Introduction
We proposed [Portier2009] a methodology for the construction of multi-structured documents. We add tools for documenting and managing the evolution of the terms and relations created by the users for the description of structures.
The following ideas have been conceived in the context of a digital library project that includes a group of philosophers interested by the work of Jean-Toussaint Desanti[1]. Our documents are digital images of manuscripts' pages (more than 35 000 pages). From a technical point of view, our users transcribe, annotate and reorder those pages.
The transcription is the association of the image of a manuscript's page with the digitized version of its textual content. Many levels of transcription have been defined[2]: from the diplomatic transcription whose result should be the exact copy of the manuscript (the layout of the page is retained, abbreviations are not expanded, etc.) to transcriptions that remain easy to read. However, with the rich underlying data structures of existing philological software platforms this choice can be postponed to the editorial phase when multiple versions of the transcription will be produced. Moreover, the TEI[3] defines well documented and customizable tag sets (thanks to the Roma tool that generates validators for ad-hoc customizations[4]). Finally, there are useful case studies ([Huitfeldt2004], [Gants2006], ...) of electronic editions projects. They give us perspectives on the processes of choosing a tag set, establishing encoding rules, etc. They also introduce to more general problems that most certainly appeared from the required formalization of electronic edition. For example, the two notions of representation and interpretation benefit from being presented as a conceptual continuum: "common sense" always seems to be able to distinguish between the two concepts, to draw a border, but every time we look closer this border vanishes. As a second example, the computer programs considered as tools make the interactive relationship between the user and the text explicit.
A particularity of the Jean-Toussaint Desanti Archives is the necessity of reordering the handwritten pages. In fact, we have noticed that this problem applies to many projects of electronic edition of handwritten manuscripts. Often, the pages are initially disordered: the documents may have passed through the hands of many people and lost their initial order. More importantly, for testing philological hypothesis, it is often interesting to reorder collections of pages, even though these reorderings do not correspond to explicit choices of the author. We choose two examples from the J.T.Desanti Archives in order to illustrate this problem.
For the first example, let say a user isolates the four pages of Figure 1 from a set of unclassified pages. Since three of the four pages are being numbered in their top right corner, he easily manages to reorder them. Nonetheless this reordering is to be considered as an interpretation and the original order and context must be preserved. Later, inside an other unclassified set of pages, a page is found that shares many similarities with the first page of the new four pages collection. Some researcher concludes that the newly created collection may be an alternative version of the page just found.
Figure 1

Four pages from an unclassified collection
For the second example, a user finds, in the last page of a notebook, a reference to an unknown appendix (see Figure 2). Later, the appendix is found inside an unclassified set of pages (see Figure 3). He will insert the appendix after the last page of the notebook, but the original context in which the appendix was found must be preserved as it is highly significant since it helped to link the content of the notebook with the themes developed by the unclassified set of pages where the appendix was found.
Figure 2
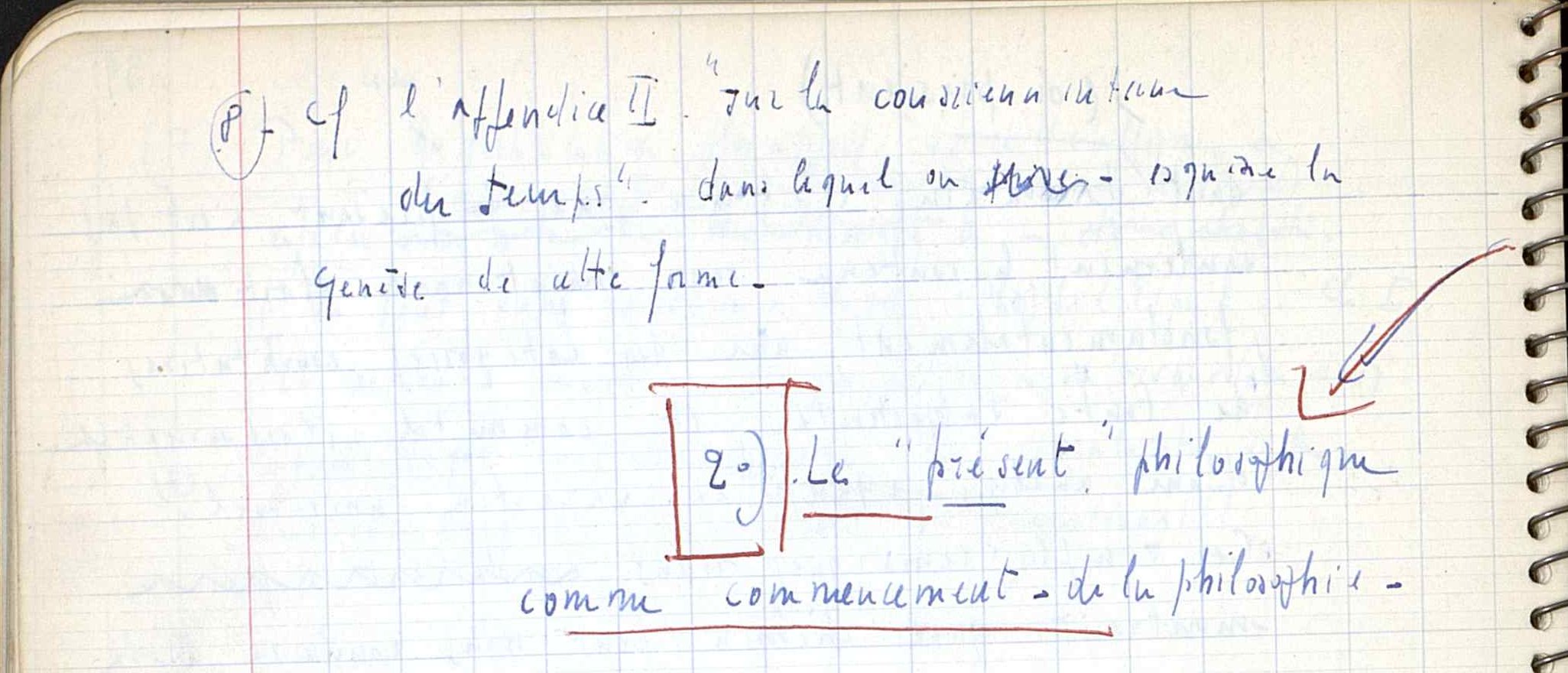
A reference to an unknown appendix
Figure 3

Found appendix
We spent some time describing this simple situation of reordering set of pages ... for we find it interesting and relevant to the forthcoming considerations. A reordering is formally quite simple: we move a few pages, we add some annotations ... But it may convey valuable interpretations.
We divided the users activity into three main operations: transcription, reordering and annotation. We briefly covered the first two and should now introduce to the third one. However, the annotation operation is much more generic: transcription as well as reordering depend on annotations. But it seemed convenient to introduce them separately. Our annotations are simple relations and we keep them in a RDF store.
Users create those relations in a GUI (see Figure 4) that imitates the graph structure of the data.
Figure 4
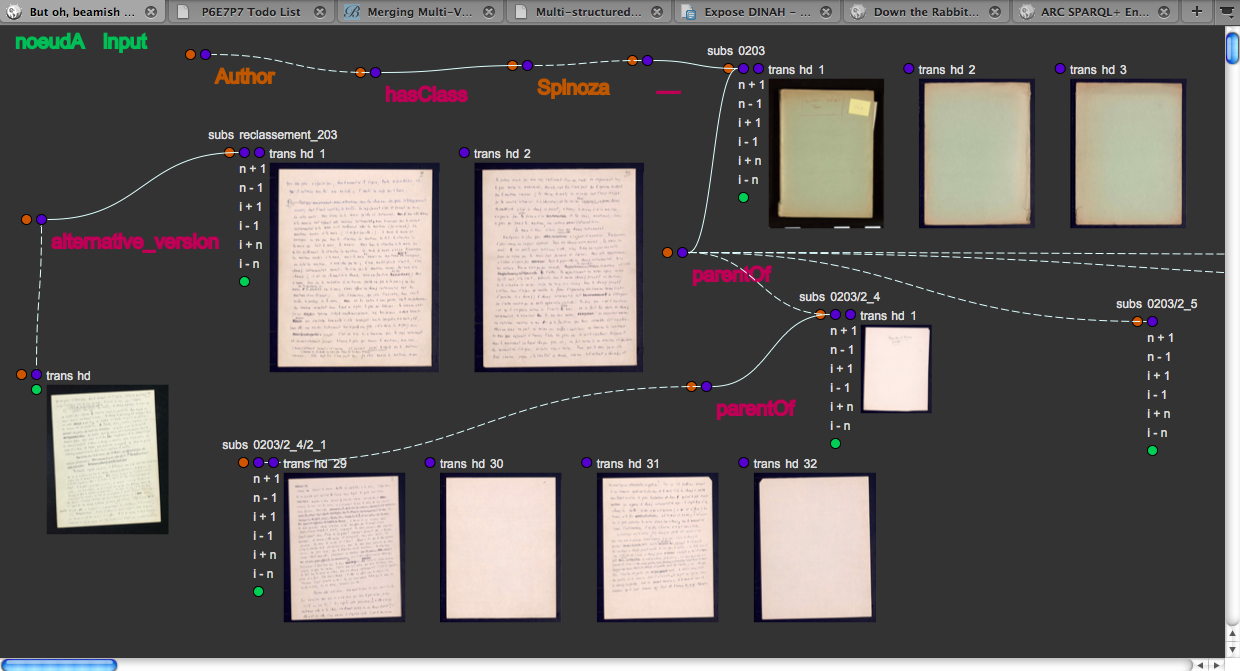
DINAH main interface
Those relations are used to build a faceted navigation interface (see Figure 5).
Figure 5
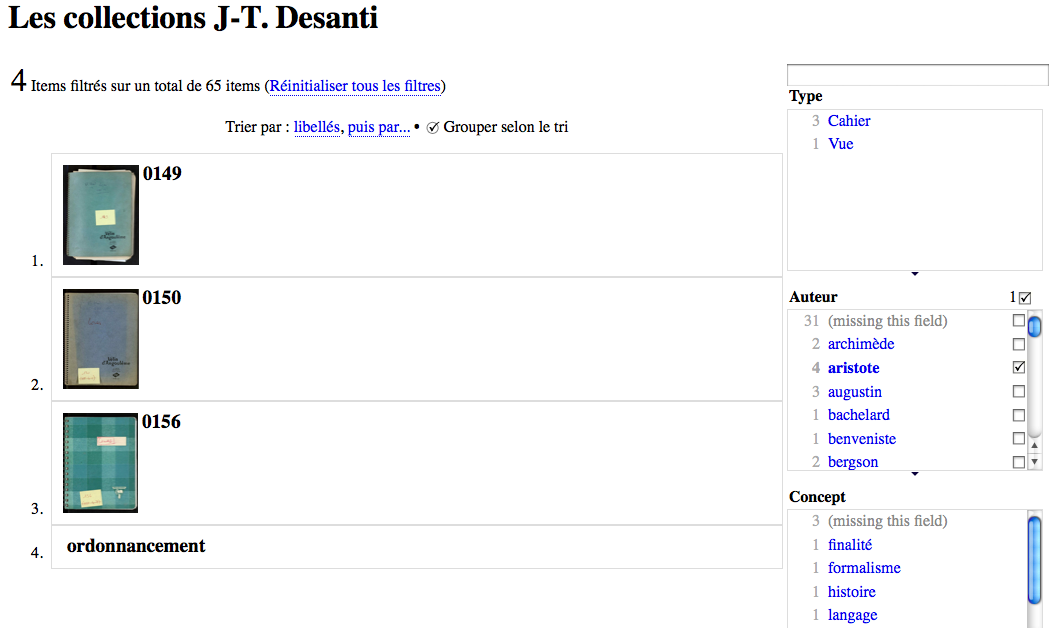
Faceted navigation interface
We should now clarify our orientation towards vocabularies of terms. According to Patrick Durusau [Durusau2006], vocabularies of terms and relations have to be defined before any annotations are created. However, as explained by Dino Buzzetti and Jerome McGann [Buzzetti2006], a new annotation modifies the semiotic nature of the document by facilitating new interpretations that can themselves arouse the desire to add new annotations in order to formalize those interpretations, ... thus feeding a theoretically endless hermeneutic process. Thereby, it seems necessary to allow a continuous creation of terms. Our work focuses on how to effectively enable this creation. That being said, we recognize the relevance and importance of capitalization work such as the TEI. However, we try to focus on the problem of the emergence of annotation vocabularies when some researchers study a set of documents.
We first provide a short introduction to the notion of "sign". We then describe the evolutions of our model for the construction of multi-structured documents. Next, we introduce the notion of the "trace of users interactions" and we show how this trace can be used for managing and documenting vocabularies of terms and relations. Then, we explain how a very interesting activity of models confrontation emerged from the possibility of interacting with the trace. We will illustrate the notions with examples from our philological platform named DINAH (Dinah is Irrelevantly Not Alice Heron). In the end, we will compare DINAH with other philological platforms.
Around the concept of sign
The ideas that will be presented in the next sections were conceived from reflections about the concept of sign. Historically, this concept was created approximately at the same time by two unrelated men: Ferdinand de Saussure (1857-1913) a Swiss linguist and Charles Sanders Peirce (1839-1914) an American philosopher and logician (and statistician, and astronomer, and ...). Their conceptions were in many aspects quite similar.
Saussure concept of sign makes use of two notions: the signifier and the signified. The signifier is the form of the sign while the signified is the concept represented by the sign. Figure 6 shows the traditional way of representing the Saussurean sign. A simplistic interpretation of Saussure ideas would tend to consider the sign as a univocal relation between a signified and a signifier. But it would clearly be a misinterpretation! For Saussure, the relation signified/signifier is linguistically arbitrary. Moreover he saw "meaning" as wholly relational or structural: the meaning of a sign arises from its relations with other signs and not from some essential property or reference to a material world.
Figure 6
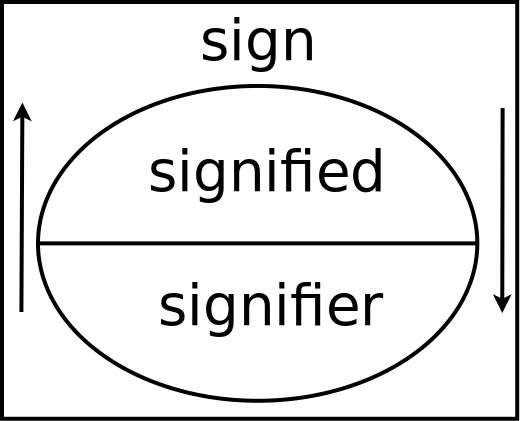
A representation of the Saussurean concept of sign: the signification is the relationship between the signified and the signifier represented by the arrows.
Peirce produced a triadic model of the sign whose terms are: the representamen or the form of the sign, the interpretant or the sense made of a sign (not to be confused with the interpreter) and the object to which the sign refers. The representamen can be related to the signifier and the interpretant to the signified. So, the new term present in Peirce's model with no equivalent in Saussure's model is the object. However, it can be argued that a referent was implicitly present in Saussure's model. What really differentiates the two models is that the interpretant can be considered as a sign in the mind of the interpreter. It implies that the interpretation is a process, Peirce has named this process the semiosis. It seems clear from the above definitions that the semiosis is theoretically unlimited (the notion of "unlimited semiosis" was first introduced by Umberto Eco). For Saussure the interpretation was the highlighting of the complex relations a sign maintained with other signs within a linguistic structure ; while for Peirce the interpretation is the always to be done process of connecting signs.
Modern interpretations of Peirce's model, with its concept of semiosis, tend to erase the notion of "signified" since the interpretant can always become a new sign. We found a quite interesting example in Gregory Bateson work [Bateson1979] (it should be noted that we modify it quite slightly). We consider a mathematical property: "The sum of the first n odd numbers is equal to n squared". Figure 7 shows three representations of this property. Is the content the same, and only the form varying? It seems more satisfying not to speak in terms of signifier/signified, form/content, etc. but to consider different configurations of signifiers leading to different interpretations. Incidentally, this last example can lead to the understanding of difficult concepts: the difference between cardinal and ordinal numbers.
Figure 7
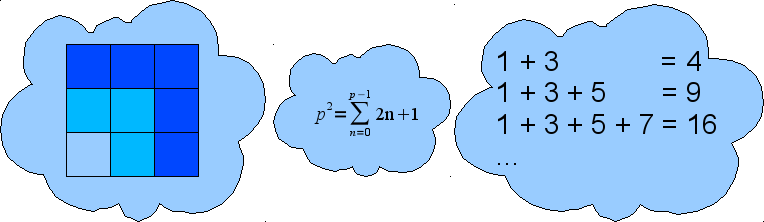
Three representations of a mathematical property
In computer science, when references are made to Peirce, it is most of the time in a logical framework where first order logic is used as a uniform way to represent assertions in order to compute new assertions. The best example of this trend being the work of John F. Sowa [Sowa2000]. In fact, the conceptual graphs were derived from the work of Peirce. However, we rarely find work inspired by the notion of semiosis. That is what we try to do by offering to the user signifiers to interpret and by taking into account results from its interpretations. The next sections will illustrate this approach.
A model for the construction of multi-structured documents
Definitions
We first give some definitions:
-
A resource is anything uniquely identified by an URI. Fragments, intervals, zones, terms, classes, binary relations, vocabularies and documents are resources.
-
A fragment is a part of document content. Our documents are textual documents and manuscripts images. In the case of textual documents a fragment is the pair (D, (inf, sup)) where D is a document identifier, and (inf, sup) is an integer interval addressing a part of the document. In the case of images a fragment is the pair (I, ((x1, y1), (x2, y2)) where I is an image identifier and ((x1, y1), (x2, y2)) are the coordinates of a rectangular zone of the image.
-
A term is a string of characters.
-
A class is a set of terms.
-
A binary relation R(x, y) links together two resources
-
A vocabulary is a set of binary relations
-
A multi-structured document is a document with fragments participating in relations that belong to multiple vocabularies.
How can these vocabularies be constructed? This is the problem we address. But before proceeding further, we illustrate the previous definitions with an example. Consider the following scenario: a philologist finds a consistent subset about Marx inside a stack of pages of consequent size. He isolates this subset by creating a new collection (using the GUI of Figure 4). He creates a relation ”mainSubject” between this collection and the term ”marx” from the class ”Author”. He starts the transcription of the collection and also creates relations, such as ”quotation”, ”citationTitle”, between intervals of the transcribed text and the document (using the GUI of Figure 8). He discovers later that this collection is in fact a preparation for another work he found in the archive. He creates a relation ”preparationFor” between the two collections. Etc. Etc. These newly created relations dynamically update the faceted navigation interface that can be used to find specific collections or pages by iterative refinement (see Figure 5).
Figure 8
Screenshot from the transcription interface
How is it that, for example, a user chooses to place the relation ”citationTitle” within the ”citations” vocabulary while he affects the relation ”hasLine” to the ”physicalStructure” vocabulary? In a multi-users context, how a user will know the meaning of a relation created by someone else? We will address the first question in the remaining parts of this section, and the second question in the next section. We should now recall some characteristics of the existing models for the representation of multi-structured documents.
Existing models
Multi-structured documents have to be analyzed in their historical context where the most used formalisms for documents representation (first SGML then XML) implied tree structures. That is why this problem has so far been considered under the technical point of view of overlapping hierarchies. From our previous example, let say a page has been transcribed and relations have been created to indicate some citations. Then, the lines of text are isolated in order to align the transcription with the manuscript facsimile. It might happen that a quotation overlaps two lines and there would be locally a graph structure: a natural use of XML becomes impossible (see Figure 9). We now describe different solutions for the representation of multi-structured documents.
Figure 9

An example of overlapping markup
We divide the set of existing solutions into four classes: historical solutions, adhoc solutions, models not compatible with XML and finally models compatible with XML.
CONCUR [Goldfarb1990] is a feature of SGML designed to allow the integration inside a same document of tags extracted from different DTDs. Thus, if the definitions of the overlapping tags appear in different DTDs, the representation problem of multi-structured documents is solved. However, because of its complexity, this SGML proposal has never been fully implemented.
The TEI describes different syntactic solutions for the representation of multiple hierarchies into the same text (as the use of milestones or the fragmentation of elements, etc.). These solutions make impossible using standard XML tools (XQuery, XPath, ...).
Since the main problem for the representation of multi-structured documents seems to be the syntactic limitations of XML, some solutions are based on models with alternative syntaxes. However they cannot profit from the galaxy of tools offered by XML. Among those solutions, we can distinguish LMNL [Tennison2002] and TexMecs [Huitfeldt2003] which are alternatives to XML (formal models and syntaxes) specifically designed for the representation of overlapping structures, from propositions that take advantage of the native graph model of RDF to represent multi-structured documents. Among these, the most convincing one certainly is EARMARK [Peroni2009]. The notions of ”location”, ”range”, ”markup item”, etc. for the modeling of multi-structured documents are precisely defined in an OWL ontology. Moreover, the SPARQL language can be used to query the documents. The origins of the EARMARK proposal are to be found in two previous works: annotations graphs [Maeda2002] are used, in the context of linguistic research, to represent documents as graphs so as to avoid the overlapping hierarchies problem ; RDFTef [Tummarello2005] can be seen as an adaptation of annotations graphs to the RDF standard formalism. At last, XCONCUR [Schonefeld2006] has the same notation as the SGML CONCUR option and is based on a multi-rooted trees model. Moreover, the XCONCUR-CL language can define constraints between tree layers.
Finally there are solutions compatible with XML. They either extend the XML model itself or modify some XML tools (such as XPath and XQuery) to work with multi-structured documents. As representatives of the first category, the multi-colored trees [Jagadish2004] and the delay nodes [LeMaitre2006] solutions have very similar models based on an extension of the core XML model to consider documents as set of XML trees. Unlike multi-colored trees, delay nodes need no XPath extension in order to navigate inside the structures.
We now introduce members of the second category (modification of XML tools to operate on otherwise standard XML documents). GODDAG [Sperberg-McQueen] (General Ordered Descendant Directed Acyclic Graph), MSXD [Bruno2006], MonetDB [Alink2006] and MultiX [Chatti2007] are similar proposals since in each case several trees are defined over the same textual content by sharing their leaves (textual fragments). MSXD is the first to introduce the idea of a schema for multi-structured documents. The MonetDB proposal is an extension of the MonetDB/XQuery XML SGBD with optimized XPath query operators with four new axis steps. These steps have been implemented very efficiently by using a region index and fast algorithms. MSDM is a lightweight solution that needs no more than a few specialized XQuery functions. Each one of these four previous solutions fails at managing change in content or structures since the entire structures have to be reconstructed every time modifications happen. MuLaX [Hilbert2005] is an adaptation of the previously described SGML CONCUR option to the XML world. An editor has been developed as an Eclipse plugin for the creation of MuLaX documents, but no query mechanism has been defined. Finally, feature structures [Stegmann2009] are a general purpose knowledge representation format that can be used for XML documents annotated with heterogeneous tag sets, it was adopted as a standard by the TEI in 2006. Feature structures have solid mathematical foundations. In particular the two operations of unification and generalization are well defined and offer very interesting perspectives for the combination of multi-structured documents. However, there is no specialized query mechanism and no way of managing change in content or structures.
Finally, there is the solution proposed by Desmond Schmidt [Schmidt2009]. Its model is named MVD for Multi-Version document. It is very similar to the kind of acyclic graph models we saw before (GODDAG, MSDM, etc.). But this is the only solution to provide an efficient algorithm for updating multi-structured documents. The author explains that updating reduces to merging a new version into an existing MVD. Thus, he finds inspiration from algorithms conceived for the alignment of genetic sequences. Moreover, an heuristic has been developed to manage block transpositions in a very short time !
Strategy for the construction of multi-structured documents
With the previous solutions, we understand what multi-structured documents are and how they can be represented, but none of them seem to be interested in the way structures appear! They must appear in the process of document construction. In this section we study this process. First of all, we choose to represent our documents in the RDF formalism but, as it will soon be explained, we voluntarily impose each structure to be hierarchical (as for the MultiX, MSXD and GODDAG solutions).
The technical issue of multi-structured documents is the one of overlapping hierarchies. Moreover, if we do not consider the documents as immutable objects but as dynamic objects that have to be constructed, overlapping hierarchies happen at precise moments. Let say a user annotated some citations titles and quotations he found in his transcription of a manuscript. Later he is told that in order to precisely align his transcription with the original facsimile he should annotate each line of the manuscript. So, he starts this new annotation task and since the ”line” relation did not exist he adds it to the current vocabulary (the one already containing ”citationTitle”, ”quotation”, etc.). Then, while he has already marked some lines, a line overlaps with an existing citation title. Our system (DINAH) will then alert him about an incompatibility between the relations ”citationTitle” and ”line” and will advice him to assign either ”citationTitle” or ”line” to another, and possibly new, vocabulary. In this case, he may assign ”line” to a ”physical structure” vocabulary. Figure 10 is a sample of the resulting graph.
Figure 10
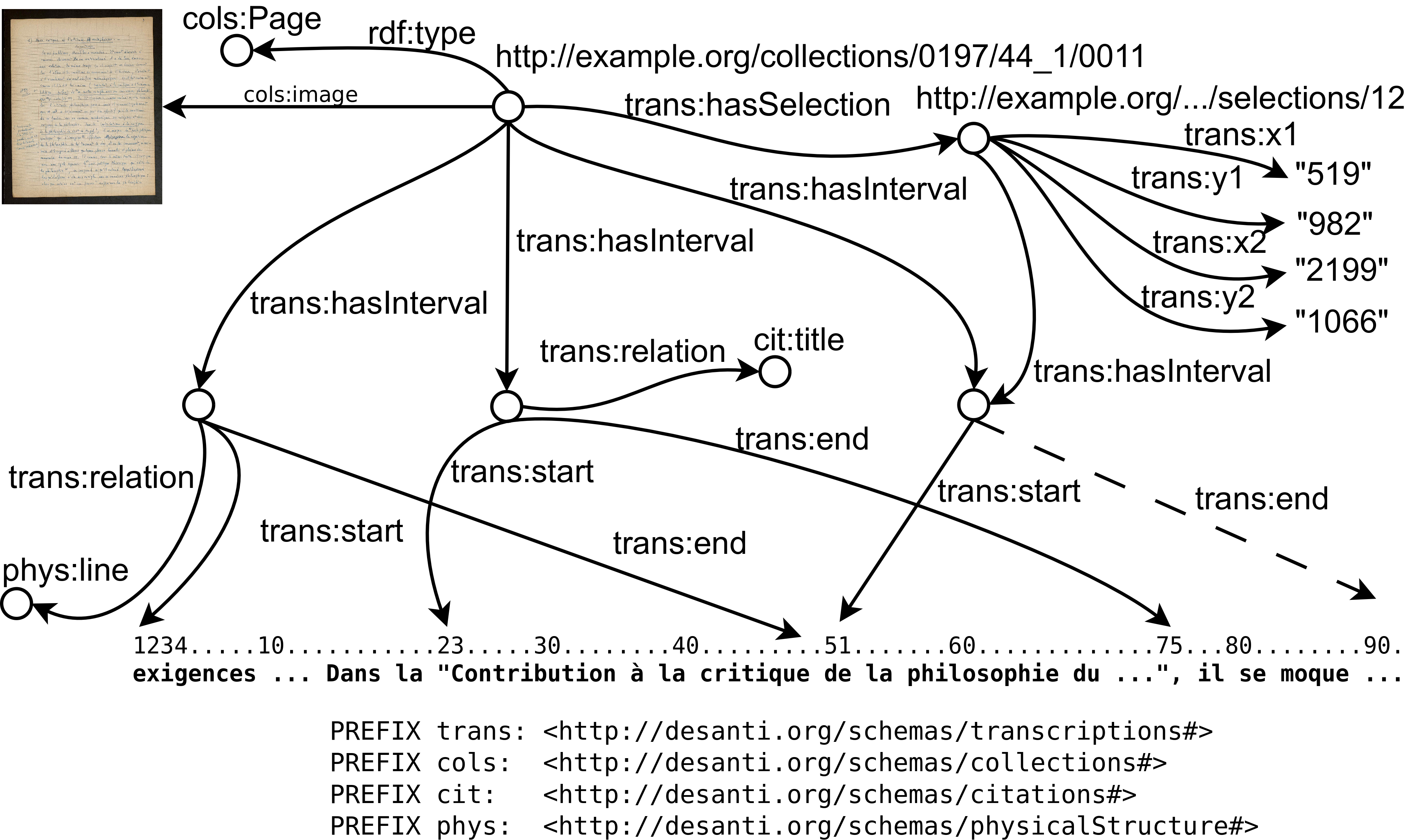
A sample RDF representation of a multi-structured document
Finally, our strategy for the management of multi-structured documents promotes the construction of a multiplicity of structures that should reflect the perspectives adopted by the users while accessing the documents. Each user has the liberty to create new vocabularies. Moreover, when overlapping hierarchies are detected users are encouraged to solve the problem by introducing a new vocabulary. In our multi-users context, this liberty could lead to an uncontrolled growth of vocabularies with lots of duplicate usages, synonyms, etc. That is why the next section presents a solution for the dynamic documentation of vocabularies.
Managing and documenting vocabularies with the trace of users interactions
Dynamic documentation
Our idea for the dynamic documentation of vocabularies relies on the monitoring of user actions. When a user wants to know how to use a term or a relation he can ask for a representation of the trace of users actions centered on the term (or relation) creation or any of its instances. This trace can itself be annotated. Thanks to these annotations users can document the vocabularies (see Figure 11 and Figure 12).
Figure 11
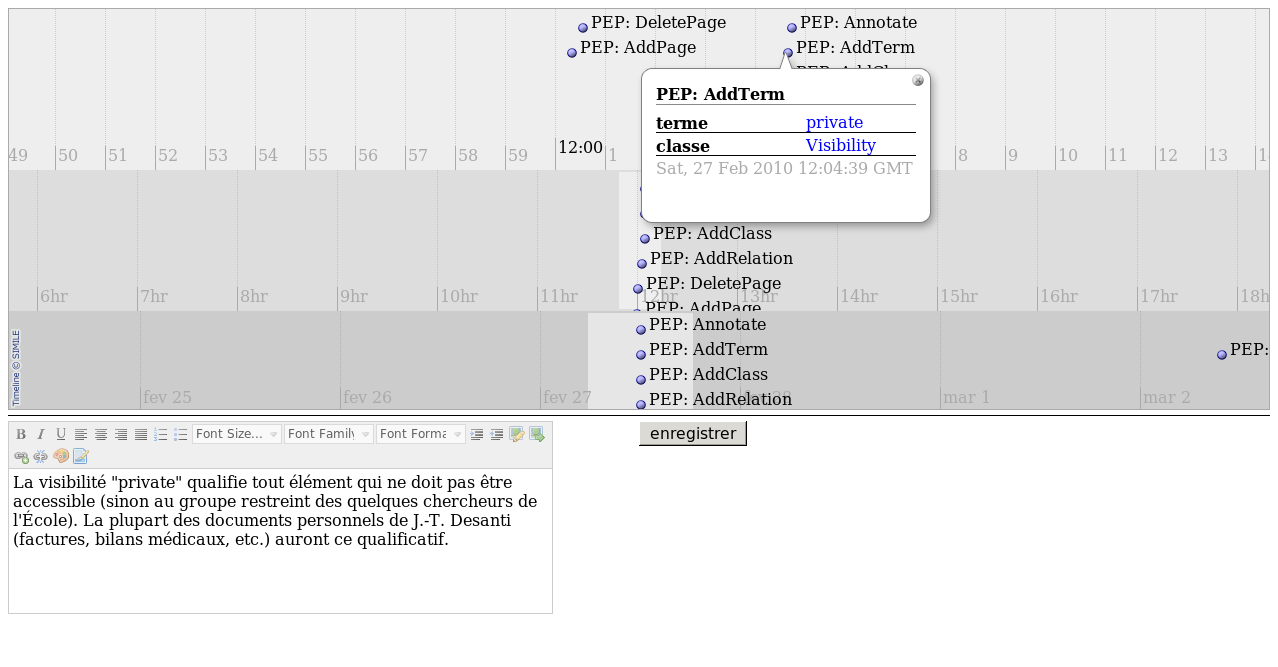
Presentation of the trace of users interactions: the user PEP added the term "private" to the class "Visibility" ; an annotation documents this term.
Figure 12
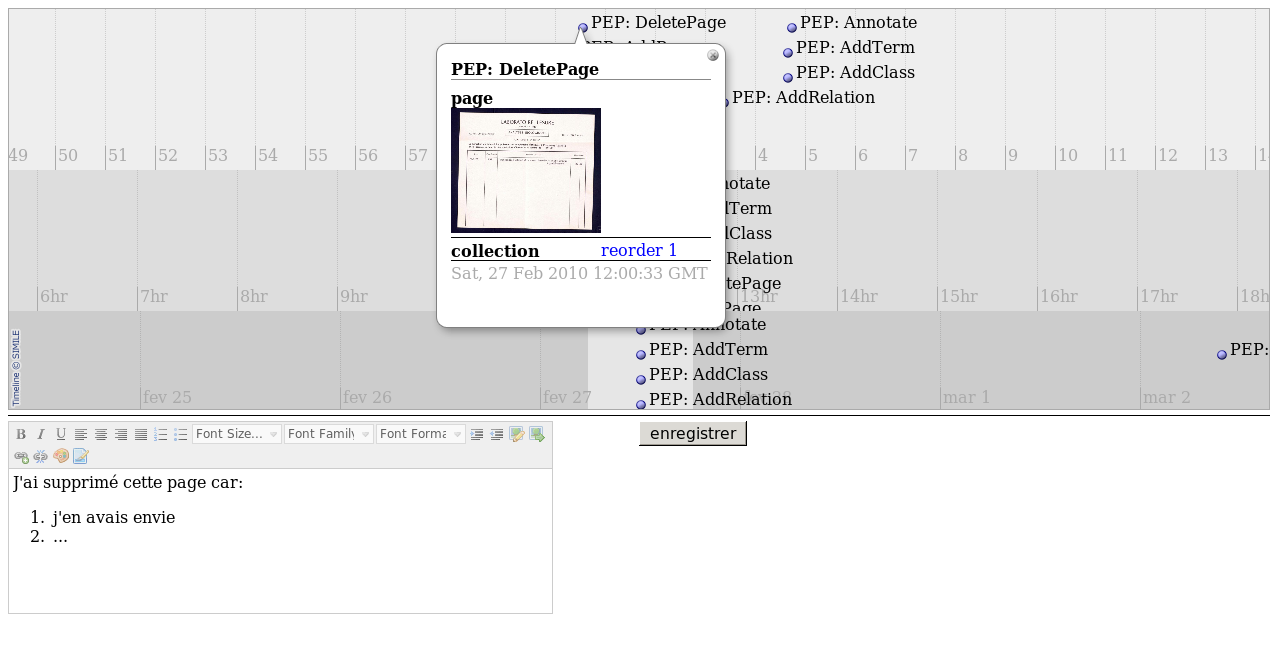
Presentation of the trace of users interactions: a page has been deleted just before the new term "private" was added.
Trace model
The first work we are aware of that made use of traces, dealt with the development of HCI for collaborative systems [Dourish1995]. There are few works dealing with the use of activity traces for knowledge management ([Laflaquiere2006] being one of the most representative). They insist on the reflexive nature of the trace as a way of sharing knowledge. They also define generic (and quite complex) activities' models, as well as rules to transform the granularity of the original trace so as to make sense for the user. However, we choose to adopt a more lightweight approach, well adapted to our needs.
We define a simple RDF vocabulary to model actions (below is a definition in the turtle RDF syntax). Every time a developer adds a new Action to the system he has to create sub-properties of the ”withArgument” property for each argument of the new action. Moreover, we have simple SPARQL queries to build representations of the trace (see Figure 11 and Figure 12).
PREFIX users: <http://desanti.org/schemas/users#>
PREFIX traces: <http://desanti.org/schemas/traces#>
INSERT INTO <http://desanti.org/>
{
traces:Action a rdfs:Class .
traces:hasDoer a rdf:Property .
traces:hasDoer rdfs:domain traces:Action .
traces:hasDoer rdfs:range users:User .
traces:hasTimestamp a rdf:Property .
traces:hasTimestamp rdfs:domain traces:Action .
traces:withArgument a rdf:Property .
traces:withArgument rdfs:domain traces:Action .
traces:documentation a rdf:Property .
traces:documentation rdfs:domain traces:Action .
traces:documentation rdfs:range rdfs:Literal .
traces:withInterval rdfs:subPropertyOf traces:withArgument .
traces:withInterval rdfs:range trans:Interval .
traces:withInterval rdfs:label ”intervalle” .
...
}
The emergence of a new way of confronting models
As explained, users of our system need to reorder subsets of the archive. We have insisted on the fact that this operation may require a lot of interpretation. Therefore, we were very interested to find the users of our system engaged in an activity we didn't anticipate. While disagreeing with an ordering from user B, user A navigated inside the trace and found the actions that lead to the problematic ordering. Then we encouraged him to annotate these actions in order to share his disagreement. It appeared that the trace is a very well adapted tool for documenting a new term (or relation) or finding interesting configurations. But it may not be the correct tool for the development of arguments as it relies on a recursive mechanism of annotations that is not meant to support conversations.
Comparisons with some existing philological platforms
We analyze our work relatively to other philological platforms. We divide them in two categories: first platforms of historical interest, next Web based platforms.
Historical platforms
BAMBI [Bozzi1997] (Better Access to Manuscripts and Browsing of Images) is, according to the authors, ”an hypermedia system allowing historians to read and transcribe manuscripts, write annotations, and navigate between the words of the transcription and the matching piece of image in the facsimile of the manuscript”. It was the first philological software platform. It does not allow typed annotations.
Part of the DEBORA [Nichols2000] (Digital Access to Books of the Renaissance) project consisted in a digital library system with collaborative features. It introduced the notion of ”virtual books”. A virtual book is the representation of a path among pages of the entire archive. But they are not resources themselves, they cannot be annotated. However we can consider this system as a first step towards a reflexive system that places users in front of their own activities.
HyperNietzsche [D'Iorio2007] (today Nietzschesource) was a pioneer digital library platform. A path mechanism is present, very similar to the virtual books of the DEBORA project. However as for the virtual books, the paths are not resources and thus cannot truly enter in a collaborative process that would allow to exchange and annotate them.
Web based platforms
Collate [Stein2004], TALIA [Hahn2008], PINAKES [Scotti2001], BRICKS [Bertoncini2007] and JeromeDL [Kruk2007] are philological platforms based on semantic Web technologies. They offer high quality mechanisms for collaborative annotations. But they do not provide convergence mechanisms for creating and documenting vocabularies.
Armarius [Doumat2008] is used to classify and annotate collections of manuscripts. It only provides untyped generic annotations. But it offers a view of all the user actions that occurred during the current session and plans to apply graph matching algorithms in order to, for example, deduce probabilities for the next actions. Thus, it can be compared with our use of traces.
Conclusions
We proposed an open system that allows the construction of multi-structured documents and the creation of annotation vocabularies. In order to manage the growth of the vocabularies we introduced a dynamic documentation mechanism based on the trace of users actions. Finally, all the propositions have been implemented in our philological software platform named DINAH.
References
[Portier2009] Pierre-Edouard Portier and Sylvie Calabretto, Methodology for the construction of multi-structured documents. In: Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). http://www.balisage.net/Proceedings/vol3/html/Portier01/BalisageVol3-Portier01.html. doi:https://doi.org/10.4242/BalisageVol3.Portier01. (August 2009)
[Huitfeldt2004] Claus Huitfeldt, Editorial Principles of Wittgenstein's Nachlass—The Bergen Electronic Edition. in Dino Buzzetti, Giuliano Pancaldi and Harold Short (eds): Augmenting Comprehension: Digital Tools and the History of Ideas, Office for Humanities Communication, London 2004 (ISBN 1 897791 18 6)
[Gants2006] David Gants, Editing Drama. in Electronic Textual Editing. Eds. Lou Burnard, Katherine O'Brien O'Keefe, John Unsworth. MLA, 2006. http://www.tei-c.org/About/Archive_new/ETE/Preview/gants.xml
[Buzzetti2006] Dino Buzzetti and Jerome McGann, Critical Editing in a Digital Horizon in Electronic Textual Editing. Eds. Lou Burnard, Katherine O'Brien O'Keefe, John Unsworth. MLA, 2006. http://www.tei-c.org/About/Archive_new/ETE/Preview/mcgann.xml
[Durusau2006] Patrick Durusau, How and Why to Formalize your Markup in Electronic Textual Editing. Eds. Lou Burnard, Katherine O'Brien O'Keefe, John Unsworth. MLA, 2006. http://www.tei-c.org/About/Archive_new/ETE/Preview/durusau.xml
[Bateson1979] Gregory Bateson, Mind and Nature: A Necessary Unity (Advances in Systems Theory, Complexity, and the Human Sciences). Hampton Press. ISBN 1-57273-434-5, 1979.
[Sowa2000] John F. Sowa, Ontology, Metadata, and Semiotics in B. Ganter & G. W. Mineau, eds., Conceptual Structures: Logical, Linguistic, and Computational Issues, Lecture Notes in AI #1867, Springer-Verlag, Berlin, 2000, pp. 55-81. http://users.bestweb.net/~sowa/peirce/ontometa.htm. doi:https://doi.org/10.1007/10722280_5.
[Goldfarb1990] C.F. Goldfarb, The SGML handbook. Oxford University Press, Inc., New York, NY, USA (1990)
[Tennison2002] J. Tennison and W. Piez, The layered markup and annotation language (lmnl). In: Extreme Markup Languages. (2002)
[Huitfeldt2003] Claus Huitfeldt and Michael Sperberg-McQueen, Texmecs: An experimental markup meta- language for complex documents. (2003)
[Peroni2009] Angelo Di Iorio, Silvio Peroni and Fabio Vitali, Towards markup support for full GODDAGs and beyond: the EARMARK approach. Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Peroni01.
[Maeda2002] K. Maeda, S. Bird, X. Ma and H. Lee, Creating annotation tools with the annotation graph toolkit. In: Proceedings of the Third International Conference on Language Resources and Evaluation. (Apr 2002)
[Tummarello2005] G. Tummarello, C. Morbidoni and E. Pierazzo, Toward textual encoding based on rdf. In: ELPUB. (2005) 57–63
[Jagadish2004] H.V. Jagadish, L.V.S. Lakshmanan, M. Scannapieco, D. Srivastava and N. Wiwatwattana, Colorful xml: one hierarchy isn’t enough. In: SIGMOD ’04: Proceedings of the 2004 ACM SIGMOD international conference on Management of data, New York, NY, USA, ACM (2004) 251–262. doi:https://doi.org/10.1145/1007568.1007598
[LeMaitre2006] Jacques Le Maitre, Describing multistructured xml documents by means of delay nodes. In: DocEng ’06: Proceedings of the 2006 ACM symposium on Document engineering, New York, NY, USA, ACM (2006) 155–164. doi:https://doi.org/10.1145/1166160.1166200
[Sperberg-McQueen] C.M. Sperberg-McQueen, C. Huitfeldt, Goddag: A data structure for overlapping hierarchies. In: DDEP/PODDP. (2000) 139–160
[Bruno2006] E. Bruno, and E. Murisasco, Multistructured xml textual documents. GESTS International Transactions on Computer Science and Engineering 34(1) (november 2006) 200–211
[Alink2006] W. Alink, R.A.F. Bhoedjang, A.P. de Vries and P.A. Boncz, Efficient xquery support for stand-off annotation. In: XIME-P. (2006)
[Chatti2007] N. Chatti, S. Kaouk, S. Calabretto, and J.M. Pinon, MultiX: an XML-based formalism to encode multi-structured documents. In: Proceedings of Extreme Markup Languages’2007, Montréal (Canada). (August 2007)
[Hilbert2005] M. Hilbert, A. Witt, M. Quebec and O. Schonefeld, Making concur work. In: Extreme Markup Languages. (2005)
[Stegmann2009] J. Stegmann and A. Witt, Tei feature structures as a representation format for multiple annotation and generic xml documents. In: Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Stegmann01. (August 2009)
[Laflaquiere2006] Laflaquière, J., Settouti, L.S., Pri ́, Y., Mille, A.: Trace-based framework for experience management and engineering. In: KES. (2006) 1171–1178
[Dourish1995] Paul Dourish, Developing a reflective model of collaborative systems. ACM Trans. Comput.-Hum. Interact. 2, 1 (Mar. 1995), 40-63. doi:https://doi.org/10.1145/200968.200970
[Bozzi1997] Bozzi, A., Calabretto, S.: The digital library and computational philology: The bambi project. In: ECDL. Volume 1324 of Lecture Notes in Computer Science., Springer (1997) 269–285. doi:https://doi.org/10.1007/BFb0026733.
[Nichols2000] Nichols, D.M., Pemberton, D., Dalhoumi, S., Larouk, O., Belisle, C., Twidale, M.B.: Debora: developing an interface to support collaboration in a digital library. In: European Conference on Digital Libraries, Springer (2000) 239–248. doi:https://doi.org/10.1007/3-540-45268-0_22.
[D'Iorio2007] D’Iorio, P.: Nietzsche on new paths: The hypernietzsche project and open scholarship on the web. In: Maria Cristina Fornari, Sergio Franzese (ds.), Friedrich Nietzsche. Edizioni e interpretazioni, Pisa ETS. (2007)
[Stein2004] Stein, A., Keiper, J., Bezerra, L., Brocks, H., Thiel, U.: Collaborative research and documentation of european film history: The collate collaboratory. In International Journal of Digital Information Management (JDIM), special issue on Web-based collaboratories from centres without. (2004) 30–39
[Hahn2008] Hahn, D., Nucci, M., Barbera, M.: The talia library platform - rapidly building a digital library on rails. In: 4th Workshop on Scripting for the Semantic Web. (2008)
[Scotti2001] Scotti, A., Nuzzo, D.: Pinakes – a modeling environment for scientific heritage database applications. In: Proc. of Reconstructing science – Contributions to the enhancement of the European scientific heritage Workshop, Ravenna, Italy (2001)
[Bertoncini2007] Bertoncini, M.: On the move towards the european digital library: Bricks, tel, michael and delos converging experiences. In: Research and Advanced Technology for Digital Libraries, 11th European Conference, ECDL 2007, Budapest, Hungary, September 16-21, 2007, Proceedings. Volume 4675 of Lecture Notes in Computer Science., Springer (2007) 440–441. doi:https://doi.org/10.1007/978-3-540-74851-9_37.
[Kruk2007] Kruk, S.R., Woroniecki, T., Gzella, A., Dabrowski, M.: Jeromedl - a semantic digital library. In Golbeck, J., Mika, P., eds.: Semantic Web Challenge. Volume 295 of CEUR Workshop Proceedings., CEUR-WS.org (2007)
[Doumat2008] Doumat, R., Egyed-Zsigmond, E., Pinon, J.M., Csiszar, E.: Online ancient documents: Armarius. In: ACM DocEng’08. Proceeding of the Eighth ACM Symposium on Doucument Engineering, ACM (September 2008) 127–130. doi:https://doi.org/10.1145/1410140.1410167
[Schonefeld2006] Schonefeld, O., Witt, A.: Towards validation of concurrent markup. In: Proceedings of the Extreme Markup 2006, Montréal, Canada
[Schmidt2009] Schmidt, D.: Merging Multi-Version Texts: a Generic Solution to the Overlap Problem. Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Schmidt01.