Graham, Tony. “focheck XSL-FO Validation Framework.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). https://doi.org/10.4242/BalisageVol17.Graham01.
Balisage: The Markup Conference 2016 August 2 - 5, 2016
Tony Graham is a Senior Architect with Antenna House, where he works on their XSL-FO
and CSS formatter, cloud-based authoring solution, and related products. He also provides
XSL-FO and XSLT consulting and training services on behalf of Antenna House.
Tony has been working with markup since 1991, with XML since 1996, and with XSLT/XSL-FO
since 1998. He is Chair of the Print and Page Layout Community Group at the W3C and
previously an invited expert on the W3C XML Print and Page Layout Working Group (XPPL)
defining the XSL-FO specification, as well as an acknowledged expert in XSLT. Tony
is the developer of the ‘stf’ Schematron testing framework and also Antenna House’s
‘focheck’ XSL-FO validation tool, a committer to both the XSpec and Juxy XSLT testing
frameworks, the author of “Unicode: A Primer’, and a qualified trainer.
Tony’s career in XML and SGML spans Japan, USA, UK, and Ireland. Before joining Antenna
House, he had previously been an independent consultant, a Staff Engineer with Sun
Microsystems, a Senior Consultant with Mulberry Technologies, and a Document Analyst
with Uniscope. He has worked with data in English, Chinese, Japanese, and Korean,
and with academic, automotive, publishing, software, and telecommunications applications.
He has also spoken about XML, XSLT, XSL-FO, EPUB, and related technologies to clients
and conferences in North America, Europe, Japan, and Australia.
XSL-FO documents are typically generated by an XSLT transform and thus rarely edited
by hand. However, validating XSL-FO markup can be a useful check of the correctness
of the transformation. The focheck Validation Framework is an open source project
that bundles a Relax NG Schema for validating the structure of FO files with Schematron
rules for validating property expressions. Validation uses an expression parser generated
as an XSLT program by the REx parser generator; Schematron rules are mostly autogenerated,
using an XSLT stylesheet to extract property value definitions from the XML version
of the XSL 1.1 Recommendation. Since its introduction in 2015, focheck has added extension
formatting objects, properties specific to Antenna House Formatter V6.3, and some
Schematron Quick Fixes (SQF). Both GitHub and Oxygen framework versions of focheck
are available. See what it can do!
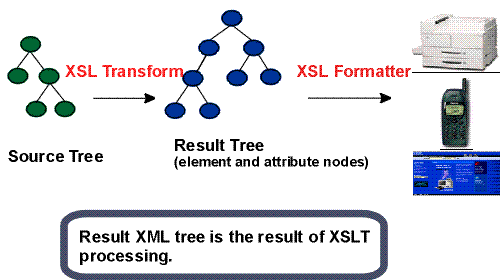
XSL-FO is a vocabulary for expressing the formatting of XML. It is defined in the
XSL 1.1 Recommendation 1 from the W3C. XSL-FO is used for formatting XML, but it originally wasn’t meant
to be written as XML. Your XML was meant to be transformed to XSL-FO inside the FO
processor, as shown in Figure 1.
Figure 1
The first XSL 1.0 Working Draft 2 mentions the option of producing formatting objects as XML output, without mentioning
it as a possible input:
When the result tree uses the formatting vocabulary, a conforming XSL implementation
must be able to interpret the result tree according to the semantics of the formatting
vocabulary as defined in this document; it may also be able to externalize the result
tree as XML, but it is not required to be able to do so.
Section 1.1, Processing a Stylesheet, from the current XSL 1.1 Recommendation contains
both:
An XSL stylesheet processor accepts a document or data in XML and an XSL stylesheet
and produces the presentation of that XML source content that was intended by the
designer of that stylesheet.
and:
In some implementations of XSL/XSLT, the result of tree construction can be output
as an XML document. This would allow an XML document which contains formatting objects
and formatting properties to be output. This capability is neither necessary for an
XSL processor nor is it encouraged.
The above definition of an XSL stylesheet processor as accepting XML and XSL first
appeared in the 1 March 2000 XSL 1.0 Working Draft 3, which was the first XSL 1.0 WD for a while to have this sort of introduction and
which also postdates XSLT 1.0 4. In contrast, the combined acknowledgement and discouragement of outputting the
result tree as XML first appeared two WDs later, in the 18 October 2000 Working Draft
5. In a similar fashion, the first version of the DTD for XSL tests 6 produced by the XSL FO Subgroup on 10 January 2001 did not support using FO files
as input, and that was later allowed in an update on 4 April 2001.
Another indication that you were not meant to externalize XSL-FO as XML is that the XSL-FO vocabulary has no mechanism to indicate the version
number of the XSL-FO document. This means, in part, that there's no way to indicate
whether the XSL-FO document uses features added in XSL 1.1. This isn’t a problem
when the transformation happens inside the XSL processor, but it could be if the transformation
was not intimately tied to the XSL formatter that does the presentation of that XML source content.
At this point, it’s not possible to say how much of the de-emphasis of producing XSL-FO
XML was from adherence to the processing model of the original XSL submission 7, which makes no mention of XML output, from a general acknowledgement that translation
to the formatting object semantics loses the original semantics, or from the lingering
shadow of the “Formatting Objects considered harmful” 8 essay[1] by Håkon W Lie, which caused some discussion when it was published in April 1999.
In practise, however, the transformation part was broken out as XSLT, and now most
people do the transformation as a separate step using an XSLT processor, and every
FO processor that I know of accepts XSL-FO as input. The two benefits of doing the
transformation separately are that you can use the XSLT processor of your choice,
possibly with your own extensions, and that you can debug the XSLT.
There are also times when you want to write your own XSL-FO, or edit an existing XSL-FO
file, particularly when you want to experiment with XSL-FO markup to see what it produces.
Most FO processors operate in batch mode either from the command line or through an
API. oXygen ships with the FOP processor and it makes it easy to use the Antenna
House and RenderX formatters.
Why make a schema?
XSL-FO documents are typically generated as the result of an
XSLT transformation and are rarely edited by hand. However,
validating generated XSL-FO markup is useful as a check of the
correctness of the transformation. Also, people do edit XSL-FO by
hand either when prototyping the XSL-FO markup that will later be
generated using XSLT or when debugging generated XSL-FO. Being
able to validate the XSL-FO in an XML editor helps in both
scenarios.
Validating XSL-FO is not easy because:
Constraints in the definitions of FOs are hard or
impossible to express in structure-checking schema
languages.
Some FOs can appear almost anywhere in an XSL-FO
document but, equally, cannot appear where they are not
allowed.
The properties of an FO are expressed in the XML as
attributes of the XML element representing the FO, but
inherited properties 11 are allowed to
appear on any FO, not just on the FOs for which they are
defined.
While the XSL 1.1 Recommendation 12
defines the allowed values of properties, most properties can
contain expressions in the expression language 13 that is defined in the spec, so determining
the correctness of an attribute in the XML initially requires
evaluating it. Figure 2 shows part of the EBNF for the XSL-FO expression language.
Figure 2
A schema for XSL-FO was in the requirements for XSL 2.0
14, but the design of XSL was shaped by the
requirements of formatting rather than any requirement to conform
to a schema language. The result has been that XSL-FO was hard to
validate except by running it through an FO formatter. Systems for
checking the formatted result exist 1516, but they require usable input.
Schemas for XSL-FO do exist, including several from RenderX
17 and the schema that is provided by the
oXygen XML Editor 18 prior to oXygen 17.1, but: they do not cover
XSL 1.1; they each cut corners in their models for element
content; and they do not properly evaluate property value
expressions. An added problem that we experienced more often than most people is that
none of the existing schemas covered the extensions built into the Antenna House formatter.
One of the validation methods tried by RenderX but noted as
longer used 17 is a validator written in XSLT
19. A 2004 paper 20 by Alexander Peshkov of
RenderX describes the XSLT approach as powerful but requiring more
resources than, for example, DTD validation and also not being
suitable for visual XSL-FO editors or document builders. That
paper then describes a Relax NG schema that includes a limited
ability to handle property value expressions.
The approach taken by Antenna House combines Relax NG and
Schematron for detailed validation of the XSL-FO. The Relax NG
handles structural validation and is, we believe, more correct
than pre-existing schemas. The Schematron handles the additional
constraints that cannot be expressed in Relax NG. The Schematron
parses property value expressions using an XSLT-based parser
generated by the REx parser generator 21 plus
an XSLT library for reducing the parse tree to XSL-FO
datatypes.
The Relax NG and Schematron is available on GitHub (https://github.com/AntennaHouse/focheck) and you can download an
oXygen add-on framework for XSL-FO validation directly from the
GitHub page 22. An earlier focheck version was bundled with oXygen 17.1 and 18.0.
We also considered wiring the Schematron directly to the
expression parser built into an FO formatter through XSLT
extension functions. However, doing the interfacing would have
been a non-trivial task, plus the Antenna House AH Formatter 23 is
a native application on each platform and wouldn’t be as portable as
purely-XSLT Schematron.
Why Relax NG?
Three features of Relax NG made it the best choice for the schema:
Non-deterministic content models
Easy extensibility by redefining or extending patterns
Ability to interleave elements in content models
Why Relax NG Compact Syntax?
The schema is written in Relax NG compact syntax (and usable with Emacs) and then
converted into the Relax NG XML syntax for use with oXygen (and into W3C XML Schema
for use with other editors). It is not
written directly in the XML syntax for multiple reasons:
Relax NG compact syntax closely matches the syntax of
the content models in the spec, which made it easier to
include their text in the generated schema. If the Relax NG XML syntax had been used,
we would have had to replicate part of the work of the Relax NG validator and parse
the delimiters and occurrence indicators when converting the textual content models
into XML syntax.
It was easy to write and check the initial patterns
that would be replicated by the programmatically generated
schema.
Reading the generated schema to check it is easier
with the compact syntax than with the XML syntax.
The handwritten parts, including the schema module
defining Antenna House extensions, were only ever going to
be written in the compact syntax.
Generating the Relax NG and Schematron
The bulk of the FO portion of the Relax NG and Schematron
is generated by transforming the XML source 24 for the XSL 1.1 Recommendation using XSLT. The XML is
consistent enough for this to be feasible: it’s not the first
time that I’ve generated code from the XML, nor am I the only
person to have done it 25.
Validating FOs
At first glance, this seems quite straightforward to do
using Relax NG: the content models are in the spec, where every
FO is in a separate div3 element and the FO’s content model is
easy to identify:
<div3 id="fo_block"><head>fo:block</head>
<p><emph>Common Usage:</emph></p>
<p>The fo:block formatting object is commonly used for formatting paragraphs,
titles, headlines, figure and table captions, etc.</p>
...
<p><emph>Contents:</emph></p>
<eg xml:space="preserve">
(#PCDATA|<loc href="#inline.fo.list" xlink:type="simple"
xlink:show="replace" xlink:actuate="onRequest"
xmlns:xlink="http://www.w3.org/1999/xlink">%inline;</loc>|<loc
href="#block.fo.list" xlink:type="simple" xlink:show="replace"
xlink:actuate="onRequest"
xmlns:xlink="http://www.w3.org/1999/xlink">%block;</loc>)*
</eg>
<p>In addition this formatting object may have a sequence of
zero or more fo:markers as its initial children,
optionally followed by an fo:initial-property-set.
</p>
The %inline; and %block; behave like parameter
entities in a DTD, though there isn’t a DTD, and their
expansions are given in the text of the Recommendation 26:
The parameter entity, "%block;" in the content models below,
contains the following formatting objects:
where inline.fo.list and
block.fo.list are defined in literal text that is
included in the generated schema.
However, the XSL 1.1 Recommendation defines neutral and out-of-line classes of FOs
that can appear anywhere where #PCDATA, %inline; or %block; is allowed in FO content
models (although additional constraints apply). Handling those simply required matching
on
#PCDATA, %inline;, or %block; in the content models in the spec. The generated pattern
for fo:block then becomes:
The neutral and out-of-line FO classes
were also in XSL 1.0. XSL 1.1 added fo:change-bar-begin and
fo:change-bar-end as point FOs that may be used anywhere
as a descendant of fo:flow or fo:static-content26. Since that couldn’t be handled by just looking at either
the FO or its content model, the XSLT contains a list of FOs to which
to not add the point FOs:
But there’s also the additional constraints about
allowing fo:marker and fo:initial-property-set as initial children of
an fo:block. This is handled by adding those elements to content models
only where the significant zero or more fo:markers or
optionally followed by an fo:initial-property-set text occurs in the
FO’s definition. The complete, and completely auto-generated,
model for fo:block is:
If only it was that simple. There are additional constraints in
the text of the XSL 1.1 Recommendation:
It is an error if the fo:footnote occurs as a descendant of a
flow that is not assigned to one or more region-body regions, or of an
fo:block-container that generates absolutely positioned areas...
...
An fo:footnote is not permitted to have an fo:float,
fo:footnote, or fo:marker as a descendant.
Additionally, an fo:footnote is not permitted to have as a
descendant an fo:block-container that generates an absolutely
positioned area.
from its content model, fo:retrieve-table-marker28 (added in XSL 1.1) would appear to be even
simpler:
EMPTY
producing:
fo_retrieve-table-marker.model =
( empty )
but it has its own constraints:
An fo:retrieve-table-marker is only permitted as the descendant
of an fo:table-header or fo:table-footer or as a child of fo:table in
a position where fo:table-header or fo:table-footer is
permitted.
These are the sorts of constraints that can’t be
expressed in Relax NG (except by exploding the size of the schema
through making separate versions of every FO that can appear in each
constrained context) but that are well suited to Schematron. There
aren’t enough of these constraints that are expressed in a
consistent way for it to be worthwhile autogenerating them, so they
have to be written by hand. For example, this is the
fo:retrieve-table-marker constraint as a Schematron rule:
<rule context="fo:retrieve-table-marker">
<assert test="
exists(ancestor::fo:table-header) or
exists(ancestor::fo:table-footer) or
(exists(parent::fo:table) and
empty(preceding-sibling::fo:table-body) and
empty(following-sibling::fo:table-column))"
>An fo:retrieve-table-marker is only permitted as
the descendant of an fo:table-header or
fo:table-footer or as a child of fo:table in a
position where fo:table-header or
fo:table-footer is permitted.</assert>
</rule>
Validating properties
Generating Relax NG patterns for the properties is
straightforward. The XML for each FO includes a list of its allowed
properties or groups of properties. For example, for
fo:footnote27:
<p><emph>The following properties apply to this
formatting object:</emph></p><slist>
<sitem><specref
ref="common-accessibility-properties"/></sitem>
<sitem><specref ref="id"/></sitem>
<sitem><specref ref="index-class"/></sitem>
<sitem><specref ref="index-key"/></sitem>
</slist>
Here, the specref/@ref refers either to a
div2 containing the div3 for multiple
properties or to a div3 for a property. The
div2 each generate a named pattern, so the pattern for
the properties of fo:footnote is:
common-accessibility-properties =
source-document,
role
Because, as stated previously, the properties are evaluated as
expressions, each property is generated in the Relax NG as containing
only text. For example, for the column-count
property:
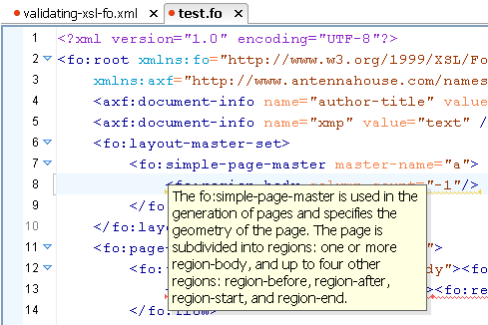
where ## begins an annotation that is the
property’s allowed value as extracted from the XML for the XSL
1.1 spec (and, similarly, annotations for FOs are also extracted from
the spec). The annotations appear in oXygen as tool-tips, as shown in Figure 3.
Figure 3: Tool-tip in oXygen
Whether or not a particular property is required for an FO is
not easy to automatically determine from the XML for the XSL 1.1 spec, so that is
enforced
by the Schematron, not by the Relax NG.
Some property values are described in terms of compound
datatypes 29, which are expressed in the XML as multiple attributes. For
example, the value of the “space-before” property is the compound <space> property.
A space-before may be specified as:
In the Relax NG, the properties that may have a value that is a compound datatype
each generate multiple attribute definitions. For example:
space-before =
## &space> | inherit
attribute space-before { text }?,
attribute space-before.minimum { text }?,
attribute space-before.optimum { text }?,
attribute space-before.maximum { text }?,
attribute space-before.precedence { text }?,
attribute space-before.conditionality { text }?
As stated previously, property values are evaluated using a
parser generated by the REx parser generator 21. The productions in the XSL 1.1 spec 13 were
mostly suitable for feeding to REx, although to get a functioning
parser required a lot of
modifications based on the example of the grammar for XPath 2.0 30 that is provided on the REx website.
Running the parser on a property value expression produces markup corresponding to
the
productions in the grammar. For example, for -1 - -2, the expression parser
produces:
This, obviously, has little resemblance to an XSL-FO
datatype. The Schematron uses a handwritten
parser-runner.xsl library that runs the expression parser
and (mostly) reduces the elements for the grammar productions into
elements representing XSL-FO datatypes. For example, this is the
current implementation of the function for the AdditiveExpr
element:
Expression evaluation is used in three Schematron phases:
Automatically generated Schematron rules that report syntax
errors and incorrect datatypes.
Handwritten Schematron rules for the additional constraints in
the XSL 1.1 Recommendation.
Handwritten Schematron rules for Antenna House extensions.
For example, the value of the column-count property
is defined as <number> | inherit, but the
definition of <number> for
column-count is:
<number>
A positive integer. If a non-positive or non-integer value is provided, the value
will
be rounded to the nearest integer value greater than or equal to 1.
The automatically generated rule for column-count is:
<rule context="fo:*/@column-count">
<let name="expression"
value="ahf:parser-runner(.)"/>
<assert test="local-name($expression) =
('Number', 'EnumerationToken', 'ERROR', 'Object')">
'column-count' should be Number, EnumerationToken.
'<value-of select="."/>' is a <value-of
select="local-name($expression)"/>.</assert>
<report test="$expression instance of
element(EnumerationToken) and
not($expression/@token = ('inherit'))">
Enumeration token is: '<value-of
select="$expression/@token"/>'.
Token should be 'inherit'.</report>
<report test="local-name($expression) = 'EMPTY'"
role="Warning">column-count="" should be Number or
'inherit'.</report>
<report test="local-name($expression) =
'ERROR'">Syntax error:
'column-count="<value-of select="."/>"'</report>
</rule>
and the handwritten rule is:
<rule context="fo:*/@column-count"
role="column-count">
<let name="expression"
value="ahf:parser-runner(.)"/>
<report test="local-name($expression) = 'Number'
and (exists($expression/@is-positive) and
$expression/@is-positive eq 'no' or
$expression/@is-zero = 'yes' or
exists($expression/@value) and
not($expression/@value castable as xs:integer))"
role="column-count">Warning: @column-count should
be a positive integer. A non-positive or non-integer
value will be rounded to the nearest integer value
greater than or equal to 1.</report>
<sqf:fix id="column-count-fix">
<sqf:description>
<sqf:title>Change the @column-count value</sqf:title>
</sqf:description>
<sqf:replace node-type="attribute"
target="column-count" select="max((1, round(.)))"/>
</sqf:fix>
</rule>
Note that the expression evaluation stops short of evaluating
the inherited value. Also, a <Number> might not
have a @value; for example, if it is the result of
‘evaluating’ an XSL-FO function that isn’t fully
implemented in parser-runner.xsl.
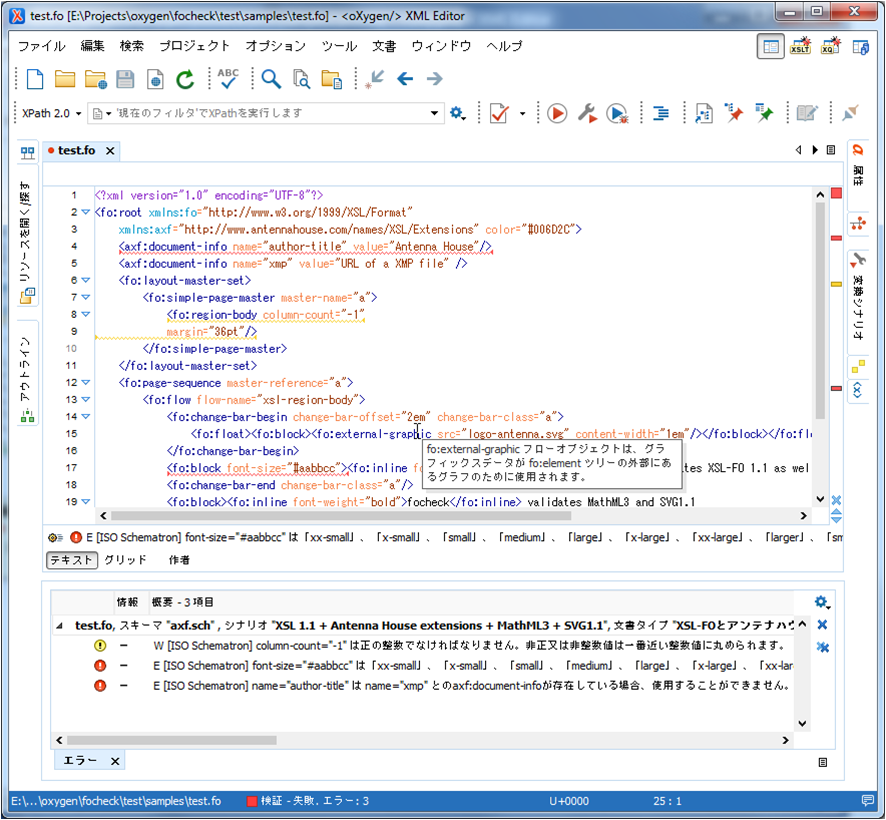
The sqf:fix element is a Schematron Quick Fix31. Schematron QuickFix is an extension of ISO standard Schematron originally by Nico
Kutscherauer that is now being developed by a W3C Community Group and is implemented
by oXygen. It allows a Schematron processor to fix the errors that it finds, or in
an editor such as oXygen, allows the editor to offer possible fixes, as shown in Figure 4.
Figure 4
Some of the property value definitions that are shared with CSS need to be expanded
32 into multiple enumeration tokens or XSL-FO datatypes
before generating the Schematron for checking a property’s
value. For example, the value of the border-start-width33
property is defined as:
<border-width> | <length-conditional> | inherit
but <border-width> is considered a ‘notational shorthand’ in XSL 1.1 32, so the
value to be checked for expands to:
although only the presence or absence of attributes for
border-start-width.length or
border-start-width.conditionality would determine whether
a length value for border-start-width is a <length>
or a <length-conditional>.
Antenna House extensions
Antenna House AH Formatter 34 implements a
number of extensions 353637 to the XSL 1.1 Recommendation to provide improvements
to the formatted output. Validation of AH Formatter extensions is also
implemented using a combination of Relax NG and Schematron.
The documentation for the AH Formatter extensions is in XML, as
you would expect. However, it’s not in a format that is
useful for automating the connections between extensions and
applicable FOs and properties, so the Relax NG and Schematron both
needed to be handwritten.
The modules for the AH Formatter extensions use the Relax NG
include pattern to include the schema for XSL-FO and
merge it with the definitions of the extensions. The shortened schema
module below demonstrates this:
This module includes fo.rnc. The
definitions of fo_change-bar-begin.model and
fo_root.model redefine and override the corresponding
definitions in fo.rnc. Conversely, the definition
of common-border-padding-and-background-properties that
is outside the include interleaves the
axf_border-radius and
axf_border-top-right-radius patterns with the existing
common-border-padding-and-background-properties defined
in fo.rnc to add additional optional attributes
to any FO defined by the XSL 1.1 spec to already have the common
border, padding, and background properties.
The definitions of axf_document-info,
axf_border-radius, and
axf_border-top-right-radius have to be outside the
include pattern. It would be an error to put any of them
inside the include since there are no corresponding
definitions in fo.rnc that they would
override.
MathML and SVG
MathML and SVG are the two formats most commonly used in fo:instream-foreign-object, so their schemas have been included in the focheck schema using 'external' references.
The new top-level schema file, axf-mathml3-svg11.rnc, contains:
default namespace axf = "http://www.antennahouse.com/names/XSL/Extensions"
namespace fo = "http://www.w3.org/1999/XSL/Format"
namespace m = "http://www.w3.org/1998/Math/MathML"
namespace svg = "http://www.w3.org/2000/svg"
namespace local = ""
# MathML 3.0 schema with Antenna House overrides.
math = external "axf-mathml3-override.rnc"
# SVG 1.1 schema with Antenna House overrides.
svg = external "axf-svg11-override.rnc"
include "axf.rnc" {
# For fo:instream-foreign-object
# Exclude axf:* elements and attributes from counting as 'non-xsl'.
# Allow MathML m:math and svg:svg
non-xsl =
( attribute * - ( local:* | axf:* | xml:* ) { text }*,
( ( element * - ( local:* | fo:* | axf:* | m:* | svg:* )
{ attribute * - (id | ref-id | internal-destination ) { text }*,
anything }* ) |
math | svg) )
# For fo:instream-foreign-object
anything =
( element * -( fo:* ) {
attribute * - (id | ref-id | internal-destination ) { text }*,
anything } |
text )*
}
This module overrides the non-xsl and anything patterns from several layers down in fo.rnc to include the elements from the 'start' patterns of the external MathML 3.0 and
SVG 1.1 grammars and to also exclude XSL-FO elements and Antenna House extension elements
and attributes from appearing in or on non-XSL-FO elements.
The standard MathML and SVG schemas need to be modified, however. For MathML, all
XSL-FO, Antenna House, and SVG elements are additionally excluded from the content
of the MathML annotation-xml element:
and for SVG 1.1, the svg/@version attribute definition is relaxed so that SVG 1.0 documents are also valid and, because
the same SVG document may be included multiple times in one XSL-FO document, the svg/@id attribute is made an NMTOKEN to avoid ID value clashes:
# SVG 1.1
include "svg11-flat-20110816.rnc" {
# Repeat entire 'attlist.svg' pattern just to override @version.
attlist.svg &=
SVG.xmlns.attrib,
SVG.Core.attrib,
SVG.Conditional.attrib,
SVG.Style.attrib,
SVG.Presentation.attrib,
SVG.DocumentEvents.attrib,
SVG.GraphicalEvents.attrib,
SVG.External.attrib,
attribute x { Coordinate.datatype }?,
attribute y { Coordinate.datatype }?,
attribute width { Length.datatype }?,
attribute height { Length.datatype }?,
attribute viewBox { ViewBoxSpec.datatype }?,
[ a:defaultValue = "xMidYMid meet" ]
attribute preserveAspectRatio { PreserveAspectRatioSpec.datatype }?,
[ a:defaultValue = "magnify" ]
attribute zoomAndPan { "disable" | "magnify" }?,
[ a:defaultValue = "1.1" ] attribute version { string }?,
attribute baseProfile { Text.datatype }?,
[ a:defaultValue = "application/ecmascript" ]
attribute contentScriptType { ContentType.datatype }?,
[ a:defaultValue = "text/css" ]
attribute contentStyleType { ContentType.datatype }?
# end of SVG.svg.attlist
# Don't treat SVG @id as an ID since may be repeated in multiple SVGs
# in one FO document.
SVG.id.attrib = attribute id { xsd:NMTOKEN }?
}
Putting it all together – the onion and the string
As shown in Figure 5, the Relax NG schema
resembles an onion: the outer layer is
axf-mathml3-svg11.rnc, which brings in the external
MathML and SVG schemas. The first substantive layer is
axf.rnc with the definitions and redefinitions for the
Antenna House extensions. The next layer, which is included by
axf.rnc, is the auto-generated definitions that
interleave the inheritable Antenna House extension properties with the
properties that are defined for each FO. That layer then includes the
auto-generated module with definitions for the XSL 1.1 inherited
properties, which in turn includes the inner layer that is the
autogenerated definitions for the FOs and their properties.
Figure 5
The Relax NG compact syntax schema is also converted into Relax
NG XML syntax for use with oXygen (since oXygen does not extract
documentation annotations from a compact syntax schema) and into W3C
XML Schema for use with other editors. As noted previously, the
annotations in the schema, which were extracted from the XML for the
XSL 1.1 spec, are presented as tool-tips when editing an FO document
with oXygen.
The Schematron is written as multiple phases strung
together. With a Schematron implementation that supports progressive
validation by executing each phase in order of its appearance, this
will lead to progressively more refined error checking. The phases
are:
Handwritten rules for FO constraints that aren’t
captured by the Relax NG.
Autogenerated rules for checking property values for
syntax errors and correct datatypes.
Handwritten rules for extra constraints on property
values, such as the rule that column-count should be a
positive integer.
Handwritten rules for the Antenna House extensions.
There is an oXygen framework file that refers to both the Relax
NG and the Schematron so that oXygen can automatically validate FO
files using them. The framework is available as a downloadable add-on
for oXygen. An earlier version of the framework was bundled with
oXygen 17.1 and 18.0.
You can also validate FO files from the command-line using the
validate target from the
build-focheck.xml Ant build file.
Testing
There are multiple levels of testing of the Relax NG and
Schematron.
At the lowest level, the parser-runner.xsl
XSLT library is tested using XSpec 38 tests, for
example:
Finally, complete documents can be validated using both
Relax NG and Schematron using the validate Ant
task.
Need for speed
The bottleneck for the validation is obviously going to be
executing the XSLT for the Schematron validation and, in
particular, the expression parser.
In oXygen, the XSLT generated from the Schematron is run using Saxon EE. Saxon EE
includes a saxon:memo-function() 40 extension that memorizes the result from every combination of arguments for an xsl:function.
The second and subsequent times that you call that function with a set of arguments
that has been seen before, the function immediately returns the result for those arguments
instead of running the function all over again just to return the same value. The
same property values tend to appear many times in the average XSL-FO file, so this
shortcuts a lot of parsing with the REx-generated parser. Figure 6 shows saxon:memo-function is use with the xsl:function for parsing XSL-FO property
value expressions.
Figure 6
<!-- ahf:parser-runner($input as xs:string) as element()+ -->
<!-- Runs the REx-generated parser on $input then reduces the parse
tree to a XSL 1.1 datatype. Uses @saxon:memo-function extension
to memorize return values (when used with Saxon PE or Saxon EE)
to avoid reparsing the same strings again and again when this is
used as part of validating an entire XSL-FO document. -->
<xsl:function name="ahf:parser-runner" as="element()+"
saxon:memo-function="yes"
xmlns:saxon="http://saxon.sf.net/" >
<xsl:param name="input" as="xs:string" />
<xsl:sequence
select="ahf:parser-runner2($input, false())"/>
</xsl:function>
Additionally, oXygen also
caches the schema used to validate a document 41,
and oXygen Support have confirmed that this includes caching a
Schematron validator, so the memorised property expression values are
available across documents.
When I demonstrated focheck running on a laptop at XML London 2015, the RELAX NG validation
and Schematron checking for a 28 MB file took six seconds. Since then, however, I
have added more ID-IDREF checking to the schema, so validation is slower now, and
I have added some keys to the Schematron to help check some XSL constraints. It is
not clear how keys interact with the XSLT caching by oXygen. On the plus side, focheck
now catches 14 errors in the 28 MB file instead of just one.
The REx parser generator 21 is able to
generate a parser as a Saxon extension function. It should, therefore,
be possible to optionally include the compiled extension function in
the classpath for Saxon and make the ‘parser runner’
library use the compiled extension function if it is available and to
fallback to the XSLT parser when the function is unavailable.
However, using Saxon extension functions with Schematron validation is
not a common use-case, so it is not possible with oXygen 18 to just
add the Jar file for an extension function to an oXygen framework and
have it be used when validating Schematron. Using the extension
function currently requires registering the extension function in the
default Saxon configuration in the oXygen preferences. Since that
can’t be done just by downloading the oXygen add-on, it's not
currently part of focheck.
Translations
Antenna House is a Japanese company with a high proportion of Japanese users of AH
Formatter, so I also wanted to make focheck available in Japanese.
There’s four parts to translating focheck into Japanese:
Schematron messages
Documentation annotations
Jing validation messages
Xerces parsing messages
I started with the Schematron messages because they are the most bespoke, since I
wrote them all. The official Schematron method for localizing messages using the
diagnostic element, detailed in Annex G of the Schemtron specification, outputs every translation
of a message at once. oXygen 18 has its own method for outputting messages from only
one language at a time, but focheck was localized before that was available, plus
focheck has to also work outside of oXygen.
I initially considered a gettext-like mechanism, such as Jirka Kosek's Saxon extension
42, but you end up in a sort of double-think as, instead of writing the message that
you want to write, you have to write a version that’s deconstructed for use with gettext(); for example:
name="<value-of select="@name"/>" cannot be used when axf:document-info
with name="xmp" is present.
becomes:
<value-of select="t:format('name="{1}" cannot be used when
axf:document-info with name="xmp" is present.', (@name))"/>
I also started an XSLT stylesheet to extract messages from the Schematron so the messages
could be input for the open source OmegaT computer-aided translation (CAT) tool, but
I didn’t get as far as reconstructing a translated Schematron using translated message.
Since I’d had to modify the CAT tool that I was using to be able to handle the Java
XML property files containing the extracted messages, it was simpler to modify it
again so it could work directly on Schematron files, as shown in Figure 7. I have more recently modified it again so that the messages in Schematron Quick
Fixes are also presented for translation.
Figure 7
Another part of translating the Schematron to Japanese was translating Schematron’s
own messages into Japanese. Since the Schematron project on GoogleCode is now read-only,
I created a Schematron organization on GitHub 43.
That covered the Schematron messages that I was creating, but it didn’t cover the
messages from validation and well-formedness errors in the XML for the XSL-FO. Neither
the Jing library that does the RELAX NG validation nor the Xerces library that does
the lower-level XML parsing has had its messages translated into Japanese, so even
when oXygen is set to use its Japanese interface, the parsing and validation messages
have remained in English. I have now had the Jing messages translated, and they have
been contributed to the official jing-trang project on GitHub 44. The Xerces messages about SAX parsing have been translated into Japanese, but it’s
less clear how to contribute them to Xerces.
Having modified the CAT tool twice, it was almost inevitable that I would modify it
again for the RELAX NG schema. The end result is that, through a combination of using
OmegaT for natural language translation and Jing for schema language translation (see
Figure 8), the three flavors of schema language are also available with documentation annotations
in Japanese.
Figure 8
Figure 9 shows a Japanese tooltip and Japanese error messages in the Japanese version of oXygen.
Figure 9
Future improvements
A necessary improvement is adding to and improving
the handwritten parts of the Relax NG and Schematron. The
constraints in the XSL 1.1 spec are spread through much of the
spec, and some of the details require careful reading.
Getting the Relax NG and Schematron to be complete and correct
is an ongoing and iterative process. Pull requests on the GitHub
project will be appreciated.
The current expression parser cannot evaluate some of the
shorthand properties, such as font 45, that are
shared with CSS2. Handling those will require either writing custom
XSLT or generating a different parser using REx. I would also like to try to write
an expression language parser that produces a simpler parse tree to see if that can
be quicker than the REx-generated parser, but the use of saxon:memo-function may reduce
the significance of any speed improvements when validating large documents inside
oXygen.
I experimented with NVDL as the solution for validating MathML and SVG inside fo:instream-foreign-object, but the current solution is working well enough that it doesn’t seem necessary to
look at it again.
I am working on adding on-the-fly Schematron checking to the Emacs mode for focheck
using `flymake-mode'. Initially, this will use Saxon on the command line to run the
compiled XSLT for the Schematron. The eventual goal is to use 'beanshell' to run
a persistent Java object for the stylesheet and so avoid the startup cost of starting
Java and reading the stylesheet each time.
Conclusion
focheck provides the most comprehensive error checking and authoring support for XSL-FO
that is currently available. It validates XSL 1.1 plus Antenna House extensions and
also validates both SVG and MathML 3 in fo:instream-foreign-object. focheck is the only XSL-FO validation utility (short of running an FO processor)
that evaluates property value expression and, because it is not an FO processor, it
can identify multiple fatal errors in an XSL-FO document instead of halting at the
first. The addition of Schematron Quick Fixes makes it easy to also correct your
XSL-FO.
focheck is open source, so the focheck approaches both to parsing attribute value
expressions and to maintaining an oXygen framework add-on project can be used by other
projects, as can the focheck contributions to the CAT tool for translating Schematron,
RELAX NG, and Java XML property files and to the Japanese localizations of Schematron,
Jing, and Xerces.
[1] “Considered Harmful” essays have a venerable history going back to Edsger W. Dijkstra’s
note in the March 1968 Communications of the ACM, “Go To Statement Considered Harmful,”
9, but over time, they themselves came to be considered harmful 10, and they are now much less common than they were.