Nordström, Ari. “ProX: XML for interfacing with XML for processing XML (and an XForm to go with
it).” Presented at International Symposium on Native XML User Interfaces, Montréal, Canada, August 5, 2013. In Proceedings of the International Symposium on Native XML User Interfaces. Balisage Series on Markup Technologies, vol. 11 (2013). https://doi.org/10.4242/BalisageVol11.Nordstrom02.
International Symposium on Native XML User Interfaces August 5, 2013
Balisage Paper: ProX: XML for interfacing with XML for processing XML (and an XForm to go with
it)
Ari Nordström is the resident XML guy at Condesign AB in Göteborg, Sweden. His
information structures and solutions are used by Volvo Cars, Ericsson, and many
others, with more added every year. His favourite XML specification remains
XLink so quite a few of his frequent talks and presentations on XML focus on
linking.
Ari spends some of his spare time projecting films at the Draken Cinema in
Göteborg, which should explain why he wants to automate cinemas using XML. He
now realises it's too late, however.
The process XML or ProX for short was
introduced to create an abstraction layer around running XProc pipelines. While
XProc is XML, running XProc pipelines using an actual engine involves a lot more,
usually batch or shell scripts that configure the engine and whatever inputs and
options, etc, that the pipeline defines, which is something of a pain. Offering the
resulting configuration options to an end user in a GUI is difficult at best and a
nightmare for any conscientious developer.
This paper describes an XML-based abstraction layer that defines all those
configuration options. The XML is made available to the user so s/he can configure
the pipeline and whatever options it has, and save the configured process as an
instance that is then converted to a shell script that runs the configured pipeline,
greatly simplifying the configuration.
XProc pipelines describe step-by-step processing of XML using XML. One step might
normalise a bunch of XML modules, the next validate the result and the last convert
the normalised XML to something more human-readable. It's easy to add various
conditionals, insert XQueries and include additional steps from XProc libraries, and
so on.
I think it is a very, very cool spec (id-xproc-spec).
The pipelines are frequently extremely configurable, with options and parameters
and outputs and various pipeline engine-specific configuration options, and they
might be used as-is with several different stylesheets or other inputs. These in
turn may be configurable, defining index generation, TOC generation, paper sizes and
other options the stylesheet author has graciously provided as configurable with
parameters.
A pipeline is run using a pipeline engine of some description, frequently from a
shell script (for Calabash), from inside an XQuery, or some other kind of script.
The various configuration options, inputs, etc, are all defined in that script,
using whatever format and syntax the script uses. And here lies the problem.
Even though XProc is XML, processes XML, and uses XML as input, you have to write
that script. And the more complex or flexible the pipeline is, the more variations
there are when writing that script. And that script is not XML.
The pipelines are often part of a larger process that may or may not include other
pipelines. The end user might want to choose between several different pipelines,
then configure the one chosen with the various options and parameters, choose
between several input stylesheets and finally configure the chosen stylesheet. And
all this ends up in a script that is supposed to run the pipeline - the process that
surrounds the pipeline, actually.
It follows that the pipeline is only as flexible as the means to configure
it.
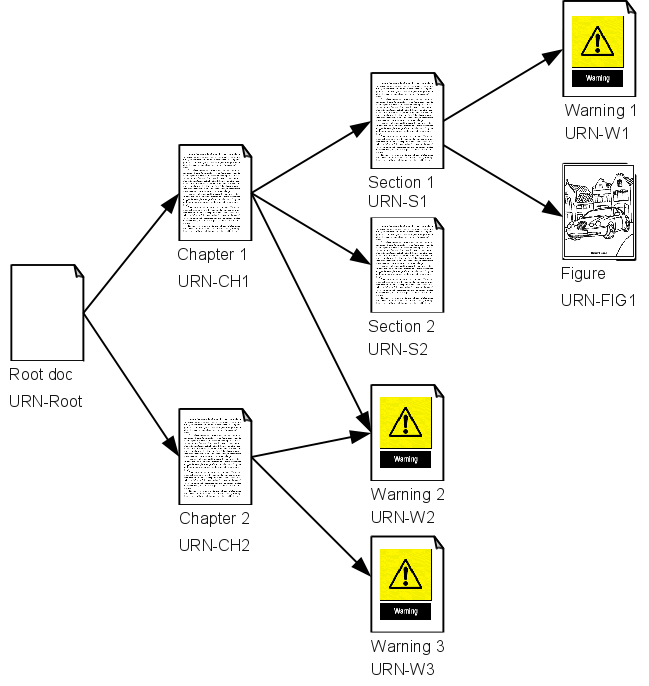
Logic
Enter the process XML. It describes XProc pipelines and their configuration,
including any available stylesheets and other input, but also puts them all in the
context of processes that surround the pipelines, and it does
it all in XML files. There might be a Print process that
includes pipelines for producing PDF, and MIF, a Web process
that produces ePUB and HTML, and perhaps a Report process with
pipelines that output reports.
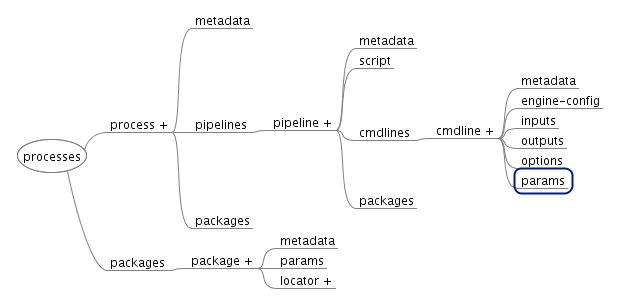
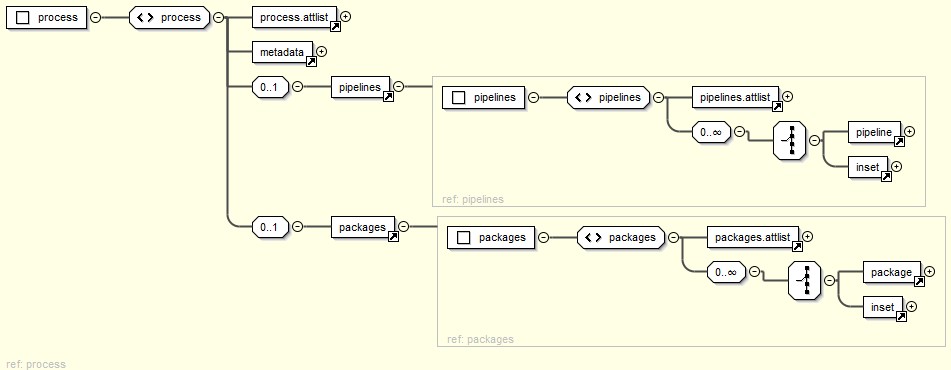
The structure is roughly this:
Figure 1: ProX Structure
The Process XML, ProX for short[1], is a blueprint that lists all available processes,
their associated pipelines, the command lines that configure these pipelines,
including the available input files used by the pipelines and the parameters used
to
configure the inputs. It's a description of what is possible and the choices that
need to be made before there can be a specific pipeline to run.
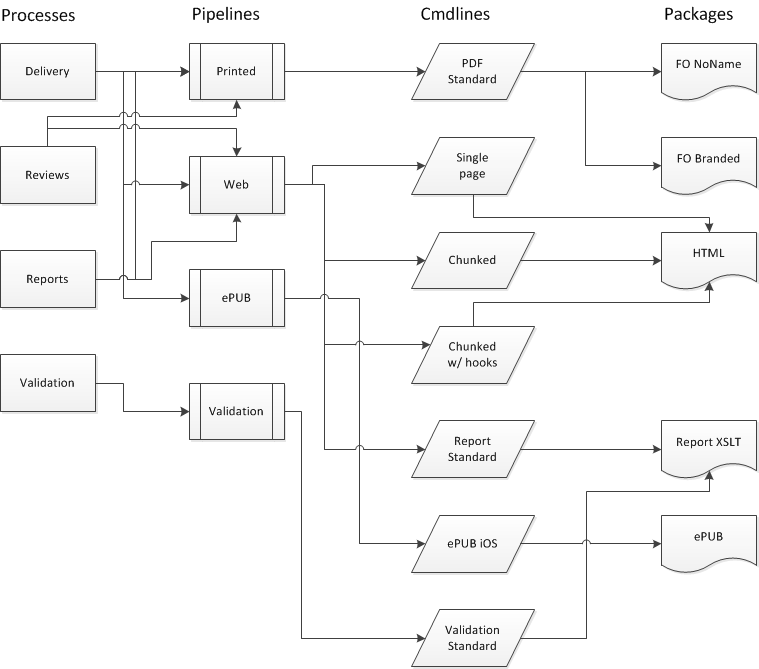
Choosing a process limits the available pipelines to those listed inside that
process, choosing a pipeline limits the available command lines to those defined for
that pipeline, and so on, like this:
Figure 2: ProX Logic
With all choices made, the blueprint is narrowed down to an
instance that describes the running of a specific pipeline,
like so:
Figure 3: A Configured Pipeline
The blueprint is an abstraction layer for a generic pipeline engine, setting the
contexts in which it can run, how, and using what. The instance describes everything
needed to run a specific process in a specific context, which is really useful
because the instance can be converted to a suitable scripting format, whatever that
format may be.
All that is required, then, is some processing to make the choices available to a
user, some more processing to generate a script from the process instance, and
finally run that script.
Uses
I'm implementing ProX in a CMS as I write this. The CMS will be able to output
various formats and media using XProc pipelines, and quite a few of those pipelines
and their input stylesheets are very configurable. Until now, it has not been
possible to offer the end users these configuration options; even including a simple
validation in a publishing process has been cumbersome at best.
Some rather different requirements come from an eXist-based Publish on Demand
solution used to output individualised PDF documents for thousands of users,
filtered from a large and infinitely variable content base. The end users are not
allowed to change a single parameter, anywhere - their whole publishing user
interface consists of a Publish button - but the publishing
chain is complex, involving about a dozen pipelines that all gather content from
various sources, convert and manipulate it, and validate the results before sending
it on to the next step. When things go wrong, it is useful to if the publishing
chain can be configured in various ways to spot where the problem is.
ProX will offer configurable publishing processes for system administrators. It
will also help describe what processes there are in a given context (the complete
blueprint document) and list the specific requirements for running a specific
pipeline.
ProX in Some Detail
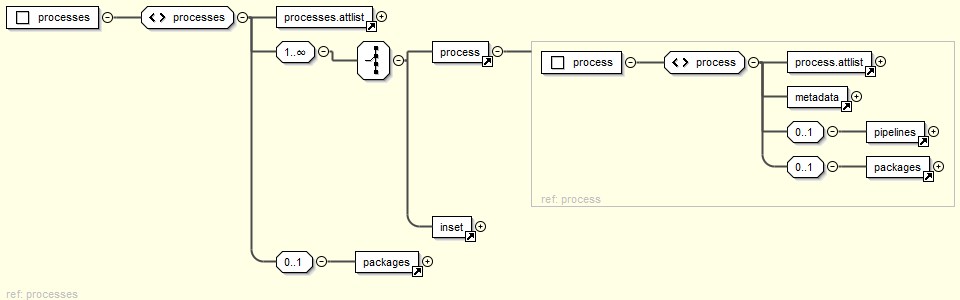
The ProX schema is not particularly complicated. basically, it describes one or more
processes defined in a system. Every such process may use one
or more pipelines, and every pipeline may be configured with various command line
options, including zero or more input files frequently grouped as
packages[2] (more about this below). The packages are usually XSLT stylesheets, and
these, again, can be configured in various ways.
Figure 4: Processes
The total XML is a list of things that are possible. The user will need to pick one
process, one pipeline, one set of command line options and the appropriate input
packages to end up with a specific process.
Processes
The process structure groups related pipelines.
Figure 5: A Single Process
The grouping is intentionally somewhat arbitrary. If a process is defined as
Delivery, the associated pipelines might be Print,
Web and ePUB, handling those outputs for delivery,
but, depending on the situation, a process might just as easily be defined as
Print Publishing, leaving the online formats to another
process, say, Web Publishing.
Note
Note that the packages are common to all pipelines in this
particular process.
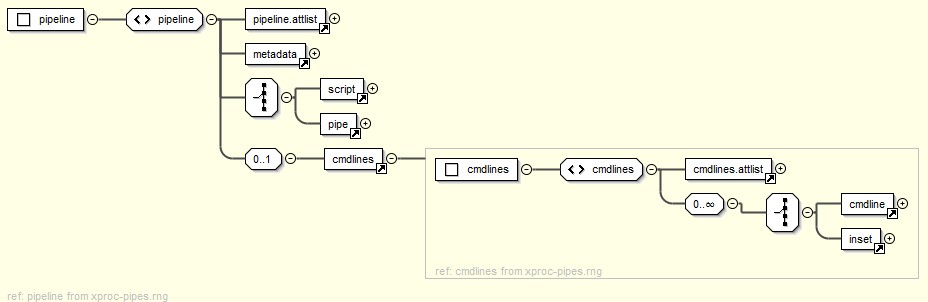
Pipelines
A pipeline is an abstraction for a single XProc pipeline[3] and its associated inputs and configuration options.
Figure 6: A Single Pipeline
The pipeline element includes a script element that that
points out the actual XProc script, defined in a package, and one or more
cmdline groups, that is, related configuration options for the
script.
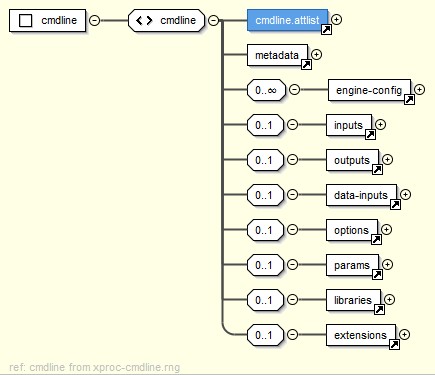
Command Lines
A command line (cmdline) is a group of related
configuration options for running the pipeline that group is associated with. A
pipeline may include one or more command lines.
Figure 7: A Single Command Line Group
The cmdline started out as the love child of various aspects of the
XProc spec and the XProc engine of (many people's) choice, Calabash, but the current
version attempts to be more generic in nature. It groups related configuration
options for an associated pipeline so that once the listed choices have been made,
the resulting cmdline instance is ready to run as-is.
The cmdline contains two basic parts, an engine configuration with
engine-specific options from configuration files to Saxon options, and an XProc
pipeline semantics-specific part that is more of a reflection of the spec[4].
The pipeline semantics define inputs, outputs, options, parameters, etc, that may
be defined either beforehand or at runtime by the system.
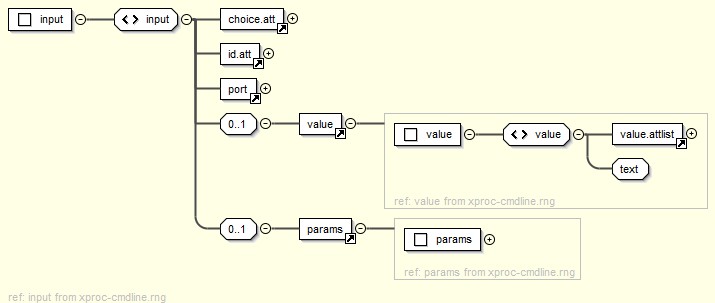
The inputs structure defines every choice available for selection
through one or more input elements.
Figure 8: A Single Input
The input element defines every kind of input available to the
pipeline. Note that not every input is made available as a choice for the user; some
are provided at runtime by the system, most notably the XML to be processed by the
pipeline[5]. The markup includes attributes for processing user-selectable input
(see section “Configuration and Parameter Handling”).
Some inputs may require parameters to be set. Typically, an XSLT stylesheet
package will use parameters to define various properties, so these are made
available in the input structure that points out the stylesheet. They
are also listed with their packages (see section “Packages”).
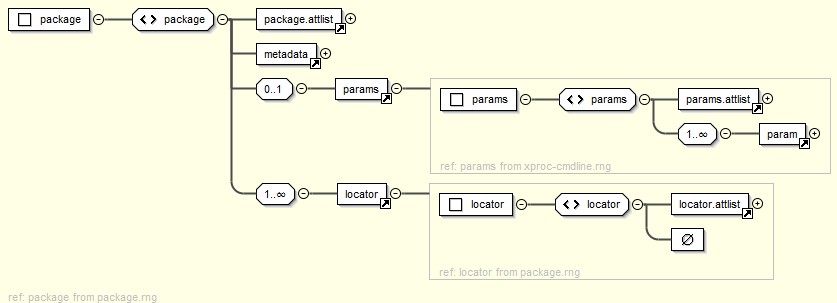
Packages
A package is a group of related files needed for some aspect
of pipeline processing. Commonly, a package is referenced as a single
resource by an input port.
Figure 9: A Single Package
The main part of package is a list of links (locator
elements) to the files that are part of the package[6], of which one or more may be identified as main file that
imports the other files for use.
Packages are used by the process XML as an abstraction layer for an input; an
input always points out a package rather than a single file. The system can locate
the participating files using the package's file list when needed without having to
look elsewhere.
The XProc script is also defined in a package rather than directly as a URL in the
script element. For a script comprising several physical files,
this is very useful. Similarly, the XProc engine configuration file (such as the one
used by Calabash) (and any other such files) is listed in a package so that the
system can retrieve everything required by a specific ProX instance before the
process runs.
Last but not least, a package may list the parameters that are available for that
package. A configurable parameter is marked as such using an attribute on
parameter, and also includes the parameter's data type[7]. Some parameters may be required, which is also reflected by the markup.
Note
The parameters defined in package list package options that
may be user-configurable. The parameters listed with a
specific input in a cmdline are those that the system
administrator had actally made available for configuration.
Naming
ProX is being implemented in a URN-based system as I write this. Every resource in
it is identified and linked to using URNs rather than URLs - XML, obviously, but
also images and other content, as well as stylesheets, schemas, etc. The URNs are
unique within the system and include version and localisation information, like
so:
urn:x-cassis:cos:00093445:sv-SE:0.19
Every resource is version handled, so it is easy to retrieve a specific version.
And here's the neat part: ProX packages in the system identify resources in the
exact same way. A package is a list of URNs with with specific versions, meaning
that a specific package always identifies specific versions of every participating
file. Prox files in the system are identified in the same way so any package version
is identifiable and retrievable.
Modularisation
The ProX XML does not need to be a single file. Processes, pipelines, command
lines and packages can all be modularised and reused. Note, for example, the
inset elements in Figure 5 that are siblings to the pipeline and
package elements; these are intended to link to pipeline and
package modules, respectively.
Metadata
Every major ProX component (process, pipeline,
cmdline, package) includes metadata used to identify
the component in a GUI, but also to include context-sensitive help in that
GUI.
Writing ProX
It is, of course, possible to write ProX XML in any XML editor. For my current
project, I've added an XMetaL-based environment that includes some styling but
otherwise uses the same features as the standard authoring environment in the
system, with an integration to the database with check-in/out and versioning,
URN-based linking, etc.
Figure 10: Adding A Package Locator
Here, authoring ProX is easy. Packages are compiled by including XLinks to the
modules and then linked to from the elements that need them, using already
implemented XLink- and URN-based linking functionality.
The ProX User Interface
The ProX blueprint was designed to be visualised in a GUI so the right process and
pipeline can be selected and configured[8]. Conceivably, the system might allow for several different versions of the
basic blueprint, each for its intended user. A power user might have several
configuration options available to her while the casual user might only be allowed
to
choose between the basic processes, leaving the details to the system.
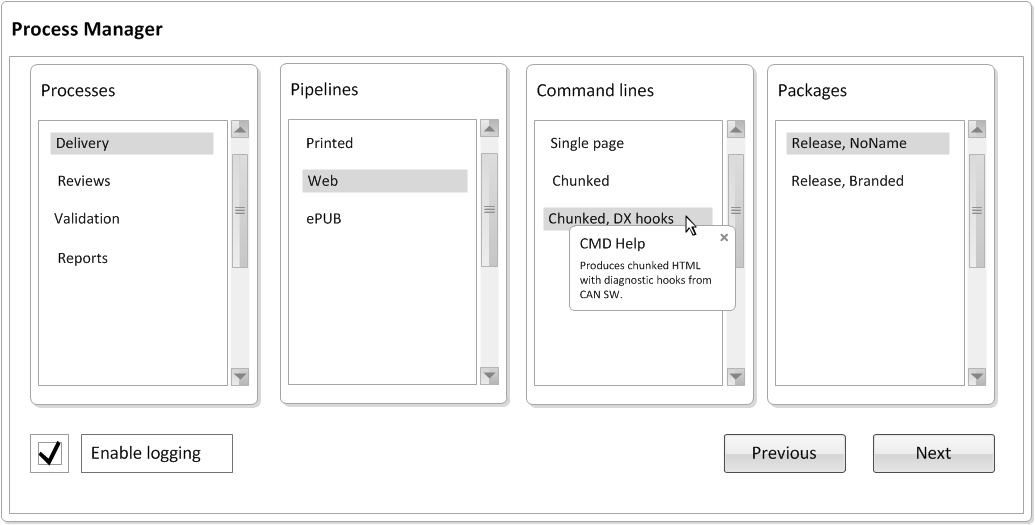
The basic selection procedure is largely sequential. Here's the first concept
GUI:
Figure 11: GUI Concept
The pipeline, command line and package steps may all include additional configuration,
but the principle should be clear.
Generating the GUI, Pt 1
There's an obvious candidate for creating a dynamic user interface based on XML
input: W3C's XForms specification (id-xforms-spec). XForms
has a somewhat bad reputation (see, for example, id-mvc-xforms-eric-vdl,
Eric van der Vlist's terrific paper on [some of] the problems and some suggested
solutions ), with some even claiming it to be dead for all practical purposes, but
it is one of the few choices available for the purpose.
My first attempt at creating a ProX user interface used an XSLT stylesheet to
generate a FreeMind mind map:
Figure 12: Generated Mind Map
The FreeMind mind map format is XML, and thus easy to grasp and convert to (id-freemind-xsd). The
idea here is to insert FreeMind marker symbols to the selected options (nodes) and
then convert the resulting FreeMind XML back to ProX, only including the marked
nodes.
Of course, this approach is not without its flaws. Nothing stops you from
inserting markers everywhere, which would result in useless
ProX markup. We need something that allows exactly what the markup allows, so while
a tree representation is useful and intuitive, it is only useful if a node can be
easily selected and its unselected siblings locked (including a clear visualisation
of the changed state).
The FreeMind format may or may not allow this, but I chose instead to have a
closer look at XForms.
Design Choices
The process abstraction reflects a pipeline configuration from a process and
systems perspective, and the resulting workflow for a user in the above user
interfaces mostly reflects this approach. This is not necessarily wrong but the
user's view regarding processing her content might actually be very different.
The User's POV
The original idea described a workflow like this:
Select process
Select pipeline
Select the pipeline's command line
Select among the stylesheet packages given as alternatives in the
command line
This is really just a formalisation of one way of
expressing a pipeline process. Only the last two (command line and stylesheet)
included user-configurable options and the basic idea was to have them show up
in a subform only when that step was selected.
The user probably doesn't care about the difference between configuring a
pipeline and configuring a stylesheet, however. The objective is to run a
process without distractions to the extent possible so better is probably:
Select process
Select pipeline
Select and configure stylesheet (or rather, process output)
And depending on the situation, this might be even more appropriate:
Select process
Select and configure output
This is perhaps too simplistic. While the user doesn't necessarily care about
the difference between a process and a pipeline, the concept of a process
surrounding the pipeline was introduced because the processes might be so
different from each other that the abstraction becomes meaningful. The original
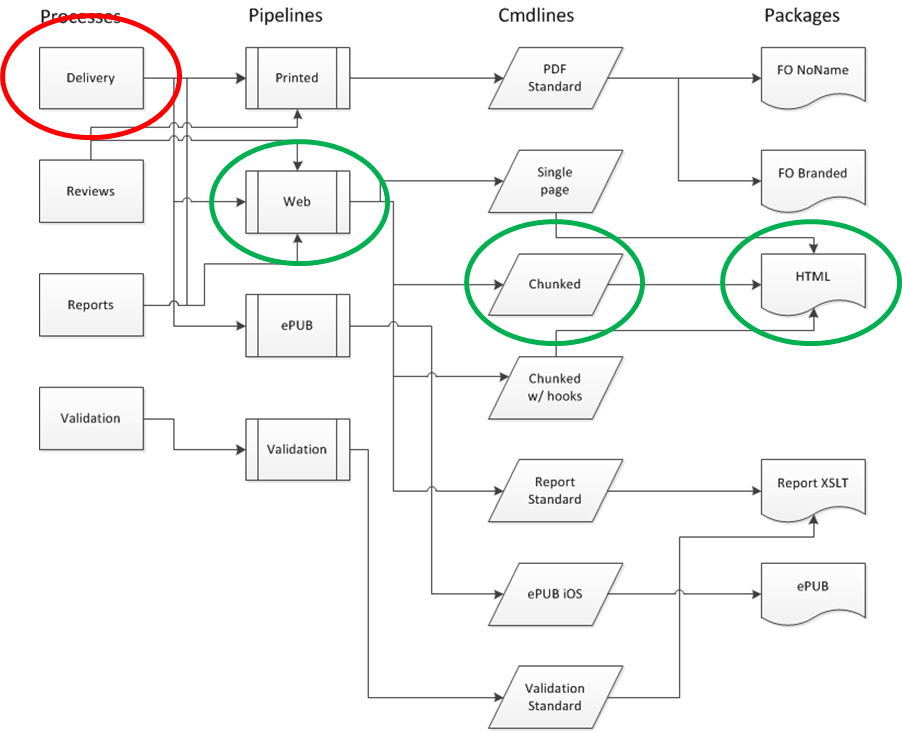
concept (see Figure 11) lists Delivery,
Reviews, Validation and
Reports as examples of different processes, the idea
being to reflect different work flows with some very different outputs as
expected results.
I'd argue that the distinction is meaningful.
But do users need to know or care about the difference between the command
line and stylesheet selections? Here, the answer is probably no. The pipeline
does something in the defined workflow while the command line and stylesheet
options configure the output. The difference between configuring the pipeline
and the stylesheet is a subtle one; unless you are an admin, you probably won't
care. Better (than the the concept GUI in Figure 11)
is something like this:
Figure 13: Pipeline, Cmdline Configuration Mixed
To the end user, this XForm is about configuring output,
not what's behind the scenes. The underlying XML does not change; with the GUI
is adapted for different user categories, the same XML can provide an admin with
a different UI. The difference happens depending on how the initial ProX is
processed to generate a form.
The right answer, then, is that these are all possible, simply
by preprocessing ProX and by writing appropriate XForms.
The Admin's POV
The underlying XML is in no way changed when simplifying the selection process
for a user. What changes is the form, and possibly some preprocessing. The above
suggests a simple GUI, with most of the configuration already made. All the
admin needs to do is to write the ProX blueprint with
complete command lines, with all of the choices split
into separate command line groups as listed in the GUI.
The GUI shown in Figure 13 is generated from this example:
The point here is that this could easily be (mostly) all that is required;
while additional configuration may be useful, it is perfectly feasible to limit
the choices to a straight-forward wizard-like behaviour.
Configuration and Parameter Handling
The ProX RNC schema includes a set of attributes used by any element that may
offer configuration choices by the user:
The choice attribute indicates if the parameter is configurable,
while ctype indicates the type of user input required.
The group attribute is an IDREF to a related parameter
and indicates a dependency to that parameter. For example, a parameter may be used
to set the table of contents depth, but it is useless if another parameter has
turned off the TOC generation. The first parameter needs to include a
groupIDREF to the second so only relevant options are made available when
configuring a ProX blueprint.
The configuration options available in a cmdline are made available
to the user by defining them as choices in the ProX blueprint. For example, logging
alternatives might be made available like so:
Here, the logging options are made available as a list1, much like
a radio button list for a user interface. Note the id
and group attributes in the first and second log-style
elements: the group attribute is an IDREF that references
the id in the first. The choice that contains the id
attribute referenced by the other is the default.
A true/false schema-aware option may only have two values and can
therefore be represented like this:
Here, a default value is given in the process attribute. Note the
ctype attribute that identifies the type to be used when
representing the choice for the user. The XForm template will show
this as a checkbox in normal circumstances.
Data types are necessary when representing XSLT parameter alternatives. This one
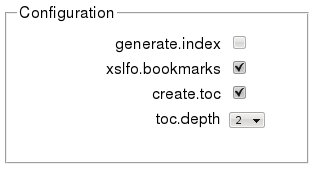
decides if an index should be generated by a PDF publishing pipeline:
choice="yes" means that this is a user-configurable option, with the
default given by the contents. This will render as a checkbox (see Figure 17), as
param/@ctype="boolean" is used to bind it to an
xs:boolean in the XForm.
These two parameters decide if and how a TOC will be generated:
The first param is an ON/OFF switch for TOC generation (hence the
@ctype="boolean"), while the second allows choosing the number of
section levels to be included in the TOC. Since the second param would
be meaningless without the first being set to true, the second
param includes a group attribute that is an
IDREF to the first param, which means that the second
value depends on the first. The group reference is used in the XForm to
show or hide controls, depending on their relevance.
The second param has ctype="list1", which means that the
listed values should be represented as a list1 in the
XForm. The first is used as default when processing.
Note
When compiling the package that lists a stylesheet's participating module, the
package needs to always include definitions for any parameters that are not
explicitly set by the stylesheets.
System Context
The ProX blueprint configuration described above only tells how to configure a
process, not what XML if any it processes, other than indirectly. It tells
how to do something, not what it
should apply the process to. Of course, for any process involving an XML file to be
processed, there will be a matching input in the pipeline, but the point here is
that the XML is only identified at runtime, if it is identified[9].
The system where proX is being implemented allows for two basic workflows: either
the process is configured first and the XML to be processed is pointed out later,
or
the other way around. The first is useful for new processes and for any process that
does not involve an XML file. If an XML file needs to be selected, it can be located
by the system using its in-place browsing capabilities after the ProX instance is
configured and saved, that is, when a publishing process has been fully configured
and saved.
Today, the system uses something called a configuration to point
out the XML to be processed. The configuration is an XML file that points out a root
XML file, including language and version, along with some system-specific metadata,
and then publishes it using an XSL-FO stylesheet[10]:
With ProX-based pipeline processing added, the XSL-FO is just one of several
stylesheets run by the pipelines, and so, if a system configuration pointing out a
root XML file is opened first, the user must associate a saved
process with the configuration or configure a new one before the XML can be
processed.
The configuration files that point out the root XML and some
system-specific metadata now also list each and every saved ProX instance (basically
an instance of the blueprint code in section “The Admin's POV”)
associated with that specific configuration, including a default PDF publishing
instance, so there will be at least one process to use. New ones can be defined
later.
<?xml version="1.0" encoding="utf-8"?>
<CassisTIConfiguration>
...
<Description>Balisage 2012 whitepaper</Description>
...
<Processes>
<Process>
<!-- Blueprint -->
<ProXBlueprint>
<ID><!-- System ID --></ID>
<URN><!-- Blueprint URN --></URN>
<ProXName><!-- Name of blueprint --></ProXName>
</ProXBlueprint>
<!-- Instances associated with config, selectable by user -->
<ProXInstance>
<ID></ID>
<URN>urn:x-cassis:r1:cos:00008295:en-GB:0.5</URN>
<ProXName>PDF Publishing</ProXName>
</ProXInstance>
</Process>
...
</Processes>
</CassisTIConfiguration>
The configuration file is used by the system by something called Process
Manager as a shortcut for processing XML, including translation
handling of the XML. I tend to liken it to a postit note placed on a specific XML
document (comprising of several modules in specific versions), describing a specific
process such as the PDF publishing for customer delivery of a specific version and
translation of the document. For more on this, see id-balVol08-Nordstrom01.
XForms: Generating the GUI, Pt 2
I set out to do the user interface with XForms, but as promising the standard was
for
me, getting my head around the MVC model was not easy.
My first hypothesis was to read the relevant nodes from the blueprint, list the
process metadata's title contents in a
select1itemset, select one and copy it to the target instance, then repeat for the
pipeline, cmdline and package choices. This
was a wizard-like approach, with every wizard step showing and hiding the appropriate
configurations in a switch/case form.
Having banged my head against the wall trying a copy inside an
itemset, Mark Lawson pointed out that XSLTForms
does not support copy and suggested a far easier way. In a somewhat
shortened form:
The scratchpad instance, containing IDs of the selected ProX
components.
The target instance and the trigger that writes
to it near the end.
And, of course, the select1s handling the
process, pipeline and cmdlineIDs, respectively.
This produces a GUI that writes the selected id to the scratchpad,
refreshing the next select1itemset, until done, like so:
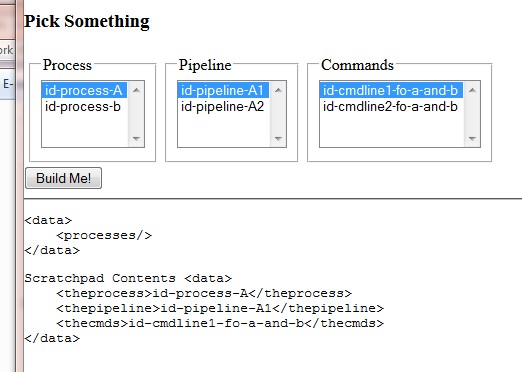
Figure 14: The Basic ProX GUI
The result is saved to a target ProX instance: instance('mysource')/process[@id
= instance('scratchpad')/theprocess] is copied using insert. The
pipelines and command lines that do not match the IDs in the
scratchpad instance, pipeline[@id != instance('scratchpad')/thepipeline]
and cmdline[@id != instance('scratchpad')/thecmds], respectively, are then
deleted from the target.
Single-Choice Problems
The first working GUI looked like this:
Figure 15: Bal2013nord-2-012812.jpg
With two or more of each choice, it worked perfectly, but if only single choice
was available, this resulted in the IDs not being updated in the scratchpad
instance:
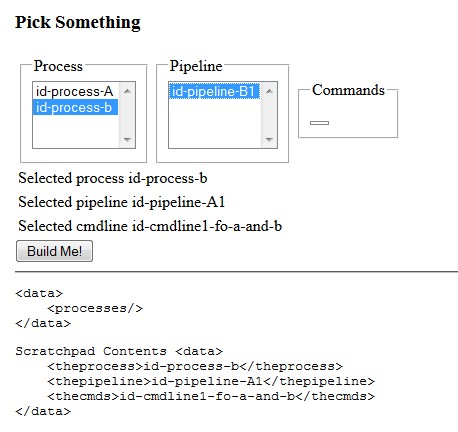
Figure 16: Pipeline ID Not Updated
Note that while the process is selected and its ID listed, the pipeline ID listed
in the scratchpad debug output (below the form) belongs to a previous selection
rather than the apparently selected one. The cmdlineID in the scratchpad also belongs to a previous selection, but the
current cmdline selection does not show any values at all. If the
current state was written to a process instance, the selections would be wrong and
the process would fail.
This happened because the selected process contained only a single
pipeline and value changed-events do not fire as expected in
single-item lists.
Better is to add a staticitems before the itemsets, like this:
This introduces a dummy value, ensuring that the form is updated
regardless of the number of items. To make sure that the selection of a
parent forces the update of the child, you set the
value of the child to a dummy value, forcing the user to actively
choose an option. For example, if you change the pipeline selection, this makes sure
that the next option in line, the command line list, is updated with a static
value:
This setup has all kinds of advantages: styling becomes easier (a nonexistent list
can't be easily fixed in the CSS, as far as I know; see Figure 16),
subforms that configure aspects of the selected group can be shown, and conditions
for saving the configured process can be imposed, not allowing a Save before all
selections have been made.
User-configurable Parameters
The user-configurable stylesheet parameters are set in the input
structure (see section “Command Lines”) that links to the package. Here's a complete
input for a stylesheet used by a PDF publishing pipeline:
Note that not all of the parameters are made available as choices
(choice="no").
Having the parameter definitions include data types greatly simplifies generating
a GUI. As the values are not usually typed in the stylesheets that use them, the
proX blueprint author must take care to define data types for every parameter made
available as a user-configurable option.
The configuration options are shown or hidden using a grouping of forms in
combination with CSS that hides a disabled group in the XForm[11]. The following group generates controls for a selected command line
(cmdline). It is hidden if there are no user-configurable
parameters for that cmdline.
<xf:group
ref="instance('mysource')//cmdline[@id=instance('scratchpad')/thecmds]//param[@choice='yes'
and @ctype='boolean']">
<div class="block-form">
<fieldset class="config">
<legend>Configuration</legend>
<xf:repeat
id="b-ctrl"
nodeset="instance('mysource')//cmdline[@id=instance('scratchpad')/thecmds]//param[@choice='yes' and @ctype='boolean']">
<xf:input
ref="value"
appearance="full">
<xf:label>
<xf:output ref="../name"/>
</xf:label>
</xf:input>
</xf:repeat>
<xf:repeat
nodeset="instance('mysource')//cmdline[@id=instance('scratchpad')/thecmds]//param[@ctype='list1' and (not(@group) or (@group=//param[@choice='yes']/@id))]">
<xf:select1
appearance="minimal"
incremental="false"
ref="value">
<xf:label>
<xf:output ref="../name"/>
</xf:label>
<xf:itemset nodeset="instance('mysource')//cmdline[@id=instance('scratchpad')/thecmds]//param[@ctype='list1' and (not(@group) or (@group=//param[@choice='yes']/@id))]/value">
<xf:label ref="."/>
<xf:value ref="@id"/>
</xf:itemset>
</xf:select1>
</xf:repeat>
</fieldset>
</div>
</xf:group>
The current GUI design gathers all configurable options within the
cmdline group rather than having any of them appear when the
pipeline is selected. This is a design choice rather than a technical one; see section “Design Choices”.
Figure 17: Parameter Configuration
The above is able to generate boolean and single-choice list controls. Of course,
other controls may be added, for example, to select a date or enter a text string
to
be included in the process output.
Initiating and Running ProX
Running the overall process, that is, initiating and running the ProX XForms template,
saving the resulting ProX instance and converting it to a shell script or batch file
(or
some other file executing a pipeline engine) involves the following:
Locate and fetch the ProX blueprint. Normalise, if necessary.
Locate and fetch all files that are part of the processing as defined by
the blueprint, including the input XML, stylesheets, XProc, XForms XHTML,
configuration files, etc. Map their URNs to temporary URLs in a resource map
XML file (see section “The Resource Map”).
Generate any runtime URLs for the target files for the process, as defined
by the blueprint. Map these in the resource map XML, adding the ProX IDs
(see section “Targets”) where needed.
Preprocess the XForms XHTML, adding the URL to the ProX blueprint and
other information required by the XForm.
Open the the XForms XHTML.
Make choices in the XForm as necessary. Save (and close) the a ProX
instance.
Replace any URNs in the source XML to be processed with matching temporary
URNs.
Add runtime information to the ProX instance (input XML, target URLs,
etc).
When processing an XML file, the system needs to list all files required by the
wrapper pipeline process and the resulting child pipeline process in a
resource map XML file, mapping their URNs to temporary
URLs. This includes the XML to be processed, of course, but also any images and
other non-XML data. Every XSLT stylesheet required for the processing (for the
wrapper process as well as the child process) must be listed, as must all XProc
scripts and whatever files they require.
Also, the system must generate temporary URLs (and, depending on the result, URNs)
for any resulting files.
The resource map is then used as the sole input by the wrapper pipeline
process.
All of these files are either listed directly in the ProX blueprint (when known),
or pointed out indirectly, using the attribute type set to
external. A ProX process starts with the generation of a basic
resource map file, using a simple XSLT stylesheet applied to the ProX
blueprint.
This is a complete resource map example, matching the example ProX blueprint in
section “The Admin's POV”.
Note that some of the URNs are for testing purposes only, while others come from the
actual system.
The resource map is very much like a recipe; it lists every ingredient for every
ProX process.
Docs
The docs structure lists the input XML and any linked files. More
than one document may be listed, and some of those documents may be duplicates
because they originate from different pipelines or processes (as is the case in
the above resource map). For example, the same document may be used for both PDF
and web publishing in a single resulting process instance, and therefore be
listed several times. The wrapper pipeline will only process distinct values,
however, and there will be no physical duplicates in the temporary processing
folder.
Targets
The targets structure lists the runtime target URLs generated by
the system. Every target URL is paired with a ProX ID so
that the subsequent processing can place the right URL in the right place in the
ProX instance:
Notable is that ProX defines different types of output: primary
(see above) means that the file is something that the system should save, while
secondary is a throwaway, a temporary URL that can be
discarded. There's also log, that means that the file can be
displayed by the system when the process has completed, but what happens to the
file later is up to the system to decide.
ProX Resources
The prox and prox-resources structures list the ProX
blueprint and the ProX (runtime) instance URN/URL pairs, and the files used by
the processes described by the blueprint. The latter include any XSLT, XProc,
XML, etc, required for processing, but also any other types of files, whatever
they may be.
Wrapper Resources
The wrapper-pipeline structure lists the resources required by
the wrapper pipeline, including the XForm and the wrapper pipeline
itself.
The Wrapper Pipeline
The wrapper pipeline has but one main task: to configure the child pipeline
process. In principle, this involves producing a ProX instance from the blueprint,
and then converting that instance to a shell script that is used to run the child
pipeline process.
The wrapper pipeline requires a single input, the resource map XML file. It
assumes that the process is carried out in a temporary folder, and that every
required file is listed in the resource map and moved by the system to the temp
folder; currently, there is no way for the wrapper to ask the system for a specific
file based on its URN, even though that functionality is planned in a future
version.
In a perfect world, the wrapper should be initiated by the system and then take
over all of the processing, including configuring[12] and opening the XForm used to configure the Prox blueprint, wait for the
user to make her choices and save the resulting instance, and then continue the
wrapper pipeline process in preparation for the child process. In reality, there are
a few problems, however:
There is currently no wait step defined in the XProc spec (see Kurt
Cagle's proposal at id-kurt-cagle-xproc, or my subsequent thread at id-wait-for-user). There
is no easy way to have a pipeline wait for user input before continuing. What comes
the closest is an XProc hack that looks something like this[13]:
<!-- Open ProX Blueprint in Browser -->
<!-- Opens with an XForms profile in order
to start a separate browser instance -->
<p:choose name="browse">
<!-- Linux -->
<p:when test="$os='linux'">
<p:exec
cx:depends-on="fix-xform"
command="/usr/bin/iceweasel">
<p:input port="source">
<p:empty/>
</p:input>
<p:with-option name="args" select="concat('-P "XForms" -no-remote ',$xform-url)"/>
</p:exec>
<p:sink/>
</p:when>
<!-- Mac OS X -->
<p:when test="$os='osx'">
...
</p:when>
<!-- Windows -->
<p:when test="$os='win'">
...
</p:when>
</p:choose>
What happens here is basically that while there is no way to tell something like
an http-request to wait, at least Calabash will happily wait for the
p:exec to complete (meaning in the above example that the browser
process is killed) before continuing with the next step, if the
XForm is opened in a new thread; if you use your default browser and it happens to
be running, the wrapper won't know that it should wait. The hack also requires the
use of the cx:depends-on extension step to make sure that they'll all
wait until the p:exec is done.
After the ProX instance is saved and the browse process killed, the wrapper
continues by preprocessing the input XML (see below) and the ProX instance that was
just saved (also see below), before finally converting the instance to a shell
script, running that shell script, and handling any logs or reports resulting from
the wrapper or child processes.
When the wrapper process ends, it is up to the system to take care of the
resulting files and to delete any temporary content, including the temp folder where
the action took place.
URN to URL
The input XML is frequently modularised, like so:
Figure 18: Modularised XML
The system uses URNs for all of its linking, which means that whenever an XML
document is published, each participating module must first be preprocessed to
replace the URN-based links with temporary URL-based ones. Only then can the XML
be normalised[14].
The wrapper pipeline runs an XSLT script that maps URNs to URLs using the
resource map.
ProX Fixes
A similar preprocessing step is required on the saved ProX instance. It
contains a number of URNs that need to be replaced with URLs, but also several
empty runtime targets that need values from the resource map.
Converting to a Shell Script
The preprocessed ProX instance is then converted to a shell script (in the
case of Calabash) using an XSLT stylesheet:
This does not process any engine-specific options, nor does it handle
data-inputs.
Note that the XSLT uses a configuration file that lists the
CLASSPATHs and other OS- and system-specific strings.
Child Process and Capturing Output
The shell script (or batch file) that results from the conversion is saved and
then run using a p:exec step:
<!-- Store generated shell script and run it -->
<p:choose>
<!-- Linux -->
<p:when test="$os='linux'">
<!-- Save shell script -->
<p:store method="text" name="save-bat">
<p:with-option name="href" select="'out2.sh'"/>
</p:store>
<!-- Run -->
<p:exec
source-is-xml="false"
result-is-xml="false"
name="run-bat"
cx:depends-on="save-bat">
<p:with-option name="command" select="'sh'"/>
<p:with-option name="args" select="'./out2.sh'"/>
<p:with-option name="cwd" select="substring($tmp-url,6, string-length($tmp-url)-1)"/>
<p:log port="errors" href="error.txt"/>
<p:input port="source">
<p:empty/>
</p:input>
</p:exec>
<p:sink/>
</p:when>
<!-- OS X -->
<p:when test="$os='osx'">
...
</p:when>
<!-- Windows -->
<p:when test="$os='win'">
...
</p:when>
</p:choose>
And yes, again, there are OS-specific hacks in there. While the system is purely
Windows, I much prefer developing on Linux or Mac, and so made the necessary changes
for at least a rudimentary OS independence.
XForms Engine
The XForm currently runs on XSLTForms. The decision to use
XSLTForms was a practical one; I'm running it locally for ProX user interfaces,
without a server, but XSLTForms is just as easy to get to run on the server.
There are some mostly minor but noteworthy issues:
xf:code is not implemented so xf:insert must
be used instead. No biggie, but it helps to know about it.
For local use (seems to be the same on Windows, OS X and Linux), the
stylesheet PI pointing out the XSLT not only needs to be relative; the
XSLT needs to be in a descendant directory. This is very strange and it
took me some time before I noticed what was going on.
Local submissions using relative URLs (for example, as described at
https://en.wikibooks.org/wiki/XForms/Submit) fail silently
on a Windows machine. It seems that Microsoft never introduced a
standard way of expressing their relative file paths, but
action="file://myfile.xml" works.
Local submits, even with the right relative URLs, will always enforce
a Save As dialogue. This is annoying but only a
problem locally where the file system is, in fact, at risk.
And, depending on the platform, the Java applet run when submitting
can cause endless grief, from warnings when running it to failing,
either silently or with a bang. OS X is particularly difficult in this
respect.
And lastly, XSLTForms converts XForms to HTML and JavaScript. Running
this locally can cause some unpredictability, depending on the browser.
On Windows, Internet Explorer can frequently refuse
to run code that works without a hitch in Firefox
and Safari. On the other hand, on that same Windows
machine, Safari then quit running XSLTForms
altogether, following a Java update.
Run from a server, XSLTForms works like a charm.
XProc Engine
Currently, I'm using Calabash (id-xmlcalabash) to run the pipelines configured with ProX. This is
unlikely to change any time soon for the system being implemented now; there aren't
that many viable alternatives that aren't part of a competitor's product. ProX
started out as a reflection of the Calabash way of doing things.
There are other systems, though, where another engine might better match the
system's requirements. eXist, for example, includes
xprocxq (id-xprocxq), an XQuery-based XProc engine that is configured using
an XML-based set of parameters. Converting a ProX instance to the xprocxq format
should be uncomplicated but the engine's current state in eXist makes it difficult
to test. A new version for MarkLogic was announced recently,
and presented (id-jimf-xmllondon) at XML London in June
2013.
End Notes
What The Future Holds
ProX is still a work in progress, even though it's now running locally and on a
pre-release system. Here are some of my future plans:
Add (and expand?) metadata where needed. The main structures
(process, pipeline, cmdline)
include metadata used to generate help for these sections, but just as
useful would be to add it to all user-configurable structures. Stylesheet
parameters, for one, would greatly benefit from help texts, but also from
better GUI display names (see Figure 17).
GUI localisation. XForms is not easily modularised in reusable components
(it's not, at all), but it would be useful to move any GUI labels and help
texts to a file that can be localised.
A ProX implementation for eXist. XProc is not currently well supported in
eXist itself. xprocxq is more or less broken in it, as
is the Calabash module, but it is perfectly feasible to
run XProc pipelines outside eXist itself using James Sulak's XProc extension
library (id-sulak, id-xmlprague-2013-existential).
Various XForms additions and fixes, specifically a standardised XForm
preprocessing step in the wrapper script that might be used to handle a
modularised XForms GUI.
To lessen the dependency on the resource map XML: Resource retrieval in
the system based on a known URN (something like getUrl(Urn)).
Also, target URL generation and better handling of the temporary folder in
the system.
Prepare and release an open source version of the ProX package. A few of
the scripts in ProX are system-specific, but it should be straight-forward
to do a generic version.
Last But Not Least
Huge thanks must go to Mark Lawson, who not only pointed out
that xf:copy is currently not supported by
XSLTForms, but also wrote the XForm that is the basis for
the ProX GUI (see section “XForms: Generating the GUI, Pt 2”). That's another way of saying that he provided
all of the basic XForms logic and I only had to add to it.
Thanks also to Norman Walsh, without whom I certainly wouldn't be writing a paper
involving XProc, to Jim Fuller, who has provided me with valuable XProc hints and
tips on numerous occasions, and to my friend Henrik Mårtensson who patiently helped
me get ProX to run on my Mac.
Thanks must also go to the Balisage program committee and their brilliant blurb.
If you read this, the blurb is probably why.
Finally, any errors and omissions on these pages should be attributed to me, and
me only. You can lead a horse to the water but you can't make it drink.
[1] Turns out XProc was already taken, as was
XPipe and some other exciting variations.
[2] Note that the packages structure in the illustration is common to
all processes. Packages may also be included at process level, in which case
they only apply to that process.
[7] This is necessary when generating the user interface that allows the user
to configure the parameter.
[8] How much of the process is configurable is decided by the author of the
blueprint.
[9] Some processes may not need an XML file to apply the process to.
[10] The system will fetch any XML modules linked by the root XML, after wich a
normalisation process is carried out, and only then are the FO stylesheets
applied.
[11] Provided that they are made available to the user in the first
place.
[12] The XForm needs to know the URL of the ProX blueprint to be used, and it
needs to be handed a temporary URL for the runtime ProX instance that
results (and a permanent new URN, if the process is saved for later).
[13] And yes, the hack does include conditionals for OS X and Windows, in
addition to Linux. Know that OS X is a pain if you want to try this at
home.
[14]If the child pipeline normalises it; the wrapper
does not.