How to cite this paper
Lenz, Evan. “The Mystical Principles of XSLT: Enlightenment through Software Visualization.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). https://doi.org/10.4242/BalisageVol17.Lenz01.
Balisage: The Markup Conference 2016
August 2 - 5, 2016
Balisage Paper: The Mystical Principles of XSLT
Enlightenment through Software Visualization
Evan Lenz
President
Lenz Consulting Group, Inc.
Evan Lenz has been a specialist in XML technologies since 1999, having served on the
W3C XSL Working Group, written XML-related books and articles, and spoken at numerous
conferences. He is also a member of the XML Guild, a consortium of top-notch independent
XML consultants. As principal of Lenz Consulting Group, he serves clients with their
XSLT,
XQuery, and MarkLogic development and/or training needs.
Copyright © 2016 by Evan Lenz
Abstract
The mature XSLT developer has an inner seeing about how a stylesheet works that can
seem almost mystical to an outsider. But demystification is possible using an XSLT
visualizer, making the structure of a transformation visible. Due to its functional
nature, XSLT is particularly well-suited to software visualization, because an XSLT
transformation can be represented and viewed as a static dataset. A subset of XSLT
visualization (using a “trace-enabled” stylesheet to generate representations of transformation
relationships) was used to empower non-programming staff to predict, understand, and
manipulate content enrichment rules. We would like to generalize these case-specific
techniques into a general tool for XSLT. There are challenges including scalability
(memory usage), what to visualize and what not to, avoiding noise for the user, and
whether to store annotations externally or within the result document.
Table of Contents
- Introduction
- The mystical principles of XSLT
- Case Study: Enrichment Tracer
- Conceiving a general software visualization tool for XSLT
-
- Early results
Introduction
The mature XSLT developer has an inner seeing that is unavailable to the uninitiated,
in
the same way that mathematicians and users of any specialized language rely on a shared
inner
seeing. They don't need to bother externally manifesting the structures because they
already
have the inner structures (knowledge and skills) for quickly building shared inner
structures
given only the essential variables (represented in code or symbols). There is much
that is
implicit in this communication. That is why the programmer can feel like (and seem
to others
like) a wizard. Short incantations yield disproportionately large or powerful computations.
This power can have an almost mystical quality to it.
However, one of Webster's definitions of mysticism is "a theory postulating the
possibility of direct and intuitive acquisition of ineffable knowledge or power."
In other
words, the promise of mysticism is precisely demystification. What was ineffable now
becomes
accessible. In the context of XSLT, if we make explicitly visible the structure of
a
transformation, we can enable new users to learn XSLT more easily, everyday users
to find bugs
more quickly, and advanced users to gain a deeper understanding of what they thought
they
already understood, leading to more innovation and better design.
This general principle can be applied to any language, and is generally considered
to fall
under the discipline of software visualization. However, XSLT's functional,
transformation-oriented nature is particularly well-suited to a conception of process
visualization as data visualization. In other words, an XSLT transformation is not
fundamentally a process; it is a data set. Using this principle as the foundation,
we can
escape from the bounds of time and conceive of many time-independent ways of traversing
the
data.
After laying out the "mystical principles of XSLT", i.e. what are the essential relational
characteristics of a transformation, we will look at how to internally represent and
externally visualize this information.
We'll look at a specific client project where a subset of software visualization for
XSLT
was employed to empower non-programmer editorial staff to predict, understand, and
manipulate
content enrichment rules. We will see how in this project, XSLT held the keys to its
own
"awakening", i.e. how using nothing other than XSLT to modify itself, a stylesheet
was made
self-aware, or "trace-enabled." The trace-enabled stylesheet then would generate an
explicit
representation of all the transformation's relationships needing to be visualized.
Finally, we'll generalize the principle of self-aware stylesheets to XSLT in general,
where no use-case-specific lines are drawn between what should and shouldn't be visualized.
We'll consider how the resulting challenges of scalability, both in terms of memory
usage and
of noise for the user, might be surmounted, including technical details and example
demos.
The mystical principles of XSLT
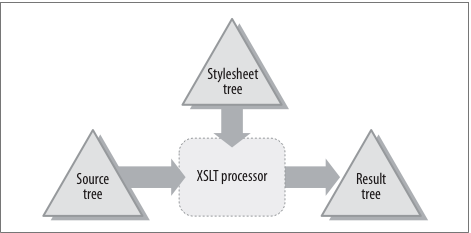
A transformation is a microcosm; we can look at it as a universe unto itself. It
is a
closed system, comprised entirely of:
Among these three consist a static set of relationships. Dynamism occurs only insofar
as
we use time as a mechanism to traverse them. Time is useful, since it helps us break
down the
information into digestible parts, but it won't be our only traversal mechanism.
The relationships are between source nodes, rules, and results. Let's define the
relational participants more precisely, for purposes of reasoning about a transformation
and
visually representing their relationships.
The XSLT Recommendation defines the focus as consisting of:
If we slightly modify the definition of focus to mean the
particular instance of a focus (tied to a particular instantiation
of a template rule, for example), then we can also treat the shallow result chunk
that the
stylesheet generates while maintaining that focus, as a property of the focus itself,
since
they have a 1:1 relationship. In other words, each instantiation of a focus-changing
sequence
constructor can be treated as an entity, which we will call a "focus".
For example, given a single instantiation of the following template
rule:
<xsl:template match="heading">
<title>
<xsl:value-of select="."/>
</title>
</xsl:template>
we might represent the instantiation like this:
<trace:focus context-id="n1a833c7b3a005151"
context-position="1"
context-size="1"
rule-id="nfa49863d62353482"
invocation-id="bc08a736-13f7-e97b-a272-15a0a4229223">
<title>This is the title</title>
</trace:focus>where each non-self-explanatory part is defined as follows:
-
context-id
-
rule-id
-
invocation-id
The content of the element is the shallow result chunk that this focus generates.
Note
that the <xsl:value-of> instruction has been evaluated and its results are
included in the result chunk.
The mystical principle represented by tying the focus to its output is this: inner
seeing
results in outer manifestation. They are not separate; they are two sides of the same
coin. To
focus on the input is to create the output, as defined by the template rule. In short,
to see is to create.
The focus's result chunk is "shallow" in the sense that any descendant invocations
(e.g.
<xsl:apply-templates/> elements), though not present in this example, will
not be replaced by their evaluated results but instead
will be replaced by a stub that links to another invocation (set of n foci having a common invocation GUID and having context-position values of 1
to n and a context-size of n).
Each invocation (represented by a GUID) always consists of one or more foci. In the
case
of our example focus, we know that it is the only focus that can belong to this invocation,
because the context-size is 1. (When an invocation is applied to an empty sequence,
no foci
are created; for all practical purposes, the invocation did not happen and does not
exist.)
Also, by virtue of its location in the transformation's call stack, each focus is
eventually
connected to every other focus in the transformation via successive invocation-ID
links.
Except for an initial context node, every focus has a parent focus, identified by
a link
appearing somewhere in the parent focus's result chunk to its child focus's invocation.
Every
invocation has exactly one invocation stub; in other words, there will only be one
invocation
stub for each invocation GUID. Below is an example of what the parent focus of our
first
example might look like. It shows what the "shallow" result chunk looks like; rather
than
seeing the resulting <title> element, we see a stub
(<trace:apply-templates>) that links to the invocation ID of our first
example focus (bc08a736-13f7-e97b-a272-15a0a4229223). That is what makes this
focus the parent of the previous example focus:
<trace:focus context-id="n292122aca28a94ca"
context-position="1"
context-size="1"
rule-id="n8ef8c66cac078ff"
invocation-id="4dd7580b-d44e-a0e4-714d-32fe33431fe0">
<html>
<head>
<trace:apply-templates trace:invocation-id="bc08a736-13f7-e97b-a272-15a0a4229223" select="/doc/heading"/>
</head>
</html>
</trace:focus>In order to represent these relationships explicitly and visually, each source node,
template rule, and result chunk needs to be addressable within the universe of the
transformation; it must have a "cosmic address." That is the role played by the context-id,
rule-id, and invocation-id properties. These allow us to begin anywhere within the
world of
the transformation and traverse to anywhere else in the world. It is all accessible
and
nothing is lost through the passage of time.
What is the relationship between the tree of foci (i.e. the call stack) and the result
tree(s)? When we consider that, using our modified definition of "focus," a focus
includes a
shallow chunk of the result tree (and this is the only way a chunk can make its way
into a
result), then it becomes more obvious that the result tree is not only isomorphic
to the XSLT
execution tree, but it is actually an adornment of that tree. The result is what we
see; the
inner structure upholds the outer result. In other words, the visible world is a decoration
of
the invisible, a manifestation of a deeper, unseen reality.
Since mysticism is all about demystification, let's get to work manifesting XSLT's
inner
world. But first, a story.
Case Study: Enrichment Tracer
Once upon a time, I briefly considered showing a clip from Finding
Nemo to a class I was teaching on XSLT. The "East Australian Current" was one of
many metaphors I imagined for how XSLT's processing model can be delightfully easy
to work
with when you know what you're doing. When you "go with the flow," you can write powerful
transformations without a lot of fuss. In contrast, if template rules are still too
mystifying, you can end up writing a lot of verbose code to do what should be easy,
and that
feels like having to swim upstream.
Besides trying to come up with metaphors and hopefully useful
explanations, I was becoming increasingly desirous of a tool that would make the
inner workings of a stylesheet visible. I wanted to see for myself what I was faintly
imagining in my head and show it to others on the theory that seeing it in action
would make
the lightbulb come on and make more people want to learn and use XSLT. I began to
write
trace-enabling stylesheets, which would turn an existing stylesheet into another one
that
adorns its output with information about how the result was created. The closest I
came to
visualizing how the result tree is built, was a slider-driven, graphical tree builder
with a
visual block representing each node. I conducted that experiment using XSLT, XAML
and WPF back
in 2009. But for the most part, I never brought the idea down to earth. It remained
abstract
and ethereal.
Enter 2016. I was rewriting a content enrichment rules engine for my client, and it
came
time to replace the tracing/debugging mechanism they had been using to diagnose enrichment
issues. The new engine and rules were written in XSLT, and the engine used a multi-stage
pipeline to help keep the rules as simple as possible. I wanted to make the new trace
mechanism (which we ended up calling the "Enrichment Tracer") as enlightening as possible
to
the analysts who would be maintaining the rules and enrichment term data. I took advantage
of
the particular constraints and assumptions of this setup, including the designation
of
particular "rule modes" (as distinct from the engine-level modes), as well as the
multi-stage
pipeline, in which each stage contains a particular set of rule modes. I later recognized
that
what I implemented was a very concrete (and reportedly extremely useful to this day!)
subset
of a software visualization tool for XSLT.
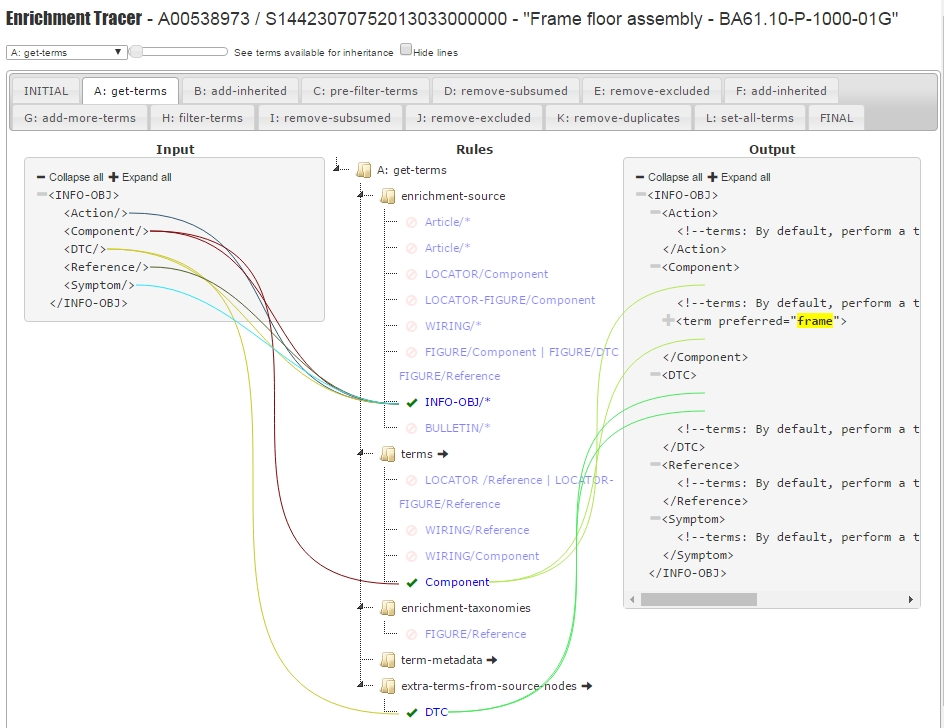
The tabbed interface in the screenshot below shows the stages of the pipeline (one
tab per
stage). The horizontal slider at the top of the screen provides an alternate way to
quickly
scroll through the stages to get a fast glance of how the data evolves through the
stages.
Within each stage are shown three columns:
-
the "Input" column, which shows the input to the current stage and the output from
the previous stage,
-
the "Rules" column, which shows a list of all the rules (match patterns) for the
current stage, grouped by mode name, and
-
the "Output" column, which shows the output from the current stage (and what will
be
the input to the next stage, if applicable).
The colored lines were a last-minute addition that helped show exactly which input
nodes
matched which rules (using one line), and which rules created which section of the
output
document (using two lines). They are automatically redrawn whenever the user adjusts
the
screen or column size, or expands or collapses any of the three trees:
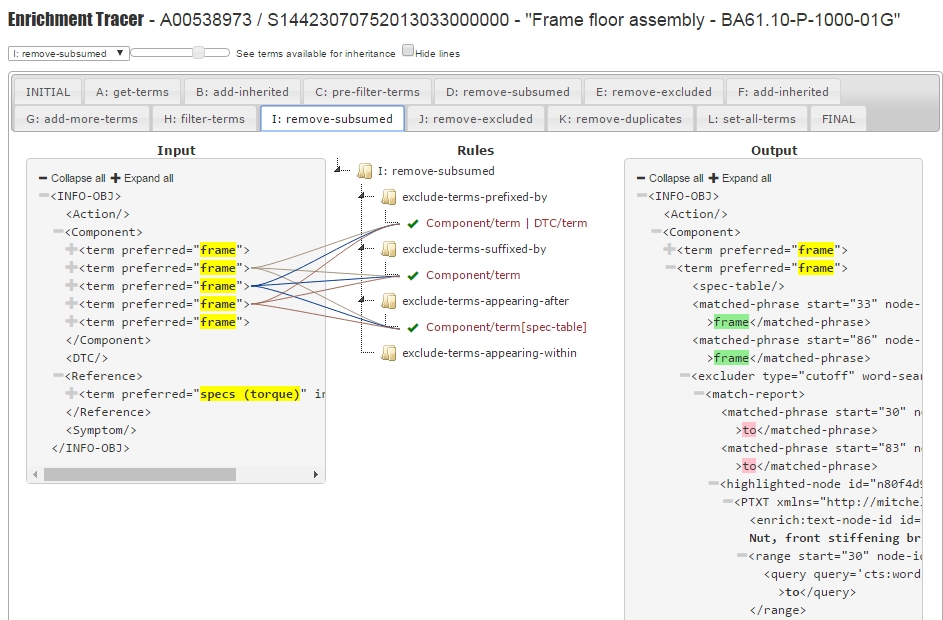
Here's another screenshot from a later stage in the same transformation:
Besides showing only the rules and matches that are relevant to the analyst (and hiding
all the "engine-level" rules), I also enhanced the interface by highlighting additional,
domain-specific nodes or values in the result, in order to draw the user's eye to
the most
relevant information. For example, the yellow highlight is applied to all the currently
determined terms that will be used to enrich the content of the current input document.
The
above screenshot also illustrates the fact that a rule match won't always result in
an output
to the (intermediate) result tree on the right. That's because, again, we're only
showing the
information that's known to be relevant, and not every one of the enrichment rules
produces a
result in the stage's result tree.
Finally, users can inspect the XSLT code for each rule by hovering over the match
pattern
(such as "Component/term" in the above screenshot). This will show the actual code
for that
template rule, as well as which XSLT module the rule resides in. Also, if the user
hovers over
the rule mode name (such as "exclude-terms-suffixed-by" in the above screenshot),
they can see
a full description of the purpose of each mode (and each stage).
To achieve this, I employed a number of techniques, including:
-
using XSLT to pre-process (trace-enable) the original engine and rules XSLT,
-
generating both:
-
documenting the rules inline, so they get fed straight to the tracer
interface,
-
storing the trace data for each input document into the (MarkLogic) database for
faster subsequent renders,
-
automatically invalidating (and thus forcing re-generation of) the cached trace data
whenever a rule or data change is detected.
Conceiving a general software visualization tool for XSLT
I want to generalize the principles and mechanisms of the specific use case above
into a
general software visualization tool for XSLT. As of the time of this writing, it is
still
emerging.
In particular, I want to preserve at least three characteristics so that the general
tool still:
-
uses the colored lines to depict the relationships between source nodes and rules,
and rules and result chunks
-
visually represents the XML as XML (as opposed to abstract block shapes)
-
includes a slider for building (and un-building) the result tree (as in my original
experiment from 2009)
The <trace:focus> docs described in Section 2 represent
the latest on my thinking about how to represent the trace data. Initially, it will
be
completely out-of-band, using a side-effect operation such as provided by MarkLogic's
extension functions xdmp:set() and xdmp:document-insert(). The reasons for storing the trace data out-of-band, as
opposed to inline in the result, are several:
-
Storing the trace data out-of-band will ensure that the effective behavior of the
stylesheet will not accidentally change (or cause type errors). In the Enrichment
Tracer, we had the luxury of babysitting the types, because the core engine itself
was
unchanging; we won't have that luxury in a general-purpose tool, which needs to handle
arbitrary XSLT.
-
Larger transformations will result in a lot of data, which may be impractical to
visualize all at once; shredding the data gives us options for rebuilding, or lazy
loading and unloading of batches of foci.
-
The discrete <trace:focus> elements succinctly and uniformly
represent the relationships that we want to visualize. Or, in other words, they make
sense to me, and that's important if the rest of this project is going to be
realized!
Disclaimer: This is just the current thinking; it's subject to change.
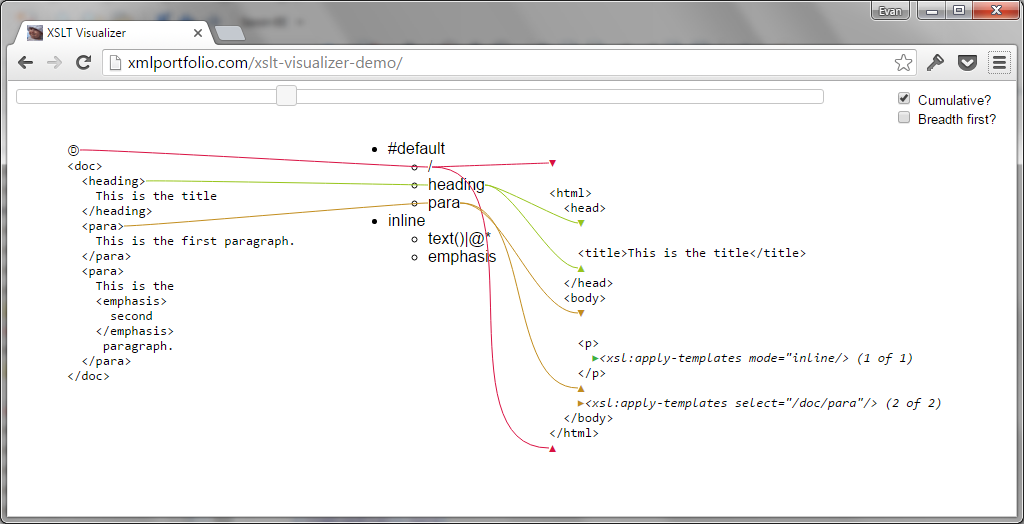
To illustrate what I mean by "building the tree" using a slider, consider the following
example result document:
<doc>
<title>This is the title</title>
<p>Let us <em>begin</em>…</p>
<p>And now let's end.</p>
</doc>
Although there is likely to be just one slider UI widget, the tool might have multiple
options for how to build the tree:
-
"Build from the past"
-
"Build from the future"
-
"Only the present"
-
"All time"
The "all time" option would mean that the tree is already completely built (as
in the Enrichment Tracer utility), rather than being successively built. In that case,
the
slider might only traverse the foci, drawing the lines as needed, and expanding the
result
tree as needed. The following table shows what the other three options ("Only the
present",
"Build from the past", and "Build from the future") might show in successive gradations
of the
slider, from left to right:
Table I
| |
Only the present |
Build from the past |
Build from the future |
| 1 |
<doc/> |
<doc/> |
<p>And now let's end.</p> |
| 2 |
<title>This is the title</title> |
<doc>
<title>This is the title</title>
</doc>
|
…
<p>And now let's end.</p>
|
| 3 |
<p>Let us </p> |
<doc>
<title>This is the title</title>
<p>Let us </p>
</doc>
|
<em>begin</em>…
<p>And now let's end.</p>
|
| 4 |
<em>begin</em> |
<doc>
<title>This is the title</title>
<p>Let us <em>begin</em></p>
</doc>
|
<p>Let us <em>begin</em>… </p>
<p>And now let's end.</p>
|
| 5 |
… |
<doc>
<title>This is the title</title>
<p>Let us <em>begin</em> …</p>
</doc>
|
<title>This is the title</title>
<p>Let us <em>begin</em>…</p>
<p>And now let's end.</p>
|
| 6 |
<p>And now let's end.</p> |
<doc>
<title>This is the title</title>
<p>Let us <em>begin</em>…</p>
<p>And now let's end.</p>
</doc>
|
<doc>
<title>This is the title</title>
<p>Let us <em>begin</em>…</p>
<p>And now let's end.</p>
</doc>
|
Major questions still include:
-
Should we visualize only template rule invocations? Or should we also include
xsl:for-each?
-
How do we represent variable values (particularly those that result in intermediate
trees that are then fed to more template rules)?
-
Where on the screen do we find a place to show all the intermediate trees, and how
do we lay them out? (Compare the Enrichment Tracer which generates at least 13 result
trees, but they are always limited to the known stages and so are layed out in the
tabs.)
Tasks that I've completed include:
-
automatically adding built-in template rules for each mode, so they can be
visualized as well
-
partially completed: the trace-enabling stylesheet for generating all the
<trace:focus> docs