Flynn, Peter. “XML (almost) all the way: Experiences with a small-scale journal publishing
system.” Presented at Balisage: The Markup Conference 2015, Washington, DC, August 11 - 14, 2015. In Proceedings of Balisage: The Markup Conference 2015. Balisage Series on Markup Technologies, vol. 15 (2015). https://doi.org/10.4242/BalisageVol15.Flynn01.
Balisage: The Markup Conference 2015 August 11 - 14, 2015
Balisage Paper: XML (almost) all the way
Experiences with a small-scale journal publishing
system
Peter Flynn
Peter Flynn runs the Electronic Publishing Group in IT
Services at University College Cork. He is a graduate of the
London College of Printing and the University of
Westminster. He worked for the Printing and Publishing
Industry Training Board and for United Information Services
as IT consultant before joining UCC as Project Manager for
academic and research computing. In 1990 he installed
Ireland’s first Web server and since then has been
concentrating on academic publishing support. He was
Secretary of the TeX Users Group, and a member of the IETF
Working Group on HTML and the W3C XML SIG, and he has
published books on HTML, SGML/XML, and LaTeX. Peter is
editor of the XML FAQ, an irregular contributor to
conferences and journals in electronic publishing and
Humanities computing, and a regular speaker and chair at the
XML SummerSchool in Oxford. He recently completed a PhD in
User
Interfaces to Structured Documents with the Human
Factors Research Group in UCC. He maintains a technical blog
at http://blogs.silmaril.ie/peter
In 2006 my university academic IT support group was
approached by an academic colleague wanting to start a new
journal, which would be available in electronic form only.
There were restrictions imposed by the technical capabilities
of the pool of authors, the requirements of the discipline,
and — unsurprisingly — the lack of financial resources.
The decision was made to implement a system using only
open source software, and building largely from scratch, as
the existing open source journal publishing systems at the
time, although comprehensive and well-established, were seen
as far too large and complex for the task.
This paper is a case study describing the process and
explaining the background to the decisions made. It attempts
to draw some conclusions about the technical viability of
creating a small-scale publishing system which attempted to
retain XML throughout the workflow, and about the human
factors which influenced the decisions.
Creating a new academic journal is not something to
undertake lightly [swan2012]. Quite apart from
the need to find articles of the quality needed for publication,
and the problems of dealing with authors, there is usually a
significant administrative workload [shap2005]. In a traditional paper-based journal,
you must deal with the typesetter and printer, and then — often
independently — deal with getting the issue onto the web. In an
academic environment, it is assumed that the editors do the work
in their free time, without payment; and that
graduate students can be co-opted onto the team for the
experience it provides them. Even if the editor’s institution
provides hosting and connectivity for a web site, the
prohibiting factor for paper-based publication is the cost of
printing and distribution.
It has therefore been common for a long time for many new
journals to be web-only, with PDFs and eBooks as download
options for readers requiring print. This is now so commonplace
that new journals are started all the time — a recent report
from the International Association of Scientific, Technical, and
Medical Publishers (STM) gives the active numbers listed in
Ulrich’s Directory (a respected resource) as growing from 23,000
in 2002 to 28,000 in 2014, with the strongest growth in
2008–2010 [ware2015] — nearly one a day, and
that just represents the journals that have succeeded. (The
report also reproduces an interesting graph showing an ongoing
growth of 3.5% a year in the number of journals since 1700
[mabe2003].) Unfortunately many journals also
disappear: some older-established journals who failed to make
the transition to the web, and some initially enthusiastic
web-only journals which simply stopped publishing [beal2015]. The numbers are probably
unknowable
Preparation
In my group — responsible in the university for electronic
publishing, including the web — we are often asked for advice
about setting up a new journal, but the number of suggested
journals which actually get established is small, as the
administrative or organisational commitment is quite large,
print or no print. In 2006 we were approached by a member of
the Department of German, asking about creating a journal on
the use of drama in second-language education. He had already
organised an editorial team, discussed articles with potential
authors, decided on a twice-yearly publication cycle, and,
crucially, made the decision that it was to be online-only and
Open Access. As the journal was to be bilingual in German and
English, a facility for two versions of the same article, one
in each language, was a necessity (in the circumstances a
common request because of the need in other areas to satisfy
the requirements of the country’s dual-language legislation as
it applies to institutions accepting public funding).
Advice
In the discussions that followed, it became clear that the
technical process of putting the material on the web would be
relatively straightforward, provided that the entire business
of pointy brackets could be kept completely out of the picture
as far as authors and editors were concerned. In this respect
we suggested that, as Microsoft Word had started using XML as
their default file save format, authors and editors should
continue using Word (with OpenOffice XML as an alternative).
We were already running a Cocoon server for several other
projects, so the underlying technology for taking in XML and
serving HTML and PDF was an established path.
Alternatives
The alternatives included the Open Journal System (OJS),
then fast growing in popularity, the Public Library of
Science’s system (now Ambra, but then an early beta of Topaz),
and several other PHP and Java systems. However, at the time
they all presupposed a large and well-funded team of people
with ample time, all well-versed in web and markup
technologies, and with sufficient administrative support to
handle a complex workflow. The new editor’s plans were that he
and the other editor would handle submissions by email from
authors, and do all the editorial work in Word on their own
desktop systems; so all they felt they needed was to be able
to drag and drop accepted articles into a folder, from where
they would automatically appear at the relevant URI for
preview and publication. The publicly-available systems, by
contrast, were written for the submission and editorial
workflow to be mediated by the software, sometimes involving
circular conversion between the publishable HTML and the
authors’ and editors’ source formats, and they also included
powerful but complex control panels. At the time of initial
evaluation, a modular approach was not seen as a viable
alternative.
Implementation and technical limitations
A number of restrictions were immediately apparent. While
drag-and-drop to a Windows share was perfectly possible
on-campus, the SMB protocol was not exposed outside the
firewall, meaning work from home or while travelling would not
be possible without the added complexity of VPN access. A static
drop-point like a Windows share would also have meant a
implementing some form of periodic trigger mechanism such as a
cron (1) script to execute at very frequent
intervals to pick up recently-deposited documents and push them
into the server workflow.
The direct use of Word 2003 .xml files was
attractive because they could be operated upon immediately by
Cocoon. However, they implemented images in Base64-encoded CDATA
sections, and no suitable decoder was available for Cocoon that
would also save the resulting binary image file into a specified
directory (decoding and serving inline in real time, each time
the article was accessed, would have slowed the process
significantly). Later, the zipped .docx file format
would store images in their binary format outside the XML file,
but in the early stages it was clear that a separate process
would be needed to extract and save them, along with the main
document and its ancillary files in XML, so a control panel
became inevitable.
Control panel
Having decided that a control panel was going to be
needed, it therefore made sense to embed the functionality of
uploading in it, so that the control panel would be aware of
uploads — no trigger mechanism needed. An Open Source utility
(osFileManager) was installed to handle
uploads. As it turned out, the frequency of re-uploading
re-edited documents, and sometimes removing them altogether,
was much higher initially than had been expected, so having
the functionality in the control panel rather than as a
separate drag-and-drop facility proved to be more
efficient.
The control panel itself was written in XSLT2, executed
within Cocoon, running against a simple XML configuration file
for the journal (title, ISBN, details of editorial board, and
expected frequency of issues). After a file upload, the issue
display gets updated via a small CGI web script on the same
server, which emits XML, so that it can be called silently
from within the XSLT2 code. The script performs the disk
housekeeping functions like creating directories for new
issues, unzipping files, stripping unwanted namespaces (!),
moving their contents into the directories where the
publishing mechanism would expect them, and deleting unwanted
articles; functions which were not directly available within
Cocoon. This represented an unavoidable departure from the
philosophy of staying within XML at all times, but the script
uses XML utilities such as those from the LTXML2 suite (from
the Edinburgh Language Technology Group) for extracting
metadata (author, title, etc) from each .docx
file; which in turn makes it easier to incorporate that in the
script’s XML output.
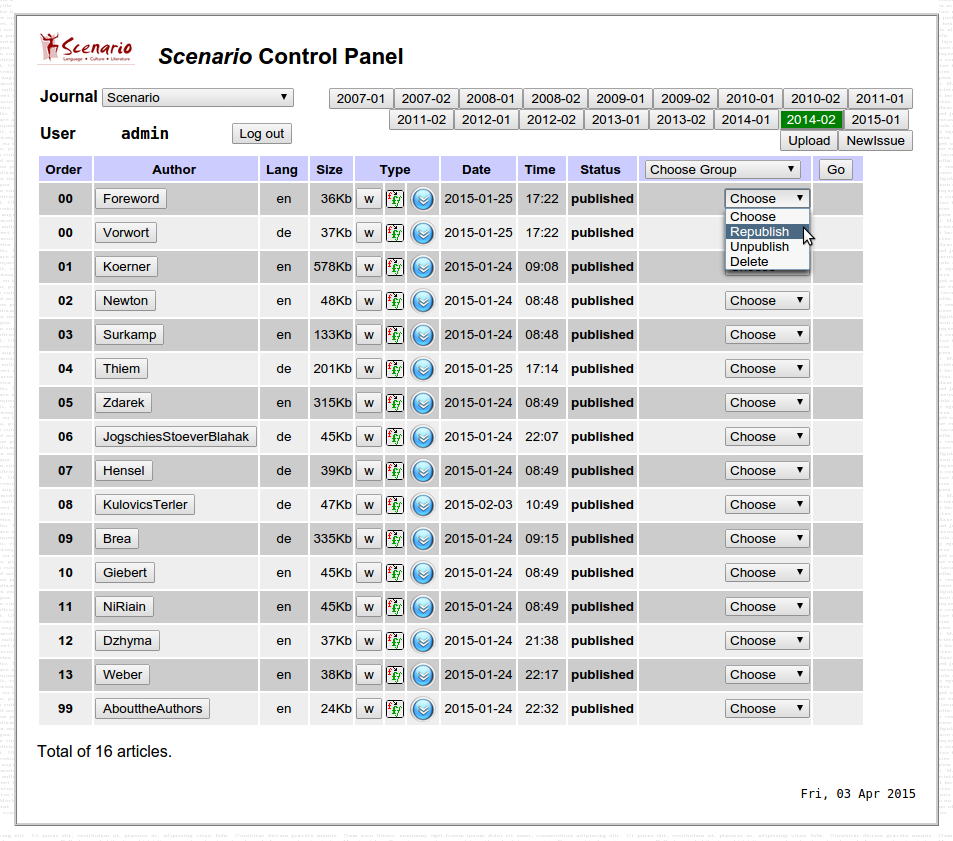
Figure 1: The control panel showing a recent issue of a
journal
As can be seen from Figure 1, the control
panel exposes the issues as buttons across the top, with the
articles for the selected issue listed underneath. The author
name is a button linking to the preview or published form of
the article in HTML (in a pop-up window). A rigid upload file
naming convention identifying sequence, author, volume, issue,
and language (NN-Author-VVVV-II-LL.docx) allows
the editors to order the articles and keep multiple articles
by the same author distinct (00 and 99 are reserved for the
Foreword and Author Details).
Three buttons under the Type column in the
control panel allow a) the pop-up of the
Word XML source for error tracking; b) a
list of the named styles used; and c) a
download of the .xml, .docx, or
.odt file (required in case a later version has
been uploaded by a colleague). The final action
column has drop-down menus to allow an article to be set as
Published; set as Republished after correction (as shown);
reverted to Editing status (and removed from public view); or
simply deleted.
Styles
Perhaps the most obvious technical requirement, however,
was that the Word files had to use rigorously-named styles in
order to be convertible in any meaningful fashion. Apart from
tables, a Word file is basically a sequence of paragraphs
distinguished only by their embedded typographic variation
(font changes, bigger and bolder type for headings, prefixed
by bullets or numbers for list items, indented for quotations,
etc). Adding a named style to each paragraph allows Word to
format it consistently without the need for manual
intervention. But it also means the editors can distribute a
stylesheet to authors, and it allows authors to play around
with the visual appearance of the styles on their own system.
Provided the names of the styles remain
unchanged, the XSLT2 code can use them to identify the type of
paragraph, ignore any the authorial modifications to the
typographic design, and apply the house style. The output can
therefore be relatively plain XHTML (HTML5) with almost all
the formatting done with CSS.
Using named styles with XSLT2 in this way is now
commonplace, but it was an experiment in this project because
the use of styles in Word is rarely taught or even mentioned,
not even when the author has undergone some training in how to
use Word, which in itself is unusual. Although most users who
write formal documents, from business reports to technical
documentation to academic papers, will freely admit to the
importance of consistency and structure, the use of styles
remains at a surprisingly low level.
Lessons learned
The original journal has now been publishing successfully
with this method for eight years, and has been joined by four
more, with another five under development. The
competing publicly-available software for the
same purpose has also developed, much further than our limited
resources permit with the in-house solution. While there is
little pressure at the moment to change, Wordpress and similar
systems with themes and plugins to perform largely the same task
are attractive to newcomers, and widely available both in-house
and on free and commercial platforms.
Universities can also sign up for limited use of publication
systems run by the larger publishers (eg Elsevier), although
these tend to be developmental rather than for production. In
the current economic and staffing environment of a state-funded
university, our (IT division) requirements are for systems
needing the smallest amount of support, and a move to one of the
other systems available is unlikely to occur in the short
term.
Simplicity is the hardest thing to achieve
In removing all evidence of pointy brackets, and having a
single control panel, the business of detecting and handling
errors falls on the XSLT2 code which drives the control panel,
and on the CGI script which deals with uploaded files. A
considerable amount of effort was necessary during the first
two years of operation to modify both programs to handle
unexpected requirements from both authors and editors, and to
deal with the unconventional and sometimes obtuse
implementation of markup which is OOXML in order to maintain
this simplicity.
Most of our editors are experienced academics, well-used
to the demands of their own publishers both for consistency
and adherence to a known style. But this cannot prepare them
for the business of dealing with inconsistent demands from
authors — even experience as a guest editor on a larger
journal, for example, usually involves the editor being
shielded from a large amount of technical detail by a
production team. A new journal also means that some of the
unforeseen requirements have to be resolved on the spot,
rather than by a planning committee working in the
background.
Authors’ reluctance to understand styles
As mentioned above, authors are generally unfamiliar with
the concept of named styles, so careful documentation was
needed to accompany the Word stylesheet (template) distributed
to them. However, subsequent calls for support showed that
this was either ignored or not understood, especially the
recommendation to set up Word to show the styles in a separate
margin (which was carefully documented in step-by-step
instructions). As this is key to any proper use of named
styles, failing to use it creates a significant additional
workload for the editors.
Authors have also grown accustomed to the liberality with
which Word allows text to be treated, and are therefore
surprised to encounter restrictions such as a house style; in
effect, the author sees it as his own
job to invent the schema [piez2007, my emphasis]. This is in direct
conflict with the assumption that academics’ experience with
their own publishers would lead them to expect such rules, and
is an unresolved problem.
Markup management
The initial document structure assumed the following
styles:
Series (eg “Review”), optional
Title
Author, Affiliation (repeatable in pairs)
Abstract
Heading1, Heading2, Heading3 (no more)
Paragraph (or null style)
NumberedList (1, 2, 3,…; with a, b, c,… as a second
level)
BulletedList (• then ·, no custom icons)
BlockQuote
Figure with Caption
Table with Caption
BibliographyItem
Inline markup is limited to bold, italics, and hypertext
links (who knew that Microsoft would come up with three
separate and mutually-incompatible ways to mark up and
implement links?).
Additions and changes
It was recognised that authors would want (and should be
permitted) freedom to express their views as best they
could, but not at the expense of making each article into a
personal typographic experiment or sandbox. The intention
was to keep the mean between the two extremes, of too
much stiffness in refusing, and of too much easiness in
admitting any variation (BCP).
Drama
As the subject matter concerned the use of drama
in language teaching, styles for Speech and Speaker
were early additions.
Epigraph
An Epigraph is allowed, both at the start (between
title block and abstract), and under a
Heading1.
Subtitle
A Subtitle must now be styled as such, even though
the formatted result may place it inline to the Title,
separated by a colon.
Tables
Tables in articles in the Humanities are more
often used as a way to arrange related blocks of text
side-by-side, than to tabulate numeric quantities. The
editors have to intervene when an author’s cells
contain headings and figures; virtually miniature
articles in their own right.
Footnotes
An unexpected hiatus was caused by finding that
instances of Word configured for different languages
insert style names in those languages. The style names
used for footnotes appear to be language-dependent, so
the XPath selectors now cater for these.
Lists
The house style is for numbers or large bullets
for the first level of lists, and lowercase letters or
small bullets for a second level (maximum). Editorial
understanding and tact is needed to maintain
consistency, which seems particularly hard for authors
to accept in the case of lists, where their own
institution, journal, or personal preference may be
for the reverse, or for more decorative fleurons as
bullets.
Author identity
There are plans to add a style to identify an
Author by ORCID, the internationally-agreed unique
author identification code. This will materially
assist in the accurate citation counting which
institutions now rely on as a measure of
output.
Enhancements which did not involve changes to the markup
included the addition of COinS metadata (ContextObject in
SPAN), which allows users of bibliographic mining and
retrieval software (eg Zotero, Mendeley, etc) to extract a
reference with a single click.
Technical knowledge
Despite the best intentions to shield editors from
pointy brackets, they do need some
basic IT knowledge, and exposure to conventions and
best-practices which are neither taught nor mentioned in
most training courses. These include the use of the filetype
(extension) which is hidden from most Windows users; the
avoidance of spaces and non-ASCII or non-alphanumeric
characters in filenames and directory names (excepting dot,
hyphen, and underscore); the distinction between
unidirectional and typographic quotation marks; and the need
for that meticulous exactness which one normally finds only
in a proofreader. An understanding of markup is also useful,
as it enables queries and explanations between academics and
technical support staff to be expressed more
succinctly.
Development
Where the original journal uses separate XSLT2 templates
for each named style, the later ones use a lookup on the
style name into a XML style configuration file, which
handles most cases of mapping from source document styles to
result tree element types.
The only two major exceptions are the handling of
repeated Author/Affiliation pairs for multiple authors (a
relative rarity in the Humanities), and the exceptionally
dense XPath statements required to deal with Word lists,
especially when list items may have embedded tables or
figures, block quotations, or sub-lists, or may need
restarting where a previous list left off several
sections (heading levels) earlier. Editors
try to discourage unnecessary structural complexity of this
type by using subsubsection levels instead.
Issue management
The journal configuration originally specified two issues
per year. This was stored in the configuration file to allow
the control panel to work out what directory naming and menu
structure to implement when the New Issue
button was pressed. As new journals were added to the fold,
other values were implemented (annual, quarterly, etc, with
both year-number and volume-number numbering). There is
currently no provision for a journal to change frequency or to
skip an issue or bring out a special issue.
The question of allowing editing after publication has
arisen a few times. Ethically, this is widely deprecated, and
the current informal practice is that it should only be
undertaken when there is a legal question over material, or
when a serious factual error is discovered (a wrongly-dated
reference, or an incorrect URI). The contrary view is that
digital publication is implicitly mutable, and that ongoing
updates to an article are in fact desirable. From the reader’s
point of view, however, this is very undesirable, as it makes
citation unreliable.
In a university, there is a reasonable guarantee of
continuity; that is, no-one is going to wipe the disk because
of specious claims about core business or
affecting our reputation. The university
repository offers both preservation and data exposure, and
arrangements are under way to lodge the issues there, once the
current work on implementing DOIs is completed (section “Missing features”).
The issue of footnote representation and positioning arose
during discussions with editors on the web layout.[1] In an earlier unrelated project (using TEI XML),
we had used pop-up windows for footnotes, migrating these to
lightboxes for HTML5, but the journal editors advised that a
more conventional format would sit better with their
readership, especially if it could more easily be printed from
the HTML pages (as distinct from the PDFs). It was clear that
the print-oriented demands of the user community, and their
other publishers in particular, would mean a pop-up, hover, or
lightbox rendering for footnotes would be
inappropriate.
The current solution is that points of reference are
signalled in the standard way with superscripted digits,
hyperlinked to the texts, but the texts themselves are dealt with
at the start of the XSLT2 template for each of the Heading styles.
This tests all preceding paragraphs that lie in the domain of
the preceding heading, and formats them (using HTML list
markup) into a footnote block which is placed
before the new heading starts (see
Figure 2).
Each footnote has a backlink to the point of reference, as
many users appeared to be unaware the the Back button —
exercised after traversal of a link
within a document — would bring them
back to where they were.
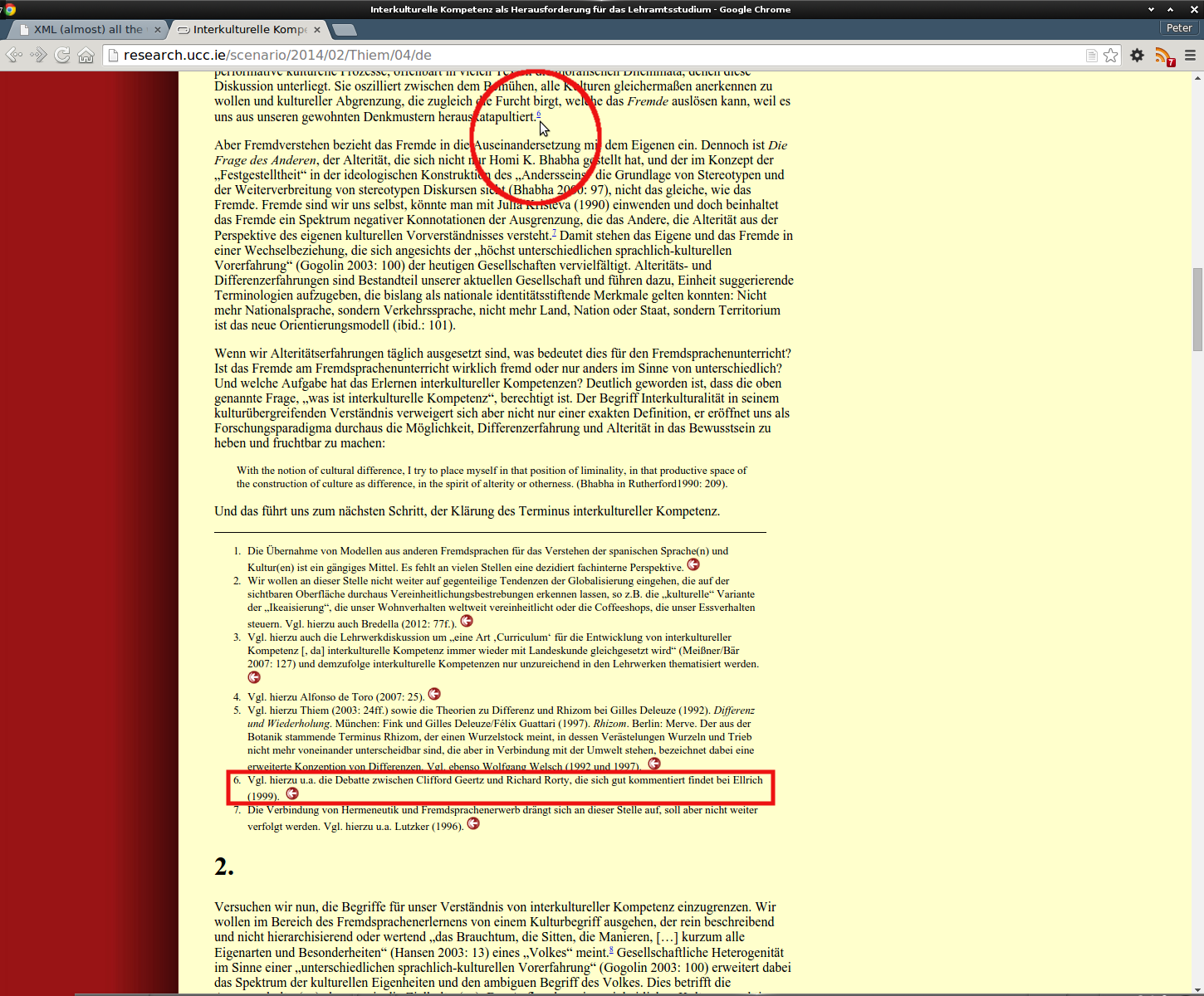
Figure 2: Example of footnote positioning
Screenshot shows the end of section 1 of an article,
with the seven footnotes that occur in that section, with the
cursor (ringed) over the point of reference to footnote 6
(outlined below).
The effect is that the footnote texts are kept relatively
close to their points of reference, often already visible as
the reader scrolls down; given the pageless model of the web,
this is a close substitute for the footnotes visible in a
conventionally paged print document. Multiple references to
the same footnote simply create an additional link: the
direction and extent of the required scroll does not appear to
be a concern for readers. Footnotes in tables and figures are
kept within the table or figure, and are output
lettered.
Design
It cannot be emphasised too much that all intending
journal owners should get a designer to design the web and
print layout at an early stage — unless the institution wishes
to impose a standard format for all its journals (certainly
easier to implement!). In reality, as noted earlier, many
academic journals operate on a best-effort basis, with no
subscription income and no other funding, so the resources to
pay for design work are non-existent. Unpaid student help is
often used, and the work of design students is frequently
excellent, but enthusiasm and good intentions are no
substitute for talent.
In the absence of a separate design input, a largely
generic (and amateur) HTML page style has been adopted for
some of the journals, and some have opted for using the
skeleton of the university’s main web page style. As we plan
to move all the designs to a responsive, mobile-aware pattern,
we aim to make use of a number of open source page layouts
which have generously been made available by several
designers.
Missing features
Over the course of seven years, a number of additional
features have been added to the TODO list. At the top are the
implementation of DOIs and the provision of EPUBs for whole
issues. Both are in train, the former awaiting agreement with
the editors, the second dependent on a more scarce resource:
time.
Digital Object Identifiers (DOIs) are unique numbers
assigned by a publisher under licence from an official
Registration Agency (RA) of the International DOI Foundation,
guaranteeing a permanently resolvable reference linking to the
original published location: conceptually they sit somewhere
between a permalink URI and an ISBN or ISSN.
Several RAs are available, such as CrossRef, and they sell
blocks of numbers at a rate per article or other digital
object. To supply feedback and contribute to their link
ranking, they also require that in each article published, any
bibliographic references which themselves have DOIs granted by
the same RA, must be clickable links; and they provide a
database of all their DOI’d articles for editors to check
(Simple Text Query). They also require indemnification against
legal challenges over copyright and plagiarism, and provide or
sell detection software for the purpose of checking articles
before publication. Implementing these is an additional
editorial task which must be agreed with all editors before
signing up for DOIs, as they require a significant amount of
time to undertake.
EPUB generation from rigorously-defined XML is complex but
commonplace (we already provide this for the TEI project
mentioned earlier). Generating EPUBs from the less well
defined morass that is a Word document — even with named
styles — is rather more onerous, and tests have shown that
some remedial post-editing of obsolescent or experimental
styles in some early articles will be needed to resolve some
of the conflicts currently handled by unnecessarily complex
XPath statements in the existing XSLT2 templates.
User response
In the journals created to date, all but one have come
from the existing academic community (the exception is a
postgraduate journal of very short articles summarising each
authors' PhD research, and does not contribute to citation
count). The editors, who were in all cases the prime movers,
are in effect the owners of their
journal. They were all very open to discussion of the various
alternative ways of undertaking publication, but they were very
conscious of the prevailing ethos of their disciplines (we have
mentioned some of these constraints already).
Paper-based publication is still the norm; web
publication is seen as a supplementary mode of
access;
Web texts needed to resemble, rather than differ from,
paper formats (this refers to the actual article text
itself; having it surrounded by other material such as
menus and headers was perfectly acceptable);
Referencing methods in most disciplines required the
existence of a page number: a URI and section number was
not only unacceptable, but there was no consensus about
how such pointers would be incorporated into the
prevailing reference formats;[2]
Authors were universally considered to be too scarce a
resource to risk alienating by requiring anything other
than Word documents. The need to use named styles was
accepted, but has been a significant contributor to the
support and editorial workload;
Most editors are in an environment where little time
can be spared from teaching, research, and administration,
and where departmental pressures (including small-p
politics) can sometimes lead to the work of journal
editing being seen as discardable. The administrative
workload of styling, uploading, testing, and releasing had
to be kept to an absolute minimum.
Despite these constraints, most editors strongly support
the idea that the publication of articles in journals must
move into an environment where formal (ie peer-reviewed)
electronic publication is evaluated and valued on a par with
paper publication. In particular, they were very receptive to
the ideas of mobile-enablement, XHTML-first, cyclical or
ongoing publication (as distinct from a strict periodic
schedule), and non-traditional modes of presentation (eg
graphic-novel styling, mixed-media, or reader-determinable).
However, they felt that their readers would not all yet be
ready for these as defaults.
Planning is nevertheless under
way for an alternative, mobile-first HTML5 design, and the
generation of eBooks for each issue. We hope to move these to
production in 2016 along with the creation of DOIs.
Conclusions
The objective was to provide the editors with as simple an
interface as possible, and this appears to have been achieved.
It is far from elegant — we have no designers on the staff — but
it performs the tasks required with the minimum effort.
The penalty for this to ourselves (IT support) is that far
more time was spent on the initial discovery of the pitfalls of
taking in user-formatted Word than was expected, but this has
repaid itself in later years with a very small need for support
to keep the system running — the unexpected language variants of
footnote style names were the only significant change in the
last year (2014).
The system depends on Cocoon, which in turn depends on
Tomcat and Apache; and the CGI script is written in
bash and uses Unix-type utilities, which
presupposes a GNU/Linux platform, but none of these is regarded
as a major limitation. However, Cocoon has undergone significant
changes recently, and no longer ships with even a
minimally-usable deployment ready to use. This means that
upgrading the current system will require a very large
commitment of time, as the new modular construction of Cocoon is
poorly documented and exampled, and is aimed at
applications very different from the
straightforward serving of XML as HTML (and building Cocoon uses
Ant, which is notoriously difficult to work with).
The temptation is strong to switch to OJS or a similar
system, as they have matured considerably since 2006, but
investigation of the resources required for setup,
configuration, and ongoing maintenance indicates that this is a
task on a par with building a new version of Cocoon, leaving the
decision moot for the moment. OJS remains attractive because of
maturity and strong support, but we remain concerned about the
complexity of the interface, the relative inflexibility of the
configuration, and the uneven control of formatting.
Currently it’s XML most of the way, and the discipline of
adhering to that standard has been a benefit throughout. Whether
it is a strong enough benefit to outweigh the perceptions of
simplicity of competing systems is a decision we have yet to
make.
References
[beal2015] Beall, Jeffrey (2015)
Obituary for an Open Access Journal in
Scholarly Open Access: Critical analysis of scholarly
open-access publishing [Web]
[piez2007] Piez, Wendell, and Usdin, Tommie
(2007) Separating Mapping from Coding in Transformation
Tasks XML Conference, Boston, 2007 (IdeAlliance)
[Slides]
[shap2005] Shapiro, Lorna (2005)
Establishing and publishing an online peer-reviewed
journal: action plan, resourcing, and costs, Public
Knowledge Project, Vancouver, BC [PDF]
[swan2012] Swan, Alma, and Chan, Leslie (2012)
Open Access scholarly information sourcebook:
practical steps for implementing Open Access,
Evaluating online publication tools [Web]
[ware2015] Ware, Mark, and Mabe, Michael
(2012) An overview of scientific and scholarly journal
publishing, 4th ed, March 2015, pp.27–29 [PDF]
[1] The PDF articles are generated (via XSLT2) with
LaTeX, which uses the standard print conventions
automatically. Using LaTeX also means that the page
numbering can be captured and reused in the web Table of
Contents, which is essential for users in the Humanities,
where some bibliographic citation formats still require a
compulsory page number even for electronic
resources.
[2] In the case of MLA, APA, and some others, this has
now changed.
Shapiro, Lorna (2005)
Establishing and publishing an online peer-reviewed
journal: action plan, resourcing, and costs, Public
Knowledge Project, Vancouver, BC [PDF]
Swan, Alma, and Chan, Leslie (2012)
Open Access scholarly information sourcebook:
practical steps for implementing Open Access,
Evaluating online publication tools [Web]