Zeldes, Amir. “Duplicitous Diabolos: Parallel witness encoding in quantitative studies of Coptic
manuscripts.” Presented at Symposium on Cultural Heritage Markup, Washington, DC, August 10, 2015. In Proceedings of the Symposium on Cultural Heritage Markup. Balisage Series on Markup Technologies, vol. 16 (2015). https://doi.org/10.4242/BalisageVol16.Zeldes01.
Symposium on Cultural Heritage Markup August 10, 2015
Balisage Paper: Duplicitous Diabolos
Parallel witness encoding in quantitative studies of Coptic manuscripts
Amir Zeldes is a computational linguist specializing in corpus linguistics.
His main area of interest is the syntax-semantics interface, where meaning and
knowledge about the world are mapped onto lexical choice and syntactic structure
in language-specific ways. He is also involved in the development of tools for
corpus search, annotation and visualization, and has worked on the development
of standards for the representation of textual data in Linguistics and the
Digital Humanities.
This paper briefly discusses markup, metadata and evaluation issues that arise
when projects do not include a critical edition adjudicating different variants, but
instead incorporate multiple, full diplomatic transcriptions. When used naively,
such corpora will cause duplicate results that are hard to discern in quantitative
studies, and in cases of incomplete, unexact or fragmentary parallel witnesses,
substantially complicate the decision about what users actually want to have. Using
a case study on Coptic manuscripts, the paper suggests that as a provisional
strategy, documents should be partitioned as finely grained as necessary such that
each section's parallel witness status is encoded, and that for each parallel set,
it can be useful to define a redundancy metadatum which identifies the 'best'
candidate for quantitative study among the available choices.
Parallel witnesses are in many ways a luxury: several instances of a textual source
mean fewer problems due to lacunae or lost material, a chance to compare for meaningful
differences and less vulnerability to idiosyncrasies or errors in one manuscript.
At the
same time, they present both technical and methodological challenges in the evaluation
of their contents. Much research and software development related to parallel witnesses
has been interested in textual criticism, stemmatology and the construction of a
critical apparatus, see for example Bakker 1996, Clement 2011; and for software see Juxta, Wheeles 2014, as well as the Versioning Machine (http://v-machine.org/), and TEICHI (see
Pape et al. 2012 for discussion). This paper will be concerned with a
different aspect of work with parallel witnesses and textual criticism – their
consequences for encoding redundancy and subsequent behavior in quantitative analysis.
The case of Coptic SCRIPTORIUM
As a case study on the issue of corpora containing diplomatic transcriptions of
parallel witnesses, we will consider the guidelines currently used in Coptic
SCRIPTORIUM, a collaborative project publishing open access diplomatic transcriptions
of
Coptic manuscripts online (http://copticscriptorium.org/). The diplomatic
transcriptions are available from the project website in several formats, including
Epidoc TEI following Cayless et al. (2009), and are made searchable and
visualized using ANNIS, a browser based corpus search tool (Krause & Zeldes, to appear). Figure 1 illustrates an excerpt
from a document body in TEI, and a corresponding visualization from ANNIS (the word
diabolos ‘devil’ has been highlighted in Greek
script in both views to show the same position).
Figure 1: The word diabolos in code and
visualization
Visualization and TEI fragment for part of a manuscript from Archmandrite
Shenoute’s I See Your Eagerness (Witness GL 29-30).
One of the advantages of publishing diplomatic transcriptions is that, unlike
editions which remain under copyright, materials can be offered over an open access
license. At the same time, we do not have the luxury of an edited, authoritative text:
for documents that have multiple witnesses, witness encoding becomes an issue, rather
than encoding facilities for a critical apparatus. Luckily, metadata standards are
generally capable of handling witness information, which we encode in the header to
the
fragment above as follows, using the TEI <listWit> element as part of
the <sourceDesc> specification, shown in Figure 2
for a manuscript abbreviated GL, which parallels another manuscript known as XJ.
Figure 2: Parallel witness encoding
Encoding parallel witness information in the TEI header with
<listWit>
The problem begins when we consider that parallel witnesses do not cover the exact
same span of text (there are parts in witness GL which do and do not correspond to
witness XJ), and ask how we can search through our corpus for quantitative
research.
The ANNIS platform allows us to search for the categories annotated in the corpus
and
get frequency breakdowns for items, such as a ranked frequency list for words of Greek
origin (notice the xml:lang attribute in Figure 1). A search for Greek
words in all data from the work I See Your Eagerness
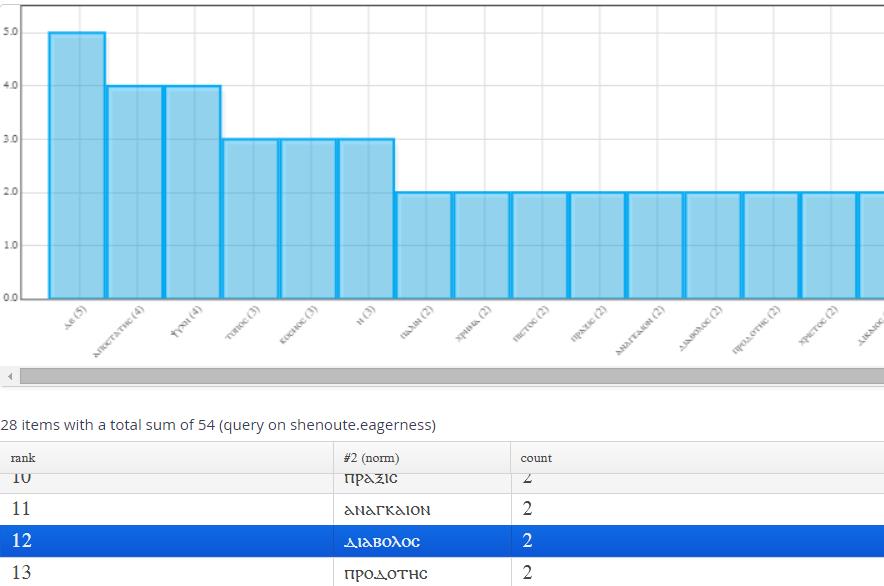
gives the frequency list in Figure 3, which shows ‘diabolos’ appearing
twice. However, this is a direct result of the parallel witness to the section
mentioning the Devil, thus skewing the quantitative results.
Figure 3: Frequency breakdown
ANNIS frequency list for Greek words in I See Your
Eagerness.
In order to deal with this issue, we require a mechanism to ‘count things only once’.
The problem is that we cannot simply exclude entire manuscripts as redundant, since
in
the current case, each manuscript contains some parts that are not found in any other
manuscript. We therefore decided to divide each manuscript into minimal portions that
correspond to the parts that do and do not have parallel witnesses, annotating each
portion with parallel witness information. We consider only the most complete witness
of
every section to be the ‘primary’ source in answering queries such as the frequency
list
above, whereas parallel portions are considered ‘redundant’. This is illustrated in
Figure 4.
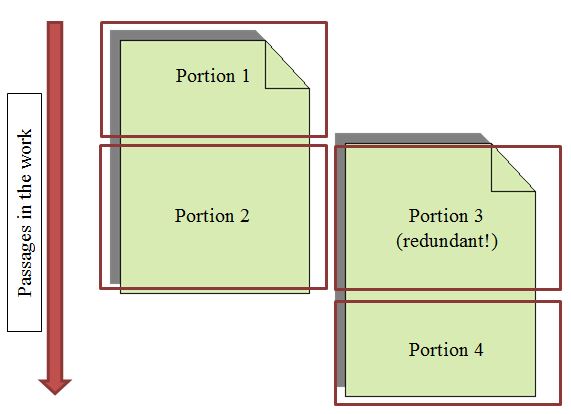
Figure 4: Partitioning parallel witnesses
Parallel witnesses. The primary witness for the middle, overlapping section is
on the left in Portion 2, while Portion 3 is marked as ‘redundant’. Portion 3 in
the second MS is unique, and therefore non-redundant.
In the ANNIS interface, the user can choose to limit queries to non-redundant
information, or to search through all the data, including duplicates.
Conclusion
The approach outlined above has been implemented in the ANNIS database and interface
for Coptic SCRIPTORIUM corpora, but it is a point for open discussion what the best
way
is to encode parallel witness information in TEI XML markup, and how to designate
information about ‘redundant’ copies. What is the best way to mark up a part of a
document as having other witnesses? How should we mark up the privileged ‘primary’
witness portions and the ‘non-primary’ ones? Can we ‘mix and match’ in multiple
documents? Is this a type of metadata or inline annotation? Methodologically too,
the
issue of choosing what to call redundant is non-trivial, as are alternative solutions
we
might have chosen. A possible alternative for quantitative evaluation is to consider
all
witnesses in every search and normalizing frequencies by number of witnesses, such
that
frequencies from a passage attested twice are weighted to be ‘worth half as much
quantity’. This will produce different results if passages are marked as parallel
which
contain small differences. We hope that further discussion of these and other strategies
will draw attention to, and improve the handling of, parallel witnesses in quantitative
research.
Acknowledgments
I would like to thank Caroline T. Schroeder for contributing to the data model and
markup decisions in this dataset and David Brakke and Rebecca S. Krawiec for providing
the data and annotations described in this paper. I am also grateful to the National
Endowment
for the Humanities (NEH) for their continuing support of this project.
References
[Bakker 1996] Bakker, H. P. S. (1996). Towards a Critical Edition of the Old Slavic New Testament: A
Transparent and Heuristic Approach. PhD Thesis, University of Amsterdam.
Bakker, H. P. S. (1996). Towards a Critical Edition of the Old Slavic New Testament: A
Transparent and Heuristic Approach. PhD Thesis, University of Amsterdam.