Introduction to ACS
ACS is a professional membership organization, chartered by the U.S. Congress in 1876, representing over 164,000 professionals at all degree levels and in all fields of chemistry and sciences that involve chemistry. Primary ACS divisions include Membership and Programs; Chemical Abstracts Service, a secondary publisher of chemical-related data, information abstracts, and databases; and the Publications Division (“ACS Pubs”).
The ACS Manuscript Workflow
The Journal and Book publishing units of ACS Pubs produces over forty STM peer-reviewed journals focused on various disciplines of chemistry. In 2012, ACS Pubs expects to publish about 325,000 pages in approximately 40,000 articles (manuscripts).
Chemists from around the world document their research results and submit manuscripts to ACS of their findings for peer review and publication. Once a manuscript has been reviewed and accepted for publication, ACS receives it in the document format submitted by the author (Microsoft Word or LaTeX, for example). ACS has standardized on XML as the internal manuscript format and uses an “XML-first” approach to facilitate the production and publication processes. Therefore, before any processing occurs, the author’s original document is sent to a vendor for conversion into XML, using a DTD that is a customized version of the NLM article DTD. (See ACS Tagsets.)
After the manuscript is converted to XML, ACS staff that have Chemistry or related scientific degrees (“Technical Editors”) prepare it for publication, editing the paper for clarity and technical content (see ACS Style Guide) and ensuring proper markup of content. A proof version of the manuscript is sent to the author (in PDF format) for their review and the author’s corrections are applied before it is published on the ACS Publications web site and also in print. The composition process of journal manuscripts (proof, web, and print PDFs) has recently been automated (see ACS Automated Composition), with great success. The high-level of quality of the XML input to the composition engine is critical to the successful composition results.
This is a simplified narrative of our workflow (see Figure 1). The actual workflow is, of course, much more involved.
Figure 1: ACS XML Workflow Overview
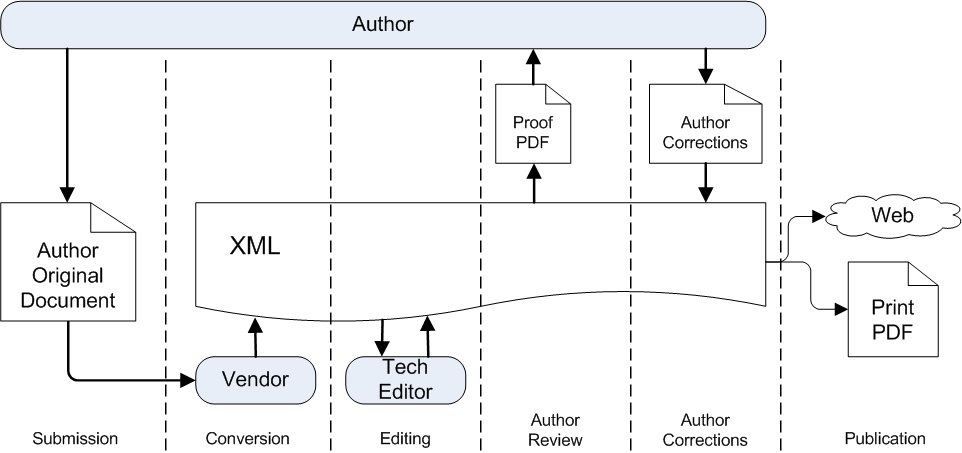
High-level overview of the ACS manuscript workflow.
Why XML Quality is Critical
All of the processing that takes place on the text of each manuscript is performed after its conversion into XML. Technical Editors use a customized XML editor when they edit the manuscript, and all of the tools which automate the processing of manuscripts expect and require XML input. The quality of this XML is critical to the successful completion of each of these tools. A manuscript in XML format must be properly tagged so that it can be parsed. This is easily checked using the DTD. If all required document elements are present in the XML, and the contents of each of the document elements are valid within their context, then a manuscript has an acceptable quality level for our automation tools. As an example, our tools cannot understand a Publication Year with a value of “next year or maybe the year after”. Documents with invalid tagging or content require manual intervention to be processed for publication. Given the sheer quantity of XML processed daily at ACS, manual intervention must be a very tiny exception to keep production costs down and time-to-publication intervals competitive.
To enhance the quality of the XML tagging and contents of each manuscript, validation tools and tools that perform automatic content and tagging changes (“edits”) were developed internally by ACS staff. The validation tools are run before the initial version of the XML content is accepted from the vendor, and again between most workflow stages. The automatic content and tagging edits are performed before and after the Technical Editors edit the manuscript.
Validations (Quality Enforced)
There are hundreds of custom validations that are performed on each manuscript. Validations are typically executed as a manuscript transitions from one workflow stage to the next. Individual validation checks are collected in logical groups, and those logical groups of validations are executed by controllers that focus on the workflow stage of the manuscript.
Some validation requests occur independently of workflow transitions. The vendor who converts the manuscript from the author’s original document format into XML executes some of our content validations before sending us the converted manuscript. Technical Editors may execute our validations directly within their XML editor (Arbortext) to check the validity of a manuscript before they attempt to promote it. Because validation requests come from a variety of sources, a web service was developed as a common entry point for execution of validations (Figure 2).
Figure 2: ACS Manuscript XML Validation Architecture
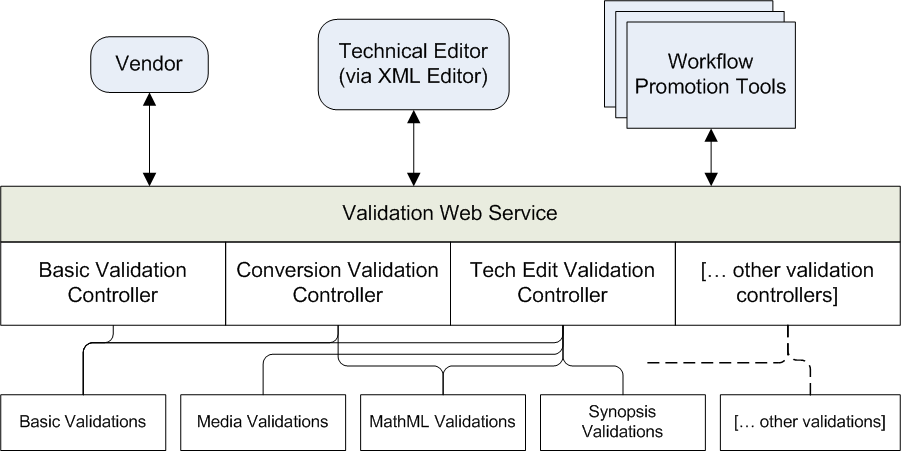
Validations may be called “on demand” by individual users or by workflow tools. The particular Validation Controller is specified as a parameter to the web service request.
Validation violations, which indicate invalid XML tagging or invalid content, are categorized into three severities: warnings, errors, and fatal errors. Severe validation violations may prevent a manuscript from proceeding to the next workflow stage, which would require manual intervention. This is dependent on the particular stage, however. Violations that would halt processing at one point might be tolerated at a different point, particularly if a following stage of processing will involve staff interaction with the manuscript.
When a violation is detected, details are enclosed in a “processing-comment” element that contains a custom message for the violation. See the example: Violation Message. That element is inserted into the manuscript XML. If possible, it is inserted close to the location where the violation occurred. If the violation is not location-specific within the XML, the message element is placed close to the top of the XML document. Validation violation messages are interpreted by staff who take the appropriate corrective action. Violation messages are removed automatically when a manuscript “passes” validations and moves along in the workflow.
If a severe violation exists in the new converted manuscript XML that is sent from the vendor, it is automatically rejected back to the vendor. Both the vendor and ACS receive notifications of the rejections so that we can track any chronic issues and also ensure that the violations are corrected and the manuscript is resent.
ACS utilizes Documentum, a content management system, to store and process manuscripts. Documentum includes a Java API for custom application integration. ACS content validations are implemented using a few different technologies, including Java and Groovy. Implementing validations in Java and Groovy allow for validation of the manuscript content against data stored in the Documentum database, and the behavior of some validations change in subtle ways depending on manuscript attributes that are stored in the Documentum database. Validations written in Groovy may be developed quickly and deployed into production without incurring down-time.
The framework and validations that were implemented using Groovy were inspired by some of the main concepts of Schematron, such as the use of XPath expressions and assertion style programming. Individual validations that had no dependency on information stored in the content management system could have been implemented using Schematron. However, many validations did have that dependency, and there was a desire for a consistent approach in validation code.
Example 1
When a manuscript is ready for publication in an issue of a journal, a check is
performed to ensure that //date[@date-type=’issue-pub’] is present in
the content XML. If it is present, it is also checked to ensure that it is a valid
date. If it is present and contains a valid date, then it is checked to ensure that
it matches the “issue publication date” value stored in the Documentum database for
that particular manuscript.
Example 2
We validate that the element <journal-id> is present as a child
of the <journal-meta> section (which must also be present), and
that the <journal-id> contents must be two characters in length.
The XPath expression that finds elements matching that condition is
//journal-meta/journal-id[string-length(.)=2]. If there are no
elements that match that expression then a violation message is inserted into the
tagging and the overall validations result is a fatal error.
Validation code (Groovy)
xmlTestXPath(vid: 'journal-id',
desc:'Journal Id must be present and be 2 characters long',
context:’//journal-meta/journal-id’,
condition:'string-length(.)=2',
messageId:'exact-string-length',
severity:ACSPubsMessage.FATAL[…]
Violation message
<tep-common:processing-comment category="Validation" error-code="exact-string-length" type="fatal">Journal Id must be 2 characters long.</tep-common:processing-comment>
Automatic Edits (“Hands-Free” Quality)
At two different times during the processing of a manuscript, content and tagging changes are automatically applied to the XML document. The first time (“pre-edit”) occurs between the stages when the manuscript is converted into XML and when the Technical Editor edits it.
Pre-edits are commonly applied content corrections and tagging enhancements. For
example, commonly misspelled (mispelled?) words are automatically corrected. Another
simple example is that <title-group> elements are added if they are
missing.
The goal of these automatic edits is twofold: to reduce the amount of time Technical Editors spend manually making common changes, and to increase quality by lowering the chances that instances of errors slip through the manual editing process. (Humans won’t catch every mispelled word!)
Automatic edits are also applied after the Technical Editors complete the manual editing process. These edits (“post-edits”) do not typically alter the element contents, but target the element tagging. Tagging is normalized (extraneous attributes removed, etc.) and the manuscript is prepared for future stages, such as web and print publication.
The automatic edit process itself is complex, and is accomplished using a combination of technologies. Many edits are implemented in Java after the XML document has been parsed. Some edits are implemented using XSL templates. We have developed thousands of individual edits, and continue to add them to our collection.
Example 1
Label and head elements whose content is enclosed entirely inside certain formatting tagging will have that formatting tagging stripped. This is implemented in Java instead of XSL so that the list of formatting tagging can be supplied in dynamic properties.
Before:
<label><bold>Label 1</bold></label>
After:
<label>Label 1</label>
Example 2
This code adds a processing comment to the document XML that contains the page count of the manuscript. This is one example of an addition to the content XML that requires retrieval of information from the Documentum database.
/**
* Add a processing comment to the document to let the TechEd know what
* the current DOTS page count is for the document.
*
* @param doc ACS Journal DOM Document
*/
public void addPageCountProcessingComment(Document doc)
{
try {
String mscNo =
acsJournalUtil.xpathFindString(doc, ACSJournalUtil.XPATH_DOCUMENT_ID_OLD_9);
String pageCount =
dotsMetaDataService.getAttribute(mscNo, DOTSMetaDataService.PAGECNT_TAG);
int pageCountNum = Integer.parseInt(pageCount);
if (pageCountNum == 0) {
acsJournalUtil.addProcessingComment(doc, null,
TEPMessageService.getInstance().
getMessageForId(STANDARD_EDITS_PAGE_COUNT_ZERO, pageCount));
} else {
acsJournalUtil.addProcessingComment(doc, null,
TEPMessageService.getInstance().
getMessageForId(STANDARD_EDITS_PAGE_COUNT, pageCount));
}
} catch (Exception e) {
logger.warn("Unable to determine DOTS page count.", e);
acsJournalUtil.addProcessingComment(doc, null,
TEPMessageService.getInstance().
getMessageForId(STANDARD_EDITS_PAGE_COUNT_UNAVAIL));
}
}
Vendor XML Quality
ACS outsourced the conversion and composition of its journals approximately five years ago, creating the need for someone to manage vendor relations. Initially, the job position didn’t include quality metrics experience but over time, metrics experience proved necessary. Ensuring vendor quality ultimately was implemented in three ways: vendor scoring, vendor validations, and vendor manual rejections.
Vendor Scoring
Measuring the quality of the XML was the first problem undertaken. XML standards, or conventions, had already been established with the vendor. For example:
For elements that allow text, any deterministic leading and trailing white space within element content should be avoided or moved outside of the tag. […] the pink spaces below should be omitted, and the blue spaces should be relocated into the adjacent text:

With a few exceptions, this largely boiled down to following the author submitted authority document. After the source document is converted to XML and returned to ACS, Technical Editors are responsible for editing the paper according to established standards. After consideration of many options, it was determined that the “goodness” of a paper was tied to the time it took the Technical Editor to fix any mistakes that happened in conversion; time that was very costly. Moreover, this added the element of the criticality of an error, rather than just the number of errors. A small team of ACS staff members worked to devise the Conversion Scorecard where the Technical Editor could record the minutes they took to fix problems while they were editing the manuscript. This process allowed ACS to integrate scoring into the existing editing process to make the data collection process as efficient as possible. Following is a sample section from the Conversion Scorecard.
Table I
| CONVERSION SCORECARD | |
| Equations | Score |
| Minutes to fix equations that were not keyed that should have been? | 1 |
| Minutes to fix equations that were not MathML that should have been? | 0 |
| Minutes to make the paper match author copy (beyond 2 items above) | 0 |
| Equation Subtotal | 1 |
The scoring methodology having been determined, the next issue was how to apply that to the approximately 40,000 manuscripts received by ACS for publication in a year in an efficient yet statistically valid manner. One important factor was that even with the scorecard, scoring was somewhat complicated. For the scores to be valid, the same criteria had to be applied in deciding if something was an issue. Also, two Technical Editors had to apply very similar resources to fix the same issue in two different papers. In order to maintain this consistency, a small team of scorers was selected who could be trained to use the same standards and then monitored to ensure that they were recording time in a similar manner. Six of our most effective and efficient Technical Editors were selected, trained, and then evaluated to ensure their scoring was uniform by having them independently score the same set of manuscripts.
With the small scoring team in place, the next determination was to find the smallest sample of manuscripts that could be scored and still give a very high degree of confidence that the sample was representative of the entire manuscript population. A sampling technique which was developed in-house by a Quality Management team in another division of ACS was used. That team started with standard sampling protocols taught in any statistical course, then created and tested a technique used to prove that scoring a relatively small number of items from a huge population was statistically representative of the entire population. The technique consisted of randomly selecting approximately 10% of the manuscripts submitted in a month, or 60 manuscripts. From that group of 60 manuscripts, 40 manuscripts were randomly selected. From that sub-sample of 40, 20 manuscripts were randomly selected. That sub-sub sample was then scored. The overall standard mean score and the standard deviation for the sub-sub sample was determined. Then the remaining 20 manuscripts were scored (those not included in the first sub-sub sample). The overall standard mean and standard deviation for this set was then determined. In looking at the standard deviation from the two sets and the mean scores, it was determined with a confidence of 90% (which is standard for non-life threatening applications), that the mean score for a random sample of 20 manuscripts was within 11% of the score for the entire population. The width of this interval was deemed acceptable.
Given this number, open source “random selector” code was used to select 240 numbers from 1-40,000, which was 20 manuscripts per month for 12 months. The 240 random numbers were entered in a table. When a manuscript was submitted to the workflow with a sequential number that matched a number in the table, that manuscript was flagged. For example, if 1253 was a number in the table, when the 1253rd manuscript of the year was submitted, then a scoring attribute for that manuscript was updated in our workflow system and an email was sent to the scoring team telling them the manuscript was ready to be scored as soon as it returned from conversion.
When ACS first started scoring, the average number of minutes to fix a manuscript was 9.5. Today the number is between 1 and 2 minutes per manuscript. This significant improvement was achieved by a collaborative effort with the vendor to focus on the same issues and apply continuous improvement to those issues. This conversion score is reported weekly both internally and to the vendor. One of the real advantages of the reporting is that it is immediately obvious if there has been a change that affects the quality.
Vendor Validations
Another way the quality of our converted XML is ensured is by allowing the vendor to call our web service to run the ACS validations program. As mentioned earlier, ACS has a robust validations system that is applied to manuscripts at many points throughout the production workflow, including when manuscripts are returned by the vendor. Rather than waiting until a manuscript is returned to run those validations, ACS opened up the validations via web service to the vendor, significantly reducing the number of manuscripts ever sent to ACS which have validation errors. This also helped the vendor to meet turnaround time SLOs.
The validations check against our DTD but also against established conversion conventions. Following is an example of a validations error the vendor might see upon executing the validations service:
Validation failures were detected for np200906s
Journal: np
Msc Type: r-Review
FATAL: The content of element type "metadata" must match "(journal-meta,document-meta,processing-meta?)".
Vendor Manual rejections
Because ACS edits XML that is relatively complex, understandably some errors that are difficult to catch with validations are introduced during technical editing. These errors often interfere with good composition. These mistakes were originally addressed via emails between ACS and the vendor. This caused problems when emails were lost or sent to out-of-office staff. There was also no enduring record of the problems being addressed. Working with the vendor, a way was implemented to reject incorrect tagging that affected composition. For example, a table attribute might have been set to be anchored instead of as float which resulted in poor rendering in the composed output. Code was installed at ACS and also at the vendor’s site which allowed the vendor to reject a composition request with a meaningful error code. Now when the ACS workflow system receives an error code, four things happen:
-
the specific instructions that the vendor entered at the time of the rejection is entered in the ACS workflow system as a note attached to the manuscript. For example, “Figure 1 appears in the document but is not cited.”
-
the code is looked up in a table and general instructions present in the table for that error code are found
-
these instructions, both specific and general, become the text of an email sent to the appropriate ACS staff member
-
the manuscript is auto-routed in the workflow system to the appropriate stage to be corrected by either a Graphics Editor, a Production Assistant, or a Technical Editor, depending on the error to be corrected
Not only did this improve publication time but it improved the quality of the work done by ACS staff by giving immediate feedback on errors committed. The rejections are also parsed periodically to help guide other efforts to improve throughput and quality.
Conclusion
The steps taken by ACS to measure, auto-correct, and validate our XML have made a positive difference in all aspects of the workflow. Technology is evolving daily and to think that efforts to ensure XML quality are complete is to already be behind. For example, we have made over 30 changes to our validations and pre-edits alone since the beginning of the year. ACS is committed to continually monitoring and improving the processes we have put in place to ensure the quality of our XML.
References
[ACS Tagsets] O'Brien, Dan and Fisher, Jeff. “Journals and Magazines and Books, Oh My! A Look at ACS' Use of NLM Tagsets.” JATS-Con Proceedings 2010. http://www.ncbi.nlm.nih.gov/books/NBK47083/.
[ACS Style Guide] Edited by Coghill, Anne M. and Garson, Lorrin R. “The ACS Style Guide: Effective Communication of Scientific Information, 3rd ed.” 2006. ISBN: 978-0-8412-3999-9 http://pubs.acs.org/page/books/styleguide/index.html.
[ACS Automated Composition] Needham, Diane. “True Automated Page Composition Process.” Presentation given at STM Innovations Seminar U.S. – Reinventing Innovation, 2012. http://www.stm-assoc.org/2012_05_01_Innovations_US_Needham_True_Automated_Page_Composition_Process.pdf.