Walpole, Robert. “Introducing The UK National Archives Digital Records Metadata Vocabulary.” Presented at Symposium on Cultural Heritage Markup, Washington, DC, August 10, 2015. In Proceedings of the Symposium on Cultural Heritage Markup. Balisage Series on Markup Technologies, vol. 16 (2015). https://doi.org/10.4242/BalisageVol16.Walpole01.
Symposium on Cultural Heritage Markup August 10, 2015
Balisage Paper: Introducing The UK National Archives Digital Records Metadata Vocabulary
While working as an IT analyst at British Telecom at the turn of the
millennium, the author rediscovered a childhood passion for programming and
elected to study part-time for an HNC in Computing at the University of Plymouth
which he completed in 2004. Following this, he became a full time software
engineer, initially in local government and later for the UK national weather
service (the Met Office) and then at The National Archives (UK). He is currently
working as a content architect for a major publishing company and lives in
London, England.
This paper describes the context and rationale for developing a new metadata
vocabulary for digital records at the UK National Archives as part of the Digital
Records Infrastructure project. It describes the specific requirements for metadata
in relation to digital records and the evolution of an approach to modelling this
metadata which is based on Dublin Core Metadata Initiative (DCMI) Metadata Terms and
RDF/XML as a markup
solution. It will demonstrate not only how this solution meets the archival
requirements but also enables powerful new ways of searching records and linking
them to other information sources.
The National Archives (TNA) are the official archives of the United Kingdom
Government. TNA holds over 11 million historical government and public records
[1] in the form of documents, files and images covering a
thousand years of history. The vast majority of the documents currently held are on
paper or parchment. However, this is gradually changing.
Government departments normally retain their own records until such a time as they
can be released to the public, at which point they are sent to the Archives.
Historically records were released after 30 years but since 2013 this is being
transitioned to 20 years, a process due to complete in 2022 [2].
In 2014 TNA received records from 1985 and 1986. As this is about the time that
computers came into common everyday use, it is easy to see how a steep increase in
digital record volumes can be expected in the coming years. It is anticipated that
by 2025 the Archives will receive almost exclusively born-digital records. These
records will take many forms including standard office documents, emails, images,
videos and sometimes unusual items such as virtual reality models.
Digital preservation brings a myriad of challenges including issues such as format
recognition, software preservation and compatibility, degradation of digital media
and more. Some of these issues were clearly demonstrated by the problems encountered
by the BBC Domesday Project [3]; a 1986 schools computer project in the UK based on the idea of
documenting everyday life. Unfortunately the technology chosen, which included BBC
Micro computers and LaserDisc storage, quickly became obsolete
and the hardware and software needed to access the discs became increasingly rare
until
there was a real danger the data would be lost forever. Eventually the entire project
had to be reverse-engineered so
that a more enduring way of keeping the information could be found.
Digital Records Infrastructure
TNA have been at the forefront of meeting this digital preservation challenge and
have made great strides in finding solutions to many of the issues, often working
together with
colleagues from other national archives, libraries, and academia. In 2006, they
deployed the Digital Repository System (DRS) which provided terabyte scale storage
for digital records. This was followed in 2014 by the Digital Records Infrastructure
(DRI). DRI built on the foundations of DRS, making use of the same Safety Deposit
Box (SDB) software provided by Tessella [4] but also
incorporating many new components. It provides a highly automated end-to-end
batch-processing system for the archiving and retrieval of digital records. Perhaps
even more importantly, DRI delivers a quantum leap in storage, providing a
theoretical maximum capacity of 13 petabytes [5]. This new system
provides long term controlled storage for a huge variety of documents and
media.
Digitised Home Guard records from the Second World War was the first collection to
be ingested (or accessioned, to be more accurate [6]) into DRI, and more record
collections have since been added including the Leveson Enquiry documents, LOCOG
(London Organising Committee of the Olympic and Paralympic Games) records and the
digitised British Army war diaries dating from the First World War[7].
At its heart, DRI provides this massive storage by using a robot tape library.
Although tapes provide highly resilient storage if treated and monitored carefully,
they are not suited to frequent access. Therefore, the archive is designed to be a
dark archive. In other words, it is powered down until an access request is
received. Although there may be frequent demands for access to the data in the
archive, many of these requests can be met by substitutes from a disk cache. For
example, scanned documents can be substituted with a lower quality JPEG file from
disk, instead of the original high resolution JPEG 2000 held on tape. Whenever data
is retrieved it is cached on disk for the next time so that frequently
requested items are always promptly available.
DRI and the Open Archival Information System
During the 1990s, the Consultative Committee for Space Data Systems (CCSDS) began
working with the International Organisation for Standardization (ISO) to develop a
standardised framework for the long term preservation of digital data. The initial
driver was the need to provide long term storage of data gathered from space missions,
but it quickly became apparent that the resulting framework would have a much broader
application. At a CCSDS workshop in 1995 a proposal was put forward to establish a
reference model for an Open Archival Information System (OAIS). This reference model
would set out the functional components, internal and external interfaces, domain
objects, and terminology needed to implement an archival information system. Drafting
of
the reference model was done in an open forum and was completed in 2003 when it was
approved as international standard ISO 14721:2003[8].
OAIS stipulates six mandatory principles that an organisation must follows in order
to
operate a compliant archive. These are as follows [9]:-
Negotiate for and accept appropriate information from information
producers.
Obtain sufficient control of the information in order to meet long-term
preservation objectives.
Determine the scope of the archive’s user community.
Ensure that the preserved information is independently understandable to the
user community, in the sense that the information can be understood by users
without the assistance of the information producer.
Follow documented policies and procedures to ensure the information is
preserved against all reasonable contingencies, and to enable dissemination of
authenticated copies of the preserved information in its original form, or in a
form traceable to the original.
Make the preserved information available to the user community.
Within The National Archives, the responsibility for much of this work is undertaken
by the Digital Preservation team. It is their task to negotiate with the information
producers (usually a Government Department) and obtain delivery and control of the
records via a formal transfer process. Data normally arrives on an encrypted hard
disk
but can also come via secure file transfer [10]. The data is then
loaded into a secure holding area and prepared for ingestion into DRI.
As well as general principles, OAIS provides a model of the information objects
managed by an archive. This model describes an information package which is
made up of the digital objects for preservation (the documents, images, videos or
other
files) together with metadata about these objects. There are three significant variants
of this model which are as follows:
Submission Information Package (SIP) — the
Information Package that is required to be able to ingest records into the
archive.
Archival Information Package (AIP) — the
Information Package that is laid down in the archive following successful ingestion.
Dissemination Information Package (DIP) — the
information package extracted from the archive for distribution
elsewhere.
The information requirements at each stage are different. For example, the quantity
and detail of information at each stage will vary significantly. The SIP will contain
everything that has been received for archiving at any one time. This could be several
gigabytes worth of files or it could be just a handful of files. When loaded into
the
archive this information package may represent the whole set of related data or it
may
be part of a much larger collection of data which is accumulating over time. When
information is extracted from the archive it could be just a few records that someone
has requested to see, for example via a Freedom of Information request, or it could
be a
large chunk of data that is perhaps destined for display on Discovery [10], the portal which
provides online access to TNA's records.
Whatever the purpose, the information package must contain appropriate metadata to
make
the context of the information clear. Metadata is fundamentally important for making
sense of the archived records and is key to satisfying the 4th, 6th, and to some extent
5th, mandatory principle laid down by OAIS.
DRI Metadata
When a block of digital files are transferred from an organisation to the Archives
it
is a requirement that a CSV file is provided with the data containing some metadata
about each file or folder. The exact contents of this file will vary but there are
currently six mandatory metadata fields for each item as follows [11]:
Title — a meaningful folder or file
name.
Identifier — a URI representing the file path
to the record (within the information package) at point of creation so that it is
clear which file is
being referred to.
Date — the date of the record, ideally the last
modified date in ISO 8601:2004[12] format.
Folder or File — is the record a folder or a
file? (needed for disambiguation)
Checksum — the SHA-256 checksum value of the
file which is used to verify the file has not been corrupted or altered in
transit.
Copyright — the copyright holder (usually this
is Crown Copyright[13])
Additional fields may include technical information about the files, transcription
information and any access restrictions that apply.
On top of this, additional metadata is generated by the ingestion process itself.
The
SDB software used by TNA for archive management uses a proprietary XML Schema for
metadata known as the XML Information Package (XIP) which is based on the OAIS
information package model. Tessella provides a tool called SIP Creator which can be
used
to generate a SIP suitable for ingestion into the archive, together with some basic
metadata. The
SIP creator takes a small number of parameters that provide some context for the
information package, such as the name and identifier of the collection it will become
a part of (e.g. War
Office: Home Guard records, Second World War), and an
accumulation reference which is used if some records from this collection have already
been ingested into the archive. This information is placed into the XIP together with
information about the folders and files that make up the digital records in the package.
As the SIP is ingested into the archive various transformations occur to the XIP as
part
of the ingest workflow. These transformations perform many functions, most of which
are
beyond the scope of this paper, which all either enhance or re-arrange the content
of
the XIP file in some way so that it is ready for long-term storage with metadata
describing, as far as possible, the structure, format, content, context, provenance,
and
sensitivity of the records it accompanies.
There is however one key transformation of the XIP file which is relevant to the topic
of this paper and that is the step that adds the metadata from the CSV file provided
with the records into the
XIP. One element of the XIP schema, simply called Metadata, is deliberately left
undefined in order that the users can define their own custom metadata. The guidance
provided for the content of this element is as follows:
"Arbitrary contents, which may conform to an XML Schema. Used to store extra
metadata, particularly descriptive metadata (i.e. cataloguing information), from
another schema (e.g. Dublin Core, METS, MODS, ISAD(G), etc.) that is relevant to a
particular entity. Allows for controlled extension of the XIP schema."[14]
This element therefore is the natural home for the CSV content. First however it must
be transformed into XML. This is achieved through a simple XSLT conversion which
converts each row to the following format:
Once this file is available it is a matter of a further transformation to convert
this
to the desired XML Schema. But what is the desired XML Schema? To begin with, a custom
schema was created
which is descibed in the next section. We will refer to this as XIP Metadata Version 1.0
XIP Metadata Version 1.0
A great deal of work went into establishing guidelines for the use of custom
metadata within the XIP files for The National Archives. Much of this work was
undertaken in 2011, as a precursor to the DRI project itself, as it was considered
to
be fundamentally important in guiding later developments.
Following the principle of DRY (Don't Repeat Yourself) and in accordance with W3C
guidance [15],
these guidelines specified the use of existing DCMI (Dublin Core Metadata
Initiative) Metadata Terms with some TNA specific refinement and additions.
To give an example of how these refinements and additions would work, consider the
following example of an identifier defined using the standard DCMI
XML Schema being used to identify a TNA catalogue reference:
Significant information is lost using this term without refinement as each part of
the catalogue reference has a meaningful purpose. If we apply the refinements
specified within the XIP Metadata Version 1.0 guidelines then we get the following
instead:
In this case we can clearly see the purpose of each component of the catalogue
reference. The way that this works is that the element tnacat:itemIdentifier is defined
in an
external XML Schema. Unfortunately the schema only functions as documentation as
there is no convenient way to validate the document based on the xsi:type attribute
value.
Validation is carried out at various stages during the ingest process to help ensure
that the integrity of the data is not lost. Both XML Schema and Schematron
are used for these validation steps. SDB supports the Namespace-based Validation Dispatching
Language (NVDL) which allows XML schemas to be looked up based on the element
namespaces. Although this would, in theory, allow validation of the dcterms:identifier
element in the example above, the tnacat:itemIdentifier is an extension of this type
which
is unknown to the schema that defines dcterms. NVDL cannot understand that the elements
inside the dcterms:identifier are defined by the tnacat:itemIdentifier element and
therefore the content
cannot be validated in this way.
A number of XML Schemas were written to describe what these refinements and
additions would look like. Each schema defines terms specific to a metadata domain
and these include subjects such as computer hardware and software, provenance,
cataloguing, digital imagery, people, and spatial data. Each schema defines a
separate namespace within the nationalarchives.gov.uk domain. Because these schemas
were written in consultation with the Digital Preservation specialists at TNA, the
elements defined constituted very exact terms that are commonly needed by these same
specialists to describe the digital objects that are being archived. These carefully
selected terms became fundamentally important in what happened later.
XIP Metadata Version 2.0
Although the initial XIP metadata guidance at TNA allowed for the embedding of
rich and extensible metadata, there were a number of drawbacks to this approach.
Firstly, as mentioned, the refinements and additions could not be validated by XML
Schema as it does not support the schema lookup by namespaced attribute values that
would
be required. It also resulted in quite verbose metadata which could prove
challenging (though certainly not impossible) to interpret in the future.
During the intervening few years, as the DRI project progressed and matured, a new
technology was added to the DRI stack, namely the Semantic Web. A challenge had
arisen in handling the very fine grained access controls needed for digital records
which
had resulted in an internal catalogue and process control system (the DRI Catalogue)
being
developed which made extensive use of Semantic Web technologies including RDF,
SPARQL, Apache Jena and the Linked Data API (Elda). The DRI Catalogue was the subject
of a separate paper presented to the XML London conference in June 2012 [16].
As part of this project an OWL ontology [17] had been
developed, known as the DRI Vocabulary, which was made up of the specific terms
needed for the management of DRI functions and the associated objects. Because of
the success of this project and the skills that had been acquired during it's
implementation, when the existing XIP Metadata terms needed extending to handle new
types of information package, it was natural and tempting to wonder whether some of
the knowledge acquired in the DRI Catalogue project could be applied to the XIP
Metadata.
One of the most obvious similarities between the original XIP Metadata and the
work that had been done on the DRI Vocabulary is that they both make extensive use
of Dublin Core Metadata Initiative (DCMI) Metadata Terms. While the XIP Metadata extended
DCMI Metadata Terms using XML
Schema definitions, the DRI Vocabulary extended it through it's ontology. The DCMI
Metadata Terms vocabulary
was originally chosen specifically because it provided interoperability
with 3rd party systems. With hindsight, this turned out to be an excellent choice
as it has also become one of the principle vocabularies at
the heart of the Web of Linked Data [18]
There was one significant obstacle however. The XIP Metadata has to be XML and
there are very good reasons for this. Recent history has shown us that technologies
change fast and we have no way of knowing whether technologies that we take for granted
today will be available to our descendants in 50, 100 or 500 years time. This means
that potentially we are storing a lot of ones and zeros on computer tape that no one
will be able to interpret in future because they won't have the appropriate tools.
XML files however are plain text. Plain text files have proven to be far more
durable and accessible than any other file formats as they do not rely on any
particular computer architecture, formatting or encoding and require only minimal
processing to view. It is not unreasonable to assume that any researchers or
archivists who want to access these files in the future would have a means of
accessing a text file. Furthermore, XML is very widely used in the publishing
industry and has been a W3C recommendation since 1998 [19]. XML grew out of
the Standard Generalized Markup Language (SGML) which became an international
standard in 1986 [20] and so it can be said to be well established and well recognised. Perhaps even
more importantly than this, it is human readable. No interpreter is needed to
translate the meaning of the text, provided you are familiar with the language being
used. Of course there is no guarantee that a future researcher will know the language,
but that's something that has always been a challenge for
those researching ancient texts [21].
Another challenge faced was the requirement that the metadata could be schema
validated. This notion sits at odds with the Semantic Web's open world assumption
[22] view which
is fundamentally schema-less. To add to this dampener, the W3C standard for
displaying RDF as XML is RDF/XML[23] which has a poor reputation among XML specialists
and is largely being replaced by newer RDF syntaxes such as Turtle within the
Semantic Web community. To quote Bob du Charme [24]:
RDF/XML never became popular with XML people because of the potential
complexity and the difficulty of processing it.."
One of the difficulties with RDF/XML is that there is more than one way to
represent the same structure. For example
<rdf:Description rdf:about=”http://example.org/book/1234”>
<ex:title>A Good Book</ex:title>
</rdf:Description>
is equivalent to:
<rdf:Description rdf:about=”http://example.org/book/1234” ex:title=”A Good Book”/>
Meaning that potentially your XML tool chain has to check for the same piece of
information in different places.
However, as part of the DRI Catalogue project we had already generated RDF/XML
using the DRI Vocabulary to describe the access restrictions on records. This
RDF/XML is sent via HTTP to an endpoint supporting the Graph Store Protocol (Jena
Fuseki). This task had been a surprisingly easy to complete. We had simply taken the
closure information as XML and transformed in to RDF/XML using XSLT. In the process
we applied the vocabulary terms that we had developed specifically for this purpose.
It seemed that having a well-defined vocabulary took some of the pain out of the
RDF/XML experience. Because of this positive experience it was agreed to undertake
some prototyping of an OWL based vocabulary for XIP Metadata and see what the
resulting RDF/XML might look like.
The first question was how we were going to mix RDF/XML into the XIP file. We knew
it needed to go within the undefined XIP Metadata element which was left for exactly
this type of thing, but RDF/XML must, by definition, start with the
<rdf:RDF/> root element. We also knew we had to be able to
schema validate this data and we also knew that there would be other XML that needed
to go into this xip:Metadata element which was not RDF/XML but vanilla XML used to
describe the closure status of the record. The answer was to define a new XML Schema
for our custom metadata that started with our own root element, the tna:metadata
element. This element is defined in XML Schema as follows:
The rdf:RDF element is defined in a separate XML Schema which we wrote to validate
the minimum set of RDF/XML elements that we would actually be using [see Appendix A]. Because we would
be using our own vocabulary terms, many of the standard RDF/XML elements such as
rdf:Description, rdf:Statement, rdf:Property etc. we had no need to use or to
validate.
In fact this is a similar approach to that which had been used in version 1.0 of
the XIP Metadata guidance. In this case a custom metadata root element was defined
which then imported the various other schemas, each with their own namespace.
Initially a similar approach was adopted for version 2.0. For each of the
namespaced schemas developed in version 1.0 a new OWL ontology was created using an
ontology URI that resembled the namespace of the schema. Although this seemed
reasonable at first, with each vocabulary having its matching RDF/XML defined in a
separate schema which used the same namespace as the vocabulary, it quickly became
apparent that managing all of these different vocabularies was going to be a
maintenance headache. It would be far easier if all of the required terms were in
the same vocabulary, using the same namespace (or ontology IRI). It then followed
that there would be just one XML Schema to
validate all of the TNA defined terms in the RDF/XML.
What's in a Digital Archive?
Having resolved that we would have one vocabulary and one schema, and knowing that
we
had lots of concise metadata terms that had previously been defined in version 1.0,
the
next question was what exactly was it we were describing?
TNA uses the term deliverable unit to refer to something that can be retrieved from an
archive. In the paper world this could refer to a single sheet of paper such as a
letter, or it could refer to a notebook or it could even refer to a cardboard box
containing
a number of notebooks. Whatever it is, it is something that an archivist can reasonably
hand over to a researcher. It would not be reasonable to expect the archivist to hand
over a single sheet of paper torn from the notebook. You get to see the whole notebook,
in its entirety, or none of it.
A deliverable unit also has what is referred to as a manifestation. The deliverable
unit represents the idea of something that can be handed over, whereas in fact what
you
receive is a manifestation. This may sound confusing at first but if you consider
that a
notebook may have been copied then it follows that you may be get to see a copy of
the notebook and not the original.
This may be because the original is considered too fragile to hand over, or that the
archive never received the original, or perhaps there just happens to be lots of copies!
This is not so strange when you think that even ancient manuscripts were frequently
copied [25].
To complicate matters further, what represents a deliverable unit in the physical
world is not necessarily the same thing in the digital world. Although the notion
of
computer files and folders seems analogous at first to the idea of physical documents
and folders, this is not always such a clear line to draw. For example, consider a
notebook that has been scanned, page by page. Whereas in the physical world you have
one
clear deliverable unit, in the digital world you may have twenty image files, one
for
each page. It is no longer clear what is the deliverable unit, so a more pertinent
question becomes, what is the record? In other words, what is the most sensible interpretation of a
record, bearing in mind the document creator's apparent intention when creating the
document or documents? It is this record that needs cataloguing, describing and
generally enriching with metadata.
Through talking to the digital preservation specialists at TNA, reviewing the existing
documentation and analysing the content planned for accession into the archive, it
became apparent that there are four clearly defined types of digital record. Each
of
these record types has different requirements for the way it is archived and described.
These types are as follows:
Born digital record - a record which was
digital at point of creation as opposed to a record that was created on paper
and then digitised. An example of a born digital record would be a digital
photograph taken by a digital camera.
Digital folder - A digital folder (also known
as a directory) is a computer cataloguing structure that can contain files
and/or more digital folders. As such it is used as a container for digitised and
born digital records.
Digital record - A digital record is the
digitised version of a paper record that no longer exists. An example of a
digital record is the digital image of a paper document that has been scanned
using an image scanner. The original paper record is then discarded and the
image becomes the record.
Digital surrogate - A digital surrogate is a
digital record that exists in addition to a paper record. An example would be a
paper document that is scanned and then both the digital image and paper
document are retained.
With these record types established, it became possible to create a basic object model
onto which we could attach our metadata terms.
Version 1.0 of the TNA metadata guidelines established a number of XML Schemas for
different metadata domains and, although this notion was dropped for convenience and
maintainability in version 2.0, it was still considered useful by the digital
preservation team to group these terms in some way. The hierarchical structure of
XML
allows for grouping simply by nesting elements and this convenience is carried
over into RDF/XML. There is a further implication of this within RDF/XML however,
as it
is representation of RDF and therefore follows the Subject – Predicate - Object pattern
of the triple. In RDF/XML a nesting within a subject indicates a predicate and the
predicate indicates the object, which can be a literal value, such as a date or
string as shown in the following example:
Alternatively the object could be another resource with it's own predicates, in which
case a URI is used to represent that resource as shown in
the next example:
Another possibility with RDF is to use blank nodes [26]. A blank node
indicates that something exists but does away with the need for a URI to identify
it. It
is an anonymous object if you like, but it can still have a specific type. In RDF/XML
a
blank node can be created simply by nesting an element representing the object inside
an element representing the predicate as in the following example:
<tna:BornDigitalRecord rdf:about="http://example.org/66/LEV/2/D4SL/Z">
<tna:cataloguing>
<tna:Cataloguing>
<dcterms:title>Telegraph Media Group Ltd Submission</dcterms:title>
</tna:Cataloguing>
</tna:cataloguing>
</tna:BornDigitalRecord>
By using blank nodes and creating classes within our ontology for these objects it
might be possible to create a rich, descriptive and readable RDF/XML structure for
the
XIP metadata files. To see whether this was true, we first started by modelling the
objects we had defined in our ontology.
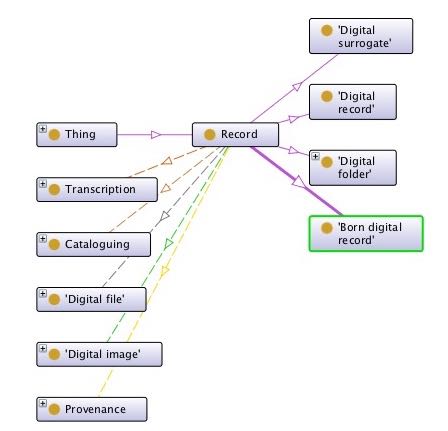
fig. 1: Record Model
fig 1. OntoGraf [22] diagram of the record model.
The diagram above, displaying part of the vocabulary model, shows that a Record is
a
type of OWL Thing (every object in an OWL vocabulary is, by definition, a subclass
of
OWL Thing) and has four sub-types, as previously described. A Record can have a number
of properties which are themselves objects (resources) that have their own properties.
So a Record
can have a Transcription object which itself will have a number of properties to do
with
transcription. The full current list of classes, object properties and data properties
is detailed in Appendix B.
Once a model had been established using the ontology it was possible to create some
prototype RDF/XML that made use of these terms. The results can be seen in Appendix C.
When presented to the Digital Preservation team, these prototype RDF/XML models were
well received and found to be highly readable. Furthermore, this type of RDF/XML
structure can be XML Schema validated. After all, it is only XML and TNA have tight
control over the terms and structure of the RDF/XML they are creating. They are not
trying to validate just any RDF/XML and so it poses no special validation challenges, once an appropriate schema
is available.
Only minor alterations were proposed to the layout and terminology before taking this
forward to production development. One of these amendments was to do with the creation
of individuals within the vocabulary and there is more detail on this in Appendix D.
The Future
One of the significant challenges that currently faces the National Archives when
handling metadata for digital records is that metadata changes. This change may be
required because there was some error in the metadata originally, or perhaps some
new
metadata becomes available, or perhaps some fact asserted in the metadata changes.
On the
other hand though, it is not desirable for the tapes in the dark archive to be updated
every time some minor modification is requested. This reading and writing to tape
causes
wear and tear which, if it happens frequently, could reduce the viable lifespan of
the
tapes and increase the risk of corruption. It would be very useful therefore to have
somewhere to keep the metadata, or at least a copy of the metadata, where it could
be
accessed and edited without touching the archive. Perhaps these edits could be written
to the tape at
a low frequency when a sufficient quantity of them had built up to make the tape edits
worthwhile (although whether this is the right thing to do, from an archival point
of view, has yet to be decided).
Fortunately, much of the computer architecture for this is already in place at TNA.
One
of the bonuses of creating RDF/XML is that these snippets of RDF/XML that are being
inserted into the XIP file could easily be copied elsewhere. The DRI project already
has
a Linked Data catalogue for maintaining processing and inventory information for DRI,
based on Apache Jena Fuseki and the Jena TDB triple-store (the DRI Catalogue), so
it
would be quite simple to post these new RDF/XML snippets to the Linked Data catalogue.
A better alternative may be to replicate this architecture
and have a separate place to keep this rich metadata for easy access. With a SPARQL
endpoint set up it
would be a matter of submitting SPAQRL update queries to modify the information held.
Probably
the only significant components that would need to be developed from scratch are a
web
service to send SPARQL Protocol queries to the endpoint and a GUI for information
management teams to add, delete and edit the metadata.
The RDF/XML metadata that is being placed into the XIP is usually the most interesting
metadata of all. It is the human-entered information that can really tell you something
interesting about the record, rather than the somewhat dry machine-generated technical
metadata. If this metadata was placed in an editable repository using Semantic Web
technologies, technologies that allow such things as context-aware searching,
inferencing and entity recognition, many new facts would likely be unearthed.
Furthermore, having this data available in a Semantic Web format means that should
TNA
wish to do so it, it could publish this metadata on the Internet as Linked Data. Doing
this would enable individuals and organisations in the wider world to search for and
link
to items buried deep within the archive. Having the technology to make connections
between
data held in different archives (and other institutions) has the potential to lead
to
valuable new insights into our past.
To make this process easier, The National Archives have decided to make their
vocabulary publicly available. It is hoped that the experiences at TNA will be of
benefit to other archival institutions and that they will make use of these terms,
either
by associating them with their own terms, or even using them as preferred terms.
The Semantic Web can trace it's roots back to ancient Greece. The field now known
as
ontology was first described by Plato (429-347BC) and later his pupil Aristotle
(384-322BC) when they talked about modelling the world [28]. It is also firmly
rooted in natural language and logic and as such, it is reasonable to assume that
its
constructs will make sense to future generations who discover it buried deep in a
digital archive.
That and the fact that Semantic Web technologies such as RDF/XML and OWL can help
to
solve the practical problems faced by archivists today, namely creating concise,
readable metadata that can be easily generated and automatically validated, make them
an
excellent choice for this situation.
Add to that the potential to open the archive to far more meaningful, context-aware
searches and the ability to make connections between pieces of information held in
different repositories, maybe in different countries, and suddenly a good idea sounds
like a very exciting one with enormous potential for the future.
An organisation like the National Archives is dedicated to preserving the national
memory of the United Kingdom. Like human memory, a national memory is important for
many
reasons. There will be good memories and bad. Some memories make great stories and
some
will be painful to recall. All memories though serve the fundamentally important tasks
of reminding us who we are and how we have learnt to do the things we do. If anything
can be done to sharpen our national memory, it can only be for the good of us all.
A record which was digital at point of creation as opposed to a record that was created
on paper and then digitised. An example of a born digital record would be a digital
photograph taken by a digital camera.
A digital folder (also known as a directory) is a computer cataloguing structure that
can contain files and/or more digital folders. As such it is used as a container for
digitised and born digital records.
A digital record is the digitised version of a paper record that no longer exists.
An example of a digital record is the digital image of a paper document that has been
scanned using an image scanner. The original paper record is then discarded and the
image becomes the record.
A digital surrogate is a digital record that exists in addition to a paper record.
An example would be a paper document that is scanned and then both the digital image
and paper document are retained.
Where a digital file has been substituted this would be the substitute
file. For example a JPEG2000 image may be substituted with a JPEG 1.0
image in order to have the same image in a smaller file.
The identifier of a batch within the context of a collection. A batch
would generally equate to a whole disk of records. This identifier is
meaningless without the presence of the collection identifier.
The identifier of a collection of records. A collection represents a
distinct and related set of records. At TNA a collection identifier is a
string of five characters which can be made up of the digits 0-9 and the
letters A-Z, e.g. ADM17 or LEVES.
A department identifier. This is used to uniquely represent a government
department or other originating organisation for the record. For example
WO is used for War Office, LEV is used for the Leveson Inquiry.
A division identifier is used to uniquely identify a division within the
context of a department. The term division refers to a division within
the TNA Cataloguing hierarchy.
A sequence of zero or more names denoting a directory path with the last
name denoting either a file or directory. The names are separated with a
file system seperator, e.g. / and the entire path should be URL
encoded.
The name of the organisation holding the record. Normal this would be
the The National Archives, Kew but it is possible that a record may be
held by another organisation. This could occur with retained records for
example.
Indicates whether the image is split or not. Valid values are yes and
no. Sometimes, very large documents (maps for example) are scanned into
multiple images files if they cannot all be scanned into one.
An ordinal used to correctly order images when a large paper document
has been scanned into multiple images. Sometimes, very large documents
(maps for example) are scanned into multiple images files if they cannot
all be scanned into one.
The UUID of one or more other digital image files which can be used to
complete the image in this digital image file. Sometimes, very large
documents (maps for example) are scanned into multiple images files if
they cannot all be scanned into one.
An item identifier is used to uniquely identify a division within the
context of a piece. The term item refers to an item within the TNA
Cataloguing hierarchy.
An official number used within an organisation to identify an individual
person. Examples of an official number would be a social security number
or military service number.
An ordinal can be used to sequence a number of items below catalogue
level. For example we may have multiple images which all have the same
TNA Catalogue reference, such as the pages of a book. An ordinal allows
these items to be sequenced correctly.
A parent identifier is the UUID of another record which is the parent of
the current record. For example where a digital folder contains a
digital file the parent of the digital file would be the digital folder.
This provides a very direct means of linking such records.
A piece identifier is used to uniquely identify a division within the
context of a series, sub-series or sub-sub-series. The term piece refers
to a piece within the TNA Cataloguing hierarchy.
A series identifier is used to uniquely identify a series within the
context of a department or division. The term series refers to a series
within the TNA Cataloguing hierarchy.
A sub-item identifier is used to uniquely identify a sub-item within the
context of an item. The term sub-item refers to a sub-item within the
TNA Cataloguing hierarchy.
A sub-series identifier is used to uniquely identify a sub-series within
the context of a series. The term sub-series refers to a sub-series
within the TNA Cataloguing hierarchy.
A sub-sub-series identifier is used to uniquely identify a
sub-sub-series within the context of a sub-series. The term
sub-sub-series refers to a sub-sub-series within the TNA Cataloguing
hierarchy.
A universally unique identifier (UUID) is an identifier standard used in
software construction. Version 4 UUIDs use a scheme relying only on
random numbers and have the form xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx
where x is any hexadecimal digit and y is one of 8, 9, A, or B.
Sub property of
http://purl.org/dc/terms/identifier
Appendix C. Appendix C
Example of embedded RDF/XML metadata about a digital file. For conveience the metadata
is kept in two locations within the XIP, within the DeliverableUnit and the associated
File elements. Were this data to be loaded into a triplestore that duplication could
be
removed.
While modelling the objects we would need in our digital records ontology, it became
apparent that there were certain record properties that would
have the same value for many different records. For example, records have a legal
status which in the UK can be either Public Record,
Not Public Record or Welsh Public Record. There were two ways to approach this. These properties
could be data properties, in other words stored as literal text values, or they could
become object properties whereby they would be represented by a resource which has
its own properties. In the case of legal status, having them as object properties
pointing to a resource which was an instance of a legal status (an
individual in ontology terms)
has a number of advantages. Firstly it becomes possible to unambiguously state the
legal status of a record. By pointing to a resource, you store all of the
information you need in one place and all of the relevant records point to this place.
This mitigates the risk of entering a text value which could be prone to typos and
ambiguity.
For example, is "Welsh public record" the same as "Welsh Public Record"? Furthermore,
because they are resources and therefore have their own
properties, we can say more about them. We can add a description for example, to help
archivists in choosing the correct status. Perhaps most
importantly of all though, it allows computers to understand the meaning of our records.
It means that a computer can logically understand that a record has
something known as legal status and that Public Record is a kind of legal status. In the future it may discover that other things have legal
status. This kind of
logical analysis is not possible if legal status is just a piece of text.
Apart from legal status, it was also desirable to use individuals for other concepts
within the archive such as Crown Copyright
and United Kingdom. This caused a dilema as we either had to create new URIs to represent each of these
resources within the archive or
use existing external URIs. For example DBpedia which holds structured data extracted
from Wikipedia provides URIs for these things, such as http://dbpedia.org/resource/Crown_copyright for Crown Copyright.
However The National Archives could itself be considered the authority on Crown copyright
so it would not be unreasonable to create a resource such as
http://datagov.nationalarchives.gov.uk/resource/Crown_copyright to represent it. Furthermore there was some anxiety expressed by the archivists about
creating links to external
resources, such as those on DBpedia, which may be outlived by the records in the archive.
A better solution was considered to be to creating resources using
National Archive URIs, which we could always guarantee and define ourselves for the
things we need. There is nothing to prevent us, or others, linking these
resources to the likes of DBpedia within specific applications but within the archive,
the definition would always be self-contained and therfore guaranteed available
to future generations.
The individuals created so far within the UK National Archives Metadata Vocabulary
are as follows: