Introduction
For the past seven years, DocBook XML has been the cornerstone of tech publisher O’Reilly Media’s book authoring and publishing toolchain. As a richly semantic markup language, DocBook provides a single maintainable source format for book content that can be readily transformed and output to a variety of formats, allowing the construction of a highly automated production infrastracture. However, as the digital book has continued to rise in importance, so has the need to architect faster, more efficient, and more lightweight workflows for book creation. O’Reilly found that there was another markup format even better suited to this paradigm: (X)HTML5.
In this paper, I argue that HTML5 offers unique advantages to authors and publishers in comparison to both traditional word processing and desktop publishing tools like Microsoft Word and Adobe InDesign, as well as other markup vocabularies like DocBook and AsciiDoc. I also consider the drawbacks currently inherent in the HTML5 standard with respect to representing long-form, structured text content, and the challenges O’Reilly has faced in adopting the standard as the new source format for its toolchain. Finally, I discuss how O’Reilly has surmounted these challenges by developing HTMLBook, a new open, HTML5-based XML standard expressly designed for the authoring and production of both print and digital book content.
Why HTML?
As the primary markup language for both the Web and two ebook formats (EPUB and Mobi), HTML offers several key advantages over both standard book source document formats (e.g., Word .doc and InDesign .indd) as well as other XML vocabularies. Authoring and producing books in HTML5 offers the potential of standardized semantics, a streamlined workflow for generating print and digital outputs, the ability to think “digital-first” when developing content, and the opportunity for Web-based, WYSIWYG authoring. In the following sections, I discuss the advances afforded by HTML5 in greater depth.
New and Improved Semantics!
Prior to HTML5, structural semantics were largely absent from the
HTML vocabulary, and rich tagging of content entailed liberal use of two
all-purpose elements: the <div> and
<span>. Compared to markup languages like DocBook,
which standardized elements for both high-level book components
(chapter, appendix, glossary) and lower-level blocks (section, sidebar,
footnote), as shown below:
<article>
<title>Rich semantics in DocBook</title>
<sect1>
<title>Mathematical elements</title>
<para>The "mathphrase" element<footnote><para>Introduced in DocBook 4.5</para></footnote> is used to tag mathematical expressions
that are readily representable in plaintext.</para>
</sect1>
</article>HTML’s vocabulary was severely lacking, and forced reliance on
nonstandardized class attributes to inject the missing
semantic context:
<div class="article">
<h1>Rich semantics in DocBook</h1>
<div class="top_level_section">
<h1>Mathematical elements</h1>
<p>The "mathphrase" element<span class="footnote">Introduced in DocBook 4.5</span> is used to tag mathematical expressions
that are readily representable in plaintext.</p>
</div>
</div>HTML5 adds a whole new category of elements used for “sectioning
content”h13, which can be used to
mark divisions of books, journals, and other long-form content:
<article> for complete, self-contained articles;
<section> for subsections of a larger book or article
(both chapters/appendices, and their subsections);
<aside> for tangential remarks (e.g., sidebars or
footnotes), and <nav> for navigational components
(such as a table of contents or an index).
Also new to HTML5 are elements for representing formal (titled)
images (<figure> and
<figcaption>), as well as headers/footers (the aptly
named <header> and
<footer>)
With the addition of these elements, the previous example can now be written as:
<article>
<h1>Rich semantics in DocBook</h1>
<section>
<h1>Mathematical elements</h1>
<p>The "mathphrase" element<aside>Introduced in DocBook 4.5</aside> is used to tag mathematical expressions
that are readily representable in plaintext.</p>
</section>
</article>These new structural elements greatly enhance the ability to semantically mark up an entire book manuscript in HTML5.
No Conversions Necessary!
Books don’t remain manuscripts forever. The goal—which hopefully is achieved—is to publish[1] them. Thus, the purpose of manuscript authoring tools is not only to facilitate writing and formatting of text, but to do so in a fashion in which it can be output as a final print and/or digital product.
Traditional word processing applications like Microsoft Word are actually far from ideally suited to this last output stage, the actual production of a manuscript. Because they are not primarily designed as compositing tools for generating printer-ready PDFs, word processors don’t offer as robust a suite of layout and prepress features as provided by desktop publishing applications like Adobe InDesign. So while it’s trivial to export a Word or Pages document to PDF, it’s not quite as trivial to export a PDF that would be considered “print-ready.” As a result, it’s common for workflows for producing manuscripts for print to entail first converting binary word-processor documents (e.g., Word .doc files) to binary desktop-publishing documents (InDesign .indd files), and then outputting the final print-ready PDF from the second set of files. In other words, the manuscript transitions through three distinct file formats: one for writing/editing, one for compositing, and one for distribution.[2] The paradigm is similar for digital production to output ebook formats of a manuscript. The two main digital formats in which ebooks are sold, EPUB and Kindle Mobi KF8,[3] are both reflowable formats, where content does not have fixed pagination like a print book but instead spreads to fill the dimensions of the ereader screen. Here, compositing is much less of a concern, but there’s still a conversion step that must be navigated to produce the ebook output. Exporting to EPUB/Mobi from a format like Word or InDesign is not typically a process that produces high-quality results out of the box without extensive configuration, troubleshooting, and possibly even post-conversion cleanup, as is evidenced by a burgeoning industry of third-party firms offering ebook conversion and consulting services.
An alternative to the Word-to-InDesign-to-(e)book shuffle is to design a single-source workflow, where there is just one set of document files used both for writing/editing the book manuscript and for completing the necessary production work for generating both print and electronic outputs. Here is where an XML format like DocBook shines, as its rich semantic vocabulary makes it highly transformable to a variety of output formats. The DocBook Project’s open source XSL stylesheets were developed to facilitate this very task, and provide transformations from DocBook to a variety of key document formats, including PDF (via FO), HTML (both XHTML1.1 and XHTML5), and EPUB (versions 2 and 3). This is the workflow that O’Reilly Media has used for the past seven years, which Andrew Savikas describes in his essay “Distribution Everywhere”:
That large ecosystem of tools and users meant that there was already a very mature and robust set of open-source stylesheets intended to do exactly what we wanted: to take a set of DocBook source files and create multiple outputs, each with its own formatting rules. We could even create multiple versions of the same output format; for example, a PDF intended for printing (with crop marks and high-resolution images) and a PDF designed for viewing digitally (with color images and hyperlinks). By customizing the stylesheets with our branding, we could deliver three different “final” outputs (print PDF, web PDF, and Safari) from the same source file at the same time, while retaining the flexibility to modify the presentation formatting independently of the content.
When EPUB emerged as the standard for the growing ebook market, we partnered with Adobe to contribute changes to those open source stylesheets to support output as EPUB (and with some additional processing, in Kindle-compatible Mobi format as well). That meant that as long as our production workflow resulted in a high-quality DocBook XML version of a book, we could deliver multiple print and digital versions at the same time from the same source.s11
The conversions in this type of workflow are optimal: all operate on a single, highly and consistently structured source format, and are wholly automated—ensuring fast, accurate results. But no matter how efficient the production infrastructure, every conversion built into one’s processses still incurs a cost. If conversions are outsourced to another vendor, the cost is in both dollars and time. If conversions are automated in-house, the cost comes in the form of the human resources on staff required to maintain the codebase. As such, the ultimate goal in creating streamlined publishing workflows isn’t solely to lower the costs of conversions whenever possible; the aim should also be to eliminate the need for conversions whenever possible.
HTML5: Both Source Format and Output Format
A huge asset that HTML5 offers as a book authoring format is that unlike Microsoft Word or DocBook, it is not just an authoring format: it is a hugely popular output format. Aside from the fact that HTML is inarguably the dominant markup for content published on the Web, it is also at the core of both the EPUB and Mobi ebook formats.[4]As a result, if HTML5 is used as the source manuscript format, the task of producing ebook outputs is reduced to one of styling the content (with CSS) and packaging it as appropriate for distribution. In the case of EPUB, creating a valid file entails creating a ZIP archive of book assets (HTML, CSS, images, script documents) with an embedded mimetype, config settings (e.g., DRM), and Package Document that contains a full manifest and metadata about the ebook. In the case of Mobi, packaging entails processing either an EPUB file or an HTML document with Amazon’s KindleGen tool.
And what about producing print books? It may be counterintuitive, but HTML5 is actually an excellent source format for producing paginated content, as the CSS3 Paged Media Module can be utilized to design the eqiuivalent of a standard book template for print. Features supported in CSS3 Paged Media include page headers, footers, folios, crop marks, font selection, distinct master pages for verso/recto/chapter-opener pages, and even a good deal of control over pagebreaking via both explicit instructions and widow/orphan controls. The process for writing the CSS for these elements is well documented in “Building Books with CSS3” by Nellie McKessonm12.
While the Paged Media Module is still in W3C Working Draft status, two major commercial tools already support its feature set for generating PDF documents: Antenna House Formatter and Prince. It’s now possible to take an HTML5 manuscript and a CSS3 stylesheet including paged-media rules, and run it through either tool to get a high-quality, print-ready PDF file. Figure 1 shows a side-by-side comparison of a PDF page excerpted from the O’Reilly Media title Interactive Data Visualization for the Web (2013), generated from a single HTML5 file using two different CSS3 stylesheets.
Figure 1: The same HTML5 file used to generate PDF content in two different templates using distinct CSS stylesheets; note the differences in styling of headers, footers, and figure images in the PDF at left versus the PDF at right.

It’s worth noting that while at first glance, a DocBook-source and HTML5-source production toolchain seem quite similar―a single input format from which multiple output formats are automatically generated―there’s a key difference between the two models. As previously stated, in an HTML5 workflow, the source format and the ready-to-package output format are identical, which means that both the toolchain and the people creating books with it only need to concern themselves with one markup language, not two. In a DocBook-based workflow, there are two problems to solve:
-
How do we convert DocBook markup into a corresponding HTML representation that is faithful to the original semantics?
-
How do we style the HTML representation with CSS to achieve the desired formatting and aesthetics?
Such a system thus has two points of failure[5] that can result in problems in the final EPUB, Mobi, or PDF output: there can be issues with the transformation engine (XSL-based or otherwise) that converts DocBook to HTML, or there can be a problem with the CSS stylesheets applied to the HTML. Troubleshooting problems in the former category requires a high level of expertise,[6] as one needs to have extensive knowledge of both source and output markup languages just to determine how best to rectify the problem. This usually entails either modifying the transformation logic used to convert from source to output, or recommending alterations to the source format to achieve the desired output with the existing transformations.
When HTML5 is used as both source and output format, this first
point of failure is completely removed from the production system. If
you review the output and find that it contains an unordered list
where you were expecting an ordered list, you simply crack open the
HTML file and change the <ul> element to an
<ol> element; you don’t need to audit the
transformation logic used for conversion of DocBook
<itemizedlist> and <orderedlist>
elements. The only thing you have to worry about is the CSS. Such a
system is much simpler and easier to maintain.
We Don’t Need Your Validator!
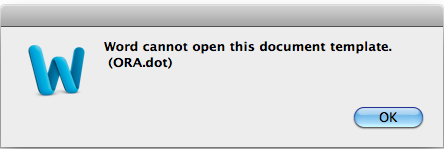
When you’re in the process of drafting your manuscript, you want to focus on expressing your thoughts in writing; you don’t want to worry about having to regularly validate your document to ensure that it conforms to a preset template or schema. There are few things more irritating than having the writing rhythm be interrupted to troubleshoot a template error (e.g., Figure 2), or a DTD error like the following:
ch01.xml:4: element chapter: validity error : Element chapter content does not follow the DTD, expecting (beginpage? , chapterinfo? , (title , subtitle? , titleabbrev?) , (toc | lot | index | glossary | bibliography)* , tocchap? , (((calloutlist | glosslist | bibliolist | itemizedlist | orderedlist | segmentedlist | simplelist | variablelist | caution | important | note | tip | warning | literallayout | programlisting | programlistingco | screen | screenco | screenshot | synopsis | cmdsynopsis | funcsynopsis | classsynopsis | fieldsynopsis | constructorsynopsis | destructorsynopsis | methodsynopsis | formalpara | para | simpara | address | blockquote | graphic | graphicco | mediaobject | mediaobjectco | informalequation | informalexample | informalfigure | informaltable | equation | example | figure | table | msgset | procedure | sidebar | qandaset | task | anchor | bridgehead | remark | highlights | abstract | authorblurb | epigraph | indexterm | beginpage)+ , (sect1* | refentry* | simplesect* | section*)) | sect1+ | refentry+ | simplesect+ | section+) , (toc | lot | index | glossary | bibliography)*), got (title para sect1 figure para sect1 sect1 sect1 ) Document book.xml does not validate
Figure 2: Why does Word hate me?
Document validity should not be considered to be inherently valuable: validation is a means toward an end. We validate to confirm that necessary constraints are met to achieve a specific goal. In the case of book production, that goal is producing a PDF to be printed and/or an ebook to be distributed digitally.
When a book-production workflow is conversion-heavy, robust validation is crucial, as it’s a key mechanism to prevent formatting mistakes in source documents from propagating to output documents, or from causing the conversion process to fail entirely. If a Word manuscript document isn’t properly tagged with its template’s paragraph styles, it likely won’t convert to InDesign cleanly, which means extra QA and cleanup work for the compositor. Similarly, if a DocBook document doesn’t meet the requirements specified in the DocBook DTD, the XSL transformations in the toolchain may not properly convert it to HTML or FO, which again means more troubleshooting. When offered a choice between placing effort on validation or on ex post facto damage control, validation is rightly seen as the lesser of two evils.
But the balance of the tradeoff between validation and cleanup
shifts dramatically when conversions are eliminated from the production
workflow. As discussed
previously, when HTML5 is used as both source and output format,
there’s one less failure point in the process, which means fewer
opportunities for something to go wrong. That doesn’t mean that all
problems will disappear. Books are written by humans,[7]and humans make mistakes. What changes when conversions are
eliminated from the workflow is a decrease in the difficulty of
troubleshooting and rectifying these mistakes. When the output format is
identical to the source format, there’s no longer a need to retrace
one’s steps to identify the source of a problem. If there’s a problem
with the <ol> markup in your EPUB, you find the
<ol> and fix it; you don’t need to backtrack to the
corresponding numbered list in Word or <orderedlist>
in DocBook and attempt to figure out why your numeration settings
weren’t converted to the proper start
attribute.
Even better, HTML5 rendering systems are generally reasonably fault-tolerant. As Liza Daly, VP of Engineering at Safari Books Online, notes in her article “The unXMLing of digital books,” it’s not necessary to have perfect, XHTML-compliant syntax to get your HTML5 to render as expected in a Web browser:
I can throw just about anything even resembling an EPUB book at our reading system — even if it’s completely invalid with HTML tag soup — and it’ll load. We have very little preprocessing necessary; XSLT, which is hard to learn and harder to master, is almost absent from our workflow.d13
As an example, if a book manuscript did contain poorly formed HTML with poor semantics like the following:
<html xmlns="http://www.w3.org/1999/xhtml">
<body>
<h1>Basic formatting</h1>
<p>Here’s a paragraph with the last word in <b>bold.</b><br><br>
Here’s another paragraph with <i>some italics.</i>
</body>
</html>Instead of well-formed, more semantic XHTML syntax like this:
<html xmlns="http://www.w3.org/1999/xhtml">
<body>
<section class="chapter" title="Basic formatting">
<h1>Basic formatting</h1>
<p>Here’s a paragraph with the last word in <strong>bold.</strong></p>
<p>Here’s another paragraph with <em>some italics.</em></p>
</section>
</body>
</html>The HTML will still render largely the same in most modern Web browsers. AntennaHouse Formatter will also render identical PDF output from both syntaxes.[8]
That’s not to say that every instance of sloppy HTML tagging will be so benign as to have no perceptible side effects on rendering. The point is that there is a fair amount of leeway, which can potentially be augmented by well-crafted CSS that accounts for potential variation in expected markup.
If your markup is relatively flexible, doesn’t need to be converted/transformed into another format, and problems are easy to correct, do you really need to focus on validation?
Digital-First Content Development!
When crafting a book that will be released in both print and ebook formats, there’s an opportunity to think “digital first,” and develop content that takes advantage of the features offered by a digital medium, such as audio/video, adaptive quizzes, games, etc.
If you opt to use traditional word-processing and desktop-publishing tools to author a book with special digital features, you’ll be faced with questions like, “How do I embed a Canvas in my Word doc?”, “How do I change all those image placeholders into video files for the ebook version?”, and so on. The answer: more scripting or manual markup rework, either as part of the conversion or as a postprocessing step.
Rich semantic markup languages like DocBook XML and AsciiDoc are a
bit better suited to the goals of representing and converting multimedia
content. DocBook in particular contains elements designated for
representing audio and video media: <audiodata> and
<videodata>, respectively. Similarly, the HTML5
backend toolchain for AsciiDoc comes with a configuration file with
audio:: and video:: macros you can use to
embed audio/video references into your documents. But there’s still no
out of the box analog to the <canvas> element, so
some custom modeling and handling may still be in order for interactive
features.
In contrast, HTML5 was expressly designed for the purpose of marking up digital media, and the ebooks you produce will use HTML5 to render it. Choosing to author the entire book in HTML5 just makes sense, because it will then be trivial to integrate these digital-first elements directly into the manuscript.
Web-Based, WYSIWYG Authoring
Two increasingly important features for authoring tools in the age of ebooks and self-publishing are having a Web-based platform and a WYSIWYG editing interface.
It’s not much of an overstatement to say that in recent years, cloud computing has revolutionized the whole realm of document production (not just books, but also articles, spreadsheets, and correspondence). The two key advances a platform like Google Docs offers over desktop word processors are “access everywhere” and live, versioned collaboration.[9] Documents stored in the cloud can be retrieved from any Internet enabled device—desktop, laptop, tablet, smartphone—which completely obviates the need to traffic and sync files among machines via email or FTP. Cloud storage platforms like Dropbox also offer that functionality, but what they don’t provide is the ability to collaborate on documents in real-time and track the history of changes made by different users. If more than one person is going to be accessing the book manuscript as it’s being developed (co-authors, editors, copyeditors, reviewers), a Web-based platform with cloud storage is a huge boon in facilitating the logistics so that all parties can focus at the task at hand, instead of worrying about file management.[10] A Web app also greatly reduces the risks of hiccups being introduced into the process when collaborators are working on machines running different operating systems and/or different versions of desktop apps—no more “Could you resave as .doc instead of .docx” or “Your template doesn’t work in Word 2008 for Mac.”[11]
Equally valuable to a lightweight authoring model (e.g.,
self-publishing) is the ability to instantly get feedback while writing
as to how the content renders. By WYSIWYG authoring, I not only mean
that when content is tagged to be rendered in italics, the content
onscreen actually appears in italics (as opposed to
being displayed as _in italics_ or <emphasis>in
italics</emphasis>). WYSIWYG should mean that the onscreen
display mirrors as closely as possible what the final product will
actually look like. In a model where a book manuscript is written in
Microsoft Word and then composited in Adobe InDesign, this is rarely the
case. At best, the onscreen display in Word is usually a rough
approximation of how the content will end up
looking when the real template is applied in
InDesign. That’s not a great model when you’re looking to quickly
iterate on both content development and typesetting.
HTML5 offers an elegant path forward toward constructing both a Web-based and WYSIWYG authoring environment. If you need to construct an authoring frontend in HTML5, CSS, and JavaScript to get it on the Web, why not just accept the manuscript files in HTML5, CSS, and JavaScript as well? That means no additional interpreters are needed to render the source content in the editor for WYSIWYG display.
The cornerstone of the WYSIWYG HTML5 editor is the contenteditable
attribute, which, when set on any element in a HTML5 document,
allows the interior content of that element to be dynamically edited in
real time by the end user who loads that document in her Web browser.
With the help of some JavaScript to allow manipulation of
contenteditable elements via a GUI interface (formatting
buttons, etc.), and CSS to provide the appropriate styling of the added
content, it is possible to create the analog of an InDesign template
right in the Web browser, where the user can write and composite a
manuscript without having to manually modify the HTML source or CSS
stylesheets.
A plethora of open
source, contenteditable-based
GUI HTML5 web editors
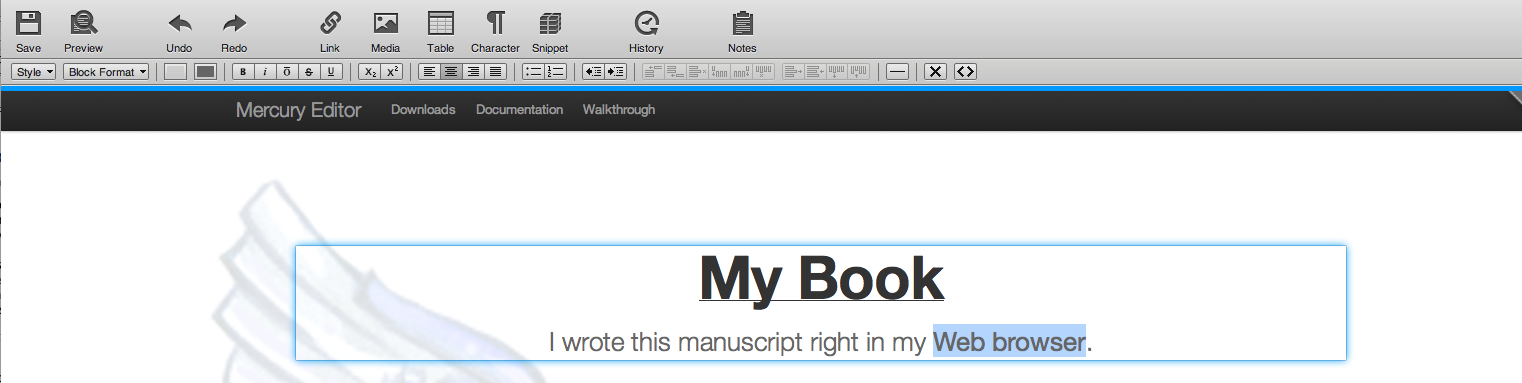
have been created in this fashion. Figure 3 shows a screenshot of Mercury Editor’s
contenteditable interface in action.
Figure 3: The open source Mercury Editor has a GUI contenteditable
interface that can be used to dynamicallly update Web content
The fact that so many contenteditable editors are available right
now is strong evidence that it is relatively easy to code this type of
interface into an HTML5 app. But the fact that so many contenteditable
editors are available right now is also strong evidence that no one’s
really completely nailed the right feature set yet for this kind of app.
The WYSIWYG part is there, but many of the features folks have grown
accustomed to expect from suites like Google Docs aren’t baked in yet:
collaborative editing, versioning, spellcheck, and so on. But it’s just
a matter of time before that happens, as Web-based self-publishing
platforms like PressBooks and Inkling Habitat have already embraced HTML as
source format and have built their own Web editing interfaces.
Where HTML5 Falls Flat
Between the potential benefits available in terms of streamlining production workflows to eliminate costly conversions, mitigate the overhead of validation, and construct a truly WYSIWYG Web authoring platform, O’Reilly Media has aggressively been pursuing a switch from a single-source workflow based on DocBook XML to one based on HTML5. But effecting this shift has not been without its challenges, and ironically, some of the issues we’ve faced in attempting to implement authoring and production in HTML5 are directly related to the markup format’s key strengths.
New-and-Improved Semantics?
Yes, as discussed previously, HTML5 introduces a collection of
semantic sectioning elements that greatly facilitate one’s ability to
structure long-form textual content. However, HTML5’s sectioning
vocabulary still pales in comparison to that of an XML vocabulary like
DocBook, which was specificallly designed to support semantic tagging of
book content. So, while HTML5 now offers <article>,
<aside>, <nav>, and
<section> for blocking off book subsections, some key
omissions include analogs to the following DocBook elements:
<appendix>, <bibliography>,
<chapter>, <glossary>,
<index>, and <part>. Without
standardized semantics for these book components, it’s left to
individuals to improvise their own custom semantics within the
constraints of the HTML5 specification. But when the tagging for a book
chapter can fairly accurately be represented as:
<div class="chapter">
Or:
<section class="chapter">
Or maybe:
<section data-book-division="chapter">
Or if you’re not a native English speaker, perhaps:
<section class="chapitre">
Then the vocabulary really isn’t precise enough to serve the
intended purpose. Just as many HTML 4.01 Web developers felt that
<div> was insufficient to meet their needs, many
HTML5 book authors will likely feel the same way about the relatively
small set of sectioning elements available.
No Conversions Necessary?
It’s true that when HTML5 is used as both source format and output format that no mappings are needed between markup types, but that doesn’t necessarily mean that no document transformations are needed. In a DocBook single-source workflow, the conversion of book files to the desired output format typically serves two functions. One purpose is indeed the markup translation, but the other is the autogeneration of book content that is implicit in the structure of the source files: the Table of Contents, the Index (if present), and intrabook cross-references. These elements are generally not hardcoded into the document because doing so is both tedious and redundant.
A standard Table of Contents simply lists chronologically the titles of each major division of the book (chapters, subsections, etc.) with hyperlinks and/or page numbers that reference the corresponding content in the body of the book. It makes little sense to manually mark up the Table of Contents by hand when the process can be automated, which is faster and less error-prone. The DocBook XSL stylesheets contain logic to handle TOC generation, as do Microsoft Word and Adobe InDesign.
Similarly, it’s desirable to have an Index that is autogenerated
based on tags embedded in proper context in body text, rather than one
hardcoded at the end of the book that is alphabetized by hand. A manual
indexing process is typically so labor-intensive and not amenable to
ongoing maintenance that it’s left to the very end of the production
process to ensure that it won’t need to be repeated if text is added,
deleted, or shuffled about). And for the same maintenance reasons,
albeit on a smaller scale, “softcoded” cross references are preferable
to their hardcoded counterparts. Hardcoding text in the manuscript like
“See Chapter 7 for more details” opens the door to mistakes if at a
later point in the writing/editing process, a decision is made to
flip-flop Chapters 7 and 8 in the book. Much better to mark up the
reference by linking to an anchor, as in the DocBook syntax “See
<xref linkend="chapter_about_xml"/> for more
details”, and leave the work of generating the proper chapter number in
the output to a script.
Any robust, agile production workflow based on HTML5 is going to need to have the capability to autogenerate tables of contents, indices, and cross-reference text when appropriate[12]—whether via XSL, JavaScript, or another set of tools. So while it’s a good thing that no formal conversions are needed in this model, HTML5-to-HTML5 document transformations are still very much on the table. Unfortunately, it’s not especially realistic to presume that it will be possible to just apply some CSS to the HTML manuscript and call it a day.
We Don’t Need Your Validator?
Once transformations are back in the mix, the scale starts tilting back in favor of validation again. At minimum, most XML parsers are going to require well-formed markup, which means you don’t just need HTML5; you need XHTML5. Additionally, if automated Table of Contents, Index, or cross-reference generation are part of the toolchain, you may also want to validate against some additional requirements such as the following:
-
All major book divisions must have titles (e.g., every chapter must have a corresponding nonempty
<h1>) -
Book-division nesting and headings must follow a sensible hierarchy (e.g., no
<h1>elements lower in the hierarchy than<h2>elements) -
All softcoded cross-references must reference ids that are present in the markup (e.g., an anchor like
<a href="#chapter_2">must point to a corresponding element withid="chapter_2")
The effort expended in catching these sorts of issues up front may pay dividends in terms of less cleanup required when producing the final product.
Bridging the Gap
To make HTML5 a truly viable markup format for authoring and producing long-form text content, it needs to be augmented with a semantic vocabulary for book-specific components. Once that’s in place, validation rules can be formulated to ensure conformance, and code can be written to script generation of navigation elements (table of contents, index, etc.). While it’s certainly possible for individual authors and publishers to create their own custom schemas and toolsets for HTML5 to fill this void, there are standard, universal semantics for book sectioning (e.g., chapter, glossary, afterword), which means there’s a clear opportunity and need for an open HTML5-based standard geared toward book authoring so that there’s not a constant reinventing of the wheel by each entrant into the HTML5-based publishing space. When O’Reilly Media started exploring the options for HTML5-based book markup, the first standard we looked at was the EPUB ebook format, which added a new semantic vocabulary for book components in version 3.0 of the specification.
EPUB 3 and the Structural Semantics Vocabulary
The International
Digital Publishing Forum (IDPF), the organization that developed
and maintains the EPUB standard, recognized the need for richer
semantics in HTML-based ebook content. In version 3.0 of the EPUB
standard, they added a new EPUB-specific attribute to the format’s
supported HTML5 markup called epub:typee11. The epub:type attribute can be
applied to any element in any content document,[13]and its supported values include any terms defined in the
“EPUB 3 Structural Semantics Vocabulary”e11_2. Also drafted by the IDPF, the Structural
Semantics Vocabulary is a companion spec that standardarizes a set of
semantics for book components. It encompasses a broad lexicon with which
most in the publishing industry should be familiar, including terms such
as “chapter”, “appendix”, “part”, “copyright-page”, “errata”,
“pagebreak”, and “sidebar”.[14]
Using epub:type, content creators can inflect
existing HTML5 elements with the additional proper book semantics. For
example, the following markup:
<section epub:type="chapter">
Indicates a section of the document that corresponds to a book chapter.
While epub:type in conjunction with the Structural
Semantics Vocabulary does provide a standard mechanism for tagging book
components, it was not intended to serve the needs of content authoring
and production; it was designed for consumption by ereader software. Per
the
EPUB 3 specification, epub:type “provides a
controlled way for Reading Systems and other User Agents to learn more
about the structure and content of a document, providing them the
opportunity to enhance the reading experience for Users.” As such, there
are a couple key shortcomings that arise when using
epub:type as a semantic authoring solutions:
|
It’s EPUB-specific |
The Having semantics that were valid against the HTML5 spec and thus output-format-agnostic would be a cleaner, more elegant solution for content creators. |
|
It doesn’t specify any content model restrictions |
Having proper semantics for HTML elements is likely not enough to support more robust validation of the type described in section “We Don’t Need Your Validator?”. In EPUB 3, the following markup for a chapter and subsection: <section epub:type="chapter"> <h2>This is the chapter heading</h2> <p>I am now going to include a subsection here:</p> <section> <p>It would be odd to put a body-text paragraph before the main section heading</p> <h1>Book Markup Best Practices</h1> </section> </section> Is as equally acceptable as this markup: <section epub:type="chapter"> <h1>This is the chapter heading</h1> <p>I am now going to include a subsection here:</p> <section> <h2>Book Markup Best Practices</h2> <p>It would be odd to put a body-text paragraph before the main section heading</p> </section> </section> However, it’s hard not to argue that the latter markup is
far superior to the former markup in terms of clean, sensible
representation of hierarchical book components, as it conforms to
two rules: a formal section begins with a heading, and subheadings
should be of lesser importance than their parent headings[15] (i.e., it’s bad practice to nest a
I’m not arguing that EPUB 3 should be enforcing these kinds of restrictions; as an output format meant for HTML rendering, I think it’s an asset that any valid XHTML is acceptable. But as an authoring format, these additional restrictions are valuable, as consistent, high-quality source markup ensures high-quality output. |
It’s not the EPUB specification’s mission to address either of these content-authoring concerns, and as such, I feel it’s misguided to consider EPUB 3 to be an appropriate HTML authoring format.
HTMLBook: A New HTML5 Authoring Standard
If EPUB 3 isn’t a good fit as an HTML5 authoring format, what should be used instead? Since we weren’t aware of another existing open standard for authoring in HTML5, my colleagues and I at O’Reilly developed our own: HTMLBook. The first Working Draft of the HTMLBook specification was released publicly in April 2013, along with an XML Schema that can be used for validation.
Unlike EPUB 3, the HTMLBook specification does not include any custom add-on elements or attributes that cannot be found in standard HTML5. Instead, HTMLBook subsets the content model defined in the HTML5 specification to add additional requirements and restrictions that apply specifically to book components such as chapters, figures, and sidebars. This means that documents that are valid HTMLBook documents are also valid against the standard HTML5 specification[16] and can be used as is in all HTML5-based output formats.
The key supplemental requirements imposed by HTMLBook are semantic inflections on all structural book elements, as well as some additional restrictions in the content models of these elements.
Whenever possible, the values for semantic inflections were drawn
from those available in the EPUB 3 Structural Semantics Vocabulary, but
when appropriate terms did not exist in this corpus, values were drawn
from the DocBook XML vocabulary. In contrast to EPUB 3, the
data-type attribute is used for semantic inflection instead of epub:type, which
serves to maintain conformity with the HTML5 spec.
In a standard HTMLBook document, the <body>
element is the root element for book content, and requires a
data-type value of book (any book-related
metadata―such as ISBN or price—can be captured in
<meta> elements in the document
<head>). Nested in the <body> must
be one or more <section>, <nav>,
and/or <div> elements that represent standard book
divisions and that must be inflected accordingly. Here is an example of
a standard HTMLBook skeleton for a book that has a titlepage, table of
contents, preface, several chapters, and an appendix:
<html xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/1999/xhtml ../htmlbook.xsd"
xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>This is the book title</title>
</head>
<body data-type="book">
<section data-type="titlepage">
<!-- Titlepage content here -->
</section>
<nav data-type="toc">
<!-- Table of Contents content here -->
</nav>
<section data-type="preface">
<!-- Preface content here -->
</section>
<section data-type="chapter">
<!-- Chapter 1 content here -->
</section>
<section data-type="chapter">
<!-- Chapter 2 content here -->
</section>
<section data-type="chapter">
<!-- Chapter 3 content here -->
</section>
<section data-type="appendix">
<!-- Appendix content here -->
</section>
</body>
</html>Each of these main book divisions can have subdivisions of their
own, which are <section> elements inflected with a
data-type value of sect1, sect2,
sect3, or sect4[17], the appropriate value enforced based on position in the
overall hierarchy. Additional requirements imposed on book divisions
that are both direct children of <body> and
lower-level descendants:
-
Each division’s first child must be a heading using a heading element (
<h1>–<h6>) that is appropriate to the hierarchy level. -
Each division can only contain children that belong to a predefined set of Block elements (no raw text nodes). HTMLBook’s classification of Block elements is largely consistent with the HTML5 specification’s classification of Flow Content, minus elements that can also be found in the HTML5 categories of Heading Content, Phrasing Content, and Sectioning Content.
-
The Table of Contents content in a
<nav>element must contain<ol>markup that is consistent with the requirements for the Navigation Document specified in the EPUB 3 standard.
The goal of HTMLBook is not to overlay a panoply of burdensome supplemental requirements on top of the HTML5 standard; rather, it’s to add the minimum requirements necessary to support consistant, semantic tagging of book content to facilitate templating and styling with CSS3—as well as auto-generation of navigation content and any requisite postprocessing via XSL or other scripting language—to produce high-quality outputs in multiple formats (both print and digital). Within this general framework, users of HTMLBook can employ whatever HTML5 markup they wish, including MathML and SVG content.
Along with the formal specification and Schema document, the HTMLBook project contains some sample CSS stylesheets, which authors can either use wholesale as design templates for their ebook outputs, or adapt to create their own custom styling. It also contains a set of XSL stylesheets that can be used to autogenerate Table of Contents, Indices, and cross-references for HTMLBook content, as well as assist in packaging it as PDF, EPUB, and Mobi.[18] We are currently in the early phases of developing this toolchain, but we hope over the coming months to continue to extend and refine this open source software to support the growing community of authors and publishers who are looking toward HTML5 and Web technologies for developing and producing book content.
Conclusion
HTML5 is better suited than any other document format to the unique demands of next-generation book authoring workflows, where creating both print and digital products is the aim, and the value lies in having a lightweight, low-cost, efficient toolset. While we’re still in the early stages of book authoring platforms and ebook tooling for HTML5-as-source, I expect that in a few years, drafting a book manuscript in HTML5 will be as commonplace as drafting a manuscript in Microsoft Word is today, and that the tools available for both editing and producing books in HTML5 will continue to grow and evolve.
References
[d13] Daly, Liza. “The unXMLing of digital books,” February 1, 2013, http://techblog.safaribooksonline.com/2013/02/01/the-unxmling-of-digital-books/
[e11] “EPUB Content Documents 3.0,” IDPF, http://www.idpf.org/epub/30/spec/epub30-contentdocs.html
[e11_2] “EPUB 3 Structural Semantics Vocabulary,” IDPF, http://www.idpf.org/epub/vocab/structure/
[m12] McKesson, Nellie. “Building Books with CSS3,” June 12, 2012, http://alistapart.com/article/building-books-with-css3
[s11] Savikas, Andrew. “Distribution Everywhere,” Book: A Futurist’s Manifesto: O’Reilly Media, Inc, pp 21-34
[h13] “Sectioning content,” HTML 5.1 Nightly, A vocabulary and associated APIs for HTML and XHTML, Editor’s Draft 8 April 2013, http://www.w3.org/html/wg/drafts/html/master/dom.html#sectioning-content-0
[w13] Wischenbart, Rüdiger, Carlo Carrerho, Veronika Licher, and Vinutha Mallya. “The Global eBook Market: Current Conditions & Future Projections”: O’Reilly Media, Inc., 2013.
[1] Traditionally, “publishing” a manuscript has meant reifying its textual content through the act of printing its words in ink on reams of paper that are sliced and bound to create a physical book. In the digital age, the distintiction between a “manuscript” and “published book” is more nebulous, given that both typically refer to an electronic document. As such, I’m defining “publish” here to mean the act of packaging manuscript content (either physically or digitally) such that it is suitable for distribution to and consumption by readers.
[2] Historically, dividing the book lifecycle into distinct phases that employed specialized software applications made perfect sense, because there was just one desired output format (a print product) and two actors needed to bring it to fruition: the author who did the writing and the publisher who did the production. The rise of digital publishing and self-publishing has effectively detonated the assumptions undergirding ths model, as contemporary publishing rewards a much more lightweight, flexible workflow, which can produce multiple output formats quickly.
[3] The largest U.S. ebook sales channels (per O’Reilly’s “Global eBook Market” reportw13, Amazon, Barnes & Noble, and the Apple iBookstore) all sell ebook content in either EPUB or Mobi format. However, many other digital channels (such as Scribd) sell ebook content in PDF format, either exclusively or in addition to other formats. Producing PDF for digital consumption entails generally the same process as preparing a PDF for print, with the exception that more effort can and should be paid to providing rich intradocument navigation (e.g., a hyperlinked Table of Contents and Index, bookmarks for key sections, and clickable cross-references between chapters).
[4] The latest versions of EPUB (3.0) and Mobi (KF8) both
support HTML5 as a core content-document format. The EPUB 3
specification largely supports the full HTML5
document model (provided XHTML syntax is used), with just a
handful of minor
exceptions. KF8 currently supports only a subset
of elements new to HTML5, but this subset encompasses the
majority of new semantic elements, including
<section>, <aside>, and
<figure>.
[5] It’s certainly possible to have a single-source workflow that has more than two points of failure, if the toolchain permits intermediate formats used between source and output. For example, if authors write their manuscript in a lightweight markup language that exports to DocBook (e.g., AsciiDoc), then there are two transformations built into the system—AsciiDoc to DocBook, and DocBook to HTML—which means two opportunities for problems to be introduced before the markup is even styled.
[6] It’s true that the open source DocBook XSL stylesheets available in the DocBook project are quite mature and robust, as they have been refined over the course of the past eleven years, but that does not eliminate the need for expert-level knowledge to both maintain the toolchain as additional requirements arise (e.g., add support for new EPUB 3 features in HTML5 output) or customize the DocBook-to-HTML mappings to meet publisher-specific style conventions. Performing translations between two markup languages is not all that different from translating between two spoken languages: to do it well, you need to be fluent in both vocabularies and be able to effectively map and pattern words to meet the specific syntax demands of each. Even for the most knowledgeable and capable engineers, that level of complexity is likely to slow down the software development process.
[7] Still true in 2013, although artificial intelligence is clearly already making inroads into the field of journalism.
[8] The EPUB format, however, requires that content be well-formed
XHTML, and many EPUB ereaders (including iBooks, Adobe Digital
Editions, and Kobo) will not be able to properly render HTML that is
not well-formed XML (e.g., no <br> instead of
<br/> or <br></br>).
Additionally, even if these readers did render EPUBs with non-XHTML
content properly, these files would still not conform to the EPUB
specification and would fail epubcheck,
the official EPUB validation tool. However, given that non-XHTML
HTML5 content is good enough for the Web, and modern browsers can
handle “tag soup” just fine, I tend to agree with Daly’s argument in
“The unXMLing of digital books”[d13] that
it’s excessively restrictive to impose higher standards on EPUB
content documents.
[9] Google is really doubling down on its stake on the cloud being the future of business computing with Chrome OS and its line of Chromebooks, which effectively turn the computer’s entire OS into a web app.
[10] Whenever the virtues of a Web-based authoring tool are touted, there’s always one objection that is raised: online editing environments are no good because you can’t use them if you lack internet connectivity. Obviously that’s true, but you could equally well make the argument that computer-based authoring tools are also no good because they’re dependent on electricity or battery power. The utility of any given tool is context-dependent, and given that our modern infrastructure continues to come closer and closer to delivering on the promise of constant, ubiquitous internet access, it seems prudent to take full advantage of this connectivity when developing modern collaboration tools—with fallback offline functionality added as feasible.
[11] Of course, there’s still the risk of “Your webapp won’t run in IE6,” but in general, these sorts of issues are much easier to deal with. It’s much easier to say “Download another free Web browser” than it is to say “Please buy the latest version of this expensive software suite” or “Please stop using Windows.”
[12] If you’re also aiming to produce ebook outputs like EPUB and Mobi, some additional transformations may be desirable for these output formats to account for the vagaries of HTML rendering on different ereader devices. O’Reilly maintains a set of XSL stylesheets that preprocess HTML targeted for the Kindle before generating Mobi output to achieve better rendering results on devices that are not compatible with the KF8 format.
[13] This includes any HTML5 element, but also any SVG or MathML elements embedded in the document, as these vocabularies are also supported in EPUB 3 content documents.
[14] If needed, the default value set offered by the Structural
Semantics Vocabulary can be extended with terms from other
vocabularies by using prefixes and the prefix
attribute. See http://www.idpf.org/epub/30/spec/epub30-publications.html#sec-metadata-assoc
for more details.
[15] THe HTML5 specification does formally encourage this practice: “Sections may contain headings of any rank, and authors are strongly encouraged to use headings of the appropriate rank for the section’s nesting level.” But it’s not a requirement, and the EPUB 3 epubcheck validator doesn’t enforce it.
[16] However, the converse is not necessarily true. Just as not all rectangles are squares, not all HTML5 documents will meet the additional requirements of HTMLBook.
[17] Borrowed from DocBook XML
[18] These stylesheets are modeled after the docbook-xsl stylesheets, but with a focus placed solely on postprocessing and packaging HTML5 content, not on translating it.