Introduction
The XML chip is purpose-built silicon for high performance XML processing. It has the potential to reduce server costs, to reduce power consumption, and to reduce latency. The paper compares the performance of the XML chip (hybrid specialized hardware and software) with optimized XML software for a number of operations. The benefits of the XML chip increase as CPUs get faster, especially with the introduction of multi-core technology. There are challenges, notably the cost of copying data to and from the co-processor, but the challenges can be overcome. Results show that the use of an XML co-processor can reduce CPU cycles per byte of XML processed by amounts ranging from a factor of 3 to a factor of 50 depending on the workload, while power consumption can be reduced by a factor of 7.
The purpose of the XML chip is not so much to make XML processing efficient as it is to make server usage more efficient and cost-effective. Bandwidth can always be increased by multiplying the number of servers but it may not be cost effective to do so. Latency reducation, on the other hand, is another prime objective for the XML chip since latency is not improved either by multiplying cores or multiplying servers. From the point of view of server efficiency XML is interesting to accelerate because it is the closest thing there is to a ubiquitious computing workload. XML is the de facto choice for virtually all communication between applications including web traffic (HTML, XHTML, and POX (plain old XML)), inter- and intra-enterprise software (Web Services, REST and SOAP styles and POX, transaction processing (e.g., financial, health records, government services), and identity management. Jon Bosak of Sun once famously said “XML exists to give Java something to do.” Java and .NET as well as a plethora of popular scripting languages all prominently feature XML APIs and the vast enterprise applications are constructed with XML as the external – and sometimes internal – interface.
Is there economic benefit to a special-purpose chip for XML processing?
Assertion: Significant acceleration/offload of XML processing would improve the efficiency and value proposition of business-grade standard servers.
Metrics on the percentage of time spent processing XML on servers are, frankly, not fiable. However, our studies of major enterprise software applications has demonstrated a clear potential benefit to XML acceleration for the important class of servers dedicated to this task. There is an experimentally-demonstrable argument that XML acceleration will enable important classes of applications that clearly consume an unacceptable number of CPU cycles. These include: message-level security, federated identity management, and message transformation for inter-application communication. These XML-based technologies are key to addressing deep problems in security and identity and will further an open, cloud-based flexible computing model. The value of enabling ultra-low cost XML processing cannot be fully appreciated only by looking at the computing environment that exists where ulta-low cost XML processing capabilities do not exist.
The specific value-related benefits that can be realized from XML acceleration include:
-
Less CPU power needed as processing is offloaded onto a more effective special-purpose processing unit. Lower unit cost.
-
Lower power consumption as the XML processing unit is more energy-efficient on XML workloads. Lower operating costs.
Figure 1
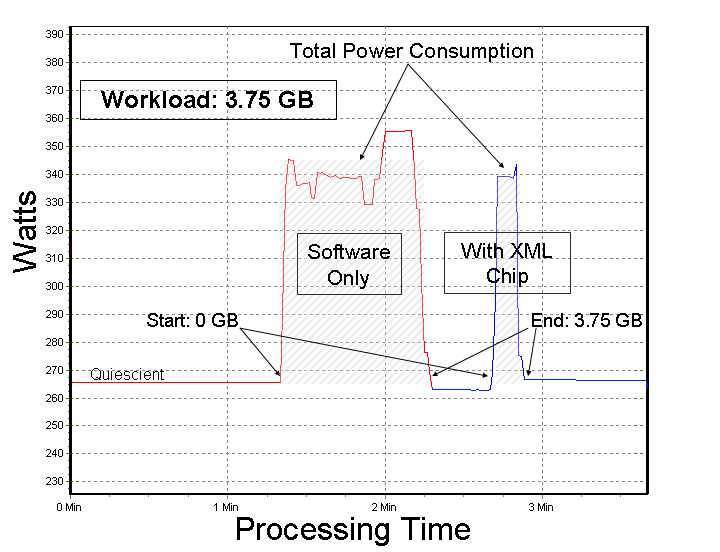
Power Consumption over XML Workload
-
Higher core utilization. Much of the hard work of parallelizing applications to take advantage of multicore applications has been done in the XML chip in the controller and software interface layer between the application software and hardware. Reduction in the number of servers needed for peak loads.
-
Simplifies implementation and maintenance and management through ability to meet peak loads, reduction in number of servers, elimination of bottlenecks, less programming effort to parallelize applications. Lowers failure rate and cost overruns of major IT projects.
Isn't XML acceleration in hardware an unproven approach?
Assertion: LSI’s Tarari group has successfully delivered XML acceleration co-processors for over six years. These products have been used in high-performance, specialized XML processing appliances.
This technology is not a flash-in-the-pan; it has been proven by demanding customers of Tarari over six years, processing billions of XML messages. It is a remarkable success story for hardware-based acceleration, albeit, not generally well-known due to its initial targeting to the niche market of specialized, network-oriented, XML processing appliances. The work on XML acceleration actually goes back 4 years earlier, originating in a company acquired by Intel. Thus a total of ten years of R&D has been invested in this technology leading to successful commercialization.
The Tarari XML processor was used in web services gateways, application-oriented networking devices, and security appliances. Tarari was bought by LSI Corporation in October of 2007. LSI continues to sell an XML processor and to develop the technology. In May of 2009 HP announced an appliance product integrating the LSI Tarari XML chip and associated software with SAP’s integration platform software NetWeaver PI. This product is first use of the XML chip directly integrated with a major enterprise application software package, as opposed to prior experience with special-purpose XML acceleration appliances and network devices. This development may be an important step in the mainstreaming of XML acceleration hardware.
Isn't an XML chip destined to quick obsolesence due to frequency scaling (Moore's Law) and parallelization (multicore)?
Assertion: The XML chip has increased in value with improvements in CPUs. The value proposition has greatly improved with the introduction of multicore.
Moore's Law: Debatable, of course, but the scientists and engineers in the chip making business seem to mainly agree that we've hit the limitations of physics in process technology. Which is why frequency is now increasing very slowly (or even decreasing)and every chipmaker is now focused on parallelization through multiple cores.
Multicore: Again, plenty of room for disagreement, but a critical mass of scientists and engineers caution that multiplying cores is not the new equivalent to Moore's Law because parallelization is difficult - and also, often, labor intensive as many computer processing tasks must be redesigned by algorithmists and reprogrammed by engineers.
While bearing the above viewpoints in mind, which strengthens the case for workload-specific computing solutions, it is also our experience that the XML chip benefits from whatever improvement can still be eked out from the remaining life in Moore’s Law; as frequency has scaled the relative value of the accelerator increases. This is because the chief bottleneck in use of the accelerator is the ability to feed the beast – that is, to get enough data fast enough from the network interface to the XML co-processor. Same is true for multicore. Multicore helps the accelerator and the XML chip also helps multicore because much of the hard work of parallelizing applications to take advantage of multicore applications has been done in the XML chip in the controller and software interface layer between the application software and hardware.
Intel, among many other chip manufacturers, promotes the use of workload-specific "cores" or accelerators as a complementary part of its multicore strategy. The authors of this paper have joined with Intel the last couple of years at IDF (Intel Developer Forum), showing the integration of the XML accelerator with Intel multicore platforms. The figure below is based on the Intel view of the respective domains of monocore, multicore, and multicore with additional, workload-specific cores such as an XML accelerator. Multicore + the accelerator is needed to get to the upper right quadrant of efficiency and performance.
Figure 2
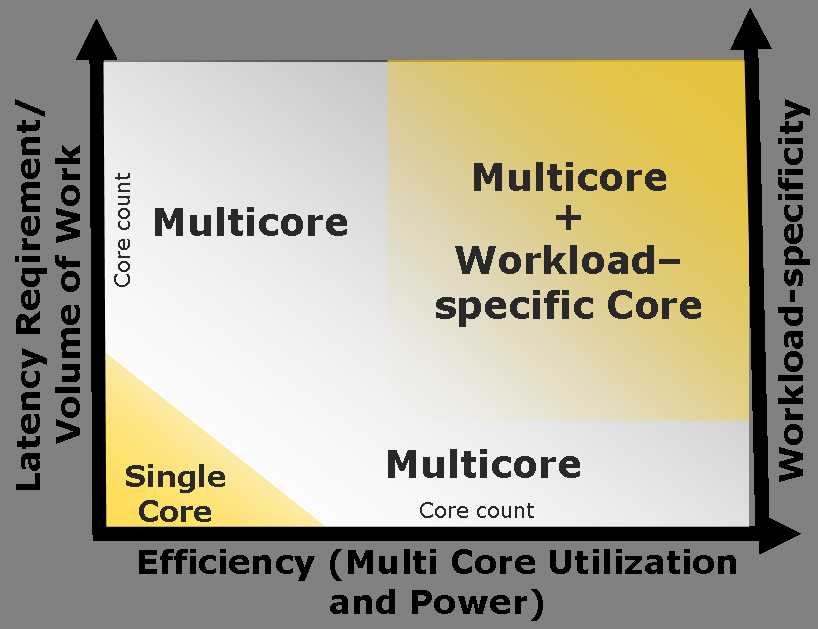
Multicores and Workload-Specific Cores
The successes with acceleration coprocessors have been few and far between. Graphics, floating point, cryptography, RAID, TOE – against many failures. Why will the XML chip be one of those rare exceptions?
Assertion: The success of the XML chip may be said to be unexpected as it is a symbolic-computing device and not a number cruncher, the primary domain where acceleration has been successful. Unique factors have contributed to make this the right technology to succeed at this time.
First, a ubiquitious symbolic computation data format was a pre-condition, not just success in the technology, but just for justification for enough R&D dollars to create the possibility of an XML chip. The success of XML might have run counter to expectations as well, but perhaps may have become inevitable once the a worldwide information infrastructure became a reality.
Second, the evolution of FPGA technology that has taken place was another game-changer without which the success of the XML chip would have been impossible. The choice of reconfigurable logic has permitted the designers to pursue an evolutionary development path of approximately two major design iterations per year and countless minor revisions over the lifetime of the product. This has been very advantageous in an area where there was little hard science and engineering history to guide us. It also permitted us to closely track the rapid evolution of microprocessor architecture and technology instead of following one to two years in the wake of new general purpose processor introductions. FPGA has also been the most cost-effective choice at the relatively low production volumes characteristic of the early years of the introduction of a new infrastructure technology.
Author Lemoine was a student of the great pioneer of reconfigurable logic, Jean Vuillemin, who demonstrated in the late 1980 and early 1990s that the programmable active memory could be used to implement any computing function and serve as universal hardware co-processor coupled with the host computer.
XML processing, a byte-oriented symbolic computing problem, is, in the application domain, not an obvious choice for FPGA technology, Symbolic computing is difficult due to the lack of known algorithms for acceleration in this area and a readily reducible problem space where bottlenecks have been identified. The strategy, therefore, had to be evolutionary based on iterative and modular design as experience was accumulated and also as the price-performance and capacity of FPGAs has improved, expanding potential capabilities. It became evident that the development program would only have been feasible with the use of reconfigurable logic; having now spanned 6 years,it has consistently yielded progressively better results and a wider functional footprint.
Finally, the proof of success is shown simply in the fact that we are still here. The XML chip technology has shown staying power, with 10 years of R&D and a solid position in the niche market of XML network appliances. It is already a limited success and is ready to enter a wider market.
The potential for a broader success is predicated on advances which, effectively, lower the payoff range for the added cost the co-processor and the continued use of XML as the ubiquitious language of computer-to-computer communication. Further expansion of XML use in the emerging IT landscape will help with new XML-intensive workloads in message-level security, identity management, inter-application message transformation and control-plane management of the cloud.
Don’t all “transformation” accelerators have the fundamental problem that the acceleration value is largely neutralized by the copy-in, copy-out overhead? At least until you have cache coherence and accelerators have access to memory as equal citizens with the CPUs.
Assertion: Getting the data to and from the board is indeed among the major challenges; in the early years the XML chip was often a marginal solution because of it. With advances in the chip, it is rarely a major challenge today.
Copy-in, copy-out is certainly among the challenges with the current generation of accelerators. The XML chip is not strictly a transformation processor; many the processing problems it solves involve a computed result on the input and may save the copy-out step. Where a full copy-in, copy-out sequence is required very high acceleration values may still be obtained in most cases because of the goodness of the output structures produced by the accelerator. These structures would be prohibitively costly to construct with a software process but once they are constructed by the hardware they can be used to greatly accelerate subsequent processing of the XML content in software.
The key to understanding this is to understand that the XML chip produces only limited acceleration for many of the established approaches to constructing XML processing software where copy-in, copy-out remains a serious problem and produces remarkable levels of acceleration for equally-valid approaches that have been little exploited in the past due to their inefficiency without purpose-build XML hardware. The LSI XML chip has an extensive API which enables easy construction of applications using approaches essentially unique to performance characteristics obtainable using its special features.
An example of a well-established XML processing approach which yields only limited acceleration with the XML chip is use of the Document Object Model (DOM). The DOM is memory intensive, constructing a tree-structure model of the XML document prior to navigating the document to extract the desired data. The cost of construction of the tree may be amortized in a long-lived document which is scanned repeatedly and deeply but is generally a poor performer in typical transactional applications. The vast majority of XML applications are implemented using the DOM due to the number of robust free tools. In some cases an underlying DOM representation can be replaced by our Random Access XML (RAX) API. This is the strategy we employed in creating our own version of an XSLT engine, RAX-XSLT.
We would, however, like very much to accelerate "inefficient" software processes to enable acceleration with the XML chip to be applied to legacy applications. There are developments in computer architecture that may make this feasible. Cache-coherent accelerator-friendly architectures may be the next wave for special purpose co-processors. While the integration between the XML accelerator and CPU has been designed successfully around the memory-copy problem, eliminating this problem will certainly enable new approaches to co-processing.
Prove to me you can’t do accelerated XML with a Von Neumann core.
Assertion: It is the guaranteed structure of that enables a non-Von Neumann micro-parallelism which gets much more work done on a single tick. The question really is can a special-purpose device created by a handful of people from the most efficient design possible beat a general computing device at the same task when thousands have labored to make that device as fast as possible? The success of the XML chip seems to lie in XML itself, which challenges the Von Neumann architecture yet has proven highly tractable to alternate approaches.
Nonetheless, there are many things we cannot do at the scale of effort put into the XML chip and for this reason our strategy has always been to accelerate the software running on the host processor. Simply in terms of logic components, We can’t implement that much XML processing on our chip. The XML chip, asan XML software accelerator, is expressly designed to improve the performance of software run on a Von Neumann core. While we continue to carve more and more of the XML processing problem into hardware the problem remains too general and hence too large that we would anticipate that a chip will ever fully offload XML processing. The intelligence of our design rests in the way we have integrated special-purpose XML hardware with the XML software stack to fully leverage the value of the capability of the hardware again and again in software processes.
The strongest evidence the hybrid of special-purpose hardware with a non-Von Neumann architecture and software running on a Von Neumann architecture is in the comparative results obtained with highly optimized XML software and also with our own software which emulates the exact functionality of the hardware. XML has been use for over a decade and there have been many attempts to create high-performance XML software components. We test our hardware against these continuously. Our software which emulates the hardware tends to perform in the higher range, comparable to the best of software-only approaches.
The following table compares the performance of hardware (hybrid specialized hardware and software) versus optimized XML software for a number of operations. The measurement is normalized into host cycles per byte of processed XML. These are numbers with the current LSI product.
Table I
Hardware/Software Compared to Software-Only (Von Neumann architecture) Performance
| XML Operation | Description | Host Cycles/Byte | |
| Chip | Optimized SW | ||
| Parser Attack Checks | Parallel to parsing; detects buffer overflow and resource exhaustion attacks against parser | 10 | N/A |
| Well-formed Checks | Parser-based well-formed check | 80-400 | |
| Message-based anomaly detection | Detects messages which deviate from statistical norm; adaptive; stronger than schema validation | N/A | |
| Parsing | Token-based parsing with sequential and random-access to all XML objects | 20 | SAX 80 DOM 400 |
| Content-based Routing | Routing decisions based on large XPath sets | 30 | 500-1600 |
| Schema Validation | XML Schema Validation | 40 | 600-2000 |
| XSLT | XSLT | 400-900 | 1200-10000 |
| XML Security | XML-based Authentication based on XML and WS Security specifications | 450-800 | 1400-2600 |
If I start a project to use an XML chip won’t I find that after 3 years of planning and development that “Moore’s cores blew up our tailpipe again”?
Assertion: You sort of have already asked this. The XML chip has been a bold experiment, not, until today, for the faint of heart. But it is starting to look like a safe choice.
The XML chip, as an XML software accelerator, increases in acceleration value as CPUs get faster. Since we began commercialization of the technology CPU frequencies have doubled and the number of cores has quadrupled while the acceleration value of the co-processor has steadily increased with each advance in CPU architecture and performance. We're still here.