Miłowski, R. Alexander. “Using Atom Categorization to Build Dynamic Applications.” Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 - 15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). https://doi.org/10.4242/BalisageVol1.Milowski01.
Balisage: The Markup Conference 2008 August 12 - 15, 2008
Balisage Paper: Using Atom Categorization to Build Dynamic Applications
Atom feeds provide the ability to categorize both the feed and its
entries. This categorization provides a simple and easy way for feed authors
to associated terms and semantics to their feed contents. By using this
categorization, authors can keep their information organized while
re-purposing them to build dynamic web applications.
If you could see my desk at home or my office, you'd probably find
it a horrific disorganized disaster with post-it notes on the desktop and
monitor, stacks of papers and other items, and giant pile at one end. On
the other hand, I see it as disorganized ordered mess. I know where to
find what I need and there is a system of lists, stacks, and piles.
The post-it notes contain lists of things I need to do, information
from "recent queries", reminders on one sort or another, and they are all
ordered and carefully placed on my desk as to their importance. In
relation to these lists, I have stacks of bills, papers, and other urgent items
that need to be filed, where each stack has its purpose
or category. Finally, I have giant pile of things that were
formally in stacks. For some reason or another, they've expired but need
to be filed. Someday I'll get around to that filing and make that giant
pile not so giant anymore.
It shouldn't surprise you to find that my computers are similarly
organized. It is easy to recognize the stacks of documents shuttered into
folders by their relationship to each other or my stacks of photos or
videos from my camera. My desktop has become a giant "pile of things
downloaded" overtime and the whole computer is somewhat of a giant pile of
information I've retained.
I've come to realized that this isn't going to change. What I need
is for software and applications to adjust themselves to my way of storing
information. Not finding what I needed and discovering the usefulness of
Atom feeds, I created the open-source atomojo atomojo project to serve my "disorganized ordered
mess" nature and store my information.
What I discovered was that even though I'm a software developer and
work with things are often tightly controlled and highly structured, much
of the information I produce or interact with--media, information bits,
documents of all kinds--tends to be loosely organized into "stacks" rather
than tightly controlled "lists". This is especially true when it comes to
media coming from personal interactions, family, vacations and other
things not related to business.
In fact, I'd say that the immense popularity of web search and the
introduction of desktop search trends well with the idea that people
generate stacks and piles of information that are loosely grouped
together. I'd go even further to say that a "list" is a rare thing and can
be hard to develop.
Let's then face the fact that people don't produce lists
as much as they produce stacks and piles. Producing organized and
structured information takes time and so we just shove our media, documents, and other
information into the nearest stack (or pile) that looks appropriate. We do
that with a slightly dishonest hope that we'll come back to it later and
"get organized."
In the end, this information should be the basis for the
applications and communications that we share with others on the Internet.
It could drive our websites, our picture galleries, and our commerce
engines if we only had a way to get it organized. Thus, my messy desk led
me to believe that if I got organized I could build better dynamic
applications.
Getting Organized with Atom Feeds
Atom feeds are like stacks of objects. There is an order to the
stack from the first entry to the last. You often have to sort through the
entries from first to last to find what you want. But the feed has a
purpose and so there is a loose relationship between each entry.
While certain information resources have processable content, many
others are not so easily searched. That is, an image is difficult to
search against without human interaction unless there are annotations. As
a result, the metadata encoded in the feed entry is very
important.
With the recent invention of the Atom Publishing Protocol
(AtomPub) apprfc, creation and manipulation
of both entries and their associated metadata is relatively easy. As such,
rather than shoving that picture from your last vacation into the nearest
folder, you can tuck it away nicely into a Atom feed. The consequence is
the natural next step is to author some metadata.
Entries have a rich vocabulary with which you can annotate your
resources. Just by looking at the entry you can learn about the author,
titles, summaries, and many other aspects. This enhances the
ability to retrieve that object later.
Term Categorization in Atom
One of the interesting parts of the Atom vocabulary is the
category element associated with both feeds and entries.
This element has two important attributes called
scheme and
term. The scheme attribute is
an URI value that qualifies or scopes the term
attribute's value. The element itself can contain any content--text or
elements--but none is defined by the Atom Syndication Format atomrfc.
If you concatenate the scheme and term
attribute values and assume a default for when the scheme
attribute is omitted, the result is a URI. This
value can be interpreted as a leaf term in some unnamed ontology
that labels the entry or feed with that term. As the
category element may contain content, a value can be
associated with the term.
This interpretation means that for each category
element you get a RDF rdf triple. This
triple is constructed such that the subject is the entry or feed,
the predicate is the term URI, and the object is the value of the
element. When the category element is empty, the value
defaults to rdf:nil.
Graphical Models for Terms
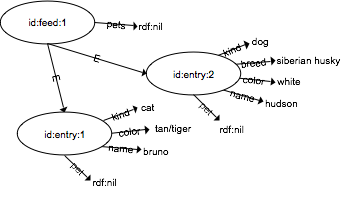
Each feed generates a simple graphical model using the unique
id element values to represent the subjects in the triples.
For example, given the feed in Figure 1,
the graph in Figure 2 is generated using
edge labels:
Being able to query your feeds becomes very important after enough
content as been collected. That is, your feeds start to look a lot like
an unorganized pile. Past a certain number, keeping track of just where
something can be found gets to be very difficult.
While the Atom vocabulary provides many interesting elements (e.g.
title) by which you might search, the entry and feed categorization
provide a fine-grained set of information on which a query can be
performed. Simple queries can be used to retrieve entries from feeds
simply by pulling those entries who have certain terms.
We'd like a query that can:
provide a set of terms for the basis of the query,
allow comparison of any values associated with those
terms,
return the query result as a "reconstituted" feed.
Fortunately, SPARQL sparql has
recently become a W3C recommendation and we can use this to query our
pile of feeds.
For example, if we want to retrieve the feed with the keyword
pets, we could query on the term
http://www.atomojo.org/O/keywords/pets as shown in Figure 3.
As a query language, SPARQL is sufficiently powerful to express
many types of queries. If the graphical model of the feeds is extended
to include properties from the atom feed vocabulary, queries can be
formulated that mix categorization with the feed structure (e.g. find
all pet entries whose title contains a certain word).
Since we are interested in feeds and entries, the real use of the
query is to reconstitute the result into a feed. This can be done by
a simple process using these rules:
For each matching feed, return an entry that summarizes the
feed, its categorization, and a single link of relation related
that points to the feed's resource URI.
For each matching entry, return the entry with the
xml:base attribute set such that the link relations are
preserved.
As a result of this process, the query result is just another feed
that can be consumed by any Atom-enabled client.
Building Applications from Atom Feeds
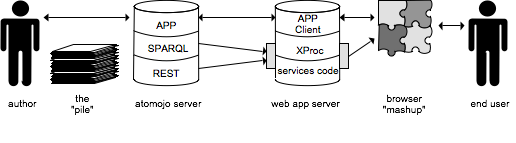
Architecture Overview
With our ability to annotate and query arbitrary content as feed
entries, we can now describe a dynamic application architecture show in
Figure 6 that is based on atomojo's AtomPub and
SPARQL abilities. On the far left is the application author who is
responsible for loading content and configuring the application. On the
far right is the end user of the application who is using a
browser-based application presented by the system. In the middle is the
web application server and atomojo server instances.
Figure 6: Atomojo-based Architecture
The author's responsibility is not only to provide the content
from the pile and appropriate annotations, but also to provide
instructions through the same means. These instructions provide
content layouts, rules for content organization, web content such as
javascript code or CSS stylesheets, and even service components. While
some of this content is the domain of a web programmer, much of it is
just simple entries with categorizations as to how to build resources on
the web application server.
The web application server performs several tasks:
provides content proxies from the atomojo server to deliver
content to the browser,
loads and configures layouts for web pages that are to be
built from atom feeds,
loads and configures resources that are SPARQL queries to the
atomojo server,
loads custom application components for specialized
services.
The configuration information is retrieved from the atomojo server
by a series of SPARQL queries. These queries allow the configuration
information to be stored anywhere the author prefers.
An Example
When the web application server periodically updates itself, it
performs a set of queries against the atomojo server to retrieve
configuration information. For example, to find all the layouts, the
server uses the
query shown in Figure 7. This query
returns a set of entries that are the instructions for how each feeds is
processed to produce a web page.
A typical layout entry is a media resource entry that contains a
script (e.g. XSLT) for transforming the feed on the server into
appropriate web content. While the
transformation as shown in Figure 8 produces HTML, nothing precludes generation of images or other
non-XML media types.
The layouts are used by internal or custom components where the
choice of layout is based on a
number of matching criteria. These layout rules can be restricted to
match by resource path or require that the feed being rendered to have
certain terms (i.e. category elements). This allows the author to select
the layout based on categorization rather than location in the atomojo
server.
This approach has been used to configure the proxies, layouts,
queries to the server, and application components as shown in
Figure 9.
In Figure 9, the first entry
is the layout, the second entry is a proxy for content, and the third is
an application component that comes packaged with atomojo. This
component is used to create index pages from feeds using the layouts and is typically
mapped to index resources (e.g. ends with a forward slash). These
mappings are shown in the match terms in the entries.
The last two entries are slightly different. Their purpose is to
use the query facilities of the atomojo server to find all software
projects on the web site and then present a listing. They do this by
associating a query to a resource that is then called by another index
component.
The last entry defines a query against the atomojo server for
retrieving all those feeds that have a keyword of software. That
resource is used by the index component defined by the preceding entry.
These two entries together configure an index page at /software/ on
the web site.
Conclusion
In Figure 9 in the last
section, the last two entries achieved finding resources in our pile of
information. An author can now put information about software in any feed
they choose and, as long as it is
annotated with a category element with a term value of software, it will
show up on that software index page.
This is not remarkable. Plenty of software system exists that allow
authored keywords to produce index information and then allow people to
browse that information. What is interesting here is that we're using
categorization and terms.
Any categorization--both formal and informal--can now be used to
annotate information stored in the feeds. The annotations are not limited
to keywords. Also, the combination of different terms and values can be
used to create a very specific set of informaiton.
Similarly, the queries are not limited to simple retrieval
exercises. The SPARQL queries can perform complex union and intersection
operations as well as filtering on term values. As such, very specific
data sets can be retrieved from the atomojo server.
As time goes by, queries can be developed to use whatever categorization
evolves from the authors. These queries can be used to
re-purpose that original content without much, if any, change to the
feed metadata. The resulting feeds can then be associated with a web resource
independent of how the author chose to organize the original entries and
feeds. That is, I can create a disorganized pile of information and keep
my website organized.