Introduction
Vast collections of information are stored in HTML files distributed over millions
of Web
pages through the Internet. Among these quite valuable data can often be found; however,
HTML
does not offer a large pool of semantically motivated elements or attributes for annotating
arbitrary data, since the language was originally created for hypertexts. Although
CSS
microformats Suda (2006) may be used to add semantic value to structuring
elements (e.g. div and span), most information is buried underneath a
"tag soup" of td, p or div elements that allow no
inference about their content. In contrast, we can have information that is highly
structured in
terms of very specialized XML markup using a document grammar (DTD SGML, ISO 8879:1986,
XML 1.0, XSD XML Schema Part 0: Primer or RELAX NG RelaxNG, ISO/IEC 19757-2:2003)) that allows for easy retrieving of very specific information. A real
world example where the origin of our data is a collection of (sometimes even invalid)
HTML 4.01
HTML 4.01 Web pages storing documents of video game reviews is a good
candidate for demonstrating how value can be added through better markup. Our goal
is to
transform these into fully structured and valid XML instance documents that allow
different
queries about the information. Since we are confronted with several hundred reviews,
an automated
conversion process is valuable. As an additional goal, we would like to stay in the
realm of XML
techniques; for example, we would like to avoid using non-XML-aware software such
as
general-purpose scripting languages (e.g. Perl, Python).
The data
Information content
Video games are a part of today's culture and are available in a huge variety in terms of supported game system, genre and — of course — quality. Finding a game that fits both one's hardware requirements and favored genre is a relatively easy task to accomplish, but basing the decision to buy a specific game only on the text written on the back of its case is daring at least. Impartial (more or less) reviews of video games may help to clarify if the money is well spent in the long run by providing rating systems for features such as graphics, sound, atmosphere or overall score (usually higher scores are better). The team of the German Mag'64 Web site [1] has tested video games for over eight years, gathering over 1500 reviews, each consisting of a single HTML Web page. Each document contains information about the game being tested, the review, including a general judgement, and images and screenshots. This information is quite valuable since among the provided items are general ones such as the title, system, or publisher, but in addition more specific items such as number of players, genre, age rating and difficulty. The review consists of running text' while the final verdict and pros and cons are summarized in a tabular view. The data we have to deal with consists generally of two types of reviews, which we call "Type A" and "Type B". Type A was used during the years 2001 through 2004, while Type B was introduced in the Autumn of 2004.
Technical analysis
From a technical point of view the data is stored in HTML Web pages. Because HTML's
original task is to structure hypertexts, it lacks specific elements and attributes
for
annotating the information we are interested in. Furthermore, the markup of our test
data is
very focussed on presentation, that is, general HTML elements such as div,
p, td are used for physically structuring the information according
to a given layout. While the two review types, A and B, do not differ regarding their
information content, there are differences in the markup techniques used.
Type A
The Type A review was originally used as part of an HTML frameset. While one frame
contained a menu for navigating through the whole service, the second frame stored
a single
review in the form of a HTML Page. This page lacks an HTML Doctype declaration, and
typical
copy and paste errors can be found, including end tags without preceding start tags,
wrong
attributes, etc. The img element for embedded graphics lacks the required
alt attribute. [2] Furthermore, no information about the character encoding is given, which leads to
encoding errors since German umlauts and other special characters were used.
Figure 1 shows an excerpt of an Type A review.
Figure 1: Type A beginning of document
<html>
<head>
<title>Mag64</title>
</head>
<body bgcolor="#FFFFFF" text="#000000" link="#0000FF"
vlink="#990099" alink="#FF0000" leftmargin="2" topmargin="2"
marginwidth="2" marginheight="2"><a name="page_top">
<table width="98%" border="0" cellspacing="5" cellpadding="0"
height="170" align="center">
<tr>
<td width="35%" align="left" valign="top">
<img src="ray3logo.jpg">
</td>
<td width="33%" align="left" valign="top" bgcolor="#CCCCCC">
<p><font face="Arial, Helvetica, sans-serif" size="3"><u>
<font face="Arial, Helvetica, sans-serif" size="3">SYSTEM:
</font>
</u><font face="Arial, Helvetica, sans-serif" size="3">
<i>GCN - PAL</i></font><u><br>
ENTWICKLER:</u> <i>Ubi Soft</i></font><br>
<u><font face="Arial, Helvetica, sans-serif" size="3">
GENRE:</font></u><font face="Arial, Helvetica, sans-serif"
size="3">
<i>Jump'n Run</i></font>
<font face="Arial, Helvetica, sans-serif" size="3"><i><br>
</i></font><u><font face="Arial, Helvetica, sans-serif"
size="3">SPIELER:</font></u><font face="Arial, Helvetica,
sans-serif" size="3">
<i>1-4 Spieler</i></font><br>This markup we have to deal with is very presentation-focussed: semantic markup such
as
h1 or h2 that could be used for structuring the text is not used at
all. The title of the game can only be found in the running text or in the graphic
image
referred by the img element — and sometimes in external cheats or tricks documents
that are referred to from the review page (the term "CHEATS: JA" in Figure 2). All useful information is buried deep inside HTML's table elements, and the
page lacks any meta elements for storing additional information. Spacing between
different parts of the text was introduced by using HTML's entity, while the
whole
markup is layout oriented, using font, i and u elements.
Sometimes font elements with identical formatting options are embedded into each other
resulting in a tag soup. Emphases are arranged solely by selecting "size 3" fonts.
The running text of the review is distributed among different table elements,
establishing a print-like layout. Each review begins with two blocks containing
meta-information, such as system, genre, number of players, etc.
Figure 2: Typical view of the beginning of a Type A document
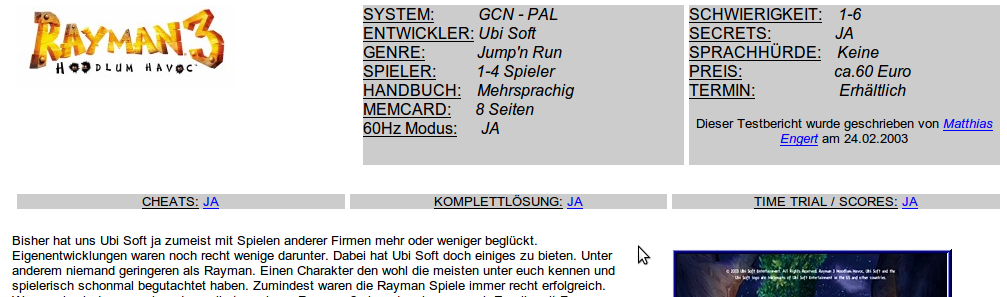
The Type A review ends with a tabular overview, consisting of the "pros" and "cons" of the game.
Type B
The Type B reviews were established in the Autumn of 2004, coinciding with the release of the Nintendo DS® handheld console. Since this videogame console introduced some features that were unknown before (e.g. split-screen and the stylus input device), a new HTML template for reviewing video games was adapted. As a new meta-information item, an age rating was added, and the running text was subdivided by headings.
Most of the HTML pages contain a doctype declaration (incorrect for HTML 4.01), a
reference to an externally declared CSS stylesheet and information about the character
encoding
(ISO-8859-1 — although the specified encoding is sometimes not correct, since some
documents
are encoded using the Windows-1252 charset or even UTF-8). In addition to the external
CSS
file, local formatting using attributes such as marginwidth, bg-color
or border can still be found. In general, the HTML pages are not valid according
to the W3C validation service. Figure 3 shows the mixture of different
formatting options used.
Figure 3: Type B beginning of document<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Strict//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html><head><title>NDS 7 Wonders of the Ancient World</title>
<meta http-equiv="Content-Type" content="text/html;
charset=iso-8859-1">
<link rel="stylesheet" href="http://www.mag64.de/test.css"
type="text/css"></head>
<body marginwidth="0" marginheight="0" leftmargin="0"
topmargin="0" bgcolor="#CCCCCC">
<table width="710" border="0" cellpadding="0" cellspacing="0"
bgcolor="#CCCCCC">
A positive difference from the Type A is the fact that the title of the game appears
(together with the platform it was released for) in HTML's title element.
Important information such as price or age rating are hidden inside a single div
element (Figure 4), divided by line breaks.
Figure 4: Hidden information<td width="226" valign="top" style="background-image:url (http://www.mag64.de/tr1.jpg)">
<div style="padding-left: 20px;padding-top: 23px">
SPRACHHÜRDE: Keine<br>
MIKRO SUPPORT: Nein<br>
ALTERSFREIGABE: <a href="http://www.pegi.info"
target="_blank">3+</a><br>
TERMIN: Erhältlich<br>
VIRTUAL SURROUND: Nein<br>
PREIS: ca.20 Euro<br>
KOMPLETTLÖSUNG: Nein<br>
CHEATS / TIPPS: Nein<br>
LESERMEINUNGEN: Nein</td>
In contrast to the Type A reviews, subheadings are included; however, these are not
marked
up by HTML's inherent h1 through h6 elements but by using formatting
elements such as b and font.
Both review types show HTML's inherent lack of support for highly structured data. Although our example application deals with document-centric texts, the data under observation contains important information that should be marked up explicitly.
Highly structured data
Our goal is to create an XML markup language capable of structuring the video game
reviews
of both Type A and B that have been discussed. This format should be used as representation
format for the output of the conversion process that will be presented in the section “Upconversion” and could be used as a storage format for future review applications.
Since we have already stated the input documents are often invalid (sometimes even
not
well-formed) and important information is buried inside HTML table elements, having
a document grammar for both validating the conversion process's output format and
providing
explicit markup of the important information is quite important for us. For these
reasons, the
use of a capable of full text search engine was not taken into account. We have chosen
XML schema
in favor of XML DTD because of its datatype library and especially for its support
of
user-defined simple and complexTypes Walmsley (2002). A RELAX NG schema (in
combination with the XML schema datatype library) would have been another option,
however, the
broader support for XML schema supplied by the XSLT processor used during the conversion
process
tipped the scales for us (Figure 5).
Figure 5: Game centered structure
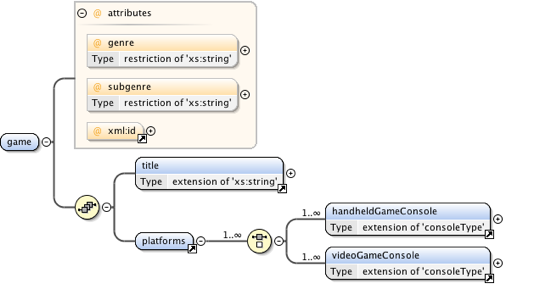
Each game can be identified by a unique xml:id attribute, further optional
attributes correspond to genre and subgenre, supporting an enumerated
list of possible values which should help avoiding typical errors such as typos. Children
of the
game element are the title and platforms elements, the
latter consisting of at least either one handheldGameConsole or
videoGameConsole, allowing to combine reviews of the same video game released on
multiple platforms [3]. Both elements are derived by extension of the globally declared complexType
consoleType, sharing common information present in stationary and handheld game
consoles (see Figure 6 for a graphical overview of the shared
information).
Figure 6: A closer look at the complexType consoleType
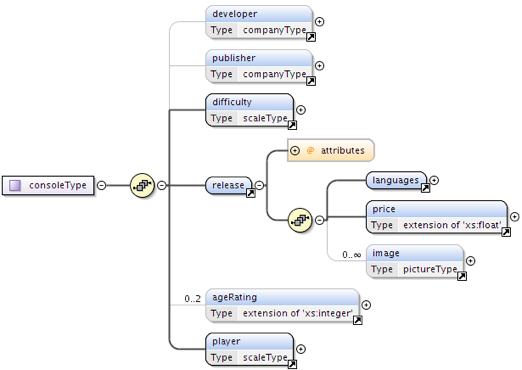
The release element stores information about the date of release (using an
xs:date Type Attribute), the different languages and price. Children of the
languages element are spoken, text and
handbook elements, depicting information about the parts of the game that have been
translated. The price element has a currency attribute that uses an
enumerated list of possible values according to ISO Country Codes, ISO 4217:2008.
An optional image element can be used to represent box pictures or screenshots
of the game reviewed.
As mentioned above, the handheldGameConsole and videoGameConsole
elements are derived from the complexType consoleType by extension. Although the
additional elements techSpecs and saving use the same names, their
content models are different with respect to the video game console, since, for example,
the
requirements for storing save games are different between handheld and stationary
consoles. Only
the videoGameConsole element allows for the compatibleInputDevices
child element. Most of these elements use enumerated lists to eliminate possible typos
and to
ease the acquisition of new reviews.
The main part of the review is stored underneath the review element that
consists of the mainText and conclusion elements and further optional
screenshots and that has a date attribute and an author attribute
group. The running text is subdivided into optional headers and paragraphs, allowing
a fine
grained division of text parts and representing both review types.
The conclusion element is used to store both further text (e.g. in a form of a
final verdict similar to the Type B reviews) and the tabular-like lists of pros and
cons,
followed by the final score element. Scoring can be expressed either via numeric
values (using the percent child element with its attributes graphics,
sound (optional), multiplayer (optional) and overall) or
through text, since both variants can be found in our sample data.
This grammar can not only be used to store the information coded in both review types but also is highly flexible for future extensions. Possible future extensions of the schema may include XSD 1.1 assertions, for example, to ensure that multiplayer scoring information is only allowed when the maximum number of players is greater than "1".
Upconversion
Our upconversion process begins in the typical manner by using XSLT 2.0 / XPath 2.0 Kay (2008). Because it requires multiple steps and must be applied to many files, we have encapsulated it in XProc.
XSLT 2.0 benefits
In his paper "Up-conversion using XSLT 2.0" Michael Kay points out the great advances XSLT made when shifting to XSLT 2.0, and he provides a real-world example that makes heavy use of the new features. The key features which produce benefit for upconversion are in short schema-awareness, support for regular expression processing, better manipulation of strings, and advanced grouping possibilities. So tasks that formerly were often solved by using a general purpose scripting language like Perl or Python, by loading XML modules can be done equally well or better with XSLT 2.0 [See Kay (2004) for an elaborated example]. Our upconversion of the reviews mostly makes use of regular expression processing and string manipulation.
The documents are preprocessed into well formed XML using HTML Tidy. [4] For the upconversion, both functions as well as named templates are used widely.
The
following snippet demonstrates the massive clean-up the stylesheet performs. It is
taken from
the extensive Figure 7: Extracting information Figure 8: Structuring information Figure 9: Extracting the game title from an external documentmain template, which uses a variable to hold the string with
information about the genre of the reviewed game (Figure 7). This
string is checked for both Type A and Type B data equally but it is applied differently
with
respect to the structure.
<xsl:variable name="genreTemp">
<xsl:choose>
<!-- new type -->
<xsl:when test="/descendant::table[3]/descendant::td[2]/descendant::div[contains(.,'GEN')]">
<xsl:analyze-string select="/descendant::table[3]/descendant::td[2]/descendant::div[contains(.,'GEN')]"
regex="GENRE:\s(.*)\sSPIEL">
<xsl:matching-substring>
<xsl:value-of select="regex-group(1)"/>
</xsl:matching-substring>
</xsl:analyze-string>
</xsl:when>
<!-- old type -->
<xsl:otherwise>
<xsl:value-of select="/descendant::table[1]/descendant::font[contains(.,'GEN')]/following::i[1]"/>
</xsl:otherwise>
</xsl:choose>
</xsl:variable><xsl:when test="matches($genreTemp, 'A[\w\.\s]*Adv')">
<xsl:attribute name="genre">Action-Adventure</xsl:attribute>
</xsl:when>
<!-- [...] -->
<xsl:when test="matches ($genreTemp, '[sS]port|[bB]all|board|Golf|Box|[hH]ock|[tT]enn|Wrest')">
<xsl:attribute name="genre">Sport</xsl:attribute>
</xsl:when>
<xsl:when test="matches($genreTemp, '[Aa]ction|Hack|[sS]hoot|Ego|Prüg|FPS')">
<xsl:attribute name="genre">Action</xsl:attribute>
<xsl:choose>
<xsl:when test="matches($genreTemp, 'Ego|FPS')">
<xsl:attribute name="subgenre">First Person Action</xsl:attribute>
</xsl:when>
<!-- [...] --><xsl:when test="/descendant::table[2]/descendant::td[1]/div[1]/
descendant::a[doc-available(concat($filepath,(replace
(attribute::href, '-i.htm', '-t.xml'))))]">
<xsl:variable name="doc" select="concat($filepath,replace
(/descendant::table[2]/descendant::td[1]/div[1]/descendant::a/
attribute::href, '-i.htm', '-t.xml'))"/>
<xsl:value-of select="document($doc,.)/descendant::table[1]/descendant::a[1]"/>
</xsl:when>
Pipelining with XProc
XProc a new standard for automating processes like ours through an XML pipeline has been developed by the W3 working group XProc. It has reached the status of W3C Recommendation on 11 May 2010 after being advanced to Proposed Recommendation in March 2010. The specification had been downgraded from Candidate Recommendation to Working Draft again in January to solve some issues. It has reached a fairly stable level now, and a book on XProc by Norman Walsh is in progress.[5] For our desired all-in-one XML solution, XProc is first choice to handle the pipeline.
The pipeline should process the documents that are stored locally in the filesystem
recursively (Figure 10). There are documents other than game reviews
(e.g. cheats and tricks), and we need some of them to extract the titles of games,
but most of
these documents are discarded. One problem here is that while we can say from the
filename what
is most likely not a test, but not what actually is.
Figure 10: An overview of the filesystem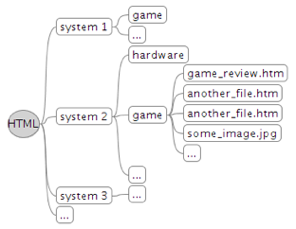
-
Use HTML Tidy to transform the HTML input into well-formed XML
-
Apply the XSLT script to the output of the former task using an XSLT 2.0 processor
-
Validate the output files according to the XML schema
-
Separate valid from invalid documents
-
Provide a log of valid documents
Figure 11: Preparatory steps

p:declare-step as root element for good control of input and
output ports. Both are set to allow any number of documents. Since parameters are
to be used for
XSLT transformation, we need the optional input port "parameters" - because it is
the only
parameter port in the pipeline it is primary by default. The source directory HTML
is bound to a
variable and made accessible for the step p:directory-list, which here returns the
system-folders in c-namespace (Figure 12).
Figure 12: Setting the basics
<?xml version="1.0"?> <p:declare-step xmlns:p="http://www.w3.org/ns/xproc" xmlns:c="http://www.w3.org/ns/xproc-step" name="main" version="1.0"> <p:input port="parameters" kind="parameter"/> <p:input port="source" sequence="true"/> <p:output port="result" sequence="true"> <p:pipe port="result" step="loglast"/> </p:output> <p:variable name="input" select="'HTML'"/> <p:directory-list name="directories"> <p:with-option name="path" select="$input"/> </p:directory-list>
p:for-each loops; of
course, the output port needs to be set to accept sequences. Next we list the subdirectories,
consisting mainly of game-folders (Figure 13).
Figure 13: The main loop
<p:for-each name="directoryloop"> <p:output port="result" sequence="true"/> <p:iteration-source select="/c:directory/c:directory"/> <p:variable name="dirpath" select="concat($input,'/', c:directory/@name)"/> <p:directory-list name="subdirectories"> <p:with-option name="path" select="$dirpath"/> </p:directory-list>
p:make-absolute-uris. Then we add slashes using p:string-replace to
ensure accordance to the file protocol. To make sure the file is accessible for the
p:http-request step we rename the element c:file to
c:request.[8] Furthermore, we need to add the proper attributes for the
p:http-request step to work. Since there is no server involved and we do not want
to work with binary data, we need to add the attribute override-content-type and
attach the value text/html (Figure 14).
Figure 14: Preparing to process HTML
<p:make-absolute-uris match="c:file/@name"> <p:with-option name="base-uri" select="concat($subdirpath, '/', c:directory/@name)"/> </p:make-absolute-uris> <p:string-replace match="c:file/@name" replace="replace(., 'file:', 'file://')" name="replace"/> <p:rename match="c:file" new-name="c:request"/> <p:rename match="@name" new-name="href"/> <p:add-attribute match="c:request" attribute-name="method" attribute-value="get"/> <p:add-attribute match="c:request" attribute-name="override-content-type" attribute-value="text/html"/>
opt|chea|tipp|herz|guid|pass.
Figure 15: Filtering documents not needed
<p:filter name="filter" select="//c:request[matches(@href, '-i.htm')] except //c:request[matches(@href, 'les[0-9]|hardware|wifi|wiiware|leser|preview|xpl|wer\.')]"/> <p:for-each name="fileloop"> <p:output port="result" sequence="true"/>
try-catch
clauses to ensure the flow of the pipeline.
Figure 16: An overview of the main steps

file holds the URI of each file. It will be available
throughout the loop and not only serve to get each file but to store each file in
its given
folder. So first we convert these files that pass the filter through HTML Tidy via
p:exec, which can take non-XML input and provides safety (Figure 17). We could use p:unescape-markup in conjunction
with Tagsoup 1.2[9] or HTML Tidy as an alternative solution here, but as XML Calabash so far only
implemented Tagsoup for reading HTML and the results from HTML Tidy and Tagsoup differ
slightly,
we stick to p:exec. Calumet supports both HTML Tidy and Tagsoup for this step, but
as we are using XPath 2.0 we cannot use this option. We set source-is-xml to false
and result-is-xml to true. By default, result lines are wrapped, and the output of
this step is also wrapped to ensure wellformed XML documents on the output port. We
negate
wrap-result-lines and unwrap the output of the step. (Note that the arguments for
HTML Tidy need to be in a single line.)
Figure 17: Using p:exec to do a first cleanup
<p:variable name="file" select="c:request/@href"/> <p:http-request/> <p:exec command="/usr/bin/tidy" source-is-xml="false" result-is-xml="true" wrap-result-lines="false"> <p:with-option name="args" select= "'--quiet yes --show-warnings no --output-xml yes --bare yes --doctype omit --numeric-entities yes --char-encoding utf8'"/> </p:exec> <p:unwrap match="c:result"/>
The output of this step is saved to folder "Tidied" as "filename.xml" and chained
to the
next step p:xslt. As a precaution, this step along with the connected saving
procedure is encapsulated into a try group. If any of this fails, we record the tidied
file to
the folder "Transform-failed". The p:xslt step takes three input ports, one for the
stylesheet, one for the XML document and one for parameters (Figure 18). The filepath needs to be provided to the stylesheet to ensure reaching the documents
that
will be consulted for missing titles. The filename and system folder are processed
inside the
transformation as well.
Figure 18: Transformation using parameters
<p:xslt name="transform"> <p:input port="source"> <p:pipe port="result" step="tidy"/> </p:input> <p:input port="stylesheet"> <p:document href="test2xml.xsl"/> </p:input> <p:with-param name="xpr.platform" select="tokenize($file, '/')[last()-2]"> <p:pipe port="parameters" step="main"/> </p:with-param> <p:with-param name="xpr.filename" select="substring-before(tokenize($file, '/')[last()], '-i.htm')"> <p:pipe port="parameters" step="main"/> </p:with-param> <p:with-param name="xpr.filepath" select="$file"> <p:pipe port="parameters" step="main"/> </p:with-param> </p:xslt>
If the transformation and the saving process can be executed successfully, the output
of
this step serves as input for Figure 19: Schema validation of transformation result Figure 20: Logging the valid filesp:validate-with-xml-schema (Figure 19). Depending on the output of this step, the documents are
saved separately. Valid documents can be found in the 'Schema-Valid' folder and the
invalid in
the 'Schema-Invalid' folder. (During the programming of the XSLT-Transformation, invalid
documents give hints for expressions in need of improvement.)
<p:try>
<p:group>
<p:validate-with-xml-schema mode="strict" name="validate">
<p:input port="source">
<p:pipe port="result" step="transform"/>
</p:input>
<p:input port="schema">
<p:document href="Struktur.xsd"/>
</p:input>
</p:validate-with-xml-schema>
<p:store name="storeValid"><!-- [...] --></p:store>
<p:identity>
<p:input port="source"><p:pipe step="storeValid" port="result"/></p:input>
</p:identity>
</p:group>
<p:catch>
<p:identity>
<p:input port="source"><p:pipe step="transform" port="result"/></p:input>
</p:identity>
<p:store name="storeInvalid"><!-- [...] --></p:store>
</p:catch>
</p:try>c:result elements returned by the step directoryloop and lists them
for an overview (Figure 20).
<p:documentation>Wrap result for info.</p:documentation>
<p:wrap-sequence wrapper="directoryloop"/>
<p:store name="loglast">
<p:with-option name="href" select="'file:///home/user/loglaststep.xml'"/>
<p:with-option name="encoding" select="'UTF-8'"/>
<p:with-option name="omit-xml-declaration" select="'false'"/>
<p:with-option name="indent" select="'true'"/>
</p:store>
This pipeline takes approximately half an hour to process the data, and is relatively independent of CPU speed on an average actual system. It results in 1573 schema-valid files.
The result of the upconversion process
Figure 21 shows an excerpt of an instance coded in the target output format according to the XML schema. The critical information is marked up with the help of appropriate elements or attributes. Conversions of a game (i.e., the release on different platforms) are supported, as well, by separating the general information such as title and genre from the platform for which the review is written. The verdict contains the list of "pro" and "con" items and the score (depending on the input review type, subdivided into single figures for game graphics, sound, multiplayer and overall) in a highly-structured form that allows easy access to relevant criteria.
Figure 21: The result of the upconversion
<?xml version="1.0" encoding="UTF-8"?>
<game xml:id="d1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="Struktur.xsd" genre="Jump 'n' Run">
<title abbreviation="rayman3">Rayman3 Hoodlum Havoc</title>
<platforms>
<videoGameConsole type="GCN">
<developer>Ubi Soft</developer>
<difficulty min="1" max="6"/>
<release>
<languages>
<spoken xml:lang="de"/>
</languages>
<price currency="EUR">60</price>
</release>
<player min="1" max="4"/>
<techSpecs>
<item>PAL</item>
<item>GCN-GBA-Link</item>
</techSpecs>
<saving mode="Memorycard" blocks="8"/>
<compatibleInputDevices>
<item>Gamecube Controller</item>
<item>GBA</item>
</compatibleInputDevices>
<review date="2003-02-24" authorFirstname="Matthias"
authorLastname="Engert">
<mainText>
<paragraph>Bisher hat uns Ubi Soft ja (...)</paragraph>
<paragraph>Durch den Score werden (...)</paragraph>
<paragraph>(...)</paragraph>
</mainText>
<conclusion>
<pro>
<item>Unterhaltsames Gameplay</item>
</pro>
<contra>
<item>Ende wird zu schnell erreicht</item>
</contra>
<score>
<percent graphics="85" sound="85" multiplayer="82"
overall="82"/>
</score>
</conclusion>
</review>
</videoGameConsole>
</platforms>
</game>Benefits of highly structured data — searching for the game according to your flavour
The result instances of the automatic upconversion process discussed in the section “Upconversion” contains highly structured information. All relevant and important data
that was formerly hidden inside HTML's table element or as part of the running text
can be accessed via XPath or XQuery expressions Chamberlin et al. (2004), allowing for
easy retrieval of reviews of games of certain types or according to certain criteria
such as
genre, price, and score. While the original structure of the Mag'64 Web site offered access to the review based on either the video game system
or the name of the game, a full-text search engine was not implemented. We have
developed some sample XQuery queries that allow for a different kind of retrieval
of game
reviews.
Alternative access to the reviews
The query genres.xq uses two parameters, genre and platform, to search for
games of a certain genre on a specific platform by using a collection of all valid
XML instance
documents. Figure 22 shows the output of the genres.xq
with the value "Wii" for the platform parameter and the value "Puzzle"
supplied for the genre paramater. Since this query was originally developed as a alternative
access mechanism, the information returned is very sparse. However, in combination
with
(X)HTML output containing hyperlinks to the respective review page, it would be
sufficient.
Figure 22: Result example for genres.xq
<?xml version="1.0" encoding="UTF-8"?> <games on="Wii" type="Puzzle"> <instance score="85" abbreviation="pqwii">Puzzle Quest: Challenge of the Warlords</instance> <instance score="80" abbreviation="jewel">Jewel Master: Cradle of Rom</instance> <instance score="79" abbreviation="phwwii">Professor Heinz Wolff's Gravity</instance> <instance score="76" abbreviation="bbawii">Big Brain Academy </instance> <instance score="50" abbreviation="jengawii">Jenga World Tour </instance> </games>
Finding a game according to specific features
Sometimes a user searches for games that support certain technical features, such
as online
content, multiplayer, etc. The techspecs.xq query uses the parameter platform and
techspec to retrieve only the reviews of games that include the provided feature.
Figure 23 shows an example result.
Figure 23: Result example for techspecs.xq
<games on="NDS" featuring="Online"> <instance score="92" abbreviation="suik">Suikoden Tierkreis </instance> <instance score="90" abbreviation="layton">Professor Layton und das geheimnisvolle Dorf</instance> <instance score="89" abbreviation="fesd">Fire Emblem : Shadow Dragon</instance> <instance score="88" abbreviation="cpor">Castlevania: Portrait of Ruin</instance>(...) </games>
A more elaborated example: a wish list
Kids love video games these days, and often they leave their parents behind when it comes to choosing the right game for a present. We will demonstrate the benefits of highly structured data in this example. Consider a seven-year-old child with a Nintendo DS® who wants to get a racing game for his system. The parents might agree but formula additional constraints: the game to be bought should have a score of at least 70% and should be appropriate for kids of his age. Furthermore, the difficulty should not be too high.
For this query different parameters have to be taken into account: the platform, the
genre,
age rating, score, and difficulty. The shoppingList.xq query provides all these
parameters (Figure 24). Using Saxon as XQuery processor with the
following call results in the output shown in Figure 25.
Figure 24: Query for a shopping list
XQuery.sh shoppingList.xq age=7 platform=NDS score=70 genre=Rennspiel maxDifficulty=7
Figure 25: Result example for shoppinglist.xq
<games maxAgeRating="7" on="NDS" maxDifficulty="7" type="Rennspiel" scoreAtLeast="70"> <instance ageRating="3" score="82" maxDifficulty="7" abbreviation="augt2" minDifficulty="1"> <title>Asphalt Urban GT 2</title> <notes> <pro>62 Meisterschaften</pro> <pro>Für Fans von Arcade Steuerung</pro> <pro>Sehr gute Framerate/Technik</pro> <pro>Fahrzeugmodelle/Anzahl</pro> <pro>Grafische Präsentation</pro> <pro>Verschiedene Rennmodi</pro> <pro>Werkstatt Feature</pro> <pro>Gamespeed/Straßenverkehr</pro> <pro>Motorrad Inhalte</pro> <contra>Leichter als der Vorgänger</contra> <contra>Polizei in den Meisterschaften</contra> <contra>Kein 1C Multiplayer</contra> </notes> </instance> <instance ageRating="3" score="77" maxDifficulty="7" abbreviation="cnr" minDifficulty="1"> <title>Cartoon Network Racing</title> <notes> <pro>Gute Grundsteuerung</pro> <pro>Umfangreich duch 4 Cups</pro> <pro>Steigende Gegner KI</pro> <pro>Lange Strecken</pro> <pro>11 gelungene Strecken</pro> <pro>Gelungene Items</pro> <pro>Viele Belohnungen</pro> <pro>Kart Curling Minispiel</pro> <contra>Kurventechnik per R-Taste</contra> <contra>5 der 16 Strecken</contra> <contra>Single Card MP</contra> <contra>Zu abruptes Bremsen bei Crashs</contra> </notes> </instance> </games>
The results are sorted according to the score in descending order (with 100 representing
the best value). Each instance element contains the age rating, score, and
information about the difficulty, encoded in attribute values. Child elements are
the title and
the review notes, consisting of the "pros" and "cons" of the game. The notes
element, in particular, may contain information that is subjective; it may occur that
our
example parents will judge a certain feature higher or lower than the reviewer did
(or even
think of a "con" as a "pro").
Conclusion
The results of our work are of many kinds: first, the newly introduced features such as regular expressions and string manipulations qualify XSLT 2.0 as a full-fledged conversion tool for transforming weak structured data into a highly structured format. Second, if a transformation process has to be carried out multiple times and if other processing is involved, automation by using the XProc pipelining language is highly recommended. Both the XProc specification and the supporting software tools are ready for a productive environment. Furthermore, the output of the upconversion clearly shows a high potential in terms of flexibility and of the ability to retrieve certain information, as shown by our example applications using XQuery.
We are certain that minor problems such as the one caused by the character encoding will be fixed during the ongoing development of XProc software. From our point of view, future modifications could result in a XSD 1.1 compatible XML schema supporting more video game systems or textual content that is not review related, such as cheats, hints, or walk-throughs. Both the XSLT script and the XQuery queries could be modified in how they interact with each other. For example, the distinction of different cases that is carried out by the XSLT script could be reformulated as pipeline step, allowing for a more maintainable XSLT script.
In general, the realization of the pipeline and query system as a Web service in conjunction with a native XML database would result in an alternative search and retrieval mechanism that would indeed search for the game according to your flavour.
References
[Chamberlin et al. (2004)] Chamberlin, D., D. Draper, M. F. Fernández, M. Kay, J. Robie, M. Rys, J. Siméon, J. Tivy, and P. Wadler, XQuery from the Experts: A Guide to the W3C XML Query Language. Pearson Education. Addison-Wesley, Boston, 2004.
[HTML 3.2 Reference Specification] Raggett, D. HTML 3.2 Reference Specification. W3C Recommendation. http://www.w3.org/TR/REC-html32, 1997.
[HTML 4.01] Raggett, D., A. L. Hors, and I. Jacobs, HTML 4.01 Specification. W3C Recommendation 24 December 1999, World Wide Web Consortium. http://www.w3.org/TR/1999/REC-html401-19991224, 1999.
[HTML (ISO), ISO/IEC 15445:2000] Information technology — Document description and processing languages — HyperText Markup Language (HTML). ISO/IEC 15445:2000, International standard, International Organization for Standardization, Geneva, 2000.
[ISO Country Codes, ISO 4217:2008] Codes for the representation of currencies and funds. ISO 4217:2008, International standard, International Organization for Standardization, Geneva, 2008.
[Kay (2004)] Kay, M. "Up-conversion using XSLT 2.0." http://www.saxonica.com/papers/ideadb-1.1/mhk-paper.xml, 2004.
[Kay (2008)] Kay, M. XSLT 2.0 and XPath 2.0 Programmer’s Reference. Wiley Publishing, Indianapolis, 4th edition, 2008.
[RelaxNG, ISO/IEC 19757-2:2003)] Information technology - Document Schema Definition Language (DSDL) — Part 2: Regular-grammar-based validation — RELAX NG. ISO/IEC 19757-2:2003, International standard, International Organization for Standardization, Geneva, 2003.
[SGML, ISO 8879:1986] Information Processing — Text and Office Information Systems — Standard Generalized Markup Language. International standard, International Organization for Standardization, Geneva 1986.
[Suda (2006)] Suda, B. Using microformats. O'Reilly, Sebastopol, CA, USA, (2006).
[Walmsley (2002)] Walmsley, P. Definitive XML Schema. Prentice Hall PTR, Upper Saddle River, NJ, USA, 2002.
[XML 1.0] Bray, T., J. Paoli, and C. M. Sperberg-McQueen, Extensible Markup Language (XML) 1.0. W3C Recommendation 10 February 1998. World Wide Web Consortium. http://www.w3.org/TR/1998/REC-xml-19980210, 1998.
[XML Schema Part 0: Primer] Fallside, D. C., and P. Walmsley, XML Schema Part 0: Primer Second Edition. W3C Recommendation 28 October 2004, World Wide Web Consortium. http://www.w3.org/TR/2004/REC-xmlschema-0-20041028/, 2004.
[XProc] Walsh, N., A. Milowski, and H. S. Thompson, XProc: An XML Pipeline Language. W3C Recommendation 11 May 2010, World Wide Web Consortium. http://www.w3.org/TR/2010/REC-xproc-20100511/, 2010.
[1] http://www.mag64.de/, for the current site.
[2] Although the alt attribute has been marked as optional in HTML 3.2 Reference Specification, HTML 4.01 introduced in 1999 and HTML (ISO), ISO/IEC 15445:2000, requires its use.
[3] The optional merging of different game instances can be carried out by an XQuery script.
[4] http://tidy.sourceforge.net for further details.
[6] http://xmlcalabash.com/ for further details.
[7] https://community.emc.com/community/edn/xmltech for further details.
[8] We will need p:http-request, although we work on the filesystem. This is
because p:data, which one could expect here, is not a step and therefore does not
accept options.
[9] http://ccil.org/~cowan/XML/tagsoup/ for further details.