In the Beginning
When publishing moved from linotype to computer assisted composition, the publishing split into two different and distinct worlds. On one side publishers developed and adopted structured markup technologies. But another major sector of publishing focused on moving publications to new levels of layout and design. Each faction had a very different philosophy. Each nurtured the development of very different publishing tool sets and hence distinctly different skillsets and workflows.
Content-Based Publishing
In one world, the world of content-based publishing, the content is the whole point of publishing. Technical publishing is a prime example of content-based publishing. Technical publishing encompasses technical documentation such as maintenance and operational technical manuals as well as reference publishing such as legal publishing, financial reports and product information along with content that is assembled from databases such as course catalogs, racing forms and even television show guides. Content-based publications are often quite lengthy, being made up of hundreds and often thousands of pages of highly structured content.
Another characteristic of a content-based publication is that it can be formatted automatically by applying style sheets or templates. Style sheets are designed to enable a reader to quickly access information in lengthy publications. Publishers with large volumes of structured content adopted publishing tools and systems based on ISO 8879:SGML and later on W3C's XML markup language. Content could be created in XML first, stored in XML content management systems that were modeled on the XML document structure. Content could then be assembled from the XML content repositories and the layout and styling were automated through the use of high-speed computerized pagination engines. Docbook, adapted for the encoding of Balisage papers, is an example of one such structured markup specification.
Content: Content-Based Publications

Content-based publications are highly structured and can be formatted through the application of style sheets or templates.
For many years, I worked in the world of content-based publishing. As an employee of Datalogics, I was involved in early SGML designs and pioneering SGML implementations for the US Air Force (ATOS), ATA 100 SGML tagging for aircraft maintenance manuals and served as chairperson for the Society of Automotive Engineering (SAE) J2008 SGML Specification. While deeply engaged in technical and reference publishing projects, I could not imagine why all publishers didn't standardize their content so they could reap the benefits that implementing structured-markup based systems could provide. And my guess is that many Balisage delegates maintain that same perspective.
Design-Based Publishing
Until 2003, I worked almost exclusively in the world of content-based publishing. Then in 2003 I joined the staff of IDEAlliance. My first assignments moved me into magazine publishing and advertising. This was a very different place for me. The tools were not at all familiar. I began working with "creatives" who developed a concept and design for everything they published. Once the creative specifications were established, content creation began. Writers were given assignments and photographers set up shoots to illustrate the concepts and complement the design. And suprisingly, other than a few standard "department" assignments such as book and movie reviews, content was relatively free flowing.
Design: Design-Based Publications

Design-based publications are often unique creations and standardizing structure is quite difficult.
I had entered the twilight zone, the very different world of publishing that based on design not content. Most magazines fall into this category along with highly designed books such as cook books, travel books and other "coffee table" books. For this type of publishing, design comes first. Here the Art Director rules. Standard style sheets that would give each issue the same look month after month would simply not do. And because design comes first, content structures cannot be effectively standardized either. Hence, very few publishers of design-based publications have adopted "XML-first" workflows. And in fact until recently very few members of this community employed XML at all. Process automation has been held to the minimum as well. In this world publishing technology is focused on enabling design.
The iPad Impact
In April 2010, the design-based publishing world was rocked when the iPad became the first of many new digital publishing platforms for magazine publishers. Publishers had only 80 days to figure out how to publish magazines in print and on the iPad simultaneously. Additionally they were challenged to move from the 2D to the 3D world of articles and advertising enhanced by slideshows, videos and highly interactive content. And the iPad was only the beginning. Nearly 2 years later we have a wide array of tablet devices available as new publishing platforms.
Until the tablet-publishing tsunami hit, design-based publications were able to justify their labor-intensive design-based publication process. But the challenge of producing well-designed publications, not only in print, but on a growing number of digital devices with different resolutions, aspect ratios and sizes soon became overwhelming. Finally it became clear that in order to publish simultaneously in print and across all a range of diverse mobile platforms with different aspect ratios, sizes and op systems, workflows must shift to a model where a platform agnostic content, an XML source format, is used feed all platforms and designs. The challenge for magazine publishers was to figure out how to leverage the benefits realized from the XML-First publishing model while protecting the seminal importance of high-quality design.
About the nextPub Initiative
nextPub, the publishing industry's technology incubator, was launched in 2010 by IDEAlliance and is supported by the Magazine Media Association, the 4A's/Ad-ID and the Japanese Magazine Publishing Association. nextPub enables publishers to engage directly with their industry peers and leading publishing technologists to foster the development of next-generation design-based publishing tools by embracing emerging technologies, developing best practices and establishing new industry specifications to serve as the foundation for tomorrow's publishing workflows.
When the nextPub Initiative began, the immediate goal was to make multi-channel publishing both simple and efficient. That is, to meet the iPad challenge. But as the Working Group explored standards and technologies, strategists began to envision monetizing content beyond today's publishing channels by utilizing a "Dynamic Content Architecture" from which additional publishing channels can emerge when new content collections are assembled based on topics from across magazines or based on personal preferences as foreshadowed by the Flipboard, Pulse or Zite models.
Assumptions
Over the past 2 years, the nextPub Initiative has developed a major set of new specifications to serve as the next generation for design-based publishing. These specifications are based on the following assumptions:
-
We have come to believe the Source is the Solution. We must capture and store platform-agnostic content as early as possible. For design-based publications, this will likely not mean XML First, but it certainly implies XML Early.
-
Since design-based content cannot be highly structured,
-
We must foster the development of new dynamic display/layout technologies that enable simultaneous design for multiple publishing platforms and automatic content layout capabilities supporting high-quality design aesthetics
The nextPub Design-Based Publishing Model
nextPub Publishing Model is based on digital capture and management of all content and associated rich media. Source content must be semantically rich enough to enable the publisher to select content and automate layout and delivery to a wide variety of publishing platform in platform-native formats. To support the nextPub publishing model, the Working Group has developed the PRISM Source Vocabulary (PSV) Specification. PSV has been designed to support today's issue-based publications as well as to enable publishers to aggregate content in new ways to create new digital content channels that extend beyond the traditional publication models.
The PRISM Source Vocabulary (PSV) Specification, defines a framework of robust metadata elements and controlled vocabularies that can be used to configure federated source content / rich media repositories. Metadata fields and values used in this specification are drawn from the IDEAlliance PRISM 3.0 Metadata and Controlled Vocabulary Specifications. In order to future-proof content, nextPub recommends encoding content using HTML5 tagging enhanced with PRISM-based class semantics.
Model: nextPub Design-Based Publishing Model
The nextPub Publishing Model is based on digital capture and management of all content and associated rich media.
About the PRISM Source Vocabulary (PSV)
When designing the PRISM Source Vocabulary, the nextPub Working Group was committed to build on existing publishing infrastructures. This meant basing our work on the PRISM (Publishing Requirements for Industry Standard Metadata) Specification which is already in wide use by design-based publishers. Since most major magazine publishers have implemented today's publishing systems based on this robust IDEAlliance metadata specification, it was deemed to be the ideal starting point to build on for the future.
nextPub was also committed to leveraging emerging technologies. Most of the current publishing systems based on PRISM use an XHTML-based content coding scheme that publishers to deliver content to aggregators. But the nextPub Working Group found great limitations in remaining with XHTML and great opportunity to move to HTML5, a semantically-based Vocabulary for HTML and XML /[HTML5/]. HTML5, working in conjunction with CSS3 and JS, provided the support for rich media and interactivity that design-based publishers require for the future.
Foundation: The PSV Foundation

PSV is based on PRISM 3.0 metadata and HTML5 enhanced with PRISM semantics
While some from the content-based publishing world may question the use of HTML5 for encoding magazine article content based on what they view as a limited functionality due to the high degree of structural flexibility and limited hierarchy of HTML5, it is that very flexibility plus the ability to carry semantics on any structure tag that makes HTML5 a perfect fit for design-based content. Because of the high variability of content developed as part of a creative design process, the magic of the dynamic c5 ontent architecture is in the metadata not in the XML structured tagging. In addition PSV adds PRISM semantics to the HTML5 to enhance functionality.
A Flexible Framework
Another principle behind the design of PSV was the requirement for flexibility. Each publisher has their own business models and publishing strategies. So a single, rigidly defined framework will not work for anyone. Rather, the PSV design provides a framework and the building blocks required to implement a dynamic publishing system that can easily be tailored for the business requirements of each publisher. By selecting appropriate PSV metadata building blocks, a publisher can build a federated digital content repository that satisfies their unique business requirements and strategies. And the publisher is free to use any conformant HTML5 to semantically encode source content.
PSV's modular design provides the building blocks for a publisher to implement a dynamic, cross-platform publishing system. PSV can easily be tailored for the business requirements of each publisher. Blocks shown in dark colors are required. These blocks are minimal and include a unique ID for the content object, a specification of the content type (or object type) and of course the HTML5-encoded content.
BuildingBlocks: PSV Building Blocks
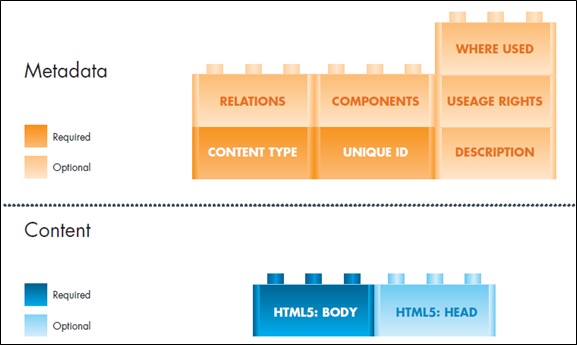
PSV is flexible framework of building blocks
About Content Types
PSV states that an article is the basic unit of content storage. But it is important to note that we are referring to a generic article rather than a physical article of a magazine. In the early days of PRISM, it could be assumed the unit was an article of a magazine, journal or other serial publication. Now, expanding the scope to cover the broader publishing use cases, the unit-of-content is not so obvious. This is particularly true when advertising material, blog or book content is added to the scope. In order to refine what we mean by the generic term article, the PRISM Content Type Controlled Vocabulary has been developed. A content type identifies the highest-level indicator of the nature of the asset that is tagged. Some content types that describe the unit-of-storage include an advertisement, article, blog entry, book chapter, cover, masthead, introduction and navigational aid.
About Where Used Metadata
The Where Used metadata block allows for usage tracking. Many companies that you think of as magazine publishers are really media companies that own television shows, websites and book content channels. So tracking usage is critical. Key metadata choices for the publisher include tracking content usage by the publication name, its ISBN, ISSN, product code and issue name. PSV allows for tracking the platform and even the device where the content was published. PSV also allows for tracking the section or page of the publication where the content appeared. Altogether, PSV offers nearly 40 optional fields to describe where content was used.
About Usage Rights
When publishing content across platforms and publication titles, the publisher's right to use the content is not always guaranteed. This is especially true when content is enhanced with images and videos. The Usage Rights metadata block provides optional metadata fields that can be used by publishers to track usage rights of content in a repository. The 15 optional metadata fields in this block are based on the PRISM Usage Rights Metadata Specification -/[PRISMURMS/]
Inside Each Metadata Building Block
Each of the PSV metadata building blocks is made up of PRISM 3.0 metadata fields. Again the design is flexible so each publisher can select the fields that they need to use to manage and assemble content from a PSV repository. All possible metadata fields for each building block are doucumented in the PSV Specification. For example the description metadata includes fields such as dc:subject, prism:publicationName and prism:genre.
Description: PSV Description Metadata
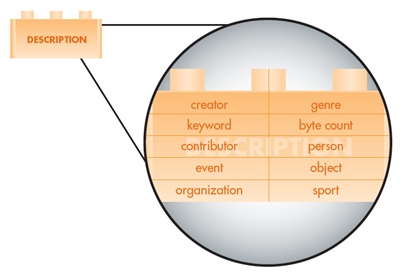
The description block is made up of 25 metadata fields
HTML5 for Content Encoding
The HTML5 Body is one of the required PSV building blocks and is used to encode content. Unlike EPUB3, PSV makes no extensions to HTML5 and has no restrictions. PSV recommends that the new HTML5 <article tag be used as the root element for any content unit. According to the latest HTML5 Draft, "The article element represents a section of a page that consists of a composition that forms an independent part of a document, page, or site. This could be a forum post, a magazine or newspaper article, a Web log entry, a user-submitted comment, or any other independent item of content." PSV also recommends using a number of the other new HTML5 tags including <section, <nav and <aside that are representative of general magazine article structures.
To enable semantic content encoding, HTML5 has added a "class" attribute on every element. PSV recommends a number of PRISM semantic classes that you can use to qualify any HTML5 element. Examples include box, caption, dateline, credit, and pull quote.
<aside class="prism:pullQuote"> <p>WE TALK ALL THE TIME ABOUT HOW TO SET THE RIGHT TONE FOR OUR PLAYERS</p> </aside>
Appendix A. References
THE PSV 1.0 DOCUMENTATION PACKAGE
The IDEAlliance nextPub Initiative has developed a series of specifications collectively known as the PRISM Source Vocabulary or PSV. The use case for PSV is to encode semantically rich content for assembly, transformation and delivery to any platform. This Specification is made up of a modular documentation package that builds on PRISM 3.0 and HTML5. Over time new modules may be added to the documentation package. The documentation package for the nextPub PRISM Source Vocabulary Specification consists of:
Table I
| PRISM Source Vocabulary Specification Overview /[PSVSO/] | The Overview to the PRISM Source Vocabulary provides an introduction and a non-technical overview of the PRISM Source Vocabulary. http://www.nextpub.org/specifications/1.0/PSV_Overview_1.0_NEW.htm |
| PRISM Source Vocabulary Specification /[PSVS/] | The PRISM Source Vocabulary Specification defines semantically rich for source metadata and content markup that can be transformed and served to a wide variety of output devices including eReaders, mobile tablet devices, smart phones and print. http://www.nextpub.org/specifications/1.0/PSV_Specification_1.0_NEW.htm |
| PRISM Source Vocabulary Markup Specification /[PSVMS/] | The PSV Markup Specification documents the XML tags in the PSV namespace that are used to encode XML Source Content. http://www.nextpub.org/specifications/1.0/PSV_Markup_1.0_NEW.htm |
| PAM to PSV Guide /[PAMPSVGUIDE/] | This Guide documents mappings from PAM XML to PSV XML. It is normative only. http://www.nextpub.org/specifications/1.0/PAM_to_PSV_1.0_NEW.htm |
THE PRISM DOCUMENTATION PACKAGE:
Because PSV is built on PRISM 3.0, there is a close relationship between the two specifications. In fact, access to the PRISM 3.0 Documentation Package is critical to the implementation of PSV. The PRISM 3.0 Documentation Package consists of:
GENERAL PRISM DOCUMENTATION
This is a set of general or overview documents that apply to PRISM.
Table II
| PRISM Introduction /[PRISMINT/] | Overview, background, purpose and scope of PRISM; examples; contains no normative material. http://www.prismstandard.org/specifications/3.0/PRISM_Introduction_3.0_NEW.htm |
| PRISM Compliance /[PRISMCOMP/] | Describes three profiles of PRISM compliance for content and systems; includes normative material. http://www.prismstandard.org/specifications/3.0/PRISM_Compliance_3.0_NEW.htm |
PRISM METADATA SPECIFICATIONS
This is the set of documents that outline the prism metadata fields and values by PRISM metadata category. PRISM has modularized its metadata specification by namepace so users may pick those modules that meet their unique business requirements without having to implement the entire PRISM specification.
Table III
| The PRISM Basic Metadata Specification /[PRISMBMS/] | Describes the basic metadata elements contained in the PRISM namespace to describe article content; includes normative material. http://www.prismstandard.org/specifications/3.0/PRISM_Basic_Metadata_3.0_NEW.htm |
| PRISM Advertising Metadata Specification /[PRISMADMS/] | Describes advertising metadata elements including those drawn from Ads-ML, GWG and Ad-ID; includes normative material. http://www.prismstandard.org/specifications/3.0/PRISM_Advertising_Metadata_3.0_NEW.htm |
| The PRISM Subset of Dublin Core Metadata Specification /[PRISMDCMS/] | Describes metadata elements from the Dublin Core namespace that are included in PRISM; includes normative material. http://www.prismstandard.org/specifications/3.0/PRISM_Dublin_Core_Metadata_3.0_NEW.htm |
| The PRISM Image Metadata Specification /[PRISMIMS/] | Describes the metadata elements contained in the PRISM Metadata for Images Namespace and other related image namespaces, includes normative material. http://www.prismstandard.org/specifications/3.0/PRISM_Image_Metadata_3.0_NEW.htm |
| The PRISM Recipe Metadata Specification /[PRISMRMS/] | Describes the metadata elements contained in the PRISM Recipe Metadata Namespace, includes normative material. http://www.prismstandard.org/specifications/3.0/PRISM_Recipe_Metadata_3.0_NEW.htm |
| The PRISM Usage Rights Metadata Specification /[PRISMURMS/] | Describes the metadata elements contained in the PRISM Usage Rights Namespace; includes normative material. This namespace will supersede elements in both the prism: and prl: namespaces in version 3.0 of the specification. http://www.prismstandard.org/specifications/3.0/PRISM_Usage_Rights_Metadata_3.0_NEW.htm |
PRISM CONTROLLED VOCABULARY SPECIFICATIONS
These modules are new with PRISM 3.0. Previously both the Controlled Vocabulary Markup and the documentation of controlled vocabularies were published as a single document. All controlled vocabularies and their terms are documented in this publication set.
Table IV
| The PRISM Controlled Vocabulary Markup Specification /[PRISMCVMS/] | Describes metadata fields in the PRISM Controlled Vocabulary Namespace that can be used to describe a controlled vocabulary. Actual PRISM controlled vocabularies are now placed in the PRISM Controlled Vocabularies Specification /[PRISMCVS/] http://www.prismstandard.org/specifications/3.0/PRISM_Controlled_Vocabulary_Markup_3.0_NEW.htm |
| The PRISM Controlled Vocabularies Specification /[PRISMCVS/] | The PRISM Controlled Vocabularies are now documented in this document. http://www.prismstandard.org/specifications/3.0/PRISM_CV_Spec_3.0_NEW.htm |
NOTE: In addition to the PSV and PRISM Specification a series of implementation guides are provided by IDEAlliance.