Ogbuji, Uche, and Mark Baker. “Data transforms, patterns and profiles for 21st century Cultural Heritage.” Presented at Symposium on Cultural Heritage Markup, Washington, DC, August 10, 2015. In Proceedings of the Symposium on Cultural Heritage Markup. Balisage Series on Markup Technologies, vol. 16 (2015). https://doi.org/10.4242/BalisageVol16.Ogbuji01.
Symposium on Cultural Heritage Markup August 10, 2015
Balisage Paper: Data transforms, patterns and profiles for 21st century Cultural Heritage
Uche Ogbuji is a pioneer in the integration of Web architecture with traditional
enterprise data technology. An Electrical/Computer Engineer by education, Uche has
written over 300 articles on XML, RDF, Web services and related topics, having pioneered
open source and commercial software development in those areas. Uche was a lead architect,
working with the US Library of Congress, on the Bibliographic Framework BIBFRAME as
well as Zepheira's BIBFRAME tools, products and services.
Mark Baker, Principal Architect at Zepheira, is a specialist in Web architecture,
the first evangelist of the REST architectural style, an entrepreneur, and a pioneer
of the mobile Web.
If you search for books and other media on the Web, you find Amazon, Wikipedia, and
many other resources long before you see any libraries.
This is a historical problem of librarians' having started ahead of the state of the
art in database technologies, and yet unable to keep up with mainstream computing
developments, including the Web.
As a result, libraries are left with extraordinarily rich catalogs in formats which
are unsuited to the Web, and which need a lot of work to adapt for the Web.
A first step towards addressing this problem, BIBFRAME is a model developed for representing
metadata from libraries and other cultural heritage institutions in linked data form.
Libhub is a project building on BIBFRAME to convert traditional library formats, especially
MARC/XML, to Web resource pages using BIBFRAME and other vocabulary frameworks.
The technology used to implement Libhub transforms MARC/XML to a semi-structured,
RDF-like metamodel called Versa, from which various outputs are possible, including
data-rich Web pages.
The authors developed a pipeline processing technology in Python in order to address
the need for high performance and scalability as well as a prodigious degree of customization
to accommodate a half century of variations and nuances in library cataloging conventions.
The heart of this pipelining system is in the open-source project pybibframe, and
the main way to customize the transform for non-technical librarians is a pattern
microlanguage called marcpatterns.py.
Using marcpatterns.py recipes specialized for the first Libhub participant, Denver
Public Library, further specialized from common patterns among public libraries, (FIXME
- not quite sure what is being said here)
The first prerelease of linked data Web pages has already demonstrated the dramatic
improvement in visibility for the library and quality, curated content for the Web,
made possible through the adaptive, semistructured transform from notoriously abstruse
library catalog formats.
This paper discusses an unorthodox approach to structured and heuristics-based
transformation from a large corpus of XML in a difficult format which doesn't well
serve the richness of its content. It covers some of the pragmatic choices made by
developers of the system who happen to be pioneering advocates of The Web, markup,
and standards around these, but who had to subordinate purity to the urgent need to
effect large-scale exposure of dark cultural heritage data in difficult circumstances
for a small development and maintenance team. This is a case study of where proper
knowledge of XML and its related standards must combine with agile techniques and
"worse-is-better" concessions to solve a stubborn problem in extracting value from
cultural heritage markup.
If you’ve ever done an online search for a book, music or a film you want to check
out, you might have noticed that you never find any libraries.
Information went digital, we emerged in the information age, and libraries, for
millennia at the center of information in human affairs, have been left utterly behind.
Libraries are aware of this problem. They have tried many desperate measures to
bring people back to their patronage.
Your local public library probably has a huge wealth to offer well beyond the traditional
stacks of books.
3D printers and maker spaces, meeting rooms for reservation, telescopes and other
such amateur scientific equipment, and certainly electronic materials.
You can probably take your e-reader to your library and download a book to read
at no cost within a limited time.
You can also probably do so without leaving your home. But again good luck finding
all this out from a casual Web search.
The problem for libraries is not one of interest or ambition, but rather one of
data. Libraries have phenomenal catalogs of information.
They have been developing catalogs and databases long before Joseph Jacquard, Charles
Babbage, Ada Lovelace and company had the inkling of an idea for anything like a computer.
In fact, though these pioneers anticipated computers as a tool for improving labor
productivity, librarians have long pioneered ideas and techniques for accumulating
as much value as possible into bodies of information, a topic which really only started
to reach full maturity in mainstream computing around the emergence of markup languages
leading up to SGML.
Naturally, then, libraries became early adopters in the early days of computers.
Henriette Avram, a computer programmer and systems analyst developed the MAchine
Readable Cataloging (MARC) format MARC starting in the 1960s at the Library of Congress.
MARC is a records format designed to provide a database implementation of iconic
old card catalogs, but with the ability to go beyond what was possible with card catalogs,
adding rich indexing according to the linguistic and contextual nuances curated by
librarians, and to support them with automation, including a way to share catalog
records to reduce labor (MARC was eventually given an XML serialization called “MARC/XML”
MARC/XML).
Another giant of library science, S. R. Ranganathan developed the idea of multi-faceted
classifications of items in metadata Subject heading and facet analysis, again a concept which came later on to mainstream computing, through the area of
search engines, especially those designed to support multi-faceted exploration in
networked applications.
The theory and frameworks in libraries, however, emerging far ahead of mainstream
computing applications, and left them in a state where they had richer data than traditional
database technology could easily process, in massive volume, and now in formats and
conventions which are very unsuited to the Web.
This is a great loss to culture because so many look to the Web for information,
but the Web at present has very little of the benefit from the enormous amount of
information curated by librarians.
Libraries are just one of several types of cultural heritage institutions, sharing
such problems with museums, archives, and to some extent galleries.
As business and the rest of the world evolved with highly structured and semi-structured
databases and metadata standards, libraries have tried to keep up, but find themselves
tangled up in the long tail of their own legacy.
Introducing Libhub
The authors, through their employer Zepheira Zepheira, have been involved in several developments to help libraries deal with these problems
and take fuller advantage of the Web, which is where our children and their generation
discover and learn so much of what we did in the brick and mortar institutions.
Our company had been working with the Library of Congress Library of Congress since 2011 developing Viewshare Viewshare, a project to make it easier for digital curators and archivists to improve access
to cultural heritage materials which had been digitized for preservation.
Viewshare provided an interface to build Web-based special collection views using
faceted search and navigation.
At the same time the Library of Congress was looking to deprecate MARC and replace
it with a linked data format more native to the Web. In 2012 they engaged Zepheira
to lead this project LOC Modeling Initiative.
In this effort we developed BIBFRAME BIBFRAME, a bibliographic framework for the Web. BIBFRAME allows libraries to represent the
sort of metadata that’s in legacy MARC records, but also to encode new and emerging
types of information from social media postings to 5D-printed materials.
As such it is a broad, semi-structured data model centering on a small number of
core constructs representing how most cultural heritage applications express intellectual
and creative content.
BIBFRAME is its own abstract metamodel, but in the specifications and a lot of the
other communication, examples are given using RDF concepts and syntax, since many
librarians on the technical end of the spectrum have already been learning about RDF
and linked data.
This also makes it easier to apply BIBFRAME on the Web using technology such as
RDFa RDFa.
Zepheira is developing a platform for taking library records and converting them to
a Web-friendly representation based on BIBFRAME where each resource implicit in MARC
becomes a Web page, and the relationships buried in MARC codes become Web links.
Early experiments demonstrated just how exceedingly rich were the possible results
from such work.
This platform, called Libhub Libhub is currently in beta with a dozen public libraries, starting with the first library
partner, Denver Public Library Denver Public Library in April, 2017.
Libhub publishes a collection for each participating library as well as a centralized
representation of the aggregated resources, derived from these collections, called
the Visible Library Network (VLN).
We think this represents a simple and sensible step towards increasing the prominence
of libraries on the Web, and enriching the Web itself.
Denver Public Library is a good example of the promise and trouble facing public
libraries.
As the City Librarian Michelle Jeske says, “We at Denver Public Library realize
that our customers are regularly using search engines to satisfy their information
needs and are often bypassing the physical Library.” Zepheira Linked Data Readiness Assessment
Not only do people searching on the Web miss the opportunity to find the materials
DPL has available without requiring purchase, but DPL also has unique and special
materials from which the public can profit, for research, education or leisure.
The Denver Public Library Western History and Genealogy Denver Public Library History division is a valuable collection of historical resources from the region, in physical
and digital form.
DPL also has some interesting records around one of Denver’s more famous citizens,
“The Unsinkable” Molly Brown.
As Zepheira was working with DPL to apply BIBFRAME in a way that covers the many different
needs of public libraries, the example of Molly Brown came up as an interesting exercise.
Around the abstract entity of her person are entities such as her autobiography,
and other biographies, her cookbook, a musical play about her, the topic of the Titanic
shipwreck, which she survived, the museum established from her house, her personal
papers (correspondence, etc.) and more.
Molly Brown’s papers are an example of a unique resource held by DPL.
After some brainstorming with colleagues at National Library of Medicine and George
Washington University, Gloria Gonzalez of Zepheira came up with a sample graph model
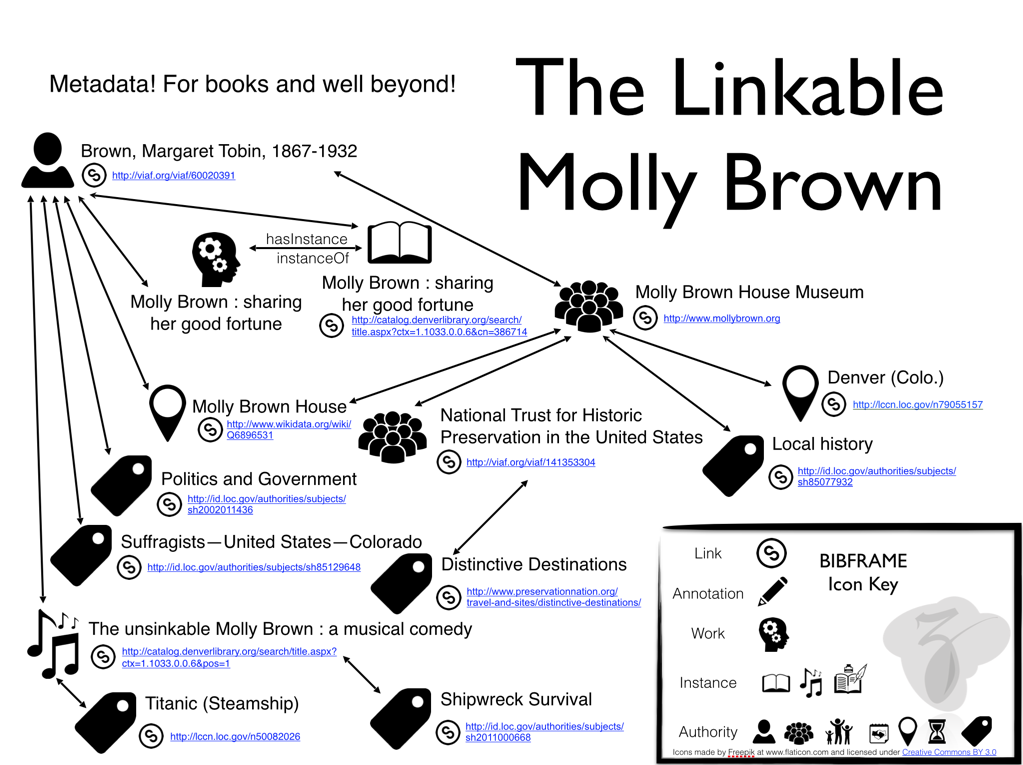
around the topic, shown in Figure 1.
Figure 1: The Linkable Molly Brown
The Linkable Molly Brown information graph, based on BIBFRAME
In February Zepheira did a small but significant experiment, asking DPL for a dozen
records pertaining to Molly Brown, including some of the resources referenced in the
sample model. After specializing the transform based on the developed model, the Libhub
tools were used to generate resource pages, and these were published to the Web, to
see whether they would be picked up by search engines.
To our own amazement within 3 days the relevant test Libhub resource page shot to
the top of Google Search rankings for the search “Molly Brown Papers.”
Within another week DPL’s own catalog page, which was prominently linked and redirected
from the resource page, took top spot.
This illustrated an important principle for Libhub: that the intrinsic quality and
richness of information content present within Library catalogs is indeed sufficient
to significantly influence the Web, increasing the visibility of libraries and making
more credible and valuable material available online. No dark and gnomic Search Engine
Optimization (SEO) were required. If value of content and links are the cornerstone
of effective SEO, our project demonstrates that libraries already have the material
ready made.
From broom closets to the Web
Getting to the meat of the problem, how one processes traditional library formats
to extract rich data for the Web, it became rapidly clear that the watchword was going
to be pragmatism and flexibility.
Even though we have focused mostly on MARC, rather than other formats such as MODS
MODS or plain Dublin Core XML Dublin Core XML, we have found a staggering degree of variants in use of this half-century-old standard.
When Zepheira started with the US Library of Congress working to develop BIBFRAME
in 2012, we decided that we were going to take an implement-as-you-go approach.
All our design decisions would be informed by code we wrote which worked on actual
use-cases of MARC records.
We realized that what we needed was not a monolithic conversion routine but rather
a pipeline of processing stages which could be quickly fixed, tweaked and specialized
for particular patterns and needs as we learned lessons getting on with real-world
MARC records.
The architectural idea is not unlike XProc XProc, but in our case implemented entirely in Python.
There is a core, free/libre open source software (FLOSS) library called pybibframe
pybibframe, designed to be extensible. We have separate, proprietary components, Libhub-specific
enhancements for Web publishing, built as extensions to the FLOSS platform.
We also needed an internal processing representation for the logical data model,
and thought it useful to be able to use the same basic metamodel for input (MARC)
as well as output (BIBFRAME).
We chose Versa Versa, a language like RDF but where each of the “statements” were modeled to be more like
abstract HTML (or XLink) links rather than RDF statements.
Given that our goal in applying BIBFRAME is to generate fairly straightforward corpora
of cross-linked pages, we found the expressiveness of this metamodel particularly
attractive.
Because RDF is such a popular and important metamodel we do have an option to translate
the Versa output to RDF.
Versa is in many ways an implementation detail, used within our pipeline architecture,
and not directly relevant to people who merely want to convert MARC to linked data,
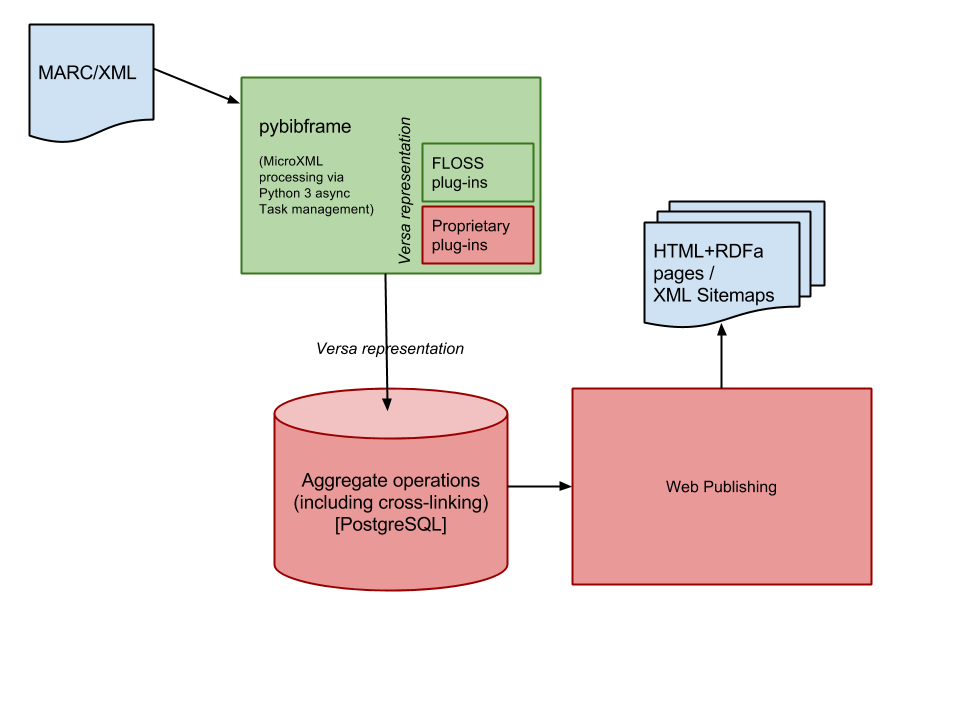
but the details of the pipeline are of interest for this paper. Figure 2 is a rough
data flow diagram of the Libhub pipeline.
Figure 2: Data flow of Libhub pipeline
Data flow of Libhub pipeline for publishing from MARC to the Web
Our approach provides for several points where behavior can be branched and managed,
and perhaps the most important of these points is marcpatterns.py.
This file of recipes expresses how patterns matched from the MARC input are translated
into output patterns in BIBFRAME.
MARC/XML patterns
The following is a portion of a MARC/XML record describing a book with a MARC 245
field title "I am Ozzy", and a MARC 100 field creator/author of Ozzy Osbourne, born
in 1948. Namespace declarations are omitted but all elements are in the http://www.loc.gov/MARC21/slim namespace.
You can tell this is not a format designed in the era of self-describing data.
It's XML only in the most superficial form. Radically different patterns and types
of content are shuffled into datafield elements according to tag designator attribute, a number from 001 through 999. Additional structure is offered
by subfield elements with their code designator attribute. In addition the semantics of datafield and subfield are further modified by indicators, given as ind attributes. The resulting, bewildering set of schematic rules are provided in the
MARC specification pages, for example those for "100 - Main Entry-Personal Name."
MARC 100
The following are two simplified rules using the marcpatterns.py microlanguage.
The first prescribes that any encountered 100 datafield will create a resource of
type Person and via the onwork primitive, identifies that person as the creator of the Work, a resource implicitly created by the presence of the record, and representing, in
this case, the abstract book.
Though not used in this example, oninstance can be used instead of onwork to connect a resource or property to the Instance, a BIBFRAME class representing
physical manifestations of Works, e.g. a physical binding of a book with page count,
dimensions, etc..
Various other properties of the person in the links structure are attached to the new resource.
The 245$a rule creates no new resource, but simply attaches a title from subfield a to the Work.
When these rules are applied to the MARC/XML snippet above, the resulting BIBFRAME
is presented in RDF graph form in figure 3.
Figure 3: RDF Graph of "I am Ozzy" BIBFRAME
RDF Graph of "I am Ozzy" BIBFRAME
In the unique() function, the rule specifies the subfields that contribute to the resource’s identity,
in this case a, b and c.
Any other reference found to “Osbourne, Ozzy” with no b and c subfields present will be considered to be a reference to the same person and will
produce the same relative URI reference, te1jl-e9.
It is also the case that an “Osbourne, Ozzy” with a different birth date (and still
without b and c subfields) will yield the same relative reference as the unique() statement does not include the d subfield.
On Libhub
The transformation described thus far is available through the FLOSS pybibframe project.
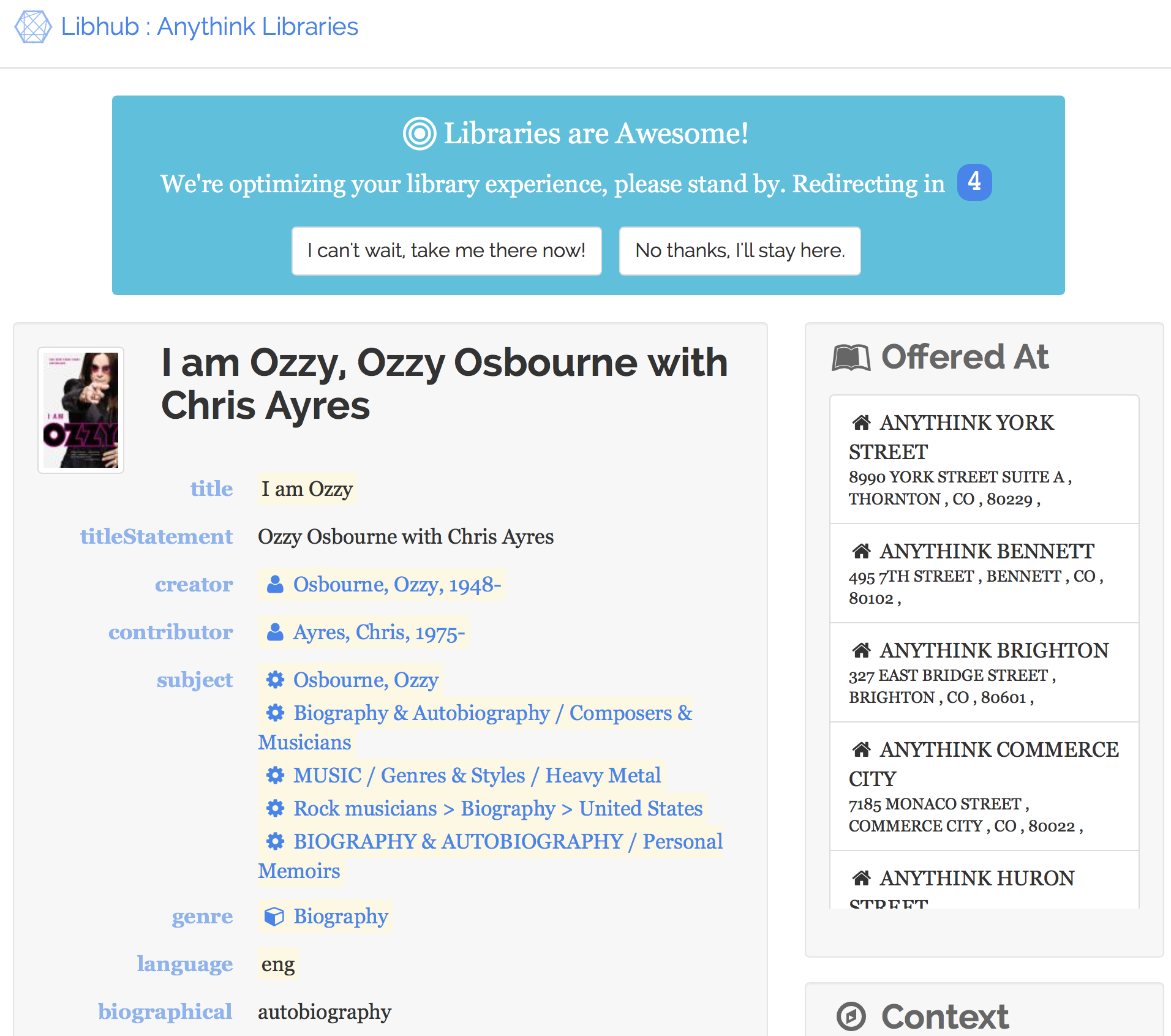
The additional transformations implemented in Libhub produce a page such as in figure
4, from Anythink Libraries. I am Ozzy
Figure 4: Libhub page for "I am Ozzy"
Libhub page for "I am Ozzy"
This page uses RDFa for embedded data, as illustrated in the following snippets.
The main overall input to the Libhub processing pipeline is MARC/XML and the output
is a variety of other markup formats, including an RDF-like graph and HTML/RDFa Web
pages.
One might ask why more common parts of the XML stack were not used, such as XSLT
and XQuery.
The Library of Congress actually maintains a separate FLOSS project for MARC/XML
to BIBFRAME/RDF conversion, written in XQuery.
This was developed in parallel to PyBIBFRAME starting in 2012 in part to demonstrate
multiple implementations to accelerate adoption of the BIBFRAME standard.
LC had recently adopted a MarkLogic platform for a large portion of its emerging
records management, so the XQuery implementation was a natural approach.
We've mentioned our implement-as-you-go process for BIBFRAME development and we
had a very close insight into the expected pace and cost of development and maintenance
of both approaches.
We knew that we wanted to move quickly on this project of applying BIBFRAME for
Web visibility of libraries.
It seemed quite clear to us that the chaotic nature of MARC, and its many uses and
misuses in legacy data, the many local conventions which had sprung up around it,
and the way that turning hundreds of millions of MARC records into billions of published
resource pages would be very difficult to accomplish by our small team with common
XML standards as they were.
We needed a very flexible and tunable pipeline, and we in effect ended up assembling
one from existing bits of high-performance and high-flexibility data processing kit
such as Versa and our Python 3 asynchronous task queue system.
Our experience collaborating on this other project made it clear that we needed
something more scalable, more expressive and easier to customize and maintain by a
small team.
We designed our Python-based processing pipeline with just these characteristics
in mind.
So far the value of this approach has proved itself apparent. DBpedia, a project
to represent data from Wikipedia, is probably the best known body of linked data emerging
and growing over the past eight years. As of mid 2015 DBpedia includes some describe
40 million concepts (of which 24 million are localizations of concepts in the English
Wikipedia). This translates to some 3 billion RDF statements, of which some 600 million
were extracted from the English edition of Wikipedia. DBpedia
The catalogs of the first twelve Libhub early adopter libraries alone translate to
going on 50 million resource pages (each roughly analogous to a DBpedia concept),
and a few billion RDF statements in total. This is data published in less than four
months, and shall be dwarfed by the subsequent growth of Libhub's Visible Library
Network with thousands of libraries likely to participate over a shorter lifespan
than that of DBpedia. Our unorthodox approaches to processing XML into linked data
have proved scalable to our great satisfaction.
Conclusion
Libhub is an ambitious effort to bring to the Web an enormous volume of valuable
cultural heritage information which has languished too long in dark library catalogs.
Special needs for flexibility, performance and maintainability compelled us to develop
a rich processing pipeline implementation for the purpose, including a mini-language
which allows users in the librarian domain to customize transformation logic themselves
without being experts on markup.
Libhub aims to enrich the Web with the efforts of the army of cataloguers working
in libraries, and further take advantage of their information organization expertise
to maintain the information as it grows to enormous volume. A typical library holding
half a million items may generate up to 5 million concept resources described by several
hundred million RDF statements in RDFa. Efforts to harness cataloger expertise to
reconcile the high degree of overlap across libraries is already under way with development
of the Libhub Virtual Library Network.
The resulting body of linked data will provide a valuable resource to applications
of cultural heritage materials, especially for use in markup technology applications,
which are well adapted for integration with Web resources.