Introduction
What is the “meaning” of markup? How is the meaning of a document augmented or otherwise affected by the presence of markup? Those questions have preoccupied markup theorists (and many others) for probably as long as markup conventions have existed.
Fundamentally, two approaches can be taken. First, one can devise a formal framework in which the meaning of a document is represented by a set of formal statements. Second, one can seek an informal framework in which the meaning of a document is represented by a set of sentences in an informal language. An example of suitable formal framework is first-order logic; an example of suitable informal framework is any natural language. In both cases, the statements may or may not say something about “the world” beyond the document as such.
The two approaches are not aimed at the same goals. If automatic inferencing (through an inference engine) is in sight, then the formal approach probably has a leading edge. However, if some other use of the “meaning” of the document is envisioned, which for example involves showing that meaning to humans, then it is possible the informal approach has a leading edge.
In [Sperberg-McQueen et al. 2000a], Sperberg-McQueen et al. describe a framework in which the semantics of a structured document is represented by the set of inferences (statements) licensed by the document, that is, statements which can be considered to hold on the basis of the document. The authors suggest that an adequate set of basic inferences can be generated from the document itself by a fairly simple skeleton sentence and deictic expression mechanism. These ideas were taken up and developed in various ways and contexts in later work (see for example [Sperberg-McQueen et al. 2002] and [Sperberg-McQueen & Miller 2004]), which we here call the “Formal tag-set description” approach (FTSD). The approach is independent of any particular logical system, and the possibility that the statements licensed by a document be in natural language has been mentioned and exemplified, though not systematically.
With a different set of preoccupations in mind (namely, showing a “preview” of the meaning of a document to an author during the writing process), Marcoux introduced in [Marcoux 2006] intertextual semantics (IS), a framework in which the meaning of a document is entirely and exclusively represented by natural language segments.
In this paper, we compare the IS and FTSD approaches, and argue that the insights into the meaning of a document supplied by the two approaches actually complement each other. After a brief review of each approach (this paper is not meant to be a complete introduction to either), we give a number of concrete examples of increasing complexity, including the set of formal and informal statements derivable in each case, to substantiate our claim.
Formal tag-set descriptions
The essential ideas of the FTSD approach are:
-
The
meaning
of a markup construct M in an instance document can be identified with the set of sentences S true because of M, or (equivalently) the set of sentences that can be inferred from M.[1] When necessary, we distinguish the sentences in S from other sentences by calling the former instance sentences. -
The
meaning
of a markup construct M in the abstract can be captured effectively byskeleton sentences
, sentence schemata with blanks to be filled in appropriately for each instance of construct M in a document instance.The skeleton sentences are generalizations of the instance sentences mentioned in the preceding point; each instance sentence should be an instantiation of some skeleton sentence.
-
For existing colloquial XML vocabularies, when the inferences licensed by a particular element instance are being tabulated, the values to be inserted for the blanks in the appropriate skeleton sentences often vary with the element's position; XPath expressions can be used to specify a concise rule for finding the appropriate values, given a particular element as context node. Because the value of the XPath expressions varies with context, they are (in the linguistic sense)
deictic
expressions. -
Skeleton sentences, together with the deictic expressions used to specify how to fill in their blanks, can provide useful documentation of a markup vocabulary. They could be integrated, for example, into the Tag Set Documentation (TSD) vocabulary defined by the Text Encoding Initiative. If the skeleton sentences are written in a formal notation like predicate calculus, the conventional tag set documentation (TSD) becomes a
formal
tag set documentation (or FTSD), which can provide the kind of formal definition of the semantics of an XML vocabulary which some observers have occasionally desired, and which some others (who give signs of wishing to displace colloquial XML and replace it with RDF or some other formalism instead) have simply claimed does not or cannot exist.
Intertextual semantics
The intertextual semantics (IS) approach is based on a view of which
traces can be found in, among other places, the works of Wirzbicka [Wirzbicka 1992], Smedslund [Smedslund 2004] and even
Wittgenstein [Wittgenstein 1953]. This is the view that humans
ultimately make sense
of artefacts through the use of
natural language, or rather, that to the
extent that they can make sense of an artefact, this sense can be expressed in
natural language (NL). Thus, in designing artefacts such as markup, one should
be preoccupied by how, and how easily and with how much ambiguity (or
unambiguity), humans can understand those artefacts in NL terms. No matter how
useful intermediate formal representations of meaning (including marked-up
documents) may be for conciseness, machine processing, etc., they must
ultimately be translatable (not necessarily translated) to NL, and are ever only as “meaningful”
as such NL expressions of them are.
In the realm of markup, IS suggests the creators of tag-sets (modelers) must be preoccupied by how markup can be translated to NL. Even if “end users” never see any marked-up document, some other humans, for example, processing software developers, or archivists, will have to deal with them directly or indirectly, unless the documents are totally pointless. One might say it is even more important to be preoccupied by that translation as the number of intermediate representations increases, because there are then more opportunities for misinterpretations. Dubin et al. have recently illustrated some difficulties that can arise from failures in automatic translation from one representation to another [Dubin et al. 2006].
IS proposes a mechanism by which NL passages (or whole documents) are generated from marked-up documents, according to an IS specification for the tag-set. So far, only very weak NL generation mechanisms have been explored, and it is extremely important that those mechanisms be weak, because too powerful mechanisms would “hide under the carpet” inherent interpretation complications which IS, in contrast, seeks to uncover.
In the current state of the IS framework, an IS specification takes the form of a table giving, for each element type two NL segments: a “text-before” segment and a “text-after” segment (generically called “peritexts”). Attributes are handled by the possibility of including in the peritexts “guarded segments,” segments guarded by an attribute name, that are only included if the corresponding attribute is specified on the element, and that can refer to the attribute value. “Local” elements (in the sense of W3C schemas) are supported, so that different peritexts can be assigned depending on the ancestors of the element. The IS generation process is similar to styling the document with the peritexts, concatenating peritexts and element contents as the document tree is traversed depth-first. The IS, or IS-meaning, of the document is the resulting character string.
IS has similarities with various mechanisms aimed at presenting
markup in more or less explicit or explicated forms, such as Piez's
false-color proofs
[Piez 2006, slide 12].
However, it is important to stress that the preoccupations of IS are not at the
presentational level, but really at the semantic level. The
“presentation” obtained through the IS mechanism
defines the meaning of a document. In the
other approaches we are aware of, the presentation (if successful) accurately
represents the meaning of a document, but that
meaning is defined elsewhere.
It is also important to mention that IS is not first and foremost intended to give interpretations of existing tag-sets, but is mostly meant to assist in the development of new tag-sets. Applying it to existing tag-sets often gives rise to improbable or awkward formulations in the IS (meaning) of documents, in part because such tag-sets were not in the first place designed with IS preoccupations in mind. In our view, this only brings to light the inherent complexities of the tag-set, or the difficulty or possible variability (sometimes deliberate, it is important to say) in interpreting conforming documents.
A full presentation of IS in general can be found in [Marcoux & Rizkallah 2009]. For structured documents, it is defined in [Marcoux 2006] and [Marcoux & Rizkallah 2007].
Comparison of FTSD and IS
Suppose document D conforms to a certain tag-set TS, to which corresponds a collection F of formal skeleton sentences. We will denote by F(D) the set of actual formal sentences (not skeleton ones) generated by applying F to D. Now, let I be an IS specification for TS, and let us denote by I(D) the set of (natural language, or “informal”) sentences generated by I when applied to D.[2]
What can we say about how I(D) compares to F(D)? Of course, it all depends on exactly how F and I are constructed, that is, ultimately, on what the actual meaning of markup is intended to be. However, we can say something about what I and F would typically look like.
-
Ordering
Typically, F(D) is an unordered set of discrete statements in some formal language. In our examples (as in most of previous work on FTSD), we will use first-order logic sentences. Even when natural language is suggested as a potential language for statements, F(D) is first and foremost envisoned as an unordered set of sentences.
In contrast, I(D) is typically a single string of characters, possibly forming multiple sentences (in natural language), in which case, however, the order of the sentences matters. I(D) is first and foremost meant to be readable sequentially, as normal text (as opposed to hypertext). That being said, I(D) can contain hypertext links, but they must only be used to point to “background” or “complementary” material, which more or less forms a whole, and not in a way that disrupts sequentiality.
-
Universe of discourse and target community
In the FTSD approach, the actual set of predicates used in the sentences for a given tag-set depends on the “universe of discourse” of the documents, that is, the collection of things and concepts the documents in that tag-set “talk about.” For example, in defining the meaning of the OAI 2.0 tag-set [Sperberg-McQueen 2005], predicates to the effect that something “is an OAI-server,” “is an OAI-request,” or “is a response sent by an OAI-server,” are naturally introduced. In addition to defining predicates (which include types and relations), characterizing the universe of discourse in the FTSD approach involves making assertions about that universe (facts or inference rules), e.g., assertions that certain individuals satisfying certain predicates exist.
In IS, the rough equivalent of defining the universe of discourse is identifying the target community of users of the documents (“users” is used here in a generic sense, which includes authors, readers, analysts, processing software developers, information managers, archivists, etc.). Intuitively, one can view the universe of discourse as the intersection of what the community members know or, at least, can name. In identifying the target community, one is required to make (preferably explicit, but at least implicit) assumptions about what vocabulary and level of language is appropriate for the community members, what their previous knowledge is, what profiles they have, through which use cases will they interact with the documents, etc. Note how similar assumptions are involved in making a sensible and useful selection of predicates and other elements in the FTSD approach.
-
Deixis and locality of references
In the context of markup, deictic expressions are expressions pointing to various “locations” within a document (usually in a relative way). Relative XPath expressions provide a good approximation of what deictic expressions are. For example, a deictic expression evaluated at some given element in a document may point to a specific attribute of that element, or to the first child of that element, or to a specific attribute of the last child of that element, etc.
Although far from exploiting the full expressive power of XPath 1.0 (let alone XPath 2.0), deictic expressions in the FTSD approach often point outside of “the current element.” For example, they might point to the parent, a child, or a sibling of the current element. In contrast, if we were to express the “pointing” power of the IS generation mechanism as deictic expressions, the only expressions allowed would be “the current element,” or “the attribute named X of the current element.” So, the reach of a skeleton sentence in IS is very limited. But that limitation is quite deliberate; in a nutshell, it stems from the assumption that the closer the artificial (marked-up) form of knowledge is to its informal (natural-language) form, the higher the odds it will be properly understood. Any complexity in the deictic expressions used in the skeleton sentences translates (or, at least, so goes the IS story) into complexity for anyone required to comprehend the tag-set (whether they be readers, authors, archivists, software developers, or what have you).
Examples
We now compare FTSD and IS through examples.
A single paragraph
For simplicity, we start with a very simple example, perhaps trivial. (But its simplicity allows the machinery to be more readily understood.) Let D be the following document:
Example 1:
<doc>
<para>Elizabeth went to Sussex.</para>
</doc>
We have just two tags in the tag-set, doc and
para. With such a simple example, the similarity between FTSD and
IS can be quite high. The minimal universe of discourse for this example is
that of documents, paragraphs, and character strings. We assume for purposes of
the example that these are primitive notions that convey interesting
information about the nature of certain objects. Documents contain sequences of
paragraphs. Paragraphs have character-string values.[3]
Intertextual semantics
An IS specification for our tag-set just has to specify a
text-before segment and a text-after segment for the two elements
doc and para. We will present IS specifications using
the format adopted in [Marcoux 2009], which is pretty much
self-explanatory[4]:
<rule paths="doc"
text-before=" This is a document: "
text-after=" End of the document. " />
<rule paths="para"
text-before=" This is a paragraph: "
text-after=" End of the paragraph. " />which would produce the following IS for our document:
This is a document: This is a paragraph: Elizabeth went to Sussex. End of the paragraph. End of the document.
Note that the peritexts (text-before and text-after segments) are shown differently from actual contents coming from the document; this is an integral and essential feature of the IS framework (formally, we could say the strings forming the IS of documents comprise characters from two different alphabets, or of two different colors). Note also that some indentation is performed, for increased readability. This is not at the moment an integral feature of the framework, but it has been the usual presentation of IS so far [Marcoux 2006] [Marcoux & Rizkallah 2007]. In fact, the implementation described in [Marcoux 2009] does perform an automatic indentation of the IS.
FTSD
In all our examples, we will use normal first-order logic as a formalism for FTSD. For this first example, we need only a few predicates to capture the documented meaning of the markup:
|
is_document(x) |
x is a document. |
|
document_content(x,y) |
Document x contains y (a sequence of paragraphs — or in larger vocabularies, sections, heading, tables, and other paragraph-level objects). |
|
is_paragraph(x) |
x is a paragraph. |
|
paragraph_string(x, y) |
The character-string value of the paragraph x is the string y. We will write strings enclosed in quotation marks in the conventional way. |
In order to write out the second argument of
document_content, we will need a way to write a sequence of
objects (or rather, of expressions denoting objects) as a sequence. Where
possible, we adopt the convention that sequences are written with commas
separating the expressions denoting the items in the sequence, and enclosed in
parentheses: the sequence consisting of a, b, and c in that order, is
written
. In some circumstances, it proves simpler to give the
sequence a name and specify the position of its items with a predicate like
(a, b,
c)seq_pos_item(x, y,
z). (We will start counting at 1.)
Assuming two individuals to which we assign the arbitrary
identifiers d and p, we can write the instance
sentences for this document instance thus:
is_document(d) is_paragraph(p) document_content(d, (p) ) paragraph_string(p,"Elizabeth went to Sussex.")
is_document(d) is_paragraph(p) document_content(d, s) seq_pos_item(s,1,p) paragraph_string(p,"Elizabeth went to Sussex.")
A more rigorous and detailed account might include character tokens and character types in the universe of discourse, so that if (for example) two paragraphs in the same document had the same text, the formal representation of the document could make clear that while the two different paragraphs had the same string-value at the character type level, they were realized by different sequences of character tokens. Such rigor is necessary to achieve clarity and satisfactory treatment of some topics (e.g., the relation between a transcription and its exemplar), but it requires a great deal of machinery to achieve results that were intuitively obvious to start with, and we omit it here to spare our readers the ennui of working through it.
For similar reasons, we refrain here from offering a fuller
development of character strings, with definitions of length, concatenation,
and substring functions, which we do not need for now. Some universes of
discourse may need them. At this moment, all we have are string individuals,
denoted by the usual straightforward notation "a string".
If we decide the document means no more than that the content of
the para element is a paragraph, which in turn makes up the sole
content of the document, then we can be happy to say that F(D), the meaning
of the document, is the set of sentences given above.
For this purpose, a set F of a single formal skeleton sentence will suffice. For convenience, we will write skeleton sentences as literals, filling in blanks with their associated deictic expressions and distinguishing the deictic expressions from their context by enclosing them in braces (in the style of XSLT attribute-value templates).
Our F for this vocabulary might contain these skeleton sentences:
|
for |
is_document( document_content( |
|
for |
is_paragraph( seq_pos_item(
paragraph_string( |
In general, we assume that each of the skeleton sentences given
will be instantiated once for each element that matches the pattern. Here, each
doc element will generate one is_document sentence
and one document_content sentence, and each para
element will generate three sentences. As each skeleton sentence is
instantiated, each deictic expression will be evaluated with the current
element instance as the context node, and the instance sentence will be written
out with the value replacing the deictic expression.
Phrase-level markup
The “challenges” of our next example are phrase-level markup and the use of attributes.
Example 2:
<doc>
<para>
<person key="E.I.Regina">Elisabeth</person> went to
<place key="getty:7008133">Sussex</place>.
<person>Elizabeth</person>, on her part, went to
<person>Sussex</person>, and told him the whole story.
</para>
</doc>
The doc and para elements here have the
same meaning as in the preceding example; the person and
place elements mark personal names and place names in the running
text.
The optional key attribute, used for both
person and place, introduces a notion of
registry of persons and places. The value of that
attribute is the “access key” of a person or place in some known
“registry,” which establishes a univocal correspondence between
keys and entities (persons or places, in our case). A
single entity can have many different keys “pointing” to it, but
any given key points to only one entity of a given type. It would be possible
to introduce registries as individuals in our universe of discourse; however,
it is not necessary and, for simplicity, we will not do it.
FTSD
The predicate-calculus sentences for this document will use the following predicates (in addition to those defined in the preceding section):
|
is_personname(s) |
s (typically a string of characters) is (here) a proper noun denoting a person. |
|
is_person(x) |
x is a person. |
|
is_placename(s) |
s (typically a string of characters) is (here) a proper noun denoting a place. |
|
is_place(x) |
x is a place. |
|
denotes(s,x) |
The string of character tokens s here denotes the object or individual x. |
|
person_dbkey(x, y) |
The person x is denoted by the identifier y. |
|
place_dbkey(x, y) |
The place x is denoted by the identifier y. |
Note that the formulations of is_personname,
is_placename, and especially of denotes, are not
entirely satisfactory. Earlier, we simplified the discussion by not
distinguishing systematically between sequences of character tokens and
sequences of character types. Here, we pay the price for that simplification.
Strictly speaking, what is needed here is a way to specify that a
particular instance or occurrence of string s (i.e., a particular
sequence of character tokens) is used as a proper noun and
denotes individual x. Not all occurrences of the string s will necessarily
be proper nouns (consider the personal name Brown
and the place
name Bath
), nor will they all denote the same individual.
Without a rather tedious treatment of tokens and types, it is not possible to
make the necessary distinction properly; we content ourselves with the
hand-waving visible in the glosses above and in this explanatory
paragraph.[5]
The predicates person_dbkey and
place_dbkey, by contrast, need an identifier (viewed as a sequence
of character types) not a sequence of tokens, as their second argument.
Armed with these predicates, we can say in predicate calculus
terms not only that the string
is (here) a personal name, but also that
that name denotes a particular individual, also identified by a particular
prosopographical key in some known registry. And similarly, we can say that
Elizabeth
here is used once to denote the country, and
once the nobleman.
Sussex
The skeleton sentences for the new element and attribute types can be formulated thus:
|
|
is_personname( is_person( denotes( |
|
|
person_dbkey(
|
|
|
is_placename( is_place( denotes( |
|
|
place_dbkey(
|
The result of instantiating the skeleton sentences for the example document is
is_paragraph(id17806)
seq_pos_item(id19125-children, 1, id17806)
paragraph_string(id17806, "
Elisabeth went to Sussex.
Elizabeth, on her part, went to Sussex, and told him the whole story.
")
is_personname("Elisabeth")
is_person(ref-id17651)
denotes("Elisabeth", ref-id17651)
person_dbkey(ref-id17651, "E.I.Regina")
is_placename("Sussex")
is_place(ref-id19390)
denotes("Sussex", ref-id19390)
place_dbkey(ref-id19390, "getty:7008133")
is_personname("Elizabeth")
is_person(ref-id19224)
denotes("Elizabeth", ref-id19224)
is_personname("Sussex")
is_person(ref-id19558)
denotes("Sussex", ref-id19558)
Intertextual semantics
The IS specification is as follows:
<rule paths="doc"
text-before="This is a document:"
text-after="End of the document." />
<rule paths="para"
text-before="This is a paragraph:"
text-after="End of the paragraph." />
<rule paths="person"
text-before="THE PERSON NAMED "
text-after=" @key[ (identified by the registry record
{{http://my.person.registry/?@}})]" />
<rule paths="place"
text-before="THE PLACE NAMED "
text-after=" @key[ (identified by the registry record
{{http://my.place.registry/?@}})]" />
The strings "{{" and "}}" delimit
hyperlinks in peritexts. Passages of the form @attrib-name[...@...] are
“guarded,” and only appear in the IS if the named attribute in
present on the element.
Note that two text-before segments have been written in uppercase to make them independent of their position in a sentence.
Here is the resulting IS:

A sonnet
Here is a more realistic example, a TEI (P5) encoded sonnet by Québécois poet Émile Nelligan (1879-1941).
Example 3:
<TEI xmlns="http://www.tei-c.org/ns/1.0" xml:lang="fr-CA">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Le Vaisseau d'or</title>
<author>Émile Nelligan</author>
<editor>Luc Lacourcière</editor>
</titleStmt>
<publicationStmt>
<pubPlace>Montréal (Québec, Canada)</pubPlace>
<publisher>Fides</publisher>
<date>1952</date>
</publicationStmt>
<sourceDesc>
<bibl>
<author>Émile Nelligan</author>
<title>Poésies complètes 1896-1899</title>
<edition>Texte établi et annoté par Luc Lacourcière</edition>
<editor>Luc Lacourcière</editor>
<pubPlace>Montréal (Québec, Canada)</pubPlace>
<publisher>Fides</publisher>
<date>1952</date>
<biblScope>page 44</biblScope>
</bibl>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<front>
<head>LE VAISSEAU D'OR</head>
</front>
<body>
<lg>
<l>Ce fut un grand Vaisseau taillé dans l'or massif :</l>
<l>Ses mâts touchaient l'azur, sur des mers inconnues ;</l>
<l>La Cyprine d'amour, cheveux épars, chairs nues,</l>
<l>S'étalait à sa proue, au soleil excessif.</l>
</lg>
<lg>
<l>Mais il vint une nuit frapper le grand écueil</l>
<l>Dans l'Océan trompeur où chantait la Sirène,</l>
<l>Et le naufrage horrible inclina sa carène</l>
<l>Aux profondeurs du Gouffre, immuable cercueil.</l>
</lg>
<lg>
<l>Ce fut un Vaisseau d'Or, dont les flancs diaphanes</l>
<l>Révélaient des trésors que les marins profanes,</l>
<l>Dégoût, Haine et Névrose, entre eux ont disputés.</l>
</lg>
<lg>
<l>Que reste-t-il de lui dans la tempête brève ?</l>
<l>Qu'est devenu mon cœur, navire déserté ?</l>
<l>Hélas! Il a sombré dans l'abîme du Rêve!</l>
</lg>
</body>
</text>
</TEI>
Intertextual semantics
The IS specification is:
<rule paths="TEI"
text-before="This electronic document is a TEI document. @xmlns[It obeys
the general structure and definitions associated with the XML
namespace {{@}}.] @xml:lang[Its textual contents are written (except
where otherwise stated) in the natural language which, according to the
IETF RFC 1766 specification (accessible at
{{http://www.ietf.org/rfc/rfc1766.txt}}), is denoted by "@".]"
text-after="This concludes the TEI document." />
<rule paths="teiHeader"
text-before="This section gives general information about how the
document came into existence, the way it is identified, its status,
and trail of modifications."
text-after="This concludes the section giving information about how
this document came into existence, the way it is identified, its
status, and trail of modifications." />
<rule paths="fileDesc"
text-before="The document, as a computer file, can be described as
follows:"
text-after="This concludes the description of the document as a
computer file." />
<rule paths="titleStmt"
text-before="The key identifying elements of this document are:"
text-after="End of the key identifying elements." />
<rule paths="titleStmt/title"
text-before="its title, which is "
text-after=" " />
<rule paths="titleStmt/author"
text-before="its author name, which is "
text-after=" " />
<rule paths="titleStmt/editor"
text-before="its editor name, which is "
text-after=" " />
<rule paths="publicationStmt"
text-before="This document corresponds to a published work"
text-after=" " />
<rule paths="pubPlace"
text-before="which has been published in the place "
text-after=" " />
<rule paths="publisher"
text-before="by the publisher "
text-after=" " />
<rule paths="date"
text-before="on the date "
text-after=" " />
<rule paths="sourceDesc"
text-before="This document is derived from another document, called
"the source"."
text-after="End of the indentification of the source." />
<rule paths="sourceDesc/bibl"
text-before="That source corresponds to the following bibliographic
data:"
text-after=" " />
<rule paths="author"
text-before="Author: "
text-after=" " />
<rule paths="title"
text-before="Title: "
text-after=" " />
<rule paths="edition"
text-before="Edition: "
text-after=" " />
<rule paths="editor"
text-before="Editor: "
text-after=" " />
<rule paths="bibl/pubPlace"
text-before="Publication place: "
text-after=" " />
<rule paths="bibl/publisher"
text-before="Publisher: "
text-after=" " />
<rule paths="bibl/date"
text-before="Publication date: "
text-after=" " />
<rule paths="biblScope"
text-before="Part used as a source: "
text-after=" " />
<rule paths="text"
text-before="The document "per se" starts here."
text-after="End of the document "per se"." />
<rule paths="front"
text-before="Front matter:"
text-after=" " />
<rule paths="front/head"
text-before="General heading: "
text-after=" " />
<rule paths="body"
text-before="Main body of the document:"
text-after="End of the main body of the document." />
<rule paths="l"
text-before="Line: "
text-after=" " />
<rule paths="lg"
text-before="Stanza:"
text-after=" " />
Here is the resulting IS:
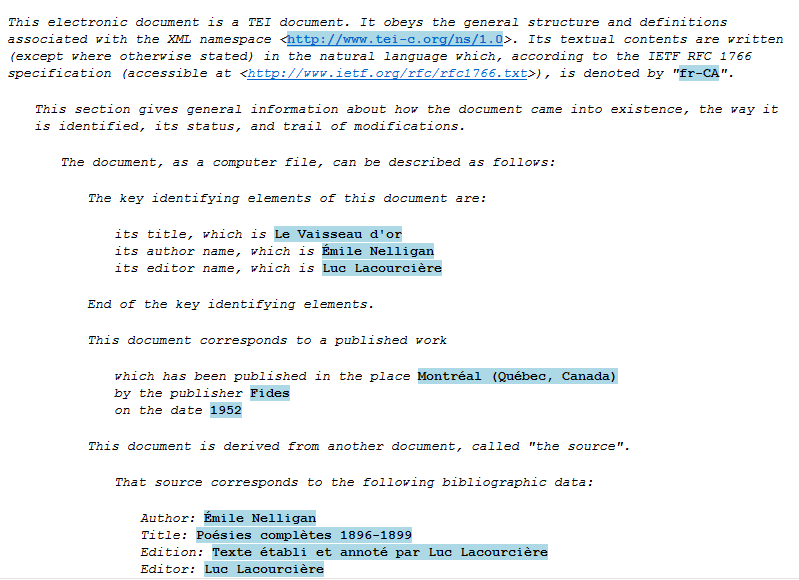
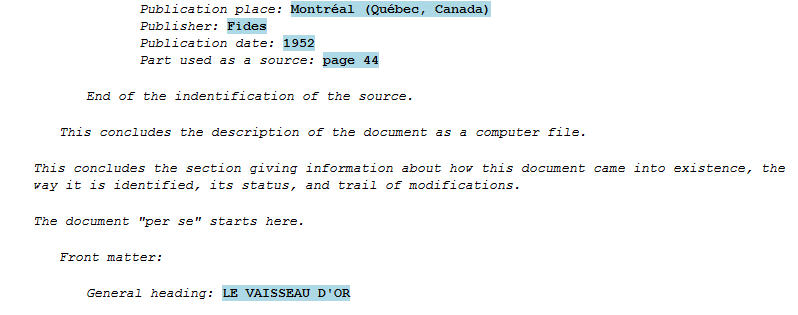

Note that we have taken advantage of the fact that
http://www.tei-c.org/ns/1.0 is a dereferenceable URL, in order to
convert it into a clickable link in the IS.
It may be an appropriate place to note that a given IS
specification (and this is also true of FTSDs) need not be tied to a tag-set
in the absolute. It can actually mirror a
certain usage of a given tag-set (e.g.,
tag-set + writing protocol). The current example illustrates that in a number
of ways, for example by the fact that the IS specification takes for granted
that lg are all stanzas.
FTSD
Like many vocabularies, the one shown here (a simple adaptation
of the TEI) divides a document into a header providing metadata and the text
proper. Taking TEI documents
, metadata, and text
proper
as primitive notions, we can express the overall structure of a
TEI document using these predicates:
|
is_TEI_document(x) |
The individual x (an XML document) is a TEI document (i.e., it's encoded following the TEI Guidelines). |
|
TEIdoc_metadata(x, y) |
The individual y (a TEI header) provides the metadata for the individual x (a TEI document). |
|
TEIdoc_textproper(x, y) |
The individual y is the |
Skeleton sentences for this information are straightforward; as
in the preceding examples, we use the generate-id() function of
XSLT to generate arbitrary identifiers for various individuals, with or without
concatenating various prefixes or suffixes.
|
|
is_TEI_document( |
|
|
TEIdoc_metadata( |
|
|
TEIdoc_textproper( |
is_document(x)
and is_XML_element(x), for any x which is a TEI
document. These could be added to the skeleton sentences in the FTSD, or we
could assume (as background knowledge) an inference rule which can be given in
the following form:[6]
is_TEI_document(x) ________________________________________ is_document(x) is_XML_element(x)This is a relatively simple example of what proves to be a general fact about the specification of FTSDs (and also of IS specifications): there is a certain latitude about what is said where, so that producing a formal tag-set description requires choices and judgement.
The actual text of the document has a simple regular structure, readily representable with the predicates:
|
is_textproper(x) |
The individual x is the textual part of a TEI document (as opposed to the metadata in the TEI header). |
|
text_contents(x,y) |
The text x contains y (a sequence of objects). |
|
is_linegroup(s) |
The sequence s is a group of verse lines (possibly with
nested line groups, and possibly with title or other heading material). (The
most common form of line group is a stanza, but in itself, without a
|
|
lg_contents(x,y) |
The line group x contains y (a sequence of lines, line groups, etc.) |
|
is_verseline(x) |
The individual x is one line of verse (not necessarily a typographic line!) |
|
line-string(x,s) |
The verse line x has (can be realized as) the character string s. |
These are used in the obvious way. A small sample of instance sentences will illustrate the result:
is_textproper(id21050)
TEIdoc_textproper(id20965, id21050)
is_sequence(id21050-children)
text_contents(id21050, id21050-children)
seq_pos_item(id21050-children, 1, id21053 )
is_title("LE VAISSEAU D'OR")
doc_title(id20965, "LE VAISSEAU D'OR")
seq_pos_item(id21050-children, 2, id21060 )
is_linegroup(id21062)
lg_contents(id21062, id21062-children)
seq_pos_item(id21060-children, 1, id21062)
is_verseline(id21064)
line_string(id21064, "Ce fut un grand Vaisseau taillé dans l'or massif :")
seq_pos_item(id21062-children, 1, id21064)
is_verseline(id21069)
line_string(id21069, "Ses mâts touchaient l'azur, sur des mers inconnues ;")
seq_pos_item(id21062-children, 2, id21069)
is_verseline(id21074)
line_string(id21074, "La Cyprine d'amour, cheveux épars, chairs nues,")
seq_pos_item(id21062-children, 3, id21074)
is_verseline(id21080)
line_string(id21080, "S'étalait à sa proue, au soleil excessif.")
seq_pos_item(id21062-children, 4, id21080)
is_linegroup(id21085)
lg_contents(id21085, id21085-children)
seq_pos_item(id21060-children, 2, id21085)
is_verseline(id21088)
line_string(id21088, "Mais il vint une nuit frapper le grand écueil")
seq_pos_item(id21085-children, 1, id21088)
is_verseline(id21093)
line_string(id21093, "Dans l'Océan trompeur où chantait la Sirène,")
seq_pos_item(id21085-children, 2, id21093)
...
is_verseline(id21136)
line_string(id21136, "Hélas! Il a sombré dans l'abîme du Rêve!")
seq_pos_item(id21125-children, 3, id21136)
The TEI header can contain a great deal of metadata, but it would be tedious to work through all the details needed even for this simple example, let alone to work through the variations in structure and semantics allowed by the TEI vocabulary. So we will pass over the TEI header almost in silence. A fragment of an FTSD for this example is given in the appendix; it covers the elements and attributes used in the example's header.
Conclusion
What can we conclude from the exercices we have been going through in
this article? Obviously, FTSD and IS have quite different goals. Yet, as we
hope to have shown, they are strikingly similar, especially with respect to the
type of intellectual effort that goes into writing a specification. Empirical
“evidence” in support of this view is that, in the FTSD approach,
the names chosen for predicates often have the look-and-feel of very compact
peritexts, such as is_document, seq_pos_item, and
paragraph_string. We think we have brought out the fact that the
same kind of knowledge of the “user community,” of their profiles,
of the use cases through which they interact with the documents, are necessary
to write both a useful FTSD and a useful IS specification for a given
tag-set.
We suggest the following complementarity between IS and FTSD: if the IS approach is used in the process of developing a tag-set, then, much of the work needed to devise a suitable universe of discourse for FTSD will have been done already, and the task of mapping that universe to predicates and other formal objects will be much simplified. It is even possible that the IS specification worked out might constitute valuable material for documenting the formal apparatus developed for the FTSD.
Appendix A. Fragment of a formal tag set description
This fragmentary FTSD includes entries for the elements and attributes used in the third example of the paper and provides skeleton sentences covering simple straightforward uses of those elements and attributes. For simplicity's sake, however, it does not attempt to cover all the cases foreseen in the full TEI Guidelines.
The basic structure of the FTSD is as given in [TEI P4], and the descriptions of elements and attributes are taken
from that source, but detailed information has been omitted for brevity. The
skeletons and ss elements have been added as
extensions; it is hoped that after the discussion above their syntax and
semantics will be clear enough without further documentation.
<tsd xmlns:t="http://www.tei-c.org/ns/1.0">
<tagDoc id="TEI.2">
<gi>TEI</gi>
<rs>TEI document</rs>
<desc>Contains a single TEI-conformant document,
comprising a TEI header and a text, either in isolation
or as part of a <gi>teiCorpus</gi> element.</desc>
<skeletons>
<ss lang="pc">is_document(<deixis>generate-id()</deixis>)</ss>
<ss lang="pc">is_TEI_document(<deixis>generate-id()</deixis>)</ss>
<ss lang="pc">is_XML_element(<deixis>generate-id()</deixis>)</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="teiHeader">
<gi>teiHeader</gi>
<rs>TEI Header</rs>
<desc>supplies the descriptive and declarative information
making up an <soCalled>electronic title page</soCalled>
prefixed to every TEI-conformant text.</desc>
<skeletons>
<ss lang="pc">is_XML_element(<deixis>generate-id(.)</deixis>)</ss>
<ss lang="pc">TEIdoc_metatdata(<deixis>generate-id(..)</deixis
>, <deixis>generate-id()</deixis>)</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="fileDesc">
<gi>fileDesc</gi>
<rs>File Description</rs>
<desc>contains a full bibliographic description of an
electronic file.</desc>
<skeletons>
<ss lang="pc">is_XML_element(<deixis>generate-id(.)</deixis>)</ss>
<ss lang="pc">is_bibliographic_description(<deixis
>generate-id(.)</deixis>)</ss>
<ss lang="pc">is_isbd(<deixis>generate-id(.)</deixis>)</ss>
<ss lang="pc">doc_bibldesc(<deixis
>generate-id(ancestor::t:TEI[1])</deixis
>, <deixis>generate-id()</deixis>)</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="titleStmt">
<gi>titleStmt</gi>
<rs>title statement</rs>
<desc>groups information about the title of a work and
those responsible for its intellectual content</desc>
<skeletons>
<ss lang="pc">isbd_titlestatement(<deixis>generate-id(..)</deixis
>, <deixis>generate-id()</deixis>)</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="title">
<gi>title</gi>
<desc>contains the title of a work, whether article, book,
journal, or series, including any alternative titles or
subtitles.</desc>
<attList>
<attDef>
<attName>level</attName>
<rs>bibliographic level (or class) of title)</rs>
<desc>indicates whether this is the title of an article,
book, journal, series, or unpublished material</desc>
<datatype>(a | m | j | s | u)</datatype>
<valList>
<val>a</val>
<desc>analytic title (article, poem, or other item
published as part of a larger item)</desc>
<val>m</val>
<desc>monographic title (book, colection, or other item
published as a distinct item, including single volumes
of multi-volume works)</desc>
<val>j</val>
<desc>journal title</desc>
<val>s</val>
<desc>series title</desc>
<val>u</val>
<desc>title of unpublished material (including theses
and dissertations unless published by a commercial
press)</desc>
</valList>
<default>#IMPLIED</default>
<skeletons>
</skeletons>
</attDef>
</attList>
<skeletons>
<ss lang="pc" match="t:fileDesc/t:titleStmt/t:title">
is_title("<deixis>string(.)</deixis>")
doc_title(<deixis>generate-id(../../../..)</deixis
>, "<deixis>string(.)</deixis>")
</ss>
<ss lang="pc" match="t:bibl/t:title">
is_title("<deixis>string(.)</deixis>")
doc_title(<deixis>concat('ref-',generate-id(..))</deixis
>, "<deixis>string(.)</deixis>")
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="author">
<gi>author</gi>
<desc>in a bibliographic reference, contains the name of the author(s),
personal or corporate, of a work; the primary
<term>sttement of responsibility</term> for any bibliographic item.</desc>
<skeletons>
<ss lang="pc" match="t:fileDesc/t:titleStmt/t:author">
is_authorname("<deixis>string(.)</deixis>")
is_author("<deixis>concat('ref-',generate-id())</deixis>")
denotes("<deixis>string(.)</deixis
>",<deixis>concat('ref-',generate-id())</deixis>)
doc_author(<deixis>generate-id(../../../..)</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
<ss lang="pc" match="t:bibl/t:author">
is_authorname("<deixis>string(.)</deixis>")
is_author("<deixis>concat('ref-',generate-id())</deixis>")
denotes("<deixis>string(.)</deixis
>",<deixis>concat('ref-',generate-id())</deixis>)
doc_author(<deixis>concat('ref-',generate-id(..))</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="editor">
<gi>editor</gi>
<desc>secondary <term>statement of responsibility</term>
for a bibliographic item, for example the name of an
individual, institution, or organization (or of several
such) acting as editor, compiler, translator, etc.</desc>
<skeletons>
<ss lang="pc" match="t:fileDesc/t:titleStmt/t:editor">
is_editorname("<deixis>string(.)</deixis>")
is_editor("<deixis>concat('ref-',generate-id())</deixis>")
denotes("<deixis>string(.)</deixis
>", <deixis>concat('ref-',generate-id())</deixis>)
doc_editor(<deixis>generate-id(../../../..)</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
<ss lang="pc" match="t:bibl/t:editor">
is_editorname("<deixis>string(.)</deixis>")
is_editor("<deixis>concat('ref-',generate-id())</deixis>")
denotes("<deixis>string(.)</deixis
>", <deixis>concat('ref-',generate-id())</deixis>)
doc_editor(<deixis>concat('ref-',generate-id(..))</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="publicationStmt">
<gi>publicationStmt</gi>
<rs>publication statement</rs>
<desc>groups information concerning the publication or
distribution of an electronic or other text.</desc>
<skeletons>
<ss lang="pc">isbd_pubstatement(<deixis>generate-id(..)</deixis
>, <deixis>generate-id()</deixis>)</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="pubPlace">
<gi>pubPlace</gi>
<rs>place of publication</rs>
<desc>contains the name of the place where a bibliographic
item was published</desc>
<skeletons>
<ss lang="pc" match="t:fileDesc/t:publicationStmt/t:pubPlace">
is_placename("<deixis>string(.)</deixis>")
is_place("<deixis>concat('ref-',generate-id())</deixis>")
denotes("<deixis>string(.)</deixis
>", <deixis>concat('ref-',generate-id())</deixis>)
doc_pubplace(<deixis>generate-id(../../../..)</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
<ss lang="pc" match="t:fileDesc/t:publicationStmt/t:pubPlace">
is_placename("<deixis>string(.)</deixis>")
is_place("<deixis>concat('ref-',generate-id())</deixis>")
denotes("<deixis>string(.)</deixis
>", <deixis>concat('ref-',generate-id())</deixis>)
doc_pubplace(<deixis>concat('ref-',generate-id(..))</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="publisher">
<gi>publisher</gi>
<desc>provides the name of the organization responsible for the publication
or distribution of a bibliographic item.</desc>
<skeletons>
<ss lang="pc" match="t:fileDesc/t:publicationStmt/t:publisher">
is_orgname("<deixis>string(.)</deixis>")
is_organization("<deixis>concat('ref-',generate-id())</deixis>")
is_publisher("<deixis>concat('ref-',generate-id())</deixis>")
denotes("<deixis>string(.)</deixis
>", <deixis>concat('ref-',generate-id())</deixis>)
doc_publisher(<deixis>generate-id(../../../..)</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
<ss lang="pc" match="t:bibl/t:publisher">
is_orgname("<deixis>string(.)</deixis>")
is_organization("<deixis>concat('ref-',generate-id())</deixis>")
is_publisher("<deixis>concat('ref-',generate-id())</deixis>")
denotes("<deixis>string(.)</deixis
>", <deixis>concat('ref-',generate-id())</deixis>)
doc_publisher(<deixis>concat('ref-',generate-id(..))</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="date">
<gi>date</gi>
<desc>contains a date in any format.</desc>
<skeletons>
<ss lang="pc" match="t:fileDesc/t:publicationStmt/t:date">
doc_publicationdate(<deixis>generate-id(../../../..)</deixis
>, <deixis>string(.)</deixis>)
</ss>
<ss lang="pc" match="t:fileDesc/t:publicationStmt/t:date">
doc_publicationdate(<deixis>concat('ref-',generate-id(..))</deixis
>, <deixis>string(.)</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="sourceDesc">
<gi>sourceDesc</gi>
<rs>source description</rs>
<desc>supplies a bibliographic description of the copy text(s)
from which an electronic text was derived or generated.</desc>
<skeletons>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="bibl">
<gi>bibl</gi>
<desc>contains a loosely structured bibliographic citation of which the
sub-components may or may not be explicitly tagged.</desc>
<skeletons>
<ss lang="pc" match="t:teiHeader/t:fileDesc/t:sourceDesc/t:bibl">
is_document(<deixis>concat('ref-',generate-id())</deixis>)
doc_bibldesc(<deixis>concat('ref-',generate-id())</deixis
>, <deixis>generate-id()</deixis>)
is_transcription(<deixis>generate-id(../../../..)</deixis>)
transcribes(<deixis>generate-id(../../../../..)</deixis
>, <deixis>concat('ref-',generate-id())</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="edition">
<gi>edition</gi>
<desc>describes the particularities of one edition of a text.</desc>
<skeletons>
<ss lang="pc" match="t:bibl/t:edition">
doc_edition_desc(<deixis>concat('ref-',generate-id(..))</deixis
>, "<deixis>string(.)</deixis>")
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="biblScope">
<gi>biblScope</gi>
<desc>defines the scope of a bibliographic refeence, for example
as a list of page numbers, or a named subdivision of a larger work.</desc>
<skeletons>
<ss lang="pc">// omitting biblScope for now ... </ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="text">
<gi>text</gi>
<desc>contains a single text of any kind, whether unitary or composite,
for example a poem or drama, a collection of essays, a novel,
a dictionary, or a corpus sample.</desc>
<skeletons>
<ss match="t:TEI/t:text" lang="pc">
is_textproper(<deixis>generate-id()</deixis>)
TEIdoc_textproper(<deixis>generate-id(..)</deixis
>, <deixis>generate-id()</deixis>)
is_sequence(<deixis>concat(generate-id(),'-children')</deixis>)
text_contents(<deixis>generate-id()</deixis
>, <deixis>concat(generate-id(),'-children')</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="front">
<gi>front</gi>
<desc>contains any prefatory matter (headers, title page,
prefaces, dedications, etc.) found efore the start of a
text proper.</desc>
<skeletons>
<ss lang="pc">
seq_pos_item(<deixis>concat(generate-id(..),'-children')</deixis
>, <deixis>1 + count(preceding-sibling::*)</deixis
>, <deixis>generate-id()</deixis> )</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="head">
<gi>head</gi>
<desc>contains any heading, for example, the title of a section,
or the heading of a list or glossary.</desc>
<skeletons>
<ss match="t:front/t:head" lang="pc">
is_title("<deixis>string(.)</deixis>")
doc_title(<deixis>generate-id(ancestor::t:TEI)</deixis
>, "<deixis>string(.)</deixis>")
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="body">
<gi>body</gi>
<desc>contains the whole body of a single unitary text, excluding
any front or back matter.</desc>
<skeletons>
<ss lang="pc">
seq_pos_item(<deixis>concat(generate-id(..),'-children')</deixis
>, <deixis>1 + count(preceding-sibling::*)</deixis
>, <deixis>generate-id()</deixis> )</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="lg">
<gi>lg</gi>
<desc>contains a group of verse lines functioning as a
formal unit, e.g., a stanza, refrain, verse paragraph,
etc.
</desc>
<skeletons>
<ss lang="pc">
is_linegroup(<deixis>generate-id()</deixis>)
lg_contents(<deixis>generate-id()</deixis
>, <deixis>concat(generate-id(),'-children')</deixis>)
seq_pos_item(<deixis>concat(generate-id(..),'-children')</deixis
>, <deixis>1 + count(preceding-sibling::*)</deixis
>, <deixis>generate-id()</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
<tagDoc id="l">
<gi>l</gi>
<desc>contains a single, possibly incomplete, line of verse.</desc>
<skeletons>
<ss lang="pc">
is_verseline(<deixis>generate-id()</deixis>)
line_string(<deixis>generate-id()</deixis
>, "<deixis>string(.)</deixis>")
seq_pos_item(<deixis>concat(generate-id(..),'-children')</deixis
>, <deixis>1 + count(preceding-sibling::*)</deixis
>, <deixis>generate-id()</deixis>)
</ss>
</skeletons>
<elemDecl>...</elemDecl>
</tagDoc>
</tsd>References
[Dubin et al. 2006] Dubin, D., Futrelle, J., & Plutchak, J. “Metadata Enrichment for Digital Preservation.” Proceedings of Extreme Markup Languages 2006 (Montréal, Canada, August 2006). http://conferences.idealliance.org/extreme/html/2006/Dubin01/EML2006Dubin01.html
[Marcoux 2006] Marcoux, Y. “A natural-language approach to modeling: Why is some XML so difficult to write?” Proceedings of Extreme Markup Languages 2006 (Montréal, Canada, August 2006). http://conferences.idealliance.org/extreme/html/2006/Marcoux01/EML2006Marcoux01.html
[Marcoux 2009] Marcoux, Y. “Intertextual semantics generation for structured documents: a complete implementation in XSLT.” To appear in Proceedings of the 12th Colloque International sur le Document Electronique (Université de Montréal, Canada, October 2009).
[Marcoux & Rizkallah 2007] Marcoux, Y. & Rizkallah, É. “Exploring intertextual semantics: a reflection on attributes and optionality.” Proceedings of Extreme Markup Languages 2007 (Montréal, Canada, August 2007). http://conferences.idealliance.org/extreme/html/2007/Marcoux01/EML2007Marcoux01.html
[Marcoux & Rizkallah 2009] Marcoux, Y. & Rizkallah, É. “Intertextual semantics: A semantics for information design.” Journal of the American Society for Information Science & Technology, Volume 60, Issue 9, 2009, pp. 1895-1906. Published Online: 21 Aug 2009. doi:https://doi.org/10.1002/asi.21134.
[Piez 2006] Piez, W. “XSLT for Quality Checking in the Publication Workflow.” Online presentation, Mulberry Technologies, Inc., 2006. http://www.mulberrytech.com/papers/XSLTforQA/
[Smedslund 2004] Smedslund, J. Dialogues about a new psychology. Chagrin Falls, Ohio: Taos Institute. 2004.
[Sperberg-McQueen 2005] Sperberg-McQueen, C. M. “The meaning of OAI 2.0 Markup: An exercise in markup interpretation.” http://www.w3.org/2004/04/em-msm/ioai.xml
[Sperberg-McQueen et al. 2002] Sperberg-McQueen, C. M., Dubin, D., Huitfeldt, C., & Renear, A. “Drawing inferences on the basis of markup.” In Proceedings of Extreme Markup Languages 2002 (Montréal, Canada, August 2002), B. T. Usdin and S. R. Newcomb, Eds. http://conferences.idealliance.org/extreme/html/2002/CMSMcQ01/EML2002CMSMcQ01.html
[Sperberg-McQueen et al. 2009] Sperberg-McQueen, C. M., Huitfeldt, C., & Marcoux, Y. “What is Transcription? (part 2)” In preparation. Abstract available in Conference Abstracts of Digital Humanities 2009 (University of Maryland, College Park, June 2009), Claire Warwick, Ed. http://www.mith2.umd.edu/dh09/wp-content/uploads/dh09_conferencepreceedings_final.pdf
[Sperberg-McQueen et al. 2000a] Sperberg-McQueen, C. M., Huitfeldt, C., & Renear, A. “Meaning and Interpretation of Markup: Not as Simple as You Think.” Proceedings of Extreme Markup Languages 2000 (Montréal, Canada, August 2000).
[Sperberg-McQueen & Miller 2004] Sperberg-McQueen, C. M. & Miller, E. “On mapping from colloquial XML to RDF using XSLT.” Proceedings of Extreme Markup Languages 2004 (Montréal, Canada, August 2004). http://conferences.idealliance.org/extreme/html/2004/Sperberg-McQueen01/EML2004Sperberg-McQueen01.html
[TEI P4] The TEI Consortium / The Association for Computers and the Humanities (ACH); The Association for Computational Linguistics (ACL); The Association for Literary and Linguistic Computing (ALLC). TEI P4: Guidelines for Electronic Text Encoding and Interchange XML-compatible edition. Ed. C. M. Sperberg-McQueen and Lou Burnard; XML conversion by Syd Bauman, Lou Burnard, Steven DeRose, and Sebastian Rahtz. Oxford, Providence, Charlottesville, Bergen: TEI Consortium, December 2001. http://www.tei-c.org/release/doc/tei-p4-doc/html/
[Wirzbicka 1992] Wierzbicka, A. Semantics, culture, and cognition : universal human concepts in culture-specific configurations. Oxford University Press. 1992.
[Wittgenstein 1953] Wittgenstein, L. Philosophical investigations. Oxford: Blackwell. 1953.
[Wrightson 2001] Wrightson, A. “Some Semantics for Structured Documents, Topic Maps and Topic Map Queries.” Proceedings of Extreme Markup Languages 2001 (Montréal, Canada, August 2001). http://conferences.idealliance.org/extreme/html/2001/Wrightson01/EML2001Wrightson01.html
[Wrightson 2005] Wrightson, A. “Semantics of Well Formed XML as a Human and Machine Readable Language: Why is some XML so difficult to read?” Proceedings of Extreme Markup Languages 2005 (Montréal, Canada, August 2005). http://conferences.idealliance.org/extreme/html/2005/Wrightson01/EML2005Wrightson01.html
[1] To avoid having all logical truths show up as part of the
meaning of every markup construct, in practice we take the set of
sentences S true because of M
to mean sentences we can infer, given
M, that cannot be inferred without M.
The set of inferences possible, given M, also depends on what other premises are available; the result is to make the set of inferences and thus the meaning of M vary with what else is known; this resembles at least vaguely the idea expounded by Wrightson's application of situation semantics [Wrightson 2001, Wrightson 2005]. If M is completely redundant with other information, its net addition to our stock of inferences may be nil.
[2] We should point out here that, since we assume that generating each of I(D) and F(D) is a terminating process, we are implicitly assuming that they both are finite sets, which in practice they are. Moreover, each member of each set is also of finite length.
[3] The number and kind of the primitive notions assumed in the semantic description of a vocabulary, and the explicit relations among them, may vary with the design and purpose of the vocabulary or with those of the FTSD itself. In some cases, it may be desired to specify the meanings of some concepts in terms of a small number of primitives. In other cases, it may be better to allow the precise relations among concepts to remain unspecified, by treating them all as primitives.
In this case, for example, one could stipulate that a
document is, by definition, a sequence of
paragraphs (in which case its title, authorship
attribution, language, etc., would be, by definition, not part of the document
but extraneous to it), or that a paragraph is, by
definition, a subdivision of a document (in which case one
might argue that no two documents can ever contain the same paragraph).
Similarly, some might prefer to say not that a paragraph has
a
character-string value, but that a paragraph consists of a
string of characters (which others, in turn, would resist on the grounds that
in reality a paragraph is a linguistic and/or rhetorical object, of which a
character string can never be more than an approximate representation. By
positing document, paragraph, and
character string as primitive notions, we avoid specifying
such details and allow the markup language to be compatible with different
views of the precise nature of documents and paragraphs.
[4] The attribute name paths is used because local
elements would be identified not only by their generic ID, but also by part
or
whole of their ancestral line (thus, effectively, by a path; later examples will illustrate that). The plural
form (paths) is used because a
rule might be applicable to more than one element, in which case the paths
identifying them would be separated from one another by spaces in the attribute
value.
[5] A fuller treatment of the type / token distinction, in the context of markup and rich document structures, will be found in [Sperberg-McQueen et al. 2009].
[6] If the sentences above the line are given, then the sentences below the line may be inferred.
Some readers may be more familiar with the convention of writing such rules as conditionals; expressed as a conditional, the rule given in the text would read (∀ x)(is_TEI_document(x) ⇒ (is_document(x) ∧ is_XML_element(x)))