Introduction
More than ten years after the birth of XML the limits of XML-based markup languages seem to become apparent: while on the one hand some people tend to see XML together with its accompanying specifications as the new (too complex) SGML and try to trim it (see Cowan, 2010, Cowan, 2011, and the discussion on the xml-dev mailing list), on the other hand the underlying formal model of a tree cannot cope with multiple and possibly overlapping structures. Together with an increasing demand for multiple annotated corpora in the Digital Humanities questions for visualizations of concurrent annotations have been posed. In this paper we will sketch out two main points: firstly, we will show that the underlying data model of XML is not a tree at all and that it is possible to serialize graph-like structures including discontinuous elements with plain XML. We will then choose two XML-based representation formats as basis for our visualization efforts which will be discussed in section “2D visualization of concurrent markup”. The paper continues with some thoughts about 3D visualization techniques and the discussion of a prototypic implementation in section “Adding the third dimension” and concludes with some remarks about possible future research.
A formal model of XML instances
The majority of people dealing with XML instances tend to believe that markup languages
which were developed to annotate mainly textual content use the formal model of a
tree. This
thinking can be traced back to statements like the one expressed in 1987 by J. H.
Coombs et al. who
stated that [d]ocuments have a natural hierarchical structure: chapters have sections,
sections have subsections, and so on, until one reaches sentences, words, and
letters
(Coombs et al., 1987, p. 945) and was encouraged by the OHCO theory
that states that a text is an ordered hierarchy of content objects.[1] From the formal perspective a tree is a special kind of directed graph. We reconsider
the definition of a
directed graph stated in Hopcroft and Ullman, 1979, p. 2:
A directed graph (or digraph), [...] denoted G = (V, E), consists of a finite set of vertices [(or nodes)] V and a set of ordered pairs of vertices E called arcs. We denote an arc from v to w by v→w.
A path in a digraph is a sequence of vertices v1, v2,...,vk, k≥1, such that v1→vi+1 is an arc for each i, 1≤i≤k. We say the path is from vi to vk. [...] If v→w is an arc we say v is a predecessor of w and w is a successor of v.
that has no predecessors and from which there is a path to every vertex). Each node other than the root node has exactly one predecessor and is connected to this single parent via one (and only one) edge. The successors of each node are ordered from left to right (Hopcroft and Ullman, 1979, p. 3).
Usually, one tends to agree on XML instances to use the formal model of a single-rooted
tree: in the XML specification it is stated that [t]here is exactly one element, called
the root, or document element, no part of which appears in the content of any other
element.
For all other elements, if the start-tag is in the content of another element, the
end-tag
is in the content of the same element. More simply stated, the elements, delimited
by start-
and end-tags, nest properly within each other.
And indeed, if we stick with the
nesting of elements (and attributes) we end up with a tree. A tree, however, has certain
limitations: since crossing arcs are not allowed, it is not possible to use a tree
model for
the annotation of discontinuous segments (for example multi-word idioms discussed
in Pianta and Bentivogli, 2004 or the Alice in Wonderland
example quoted in Sperberg-McQueen and Huitfeldt, 2008). Although it would be possible to use TEI's milestone
elements or fragmentation (see TEI P5 (v 1.9.1), 2011) one would still have to deal with
separate element instances, that is the relation between the parts of the elements
would be
implicit.
A related disadvantage of trees is that it is often not possible to annotate concurrent – and possibly overlapping – hierarchies.
A hierarchy is formed by a subset of the elements of the markup language used to encode the document. The elements within a hierarchy have a clear nested structure. When more than such a hierarchy is present in the markup language, the hierarchies are called concurrent.
Even if two concurrent hierarchies do not overlap it is impossible to merge them into a single tree if they do not share the same root, since trees are only allowed to have a single root node (see definition above). But the major problem related to concurrent markup is that multiple hierarchies may lead to multiple parentage of nodes:
Overlap can be represented by graphs that are very like trees, but in which nodes may have multiple parents. Overlap is multiple parentage.
Since one of the main driving forces behind the creation of multi-dimensionally annotated
documents are linguistic corpora, the TEI Guidelines TEI P5 (v 1.9.1), 2011 have not only
improved the awareness of scholars of the Digital Humanities for the problems regarding
this
special field of research, but also provided some solutions to it. However, the different
possible
solutions (multiple documents, milestone elements, fragmentation and standoff markup)
that are
part of Chapter 20 of the aforementioned Guidelines are flawed with several disadvantages.
Using multiple documents (cf. Section 20.1 of TEI P5 (v 1.9.1), 2011) results in redundant
storage of the primary data, that is the character stream which is to be annotated
and – as
an effect – makes further changes to both primary data and annotation files time-consuming,
which in turn can result in inconsistencies between the various instances. In addition
there is no explicit indication that the various views, which might be in separate
files,
are related to each other: it might prove difficult to combine the views or access
information
from one view while processing the file that contains the encoding of another
(TEI P5 (v 1.9.1), 2011, p. 621). The last point can be addressed by using the primary data as
reference system, that is the positions in the character stream delimit the start
and end points
of corresponding markup, see Witt, 2002 (which is already referred to in the
Guidelines) or Witt, 2004 and the standoff approaches discussed below. The
related approach of twin documents shown in Marinelli et al., 2008 in addition to the primary data redundantly stores the so-called
sacred markup, that is markup which is shared between different
annotation layers (in contrast to profane markup that is related
to a single layer). Although redundancy may lead to an improved sustainability (according
to
Rehm et al., 2010) we tend to follow the Guidelines in believing that the price in form
of possible inconsistencies is too high.
For these reasons several proposals for graph-based formal models and alternative representation formats have been discussed in the last decade. As already stated above, a graph is the superclass of trees and therefore allows both multiple parentage and multiple root nodes. Again, first proposals for the XML representation of graphs can be found in the TEI Guidelines TEI P5 (v 1.9.1), 2011 in Chapter 18 by introducing feature structures.[2] Feature structures are single-rooted labeled directed acyclic graphs, often displayed as attribute value matrices, that can be used for representing various kinds of information. The TEI approach was standardized as international standard ISO/IEC 24610-1:2006 and can be used as serialization format for multiple annotations as shown by Stegmann and Witt, 2009. However, as discussed in this special paper, the resulting XML instances can be quite huge, rendering this approach quite limited.
Another alternative formal model for markup languages that has received much attention
is the
General Ordered-Descendant Directed Acyclic Graph (GODDAG) which was introduced in
Sperberg-McQueen and Huitfeldt, 2004 (see Sperberg-McQueen and Huitfeldt, 2008a for a more
recent discussion). To be more precise, there is a whole range of GODDAG sub-classes,
such as
the restricted GODDAG (r-GODDAG), the generalized GODDAG, the clean GODDAG, the normalized
GODDAG and the colored GODDAG (the latter two have been introduced in Huitfeldt and Sperberg-McQueen, 2006). Figure 1 (taken from Sperberg-McQueen and Huitfeldt, 2008) shows a GODDAG representing the aforementioned
Alice in Wonderland
example.
Figure 1: GODDAG representation of discontinuous segments
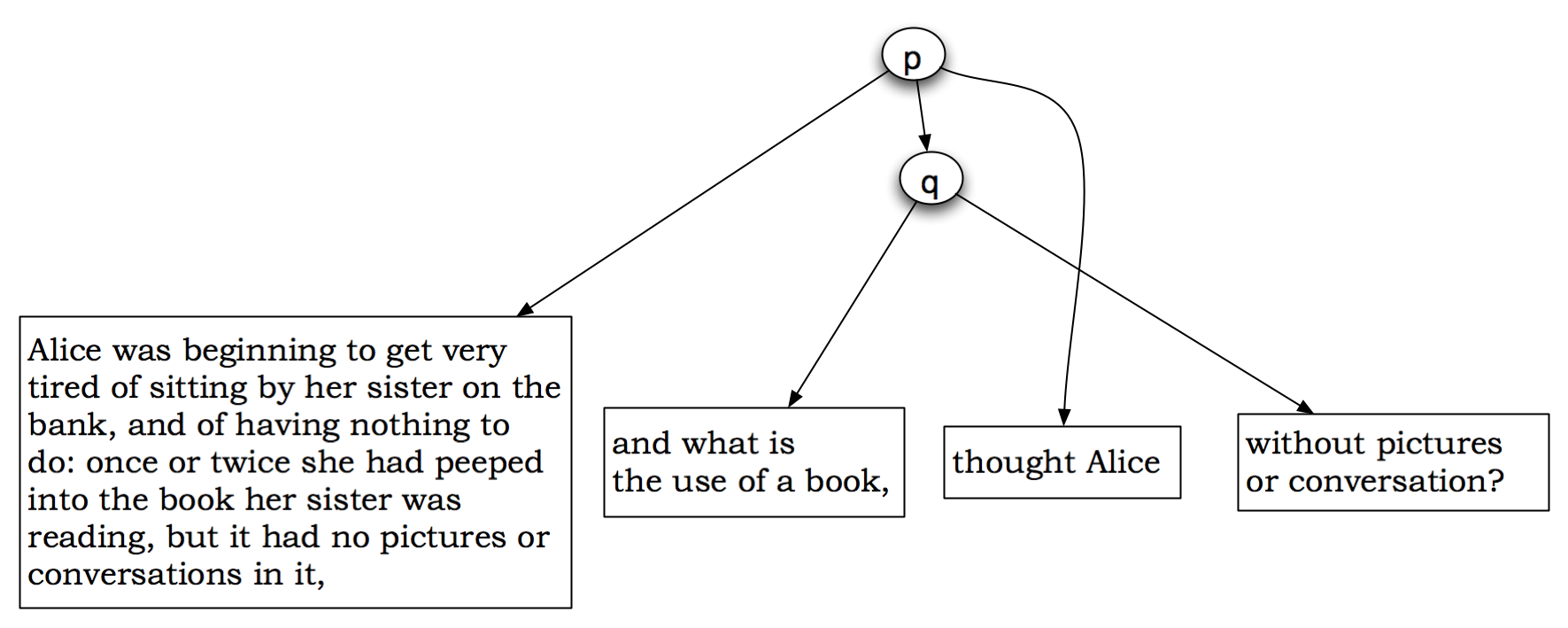
GODDAGs (and especially clean r-GODDAGs) can be serialized as TexMECS instances (see Marcoux, 2008 for a detailed discussion about the relationships between GODDAG sub-class and TexMECS serialization). The respective GODDAG serialization of the above-named example is shown below:
<p|Alice was beginning to get very tired ... it had no pictures or conversations in it, <q|and what is the use of a book,|-q> thought Alice <+q|without pictures or conversation?|q> |p>
Apart from TexMECS there are other serialization options for representing GODDAGs. Especially the work done by Di Iorio et al., 2009 is of interest, since they have shown that a data structure based on RDF, called EARMARK (Extreme Annotational RDF Markup), not only fully supports the expressiveness of GODDAGs but additionally introduces a new sub-type, called e-GODDAG (extended GODDAG) that adds anonymous non-terminal nodes (for establishing multiple arcs between two nodes and therefore allowing repetitive structures).
A second alternative data model for markup languages is the Annotation Graph introduced
by
Bird and Liberman, 1999 which was especially designed for linguistic annotations. An AG
formally is a labeled directed acyclic graph (labeled DAG) which uses an
order-preserving map assigning times to (some of) the nodes
(Bird and Liberman, 1999, p. 2). This formal model is used for example in the annotation tool
EXMARaLDA discussed in Schmidt, 2001. An extended version can be found in the
NITE Object Model (cf. Carletta et al., 2003, Carletta et al., 2005) which
combines hierarchies between nodes (similar to ordered directed trees) and the timing
information. Both formal models use plain XML as serialization format. We will discuss
this
finding in a few paragraphs.
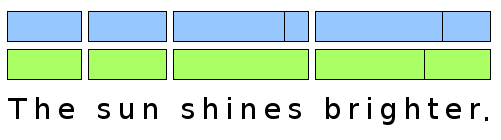
The third alternative formal model is based on the Core Range Algebra, introduced in Nicol, 2002 and extended in Nicol, 2002a. It uses flat ranges over the primary data and allows for overlapping ranges. A related serialization format is the Layered Markup and Annotation Language (LMNL, Tennison, 2002, Piez, 2004, Cowan et al., 2006). LMNL uses the primary data as base consisting of zero or more atoms (representing a Unicode char or something completely different). Ranges over the base contain the atoms between a matching start tag and end tag and may overlap. Even self-overlap (that is overlapping of elements, or ranges that bear the same generic identifier, see Marinelli et al., 2008 for an example) is supported, as well as anonymous ranges (similar to the aforementioned e-GODDAGs). Annotations can be located at both the start and end tag and since LMNL completely abandons hierarchy there is no need for a 'root range' (although the containment relation can be used via the use of base layers, see Cowan et al., 2006). Despite its naming as 'markup language' LMNL was developed as a formal model, therefore several serialization formats exist. Apart from LMNL's own Sawtooth syntax there is Canonical LMNL in XML (CLIX, formerly known as HORSE, Hierarchy-Obfuscating Really Spiffy Encoding, DeRose, 2004, Bauman, 2005), ECLIX (extended CLIX) and xLMNL. While CLIX and ECLIX use TEI milestone elements, xLMNL is a flat representation, similar to a standoff approach (examples of all these formats can be found at http://www.piez.org/wendell/papers/dh2010/clix-sonnets/). Figure 2 shows a possible graphical representation of ranges and annotations in LMNL (here syllables and morphemes). Note, that due to the two-dimensional approach the hierarchy that is implied by the vertical arrangement of the bars is not compulsory in LMNL.
Figure 2: Possible graphical representation of LMNL ranges
Other approaches that shall be mentioned here for the sake of completeness are multi-colored XML (cf. Jagadish et al., 2004), the use of delay nodes (Le Maitre, 2006), the tabling approach described by Durusau and Brook O'Donnell, 2004 and XCONCUR by Schonefeld, 2007. While some of the aforementioned data models make use of a serialization format of their own, others succeed in using plain XML. This indicates that the formal model of XML instances has a greater expressive power than a directed ordered tree. And indeed, if we leave the field of Digital Humanities, there is a number of authors that tend to agree that the formal model of XML instances is that of a graph: Abiteboul et al., 2000, Polyzotis and Garofalakis, 2002, Gou and Chirkova, 2007 or Møller and Schwartzbach, 2007. The discrepancy in the findings can be explained by the sole observation of hierarchical relations of elements or by alternatively taking the XML-inherent integrity constraints into consideration, that is ID/IDREF/IDREFS token type attributes (in DTD) or xs:ID/xs:IDREF/xs:IDREFS and xs:key/xs:keyref (in XSD) respectively. In this context a line can be drawn between well-formed XML instances (in that case we still have to deal with a tree) and valid XML instances according to a document grammar that makes use of the aforementioned integrity constraints. Using a native XML approach has the advantage of being able to make use not only of a large range of software products but also of related specifications such as XPath, XSLT, and XQuery. Especially the upcoming XSLT 3.0 is quite interesting since it supports streamable transformations allowing for the manipulation of fairly big XML instances (cf. Kay, 2010). In addition, XML-based visualization formats such as the 2D SVG and newer approaches such as the 3D X3D are promising formats for the visualization of concurrent annotations (see section “2D visualization of concurrent markup” and section “Adding the third dimension”). We have already found proofs that the full power of valid XML instances can be used to serialize Annotation Graphs or LMNL ranges. Figure 3 demonstrates that valid XML can even make use of cyclic paths (or arcs) and therefore definitely exceeds the formal power of trees.
Figure 3: Minimal valid XML instance with cyclic paths
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE a [ <!ELEMENT a EMPTY> <!ATTLIST a id ID #IMPLIED idref IDREF #IMPLIED> ]> <a id="a" idref="a"/>
Together with the standoff approach mentioned both in the TEI Guidelines and Thompson and McKelvie, 1997, this expressive power can be used to capture multiple annotated data. In Stührenberg and Goecke, 2008 and Stührenberg and Jettka, 2009 the authors discuss the XStandoff meta annotation format which is capable of representing discontinuous elements, multiple parentage and virtual elements (amongst others). Since it is XML-based we have chosen it as one of the two formats (besides xLMNL) to discuss visualization aspects.
XStandoff as a starting point for visualization
XStandoff is a representation format for multiple hierarchies which evolved from works
of
the research project Secondary structuring of information and comparative discourse
analysis
(Sekimo)[3]. The format is a successor of the Sekimo Generic Format (SGF, cf. Stührenberg and Goecke, 2008) and was presented in detail at the Balisage 2009 (cf. Stührenberg and Jettka, 2009, for current developments see the XStandoff website). XStandoff can be seen as the combination of the standoff approach
and the formal model of GODDAGs, capable of using native XML to represent multiple
hierarchies and the
specifically challenging structures such as overlaps, discontinuous elements, or virtual
elements.
Since XStandoff makes use of the XML-inherent ID/IDREF mechanism the underlying model can be seen as a graph and therefore the format is able to represent any graph-based structure. Because of this it can become quite complicated to construct XStandoff instances manually. For this reason the XStandoff toolkit was implemented[4], providing XSLT 2.0 stylesheets for the creation of XStandoff instances on the basis of standard inline XML annotations and their corresponding primary data (inline2XSF.xsl), the merging of XSF instances (mergeXSF.xsl), the extraction or deletion of levels or layers[5] from XStandoff instances (extractXSFcontent.xsl) and the transformation of standard XStandoff instances to inline XStandoff representations (XSF2inline.xsl), the latter mainly for demonstration purposes. The workflow for creating an XStandoff instance can be demonstrated by the following example. The basis for the construction is given by two separate annotations (Figure 5) for a single primary data text (Figure 4):
Figure 4: Textual primary data
Asked a girl what she wanted to be She said baby, can't you see I wanna be famous, a star on the screen But you can do something in between Baby you can drive my car Yes I'm gonna be a star Baby you can drive my car And baby I love you
Figure 5: The annotations (verse structure & direct discourse)
<?xml version="1.0" encoding="UTF-8"?>
<text xmlns="http://www.tei-c.org/ns/1.0">
<body>
<lg type="verse">
<l>Asked a girl what she wanted to be</l>
<l>She said baby, can't you see</l>
<l>I wanna be famous, a star on the screen</l>
<l>But you can do something in between</l>
</lg>
<lg type="chorus">
<l>Baby you can drive my car</l>
<l>Yes I'm gonna be a star</l>
<l>Baby you can drive my car</l>
<l>And baby I love you</l>
</lg>
</body>
</text><?xml version="1.0" encoding="UTF-8"?>
<text xmlns="http://www.tei-c.org/ns/1.0">
<body>
<p>Asked a girl what she wanted to be
She said <q>baby, can't you see
I wanna be famous, a star on the screen
But you can do something in between</q></p>
<p><q>Baby you can drive my car
Yes I'm gonna be a star
Baby you can drive my car
And baby I love you</q></p>
</body>
</text>The stylesheet inline2XSF.xsl can be used to build XStandoff instances for each of the input annotations, by using the Saxon XSLT Processor[6]:
saxon -o:[output.xml] -s:[input.xml] -xsl:inline2XSF.xsl
primary-data=[primary-data-file.txt]
Afterwards the two instances can be merged with the help of the stylesheet mergeXSF.xsl:
saxon -o:[combined-output.xml] -s:[input-xsf-1.xml] merge-with=[input-xsf-2.xml])
This process results in the integration of the separate annotations into a single XStandoff instance:
Figure 6: XStandoff instance
<?xml version="1.0" encoding="UTF-8"?>
<xsf:corpusData xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsf="http://www.xstandoff.net/2009/xstandoff/1.1"
xsfVersion="1.1"
xml:id="drive_my_car_lines-drive_my_car_quotes"
xsi:schemaLocation="http://www.xstandoff.net/2009/xstandoff/1.1 http://www.xstandoff.net/2009/xstandoff/1.1/xsf.xsd">
<xsf:primaryData start="0" end="235">
<xsf:primaryDataRef uri="../pd/drive_my_car.txt"/>
</xsf:primaryData>
<xsf:segmentation>
<xsf:segment xml:id="seg1" start="0" end="235"/>
<xsf:segment xml:id="seg2" start="0" end="140"/>
<xsf:segment xml:id="seg3" start="0" end="34"/>
<xsf:segment xml:id="seg4" start="35" end="63"/>
<xsf:segment xml:id="seg5" start="44" end="139"/>
<xsf:segment xml:id="seg6" start="64" end="103"/>
<xsf:segment xml:id="seg7" start="104" end="139"/>
<xsf:segment xml:id="seg8" start="140" end="235"/>
<xsf:segment xml:id="seg9" start="140" end="165"/>
<xsf:segment xml:id="seg10" start="166" end="189"/>
<xsf:segment xml:id="seg11" start="190" end="215"/>
<xsf:segment xml:id="seg12" start="216" end="235"/>
</xsf:segmentation>
<xsf:annotation>
<xsf:level xml:id="drive_my_car_lines-level1">
<xsf:layer xmlns="http://www.tei-c.org/ns/1.0" priority="0">
<text xsf:segment="seg1">
<body xsf:segment="seg1">
<lg xsf:segment="seg2" type="verse">
<l xsf:segment="seg3"/>
<l xsf:segment="seg4"/>
<l xsf:segment="seg6"/>
<l xsf:segment="seg7"/>
</lg>
<lg xsf:segment="seg8" type="chorus">
<l xsf:segment="seg9"/>
<l xsf:segment="seg10"/>
<l xsf:segment="seg11"/>
<l xsf:segment="seg12"/>
</lg>
</body>
</text>
</xsf:layer>
</xsf:level>
<xsf:level xml:id="drive_my_car_quotes-level1">
<xsf:layer xmlns="http://www.tei-c.org/ns/1.0" priority="0">
<text xsf:segment="seg1">
<body xsf:segment="seg1">
<p xsf:segment="seg2">
<q xsf:segment="seg5"/>
</p>
<p xsf:segment="seg8">
<q xsf:segment="seg8"/>
</p>
</body>
</text>
</xsf:layer>
</xsf:level>
</xsf:annotation>
</xsf:corpusData>There are several parameters which can be specified by the user to influence the
actual serialization of the XStandoff annotation (for a detailed overview see the
online stylesheet documentation).
Apart from this, it should be obvious how the format deals with
challenging structures like overlaps or discontinuous elements, namely by instantiating
an
underlying graph model through the use of string range references to parts of the
primary data
(xsf:segment elements). At the same time the hierarchical structures of the input annotations
are kept nearly
unchanged (except for the addition of the xsf:segment attribute which refers to the respective
xsf:segment element) by storing them separately under <xsf:level> and
<xsf:layer> elements. Note that there is no mandatory relationship
between the string ranges (containment) and the dominance relations implied by the
hierarchical structure
(cf. the Alice in Wonderland
example in Stührenberg and Jettka, 2009).
In section “Rendering SVG from XStandoff” and section “Adding the third dimension” we will present approaches to the visualization of XStandoff instances like the one shown in Figure 6. However, as discussed above, we would like to have a second XML-based option as starting point for a visualization of concurrent markup. Therefore we explored the possibility of converting other formats into XStandoff and vice versa. This would allow for the graphic rendering of distinct formats by the visualization approaches we will introduce in section “2D visualization of concurrent markup” and section “Adding the third dimension”. As a possible candidate for conversion we have chosen xLMNL which we will briefly present in the following section.
xLMNL as a starting point for visualization
Since xLMNL, an XML-based serialization format for LMNL, which was introduced by Piez, 2010 as
an ad-hoc solution for representing LMNL in XML, makes a similar use of string
ranges like XStandoff, it was chosen as a starting point for a conversion project
between
XStandoff and other XML-based formats.
The corresponding simplified xLMNL
serialization for the annotations shown in Figure 5 can be
seen in Figure 7 which demonstrates the use of character positions (in start and
end attributes) referring to the normalized textual content of x:content.
Figure 7: xLMNL representation
<x:lmnl-document>
<x:content>Asked a girl what she wanted to be
She said baby, can't you see
I wanna be famous, a star on the screen
But you can do something in between
Baby you can drive my car
Yes I'm gonna be a star
Baby you can drive my car
And baby I love you</x:content>
<x:range name="text" ID="text-1" start="0" end="235"/>
<x:range name="text" ID="text-2" start="0" end="235"/>
<x:range name="body" ID="body-1" start="0" end="235"/>
<x:range name="body" ID="body-2" start="0" end="235"/>
<x:range name="lg" ID="lg-1" start="0" end="140">
<x:annotation name="type" role="start-annotation">
<x:content>verse</x:content>
</x:annotation>
</x:range>
<x:range name="p" ID="p-1" start="0" end="140"/>
<x:range name="l" ID="l-1" start="0" end="34"/>
<x:range name="l" ID="l-2" start="35" end="63"/>
<x:range name="q" ID="q-1" start="44" end="139"/>
<x:range name="l" ID="l-3" start="64" end="103"/>
<x:range name="l" ID="l-4" start="104" end="139"/>
<x:range name="lg" ID="lg-2" start="140" end="235">
<x:annotation name="type" role="start-annotation">
<x:content>chorus</x:content>
</x:annotation>
</x:range>
<x:range name="p" ID="p-2" start="140" end="235"/>
<x:range name="q" ID="q-2" start="140" end="235"/>
<x:range name="l" ID="l-5" start="140" end="165"/>
<x:range name="l" ID="l-6" start="166" end="189"/>
<x:range name="l" ID="l-7" start="190" end="215"/>
<x:range name="l" ID="l-8" start="216" end="235"/>
</x:lmnl-document>This illustrates the main difference of XStandoff and xLMNL in that the latter does not consider a hierarchical structure and imposes a completely flat structure of annotations. Admittedly, in contrast to dominance relations, containment relations can well be derived by taking into account the string ranges. Nevertheless, the distinct approaches of xLMNL and XStandoff towards the representation of potentially concurrent annotations constitute a serious challenge for the conversion enterprise because annotation hierarchies are not present in xLMNL. There are two possible ways to deal with this issue. Since XStandoff in principle allows for the capturing of arbitrary graph-like structures, the xLMNL representation could be integrated without making any assumptions about hierarchies. Another strategy, which would make more sense if one wanted to visualize the annotations by the methods introduced later on, would be the analysis of the individual relations between annotations on the basis of their string ranges and to try to construct hierarchies of annotations by considering the containment relations. Conflicting annotations could be separated from each other to avoid representation problems. This strategy admittedly inserts information which is not directly present, however it would not be a problem to remove the additional information again in a later step.
Perspectively there will be an examination of creating or integrating XStandoff into a syntactic conversion framework for existing representation formats like the one described in Marinelli et al., 2008. Although it would be possible to realize individual format-to-format conversions, it seems much more straightforward to have a framework which is based on a common model. For this purpose the above-mentioned meta markup language EARMARK, which can be used to represent GODDAGs, appears to be a quite promising candidate for a pivot format.
2D visualization of concurrent markup
Basic principles of the visualization of concurrent markup
For the visualization of concurrent markup there are two main issues to be regarded and to be solved:
-
the illustration of the relationship of primary data and annotations
-
the visualization of potentially overlapping annotations (including other tree-challenging phenomena like discontinuous elements)
In the case of XStandoff the visualization of multiple hierarchies at first glance can be based on a relatively simple principle, namely the delineation of separate tree structures. This of course only makes sense when the focus is on dominance relationships. As stated above, it is possible to represent graph structures, too. This will be addressed in more detail in section “Adding the third dimension”. But before, we want to take a look at a general visualization principle for multiple tree structures. A very basic visualization method is given in Witt, et al., 2005 where two annotation layers corresponding to common textual primary data are represented by vertically ordered colored bars:
Figure 8: Visualization of annotation layers (Witt, et al., 2005: 76)
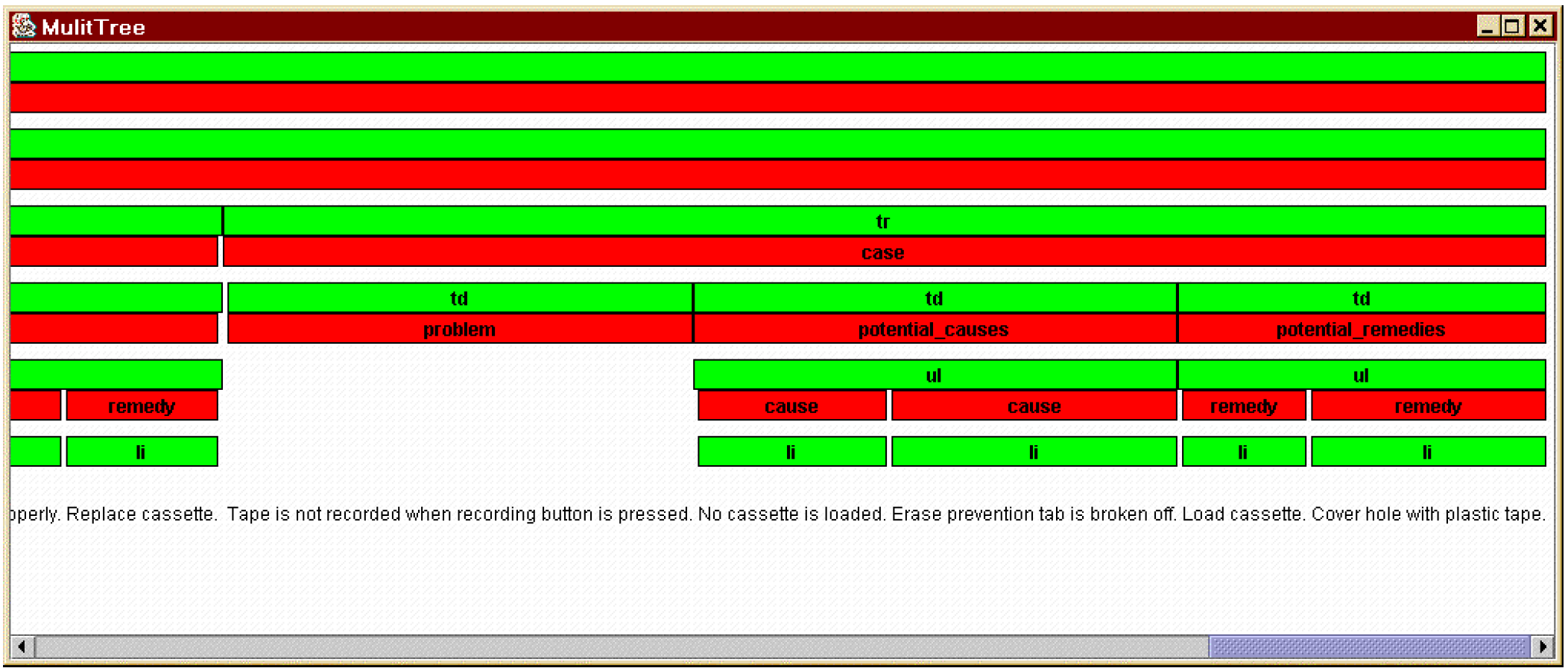
Here the horizontally ordered segments of each level represent the individual
annotations and their length is used to demonstrate the correspondence to the dominated
annotations (edges are inferable by the width of the bars) and the spanned textual
content.
This strategy, as indicated above, is based on tree structure visualization. Admittedly
it
could be used to represent minimal extensions to trees, for example multiple parents,
which would
allow for the capturing of overlapping structures; remember that overlap is multiple
parentage
(Sperberg-McQueen and Huitfeldt, 2004). However, there seems to
be no way to represent more advanced graph structures. In addition there are some
stylistic disadvantages: first of all, the overall width of the graphic and the visual
accessibility mainly depend on the length of the primary data. Secondly, in this basic
strategy line breaks from the primary data would have to be replaced in order to facilitate
the visualization of continuously ordered annotation segments.
The named stylistic shortcomings could be dealt with by changing the direction of
the
illustration and ordering the annotation levels horizontally. This concept can be
demonstrated on the basis of the annotations introduced in Figure 5. Since there
is a classic overlap of the second l element
(/text/body/lg[1]/l[2]) of the verse annotation and the first q
element (/text/body/p[1]/q) of the direct discourse annotation which holds for
the string baby, can't you see
, the annotation levels cannot simply be
integrated into a common tree structure. Following the representation in Witt (2005)
the
present annotations could be visualized like in Figure 9
(in order to emphasize the present tree
structures there is an additional representation of nodes and edges):
Figure 9: Graphic representation of annotations from Figure 5


To avoid the above-mentioned stylistic disadvantages of the horizontal ordering of annotation segments (vertical ordering of annotation levels), the representation could be rotated in a 90° angle to the right and mirrored horizontally:
Figure 10: Graphic representation of annotations from Figure 5 (different perspective)


From this state, it is only a few steps towards an adequate readability of the text and the consideration of line breaks from the primary data. This can be shown by a visualization method implemented by Piez, 2010. On the basis of LMNL markup he realized the visualization of concurrent annotations by both an 'arcs'-visualization and an interactive SVG 'map' (shown in Figure 11 below).
{kind=link}
Figure 11: Visualization of xLMNL instance by Piez, 2010
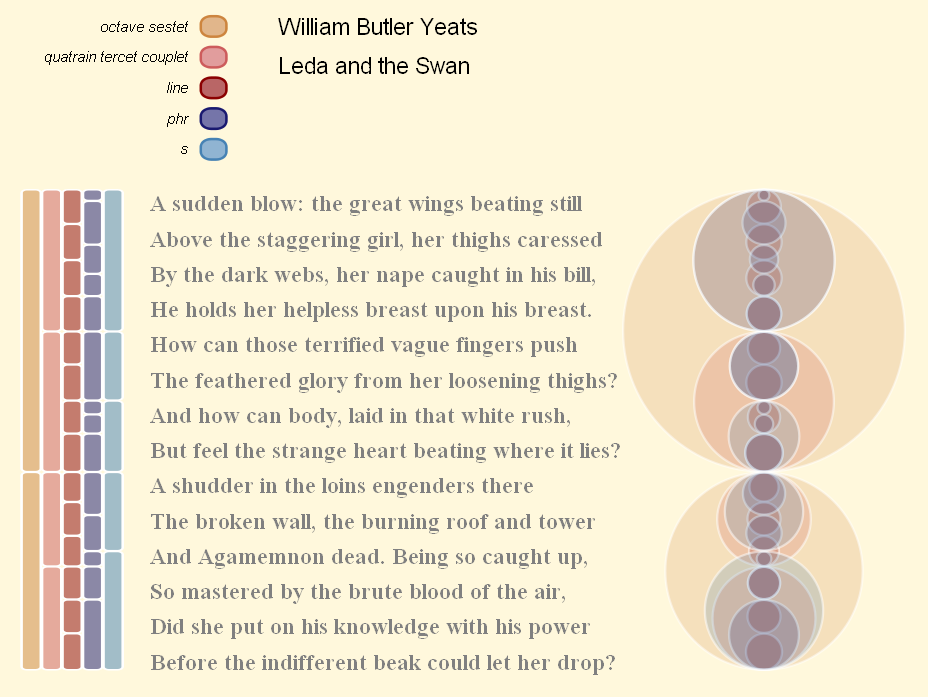
The present annotation layers and element types are displayed in the left top corner of the graphic and their appearance can be switched on and off by mouse click. The actual instances of the underlying annotation are represented by two distinct illustrations: as bars on the left hand side and circles on the right hand side. The primary data text is located in between. The correspondence of segments of the primary data and annotations is demonstrated by interactive mouse-over effects (see the SVG provided online at Piez' website).
{kind=link}
Overlaps of annotations from the individual layers can be identified in the graphic by having a look at non-matching borders of the bars or cutting lines of the circles. While Piez, 2010 explicitly states that the described visualization method primarily takes the function of a basic demonstration, there are certain technical and theoretical difficulties which should be named:
-
The annotation layers of Piez' examples only contain elements which span over text segments large enough to avoid problems with the visualization of the corresponding bars. If there were annotations for single words or even smaller parts of the text, the bars and circles would become too small for a reasonable visualization (see Figure 13).
-
The use of circles for representing annotations is only feasible as long as there are no very large annotated segments because the diameter could grow too big.
-
Since all of the present annotation layers span the complete textual content without any gaps, there might be the impression that the method is arranged very clearly. In fact, other configurations of annotations which leave out certain parts of the text could lead to a less clear picture.
Rendering SVG from XStandoff
The creation of two-dimensional SVG-based visualizations for XStandoff instances is to a great extent inspired by the approach of Piez, 2010 discussed in the previous section. Accordingly, the visualization includes a section displaying the textual primary data and a section with representations of annotations which in return correspond to spanned segments of the primary data. The possible visualization of annotations by circles was not implemented since it can be assumed that this method leads to problems for large annotation segments, as already stated. Piez' method was extended by some additional features for user interactivity like the horizontal switching of annotation levels and the optional display of classic overlaps. The general appearance of an XStandoff instance visualized in SVG can be seen in Figure 12. This representation is based on the XStandoff instance given in Figure 6 (an online version of the example is available for testing the interactive features)[7].
{kind=link}
Figure 12: Visualization of XStandoff instance

There are two options for the user to influence the configuration of the responsible
XSLT stylesheet
XSF2SVG.xsl[8] and the
resulting visualization: the stylesheet parameters font-size and
max-line-length. Since most SVG viewers enable the user to zoom in and out of
the graphic anyway, the parameter font-size simply determines the initial
appearance of the resulting graphic. More attention should be drawn to the parameter
max-line-length which determines the maximal length of a single line of
primary data. This has to be considered since lines of a certain length in
combination with relatively small annotation segments can lead to visualization difficulties.
Due to the correspondence between the height of a displayed annotation
segment and the individual characters of a line of the primary data, annotations spanning
over only a few characters might not be visualized accurately. That is the reason
why the
value of the parameter max-line-length is determined
automatically by default in order to provide an optimal illustration of the annotation
segments.
Although generally it is up to the user to vary the maximal line length, the
circumstance that a high value could lead to inaccurate visualizations has to be kept
in
mind. Figure 13 demonstrates the possible difficulties by comparing a
visualization based on a maximal line length of 15 characters (automatically computed
as maximum) with one
which is based on 40 characters per line:
Figure 13: Influence of parameter max-line-length on readability of SVG
visualization
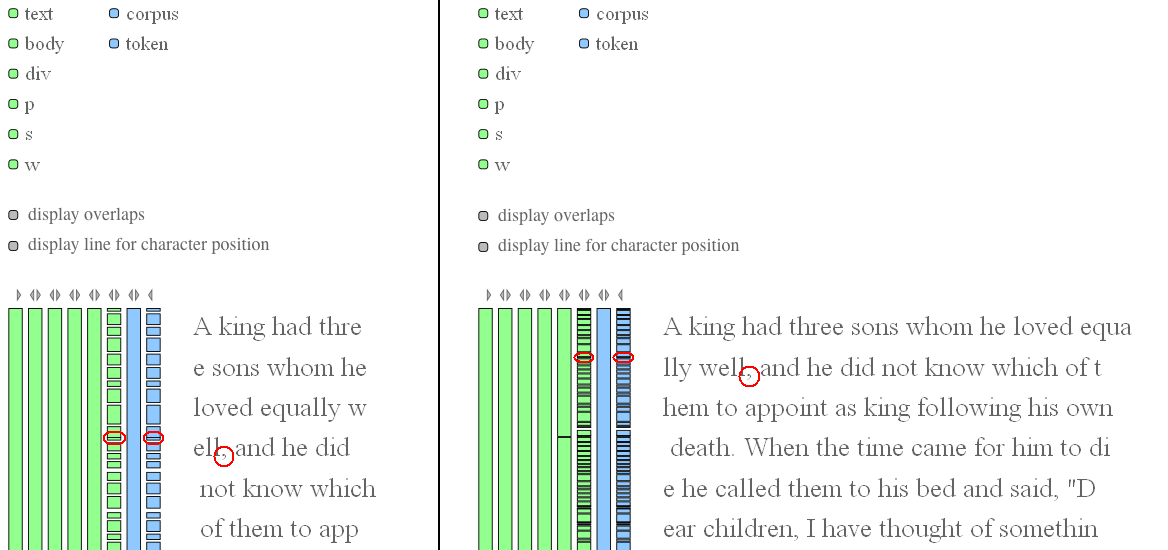
Even in the case of a short line length of 15 characters (on the left hand side of Figure 13) it is difficult to spot the segment for the tagged comma. Certainly, there are possible solutions to this problem. For instance, an advanced zooming method for the individual annotations and the corresponding textual content from the primary data could be implemented. Furthermore, it would be possible to realize some kind of page-wise navigation through the primary data, which would reduce the amount of simultaneously displayed text. Nevertheless, the main problems for the present SVG visualization are manifested by its conceptual foundation. The focus on tree structures (with minimal possible extensions) prohibits the coverage of other phenomena than overlaps and discontinuous elements, e.g. repetitive structures. This circumstance could be addressed by an increased focus on the annotations, which will be demonstrated in the following section.
Adding the third dimension
A different perspective on the visualization of concurrent annotations can be taken
by the consideration of possible 3D graphic rendering. The
recent developments in native browser support for 3D graphics, especially the specification
of
HTML5 (HTML5 WD 2011) and its element <canvas> allowing for
programmatic rendering of APIs like WebGL (cf. WebGL, 2011), promises to
provide a fruitful development and application framework for advanced graphical representation
of concurrent markup. By the time of writing this article, WebGL is supported by the
currently available builds of the browsers Firefox 5 and Chrome 12[9].
With X3DOM[10] and the serialization format X3D (ISO/IEC 19776-1:2009) there is an appropriate solution for defining 3D graphics in XML. Accordingly, it is possible to implement transformation scenarios for XML-based representation formats for concurrent markup similar to the one shown for XStandoff and SVG for 3D visualizations without leaving the XML context. Certainly, a native browser support of XSLT 2.0 would make the framework even more straightforward, which naturally holds for the SVG approach, too. As an alternative Kay, 2011 has shown some pretty advantages in implementing a JavaScript version of Saxon, called Saxon Client Edition or Saxon-CE, bringing XSLT 2.0 to the browser.
Considerations
Since 3D visualizations accompanied by interactive user navigation open up different perspectives than the SVG approach presented in the previous section, the basic underlying principle could focus on different aspects. While in the mentioned two-dimensional representation the primary data is in focus and minimally extended tree structures for concurrent markup can be represented, a three-dimensional approach could envisage the comprehensible visualization of annotations with an underlying graph-based model by constructing horizontally (along the z-axis of a 3D space) ordered trees, extended tree structures (e.g., allowing multiple parentage), or even full-blown graphs (including repetitive structures and cyclic paths).
In order to construct comparable layers of annotations, the structures could be normalized with respect to the corresponding primary data. In this context two methods could be considered: horizontal normalization and vertical normalization. The horizontal normalization of the displayed structures refers to the horizontal position of the nodes representing annotations and could be based on the primary data virtually transformed into a single line. Along this line of characters the nodes could be located by positioning them at the center of their spanned character string (x-axis of Figure 14).
The vertical normalization could make use of a very similar strategy. By dividing the amount of spanned characters of an annotation by the total amount of characters in the primary data, the vertical position of nodes could be determined. Admittedly, this strategy could lead to confusion since it is probable that nodes of one level do not have the same vertical position, while nodes from different levels have the same position. Having in mind that the described normalization method arranges nodes with respect to the concept of containment, it would be possible to allow for different realizations of layer visualizations, that is, a containment perspective and a dominance perspective.
Figure 14: Normalized positioning of nodes in 3D space
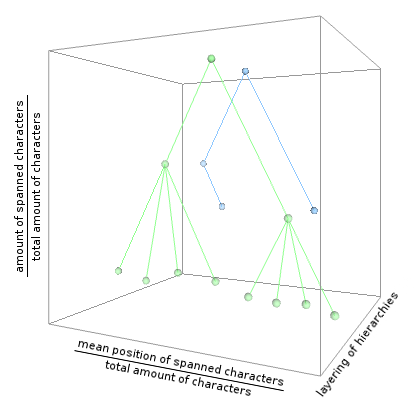
The graphic incorporates the normalized structures of the two annotation layers of the above-mentioned XStandoff instance (Figure 6). The normalized node positions reflect the concept of containment. In addition to the respective XStandoff instance, the first structure can also be seen as a visualization of the containment relations from the xLMNL instance (Figure 11) if a virtual node is imposed which spans the complete primary data. Note, that the hierarchy between the nodes in the structure for an xLMNL instance is only implicitly present as already shown in Figure 2 – in contrast to hierarchies in XStandoff instances. Thus, in general, for the visualization of concurrent markup two distinct visualization methods (containment vs. dominance) should be considered.
XStandoff supports the differentiation of containment and dominance relations (see Stührenberg and Jettka, 2009), using the start and end positions of the referenced segments for computing whether a string range virtually delimited by an annotation is contained inside a second one and using the hierarchical relations between two nodes on the same annotation layer to express a dominance between these nodes. Therefore, it would be reasonable to consider these two possible normalization methods, allowing for the generation of both visualization methods.
As a benefit from using a 3D approach it would still be possible to use tree-like visualizations as a starting point since both the handling of overlapping annotations and the arrangement of different annotation layers can be managed by using the z-axis.
The actual realization of a 3D rendering of concurrent markup could vary in its complexity and in the amount of the realized features. Figure 15 (corresponding to the XStandoff instance in Figure 6) demonstrates the dominance perspective mentioned above (in opposition to the containment persective), in which there is a 1:1 relationship between nodes and annotation elements. It is based on a hierarchical organization of the annotations.
Figure 15: Basic visualization of referenced primary data
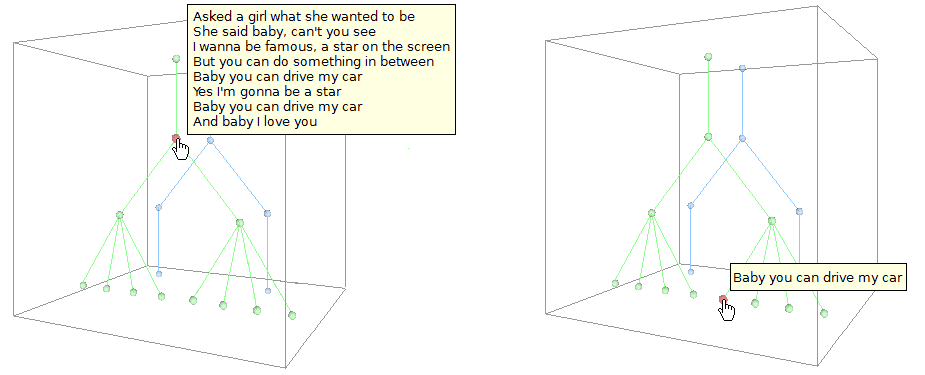
Besides these minimalistic illustrations, more complex and sophisticated graphics could be realized. For example, it would be possible to represent hierarchies which are based on graphs and include phenomena like discontinuous elements or repetitive structures. These would be visualized on the basis of present containment relations, that is, nodes are normalized with regard to their referenced textual content and edges reflect containment relations.
Regarding the visualization of the relationship between primary data and annotations there are several imaginable solutions. Firstly, it would be possible to simply display the spanned textual content of a node in tooltips as indicated in Figure 15. Alternatively, it would be conceivable to take a 3D space like in Figure 14 as a basis and project the textual primary data onto the back wall. By mouse-over effects the user could focus the spanned textual content, for example by evoking light and shadow effects which highlight the corresponding primary data section(s). At the same time information about the annotation could be shown in a tooltip.
Figure 16: Advanced primary data visualization
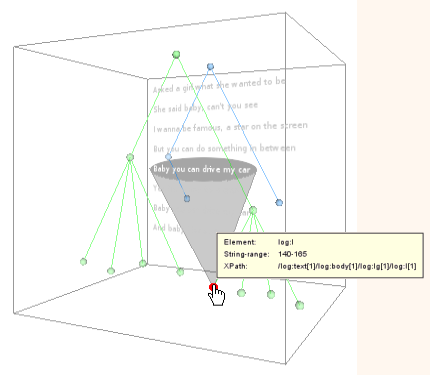
In the visualization from Figure 16, which shows horizontally and vertically normalized trees, the appearance and position of nodes depend on the presence of distinct string ranges for which there are annotations, that is, a single node might represent more than one annotation element. This should be kept in mind.
Apart from the actual design there are some core features which should be realized in the envisaged approach:
-
free user navigation through the graphic, including zooming in and out;
-
draggable structures for layers (e.g. draggable as a whole along the z-axis);
-
mouse-over effects: for example information on spanned primary data (textual content & positions), information on annotation, XPath;
-
highlighting of specific structures (distinct element relations, overlaps, discontinuous elements, virtual/repetitive structures);
-
the choice between displaying annotated or plain textual content for a node;
-
illustration of left and right context of focused annotation elements and corresponding textual content (+ specification of the range of considered context).
Besides these rather stylistic considerations, which focus on the informational level of the visualization, the conceptual advantages of a 3D approach to concurrent markup should have become clear. Since it is not automatically restricted to strictly hierarchical structures, it would be possible to display graph-based constructs like repetitive/reentrant structures. Furthermore, relations between individual hierarchies of graph structures could be illustrated and there could be a distinction of representations of dominance and/or containment relations being reflected by the actual instantiation of the edges of graphs.
Prototypic 3D visualization
We've implemented a first prototypic 3D visualization based on an XSLT stylesheet named XSF2X3D.xsl that transforms XStandoff instances into X3D graphics like the one in Figure 14. Since there is no complete implementation available yet, in the remainder of this section we will concentrate on the things already accomplished, followed by possible future enhancements.
The current implementation of a 3D visualization of concurrent hierarchies reflects the considerations from the previous sections. The direct embedding of X3D into HTML5 allows for the rendering of 3D visualizations in current browser versions.[11] The actual appearance of the current state of the prototype is shown in Figure 17.
Figure 17: Screenshot of the prototype (Google Chrome)
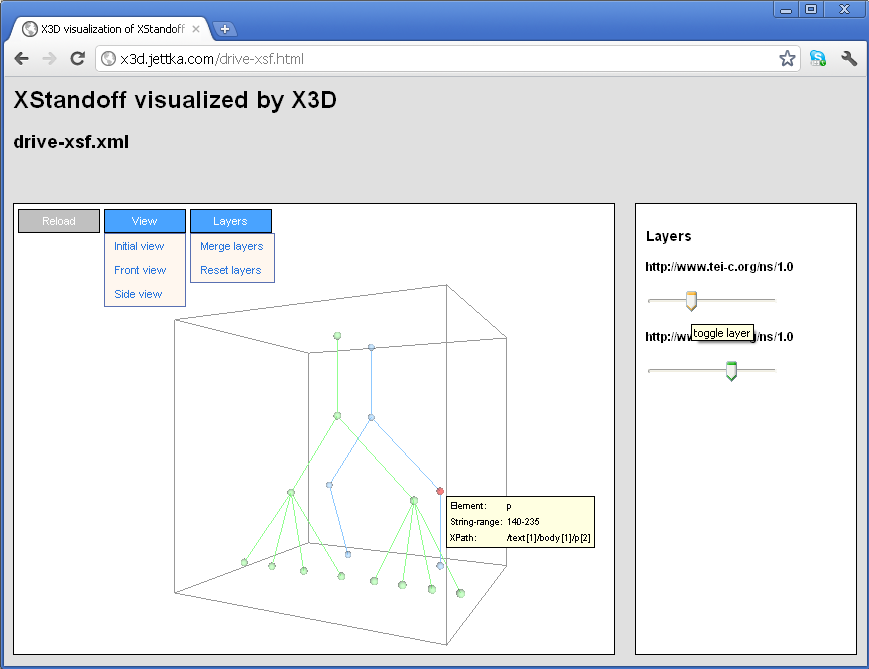
The main component of the visualization is a 3D space indicated as a cube which contains the layers from the corresponding XStandoff instance (Figure 6) ordered along the z-axis. At present, the normalization methods described in the previous section have not been fully implemented. In a later realization of the XSLT stylesheet it should be possible for the user to choose the normalization method, that is, the visualization of dominance or containment relations.
The illustration given in Figure 17 indicates most of the available user interactivity. Besides free navigation like zooming in and out of the graphic and rotating it, there are certain predefined viewpoints like front view and side view, which could be interesting for the user and can be taken by selection from the menu item 'View'. In addition, it is possible to freely drag the hierarchies along the z-axis by using the sliders, which are available for each individual layer in the info box on the right hand side. An interesting feature of the graphic is the possibility to virtually merge layers by either dragging them into the appropriate positions or selecting the predefined 'Merge layers' option from the 'Layers' submenu. The initial configuration of the layers can be reestablished by a click on 'Reset layers'. In the case of feeling lost in 3D space the 'Reload' button on the left hand side restores the initial state of the graphic.
Information on the present annotations in the individual layers can be gathered by hovering over the nodes with the cursor evoking a tooltip, which contains basic information like element names, string ranges, and XPath expressions. Other desirable features for an appropriate visualization of concurrent markup, like the ones listed in the previous section, will be considered in a later version.
Conclusion and future research
In this paper we demonstrated two aspects: firstly, that the formal model of XML instances can exceed that of trees; in fact, we have proven that it is fully capable of representing graphs. This, secondly, was used as a starting point to choose two XML-based representation formats for multiple annotations that can be converted into 2D visualizations. Although it could be shown that the first visualization approach provides an adequate (though admittedly suboptimal) solution to overlapping structures, it is not capable of illustrating enhanced graph-based phenomena like discontinuous elements or repetitive structures. Therefore we have sketched possible 3D renderings of concurrent markup. A first prototypic realization demonstrated how the adding of an additional dimension could in principle contribute to the appropriate visualization of concurrent markup and could serve as the basis for further research. The current version will be made available under the GNU Lesser General Public License (LGPL v3) at the XStandoff website. Unresolved tasks like an improved visualization of overlapping annotations and the treatment of discontinuous and repetitive structures could be tackled in a future release.
References
[Abiteboul et al., 2000] Abiteboul, S., Buneman, P., and Suciu, D. Data on the Web: From Relations to Semistructured Data and XML. San Francisco, California: Morgan Kaufmann Publishers, 2000.
[Bauman, 2005] Bauman, S. TEI HORSEing Around. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2005.
[Bird and Liberman, 1999] Bird, S. and Liberman, M. Annotation graphs as a framework for multidimensional linguistic data analysis. In: Proceedings of the Workshop "Towards Standards and Tools for Discourse Tagging". Association for Computational Linguistics, 1999.
[TEI P5 (v 1.9.1), 2011] Burnard, L. and Bauman, S. (eds.). TEI P5: Guidelines for Electronic Text Encoding and Interchange. Published for the TEI Consortium by Humanities Computing Unit, University of Oxford, Oxford, Providence, Charlottesville, Bergen. Version 1.9.1. Last updated on March 5th 2011.
[Carletta et al., 2003] Carletta, J., Kilgour, J., O’Donnel, T. J., Evert, S., and Voormann, H. The NITE Object Model Library for Handling Structured Linguistic Annotation on Multimodal Data Sets. In: Proceedings of the EACL Workshop on Language Technology and the Semantic Web (3rd Workshop on NLP and XML (NLPXML-2003)), Budapest, Ungarn, 2003.
[Carletta et al., 2005] Carletta, J., Evert, S., Heid, U., and Kilgour, J. The NITE XML Toolkit: data model and query language. In: Language Resources and Evaluation, Springer, Dordrecht, 2005, 39.
[Coombs et al., 1987] Coombs, J. H., Renear, A. H., and DeRose, S. J. Markup Systems and the Future of Scholarly Text Processing. In: Communications of the ACM 30.11, 1987.
[Cowan et al., 2006] Cowan, J., Tennison J., and Piez, W. LMNL Update. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2006.
[Cowan, 2010] Cowan, J. MicroXML. Poster presented at XML Prague 2010.
[Cowan, 2011] Cowan, J. MicroXML. Editor's Draft 2011-06-30. http://www.ccil.org/~cowan/MicroXML.html.
[DeRose, 2004] DeRose, S. J. Markup Overlap: A Review and a Horse. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2004.
[Dekhytar and Iacob, 2005] Dekhtyar, A. and Iacob, I. E. A framework for management of concurrent XML markup. Data & Knowledge Engineering, 52(2):185–208, 2005.
[Di Iorio et al., 2009] Di Iorio, A., Peroni, S., and Vitali, F. Towards markup support for full GODDAGs and beyond: the EARMARK approach. In: Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Peroni01.
[Durusau and Brook O'Donnell, 2004] Durusau, P. and Brook O'Donnell, M. Tabling the Overlap Discussion. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2004.
[Goecke et al., 2010] Goecke, D., Lüngen, H., Metzing, D., Stührenberg, M., and Witt, A. Different views on markup. Distinguishing Levels and Layers. In: Witt, A. and Metzing, D. (eds.), Linguistic Modeling of Information and Markup Languages. Dordrecht: Springer, 2010. doi:https://doi.org/10.1007/978-90-481-3331-4
[Gou and Chirkova, 2007] Gou, G. and Chirkova, R. Efficiently Querying Large XML Data Repositories: A Survey. In: IEEE Transactions on Knowledge and Data Engineering 19.10, 2007.
[Hopcroft and Ullman, 1979] Hopcroft, J. E. and Ullman, J. D. Introduction to Automata Theory, Languages, and Computation. Addison-Wesley, 1979.
[HTML5 WD 2011] HTML5: A vocabulary and associated APIs for HTML and XHTML, W3C Working Draft 05 April 2011. World Wide Web Consortium. http://www.w3.org/TR/html5/.
[Huitfeldt and Sperberg-McQueen, 2006] Huitfeldt, C. and Sperberg-McQueen, C. M. Representing and processing of GODDAG structures: implementation strategies and progress report. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2006.
[ISO/IEC 19776-1:2009] ISO/IEC 19776-1:2009, Information technology – Computer graphics, image processing and environmental data representation – Extensible 3D (X3D) encodings – Part 1: Extensible Markup Language (XML) encoding. International Standard, International Organization for Standardization, 2009.
[ISO/IEC 24610-1:2006] ISO/TC 37/SC 4. ISO 24610-1:2006: Language Resource Management – Feature Structures – Part 1: Feature Structure Representation. International Standard, International Organization for Standardization, 2006.
[Jagadish et al., 2004] Jagadish, H. V., Lakshmanany, L. V. S., Scannapieco, M., Srivastava, D., and Wiwatwattana, N. Colorful XML: One hierarchy isn’t enough. In: Proceedings of ACM SIGMOD International Conference on Management of Data (SIGMOD 2004), ACM Press, New York, NY, USA, 2004. doi:https://doi.org/10.1145/1007568.1007598
[Kay, 2010] Kay, M., 2010. A streaming XSLT processor. In: Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). doi:https://doi.org/10.4242/BalisageVol5.Kay01.
[Kay, 2011] Kay, M., 2011 XSLT in the Browser. In: Kosek, J. (ed), XML Prague 2011 Conference Proceedings, number 2011-519 in ITI Series, pages 125–134, Prague, Czech Republic, 3 2011. Institute for Theoretical Computer Science.
[Le Maitre, 2006] Le Maitre, J. Describing multistructured XML documents by means of delay nodes. In: DocEng ’06: Proceedings of the 2006 ACM symposium on Document engineering, ACM Press, New York, NY, USA, 2006.
[Marcoux, 2008] Marcoux, Y. Graph characterization of overlap-only TexMECS and other overlapping markup formalisms. In: Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). doi:https://doi.org/10.4242/BalisageVol1.Marcoux01.
[Marinelli et al., 2008] Marinelli, P., Vitali, F., and Zacchiroli, S. Towards the unification of formats for overlapping markup. In: New Review of Hypermedia and Multimedia, 14(1), 2008. doi:https://doi.org/10.1080/13614560802316145.
[Møller and Schwartzbach, 2007] Møller, A. and Schwartzbach, M. I. XML Graphs in Program Analysis. In: PEPM ’07: Proceedings of the 2007 ACM SIGPLAN symposium on Partial evaluation and semantics-based program manipulation. Nice, France, 2007.
[Nicol, 2002a] Nicol, G. T. Attributed Range Algebra. Extending Core Range Algebra to Arbitrary Structures, 2002.
[Nicol, 2002] Nicol, G. T. Core Range Algebra: Toward a Formal Model of Markup. In: Proceedings of Extreme Markup Languages. Montréal, Québec, 2002.
[Pianta and Bentivogli, 2004] Pianta, E. and Bentivogli., L. Annotating Discontinuous Structures in XML: the Multiword Case. In: Proceedings of LREC 2004 Workshop on "XML-based richly annotated corpora", Lisbon, Portugal, 2004.
[Piez, 2004] Piez, W. Half-steps toward LMNL. In: Proceedings of Extreme Markup Languages. Montréal, Québec, 2004.
[Piez, 2010] Piez, W. Towards Hermeneutic Markup: An architectural outline. In: Digital Humanities 2010 Conference Abstract, London, 2010.
[Polyzotis and Garofalakis, 2002] Polyzotis, N. and Garofalakis, M. Statistical Synopses for Graph-Structured XML Databases. In: Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, Madison, Wisconsin, 2002. doi:https://doi.org/10.1145/564691.564733.
[Rehm et al., 2010] Rehm, G., Schonefeld, O., Trippel, T., and Witt, A. Sustainability of linguistic resources revisited. In: Proceedings of the International Symposium on XML for the Long Haul: Issues in the Long-term Preservation of XML. Balisage Series on Markup Technologies, vol. 6 (2010). doi:https://doi.org/10.4242/BalisageVol6.Witt01.
[Schmidt, 2001] Schmidt, T. The transcription system EXMARaLDA: An application of the annotation graph formalism as the Basis of a Database of Multilingual Spoken Discourse. In: Proceedings of the IRCS Workshop On Linguistic Databases. Philadelphia: Institute for Research in Cognitive Science, University of Pennsylvania, 2001.
[Schonefeld, 2007] Schonefeld, O. XCONCUR and XCONCUR-CL: A constraint-based approach for the validation of concurrent markup. In: Rehm, G., Witt, A., Lemnitzer, L. (eds.), Datenstrukturen für linguistische Ressourcen und ihre Anwendungen. Data Structures for Linguistic Resources and Applications. Proceedings of the Biennial GLDV Conference 2007, Tübingen, Germany, 2007. Gunter Narr Verlag.
[Sperberg-McQueen and Huitfeldt, 2004] Sperberg-McQueen, C. M. and Huitfeldt, C. GODDAG: A Data Structure for Overlapping Hierarchies. In: King, P. and Munson, E. V. (eds.), Proceedings of the 5th International Workshop on the Principles of Digital Document Processing (PODDP 2000), volume 2023 of Lecture Notes in Computer Science, Springer, 2004.
[Sperberg-McQueen and Huitfeldt, 2008] Sperberg-McQueen, C. M. and Huitfeldt, C. Markup Discontinued Discontinuity in TexMecs, Goddag structures, and rabbit/duck grammars. In: Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). doi:https://doi.org/10.4242/BalisageVol1.Sperberg-McQueen01.
[Sperberg-McQueen and Huitfeldt, 2008a] Sperberg-McQueen, C. M. and Huitfeldt, C. GODDAG. Presented at the Goddag workshop, Amsterdam, 1-5 December 2008.
[Stegmann and Witt, 2009] Stegmann, J. and Witt, A. TEI Feature Structures as a Representation Format for Multiple Annotation and Generic XML Documents. In: Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Stegmann01.
[Stührenberg and Goecke, 2008] Stührenberg, M. and Goecke, D. SGF – An integrated model for multiple annotations and its application in a linguistic domain. In: Proceedings of Balisage: The Markup Conference 2008. Balisage Series on Markup Technologies, vol. 1 (2008). doi:https://doi.org/10.4242/BalisageVol1.Stuehrenberg01.
[Stührenberg and Jettka, 2009] Stührenberg, M. and Jettka, D. A toolkit for multi-dimensional markup: The development of SGF to XStandoff. In: Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Stuhrenberg01.
[Tennison, 2002] Tennison, J. Layered Markup and Annotation Language (LMNL). In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2002.
[Thompson and McKelvie, 1997] Thompson, H. S. and McKelvie, D. Hyperlink semantics for standoff markup of read-only documents. In: Proceedings of SGML Europe ’97: The next decade – Pushing the Envelope, Barcelona, 1997.
[WebGL, 2011] WebGL Specification. Version 1.0, 10 February 2011. Khronos Group. https://www.khronos.org/registry/webgl/specs/1.0/.
[Witt, 2002] Witt, A. Multiple Informationsstrukturierung mit Auszeichnungssprachen. XML-basierte Methoden und deren Nutzen für die Sprachtechnologie. Dissertation, Universität Bielefeld, 2002.
[Witt, 2004] Witt, A. Multiple hierarchies: New Aspects of an Old Solution. In: Proceedings of Extreme Markup Languages, Montréal, Québec, 2004.
[Witt, et al., 2005] Witt, A., Goecke, D., Sasaki, F., and Lüngen, H. Unification of XML Documents with Concurrent Markup. Literary and Linguistic Computing, 20(1):103–116, 2005. doi:https://doi.org/10.1093/llc/fqh046.
[1] Of course one could easily dig any deeper down to the beginnings of the GenCode(r) project and GML, but the point we want to take here is that there is a historic relation between markup languages on the one hand and the formal model of a tree on the other hand.
[2] It may be of interest that the mention of feature structures in the TEI Guidelines can be traced back to the first proposal (P1) written in Waterloo script. Even this very draft version dated from 1990 covered feature structures as a means for linguistic annotation.
[3] The project Sekimo was a part of the distributed research group Text Technological Modelling of
Information
which lasted from 2003 to 2009.
[4] The stylesheets and corresponding documentation are available at http://www.xstandoff.net/tk.html.
[5] Levels refer to the conceptual realization of annotations and layers to the technical
realization (cf. Goecke et al., 2010). This distinction is reflected by XStandoff
in providing the corresponding meta elements <xsf:level> and
<xsf:layer>.
[6] inline2XSF.xsl makes use of Saxon specific extensions which are available in the older XSLT 2.0 versions of Saxon (-B and -SA) and the newer versions PE and EE; see http://saxon.sourceforge.net/.
[7] Also consider the online visualization corresponding to Figure 11.
{kind=link}
[8] The stylesheet XSF2SVG.xsl is available at http://www.xstandoff.net/tk.html
[9] See http://www.khronos.org/webgl/wiki/Getting_a_WebGL_Implementation for further details.
[10] See http://www.x3dom.org/ for further details.
[11] The visualization has been successfully tested in Google's Chrome 12.0.742.112 and Mozilla Firefox 5.0 except for certain HTML5 constructs like range inputs on the latter. Support is dependent on the GPU installed – it runs fine on an NVIDIA GeForce GT 330M installed in a MacBook Pro, while on other configurations Chrome had to be started with the '--ignore-gpu-blacklist' startup parameter while Firefox had to be customized via the about:config page and enabling the parameter 'webgl.force-enabled'.