhc2012-cummings.
Dillen, Wout. The editor in the interface: guiding
the user through texts and images. In Roman Bleier, Martina Bürgermeister, Helmut W. Klug, Frederike
Neuber, Gerlinde Schneider, ed., Digital scholarly editions as interfaces,
Schriften des Instituts für Dokumentologie und Editorik 12. Books on Demand, 2018,
35–59.
https://kups.ub.uni-koeln.de/9085/1/SIDE_12_digital_scholarly_editions_as_interfaces.pdf
Pierazzo, Elena. What future for digital
scholarly editions? From Haute Couture to Prêt-à-Porter. July 2019, Volume 1, Issue 2, pp 209–20.
International journal of Digital Humanities (2019) 1: 179.
doi:https://doi.org/10.1007/s42803-019-00019-3
Wicentowski, Joe. Punch. A simple application written in
XQuery for eXist-db demonstrating how to create a dynamic, searchable website for
TEI text.https://github.com/joewiz/punch
van Zundert, Joris J. and Ronald
Haentjens Dekker. Code, scholarship, and criticism: when is code scholarship and when is it
not?Digital scholarship in the humanities, Vol. 32, Supplement 1,
2017, i121–33. doi:https://doi.org/10.1093/llc/fqx006
Wicentowski, Joseph C. and
Magdalena Turska. Bringing TEI PM to Foggy Bottom. Claudia Resch, Vanessa Hannesschläger, and
Tanja Wissik, eds. TEI conference and member’s meeting 2016. Book of
abstracts, 155–56. Vienna: Austrian Centre for Digital Humanities, Austrian Academy of Sciences.
http://tei2016.acdh.oeaw.ac.at/sites/default/files/TEIconf2016_BookOfAbstracts.pdf