Introduction
XML provides mature facilities for processing and presenting information. The solution developer's toolkit includes XSLT (see XSL2) to transform XML documents from one vocabulary to another, XQuery (see XQ1) to retrieve and modify persisted XML documents for applications, and XHTML (see XH) and XSL-FO to present information on the screen or in print. These standards have become essential tools for web applications, publishing pipelines, electronic interchange, and many other challenges. Having successfully addressed such fundamental challenges, the XML community can now refine the toolkit. In particular, the XML community can consider whether lessons learned by other communities could have benefits for the XML technology portfolio.
The experience of the Java community with tag libraries offers one such opportunity. Java introduced tag libraries to broaden the appeal of an existing, successful technology, JSP (Java Server Pages) (see JSP). Widespread adoption exposed a fundamental issue with JSP: JSP required skill levels that limited the set of users who could define dynamic documents and, by exposing robust programming capabilities, provided for a poor separation of concerns. The Java community solved these problems by introducing tag libraries.
In the Java technology stack, tag libraries are function libraries called by embedding a markup vocabulary (the tags) within documents. The approach is open-ended in that each tag library supplies its own markup vocabulary.
The canonical example of a tag library retrieves rows from a database
for layout and styling in a document. The following example fragment has
a single taglib:attendees tag:
<html:table>
<taglib:attendees>
<html:tr>
<html:td>${last-name}</html:td>
<html:td>${first-name}</html:td>
</html:tr>
</taglib:attendees>
</html:table>
The taglib:attendees tag calls a function in a tag library
(whose Java implementation is omitted here). The function implementation retrieves
attendees from a database and repeats the content of the tag for each attendee.
When generating output from the tag content, the function replaces the embedded
${last-name} and ${first-name} expressions with the
last name and first name values for the currently processed attendee. Thus,
a generated result document would resemble the following example:
<html:table>
...
<html:tr>
<html:td>Fitzgerald</html:td>
<html:td>Elena</html:td>
</html:tr>
<html:tr>
<html:td>Green</html:td>
<html:td>Alfonso</html:td>
</html:tr>
<html:tr>
<html:td>Hutz</html:td>
<html:td>Egberto</html:td>
</html:tr>
...
</html:table>
As the example shows, the tag library approach provides for a useful division of responsibilities. The tag library developer is responsible for packaging functionality (often information retrieval and manipulation as in the example but also a widget gallery or anything else that can be executed with a simple interface) as an embeddable vocabulary. The tag document author is responsible for assembling the tag library vocabulary with static elements (often providing style and layout specifications) to produce a dynamic document. By fostering collaboration between these audiences, tag libraries extend the reach of both participants. The Java community has confirmed the value of this collaboration with comprehensive toolkits such as JSF (Java Server Faces).
While XSLT and XQuery have always had the ability to combine literal result elements with dynamic content, the XML technology stack currently lacks a complete solution for providing this kind of division of responsibilities. This paper proposes adapting the Java Tag Library approach by implementing tag libraries in XSLT or XQuery and making use of tag vocabularies in XHTML, XSL-FO, or other XML documents. We use XSTag (for XML Style Tags) as the working title for this variant on the tag library approach.
Essential Terms, Concepts, and Limitations
The introduction made casual use of several terms that we summarize more formally here:
|
tag |
An XML element that can be embedded in a document to call a function in a tag library to produce dynamic XML result nodes. |
|
tag vocabulary |
The tag element set that declares the functions exposed by a tag library. |
|
tag library |
A function library (typically implemented in XSLT or XQuery) exposed by means of a tag vocabulary. (Note that this sense of the term differs from other senses such as the documentation for an XML vocabulary.) |
|
host vocabulary |
A static XML vocabulary for documents; typically a presentation vocabulary such as XHTML or XSL-FO. |
|
tag document |
A document that mixes a host vocabulary and the tag vocabularies from one or more tag libraries, potentially with other dynamic constructs such as embedded XPath expressions and XSTag statements (a small set of flow control, evaluation, and constructor statements equivalent to the core statements from Java Tag Libraries). Because the tag vocabularies are not part of the host vocabulary, tag documents are typically well formed rather than validated. In practice, this limitation is not burdensome because the generated result document should be inspected anyway after most changes to the tag document. |
|
handler |
A document fragment that is supplied by the tag document but
parameterized by the tag library. The section “Introduction”
gives a handler example in the content of the |
|
tag processor |
An engine that reads a tag document and one or more tag libraries and generates a result document. |
|
result document |
A document produced by processing the dynamic elements within a tag document. A result document can be validated with the schema of the host vocabulary. |
The essential features of the XSTag approach are as follows:
-
Simplicity of the tag document. By constructing documents with special XML elements instead of programming with calls and variable assignments, people with less expertise can successfully generate dynamic documents. In particular, the use of special XML elements puts the emphasis on the semantics of the tag rather than the syntax of the tag call. From the perspective of the tag document author, the XML element effectively is the call to a function (without needing any other annotations).
-
Assembly of tag libraries by the tag document. This feature removes the need for programming expertise to produce new combinations of libraries and thus maximizes the potential reuse of tag libraries. (UNIX pipes provide a good demonstration of the benefitss of assembly by the consumer.)
-
Both pull and push processing (see PUSHPULL) in the tag document. Tags let the tag document pull processing defined in a tag library, while handlers let the tag library push processing control to the tag document. Having both pull and push capabilities adds some conceptual complexity but simplifies tag documents for cases similar to the example in the introduction. In particular, handlers give the tag document author the ability to interleave tags from different tag libraries at the fine-grained level in ways unforeseen by the tag library developer.
The XSTag approach is not a solution for every document processing challenge. The tag library approach is designed for producing dynamic documents (especially HTML) through layout and configuration or styling of components and data provided by reusable libraries. In particular, handlers are sufficient for push processing of a pre-defined set of events that occur during execution of one tag. Handlers don't provide a good tool for transformation of a complex document from one large vocabulary into a different vocabulary.
Before explaining our approach in detail, we review some existing solutions for document authors.
Related Work
Several XML initiatives address the challenges of dynamic documents, including:
|
Simplified Stylesheets |
XSLT provides Simplified Stylesheets (see XSL2) as a method for embedding XSLT statements inside a result element at the root level of a document. Limited to the statements valid within an XSLT template, Simplified Stylesheets cannot include or import other stylesheets and cannot provide matching templates. In addition, template calls in Simplified Stylesheets use the xsl:call statement and thus emphasize the XSLT syntax of the call. As a result, Simplified Stylesheets have some key limitations with respect to the simplicity of the document, to assembly of libraries by a document, and to push processing defined in a document. An additional stylesheet can include or import Simplified Stylesheets but this approach requires programming expertise to integrate documents and libraries. |
|
Cocoon XSP |
XSP (see XSP) provides a method for replacing placeholders in XML documents with the results from Java logic using bindings defined with XSLT. Because Cocoon runs in a Java web application environment, the primary focus of XSP is leveraging Java capabilities for producing content within XML documents. |
|
XBL |
XBL (see XBL2) provides flexible aggregation of content fragments and of client resources such as JavaScript methods. XBL has seen only partial implementation and limited adoption, perhaps because the sophistication of the binding mechanisms is challenging for document authors. |
|
Template placeholder replacement |
The general approach of writing stylesheets to replace placeholders in a template document with dynamically generated content was worked out ten years ago (see XSTEMP). RunDMC (see RDMC) is a more recent XSLT-based framework exemplifying the approach. RunDMC includes the ability to parameterize dynamic generation with content supplied by the placeholder. While encouraging simple documents, template placeholders typically don't address assembly of libraries by a document or push processing defined in a document. These tasks typically remain the responsibility of the template processor, minimizing the potential for a library approach. |
|
XForms |
XForms (see XForms) supports forms interaction with a separation of model, view, and controller. Such interactions are behaviors of the runtime document. Thus, XForms solves a fundamentally different problem than dynamic composition of the runtime document. For instance, a tag library could encapsulate the XForm model, view, and bindings for a form, providing a simpler interface for inserting the form into the document. As another example, a tag library could encapsulate alternative event handlers, providing a gallery of options of predefined behaviors for a specific form. |
Similarities and Differences Between XSTag and Java Tag Libraries
While borrowing heavily from Java Tag Libraries, XSTag also differs in some important ways:
|
Expression language |
Java Tag Libraries can embed a simple expressions in attribute values or element content. Scenarios for use of expressions include:
XSTag follows XQuery in supporting delimited XPath expressions in both attribute value and element content (thus differing from XSLT, which allows delimited XPath expressions only in attribute values). |
|
Basic Statements |
Java Tag Libraries provide a reserved XML vocabulary for basic statements within a tag document including capturing the result of an expression in a variable, conditional branching, looping and so on. These statements have equivalents in the XSLT statements allowed within a template including xsl:choose, xsl:if, and xsl:variable. While tag libraries can minimize the need for such statements, the availability of such statements can have practical importance as a workaround. |
|
Function Binding |
Java Tag Libraries use declarations to associate XML elements with Java functions. In an XML processing contexts, such indirection seems potentially confusing instead of useful. Instead, XSTag binds a tag call in the tag document to a tag definition with the same QName in the tag library. |
|
Handlers and Parameters |
Java Tag Libraries refer to a handler as a tag body. In Java Tag Libraries, a tag can have at most one handler. The Java tag body is also a closure with respect to the tag document in that variables in scope within the tag document can be evaluated in the tag body. While the limitation to one handler is adequate for regular relational data, a single handler is not enough to process an XML tree structure or complex XML data vocabularies. XSLT has template match rules and XQuery has typeswitch expressions for this reason. To process XML content with a tag, different dynamic content must be produced for different elements. For that reason, XSTag allows multiple handlers for a single tag and permits atomic values or XML nodes as parameters. |
|
Tag Document Inclusion |
Java Tag Libraries have inclusion statements to insert one tag document inside another tag document. Such inclusion statements resemble a tag call. Rather that introduce two different kinds of tag calls, XSTag supports reuse of document fragments through basic tag libraries with tags that merely return a static document fragment. |
Having reviewed alternative strategies and Java Tag Libraries background, we now introduce our approach for processing tag libraries.
Tag Processors
The tag processor is responsible for parsing the tag document and imported tag libraries and producing a result document. Whether implemented by interpretting the sources or by preprocessing and then executing XSLT, XQuery, or some other language, the steps for producing a result document are conceptually similar:
-
The tag processor descends the XML tree of a tag document, defining variables in scope within a branch. Those variable are outside any tag call and, essentially, are constants. The tag processor also evaluates any expressions outside of a tag call, replacing each expression with its result.
-
When the tag processor reaches a tag call, it performs evaluation and replacement on expressions outside of any handler. We call this phase the time of the call. Conceptually, for any expression within a handler, the tag processor replaces any variable defined outside the handler with its value at the time of the call. That is, a handler is a closure with respect to the tag document outside the tag call.
-
As the tag processor is executing the tag, when the processor reaches a call to a handler, the processor evaluates the expressions in the handler, replacing parameters of the handler with their values before replacing each expression with its result. This phase is called the time of handler processing.
As shown in Workflow, a tag processor can be implemented in XSLT as a preprocessor that generates XSLT modules for execution by a general-purpose XSLT processor; a parallel approach is possible in XQuery.
Workflow: Tag Processing Workflow
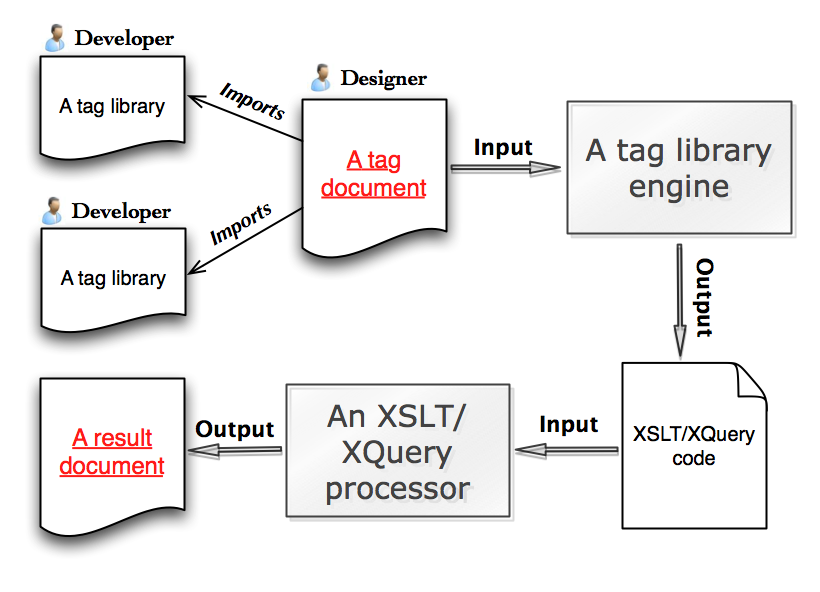
Preprocessing a tag document and tag libraries and then executing XSLT or XQuery.
XSTag Syntax
Due to the division of responsibilities, tag libraries and tag documents have different audiences and thus different syntax.
Top-Level Elements of Tag Libraries
The XSTag statements in the tag library and tag document have
a namespace to distinguish them from other XML vocabularies.
(For our prototype, we have used http://code.google.com/p/xstag/ns/2011/.)
Throughout the paper, the XSTag namespace is indicated with the prefix xst.
Tag libraries can be implemented using a basic statement set that all XSTag processors must support or using the language of the tag processor (either XSLT or XQuery in our prototype) to implement the tag. Basic and processor-specific tag libraries have similar declarations for the root element and its top-level child elements:
|
|
The required root element, which must have an |
|
|
An optional statement to import other libraries. The body of tags
can call the functions or tags supplied by the imported library.
The |
|
|
Declares a tag and its parameters.
The Similar to XSLT, parameters take a In addition to the standard XPath atomic or node types, parameters can also have a handler type. A handler type resembles an XPath 2.1 function signature but requires a name for each parameter of the handler. The handler is required or optional on the tag call based on whether its signature has a required or optional return value. A tag's handler parameter may contain a default handler definition. |
Basic tag libraries and processor-specific tag libraries differ in the implementation of the body of the tag definition.
Basic Tag Libraries
Within a basic tag library, tag definitions are implemented with basic tag statements. These statements are modeled on a subset of XSLT instead of introducing a new vocabulary so that XSLT developers can easily write tag libraries and so that advanced document authors who learn how to write basic tag libraries can progress to XSLT.
|
branching and looping |
The |
|
variables and evaluation |
Because XSLT has three alternatives ( |
|
constructors |
|
|
calls |
|
A tag library can define a handler only as the default implementation for a handler parameter (and not, for instance, as the content of a variable).
Intentionally less powerful than XSLT or XQuery, basic tag libraries provide functionality that can be supported on any tag processor. Basic tag libraries can support reuse of headers and footers through simple tags that take no parameters and return a document fragment.
Example of a Basic Tag Library
As an example, we will use the typical XML example of a book store. For simplicity we consider a flat book structure in XML documents. Assume that we have multiple XML documents that contain a list of books where each of those may contain the following information: a title, genre, multiple authors, a description, a publish date and price. Some sample data in this structure:
<books id="publisherX">
<book id="203">
<title>XQuery Kick Start</title>
<author>James McGovern</author>
<author>...</author>
...
<genre>Computer</genre>
<year>2010</year>
<price>46.99</price>
<description> This book is about ... </description>
</book>
</books>
To support a book store use case, a basic tag library with a single tag definition might resemble the following example:
<xst:taglib version="0.2"
xmlns:fn = "http://www.w3.org/2005/xpath-functions"
xmlns:xst = "http://code.google.com/p/xstag/ns/2011/"
xmlns:tag = "http://code.google.com/p/xstag/ns/demo/tag/books">
<xst:tag name="tag:books" as="element()*">
<!-- tag definition parameters -->
<xst:param name="years" as="xs:gYear*"/>
<xst:param name="onBook" implicit="true"
as="handler($title as xs:string, $authors as xs:string+)
as element()?">
<!-- default handler implementation -->
<tr>
<td><xst:content select="$title"/></td>
<td><xst:content select="fn:string-join($authors, '; ')"/></td>
</tr>
</xst:param>
<!-- The tag definition body -->
<!-- getting the books for the requested years -->
<xst:variable name="books" as="element()*"
select="document('books.xml')/books/book[fn:empty($years) or data(year)=$years]"/>
<!-- processing each book by calling the handler -->
<xst:for-each name="book" select="$books">
<xst:call handler="$onBook">
<xst:with-param name="title" select="$book/title/fn:string(.)"/>
<xst:with-param name="authors" select="fn:string-join($book/author/fn:string(.), ', ')"/>
</xst:call>
</xst:for-each>
</xst:tag>
</xst:taglib>
The above tag library contains only one tag definition that is bound to
namespace http://code.google.com/p/xstag/ns/demo/tag/books
via the prefix tag. The books tag
takes two parameters: a list of xs:gYear values that denote years
of publications and a handler parameter that, in turn, takes a title and
a list of authors. If a tag caller does not provide
a handler definition then the default implementation within the handler
is used. In the example, the default
handler implementation returns an HTML table row that contains two columns: a book
title and
concatenated list of authors. The default handler assumes that the tag document
will wrap
an HTML table around the call to the books tag.
The handler definition body retrieves books based on
supplied years.
Then, for each retrieved book element, the tag definition body calls the
handler definition with the title and authors
parameters of the handler.
Processor-Specific Tag Libraries
A processor-specific tag library has the same
top-level statements (see section “Top-Level Elements of Tag Libraries”) as
a basic tag library including the tag declaration statements
(that is, the xst:tag and xst:param statements).
The root xst:tag-lib statement must have a for
attribute identifying the processor-specific language
of the tag library.
The body of the tag definitions must be implemented
in the processor-specific language.
For instance, an XQuery-specific tag library uses XQuery statements
after the xst:param elements inside the xst:tag definition.
The only exception applies to calls to handlers.
The tag processor must be able to parse these calls, so calls to handlers must embed
the xst:call statement where appropriate within the tag definition.
The example from section “Example of a Basic Tag Library” could be rewritten as an XQuery-specific tag library as follows:
<xst:taglib version="0.2"
for="xquery"
xmlns:fn = "http://www.w3.org/2005/xpath-functions"
xmlns:xst = "http://code.google.com/p/xstag/ns/2011/"
xmlns:tag = "http://code.google.com/p/xstag/ns/demo/tag/books">
<xst:tag name="tag:books" as="element()*">
<!-- tag definition parameters -->
<xst:param name="years" as="xs:gYear*"/>
<xst:param name="onBook" implicit="true"
as="handler($title as xs:string, $authors as xs:string+)
as element()?">
<!-- default handler implementation -->
<tr>
<td><xst:content select="$title"/></td>
<td><xst:content select="fn:string-join($authors, '; ')"/></td>
</tr>
</xst:param>
<!-- The tag definition body -->
<!-- getting the books for the requested years -->
let $books as element()* :=
document('books.xml')/books/book[fn:empty($years) or data(year)=$years]
<!-- processing each book by calling the handler -->
for $book in $books
return
<xst:call handler="$onBook">
<xst:with-param name="title" select="$book/title/fn:string(.)"/>
<xst:with-param name="authors" select="fn:string-join($book/author/fn:string(.), ', ')"/>
</xst:call>
</xst:tag>
</xst:taglib>
The revision above does the same thing as the basic tag library but in XQuery. Reasons for using a processor-specific tag library include familiarity with the language as well as requirements that exceed the limited capabilities of basic tag libraries.
Tag Documents
A tag document calls a tag provided by a tag library by embedding an XML element with the same QName as the tag. The element making the tag call can have:
-
Subelements or attributes that supply parameters of the tag.
-
Subelements that supply handler definitions for handler parameters of the tag. The container subelement must take an
xst:handlesattribute that lists the parameters received by the handler.If the tag definition passes a parameter to the handler definition that the handler definition does need, the handler definition can simply ignore the parameter. In particular, the
xst:handlesattribute does not have to list parameters that aren't used in the handler definition. The order of parameters in thexst:handlesattribute does not matter.
A tag document can only define handlers as part of a tag call. A tag call can be nested within a handler.
If a tag has an implicit parameter (as explained in section “Top-Level Elements of Tag Libraries”), the
tag element can omit the subelement container and contain the content of the parameter
directly. When containing the content of an implicit handler, the tag call must supply
xst:handles attribute.
Variable scope is limited to following siblings and their descendants. Handlers can refer to variables in scope. An example of a tag document:
<html xst:version="0.2"
xmlns:xst = "http://code.google.com/p/xstag/ns/2011/"
xmlns:fn = "http://www.w3.org/2005/xpath-functions"
xmlns:tag = "http://code.google.com/p/xstag/ns/demo/tag/books"
>
<!-- Importing a books tag library -->
<xst:import href="BooksTaglib.xstag"/>
<xst:variable name="years" select="(2010, 2009, 2008)"/>
<head>
<title>Books for {$years} years</title>
</head>
<body>
<table>
<tag:books years="{$years}" xst:handles="$title, $authors">
<tr>
<td>{$title}</td>
<td>{fn:string-join($authors, ', ')}</td>
<td>{fn:count($authors)}></td>
</tr>
</tag:books>
</table>
</body>
</html>
The example above creates an HTML document with a table of
books for particular years. This tag document makes use
of a tag library presented in section “Basic Tag Libraries”.
First of all we import the tag library using the import statement:
<xst:import href="BooksTaglib.xstag"/>.
In order to use tags from that library, the namespace for
the tag call element (tag:books)
has to match the namespace for the tag definition element but does not have to have
the
same prefix.
Our tag has two parameters (refer to section “Basic Tag Libraries”
for more details): a sequence of publishing years and
a handler parameter that takes a string parameter for a title and a
sequence of strings for the list of authors.
The tag:books tag call contains
a years attribute to supply the years parameter
and content to supply the handler definition for the onBook handler parameter.
The xst:handles attribute on the tag call identifies the set of parameters
that the handler expects the tag definition to pass.
While a tag processor can check consistency by looking at both a tag
library and a tag document,
there are some advantages to having the xst:handles attribute:
-
By looking for the
xst:handlesattribute, a document author can find the handlers (for instance, after taking on maintenance responsibility for someone else's tag document). -
A tag processor can compare the parameters expected by a handler definition with the parameters declared formally for the handler by the tag definition and detect errors if, for instance, a change in the tag library invalidates the tag document.
-
A tag processor can also check to confirm that every variable reference in the tag document is in scope either within the tag document or as a parameter of the handler definition.
The xst:handles attribute does not control the handler call
from the tag definition to the handler definition.
Instead, the handles attribute declares the tag document's expecations
for how the tag definition will call the handler (in this respect, similar
to a C external function signature for a function defined in a library).
Results of tag calls can be bound to some variables and those variables can be reused in other tag calls.
Tag Processor Implementation
Prototype XSLT and XQuery implementations of XSTag are available
at http://code.google.com/p/xstag/.
The XSLT implementation makes use of Dimitre Novatchev's technique for dynamic templates (see FXSL):
-
A tag call is preprocessed to a call passing a temporary XML document that has a subelement for each handler and a subelement capturing the state of each variable defined outside the call but referenced in a handler.
-
A handler is preprocessed to a match template for the handler subelement, assigning local variables from the state subelements for each out of scope variable that is referenced in the handler.
-
A tag template is preprocessed to a named template with a single parameter for the temporary XML document and local variables for the handler subelements that (when not provided by the temporary document) default to the content of the handler parameter.
-
A handler call is preprocessed to an apply on the handler subelement of the call document.
In the XQuery implementation:
-
If the XQuery processor supports closures, a preprocessor can convert a handler into a closure that is passed as part of the tag call. The preprocessor can treat the handlers in a tag library as a function item parameter.
-
If the XQuery processor supports function items, a preprocessor can convert a handler into function and pass the function to the tag. The preprocessor can also capture the state at the point of call and restore the state within the constructed function by passing a temporary XML document (as in the XSLT implementation).
-
Otherwise, a preprocessor can generate a copy of the tag library for each tag document, generating a function for each handler from the tag document and passing and restoring the state as a temporary XML document.
Both the XSLT and XQuery implementations in the prototype have limitations, especially in their support for processor-specific tag libraries.
Potential Investigations
Tag library developers must provide guidance to tag document authors on the use of the library. To make that easier and more consistent, a mechanism similar to JavaDoc is important for maintaining documentation source within tag libraries and generating viewable documentation. Existing projects such as XSLTdoc XSLD or xqDoc XQD may be adaptable for this purpose.
All of the examples in this paper focus on events during single-pass generation of a result document within an XML processing environment. Other scenario are equally possible:
-
For Client UI scenarios, a tag library could generate HTML documents that use JavaScript to process some handlers in response to UI events such as button clicks.
-
For AJAX scenarios, a tag library could generate HTML documents that process some handlers by connecting to a service on a server.
More generally, tag documents and basic tag libraries with a simpler expression language than XPath could be converted to JavaScript and executed on the client. The advent of JavaScript-based XSLT and XQuery implementations also raises the possibility of using XPath in the browser. The specifics for processing some tag calls on document request, some tag calls entirely on the client, and some tags calls through AJAX requests requires more investigation.
Tag libraries benefit from the movement by the current draft XQuery and XSLT standards to support function objects. Where the processor supports function objects with closure over variables in scope for the function definition, handlers become trivial to implement. The current XQuery draft envisions such function objects. The tag library approach suggests the value of such function objects for XSLT as well.
A more interesting possibility would be incorporating a tag library capability within the XSLT and XQuery standards as a shared definition (similar to XPath). Tag library developers would benefit because (especially in XQuery) a more natural syntax could be specified for a processor-specific tag library that is difficult to support with a preprocessor. Tag document authors would also benefit from direct processing instead of preprocessing. For instance, type coercion errors during runtime processing could be traced directly to the tag document or tag library source for better debugging output.
Conclusion
Java Tag Libraries have seen wide adoption as a strategy for dynamic documents because of the division of responsibilities between tag document authors and tag library developers and because of the ability to combine tag libraries as needed for new solutions. In particular, the approach removes the need to write binding logic to add or change the libraries used in a document.
This paper demonstrates the feasibility of adapting the Java Tag Libraries approach for use with XML technologies. Tag libraries can support a set of data retrieval and manipulation functions as well as UI components. Tag documents can support these functions by embedding tags within a presentation vocabulary such as XHTML or XSL-FO. In particular, tag documents can pass handlers to tag libraries for parameterization of document content by the tag library.
Tag libraries can be implemented in either XSLT or XQuery, enlarging the environments in which tag libraries can be deployed as well as the pool of potential tag library developers. A tag document can be processed in both environments, allowing tag document authors to provide designs for either kind of environment without having to learn a new syntax. Through the contract of the tag signature -- the parameters and handlers and return type passed to the tag -- contributors can apply their distinct expertise to collaborate for information processing and presentation.
Glossary
Some terms introduced in section “Essential Terms, Concepts, and Limitations” also appear here for completeness.
|
tag document |
A document that mixes a static XML vocabulary (such as XHTML or XSL-FO) with XPath expressions, XML Simple Tag statements, and tags from one or more tag libraries to produce dynamic documents. |
|
tag library |
A function library (typically implemented in XSLT or XQuery) that produces XML content for a tag document. |
|
simple tag statement |
|
|
tag call |
An element in a tag document processed as a function call to a tag definition with the same QName, supplying parameters with its attributes and content and replaced by the return value from the tag definition. |
|
tag definition |
A function provided by a tag library that processes parameters to produce XML content. |
|
tag parameter |
An atomic value, XML node (typically one or more elements), or handler definition passed by a tag call to a tag definition to control production of the XML content or to supply content for insertion into the XML content. |
|
tag definition body |
Content of a tag definition followed after declaration of all tag parameters. A tag definition body defines the logic how a tag call will be executed. |
|
parameter container |
A subelement of the tag call supplying a tag parameter with its content; the subelement has a namespace prefix that is the same as the prefix of the tag call and a local name that's the same as the name of the tag parameter. |
|
handler definition |
An XML fragment that is passed as a tag parameter and that is processed with values generated during execution of the tag definition; a callback. |
|
handler definition call |
Processing of a handler definition with values during execution of a tag definition. |
|
handler definition parameter |
A value passed by the tag definition to a handler definition. |
|
tag processor |
An implementation of the tag library and tag document functionality that takes them as an input and produces a result document. |
|
result document |
A document produced by a tag processor based on tag libraries and a single tag document that import those libraries. |
References
[FXSL] Novatchev, Dimitre, Functional programming in XSLT using the FXSL library, In Proc. Of the Extreme Markup Languages Conference 2003, seen July 2011. Available at http://conferences.idealliance.org/extreme/html/2003/Novatchev01/EML2003Novatchev01.html#t2-2.
[JSP] JavaServer Pages Technology, seen July 2011. Available at http://www.oracle.com/technetwork/java/javaee/jsp/index.html.
[PUSHPULL] Push, Pull, Next!, Bob DuCharme, seen July 2011. Available at http://www.xml.com/pub/a/2005/07/06/tr.html.
[RDMC] A peek inside RunDMC, seen July 2011. Available at http://developer.marklogic.com/blog/a-peek-inside-rundmc-part-2.
[XBL2] XML Binding Language (XBL) 2.0, seen July 2011. Available at http://www.w3.org/TR/xbl/.
[XForms] XForms 1.1, seen July 2011. Available at http://www.w3.org/TR/xforms/.
[XQ1] XQuery 1.0: An XML Query Language (Second Edition), seen July 2011. Available at http://www.w3.org/TR/xquery/.
[XQ3] XQuery 3.0: An XML Query Language (W3C Working Draft 14 June 2011), seen July 2011. Available at http://www.w3.org/TR/xquery-30/.
[XSL2] XSL Transformations (XSLT) Version 2.0, seen July 2011. Available at http://www.w3.org/TR/xslt20/.
[XSP] XSP Logicsheet Guide, seen July 2011. Available at http://cocoon.apache.org/2.1/userdocs/xsp/logicsheet.html.
[XSLD] XSLTdoc - A Code Documentation Tool for XSLT, seen July 2011. Available at http://www.pnp-software.com/XSLTdoc/index.html.
[XQD] XSLTdoc - A Code Documentation Tool for XSLT, seen July 2011. Available at http://xqdoc.org/xqdoc_comments_doc.html.
[XH] XHTML 1.0: The Extensible HyperText Markup Language (Second Edition), seen July 2011. Available at http://www.w3.org/TR/xhtml1/.
[XSTEMP] Style-free XSLT Style Sheets, Eric van der Vlist, seen July 2011. Available at http://www.xml.com/pub/a/2000/07/26/xslt/xsltstyle.html.