Introduction
"That’s right," shouted Vroomfondel, "we demand rigidly defined areas of doubt and uncertainty!"
— The Hitchhiker’s Guide to the Galaxy, Douglas Adams
This paper describes an internal project to develop a system for:
-
Running the CSS WG test suite of more than 17,000 tests on a CSS formatter;
-
Producing PDF output; and
-
Recording the status of the test results.
Just as importantly, the system needs to track whenever a test’s result changes so that the changes can be verified and the test’s status updated.
Finding differences is not the same as checking correctness. The first time that you look at a test’s result, you can (hopefully) tell if it is right or wrong. If the result changes, either because of changes in the formatter or because of changes in the test itself, you need to look at it again since:
-
The result could still be right;
-
The result could still be wrong;
-
The result could change from right to wrong; or, more preferably,
-
The result could change from wrong to right.
Origins
In the beginning the Universe was created.
This has made a lot of people very angry and been widely regarded as a bad move.
— The Restaurant at the End of the Universe, Douglas Adams
The current system has multiple origins or predecessors:
-
Antenna House Regression Testing System (AHRTS) – Software for comparing two PDFs or images – or two whole directories containing PDFs or images – and producing an overview report and plus individual reports for each pair of files with differences.
-
Customized AHRTS reports – Modifications and additions made to the default stylesheets for generating PDF of AHRTS reports from XML source.
-
CSS Working Group test results – The CSS WG have their own format for recording the status of a browser’s results for the CSS WG tests.
-
SVG and MathML test results – Previous tests of formatting of both SVG and MathML had their results recorded in a manually-maintained HTML file.
-
XSL 1.0 Candidate Recommendation test results – The XML format for recording a test’s result allowed recording both an indication of the result’s state plus a comment about the test result.
-
eXist-db demo application – The current eXist-db app started out by copying and modifying the demo app provided with eXist-db 3.0.0.
Antenna House Regression Testing System (AHRTS)
Out of the box, AHRTS makes a pixel-by-pixel, visual comparison of the differences between the PDF (or image) files in a ‘base’ directory against the same-named files in a ‘new’ directory. It produces an overview PDF report listing the state of each test file plus, for each test file with differences, an individual PDF report that contains some data about the ‘base’ and ‘new’ test files plus, for each page with differences, the individual PDF report has a page: showing the ‘base’ page; a composite of the ‘base’ and ‘new’ pages with the differences highlighted; and the ‘new’ page.
AHRTS can be run from a GUI or through the command line. As Figure 1 shows, its additional inputs are an ‘ahrts.properties’ file for controlling the operation plus the XSLT stylesheets for the overview and individual reports.
Figure 1: AHRTS block diagram
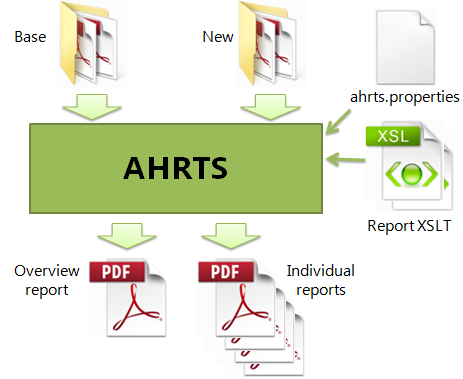
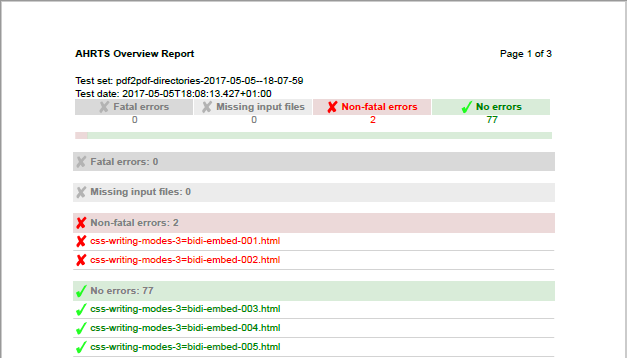
Figure 2 shows part of an AHRTS overview report with its indications of which files showed differences.
Figure 2: AHRTS overview report (detail)
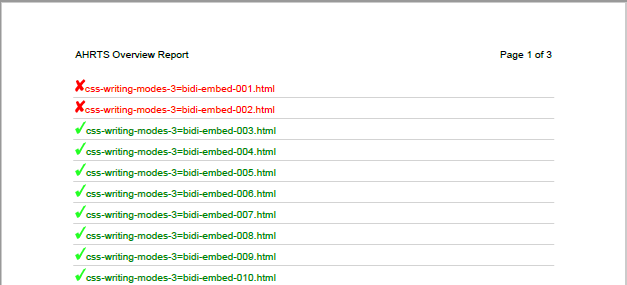
Figure 3 shows one page from an individual report. The same page from the ‘base’ and ‘new’ files are shown on the left and right panels, respectively. The center panel is an overlay of the ‘base’ and ‘new’ pages with their differences highlighted.
Figure 3: AHRTS individual report differences page
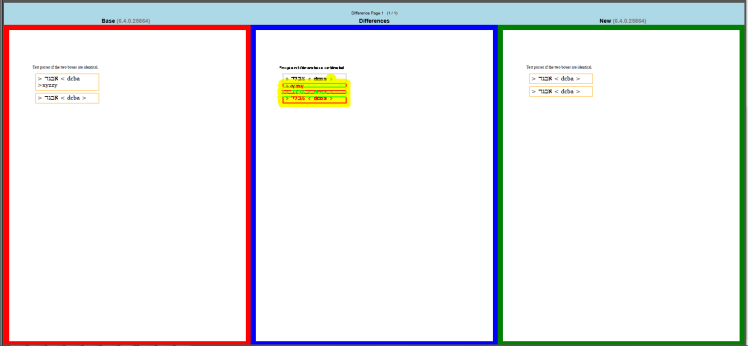
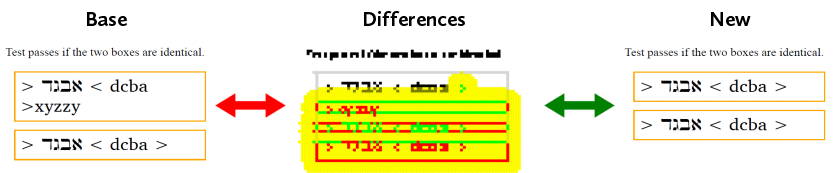
Figure 4 illustrates the overlaying of the ‘base’ and ‘new’ results and the highlighting of their differences.
Figure 4: AHRTS difference reporting
Customized AHRTS Reports
When I started working with AHRTS, it was to check the effect of my changes to XSL-FO processing. I didn’t want to look through pages of results to spot the ones with differences, so I used AHRTS and I used the Jenkins Continuous Integration Server to automate the running of both the formatter and AHRTS.
AHRTS generates its listing of differences as an XML file, and its PDF reports are produced by using XSLT to generate XSL-FO that is formatted using a built-in version of AH Formatter. Since the presentation aspects come from the XSLT, I also made an alternative XSLT stylesheet that groups tests by their results. From there, it wasn’t much more effort to add counts of each result type.
Figure 5 shows a portion of the overview report produced using the ‘alternative’ stylesheet that is included with AHRTS 1.4.
Figure 5: Alternate AHRTS overview report (detail)
With AHRTS 1.4, it’s now possible to include metadata from the ‘base’ and ‘new’ PDFs in the individual report, as Figure 5 shows.
Figure 6: Alternate AHRTS individual report (detail)

Setting the XSLT stylesheets to use is done in the AHRTS GUI’s ‘Settings’ tab, in the AHRTS properties file, or on the AHRTS command line.
CSS Test Suite Results
When it was time to check the CSS features defined in some of the newer CSS modules that were stable enough to be implemented, we looked again at how the CSS WG reports its results.
The CSS WG has a comprehensive test suite of about 17,000 test files (and growing) and has at least two test harnesses for looking at tests in a browser and reporting results. The test harnesses obviously aren’t unusable when producing PDF.
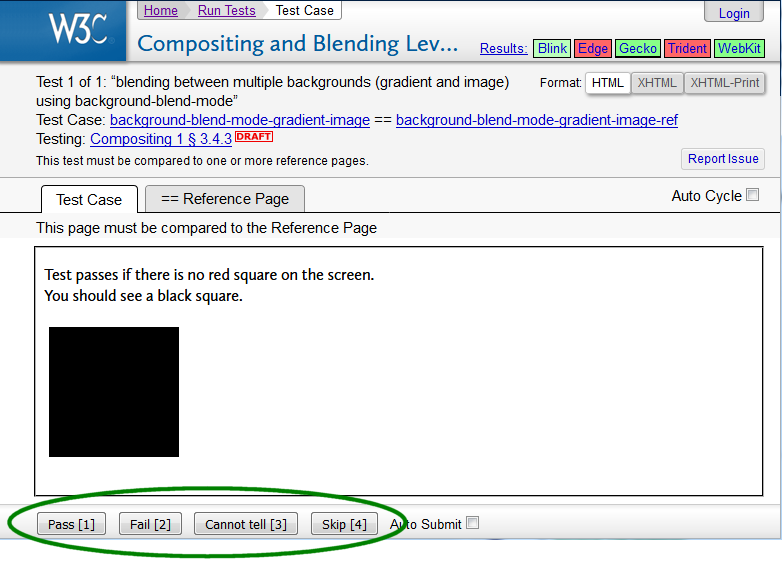
Figure 7 is a screenshot of a page from the CSS test harness in action. The buttons for selecting the status of the test result are highlighted.
Figure 7: CSS test harness
The CSS WG reports test results as one of five categories 1:
|
pass |
Test passes |
|
fail |
Test fails |
|
na |
Test does not apply |
|
invalid |
Test is invalid |
|
? |
Can’t tell or don’t know |
Since I was already using Jenkins to run both AH Formatter and AHRTS, rather than adding or writing yet another application, I wanted a simple way to use Jenkins to collect CSS test results. I made a version of the XSLT for individual reports that added a set of links, one for each CSS test result state plus a sixth that just copies the test’s PDF file. Each link triggers the same ‘testresult’ Jenkins job but provides different parameters, most noticeably the parameter indicating the test result.
Figure 8 shows a portion of an individual AHRTS report with the links for the test results highlighted.
Figure 8: AHRTS individual report with CSS result links

The ‘testresult’ Jenkins job simply runs an Ant task that appends the supplied parameter values as a new line in a log file and also copies the test’s PDF to the test job’s ‘base’ directory[1]. The next run of the AHRTS job uses the log file information to display the test’s state alongside the indication of whether the current result is the same as the base. And, since I already had similar plumbing for counting tests with differences, the summary report also showed counts of the reports with each state.
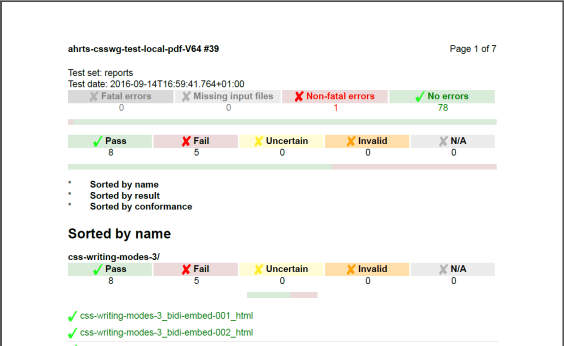
Figure 9 shows a portion of an overview report showing both differences found by AHRTS and test result statuses.
Figure 9: AHRTS overview report with CSS status (detail)
Localization
Along the way, I also implemented some localization functions in XSLT to make it easy to generate AHRTS reports in Japanese for use by colleagues in Japan. Figure 10 shows a similar portion of an overview report localized for Japanese.
Figure 10: Japanese AHRTS overview report with CSS status (detail)

AHRTS is written in Scala, and it uses Java property files in either textual and XML format for run-time lookup of localized strings. AHRTS’s XML property localization files are installed with AHRTS, so it was easy to write XSLT that would work with them.
The localization XSLT functions support lookup of fixed strings:
<fo:block>
<xsl:value-of select="axf:l10n('Test set: ')" />
<xsl:value-of select="overview/@test-set" />
</fo:block>
which can be subverted to look up more that just the text that appears in the formatted
output:
<fo:simple-page-master
master-name="report-page"
page-height="{axf:l10n('-page-height')}"
page-width="{axf:l10n('-page-width')}">
It also supports positional parameters for when the sentence structure differs between languages:
<xsl:copy-of
select="axf:l10n('Page %1 of %2',
($fo-page-number, $fo-page-number-citation-last))" />
HTML Report
However, and there’s always a ‘however’, I was now told that my colleagues in Japan wanted an HTML report. Producing an HTML version of the current overview report was straightforward, and it re-uses some of the existing XSLT modules that are more concerned with logic than with presentation. I was then told that they wanted a report in a format similar to that which had been used previously when testing SVG and MathML support, and they provided a copy of their current CSS test results.
Figure 11 shows a portion of the HTML report being produced by staff in Japan.
Figure 11: Manually produced HTML report (detail)
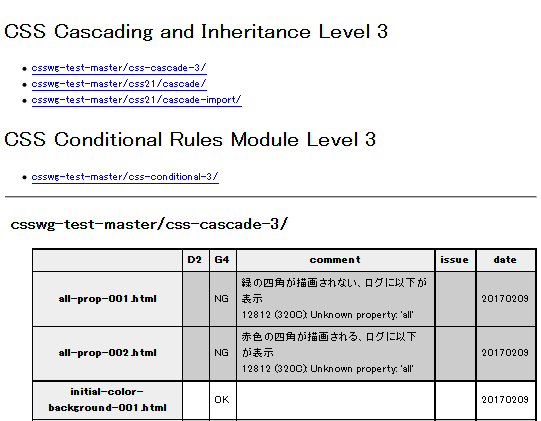
Their report just recorded the state of the test as ‘OK’ or ‘NG’ (No Good). The real ‘however’, however, was the possible additional comment about the test, issue number, and status of the issue’s resolution.
Adding the extra fields to the PDF for an individual report was straightforward. Instead of using just links, the test results were captured using an Acrobat form.
So far, so good, but this had four problems:
-
I couldn’t find a PDF reader for Linux that would submit the form, so had to use Acrobat Reader on Windows.
-
Acrobat could submit the form to Jenkins, and Jenkins could pass ASCII data to Ant okay, but Japanese text in the comment field was garbled in a way that I couldn’t decipher.
-
Acrobat would store every HTTP response from Jenkins in a different temporary file, and, for every response, Acrobat would pop-up a dialog box asking permission to open the file. Acrobat Reader could be made to trust remote sites, but apparently it can’t be set to trust local files.
-
Acrobat also views filling in the form as a change to the file, so it wasn’t possible to close the file without Acrobat prompting to save the ‘changed’ file. I’ve since been advised of a way to stop this, but by then I had already moved on to using eXist-db.
The encoding issue was the killer issue. It completely ruled out Jenkins for collecting test results, even though Jenkins was still wanted for compiling the code and running the tests. Collecting test results in a text file had always been a temporary solution. The intention had always been to move to using an XML database once the data was complex enough to justify doing so. The data still wasn’t particularly complex, but the need to preserve the Japanese text made a good reason to change.
eXist-db
So the project moved to using eXist-db 6. I chose eXist-db partly because I was more familiar with it than with BaseX, but also because I’d had more contact with the eXist-db developers so I knew who to ask if I had problems. I did have problems, but eXist-db has an active and helpful mailing list as well as developers who respond quickly to GitHub issues.
My approach to developing the eXist-db code was initially to copy and modify one of eXist-db’s demo apps. This worked, but the eXist-db documentation has evolved over time, and older documentation advises separate XQuery modules in the ‘modules’ collection, whereas newer documentation favors (almost) all XQuery code for the app in a single ‘modules/app.xql’ file.
Figure 12: App ‘About’ page and default page for a new application
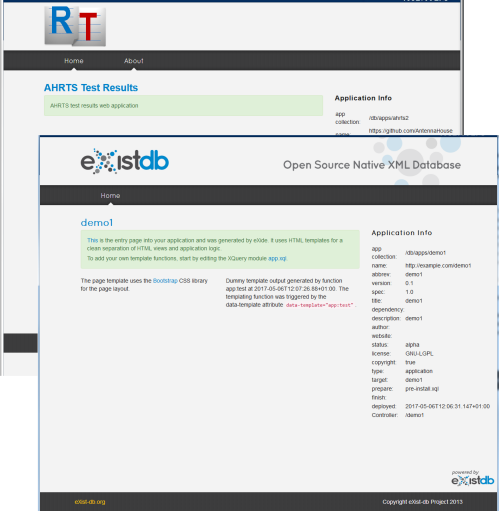
The initial attempt to use eXist-db was by inserting a link to the eXist-db ‘app’ in the PDF of an individual test result. I had also tried making eXist-db return a 206 HTTP response code and no response body (to avoid one of the problems with Acrobat) but I couldn’t get that to work.
eXist-db Application
Share and enjoy!
— Sirius Cybernetics Corporation motto
An XML database could solve the problem of how to store the data about the tests, but that didn’t solve the rest of the problems with the form in the PDF file. The usability breakthrough came when, instead of putting the form in the PDF, I put the PDF inside the form and created an eXist-db ‘app’ for reviewing test results in a web browser.
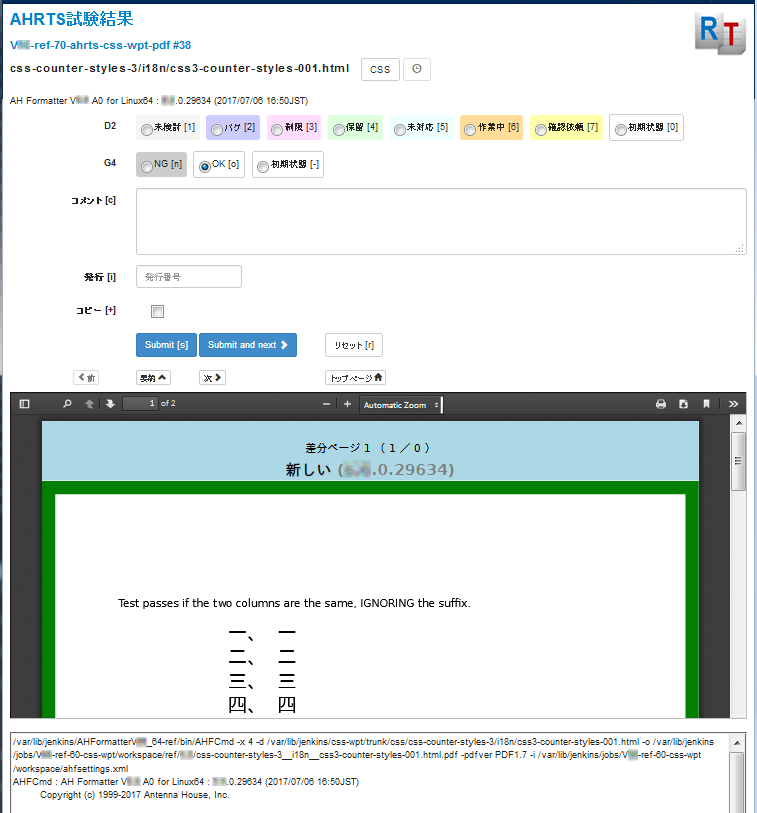
Figure 13 shows the first version of an individual report served from eXist-db, and Figure 14 shows a more recent version of an individual report.
Figure 13: Initial individual result page (reduced)
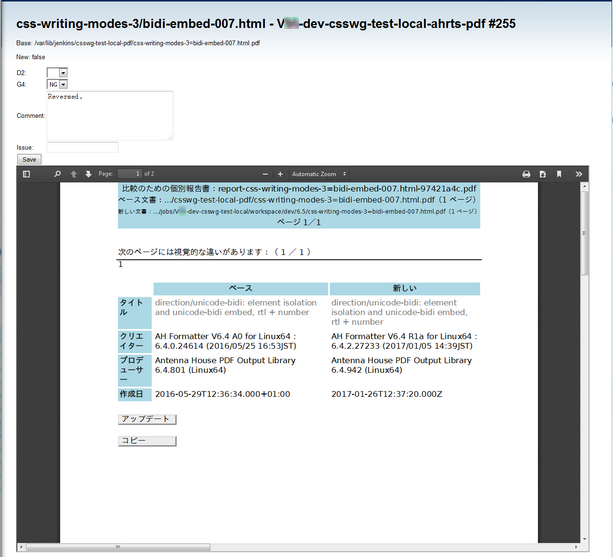
Figure 14: Later individual result page (reduced)
Loading
A sequence of Jenkins jobs runs the CSS formatter on the CSS tests then runs AHRTS to compare the latest result with a set of ‘base’ PDF files. The Jenkins job that runs AHRTS also uploads the AHRTS-generated XML files to eXist-db.
The XML for the overview report begins:
<overview date="2017-05-05T20:36:42.638+01:00"
overview-report-title="Vxx-ref-70-ahrts-csswg-test-pdf #252" test-set="reports">
<compare name="WOFF2-UserAgent=Tests=xhtml1=available-001.xht" module="WOFF2-UserAgent"
missing-input-file="false" error-detected="false"
individual-report-unicode-safe-filename-pdf="000000001_97421a4c.pdf"
fatal-error="false" difference-detected="true"
individual-report-pdf="report-WOFF2-UserAgent=Tests=xhtml1=available-001.xht-97421a4c.pdf">
<warn name="pdf-annotation">どちらのPDFにも注釈タグが含まれています。
タグは、レポートに埋め込まれたPDFには表示されませんが、比較に含まれます。</warn>
</compare>
This XML is augment before being uploaded to eXist-db to add the log from AH Formatter and to pre-compute some values.
The individual PDF files from AHRTS are also uploaded into the database. Storing PDF is arguably not a good use for an XML database, but it is much simpler than storing the PDFs elsewhere on the application server and then using URL rewriting to access them. My colleagues in Japan operate their own eXist-db instance, which was set up for them by their IT support staff with whom I have no contact. Since no-one in the Japan office had used eXist-db before, keeping the database installation as simple as possible is, for the moment, more important than shaving a few milliseconds off the time to serve a two-page PDF file.
Summary view
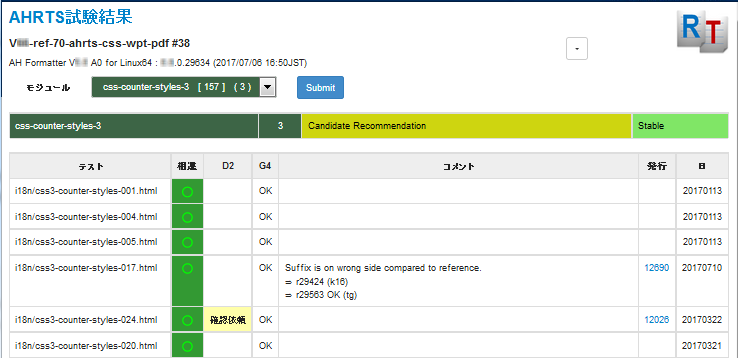
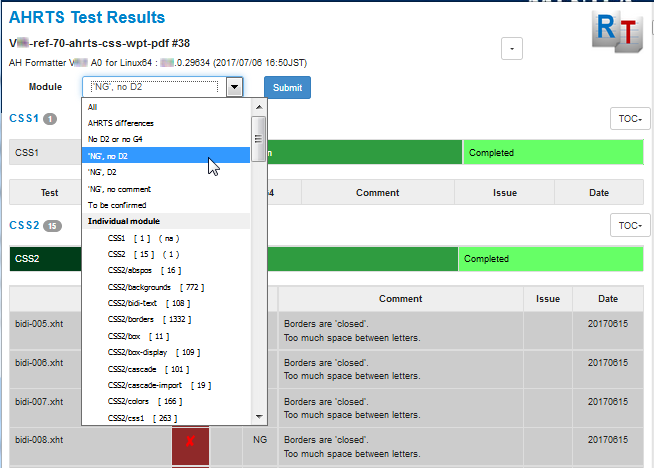
It is straightforward to generate a summary page from the overview XML. Early versions of the application generated a single HTML page with results for every test. Following a request by my colleagues in Japan, more recent versions present one module at a time, as shown in Figure 15:
Figure 15: Summary page
In theory, every top-level directory in the CSS tests corresponds to a same-named
CSS
Recommendation or Working Draft. In practice, some of the directory names differ from
the
short name of the module they test. Also, CSS 2.1 has nearly 10,000 tests, so the
subdirectories of the CSS2 directory – CSS2/colors,
CSS2/fonts, and so on – are treated as separate modules just to keep
things more manageable[2].
Individual test results
A sample testresults.xml file containing the information recorded about the
results of a single test is shown below:
<testresult date="20170630" ahf-version="AH Formatter Vx.x A0 for Linux64 : x.x.0.29482 (2017/06/27 09:25JST)">
<d2/>
<g4>OK</g4>
<comment>r28137:NG(Letters of the "Don't Panic" aren't friendly enough.)
r29557:OK</comment>
<issue>12345</issue>
</testresult>
The format of the XML was determined, firstly, by the information that was already being recorded by my colleagues in Japan (see section “HTML Report”) and, secondly, by needing a simple, ‘XForms-able’ form for the XML. eXist-db ships with two XForms implementations 7 – XSLTForms, which works client-side, and betterFORM, which works server-side. Indeed, the template XForms instance existed before the first results could be added to the database.
Once the XML format was fixed, however, two simple XSLT stylesheets were written to
convert the pre-existing log file and HTML results into testresult.xml files that were then uploaded to eXist-db to bring the database up-to-date.
Fatal Attraction
Files with fatal errors are sometimes the most interesting tests. However, they’re rather less interesting if you don’t know why they failed, and are totally uninteresting if you don’t know that they exist.
AHRTS compares PDF output from the CSS formatter, but it has nothing to work with if the formatter aborts with a fatal error because of a problem in its source. Reporting files with fatal errors to eXist-db and including the logs from all tests required more interdependency between Jenkins jobs and between Jenkins and eXist-db.
Firstly, the Jenkins job that runs the formatter had to be modified to save the formatter’s
log. Secondly, the Jenkins job that runs AHRTS was modified to add XSLT transforms
that augment the AHRTS overview XML to add compare elements for tests with fatal errors and add log elements to (almost) every compare.
The first attempt at saving the formatter log saved the log from the entire test suite
as one file and used XSLT to split the text when adding log elements to the overview XML. However, some of the tests generated control characters
in the log – for example, the "\f" in \format is a hexadecimal character reference that produces a literal Ctrl-o in the log.
That could be handled by switching the XSLT processing to use XML 1.1, which allows
control codes in the form , etc. The literal control code wasn’t a problem for the unparsed-text() function, but even the unparsed-text() function and XML 1.1 couldn’t cope with an unpaired Surrogate Pair character code.
To avoid a problem with one file affecting all logs, the current processing: saves
the log from each test as a separate log file; prepends and appends markup to each
log to make the log text be in a CDATA section in a log element; then accesses the XML logs from XSLT by using collection(). Tests with fatal errors now show up in the eXist-db app, and only a handful of
tests don’t also have the log from running the test.
Making changes to the XML before uploading it to eXist-db is a slippery slope. The
same Jenkins job now also runs more XSLT to group the compare elements by module and to pre-compute and annotate the compare elements with the result of a per-compare calculation that was previously done on-the-fly in eXist-db.[3]
Import and Export
As stated above, my colleagues in Japan also operate their own eXist-db instance with their own copy of the app. The Japan office maintains the master copy of the test results, so it was necessary to add a way to export results from my database for import into their database. eXist-db has XQuery functions for reading and writing Zip files 8, so this was quite easy.
Export
The web page for selecting the module or modules to export, and the date range of results from those modules, is shown below.
Figure 16: Export page
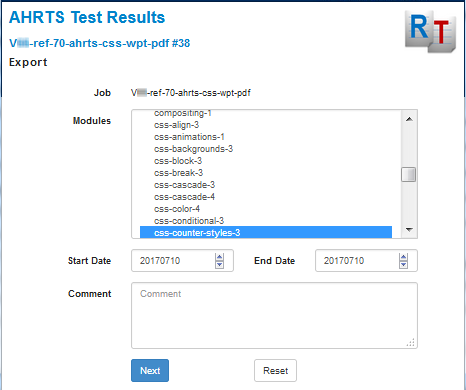
Clicking ‘Next’ takes you to a page where you can review your selection
before generating the Zip file to be downloaded. eXist-db provides a
compression:zip() function that takes a sequence of sources to zip. The
sources can either be an URI referring to a resource in the database or an
entry element for adding content to the Zip file on-the-fly. The exported
Zip file contains the test results plus manifests of what is being exported so that
a
person can make sense of what’s in each Zip file. In principle, multiple export Zip
files can be unzipped into one directory with no overlap of their metadata files (other
than export.xml) and the sum of the test results can then be uploaded
manually using, e.g., eXist-db’s Java client. In practice, no-one has had to do
that, since the import facility has yet to cause a problem.
let $job as xs:string := request:get-parameter("job", ()),
$start-date as xs:string := request:get-parameter("start-date", ()),
$end-date as xs:string := request:get-parameter("end-date", ()),
$modules as xs:string+ := request:get-parameter("modules", ()),
$all-modules as xs:string* := request:get-parameter("all-modules", ()),
$comment as xs:string? := request:get-parameter("comment", ()),
...
$tests-list-entry-name as xs:string :=
concat("tests-", $basename, ".txt"),
$tests-list-entry as element(entry) :=
<entry name="{$tests-list-entry-name}"
type="text" method="deflate">{
string-join(($tests, ""), "
")
}</entry>,
$export-entry as element(entry) :=
<entry name="export.xml" type="xml" method="store"><export
version="{$export-format-version}"
job="{$job}"
start-date="{$start-date}"
end-date="{$end-date}"
modules="{$modules-list-entry-name}"
tests="{$tests-list-entry-name}"
comment="{$comment-entry-name}"
/></entry>,
$testresults as xs:anyURI* :=
for $test in $tests return xs:anyURI(concat($compare-output-base-uri, $test, '/testresult.xml')),
$version-entry as element(entry) :=
<entry name="version.txt" type="text" method="deflate">{$export-format-version}</entry>,
$zip-name as xs:string := concat($basename, ".zip"),
$zip := compression:zip(($export-entry,
$version-entry,
$comment-entry,
$modules-list-entry,
$tests-list-entry,
$testresults), true(), concat($ahrts-data-home, $job))
return (
response:set-header("Content-Disposition", concat("attachment; filename=", $zip-name)),
response:stream-binary($zip, "application/zip", $zip-name)
)An example export.xml file is below:
<export version="0.1" job="Vxx-ref-70-ahrts-csswg-test-pdf" start-date="20160101" end-date="20170506" modules="modules-Vxx-ref-70-ahrts-csswg-test-pdf-css-counter-styles-3-20160101-20170506.txt" tests="tests-Vxx-ref-70-ahrts-csswg-test-pdf-css-counter-styles-3-20160101-20170506.txt" comment="comment-Vxx-ref-70-ahrts-csswg-test-pdf-css-counter-styles-3-20160101-20170506.txt"/>
Import
The web page for selecting an export Zip file to import is shown below:
Figure 17: Import form
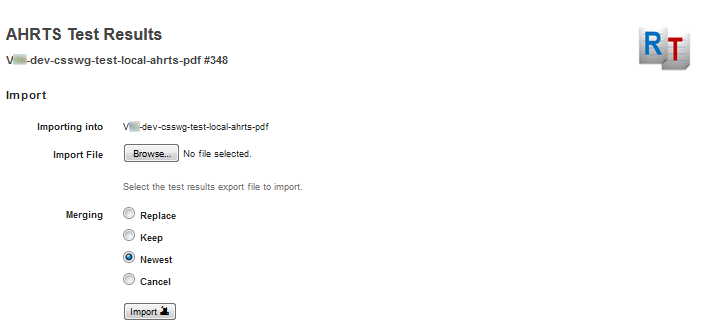
The only difficulty with importing test results is knowing what to do when the imported data has a result for a test that already has a result in the database. The form offers four alternatives:
|
Replace |
A result in the imported data replaces an existing result. |
|
Keep |
Do not import a result for which there is an existing result. |
|
Newest |
Use the newer of the imported or existing result for a test. When the date for both is the same, keep the existing result. |
|
Cancel |
Import the results from the import Zip file only if it has no duplicates with existing results. |
Importing a zip file also shows a summary of the imported data and the result of any merges:
Figure 18: Import check page (detail)
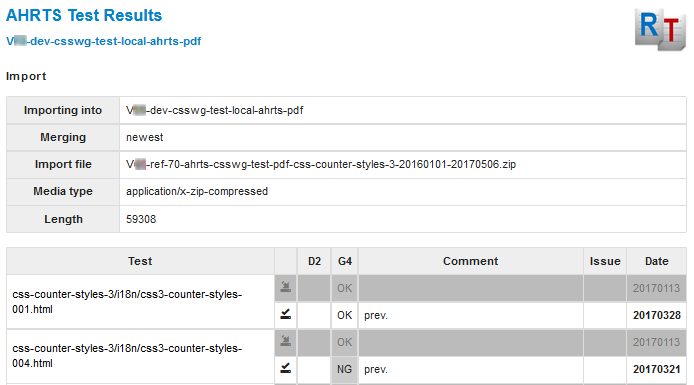
eXist-db also makes it easy to unzip files. The compression:unzip() function takes function arguments that are used, firstly, to filter out Zip-file
entries that are not to be extracted – in this case, the export.xml and textual metadata files – and, secondly, to do the actual storing of extracted
resources. Since the app shows a summary of the imported data and the result of any
merges, this second function simply returns information about the resource. This
information is to generate the table of results and is then reused to control the
storing of the data.
declare function
local:filter($path as xs:string, $data-type as xs:string, $param as item()*) as xs:boolean {
if ($path eq 'export.xml' or ends-with($path, '.txt'))
then false()
else true()
};
declare function
local:lookup($path as xs:string, $data-type as xs:string, $data as item()?, $param as item()*) {
let $job as xs:string := $param[1],
$merging as xs:string := $param[2],
$existing-path as xs:string :=
concat($ahrts-data-home, $job, '/', $path),
$existing as document-node()? :=
if (doc-available($existing-path))
then doc($existing-path)
else (),
$action as xs:string :=
if (exists($existing))
then if ($merging eq 'replace')
then 'replace'
else if ($merging eq 'keep')
then 'keep'
else if ($merging eq 'newest')
then if ($data/testresult/@date/string() > $existing/testresult/@date/string())
then 'newest-replace'
else 'newest-keep'
else if ($merging eq 'cancel')
then 'conflict'
else 'error'
else 'new'
return
[ $path, $action, $data, $existing ]
};
declare function
local:import-zip($file as element(file), $job as xs:string, $merging as xs:string) as item()* {
let $filter := function-lookup(QName('http://www.w3.org/2005/xquery-local-functions','filter'), 3),
$list := function-lookup(QName('http://www.w3.org/2005/xquery-local-functions','lookup'), 4),
$results as array(*)* := compression:unzip($file, $filter, (), $list, ($job, $merging)),
$html := local:results-to-html($results),
$conflict as xs:boolean :=
some $result in $results satisfies $result(2) = 'conflict'
return
(...,
if ($conflict)
then local:alert("Conflicts between imported and existing test results. Cannot continue")
else (<p>{local:store-results($job, $results)}</p>,
local:success("Inserted " || count($results[?2 = 'new']) || " results."),
local:success("Replaced " || count($results[?2 = ('replace', 'newest-replace')]) || " results."))
)
};Running Jenkins from eXist-db
The eXist-db app copies a test’s PDF output to the appropriate AHRTS ‘base’ directory using the same ‘testresult’ Jenkins job that was used back when updating was done using links in the AHRTS individual report PDF files. This, too, is straightforward since the eXist-db app can make a HTTP request to Jenkins to remotely trigger execution of the Jenkins job.
(: Get Jenkins to copy the 'new' PDF to the 'base' PDF directory :)
declare function common:jenkins-update($job as xs:string, $test as xs:string) {
let $config-uri := concat($common:ahrts-data-home, $job, '/jenkins-config.xml'),
$config as element(jenkins-config)? :=
if (doc-available($config-uri))
then doc($config-uri)/jenkins-config
else ()
return
if (exists($config))
then let $external-destination :=
concat('http://', $config/host, ':', $config/port, '/job/',
$config/updatejob, '/buildWithParameters'),
$copy-uri := concat($external-destination,
'?',
'RESULT=copy&PDFDIR=',
encode-for-uri($config/pdfdir),
'&TESTNAME=',
encode-for-uri($config/testname),
'&EDITION=',
encode-for-uri($config/edition),
'&VERSION=',
encode-for-uri($config/version),
'&NEWPDF=',
encode-for-uri($test),
'.pdf'),
$get := httpclient:get($copy-uri, false(), ())
return $copy-uri
else ()
};XForms or Bootstrap?
"Wait a minute," shouted Ford Prefect. "Wait a minute!"
He leaped to his feet and demanded silence. After a while he got it, or at least the best silence he could hope for under the circumstances: the circumstances were that the bagpiper was spontaneously composing a national anthem.
"Do we have to have the piper?" demanded Ford.
"Oh yes," said the Captain, "we’ve given him a grant."
— The Restaurant at the End of the Universe, Douglas Adams
When developing an XML project that uses a web browser, it’s hard to avoid thinking that you should use XForms. eXist-db ships with two XForms implementations, and so the first versions of the eXist-db dutifully used XForms for collecting input. However, eXist-db also ships with the Bootstrap, which is the HTML, CSS, and JavaScript framework that provides the look-and-feel of a large proportion of sites on the Web. Two of the three provided templates for an eXist-db app install Bootstrap in the new app, and, as shown in Figure 12, this app’s pages that don’t need forms do use the Bootstrap-based eXist-db design. eXist-db also provides an "HTML Templating Module" 11 that makes it easy to generate HTML pages, but none of the XForms examples in the documentation use it.
Bootstrap can also style HTML forms 12. Partly to provide a consistent ‘look’ for the app, but mostly because the XForms pages looked dated compared to the Bootstrap pages, all but one of the original XForms in the app have been replaced by HTML forms that are styled using Bootstrap. Can you pick which of the preceding screen shots uses an XForm?[4]
It is possible to achieve a ‘mostly-Bootstrap’ appearance by combining Bootstrap classes for structural elements with XForms markup for the form fields, for example:
<div class="form-group">
<label class="col-xs-2 col-sm-2 control-label">Import File</label>
<div class="col-sm-10">
<xf:upload id="upload1" ref="file"
mediatype="application/x-zip-compressed"
accept="application/x-zip-compressed">
<xf:filename ref="@filename"/>
<xf:mediatype ref="@mediatype"/>
<xf:size ref="@size"/>
<!--<xf:send ev:event="xforms-value-changed" submission="save"/>-->
</xf:upload>
<span class="help-block" style="margin-bottom: 0">Select the test results export file to import.</span>
</div>
</div>but the end result is still unsatisfactory since some parts of the form
don’t quite line up correctly and some aspects of the styling, such as the appearance
of the buttons, can’t be worked around, as shown in the following figure.
Figure 19: Bootstrap and XForms ‘Import’ buttons

HTML Templating
The HTML templating mechanism 11 is separate from Bootstrap. It provides a convenient mechanism for generating HTML pages since:
-
The bones of a class of pages can be provided by a single structural template HTML file.
-
An individual HTML page contains the HTML markup for just the part of the template – e.g., a
divin thebody– that are specific to that page. -
That HTML markup can include
data-*attributes to specify XQuery functions and function parameters. The result of an XQuery function can replace or be wrapped by the markup in the HTML file. Alternatively, the XQuery function can add values to an XQuery map that is available to all XQuery functions that are called for elements nested within the current HTML element. -
The framework also handles HTML parameters, which means less house-keeping code in your XQuery.
The theory, from the documentation, is that:
Ideally people should be able to look at the HTML view of an application and modify its look and feel without knowing XQuery. The application logic - written in XQuery - should be kept separate. Likewise, the XQuery developer should only deal with the minimal amount of HTML which is generated dynamically.
My practice, however, has tended towards putting a minimum in the HTML:
<div xmlns="http://www.w3.org/1999/xhtml" data-template="templates:surround"
data-template-with="templates/report-page.html" data-template-at="content">
<div class="col-md-12" data-template="app:individual">
<div class="row">
<div class="col-xs-10 col-sm-10">
<h1 data-template="app:individual-title">Generated page</h1>
</div>
<div class="col-xs-2 col-sm-2">
<a id="poweredby" href="index.html"/>
</div>
</div>
<div data-template="app:individual-form"/>
<div data-template="app:individual-nav"/>
<div data-template="app:individual-pdf"/>
<div data-template="app:individual-log"/>
</div>
</div>and doing more in the XQuery:
(: Populate $model for an individual page. :)
declare
%templates:wrap
function app:individual($node as node(), $model as map(*), $job as xs:string, $test as xs:string) {
let $report as element(report)? :=
doc(concat($app:data-home, $job, '/compareOutput/', $test, '/base_vs_new.xml'))/report,
$result := $report/analysis/result,
$base as xs:string? := $result/inputfile[@version = 'base']/string(),
$new as xs:string? := $result/inputfile[@version = 'new']/string(),
$compare := doc(concat($app:ahrts-data-home, $job,
'/reports/digest_vs_reports.xml'))/overview/compare[@name eq $test],
$prev as xs:string? := $compare/preceding-sibling::compare[1]/@name/string(),
$next as xs:string? := $compare/following-sibling::compare[1]/@name/string(),
$pdf as xs:string? := $compare/@individual-report-pdf/string(),
$log as element(log)? := $compare/log
return
map { "report" := $report,
"compare" := $compare,
"prev" := $prev,
"next" := $next,
"pdf" := $pdf,
"log" := $log }
};
(: Page title for an individual page. :)
declare function app:individual-title($node as node(), $model as map(*), $job as xs:string, $test as xs:string?) {
let $report := $model("report")
return
(<h1 class="main-title"><a href="index.html">{$config:expath-descriptor/expath:title/text()}</a></h1>,
<h3 class="report-title">
<a href="summary.html?job={encode-for-uri($job)}">{
if (exists($report))
then $report/@overview-report-title/string()
else $job
}</a>
</h3>,
if (exists($test)) then <h2>{translate($test, '=^', '//')}</h2> else ())
};
I find that the templating mechanism works quite well and is easy to use once you get the hang of it. One problem, however, is that the keys of the map entries are not validated, so a typo where the key is defined or anywhere where it is referenced can lead to a mysterious empty sequence simply because the keys don’t match.
‘=’ in file names
AHRTS can currently only compare files in two directories, and it does not look into subdirectories. Most test suites – including the CSS test suite – have files arranged in subdirectories. To get around this difference, the Jenkins job that runs the formatter would write the PDFs to file names where ‘=’ – which does not appear in any test file names – was used in place of the directory separator. This worked fine before eXist-db was used. However, ‘=’ needs to be escaped in parameters in URLs, and the ‘=’ in file names exposed multiple bugs in eXist-db. For example, collections with names containing ‘=’ can’t be opened in the eXide editor’s ‘Manage’ interface, and the only way found for deleting them is by using eXist-db’s Java interface.
To their credit, the eXist-db developers responded quickly to the initial bug reports, but fixing them all will take time. It was simply be more reliable to just use a different separator character sequence, but doing that required a lot of renaming of files on Jenkins’s file system and renaming resources in eXist-db. Since the PDF files couldn’t be renamed programmatically, the collection that contained them had to be deleted and a whole new set of PDFs uploaded.
CSS Tests now Web Platform Tests
In the first half of 2017, the CSS Working Group migrated from their tests from their own GitHub repository to being under a subdirectory of the Web Platform Tests project. Several of the modules were renamed during the migration, so it was necessary to migrate the corresponding test results to new URIs to match.
It is unlikely that export files from before the changeover will ever be needed again but, just to make sure that nothing is lost, the code for importing test results now handles both old file names containing ‘=’ and old, pre-WPT module names and maps them to current usage.
Localization
The practical upshot of this is that if you stick a Babel fish in your ear you can instantly understand anything said to you in any form of language.
— Hitchhiker’s Guide to the Galaxy, Douglas Adams
The current ‘app’ is almost completely localized for both English and Japanese. Some localization into English was necessary because the ‘D2’ states were initially only provided as Japanese text. Some of the localizations into Japanese were rolled back at the request of my colleagues in Japan because they found the English easier to understand than the notionally equivalent nouns and verbs that I’d plucked from an online English–Japanese dictionary.
eXist-db has a localization library 13 that uses files with a format that is very similar to Java XML property files.
<catalogue xml:lang="ja"> <msg key="Comment">コメント</msg> <msg key="Date">日</msg> <msg key="Diff">相違</msg> <msg key="Issue">発行</msg> <msg key="Test">テスト</msg> </catalogue>
Localizations are applied using i18n:text elements
in a mechanism similar to the HTML templating mechanism:
<tr> <th><i18n:text key="Test">Test</i18n:text></th> <th><i18n:text key="Diff">Diff</i18n:text></th> <th>D2</th> <th>G4</th> <th><i18n:text key="Comment">Comment</i18n:text></th> <th><i18n:text key="Issue">Issue</i18n:text></th> <th><i18n:text key="Date">Date</i18n:text></th> </tr>
This works well enough, but language selection (in my opinion) is not straightforward,
and the standard library does not provide the option of selecting the language from
the
browser’s Accept-Language header. At present, the app uses its own
version of the i18n library that is based on a versoin 14 by
Wolfgang Meier, one of the eXist-db developers. This version can use either the
Accept-Language header or a language setting configured in the app.
Using elements to handle localization isn't helpful for localizing attribute values
and
the functions provided for use from XQuery require specifying both the path to the
localization files and the current language, plus repeating the text in the
i18n:text element’s content and its key attribute seemed
redundant, so I made some convenience functions that wrap the regular i18n processing,
work
in attribute values, get the localization files’ path and language from the
app’s configuration, and require only one copy of the text, for example:
<input type="text" class="form-control" name="issue" id="issue"
placeholder="{common:i18n-text('Issue numbers')}"
value="{$testresult/issue/string()}" accesskey="i"/>No way has yet been found to localize the messages popped up by the BetterForms XForms implementation.
Dashboard
As stated previously, the mass of tests is divided into modules to make the work more manageable. Information about the modules and their relative priorities was initially maintained as a wiki page, but that was later migrated to a spreadsheet. When my colleagues in Japan wanted to also see the priorities in the eXist-db app, I both added a mechanism to paste tab-delimited text from the priorities spreadsheet into the app and provided a dashboard summarizing the results for each module and each priority level.
Over time, however, my colleagues in Japan have requested additional information on the dashboard for combinations of test result status values that are useful to them, as shown in Figure 20.
Figure 20: Dashboard
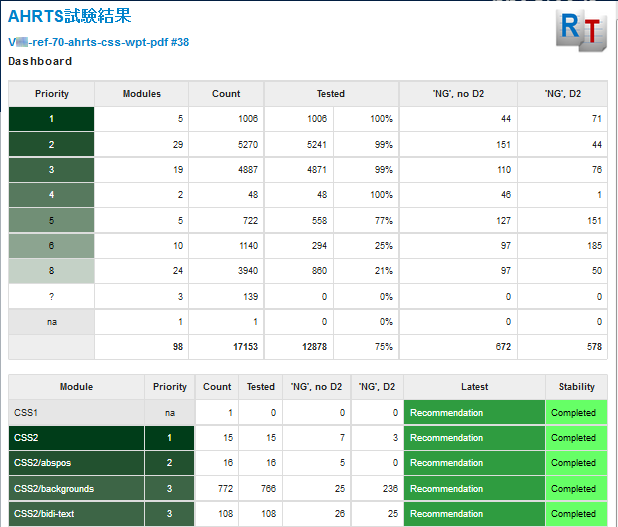
And despite their being the impetus for dividing the summary view by module, they also request views of all tests with particular status combinations, as shown in Figure 21.
Figure 21: New summary views
Conclusion
Feedback from colleagues in Japan has been uniformly positive. The effort required to correct problems and fill in comments is about the same as for the previous HTML form, but the advantages that they stated include:
-
Using AHRTS for automatically identifying changed test results is a big advantage.
-
Managing the tests is much more effective than with the HTML report.
-
Having the test result status, comment, AHRTS report, and AH Formatter log on one page is useful.
-
The extra functionality added during the course of the project has made it even more useful.
-
The system has saved time and effort.
Developing a system for checking the results from 17,000 CSS tests has had a few twists and turns, but the current implementation as an eXist-db app fits the requirements as they have developed over time, is proving useful, and has made the task much easier.
References
[1] https://lists.w3.org/Archives/Public/public-css-testsuite/2010Aug/0020.html, Implementation Report Template for CSS2.1 Test Suite
[2] https://www.antennahouse.com/antenna1/antenna-house-regression-testing-system/, Antenna House Regression Testing System
[3] https://www.w3.org/Style/XSL/TestSuite/tools/testsuite.dtd, XSL 1.0 Test Suite DTD
[4] https://www.w3.org/Style/XSL/TestSuite/index.html, XSL 1.0 Test Suite
[5] https://test.csswg.org/harness/test/compositing-1_dev/single/background-blend-mode-gradient-image/
[6] http://exist-db.org/exist/apps/homepage/index.html, eXist-db
[7] http://exist-db.org/exist/apps/doc/xforms.xml, eXist-db ‘XForms Introduction’
[8] http://exist-db.org/exist/apps/fundocs/view.html?uri=http://exist-db.org/xquery/compression&location=java:org.exist.xquery.modules.compression.CompressionModule, eXist-db Compression module
[9] http://localhost:8080/exist/apps/doc/build/doc-0.4.8/triggers.xml, eXist-db "Configuring Database Triggers"
[10] http://getbootstrap.com/, Bootstrap
[11] http://exist-db.org/exist/apps/doc/templating.xml, eXist-db "HTML Templating Module"
[12] http://getbootstrap.com/css/#forms, Bootstrap Forms
[13] http://exist-db.org/exist/apps/demo/examples/special/i18n-docs.html, eXist i18n XQuery Module Documentation
[14] http://markmail.org/message/l7x6bfyyg3ohwlna, Re: [Exist-open] I18n and 'Accept-Language' header?
[1] Ant works the same on both Linux and Windows, so using Ant avoids having to write both a Linux-specific and a Windows-specific version of the same script.
[2] With 1,332 CSS2/borders tests and 1,119 CSS2/tables tests,
‘manageable’ is a relative term.