Introduction
The Cultures of Reception initiative offers a case study in the migration, normalization, enhancement, and transformation required to publish a set of TEI-encoded data. The initiative’s corpus consists of almost 700 transcriptions demonstrating the cultural engagements and influences of women writers in the eighteenth and nineteenth centuries. The corpus is large enough and most of its transcriptions are short enough that publishing this corpus required prioritizing the use of data in aggregate over individual transcriptions. And, while the corpus is also small enough that it cannot be considered definitive, cleaning and enhancing the transcriptions’ metadata enabled their publication in an interface that allows users to discover, to explore, and to make connections among a set of texts and authors that enact a key moment for women’s participation in transatlantic print culture. The data enhancement and publication processes required, among other things, the migration of data from JavaScript Object Notation (JSON) to XML encoded following the Text Encoding Initiative (TEI)’s guidelines[1]; the rehabilitation of ill-formed transcriptions; the identification of entities such as people and literary works; the formalization of metadata associated with texts and publications; and, of course, the development of a web interface capable of accomplishing the project’s goals for these materials.
The Women Writers Project (WWP)[2] began work on the Cultures of Reception initiative in 2010. To support research into the transatlantic reception and readership of early texts by women, the WWP transcribed close to 700 brief documents—such as literary reviews, publication announcements, textual excerpts, and subscription notices—published in Great Britain, Ireland, and America between 1770 and 1830. This paper focuses on the tasks which preceded and enabled the release of an exploratory web interface, Women Writers in Review,[3] which makes the Cultures of Reception corpus available for discovery and reading. As is evident in this project—in which transcriptions were created in one web interface, edited and transformed into well-formed XML through another interface, and then published through a third—the processes of authoring XML files for web publication and of developing web interfaces to publish XML files need not be entirely distinct; in fact, they can be productively linked. This paper discusses how, by focusing extensively on the corpus’s metadata, we at the WWP managed the complexity of the Cultures of Reception source materials and addressed the need to create a publication platform in which even novice users can navigate these materials.
Context for Cultures of Reception
The Cultures of Reception corpus represents a major encoding and publication endeavor
for the
WWP—but it was produced in the context of a much longer established collection of
TEI-encoded texts: Women Writers Online (WWO).[4] WWO is full-text collection of early women’s writing in English; it includes
transcriptions of texts written, translated by, or attributed to women, published
between
1526 and 1850, and it has been central to the WWP’s research output for close to thirty
years. The various reviews
(a term we have broadly defined to include not only reviews, but
also publication notices, literary histories, and other texts discussing women’s writing)
that make up the Cultures of Reception corpus were selected because they respond to
texts by
authors who are published in WWO. Thus, while the two collections are distinct in
their contents,
encoding practices, and publication interfaces, they are closely linked to each
other through their shared focus on a set of authors and texts.
Although both Cultures of Reception and WWO are TEI projects, their encoding practices differ significantly. The tagset for Cultures of Reception is fairly minimal, designed to capture basic document structures, significant renditional details, and the evidences of textual exchanges (such as quotations and references to titles) that are important for the project’s concerns with early transatlantic review culture.[5] The WWO collection, by contrast, has a tagset that currently includes approximately 165 elements and that reflects decades[6] of development with a generically and chronologically diverse collection of texts. Finally, while the two interfaces will be linked extensively, their purposes and display needs are quite different. WWO is designed as a reading interface, making individual texts easy to locate and read online. Cultures of Reception places a high priority on aggregation; its texts are generally shorter than those in WWO and they are more likely to be discovered through their periodicals of publication or subject matter than by reviews’ titles or authors. For this reason, Women Writers in Review (WWR), the web interface in which the Cultures of Reception collection is published,[7] foregrounds metadata much more than WWO does and fosters exploration by a wider range of facets.
The Cultures of Reception transcriptions require significantly more context to be useful and their metadata reflects that. Where each WWO text only needs to track information about the individual publication and its author(s), a Cultures of Reception review needs to track information about where the review was originally published, which publication was reviewed, which edition is likely to be the one reviewed, and which authors were mentioned. We also wanted the materials in Women Writers in Review to enrich the experience of reading the texts in Women Writers Online, linking between the two corpora as much as possible. See Appendix A for a tabular comparison of metadata captured in WWO versus in Cultures of Reception. While the complexity of the Reception data is specific to the project, we hope to demonstrate that our focus on metadata added a great deal of value to the web publication of our small- to mid-size corpus.
The First Phases
The initial phases of the Cultures of Reception initiative were completed between 2010 and 2013, during which time the Women Writers Project had its institutional home at Brown University. These phases included selecting, sourcing, and gathering data on the texts to be encoded; setting up a web interface connected to CouchDB[8] for a first pass of transcription and encoding; and performing a substantial amount of the encoding work itself. The WWP’s project manager at that time, John Melson, took the lead in creating the transcription interface and gathering metadata on the reviews and periodical sources. The bulk of the transcription and encoding work was performed by the WWP’s graduate and undergraduate student encoders.
Figure 1: The transcription interface
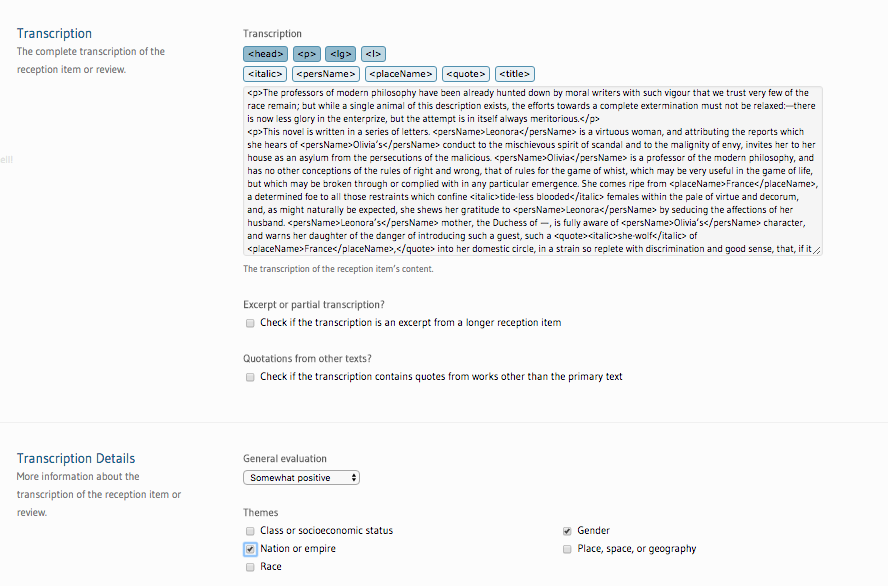
The transcription interface, showing an example review with buttons for entering markup and additional tagging through checkboxes and dropdowns.
It was after the WWP moved to Northeastern University in 2013 that this paper’s authors became involved with the Cultures of Reception initiative. Sarah Connell, the WWP’s current project manager, directed a team of graduate students as they continued encoding in the transcription interface and worked with Ashley Clark, the WWP’s XML Applications Developer, on proofing the corpus and preparing the transcribed texts for web publication. In the sections that follow, we discuss the decisions that we made and the work that we performed after the first transcription phase had been completed and we began to focus extensively on publishing the collection.
Reports and Initial Cleanup
As transcription wrapped up, we began to take stock of the data stored in CouchDB as JSON objects.[9] We used XQuery to pull records from CouchDB’s API. Examining the query results, we realized that we could not yet create accurate reports on the writers, works, and periodical sources represented in the database. Most of the JSON objects’ values were inconsistently formatted and difficult to parse programmatically. From a human standpoint, the sheer volume of reviews in the corpus made it extremely difficult to find specific transcriptions. Browsing the list of records was overwhelming even for those who knew the project.
These first queries shaped the rest of the pre-publication phase by helping us to recognize that, in order to appeal to the casual user, the corpus needed to be browsable. Moreover, in order to appeal to the researcher, records needed to be discoverable. We decided that the best way forward would be to focus our pre-publication efforts on consolidating and normalizing metadata and determined that this would be easiest for our team to do once the corpus was migrated out of JSON and into XML.
First, however, we needed to take care of the transcriptions.
The Ill-formed Transcriptions
From the transcription interface, we knew we had 690 completed transcriptions stored in CouchDB. However, those transcriptions were stored as plain-text strings—pseudo-XML—in JSON.[10] While CouchDB has built-in methods of validating its databases using JavaScript, those methods could not tell us how many of those transcriptions could be exported as well-formed XML, much less valid TEI. Instead, we turned to an instance of eXist-DB[11] already running on the same server as CouchDB. We wrote an XQuery library to let eXist communicate with the Cultures of Reception database through CouchDB’s API. Using that library, we attempted to serialize the JSON records as XML and save them into eXist. But, while CouchDB didn’t care at all about the transcriptions’ XML-esque pointy brackets, eXist cared a little too much. It refused to store ill-formed transcriptions as XML because, of course, they weren’t XML. Forget running XSLT on the strings! A direct export to TEI was just not possible.
Figure 2: JSON record CouchDB
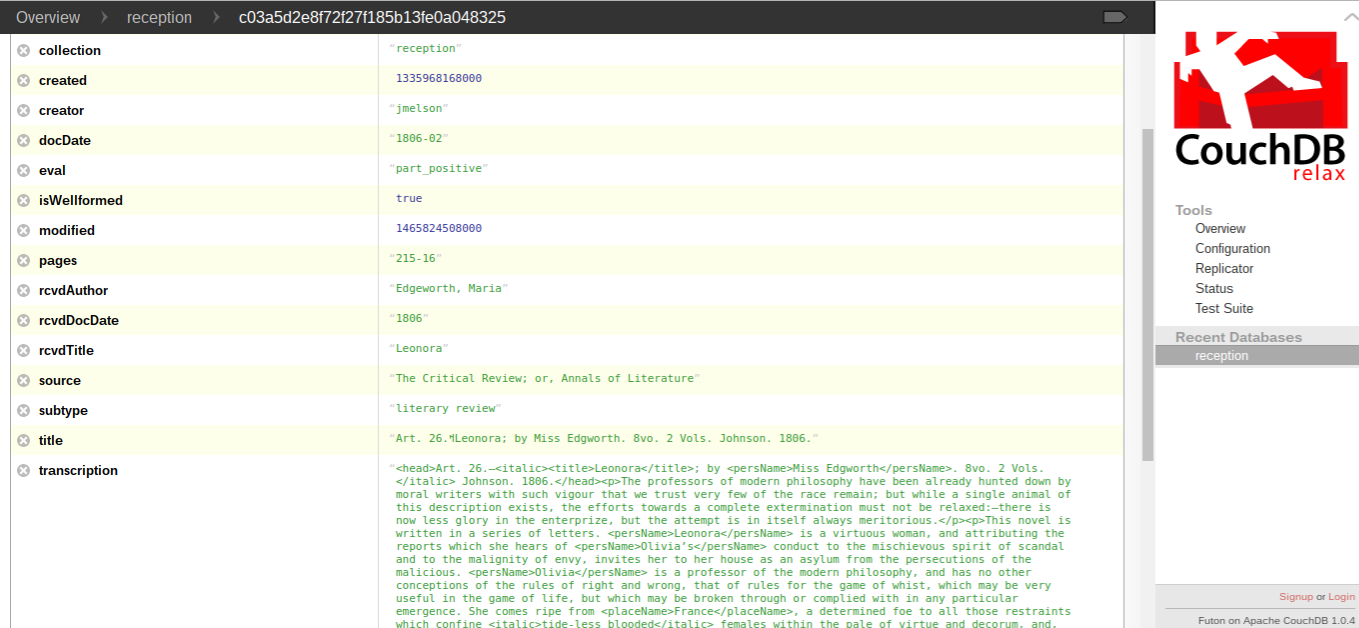
The same example review as it displays in CouchDB, showing both metadata fields and, in the transcription field, the XML-like strings.
Rather than strong-arming the JSON into a binary format, we decided to keep the transcribed reviews in CouchDB a little longer. eXist would serve as an intermediary for the transcriptions, running XQueries and storing XML reports on the CouchDB documents (rather than storing the documents themselves).
Figure 3: Ill-formed report-maker
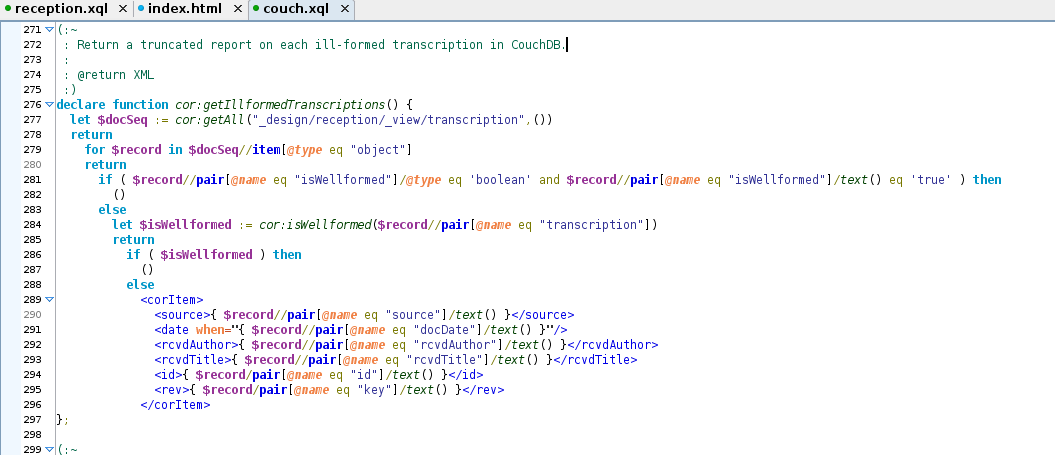
A snippet from the XQuery library used to communicate with CouchDB. This function returns a sequence of records which fail a transcription well-formedness test.
Figure 4: Ill-formed XML report
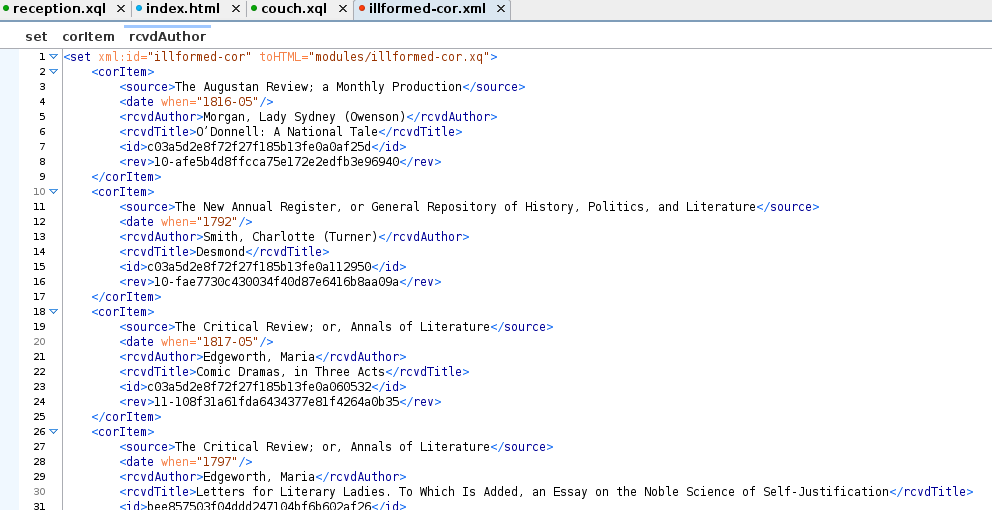
This report was used to identify ill-formed transcriptions for human intervention.
From the first of these reports, we learned that of the 690 transcriptions, 556 were ill-formed. After a moment of horror, we were relieved to discover that most of the 556 were actually just XML fragments; they only needed a wrapper element to be well-formed. That left us with 167 ill-formed transcriptions.
The Lack of Identifiers
Complicating this process, the records in CouchDB were not always consistent in terms of their metadata. There were no identifiers associated with the names of people, places, or publications. Instead, the transcription interface relied on alphabetical sorting of strings as a grouping mechanism. Because the names were typed in by hand, these fields varied in terms of punctuation, capitalization, and spelling—as one might expect—but also they also reflected variations in the amount of information and context included.
For example, one record might provide a reviewed author’s maiden name (Barbauld,
Anna Laetitia (Aikin)
) and another might not. Mary Robinson’s works were listed
under both her real name and her pseudonym, Horace Juvenal. And in the reviewed works,
we
found that two conflicting titles, Harrington and Ormond,
Tales and Harrington, a Tale; and Ormond, a
Tale were in fact both correct. The title had changed in a
later edition.
The encoding interface was not flexible enough to handle the complex relationships among textual editions, or between two seemingly distinct persons. To address this limitation, some encoders wrote in-depth notes, attempting to capture context that would not fit in the HTML form.[12] The transcription interface did not encourage these contextual notes, though, and in any case, we couldn’t reliably draw out those connections except with human intervention. Without identifiers to link key persons and publications, there was no ready way to programmatically categorize the 690 transcribed files by reviewed author or work. Additionally, it was not always clear which works referenced in the reviews corresponded to specific publications in Women Writers Online. We could not link transcriptions to each other, nor link out of the Reception project. We had a context problem. We needed...
The Inspecter
The Reception corpus was not small enough to allow human intervention on each and
every
item inside it, but the problems we faced were too complex for a purely programmatic
approach. Instead, we used XPath and XQuery to create XML reports, then use a web
interface—named the Inspecter
[13]—to limit human intervention to situations requiring judgement calls, such as
categorization or entity uniqueness. Any fixes would be ported back to CouchDB using
its
RESTful API.[14]
Formedness, Well-Done
For the ill-formed transcriptions, the XML report was simply a list of problematic records by their CouchDB identifier. The web interface was simple, too—an Ace editor[15] set up to parse an input field as XML. When the transcription was submitted, eXist would check it, only accepting the change if the XML fragment was well-formed.
Figure 5: Inspecter index page
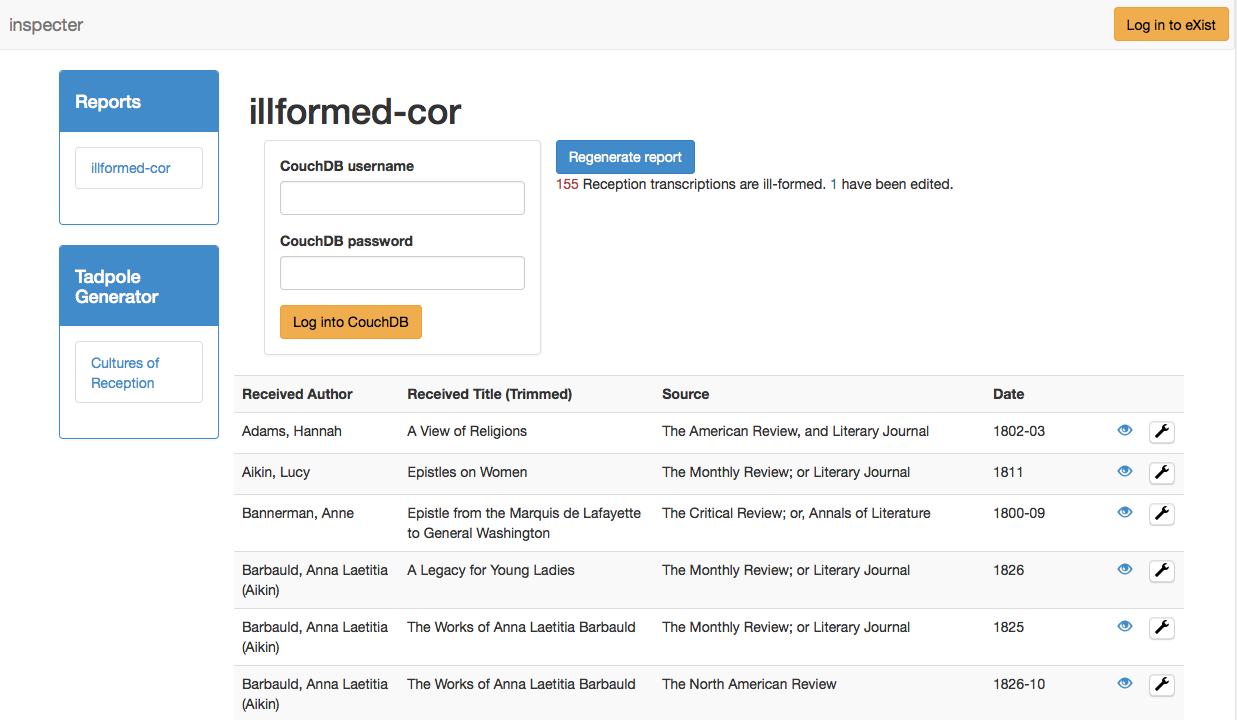
The index page of the ill-formedness Inspecter report.
Figure 6: Inspecter editing screen
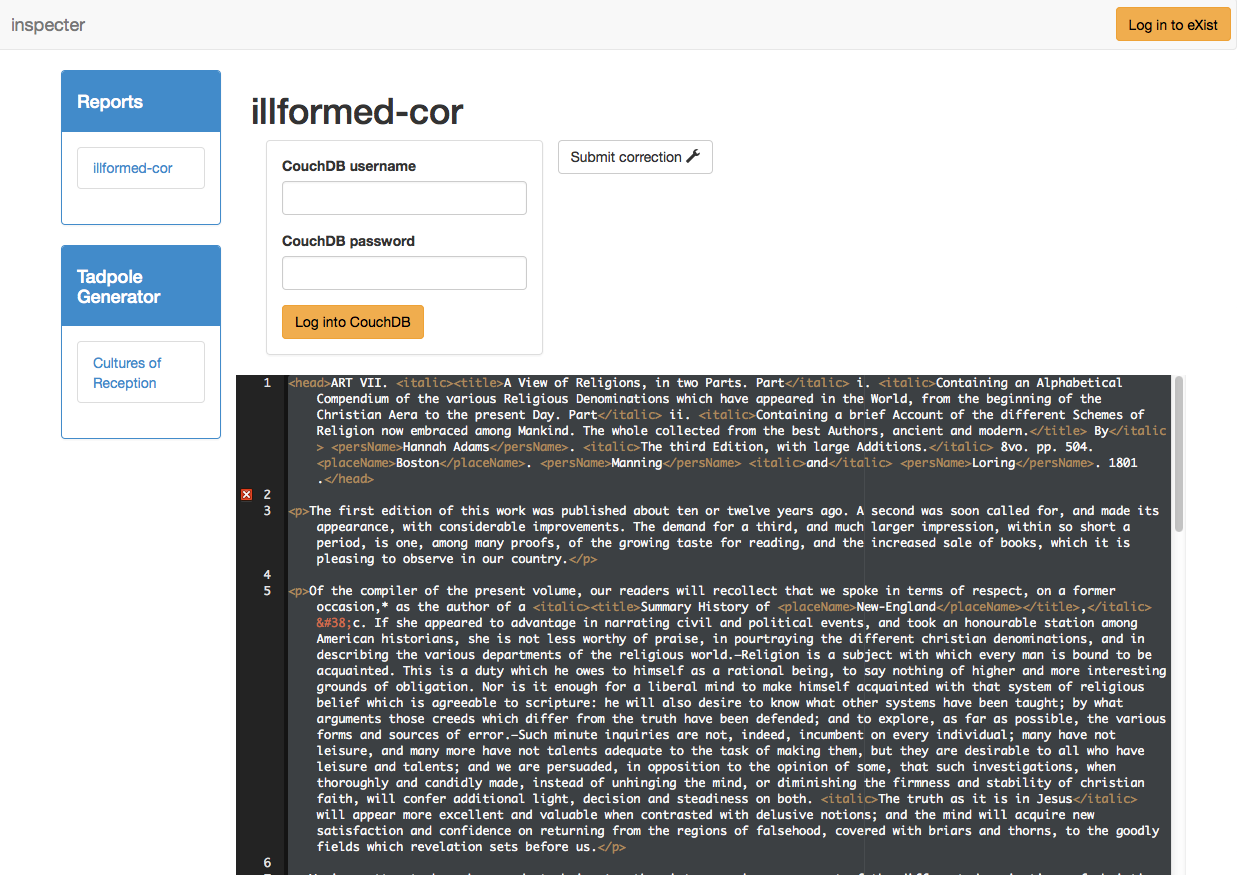
The editing screen of the ill-formedness report.
While Ace was an improvement over the original transcription interface, we quickly found that Ace’s editing environment could barely keep up with the faux-XML. The editor could tell the data was ill-formed, but its error messages were not helpful in conveying why, nor in precisely locating problems within each document. Did an element lack a closing tag? Was there overlap? In cases where there was more than one ill-formedness error,[16] oXygen’s interface proved more useful than Ace. By moving between oXygen and the Inspecter as the complexity of the errors demanded, we were able to resolve all but 20 of the 167 ill-formed files relatively quickly.
Entity Recognition
The second report was generated by identifying unique strings for both authors and
the titles of works and then listing out corresponding reviews. The XQuery generating
the report
didn’t even try to ignore punctuation or normalize misspellings, relying instead on
the
web interface to highlight subtle differences for the human reviewer. The displayed
report
sorted data by author name, then by work title, which made it easy to tell when authors’
names or works’ titles needed to be normalized, and allowed us to port the corrected
string
value back to the affected CouchDB records. It also provided the ability to link those
reviewed works with an identifier for an edition in Women Writers Online, marking
the
transcriptions that did not have associated TR numbers
[17] so that we could either add identifiers where they were missing, or mark
reviewed works as not yet having entries in the WWP’s records.
Figure 7: Missing TRs report

The XML report.
This Inspecter report was the first time we found the web interface to give us a greater degree of power than specialized software like oXygen. The Inspecter’s strengths lie in: (1) reducing a complex dataset into a human-readable report, and (2) changing multiple records at once. The XML reports could be regenerated at the click of a button, so fixes were never held back by inaccurate reports.
However, the Missing TRs
report also showed the
value of simplicity. This report was used to trigger three separate
data munging tasks:
-
normalizing reviewed author names,
-
normalizing reviewed work titles, and
-
linking reviewed works to their WWO versions.
The JSON-to-XML Migration
With the first two Inspecter reports completed, converting the CouchDB records into TEI-encoded XML was fairly simple. We used XQuery to request each transcribed, well-formed record in the CouchDB database, then turned that record into XML using the XQJSON library[18]. Each transcription was parsed as an XML fragment instead of a string representation. This XML representation of the JSON record was then transformed into TEI using XSLT, and stored in one of the WWP’s eXist-DB instances. For simplicity’s sake, the files were named by their CouchDB identifiers.[20] We then compressed the results into a ZIP file, and added the new files to a Subversion repository created and maintained by the Women Writers Project. Appendix B is a list of the JSON keys stored in CouchDB on export. Appendix C has screenshots of selections from the XSLT and XQuery files used to convert the JSON into TEI.
As for the 20 transcriptions with particularly thorny ill-formedness errors, the XQuery
was used to transform all of the JSON data except the transcriptions.
Each transcription was then treated as a string and wrapped in the
<body>. The resultant files were also placed into the Subversion
repository, in a directory for sequestered reviews.
We hope to rehabilitate these in the future, when there is more time to tackle the errors. In the meantime, the ill-formedness errors bothered our colleague Syd Bauman enough that he added attribute pointers, and split wrapper elements into empty ones.[21] The result is a collection of files in which the placement of the original encoding is preserved, and the files are not just recognizable to humans as XML, but parsable by XML processors.
Preparing for Publication
Building Entity Records
With the transcriptions in XML format and entities’ names and titles normalized, we were able to query the data much more easily, which enabled us to discover that each transcription differed in how much data was included on any given entity. We could depend on the periodical title’s presence, but not on the title under which the review was published. Some entries on periodicals included the publication place of the periodical, while others gave only the date.
One solution would have been to get compiled information for each entity and then propagate the condensed versions back to the reviews, as the Inspecter reports did to the records in CouchDB. This would have worked in the sense that every review would have access to the same information on its source periodicals and mentioned authors and works. But it would also retain the fragility of the CouchDB database—the reviews would easily get out of sync with each other as the collection continued to grow past publication.
Instead, we decided to create TEI files to house the canonical records of these entities.
Previous WWP work had already established a research database of people and so we
were able to make use of the WWP’s personography
[22] as context for any authors referenced in the reviews. For referenced works and periodicals,
we used XQuery to create stub <biblStruct>s with only the distinct titles and newly-generated identifiers. After we created
a TEI file for each set of bibliographic information, we used another XQuery to compile
all the TEI elements associated with the <title>s, then save them to the new file, under the new identifier. We were then able to
associate the reviews with identifier references to the canonical entries for their
source periodicals and for any works mentioned.
The bibliography of mentioned works required a further step, since some reviews
discussed different editions of the same work. We needed a way to show the relationship
between different versions of the same work, not least because a goal of the project
has been to investigate the international scope and
cultural impact of women’s writing. We settled on a loose correspondence of TEI bibliographic
elements
with Functional Requirements of Bibliographic Records
(FRBR) entities.[23] The FRBR report conceptualizes intellectual products as four different types of
entities: works
, expressions
, manifestations
, and items
. Works can have multiple
expressions, and expressions can manifest in multiple ways:
Table I
| FRBR Entity | Description | TEI Element |
| work | the text as a distinct artistic creation | <biblStruct> |
| expression | the text as created or interpreted in different ways | <monogr> |
| manifestation | the text as embodied in a published edition | <imprint> |
We chose to identify works as having multiple expressions on the basis of on how much changed between different versions. For example, Hannah Adams wrote A Summary History of New England, and later reinterpreted her work for a younger audience: An Abridgement of the History of New England for the Use of Young Persons. We classified these two texts as expressions of the same work. Since the records were all in the same file and since intervention required a fair amount of bibliographic expertise, much of this identification was done by hand.
Figure 8: Bibliography sample

A bibliography entry for Maria Edgeworth’s Comic Dramas. The Cultures of Reception corpus includes references to a London edition (CR0030.1) and a Boston edition (CR0030.2), both of which roughly correspond to FRBR manifestations.
When we were satisfied with the bibliography of reviewed works, we used XQuery Update
to replace
the bibliographic metadata in each file with an identifier reference to the most applicable
version of
each work from the bibliography. This
was done by comparing the <biblStruct> parts listed in each review with the
condensed, canonical metadata in the bibliography. If the XQuery could not determine
the
most accurate FRBR entity, it used the work identifier with an attribute flag for
low
certainty. We were then able to search for that attribute and resolve the handful
of problem
cases.
Figure 9: Bibliography update script

Part of the XQuery used to test for accurate work identifiers.
Creating Display Titles
Another bibliographic issue we had to address resulted from the fact that very few
of
the items we transcribed had either titles or identifiable authors.[24] And, even for those that did, we knew that users
would be far more likely to look for items based on the works being reviewed or the
source
publications. That is, we expect that readers would be more interested in retrieving
the Edinburgh Magazine’s various articles on Maria Edgeworth than in
searching for Review of New Publications
or
To the Editors of the Virginia Religious Magazine
in particular. And so, we decided to label each review
according to the information that would be most useful to readers: its date, the source
in which it was published, and the author and work that are its primary subjects.
For example:
1817-09: The Edinburgh Magazine on Edgeworth’s
Comic Dramas
.
We also knew that we would want to allow sorting and retrieval by source, reviewed
author, and reviewed work. However, many of the texts in the Reception corpus have
very
lengthy names, making them unwieldy for web display, and so it was necessary to create
display versions of these titles. In the relevant bibliographies for reviewed texts
and
sources, we added a second <title> with a @type of "display" and decided
on a shortened version of the title (for the rare cases where titles were short enough
already, we instead added a @subtype of "display" to the <title>). For
example, Hannah Adams’s
A View of Religions, in two Parts. Part i. Containing an Alphabetical Compendium of the various Religious Denominations which have appeared in the World, from the beginning of the Christian Æra to the present Day. Part ii. Containing a brief Account of the different Schemes of Religion now embraced among Mankind. The whole collected from the best Authors, ancient and modern
Establishing these display titles ensured that the Women Writers in Review interface could substitute the shortened form when the work or periodical source is referenced in headings and lists of results. In turn, users of the Women Writers in Review interface can scan through the significant amount of metadata necessary to locate individual reviews—and search through the collection overall—efficiently and without having to parse verbose titles such as La Belle Assemblée, or, Bell’s Court and Fashionable Magazine Addressed Particularly to the Ladies.
Reconciling Inconsistencies
Our data cleanup process also required that we address the inevitable encoding inconsistencies
that arise in projects on this scale.
One such issue was the encoding of notes, which were handled in a range of ways (often
reflecting the amount of experience the encoder had with WWO encoding practices);
some encoders were simply typing notes as
content where they happened to appear in the text while others were using <note> either at the location of the note or
in a separate <div> at the end of the text. Fortunately, once we had all of the reviews
well-formed and added to version control, it was easy to locate and reconcile the
different practices
so that all notes could be encoded in <note> elements at the end of each review. We were similarly able to address the occasional
cases
in which encoders both used the <quote> element and also typed quotation marks directly into
the text. In fact, we found that many of the consistency issues that were difficult
to enforce in
the transcription interface proved to be very simple fixes once we had the
files in XML because they could be identified, located, and addressed globally.
Figure 10: Sample encoding of notes

An example of transcription footnotes.
Another inconsistency we reconciled was, in fact, planned as part of the encoding
process. During the early stages of the project, the WWP had identified several key
themes
that we were interested in tracking across the corpus—including topics such as Nation
or empire
, Gender identities
, and Review culture
. We
also wanted encoders to add their own thematic keywords, reflecting the specific content
of
different reviews and capturing themes that we hadn’t anticipated. And so, we ended
up with
a broad set of encoder-created tags, many of which were expressing essentially the
same concepts in slightly different language. For example, one encoder might mark
a review
as discussing Irish literature
while another might use literature of
Ireland
. We consolidated variations in the keywords, taking note of which
encoder-authored tags were appearing frequently. In this way, the review process was
also a method
for us to get a sense of the content and concerns of the corpus overall and to refine
the
list of corpus-wide thematic tags, which we expect will be one of the major ways that
readers discover content in the Women Writers in Review interface.
Women Writers in Review
Interface Goals
We had several key goals in mind when designing the corpus’s web presence: we wanted
to
make the materials easy to browse and search; we wanted to have linking among the
reviews
and to Women Writers Online; and we wanted to foster exploration of the materials
as a corpus. These goals were in many ways driven by the
transcribed texts themselves, which tend to be brief and are more likely to be of
interest
to users as they reveal information about other texts and the larger topic of transatlantic
reception culture.
Women Writers Online, by contrast, tends to treat each text on its own
merits; accordingly, the WWO interface is designed to make it easy to find and read
individual texts. We expect that users of Women Writers in Review will be asking questions
such as: How has Maria Gowen Brooks been reviewed in British and American
periodicals?
or What changes are evident in the British Review
over time?
or How did periodicals in this
period discuss questions of women’s authorship?
(rather than Where is
Margaret Cavendish’s The Blazing World?
—a
question that brings a great many readers to WWO).
That said, we also wanted to do justice to the very lively and interesting content of the reviews in presenting them to readers—we don’t expect that many readers will go looking for the British Review’s article on Maria Edgeworth’s Harrington and Ormond, Tales, but once that reader has found the article, we want to be sure it is easy to read online, despite the fact that it is one of the longer reviews in the collection. We also wanted to foster continued discovery and exploration from each individual review. For example, if a reader lands on this article from the British Review, they could go on to explore other literary reviews, other items tagged as dealing with nation and empire, other articles from the British Review, other reviews of Maria Edgeworth in general or of Harrington and Ormond in particular—and so on. For this reason, it was important that Women Writers in Review present all of the metadata associated with these items in intuitive and clearly organized ways.
Infrastructural Design
The web application for Women Writers in Review makes use of BackboneJS[25] to interface with eXist’s RESTXQ endpoint[26]—more specifically, with an XQuery designed to return JSON datasets and HTML representations of the corpus. The web application was built out while the TEI files were in constant flux from undergoing the normalization tasks noted above, but because we started with the RESTXQ API, the BackboneJS app always had the latest data from eXist. Additionally, within the eXist database, the transcription files are stored separately from the EXPath app. These abstractions allowed for flexibility in our workflows. An update to the API did not require all records to be saved back into eXist and an update to the transcriptions did not require the re-engineering of the BackboneJS app.
Figure 11: Women Writers in Review web components
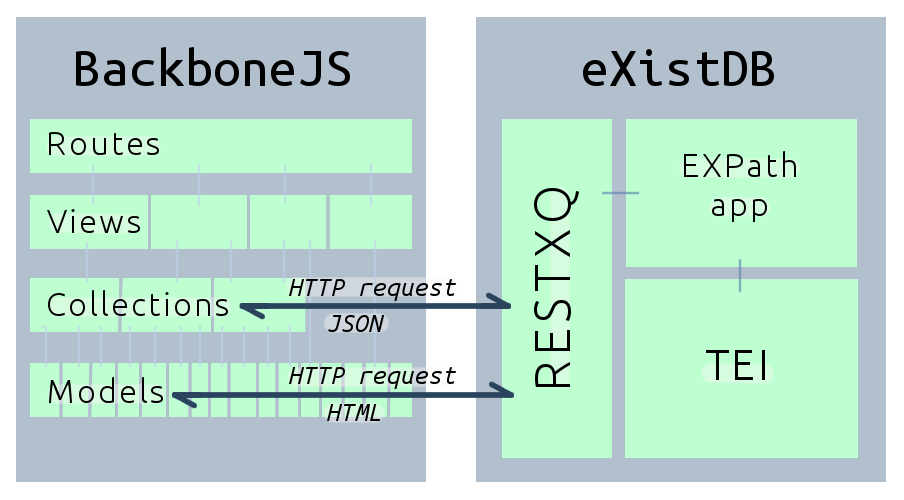
WWR makes use of BackboneJS to interface between the website reader and the XML corpus stored in an instance of eXistDB. However, because Backbone makes use of data compiled within eXist and served out using RESTXQ, researchers can also request the same data directly from eXistDB.
To accomplish the goals outlined above, we created a clean, simple reading interface using XSLT, and put much of our efforts into developing a series of landing pages, or pivot points, where users can view sets of items by reviewed author name, by reviewed work, by source, and by tags (such as format, genre, overall positive or negative evaluation, and thematic content). Each landing page is generated directly from the requested bibliographic or biographic canonical entry, using XSLT to create a representation of the appropriate context for that particular pivot. For example, the landing page for an author like Maria Edgeworth includes information on her pseudonym, her birth and death dates, her birth and death locations and the countries she resided in; it also links out to her entries in the Library of Congress Name Authority[27], the Virtual International Authority File[28], and WorldCat Identities[29]. Similarly, in addition to imprint data (such as publishers and publication dates and locations), reviewed works have a link to a version published in WWO, wherever WWO texts are available.[30]
Figure 12: WWR landing page sample
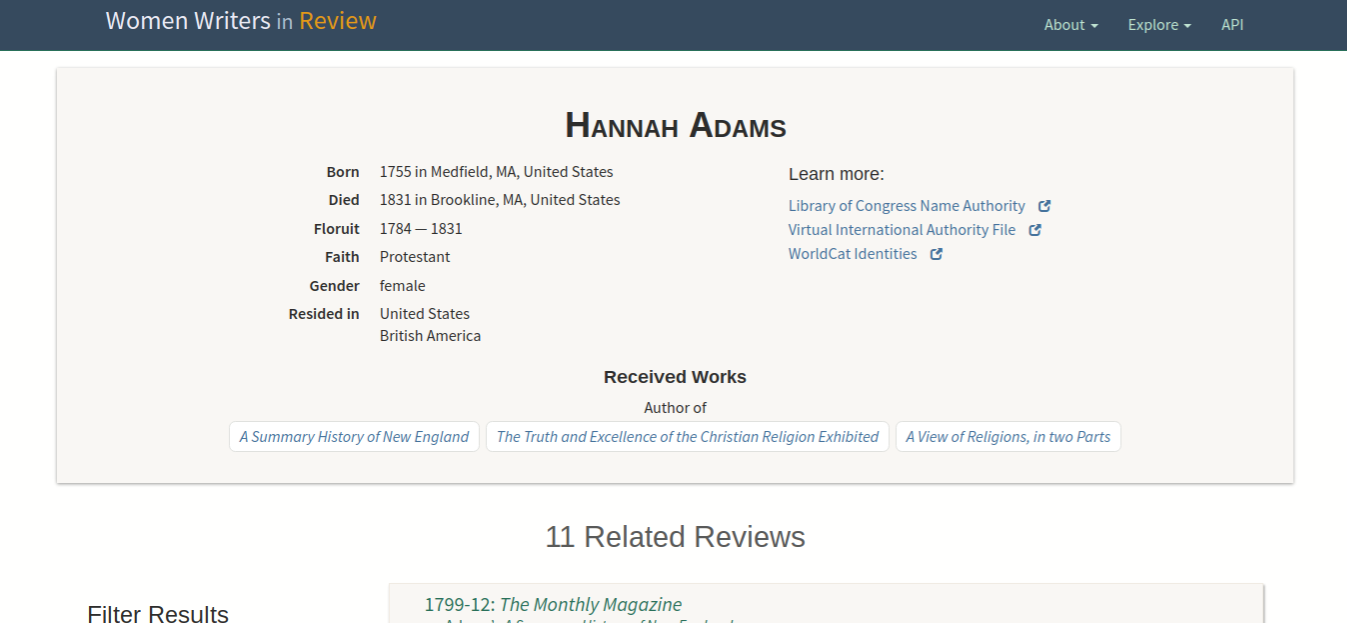
An example landing page for an author.
Landing pages also contain lists of reviews related to that particular pivot,
and a facets sidebar. The sidebar is broken out by sources, tags, and mentioned authors
and
works. The sidebar distinguishes between facets that identify features of the
result set, and those which can be used to reduce results to a subset. The latter
are
collapsed by default, while the former can be seen at a glance. For example, as one
would expect,
every item listed on the landing page for The Literary Gazette; and
Journal of Belles Lettres, Arts, Sciences, &c. has that periodical
listed as a source, so the Source
facet in this case is used to indicate the number of
results in the set, rather than to filter among those results. In a less predictable
(and more interesting!) usage of facets for
counting rather than filtering, the interface also shows that all results for this
publication are articles with very
positive reception of the primary author.
Figure 13: WWR results list sample
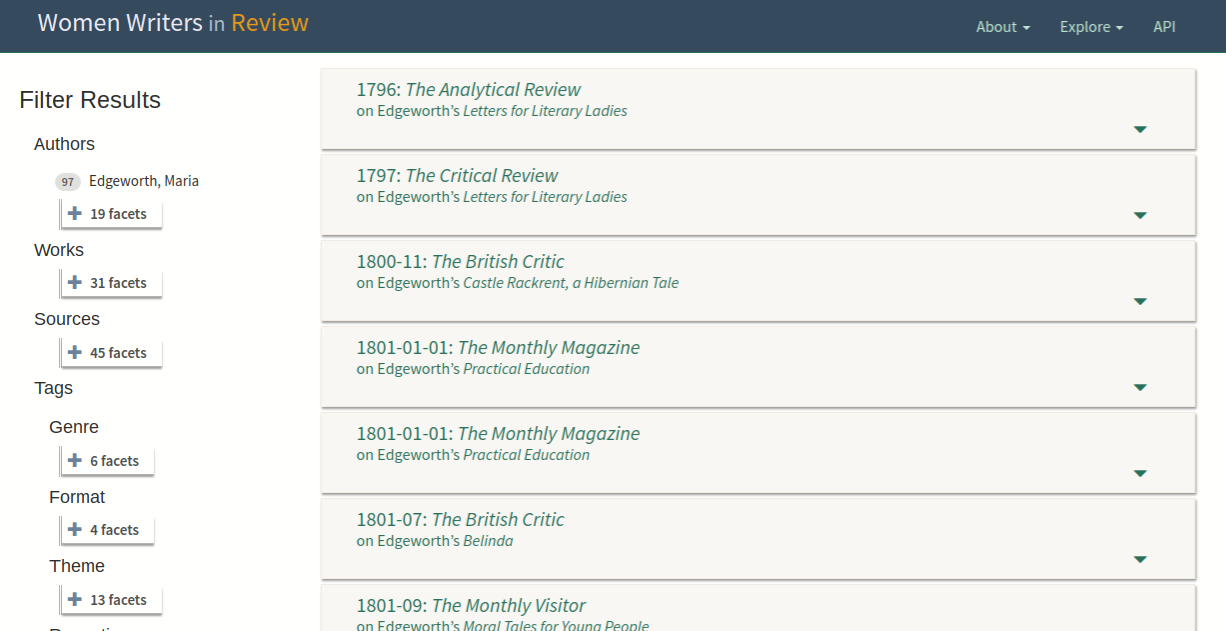
A sample result list on a landing page.
Figure 14: WWR faceting sample
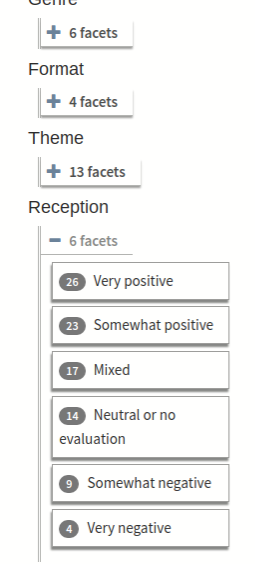
An expanded facet category.
When users expand the actionable facets and select one, any items that do not match that facet are hidden, and items that do match are shown. Currently, only one facet can be selected at a time and the facets cannot be stacked or used to create a union of two subsets. As we continue creating features past initial publication, we plan to make the faceting system a better tool for querying, manipulating, or exploring aggregations of data.
Figure 15: WWR reading view sample

The reading view for a sample review.
Both landing pages and reading views also include links within
Women Writers in Review, to the landing pages for related entities or to sets
of items with the same metadata. For example, one can link from the top of reading
views
to other reviews with the same tags as in the example above, which shows buttons linking
to
all items that are tagged as literary review
, article or essay
, and
somewhat positive
. We hope that these connections among texts with shared characteristics
will increase discoverability and make for an intuitive
browsing experience.
In Conclusion: Metadata Narratives
The Cultures of Reception grant work has ended, but the Women Writers Project still
has
aspirations for improving Women Writers in Review. In the future, we want to use the
refined metadata to
offer readers more ways of exploring these reviews and of considering the corpus as
a whole.
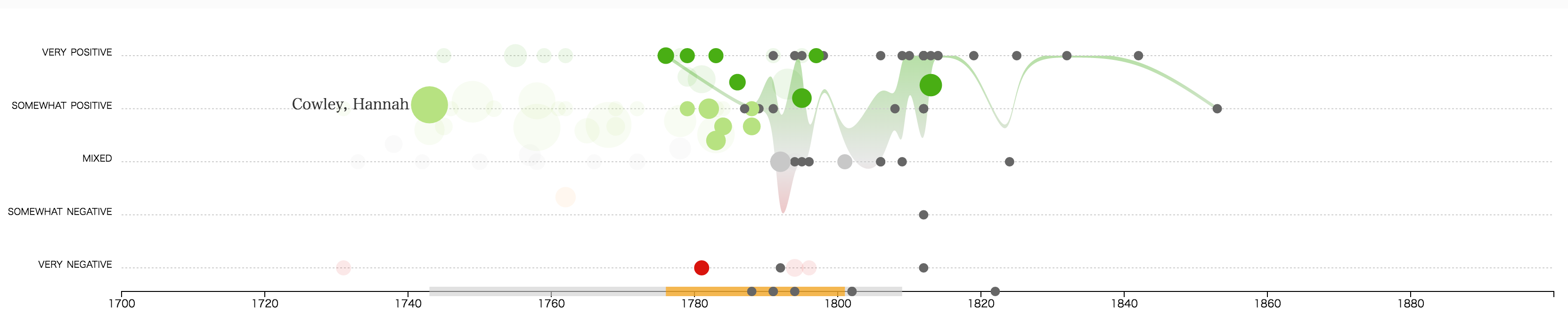
We are currently adding visualizations showing trends in the corpus across time and
location—such as positive and negative reviews of individual authors during the course
of
their writing careers—and we are working on making these visualizations themselves
a mechanism
that readers can use to explore the collection.
Figure 16: Sample visualization: evaluations over time A prototype visualization for exploration of Women Writers in Review by positive and
negative evaluations over time. Courtesy of Steven Braun.
Much of the framework is already in place for these goals. Metadata played a crucial role in the Cultures of Reception initiative, providing signposts from the earliest stages of transcription through the development of the Women Writers in Review publication interface. In the initial transcription phase, establishing a data capture mechanism that could accommodate our complex and highly structured textual and bibliographic data, while allowing a necessary degree of flexibility in the input, enabled us to complete a high volume of transcription work in a very short period of time.[31] Normalizing variations in that data early in the pre-publication process made it possible for us to map out and navigate the remaining data enhancement tasks, despite the diversity and size of the corpus. And it was the experience of navigating the XML files through their bibliographic and biographic data that inspired the design of Women Writers in Review. The result is a publication with a contextual foundation sturdy enough to build on. More importantly, we believe that foundation will empower users to read and to question, to explore and to discover, to experiment with and to theorize about the collection we have built.
Acknowledgments
The Cultures of Reception project was generously funded by a National Endowment for the Humanities Collaborative Research Grant.
The authors owe a considerable debt of gratitude to Julia Flanders, Syd Bauman, Steven Braun, John Melson, and the encoding staff at the WWP for their expertise and enthusiasm in developing the project.
Appendix A. Appendix A: Metadata Comparison between Women Writers Project Publications
All Women Writers Project initiatives include references to the same WWP-canonical personography—a TEI file with data on persons significant to the WWP. We at the WWP collect information on names (including birth names, married names, honorifics, pseudonyms, and name variants); geographic information (including birth and death locations as well as residences); dates (birth, death, and floruit); identifiers (including WWP and LCNA); and some biographic details (faith, marital status, parental status, and languages known). We also track authors’ roles in the WWP’s information systems—such as their roles as authors of texts in WWO, Women Writers in Context, and Women Writers in Review—and we keep open fields for notes, sources, and queries.
Table II
Identifiers are marked "ID", and identifier references are marked "IDREF".
| Women Writers Online | Women Writers in Review | ||
| transcription metadata | transcription metadata | canonical lists (’ographies) | |
| WWP publication | file title | file title | |
| publication information (publisher, date, place) | publication information (publisher, date, place) | ||
| file ID | file ID | ||
| CouchDB IDREF | |||
| work attributed to a woman | IDREF(s) to any work reviewed, including the specific edition, if known | work ID(s) | |
| work title | work title(s), optionally including a shortened title suitable for web display | ||
| contributor IDREF(s) | contributor IDREF(s) | ||
| contributor name(s) | |||
| edition | edition(s), if known | ||
| publication information (publisher, date, place) | publication information (publisher, date, place) for each known edition | ||
| physical characteristics, such as the number of pages | |||
| Related WWO file IDREF, if one exists | |||
| source periodical | periodical IDREF | periodical ID | |
| review title | |||
| review author, if known | |||
| periodical title | periodical title(s), optionally including a shortened title suitable for web display | ||
| publication date | publication date range, if known | ||
| volume, issue | |||
| publication place | |||
| publisher name(s), if known | |||
| editor name(s), if known | |||
| contributor name(s), if known | |||
| politics, if known | |||
| frequency of publication, if known | |||
| categories | work genre IDREF(s) | review genre IDREF(s) | |
| review format IDREF | |||
| review theme IDREF(s) | |||
| IDREF of the evaluated tone the review takes to the main received work | |||
| keywords | |||
| Mentioned WWP author IDREF(s) | |||
Appendix B. Appendix B: Original JSON Keys
-
title
-
transcription
-
isWellformed
-
author
-
editor
-
pub[lisher]
-
docDate
-
volume
-
issue
-
pages
-
source
-
url
-
wwp_tr
-
rcvdTitle
-
rcvdAuthor
-
rcvdContributor
-
rcvdEditor
-
rcvdTranslator
-
rcvdNotes
-
rcvdEdition
-
rcvdPub
-
rcvdDocDate
-
rcvdVolume
-
rcvdIssue
-
rcvdPages
Appendix C. Appendix C: JSON to TEI
Figure 17: Conversion step one: XQuery
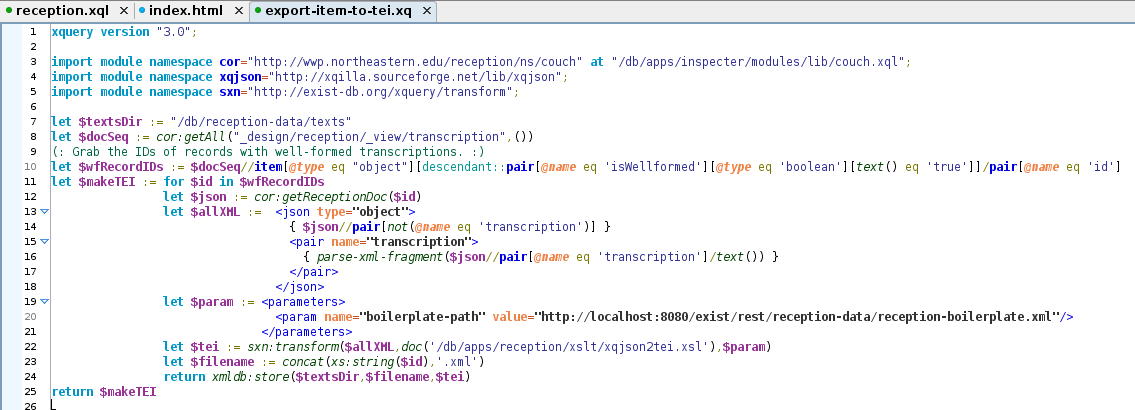
This XQuery transformed each well-formed CouchDB record into TEI using XSLT. The TEI was then stored in eXist.
Figure 18: Conversion step two: XSLT
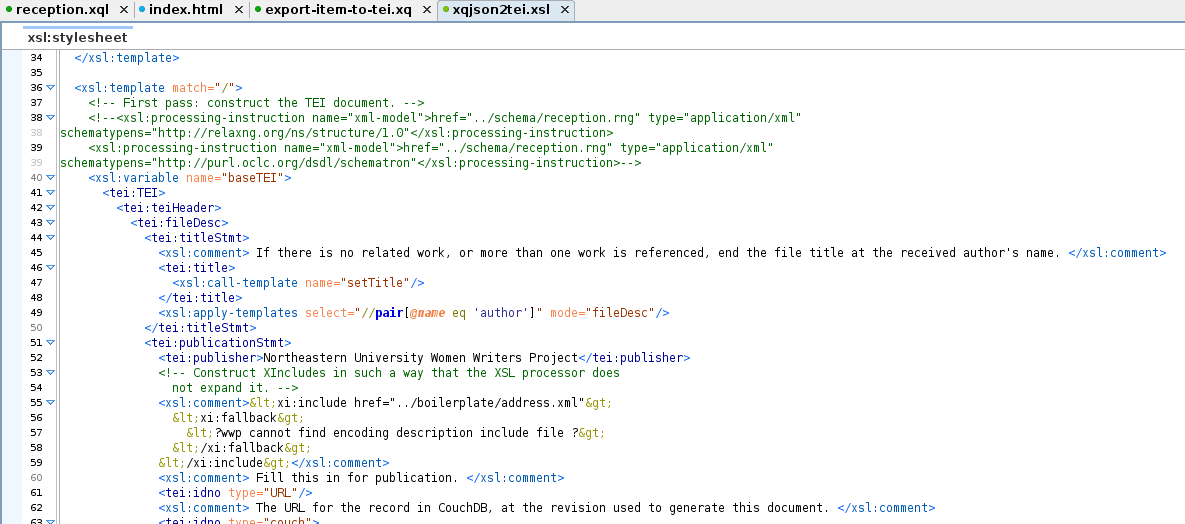
A snippet from the XSLT. The stylesheet’s first pass constructed a TEI document from
the XQJSON intermediate format. As templates were matched, some debugging elements
were
created. For example: <DEBUG target="#cr.debug-andperson"/> was created
if a contributor field contained the word "and", suggesting that two
<persName>s might be needed instead of one.
Figure 19: Conversion step three: XSLT
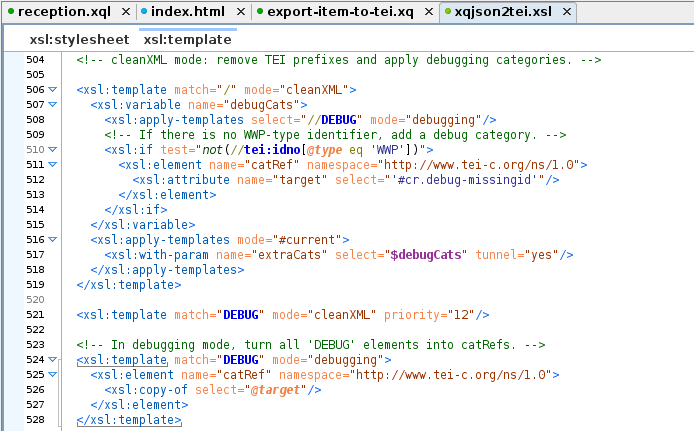
A snippet from the XSLT. With all templates applied to the pseudo-JSON record, the
stylesheet then consolidated all debugging elements and turned them into TEI
<catRef>s within the header. These could be found again using
XPath.
[2] A long-term research and publication project focused on early women’s writing in English. http://wwp.northeastern.edu
[5] Restricting the tagset enabled the project to complete a relatively high volume of encoding work in a constrained period of time; it is possible that future research at the WWP will entail enriching the Cultures of Reception corpus with more detailed encoding.
[6] WWO itself was first published in 1999 and encoding work began years earlier.
[7] More information on Cultures of Reception and Women Writers in Review here: http://wwp.northeastern.edu/research/projects/reception/index.html
[8] A NoSQL database which stores JSON documents. https://couchdb.apache.org/
[9] JSON objects are unordered lists of keys and their associated values.
[10] The plain-text looked like XML in that it had pointy brackets and element-like structures, but it was not serialized as XML. Because it hadn’t been serialized as XML, there was no guarantee that the text was hierarchical or had only one root element.
[11] An open source XML database. http://exist-db.org
[12] For example, one note on a text discussing Elizabeth Ogilvy Benger’s Poems on the Abolition of the Slave Trade reads:
Elizabeth Benger is apparently only named in the work as E. Benger, and she is
referred to as Mr. Benger throughout the review. There is an interesting footnote
on
the bottom right of page 104, which speculates that E. Benger might be a
woman.
[13] The idea for the interface was conceived around Halloween. Its name combines inspector
(for its task-based reports) with specter
(for the ghostly way those reports were displayed: data unmoored from its context).
In the future, the name will be changed to inspectre
to better embody the pun.
[15] AceJS is a JavaScript-based, embeddable code editor. https://ace.c9.io
[16] This was, unfortunately, common.
[17] The unique identifier for WWO texts (TR
is short for
transcription
).
[18] This helpful EXPath library[19] aids in JSON-XML translation, though conversion can certainly be accomplished using other methods. https://github.com/joewiz/xqjson
[19] XQuery functions packaged for easy installation and propagation. http://expath.org/spec/pkg
[20] CouchDB identifiers are long and not particularly human-readable, but they had the advantage of being unique. We later changed the filenames to use the primary reviewed author’s surname, a key for the primary reviewed work, and a key for the periodical in which the review was published. This yielded filenames that were at least human-readable, though still lengthy.
[21] An unofficial lesson from this project: offending developers’ sensibilities can be a positive force for change.
[22] A TEI file with structured data on persons.
[23] FRBR is recommendation by the International Federation of Library Associations and Institutions (IFLA). http://www.ifla.org/publications/functional-requirements-for-bibliographic-records
[24] In fact, all but a handful are either anonymous or pseudonymous.
[25] A model-view-controller library for creating web applications in JavaScript. http://backbonejs.org
[30] Reviews were selected for transcription by author, rather than by work, so some reception items discuss works that are not themselves published in WWO, though other works by that author are.
[31] For the WWP, at least, given the project’s long-term approach to research and publication.