Casimirri, Maurizio, Paolo Marinelli and Fabio Vitali. “Optimized Cartesian product: A hybrid approach to derivation-chain checking in XSD
1.1.” Presented at Balisage: The Markup Conference 2008, Montréal, Canada, August 12 - 15, 2008. In Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). https://doi.org/10.4242/BalisageVol1.Marinelli01.
Balisage: The Markup Conference 2008 August 12 - 15, 2008
Balisage Paper: Optimized Cartesian product: A hybrid approach to derivation-chain checking in XSD
1.1
Maurizio Casimirri
Graduate student
Department of Computer Science, University of Bologna
Paolo Marinelli holds a Master Degree in Computer Science from the University of Bologna.
He is a temporary research associate at the Department of Computer Science of the
University of Bologna.
Fabio Vitali
Associate professor
Department of Computer Science, University of Bologna
Fabio Vitali is an associate professor at the Department of Computer Science at the
University of Bologna. He holds a Laurea degree in Mathematics and a Ph.D. in Computer
and Law, both from the University of Bologna. His research interests include markup
languages; distributed, coordinated systems; and the World Wide Web. He is the author
of several papers on hypertext functionalities, the World Wide Web, and XML.
As XPath predicates are involved, XSD 1.1 conditional declarations make difficult
the problem of statically verifying whether a type is a legal restriction of its base.
The XSD 1.1 current draft adopts a full dynamic approach to the problem. In this paper
we propose a hybrid solution (neither completely static, nor completely dynamic) to
the same problem.
In this paper we propose an hybrid solution to the problem of verifying whether a type is a legal restriction of its
base in XSD 1.1.
Version 1.1 of XML Schema (XSD) in now in Working Draft [XSD 1.1: Structures, XSD 1.1: Datatypes]. One of the most important features introduced by XSD 1.1 is Conditional Type Assignment,
i.e., the possibility for element declarations to assign a type based on XPath predicates.
CTA is meant to address one of the most evident limitations of XSD 1.0: the co-constraint definition support.
The CTA introduction in XSD arises an issue concerning the derivation by restriction
between types containing conditional declarations. Indeed, the type actually assigned
by a conditional declaration can be known at run-time only and it may vary from element
to element. Thus the problem of statically verifying whether a type is a legal restriction of its base when conditional declarations
are involved is difficult. It is possible to identify three alternative approaches
to the problem:
Limiting the CTA usage in type restrictions.
Dynamic verification: at schema compile time no check is performed, but if at run-time
we have a document proving that a type is not a legal restriction of its base, an
error is thrown.
Hybrid approach: similar to the previous approach, with the exception that at schema
compile time some analysis is performed providing the dynamic phase information that
might decrease the operations to be performed.
Co-occurrence constraints (also known as co-constraints ) are rules relating the presence and values of elements and attributes that may
occur in distinct fragments of an XML document. E.g., we have a co-constraint when
an attribute value governs the content of an element, or when two attributes are in
some logic/arithmetic relation, and so on. Co-constraints are present in several XML-based
languages, among which also languages recommended by W3C.
One of the widely recognized limitations of XSD 1.0 [XSD 1.0: Structures, XSD 1.0: Datatypes] is the inability to define co-constraints. This is a serious shortcoming for a schema
language, and especially for XSD, given its widespread use. Indeed, when a schema
is not able to capture every validity constraints of a class of XML documents, in
order to reach a complete validation process specific modules are required to verify
those constraints not covered by the schema. In such cases, not only the validation
process becomes more complex, but also the interoperability between applications decreases.
Version 1.1 of XSD introduces two mechanisms for the co-constraint definition: assertions and Conditional Type Assignment (CTA). The former is inspired by Schematron [Schematron ISO specification]. It permits to augment type definitions with XPath predicates (called assertions),
each specifying a further validity condition besides those enforced by the content
model. Assertions are particularly useful to require some elements and attributes
to be in logic or arithmetic relations.
CTA, inspired by SchemaPath [P. Marinelli, C. Sacerdoti Coen, and F. Vitali, 2004], allows an element declaration to conditionally assign a type based on XPath predicates.
Here we refer to declaration of such a typology as conditional declarations. CTA is particularly suitable for those situations where an attribute value governs
the content of an element. For instance, in order to subject the content of a <entry> element (representing a bibliographic entry) to the value of the kind attribute, the following conditional declaration might be used
The above declaration reads as "if @kind is proceedings then <entry> is of type ProceedingsEntry, otherwise if @kind is journal then <entry> is of type JournalEntry, otherwise if @kind is book then <entry> is of type BookEntry, otherwise (none of the above conditions hold) <entry> is of type Entry (which is a type for generic bibliographic entries). Each <xs:alternative> element is named type alternative in XSD 1.1.
Conditional declarations arise an issue in the derivation by restriction. XSD (both
1.0 and 1.1) allows to define new types deriving existing ones. A derivation method
is by restriction. The general principle behind the derivation by restriction is that
the derived type accepts a subset of what the base type accepts. Thus, given an element
E, it is required that the type assigned to E in the context of the derived type, be a restriction of the type assigned to E in the context of the base type. The presence of conditional declarations heavily
complicates the static verification of such principle, as it require to analyze logic
relations among XPath predicates. However, there are at least three alternative approaches
to the problem of verifying whether a type is a legal restriction of its base:
CTA limitation
Ad hoc limitations are imposed on the CTA usage to ensure a simple static verification
of the restriction. For instance, a radical limitation is that when a type contains
a conditional declaration it is implicitly final w.r.t. the derivation by restriction.
Full dynamic approach
At schema compile type, it is never checked whether a type is a legal restriction
of its base. However, at validation time, it is checked whether the instance document
is an evidence of the fact that a type is not a legal restriction of its base.
Hybrid approach
Very similar to the full dynamic approach, but at schema compile time conditional
declarations are processed in order to precompute those cases in which the derivation
by restriction is violated. Such precomputed information is then available (in some
form) at run-time, and it can be used by the validator to decrease the number of operations
required to conclude whether the current document is an evidence of the fact that
a type is not a legal restriction of its base.
The XSD current draft adopts the full dynamic approach. Indeed, at schema compile
time the derivation by restriction is checked simply ignoring type alternatives. Given
an element E, at run-time it is checked that the type conditionally assigned to E in the context of a derived type is a restriction of the type which would be assigned
to E in the context of the base type. Such a condition is then recursively checked also
for E and the base type, until the type hierarchy root is reached. I.e., the condition
is checked on the entire derivation chain of the initial derived type. We call such
a solution Run-Time Check (RTC). The XSD Working Group publicly solicit input from implementors and users of this specification as to whether the
current run-time rule should be retained [XSD 1.1: Structures].
Cartesian Product (CP) is another solution but adopts a hybrid approach. At schema compile time it
analyzes all possible cases that may occur at run-time. As the number of such cases is very high,
it has serious shortcomings concerning the computational cost of the static phase.
In this paper we propose a hybrid solution to the problem of the verification of the
derivation by restriction in presence of conditional declarations. We call our solution
Optimized Cartesian Product (OCP). OCP, CP, and RTC have the same extensional behavior. OCP can be seen as an
optimization to RTC. Indeed, at run-time the number of XPath predicates evaluated
by OCP is less than or equal to the number of XPath predicates evaluated by RTC. Moreover,
the OCP static phase requires an acceptable computational cost. So OCP is also an
optimization to CP (and hence its name). Our paper contribute is two-fold:
it proposes an optimization to the solution adopted by the XSD current draft;
it answers the feedback request about RTC, discussing various possible approaches
to the derivation problem, and thoroughly describing three solutions: RTC, CP and
OCP;
Our paper is organized as follows. The next section describes XSD 1.1 in relation
to the problem of the co-constraint definition. In particular it describes CTA and
assertions. Then we introduce some XSD 1.1 specific terminology in Section “XSD Terminology”. In Section “Derivation by Restriction in XSD 1.1” we describe the problem of the derivation by restriction in presence of conditional
declarations. There we describe some possible approaches and solutions. In particular,
we provide a detailed Run-Time Check description, including a computational cost analysis.
We also discuss about Cartesian Product. Then in Section “Optimized Cartesian Product” we describe our proposal, providing a computational cost analysis for both the static
phase and the dynamic phase. Then in Section “Comparing CP, OCP, and RTC” we compare RTC, CP and OCP, mainly focusing on the number of XPath predicates evaluated
at validation time by the three techniques. Then we describe a prototype implementation
for OCP, which demonstrates the feasibility of our proposal. Before concluding, in
Section “Related Works” we discuss about some related works.
XSD 1.1 and Co-Constraints
XSD (XML Schema Definition Language) is the schema language proposed by W3C. Its current version is 1.0, and it is described
by two W3C recommendations [XSD 1.0: Structures, XSD 1.0: Datatypes]. Although there are many other schema languages (such as RELAX NG [RELAX NG ISO specification], and Schematron [Schematron ISO specification]), XSD probably is the most known and supported. XSD 1.0 provides support for the
definition of a number of constraint kinds. For instance, by means of content models,
it is possible to define the legal content of elements. XSD provides a rich set of
built-in types for the definition of legal data values. It also provides derivation
mechanisms, permitting to construct new types from existing ones. Moreover, XSD allows
to define uniqueness and reference constraints on elements and attributes (cumulatively
called identity-constraints).
However, XSD 1.0 is widely recognized as unable to express a particular kind of constraints:
co-occurrence constraints (commonly referred to as co-constraints). According to the definition given by the ESW Wiki, co-constraints are rules which govern what kinds of markup (elements, attributes) can occur together
(co-occur) in an XML document. [Co-occurrence constraints ESW Wiki]. In other words, a co-constraint relates the existence or values of an element (or
attribute) to the existence or values of other elements (or attributes).
Some categorizations for co-constraints do exist. Within the ESW Wiki about 30 use-cases
are listed, ranging from the mutual exclusion of attributes, to the requirement that
two elements values must be in some arithmetic relation. In 2001, Norman Walsh and
John Cowan identified seven kinds of co-constraints [N. Walsh and J. Cowan, 2001].
XSD 1.0 is unable to express co-constraints. Such an inability is heavily felt for
in many user communities. For instance, validation of incoming data is critical for
e-business infrastructures, that require also the adoption of co-constraints. Adopting
XSD 1.0 as validation language requires them to implement application-specific modules,
in order to provide a complete validation process.
W3C is releasing a new version of XSD: XSD 1.1. At the time of writing, it is in Last
Call Working Draft [XSD 1.1: Structures, XSD 1.1: Datatypes]. One of the major improvements over 1.0, is the support for co-constraints definition.
For this purpose, XSD 1.1[1] introduces two mechanisms: assertions and Conditional Type Assignment. Both mechanisms will be described in the next two sections.
Assertions
In XSD 1.1, a complex type may define a sequence of assertions. Each assertion basically
is an XPath 2.0 predicate. In order to be considered valid, each element assigned
to a type must satisfy all the assertions defined by that type. Syntactically, an
assertion is represented by an <assert> element, whose test attribute specifies the XPath predicate.
An example of XSD assertions. This assertion enforces the from attribute being less than the to attribute.
For instance, suppose we want to define an XML language to represent bibliography
entries. In order to specify the conference proceedings pages in which a paper appears,
we might define a <pages> element with two attributes from and to. In order to enforce from being greater than to, the type definition shown in Figure “Assertion Example” might be used.
Assertions are clearly inspired by Schematron. However, there are some points of distinction.
XSD associates assertions to type definitions. On the other hand, Schematron is not
a typed language, and thus it associates assertions to elements, or, more precisely,
to a set of elements identified by an expression. Moreover, Schematron allows to define
assertions involving elements and attributes placed anywhere in the document. On the
other hand, in XSD an assertion is allowed to involve only elements and attributes
of the subtree rooted by the element the assertion is checked on: nodes outside that
subtree are not visible.[2]
Conditional Type Assignment
XSD supports co-constraint definitions by means of another mechanism known as Conditional Type Assignment (CTA). An element declaration may specify a sequence of alternative types, each associated
with an XPath predicate. Within this paper we refer to such declarations as conditional. When an element of the instance document is validated against a conditional declaration,
the XPath predicates are evaluated using the element as context node. The type assigned
to the element is the one corresponding to the satisfied predicate. If the element
satisfies more than one predicate, the one occurring first within the schema takes
precedence. A conditional declaration always specifies a default type, which is assigned
when no predicates are satisfied. Each alternative type derives from the declared
type.
An example of CTA usage. The conditional declaration assigns type Proceedings if the entry is of kind proceedings, otherwise it assigns type Entry.
In order to show the usefulness of CTA within the co-constraint definition, we consider
again our language for bibliographic entries. Suppose we want to represent an entry
through an <entry> element, whose kind attribute specifies the entry kind (i.e., conference proceedings, technical report,
and so on). Suppose that we want to enforce the following co-constraint: if the entry
is of kind proceedings, than the <conference> and <pages> elements must be present. Then we might define:
an Entry type, constraining the content of a generic entry
a ProceedingsEntry type, derived by Entry and requiring the presence of both <conference> and <pages>.
a conditional declaration for <entry> assigning type ProceedingsEntry if the kind attribute has value "proceedings", and type Entry otherwise.
Note that, by default if an element does not satisfy any alternative, then it is assigned
the type specified through the type attribute (known as the declared type). In order to specify a default type other than the declared type, it is possible
to explicitly define a default type alternative, i.e., a type alternative occurring in last position and without any XPath predicate.
XSD 1.1 introduces a new built-in simple type named error. No element or attribute is valid against such a type. error is typically used in default type alternatives to states that it is an error if no
type alternative is selected.
The CTA mechanism is inspired by SchemaPath, an extension to XSD 1.0 introducing the
concept of conditional type assignment [P. Marinelli, C. Sacerdoti Coen, and F. Vitali, 2004]. However, there are some remarkable points of distinction (besides some syntactic
aspects). In SchemaPath, a conditional declaration does not have the declared type.
Moreover, while SchemaPath does not put any restriction on XPath predicates, XSD allows
predicates to access attribute nodes only. Thus, it is not possible to put conditions
on neither preceding, ancestor, nor descending nodes.
XSD Terminology
For the reader unfamiliar with XSD, this section introduces some CTA-related definitions
taken from the XSD current draft [XSD 1.1: Structures].
Declared type
Given an element declaration D the declared type of D is either the type referred to by the attribute type, or the anonymous type definition within D
Context-determined type
Given an element E and a type T, the context-determined type of E in T is the declared type of the declaration D assigned to E by the T content model.
Type Table
A Type Table is a property of conditional declarations, and it is a sequence of type
alternatives (or simply, alternatives). Each alternative corresponds to a xs:alternative element, and it mainly consits of an XPath predicate and a type.
Selected type
Given an element E and a Type Table TT, the selected type of E is the type associated to the TT alternative satisfied by E.
Context-determined Type Table
Given an element E and a type T, the context-determined Type Table of E in T is the Type Table of the declaration D assigned to E by the T content model. If D is non-conditional, the context-determined Type Table has the default alternative
only, which assigns the declared type.
Derivation by Restriction in XSD 1.1
XSD allows to define new types from existing ones through two derivation mechanisms,
extension and restriction. The latter is meant to define a type whose content model accepts a subset of what
the base type content model accepts.
An example of derivation by restriction involving conditional declarations.
The presence of conditional declarations within content models immediately arises
a question concerning the derivation by restriction. In order to explain the issue,
let us consider the schema snippet shown in Figure “CTA Restriction Example”. We can observe that neither T1 derives from T2, nor the converse. Also it is easy to observe that whenever the conditional declaration
within B assigns T1, the conditional declaration within R assigns T2, and vice versa.
As <p> is assigned type R, its child <e> is assigned type T2. According to the schema, <e> is valid against T2. For what previously observed, the type that would be assigned to <e> if <p> was of type B is T1. Clearly, <e> is not valid against T1. Thus we have that B rejects something R accepts. We can reasonably argue that this is a violation of the principle behind
the derivation by restriction. And actually, the XSD current draft imposes constraints
meant to detect as illegal situations like the one above.
Before discussing in details how the XSD current draft faces the derivation by restriction
in presence of conditional declarations, we examine some general approaches to the
problem.
Full Static Approach
We can think about approaches statically (i.e., at schema compile time) deciding whether a conditional declaration within
a restricted type is compatible with a conditional declaration within the base type.
I.e., such an approach should decide the following problem. Given two conditional
declarations R and B, is there any XML document containing an element E such that if E is validated against R then it is assigned a type which is not a valid restriction of the type that would
be assigned if E was validated against B?
This is not a simple problem, as it is necessary to verify logic relationships among
XPath predicates. For instance consider again the conditional declarations shown in
Figure “CTA Restriction Example”. Clearly, the answer to the above question is yes, as if the conditional declaration within the restricted type assigns T1, then the conditional declaration within the base type assigns T2. Thus, we can assert that the derived type is not a legal restriction of its base.
In order to prove it, we should consider the semantics of the relational operators
> and <=. Probably, it is not a so difficult task, as the XPath predicates involved in the
example are quite simple. But if we move to the general case, the problem becomes
much more difficult, as we have to consider also the other XPath functions and operators.
Expressivity Limitation Approach
It is possible to identify a class of approaches facing the problem by narrowing the
CTA usage, in order to avoid the XPath predicates analysis. For instance a simple
and radical solution to the problem consists in implicitly setting as final[3] every complex types containing a conditional declaration. This is the solution adopted
by SchemaPath. Obviously, this solution might be felt as overly restrictive.
Less restrictive solutions may be found. The XSD Working Group discussed a number
of them. One of such solutions, known as Prefix, forces the conditional declaration within the derived type to repeat all the alternatives
of the conditional declaration within the base type, and allows to append new alternatives.
Requiring new alternative types to be a restriction of the default type of the base
declaration, ensures that every type assigned in the context of the derived type is
a restriction of the type that would be assigned in the context of the base type.
CTA Restriction Use Case: CTA Restriction Use Case
An example of restriction in presence of CTA. The restricted type definition is meant
to accept a subset of what the base type definition accepts.
Let us consider the schema shown in Figure “CTA Restriction Use Case”, which is inspired by the example of CTA usage described in the XSD current draft.
Within type B, the conditional declaration for <message> elements assigns a specific message type based on the kind attribute value. Type R is meant to accept string messages only. In this respect, we might argue that R is a legal restriction of B. However, Prefix rejects the above schema, as the alternative sequence of the base
type are not listed in the alternative sequence of the restricted type.
Full Dynamic Approach
Another approach to the problem is the following: do not perform any check at compile
time and let schema authors to write conditional declarations as they like, but if
at run time (i.e., at validation time) there is an evidence of the fact that a type
is not a legal restriction of its base type, then report the error. W.r.t. the approach
described in the previous section, this one reaches the maximum expressivity degree
in writing conditional declarations. Clearly, the drawback is that the same schema
error might become evident only for certain instance documents, and not for others.
This is the approach adopted by the XSD current draft, and will be described in details
in Section “Run-Time Check”.
Run-time Check
As already mentioned in the previous sections, the XSD current draft adopts a dynamic
approach to the verification of the derivation by restriction in presence of conditional
declarations. Indeed, the general problem of verifying whether a type R is legal restriction of a type B is divided in two phases. The first one is meant to be performed at schema compile
time, and it considers the declared type of element declarations only, thus simply
ignoring the presence of Type Tables. For the implementation of such a phase, the
XSD draft refers to the algorithms described in [H. S. Thompson, and R. Tobin, 2003], [M. Fuchs, and A. Brown, 2003], and [C. M. Sperberg-McQueen, 2005].
The second phase (which we call Run-Time Check or simply RTC) is meant to be performed at run-time, and it takes into considerations
Type Tables. The XSD specs describe it as a rule to decide the validity of an element
w.r.t. a type. In order to be valid against a type T, an element must satisfy a number of constraints. One of such constraints states
that each child E together with T must satisfy the Conditional Type Substitutable in Restriction constraint (CTSR).
Informally, given an element E and a type T, E and T satisfy CTSR if the type assigned to E in the context of T, is a valid restriction of the type assigned to E in the context of T's base type. Moreover, E and T's base type must recursively satisfy CTSR.
For instance, consider again the schema in Figure “CTA Restriction Example”, and the following XML document fragment:
<p xsi:type="R">
<e a="5" b="2">
<t2 />
</e>
</p>
The first phase checks whether type R is a legal restriction of B, taking into consideration declared types only. In particular, it is checked whether
the declared type of the element declaration within R (i.e., anyType) is a valid restriction of the declared type of the element declaration within B (i.e., anyType). As anyType is a valid restriction of itself, the first phase succeeds.
The second phase checks whether or not the input document is an evidence of the fact
that R is not a legal restriction of B. In particular, RTC checks whether <e> and R satisfy CTSR. Thus, the Type Table determined by R is evaluated, obtaining the selected type T2. Then, also the Type Table determined by B is evaluated, obtaining the selected type T1. As T2 is not a valid restriction of T1, <e> and R does not satisfy CTSR. As a consequence, <p> is not valid against R.
An Algorithm for Run-Time Check
RTC Algorithm: RTC Algorithm
void process-element(Element e) {
...
Type T = get-current-type(); // e's parent type
TypeTable TTT = get-context-determined-type-table(e, T);
int i = evaluate-type-table(e, TTT);
Type ST = TTT.get-alternative(i).getType();
boolean error = false;
// walk on the derivation chain
while (T is not xs:anyType and !error) do {
Type B = T.base;
TypeTable TTB = get-context-determined-type-table(e, B);
int j = evaluate-type-table(e, TTB);
Type SB = TTB.getAlternative(j).getType();
if (validly-substitutable-as-restriction(ST, SB)) {
T = B;
ST = SB;
} else {
// CTSR violation
error = true;
report-schema-error("vr-cta-substitutable");
}
}
...
}
An algorithm implementing RTC.
In Figure “RTC Algorithm” we present an algorithm implementing RTC, in Java-like pseudo-code. The process-element function is meant to be invoked for each element of the instance document. The function
body is a simple iterative version of the CTSR constraint definition given in the
XSD draft. It iterates over the derivation chain for T, and it stops when either a violation of CTSR occurs or the type hierarchy root (i.e.,
anyType) is reached.
RTC Algorithm Cost Analysis
In presenting our cost analysis for the algorithm shown in the previous section, we
need to introduce some notations. A Type Table TT is an ordered sequence of n pairs <c1, T1>, ..., <cn, Tn>, where cn is the always true condition. We also say that TT has size n.
Now, let E and T be an element and a type definition respectively. Consider the derivation chain for
T. We indicate it with T1, ..., Tk, where T1 is anyType, Tk is T, and for each i < k, Ti is Ti+1's base type. For each i between 1 and k, we denote the context-determined Type Table for E in Ti by TTi. Moreover we denote the TTi size by di.
Now, we can start the RTC algorithm cost analysis. If there is no CTSR violation,
the RTC algorithm iterates over the entire derivation chain for T. For each i between 1 and k, the following operations are performed:
get the context-determined Type Table for E in Ti, i.e., TTi
calculate the selected type for E according to TTi
check whether the selected type is validly substitutable as restriction for the selected
type calculated at step i - 1.
We assume the first operation has a negligible cost. Indeed, given an element E and a type T, the Element Declarations Consistent (EDC) constraint ensures that the context-determined type table for E in T depends on the E name only. Thus it suffices to scan the T content model, looking for an element declaration named as E. As we are not interested in the content model size here, we assume TTi can be found through a single memory access.
We assume the third operation has a negligible cost too. Indeed, we assume for each
pair of types <A, B>, the schema compile phase already decided whether A is validly substitutable as restriction for B, and that the result is available at run-time and can be read through a single memory
access.
In our analysis, we do not neglect the second operation cost. Given an element E and a Type Table TT, in order to decide the selected type for E in TT, it might be necessary to evaluate all the XPath conditions in TT.[4] Indeed if TT has the following alternatives <c1, T1>, ..., <cn, Tn>, then Ti is chosen if and only if none of the conditions c1, ..., ci-1 hold, and ci holds. Thus a correct algorithm for a Type Table evaluation is that evaluating each
alternative in order, and stopping as soon as a condition is satisfied. Clearly, such
an algorithm is linear in the Type Table size.
Coming back to our cost analysis, as TTi has size di, the second operation requires the evaluation of at most di XPath conditions.
Thus in our analysis, the RTC algorithm cost is given by the number of XPath predicates
evaluated. By the observations above, we have that such a cost is upper-bounded by
the equation shown in Equation “RTC algorithm upper-bound”.
RTC algorithm upper-bound
d1 + ... + dk
Hybrid Approach: Cartesian Product
There also exist an hybrid approach to the problem, i.e., an approach neither fully dynamic, nor fully static.
A solution taking such an approach is named Cartesian Product (CP), and the XSD Working Group considered it for a period. As RTC, CP does not impose
any limitation on the CTA usage.
Adopting a hybrid approach, CP consists of two phases. The former is performed at
schema compile time, the latter at validation time. During the static phase, the Type
Tables of the input schema are rewritten. In particular, given a Type Table TTR within a type R and the corresponding Type Table TTB within R's base type, the static phase substitutes TTR with the Type Table resulting from the Cartesian product between TTR and TTB.
The Cartesian product between TTR and TTB is a Type Table denoted by TTR × TTB whose size is the product of the sizes of TTR and TTB. For each pair of alternatives <<ri, Ri>, <bj, Bj>> (where the first item is the i-th alternative of TTR, and the second item is the j-th alternative of TTB), TTR × TTB has an alternative whose condition is the conjunction of ri and bj, and whose type is:
Ri, if Ri is a valid restriction of Bj
error, otherwise.
At run-time, given a type T and an element E, in order to know whether E and T satisfy CTSR, it suffices to evaluate the (rewritten) context-determined Type Table
of E in T. And thus there is no need to walk on the derivation chain.
However, given a derivation chain T1, ..., Tk, and an element E, let TT1, ..., TTk be the sequence of context-determined Type Tables before the static phase rewrite
them. The static phase rewrites those Type Tables in TT'1, ..., TT'k, where:
TT'1 is TT1, and
TT'i is TTi × TT'i-1, for every 1 < i <= k
The condition of each alternative of TT'k is the conjunction of k XPath predicates. Moreover, the TT'k size is d1 ⋅ ... ⋅ dk, where di is the TTi size. Fixing each di to a constant d, that product is dk. Such an observation makes clear that the CP static phase might be too expensive.
Optimized Cartesian Product
In this section we present our solution to the problem of the derivation by restriction
in presence of conditional declarations. We call it Optimized Cartesian Product (OCP). From the expressivity point of view, our proposal is meant to be fully equivalent
to Runt-Time Check and Cartesian Product. While being inspired by CP (and hence its
name), it can also be seen as an RTC optimization.
General idea
Our idea is to perform a static analysis on Type Tables, anticipating at compile time
those cases in which a CTSR violation occurs. Such an analysis is meant to avoid at
run-time the evaluation of those XPath predicates which do not affect the CTSR checking
result.
For instance, consider the schema shown in Figure “CTA Restriction Use Case”. As error is not a valid restriction of any type, it is clear that whenever at run-time a <message> element does not satisfy the @kind='string' predicate within the R context (and hence is assigned type error), a CTSR violation occurs regardless of the actual type that would be assigned within the B context.
So our approach is to perform a static analysis in order to tell the run-time phase
something like: if within the context of type R the predicate a is satisfied, do not evaluate any of the predicates b, c, or d within R's base type, because such an evaluation will not affect the CTSR checking result.
Note that our approach does not consider the actual XPath predicate semantics during
the static analysis. As we already observed, it would be too difficult. Moreover,
note that, as seen for Cartesian Product, our approach is neither completely static,
nor completely dynamic, i.e., it is a hybrid approach.
Before discussing in details our technique, it is worth considering some major problems
our hybrid approach has to face
The corresponding Type Table problem
Given a type T and an element declaration D, our general idea is to perform a static analysis of the cases in which T and a generic element matching D violate CTSR. Thus, the context-determined Type Table of that generic element in
the base type of T have to be statically decided. Put in a bit more formal way, let B be T's base type. The static analysis has to answer the following question: which is the
Type Table TT' determined by B for an element matching D?
The potential case enumeration problem
Assume for the moment the previous problem can be solved. Thus consider a derivation
chain T1, ..., Tk, and the sequence of Type Tables TT1, ..., TTk such that each TTi is the Type Table determined by Ti for a given element. If each TTi has size di, the number of cases that might potentially be verified at run-time is given by d1 ⋅ ... ⋅ dk. If the Type Tables average size is d, that product is similar to dk. Enumerating all such potential cases, might lead to an unacceptable static analysis
cost. It precisely is the problem of the Cartesian Product technique.
For what concerns the first problem, both the Element Declarations Consistent (EDC) constraint and the context-determined Type Table definition provided by the
XSD current draft help us. Indeed, by EDC it is possible to define for each type T a partial function tt-mapT : QName → Type Table, such that for each element name e, tt-mapT(e) returns, if any, the Type Table of an element declaration named e within T.
Given:
T, a type;
B, the base type of T;
D, an element declaration within T;
e, the name of D
the context-determined Type Table within B for any element matching D, cannot be directly calculated as tt-mapT(e), as we have to deal with wildcards (and some other minor details). However, wildcards
do not pose any particular problem, as EDC states that if a type contains both an
element declaration D and a wildcard W, then D's Type Table and the Type Table of any top-level declaration matching W must be the same. Moreover, the context-determined Type Table definition states that
if, within a type T, an element E does not match any declaration, but matches a wildcard W, then the context-determined Type Table within T for E is the Type Table of the top-level declaration matching W, if any. Here, the match predicate is always defined in terms of string matching, and never in terms of schema
component semantics.
Thus, it is easy to extend our tt-mapT function definition so that for any name e, tt-mapT(e) returns the context-determined Type Table within T for any element E named e, exactly as defined by the XSD current draft.
Note also that although the set of qualified names is infinite, tt-mapT is defined only for those qualified names matching some element declaration of the
schema. As the number of element declarations within a schema is finite, also the
tt-mapT domain is finite. The possibility to statically define the function tt-mapT solves the corresponding Type Table problem.
For what concerns the potential case enumeration problem, our idea is the following. Given a sequence of Type Tables TT1, ..., TTk as previously described in the problem definition, we do not consider all the k Type Tables together, but rather we analyze each pair of Type Tables TTi and TTi-1 separately. In particular, for each such pair of Type Tables, we identify the cases
that would cause a CTSR violation for that single derivation step. The results of
such analysis are made available at run-time as annotations on TTi. As we will see, this guarantees an acceptable cost for the static phase. Obviously,
for any element E whose context-determined Type Table is TTi, we have information about CTSR for a single derivation step only, and not for the
whole derivation chain. If that information is not sufficient to decide whether CTSR
is satisfied or not, it is necessary to walk on the derivation chain in order the
access the annotations for TTi-1.
OCP Static Phase
The static phase consists of two steps. The first step just builds for any type T of the schema type hierarchy the tt-mapT mapping. For any T of the schema type hierarchy, the second step annotates the Type Tables within the
tt-mapT codomain with error conditions.
In particular, for each type T and for each name e within the tt-mapT domain, the alternatives of the Type Table tt-mapT(e) are annotated with an error condition. Such a condition specifies the cases in which
CTSR is broken w.r.t. the context-determined Type Table within T's base.[5] Each error condition simply is a boolean expression built on the base Type Table
predicates.
// visits a type of the schema type hierarchy
void visit-type(Type T) {
// annotate each context-determined Type Table within the current type
for each QName name in tt-mapT.domain {
annotate-type-table(tt-mapT(name));
}
// recursive call
for each Type D derived from T do {
visit-type(D);
}
}
// annotates a context-determined Type Table
void annotate-type-table(TypeTable ttr) {
for each int i s.t. 1 <= i <= ttr.size {
// build the error condition for the current alternative
Expression expr = build-error-condition(ttr, i);
// simplify the error condition
expr = simplify(expr);
// annotate the current alternative with the simplified condition
ttr.get-alternative(i).error-condition = expr;
}
}
// builds an error condition for a Type Table alternative
Expression build-error-condition(TypeTable ttr, int i) {
// get the base Type Table
TypeTable ttb = ttr.base;
if (ttb is absent) {
return Expression.FALSE; // In such a case no CTSR violation may occur
} else {
return build-error-condition_aux(ttr, ttb, i, Expression.FALSE, 1, STATE_OR);
}
}
Expression build-error-condition_aux(TypeTable ttr, TypeTable ttb, int i, Expression left, int j, short state) {
if (j > ttb.size) {
return left;
} else {
Expression a;
if (j == ttb.size) {
a = Expression.TRUE;
} else {
a = ttb.get-alternative(j).getTest();
}
Expression right;
Type r = ttr.get-alternative(i).getType();
Type b = ttb.get-alternative(j).getType();
if (r validly restricts b) {
NotExpression negatedLiteral = new NotExpression(a);
right = build-error-condition_aux(ttr, ttb, i, negatedLiteral, j + 1, STATE_AND);
} else {
right = build-error-condition_aux(ttr, ttb, i, a, j + 1, STATE_OR);
}
if (state == STATE_OR) {
return new OrExpression(left, right);
} else { state == STATE_AND
return new AndExpression(left, right);
}
}
}
Pseudo-code for the static analysis of OCP.
The procedure described above is shown in Java-like pseudo-code in Figure “OCP Static Phase Algorithm”. The simplify function is not shown: its purpose is to rewrite the error condition in a simpler
form. In particular, if by atom we mean a Type Table XPath predicate, the simplify purpose is to minimize the number of atoms within the input expression. simplify can be implemented visiting the structure of the expression produced by build-error-condition, and applying the lazy boolean evaluation rules shown in the following table:[6]
Input expression
Rewritten expression
or-rules
FALSE or expr
expr
TRUE or expr
TRUE
and-rules
FALSE and expr
FALSE
TRUE and expr
expr
not-rules
not(TRUE)
FALSE
not(FALSE)
TRUE
The evaluation of the algorithm of Figure “OCP Static Phase Algorithm” on the schema shown in Figure “CTA Restriction Use Case”, annotates the alternatives of the Type Table within R with the following error conditions:
not(@kind='string') and (@kind='base64' or (@kind='binary' or (@kind='xml' or @kind='XML')))
TRUE
The error condition associated to the first alternative states that an element E of the instance document and R violates CTSR whenever E is assigned one of the types messageTypeBase64 and messageTypeXML in the context of B (we are in the hypothesis that messageTypeString is not a valid restriction of any of those two types). The error condition associated
to the second alternative states that regardless of the type assigned in the context
of B, a CTSR violation occurs. This is because error is not a valid restriction of any of the types of the Type Table within B.
On the other hand, the algorithm annotates each alternative of the Type Table within
B with the error condition FALSE. It means that for any element E, E and B do not violate CTSR. This is because B's base is anyType and obviously the types within the Type Table within B are valid restrictions of anyType.
OCP Run-Time Phase
At validation time, the annotations on context-determined Type Tables are read in
order to check CTSR. In particular, let E be an element of the instance document, T be the type of E's parent, and TT be the context-determined Type Table of E in T. Firstly, TT has to be evaluated. Then, the error condition associated to the satisfied alternative
is also evaluated. If the error condition evaluates to true, then it is possible to
conclude that CTSR is not satisfied. Otherwise, the same procedure has to be recursively
executed using T's base type. The recursive process stops either when a CTSR violation occurs, or
anyType is reached.
void process-element(Element e) {
...// e's parent type
Type T = current-type();
// get the context determined Type Table for e
TypeTable tt = tt-mapT(e);
// evaluate the type table
int i = evaluate-type-table(e, tt);
if (!check-CTSR(e, tt, i)) {
report-schema-error("vr-cta-substitutable");
}
...
}
boolean check-CTSR(Element e, TypeTable ttr, int i) {
Alternative alt = ttr.get-alternative(i);
Expression err-epxr = alt.error-condition;
if (evaluate-error-condition(e, err-expr)) {
return false;
} else {
TypeTable ttb = ttr.base;
if (ttb is absent) {
return true; // implicitly handles the xs:anyType case
} else {
int j = evaluate-type-table(e, ttb);
// recursive call
return check-CTSR(e, ttb, j);
}
}
}
Algorithm for the run-time phase of OCP.
The procedure described above is shown in Java-like pseudo-code in Figure “OCP Run-time Phase Algorithm”. In order to show how it works, let us consider following document:
and suppose we have to validate it against the schema depicted in Figure “CTA Restriction Use Case” (the error conditions built during the static phase are described in Section “OCP Static Phase”). When the first <message> element is processed, its context-determined Type Table is evaluated. It is then
checked that it satisfies the first condition @kind='string'. As a consequence, it is assigned the first alternative. So the error condition associated
with that alternative is evaluated. Such a condition is not(@kind='string') and (@kind='base64' or (@kind='binary' or (@kind='xml' or @kind='XML'))). Clearly, the error condition is not satisfied (not(@kind='string') evaluates to false). Consequently, the Type Table within B has to be evaluated. Again, the first alternative is chosen, and thus its error condition
is evaluated. But such a condition is FALSE. And so it is possible conclude that the first <message> element and R satisfy CTSR.
For what concerns the second <message> element, we have that it does not satisfy the first alternative predicate, and so
it is assigned the default alternative. The error condition associated to such alternative
is TRUE. So we have that the second <message> element and R do not satisfy CTSR.
OCP Cost Analysis
In this subsection we provide a cost analysis for the static phase and a cost analysis
for the run-time phase of OCP.
OCP Static Phase Analysis
Here we are not interested in analyzing the cost of the static phase applied to the
entire schema type hierarchy. Rather, we fix an element name and we consider a single
path from the root to a generic leaf of the type hierarchy.
Thus, let T1, ..., Tn be a derivation chain, and e be our element name. We can now consider the sequence of Type Tables TT1, ..., TTn, where TTi is the context-determined Type Table for an element named e within Ti. The size of each TTi is denoted by di.
Given a 1 < i <= n, now we analyze the time needed to annotate TTi.
The function build-error-condition iterates over the whole alternative sequence of TTi-1, and for each alterantive it computes a number of operations whose cost is constant.
Thus the function cost is linear in the TTi-1 size, i.e., di-1
The function simplify can be implemented visiting the structure of the expression returned by build-error-condition. The number of nodes of such an expression is linear in di-1. Thus, the simplify computational cost is linear in di-1 too.
As both simplify and build-error-condition are called for each alternative of TTi, the asymptotic computational cost for the function annotate-type-table is di-1⋅di.
Thus, the asymptotic cost for building and simplifying the error conditions of the
whole sequence of Type Tables, is given by:
d1 + d1⋅d2 + ... + dn-1⋅dn
We believe such a cost is perfectly acceptable at schema compile time.
OCP Run-Time Phase Analysis
Here we provide a computational cost analysis of the run-time phase of OCP. As similarly
done for RTC, we are interested in determining the number of XPath predicates that
have to be evaluated for a generic element of the instance document.
Let E be an element of the instance document, and T be the type assigned to E's parent. Consider the derivation chain T1, ..., Tk, where T1 is anyType and Tk is T. Also consider the usual Type Table sequence TT1, ..., TTk, where TTi is the context-determined Type Table for E within Ti.
If E and T satisfy CTSR, the entire Type Table sequence is processed. For any 1 < i <= k, TTi is evaluated to obtain the assigned alternative. The cost of such an operation is
linear in di. Once the assigned alternative has been determined, the algorithm evaluates the corresponding
error condition. As already discussed, such a condition is a boolean expression over
the XPath predicates of TTi-1. In our analysis, the cost of evaluating an error condition with n predicates is linear in n. As by construction none XPath predicate appear more than once within the same error
condition, we have that the error condition associated to the assigned alternative
contains at most di-1 predicates of TTi-1. So its evaluation cost is linear in di-1. Thus, the number of predicates evaluated for TTi is upper-bounded by di + di-1.
Considering the whole Type Table sequence, the number of evaluated XPath predicates
is given by the formula shown in Equation “OCP run-time phase upper-bound”.
OCP run-time phase upper-bound
2⋅d1 + ... + 2⋅dk-1 + dk
Comparing CP, OCP, and RTC
In this section we provide a comparison among the main techniques discussed so far:
Optimized Cartesian Product, Run-Time Check, and Cartesian Product. The comparison
focuses on the number of XPath predicates evaluated at run-time. Before starting,
let us first fix some notations. Let:
E be an element of the instance document;
T be the type assigned to E's parent;
T1, ..., Tk be the derivation chain for T, where T1 is anyType and Tk is T;
TT1, ..., TTk be the sequence of context-determined Type Tables of E along the derivation chain;
di be the TTi size, for every i;
TT'1, ..., TT'k be the Type Tables generated by the Cartesian Product static phase.
Both OCP and RTC evaluate TTk in order to decide which type alternative E has to be assigned. Clearly, both techniques evaluate the same XPath predicates of
TTk. The number of evaluated XPath predicates ranges from 1 to dk.
On the other hand, CP evaluates TT'k. If, for any i between 1 and k, E satisfies the first alternative of TTi, CP is assigned the first alternative of TTk, and thus the condition of that alternative only is evaluated. However, that condition
is the conjunction of k XPath predicates. So in the best case, CP evaluates k XPath predicates. But if for every i between 1 and kE satisfies the last alternative of TTi, than CP has to process every alternative of TT'k. It means that it has to evaluate d1 ⋅ ... ⋅ dk conditions, where each condition is the conjunction of k XPath predicates.
After the TT'k evaluation, CP already knows whether E and T satisfy CTSR without the need to walk on the derivation chain: if TT'k selected type error then CTSR is violated, otherwise CTSR is satisfied. The problem is that the evaluation
of TT'k might be very expensive.
On the other hand, after the TTk evaluation, both OCP and RTC execute further operations. OCP evaluates the error
condition linked to the alternative returned by TTk, while RTC evaluates TTk-1. Thus, for the purposes of our comparison, it is important to understand whether
evaluating the error condition is more or less expensive than evaluating TTk-1. In order deal with a clearer notation, we temporarily rename some variables:
Tk becomes R;
Tk-1 becomes B;
TTk becomes TTR;
TTk-1 becomes TTB;
dk becomes n;
dk-1 becomes m;
We denote the TTR alternatives by <r1, R1>, ..., <rn, Rn>; and the TTB alternatives by <b1, B1>, ..., <bm, Bm>. Moreover, let i be the (index of the) alternative selected by TTR. We denote the error condition associated to that alternative by erri.
As already observed in Section “OCP Static Phase”, erri is a boolean expression over the XPath predicates (here called atoms) of TTB. Assuming the simplification process did not rewrite it, erri contains each of the m atoms of TTB.
OCP Error Condition Example: OCP Error Condition Example
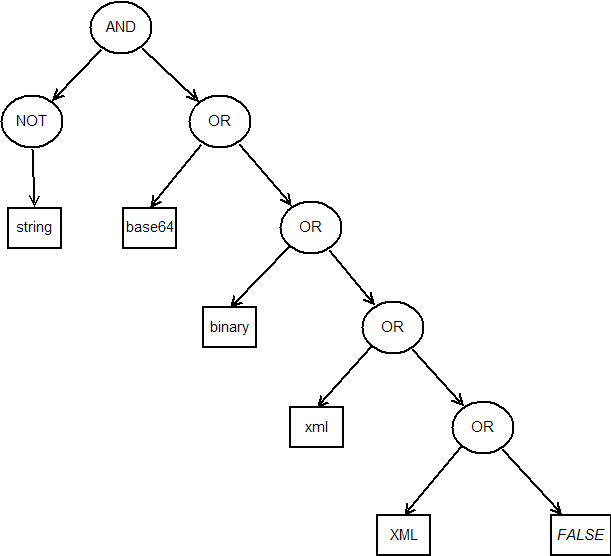
Structure for the error condition not(@kind='string') and (@kind='base64' or (@kind='binary' or (@kind='xml' or (@kind='XML'
or FALSE)))). XPath predicates have been abbreviated for conciseness reasons.
At this point it is important to study the structure of a generic error expression
erri. As also shown in Figure “OCP Error Condition Example”, an error condition has a fixed structure: for each or (and) operator, its left operand is always a (negated) atom, while its right operand is
either another binary operator, or FALSE (TRUE). Moreover, we can observe that the atoms appear in the same order they appear in
TTB.
It is easy to implement an error condition evaluator as a lazy boolean evaluator: for any input binary operator it always evaluates the left operand first, and it
evaluates the right operand only if necessary. The atoms of erri actually evaluated by such a boolean evaluator are exactly the same as those evaluated
by RTC to decide the TTB selected type.
For instance, suppose that for a given j our E element does not satisfy none of b1, ..., bj-1, and it does satisfy bj. RTC evaluates b1, ...,bj. Also our technique evaluates those predicates, and it does not evaluate further
ones. Indeed within erri, bj appears either in negated form as left operand of an and operator, or directly as left operand of an or operator (it depends on whether or not Ri is validly substitutable as restriction for Bj). In either case, the erri evaluation stops before processing the right operand.
Thus we can conclude that even if it is not possible to simplify erri, OCP and RTC are equivalent in terms of evaluated atoms. But there are cases in which
erri is simplified by the rewriting rules described in Section “OCP Static Phase”. Indeed, if there exists a j such that either
for each j < j' <= m, Ri is not validly substitutable as restriction for Bj'
or
for each j < j' <= m, Ri is validly substitutable as restriction for Bj',
then the simplification process removes from erri the atmos bj+1, ..., bm.
In such cases, if E does not satisfy any of the predicates b1, ..., bj+k, for some k, then OCP does not need to evaluate the k atoms bj+1, ..., bj+k in order to decide whether CTSR is satisfied or not. On the other hand, RTC does
evaluate those atoms, because it has to find the type actually selected by TTB.
Thus, we can conclude that on a single step of a derivation chain, OCP evaluates a
number of predicates less than or equal to the number of predicates evaluated by RTC.
However, as can be noted from the formulas shown in Equations “RTC algorithm upper-bound” and “OCP run-time phase upper-bound”, OCP might evaluate twice the same atoms. Coming back to the notation introduced
early in this section, if E does not satisfy the error condition of the alternative selected by TTk, then OCP has to evaluate TTk-1. But as the error condition previously processed was built on the atoms of TTk-1, it is clear that some predicates of TTk-1 might be processed twice.
However, it is possible to ease such an additional cost if during the processing of
an error condition, the result of each atom evaluation is stored in some data structure.
In this way, an XPath predicate is actually evaluated only if it has not been evaluated
yet.
So we conclude that for a given derivation chain, OCP evaluates a number of XPath
predicates less than or equal to the number of XPath predicates RTC evaluates.
Implementation
We realized a prototype implementation of Optimized Cartesian Product, thus demonstrating
its feasibility. We implemented it in Java within Xerces [Xerces]. Our prototype patches Xerces under three aspects:
support for XSD 1.1 related components;
implementation of the OCP static phase;
implementation of the OCP run-time phase within the existing validation code.
As Xerces is an XML parser for XSD 1.0, it does not handle 1.1-specific constructs.
Our prototype modifies the Xerces modules delegated to the construction of schema
components (package org.apache.xerces.impl.xs.traversers). It also modifies the Xerces implementation of the XML Schema API [XML Schema API], in order to represent type alternative components, and to give element declarations
awareness of their Type Tables (packages org.apache.xerces.xs and org.apache.xerces.impl.xs).
The OCP static phase is implemented within a separated package it.unibo.cs.cta. The code for the error condition construction is within the class it.unibo.cs.cta.preprocessor.impl.ErrorConditionBuilder. Such a class processes an input XSD schema, associating each type with a map. That
map is our implementation of tt-mapT. Indeed, it associates element names to context-determined Type Tables. ErrorConditionBuilder also annotates each context-determined Type Table with its error conditions. Error
conditions are built directly using the algorithm described in Section “OCP Static Phase”. The classes handling error conditions are within the package it.unibo.cs.cta.errorexpr. In particular, the simplification of error conditions is implemented by ErrorExpressionSimplifier, while their evaluation is implemented by ErrorExpressionEvaluator.
The static phase is delegated to a pre-processor invoked when a schema document is
loaded. In order to invoke it, the simple and compact code below is used:
// instantiation
PreprocessorFactory pf = PreprocessorFactory.getInstance();
fPreprocessor = pf.createPreprocessorSequence(
new String[]{"ErrorConditionBuilder"}
);
// invocation on an XS Model
fPreprocessor.processModel(model);
The static phase result (i.e., association between types and maps) is read calling
the pre-processor method getStateByName("type-table-map").
The OCP run-time phase is implemented within the class org.apache.xerces.impl.xs.OptimizedCTAXMLSchemaValidator, a patched version of the original XSD validator provided by Xerces. In particular,
the code for the CTSR verification is within the method handleStartElement. XPath predicates are evaluated using the interfaces in javax.xml.xpath. Currently, our prototype does not check whether an XPath predicate has already been
evaluated. Thus, as observed in Section “Comparing CP, OCP, and RTC”, an XPath predicate might be evaluated twice for the same element.
Our prototype is meant to prove the OCP feasibility, and as such it is not aimed to
be XSD 1.1 conformant. In particular it has some limitations, the most important of
which are:
XPath 1.0 expressions only are accepted;
all non CTA related syntax is ignored. E.g., <assert> elements are not considered legal within a schema;
derivations by restriction are checked using the original Xerces code, i.e., XSD 1.0
rules are applied.[7]
Among the most known validation languages (DTD [XML 1.1], RELAX NG [RELAX NG ISO specification], Schematron [Schematron ISO specification], DSD [DSD 2.0], etc), the problem of verifying the subtype relation in presence of conditional
declarations is very specific to XSD 1.1. Indeed, although there exist at least one
language, DSD, permitting the definition of conditional content models, that language
is not type-based, and consequently nor it has any concept of type derivation. We
do not know works about restriction checking in presence of conditional declarations.
However, there exist works on the problem of verifying whether an XSD 1.0 type is
a legal restriction of another type [H. S. Thompson, and R. Tobin, 2003], [M. Fuchs, and A. Brown, 2003], [C. M. Sperberg-McQueen, 2005]. Those works propose techniques to statically verify whether a type accepts a subset
of what the base type accepts. On the same line, Neven et al present theoretical results
about some basic decision problems concerning schemas, among which the problem of
testing for inclusion of schemas [W. Martens, F. Neven, and T. Schwentick, 2005].
Conclusions
In XSD 1.1, the presence of conditional declarations increases the difficulty in verifying
whether a type is a legal restriction of its base. We discussed about three main approaches
to the problem: CTA usage limitation, run-time verification, and hybrid verification.
Solutions of the first kind ensure it is possible to statically verify whether a type is a legal restriction of its base, but at the cost of limiting
the CTA expressivity. Solutions of both second and third kinds allow the highest degree
of expressivity, but they may recognize as legal restriction also a type accepting
something its base rejects. They throw an error only for those instance documents
actually proving that a type is not a legal restriction of its base. Hybrid solutions
are meant to precompute during the static phase some information that might decrease
the work to be done at run-time.
In particular, we described the solution adopted by the XSD current draft, which follows
a run-time approach described within the specs by the Conditional Type Substitutable
in Restriction (CTSR) constraint. We discussed about an algorithm verifying CTSR,
and we called it Run-Time Check (RTC). Then we proposed an alternative solution to
RTC, named Optimized Cartesian Product (OCP). OCP is a hybrid solution. Its idea is
to analyze conditional declarations in order to statically decide which XPath predicates
can be ignored at run-time. We showed as, contrary to Cartesian Product (CP) - another
hybrid solution OCP can be seen as an optimization of - the OCP static analysis cost
is perfectly acceptable.
We than compared the RTC, OCP and CP techniques, focusing on the number of XPath predicates
evaluated at run-time. We showed as CP is the worst technique, as it inherits from
the static phase a high volume of information that might heavily slow down the run-time
phase. We also showed that although OCP might process the same alternatives twice,
storing the XPath predicate evaluation results, we can assert that OCP evaluates a
number of predicates less than or equal to the number of predicates RTC evaluates.
An interesting future work is the experimental comparison among RTC, OCP and CP on
a base of real schema documents. Moreover it is interesting to improve our error condition
simplification process. For instance, our simplification rules are not able to rewrite
expressions like not(@a = 'v1') and (@a = 'v2') into (@a = 'v2'). There are also error conditions that are clearly unsatisfiable when associated to
a particular alternative. For instance, if the alternative predicate is (@a = 'v1') and the error condition is (@a = 'v2'), it is clear that the error condition will never be satisfied. Improving the simplification
rule set should increase the number of situations in which OCP is preferable to RTC.
Acknowledgements
We would like to thank Stefano Zacchiroli for the technical discussions we had during
the design of the Optimized Cartesian Product technique, the anonymous reviewers for
their comments, and the XML Schema Working Group for the several and inspiring discussions
on the topics covered by this paper.
[DSD 2.0] Møller, A. 2002. Document Structure Description 2.0. BRICS, Department of Computer
Science, University of Aarhus, Aarhus, Denmark. http://www.brics.dk/DSD/.
[P. Marinelli, C. Sacerdoti Coen, and F. Vitali, 2004] P. Marinelli, C. Sacerdoti Coen, and F. Vitali. SchemaPath, a Minimal Extension to
XML Schema for Conditional Constraints. In Proceedings of the Thirteenth International World Wide Web Conference. New York, NY, USA. May, 2004. Pages 164-174. ACM Press.
[W. Martens, F. Neven, and T. Schwentick, 2005] W. Martens, F. Neven, and T. Schwentick. Which XML Schemas Admit 1-Pass Preorder Typing?
In Proceedings of the 10th International Conference on Database Theory. Edinburgh, UK, January 5-7, 2005. LNCS. Volume 3363. Pages 68-82.
[1] From here on, we refer to XSD 1.1 just as XSD.
[2] This limitation is not enforced by a syntactic limitation on the XPath expression,
but rather by the way the XPath Data Model is constructed.
[3] In XSD, if a type is set as final, it cannot be derived.
[4] To be more precise, as the last predicate of a Type Table is the always true condition,
it suffices to evaluate n-1 predicates, where n is the Type Table size.
[5] From here on, given a type T, an element E and the context-determined Type Table TT of E in T, by “TT's base Type Table” we mean the context-determined Type Table of E in T's base.
[6] Symmetric rules for binary operators are not shown.
[7] XSD 1.0 defines the derivation by restriction in terms of ad hoc rules provided by
the recommendation itself. XSD 1.1 allows processors to choose the algorithm they
like to check whether a content model includes another content model.
Møller, A. 2002. Document Structure Description 2.0. BRICS, Department of Computer
Science, University of Aarhus, Aarhus, Denmark. http://www.brics.dk/DSD/.
P. Marinelli, C. Sacerdoti Coen, and F. Vitali. SchemaPath, a Minimal Extension to
XML Schema for Conditional Constraints. In Proceedings of the Thirteenth International World Wide Web Conference. New York, NY, USA. May, 2004. Pages 164-174. ACM Press.
W. Martens, F. Neven, and T. Schwentick. Which XML Schemas Admit 1-Pass Preorder Typing?
In Proceedings of the 10th International Conference on Database Theory. Edinburgh, UK, January 5-7, 2005. LNCS. Volume 3363. Pages 68-82.