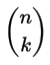Holstege, Mary. “The Concrete Syntax of Documents: Purpose and Variety.” Presented at Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). https://doi.org/10.4242/BalisageVol19.Holstege01.
Balisage: The Markup Conference 2017 August 1 - 4, 2017
Balisage Paper: The Concrete Syntax of Documents: Purpose and Variety
Mary Holstege is Principal Engineer at MarkLogic
Corporation. She has over 25 years experience as a software engineer in and
around markup technologies and information extraction. She holds a Ph.D. from
Stanford University in Computer Science, for a thesis on document
representation.
In the mid-eighties a group at Stanford built the MUIR language-development environment
as a system for notation design with rendering and layout from the abstract syntax,
parsing from concrete syntax, and semi-automated transformation between language variants.
We developed models for representing documents at all levels and understanding how
the levels relate to one another.
Presentation widgets have a purpose: to convey specific abstract syntax relationships.
Having an account of what kinds of widgets there are, what kinds of abstract relationships
there are, and how the two connect allows for an analysis of how the notation works
as a whole. The concept of "notation" taken here is a broad one, encompassing programming
or technical notations as well as the form of structured documents of various kinds.
Notation designers can apply such an analysis to improve their designs so that the
structure is more clearly conveyed by the concrete syntax or so that humans can more
readily use the notation without confusion. Software can render or parse instances
of notations using rules that capture the concrete syntax, the abstract syntax, and
the rules between them in a declarative.
The Muir system (Winograd87) was built in the mid-eighties as a language development environment: to support
parsing and rendering of samples of a programming language under development, but
to also support changes in language design over time, and the re-rendering of scores
of examples given changes to that design. As such, traditional parsing technologies
were not up to the task, as details about keywords and ordering are intertwined. In
addition, the motivating language relied on the use of nested space and tabular presentations
for many effects. Again, traditional parsing technologies were not up to the task,
and considerations that were normally part of document layout design came into play.
What did we learn building this system?
Separate the abstract syntax from the concrete system (aka separate presentation from
structure). For this system this amounts to almost a pre-requisite, as the concrete
syntax changed constantly.
Run rules both ways: from form to structure via parsing and from structure to form
via rendering.
Language versioning is a form of language translation, differing mainly in degree.
Language versioning entails transformations of examples and the application of new
rules. Some inference or human guidance may be required for difficult cases (see Normark87).
Use an abstract syntax specification that distinguishes rules that would manifest
in the structure from rules that allow better organization of the grammar itself.
In BNF, organizational non-terminals end up in the parse tree, but when the language
is changing, this becomes clutter than makes change and language-to-language transformation
more difficult. The Muir system used a kind of operator-phylum grammar derived from
similar grammars in Donzeau-Gouge80 and Notkin86.
Separate the type of abstract syntax unit from its (named) role within its parent
construct. The extensions made to the operator/phylum grammar gave us this, and allowed
us to target specific subcomponent with rules.
Separate concrete syntax into distinct mini-rules. For change, it is better to pin
keywords to specific pieces of the abstract syntax in separable chunks.
Presentation order relates closely to layout across space, and for non-lists is an
aspect of concrete syntax that can change from one language version to another.
Bootstrap from a self-describing meta-grammar (Holstege87). This allowed us to change the rules driving the system itself more easily, using
the system itself.
Holstege89 grew out of work on the Muir system, and extended the ideas to provide an account
for documents of various kinds. It extended the model with several key notions:
Presentation widgets have a purpose: to convey specific abstract syntax relationships.
Knowing the purpose of presentation widgets allows for analysis of a notation as a
whole.
The introduction of an abstract geometry as well as a concrete geometry, having a
similar relationship to each other as abstract syntax and concrete syntax do. The
abstract geometry describes an abstract partitioning of 2½D space and provides a target
for certain relationships. Concrete geometry handles physical constraints.
Various presentational effects can be analyzed as the fracturing of an abstract geometric
space due to the constraints of the concrete geometry and the rendering of the content
within its constraints.
Extension of the operator/phylum grammar for the abstract syntax rules to allow for
cross-classifications by more than one phylum, partial inheritance of structural components
from phyla to operators, and the introduction of a special "unmarked" operator.
A taxonomy of concrete syntax functions. These relate directly to the fairly small
set of basic abstract syntax relationships.
A taxonomy of concrete syntax mechanisms. There is a wide variety of concrete syntax
widgets, more if non-textual media are considered. The taxonomy provides for some
way of organizing the madness, and making reasoned decisions about how mechanisms
and functions relate in notational systems.
Use of case frames and marking theory as a inspiration for some aspects of the model.
The overarching theme of the work is that notations are notational systems that can be understood in relation to other notations and conventions. Furthermore,
"notation" can be taken very broadly indeed, to encompass both programming languages,
such as C++ or DL (the original target of the Muir system), but also layout conventions
in natural language documents of various kinds such as restaurant menus, dictionaries,
and research papers.
In this paper I will look at that model. Rather than attempt to recap an entire thesis
in detail in one short paper, I will focus on the taxonomies and their application
to understanding notational systems. A brief overview of the overall model will be
provided, to provide the necessary context.
Model Overview
The gist of the model is that there is content (the flow of text and such) which is
structured hierarchically (with some amount of cross-referencing) according to the
rules of the abstract syntax. On the other hand there is the abstract geometry, which
partitions space into hierarchical regions according to a set of abstract geometry
rules (very similar to abstract syntax rules). Concrete syntax rules define how the
content is annotated and partitioned into the abstract space. Given a particular concrete
geometry (e.g. a specific page size) and a particular concrete rendering of the content
into the abstract spaces, layout rules come into play, as well as rules for fracturing
content groups that won't fit into their allocated space.
Running the rules the other way is, of course, rather more difficult, and may involve
some amount of inference, depending on how well the notational system is put together.
Given a formatted text, and knowledge of the rules of space and annotations, one can
recover the marked text from the formatted text and the structured text from the marked
text, because that is the point of those presentational devices. The hard part in practice, when applied to human texts, is (a) knowing what the rules
are, because they differ from document to document and (b) handling ambiguities that
humans are more tolerant of or that humans are indifferent to.
Abstract syntax rules define the kinds of logical structures there are: programs,
statements, and expressions or articles, paragraphs, and figures. Cross-classifications
may define secondary organizations as well. Abstract syntax rules define the composition
of logical structures as either lists of the same kind of logical component, or as
a group of named subunits of various kinds: condition:expression, consequence:statement,
alternative:statement. Some of the subunits are identified as references to logical
units of some kind: reference to section, location of figure.
Abstract geometric rules define the kinds of logical spaces there are: book, page,
line. They define how those spaces are subdivided: a book consists of list of pages,
a page consists of a header, a footer, and a body.
Concrete syntax rules bind the two together and define what other presentational devices
come into play.
Figure 1: Overview
BASE TEXT (CONTENT) ⟲ rethink
⭣ ⭡
formulate interpret ⟸ ABSTRACT SYNTAX ⟲ change structure
⭣ ⭡
STRUCTURED TEXT ⟲ reformulate
⭣ ⭡
mark parse ⟸ CONCRETE SYNTAX ⟲ change marking
⭣ ⭡
MARKED TEXT ⟲ hand mark
⭣ ⭡
format tokenize ⟸ ABSTRACT GEOMETRIC ⟲ change layout
⭣ ⭡
FORMATTED TEXT ⟲ hand layout
⭣ ⭡
render decode ⟸ MEDIA RULES ⟲ change media spec
⭣ ⭡
CONCRETE DOCUMENT ⟲ redraw
Rules of various sorts mediate processing between layers. Editing at various levels
circumvents or augments those rules.
Taxonomy of Marking Functions
Marking functions are broken into broad classes based on their significativity, which defines their standing with respect to logical units in the abstract syntax
structure.
Identifying
An identifying mark is significative, standing for the logical unit itself. Such marks
are used to either label or reference a specific logical unit. For example, "§3.4.1" references a particular subsection of a document from elsewhere within it.
Label
A label defines a unique logical unit.
Labels may be some name component of that logical unit, or may involve counters of
some kind (e.g. "Table 22").
Cross-reference
A cross-reference captures a long-distance dependency. References are references to
something of a specific kind. References may normal references, location references
(referring to the geometric space in which the referred component is placed), or indexed
references (referring to some index count relative to a scoping logical unit).
Cross-references cut across the hierarchical organization and linear flows: "$definedVariable", "see section 12.1".
Structural
A structural mark is parasignificative, standing for some characteristic of the logical
unit. Such marks are key to highlighting (or inferring, if you run the rules the other
way) the logical structure of the document. Structural marks indicate the class of
a logical unit or the case relationship between a logical unit and its parent. For
example, "Education:" on a resume indicates the section of a resume containing information about degrees
attained. The "else" in a conditional statement indicates the alternative part of the statement.
Type mark
A type mark identifies the logical type or class of a logical unit. An empty type
mark is a special case. It is used for an empty or absent component.
The use of the word "Figure" to label a figure in a document is a type mark. The keyword "class" in C++ class declarations is a type mark.
Case mark
A case mark indicates composition of logical units into their subparts. An empty case
mark is a special case. It is used for an empty or absent subcomponent.
Keywords such as "then" (C, etc.) or "where" (SQL, etc.) are case marks. They indicate not what kind of thing follows, but what
its relation to the parent construct is.
Coherency
A coherency mark is non-significative, not standing for a logical unit at all. Such
marks serve to bind or separate logical units, distinguishing them visually. Separation
and binding are duals: binding one group necessarily separates it from other groups.
For example, the lines around a table provide a boundary to contain the contents of
the table and to distinguish it from its surroundings. Fracture marks are a special
kind of binder, to handle situations where a group would be broken across concrete
spaces due to limitations in the concrete geometry. Extra space at the bottom of a
page to prevent a table from breaking is one example of a fracture mark. A discretionary
hyphen at the end of the line to indicate a word break is another. So is the reduction
in font size for an entry in a table that won't fit in the space allocated for a column.
Separator
A separator creates some visual break between the logical unit and others.
Whitespace is commonly used as a separator. In XQuery, commas separate items in a
sequence.
Binder
A binder creates visual unity among a group of logical units. A fracture mark is a
special case. It is used when concrete geometry limitations forces a group to break
into a new concrete space.
Boxes, lines, and changes in background colour often serve as binders in human documents.
In programming notations, binders usually fall into the informal practice, although
some cases exist in the formal notation: the use of "BEGIN" and "END" to mark statement blocks in Pascal, for example.
Affective
Affective marks have a non-functional role, serving to set a tone or style for the
document as a whole, or relate it to other documents by its similarity or contrast
with them. For example, the choice of particular font family for the text in a document
usually serves only a stylistic purpose. It may be possible to analyze affective marks
as having functional roles in relating different documents or different kinds of documents,
but that is outside the scope of this model.
Style Mark
A style mark sets default choices, defining the standard baseline against which all
other marks are set in contrast.
Taxonomy of Marking Mechanisms
Marking mechanisms (or, for brevity, marks) are broken into broad classes based on
their scriptality, which defines their standing with respect to script elements, and their lexicality, which defines their standing with respect to the characters forming the base of
the notation. Lexical marks consist of lexical units (characters) themselves. Paralexical
marks are co-occurrent with the lexical units, but not themselves lexical. Non-lexical
marks use relationships between lexical units or other means not involving lexical
units: arrangement in space, for example.
These dimensions are not entirely independent: a non-scriptal mark must be non-lexical,
under the assumption we are describing a lexically based visual notation. Similarly,
a scriptal mark cannot be paralexical: it either introduced a lexical element or it
did not.
Punctive
Punctive marks add scriptal elements to the marked logic unit. They may be pure or
symbolic, depending on whether the added element is lexical or non-lexical. For example,
a question mark is a pure punctive mark. A logo marking the bottom of every page would
be a symbolic punctive mark. Punctive marks are generally what people talk about when
they talk about concrete syntax rules: what are the keywords?
Insertion
An insertion marks a logical unit by introducing a concrete mark to stand in place
of it.
The use the "null" to stand for an empty list is an insertion.
Adjoinment
An adjoinment marks a logical unit by adding a concrete mark next to it, in some direction.
Direction may be absolute (e.g. left, down) or relative to the prevailing direction
(pre, super). The adjoinment creates a new group, consisting of the marked element
and the concrete mark. Different groups of this kind may have different strengths,
which may be specified.
Keywords in programming language notations are frequently adjoinments. The angle brackets
in XML are adjoinments. Starting each item in a numbered list with a counter is an
example of a prefixing adjoinment.
Lining
Lining is the adjoinment of an extended or repeated mark. In the abstract geometry
of the model, it is placed not within a box, but within the margin of the box. The
stretch and shrink of the margin carries the mark with it. In addition, since the
mark is in a margin, it is inseparably cohesive with the contents of the box and cannot
be subject to fracturing.
Underlining the words in a title is an example of lining in the down direction.
Prosodic
Prosodic marks are parascriptal, altering the appearance of existing scriptal elements.
These tend not to see much action in the context of programming language notations,
but play a significant role in structuring human documents. Italics, indentation,
uppercase letters: the kinds of marks see a great deal of use. That said, even in
programming languages as practiced, "stylistic rules" involving the use of space and
font apply. You doubt me?
Lexical
Lexical prosodic marks use character functions to map one lexical element to another.
For example, rendering clickbait headlines in uppercase letters would be a lexical
prosodic mark.
Intonational
Pure intonational marks are paralexical, changing the rendering of marked logical
unit by substituting different character glyphs.
Many common font effects, such as size, boldness, or colour are pure intonations.
Positional
Positional intonational marks are non-lexical, using a local variation in the positioning
of the marked logical unit relative to the normal positioning. If affects the attributes
of the abstract geometric box into which the marked item is placed. There are several
different kinds of positional intonations, depending on which attribute is being affected.
(See below.)
Use Function
A function defined in terms of combinations of marks can be applied in a way that
acts a lot like an intonation.
Boxes have a variety of properties that positional intonations may affect: their orientation,
the direction of text flow, their internal and external alignments, their size, and
the size, stretch, and shrink of their margins.
Reorientation
Reorientation changes the orientation of the text, for example, from horizontal to
vertical. Reorientations are uncommon, although they may occur as fracture marks.
The mathematical choice operator uses a reorientation to vertical, for example:
Redirection
Redirection changes the direction of the text flow, for example, from forwards to
reverse.
Boustrophedon writing can be analyzed as a redirection used as a fracture mark on
the line, for example.
Realignment
Realignment may be internal, shifting the contents of a box with respect to its boundary,
or external (reframing), shifting the contents of the box with respect to the box's
neighbours. Realignments are defined by changes to the appropriate reference point.
For example, matrix subscripts in "Mij" are a lower reframing.
Repadding
Repadding is a change to the size or extensibility of the margins of the box containing
the marked item. Such effects may be subtle if there is substantial stretch and shrink
to make up for the difference.
Indentation of the start of a paragraph is one example of repadding. The reduction
in space between items in certain kinds of lists is another.
Reshaping
Reshaping is a change to the size and shape of the box containing the marked item.
Expanding column sizes in a table to exactly fit the contents is a reshaping.
Relational
Relational marks are non-scriptal and therefore non-lexical. They work somewhat indirectly.
For programming language notations, typically only ordering gets much use, although
there are some that do rely on placement (with respect to lines).
Placement
Placement is the encapsulation of a logical group into a box in the abstract geometry.
Placement can be into a simple box, into a named subbox, or into a box which has subboxes.
The group will fill the box (or subbox), subject to fracture rules. Placement into
a box with subboxes will fill each subbox in turn.
Placement is the basic binding to the abstract geometry, and is ubiquitous.
Ordering
Ordering defines the relative position of a logical unit with respect to its parent
in the text flow. List operators have an intrinsic order, although in rare circumstances
this may be perturbed.
The notational difference between a do loop and a while loop is, under this account,
both a difference in keywords (adjoinments) but also a difference in ordering (condition
before statement vs statement before condition).
Rebinding
Groups have an inherent cohesiveness, that comes into play when fracturing occurs.
Adjoinments create groups. Each operator defines a group implicitly. Rebinding changes
the relative cohesiveness of a group. Strengthening the binding of a group reduces
the chance of it being broken due to constraints of the concrete geometry. Weakening
the binding increases that strength.
Zeroing
Zeroing removes marks that would otherwise be present. This is an unexpected reversal
of the norm, where marks are added to reflect a non-default situation. Zeroing therefore usually occurs in combination
with the addition of some replacement mark.
Deletion
Deletion is the complete removal of a logical element from the presentation.
Full deletions typically involve specialized modes of presentation, for example, an
outline mode where all by the section headers is deleted.
Cancellation
Cancellation suppresses some other mark.
For example, if all lists are rendered surrounded by parentheses, rendering an empty
list as "null" requires the cancellation of these adjoinments. In XML, the empty element syntax
"<i_am_empty/>" involves a cancellation of the normal start and end tag syntax.
Since we last were here
Much has changed since the development of the model described above: Unicode, the
entire XML stack (XML, XSD11.1, XQuery31, XSL1.1, XSLT2.0), HTML (HTML4.01), CSS (CSS). While the model certainly covers much of the same territory, it comes from a very
different community with very different concerns: syntax-directed program editing.
There is a difference in emphasis: where the XML stack puts more emphasis on rendering
concrete documents from structured documents, the program editors have always been
more concerned with parsing at least fragments of concrete documents to get to the
structure. This is not to say that syntax-directed editing of XML has not been a concern:
it has, and there have been a number of commercial tools that do it. On the other
hand, they do not typically concern themselves much with parsing concrete renderings
to produce XML, but more with using XML constraints to guide a WYSIWYG presentation.
The Muir language development environment, in part due to the more layout oriented
features of the original target language, and in part due to the linguistic sensibilities
of the participants, took a more expansive view of the scope of syntax-directed editor
than other projects. It therefore has more to say about human documents in an XML
context.
Lessons
Many of the lessons and insights from the model find their echo in these newer technologies
and others could perhaps be applied to great benefit:
Separate the presentation from the structure.
As I type these words in an XML format in which font, layout, and indentation choices
do not appear, it is clear this is not a novel observation. Even in the much more
presentation-focused HTML world, a great deal of the presentation is usually separated
into CSS rules. Setting aside ordering (and in some cases even that), a W3C XML Schema
or Relax NG Schema can be seen as defining abstract syntax rules for a document. True,
there is also a conventional concrete syntax for an unrendered structured document:
the XML form. This makes the claim confusing. Is it not a concrete syntax specification,
then? Where XML is the abstract syntax and the XML document is its rendering, yes.
Where the formatted document of some specific kind is its rendering, no. The form
of this document that would appear on the Balisage web site: this is the concrete
syntax form of the document whose abstract syntax rules are defined by the Balisage
tag set schema.
Run rules both ways.
Up-conversion from a concrete document to well-structured XML is a process of undoing
the rules at all levels. In practice this also requires uncovering what those rules
are in the first place. This is most of what makes it difficult. The other part that
makes it difficult is notations that do not work well as a system, or that have a
lot of ambiguity. Documents in these notations can be (and are) misinterpreted by
human beings also, but human beings are more clever than programs, and more adept
at bringing to bear common sense reasons to prefer one interpretation over another.
Nevertheless, I believe it is helpful to regard the problem of up-conversion as fundamentally
a parsing problem combined (perhaps) with a rule discovery problem.
Language versioning is a form of language translation.
The entire vexed discussion of namespace versioning and XML schema versioning speaks
agreement to this point. Try as you might to plan for it or minimize it, some changes
to vocabularies are breaking changes, and must be treated in some ways as a new language.
Language versioning entails transformations and the application of new rules.
The same is true in the XML world, where (a concrete representation of) the structured
form holds primary. Putting that document in a new language version means transforming
that document. XSLT suits this purpose admirably.
Use an abstract syntax specification that distinguishes rules that would manifest
in the structure from rules that allow better organization of the grammar itself.
Such mechanisms as DTD parameter entities, XML Schema named groups, type inheritance,
and substitution groups and the abstract elements that go with them accomplish some
of the same goals.
Separate the type of abstract syntax unit from its (named) role within its parent
construct.
One could write XML Schemas using only local elements and named types to get close
to this. The case relation (the role) would be captured by the local element name,
and the structural kind would be captured by the type name. Unfortunately, the type
name is not manifest in the abstract syntax representation, and following this pattern
interferes with the ability to use substitution groups to provide for organizational
classes. The idea that each piece of an abstract syntax instance has a manifest named
role distinct from the name of that non-terminal is absent.
Where the XML stack needs to target components of a parent, it relies on parent child
XPath match patterns perhaps with position counters (in XSLT) or CSS selectors (in
CSS). Adding metadata through attributes can reclaim the distinction. CSS classes
are often used to provide role information. Sometimes other attributes are used instead,
or as well.
Should XML element names name kinds of things or roles of things within a larger entity?
The debate rages, and vocabularies are inconsistent. Being able to consistently name
both aspects would be helpful.
Separate concrete syntax into distinct mini-rules.
Both CSS and XSLT provide for the ability to define separate rules for pieces of a
larger construct. This enables a great deal of their flexibility.
Presentation order relates closely to layout across space, and for non-lists is an
aspect of concrete syntax.
In the XML stack, XSLT can be used to output in an order distinct from the underlying
order in the abstract syntax, but ordering is clearly taken as part of the abstract
syntax. Reordering is seen as a transformation effect, not a rendering effect.
Where order is fixed, a specific ordering conveys no information. Since the order
is known in advance, additional presentation marks are not required to tell you which
subcomponent is which. Where order is free, every specific order conveys specific
information. Since the order could be anything, other presentational marks are required
to keep subcomponents straight. As such, ordering is intrinsically bound up with other
presentational devices, just as word order in natural language is intrinsically bound
up with morphological devices.
Failing to treat it that way leads to adding pointless flexibility and complexity
to content models, or pointless complexity and the need for transformations in order
to render properly, to the detriment of all.
Bootstrap from a self-describing meta-grammar.
The W3C XML Schema for schemas is self-describing, but neither the stack as a whole
nor other pieces of it are. While this is a handy property for getting systems off
the ground, testing their efficacy, and for accommodating changes to them, it is by
no means crucial.
Presentation widgets have a purpose: to convey specific abstract syntax relationships.
Knowing the purpose of presentation widgets allows for analysis of a notation as a
whole.
This is the key to designing better notations (by which I mean to include rendered
documents in general) and to recover the structure of such concrete rendered documents.
Separate the abstract geometry from concrete geometry.
Various presentational effects can be analyzed as the fracturing of an abstract geometric
space due to the constraints of the concrete geometry and the rendering of the content
within its constraints.
Neither CSS or XSL-FO has a concept of abstract geometry, per se. Various common specific
fracture situations need to be captured through specialized rules and properties.
Given that these are common solutions to similar problems, it is by no means a bad
thing that systems designed for humans with those problems take special note of them.
Still, the concept of certain marks as responses to fractures can be a useful unifying
principle for understanding concrete documents.
Extension of the operator/phylum grammar for the abstract syntax rules to allow for
cross-classifications by more than one phylum, partial inheritance of structural components
from phyla to operators, and the introduction of a special "unmarked" operator.
W3C XML Schema complex types and multiple substitution groups (in 1.1) capture many
of the same instincts.
A taxonomy of concrete syntax functions.
Understanding CSS or XSLT stylesheet rules in terms of their functional role can serve
to clarify how to organize them. In the context of developing a vocabulary and thinking
about the rules for rendering it, considering marking functions can help in clarifying
what the underlying vocabulary needs to distinguish, and what metadata may need to
be added.
A taxonomy of concrete syntax mechanisms.
There sometimes seem to be an endless sea of possible presentation widgets in the
world. A perusal of all the CSS or XSL-FO properties is mind-numbing. It can be helpful
to see that in general a notation picks similar kinds of devices to convey parallel
functions: if adjoinment is used to mark one case relation, it will be used to mark
another. Thinking of a notation in such a holistic way, as a system of rules, can
help in producing better and more consistent notations (or document renderings). It
can also help guide rule inference. Knowing that larger scale components are marked
with larger scale marks — more space, larger fonts, bolded text — one can infer something
about the rules used to mark different levels of subdivision, and from this recover
the structure of a document from its concrete form.
Use of case frames and marking theory as a inspiration for some aspects of the model.
Marking theory teaches us that marks indicating more specific or unusual entities
will be more elaborate than marks indicating more common situations. It followed that
mark cancellations apply in the same direction: marks for more specific functions
cancel marks for more generic ones, in order that the mark we end up with is the more
specific one. This principal finds an echo in the rules about template selection in
XSLT and selector selection in CSS. Specificity wins. Case relations (parent/child)
win over type relations (bare element names). Labels (ids) win over case relations.
XSLT and CSS obviously have more elaborated sets of relations expressed in their selectors,
however.
Applying the same perspective to document up-conversion allows us to make inferences
about structural relationships. If a certain kind of mark (a bolded adjoinment with
a colon separator, perhaps) indicates a case relation in one instance, it likely does
in another as well. A very different kind of mark likely indicates that the component
stands in a different logical relationship: part of a different parent group entirely.
Designing a Notation: A Small Exercise
Let us conduct a small thought experiment: let us design a notation, say, the price
sheet for Mary's House of Excellent Jams and Jellies, applying these insights.
Our task list looks something like this:
Define the abstract syntax: what are the types? the case frames? the unique and referenced
entities?
I have a price sheet. It has information about the store and a collection of items
for sale. The store information includes a name, a description, various kinds of contact
information (physical address, email address, phone number). Those items for sale
come in groups, where each group has a label and a description. The items have a name,
a description, and a price.
Here I have followed a convention of using named types and local elements, with lists
x elements defined by a x-list type. Complex types are defined using xs:sequence but this ordering matters not to my notation, but to an XML parser processing an
XML document that satisfies this schema. In fact, since ordering does not matter at
the abstract syntax level, fixing the order at that level is fine.
<price-sheet xmlns="http://mathling.com/price-sheet">
<store-info>
<name>Mary's House of Excellent Jam and Jellies</name>
<description><para>We have been making artisanal jams and jellies from all-natural organic ingredients since 1998.</para></description>
<contact-info>
<address>111 Any Road, Some Town, USA</address>
<email>nonesuch@example.com</email>
<phone>408-555-1212</phone>
</contact-info>
</store-info>
<groups>
<group>
<title>Jams</title>
<description>
<para>Jams are filled with delicious organic fruit.</para>
<para>They retain more of fruit pulp than jellies.</para>
</description>
<items>
<item>
<name>Golden Summer</name>
<description><para>Yellow plums, habañero, meyer lemons. Excellent with brie.</para></description>
<price>5.25</price>
</item>
<item>
<name>Christmas Jam</name>
<description><para>Cranberries, oranges, ginger, and cinnamon. Have it with your turkey!</para></description>
<price>6.00</price>
</item>
</items>
</group>
<group>
<title>Jellies</title>
<description><para>Jellies are strained and no longer contain fruit pulp.</para></description>
<items>
<item>
<name>Hot Quince</name>
<description><para>Quince and ghost pepper. Sweet heat!</para></description>
<price>6.25</price>
</item>
<item>
<name>Purple Bliss</name>
<description><para>Pomegranate and blackberry. Pure decadence!</para></description>
<price>10.25</price>
</item>
</items>
</group>
<group>
<title>Chutneys</title>
<description><para>Chutneys balance sweet, spice, and savoury.</para></description>
<items>
<item>
<name>Classic Indian Chutney</name>
<description><para>An exciting blend of fruits and spices. Water chestnuts add crunch. You'll eat it with a spoon!</para></description>
<price>5.25</price>
</item>
</items>
</group>
</groups>
</price-sheet>
Define the abstract geometry: what are the spaces? how do they compose? what are their
properties?
I have a sheet, which may have multiple pages, each of which has a header space, a
body space, and a footer space. The body space has columns, which consist of lines.
Expressing this in the context XML/HTML stack is a little tricky, because neither
XSL FO nor HTML/CSS make a distinction between abstract and concrete geometry and
various common document devices (headers, footers, columns, lines) are treated specially
and asymmetrically. We could sketch this out as an HTML template:
/* No "page" object to specify: use @page */
@page {
height: 11in;
width: 8.5in;
}
.header {
line-height: 15pt;
height: 2in
}
.footer {
line-height: 15pt;
height: 1in
}
/* No "column" object to specify: use column properties */
/* Note: to get this working in real browsers need more here */
.body {
column-count: 2;
column-gap: 1in
}
/* No "line" object to specify: put properties as document default */
html {
line-height: 15pt
}
We could capture the full abstract geometry model for design purposes in another XML
Schema with extensions. It could then be used to generate HTML or XSL FO with the
full concrete syntax:
Define the concrete syntax: how do we choose to mark the types? the case relations?
the unique and referenced entities? how do we choose to bind the abstract components
to space? how shall we handle breaks?
Start with the type marks. Think of this as "which entities to I wish to mark in a
way that makes them distinct from other kinds of entities?" Let us say we want to
indicate the store info with surrounding box, and descriptions with italics, prices
with a dollar sign.
Case marks are next. In technical notations or data tables literals are common. In
human prose ordering comes into play. Here we decide that the email, and phone components
of the contact info should be indicated with some text marks, and we will fix the
ordering of the heterogeneous children of all components.
Are their labels or cross-references? How should they be marked? The short labels
(variously with the case 'name' or 'title') will function as labels and be marked
with bold, centered text, in decreasing sizes depending on the scope of the label.
Finally, let us consider grouping and separators. Certainly we will use whitespace
to separate items in lists (group from group, paragraph from paragraph, etc.) with
larger scale units separated by larger amounts of space. We also decide to separate
the groups with horizontal rules. For grouping we determine which components are bound
to which boxes: the store info to the header, the groups to the body. Finally, the
fracturing rules are conventional: filling up a line overflows creates a new line,
filling up a column creates a new column, filling up a page creates a new page and
replicates the header.
Concrete syntax rules can be representing with a combination of XSLT and CSS. The
XSLT maps the XML to something CSS can target and applies ordering rules.
The general strategy here is to use modes to properly order the different kinds of
marks from the least to most specific: affective marks before coherency marks before
structural marks before identifying marks. We order case marks before type marks to
ensure that the children of a grouping element have class names with the case labels.
Joint case marks (ordering, principally) are separated from other case marks. We also
need to use <xsl:next-match/> to march up the type hierarchy and make sure we get type and subtype marks. Priority
is necessary to ensure we match subtypes first. For type marks we use match patterns
that target those types.
Once we have the XSLT generating HTML with proper class attributes, the CSS applies
the other marking mechanisms.
Define the concrete geometry: how big is the paper? how much space do we allocate
for each part?
In an HTML plus CSS world, this comes down to @media rules for printed output, perhaps with exact positioning. This is the level XSL FO
plays at, for the most part. It is also where this model gets tricky to apply directly,
because the explicit separation of abstract and concrete geometry is not how rendering
is conceptualized and the conventionalized rules (e.g. flowing from line to line and
page to page) are not something we have direct control over, so there is nothing to
add.
Iterate with actual or sample content until satisfied
Let's take a moment to look at the design of this notation as a system: where are
we using similar kinds of devices for marking and where are we using different kinds
of devices? Where will these choices create a harmonious and easy to understand form,
and where might they be confusing or awkward?
The first thing to note is that our type marks are all over the map: we have lexical
intonations (contact-info and description), linings (store-info), adjoinments (price),
and no marking at all (group and item). Not having any marking at all is not a problem
per se: it tells us that these types are the "normal" or "expected" type against which
other types contrast. Is that our understanding of our little price sheet? Yes.
The case marks are mostly ordering, with a couple of adjoinments. The fact that we
also use adjoinment for just one of the type marks is suggestive: perhaps we are analyzing
our notation incorrectly, or leading readers to analyze it incorrectly: perhaps the
email and phone marks are type marks, not case marks. Or perhaps the price mark is
a case mark, not a type mark. Either way, it is suspicious to have components that
function similarly at one level treated differently at another.
Moving on to the separators, we spot another anomaly: the use of lining as a separator
for components of a group list. This is the only separator using this kind of mechanism,
and the only other place such a mechanism is used is for the store information type
mark. So again we ask the question: are we misanalyzing our notation, or leading readers
to misinterpret it? Or creating ugliness?
In this small example, these small inconsistencies are unlikely to cause any problems.
Indeed, there are small inconsistencies in any notation and it is a fool's errand
to try to purge them entirely. However, inconsistencies like this can cause real problems
in real notations. Pascal suffers from the inconsistent use of semi-colon adjoinment
to indicate sometimes a separator and sometimes to bind a type as well as the inconsistent
use of semi-colon versus comma as a separator. Ripley78 shows that programmers make disproportionate number of syntax errors in these areas.
Similarly with Java, which uses semicolons to terminate most (but not all) declarations
and statements and sometimes as a separator, and which uses small syntactic differences
to mark large semantic ones. One large scale study of Java novices Altadmri15 found that the most frequent syntax errors, after unbalanced parentheses, involve
confusing doubled symbols with single symbols ("==" vs "=", "||" vs "|" etc.), adding
extraneous semicolons where they don't belong (after condition in conditional statement,
after signature in a function declaration), and confusing function call syntax with
function declaration or method use.
Summary
When presented with a concrete document, we use the various presentation devices and
widgets to recover the deep structure of the document: the hierarchy of organization,
the components and their relationships to one another within and across that hierarchy,
their classifications. We recover the relationship of the document as a whole to a
genre of similar documents. That is the fundamental purpose of those presentation
devices. By having an account of purpose of them, we can begin to see how they work
together in a notational system and begin to understand how to recover deep structure
from concrete presentation.
Going the other direction, having an account of the organization of notations at different
levels can drive methodologies for developing notations, be they technical notations
or more general styled documents.
References
[Altadmri15]
Altadmri, Amjad and Brown, Neil C.C. (2015)
37 Million Compilations: Investigating Novice Programming
Mistakes in Large-Scale Student Data.
In: SIGCSE '15: The 46th SIGCSE technical symposium on Computer science
education, 4th - 7th March 2015, Kansas City, Missouri. doi:https://doi.org/10.1145/2676723.2677258.
[CSS]
W3C: Tab Atkins Jr., Elika J. Etemad, Florian Rivoal, editors.
CSS Snapshot 2017
Working Group Note. W3C, 31 January 2017
http://www.w3.org/TR/css-2017/
[XSL1.1]
W3C: Anders Berglund, editor.
XSL Transformations (XSLT) Version 2.0
Recommendation. W3C, 05 December 2006.
http://www.w3.org/TR/xsl11/
[XML]
W3C: Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, Eve Maler, François Yergeau, editors.
Extensible Markup Language (XML) 1.0 (Fifth Edition)
Recommendation. W3C, 26 November 2008,
http://www.w3.org/TR/xml/
[Donzeau-Gouge80]
Veronique Donzeau-Gouge, Gerard Heut, Gilles Kahn, and Bernard Lang.
Programming Environments based on Structured Editors: The Mentor Experience
Rapports de Recherche 26, INRIA, July 1980.
[XSD11.1]
W3C: Shudi (Sandy) Gao 高殊镝, C.M. Sperberg-McQueen, and Henry S. Thompson, editors.
W3C XML Schema Definition Language (XSD) 1.1 Part 1: Structures
Recommendation. W3C, April 2012.
http://www.w3.org/TR/xmlschema-11-1/
[Holstege89]
Holstege, Mary.
Marking and the Design of Notations,
PhD thesis, Stanford University, Department of Computer Science,
Stanford, CA 94305, June 1989. Report No. STAN-CS-89-1270.
[Holstege87]
Holstege, Mary.
The Meta Grammar for the Muir System.
Informal note IN-CSLI-87-7, Center for the Study of Language and Information, March,
1987.
[Normark87]
Normark, Kurt.
Transformation and Abstract Presentations in a Language Development Environment,
PhD thesis, Aarhus University, 1987. Published also as informal note IN-CSLI-87-9,
Center for the Study of Language and Information.
[Notkin86] Sharing and Modularization in Structure Editing Environments.
In proceedings of the 19th Annual Hawaii International Conference on System Science,
Volume II: Software, pages 567-575. 1986.
[HTML4.01]
W3C: Dave Raggett, Arnaud Le Hors, Ian Jacobs, editors.
HTML 4.01 Specification
Recommendation. W3C, 24 December 1999.
http://www.w3.org/TR/html4/
[XQuery31]
W3C: Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson, editors.
XQuery 3.0: An XML Query Language
Recommendation. W3C, 21 March 2017
http://www.w3.org/TR/xquery-31/
[Winograd87]
Winograd, Terry.
Muir: A Tool for Language Design
Technical Report CSLI-87-81, Center for the Study of Language and
Information, March 1987.
Altadmri, Amjad and Brown, Neil C.C. (2015)
37 Million Compilations: Investigating Novice Programming
Mistakes in Large-Scale Student Data.
In: SIGCSE '15: The 46th SIGCSE technical symposium on Computer science
education, 4th - 7th March 2015, Kansas City, Missouri. doi:https://doi.org/10.1145/2676723.2677258.
W3C: Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, Eve Maler, François Yergeau, editors.
Extensible Markup Language (XML) 1.0 (Fifth Edition)
Recommendation. W3C, 26 November 2008,
http://www.w3.org/TR/xml/
Veronique Donzeau-Gouge, Gerard Heut, Gilles Kahn, and Bernard Lang.
Programming Environments based on Structured Editors: The Mentor Experience
Rapports de Recherche 26, INRIA, July 1980.
W3C: Shudi (Sandy) Gao 高殊镝, C.M. Sperberg-McQueen, and Henry S. Thompson, editors.
W3C XML Schema Definition Language (XSD) 1.1 Part 1: Structures
Recommendation. W3C, April 2012.
http://www.w3.org/TR/xmlschema-11-1/
Holstege, Mary.
Marking and the Design of Notations,
PhD thesis, Stanford University, Department of Computer Science,
Stanford, CA 94305, June 1989. Report No. STAN-CS-89-1270.
Normark, Kurt.
Transformation and Abstract Presentations in a Language Development Environment,
PhD thesis, Aarhus University, 1987. Published also as informal note IN-CSLI-87-9,
Center for the Study of Language and Information.
Sharing and Modularization in Structure Editing Environments.
In proceedings of the 19th Annual Hawaii International Conference on System Science,
Volume II: Software, pages 567-575. 1986.
W3C: Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson, editors.
XQuery 3.0: An XML Query Language
Recommendation. W3C, 21 March 2017
http://www.w3.org/TR/xquery-31/