BalisageUp-Translation and Up-Transformation: Tasks, Challenges, and Solutions2017
How to cite this paper
McRae, Mary. “Looking for Rumpelstiltskin: A Case Study of Spinning Straw into Gold.” Presented at Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions, Washington, DC, July 31, 2017. In Proceedings of Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions. Balisage Series on Markup Technologies, vol. 20 (2017). https://doi.org/10.4242/BalisageVol20.McRae01.
Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions July 31, 2017
Mary first sat at a keyboard at the age of 6 and always knew that she’d pursue a
career in music until she traded keyboards and decided to pursue a career in
publishing technology instead. Since 1993, she’s been engaged in helping
organizations adopt structured markup along with the tools, techniques, and systems
that support content creation, editorial workflows, production, and content
management. She is a past OASIS Board Member (1999), and served as the OASIS
Technical Committee Administrator and Director of Standards Development from 2004
to
2010, shepherding standards – and the committee members that produce them – from
initial draft submission through final approval. Today, Mary is a member of the NISO
Z39-96, JATS: Journal Article Tag Suite Working Group as well as the BITS Working
Group.
Up translations are a black art; the stuff of conjurers and tricksters. The focus
of
this case study is the migration of unstructured and semi-structured formats to XML
for
a healthcare information provider with more than 20 different product offerings targeted
to healthcare facilities, insurers, and practitioners. This paper examines the
approaches taken to spin their unstructured and semi-structured content into XML and
the
challenges encountered along the way.
The focus of this case study is the migration of unstructured and semi-structured
formats to XML for a healthcare information provider with more than 20 different product
offerings targeted to healthcare facilities, insurers, and practitioners. Much of
their
content is maintained as fairly short articles that range from a paragraph or two
to
several pages in length. As their product lines – and the internal teams associated
with
the products – grew, so did the number of disparate systems and tools used to manage
and
deliver the content. The existing systems were aging, and print was no longer the
primary
deliverable. Their customers are constantly on the lookout for new and better ways
to
engage their end-users, whether they be providers, patients, or caregivers. In order
to
“continue on a path of innovation and momentum by offering even more digital options
for
patients and employees to access health solutions that enable around-the-clock health
engagement,” they needed to eliminate the departmental content silos and create an
architecture where all content – their corporate currency – could be shared, reused,
and
repurposed.
Table I
Current Systems Landscape
System
Description
Format(s) Used
A
used for metadata only; tracks medical review process and retains historical
version information
relational tables
B
older customer-facing platform; drives several products, such as one used by
hospitals to print patient discharge instructions
article content: modified HTML schema; metadata: relational tables
C
newer customer-facing platform; allows for some client customization
older system used by internal team to hold individual articles and images that
are then used to create custom publications for customers, such as wellness
newsletters
article content: Microsoft Word; metadata: relational tables
E
new customer-facing platform for resellers (output only); aggregate of
transformed content from systems B, C, D, and F
zip packages containing XML, HTML, images, and other assets
F
modular learning units
zip packages containing HTML, images, javascript, css, json, PDF, other
related assets
One of the first questions to be answered was how to best manage all of their content
"under one roof," and in a manner that would not only support content reuse across
product
offerings, but content reuse at a more granular level. While most of the existing
content
consisted of fairly short articles, they had already begun to experiment with modular
reuse
by incorporating fragments of existing articles into new, interactive product offerings
focused on wellness and patient education. They had also developed a new offering
that
allowed their clients to display or hide optional content, as well as assign values
to
variable content. They knew that, in order to continue to expand their offerings,
they
needed to migrate their content to XML. Not to be deterred by the level of effort
that
would be required to transform their existing content into XML, they were already
planning
new product offerings that they could automatically generate from an XML content library,
such as System E in Table I.
Choosing an Architecture
The content is varied; articles (the term is used loosely to identify content assets
most often delivered as a single unit) are identified as one of 30+ “types.” The key
requirements were:
to create and maintain content independent of the particular product or
products in which it is currently used,
to reuse content at a more granular level than article, and
to use a standards-based tag suite that would support the existing content
library with little to no customization.
In most environments, the choice of whether to use a standard markup tag suite such
as
DITA, S1000D, DocBook, or JATS, or to build a custom vocabulary, is driven by the
type of
content being produced. In this particular case, the source content is straightforward
–
headings, list items, an occasional table, often an image or two. No footnotes or
complex
tables; no citations to manage (at least not in the content itself); no linking within
or
across articles. No matter which architecture is chosen, the challenges would be same;
that
is to say, the ability to transform from the existing formats into any of the well-known
standards, or even a custom architecture, would be no more or less difficult. In many
cases, XHTML would be more than sufficient for this content. However, it's not just
about
maintaining the current state, but putting an architecture in place that will support
the
products of the future – modular content, semantic enrichment, on-demand output to
delivery
formats such as PDF and ePub, or delivery to downstream systems with their own unique
formats. Coupled with the need to continue to support content creation in Word and
the
availability of the DITA Open Toolkit and DITA for Publishers toolsets, DITA was chosen
as
the best option.
Some Types of Straw Are Better Than Others
The less structure, consistency, and semantic identification in the source content,
the
more challenging it is to create structurally and semantically rich content in the
resulting output. Some content types might lend themselves fairly easily to up translations
– consider recipes, for instance. If you begin with the premise that they all contain
a
title, a description, a listing of the ingredients, a set of steps to follow, serving
suggestions, and possibly nutritional information, the structure should be able to
be
inferred from the headings. If it's possible to ascertain the type of article from
the
content somehow – such as Recipe, Q & A, or How-To – then XSLT templates can take
advantage of the hints provided in the minimal structure, or even headings themselves,
to
help create a more structured result.
Unfortunately, just because documents are of the same "type" – such as Recipe – doesn't
necessarily mean that they were written or styled consistently. Unless the organization
is
in the business of creating cookbooks, it's likely that different authors used different
formats over time, and either followed differing style guides, or no style guide at
all.
Consider the following:
Figure 1: Recipe Sample 1
Figure 2: Recipe Sample 2
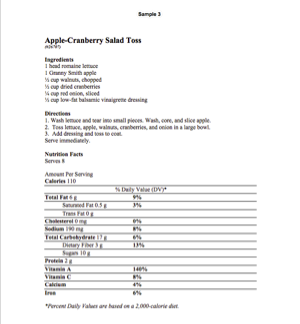
Figure 3: Recipe Sample 3
Figure 4: Recipe Sample 4
Figure 5: Recipe Sample 5
Although each recipe contains an ingredient listing, some directions, and possibly
nutritional information, the formatting of the content – with or without headings,
as a
list, a bulleted list, a numbered list, a paragraph or a table – would make it very
difficult to apply markup that could support reuse or automated composition.
These examples highlight another problem: if the goal is to create XML that conforms
to
a particular structure that will facilitate reuse, what should be done about non-conforming
content? While it's possible to do some automated restructuring of content, it's likely
that someone will need to go in and modify the content manually. When that step is
executed
– if needed at all – depends on the customer's requirements.
Unstyled Microsoft Word Documents
Microsoft Word documents present the biggest challenge. One of the product teams
authors and maintains content as Microsoft Word documents (System D in Table I). The collection includes short articles, Q & A, Recipes, and
other wellness information that is combined into newsletters, magazines, e-blasts,
or
other custom publications for their clients. The Word files are often shared with
clients beforehand, who may request changes to the content prior to incorporation
in the
final deliverable.
The articles themselves are short – fewer than 3 double-spaced pages in length – and
inconsistently styled (see Figure 1 through Figure 5). The most
commonly accepted approach when dealing with Microsoft Word is to develop a set of
named
styles (as opposed to the toolbar icons or the generic 'Heading 1' through 'Heading
n') that mimic, to a greater or lesser extent, the XML markup
that should be applied to a particular piece of content. There are a number of products
in the marketplace that act as add-ins to Microsoft Word that customize the toolbar,
restrict style usage, and through some behind-the-scenes coding, detect various bits
of
content and automatically apply the appropriate style. This is coupled with an embedded
transformation to a given XML vocabulary; the end result being a valid – and hopefully
correct – XML instance. In this particular case, neither the expense nor time needed
to
configure such applications was deemed worthwhile; instead it was decided that the
first
set of documents to be converted (approximately 3500 files) would be styled
manually.
The DITA for Publishers Toolkit provides a set of utilities to transform
Microsoft Word styles into DITA markup. The only pre-requisite is that your Microsoft
Word document has been styled using named styles and is saved in Word's XML format
(.docx).
Step 1: Since styles weren't used to create the original documents, a set of styles
needed to be created and then applied to the documents. Samples covering the various
document types were provided and Microsoft Word templates were created.
Step 2: A style to tag map file was created and tested with the sample set (see Figure 6.
Step 3: After several review sessions, a training session was held (and recorded),
and the team set about styling the initial batch for conversion.
Figure 6: Microsoft Word Style to DITA Tag Map Sample
Step 4: Run the transformations and QC the results.
The styling was fairly straightforward, however, since no toolbar customizations or
other developent was done, users weren't prevented from using toolbar shortcuts for
bold, italic, lists, etc., or from choosing character styles rather than an appropriate
heading style. In some instances, Microsoft Word-supplied styles were used rather
than
the custom styles. This resulted in character styling being dropped (while text was
not
lost, bold or italic was not carried forward), or hierarchical structures not being
created (a paragraph styled as body text with the character style "bold" applied to
the
entire content is not the same as the paragraph style "Topic - Section"), and in the
worst case scenario, mis-styled content being dropped. While the resulting XML is
valid,
it isn't correct.
Result: The content will need some additional cleanup – either
by fixing the Microsoft Word document and re-executing the transform, or editing the
resulting XML. In this particular case, since the Microsoft Word documents will continue
to be used until the project team is migrated off of their existing platform, it makes
sense to restyle the Word files.
HTML
Another product team creates and manages content related to diseases and conditions,
tests and procedures, prevention, management, and care, targeted to the patient, their
caregiver, or family members. This content is often presented as a collection of
articles, integrated into your health insurance provider’s, medical association’s,
or
practice’s website, discharge instructions received after a visit to the ER or hospital
procedure, or hand-outs after a medical appointment. All content in this group must
be
reviewed at least every two years, or whenever a change in protocol is recommended.
There are three different systems currently in use – one used to track the review
cycles, support an online medical review process, and maintain historical versions
of
record, and two other systems that are customer-facing and support a number of product
offerings. Two of the three systems are scheduled to be retired (See Systems A, B,
and C
in Table I).
The two customer-facing systems serve much of the same content to different
audiences. The older system (B) uses a custom schema to describe article content (see
Figure 7 – it's mostly HTML, but limits certain functionality and
incorporates several non-HTML elements to support the downstream applications.
Figure 7: Content Schema
While it's still possible to create a heading by applying <bold> to an entire
paragraph, users are much more likely to use the well-known <h#> elements to identify
the start of a section. What isn't typical, however, is for users to follow the logical
progression from <h1> to <h2> to <h3>, etc. Instead, depending on how they
think the heading should be styled, they might skip a level or two, progressing from
<h1> to <h3>, or skipping <h1> entirely and starting with <h2> or <h3>.
Throw the <Section> element into the mix, and the task becomes much more complex.
Thankfully, the <div> element was excluded from the schema.
The newer system (C) does not use a schema; instead, it uses the HTML5 tag set, and
supports modular content types not possible in the older system. The markup is much
more
complex, including the use of custom data attributes (<data-*) and an expanded use
of
@class attributes to further identify the content. The entire archive needed to be
searched to discover all of the data attributes and class attribute values to ensure
they were accounted for in the transform and that no information would be
overlooked.
This system also supports a segmented content model that explicitly identifies
sections that can be eliminated or revised at the client’s discretion. The <div>
element is supported as is <section>, and segments may be further broken down by any
one of <h#>, <div>, or <section> elements, in any combination. These articles
may have been in existence for quite some time; there is a requirement that they be
medically reviewed at least once every two years and updated in accordance with the
latest primary source literature. At least three different individuals are involved
in
sequentially reviewing the content and incorporating changes. The end result is
inconsistent application of markup to the content.
The initial set of documents to be converted consisted of 20 content types, including
four segmented types. As each type was added to the testing pool, new use cases were
encountered that needed to be addressed in the transforms. In one group of documents,
unordered lists contained nested unordered lists (ul/ul) rather than the sub-list
being
tagged as a child of an individual list item (ul/li/ul). In another group, images
were
tagged as bold (b/img). It was also very recently discovered that while
optional/required indicators were maintained on individual segments within the
customer-facing system, they weren't reflected in the HTML being used as the source
content for the transforms; in that instance, the export utility needed to be modified
to include an attribute on each segment noting required or optional and then added
to
the transform, and the four segmented content types reprocessed.
This content also makes extensive use of images (an average of 3 per article),
external links, and on rare occasions, links to other articles. The image references
were all hard-wired to IDs and locations in the existing system; the transform needed
to
resolve the IDs to image names and remove the hard-wired paths.
While more effort was required, the quality of the results is much higher and the
XML
is now the version of record. It should also be mentioned that more analysis, testing,
and refinement of the processes involved went into this content set, given its usage
(and accreditation status) within the medical community.
JSON
Another team is creating e-learning content (System F in Table I). for
patient and wellness education. The content is highly interactive, and designed to
be
viewed online from any type of device. The design itself is modular, with each "unit"
consisting of a shell index.html file, several javascript files, css files, images,
a
single PDF file that can be downloaded for future reference, and a set of three JSON
files that contain the actual prose.
Figure 8: Interactive MicroLearning Unit - Style 1
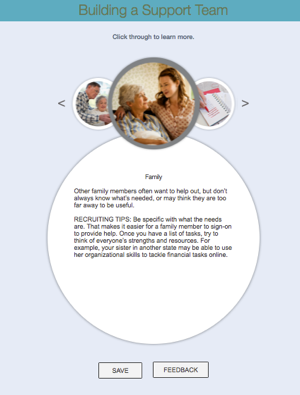
Figure 9: Interactive MicroLearning Unit - Style 2
There are currently 10 different styles in use, each one portraying information in
a
different format; several incorporate interactive quizzes. In Figure 8, as
the slider is progressed from left to right, the image changes and the corresponding
text appears in the circle below. In Figure 9, hotspot locations have been
identified and as the user clicks on each location, descriptive text is displayed
either
below or beside the illustration, depending on the size of the screen. This content
was
originally created by subject matter experts who reviewed existing article content
and
extracted relevent bits to be incorporated into a learning object; Word files were
then
sent to the developer and the text from the Word document was transferred and tagged
in
the JSON files. The long-term goal was for the subject matter experts to use styled
Microsoft Word documents that would then be transformed to create the necessary JSON
components.
This has been the most challenging of the transforms to accomplish both due to the
newness of the project and the inconsistent structure of the JSON templates. When
the
project was originally conceived, the plan was for content to be copied from the Word
document into the JSON file, giving the user the opportunity to incorporate any
additional markup or changes that might be needed. Over time, the learning unit
templates were refined and additional CSS rules added to facilitate automated
transformations. When we first began developing the transforms, we only had one or
two
samples of each of the styles; as more content was developed, the requirements grew
more
complex. Once we reached critical mass, we were able to go back and refine the work
that
had been done. While all of the styling is intended to be handled in the css files,
there are valid use cases where the defaults do not work; formatting instructions
are
slowly creeping into the Word styles and transforms. There are additional content
types
in the pipeline that will provide yet more challenges.
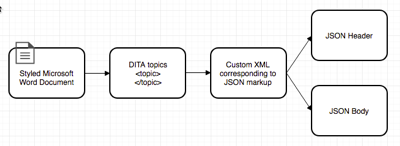
Figure 10: Word -> DITA -> MLUXML -> JSON
On any given day there is at least one learning unit created that doesn't function
properly; this is most commonly due to improper use of the designated Microsoft Word
styles. The plan going forward is to impement a forms-based content creation process
that will eliminate the reliance on user-applied styles and more closely align with
the
desired output.
Metadata
Metadata is maintained in at least 4 different systems, not including metadata
embedded in images. Different product teams use different taxonomies to identify similar
content. When transforming the articles, the associated metadata can't be left behind;
it's an integral piece of the content. Most of this metadata is managed in relational
tables in the legacy systems and is exported as XML. For those systems managing content
as HTML, the metadata is prepended to the HTML file and extracted; for systems managing
content as Microsoft Word files, a separate XML file is associated with the Word
document so that the metadata can be maintained along with the resulting DITA
files.
Since all of the content is intended to be managed in a single repository going
forward, the taxonomies needed to be harmonized; metadata that was required in one
system needed to be added to content from another; discrepencies in how metadata was
entered needed to be resolved. Take age groups, for example. One product team simply
used "child," "adult," or "senior," while another team used a more detailed breakdown
"infant," "child," "teen," "young adult," "middle adult," "mature adult," and "senior."
In another example, a fairly sophisticated medical taxonomy was matched up with a
more
consumer-friendly identification scheme. In yet another example, while the terms used
were fairly consistent across product groups, different identifiers were used –
serviceline vs category; and the reverse – audience used to identify two very different
sets of values. Decisions needed to made not only on the values but on the identifers
as
well, and then transforms written.
In addition to classification metadata, information relating to when an article was
last reviewed and by whom also needed to be retained, as well as, for the product
team
using Microsoft Word, where each article was used – including the name of the client,
the product, and the date.
In this particular instance, the content will be managed in a repository that sits
on
top of a MarkLogic database; the metadata will be maintained separately from the
articles themselves. In other use cases, some if not all of the metadata might be
embedded in the actual XML content. The planned environment is such that metadata
can be
extracted from or incorporated into the XML articles as needed.
Is it Really Gold?
Only you can decide what equates to 24 karat for your project, and which content sets
need to hit that target. In the U.S., 10 karat gold (41.7%) is the lowest gold content
that
can be marketed as gold; 24 karat is pure (100%) gold. In my personal ranking system,
10K
gold would be equivalent of the content being valid against the requisite DTD or schema,
and that no content is unintentionally dropped; 24K would imply that content has not
only
been accurately transformed according to element/attribute definitions, but enriched
–
adding markup where none previously existed by pattern recognition, positioning, or
editing
by hand.
Table II
Karats
Description
10K
minimum acceptable level. XML instance must be valid, and no displayable
content unintentionally dropped. markup may not be correct.
18K
all existing content (elements and attributes) correctly transformed;
hierarchical structures accurately reflected in the markup.
24K
the gold standard. all fragments have been properly identified (i.e.
bibliographic entries, intra-document cross-references, footnote
references/footnotes, external websites, semantic enrichment, other
application-specific information).
No matter what the source, all content should be checked for accuracy. The timing,
however, might vary. For the first group of content mentioned – articles authored
and
maintained in Microsoft Word – only the most recent content (authored less than 3
years
ago) was converted to XML; there's still a backlog of thousands of articles to be
addressed. They may be converted on an as-needed basis, or the decision might be made
to go
ahead and convert another batch – say, 3 to 5 years old, or content focused on a particular
topic that is still in demand. Regardless of when the conversion takes place, the
most
important thing to remember is that just because the resulting XML file is valid (that
is,
validates against a given DTD or schema), it doesn't mean it's correct. A visual inspection
might indicate some errors (for instance, bold or italic being dropped) but it will
be
harder to spot if a list is properly tagged as an unordered list with individual list
items, or simply a bunch of paragraphs beginning with a bullet character followed
by a
space.
As an example, as part of the post-conversion quality inspection, it was discovered
that
some articles contained references to websites that weren't captured as hypertext
links;
instead, they were simply bold or italic character strings. It was decided to revise
the
transforms to detect strings such as "http://," "https://," and "www." to try to auto-tag
as many of these references as possible, which would raise the quality of the resulting
content from 10k to 18k.
In Conclusion ...
The quality of the resulting XML is a factor of the quality of the input, the time
and
effort put into building the transformations, and the additional manual clean-up needed.
Time spent in any one of these three areas will reduce time needed in another.
The good news is that the current project is in the wash, rinse, repeat phase; that
is,
we will be executing the transformations multiple times over the next few months and
have
the chance to make improvements after each cycle is complete. We are successfully
delivering content to the newest customer-facing platform (System D), and expect to
retire
at least one of the legacy systems (System A) within the next few weeks.
One missing piece is a rigorous set of test cases. As each new content type was
reviewed, new challenges were identified, possible solutions explored and tested,
and
resolutions implemented. Each modifcation of the code required some amount of regression
testing to ensure that new problems weren't introduced, however the test suite is
far from
exhaustive. Ongoing plans call for the development of an XSpectesting framework.
Acknowledgements
The project could not have been successful without the direct involvement of the
individuals responsible for creating and maintaining the content, as well as members
of the
development team responsible for the systems currently in place. Without their ongoing
support of the project, including their willingness to attend meetings, review samples,
revise styles, give demos, answer questions, and most importantly, be patient with
those
less familiar with their content and their business, this would be yet another languishing
project instead of a successful migration to XML.
Lastly, thank you to the Balisage Peer Reviewers; your input was greatly
appreciated.