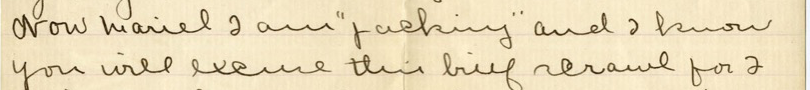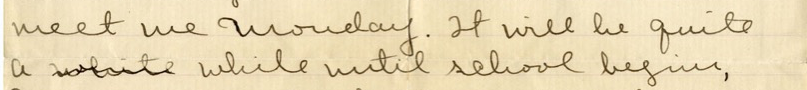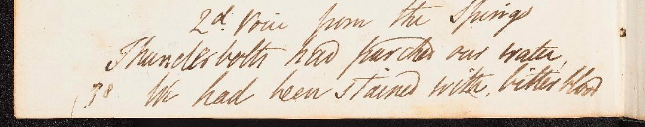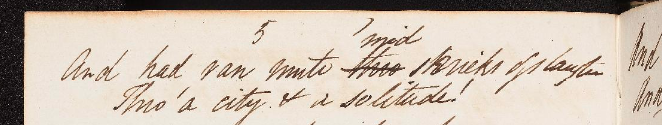Haentjens Dekker, Ronald, Elli Bleeker, Bram Buitendijk, Astrid Kulsdom and David J. Birnbaum. “TAGML: A markup language of many dimensions.” Presented at Balisage: The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.HaentjensDekker01.
Balisage: The Markup Conference 2018 July 31 - August 3, 2018
Balisage Paper: TAGML: A markup language of many dimensions
Ronald Haentjens Dekker
Head of Research and Development and Software Architect
Research and Development Team, KNAW Humanities Cluster
Ronald Haentjens Dekker is a software architect and lead engineer of the
Research and Development Team at the Humanities Cluster, part of the Royal
Netherlands Academy of Arts and Sciences. As a software architect, he is
responsible for translating research questions into technology or algorithms
and
explaining to researchers and management how specific technologies will
influence their research. He has worked on transcription and annotation
software, collation software, and repository software, and he is the lead
developer of the CollateX collation tool. He also conducts workshops to teach
researchers how to use scripting languages in combination with digital editions
to enhance their research.
Elli Bleeker
Software Developer, Research and Development
Research and Development Team, KNAW Humanities Cluster
Elli Bleeker is a postdoctoral researcher in the Research and Development Team
at the Humanities Cluster, part of the Royal Netherlands Academy of Arts and
Sciences. She specializes in digital scholarly editing and computational
philology, with a focus on modern manuscripts and genetic criticism. Elli
completed her PhD at the Centre for Manuscript Genetics (2017) on the role of
the scholarly editor in the digital environment. As a Research Fellow in the
Marie Sklodowska-Curie funded network DiXiT (2013–2017), she received advanced
training in manuscript studies, text modeling, and XML technologies.
Bram Buitendijk
Software Developer, Research and Development
Research and Development Team, KNAW Humanities Cluster
Bram Buitendijk is a software developer in the Research and Development team
at the Humanities Cluster, part of the Royal Netherlands Academy of Arts and
Sciences. He has worked on transcription and annotation software, collation
software, and repository software.
Astrid Kulsdom
Project Manager, Research and Development
Research and Development Team, KNAW Humanities Cluster
Astrid Kulsdom is a project manager and researcher in the Research and
Development team at the Humanities Cluster, part of the Royal Netherlands
Academy of Arts and Sciences. After completing her research Master’s in Literary
Studies at Radboud University in 2012, she has worked as a project manager for
several government institutions. As project manager of the Research and
Development team, she combines her philological knowledge with her project
management skills in order to effectively manage all strands of research within
the team.
David J. Birnbaum
Professor and Co-Chair
Department of Slavic Languages and Literatures, University of
Pittsburgh
David J. Birnbaum is Professor and Co-Chair of the Department of Slavic
Languages and Literatures at the University of Pittsburgh. He has been involved
in the study of electronic text technology since the mid-1980s, has delivered
presentations at a variety of electronic text technology conferences, and has
served on the board of the Association for Computers and the Humanities, the
editorial board of Markup languages: theory and
practice, and the Text Encoding Initiative Council. Much of his
electronic text work intersects with his research in medieval Slavic manuscript
studies, but he also often writes about issues in the philosophy of
markup.
This report presents new developments in three areas pertaining to Text As Graph
(TAG), a data model that conceptualizes what text really is as a
property hypergraph, which we first introduced at Balisage 2017. (Haentjens Dekker and Birnbaum 2017) In this new report 1) we propose a markup language
for TAG, which we call TAGML; 2) we discuss a workflow, implemented in our Alexandria reference implementation of TAG, for editing
TAG documents selectively, so as to retain a legible interface; and 3) we introduce
some modifications in the TAG data model (principally the use of undirected edges
to
connect Text nodes).
From cave wall to clay tablet, and from codex to bits, the way we write and the
ways in which we model, store, and process textual objects are influenced by the
medium and technologies at our disposal. Hence, over time, we have had various
understandings of text, ranging from a sequence of characters designed to support
oral recital to a hierarchical tree of objects. Our changing understanding and
implementation of our perspectives on what text really is has had
consequences for how we interact with textual objects, since the affordances and
limitations of a prevailing technology may blind us to aspects not supported by
that
technology (Dillen 2015, 69). Encoding a historical text in
TEI-XML, for instance, might subtly encourage us to ignore textual phenomena that
are not part of the TEI-XML encoding model (Sahle 2013, 381–82).
We maintain that it is most natural, idiomatic, and inclusive to consider text
as a
network of often implicit information. Adhering to this conceptual idea of text
opens the way to an innovative approach to creating, modeling, and processing
textual objects.
This article describes recent progress in the design and implementation of TAGML,
a markup language for the Text As Graph (TAG) model of text, from a conceptual
and a
technical perspective. We characterize the relationship between the markup language
and the data model, and we outline how creating layers of markup and annotation
on
the text allows the user to formally describe complex textual features in a
straightforward manner. The article builds on two previous articles on the same
topic (Haentjens Dekker and Birnbaum 2017; Bleeker et al. 2018a), which
respectively introduced the TAG model and described how to model textual variation
in TAG.
Over the past decades, a variety of definitions of the term text has been suggested. In order to construct a well-grounded and
useful model, we need a highly refined definition of the textual object, a
definition that holds on a conceptual level and one that translates informatically.
We therefore propose to distinguish between a conceptual description and a technical
description of text. On the one hand, we define written
text as a sequence of characters (e.g., letters, digits, spaces, and
punctuation in most alphabetic writing systems) inscribed in a document. A document, here, is a physical object that contains some
sort of inscribed information. Both text and document are broadly defined, and
may
also include, for example, the bits on a disk or the symbols carved in a tree.
The
items that make up written text are culturally determined, and although not all
writing is alphabetic, nonalphabetic writing systems also use written symbols
to
express linguistic textual content.
On the other hand, the TAG model understands text
to be a multi-layered, non-linear construct containing information that is at
times
ordered, partially ordered, and unordered. A layer
is, in principle, defined as a hierarchical set of Markup nodes (including
associated annotations). By multi-layered we mean
that a text in TAG can have multiple layers of markup. A layer is hierarchically
structured; layers may overlap. Layers have a key function in TAGML, as is described
in Layers.
By non-linear we mean that the text nodes
(textual content) of a TAG document do not necessarily form a single ordered list.
The TAG model distinguishes three types of information: textual content, textual
variation, and markup. These three types of information can be expressed without
workarounds in TAGML, as illustrated in Order of textual content.
Textual content in TAG, from an informational
perspective, is a sequence of characters (including symbols, but excluding any
type
of formatting). In the following excerpt from a letter by Willa Cather, the phrase
now Mariel I am "packing" and I know you will excuse this brief
scrawl makes up the textual content:
Figure 1
Excerpt from a letter from Willa Cather to Mariel Gere, source: letter ID
0005, in the Willa Cather archive, edited
by Andrew Jewell (20104-2018)
Markup can be used to make implicit information
explicit. Adding markup to a document can be understood as adding one or more
layers
of additional information (structural, interpretive, etc.) to the information
expressed by the sequence of textual characters.
In TAGML, markup consists of start-tags and
end-tags. A start-tag and an end-tag together
constitute a Markup node. Markup nodes can have
attributes, which are called annotations. Annotations are comparable to the attributes on XML elements in that
they represent properties of an object. Annotations in TAGML, unlike XML, are
typed
(Data typing).
Alexandria is a text repository system that serves
as the reference implementation of the TAG model, under ongoing development at
the
Research and Development team of the Humanities Cluster of the Dutch Royal Academy
of Science (Alexandria). Within the framework of Alexandria, a view is a
version of a TAG document with one or more layers of markup. The concept of view
can
best be understood from a user’s perspective: similarly to the git (Git) workflow, working with text in Alexandria entails checking out
from the Alexandria repository a version of the TAG
document with a specified set of layers (the view), editing this view, and checking in the edited view back into the repository. The
motivation for supporting customizable views of a TAG document is that the TAG
document in its full, hypergraph glory may contain more information (layers of
Markup nodes and annotations) than can be visualized in any informative way. In
situations where users are able to interact meaningfully with a text without seeing
all Markup layers simultaneously, a view enables them to work on specific aspects
of
a document without distraction by other features. A more detailed description
of
these concepts is given in TAGML, and the theoretical dimensions
of views are laid out in Workflow.
Overview
It is a truth universally acknowledged—at least within the markup community—that a
markup technology stack is a complex business. Such a stack typically includes
at
least four ingredients: a model, a syntax, a query language, and a schema. Haentjens Dekker and Birnbaum 2017, presented at Balisage 2017, introduced the model—a
hypergraph model for text—that understood text as a network of information. Our
2017
paper identified a number of textual phenomena that the hypergraph model needs
to
express, and it showed how the model represents each of them. That paper also
introduced the Alexandria prototype implementation
of TAG (Alexandria), which can import documents marked up in
either LMNL (Piez 2008) or TexMECS (Huitfeldt and Sperberg-McQueen 2003). At that time TAG did not have its own markup language, and it borrowed from the
syntax from LMNL and TexMECS to represent features of TAG. Finally, an Appendix
to
our 2017 paper identified five issues that were not yet part of the TAG model,
although they had been identified as important, and therefore as goals for future
development:
simultaneity
constraints
a markup language
textual variation (on an intradocumentary as well as an
interdocumentary level)
transposition
A number of these features have now been included into the TAG model
and are discussed below in the present article: simultaneity, constraints (for
now
only from a technical perspective, and not yet from a user perspective), the TAGML
markup language, and textual variation (for now only on an intradocumentary, and
not
interdocumentary, level). The other aspects of constraints and textual variation,
as
well as transposition, are still under development, and are not within the scope
of
the present paper.
Our paper begins with an introduction to the syntax of the TAG markup language
(TAGML, section “Syntax”), including a formal grammar of TAGML (TAGML grammar). The next section describes a workflow that
facilitates editing a multilayered document (Workflow) and
sketches at least three implementations of the layer functionality. As an
illustration of the workflow we focus on editing a historical manuscript, but
TAG
also facilitates modeling and processing other types of text, e.g., born-digital
texts, or non-literary texts, such as those represented in judicial or pedagogical
documents. The consequences and implications for the way we model, work with,
and
understand text are discussed in the Discussion and Conclusion.
Two essential ingredients of the markup technology stack are not addressed at all
in the present article: schema language validation and the query language. We
introduce the concept of the schema language in this paper, but it remains at
an
early stage of development. The query language was introduced in an exploratory
way
in our Balisage 2017 article, and will be extended in the future. The aspects
of the
project that we regard as ready for presentation at the Balisage 2018 conference
are
the TAGML markup language, our modifications to the TAG hypergraph model, and
the
proposed workflow for managing multiple Markup layers.
Despite work on the (implementations of the) TAG model being under active
development, we consider our experiences with developing TAGML as beneficial to
a
productive discussion on designing a markup language. The affordances of TAG’s
hypergraph model allowed us to reconsider ingrained notions of textual features
and
how to model them most effectively. Our article, then, can be read not only as
a
technical report of recent project developments, but also as a conceptual and
methodological reflection on the potential of markup to express our understandings
of text.
TAGML
Preamble
TAG is designed to be able to model (and TAGML is designed to be able to encode)
text and markup, including overlapping markup and ordered, partially ordered,
and
unordered information. This design principle means that TAG processing can support
any type of query, from Boolean to ranked pattern matches at
the level of the model, and that the complex mixture of information
can be parsed and processed in an idiomatic manner and without
work-arounds. Encoding of unordered data is supported in a JSON-like
manner (Data typing); as is linking from a TAGML transcription of
ordered text to unordered information (Linking elements).
Annotations in TAG, unlike attributes in XML, can contain both text and markup.
This
feature is defined as Rich text (Rich text annotations). Annotations may also have annotations.[1]
TAGML allows the straightforward expression of the multi-layered, non-linear
features of text described in Philosophy-and-Definitions. The following
subsections first describe the general features of TAGML: layers, non-linear
structures, and order. They then go on to discuss TAGML’s syntax in detail. TAGML’s
general specifications are then illustrated with examples that include the (main)
constraints of the syntax. Finally, the specifications are summarized in tabular
format.
Layers
Layers are used to classify a specific set of Markup nodes. The reasons for
grouping Markup nodes together into a set may vary. For example, a set of Markup
nodes may express a research perspective on text, as with a layer that consists
of
Markup that describes the physical aspects or the poetic structure of a text.
Alternatively, in the case of an editorial workflow with two or more users, a
layer
could identify a set of Markup nodes that is added by a particular user.
In TAGML we model containment as well as
dominance.[2] To understand this feature, it is helpful to examine the distinction
between total containment, partial containment, and dominance. Partial containment, or partial overlap, occurs when content is
shared by two or more Markup nodes. Total
containment occurs when all content in one Markup node is shared with
another Markup node. In hierarchical terms, A fully contains B means
A is an ancestor of B, etc.[3] Dominance presupposes total containment, but also requires meaningful semantics:
Containment is a happenstance relationship between ranges while dominance
is one that has a meaningful semantic. A page may happen to contain a stanza, but a poem dominates the stanzas that it contains. (Tennison 2008)
If we apply the preceding explication to the case of Folium 23r, Prometheus unbound, we can say that the manuscript page contains a number of
lines, but also that the first two lines are dominated by a stanza. Accordingly,
TAG
assumes that dominance reflects a user’s interpretation of a text’s hierarchical
structure(s), and is therefore applied intentionally.
Two basic ways are available to record dominance within an encoding: in the syntax
of the document instance or in a schema. In the model of Extended Annotation Graphs
(eAG), dominance is represented in the syntax, which means that the dominance
needs
to be recorded per individual item or element (e.g., A extends B or
a > b [Barrellon et al. 2017]).
In TAGML dominance is also represented in the syntax, but in a different way.
Rather than specifying the parent node of each node, nodes are grouped in a layer.
This means that markup within a layer represents a dominance relationship, while
layers that overlap represent containment. This is somewhat similar to the notation
that XConcur uses to indicate that an element belongs to multiple hierarchies
(Hilbert et al. 2005), but with an important distinction: in XConcur,
complete subtrees are shared, while in TAGML indidivual markup nodes are shared
between layers. This is more akin to how nodes are shared in Multi-Colored-Trees
(MCT, Jagadish et al. 2004). Layers do not have to be defined at the
beginning of the document, a new layer can be started at any point in the document,
and Markup nodes may be part of multiple layers.
Order of textual content
In general, the text of a TAGML document is to be read in the order in which it is
transcribed. Continuous textual content is normally fully
ordered. The value of the data is represented by the character
sequence, and the order of the characters is therefore an inalienable part of
the
meaning. Because of its fully ordered nature, the information is parsed and
processed by traversing the characters in a manner determined by the writing system
(from left to right, proceeding from top to bottom, in the Cather letter).
Textual variation constitutes partially ordered
information. Consider the following example, also by Willa Cather:
Figure 2
Excerpt from a letter from Willa Cather to Mariel Gere, source: letter ID
0005, in the Willa Cather archive, edited
by Andrew Jewell (20104-2018)
The word white is crossed out, so that the phrase can read either
It will be quite a white until school begins or It will be
quite a while until school begins.[4] There are, metaphorically speaking, two paths through the sequence of
text characters, which diverge after the word a and reconverge before
the word until. Cather wrote the word white before she
wrote the word while, and that order is meaningful with respect to the
genesis of the text, but synchronically the variation is simultaneous: there is
an
erroneous path through white and a correct path through
while. The two words that alternate are mutually exclusive in
terms of whether we choose the original or the corrected reading, and they are
at
the same distance from the beginning of the sentence, a phenomenon we describe,
using terms from graph theory, by saying that they have the same rank. Items at the same rank are logically unordered,
which means that although the textual content in general is fully ordered, at
the
points in the text where variation occurs the textual units (which we call Text
nodes) at the same rank on different paths are unordered. Within each path, however,
the textual information is again fully ordered.
Order of metadata
Although the combined set of information (i.e., text and markup) is at times
ordered, unordered, or partially ordered (see also Order of textual content), depending on the kind of information that
is expressed, existing text models and markup languages in wide use are typically
well-suited to handle only specific types of information. For example, unordered
data can be represented naturally in JSON objects, the contents of which are
necessarily unordered. Meanwhile, the XML data model (and associated markup syntax)
require that all elements be ordered (and that XML attributes be unordered, about
which see below).
Unordered information is commonly found in
metadata contexts. For example, a corpus of Willa Cather’s letters might include,
perhaps in an ancillary document, biographical information about her correspondents,
such as their first names, surnames, birth and death dates, addresses, etc. This
type of information is often encoded in name:value pairs, as in a JSON object,
and
the order of the properties of a JSON object is, by definition, not informational.
(An object is an unordered set of
name/value pairs.Introducing JSON) In so-called data-centric XML,[5] a schema may specify that sibling elements that encode name/value pairs
may appear in any order, and in this sense data-centric XML may seem similar to
name:value pairs in JSON objects in not ascribing meaning to the order of
properties. There is, however, an important difference. Two JSON objects that
happen
to store their name:value pairs in different orders (on disk or in memory) are
informationally identical because the order of properties in a JSON object is
undefined. But two XML documents that have the same properties in a different
order
are never informationally identical, that is, deep-equal(). A schema
may license alternative orders, and a query may ignore order, but order is an
inherent and inalienable part of XML element structure. For example, the use of
TEI-XML elements to represent regularization (orig/reg),
correction (sic/corr), or abbreviation
(abbr/expan) is ordered in the sense that two XML
documents that differ in the order of an orig/reg choice
are different XML documents, and that difference can be ignored only at the
application level. (Bleeker et al. 2018a) XML attributes are unordered,
but the type of values they can represent is limited because attributes cannot
contain markup, which means that they can represent only flat, atomic content.
This
means that at the level of the model and syntax, XML has no way of representing
unordered content that is more complex than atomic values.
Intermediate conclusion
Many of the features of TAGML discussed above are adopted or adapted from other
markup languages, including LMNL, TexMECS, XML, and FtanML. Wherever possible,
our
goal has been to synthesize effective solutions originally developed elsewhere,
and
we regard their relative familiarity to the markup community as a virtue. Combined
with the affordances of TAG’s hypergraph model, TAGML seeks to realize the full
potential of markup for text modeling.
The support for ordered, partially ordered, and unordered information results in
an inclusive textual model that not only broadens our understanding of what text
really is, but also expands our means of expressing it and improves our means
of
processing it. These features of TAGML offer users the means to express their
interpretation of a text’s structure, its whitespace, and the various data types
used in the model. As a result, a TAG file contains a refined and explicit model
of
text.
Syntax
Encoding text
A TAGML document consist of Unicode characters (encoded as UTF-8) and adheres
to the syntax defined in this description. We assume that encoding a text is
equivalent to creating a plain text file.
In a TAGML document, the following characters may need to be escaped using the
escape character \ :
However, these 7 specific characters do not need to be escaped every time they
occur. In regular text we only need to escape the two characters that start a
markupStartTag, markupEndTag or markupMilestone, plus the escape character
itself.
< -> \<
[ -> \[
\ -> \\
For text inside textVariation tags we also have to escape the variation
divider character |.
< -> \<
[ -> \[
\ -> \\
| -> \|
For text inside a comment we only have to escape the character that starts the
comment ending tag !], plus the escape character itself.
! -> \!
\ -> \\
Single or double quotation marks may be used interchangeably where a
quote-delimited value is required, with the stipulation that the starting and
ending delimiter must be the same (both single or both double). Where the
delimiter character must also be used within the string, it can be escaped, as
well:
' -> \'
" -> \"
\ -> \\
Whitespace
In TAGML Whitespace is insignificant unless
specified otherwise. The advantages of making whitespace insignificant by
default is similar to the reason why TAG takes dominance to be intentional and
semantically relevant. When all whitespace is considered significant, it may
be
impossible to distinguish its meaning: is the whitespace merely the result of
pretty-print formatting settings, or is it in the original document? The
principle that whitespace is not significant in TAG by default allows users to
specify the function of whitespace. TAGML thus prevents the accidental
introduction of unwanted significant whitespace, which means that TAG files can
be reformatted and pretty-printed without changing the meaning of the document
and without introducing processing errors.
Adding markup
[line>The rain in Spain falls mainly on the plain.<line]
A tag (lowercase) is the entity used to indicate markup boundaries. For every
start-tag [markup> there should be a corresponding end-tag
<markup], and vice versa. The example below will raise an
error because of a missing end-tag:
[line>The rain
Similarly, a missing start-tag produces an error:
on the plain.<line]
In the example below, the line markup is never ended and the
paragraph markup is never started:
[line>The Spanish rain.<paragraph]
In principle, each tag needs to have a name,
so
[>The Spanish rain.<]
results in an error, since start-tags and end-tags without a name are not
allowed. However, this constraint applies only to tags in the main text, because
[> and <] are allowed in annotations as
delimiters of rich text.
Markup can be assigned to one or more layers by adding a layer indicator in
the start-tag and end-tags after the | symbol. If the layer
indicator is used for the first time in the file it needs to be preceded by a
+ symbol in the start tag.
[line|+A>Cookie Monster likes cookies.<line|A]
In this example the markup line is part of a new layer called
A.
Adding annotations
[line month_1='November' month_2=11>In the eleventh month...<line]
Markup has a name and zero or more annotations on the start-tag. In the example above,
line is the name, and month_1 and
month_2 are the names of the annotations. Every annotation name
on a markup start-tag must be unique, and the following example raises an error
because the annotation type is repeated:
[animal type="cat" type="feline">Puss in Boots<animal]
Milestones, placeholders, empty markup elements
TAGML supports empty markup elements with a placeholder function like
milestones:
[img src='http://example.com/img.png']
Comments
Comments can appear anywhere in a TAG document except within a markup
tags:
[l>When in the course of human events,<l]
[! The spelling and punctuation reflects the original.!]
[l>it becomes necessary...<l]
Comments cannot be nested in TAGML. Comments can contain markup.
Namespaces
Namespaces can be used to refer to external vocabularies. Similar to XML,
markup elements are given a unique identifier that refers to the
namespace.
[!ns p http://tag.com/poetry]
...
[p:poem>Roses are red, .....<p:poem]
Data typing
In XML, all annotation values are by default (that is, in the absence of a
schema specification) of type xsd:untypedAtomic, which in practical
terms means that they behave like strings. If the value of an XML attribute type
@date is, in fact, a date, this needs to be specified in the
schema. In line with FtanML (Kay 2013) and JSON, TAGML
therefore supports simple data typing, so that
users can make explicit the type of the annotation value (e.g., a List, a
Number, a character String, and so on). More detailed or complex data types can
be expressed in the TAG schema, where users can record that a specific
annotation value contains text, markup, and/or annotations. For example, in the
TAG schema a stringAnnotationValue may be typed as
personName, or a numberAnnotationValue may be
typed as identifier. TAGML thus integrates useful features of JSON,
FtanML, and XML.
[poem type="limerick"
author='John'
year=1818
rhymes=true
keywords=["unfinished","censored"]>There once was a vicar from Slough...<poem]
As mentioned in Philosophy-and-Definitions, TAG annotation values can
include both text characters and markup, (this is called the rich text content
datatype) and annotations may also have their own annotations (this is called
the nested annotation data type)
Annotations can be added to the start-tag of any markup, and annotation values
can be of any of the following data types:[6]
string:"string" or 'string' (bracketed by
" or ')
rich text content: |>rich text
[b>content<b]<| (bracketed by |> and
<|)
boolean: true or false (not
bracketed)
number: 3.14 (not bracketed)
(nested) annotation: {x=1 y=2}
(bracketed by { and })
list of these data types: ['Huey', 'Dewey',
'Louie'](bracketed by [ and
])
By using an annotation data type as value for an annotation, TAG supports
nested (hierarchical) annotations:
In the example above, whitespace is used to make the code snippet more
readable, but because in TAGML whitespace is insignificant, this has no
implications for processing.
When an annotation is of the data type list, all values within
the List have to be of the same type: a list of Strings, a list of Numbers, etc.
Mixed typing is not allowed. The following markup is therefore incorrect:
In some manuscripts there may be different paths through the text, for example
when a deletion/addition has been encoded as a pair:
[q>To be, or [del>to be not<del][add>not to be<add].<q]
To
indicate that the del and add markup pair is where the
text diverges, with the del part constituting one path, and the
add part constituting the other, these markup elements can be
grouped by enclosing them in textvariation tags <|
and |>, with | to separate the diverging markups:
[q>To be, or <|[del>to be not<del]|[add>not to be<add]|>!<q]
In
case of a solitary del without a corresponding add,
mark the markup as optional to indicate there are two
paths: one with the text marked up by del, and
one without (grouping is not necessary in this
case):
[q>To be, or [?del>perchance<?del] not to be?<q]
To enable addressability of the different branches when querying it is
required to tag each branch with markup. In cases of non-linearity like open
variants textual content is located at the same position, so it is not possible
to speak of the third word. The following example is thus
incorrect. The branches "to be not" and "not to be" in the text do not have tags
surrounding them.
[q>To be, or <|to be not|not to be|>.<q]
Rich text annotations
As mentioned previously, Rich text content in annotations constitutes a new
inner document. Therefore, the contents of Rich text annotations are not part
of
the main text. This is particularly useful for the encoding of images, glosses,
or marginalia:
[text>Hello, my name is [gloss addition=[>that’s [qualifier>Mrs.<qualifier] to you<]>Doubtfire. How do you do?<gloss]<text]
In
contrast to XML, TAG applications will not render Rich text annotations (e.g.,
glosses or notes) in the main text by default. If users prefer to see the text
of glosses as part of the main text, they can specify this in stylesheets or
transformation files.
In the case of self-overlap we can distinguish between partial overlap and
full overlap. By default, an end-tag belongs to the last start-tag with the same
name, so that the following sentence is a simple case of full
containment:
[phrase>[phrase>Oscar the Grouch is<phrase] a trash can-dwelling creature.<phrase]
Partial overlap is expressed by placing layer suffixes on the corresponding
start- and end-tags:
[phrase|+P1>[phrase|+P2>Rosita is<phrase|P1] a bilingual monster.<phrase|P2]
Suffixes on markup should be used only when strictly necessary, as in the
following example of partial overlap:
[text>[phrase|+P1>[phrase|+P2>Music is<phrase|P1] part of<phrase|P2] being human.<text]
Discontinuity
A well-known example of discontinuity is the tagging of citations or quotes in
a text:
[q>and what is the use of a book,<-q] thought Alice[+q>without pictures or conversation?<q]
In this text, the fact that the two sets of q tags define one
interrupted quote is indicated by suspend/resume indicators before the markup
name: a - in the first end-tag, and a + in the
following start-tag, respectively.
There are several constraints that apply to the use of pause and resume tags.
For one, there must be text between a pause and a resume tag, so the following
example is not
allowed:
[markup>Cookie <-markup][+markup> Monster<markup]
The second constraint is that between pause and resume tags of markup in a
layer no opening or closing tags within that same layer are allowed. In the following example the
q markup belongs to layer A and is paused after
one word. In between the q pause and resume tag there are
w tags that also belong to layer A.
This is not allowed, because it would break the hierarchy within the layer
A. The correct way to encode a situation like this is to put
the w markup in its own
layer.
The last constraint is that if a markup node occurs in multiple layers, a
pause and resume tag must be applied to all the layers at the same time. In the
following incorrect example the markup q is part of two layers
A and B. It is paused in both layers, but resumed
one layer at a time.
In XML, the @xml:id attribute is commonly used to identify an
element uniquely within its document. The @xml:id value can then be
used as the value of pointer attributes on other elements as a way of linking
to
the first element. For example:
In TAGML, there is a special annotation :id to uniquely identify
an element (markup or annotation), and a special annotation data type whose
value is the :id of another element. In TAGML, the example can be
expressed as
follows:
The TAGML parser will give a warning when an :id is never
referred to, or when an annotation refers to a non-existing :id.[8]
Combining discontinuity and non-linearity
The rule that every pause tag should have a resume tag, and that every resume
tag should have a pause tag can be problematic when discontinuity is combined
with non-linearity:
[q>and what is the use of a <|[del>book,<-q]<del]| [add>thought
Alice<add]|> [+q>without pictures or conversation?<q]
In this example of incorrect use of the pause/resume tags, the pause tag
<-q] only occurs in one path (the [del> path),
so that the resume tag [+q> does not have a corresponding tag when
the [add> path is traversed. We can solve this problem by adding
either a more flexible constraint or a less flexible constraint. A more flexible
constraint would require that, at the point of convergence, all paths must be
in
the same suspend-and-resume state. A less flexible constraint
would be that, at the point of convergence, all paths need to be in the same
state as before the divergence. TAGML implements the less flexible
constraint.
Combining overlap and non-linearity
Consider the following, incorrect transcription:
[text>It is a truth universally acknowledged that every <|[add>young [b>woman<add]|[del>rich<del]|> man <b] is in need of a maid.<text]
The [b> markup is started in one path through the text (the
[add> path), but not in the other path (the [del>
path). Consequently, the end-tag <b] in the main text does not
have a corresponding end-tag in the [del> path through the text.
Again, there are two ways to solve this issue by adding a constraint, one more
flexible and one less so. The more flexible constraint is that at the point of
convergence all paths through the text should have the same set of tags
started.
[text>It is a truth universally acknowledged that every <|[add>young [b>woman<add]<b]|[b>[del>rich<del]|> man <b] is in need of a maid.<text]
The less flexible version is that before convergence all paths should be in
the same state as the moment of divergence:
[text>It is a truth universally acknowledged that every <|[add>young [b>woman<add]<b]|[b>[del>rich<del]<b]|>[b>man<b] is in need of a maid.<text]
In the first of the two preceding examples, the set of start-tags at the point
of convergence is: [text> and [b>. The more flexible
constraint works for both transcriptions. The second example illustrates the
stricter constraint. TAGML implements the less flexible contraints. This means
that all markup opened before divergence needs to remain open and cannot be
closed in a branch. All markup started within one branch needs to be closed
before the convergence.
Main document, inner documents, and discontinuity
Annotation values are not related to the rest of document, which means that,
as mentioned above, Rich text annotations are not part of the content of the
main document, and function as documents themselves. To distinguish them from
the main document we call them inner documents.
Discontinuity (pause-and-resume tags) is not permitted to cross document
boundaries:
[text> [q>Hello my name is [gloss addition=[>that’s<-q] [qualifier>mrs.<qualifier] to you<]>
Doubtfire, [+q>how do you do?<q]<gloss]<text]
The transcription above produces an error, because the pause tag
<-q] is located inside the Rich text of the annotation,
which means that the resume tag [+q> located in the main text does
not have a corresponding pause tag.
:id values defined on markup tags are global, and are therefore
in scope even across inner document boundaries.
Grammar
The syntax of TAGML is specified by the formal grammar listed below:
Each grammar rule is expressed as a line that reads lefthand ::=
righthand, where the lefthand consists of a template name,
starting with document. The righthand of a grammar rule
consists of characters or references to other templates. The righthand
incorporates the same repetition indicators as regular
expression syntax and Relax NG compact syntax. Specifically, ? means that
the preceding pattern is optional (occurs zero or one time), * means that
the preceding pattern is optional and repeatable (occurs zero or more times), and
+ means that the preceding pattern is required and repeatable (occurs
one or more times). The absence of a repetition indicator means that the pattern
is
required and not repeatable (occurs exactly once). For example:
Rule 1 specifies that a TAGML document consists of an optional
documentHeader followed by zero or more instances of
richText. The fact that the documentHeader is
optional is specified by the ? after the template name. The fact
that richText appears zero or more times after the document header
is specified by the *.
In the same way, Rule 2 states that the documentHeader consists
of zero or more namespace definitions (that is, zero or more instances of
whatever is represented by the namespaceDefinition
template).
Rule 3 introduces the ' character to the grammar. Everything
between paired quotes (a pair of single quotes ' or a pair of
double quotes ") should appear in literal form in a file that
conforms to the grammar. Rule 3 states that a namespace definition consists of
the four-character string [!ns (the fourth character is a space
character), followed by an identifier for the namespace, followed by a space
character, followed by a namespace URI, followed by the one-character string
].
In Rule 4 the + symbol, mentioned above, appears for the first
time in this grammar, signifying that the preceding pattern is required and
repeatable (occurs one or more times). This means that a
namespaceIdentifier consists of one or more
nameCharacters (defined in Rule 29).
Rules 5 and 6 introduce the reserved symbols (, ),
and |. ( and ) define a group. The
| symbol means or; for example, a |
b means a or b. Hence, Rule
6 states that textEnrichtment consists of a choice among whatever
is represented by the templates markupStartTag,
markupEndTag, markupMilestone,
textVariation, and comment, and the choice (the
same choice or a different choice) may be made zero or more times.
In Rules 8, 39, 40 the special symbols [, ], and
- are introduced. [ and ] are used to
delimit character classes, similarly to their
use in regular expression syntax. In Rule 8 the [ and
] symbols are used without the - symbol, but with
the new ^ symbol. ^ at the beginning of a character
class, as in regular expression syntax, means negation. Here the
textCharacter character class in TAGML is defined as every
character except [, <, and \. Rule 39
states that a digit in TAGML consists of a Unicode character in the range of
0 through 9 and that digits is
defined as one or more digit characters. The same pattern is used in Rule 40
to
specify that a name character is either a lowercase letter between
a and z or an uppercase letter between
A and Z.
Rule 9 makes use of grouping functionally to specify that a
markupStartTag consists of a literal square bracket followed by
an optional optional or resume character followed by a
required tagIdentifier followed by zero or more
annotations. Every annotation is prefixed by a
space character.
Rule 10 states that a markupEndTag starts with a left angle
bracket, followed by an optional optional or suspend,
followed by a tagIdentifier, and then a square bracket.
Workflow
This section describes the workflow of dealing with a network of information in a
step-by-step manner. As noted, documents with TAG markup (that is, with multiple
overlapping markup layers) are, at least potentially, too complex to see and edit
in
their entirety. In order for the (end) user to work effectively with TAG documents
in
Alexandria, we therefore propose a workflow comparable to the Git source code management
and repository system.
The basic concept is as follows: the complete TAG model for each document (which we
refer to as the TAGML master file) is stored in a
directory that is hidden from the end user. Just as in Git, users can check out a version of the TAGML file containing a selected
set of markup layers. They can subsequently edit this version, and then commit the file to the repository, where it is merged with
the master.
Throughout this section we will predominantly use examples from the text of the
manuscripts of Prometheus unbound by Percy Bysshe Shelley. To be
sure, literary manuscripts and comparable historical documents provide a grateful,
inexhaustible source of complex textual phenomena that continue to challenge the
fields
of digital text modeling and computational philology. However, as noted above,
TAG
offers a model of text whose potential uses surpass these, admittedly niche, fields
and
can be extended to practically any type of text.
Working with multiple views in a Git-like manner requires a number of tools,
including:
A tool to init the workspace.
A tool to register a document with a
master file.
A tool to define a view on a
document, determining which tags should be visible in the document and
which are to be filtered out. This may be positive or negative
filtering.
A tool to check out a view of a
document. The first time an identifier (name) and a view definition are
specified, a file instantiating that view is created in the user’s
workspace.
A tool to check in an edited view of
a document. After editing a view, the user needs to check in the view to
commit the changes.
A tool to diff markup files, that is,
to check the edits the user made and show a comparison between the
original and the edited view.
In practice, the workflow for interacting with a TAG document using the Alexandria TAG repository may look as follows:[9]
The user edits the view on <name document> in an editor of their
choice.
$ alexandria diff <filename view>
(optionally, the user diffs the edited view with the master file)
$ alexandria commit <filename view>
(The user commits the view on <name document> to the repository, an
action that merges the edit view with the TAG master <name
document>.)
The edits are now committed to TAG master.
This workflow is similar to the one described for concurrent XML in Iacob and Dekhtyar 2003 and Dekhtyar and Iacob 2005; see also their Iacob and Dekhtyar 2005. Concurrent XML, however, refers to multiple markup
layers over a common text layer, while the TAG workflow permits editing the textual
content of a view, and not only the markup.
In principle, the user never interacts directly with the master file TAG. In the
process of checking out a version of the master file, the user specifies which
layers of markup to expose and which to conceal. The TAG document with the markup
layers that they check out is referred to as a
view. A view thus represents one or more layers of markup. It is a part
of the entire TAG hypergraph in the repository, rendered in a human-readable
format.
Views and layers
Because the concepts of view and layer are central to this workflow, it is helpful to
revisit the difference between a layer and a view.
As described in Layers, a layer is a grouped set of markup and
annotations. A view is a selection from among all available layers. Turning off
(that is, not checking out) certain markup does not mean that the text to which
the
markup points is ignored, but it is then possible to choose only certain paths
(e.g., in case of text with and without deletions and additions or with diverging
paths for original and regularized versions of the same textual moments).
The reasons for grouping a set of markup and annotations may vary. In the
paragraphs below we identify three scenarios: first, a layer as representation
of a
research perspective on text; second, a layer identifying user edits; third, a
layer
as a resolution to local overlap. The textual fragment from Prometheus
Unbound is used as illustration.
For reasons of clarity our example sentences are short and simple, but in practice
the master TAG document can be as large as needed, and may thus become highly
complex. Here, we focus on the speech of the second voice from the Springs, which
runs over two folium pages, as Figure 4 and Figure 5 show.
Let us assume that User A (Albert) wants to focus on the poetic
structure of this text, while User B (Bertina) is interested in
the text as it interacts with the materiality of the manuscript. In other words,
Albert and Bertina have different textual perspectives, informed by their
research interests.
Albert creates a first TAGML transcription:
[poem>
[sp>
[speaker>2d. Voice from the Mountains<speaker]
[stanza rhyme="abac">
[lg type="quatrain">
[l>Thunderbolts had parched our [w rhyme="a">water<w]<l]
[l>We had been stained with bitter [w rhyme="b">blood<w]<l]
[l>And had ran mute ’mid shrieks of [w rhyme="a">slaugter<w]<l]
[l>Thro’ a city & a [w rhyme="c">solitude<w]<l]
<lg]
<sp]
<stanza]
<poem]
Albert subsequently prepares the Alexandria repository
and uploads his transcription, which he saves under
MS-e1-21v-22v.tagml:
MS-e1-21v-22v.tagml is the TAG master file. Bertina now wants to
work on the same fragment, but as the poetic features of the text are not
relevant for her research, she defines a view that contains only a selection
of
the markup in the master file: the elements [l><l] and
[speaker><speaker].[10] Bertina subsequently checks out the view.
This will export the view of document MS-e1-21v-22v using view
definition material-view to a new TAG document
MS-e1-21v-22v-material-view.tagml, which contains one layer of
markup:
[l>2d. Voice from the Springs<l]
[l>Thunderbolts had parched our water<l]
[l>We had been stained with bitter blood<l]
[l>And had ran mute 'mid shrieks of slaugter<l]
[l>Thro’ a city & a solitude<l]
Bertina edits this view, using the structure indicated by Albert, but she
changes the [l><l] and [speaker><speaker]
elements to [line><line] elements, and adds further information
about the physical features of the manuscript. She creates the following TAGML
transcription:
[page n="21v">
[p>
[line rend="indent2">2d. Voice from the Springs<line]
[line>Thunderbolts had parched our water<line]
[line rend="indent2">We had been stained with bitter blood<line]
<page]
[page n="22v">
[line>And had ran mute <|[del>thro<del]|[add>'mid<add]|> shrieks of <|[sic>slaugter<sic]|[corr>slaughter<corr]|> laughter<line]
[line rend="indent2">Thro' a city & a solitude!<line]
<p]
<page]
After editing MS-e1-21v-22v-material-view.tagml, Bertina commits
her view and it is merged with the master TAG document, which now contains
several markup layers representing a poetic and a material view on the text.
We
can use layers to identify which Markup elements belong to which perspective.
The first sentence of the TAGML master file would then look as follows:
[line rend="indent2"|material>[speaker|poetic>2d. Voice from the Springs<speaker|poetic]<line|material]
Layers as user identification
In addition to indicating perspectives, layers can also be used to identify
(sets of) user edits. It is worthwhile to take a closer look at how a view is
merged with the master file. Technically speaking, the process of merging the
edited view with the entire TAG document model is supported through an extended
diff algorithm that recognizes markup as well as text. Hence the input of the
diff is two streams, of the original view and of the edited view, each
containing markup tokens and text tokens.
Besides detecting edit operations on textual content, the diff algorithm of
Alexandria is able to detect joins and
splits for markup elements. This feature ensures that TAG/Alexandria can process both textual and structural edits. We
define five edit operations on text and markup: deletion, addition, replacement, split,
and join.
Let us reconsider the editorial workflow of Albert and Bertina outlined above.
In this scenario, there are two possibilities: either Bertina’s changes
regarding to the [line><line] element are considered as
replacing Albert’s [l><l] and [speaker><speaker]
elements, or they are considered as additional markup.
The split operation is illustrated by the
following example (a simplified transcript of the text above), in which user
C
(Claire) has transcribed the text as one sentence and user D
(Dirk) as two sentences:
Figure 6
[s>We had been stained with bitter blood And had ran mute 'mid shrieks of slaughter<s]
Claire’s transcription
Figure 7
[s>We had been stained with bitter blood<s] [s>And had ran mute 'mid shrieks of slaughter<s]
Dirk’s transcription
Both sentences start with start-tag [s> and end with end-tag
<s], so a simple diff algorithm would consider them a match
and the two tags <s] and [s> in the middle of the
sentence as an addition. However, a more accurate representation of the
situation from a markup perspective would be for the algorithm to detect that
the one [s><s] element in Claire’s transcription is split into
two in Dirk’s transcription. In fact, because the markup start-tags know with
which markup end-tags they are paired, the diff in Alexandria is able to recognize this situation as a split, and
to label the markup edits accordingly.
Using layers to distinguish between Claire’s markup and Dirk’s markup edits,
we would arrive at the following TAGML master file:
[s|claire>
[s|dirk>We had been stained with bitter blood<s|dirk]
[s|dirk>And had ran mute 'mid shrieks of slaughter<s|dirk]
<s|claire]
Layers as solution to local overlap
Last but certainly not least, layers can be used to address overlap issues.
Section Layers addresses the technical and conceptual aspects
of this functionality. In short, markup within a layer represents a dominance
relationship, while layers that overlap represent containment. A new layer can
be started at any point in the document. Markup nodes can be part of multiple
layers.
Let us take a look at a simple case of overlap between a logical structure and
a document structure of Claire’s and Bertina’s respective transcriptions:
Figure 8
[s>We had been stained with bitter blood And had ran mute 'mid shrieks of slaughter<s]
Claire’s linguistic transcription
Figure 9
[page>
[line>We had been stained with bitter blood<line]
<page]
[page>
[line>And had ran mute 'mid shrieks of <|[sic>slaugter<sic]|[corr>slaughter<corr]|><line]
<page]
Bertina’s material transcription
Merging these document would cause a conflict due to the overlapping
structures. To solve these, a material and a
linguistic layer are created.
Figure 10
[page|material>
[s|linguistic>[line|material>We had been stained with bitter blood<line|material]
<page|material]
[page|material>
[line|material>And had ran mute 'mid shrieks of <|[sic|material>slaugter<sic|material]|[corr|material>slaughter<corr|material]|><line|material]<s|linguistic]
<page|material]
TAGML master file of Claire’s and Bertina’s transcriptions
Within each layer the markup elements have a relationship of dominance, but
between the layers is a relationship of containment. For instance, the
[page> element contains the [s> element, but does
not dominate it. Although in this simple example the layers start at the
beginning of the transcription, a new layer can be started at any point in the
document and markup nodes can be part of multiple layers.
Discussion
Taken together, the features of TAG and TAGML offer users a powerful model for
expressing their interpretation of the structural properties of text and document,
resulting in a TAG document that reflects a rich, nuanced, and explicit model of
text.
In order to fully grasp the implications of TAGML, it is important to consider
that all
forms of text modeling involve at least three components:
A source text, e.g., a facsimile of a historical manuscript, a document from
the publishing industry, a newspaper article, a judicial text, etc.
A transcription of the source text
A model of the source text (in TAG, the hypergraph document)
These components (source, transcription, and model) are shared by many methods of
text
modeling, and the significance and value of TAG lies in the interaction of and
the
relationships among these components. The TAGML markup language gives users the
opportunity to record and model in a transcription a wide variety of textual aspects
from and information about the source text; the hypergraph model as implemented
in Alexandria processes and stores the TAG
documents; and, furthermore, the Alexandria
implementation of TAG allows the user community to interact intuitively with the
texts
by using views. The following paragraphs summarize three main features of TAGML
as
described in this article: the nature of TAGML files and how they affect text modeling
approaches; the separation of responsibilities between syntax and schema; and,
finally,
implications for the workflow of modeling and editing textual objects.
TAGML files
TAGML documents are inherently multi-layered and non-linear, and can best be
represented by combining ordered and unordered information. This conceptual
understanding of text is reflected in the syntax of TAGML: textual features such
as
non-linearity and discontinuity can easily be expressed; annotations can be nested
within other annotations; annotation values can contain both text and markup (cf.
Rich text annotations). Together with the data typing feature of TAGML,
the recursivity of Rich text allows for explicit modeling of many textual features.
Layers remove boundaries by allowing for overlap and the modeling of dominance
and
containment without the need for a schema, all of which facilitates the mapping
of
semantic information to the Text nodes in the hypergraph model.
Complete semantic mapping and querying would also require TAG to map semantic
information to the properties of nested annotations. JSON-LD, for instance, provides
a notation for linking the properties of JSON objects to ontologies. A similar
feature will be part of the future development of TAG and TAGML.
Syntax and schema
Designing a new markup language means deciding which functionality to put into the
syntax which responsibilities to put into the schema. Initially we tried to include
only non-linear aspects of the text, such as containment, into the syntax, while
making information about dominance explicit in the schema. When the syntax allows
for arbitrary overlap, however, it is no longer possible for a parser to
consistently extract a hierarchical structure from the data, which means that
many
use cases would require a schema. In the end we decided on the use of the layer
mechanism in the syntax to allow the user to explicitly model containment and
dominance relations without the need for a schema, while allowing for overlap.
The
syntax contains basic data types, such as String, Lists and nested annotations.
The
schema is used to make explicit any information about complex data types, such
as
persons, dates, and significant whitespace.
TAGML agrees in certain respects with other markup languages, much as the TAG
model corresponds to some extent to other text models. Many textual aspects
discussed in this paper can be modeled in, for instance, an XML-transcription
with
an associated schema and application-level rules. TAGML, however, moves much of
that
responsibility to the syntax by having explict encoding mechanisms for containment,
dominance, discontinuity, non-linearity, and overlap, with the goal of removing
ambiguity from the application level. Accordingly, TAGML brings together and expands
on qualities of existing formats, and creates an inclusive and definite framework
for modeling textual and structural information.
Users, views, and Alexandria
The TAG and TAGML division of labor requires the active engagement of the user,
who needs to think in great detail about the informational structures and elements
in the text, and about how these are best represented so that the modeling of
a
textual object conforms to the developer’s conceptual understanding of it. In
principle, we regard this increased textual consciousness as a positive feature.
In
a similar way, the TAG repository Alexandria
compels its users to make explicit their views on text.
Alexandria is designed to accommodate complex and
information-rich TAG documents, while at the same time exposing an intuitive and
straightforward method of interacting with that information. While understanding
text as a graph may not be straightforward, especially for those who are accustomed
to modeling text as a mono-hierarchical ordered tree (that is, in XML), the idea
of
adding layers of information to a text appears to be intuitive. Alexandria, then, accommodates a theoretically unlimited
number of informational layers on a text, using views to allow users to query
this
information and to add and edit new layers.
The editorial workflow of Alexandria has a number of
implications, in particular with regard to the diff and the merge functionalities
and the command line tool. The first of these involves Alexandria’s diff and merge functionalities. In the Workflow we clarify our decision to keep both layers of markup,
instead of considering the edit operations in the markup layer (e.g., from
l to line) as replacements (a deletion of the
l layer and an addition of the line layer). We reason
that it is undesirable to have Bertina’s changes overwrite Albert’s markup, and
propose to store both layers of markup in different layers that identify the two
users.[11]
An open question, however, is whether changes in the textual content should be
treated in the same way. For example, if Bertina were to alter some text characters,
should the master file adopt her changes as replacements for Albert’s, or as
alternatives? The first option implies that the text from Albert’s view will be
lost, while the second option implies that the Albert’s text and Bertina’s text
will
be stored in the TAG master file as textual variation. Since both options are
supported by Alexandria, the question is
philosophical, rather than technical.
As for our decision to have users work on the command line instead of providing a
Graphical User Interface to interact with Alexandria: we
recognize the wide variety of editor software that exists within text editing
communities, as well as the fact that many users work with a preferred editor
whose
interface they are familiar with and appreciate. For that reason, our goal for
interacting editorially with TAG documents has been not to develop a custom TAG
editor, but to ensure that TAG works with any editor. This allows users to engage
with the results of individual decisions about layers and views in the generic
programming editor of their choice.
Conclusion
When starting with the development of a new markup language, it may feel most natural
to be open-minded and maximalist: everything should be possible, and the more freedom,
the better. As the consequences of that freedom become clearer, one may become
more
conservative, adding constraints. Texts with markup need to be processed and queried,
and the more freedom the markup permits, the more difficult the processing and
querying
becomes. A reasonable goal is to strike a balance between supporting expression,
which
may tend toward openness, and facilitating processing, which may tend toward
constraint.
This report has introduced three new aspects of the Text As Graph project, involving
markup, model, and workflow. With respect to markup, the TAGML markup language
is
designed to represent syntactically the TAG data model. With respect to the model,
the
revised TAG data model replaces the directed Text-to-Text edges of Haentjens Dekker and Birnbaum 2017 with undirected Text-Text edges, instead using
hierarchical rank (distance in path steps from the Document node) to model order.
With
respect to workflow, the TAG workflow, implemented in Alexandria, borrows concepts from earlier proposals for editing
concurrent XML, while also permitting concurrent variation in text, and not only
in
markup, With respect to future work, TAG does not yet have a fully functional schema
language or a fully functional query language, although both are under early development.[12]
Appendix A. The TAG model
The TAG data model in this report combines the multi-layered data model presented
at
Balisage 2017 with the nonlinear data model presented at XML Prague 2018. It is
a cyclic
non-uniform property hypergraph model for text. The hypergraph model consists of
a set
of vertices (or nodes) and a set of hyperedges that connect two or more nodes with
one
another. The following key concepts merit specific attention:
Cyclic. The TAG hypergraph is cyclic. As we
describe under Edges, all edges in the hypergraph are
undirected, which, together with the Convergence Nodes (explained in Text nodes), produces a cyclic graph. Traditionally, cyclic
graphs have been considered problematic for traversal, but the hypergraph for
text is a rooted graph. This means that
traversing from and to the root is not difficult, and can be effectuated without
falling into cycles as long as each traversal proceeds consistently in one
direction (toward or away from the root).
Non-uniform. The edges of the kind of graphs
we are most familiar with (e.g., tree, acyclic graph, RDF) connect two nodes
with each other, and we therefore say the edges have a cardinality of 2. A
hyperedge, in contrast, connects an arbitrary set of nodes. As the hyperedges
in
the TAG data model do not have a fixed number of nodes, we say the graph is
non-uniform.
Property. We refer to the TAG hypergraph as a
property graph because properties are stored on the nodes and edges.
Typed. Nodes are typed, which means that they
have a type property.
Text in a TAG document is fully connected, rooted, and undirected. By fully connected we mean that there is a path to all Text
nodes from the Document node (see the discussion of node types, below).[13] By rooted we mean that the text has an
obligatory single start point, represented by the Document node. By undirected we mean that the consecutive Text nodes are
connected to each other by undirected edges, that is, edges that do not distinguish
a
head and tail (source and target). The relative logical order of Text nodes is
represented by rank, that is, by the number of path steps between the Document
node and
a Text node. By defining the relative position of Text nodes in terms of ancestors
(Text
nodes of lower rank, closer to the Document node) and descendants (text nodes of
higher
rank, farther from the Document node), we use hierarchical rank to represent the
order
of Text nodes without employing directed edges.[14]
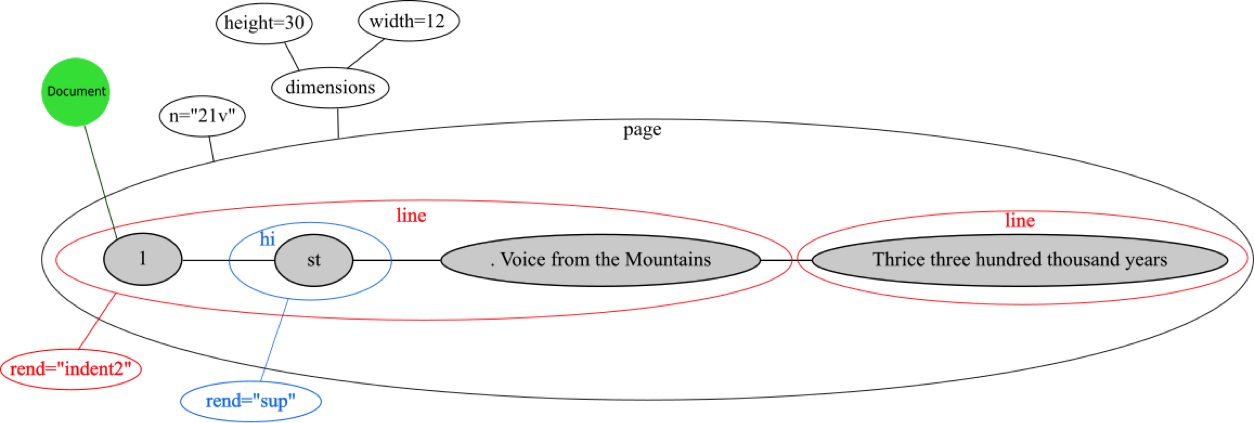
Consider the following illustration of the physical layout of a poetic text on a page:[15]
[page n="21v" dimensions={width=12 height=30}>
[line rend="indent2">1[hi rend="sup">st<hi]. Voice from the Mountains<line]
[line>Thrice three hundred thousand years<line]
<page]
Figure 11
Sample visualisation of the hypergraph model of the fragment from Prometheus unbound given above.
Nodes
There are four types of node, each with different requirements and constraints.
These are discussed schematically below.
Document nodes
Description. Every Document node
represents a single document in the hypergraph and serves as a root
node. There can be multiple documents in a hypergraph, in which case
each document constitutes a connected subhypergraph, where connected means that there is a path from
every node to every other node of the subhypergraph. Nodes from one
subgraph cannot be connected to nodes from another subgraph.
Properties. Every Document node has a
unique name. Every document stores information about its creation and
modification(s).
Constraints. Every Document node must
be connected to (have a path to) at least one Text node. The Text node
may be empty.
Text nodes
Description. A Text node represents
(a part of) the textual content of the document. Whitespace, if present,
is included in the textual content. Text nodes must be as long as
possible. Text nodes may be empty, i.e., have no textual content. We
identify two cases of empty Text nodes:
Empty Text nodes are used to store milestone Markup nodes,
e.g., in case of images or marginalia in the source text.
These milestones must have a Markup-Text hyperedge (cf.
Markup-text undirected hyperedge).
Properties. A Text node has a
content property of type String, which stores the
textual content of a segment.
Constraints. Each Text node is part
of exactly one document. In HyperCollate a Text
node can be part of multiple documents (cf. Bleeker et al. 2018a, Bleeker et al. 2018b). All the
Text nodes have to be connected. Text nodes can have multiple hyperedges
with markup on them.
Two subtypes of Text nodes are Text divergence and Text convergence
nodes:
Text divergence nodes
Description. Text divergence
nodes are a subtype of Text node, without content. Text divergence
nodes are one of two exceptions to the constraint that a Text node
has two edges.
Properties. none
Constraints. All text divergence
nodes have 1 edge connecting an ancestor, which is either a Document
node or a Text node, and multiple (n>1) edges to Text nodes as
descendants.
Text convergence nodes
Description. Text convergence
nodes are a subtype of Text node, without content. Text convergence
nodes are the other exception to the constraint that a Text node has
two edges.
Properties: none
Constraints: All text convergence
nodes have multiple (n>1) edges connecting Text nodes as ancestors,
and 1 edge connecting a Text node as descendant (or 0, if the Text
convergence node is the last node in the text).
Markup nodes
Description. A Markup node stores the
name of the markup.
Properties. Markup nodes have the
following three properties:
A required tag property of type String, which
stores the name of the tag.
An optional namespace property of type String
with the name of the namespace within which the tag is
defined.
An optional identifier property of type
String, which uniquely identifies this instance of markup
with this tag. This is a special type of annotation, used
for linking.
Constraints. All Markup nodes have to
be connected to one or more Text nodes. Markup nodes can only have one
Markup-to-Text hyperedge. Markup nodes can have zero or more Annotation
nodes on them.
Annotation nodes
Description. An Annotation node
stores a property as a key:value pair.
Properties: Annotation nodes have two properties:
The propertyname property, of type String,
stores the name of the property and acts as the key of the
key:value pair.
The propertyvalue property stores the value
of the key-value pair. The value can be one of the following
types: String, Number (default Float, unless specified
otherwise in the schema), Array, Rich text, or Nested
annotation. A value of type Array must contain values of the
same type, and an array of Rich text is not allowed, which
means that valid array types are String, Number, Array or
Nested annotation.
Constraints: An Annotation must be
connected to a Markup node or an Annotation node. An Annotation node may
be connected to more than one Annotation node in case of nested
annotations (Data typing) represented by a {
} in TAGML. The name of the property needs to be unique among
its siblings, i.e., two properties with the same name are not permitted
on the same level in the annotation hierachy of a Markup node.
Node types, properties, and constraints
Table I
Nodes
Description
Properties
Constraints
Document node
Represents one single document in the Hypergraph
Is a root node
name: document
name
type: String
meaning: identifies a
document in the hypergraph
Must point to only the first Text node of the
document
name: creation
date
type: Date
meaning: info about
creation date
name: modification
date
type: Date
meaning: info about last
modification date
Text node
Can have multiple hyperedges with markup
May be empty
Includes whitespace
name: content
type: String
meaning: stores the
content of a (part of) a document
Part of exactly one Document node
All Text nodes are connected through undirected edges, one
from the ancestor and one to the descendant
Text divergence node
Represents diverging paths in the case of intradocumentary
variation
No properties
Multiple edges connecting two or more Text nodes as
descendants (which could also be a Text divergence or a Text
convergence node)
Text convergence node
Represents converging paths in the case of
intradocumentary variation
No properties
Multiple edges connecting two or more Text nodes as
ancestors (this could also be a Text divergence node or a
Text convergence node)
Markup node
Connected to one or more Text nodes
Has zero or more Annotation nodes
name: tag
type: String
meaning: stores name of
the tag
There must be exactly one Markup-Text hyperedge for each
Markup node
name: namespace
type: String
meaning: stores name of
the namespace that contains the tag
name: identifier
type: String
meaning: identifies
markup instance with the corresponding tag
Annotation node
Connected to a Markup node or an Annotation node
May be connected to one or more Annotation nodes (in case
of nested annotations)
name:
propertyname
type: String
meaning: stores name of
property
A property value cannot have an array of Rich text
annotations.
A property value cannot have an array of items of mixed
type
name:
propertyvalue
type: String; Number
(Int and Float); Array; Rich text (pointing to first Text
node of new Annotation node); Nested annotaton.
meaning: value of
annotation property
Edges
We identify six types of edges:
Document-Text undirected edges
A Document-Text edge associates a Document node with its first Text node in a
one-to-one relationship. Every Document node can only have one first Text node.
In Alexandria a Text node can belong to only
one Document.
Text-Text undirected edges
Text-Text edges encode the flow of the text. The start of the hierarchy is
indicated by the Document-Text edge, which connects the Document node to the
first Text Node. In case of intradocumentary textual variation, the Text
divergence and Text convergence nodes can have multiple ancestor or descendant
Text-Text edges (see Text divergence node and Text convergence node. Text-Text edges form a hierarchy of Text nodes
that is partially ordered, and may connect a Text node only to its immediate
ancestor or descendant in order.
Markup-Text undirected hyperedges
Markup-Text hyperedges associate markup with its textual content.
Annotation-Markup multiple undirected edges
There can be multiple Annotations on a Markup node, but each Annotation node
can be associated with only one Markup node. This relationship can be understood
as a tree: the Markup node is the root of the tree and the Annotation nodes are
its children.
Annotation-Annotation multiple undirected edges
Annotation-Annotation edges are used for nested annotations in TAGML (Data typing). The Markup node and the annotations form a rooted
tree with the Markup node as root.
Annotation-Text undirected edges
Annotation values can be of Rich text format (cf. Rich text annotations). If the annotation is of type Rich text, the value is a new inner document.
Because Rich text content can itself contain markup with annotations on it, this
is a recursive feature.
Edge types, constraints
Table II
Edges
Description
Relationship
Constraints
Document-Text edge
Associates Document node with its first Text node
Undirected edge
Alexandria: a Text node can be
part of exactly one Document
HyperCollate: a Text node can be
part of multiple Documents
Text-Text edge
Encodes the flow of the text by forming a partially ordered
hierarchy of Text nodes
Undirected edge
If a Text node has two Text-Text edges, one must be connected to a
Text node of higher rank (a descendant) and the other to a Text node
of lower rank (an ancestor).
Markup-Text edge
Associates markup with textual content
Undirected hyperedge
Markup-Text hyperedges must have exactly one Markup Node
Markup-Annotation edge
Associates a Markup node with an Annotation node and vice
versa
Undirected edge
One Markup node may have multiple Annotation nodes, but an
Annotation node cannot connect to more than one Markup node
Annotation-Annotation edge
Represents a nested annotation
Undirected edge
Each Annotation node is connected to exactly one ancestor, either a
Markup node or an Annotation node in case of nested annotations. An
Annotation node can be connected to multiple Annotation nodes as
descendants.
Annotation-Text edge
Associates an annotation with the textual content of an annotation
(= Rich text)
[Bleeker et al. 2018b] Bleeker, Elli, Bram
Buitendijk, Gijsjan Brouwer, and Ronald Haentjens Dekker. From graveyard to
graph. Reappraising textual collation in a digital paradigm. Accepted for
publication in Digital Scholar, 2018.
[Dillen 2015] Dillen, Wout. Digital
scholarly editing for the genetic orientation: the making of a genetic edition
of
Samuel Beckett’s works. Ph.D. thesis, University of Antwerp.
2015.
[4] That while is a replacement for white is an
interpretation. At least in principle, a writer might complete a sentence
and then cross out a word that feels unnecessary, a situation where the word
following the excision may function as stable text in any reading, and not
as a replacement or alternative for the deletion.
[5]The terminology [data-centric vs document-centric] is unfortunate,
since running narrative prose and mixed content models are no less data
than records and fields and a data-centric document is, as the name
implies, also a document. A more useful distinction might be between
narrative prose and databases or between mixed content and element
content (or between otherwise different types of content models), rather
than between documents and data. (Birnbaum 2007)
[6] Data types are expressed lexically (e.g., values like
true or false are of type Boolean) or
distinguished by markup punctuation (e.g., bare digits are of type
Number, items [including digits] inside quotation marks are of type
String, etc.).
[8] Currently Alexandria understands
pointers only to a single :id value and only within the
same TAG document (similar to xsd:IDREF). It is intended
that pointing to multiple :id values (similarly to
xsd:IDREFS) and to :id values in different
documents will also be supported.
[9] Information about installing and using the Alexandria command line app is available at links on the TAG
portal at https://github.com/HuygensING/TAG.
[11] This means that, in the TAG master file, the markup elements l and line
are stored in the same locations, but overlap is unproblematic for the TAG
hypergraph model.
[12] We are grateful to the anonymous referee who reminded us that:
There are considerable down sides to inventing a new syntax. These
include training/learning, paucity of extant tools, unfamiliarity, but
they also include a need to reinvent. For example, there’s no obvious
equivalent to xml:lang, xml:base,
xml:include, ITS, XSLT, XSD, XSL-FO, CSS,
XQuery.
We could extend that list, and whether it is worth the effort to
try to overcome the challenges depends, among other things, on whether TAG can
eventually be shown to offer benefits that justify the cost. Our focus at this
point is on development, exploration, and evaluation, and not on evangelizing,
but we can offer now two thoughts about the cost of uptake:
Ancillary technologies emerge over time, and XML (and SGML) were
understood as useful before the development of many of the features
listed above. New technologies may be adopted when the benefit
exceeds the cost, and we are eager to continue to explore that
balance in the context of TAG.
Our frame of reference is not individual XML technologies, but the
outcome goals and functionality those technologies provide. For that
reason, we are not prioritizing bespoke TAG counterparts to specific
aspects of the XML ecosystem. For example, XQuery and XSLT are ways
of interacting with XML, but developers may also interact with XML
using general-purpose languages like Java or Python. A TAG
implementation (like Alexandria) might expose an API that offloads
transformation or styling or other subsequent processing onto a
general programming language. For that reason, although there is,
for example, an obvious need to be able to query a TAG document and
to transform it into other formats, it is less obvious that the
solution will resemble an architecture like the XPath / XQuery /
XSLT / XSL-FO stack.
[13] Rich text annotation values function as separate subdocuments, and in their
case the Annotation node takes the place of the Document node in the main
text.
[14] In Haentjens Dekker and Birnbaum 2017 we described Text nodes in TAG as
connected by directed edges; our revision of that earlier model to use
undirected edges is motivated by a formal limitation on directed edges that
permits them to describe a relationship only in one direction. A directed edge
is an asymmetric relation between two adjacent vertices in a graph, represented
as an arrow. In mathematical terms, an asymmetric relation is a binary relation
on a set X where: For all a and b in
X, if a is related to b, then
b is not related to a. This means that when
traversing a directed graph, if there is a directed edge from a to
b, it can only be traversed from a to
b, and not from b to a. See: https://en.wikipedia.org/wiki/Glossary_of_graph_theory_terms#Direction and https://en.wikipedia.org/wiki/Asymmetric_relation
[15]line markup here refers to physical lines on the page, rather
than poetic lines.
Bleeker, Elli, Bram
Buitendijk, Ronald Haentjens Dekker, and Astrid Kulsdom. Including XML markup in
the automated collation of literary texts. Presented at XML Prague 2018,
Prague, Czech Republic, February 8–10, 2018. In XML Prague 2018 -
Conference Proceedings, pp. 77–95.
http://archive.xmlprague.cz/2018/files/xmlprague-2018-proceedings.pdf
Bleeker, Elli, Bram
Buitendijk, Gijsjan Brouwer, and Ronald Haentjens Dekker. From graveyard to
graph. Reappraising textual collation in a digital paradigm. Accepted for
publication in Digital Scholar, 2018.
Dillen, Wout. Digital
scholarly editing for the genetic orientation: the making of a genetic edition
of
Samuel Beckett’s works. Ph.D. thesis, University of Antwerp.
2015.
Iacob, Ionut E. and
Alex Dekhtyar. Towards a query language for multihierarchical XML: revisiting
XPath. Eighth International Workshop on the Web and Databases (WebDB 2005),
June 16–17, 2005, Baltimore, Maryland, USA.
http://users.csc.calpoly.edu/%7Edekhtyar/publications/webdb05.pdf