O'Connor, Charles, Antony Gnanapiragasam and Michael Hepp. “ProofExpress: An Online, Browser-Based XML Article Proofing System for STM Journals.” Presented at International Symposium on Native XML User Interfaces, Montréal, Canada, August 5, 2013. In Proceedings of the International Symposium on Native XML User Interfaces. Balisage Series on Markup Technologies, vol. 11 (2013). https://doi.org/10.4242/BalisageVol11.OConnor01.
International Symposium on Native XML User Interfaces August 5, 2013
Balisage Paper: ProofExpress
An Online, Browser-Based XML Article Proofing System for STM Journals
Charles O'Connor
Workflow Automation Specialist
Dartmouth Journal Services
Charles has a degree in biology and had previous lives as an indexer,
copyeditor, and video store clerk before getting involved in this XML
thing.
Antony Gnanapiragasam
Workflow Automation Specialist
Dartmouth Journal Services
Antony has masters degrees in computer science and public administration and
works as a system architect.
Michael Hepp
Director, Technology Strategy
Dartmouth Journal Services
Mike has a bachelor's degree in printing management and sciences and is the
project leader for ProofExpress.
For a browser-based XML article proofing system to function well in a journal
publishing workflow, it must embody two virtues: It must have a very shallow
learning curve, because the majority of users will be encountering it for the first
time, and they may have no knowledge whatsoever of XML. It must also have a
comprehensive and accurate change-tracking feature that allows editors to accept and
reject changes without breaking the XML. A system designed for a publication
services company with many publisher-customers must have the additional virtue of
being highly customizable to account for wide variations in journal styles and the
particular needs of online hosts.
To achieve usability, we based ProofExpress on LiveContent Create (formerly
Xopus), a browser-based, WYSIWYG XML editor, and designed form-based tools to guide
users in the creation of more complex XML structures. Our change-tracking feature
employs denormalization of nested elements to granularly expose all edits and a rule
engine that protects the structure of the XML by governing the order of acceptance
and rejection of edits. XML configuration files control the content of the nodes
added by the tools, allowing ProofExpress to accommodate the differences in, for
example, reference, citation, and footnote styles used by journals that publish
articles in XML that conforms to the JATS 1.0 DTD.
The advent of PDFs represented a leap forward for article proofing. No longer did
proofs need to be printed out and either mailed or faxed to the author for correction.
The PDF could be delivered instantly over the Internet, and the author could view
and
annotate the PDF on a computer in a different environment, using a different operating
system. (Of course, that does not stop them from printing the pages out, correcting
them
by hand, and mailing or faxing them back.) The question then becomes, how can we bank
the gains that were made in delivery and interoperability and take them to the next
level? The answer, of course, is online XML editing.
The clearest advantage of an online, XML-based proofing system is that everyone
involved can work on the same document from copyediting through final corrections.
This
stands in contrast to PDF-based proofing, where authors and editors may mark up
different PDFs, which are then given to a typesetter to transfer the corrections.
Sources of error at this stage include the misinterpretation of sometimes ambiguous
corrections and the rekeying itself (http://www.councilscienceeditors.org/files/scienceeditor/v27n5p155.pdf). A
new PDF is then generated, and another review cycle is initiated. PDF proofing is
thus
both inefficient and prone to error due to the degree of manual intervention. As
attractive as an XML-based proofing system can seem from a workflow standpoint, however,
it will come to nothing unless it is adopted. An online, XML-based article proofing
system designed for science, technical, and medical (STM) journals must be easy to
use
for authors, editors, and publishers and maintain the XML in good shape for the
typesetting system and the online providers that host the resulting content.
Authors of STM journal articles can be many things--researchers, engineers, students,
doctors. One thing they often are not is readers of instructions. (Many jobs in
publishing, from copyeditors to developers of editorial software, depend on this fact.)
In addition, authors may not be especially eager to learn new software. When Dartmouth
Journal Services (DJS) instituted PDF annotation as our preferred method of proof
review, many authors pointed out that they had written their paper in MS Word and
did
not appreciate having to learn how to use the annotation tools in Acrobat Reader.
(We
use eXtyles to apply structure to authors' Word files. After copyediting, we again
use
eXtyles to export JATS XML.) So, the ideal system will give authors a set of tools
similar to those they are accustomed to in word processing programs.
Editors must review the corrections made by authors, and to do so, they need an
accurate change-tracking mechanism. In addition, they need a way to accept or reject
the
changes that an author has made to their proof. A likely solution, and the one we
tried
first, is XML differencing. However, XML differencing must work around the longest
common subsequence problem
(https://en.wikipedia.org/wiki/Longest_common_subsequence_problem). Whatever the
solution arrived at, for example, applying a semantic cleanup or a cleanup based on
string length
(http://neil.fraser.name/software/diff_match_patch/svn/trunk/demos/demo_diff.html), XML
differencing can only tell you how two versions of a piece of text are different,
it
cannot tell you what was done to make the versions different. Thus, editors would
be
faced with accepting or rejecting these differences, not the actual edits made by
the
author.
A problem particular to publication services companies is accommodating the wide
variations in journal style across their publisher-customers. The DTDs based upon
the
NISO Journal Article Tag Suite 1.0 (JATS 1.0) (http://jats.niso.org/) are to varying degrees descriptive, not prescriptive.
They are silent, for example, on questions of what symbols to use in footnotes, whether
to use numbered or author-date reference citations, and whether items in ordered lists
should have labels or not. Another complication arises from the needs of the different
online hosts that a publication services company must deliver XML to. One online host
may require that a <glossary> appear within the <back> element, whereas another
may want it within the <notes> in the <front>.
User Interface
The great majority of proof corrections made by authors and editors are simple text
edits: insertions, deletions, and formatting changes. As ProofExpress is intended
to be
a web-delivered application, SDL LiveContent Create (formerly Xopus;
http://www.sdl.com/products/livecontent/create.html) was a natural choice to base the
system upon. LiveContent Create is a continuously validating XML editing environment
that allows authors to make text corrections using tools familiar to users of word
processing programs. They can insert and delete text without having to enter a
particular text editing mode. They can cut, copy, paste, and format text using toolbar
buttons or keyboard shortcuts. They can insert new paragraphs and sections. All of
these
edits can be made without any knowledge of the underlying XML structure.
To allow authors to add or edit more complex XML structures such as citations,
references, and links, we not surprisingly settled on a form-based approach. In its
simplest implementation, fields in the forms correspond directly correspond to elements
that will be added to the XML. Rather than using element names for the field labels,
ProofExpress uses natural language labels that authors are likely to interpret
correctly. When the author completes and submits the form, the system adds the correctly
structured XML to the file.
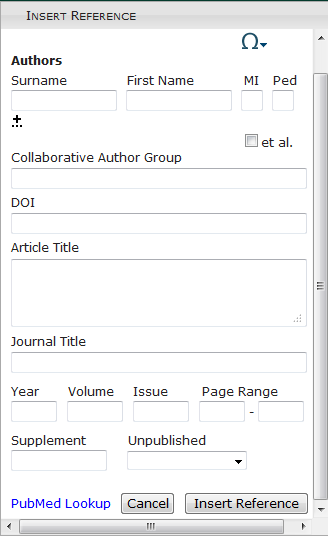
Figure 1: Insert Journal Reference Form
The form for adding references uses natural language labels such as Journal
Title and Page Range rather than element names such as <source> and
<fpage>/<lpage>, respectively.
In addition to providing a way for authors to add more complex XML structures to an
article, forms can also restrict author input to choices that make sense in the context
of the particular article. That is, when the author wants to add a cross-reference
to
some other part of the document, the system can examine the relevant nodes and offer
a
list of choices in a dropdown. The form can then give feedback to the author to confirm
the correct choice. For example, the Add/Edit Reference Citation tool reads the list
of
available citations and puts identifying information into the dropdown. When the author
chooses a reference and submits the form, the system adds the cross-reference. Standard
variable items that the author should not be expected to keep track of, for example,
in
this case, the correct rid attribute, are added by the system.
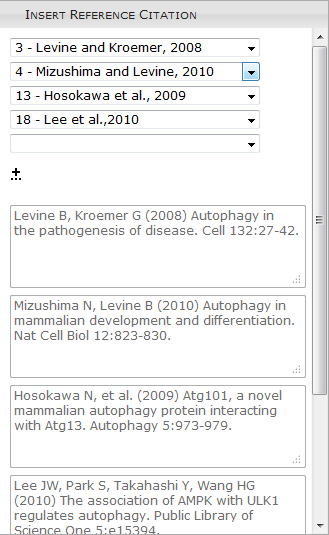
Figure 2: Add/Edit Reference Citation Form
The add/edit reference citation form offers the author a list of references to
choose from. When the author chooses from the list, the full reference is shown
below in a read-only box as a confirmation that the correct reference has been
chosen. This confirmation is especially important because multiple references
can share the same authors and years.
Change Tracking
The one absolutely essential feature of any proofing system is change tracking.
Editors must have the ability to see exactly what corrections authors have made, not
only to ensure that these corrections conform to journal style, but also to confirm
that
the authors have made no changes to data or to claims that would require the article
to
undergo another round of peer review. A great advantage can be gained if the
change-tracking feature also includes an easy way to accept and reject changes. Although
such features are available in desktop XML editors such as Arbortext (http://www.ptc.com/products/arbortext/), no online XML editor has a change
tracking feature that is adequate for the task. LiveContent Create itself has a change
tracking feature, but it's features are rather limited. It tracks insertions and
deletions, but not formatting changes. In fact, as we discovered when we tried to
build
upon the native feature, deletions of text that include formatted text are not tracked
at all.
The Limitations of XML Differencing
When we first started building ProofExpress, we naturally gravitated towards
differencing to serve as the basis for our change-tracking feature. This method
promised to be accurate while placing no burden on the user's perception of the
performance of the application. However, we soon ran into difficulties related to
how differencing engines work around the longest common subsequence problem. If we
take the raw output of a differencing engine, we may get an accurate representation
of the difference between the original and edited versions of the text, but it may
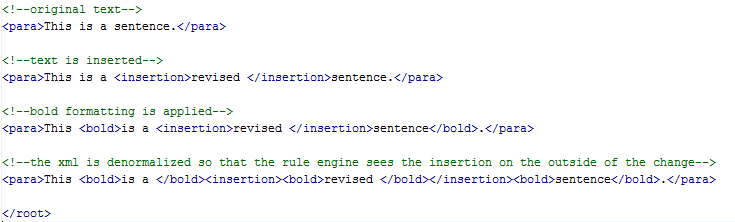
not tell us what the author actually did. For example, if an author changes the
sentence "I say cheese to you" to read "I say oh pleeze to you", the engine will
depict the change as "coh
pleesze" (where underline=insertion and subscript=deletion).
This is not only difficult to read, but it gives the editor multiple changes to
accept or reject, instead of one deletion and one insertion, inviting the
possibility of introducing error during review.
Attempting to overcome this problem by applying a cleanup parameter or otherwise
grouping changes can lead to a loss in the granularity of changes. Changes within
changes will not be marked individually as changes, which is a problem if they
should be dealt with discretely. For example, if you take "<p>hello
world</p>", italicize it and add text in the middle to form
"<p><italic>hello silly italic world</italic></p>", the XML differencing
engine DeltaXML (http://www.deltaxml.com) will accurately identify the former as the
original text and the latter as the revised text. What it will not tell you
specifically is that two changes have occurred: text has been italicized and text
has been added. An editor rejecting the italic formatting of the text could
inadvertently reject the insertion as well.
Figure 3: Results from the DeltaXML "Sandbox"
The original node, <p>hello world</p>, was revised to <p><italic>hello silly
italic world</italic></p>. The diff presented by DeltaXML is correct, but
it does not serve journal production workflows because it does not mark the
internal insertion as a discrete change.
Rule Engine for Changes Acceptance and Rejection
Editors must not only be able to see the changes made by authors, but they must
have an easy way to accept or reject these changes. So, we built a widget that lists
all of the changes and allows the editor to accept or reject them. (This feature is
also available to corresponding authors that share editing with colleagues.) All
decisions about acceptance or rejection are considered provisional until the article
moves to the next stage in the workflow, making it easy for the editor to reverse
a
decision if necessary.
A potential problem arises when accepting and rejecting changes. If the system
does not enforce an order of decision making, then the process may break the XML.
Consider this case: Author1 adds some text to a paragraph. Author2 deletes the
entire node where this paragraph resides. If the editor accepts both the insertion
of the text and the deletion of the node, the text would be left outside of its
proper parent node, breaking the XML structure. To alleviate this problem, we group
nested changes together and force editors to act upon the outer change before they
can act on the inner change. According to our rule engine, a particular action by
the user on an outer change may or may not force the accept/reject decision on the
inner change. In this case, acceptance of the outer deletion forces the rejection
of
the inner insertion. Rejection of the outer deletion would allow either rejection
or
acceptance of the inner insertion. These rules can be applied through multiple
layers of nesting.
Figure 4: Acceptance and Rejection of Edits
Unless a rule engine is imposed, the process of accepting and rejecting
changes could break the XML. In this case, accepting the deletion of the
paragraph node forced rejection of an internal insertion (indicated by the
entry being grayed out).
Custom Elements and XML Denormalization
To create a change-tracking system that notes not just the difference between the
original file and the edited version, but actually records what the author did, we
used the extensive set of event handlers in LiveContent Create to add custom
elements to the XML on the fly. Doing so turned out to be rather more difficult than
it first seemed, as there can be many ways to perform the same edit. For example,
there are many ways to delete text. You can delete character-by-character using the
Backspace or Delete keys. You can select a text range and use Backspace or Delete.
You can select and Cut or select and type over. All of these methods of deletion
should be presented in the same way to the user, but they had to be dealt with
individually through the event handlers.
The changes that we made to the JATS schema to accommodate our track changes
feature reflect the different ways an edit can be performed as well. Again using the
example of deletion, the LiveContent Create event handlers provide different
information depending on whether deletions are done to a block of text at once or
are done character-by-character and, in addition, whether the text being deleted
contains a formatting node or not. As a consequence, we use one deletion tag for
deletions that are done character-by-character and contain formatting nodes and
another tag for deletions done to blocks of selected text or text that does not
include a formatting node. Another modification of the JATS schema is the addition
of "unformatting" nodes. If a user makes text bold, the system naturally adds a
<bold> tag. If another user removes the formatting from that text, an <unbold>
tag is applied.
When the track changes elements are added to the XML, a set of attributes are
added as well. These give the system information about who made the change at what
time, whether the change has been accepted or rejected by the editor, etc. In the
example of different users toggling on and off formatting, the element reflects the
current state of the formatting while attributes contain the history of how the
current state was arrived at. These attribute values also inform the XSLTs that are
run when a user toggles on the Track Changes Show mode. These XSLTs perform a
variety of functions, for example, merging contiguous insertions or deletions made
by the same author that may have been performed using different methods.
Figure 5: Toggling Formatting On and Off
In this example, user "cl1" made the text bold, user "cl2" removed the
bold, user "cl3 reapplied the bold, and user "ca", finally, removed the bold.
The element <unbold> reflects the final state. The attribute @fmhist records
the users who applied bold, while @unfmhist records the users who removed bold.
Changes made by an author should not always be merged; sometimes they need to be
broken up. For our accept/reject rule engine to work properly, the Track Changes
tool must show how changed nodes are nested within each other. Also, insertions and
deletions should always be the outside changes when they occur in relation to
changes in formatting, because the acceptance or rejection of an outside formatting
change should have no effect on an internal insertion or deletion. To achieve the
desired result, the XSLTs that are run on toggling to Track Changes Show mode
denormalize nodes related to Track Changes and move insertions/deletions to the
outside of formatting nodes.
Figure 6: Denormalization of Formatting Nodes
Formatting nodes are denormalized and placed on the inside of insertion or deletion
nodes to serve the functioning of the accept/reject rule engine.
Figure 7: Denormalized Nodes in the Track Changes Tool
Acceptance or rejection of a formatting change should have no effect on the status
of insertions and deletions. Therefore, formatting changes should appear
"inside" insertions and deletions.
Customization
A publication services company, DJS delivers XML for over a hundred journals from
different publishers. These journals differ in the style they use for everything from
the casing of headings to the italicization of foreign words. Many of these differences
must be accounted for in ProofExpress. For example, some journals use numbered citations
while others use author-date citations. Among those that use author-date citations,
some
list one author before "et al." while others list six, some place a comma before the
year while others do not, some put citations in brackets while others put them in
parentheses, etc. The tool used for adding and editing citations must know not only
the
correct elements and attributes to add, it must know what the text content of the
citation will be. Adding an additional level of complication, DJS delivers XML to
several online hosts, and each of these has its own requirements that must be
accommodated as well.
To customize ProofExpress, each article is transmitted by our production management
system with a set of configuration files. In addition to XSLTs and CSS file that control
display of the article, a set of XML files (naturally!) controls the output of the
program's editing tools. A good example of a tool that requires configuration is the
Add/Edit Footnote/Affiliation/Correspondence tool. Journals can use numbers, letters,
or
symbols to cite footnotes. The numbers used for citations may start with affiliations,
continue through the correspondence line, and be used for author footnotes as well,
or
different citation schemes could be used for each. The same type of footnote may appear
in the <author-notes> wrapper in one journal but in an <fn-group> in the <back>
in another. The following is a snippet from a footnote configuration file that describes
a financial disclosure footnote:
This snippet tells the system what kind of footnote this is, what fn-type attribute
to
apply, where it is placed and where it can be cited, what formatting, if any, should
be
applied to the <xref> (tag abuse!), and the prefix used in its id attribute. However,
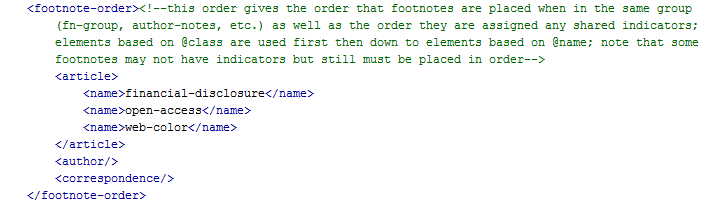
description of the footnote is not sufficient; the order that footnotes are assigned
indicators and placed in each respective group must be spelled out:
When different citation indicators can be used together, such as in the author line,
the system needs to know the order to place them:
Finally, when symbols such as asterisks and daggers are used, their order of use must
also be specified:
The use of XML files for configuration of ProofExpress provides distinct advantages.
The files are easily generated and allow very granular control of elements of style.
Use
of configuration files obviates the building and maintenance of a complex administrative
interface. New elements can be added as new configuration points are uncovered. As
a
bonus, we are looking into developing XSLTs that will pull information from these
configuration files and construct Schematron rules to ensure that articles coming
into
the system conform to the same style points specified by the configuration.
Conclusion
Designing and building a browser-based XML article proofing system has been a
challenge. ProofExpress must let users with no prior knowledge of XML easily make
any
possible edit. It must track every change, and give editors a tool to review the changes
and accept or reject each one individually without breaking the XML. The same tools
used
across all journals must be configured to output different XML to accommodate the
styles
of each.
The rewards of having such a system are great as well, and we may eventually expand
its usage to copyediting (though not to authoring; we have no control over authors
until
their articles are accepted and in our production workflows). By allowing all work
to be
done on a single file, ProofExpress increases efficiency as it removes potential sources
of error. Schematron validation can be applied during the correction cycle instead
of
after back-end conversion, when the errors it uncovered would be more expensive to
fix.
In addition, having such a system opens up new possibilities in the journal production
workflow. Notably, ProofExpress enables us to add fully automated page generation
to our
workflows, even when the system that creates the PDF cannot "round-trip" the XML.
A new
PDF of the article can be generated at any stage, simply by feeding the revised XML
to
the page-generation system. This capability puts the entire production process where
it
should be, in the hands of authors and editors.