Harvey, Betty. “Methodology For Providing National Information Exchange Model (NIEM) Model Understanding
to XML and NIEM Novices.” Presented at Balisage: The Markup Conference 2014, Washington, DC, August 5 - 8, 2014. In Proceedings of Balisage: The Markup Conference 2014. Balisage Series on Markup Technologies, vol. 13 (2014). https://doi.org/10.4242/BalisageVol13.Harvey01.
Balisage: The Markup Conference 2014 August 5 - 8, 2014
Balisage Paper: Methodology For Providing National Information Exchange Model (NIEM) Model Understanding
to XML and NIEM Novices
As President of Electronic Commerce Connection, Inc. since 1995, Ms. Harvey
has led many federal government and commercial enterprises in planning and
executing their migration to the use of structured information for their
critical functions. She has helped develop strategic XML solutions for her
clients. Ms. Harvey has been instrumental in developing industry XML standards.
She is the co-author of "Professional ebXML Foundations" published by Wrox. Ms.
Harvey founded the Washington, DC Area SGML/XML Users Group. Ms. Harvey is a
member of "The XML Guild" and was a coauthor of the book "Advanced XML
Applications From the Experts at The XML Guild" published by Thomson.
NIEM is a U.S. government initiative to enable the sharing of data. NIEM consists
of many domains. The NIEM model relies heavily on the use of references to create
relationships between data. It also relies on different namespaces for each domain.
Many large government projects have mandated that NIEM be used for exchange of data
between the government agencies, states and other trading partners. NIEM data models
are very complex. One of the challenges with using NIEM is how to provide a
mechanism to present a complex data model in a way that will provide business
analysts, SMEs, programmers and testers the ability to understand the complexity
of
elements, relationships and bi-directional linkages between pieces of information
that can be understood by both technical and non-technical individuals.
Most of the projects have software development lifecycle (SDLC) artifacts, i.e.,
UML models, data dictionaries, business analysis documents etc. However, these
artifacts do not provide the clarity of schema design needed from a NIEM and XML
perspective. This paper will describe a 'crazy'
mechanism (out of the norm) for providing an understandable artifact of the a very
large NIEM schema that that was provided to possibly thousands of diverse trading
partners for very large federal and state government program
Every large project has to create and maintain documentation that conveys information
about every aspect of that project. These include but are not limited to:
Data models
Information consumers
Data flows
Information transformations
Information storage
Etc.
In a recent large project we were faced with all of these issues. The data model
that
was used was a customized National Information Exchange Model (NIEM) data model.
The
NIEM data model is very complex. NIEM uses redirection and references that on the
surface makes the data model hard to understand and navigate. We were faced with
the
prospect of trying to convey the data model to literally hundreds, possibly thousands,
of business analysts and developers (mostly JAVA) in an efficient and understandable
way. The consumers of the data model were unknown to us. Their skill level and
understanding of NIEM were unknown, although we suspected that this understanding
was
low, especially where NIEM was concerned.
This paper will describe an approach that I developed for conveying the complexities
of the data model. Although, at first I thought it was a 'crazy' idea, it proved
to be
very useful and much more efficient in understanding the data model.
Challenges
NIEM is an XML vocabulary for describing information. NEIM creates profiles based
on
specific business domains. NIEM was designed as an exchange model. The XML schemas
and
information artifacts are packaged into what NIEM calls an Information Exchange Package
Documentation (IEPD). The directory structure of an IEPD is complex. At the leaf of
every directory are one or more schemas that is referenced by another schema.
Individuals that have worked with XML are able to pick up a W3C Schema, DTD or RelaxNG
schema and obtain an understanding of the schema. The fragmentation and referencing
used
in NIEM makes it virtually impossible to gain knowledge by reading the schemas.
The project that this paper concerns was and continues to be a very large project.
There are hundreds of organizations (federal government, state governments, local
governments and commercial) that were required to use the IEPD to exchange information
between the various organizations.
There are also hundreds, maybe thousands of consumers of the information. The actual
consumers of the IEPD were unknown at the project level, except at a high level. We
knew
that the types of consumers would be:
Business Analysts
Programmers (JAVA, C++, possibly COBOL)
Technical Writers
Relational Database Developers/Administrators
Testers
XML Professionals (XQuery, XSLT, Transformations)
We were faced with the challenge of how to provide documentation that would convey
information about 460+ elements in a meaningful way to prospective consumers. Even
with
a constraint schema, most of the elements were optional and used based on specific
scenarios of the data.
NIEM Directory Structure
The structure of the schema is rigidly controlled by NIEM and the IEPD
specification. Below is an example of an IEPD that was used to support this
methodology.
Figure 1: IEPD Directory Structure
NIEM Directory Structure
The IEPD in the above directory structure contains a total of 30 schemas.
NIEM Flexibility
NIEM by default has no constraints. What this means is that the structure is
somewhat rigorous but all the elements, except the root element are optional. Most
organizations cannot sustain a data model without constraints. NIEM has a concept
of
'unconstrained' and 'constrained' data model. If an organization decides to
constrain its data model it must maintain 2 copies of the schema (constrained and
unconstrained) and provide both in the IEPD.
NIEM and Substitution Groups
NIEM uses substitution groups instead for choices in the schema. Substitution
groups are choices. The element that is included in the root model is not valid in
the XML instance but can be substituted by other elements. The use of substitution
groups is useful but can be very confusing to both business analysts and
programmers. Also, many web services software could not consume the schemas with
included substitution groups. We were never able to determine the exact reason but
my hypothesis is that many of the substitution groups are cyclical and the software
cannot handle the recursion. Substitution groups and software consumption of
schema's that contain substitution groups is possibly a subject for another paper
and not part of this paper!
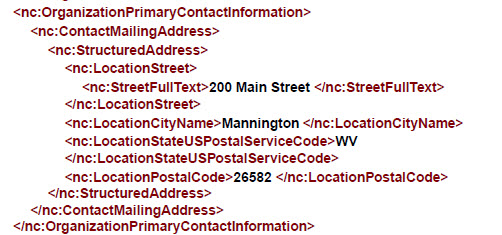
NIEM and Referencing
Although NIEM is an XML exchange model, in actuality you can envision it more
as a relational database model. Instead of a true hierarchical model where
relationships can be construed by ancestor or descendant components, NIEM uses XML
ID/IDREF constructs to provide relationships between different components. For
example, in the model we were working with there were several major structures that
belonged to a person. In other models you might embed all the information related
a
person with the person information. In NIEM, these components are separate and the
information is 'tied' together by using a reference element:
In the above example, this piece of information is referring back to the 'Dad'
person. One of the sample XML documents that were provided as part of the
documentation package for the IEPD had over 70 reference elements.
Namespaces
In the IEPD that was developed, there were a total of 15 namespaces. The more
namespaces that you have, the more complicated the developing processes against the
XML can be. Using 15 namespaces became challenging, not only for us but for
developers with exchange partners. The 15 namespace prefixes that are used in the
IEPD are: exch, ext, fips_6-4, i, i2, iso_3166, nc, niem-xsd, s, scr, usps, and 3
custom namespaces used by the project.
Nillable Elements
Nillable elements are elements that are allowed to be empty. This is true even
when the element has required children elements. Nillable elements are slightly
different than true empty elements. Elements can be defined as having no content,
or empty. For example, HTML elements <br/> and <hr/> elements are empty
because they are using to define either a line break or a horizontal rule. Content
would be meaningless for these elements. Whereas, nillable elements are designed
to
have content but the schema says they can be empty.
NIEM elements, by default, allow elements to be nillable. The NIEM specification
was the first XML vocabulary that I have used that has actually used the 'nillable'
capability of the XML schema. The use of nillable elements caused problems with
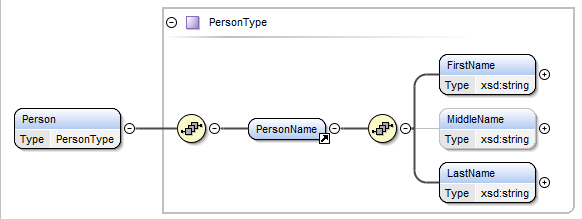
both understanding the model and with software. Let's say you have the following
model for a Person. In this model, the <PersonName> is required. The
<PersonName> requires a <FirstName> and <LastName>. <MiddleName> is
optional.
Figure 2: Person Name is Nillable
Normally you would look at this model and see that the following XML tagging is
valid:
However, when the "nillable='true'" attribute is set on the element declaration
than the entire element is allowed to be null. By default, most NIEM elements are
set as nillable. Therefore, the following is allowed for a Person described
above:
<Person>
<PersonName xsi:nil="true"/>
</Person>
Approach
Considering the challenges that we had and the reality that we weren't in a position
where we could adequately document and convey the challenges of the complex model,
it
was necessary to 'think out of the box'. The model was
complex and different components were required for different scenarios. These various
scenarios were provided as XML documents as part of the IEPD documentation. Also,
Schematron was developed to ensure that the XML validated against the various scenarios.
We understood that looking at the XML itself would only only provide a limited
understanding of what the data actually means. The sample documents were heavily
commented but traversing and understanding 3,000 + lines of XML would be difficult.
In
order to achieve success, the exchange partners had to understand the underlying XML
to
ensure that the exchange of information between partners was understandable.
I came up with an approach that would take the XML, turn it into PDF that looked like
the XML, including 'pointy brackets' using XSLT and XSL-FO. The approach provided
the
following functionality:
The XML was kept intact.
Cross-references were 'live' hyperlinks. This allowed the reader to see how
the cross-references worked.
A navigation bar was added to allow traversing the model and visualizing the
structure of the XML.
Comments were included in the text and highlighted as comments.
A table was included at the end of the XML to show all the cross-references,
by element and by ID.
A data dictionary of all the elements was included at the end of the PDF file.
This provided documentation in a single file.
Default XML Template
Surprisingly, it is relatively easy to display the XML as XML, including pointy
brackets and attributes. The default template took care of the bulk of the
conversion. Below is the code for the default template:
Below is the resulting PDF output from the default template.
Figure 3: Resulting Display from PDF File
Headers and Footers
I felt it was important to provide both headers and footers in the PDF file. The
headers provided information about which element you were viewing. The footer
contained page numbers. Both the recto (right-hand) and verso (left-hand) pages
were formatted appropriately. The header information shows the hierarchy of the
elements on the page.
NOTE: Part of the header is redacted.
Figure 4: Example Header
Figure 5: Footer Example
Comments
The sample XML documents had many comments. These were used to convey important
information and insight into the model for the users of the XML. It was important
that these comments be included in the resulting PDF. In the XML instance the
scenario was described as an XML comment. Below is an example of a comment that is
in the XML instance.
Figure 6: Comment Example
Dealing with Attributes
There are only 3 attributes that are used in the XML. The default template called
another template to create the attributes.
I wanted the ability to differentiate the different sections. A separate template
was made for major sections. This provided the ability to have titles and have the
sections start on new pages. This enabled better readability of the XML. Below is
an example of a template for a person section.
Figure 8: Person Major Section
Navigation Bar/Bookmarks
A navigation bar was created to allow the reader to navigate the hierarchy. It
included expanding and collapsing of the hierarchy. The navigation bar proved to
be
one of the most useful features of the PDF. Business Analysts do not have XML tools
and to our surprise, neither do programmers. Navigating the schema in a graphical
representation with tools such as Oxygen, XML Spy and Stylus Studio are really
beneficial. With NIEM it is almost essential. To our surprise we found that most
organizations to not provide XML tools to their programmers. They only have access
to tools available in JAVA toolkits. Most programmers were using SOAPUI for
development and testing. Therefore, the navigation bar became quite useful.
Figure 9: Snippet of Navigation Bar
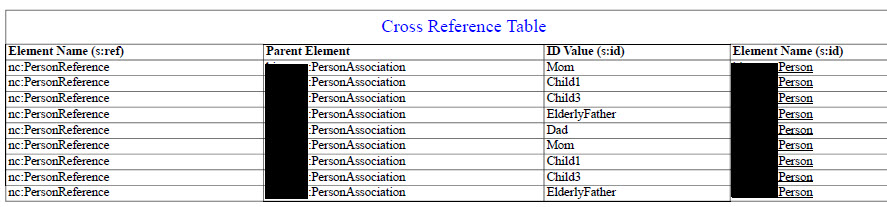
Cross-References
As stated previously NIEM relies heavily on cross-references. In one sample there
were over 70 cross-references. In the PDF, cross-references are 'hot'. This
enables the user to link to the location where the information is located. We used
'meaningful' identifiers in the samples, just to make it easier to understand and
navigate the XML. However, in practice the id's are normally not human ingestible.
As a standard all blue text in the PDF are active links.
The PDF created a table of cross-references which provided just another look at
how the cross-references actually worked.
Figure 10: Active Cross-references
Figure 11: Cross-Reference Table
The last column of the table is a hyperlink to the location in the PDF where the
id attribute is located.
Data Dictionary
The final component in the PDF included a Data Dictionary of the schema. The NIEM
specification requires that all elements are documented. The XSLT traversed the
schema and created a data dictionary that contained all the elements, sorted
alphabetically, and their definition. This provided a mechanism for the user to
quickly find the definition for an element. In most cases the elements were
self-describing, i.e., <PersonAmericanIndianOrAlaskaNativeIndicator>, but there
were elements that were named ambiguously.
The navigation bar provided an expansion to link to an individual alphabetic
location.
Figure 12: Data Dictionary Navigation Bar
Benefits
I believe that the benefits to this approach are many. The users very quickly became
dependent on the PDF to help them understand the model. Most developers and testers
used the PDF version of the XML as a guideline instead of the native XML sample that
was
provided to them. Before the PDF was developed internal testers had many questions
and
misunderstandings of the model. Although the PDF didn't completely alleviate questions,
the amount of questions were reduced in number.
The PDF file was understandable to any discipline in the business and development
process. The result of the PDF was:
Quicker understanding of data model
More accurate understanding of data model
Faster development
Easier validation and testing by independent testers
Less coding errors
Although there isn't any way to quantitatively evaluate the cost-savings, I believe
that the PDF did result in cost savings through the entire life-cycle.
Conclusion
Although this approach may seem a little 'extreme', I believe that it is very
beneficial to providing information on complex data models. It proved invaluable
for
our project. I also believe that this approach would be useful to any complex XML
project. It provides clarity of the model that may not be available otherwise. The
XML
schema (especially NIEM) can only provide so much information about how to knit the
data
together.
It also amazes me how many organizations do not provide XML tools to their developers
and other individuals working with XML. The cost benefits they would reap by providing
adequate tools would far outweigh the cost of the software. Without these tools
navigating and understanding complex models are difficult at best. I don't have a
scientific analysis of how many of the programmers on this project did not have adequate
XML tools but I guess that at least 75% did not.
If faced with the same challenges in the future, would I take this same approach.
Unequivocally yes!